dynamic and generic workflows in · dynamic and generic workflows in .net bart de smet promoters:...
TRANSCRIPT

Universiteit Gent
Faculteit Ingenieurswetenschappen
Vakgroep Informatietechnologie
Voorzitter: Prof. Dr. Ir. P. LAGASSE
Dynamic and generic workflows in .NET
door
Bart DE SMET
Promotors: Prof. Dr. Ir. B. DHOEDT, Prof. Dr. Ir. F. DE TURCK
Scriptiebegeleider: Lic. K. STEURBAUT
Scriptie ingediend tot het behalen van de academische graad van burgerlijk ingenieur in de
computerwetenschappen
Academiejaar 2006-2007


Ghent University
Faculty of Engineering
Department of Information Technology
Head: Prof. Dr. Ir. P. LAGASSE
Dynamic and generic workflows in .NET
by
Bart DE SMET
Promoters: Prof. Dr. Ir. B. DHOEDT, Prof. Dr. Ir. F. DE TURCK
Assistance by Lic. K. STEURBAUT
Master Thesis written to obtain the academic degree of Master of Computer Science Engineering
Academic year 2006-2007

iv
Preface
Two exciting years have flown by... I still remember the sunny summer day in 2005 when I decided to
continue my studies at Ghent University with a special study “bridge program” to obtain a Master of
Computer Science Engineering – Software Engineering degree in two years. Thanks to Prof. Dr. Ir. K.
De Bosschere and Prof. Dr. Ir. L. Eeckhout for their support in composing a special personal study
program. I’d like to thank my parents too for giving me this opportunity; housing and supporting a
student for two additional years is a real challenge as well.
Without doubt, it’s been a challenging two years to combine courses from the Bachelor and Master
curricula, sometimes having to attend three lessons at the same time, fighting conflicting project
deadlines while reserving time for extra-curricular activities. Luckily, this final year’s Master Thesis
allows for a personal touch to put the crown on the work.
The subject of this Master Thesis is Windows Workflow Foundation, a core pillar of Microsoft’s latest
release of the .NET Framework. When choosing a topic for the thesis, back in the spring of 2006, the
technology was still in beta, imposing quite some other challenges. Lots of betas, breaking changes
and sometimes a bit of frustration later, the technology has reached its final version, and to be
honest I’ve been positively surprised with the outcome and certain aspects of the technology.
Although my interest in .NET goes back to the early 2000s, workflow didn’t cross my path until one
year ago, wetting my appetite for this topic even more.
I’d like to thank Prof. Dr. Ir. B. Dhoedt and Prof. Dr. Ir. F. De Turck for their support to research this
cutting edge technology and to support this thesis. Furthermore, I can’t thank enough Kristof
Steurbaut for his everlasting interest in the topic and for providing his insights in practical use cases
for the technology at INTEC.
Researching the topic of workflow also opened up for another opportunity during this academic year,
writing a scientific paper entitled “Dynamic workflow instrumentation for Windows Workflow
Foundation” for the ICSEA’07 conference. Without the support from Bart, Filip, Kristof and Sofie this
wouldn’t have been possible. Their incredible eye for detail was invaluable to deliver a high quality
work and made it a unique and wonderful experience.
This year hasn’t only been a massive year at university; it’s been a busy year outside as well. In
November 2006, I went to Barcelona to attend the Microsoft TechEd 2006 conference where I was
responsible for some Ask-the-Experts booths, attended numerous sessions on various technologies
including Workflow Foundation and where I participated in Speaker Idol and won. Special thanks to
Microsoft Belux to support this trip and to provide lots of other opportunities to speak at various
conferences.
Looking at the future, I’m happy to face another big oversea challenge. In February 2007 I visited the
US headquarters of Microsoft Corporation in Redmond, WA. After two stressful days with flight
delays, tough interview questions and meeting a bunch of great people, I returned home on my
birthday with what’s going to be my most wonderful birthday gift so far: a full time job offer as
Software Design Engineer at Microsoft Corporation. I’m proud to say I’ll take on this opportunity
starting from October this year.

v
The cutting edge nature of the technology discussed in this thesis, contacts with Microsoft and my
future plans to work at Microsoft Corporation have driven the decision to write this work in English,
supported by Prof. Dr. Ir. B. Dhoedt. Special thanks to Prof. Dr. Ir. Taerwe and Prof. Dr. Ir. De
Bosschere to grant permission for this.
Finally, I’d also like to thank my colleague students in the Master of Computer Science Engineering
“bridge program” for their endless support on a day-to-day basis. Arne and Jan, you’ve been a great
support the last two years and I hope to stay in touch.
Bart De Smet, May 2007
Toelating tot bruikleen
“De auteur geeft de toelating deze scriptie voor consultatie beschikbaar te stellen en delen van deze
scriptie te kopiëren voor persoonlijk gebruik. Elk ander gebruik valt onder de beperkingen van het
auteursrecht, in het bijzonder met betrekking tot de verplichting de bron uitdrukkelijk te vermelden bij
het aanhalen van resultaten uit deze scriptie.”
Rules for use
“The author grants the permission to make this thesis available for consultation and to copy parts of
this thesis for personal use. Every other use is restricted by the limitations imposed by copyrights,
especially concerning the requirement to mention the source explicitly when referring to results from
this thesis.”

vi
Dynamic and generic workflows in .NET
door
Bart DE SMET
Scriptie ingediend tot het behalen van de academische graad van burgerlijk ingenieur in de
computerwetenschappen
Academiejaar 2006-2007
Promotors: Prof. Dr. Ir. B. DHOEDT, Prof. Dr. Ir. F. DE TURCK
Scriptiebegeleider: Lic. K. STEURBAUT
Faculteit Ingenieurswetenschappen
Universiteit Gent
Vakgroep Informatietechnologie
Voorzitter: Prof. Dr. Ir. P. LAGASSE
Samenvatting
In november 2006 bracht Microsoft de Windows Workflow Foundation (WF) uit als deel van de .NET
Framework 3.0 release. Workflow stelt ontwikkelaars in staat om businessprocessen samen te stellen
op een grafische manier via een designer. In dit werk evalueren we de geschiktheid van workflow-
gebaseerde ontwikkeling in de praktijk, toegepast op medische ‘agents’ zoals deze in gebruik zijn op
de dienst Intensieve Zorgen (IZ) van het Universitaire Ziekenhuis Gent (UZ Gent). Meer specifiek
onderzoek we hoe workflows dynamisch aangepast kunnen worden om tegemoet de komen aan
dringende structurele wijzigingen of om aspecten zoals loggen en authorizatie in een workflow te
injecteren. Dit deel van het onderzoek resulteerde in het bouwen van een zogenaamd
instrumentatieraamwerk. Verder werd ook onderzoek verricht naar het bouwen van een generieke
set bouwblokken die kunnen helpen bij het samenstellen van data-gedreven workflows zoals dit
typisch gebeurt bij het bouwen van medische ‘agents’. Ontwerpbeslissingen worden in detail
besproken en prestatieanalyses worden uitgevoerd om de toepasbaarheid van workflow, via de in dit
werk gebouwde technieken, te toetsen.
Trefwoorden: .NET, workflow, dynamic adaptation, instrumentation, generic frameworks

vii
Dynamic and generic workflows in .NET
by
Bart DE SMET
Master Thesis written to obtain the academic degree of Master of Computer Science Engineering
Academic year 2006-2007
Promoters: Prof. Dr. Ir. B. DHOEDT, Prof. Dr. Ir. F. DE TURCK
Assistance by K. STEURBAUT
Faculty of Engineering
Ghent University
Department of Information Technology
Head: Prof. Dr. Ir. P. LAGASSE
Summary
Recently, Microsoft released Windows Workflow Foundation (WF) as part of its .NET Framework 3.0
release. Using workflow, business processes can be developed much like user interfaces, in a
graphical fashion. In this work, we evaluate the feasibility of workflow-driven development in
practice, applied on medical agents from the department of Intensive Care (IZ) of Ghent University
Hospital (UZ Gent). More specifically, we investigate how workflows can be modified dynamically to
respond to urgent changes or to crosscut aspects in an existing workflow definition. This resulted in
the creation of an instrumentation framework. Furthermore, a generic framework is created to assist
in the development of data-driven workflows by means of composition of generic building blocks.
Design decisions are outlined and performance analysis is conducted to evaluate the applicability of
workflow in this domain using the techniques created and described in this work.
Keywords: .NET, workflow, dynamic adaptation, instrumentation, generic framework

viii
Dynamic and generic workflows in .NET
Bart De Smet
Promoters: Bart Dhoedt, Filip De Turck
Abstract – Workflow-based programming is a recent
evolution in software development. Using this technology,
complex long-running business processes can be mapped
to software realizations in a graphical fashion, resulting in
many benefits. However, due to their long-running
nature, the need for dynamic adaptation of workflows
grows. In this research, we investigate mechanisms that
allow adapting business processes at execution time. Also,
in order to make composition of business processes easier
to do – ultimately by the end-users themselves – a set of
domain-specific building blocks is much desirable. The
creation of such a set of generic and flexible blocks was
subject of our research as well.
Keywords – .NET, workflow
I. INTRODUCTION
Recently, workflow-based development has become
a mainstream programming technique. With workflow,
software processes can be represented graphically as a
composition of building blocks that encapsulate various
kinds of logic, much like flowchart diagrams. Not only
does this close the gap between software engineers and
business people, it has several technical advantages too.
This research focuses on Microsoft Windows
Workflow Foundation (WF) [1].
One typical type of application that greatly benefits
from a workflow-based approach is the category of
long-running business processes. For example, in order
processing systems an order typically goes through a
series of human approval steps and complex service
interactions for payment completion and order delivery.
Workflow helps to build such processes thanks to the
presence of runtime services that keep long-running
state information, track the stage a workflow is in, etc.
However, the use of long-running processing results
in new challenges that have to be tackled, one of which
is dynamic adaptation of workflows. Imagine the case
in which company policies change during the lifetime
of an order process workflow, e.g. concerning payment
validation checks. In order to reflect such structural
changes we need a mechanism to modify running
workflow instances in a reliable manner.
Another research topic embodies the creation of a set
of domain-specific building blocks that allow for easy
workflow composition, ultimately putting business
people in control of their software processes. The
results of this research were put in practice based on
practical eHealth applications from the UZ Gent where
patient info is processed in an automated manner.
II. DYNAMIC ADAPTATION
WF comes with a feature that allows a workflow
instance to be adapted at runtime. Based on this
dynamic update feature we‟ve built a more complex
tool to assist in dynamic workflow adaptation and
instrumentation.
Dynamic workflow adaptation can be summarized as
the set of actions that have to be taken in order to
change a workflow instance at runtime. For example,
the processing of an order or a set of orders might
require additional steps based on business decisions.
Using our tool, such an adaptation can be applied in a
safe manner, without causing any downtime of the
order processing application and with guarantees
concerning the workflow instance‟s correctness.
Instrumentation on the other hand has a more
technically-driven background. It‟s very common for
software to contain lots of boilerplate code in order to
authorize users or to log diagnostic information at
execution time. In workflow-based environments we
don‟t want to spoil the visual representation of a
workflow with such aspects. Instrumentation helps to
inject these aspects dynamically (see Figure 1). At the
left-hand side of the figure the original workflow
definition is shown. This workflow has been
instrumented with timers, an authorization mechanism
and a logging activity at runtime, the result of which
can be seen on the right-hand side of the figure.
Figure 1 - Example of workflow instrumentation

ix
As part of our research we investigated the impact of
dynamic adaptation and instrumentation on the
application‟s overall performance. It was found that
various shapes of dynamic adaptation have non-trivial
costs associated with them, especially in case ad-hoc
updates are applied to a running workflow.
Instrumentation has a significant cost too but its
advantages of increased flexibility and the preservation
of a workflow‟s pure and smooth graphical nature
outweigh the costs.
This part of the research was the subject of a paper
entitled “Dynamic workflow instrumentation for
Windows Workflow Foundation” that was submitted to
and accepted for the ICSEA‟07 conference [2].
III. GENERIC COMPOSITION
Another important aspect when creating workflows is
the use of specialized building blocks that reflect the
business the workflow is operating in. In our research
we created a set of generic building blocks to retrieve
and manipulate data from databases as part of a
medical agent used in the Intensive Care (IZ)
department of Ghent University Hospital (UZ Gent).
The sample “AB Switch” agent performs processing of
medical patient data on a daily basis to propose a
switch of antibiotics for patients that match certain
criteria [3].
Using a few well-chosen building blocks we were
able to express the AB Switch agent in workflow using
graphical composition. A part of the agent‟s workflow-
based implementation is shown in Figure 2. The
yellow, green and red blocks in the displayed workflow
fragment are highly specialized components written
during the research. For example, the yellow data
gathering block can execute a query against a database
in a generic manner, boosting its flexibility and
usability in various kinds of workflows, hence the label
„generic‟.
Figure 2 - A part of the AB Switch agent workflow
Of course one should take various quality attributes
into account when replacing code-based applications by
a workflow-based variant. Various design decisions
have been outlined in our research, including the
applicability in service-based architectures [4].
Another important consideration is performance. It
was shown that workflow can boost the application‟s
performance when exploiting the intrinsic parallelism
of workflow instances. For example, when processing
patient data it‟s beneficial to represent each patient as
an individual workflow instance, allowing the decision
logic for multiple patients to be executed in parallel.
Since developers don‟t have to bother much about the
complexities of multi-threaded programming when
working with WF, this should be considered a big plus.
The performance results for parallel data processing
using workflow compared to a procedural alternative
are shown in Figure 3.
Figure 3 - Parallel workflow execution vs. procedural code
IV. CONCLUSION
Workflow seems to be a valuable candidate for the
implementation of various types of applications. Using
dynamic adaptation and instrumentation workflows can
be made highly dynamic at runtime. Generic building
blocks allow for easy composition of pretty complex
(data-driven) workflows, while having the potential to
raise the performance bar.
ACKNOWLEDGEMENTS
The author wants to thank promoters Bart Dhoedt
and Filip De Turck for the opportunity to conduct this
research and to create a paper on dynamic
instrumentation for the ICSEA‟07 conference. The
realization of this work wouldn‟t have been possible
without the incredible support by Kristof Steurbaut
throughout the research.
REFERENCES
[1] D. Shukla and B. Schmidt, Essential Windows Workflow
Foundation, Addison-Wesley Pearson Education, 2007.
[2] B. De Smet, K. Steurbaut, S. Van Hoecke, F. De Turck and B. Dhoedt, Dynamic workflow instrumentation for Windows
Workflow Foundation, ICSEA‟07.
[3] K. Steurbaut, Intelligent software agents for healthcare decision support – Case 1: Antibiotics switch agent (switch IV-
PO), UGent-INTEC, 2006.
[4] F. De Turck, et al, Design of a flexible platform for execution of medical decision support agents in the Intensive Care Unit,
Comput Biol Med. 37, 2007.
0
5
10
15
20
25
1 2 3 4 5 6 7 8 9 10Ex
ecu
tio
n t
ime
(s)
Number of workflow instances
ProceduralWorkflow

x
Table of contents
Chapter 1 - Introduction ........................................................................................ 1
1 What’s workflow? ............................................................................................................................ 1
2 Why workflow? ................................................................................................................................ 2
3 Windows Workflow Foundation ...................................................................................................... 2
4 Problem statement .......................................................................................................................... 4
Chapter 2 - Basics of WF ......................................................................................... 5 1 Architectural overview ..................................................................................................................... 5
2 Workflows and activities .................................................................................................................. 6
2.1 Types of workflows .................................................................................................................. 6
2.2 Definition of workflows............................................................................................................ 7
2.2.1 Code-only ......................................................................................................................... 7
2.2.2 Markup-based definition with XOML ............................................................................... 8
2.2.3 Conditions and rules ........................................................................................................ 9
2.3 Compilation .............................................................................................................................. 9
2.4 Activities ................................................................................................................................. 10
3 Hosting the workflow engine ......................................................................................................... 11
3.1 Initializing the workflow runtime and creating workflow instances ..................................... 11
3.2 Runtime services .................................................................................................................... 12
4 Dynamic updates ........................................................................................................................... 12
Chapter 3 - Dynamic updates ............................................................................ 13 1 Introduction ................................................................................................................................... 13
2 The basics ....................................................................................................................................... 13
2.1 Internal modification ............................................................................................................. 13
2.2 External modification ............................................................................................................. 14
3 Changing the transient workflow................................................................................................... 14
3.1 Inserting activities .................................................................................................................. 14
3.2 More flexible adaptations ...................................................................................................... 15
3.3 Philosophical intermezzo – where encapsulation vanishes… ................................................ 16

xi
3.4 Establishing data bindings ...................................................................................................... 16
4 Changing sets of workflow instances ............................................................................................. 19
5 An instrumentation framework for workflow ............................................................................... 19
5.1 A simple logging service ......................................................................................................... 20
5.2 Instrumentation for dynamic updates ................................................................................... 21
5.2.1 Instrumentation with suspension points ....................................................................... 21
5.2.2 Responding to suspensions ............................................................................................ 23
5.3 Advanced instrumentation logic ............................................................................................ 26
5.4 Conclusion .............................................................................................................................. 27
6 A few practical uses of instrumentation ........................................................................................ 27
6.1 Logging ................................................................................................................................... 28
6.2 Time measurement ................................................................................................................ 30
6.3 Authorization ......................................................................................................................... 32
6.4 Production debugging and workflow inspection ................................................................... 35
7 Tracking in a world of dynamism – the WorkflowMonitor revisited ............................................. 39
8 Performance analysis ..................................................................................................................... 41
8.1 Research goal ......................................................................................................................... 41
8.2 Test environment ................................................................................................................... 41
8.3 Test methodology .................................................................................................................. 41
8.4 Internal workflow modification ............................................................................................. 42
8.4.1 Impact of workload on adaptation time ........................................................................ 43
8.4.2 Impact of dynamic update batch size on adaptation time ............................................ 44
8.5 External workflow modification ............................................................................................. 45
8.6 Instrumentation and modifications – a few caveats ............................................................. 47
9 Conclusion ...................................................................................................................................... 48
Chapter 4 - Generic workflows ......................................................................... 50 1 Introduction ................................................................................................................................... 50
2 A few design decisions ................................................................................................................... 52
2.1 Granularity of the agent workflow ........................................................................................ 52
2.2 Encapsulation as web services ............................................................................................... 53
2.3 Database logic ........................................................................................................................ 54
3 From flowchart to workflow: an easy step? .................................................................................. 56
3.1 Flow control ........................................................................................................................... 56

xii
3.2 Boolean decision logic ............................................................................................................ 56
3.3 Serial or parallel? ................................................................................................................... 57
3.4 Error handling ........................................................................................................................ 58
4 Approaches for data gathering ...................................................................................................... 60
4.1 Design requirements and decisions ....................................................................................... 60
4.2 Using Local Communication Services ..................................................................................... 60
4.3 The data gathering custom activity ....................................................................................... 62
4.4 Implementing a query manager ............................................................................................ 63
4.4.1 An XML schema for query representation ..................................................................... 63
4.4.2 Core query manager implementation ........................................................................... 65
4.4.3 The query object ............................................................................................................ 66
4.5 Hooking up the query manager ............................................................................................. 68
4.6 Chatty or chunky? .................................................................................................................. 68
4.6.1 Chatty ............................................................................................................................. 68
4.6.2 Chunky ........................................................................................................................... 68
4.6.3 Finding the right balance ............................................................................................... 69
5 Other useful activities for generic workflow composition ............................................................ 69
5.1 ForeachActivity ...................................................................................................................... 69
5.2 YesActivity and NoActivity ..................................................................................................... 71
5.3 FilterActivity ........................................................................................................................... 74
5.4 PrintXmlActivity ..................................................................................................................... 75
5.5 An e-mail activity ................................................................................................................... 77
6 Other ideas ..................................................................................................................................... 77
6.1 Calculation blocks .................................................................................................................. 77
6.2 On to workflow-based data processing? ............................................................................... 80
6.3 Building the bridge to LINQ .................................................................................................... 80
6.4 Asynchronous data retrieval .................................................................................................. 81
6.5 Web services .......................................................................................................................... 82
6.6 Queue-based communication ................................................................................................ 82
7 Putting the pieces together: AB Switch depicted .......................................................................... 83
8 Designer re-hosting: the end-user in control ................................................................................. 85
9 Performance analysis ..................................................................................................................... 88
9.1 Research goal ......................................................................................................................... 88
9.2 Test environment ................................................................................................................... 88

xiii
9.3 A raw performance comparison using CodeActivity.............................................................. 88
9.4 Calculation workflows with inputs and outputs .................................................................... 91
9.5 Iterative workflows ................................................................................................................ 91
9.6 Data processing ...................................................................................................................... 94
9.6.1 Iterative data processing ................................................................................................ 94
9.6.2 Nested data gatherings .................................................................................................. 96
9.6.3 Intra-workflow parallelism ............................................................................................. 99
9.6.4 Inter-workflow parallelism ............................................................................................. 99
9.6.5 Simulating processing overhead .................................................................................. 101
10 Conclusion ................................................................................................................................ 103
Chapter 5 – Conclusion ..................................................................................... 106
Appendix A – ICSEA’07 paper .......................................................................... 108
Bibliography .......................................................................................................... 116

Chapter 1 – Introduction | 1
Chapter 1 – Introduction
1 What’s workflow? The concept of workflow exists for ages. On daily basis humans execute workflows to get their jobs
done. Examples include shopping, decision making process during meetings, etc. All of these have
one thing in common: the execution of a flow of individual steps that lead to some desired result. In
case of the shopping example, one crosses a market place with a set of products in mind to find the
best buy available, performing decision making based on price, quality and marketing influences.
In the computing space, programmers have been dealing with workflow for ages as well. Application
development often originates from a flowchart diagram being translated into code. However, that’s
where it often ends these days. The explicitness of a visual representation of a workflow is turned
into some dark piece of code, which makes it less approachable by management people, not to speak
about the problem of code maintenance especially when code is shared amongst developers. Today’s
workflow concept is all about keeping the graphical representation of some kind of business process
that can be turned to execution by a set of runtime services.
Workflow is based on four tenets. Although not so well-known (yet) as the web service SOA tenets or
the database ACID properties, these four tenets are a good starting point for further discussion:
Workflows coordinate work performed by people and software
This first tenet categorizes workflows in two major groups: human workflows and automated
system processes. The former one involves direct interaction with humans, such as approvals
of invoices as part of a larger workflow, while the latter one is situated in the business
processing space and involves communication between services and machines.
Workflows are long-running and stateful
Using workflow, business processes are turned to execution. Since human interaction or
reliance on external parties is often part of such a business process, workflows tend to be
long-running and keep state. It’s not atypical to have a workflow instance running for many
hours, days or even months. Runtime services are required to support this.
Workflows are based on extensible models
To deal with ever changing business processes and changes of business rules, workflows
need a big deal of flexibility that allows for rapid modification without recompilation and a
deep knowledge of the software internals of the business application. In the end, this should
allow managers to adapt the business process themselves without developer assistance.
Workflows are transparent and dynamic through their lifecycle
The long-running characteristic of workflows should not turn them into a black box. There’s a
big need for transparency that allows analysts to see what’s going on inside the workflow in
a near real-time fashion. Also, workflows should allow for dynamic changes at runtime to
deal with changing requirements. When providing services to 3rd parties, it’s important to
meet Service Level Agreements (SLA) which further strengthens the need for transparency.
It’s also important to remark that the second tenet on the long-running and stateful character of
workflows is in strong contrast to the stateless character of web services. The combination of both

Chapter 1 – Introduction | 2
principles can unlock a lot of potential however, for instance by exposing a workflow through a web
service to allow cross-organization business processing (e.g. a supply chain).
2 Why workflow? In order to be successful, workflow needs a set of compelling reasons to use it. In the previous
paragraph a few advantages were already pointed out. One good reason to use workflows is the
visual representation of workflows that makes them easier to understand and to maintain. This
graphical aid provided by tools makes workflows approachable to a much broader set of people,
including company management.
Furthermore, the need for long-running workflows implies the availability of a set of runtime services
to allow hydration (i.e. the persistence of a running workflow when it becomes idle) and dehydration
(i.e. the process of loading a workflow in memory when it becomes active again) of a workflow. In a
similar way, the need for transparency leads to the requirement of having runtime services for
tracking and runtime inspection. Considering these runtime services (amongst others like scheduling
and transactions), workflow usage becomes even more attractive. Having to code these runtime
services yourself would be a very time-consuming activity and lead to a productivity decrease.
In the end, workflow is much more than some graphical toy and has a broad set of applications:
Business Process Management (BPM) – Workflows allow for rapid modification in response
to changing business requirements. This makes software a real tool to model business
processes and to use software for what it should be intended for: supporting the business.
Document lifecycle management – Versioning, online document management systems and
interactions between people have become a must for companies to be productive when
dealing with information. Approval of changes is just one example workflow can be used for.
Page or dialog flow – A typical session when working with an application consists of a flow
between input and output dialogs or pages. Using workflow, this flow can be modeled and
changed dynamically based on the user’s input and validation of business rules.
Cross-organization integration – Combining workflow with the power of web services, one
can establish a more dynamic way to integrate businesses over the internet in a “Business-
to-Business” (B2B) fashion, e.g. in order-supply chain processing.
Internal application workflow – The use of workflow inside an application can allow of
extension and modification by end-users. Pieces of the application that rely on business rules
can be customized more easily and with out-of-the-box tool support.
3 Windows Workflow Foundation The last couple of years, workflow has evolved from a niche to an applicable paradigm in software
development. Products like Microsoft BizTalk Server have been successful and introduced workflow
to enterprises as an approach to deal with inter-organization process integration (“biz talk”). In
BizTalk we often talk about orchestration rather than workflow. Orchestration helps developers to
automate business processes that involve multiple computer systems, for example in a B2B scenario.
Workflow can be seen as a way to compose such an orchestration in an easier way.

Chapter 1 – Introduction | 3
With Windows Workflow Foundation (WF), a technology introduced in the .NET Framework 3.0,
workflow is brought to the masses and becomes a first class citizen of the .NET developer’s toolbox.
The .NET Framework 3.0, formerly known as WinFX, is a set of managed code libraries that’s created
in the Windows Vista timeframe and ships with Windows Vista out-of-the-box but is also ported back
to run on Windows XP and Windows Server 2003. Other pillars of .NET Framework 3.0 include (see
Figure 1):
Windows Presentation Foundation (WPF) code-named “Avalon”, a graphical foundation that
unifies the worlds of GDI, Windows Forms, DirectX, media and documents based on a new
graphical composition engine. WPF can be programmed using XAML (eXtensible Application
Markup Language) which we’ll use in the WF space too. A related technology is XPS or XML
Paper Specification, used for document printing.
Windows Communication Foundation (WCF) code-named “Indigo”, a unified approach to
service-oriented programming based on the principles of SOA (service-oriented architecture),
bringing together the worlds of DCOM, .NET Remoting, MSMQ, Web Services and WSE. It’s
built around key concepts of service and data contracts and has a high amount of code-less
XML-based configuration support.
Windows CardSpace (WCS) code-named “InfoCards”, a technology to deal with digital
identities and to establish an Identity Metasystem, based on a set of WS-* standards. WCS
can be seen as a new approach to federated identity which was formerly considered in the
.NET PassPort initiative that lacked openness and wide customer adoption due to trust
issues. The use of open standards should help digital identity management to become a
more widely accepted paradigm.
Figure 1 - .NET Framework 3.0
Just like we’ve seen the availability of the DBMS extend to the desktop with products like SQL Server
2005 Express and more recently SQL Server Everywhere Edition, WF brings the concept of workflow

Chapter 1 – Introduction | 4
processing to the desktop. Essentially WF is an in-process workflow processing engine that can be
hosted in any .NET application, ranging from console applications over Windows Forms-based GUI
applications to Windows Services and web services.
Compared to BizTalk Server, WF is a pluggable lightweight component that can be used virtually
anywhere but lacks out-of-the-box support for complex business integration (e.g. using data
transformations), business activity monitoring (BAM), adapters to bridge with external systems (like
MQ Series, SAP, Siebel and PeopleSoft) and reliability and scalability features. Although there is a
blurry zone between both technologies, it’s safe to say BizTalk is rather to be used in complex cross-
organization business integration scenarios while WF benefits from its more developer-oriented
fashion and is to be used more often inside an application. For the record, Microsoft has already
announced to replace the orchestration portion of BizTalk by WF in a future release of the BizTalk
product, leading to convergence of both technologies.
That Microsoft puts a bet on workflow-based technologies should be apparent from the adoption of
the WF technology in the next version of the Microsoft Office System, i.e. Office System 2007
(formerly known as Office “12”) and the Windows SharePoint Services 3.0 technology for document
management scenarios. Other domains where WF will be implemented are ASP.NET to create a
foundation for page flow, future releases of BizTalk as mentioned previously and Visual Studio Team
System for work item processing.
More information on Windows Workflow Foundation can be found on the official technology website
http://wf.netfx3.com.
4 Problem statement This first part of this work focuses on dynamic adaptation of workflows at runtime. Without doubt,
scenarios exist where it’s desirable to modify a workflow instance that’s in flight. A possible scenario
consists of various business reasons that mandate a dynamic change (e.g. introducing an additional
human approval step after visual inspection of the workflow instance’s state). However, also in other
situations dynamic adaptation can be beneficial, for example to weave aspects in a workflow
definition without making the core workflow heavier or clumsier.
In the second part, focus is moved towards the creation of generic workflow building blocks that
makes composition of data-driven workflows easier. The results of this research and analysis are
applied on workflow-based agent systems that are used by the department of Intensive Care (IZ) of
Ghent University Hospital (UZ Gent).
For both parts, performance tests are conducted to evaluate the feasibility of the discussed
techniques and to get a better image of possible performance bottlenecks.

Chapter 2 – Basics of WF | 5
Chapter 2 – Basics of WF
1 Architectural overview On a macroscopic level, the WF Runtime Engine gets hosted inside some host process such as a
console application, a Windows Forms application, a Windows Service, a web application or a web
service. The tasks of the runtime engine are to instantiate workflows and to manage their lifecycle.
This includes performing the necessary scheduling and threading.
The concept workflow is used to refer to the definition of a workflow, which is defined as a class, as
discussed further on. Each workflow is composed from a series of activities which are the smallest
units of execution in the workflow era. One can reuse existing activities that ship with WF but the
creation of custom activities either from scratch or by composition of existing activities is supported
too. We’ll discuss this concept further on.
A single workflow can have multiple workflow instances, just like classes are instantiated. The big
difference compared to “simple objects” is the runtime support that workflow instances receive, for
example to dehydrate a running workflow instance when it is suspended. The services in charge of
these things are called the Runtime Services.
Figure 2 outlines the basic architecture of WF.
Figure 2 - General architecture [1]
Next to the runtime, there is tools support as well. In the future these tools will become part of
Visual Studio “Orcas” but for now these get embedded in Visual Studio 2005 upon installation of the
Windows SDK. An interesting feature of the graphical workflow designer is that it allows for re-

Chapter 2 – Basics of WF | 6
hosting in other applications, effectively allowing developers to expose a designer to the end-users
(e.g. managers) to modify workflows using graphical support.
2 Workflows and activities
2.1 Types of workflows WF distinguishes between two types of workflows. The first type are the sequential workflows that
have a starting point and an ending point with activities in between that are executed sequentially.
An example of such a workflow is depicted in Figure 3.
Figure 3 - A sequential workflow

Chapter 2 – Basics of WF | 7
The second type of workflow supported by WF is the state machine workflow. This type of workflow
is in fact a state machine that has a starting state and ending state. Transitions between states are
triggered by events. An example of a state machine workflow is shown in Figure 4.
Figure 4 - A state machine workflow
2.2 Definition of workflows As mentioned in the previous paragraph, workflows are defined as classes, essentially by composing
existing activities. There are different ways to define a workflow.
2.2.1 Code-only
When choosing the code-only approach, the Integrated Development Environment (IDE) creates at
least two files. One contains the “designer generated code” (Code 2), the other contains additional
code added by the developer, for example the code executed by a CodeActivity activity (Code 1).
public sealed partial class SimpleSequential: SequentialWorkflowActivity
{
public SimpleSequential()
{
InitializeComponent();
}
private void helloWorld_ExecuteCode(object sender, EventArgs e)
{
Console.WriteLine("Hello World");
}
}
Code 1 - Developer code for a sequential workflow

Chapter 2 – Basics of WF | 8
partial class SimpleSequential
{
#region Designer generated code
/// <summary>
/// Required method for Designer support - do not modify
/// the contents of this method with the code editor.
/// </summary>
[System.Diagnostics.DebuggerNonUserCode]
private void InitializeComponent()
{
this.CanModifyActivities = true;
this.helloWorld = new System.Workflow.Activities.CodeActivity();
//
// helloWorld
//
this.helloWorld.Name = "helloWorld";
this.helloWorld.ExecuteCode +=
new System.EventHandler(this.helloWorld_ExecuteCode);
//
// SimpleSequential
//
this.Activities.Add(this.helloWorld);
this.Name = "SimpleSequential";
this.CanModifyActivities = false;
}
#endregion
private CodeActivity helloWorld;
}
Code 2 - Designer generated code of a sequential workflow
2.2.2 Markup-based definition with XOML
Automatically generated code like the one in Code 2 consists of the same elements all the time:
classes (the activity object types) are instantiated, properties are set, event handlers are registered
and parent-child hierarchies are established (e.g. this.Activities.Add). This structure is an ideal
candidate for specification using XML. This is what XOML, the eXtensible Object Markup Language,
does. The equivalent of Code 2 in XOML is displayed in Code 3.
<SequentialWorkflowActivity
x:Class="WorkflowConsoleApplication1.SimpleSequentialMarkup"
x:Name="SimpleSequentialMarkup"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/workflow">
<CodeActivity x:Name="helloWorld"
ExecuteCode="helloWorld_ExecuteCode" />
</SequentialWorkflowActivity>
Code 3 - XOML representation of a sequential workflow
XOML gets translated into the equivalent code and is compiled into an assembly that’s equivalent to
a code-based definition. It’s a common misunderstanding that XOML is only used by WPF (where it is
called XAML) to create GUIs; XOML can be used for virtually any object definition that’s based on
composition, including user interfaces and workflows.

Chapter 2 – Basics of WF | 9
2.2.3 Conditions and rules
Beside of the workflow definition itself, a workflow often relies on conditional logic. Such conditions
can be defined in code or declaratively using XML. The latter option allows for dynamic changes of
rules at runtime without the need for recompilation, which would cause service interruption. The
creation of such a declarative rule condition is illustrated in Figure 5.
Figure 5 - Definition of a declarative rule
2.3 Compilation Workflow compilation is taken care of by the Visual Studio 2005 IDE using the MSBuild build system.
Under the hood, the Workflow Compiler wfc.exe is invoked to build a workflow definition. This
workflow-specific compiler validates a workflow definition and generates an assembly out of it. The
command-line output of the compiler is shown in Listing 1.
C:\Users\Bart\Documents\WF>wfc sample.xoml sample.cs
Microsoft (R) Windows Workflow Compiler version 3.0.0.0
Copyright (C) Microsoft Corporation 2005. All rights reserved.
Compilation finished with 0 warning(s), 0 error(s).
Listing 1 - Using the Windows Workflow Compiler
Additionally, WF supports dynamic compilation of XOML files using the WorkflowCompiler class, as
shown in Code 4. This allows a new workflow definition to be compiled and executed dynamically. An
applicable scenario is when the workflow designer is hosted in an application and an end-user
defines a workflow using that tool.
WorkflowCompiler compiler = new WorkflowCompiler();
WorkflowCompilerParameters param = new WorkflowCompilerParameters();
compiler.Compile(param, new string[] { "Sample.xoml" });
Code 4 - Invoking the workflow compiler at runtime

Chapter 2 – Basics of WF | 10
2.4 Activities The creation of workflows is based on the principle of composition. A set of activities is combined
into a workflow definition in either a sequential or event-driven state manner, in a similar way as GUI
applications are composed out of controls.
WF ships with a series of built-in activities that are visualized in the Visual Studio 2005 Toolbox while
working in a workflow-enabled project. An extensive discussion of those activities would lead us too
far, so we’ll just illustrate this toolbox in Figure 6. When required through the course of this work,
additional explanation of individual activities will be given in a suitable place.
Figure 6 - Built-in activities
Remark that a large portion of these activities has an equivalent in classic procedural programming,
such as if-else branches, while-loops, throwing exceptions and raising events. Others enable more
complex scenarios such as replication of activities, parallel execution and parallel event listening.

Chapter 2 – Basics of WF | 11
A powerful feature of WF and the corresponding tools is the ability to combine multiple activities
into another activity. Using this feature, one is able to create domain-specific activities that allow for
reuse within the same project or cross-project by creating a library of custom activities. This also
creates space for 3rd party independent software vendors (ISVs) to create a business out of
specialized workflow activity creation.
3 Hosting the workflow engine As mentioned a couple of times already, WF consists of a workflow engine that has to be hosted in
some kind of managed code process. Visual Studio 2005 provides support to create console
applications as well as other types of application projects with workflow support. A simple example
of a workflow host is displayed in Code 5 .
3.1 Initializing the workflow runtime and creating workflow instances The most important classes in this code fragment are WorkflowRuntime and WorkflowInstance. The
former one effectively loads the workflow runtime engine in the process; the latter one instantiates
an instance of the workflow in question. Generally spoken, there will be just one WorkflowRuntime
object per application domain, while there will be one workflow instance per invocation of the
workflow. For example, when using a web service host, the invocation of a certain web method could
trigger the creation of a workflow instance that then starts its own life. This effectively allows to
expose long-running stateful workflows through web services.
class Program
{
static void Main(string[] args)
{
using (WorkflowRuntime workflowRuntime = new WorkflowRuntime())
{
AutoResetEvent waitHandle = new AutoResetEvent(false);
workflowRuntime.WorkflowCompleted +=
delegate(object sender, WorkflowCompletedEventArgs e)
{
waitHandle.Set();
};
workflowRuntime.WorkflowTerminated +=
delegate(object sender, WorkflowTerminatedEventArgs e)
{
Console.WriteLine(e.Exception.Message);
waitHandle.Set();
};
WorkflowInstance instance = workflowRuntime.CreateWorkflow
(typeof(WorkflowConsoleApplication1.Workflow1));
instance.Start();
waitHandle.WaitOne();
}
}
}
Code 5 - A console application workflow host
We won’t cover all possible hosts in here, as the principle is always the same. Nevertheless it’s worth
to note that the web services hosting model relies on the WebServiceInput, WebServiceOutput and

Chapter 2 – Basics of WF | 12
WebServiceFault activities to take data in and send data or faults out. Another interesting thing to
know is the lack of direct WCF support in WF, something that can only be established by manual
coding. According to Microsoft this is due to timing issues since WF was introduced relatively late in
the .NET Framework 3.0 development cycle. This shortcoming will be fixed in a future release.
3.2 Runtime services We already discussed the need for a series of runtime services in order to enable a set of workflow-
specific scenarios such as dehydration, which is the act of persisting runtime data when a workflow
goes idle. A brief overview of runtime services and their role is given below:
Scheduling Services are used to manage the execution of workflow instances by the
workflow engine. The DefaultWorkflowSchedulerService is used in non-ASP.NET applications
and relies on the .NET thread pool. On the other side, the ManualWorkflowSchedulerService
is used by ASP.NET hosts and interacts with the ASP.NET host process (e.g. the worker pool).
CommitWorkBatch Services enable custom code to be invoked when committing a work
batch. This kind of service is typically used in combination with transactions and is used to
ensure the reliability of the workflow-based application by implementing additional error-
handling code.
Persistence Services [2] play a central role in workflow instance hydration and dehydration.
Putting a workflow instance’s runtime data on disk is a requirement to be able to deal with
long-running workflows and to ensure scalability. By default SQL Server is used for
persistence.
Tracking Services [3] allow inspection of a workflow in flight by relying on events that are
raised by workflow instances. Based on a Tracking Profile, only the desired data is tracked by
the tracking service. WF ships with a SQL Server database tracking service out of the box.
Local Communication Services enable communication of data to and from a workflow
instance. For example, external events can be sent to a workflow instance and data can be
sent from a workflow instance to the outside world, based on an interface type. The type of
service is often referred to as “data exchange”.
Services can be configured through the XML-based application configuration file or through code. All
of these services are implementations of a documented interface in the Windows SDK which allows
for custom implementation, e.g. to persist state to a different type of database.
4 Dynamic updates Changing a workflow instance that’s in progress is one very desirable feature. In order to respond to
rapid changing business requirements, workflow changes at runtime are a common requirement.
With WF, it’s possible to modify a workflow instance both from the inside (i.e. the workflow’s code)
and the outside (i.e. the host application). This is accomplished by means of the WorkflowChanges
class which we’ll deal with quite a lot in this work.

Chapter 3 – Dynamic updates | 13
Chapter 3 – Dynamic updates
1 Introduction Due to the typical long-running character of workflows, it’s often desirable to be able to change a
workflow while it’s in flight. Common scenarios include the change of business requirements and
adaptation of company policies that need to be reflected in running workflow instances. Windows
Workflow Foundation recognizes this need and has support for dynamic updates built in. This way a
business process can be adapted dynamically, reducing downtime that would occur in typical
procedural code due to recompilations. Furthermore, workflow adaptation occurs on the level of
workflow instances, which reaches far beyond the flexibility one would have with procedural coding.
2 The basics In order to make changes to a workflow instance, one has to create an instance of the type
WorkflowChanges. This class takes the so-called transient workflow, which is the activity tree of the
running workflow, and allows application of changes to it. Once changes have been proposed, these
have to be applied to the running instance. At this point in time, activities in the tree can vote
whether or not they allow the change to occur. If the voting result is positive, changes are applied
and the workflow instance has been modified successfully. This basic process is reflected in code
fragment Code 6.
WorkflowChanges changes = new WorkflowChanges(this);
//Change the transient workflow by adding/removing/... activities
changes.TransientWorkflow.Activities.Add(...);
foreach (ValidationError error in changes.Validate())
{
if (!error.IsWarning)
{
string txt = error.ErrorText;
//Do some reporting and/or fixing
}
}
this.ApplyWorkflowChanges(changes);
Code 6 - Basic use of WorkflowChanges
2.1 Internal modification Code fragment Code 6 employs so-called internal modification of a workflow. Basically, this means
that the workflow change is applied from inside the workflow itself. So, the piece of code could be
living inside a CodeActivity’s ExecuteCode event handler for instance. Notice the constructor call to
WorkflowChanges uses ‘this’ to change the current workflow instance from the inside.
This type of modification can be useful in circumstances where the change can be anticipated
upfront. As an example, the workflow could add a custom activity somewhere in the activity tree
when certain conditions are fulfilled. Needless to say, a similar effect could be achieved by means of
an IfElseBranchActivity. However, one could combine this with reflection and instantiate the desired

Chapter 3 – Dynamic updates | 14
activity by loading it from an assembly. For instance, some custom order delivery processing activity
could be inserted in the workflow definition. If another shipping company requires a different flow of
activities, this could be loaded dynamically. Instead of bloating the workflow definition with all
possible side paths, dynamic adaptation could take care of special branches in a running workflow
tree. Furthermore, in combination with “Local Communication Services” the workflow instance could
retrieve information from the host that’s used in the decision process for dynamic adaptation.
2.2 External modification The opposite of internal modification is external modification, where a workflow instance is adapted
by the host application. Although this limits the flexibility for investigation of the internal workflow
instance state, one has full access to the context in which the workflow is operating. External stimuli
could be at the basis of the change, either automatically or manually (by business people). It’s safe to
state that external modification is the better candidate of the two to apply unanticipated changes.
External modification is applied using the same WorkflowChanges class that exposes the transient
workflow. In order to apply changes, the workflow instance has to be in a suitable state that allows
for dynamic adaptation. Typically, this is the suspended state, as illustrated in code fragment Code 7.
WorkflowRuntime workflowRuntime = new WorkflowRuntime();
workflowRuntime.WorkflowSuspended +=
delegate (object sender, WorkflowSuspendedEventArgs e) {
WorkflowChanges changes = new WorkflowChanges(e.WorkflowInstance);
//Change the transient workflow
changes.TransientWorkflow.Activities.Add(...);
foreach (ValidationError error in changes.Validate())
{
if (!error.IsWarning)
{
string txt = error.ErrorText;
//Do some reporting and/or fixing
}
}
e.WorkflowInstance.ApplyWorkflowChanges(changes);
};
Code 7 - External modification during workflow suspension
3 Changing the transient workflow As mentioned before, changes are applied on a transient workflow that represents a workflow
instance that is in flight. One obtains access to this transient workflow by using the WorkflowChanges
class. In this paragraph, we take a closer look at dynamic adaptation using this transient workflow.
3.1 Inserting activities A typical situation that might arise is the need for additional logic in a workflow’s definition. For
example, in an order processing scenario it might be desired to change running workflow instances
to incorporate a new step in the (typically long-running) order processing workflow.

Chapter 3 – Dynamic updates | 15
Adding a new activity to a transient workflow is accomplished by the Activities collection’s Add and
Insert methods. The former one adds an activity to the end of the activities collection which might
not be the best choice since a change typically employs locality. Using the Insert method, one has
more control over the position where the activity will be inserted.
However, this is often not enough to accomplish the required level of flexibility since the positions of
activities in the tree are often not known upfront. If changes are applied only once, position indices
could be easily inferred from the compiled workflow definition by human inspection. Things get
worse when the original definition changes and when dynamic updates are made accumulative. In
order to break the barrier imposed by this limitation, the GetActivityByName method was
introduced. For example, one could insert an additional step in a workflow right after the submission
of an order, as illustrated in code fragment Code 8.
WorkflowChanges changes = new WorkflowChanges(instance);
//Find the location to insert
Activity a = changes.TransientWorkflow.GetActivityByName("SubmitOrder");
int i = changes.TransientWorkflow.Activities.IndexOf(a) + 1;
SendMailActivity mailer = new SendMailActivity();
changes.TransientWorkflow.Activities.Insert(mailer, i);
instance.ApplyWorkflowChanges(changes);
Code 8 - Applying positional workflow changes
Composite activities, like a WhileActivity or an IfElseActivity, are a bit more difficult to change since
one needs to touch the “body” of these activities. Basically, the same principles apply, albeit a bit
lower in the tree hierarchy, typically using tree traversal code.
3.2 More flexible adaptations More powerful mechanisms can be employed to find the place where a change needs to be applied.
Because the Activities collection derives from the collection base classes in the .NET Framework, all
the power of System.Collections.Generic comes with it for free in the context of workflow. As an
example, one could use the FindAll method to locate activies that match a given predicate:
WorkflowChanges changes = new WorkflowChanges(instance);
//Find activities to adapt
List<Activity> lst = changes.TransientWorkflow.Activities.FindAll(
delegate(Activity a) {
InterestCalculatorActivity ica = a as InterestCalculatorActivity;
return (a != null && ica.Intrest > 0.05);
});
foreach (InterestCalculatorActivity ica in lst)
{
//Change parameterization, delete activites, add activities, etc.
}
Code 9 - Advanced activity selection
Of course it’s also possible to delete activities by means of the Remove method of the Activities
collection.

Chapter 3 – Dynamic updates | 16
3.3 Philosophical intermezzo – where encapsulation vanishes… All of this dynamic update magic comes at a cost. Encapsulation of activities and their composition in
a workflow is left behind once dynamic updates from the outside (“external modification”) are
considered. Therefore, one has to consider carefully whether or not dynamic updates from the
outside are really required. At the stage of applying external modification, the black box of the
workflow definition has to be opened in order to apply changes.
Whenever the original workflow type definition changes, workflow adaptation logic might break. It’s
important to realize that there is no strong-typed binding between the transient workflow and the
underlying workflow definition by default. In the code fragment Code 8, we’ve illustrated the use of
finding activities by name, which clearly is very dependent on internal details of the workflow
definition.
This being said, adaptation logic is often short-lived and created to serve just one specific type of
adaptation associated with a given version of a workflow definition (e.g. because the underlying
business process has changed – a change that could be incorporated statically in the next version of
the workflow definition). Furthermore, when creating adaptation logic on the fly – with the aid of a
graphical workflow designer – the verification of adaptation logic against the underlying workflow
definition becomes easier because of designer support, e.g. to find the names of activities in the
workflow.
3.4 Establishing data bindings Adding an activity somewhere in a workflow instance dynamically is one thing; connecting it to other
colleague activities is another thing. Essentially, we want to be able to bind input properties on the
newly inserted activity to some kind of data sources in the workflow definition; the other way
around, we want to be able to feed the output properties of our inserted activity back to the
surrounding workflow class for further consumption down the line.
To support data bindings by means of properties, WF introduces the concept of dependency
properties which act as a centralized store for workflow state. The code to create a sample activity
with dependency properties that allow for data binding is shown in code fragment Code 10.
public class DemoActivity : Activity
{
private double factor;
public DemoActivity() {}
public DemoActivity(double factor) { this.factor = factor; }
public static DependencyProperty InputProperty =
DependencyProperty.Register(
"Input",
typeof(double),
typeof(DemoActivity)
);
public double Input
{
get { return (double)base.GetValue(InputProperty); }
set { base.SetValue(InputProperty, value); }
}

Chapter 3 – Dynamic updates | 17
public static DependencyProperty OutputProperty =
DependencyProperty.Register(
"Output",
typeof(double),
typeof(DemoActivity)
);
public double Output
{
get { return (double)base.GetValue(OutputProperty); }
set { base.SetValue(OutputProperty, value); }
}
protected override ActivityExecutionStatus Execute(
ActivityExecutionContext executionContext)
{
double input = (double)GetValue(InputProperty);
double res = input * factor;
SetValue(OutputProperty, res);
return ActivityExecutionStatus.Closed;
}
}
Code 10 - Using dependency properties for data binding flexibility
This sample activity opens the doors to data binding. The use of the custom activity in the WF
designer in Visual Studio 2005 is shown in Figure 7.
Figure 7 - Design-time support for bindable properties
Binding support at design-time is visualized by the presence of a small blue-white information icon in
the right margin of the property names column. Clicking it allows to bind the property of the activity
to a property of the enclosing workflow definition, as shown in Figure 8.
However, when applying dynamic updates we want to be able to establish such a binding at runtime.
This is made possible through the use of the ActivityBind class in WF. An example of this class’s
usage is illustrated in code fragment Code 11.

Chapter 3 – Dynamic updates | 18
Figure 8 - Binding a property at design-time
For simplicity’s sake, this sample inserts a DemoActivity activity at the end of a sequential workflow that would otherwise return the same value as the input value. By feeding the workflow’s input to the dynamically added DemoActivity and the DemoActivity’s output in the reverse direction, we can adapt the original input value dynamically. This mechanism could be used to apply a correction factor to numerical data that flows though a workflow, e.g. to account for increased shipping costs. private void UpdateWorkflow(WorkflowInstance instance)
{
WorkflowChanges changes =
new WorkflowChanges(instance.GetWorkflowDefinition());
DemoActivity da = new DemoActivity(2.0);
ActivityBind bindInput = new ActivityBind("Workflow1", "Input");
da.SetBinding(
MultiDynamicChange.DemoActivity.InputProperty, bindInput);
ActivityBind bindOutput = new ActivityBind("Workflow1", "Output");
da.SetBinding(
MultiDynamicChange.DemoActivity.OutputProperty, bindOutput);
changes.TransientWorkflow.Activities.Add(da);
instance.ApplyWorkflowChanges(changes);
}
Code 11 - Establishing dynamic data binding

Chapter 3 – Dynamic updates | 19
4 Changing sets of workflow instances Rarely one needs to change just one instance of a workflow. If this is the case, additional logic can be
added to code fragment Code 7 in order to select the desired workflow instance, e.g. by means of its
unique workflow identifier (using the WorkflowInstance’s InstanceId property).
In the majority of scenarios however, changes have to be applied to all workflow instances in
progress or a certain subset of workflow instances based on some filter criterion. Furthermore, it’s
often desirable to be able to apply changes out of band, meaning that we don’t want to wait for a
suspension to happen due to some workflow instance state transition, for example because of
workflow instance state persistence. Based on human inspection of one workflow instance, business
people might decide to change a whole set of workflow instances and they want the change to
become effective right away.
To support this out-of-band multi-instance adaptation, the host application can query the runtime
for all running workflow instances, as illustrated in code fragment Code 12.
foreach (WorkflowInstance instance in wr.GetLoadedWorkflows())
UpdateWorkflow(instance);
Code 12 - Querying loaded workflows
Each WorkflowInstance can be queried for the underlying workflow definition using a method called
GetWorkflowDefinition that obtains a reference to the root activity. Based on the workflow instance
information, additional filtering logic can be applied to select a subset of workflow instances and/or
workflow instances of a given type. Once such a set of workflow instances is retrieved, changes can
be applied using WorkflowChanges. The WF runtime takes care of suspending the workflow prior to
making the dynamic update and resuming it right after the change was applied. Since changes are
applied on an instance-per-instance basis, exceptions thrown upon failure to change an instance only
affect one particular workflow adaption at a time, so rich failure reporting and retry logic can be
added if desired.
5 An instrumentation framework for workflow Now that we’re capable of applying changes to a workflow instance, we can take it to another level.
In this paragraph, we’ll discuss the possibility to create an instrumentation framework that allows for
dynamic aspect insertion into a workflow instance at runtime. A few usage scenarios include the
instrumentation of workflows for debugging purposes, adding logging logic, insertion of timing
constructs to measure average delays and waiting times for customers, dynamic addition of security
checks to protect certain workflow branches from being executed by non-authorized users, etc.
When considering instrumentation, we’re talking about a dynamic change to a fixed definition at
runtime. This makes WF’s dynamic update feature the ideal candidate to build an instrumentation
framework on. Essentially, we’ll instrument a workflow instance from the outside prior to starting it.
The instrumentation process can be driven by a wide variety of decision logic (e.g. based on input
values), additional data (such as threshold values), dynamic assembly loading using reflection (e.g. to
add more flexibility to the instrumentor itself), or ultimately another workflow itself.

Chapter 3 – Dynamic updates | 20
5.1 A simple logging service An example of a simple workflow instrumentor that tracks progress via a logging service is illustrated
in code fragments Code 13 and Code 14.
The former one shows the interface – and a simple implementation – for a logging service that’s used
in the logging activity itself to submit logging information to. Notice that this way of tracking is
slightly different from the built-in tracking service in WF. Tracking is either enabled or disabled, while
instrumentation can be done selectively, meaning that a specific subset of the created workflow
instances could be instrumented based on decision logic. Also, the “logging points” in the workflow
can be limited to a few interesting places in order to reduce overall overhead.
Code fragment Code 14 illustrates a logging activity that pushes data to the registered logger service
through its interface contract. We limit ourselves to simple (positional) tracking messages.
[ExternalDataExchange]
interface ILogger
{
void LogMessage(string message);
}
class Logger : ILogger
{
private TextWriter tw;
public Logger(TextWriter tw) { this.tw = tw; }
public void LogMessage(string message)
{
tw.WriteLine(message);
}
}
Code 13 - Local Communication Service definition and sample implementation for logging
class LogActivity : Activity
{
private string message;
public LogActivity() { }
public LogActivity(string message) { this.message = message; }
public string Message
{
get { return message; }
set { message = value; }
}
protected override ActivityExecutionStatus Execute
(ActivityExecutionContext executionContext)
{
executionContext.GetService<ILogger>().LogMessage(message);
return ActivityExecutionStatus.Closed;
}
}
Code 14 - A static message logging activity

Chapter 3 – Dynamic updates | 21
Logging becomes more interesting when we’re able to capture and format interesting data that’s
fueling the workflow instance, i.e. some kind of white box inspection on demand. Our generic
approach to data processing workflows in Chapter 4 makes such inspection even more manageable.
5.2 Instrumentation for dynamic updates Although instrumentation itself is driven by dynamic updates, it can be used as a starting point for
dynamic updates on its turn. So far, the discussed methodologies of adapting a workflow in progress
are fairly risky in a sense that there’s no guarantee that the service is in a state where a dynamic
update is possible. Also, it’s possible that an update is applied at an unreachable point in a workflow
instance, for example to an execution path already belonging the past.
Ideally, we’d like to have control over dynamic updates much like we had in the internal modification
scenario but without sacrificing the cleanliness of the underlying workflow definition. To state it
another way, we don’t want to poison the workflow definition with lots of “possibly we might need
to adapt at this point sometimes” constructs. After all, if we were building this kind of logic into the
workflow definition itself, we really do need to ask ourselves whether dynamic updates are required
in the first place.
Dynamic update instrumentation combines the best of both worlds. First of all, we’ll have exact
control over when an update takes place, by so-called suspension points. Secondly, we preserve the
flexibility of external modification to consume data and context available in the workflow hosting
application layer. Finally, it’s possible to have tight control over the internal workflow instance state,
much like we have in pure internal modification.
Let’s start with an outline of the steps taken to establish dynamic update instrumentation:
1. When a workflow instance is created, suspension points are added to the workflow
definition based on configuration. All these points are uniquely identified.
2. The workflow host application responds to workflow instance suspension events and – based
on configuration – decides whether or not action has to be taken at that point in time.
a. If an update is demanded, different options are available:
i. Slight changes that don’t require access to internal state can rely on external
modification.
ii. More advanced changes that require internal state can be realized by
injecting a custom activity that carries update logic into the workflow
instance from the outside.
b. Regardless of the application of an update, the workflow instance is resumed.
5.2.1 Instrumentation with suspension points
Step one involves the instrumentation itself. During this step, SuspendActivity activities are added to
the workflow at configurable places. This realizes our requirement to have control over the timing of
workflow modifications. For example, we could inject a suspension point right before an order is
submitted to a courier service to account for possible last-minute market changes or courier service
contract changes. Essentially, we’re creating a callback mechanism at a defined point in time, without
having to change the original workflow definition and allowing for flexible configuration.
Code fragment Code 15 shows simple instrumentation logic.

Chapter 3 – Dynamic updates | 22
WorkflowInstance instance =
workflowRuntime.CreateWorkflow(typeof(SampleWorkflow));
WorkflowChanges c = new WorkflowChanges(instance.GetWorkflowDefinition());
SuspendActivity s = new SuspendActivity("suspend1");
s.Error = "between_1_and_2";
int pos = c.TransientWorkflow.Activities.IndexOf(
c.TransientWorkflow.GetActivityByName("demoCode1"));
c.TransientWorkflow.Activities.Insert(pos + 1, s);
instance.ApplyWorkflowChanges(c);
instance.Start();
Code 15 - Injecting a suspension point
Needless to say, this code can be extended to inject multiple suspension points in a configuration-
driven manner. Notice that every suspension point needs to have a unique name (e.g. “suspend1”)
which can be generated at random. Next, an Error property value has to be set. This will be used in
the decision logic of step two (see next section) to identify the suspension location. Error really is a
bit of a misnomer, since workflow suspension doesn’t necessarily imply that an error has occurred. In
our situation it really means that we want to give the host application a chance to take control at
that point in time. Finally, the suspension point has to be inserted at the right place in the workflow,
e.g. before or after an existing activity in the workflow. In our sample, the suspension point is
injected after an activity called “demoCode1”. The original sample workflow and the corresponding
instrumented one are depicted in Figure 9.
Figure 9 - Dynamic workflow instrumentation before (left) and after (right)
When making this more flexible, we end up with a configurable table of suspension point injections
that consists of tuples {Before/After, ActivityName}. Based on this, instrumentation can be applied in
a rather straightforward iterative fashion. Changing this table, for instance stored in a database, at
runtime will automatically cause subsequent workflow instances to be instrumented accordingly.

Chapter 3 – Dynamic updates | 23
If desired, existing workflows could be (re)instrumented too at database modification time, keeping
in mind that some suspension points won’t be hit on some workflow instances because of their
temporal nature. This effect could be undesired since intermediate states could be introduced, e.g.
when implicit assumptions are made on different suspension points and actions. An example of this
pathological situation is instrumentation and adaptation for performance measurement. Consider
the situation in which we want to inject a “start counter” activity on position A and a “stop counter”
activity on position B. If position A already belongs to the past in some workflow instance, an injected
“stop counter” activity will produce invalid results (or worse, it might crash the workflow instance)
since the corresponding “start counter” activity won’t ever be hit.
5.2.2 Responding to suspensions
In the previous step, we took the steps required to set up “rendez-vous points” where the workflow
instance will be suspended, allowing the surrounding host application to take control. This is the
place where further actions can be taken, such as modifying the workflow. A business-oriented
sample usage is the injection of additional order processing validation steps due to company policy
changes before the workflow continues to submit the order.
Code fragment Code 16 outlines the steps taken in the workflow host to respond to the suspension
point introduced earlier by Code 15. Observe the consumption of the e.Error property in the decision
making process to trace back the suspension point itself.
workflowRuntime.WorkflowSuspended +=
delegate(object sender, WorkflowSuspendedEventArgs e)
{
switch (e.Error)
{
case "between_1_and_2":
//adaptation logic goes here
Console.WriteLine("Instrumentation in action!");
e.WorkflowInstance.Resume();
break;
}
};
Code 16 - Adaptation in response to a suspension point
Again, additional flexibility will be desirable since we can’t recompile the host application to embed
this switching logic. Different approaches exist ranging from simple adaptations to far more complex
ones. An overview:
The tuple {Before/After, ActivityName} could be linked to a set of tuples containing actions to
be taken when the suspension point is hit, optionally with additional conditions. Such an
“action tuple” could look like ,Before/After, ActivityName, ActivityType- meaning that an
activity of type ActivityType has to be inserted before or after ActivityName in the workflow.
Evaluation of conditions could be expressed using the rule engine in WF and by serializing the
rules in an XML file.
A more generic approach would use reflection and application domains to load the switching
logic dynamically. For each suspension point, the “response logic type” is kept as well (see
tuple representation in Code 17). At runtime, these response logic types (which implement
the interface of Code 18) – are loaded dynamically (Code 19). When the WorkflowSuspended

Chapter 3 – Dynamic updates | 24
event is triggered, the “Error” event argument is mapped to the corresponding “response
logic type” that gets a chance to execute. This is illustrated in Code 20.
enum InstrumentationType { Before, After }
class InstrumentationPoint {
private Guid id;
private InstrumentationType t;
private string p;
private string a;
public Guid Id { get {return id;} set {id = value;} }
public InstrumentationType Type { get {return t;} set {t = value;} }
public string Point { get {return p;} set {p = value;} }
public string ActionType { get {return a;} set {a = value;} }
}
Code 17 - Type definition for instrumentation tuples
interface IAdaptationAction : IDisposable {
void Initialize(WorkflowInstance instance);
void Execute();
}
Code 18 - A generic adaption action interface
private Dictionary<string, IAdaptationAction> actions =
new Dictionary<string, IAdaptationAction>();
...
WorkflowInstance instance =
workflowRuntime.CreateWorkflow(typeof(SampleWorkflow));
WorkflowChanges c = new WorkflowChanges(instance.GetWorkflowDefinition());
int i = 0;
foreach (InstrumentationPoint ip in GetInstrumentationPoints())
{
SuspendActivity s = new SuspendActivity("suspend" + ++i);
s.Error = ip.Id.ToString();
int pos = c.TransientWorkflow.Activities.IndexOf(
c.TransientWorkflow.GetActivityByName(ip.Point));
c.TransientWorkflow.Activities.Insert(
ip.Type == InstrumentationType.After ? pos + 1 : pos, s);
actions.Add(ip.Id.ToString(),
(IAdaptationAction) Assembly.Load(ip.Assembly).GetType(ip.Type));
}
instance.ApplyWorkflowChanges(c);
instance.Start();
Code 19 - Fully dynamic instrumentation
Notice that the code fragments above need robust error handling to keep the workflow runtime from
crashing unexpectedly when creating workflow instances. The dynamic nature of the code makes
compile-time validation impossible, so runtime exceptions will be thrown when invalid parameters
are passed to the instrumentor. For example, activities with a given name could be non-existent or
the instrumentation action type could be unloadable. One might consider running a different
WorkflowRuntime instance to check the validity of instrumentation logic using dummy workflow

Chapter 3 – Dynamic updates | 25
instances prior to pushing it to the production runtime environment. Furthermore, caching and
invalidation logic for the configuration will improve performance significantly since reflection is
rather slow. A final note embodies the use of dynamic assembly loading in a rather naïve way. In the
current version of the CLR, loading an assembly in an application domain is irreversible [4]. This could
lead to huge resource consumption by short-lived “adaption actions”. A better approach would be to
load the assemblies in separate application domains (for example on a per-batch basis for workflow
adaptations) which can be unloaded as elementary units of isolation in the CLR. However, to cross
the boundaries of application domains, techniques like .NET Remoting will be required. Because of
this increased complexity we won’t elaborate on this, but one should be aware of the risks imposed
by naïve assembly loading.
workflowRuntime.WorkflowSuspended +=
delegate(object sender, WorkflowSuspendedEventArgs e)
{
using (IAdaptationAction action = actions[e.Error])
{
action.Initialize(e.WorkflowInstance);
action.Execute();
e.WorkflowInstance.Resume();
}
};
Code 20 - Dynamic adaptation action invocation at suspension points
As an example, we’ll build a simple adaptation action (Code 21) that corresponds to the one shown in
Code 11, including the data binding functionality. However, encapsulation in an IAdaptationAction
type allows for more flexible injection when used together with the instrumentation paradigm.
public class TimesTwoAdaptor : IAdaptationAction
{
private WorkflowInstance instance;
public void Initialize(WorkflowInstance instance)
{ this.instance = instance; }
public void Execute()
{
WorkflowChanges changes =
new WorkflowChanges(instance.GetWorkflowDefinition());
DemoActivity da = new DemoActivity(2.0);
ActivityBind bindInput = new ActivityBind("Workflow1", "Input");
da.SetBinding(DemoActivity.InputProperty, bindInput);
ActivityBind bindOutput = new ActivityBind("Workflow1", "Output");
da.SetBinding(DemoActivity.OutputProperty, bindOutput);
changes.TransientWorkflow.Activities.Add(da);
instance.ApplyWorkflowChanges(changes);
}
public void Dispose() {}
}
Code 21 - Encapsulation of a workflow adaptation

Chapter 3 – Dynamic updates | 26
5.3 Advanced instrumentation logic In code fragment Code 19 we’ve shown a simple way to instrument a workflow instance based on
positional logic (i.e. “after” or “before” a given activity). However, this logic won’t work with more
complex workflow definitions which do not have a linear structure. For example, when a workflow
contains an IfElseActivity, the workflow definition’s Activities collection won’t provide access to the
activities nested in the branches of the IfElseActivity. In order to instrument the workflow at these
places too, one will need to extend the code to perform a recursive lookup, or alternatively the
activity name reference could take an XPath-alike form to traverse the tree up to the point where
instrumentation is desired.
An example of a recursive instrumentation implementation with user interaction is shown in code
fragment Code 22.
delegate void Instrumentor(Activity activity,
WorkflowChanges changes,
bool before, bool after);
public void Instrument(Activity activity,
WorkflowChanges changes,
Instrumentor DoInstrument) {
char r;
do {
Console.Write(
"Instrument {0}? (B)efore, (A)fter, (F)ull, (N)one ",
activity.Name);
r = Console.ReadLine().ToLower()[0];
} while (r != 'b' && r != 'a' && r != 'f' && r != 'n');
if (r != 'n')
DoInstrument(activity, changes,
r == 'b' || r == 'f', r == 'a' || r == 'f');
if (activity is CompositeActivity)
foreach (Activity a in ((CompositeActivity)activity).Activities)
Instrument(a, changes, DoInstrument);
}
Code 22 - Recursive workflow definition traversal for instrumentation
Using the Instrumentator delegate, it becomes possible to adapt the instrumentation logic at will.
This further increases the overall flexibility of the instrumentation framework. This way, one could
instrument with suspension points but also with, for instance, logging activities. Furthermore, one
could get rid of the Console-based interaction by querying some data source through a querying
interface to get to know whether or not an activity has to be instrumented.
This form of recursion-based instrumentation is most useful when lots of instrumentations will be
required and if the underlying querying interface doesn’t cause a bottleneck. On the other side,
when only a few of sporadic instrumentations are likely to be requested and when workflow
definitions are quite huge, it might be a better idea to use an approach based on instrumentation
points without having to traverse the whole workflow definition tree.
Last but not least, notice that instrumentations can be performed on already-instrumented workflow
instances too, allowing for accumulative instrumentations.

Chapter 3 – Dynamic updates | 27
5.4 Conclusion As we’ve shown in this paragraph, dynamic instrumentation of workflows through the use of
suspension points is a very attractive way to boost the flexibility of WF. This technique combines the
goodness of external modifications on the hosting layer – having access to contextual information –
with the horsepower of internal modifications that have a positional characteristic in a workflow
definition allowing for “just-in-time” adaption. To realize the flexibility of this mechanism, one should
think of the result obtained by encapsulating the instrumentation logic itself in an “adaptation
action” (the snake swallowing its own tail).
During the previous discussion, one might have observed a correspondence to the typical approaches
employed in the aspect-oriented development, such as crosscutting. Indeed, as we’ll show further in
this work, combining dynamic adaptation with generic components for “aspects” like logging,
authorization, runtime analysis, etc. will open up the door for highly-dynamic systems that allow for
runtime modification and production debugging to a certain extent.
The primary drawback to this methodology is the invasive nature of dynamic activity injections that
can touch the inside of the workflow instance, effectively breaking encapsulation. Notice that the WF
architecture using dependency properties still hides the real private members of workflow types, so
unless you’re reflecting against the original workflow type you won’t be able to get access to private
members from an object-oriented (OO) perspective.
However, philosophically one could argue that the level of abstraction that WF enables is one floor
higher than the abstraction and encapsulation level in the world of OO. Based on this argument,
injection of activities in a workflow instance really is a breakage of encapsulation goals. Nevertheless,
when used with care and with rigorous testing in place it shouldn’t hurt. As a good practice,
developers should adopt strict rules when writing injections since there’s not much the runtime can
do to protect them against malicious actions. Flexibility at the cost of increased risk…
6 A few practical uses of instrumentation In this paragraph, we present a few practical usage scenarios for workflow instrumentation. First,
let’s define instrumentation more rigorously:
Workflow instrumentation is the action of adding activities dynamically on pre-defined places in the
activity tree of a newly created workflow instance before it’s started.
With this definition, we can suggest a few uses for instrumentation in practice:
Adding logging to a workflow. This can be used to gather diagnostic information, for example
to perform production debugging.
Measurement of service times can be accomplished by adding a “measurement scope” to
the workflow instance, i.e. surrounding the region that needs to be times with a “start to
measure” activity and a “stop to measure” activity.
Protecting portions of a workflow from unauthorized access. To do this, the workflow host
application layer could add some kind of access denied activities in places that are disallowed
for the user that launches the workflow instance. This decouples the authorization aspect
from the internals of a workflow definition.

Chapter 3 – Dynamic updates | 28
6.1 Logging As a first example, we’ll create a logger that can be added dynamically by means of instrumentation.
It allows data to be captured from the workflow instance in which the logger is injected by means of
dependency properties. To illustrate this, consider a workflow defined as in Code 23.
public sealed partial class AgeChecker : SequentialWorkflowActivity
{
public AgeChecker() { InitializeComponent(); }
static DependencyProperty FirstNameProperty =
DependencyProperty.Register("FirstName", typeof(string),
typeof(AgeChecker));
static DependencyProperty AgeProperty =
DependencyProperty.Register("Age", typeof(int),
typeof(AgeChecker));
public string FirstName {
get { return (string)this.GetValue(FirstNameProperty); }
set { this.SetValue(FirstNameProperty, value); }
}
public int Age {
get { return (int)this.GetValue(AgeProperty); }
set { this.SetValue(AgeProperty, value); }
}
private void sayHello_ExecuteCode(object sender, EventArgs e) {
Console.ForegroundColor = ConsoleColor.Green;
Console.WriteLine("Welcome {0}!", FirstName);
Console.ResetColor();
}
}
Code 23 - A simple workflow definition using dependency properties
This workflow definition consists of a single “sayHello” CodeActivity that prints a message to the
screen. Assume we want to check that the Age property has been set correctly; in order to do so,
we’d like to inject a logging activity into the workflow instance in order to inspect the internal values
at runtime. We’ll accomplish this by means of instrumentation. In code fragment Code 24 you can
see the definition of such a simple logging activity which has a few restrictions we’ll talk about in a
minute.
public class LoggingActivity: Activity
{
private string message;
private string[] args;
public LoggingActivity() { }
public LoggingActivity(string message, params string[] args)
{
this.message = message;
this.args = args;
}
protected override ActivityExecutionStatus Execute
(ActivityExecutionContext executionContext)
{

Chapter 3 – Dynamic updates | 29
ArrayList lst = new ArrayList();
foreach (string prop in args)
lst.Add(Parent.GetValue(
DependencyProperty.FromName(prop, Parent.GetType())));
executionContext.GetService<ILogger>().LogMessage(
message, lst.ToArray());
return ActivityExecutionStatus.Closed;
}
}
Code 24 - A simple LoggingActivity
This activity takes two constructor parameters: a message to be logged (in the shape of a “formatting message” as used in .NET) and a parameter list with the names of the properties that need to be fed into the formatting string. Inside the Execute method, the activity retrieves the values of the specified properties using the dependency properties of the parent. Notice that this forms a first limitation, since nesting of composite activities will make the search for the right dependency properties to get a value from more difficult. This can be solved using a recursive algorithm that walks up the activity tree till the Parent property is null. Nevertheless, for the sake of the demo this definition is sufficient. Next, the message together with the retrieved parameters is sent to an ILogger (see Code 25) service using Local Communication Services. [ExternalDataExchange]
interface ILogger
{
void LogMessage(string format, params object[] args);
}
Code 25 - The ILogger interface for LoggingActivity output
Now, to do the instrumentation it’s just a matter of injecting well-parameterized LoggingActivity instances wherever required and writing an ILogger implementation, as shown in Code 26. Needless to say, the ILogger implementation can be implemented in any fashion the user sees fit, e.g. to write the logging messages to a database or to the Windows Event Log. Notice that the host for our workflow runtime needs to be aware of the eventuality that logging might be required somewhere in the future. The registration of the logger implementation and the instrumentation logic are shown in Code 27. class Logger : ILogger
{
private TextWriter tw;
public Logger(TextWriter tw) { this.tw = tw; }
public void LogMessage(string format, params object[] args)
{
tw.WriteLine(format, args);
}
}
Code 26 - Implementation of a logger that uses a TextWriter
using (WorkflowRuntime workflowRuntime = new WorkflowRuntime())
{
ExternalDataExchangeService eds = new ExternalDataExchangeService();
workflowRuntime.AddService(eds);
eds.AddService(new Logger(Console.Out));

Chapter 3 – Dynamic updates | 30
Dictionary<string, object> args = new Dictionary<string, object>();
args.Add("FirstName", "Bart");
args.Add("Age", 24);
WorkflowInstance instance = workflowRuntime.CreateWorkflow(
typeof(WFInstrumentation.AgeChecker), args);
WorkflowChanges c =
new WorkflowChanges(instance.GetWorkflowDefinition());
c.TransientWorkflow.Activities.Insert(0,
new LoggingActivity(
"Hello {0}, you are now {1} years old.", "FirstName", "Age"));
instance.ApplyWorkflowChanges(c);
instance.Start();
...
Code 27 - Instrumentation of a workflow instance with the logger
In here, we added the logger to the top of the workflow instance’s activity tree. On top of the code fragment you can see the registration of the logger through Local Communication Services. For sake of the demo, we’ll just print the logging messages to the console.
6.2 Time measurement Another example of dynamic workflow instrumentation is the injection of a set of timing blocks,
acting as a stopwatch. In this case, we want to inject two activities around a region we want to
measure in time. The first activity will start the timer; the second one will stop the timer and report
the result.
Again, the structure of the instrumentation is the same. First, we’ll write the StopwatchActivity as
shown in Code 28. Next, an interface will be provided to allow the activity to communicate with the
host environment using the Local Communication Services (Code 29).
public class StopwatchActivity : Activity
{
private StopwatchAction action;
private string watcher;
private static Dictionary<string, Stopwatch> watches
= new Dictionary<string, Stopwatch>();
public StopwatchActivity() { }
public StopwatchActivity(string watcher, StopwatchAction action)
{
this.watcher = watcher;
this.action = action;
if (!watches.ContainsKey(watcher))
watches.Add(watcher, new Stopwatch());
}
protected override ActivityExecutionStatus
Execute(ActivityExecutionContext executionContext)
{
if (action == StopwatchAction.Start)
watches[watcher].Start();

Chapter 3 – Dynamic updates | 31
else
{
watches[watcher].Stop();
TimeSpan ts = watches[watcher].Elapsed;
watches.Remove(watcher);
executionContext.GetService<IStopwatchReporter>()
.Report(WorkflowInstanceId, watcher, ts);
}
return ActivityExecutionStatus.Closed;
}
}
public enum StopwatchAction { Start, Stop }
Code 28 - Time measurement using a StopwatchActivity
[ExternalDataExchange]
public interface IStopwatchReporter
{
void Report(Guid workflowInstanceId,
string watcher, TimeSpan elapsed);
}
Code 29 - Reporting measurement results through an interface for Local Communication Services
Finally, the instrumentation can be done by implementing the IStopwatchReporter interface (Code
30) and injecting the measurement points in the workflow instance (Code 31).
class StopwatchReporter : IStopwatchReporter
{
public void Report(Guid workflowInstanceId,
string watcher, TimeSpan elapsed) {
Console.WriteLine("{0}: {1} - {2}", workflowInstanceId,
watcher, elapsed.TotalMilliseconds);
}
}
Code 30 - Implementation of a stopwatch timing reporter
using (WorkflowRuntime workflowRuntime = new WorkflowRuntime())
{
ExternalDataExchangeService eds = new ExternalDataExchangeService();
workflowRuntime.AddService(eds);
eds.AddService(new StopwatchReporter());
WorkflowInstance instance = workflowRuntime.CreateWorkflow(
typeof(WFInstrumentation.Workflow1));
WorkflowChanges c =
new WorkflowChanges(instance.GetWorkflowDefinition());
c.TransientWorkflow.Activities.Insert(1,
new StopwatchActivity("measureDelay", StopwatchAction.Stop));
c.TransientWorkflow.Activities.Insert(0,
new StopwatchActivity("measureDelay", StopwatchAction.Start));
instance.ApplyWorkflowChanges(c);
instance.Start();
...
Code 31 - Instrumentation of a workflow with stopwatch timers

Chapter 3 – Dynamic updates | 32
As an example we apply the instrumentation to a simple workflow that contains a single delay
activity set to a few seconds, as shown in Figure 10.
Figure 10 - Sample workflow for stopwatch testing
This sample could be extended easily to allow for more flexibility. For instance, a third stopwatch
action could be introduced to report the result. This would allow for cumulative timings where the
timer is started and stopped on various places, while the result is only reported once when the
activity is told to do so by means of the action parameter. We could also allow for reuse of the same
Stopwatch instance by providing a reset action that calls the Stopwatch instance’s Reset method.
6.3 Authorization The next sample shows how instrumentation can be applied to workflow instances to protect certain
paths from unauthorized access. In some cases, authorization might be built-in to the workflow
definition itself, for example using Authorization Manager [5], but in other cases it might be more
desirable to inject intra-workflow authorization checks at a later stage in the game.
In order to reject access to a certain portion of a workflow we’ll use a ThrowActivity that throws an
AccessDeniedException as defined in Code 32.
[Serializable]
public class AccessDeniedException : Exception
{
public AccessDeniedException() { }
public AccessDeniedException(string message)
: base(message) { }
public AccessDeniedException(string message, Exception inner)
: base(message, inner) { }
protected AccessDeniedException(
System.Runtime.Serialization.SerializationInfo info,
System.Runtime.Serialization.StreamingContext context)
: base(info, context) { }
}
Code 32 - AccessDeniedException definition for authorization barriers
Now consider a workflow definition like the one shown in Figure 11. However, in a non-instrumented
workflow we don’t want to have the accessDenied activity in place yet. As a matter of fact, a
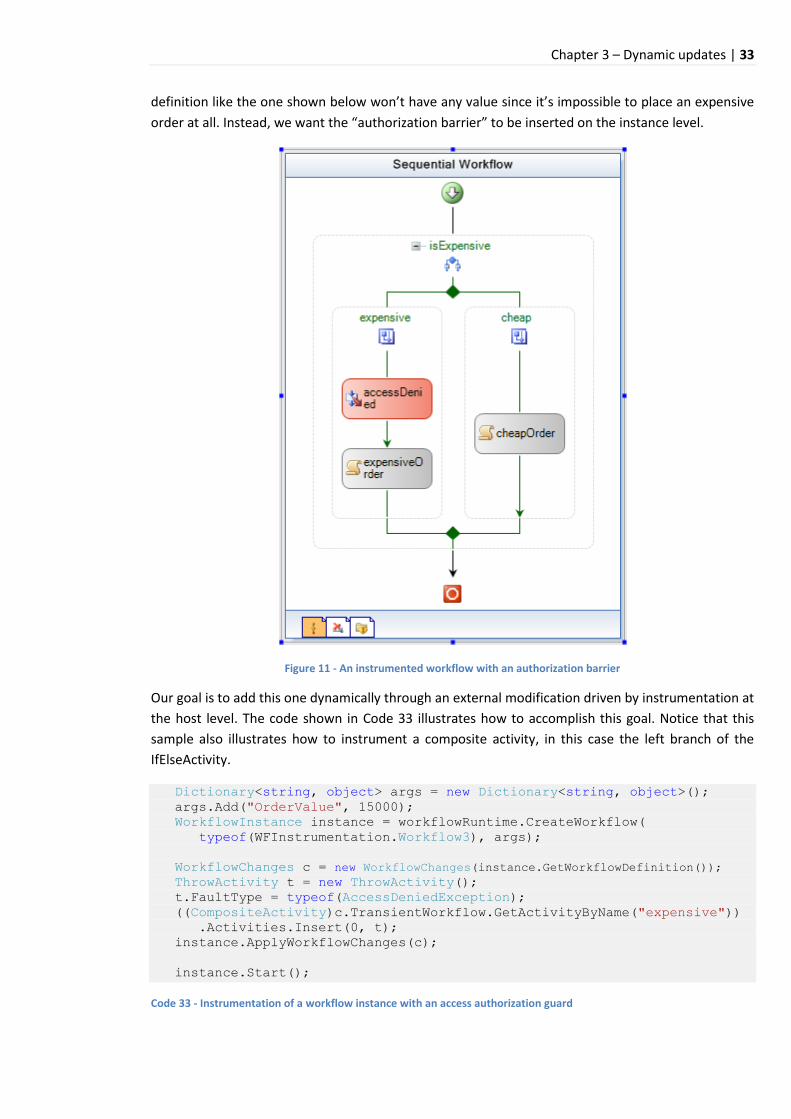
Chapter 3 – Dynamic updates | 33
definition like the one shown below won’t have any value since it’s impossible to place an expensive
order at all. Instead, we want the “authorization barrier” to be inserted on the instance level.
Figure 11 - An instrumented workflow with an authorization barrier
Our goal is to add this one dynamically through an external modification driven by instrumentation at
the host level. The code shown in Code 33 illustrates how to accomplish this goal. Notice that this
sample also illustrates how to instrument a composite activity, in this case the left branch of the
IfElseActivity.
Dictionary<string, object> args = new Dictionary<string, object>();
args.Add("OrderValue", 15000);
WorkflowInstance instance = workflowRuntime.CreateWorkflow(
typeof(WFInstrumentation.Workflow3), args);
WorkflowChanges c = new WorkflowChanges(instance.GetWorkflowDefinition());
ThrowActivity t = new ThrowActivity();
t.FaultType = typeof(AccessDeniedException);
((CompositeActivity)c.TransientWorkflow.GetActivityByName("expensive"))
.Activities.Insert(0, t);
instance.ApplyWorkflowChanges(c);
instance.Start();
Code 33 - Instrumentation of a workflow instance with an access authorization guard

Chapter 3 – Dynamic updates | 34
The instrumentation of a workflow instance with the code above results in an exception being
thrown when the left branch is hit, for example when the order value exceeds 10000. Notice that this
exception can be caught by adding fault handlers to the workflow definition, as shown in Figure 12.
Figure 12 - Handling AccessDeniedException faults in the workflow
However, the presence of such handlers assumes prior knowledge of the possibility for the workflow
to be instrumented with an authorization barrier, which might be an unlikely assumption to make.
Nevertheless, situations can exist where it’s desirable to have the entire authorization mechanism
being built around dynamic instrumentations. In such a scenario, adding fault handlers in the
workflow definition perfectly makes sense.
An alternative approach to authorization would be to add static barriers at development time, which
rely on Local Communication Services to query the host whether or not access is allowed at a certain
point in the workflow tree, based on several indicators like the user identity and various internal
values. This approach could be extended to the dynamic case by providing a generic “workflow
inspector” activity that can be injected through instrumentation. Such an activity would be
parameterized with a list of names for the to-be-retrieved properties and would take an approach
like the one used in the logging sample (Code 24) to collect the values. Using Local Communication
Services, these values can be sent to the host where additional logic calculates whether or not access
is allowed. If not, a dynamic update is applied in order to put an authorization barrier in place.

Chapter 3 – Dynamic updates | 35
6.4 Production debugging and workflow inspection The proposal of a generic “workflow inspector”, as in the previous paragraph, would provide
additional benefits, for example while debugging a workflow type in the production stage when
issues are observed. In this final sample, we’ll illustrate how one can build a generic workflow
inspector utility that can be added dynamically through instrumentation, for instance to assist in
production debugging scenarios. This tool could be used as a replacement for the logging activity we
saw earlier, by putting the text formatting logging logic in the host application and consuming the
data provided by the inspector.
Let’s start by defining what an inspection looks like. As we want to keep things as generic as possible,
we’ll make it possible to inspect “classic” properties, dependency properties as well as fields. Next, a
format is needed to point to the inspection target, for example an activity that can be nested deeply
in the activity tree. To serve this goal, we’ll introduce a forward slash separated path notation that
starts from the parent of the inspector activity itself. For example, if we inject an inspector in the
expensive branch from Figure 11, the root path (“”) will be the expensive branch itself. By using the
path “..” we’ll point at the isExpensive activity. To point at the cheap activity, we’ll need to use
“../cheap” as a path. Finally, an inspection will also hold the name of the inspection target, which can
be a (dependency) property or a field. The result is shown below in code fragment Code 34.
[Serializable]
public class Inspection
{
private InspectionTarget target;
private string path;
private string name;
public Inspection(InspectionTarget target, string path, string name)
{
this.target = target;
this.path = path;
this.name = name;
}
public InspectionTarget Target
{
get { return target; } set { target = value; }
}
public string Path
{
get { return path; } set { path = value; }
}
public string Name
{
get { return name; } set { name = value; }
}
public override string ToString()
{
return String.Format("({1}) {0}:{2}", path,
Enum.GetName(typeof(InspectionTarget), target)[0], name);
}
}

Chapter 3 – Dynamic updates | 36
public enum InspectionTarget
{
Field,
Property,
DependencyProperty
}
Code 34 - Defining type for a single workflow inspection
Notice the type needs to be marked as Serializable in order to be used correctly by Local
Communication Services when reporting the result. The reporting interface is shown in code
fragment Code 35 and is pretty straightforward. Basically, we’ll map an Inspection on the results of
that inspection. This way, the user of the inspector can trace back the retrieved values to the
inspection target.
[ExternalDataExchange]
interface IInspectorReporter
{
void Report(Guid workflowInstanceId, string inspection,
Dictionary<Inspection, object> results);
}
Code 35 - Inspector reporting interface
This interface reports the results with the corresponding inspection name (set by the inspector
activity’s constructor, see further) and the workflow instance ID.
Finally, let’s take a look at the inspector activity itself. The code is fairly easy to understand and
performs some activity tree traversal (see method FindActivity) and a bit of reflection stuff in order
to get the values from fields and properties. Getting the value from a dependency property was
illustrated earlier when we talked about a logging activity.
public class InspectorActivity : Activity
{
private string inspection;
private Inspection[] tasks;
public InspectorActivity() { }
public InspectorActivity(string inspection, Inspection[] tasks)
{
this.inspection = inspection;
this.tasks = tasks;
}
protected override ActivityExecutionStatus Execute
(ActivityExecutionContext executionContext)
{
Dictionary<Inspection, object> lst =
new Dictionary<Inspection, object>();
foreach (Inspection i in tasks)
{
Activity target = FindActivity(i.Path);
switch (i.Target)
{
case InspectionTarget.Field:

Chapter 3 – Dynamic updates | 37
lst.Add(i, target.GetType().GetField(i.Name)
.GetValue(target));
break;
case InspectionTarget.Property:
lst.Add(i, target.GetType().GetProperty(i.Name)
.GetValue(target, null));
break;
case InspectionTarget.DependencyProperty:
lst.Add(i, target.GetValue(DependencyProperty
.FromName(i.Name, target.GetType())));
break;
}
}
executionContext.GetService<IInspectorReporter>()
.Report(WorkflowInstanceId, inspection, lst);
return ActivityExecutionStatus.Closed;
}
private Activity FindActivity(string path)
{
Activity current = this.Parent;
foreach (string p in path.Split('/'))
{
if (p == null || p.Length == 0)
break;
else if (p == "..")
current = current.Parent;
else
current = ((CompositeActivity)current).Activities[p];
}
return current;
}
}
Code 36 - Activity for dynamic workflow inspection
As an example, we’ll replace the logging instrumentation as shown in Code 27 by an equivalent
inspection instrumentation. First, we’ll need to implement the IInspectorReporter interface, which
we do in Code 37.
class InspectorReporter : IInspectorReporter
{
public void Report(Guid workflowInstanceId, string inspection,
Dictionary<Inspection, object> results)
{
Console.WriteLine("Report of inspection {0}", inspection);
foreach (Inspection i in results.Keys)
Console.WriteLine("{0} - {1}", i, results[i]);
}
}
Code 37 - Implementing the inspector reporting interface
Next, we should not forget to hook up this inspector service at the workflow runtime level. This is
done in an equivalent way as shown previously in Code 27. Finally, the instrumentation itself has to
be performed, which is outlined in code fragment Code 38.

Chapter 3 – Dynamic updates | 38
WorkflowChanges c = new WorkflowChanges(instance.GetWorkflowDefinition());
Inspection[] tasks = new Inspection[2];
tasks[0] = new Inspection(InspectionTarget.DependencyProperty, "",
"Age");
tasks[1] = new Inspection(InspectionTarget.DependencyProperty, "",
"FirstName");
InspectorActivity inspect =
new InspectorActivity("FirstName_Age", tasks);
c.TransientWorkflow.Activities.Insert(0, inspect);
instance.ApplyWorkflowChanges(c);
Code 38 - Instrumentation of a workflow with the inspector
The result of this inspection when applied on the workflow defined in Code 23 is shown in Figure 13.
Figure 13 - The workflow inspector at work
Of course we don’t want to shut down the workflow runtime in order to attach a workflow inspector
to an instance. Therefore, the hosting application needs to be prepared to accept debugging jobs
when demanded. A first scenario consists of attaching a “debugger” to an existent workflow instance
that is specified by its instance ID. Then the host application can accept calls to debug a workflow
instance, obtain the instrumentation logic (for example by dynamically loading the instrumentation
job that injects the “workflow inspector” or by applying an auto-generated inspection activity that
reflects against all the available properties of the workflow instance in order to get access to it).
Another scenario is to instrument workflow instances at creation time to capture information about
newly created instances and what’s going on inside these instances.
From the elaboration above, one might see a pretty big correspondence to the definition of tracking
services. It’s the case indeed that there is quite some overlap with the goals of tracking in WF since
serialized workflow information can be used to inspect workflow instance internals. However, using
dynamic instrumentation, one can get a more fine-grained control over the inspections itself and the
places where these inspections happen. One could take all of this a step further by using the
inspections as a data mining tool to gather information about certain internal values that occur
during processing, which might otherwise remain hidden. Last but not least, where tracking services
impose a fixed overhead till the workflow runtime is reconfigured to get rid of tracking, dynamic
instrumentation does not and, hence, is more applicable when sporadic inspections are required.

Chapter 3 – Dynamic updates | 39
7 Tracking in a world of dynamism – the WorkflowMonitor revisited In our introduction to WF, we briefly mentioned the existence of so-called tracking services:
Tracking Services allow inspection of a workflow in flight by relying on events that are raised by
workflow instances. Based on a Tracking Profile, only the desired data is tracked by the tracking
service. WF ships with a SQL Server database tracking service out of the box.
Being able to capture the progress of a workflow instance is one thing, consuming the tracking data is
even more desirable. To illustrate how to visualize tracking data, the Windows SDK ships with a WF
sample called the WorkflowMonitor. The tool allows inspecting workflows that are still running or
have terminated their lifecycle.
As a matter of fact, it serves as a sample to two core WF features: tracking and workflow designer re-
hosting. The latter one empowers developers to embed the workflow designer, which is also used by
the WF Extensions for Visual Studio 2005, in their own applications. For the WorkflowMonitor
sample, the designer serves as a convenient way to visualize a workflow instance in a read-only
manner. Figure 14 shows the WorkflowMonitor in action.
Figure 14 - The WorkflowMonitor in action
In our world of dynamic workflow updates, the WorkflowMonitor as it ships with the SDK falls short
since it’s not able to visualize dynamic changes in real-time when a workflow instance is running. In
order to overcome this limitation, we made a simple change to the WorkflowMonitor’s code [6] in
order to update the designer view on a periodic basis, allowing for dynamic updates to become
visible.
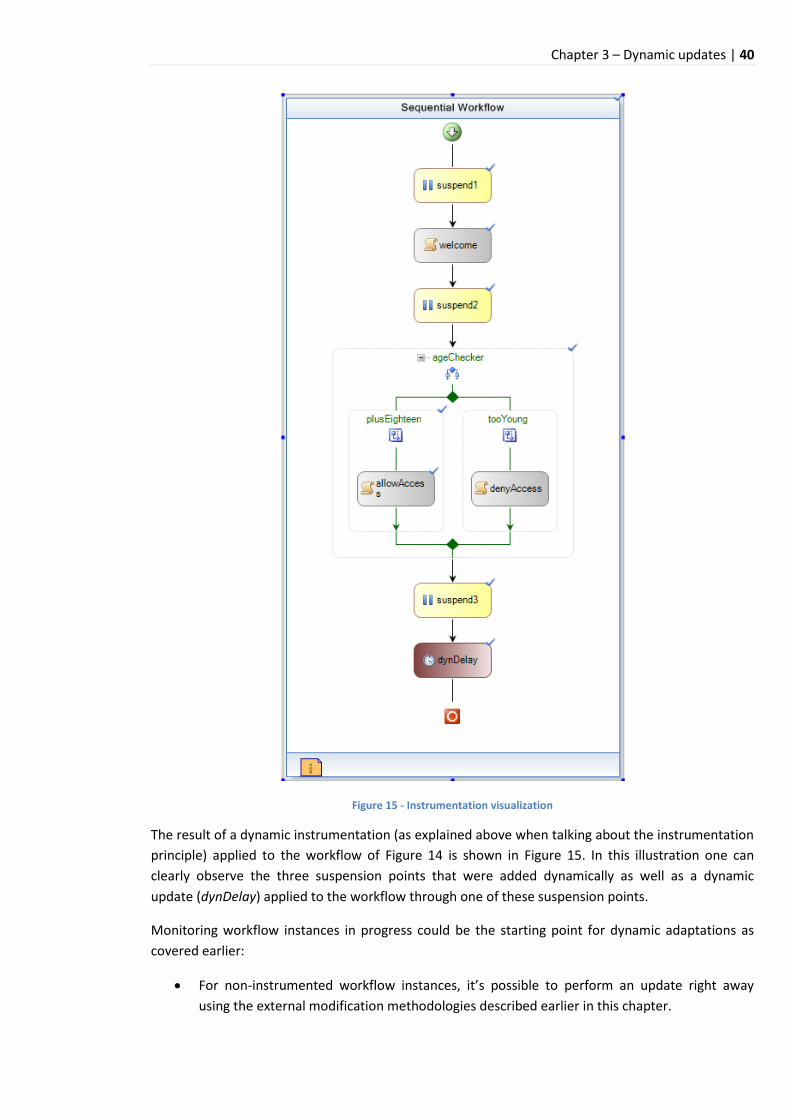
Chapter 3 – Dynamic updates | 40
Figure 15 - Instrumentation visualization
The result of a dynamic instrumentation (as explained above when talking about the instrumentation
principle) applied to the workflow of Figure 14 is shown in Figure 15. In this illustration one can
clearly observe the three suspension points that were added dynamically as well as a dynamic
update (dynDelay) applied to the workflow through one of these suspension points.
Monitoring workflow instances in progress could be the starting point for dynamic adaptations as
covered earlier:
For non-instrumented workflow instances, it’s possible to perform an update right away
using the external modification methodologies described earlier in this chapter.

Chapter 3 – Dynamic updates | 41
When a workflow instance has been instrumented, applying updates at suspension points
becomes dependent on the way the IAdaptionAction has been implemented. For example,
the action could query a database that contains adaptation hints on a per-workflow instance
basis. When such a hint is present for the suspended workflow instance and for the current
suspension point, an update is applied, possibly loading an activity dynamically from disk in
order to be inserted in the workflow instance.
8 Performance analysis
8.1 Research goal In this paragraph we take a closer look at the results of a performance study conducted to measure
the impact of dynamic updates on the overall system throughput. As we’ve seen previously,
workflow instances are hosted by a workflow runtime that’s responsible for the scheduling, the
communication with services and the instance lifecycles. Depending on the application type, the
workflow runtime will have a workload varying from a few concurrent instances to a whole bunch of
instances that need to be served in parallel, a task performed by WF’s scheduling service. There are a
few metrics that can be used to get an idea of the system’s workload:
Number of concurrent workflow instances that are running.
Total number of workflow instances hosted by the runtime, some of which might be idle.
Average time for a workflow instance to reach the termination state.
Other influences are caused by the services hooked up to the runtime. For instance, when tracking
has been enabled, this will have a big impact on the overall performance. In a similar fashion,
persistence services will cause significant additional load on the machine as well as network traffic to
talk to the database. It’s clear that the network layout and other infrastructure decision will influence
WF’s performance. An interesting whitepaper on performance characteristics is available online [7].
8.2 Test environment All tests performed were conducted on a Dell Inspiron 9400 machine, with dual core Intel Centrino
Duo processor running at 2.16 GHz with an L1 cache of 32 KB and an L2 cache of 2 MB. The machine
has 2 GB of RAM and is running Windows Vista Ultimate Edition (32 bit). Tests were conducted with
persistence services disabled, with the workflow runtime hosted by a simple console application,
compiled in Release mode with optimizations turned on and started from the command-line without
a debugger attached. In a production environment, the workflow runtime would likely be hosted
inside a Windows Service or using IIS on a Windows Server 2003 configuration and with other
services turned on. Therefore, our results should be seen as a lower bound, ruling out influences
from network traffic, database loads and other stress factors.
8.3 Test methodology Each test was conducted in a pure form, meaning that it’s the only scenario that’s running at the
same time. In hosting scenarios where multiple workflow types are running in parallel, figures will
vary. However, on dedicated systems it’s likely the case that only a few workflow types and
adaptation or instrumentation mechanisms are running on the same box.

Chapter 3 – Dynamic updates | 42
For the workflow host, we’ve chosen to use a straightforward console-based application that prints
test results to the console output in a comma-separated format ready for processing in Excel. This
way, we eliminate possible overhead that could result from writing the test results to Excel or some
other data store directly by means of a data provider.
In order to make accurate timing possible, the Stopwatch class from the System.Diagnostics
namespace was used. This class encapsulates a high-resolution timer based on the Win32 API
QueryPerformanceCounter and QueryPerformanceFrequency functions [8]. An example of the use of
this class is shown in code fragment Code 39.
Stopwatch sw = new Stopwatch();
sw.Start();
//
// Perform work here.
//
sw.Stop();
TimeSpan ts = sw.Elapsed;
sw.Reset();
Code 39 - Performance measurement using System.Diagnostics.Stopwatch
We’ll systematically measure the time it takes to adapt a workflow dynamically, i.e. the cost of the
ApplyWorkflowChanges method call. When working with suspension points, other information will
be gathered too, such as the time it takes to suspend a workflow and to resume it immediately,
which is a common scenario when instrumented workflows ignore suspension points. Suspending a
workflow instance will give other instances a chance to execute before the former instance is
resumed again, which can lead to performance losses when the runtime is under a high load.
8.4 Internal workflow modification A first set of experiments we conducted analyze the performance cost associated with internal
workflow modifications. As we’ll see, this measurement can be used as a lower bound to other
metrics, because the modification doesn’t require any suspension of the workflow instance. Since the
adaptation code runs inside the workflow itself (typically wrapped in a CodeActivity), it is a safe point
to make a change since the workflow instance is waiting for the CodeActivity to complete, ruling out
any chance to get pre-empted by the workflow scheduler.
Please refer to Table 1 for a legend of the symbols used throughout the subsequent study.
Table 1 - Legend for performance graphs
Symbol Meaning
n Number of sequential modifications
N Number of concurrent users in the system
Avg Average service time to apply the change
Worst Worst service time to apply the change
Best Best service time to apply the change

Chapter 3 – Dynamic updates | 43
8.4.1 Impact of workload on adaptation time
This first experiment shows the impact of workload on adaptation time. We considered a workload
of respectively 10, 100 and 1000 workflow instances in progress and measured how long it takes to
apply a dynamic update. This update consists of the addition of one or more activities to each
workflow instance in the same “update batch”. The results of adding one, two and three activities
are displayed in Graph 1, Graph 2 and Graph 3 respectively.
From these graphs we can draw a few conclusions. First of all, when the number of concurrent
instances increases exponentially, there’s little influence on the best and average adaptation
duration scores. However, when considering the worst possible duration it take to apply the dynamic
update, we clearly see a much worse result, due to possible scheduling issues that cause another
instance to get priority.
Graph 1 - Impact of workload on internal modification duration (n = 1)
Graph 2 - Impact of workload on internal modification duration (n = 2)
0
10
20
30
40
50
60
70
80
10 100 1000
ms
N
Best
Avg
Worst
0
20
40
60
80
100
120
140
160
10 100 1000
ms
N
Best
Avg
Worst

Chapter 3 – Dynamic updates | 44
Graph 3 – Impact of workload on internal modification duration (n = 3)
8.4.2 Impact of dynamic update batch size on adaptation time
Another conclusion we can make based on these results is the impact of applying multiple
adaptations in the same dynamic update batch (a.k.a. WorkflowChanges). Graph 4 illustrates the
impact of applying multiple adaptations at the same time for a given workload. We can conclude that
there’s a linear growth in dynamic update application time, in terms of the number of adaptations in
the dynamic update batch.
Graph 4 - Impact of update batch size on internal modification duration (N = 1000)
Since internal modifications have a precise timing – meaning that there’s no risk of missing an update
because it is applied in-line with the rest of the workflow instance execution – we can conclude that
updating a workflow instance, even under high load conditions, only introduces a minor delay on the
average. Therefore, we do not expect much delay on the overall execution time of an individual
workflow instance, a few exceptions set apart (characterized by the worst execution times shown
0
50
100
150
200
250
300
10 100 1000
ms
N
Best
Avg
Worst
1 2 3
Avg 8,981 14,570 21,871
Worst 72,600 156,500 258,000
Best 6,900 9,000 11,000
0
50
100
150
200
250
300
ms
n
Avg
Worst
Best

Chapter 3 – Dynamic updates | 45
above). Although internal modifications can be applied pretty quickly, this should be seen in contrast
with the lower flexibility of internal modification, as discussed before.
A simple but effective performance optimization when applying internal modifications exists when
adjacent activities have to be added in the activity tree. In such a case, it’s desirable to wrap those
individual activities in one single SequenceActivity, so that only one single insertion is required to get
the desired effect.
8.5 External workflow modification Next, we took a closer look at the performance implications imposed by external workflow
modification. Again, we considered different workloads and multiple update batch sizes.
Graph 5 - Impact of workload on external modification duration (n = 1)
Graph 6 - Impact of workload on external modification duration (n = 2)
0
1.000
2.000
3.000
4.000
5.000
6.000
7.000
10 100 1000
ms
N
Best
Avg
Worst
0
1.000
2.000
3.000
4.000
5.000
6.000
7.000
8.000
9.000
10 100 1000
ms
N
Best
Avg
Worst

Chapter 3 – Dynamic updates | 46
Graph 7 - Impact of workload on external modification duration (n = 3)
A first fact that draws our attention is the different order of magnitude (seconds) of the adaptation
durations compared to the equivalent internal adaptations, certainly for higher workloads. As a
matter of fact, the average execution time for external modification grows faster than the equivalent
average execution time in the internal modification case.
This difference can be explained by the fact that external workflow modifications have a far bigger
impact on the scheduling of the workflow runtime since workflow instances need to be suspended
prior to performing a dynamic update. This trend is illustrated in Graph 8, where we measured the
time elapsed between suspending a workflow instance and resuming it directly again, based on the
WorkflowSuspended event provided by the workflow runtime.
Graph 8 - Suspend-resume time
0
1.000
2.000
3.000
4.000
5.000
6.000
7.000
8.000
9.000
10.000
10 100 1000
ms
N
Best
Avg
Worst
0
20
40
60
80
100
120
140
160
180
200
10 100 1000
ms
N
Best
Avg
Worst

Chapter 3 – Dynamic updates | 47
Notice that in our tests, we didn’t use persistence services, so there’s yet no impact from database
communication that occurs upon persistence that might be triggered by suspension. So, in reality
once can expect even higher wait times.
In Graph 9 we take a closer look at the impact of multi-adaptation dynamic update batches.
Graph 9 - Impact of update batch size on external modification duration (N = 1000)
Again, we observe a linear relationship between the number of adaptations and the execution time
required to apply the dynamic update. This can be reduced by merging neighboring activities into a
SequenceActivity when applicable, in order to reduce the batch size of the dynamic update.
Comparing internal modifications with external modifications, the former ones certainly outperform
the latter ones. However, external modifications offer a more flexible way of adaptation in terms of
the ability to apply unanticipated updates from inside the workflow runtime hosting layer context.
Furthermore, external modifications have access to contextual information about the surrounding
system in which the workflow instances participate.
As a conclusion, one should adopt the best practice to evaluate carefully which internal modifications
might be desirable (i.e. update scenarios that can be anticipated upfront) and what information
“gates” (e.g. by means of Local Communication Services, providing access to the hosting layer
context) should be present for internal modifications to have enough information available.
8.6 Instrumentation and modifications – a few caveats Instrumentation can be used to serve various goals, one of which could be applying a drastic change
to the workflow’s structure by dropping activities from the workflow graph while injecting others.
However, this kind of workflow modification implies quite some risks concerning positional
dependencies. Data produced by one part of the workflow could be consumed everywhere else
down the drain. Breaking such dependencies is much easier than fixing these again.
In WF, the dataflow of a workflow is implicit in contrast to the control flow (workflow so to speak).
Although issues such as missing property assignments or type mismatches of activity properties can
be detected by the workflow compiler and hence by the dynamic update feature of WF, the
semantics of the flow can’t be validated.
1 2 3
Avg 3.450,007 4128,337 4.872,183
Worst 6.792,600 8121,500 9.441,300
Best 160,500 277,100 312,500
01.0002.0003.0004.0005.0006.0007.0008.0009.000
10.000
ms
n
Avg
Worst
Best

Chapter 3 – Dynamic updates | 48
If such a situation arises, one should double-check whether or not the workflow definition does
reflect the typical flow required by the application. One could compare – at least conceptually – the
use of dynamic adaptation with exceptions in object oriented languages: one should keep exceptions
for – what’s in a name? – “exceptional” atypical situations. If one doesn’t obey to this rule, the
application might suffer from serious performance issues, not to speak about the impact on the
overall application’s structure.
However, if a change of the dataflow for individual workflow instances still makes sense after
thorough inspection, one should be extremely cautious to wire up all activities correctly. Custom
activities therefore should have proper validation rules in place that check for the presence of all
required properties. Also, obeying to strict strong typing rules for custom activity properties will help
to avoid improper property binding.
Although state tracking could help to recover data from messed up workflow instances, it’s better to
avoid mistakes altogether. Considering the long-running nature of workflows, making mistakes isn’t a
valuable option. Therefore, putting in place a preproduction or staging environment to check the
effects of a dynamic modification with respect to the correctness of workflow instances would be a
good idea for sure.
In case an urgent modification is required and time is ticking before a workflow instance will
“transition” to the next phase, one could inject a suspension point to keep the workflow from
moving on while (manual) validation of the dynamic adaptation can be carried out on dummy
workflow instances in preproduction. Once validation has been done, one can signal the suspended
instances to grab the modification, apply it and continue their journey. Signaling can be done using
various mechanisms in WF, including external event activities.
9 Conclusion The long-running nature of workflows is typically in contrast with their static definitions. For this very
reason, it makes sense to look for dynamic adaptation mechanisms that allow one or more instances
of a workflow to be changed at runtime. In this chapter we’ve outlined the different approaches
available in WF to do this.
Even if workflows are not used in a long-running fashion, dynamic adaptation proves useful to
abstract away aspects like logging that shouldn’t be introduced statically. If such aspects would be
included in the workflow’s definition right away, one of the core goals of workflow – graphical
business process visualization – would be defeated.
Performance-wise, one can draw the distinction between external and internal modification. While
the former one allows more flexibility with respect to the direct availability of state from the
environment surrounding the workflow instances, it has a much higher cost than internal
modification, due to the need to suspend a workflow instance which might also cause persistence to
take place. Furthermore, to allow precise modifications from the outside suspension points could be
used, but these incur a non-trivial cost too.

Chapter 3 – Dynamic updates | 49
Finally, we’ve discussed instrumentation too, which can be seen as external modification that takes
place when a new workflow instance is spawned. The flexibility of this approach outweighs the slight
performance costs: no suspension is needed since the workflow instance hasn’t been started yet.
In conclusion, dynamic adaptation of workflows should be used with care and one should balance
between static, dynamic and instrumented workflows. Also, starting with one approach doesn’t rule
out another: a workflow instance’s dynamic adaptations could be fed back to the workflow definition
if the dynamic adaptation happens to become applicable to all workflow instances. This kind of
feedback loop could be automated as well.
The work of this chapter, especially the creation of an instrumentation tool, was subject of a paper
entitled “Dynamic workflow instrumentation for Windows Workflow Foundation” that was submitted
to ICSEA’07. A copy of this paper is included in Appendix A.

Chapter 4 – Generic workflows | 50
Chapter 4 – Generic workflows
1 Introduction
In the previous chapter we have been looking at the possibility to adapt workflows dynamically at
runtime, as a tool to abstract aspects such a logging, authentication, etc. but also to change the
behavior of (long-running) workflow instances. In this chapter we will move our focus towards the
composition of workflows in a generic manner, based on a pre-defined set of workflow activities that
encapsulate various kinds of operations such as data retrieval and calculation. The term composition
can be explained by analogy with puzzling. Starting from individual pieces (a set of dedicated domain-
specific activities), a workflow definition is created or “composed”. Most of these individual pieces
are created in such a way that a maximum level of flexibility is gained (e.g. a query block that hasn’t
any strong bindings to a specific database schema), hence the qualification as “generic”.
The discussion in this chapter is applied to a practical use case in the field of eHealth from the
department of Intensive Care (IZ) of Ghent University (UZ Gent) called “AB Switch” (antibiotics
switch). The AB Switch agent performs processing of medical patient data on a daily basis to propose
a switch of antibiotics from intravenous to per os for patients that match certain criteria. Currently,
the agent has been implemented as a “normal” .NET-based application that is triggered on a daily
basis. The overall architecture of the AB Switch agent is shown in Figure 16. Patient data is retrieved
from the Intensive Care Information System (ICIS) database and analyzed by the agent based on
criteria proposed by medical experts, yielding a set of candidate patients. From this information, an
electronic report is sent to the doctors by e-mail.
Figure 16 - AB Switch agent architecture [9]

Chapter 4 – Generic workflows | 51
As part of this work, the current implementation of the AB Switch agent was investigated in detail.
From this investigation we can conclude that the typical flow of operations performed by the agent
consists of many repetitive tasks, each slightly different from one another, for example to query the
database. It is clear that the real flow of operations is buried under masses of procedural coding,
making the original flow as depicted in Figure 17 invisible to end-users and even to developers.
Figure 17 - Flowchart for the AB Switch agent [9]
Therefore, workflow seems an attractive solution to replace the classic procedural coding of the
algorithm that is full of data retrieving activities, calculation activities, decision logic, formatting and
sending of mails, etc. This methodology would not only allow visual inspection of the agent’s inner
workings by various stakeholders, but it also allows hospital doctors to investigate the decision logic
being taken on a patient-per-patient basis, i.e. which criteria led to a positive or negative switch
advise. In other words, workflow wouldn’t only provide a more visual alternative to the original
procedural coding, but the presence of various runtime services such as tracking would open up for
possibilities far beyond what is possible to implement in procedural coding in a timely fashion.

Chapter 4 – Generic workflows | 52
Our approach consists of the creation of a set of easy-to-use building blocks that allows composition
of a workflow without having to worry about database connections for data gathering, mail creation
and delivery, etc.
2 A few design decisions Before moving on to the implementation of the generic building blocks, a few design decisions have
to be made. We’ll cover the most important ones in this paragraph.
2.1 Granularity of the agent workflow One important question we should ask ourselves is what we’ll consider to be the atomic unit of work
in our workflow-driven agent. Two extremes exist:
The agent is represented as one big workflow that is triggered once a day and processes all
patients one-by-one as part of the workflow execution.
Decision making for an individual patient is treated as the workflow, while the hosting layer
is responsible to create workflow instances for each patient.
Both approaches have their pros and cons. Having just one workflow that is responsible for the
processing of all patients makes the agent host very simple. It’s just a matter of pulling the trigger
once a day to start the processing. However, for inspection of individual patient results based on
tracking (see Tracking Services in Chapter 1 paragraph 7 on page 39), this approach doesn’t work out
that well since one can’t gain direct access to an individual patient’s tracking information. Also, if one
would like to trigger processing for an individual patient on another (timely) basis or in an ad-hoc
fashion, the former approach won’t help out.
From the performance point of view, having one workflow instance per patient would allow the
workflow runtime’s scheduling service to run tasks in parallel without any special effort from the
developer. On the dark side of the latter approach, the hosting layer will have more work to do since
it needs to query the database as well to retrieve a set of patients that have to be processed.
Furthermore, aggregating the information that’s calculated for the patients (e.g. for reporting
purposes or for subsequent data processing by other agents or workflows) will become a task of the
host, which might be more difficult due to the possibility for out of order completion of individual
workflow instances. This out of order completion stems from the scheduling mechanism employed in
WF. There’s no guarantee that workflow instances complete in the same order as they were started.
After all, in the light of enabling long-running processing in workflow, some instances might take
longer to execute than others. But even in the case of short-running workflows, the runtime
preserves the right to “swap out” a workflow instance in favor of another one. This behavior
becomes more visible on machines hosting multiple workflow definitions that can be instanced at
any point in time. Therefore one shouldn’t rely on any ordering assumptions whatsoever.
We’ll try to find the balance between both approaches by encapsulating the database logic in such a
way that it can be used by both the host and the workflow itself, in order to reduce the plumbing on
the host required to talk with a database.
As a final note, we should point out that composition of individual workflow definitions is possible in
WF by various means. One possibility is to encapsulate the decision making workflow for a patient in

Chapter 4 – Generic workflows | 53
a custom activity itself. However, this won’t improve the granularity at which tracking happens since
tracking is performed on the workflow instance level. Because we’d still have just one workflow
instance for all patients, we’ll only gain some level of encapsulation of the inner calculation logic
(comparable to the refactoring of a foreach loop inner code block). Another possibility is to use the
workflow invocation activity of WF. Using this activity, the treatment of an individual patient can be
spawned as another workflow instance (of another type), overcoming the problems with tracking.
However, the asynchronous invocation nature of the workflow invocation activity makes collection of
results for aggregation in a mail message more difficult again.
2.2 Encapsulation as web services Current prototypes of the decision support applications for the Intensive Care Unit (ICU) department
of UZ Gent, written by INTEC, are driven by a set of interconnected web services reflecting the
Intensive Care Agent Platform (ICAP) [10] methodology. From that perspective, it’s much desirable to
enable the “publication” of the AB Switch agent workflow through a web services façade.
Taking this one step further, it might be desirable to publish portions of the workflow as well, down
to the level of individual building blocks (i.e. the domain-specific custom activities such as a generic
query block). This could be done by wrapping the portion that’s to be exposed as a web service in an
individual workflow definition. Alternatively, when publishing just one specific building block, the
custom activity could be backed by an interface that acts as the web service’s operational contract,
ready for direct publication without going through WF at all. It’s clear that this approach will only
work when the execution logic of the custom activity is short-running, allowing it to be called via a
(duplex) web method. If it’s long-running however, it’s almost inevitable to run it in WF to guarantee
correct execution and survival from service outages. Nevertheless, such a long-running operation can
still be published via a “one way” web method.
Web services encapsulation can easily be done using various technologies, including classic web
services in ASP.NET (aka .asmx) or through WCF (Windows Communication Foundation). It should be
noted that the former technology is natively supported by WF today, by means of various activities in
the WF toolbox that help to accept web service calls, take the input and send back output or faults.
Nevertheless, we won’t use this approach since it kind of “poisons” the workflow definition with a
static coupling to a web services contract, which doesn’t make much sense if the workflow is to be
called locally (possibly in-process) on the agent host. Also, by keeping the workflow definitions
independent from communication mechanisms, a great deal of flexibility can be realized to allow a
workflow’s publication through one communication mechanism or another. Notice that WF doesn’t
support distribution of portions of a workflow across multiple hosts out of the box. Connecting
different workflows that run on separate machines using web services is possible though. WF does
support long-running workflows to be migrated from one host to another as a result of a suspend-
resume cycle of operations. That is, a workflow instance doesn’t have any binding to the host it was
created on, hence enabling another host to resume its processing.
Our approach therefore consists of defining a regular communication-poor workflow, wrapped in an
interface that’s exposed as a WCF operational contract. The agent host can call the workflow
implementation directly, while the same component can be encapsulated in a WCF service host right
away to allow for flexible communication, e.g. over web services. In this context, we remind the
reader of the generic characteristic of WCF, allowing services to be bound to various communication

Chapter 4 – Generic workflows | 54
protocols without touching the underlying implementation at all. These protocols include – amongst
others – TCP, .NET Remoting, MSMQ, web services, named pipes and support a whole set of WS-*
standards.
2.3 Database logic The AB Switch agent is highly data-driven, consuming multiple query result sets required to figure out
whether or not a patient should be considered for an antibiotics switch. From this observation, quite
some questions arise, most of which are related to the overall agent’s architecture. The most
important of these issues are elaborated on in this paragraph.
It goes without saying that retrieving lots of data from the database over the network is a costly
operation, certainly if only a slight portion of that data is required in the output of the agent, i.e. the
mail with advice for the medical personnel. Because of this, one could argue that a large portion of
the agent’s functionality could be implemented on the database layer itself, in the shape of stored
procedures. Activities such as the calculation of the recorded medication dose (e.g. the levophed
dose) for a patient are certainly well-suited for this kind of approach. Today’s database systems
support quite some built-in mathematical functions that allow for server-side calculations. In
combination with “ON UPDATE” triggers or features such as “computed columns”, one could
calculate various patient metrics on the fly when data is altered in the database, offloading this
responsibility from agents. Furthermore, implementing this logic in the database directly allows for
reuse of the same logic across multiple front-end agents that all rely on the same results.
Ultimately, one could implement the agent’s filtering logic entirely on the database layer using stored
procedures, triggers for online automatic calculation of doses when patient data is changing, etc. This
would reduce the agent to a scheduler, some database calling logic and a mailer. Although this
approach might work out pretty well, depending on various Database Management System (DBMS)-
related quality attributes and database load conditions, we’re trapped again by some kind of
procedural coding – this time in the database tier – that hides the original logic. Without workflow
support inside the database directly – which might be subject of Microsoft’s next-generation SQL
Server product – we won’t gain much from this approach.
The current AB Switch agent relies on quite some ad-hoc queries, as the ones displayed in Code 40.
During our investigation of the current implementation, a few possible enhancements were
proposed to make these queries more efficient in the context of the AB Switch agent. Making such
changes shouldn’t impose a problem since all queries are ad-hoc ones that are kept on the client and
are only used by the agent itself. Nevertheless, moving some queries to the database layer as stored
procedures would be a good thing, allowing for tighter access control at the DBMS level and possibly
boosting performance.
A few other remarks were made concerning the current implementation, such as:
The (theoretical) risk for SQL injection attacks because of string concatenation-based query
composition in code;
Quite a bit of ugly coding to handle unexpected database (connection) failures, partially
caused by the shaky Sybase database provider in .NET;
A few performance optimizations and .NET and/or C# patterns that could prove useful for
the agent’s implementation.
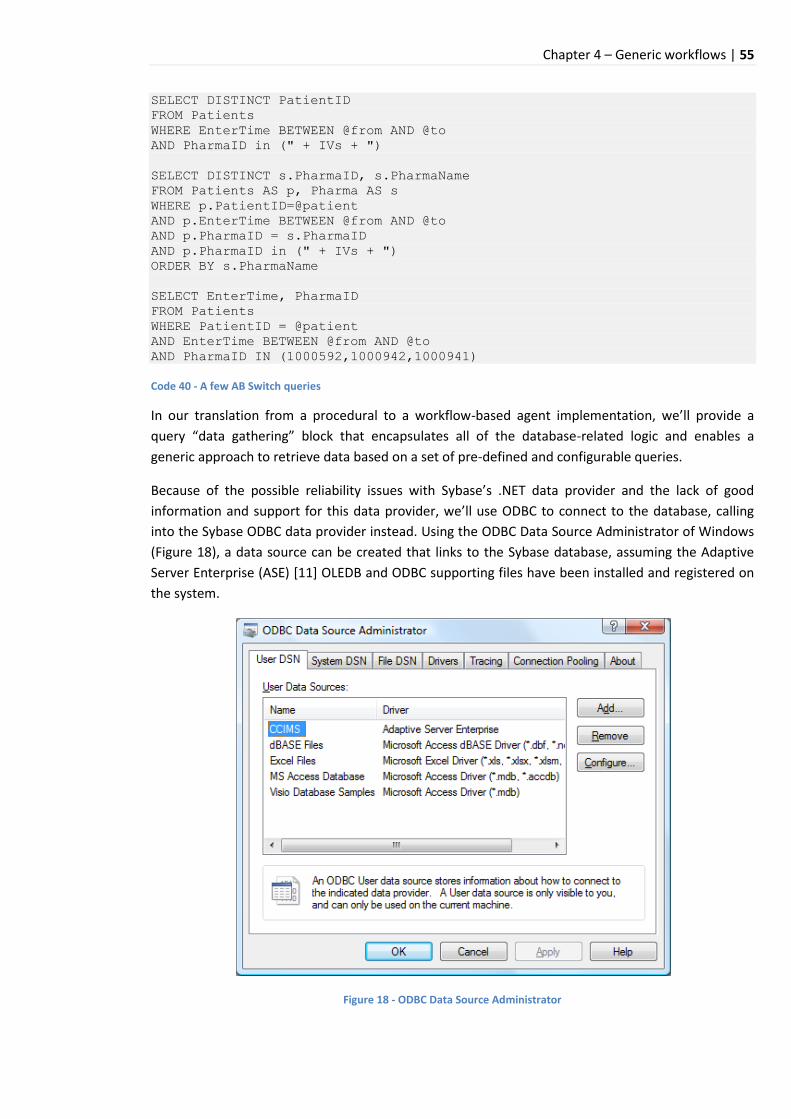
Chapter 4 – Generic workflows | 55
SELECT DISTINCT PatientID
FROM Patients
WHERE EnterTime BETWEEN @from AND @to
AND PharmaID in (" + IVs + ")
SELECT DISTINCT s.PharmaID, s.PharmaName
FROM Patients AS p, Pharma AS s
WHERE p.PatientID=@patient
AND p.EnterTime BETWEEN @from AND @to
AND p.PharmaID = s.PharmaID
AND p.PharmaID in (" + IVs + ")
ORDER BY s.PharmaName
SELECT EnterTime, PharmaID
FROM Patients
WHERE PatientID = @patient
AND EnterTime BETWEEN @from AND @to
AND PharmaID IN (1000592,1000942,1000941)
Code 40 - A few AB Switch queries
In our translation from a procedural to a workflow-based agent implementation, we’ll provide a
query “data gathering” block that encapsulates all of the database-related logic and enables a
generic approach to retrieve data based on a set of pre-defined and configurable queries.
Because of the possible reliability issues with Sybase’s .NET data provider and the lack of good
information and support for this data provider, we’ll use ODBC to connect to the database, calling
into the Sybase ODBC data provider instead. Using the ODBC Data Source Administrator of Windows
(Figure 18), a data source can be created that links to the Sybase database, assuming the Adaptive
Server Enterprise (ASE) [11] OLEDB and ODBC supporting files have been installed and registered on
the system.
Figure 18 - ODBC Data Source Administrator

Chapter 4 – Generic workflows | 56
3 From flowchart to workflow: an easy step? At the core of our workflow implementation effort for the AB Switch agent is the translation of a
flowchart (Figure 17) into a WF sequential workflow. Although it might look a pretty simple and
straightforward step, there are quite some caveats.
3.1 Flow control One commonly used structure in flowcharts is the direct connection of multiple flow paths to one
flow block, as shown in Figure 19 at the left-hand side. Such a structure is somewhat equivalent to a
procedure call in a classic programming language, or to a goto statement in older languages. WF
doesn’t support a direct mapping of this structure because of its tree-based workflow nature.
However, by wrapping the common block in a separate custom activity, one can avoid redundant
duplication of those blocks in order to improve maintainability and to keep a good deal of readability.
The result of such an approach is shown in Figure 19 at the right-hand side.
Figure 19 - Shortcuts in flow diagrams and the WF equivalent
3.2 Boolean decision logic Other flowchart structures that don’t have a straightforward mapping to a WF-based workflow are
Boolean operators. The AB Switch agent is essentially a piece of filtering logic that retrieves a set of
condition operands that are joined together using AND operators, as illustrated in Figure 20.
Such a series of AND operators can be translated into a tree of nested IfElseActivity activities, which
comes very close to the actual current implementation in code. However, this kind of nesting makes
the workflow definition rather complex and the decision logic is a bit more hidden since one has to
know which branch of an IfElseActivity represents the positive case and which one represents the
negative case. Also, the else-branches typically will be empty in case of filtering structures like the
ones in AB Switch.
A colored approach to indicate success or failure, as used in a flowchart like the one in Figure 20 is
much more intuitive. Therefore, we’ll mimic this approach by creating custom activities that signal
success or failure and act as a bit of eye candy to improve the visuals of a workflow definition.

Chapter 4 – Generic workflows | 57
Figure 20 - Boolean operators in a flowchart
The result of using true/false indicators in workflows is shown in Figure 21.
Figure 21 - Colored status indicators
3.3 Serial or parallel? Furthermore, the approach of nested IfElseActivity blocks implies serialization of the decision logic
which might or might not be a suitable thing to do, depending on the probability for conditions to be
evaluated positively or negatively.
By putting conditions with a high probability for a negative result on top of the nested IfElseActivity
tree, database traffic can be reduced significantly. However, when such a probabilistic ordering isn’t
possible, parallel execution of data gathering and evaluation using success/failure indicators might be
an attractive alternative, allowing for more parallelism. This isn’t straightforward to do in procedural

Chapter 4 – Generic workflows | 58
coding but is much easier in workflow composition using the ParallelActivity. In such a case, when
most cases evaluate positively, the overhead caused by retrieving data that’s not needed further on
will be largely overshadowed by the additional parallelism. An example of parallel data retrieval is
shown in Figure 22.
Figure 22 - Parallel data gathering
Notice that there are various kinds of parallelism in workflow, both intra-workflow and on the
runtime level. By representing the evaluation process for a single patient as a single workflow
instance, we’ll get parallel processing of multiple patients at a time. By putting ParallelActivity blocks
in the workflow definition, we do get parallelism inside workflow instances as well.
It might be tempting to wrap Boolean operators in some kind of parallel activity too. In such a
structure, all branches of the parallel activity would represent an operand of the enclosing operator.
Although such an approach has great visual advantages, it’s far from straightforward to implement
and to use during composition. Remember that WF is all about control flows and there is no intrinsic
concept of data exchange between activities in a contract-driven manner. In other words, it’s not
possible to apply a (to WF meaningful) interface (such as “returns a Boolean value”) to an activity
that’s used by an enclosing activity (e.g. the one that collects all Boolean results and takes the
conjunction or disjunction). Instead, WF is built around the concept of (dependency) properties for
cross-activity data exchange, which introduces the need for quite a bit of wiring during composition,
e.g. to connect child activities (the operands) to their parent (the operator). In addition, quite some
validation logic would be required to ensure the correctness of a “Boolean composition”.
3.4 Error handling Another important aspect occurring on a regular basis in flowchart diagrams is some kind of error
handling. In Figure 23 a dotted line is used to indicate the path taken in case of an error. Such a
construct doesn’t map nicely to code when using exception handling mechanisms. As a matter of
fact, it has a closer correspondence to an “On Error Goto …” kind of construct in BASIC languages.
Since WF is based on object-oriented design under the covers, concepts like exception handling shine
through to the world of WF. By making custom activities throw exceptions, one can take advantage
of WF Fault Handlers when composing a workflow, as shown in Figure 24.

Chapter 4 – Generic workflows | 59
Figure 23 - Error paths in flowcharts
In case data gathering results have to be validated to match certain criteria, e.g. a non-null check,
additional custom activities can be created that perform such logic and make the handling of such
corner cases visible in the workflow definition. In case of a criteria matching failure, a special custom
exception can be thrown, somewhat the equivalent of putting an implicit “throws” clause in the
custom activity’s contract. Notice however that .NET doesn’t use checked exceptions [12]. Therefore
users of such a custom activity should be made aware of the possibility for the activity to throw an
exception, e.g. by providing accurate documentation.
Figure 24 - Fault Handlers in WF

Chapter 4 – Generic workflows | 60
4 Approaches for data gathering As outlined throughout the previous sections of this chapter, the AB Switch agent is highly data-
driven, so building a data gathering mechanism is a central asset of a workflow-based approach.
Various approaches should be taken under consideration.
4.1 Design requirements and decisions In order to make the data gathering mechanism flexible a few design decisions have to be made:
Queries shouldn’t be hardcoded, allowing a query to be changed without having to touch the
workflow definition. To realize this requirement, queries will be identified by a unique name
and will be stored in a configuration base. This should make it possible to optimize queries or
even to refactor queries into stored procedures without having to shut down the agent.
Storage of queries should be implemented in a generic fashion, allowing queries to be stored
by various means. An interface to retrieve query definitions will be used to allow this level of
flexibility. For example, queries could be stored in XML or in a database, by implementing the
query retrieval interface in a suitable way.
Parameterization of queries should be straightforward in order to ease composition tasks.
Typically, the parameters required to invoke a query will originate from the outside (e.g. a
patient’s unique identifier) or from other sources inside the same workflow. Furthermore,
parameters should be passed to the data gathering mechanism in a generic fashion,
maximizing the flexibility of data gathering while minimizing composition efforts.
Results produced by invoking a query should be kept in a generic fashion too. This should
make consumption of produced values easy to do, while supporting easy chaining of various
queries as well, i.e. outputs of one query could act as (part of the) inputs for another query.
4.2 Using Local Communication Services WF’s built-in mechanism to flow data from the outside world (the host layer so to speak) to a
workflow instance is called Local Communication Services [13] and has been mentioned multiple
times in this work already. Essentially it allows for a contract-based data exchange mechanism, by
providing an interface that is used inside the workflow definition to call operations, e.g. to retrieve
data.
Such a mechanism is a big requirement when dealing with long-running workflows. Although data for
the current workflow instance could be kept in various properties of the workflow, data in a long-
running workflow is typically highly volatile, ruling out this approach. Using Local Communication
Services, accurate data can be gathered whenever required by the workflow, with the guarantee to
have the latest version of the data available regardless of any possible suspensions that have
happened throughout a workflow instance’s runtime.
In a non-generic workflow definition, one could create an interface containing all of the required
data gathering operations which are to be invoked in the workflow when that specific data is needed.
Parameterization of queries then comes down to creating parameterized methods that are called
from inside a workflow through Local Communication Services. This approach provides a big deal of
strong typing and tight coupling with queries, making it non-generic. Modifying such a workflow
definition dynamically at runtime wouldn’t be trivial too since lots of input and output bindings to
the query invocation activity would have to be applied.

Chapter 4 – Generic workflows | 61
A generic alternative for data gathering through Local Communication Services is to represent query
parameters and query results in a dictionary-based collection type, mapping query parameters or
column names to corresponding objects. Dictionaries are easy to use from code, produce nice-to-
read code using named parameters and have pretty good performance characteristics. In this work,
we’ll refer to such a dictionary as a property bag, defined in Code 41.
[Serializable]
public class PropertyBag : Dictionary<string, object>, IXmlSerializable
{
public new object this[string key]
{
get { return base[key]; }
set { base[key] = value; }
}
...
}
Code 41 - Property bag definition
Notice the XML serialization support that’s required for workflow properties of this type in order to
be persisted properly when the runtime indicates to do so. This data representation format makes
inspection at runtime, e.g. using instrumentation mechanisms, much easier than facing various
values spread across the entire workflow definition.
Next, a contract for query execution and data retrieval has to be created. In order to keep things
inside the workflow definition as simple as possible, we’ll retrieve a query object through Local
Communication Services (LCS) by means of a query manager as shown in Code 42.
[ExternalDataExchange]
public interface IQueryManager
{
IQuery GetQuery(string name);
}
Code 42 - Query manager used by LCS
Finally, the interface for query definition and execution is defined as follows:
public interface IQuery
{
string Name { get; }
List<PropertyBag> Execute(PropertyBag parameters);
}
Code 43 - Query representation and execution interface
Using this query representation, chaining of query results to query inputs becomes pretty easy to do,
because of the use of property bags both as input and as output. The WF designer supports indexing
in List<T> collections, so it’s possible to grab the first row from the query’s results collection just by
using a ‘*0+’ equivalent in the designer.

Chapter 4 – Generic workflows | 62
4.3 The data gathering custom activity The definition of these two interfaces and the property bag forms the core of our data gathering
implementation. However, in order to make data a first class citizen of our workflow definitions, we’ll
wrap all LCS communication and query invocation logic inside a custom activity called the
GatherDataActivity. The core implementation of this activity is outlined below in Code 44.
[ActivityValidator(typeof(GatherDataValidator))]
[DefaultProperty("Query")]
[Designer(typeof(GatherDataDesigner), typeof(IDesigner))]
[ToolboxItem(typeof(ActivityToolboxItem))]
public class GatherDataActivity : Activity
{
public static DependencyProperty ParametersProperty =
DependencyProperty.Register("Parameters",
typeof(PropertyBag),
typeof(GatherDataActivity));
[Browsable(true)]
[Category("Input/output")]
[Description("Parameters for data query.")]
[DesignerSerializationVisibility(
DesignerSerializationVisibility.Visible)]
public PropertyBag Parameters
{
get { return (PropertyBag)base.GetValue(ParametersProperty); }
set { base.SetValue(ParametersProperty, value); }
}
public static DependencyProperty ResultsProperty =
DependencyProperty.Register("Results",
typeof(List<PropertyBag>),
typeof(GatherDataActivity));
[Browsable(true)]
[Category("Input/output")]
[Description("Results of the query.")]
[DesignerSerializationVisibility(
DesignerSerializationVisibility.Visible)]
public List<PropertyBag> Results
{
get { return (List<PropertyBag>)base.GetValue(ResultsProperty); }
set { base.SetValue(ResultsProperty, value); }
}
public static DependencyProperty QueryProperty =
DependencyProperty.Register("Query",
typeof(string),
typeof(GatherDataActivity));
[Browsable(true)]
[Category("Database settings")]
[Description("Name of the query.")]
[DesignerSerializationVisibility(
DesignerSerializationVisibility.Visible)]
public string Query
{
get { return (string)base.GetValue(QueryProperty); }
set { base.SetValue(QueryProperty, value); }
}

Chapter 4 – Generic workflows | 63
protected override ActivityExecutionStatus Execute(
ActivityExecutionContext executionContext)
{
IQueryManager qm =
executionContext.GetService<IQueryManager>();
IQuery query = qm.GetQuery(Query);
Results = query.Execute(Parameters);
return ActivityExecutionStatus.Closed;
}
}
Code 44 - GatherDataActivity implementation
We’ve dropped the implementation of the validator and designer helper classes which provide
validation support during compilation and layout logic for the workflow designer respectively. All of
the parameters to the GatherDataActivity have been declared as WF dependency properties to assist
with binding. For more information on dependency properties we refer to [14].
The core of the implementation is in the Execute method which is fairly easy to understand. First, it
retrieves the query manager to grab the query object from, based on the query’s name. Execution of
the query is then just a matter of calling the Execute method on the obtained IQuery object using the
appropriate parameters. Finally, results are stored in the Results property and the activity signals it
has finished its work by returning the Closed value from the ActivityExecutionStatus enum.
4.4 Implementing a query manager So far, we’ve been looking at the interfaces for the data gathering block. Such an interface-driven
approach helps to boost the generic nature of our framework but without proper implementation it’s
worthless. In this paragraph, an XML-based query manager will be introduced.
4.4.1 An XML schema for query representation
In order to separate the query statements from the executable code, parameterized queries will be
described entirely in XML. The corresponding schema is depicted graphically in Figure 25.
Figure 25 - Query description schema
Each <Query> element is composed of a set of Inputs (the parameters) and Outputs (the columns)
together with a unique name, a category (for administrative purposes) and the parameterized query
statement itself. This parameterized statement will typically be mapped on a parameterized SQL
command that’s executed against the database, grabbing the parameter values from the
GatherDataActivity’s input PropertyBag and spitting out the corresponding query results which are
stored in the GatherDataActivity’s output list of PropertyBag objects subsequently.

Chapter 4 – Generic workflows | 64
A few queries are shown in Listing 2 to set the reader’s mind.
<?xml version="1.0" encoding="utf-8" ?>
<Queries>
<Query Name="AntibioticaIV" Category="Pharma">
<Statement>
SELECT DISTINCT PatientID FROM Patients
WHERE EnterTime BETWEEN @from AND @to
AND PharmaID in (1000505,1000511,1001343,1001181,1000921,
1001175,1001138,1000519,1000520)
</Statement>
<Inputs>
<Parameter Name="@from" Type="datetime" />
<Parameter Name="@to" Type="datetime" />
</Inputs>
<Outputs>
<Column Name="PatientID" Type="int" Nullable="No" />
</Outputs>
</Query>
<Query Name="PatientInfo" Category="Patients">
<Statement>
SELECT PatNumber, FirstName, LastName FROM Patients
WHERE PatientID=@PatientID
</Statement>
<Inputs>
<Parameter Name="@PatientID" Type="int" />
</Inputs>
<Outputs>
<Column Name="PatNumber" Type="varchar" Nullable="No" />
<Column Name="FirstName" Type="varchar" Nullable="No" />
<Column Name="LastName" Type="varchar" Nullable="No" />
</Outputs>
</Query>
<Query Name="BedInfo" Category="Patients">
<Statement>
SELECT b.Abbreviation AS Bed, r.Abbreviation AS Room
FROM Patients AS p, Beds AS b, Rooms AS r, RoomsBeds AS rb
WHERE PatientID=@PatientID AND p.BedID = b.BedID
AND b.BedID = rb.BedID AND r.RoomID = rb.RoomID
</Statement>
<Inputs>
<Parameter Name="@PatientID" Type="int" />
</Inputs>
<Outputs>
<Column Name="Bed" Type="varchar" Nullable="No" />
<Column Name="Room" Type="varchar" Nullable="No" />
</Outputs>
</Query>
<Queries>
Listing 2 - Sample query definitions
The data types supported on parameters and columns are directly mapped to database-specific
types. Another level of abstraction could be introduced to make these types abstract, with automatic
translation of type names into database-specific data types. However, the query definition XML isn’t
part of our core framework, so one can modify the XML schema at will. Our query representation
maps nicely on a Sybase or SQL Server database, as used by the AB Switch agent.

Chapter 4 – Generic workflows | 65
Notice that this XML-based approach allows queries to be changed without touching the workflow
definition, even at runtime. When making changes at runtime however, care has to be taken not to
disturb semantic correctness which could affect running workflow instances and which could possibly
result in bad output results or behavior. For example, if the results of one query are used as the
inputs of another one, there shouldn’t be a mismatch between both data domains. When a workflow
has passed the first data gathering block and all of a sudden subsequent queries are altered in
configuration, parameterization of those queries might become invalid.
As a countermeasure for situations like these, workflow tracking can be used to detect a safe point
for query changes or instrumentation could be used to inject suspension points that provide signaling
to detect that all running instances have reached a point in the workflow that’s considered to be safe
to allow changes. Much more complex mechanisms could be invented, for example allowing new
workflow instances to use modified queries right away, while existing workflow instances continue
their execution using the original query definitions from the time the instance was started. Such an
approach can be implemented by putting version numbers on queries and by providing query version
numbers when launching a workflow instance. During a workflow instance’s lifecycle, the same query
version will be used, ruling out possible mismatches between different queries.
4.4.2 Core query manager implementation
Next, we’ll implement the query manager itself which is really straightforward (Code 45).
class XmlQueryManager : IQueryManager
{
private XmlDocument doc;
public XmlQueryManager(string file)
{
doc = new XmlDocument();
doc.Load(file);
}
#region IQueryManager Members
public IQuery GetQuery(string name)
{
XmlNode query = doc.SelectSingleNode(
"Queries/Query[@Name='" + name + "']");
if (query == null)
return null;
else
return SybaseQuery.FromXml(query);
}
#endregion
}
Code 45 - Query manager using XML query descriptions
This implementation loads an XML file from disk and builds an IQuery object of type SybaseQuery
based on a specified query name. We should point out that the implementation shown in here is
slightly simplified for the sake of the discussion. A production-ready query manager should allow
more flexibility by detecting changes of the file on disk using a FileSystemWatcher component or by
providing some kind of Refresh method that can be called from the outside when needed. Ideally,

Chapter 4 – Generic workflows | 66
the XML document containing queries shouldn’t be read from disk any time a query is requested
since this would degrade performance significantly. A good balance between caching of the query
descriptors and XML file change detection is crucial.
4.4.3 The query object
Finally, we’ve reached the core object in our query manager: the query object itself, implementing
IQuery. A slightly simplified object definition is shown in Code 46.
class SybaseQuery : IQuery
{
private string name;
private OdbcCommand cmd;
private OdbcConnection connection;
private Column[] outputColumns;
private SybaseQuery(string name, OdbcConnection connection,
string statement, OdbcParameter[] parameters,
Column[] outputColumns)
{
this.name = name;
this.connection = connection;
this.outputColumns = outputColumns;
cmd = new OdbcCommand(statement, connection);
foreach (OdbcParameter p in parameters)
cmd.Parameters.Add(p);
}
public static SybaseQuery FromXml(XmlNode query)
{
string name = query.Attributes["Name"].Value;
string statement = query["Statement"].InnerText;
XmlElement parameters = query["Inputs"];
List<OdbcParameter> sqlParameters = new List<OdbcParameter>();
foreach (XmlNode parameter in parameters.ChildNodes)
sqlParameters.Add(
new OdbcParameter(parameter.Attributes["Name"].Value,
GetOdbcType(parameter.Attributes["Type"].Value)
));
XmlElement outputs = query["Outputs"];
List<Column> columns = new List<Column>();
foreach (XmlNode column in outputs.ChildNodes)
columns.Add(
new Column(column.Attributes["Name"].Value,
GetOdbcType(column.Attributes["Type"].Value),
column.Attributes["Type"].Value.ToLower() == "yes"
));
return new SybaseQuery(name,
new OdbcConnection(Configuration.Dsn), statement,
sqlParameters.ToArray(), columns.ToArray());
}
private static OdbcType GetOdbcType(string type)
{
switch (type)
{

Chapter 4 – Generic workflows | 67
case "int":
return OdbcType.Int;
case "datetime":
return OdbcType.DateTime;
}
return default(OdbcType);
}
public string Name
{
get { return name; }
}
public List<PropertyBag> Execute(PropertyBag parameters)
{
foreach (KeyValuePair<string, object> parameter in parameters)
{
string key = parameter.Key;
if (!key.StartsWith("@"))
key = "@" + key;
if (cmd.Parameters.Contains(key))
cmd.Parameters[key].Value = parameter.Value;
}
connection.Open();
try
{
OdbcDataReader reader = cmd.ExecuteReader();
List<PropertyBag> results = new List<PropertyBag>();
while (reader.Read())
{
PropertyBag item = new PropertyBag();
foreach (Column c in outputColumns)
item[c.Name] = reader[c.Name];
results.Add(item);
}
return results;
}
finally
{
if (connection.State == ConnectionState.Open)
connection.Close();
}
}
}
Code 46 - Query object for Sybase
Let’s point out a few remarks concerning this piece of code. First of all, the GetOdbcType helper
method was oversimplified, only providing support for the types ‘int’ and ‘datetime’ which happen to
be the most common ones in the AB Switch agent. For a full list of types, take a look at the OdbcType
enumeration. Next, the Execute method has some built-in logic that allows chaining of query blocks
by translating column names in parameter names suffixed by the @ character. In case more flexibility
is needed, CodeActivity activities can be put in place to provide extended translation battles from
gathered data into query parameterization objects. However, when naming parameters and columns
in a consistent fashion, this kind of boilerplate code can be reduced significantly. For the AB Switch

Chapter 4 – Generic workflows | 68
agent composition we had to apply only a few such parameterization translations. Finally, exceptions
occurring during the Execute method are propagated to the caller, typically the GatherDataActivity.
In there, the exception can be wrapped as an inner exception in another exception type as part of
the GatherDataActivity’s “contract”. This approach wasn’t shown in Code 44 but is trivial to
implement.
4.5 Hooking up the query manager Now we’ve implemented both the query manager and a query object ready for consumption by the
GatherDataActivity activity in workflow definitions. To make this functionality available to the
workflow instances it has to be hooked up in the Local Communication Services as shown in Code 47.
using (WorkflowRuntime workflowRuntime = new WorkflowRuntime())
{
ExternalDataExchangeService edx
= new ExternalDataExchangeService();
workflowRuntime.AddService(edx);
edx.AddService(new XmlQueryManager("Queries.xml"));
Code 47 - Making the query manager available using LCS
4.6 Chatty or chunky? An important aspect to data-driven workflows is the communication methodology employed to talk
to the database. Two extremes are chatty and chunky communication. In the former case, lots of
queries are launched against the database, each returning a bit of information that’s puzzled
together in the workflow’s logic. The latter one pushes much logic to the database tier in order to
optimize the throughput between tiers and to reduce the amount of data sent across the wire. Both
approaches have their pros and cons as outlined below.
4.6.1 Chatty
Chatty database communication puts a high load on the network stack and the database providers by
creating lots of connections and by executing lots of queries. The percentage of network traffic
occupied by queries sent to the database is relatively high and it’s not unlikely to retrieve a bunch of
data that’s thrown away in the middle-tier or somewhere else in the application because of
additional filtering logic outside the database.
On the other hand, chatty communication typically results in a (large) set of easy-to-understand
queries that might prove useful in various middle-tier components or even across applications when
exposed as stored procedures. Because of this, workflows greatly benefit from some kind of chatty
database communication, to assist in boosting a workflow’s readability.
4.6.2 Chunky
When employing chunky communication, each query results in a chunk of data that’s mostly filtered
on the database side and that has high relevance. This decreases the load on the network for what
the submission of queries and corresponding parameters is concerned.
Ultimately, one could implement a big part of the middle-tier logic at the database side itself, for
example in stored procedures. This will however result in an increased load on the DBMS and moves
a big part of the problem’s complexity to another level, ruling out a clean workflow-based approach
to data logic.

Chapter 4 – Generic workflows | 69
4.6.3 Finding the right balance
Of course, there’s not only black or white but lots of gray scale variants in between. For our AB
Switch agent implementation using workflow, quite some small changes were applied to the original
queries that are used in the procedural coding variant.
An example of merging two queries into one chunkier one is the gathering of patient and bed info in
one single operation. Figure 22 shows such a set of chatty queries that can be merged into just one
by applying a database join operation, as illustrated in Code 48. Other optimizations that have been
applied make use of richer SQL constructs or built-in DBMS functions that help to make a query more
efficient or reduce the size of the returned data. For example, checking the presence of data was
done by retrieving the data and checking the number of rows in the middle-tier layer. A more
efficient approach is to use the COUNT aggregate from SQL.
SELECT PatNumber, FirstName, LastName, BedID, RoomID FROM Patients, Beds AS
b, Rooms AS r, RoomsBeds AS rb WHERE PatientID=@PatientID AND p.BedID =
b.BedID AND b.BedID = rb.BedID AND r.RoomID = rb.RoomID
Code 48 - Merge of individual data queries
5 Other useful activities for generic workflow composition Now that we’ve created the core building block for data gathering, it’s time to focus on a few other
useful activities that make the creation of generic workflows easier. While creating the core toolbox
for generic workflow composition during our research, a total of six custom activities were created.
We’ll discuss each of these, except for the GatherDataActivity, which was covered previously.
Figure 26 - Core activities for generic workflow composition
5.1 ForeachActivity WF has one type of loop activity – the WhileActivity – that allows repetitive execution of a sequence
activity based on a given condition. However, when turning workflows into data processing units – as
is the case with the AB Switch agent –data iteration constructs seem useful. To serve this need, the
ForeachActivity was created, allowing a set of data to be iterated over while executing a sequence
activity for each data item in the set, more or less equal to C#’s foreach keyword.
However, before continuing our discussion of this custom activity we should point out that this
activity might not be the ideal choice when dealing with long-running workflow instances that can be
suspended. The limitations imposed by our ForeachActivity are somewhat equivalent to limitations
of iterators in various programming languages: during iteration the source collection shouldn’t
change. In case a workflow instance suspends while iterating over a set of data, that set of data will

Chapter 4 – Generic workflows | 70
be persisted together with the current position of the iteration. However, by the time the workflow
instance comes alive again, the data might be stale and out of sync with the original data source.
The public interface of the ForeachActivity is shown in Figure 27. To the end-users of the activity, the
two properties are the most important members. The Input property has to be bound to an ordered
collection represented by IList, while the IterationVariable is of type object and will hold the current
item of the iteration. Or, in pseudo-code, the ForeachActivity is equivalent to:
foreach (object IterationVariable in Input)
{
//
// Process iteration body activity sequence
//
}
Figure 27 - ForeachActivity
Essentially, the ForeachActivity forms a graphical representation for data iteration tasks in flowchart
diagrams, for example to perform some kind of calculation logic that uses intermediary results based
on individual data items in a set of retrieved data. As mentioned before, it’s key for the body of the
ForeachActivity to be short-running and non-suspending (at least not explicitly – the workflow
runtime can suspend instances for various reasons). If long-running processing is required on data
items, individual workflow instances should be fired to perform further processing on individual
items in an asynchronous manner, causing the main iteration loop to terminate quickly. This
approach can be realized using the InvokeWorkflow activity of WF. However, in such a case one
should take under consideration any possibility to get rid of the ForeachActivity altogether by moving
the iterative task to the host layer where workflow instances can be created for individual data
items.
An example use in the AB Switch agent could be the iteration over the list of patients that have to be
processed for the past 24 hours, as shown in Figure 28.

Chapter 4 – Generic workflows | 71
Figure 28 - Iteration over a patient list
As long as the SequenceActivity nested inside the ForeachActivity is short-running – kind of a normal
procedural coding equivalent – there’s nothing wrong with this approach. However, one shouldn’t
forget about the sequential nature of the ForeachActivity, as it is derived from the SequenceActivity
base class from the WF base class library. Because of this, no parallelism can be obtained right away
while processing records. The IList interface used for the input of the ForeachActivity nails down this
sequential ordering.
Therefore, for the macro-level of the AB Switch agent, we’ll move the patient iteration logic to the
host layer, effectively representing the processing for one single patient in one workflow definition,
enhancing the degree of parallelism that can be obtained at runtime by executing calculations for
multiple patients at the same time. Nevertheless, we can still take advantage of our query manager
object to retrieve the list of patients in a generic fashion on the host layer, even without having to
use the GatherDataActivity.
5.2 YesActivity and NoActivity Two other activities in our generic workflow library are YesActivity and NoActivity. As a matter of
fact, these activities are mostly eye candy albeit very useful one. In Figure 29 these activities are
shown, used as status indicators for Boolean decision logic indicating success or failure in colors.
Both activities essentially are Boolean assignment operators that assign a value of true (YesActivity,
green) or false (NoActivity, red) to a workflow property.
This approach improves the ease of visual inspection for a workflow during and after composition,
but proves valuable at runtime too when using tracking services. In the WorkflowMonitor, executed
activities are marked by tracking services, allowing visual inspection of workflow instances that are
executing or have been executed already. In case of the AB Switch agent where each individual
patient is represented as a single workflow instance, this kind of tracking allows to diagnose the
decisions made by the agent in order to spot errors or for analytical or statistical purposes.

Chapter 4 – Generic workflows | 72
Figure 29 - YesActivity and NoActivity in a workflow
As an example, the YesActivity is shown in the code fragment below.
[DefaultProperty("YesOutput")]
[Designer(typeof(YesDesigner), typeof(IDesigner))]
[ToolboxItem(typeof(ActivityToolboxItem))]
public class YesActivity : Activity
{
public static DependencyProperty YesOutputProperty =
DependencyProperty.Register("YesOutput", typeof(bool),
typeof(YesActivity));
[Browsable(true)]
[Category("Output")]
[Description("Target to set the output value to.")]
[DesignerSerializationVisibility(
DesignerSerializationVisibility.Visible)]
public bool YesOutput
{
get { return (bool)base.GetValue(YesOutputProperty); }
set { base.SetValue(YesOutputProperty, value); }
}
protected override ActivityExecutionStatus Execute(
ActivityExecutionContext executionContext)
{
YesOutput = true;
return ActivityExecutionStatus.Closed;
}
}
Code 49 - A look at the YesActivity implementation
Notice that an alternative approach could be the use of a single activity used to signal either a
positive case or a negative case. However, WF doesn’t support a designer layout mechanism that can
change an activity’s color based on property values set on the activity, so we’ll stick with two
separate custom activities with a hardcoded green and red color respectively.

Chapter 4 – Generic workflows | 73
As another side note, observe that the situation shown in Figure 29 does a trivial mapping from an
IfElseActivity’s conditional check on a Boolean true/false value using the YesActivity and NoActivity.
This might look a little awkward at first, corresponding to a code structure as the one shown below:
if (<condition>)
value = true;
else
value = false;
Indeed, in a procedural coding equivalent, we’d optimize this code by assigning the condition directly
to the value variable. However, such an approach in the world of workflow won’t provide any visuals
that indicate the outcome of a condition. It should be noted however that the condition builder from
WF seems to be reusable for custom activities, but no further attention was paid to this in particular,
especially since that kind of implementation again would hide the “colorful signaling”.
As an example of a more complex IfElseActivity combined with such signaling blocks, take a look at
the epilogue of the AB Switch implementation that makes the final decision for a patient (Figure 30).
The corresponding canSwitch condition for the IfElseActivity is shown in Figure 31.
Figure 30 - Final decision for a patient's applicability to switch antibiotics
Figure 31 - CanSwitch declarative condition
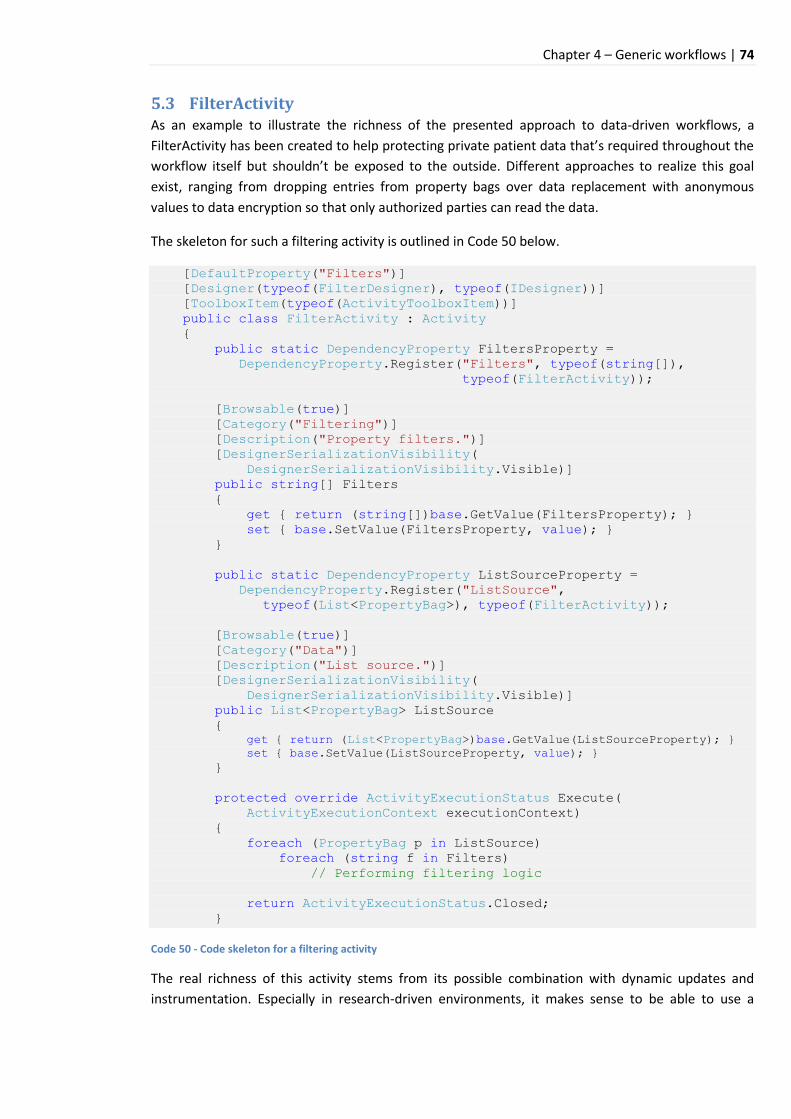
Chapter 4 – Generic workflows | 74
5.3 FilterActivity As an example to illustrate the richness of the presented approach to data-driven workflows, a
FilterActivity has been created to help protecting private patient data that’s required throughout the
workflow itself but shouldn’t be exposed to the outside. Different approaches to realize this goal
exist, ranging from dropping entries from property bags over data replacement with anonymous
values to data encryption so that only authorized parties can read the data.
The skeleton for such a filtering activity is outlined in Code 50 below.
[DefaultProperty("Filters")]
[Designer(typeof(FilterDesigner), typeof(IDesigner))]
[ToolboxItem(typeof(ActivityToolboxItem))]
public class FilterActivity : Activity
{
public static DependencyProperty FiltersProperty =
DependencyProperty.Register("Filters", typeof(string[]),
typeof(FilterActivity));
[Browsable(true)]
[Category("Filtering")]
[Description("Property filters.")]
[DesignerSerializationVisibility(
DesignerSerializationVisibility.Visible)]
public string[] Filters
{
get { return (string[])base.GetValue(FiltersProperty); }
set { base.SetValue(FiltersProperty, value); }
}
public static DependencyProperty ListSourceProperty =
DependencyProperty.Register("ListSource",
typeof(List<PropertyBag>), typeof(FilterActivity));
[Browsable(true)]
[Category("Data")]
[Description("List source.")]
[DesignerSerializationVisibility(
DesignerSerializationVisibility.Visible)]
public List<PropertyBag> ListSource
{
get { return (List<PropertyBag>)base.GetValue(ListSourceProperty); }
set { base.SetValue(ListSourceProperty, value); }
}
protected override ActivityExecutionStatus Execute(
ActivityExecutionContext executionContext)
{
foreach (PropertyBag p in ListSource)
foreach (string f in Filters)
// Performing filtering logic
return ActivityExecutionStatus.Closed;
}
Code 50 - Code skeleton for a filtering activity
The real richness of this activity stems from its possible combination with dynamic updates and
instrumentation. Especially in research-driven environments, it makes sense to be able to use a

Chapter 4 – Generic workflows | 75
(pre)production environment that operates on actual data whilst keeping data as private as possible.
This way, one shouldn’t alter the workflow definition or derive a privacy-friendly variant from the
existing workflow definition.
A more flexible approach using an IFilter interface has been investigated too, allowing for faster
development of a custom filter that plugs directly into a generic FilterActivity. Using Local
Communication Services, the FilterActivity can get access to the IFilter implementation to execute
the corresponding filtering logic.
5.4 PrintXmlActivity A final core building block in our library is the PrintXmlActivity that transforms property bags into an
XML representation and (optionally) applies an XSLT stylesheet to the data. Since property bags are
derived from a built-in collection type, serialization to XML is a trivial thing to do, resulting in a
friendly representation of the name/value pairs, as illustrated in Listing 3.
<?xml version="1.0" encoding="utf-16"?>
<ArrayOfPropertyBag>
<PropertyBag>
<Bed>E307</Bed>
<First>Marge</First>
<Last>Simpson</Last>
<ID>591122</ID>
<Number>078A93</Number>
<Antibiotics>
<PropertyBag>
<Name>Ciproxine IV</Name>
<Dose>200mg/100ml flac</Dose>
</PropertyBag>
<PropertyBag>
<Name>Dalacin C IV</Name>
<Dose>600mg/4ml amp</Dose>
</PropertyBag>
</Antibiotics>
</PropertyBag>
<PropertyBag>
<Bed>E309</Bed>
<First>Homer</First>
<Last>Simpson</Last>
<ID>370818</ID>
<Number>060A39</Number>
<Antibiotics>
<PropertyBag>
<Name>Flagyl IV</Name>
<Dose>500mg/100ml zakje</Dose>
</PropertyBag>
</Antibiotics>
</PropertyBag>
</ArrayOfPropertyBag>
Listing 3 - XML representation of property bags
Applying an XSLT stylesheet isn’t difficult at all using .NET’s System.Xml.Xsl namespace’s
XslCompiledTransform class.

Chapter 4 – Generic workflows | 76
An XSLT stylesheet that’s useful to transform this piece of XML to a text representation ready to be
sent via e-mail to the medical staff is shown in Listing 4. Notice that the resulting XSLT is easy to
understand thanks to the friendly name/value pair mappings in the property bag(s).
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0">
<xsl:output method="text" />
<xsl:template match="/">
The following patients are suitable for a switch from intravenous to
per os medication:
<xsl:apply-templates />
</xsl:template>
<xsl:template match="ArrayOfPropertyBag/PropertyBag">
Bed <xsl:value-of select="Bed"/>
<xsl:text> </xsl:text><xsl:value-of select="First"/>
<xsl:text> </xsl:text><xsl:value-of select="Last"/>
<xsl:text> </xsl:text><xsl:value-of select="ID"/>
<xsl:text> </xsl:text><xsl:value-of select="Number"/>
<xsl:text>
</xsl:text>
<xsl:apply-templates select="Antibiotics" />
</xsl:template>
<xsl:template match="Antibiotics/PropertyBag">
<xsl:text> </xsl:text><xsl:value-of select="Name"/><xsl:text>
</xsl:text>[<xsl:value-of select="Dose"/>]
</xsl:template>
</xsl:stylesheet>
Listing 4 - XSLT stylesheet for XML-to-text translation
The result of this transformation is shown below:
The following patients are suitable for a switch from intravenous to
per os medication:
Bed E307 Marge Simpson 591122 078A93
Ciproxine IV [200mg/100ml flac]
Dalacin C IV [600mg/4ml amp]
Bed E309 Homer Simpson 370818 060A39
Flagyl IV [500mg/100ml zakje]
Depending on the workflow’s level of granularity, different XSLTs can be used. If the workflow acts on
a patient-per-patient basis, the XSLT formatting activity can convert the patient’s advice to a textual
representation that acts as an output for the workflow instance. On the other hand, if the workflow
iterates over all patients, the XSLT can create the whole text output for the daily mail advice in one
single operation. Since we’ve chosen to stick with the first approach as explained earlier, the XSLT
will just take care of the individual patient entries of the output.
Also, the AB Switch agent specification mandates results to be grouped based on the outcome of the
switch advice and to be sorted based on the patient’s bed location subsequently. A simple solution to

Chapter 4 – Generic workflows | 77
implement this requirement consists of retrieving the patients and launching a workflow instance for
each individual retrieved patient. The outputs of all patient processing instances is then collected by
the workflow host that investigates the output parameters indicating the advice (negative or
positive), the bed number (since no in-order completion is guaranteed) and the XSLT output. The
host keeps two OrderedDictionary collections: one for positive advices and another one for negative
advices. Both collections are sorted by bed number. The final mail composition comes down to a join
operation for all advices using simple string concatenation with the StringBuilder class.
5.5 An e-mail activity Almost trivial to implement as a simple exercise on workflow activity creation is an e-mail activity
that allows sending mail messages, for example by taking in a string message composed using the
PrintXmlActivity. Thanks to the availability of a MailMessage class in .NET, creating such an activity is
really straightforward and because of the queuing nature of SMTP (for example using the SMTP
server component available in Windows Server 2003) one doesn’t have to bother much about
guaranteed delivery on the application layer itself. However, as explained further on, alternative
mechanisms based on queuing could provide a more flexible approach to report results by moving
the responsibility for result delivery to the host layer.
6 Other ideas
6.1 Calculation blocks Workflows similar to the AB Switch workflow tend to perform quite a bit of calculation work in order
to produce useful results based on the data fed in. The AB Switch workflow contains a good example
a “calculation block” used to calculate the levophed dose, as shown in Figure 32.
Figure 32 - Calculation block for levophed dose in AB Switch

Chapter 4 – Generic workflows | 78
Different approaches for creating such a calculation block exist, the most straightforward one being
the use of a CodeActivity that does all of the calculation logic. This approach was employed in the AB
Switch implementation, as illustrated in Code 51.
private void calcDose_ExecuteCode(object sender, EventArgs e)
{
double dose = 0.0;
foreach (PropertyBag item in LevophedRates)
dose += ((levopheds[(int)item["PharmaID"]] * 4.0 / 50 * 1000)
/ weight / 60) * (double)item["Rate"];
LevophedDose = dose;
}
Code 51 - Levophed dose calculation in code
When retrieving all of the required data for the calculation in only a few data gathering activities, the
code for the calculation block tends to be pretty easy to implement. In case of AB Switch, one well-
chosen query was used to retrieve all of the input values for the calculation block at once. This is
shown in Code 52.
SELECT PharmaID, MAX(Rate) AS Rate FROM PharmaInformation WHERE PatientID =
@PatientID and PharmaID in (1000582, 1000583, 1000584, 1000586) AND
EnterTime BETWEEN @from AND @to GROUP BY PharmaID
Code 52 - Retrieving input values for levophed calculation
In the original design of AB Switch, the maximum dose for each pharma item was retrieved
individually, resulting in four queries. Using some SQL horsepower such as aggregation and grouping,
this was reduced to one single query, making it more agent-specific but much more efficient.
One could even go one step further by writing a stored procedure that does all of the calculation at
the database layer, returning a singleton result value with the calculated value, reducing the
calculation block to a regular GatherDataActivity. This would put additional stress on the database
however and should be considered carefully.
Though the use of a CodeActivity is by far the easiest implementation for (quite complex) calculation
logic, it doesn’t have the advantage of human readability. As long as the calculation algorithm is well-
known by people who inspect the workflow definition, this shouldn’t be a big problem, especially
when the CodeActivity is well-named. In such as case the calculation block can be considered a black
box. Nevertheless, without doubt situations exist where more flexibility is desirable, reducing the
need for recompilation when calculation logic changes.
A first level of relaxation can be obtained by parameterization of calculation logic using a
PropertyBag that’s fed in by the host. Alternatively, Local Communication Services can be used to
query the host for parameterization information during a workflow instance’s execution lifecycle, in
an interface-based fashion.
However, if the logic itself needs to be modifiable at runtime, more complex mechanisms will have to
be put in place to support this. One such approach could be the use of dynamic type loading (keeping
in mind that types cannot be unloaded from an application domain once they have been loaded, see
[4]) through reflection as outlined in Code 53.

Chapter 4 – Generic workflows | 79
interface ICalculatorManager
{
ICalculator GetCalculator(string calculator);
}
interface ICalculator
{
object Calculate(PropertyBag parameters);
}
class LevophedCalculator : ICalculator
{
private Dictionary<int,int> levopheds = new Dictionary<int,int>();
public LevophedCalculator()
{
levopheds.Add(1000582, 2);
levopheds.Add(1000583, 4);
levopheds.Add(1000584, 8);
levopheds.Add(1000586, 12);
}
public object Calculate(PropertyBag parameters)
{
List<PropertyBag> rates
= (List<PropertyBag>)parameters["LevophedRates"];
double dose = 0.0;
foreach (PropertyBag item in rates)
dose += ((levopheds[(int)item["PharmaID"]] * 4.0 / 50 *
1000) / (double)parameters["Weight"] / 60) *
(double)item["Rate"];
return dose;
}
}
Code 53 - Sample implementation of a calculator
The creation of a calculator activity that invokes a calculator through the ICalculator interface is
completely analogous to the creation of our GatherDataActivity that relied on a similar IQuery
interface. The only difference is the use of reflection in the GetCalculator method implementation, in
order to load the requested calculator implementation dynamically (see Code 54). For better
scalability, some caching mechanism is highly recommended to avoid costly reflection operations
each time a calculation is to be performed.
class CalculatorManager : ICalculatorManager
{
public ICalculator GetCalculator(string calculator)
{
// Get the calculator type from the specified assembly.
// The assembly could also live in the GAC.
string assembly = "put some assembly name here";
string type = calculator;
return (ICalculator)Activator.CreateInstance(assembly, type);
}
}
Code 54 - Dynamic calculator type loading

Chapter 4 – Generic workflows | 80
Yet another approach to dynamic calculation blocks would be the description of the logic by means
of some XML-based language. The .NET Framework comes with a namespace that supports code
generation and compilation, known as CodeDOM. It allows for the creation of object graphs that can
then be translated into any .NET language that has a CodeDOM compiler (C# and VB have one that
ships with the .NET Framework itself).
Using this technology, a piece of calculation code could be translated in a corresponding XML
representation that can be compiled dynamically at runtime when the calculation block is triggered.
Changing the XML file would be sufficient to make a change to the calculation logic. WF itself uses
CodeDOM to serialize conditional expressions from IfElseActivity and WhileActivity activities to XML
that is kept in a .rules file.
Although this approach seems very attractive, .rules files in WF look frightening. For example, a
declarative rule condition as simple as “Age >= 18” is translated into a 24-lines XML file. Though
human readability is a top feature of XML, it doesn't shine through in this case… CodeDOM
essentially is a framework-supported abstract syntax tree representation that – without aid of a user-
friendly tool à la Excel to define calculations – isn’t ready for consumption by end-users. Because of
this we didn’t investigate the path of CodeDOM usage for calculation definitions, but future research
and development of a good calculation definition tool might be interesting.
6.2 On to workflow-based data processing? The described set of custom activities is pretty complete to compose the lion’s part of most data-
driven workflows. A slight amount of manual coding is still required though, especially to apply
transformations on property bags or to pass parameters to various places. Most of this plumbing is
caused by the fact that WF doesn’t have a direct notion of dataflow, except for explicit property
binding. Also, workflows are no pipeline-based structures that allow for easy composition and
chaining, something that’s largely solved by our concept of property bags although manual binding of
properties is still required.
During the research of generic workflow composition, an automatic data passing mechanism similar
to a pipeline structure was investigated briefly but there seems to be no direct easy solution except
for automatic code generation of the property binding logic. After all, such properties are required by
WF to keep a workflow instance’s state in order to recover nicely from workflow dehydration.
Nevertheless such a pipeline-based approach for data processing in workflows would be interesting
from a visual point of view, allowing data operations such as joins to be composed using a designer
while leaving a big part of the execution to the runtime, allowing for automatic parallelism which
might be especially interesting given the recent evolution to multi-core machines.
It seems though that the current framework provided by WF doesn’t provide enough flexibility to
make this possible. Tighter integration with a DBMS might be desirable, as well as a more expressive
flowgraph mechanism that allows to express complex constructs like different types of relational
joins, filtering and projection operations.
6.3 Building the bridge to LINQ LINQ stands for Language Integrated Query and is part of Microsoft’s upcoming .NET Framework 3.5
release, codenamed “Orcas”. It enables developers to write query expressions directly in a general
purpose programming language like C# 3.0 or VB 9.0. An example is shown in Code 55.

Chapter 4 – Generic workflows | 81
var res = from patient in db.Patients
where patient.ID == patientID
select new { p.FirstName, p.LastName, p.PatNumber }
Code 55 - A simple LINQ query in C# 3.0
This technology has several benefits including the unification of various data domains ranging from
relational over XML to in-memory objects (even allowing joins between domains), the generation of
efficient queries at runtime, strong type checking against a database model, etc.
From a workflow’s point of view, the LINQ entity frameworks could be useful to build the bridge
towards a strong-typed approach for query execution in a workflow context, using an alternative
GatherDataActivity implementation that binds to a LINQ query or its underlying expression tree
representation in some way.
That being said, the future applicability of LINQ in this case is still to be seen. One question that will
have to be answered is the availability of Sybase database support which is highly unlikely to be
created by Microsoft itself, although third parties can use LINQ’s extensibility mechanism to support
it. Time will tell how LINQ will evolve with respect to WF-based applications, if such a scenario is even
under consideration for the moment.
6.4 Asynchronous data retrieval In section 4 of this chapter, we’ve gone through the process of creating a fairly simple synchronous
data retrieval block. However, to boost parallelism even further we could go through the design
process of creating an asynchronous data retrieval block by leveraging WF’s scheduling mechanisms,
which is very comparable with classic threading but in this case orchestrated by the WF scheduler.
Basically, an activity (comparable to a thread) can indicate to WF that it’s performing some work in
the background by returning the Executing enumeration value in its Execute method. This is more or
less equivalent to the concept of voluntary thread yielding, putting the scheduler in control to run
other activities (from other instances) while waiting for a result to become available. An example of
this mechanism is illustrated in Code 56.
class AsyncGatherDataActivity : GatherDataActivity
{
protected override ActivityExecutionStatus Execute(
ActivityExecutionContext executionContext)
{
IQueryManager qm =
executionContext.GetService<IQueryManager>();
QueryEventArgs e = new QueryEventArgs();
e.Query = qm.GetQuery(Query);
base.Invoke<QueryEventArgs>(Process, e);
return ActivityExecutionStatus.Executing;
}
void Process(object sender, QueryEventArgs e)
{
ActivityExecutionContext context =
sender as ActivityExecutionContext;
Results = e.Query.Execute(Parameters);
context.CloseActivity();
}
}

Chapter 4 – Generic workflows | 82
class QueryEventArgs : EventArgs
{
private IQuery query;
public IQuery Query
{
get { return query; }
set { query = value; }
}
}
Code 56 - Asynchronous data retrieval
For more advanced execution control, one can use WF’s queuing mechanisms to queue work that
can be retrieved elsewhere for further processing. This concept would drive us too far from home
however. For a detailed elaboration, we kindly refer to [14].
6.5 Web services In case reuse of data gathering mechanisms is desirable, different mechanisms can be employed to
establish this. Our workflow-based data processing could act both as a consumer of a data
publication mechanism or as a provider for data itself.
In the former case, the query manager could be implemented to call a data retrieval web service that
exposes a façade with parameterized queries. In such a case, mapping the parameter types from the
property bags is a trivial one-on-one mapping of .NET types from entries in property bags to method
call parameters on the web service proxy. Reflection could be used to find out about the ordering of
parameters. In case one wants to realize a fully dynamic query manager that can adapt to new
queries right away, WSDL or metadata exchange mechanisms will have to be employed to discover
the data retrieval web methods with parameterization information.
When acting as a publisher, many alternative implementation methodologies are applicable. WF
comes with built-in activities for web service communication that are based on classic web services,
otherwise known as .asmx web services in ASP.NET. Using this mechanism is really easy to do but
provides little out-of-the-box flexibility with respect to recent WS-* standards. Therefore, one might
prefer to go through the burden of manual service implementation using WCF, which opens up for
lots of new functionality with support for the latest web service standards. Also, using WCF one can
hook up many addresses and bindings for one single service contract, for example allowing a service
to be called over very efficient TCP/binary communication using .NET Remoting on the intranet,
while providing alternative communication mechanisms towards other platforms using web service
standards. Finally, queue-based communication using MSMQ can be plugged into WCF as well.
Both approaches could be combined as well, publishing (advanced) workflow-based data processing
blocks through web services and consuming these in other workflows again. Combining this with
WCF’s multi-protocol publication mechanisms seems a very attractive option, especially because it
allows for very efficient local communication (even using named pipes between processes on a single
machine) as well as web service standards compliant communication with other hosts, while keeping
the overall distributed system architecture highly modular.
6.6 Queue-based communication Agents like AB Switch are only executed on a periodic basis, making these suitable candidates for
batched processing based on queued requests. While the agent is asleep, processing requests could

Chapter 4 – Generic workflows | 83
be queued up using mechanisms like MSMQ. When the agent is launched, for example by the
Windows Scheduler, the batch of work is retrieved from the queue, processing is done and results
are calculated. Such an approach could prove useful when triggers are used around the system to
determine work that has to be done in a deferred way. For example, the online medical database
could monitor for specific values that are changing or even for certain threshold values. When such
an event happens, work could be queued up to the agent for later (more thorough and expensive)
processing when the system isn’t under high load. This way, preprocessing of data can be performed,
decreasing the agent’s amount of work. In short, we can speak about a “push” mechanism.
The other way around, the agent could operate in a “pull” manner, actively waiting for requests to
come in through a queue on a permanent basis. Although there’s a high correspondence to a regular
synchronous invocation mechanism, this allows callers to act in a “fire-and-forget” fashion by
pushing work to a queue without waiting for a result (similar to a one-way web method invocation).
By leveraging extended queuing techniques available in MSMQ, such as dead-letter queues or
transactional queues, the overall reliability of the agent could be further improved.
Yet another application of queues is the publication of results, similar to a mail queue, ready for
consumption by some other component on the network. Using this technique, the workflow host’s
complexity can be reduced because workflow instances don’t produce results that have to be
captured by the host. By publishing results to a queue, reliability can be increased once more and
there’s less load on the workflow host. The latter benefit is relevant since inappropriate resource
usage in a workflow hosting application could lead to scheduling problems. By queuing results, the
amount of code running on the host is reduced, also reducing the possibility for uncaught exceptions
to bring down the host (and hence the agent) with possible data loss if workflow instances haven’t
been persisted to disk. To set the reader’s mind, we recall the mechanism used in a host to get
output data back from terminated workflow instances:
using (WorkflowRuntime workflowRuntime = new WorkflowRuntime())
{
//...
workflowRuntime.WorkflowCompleted +=
delegate(object sender, WorkflowCompletedEventArgs e)
{
object result = e.OutputParameters["SomeProperty"];
//record result(s)
};
Code 57 - Collecting workflow instance result data
Crashing the thread that retrieves data from the completed workflow instance isn’t a good thing and
can be avoided completely by making the workflow return nothing and having it queue up the
obtained results. Another component (in a separate process or even on another host) can then drain
the queue – optionally in a transactional manner – for further processing and/or result delivery.
7 Putting the pieces together: AB Switch depicted To get an idea of the overall structure of AB Switch as a workflow, take a look at Figure 33. Even
though the workflow isn’t readable on paper, one gets a good idea of the structure of the workflow
because of its graphical nature and the color codes used by our custom activities. Yellow blocks

Chapter 4 – Generic workflows | 84
indicate data gathering, while the green and red blocks act as status indicators driving the decision
process. Observe the inherent parallelization of the workflow too.
Figure 33 - AB Switch in workflow

Chapter 4 – Generic workflows | 85
8 Designer re-hosting: the end-user in control Another interesting feature of WF is called designer re-hosting. The workflow designer that’s
available in Visual Studio 2005 ships as a redistributable component so it can be reused in other
applications. In Chapter 3, paragraph 7 we’ve met the workflow designer already as part of the
WorkflowMonitor where the visualization of running and completed workflow instances is done by
loading the workflow instances from the tracking database, followed by display in a workflow
designer component.
As an example, we’ve extended the Workflow Designer Rehosting Example that’s available online
[15] and ships with the Windows SDK WF samples. The result is visible in Figure 34.
Figure 34 - Workflow designer re-hosting with custom activity libraries
Using designer re-hosting we were capable of composing AB Switch without requiring the Visual
Studio 2005 tools, resulting in a XOML file that can be compiled for execution. As mentioned in
Chapter 2, paragraph 2.3 the WF API has a WorkflowCompiler class aboard that can be used for
dynamic workflow type compilation and that’s exactly what’s happening in the sample application
when calling Workflow, Compile Workflow.
However, to be usable by end-users directly some issues need further investigation, resulting in more
simplification of the tool. The most obvious problem is likely the (lack of) end-user knowledge of
some WF concepts such as property binding. For example, when dragging a GatherDataActivity to
the designer surface, properties have to be set to specify the query name but also to bind the query
parameters and the result object. This is shown in Figure 35.

Chapter 4 – Generic workflows | 86
Figure 35 - WF complexity bubbles up pretty soon
Although all of the workflow designer tools (e.g. the property binding dialog, the rules editor, etc.)
from Visual Studio 2005 are directly available in the designer re-hosting suite, some are too difficult
for use by end-users directly.
One idea to overcome some of these issues is making the re-hosted designer tool more domain-
specific, with inherent knowledge of the query manager in order to retrieve a list of available queries
(notice that the query manager interface will have to be extended to allow this). Once all queries are
retrieved in a strongly-typed fashion (i.e. with full data type information for parameters and
columns), the system can populate the toolbox with all queries available (in the end one could create
a query designer tool in addition to build new queries using the same tool, provided the end-user has
some SQL knowledge). Queries in WF are nothing more than pre-configured GatherDataActivity
blocks, together with a parameterization PropertyBag and a result list of PropertyBags. This approach
reduces the burden of creating and binding input/output properties manually, increasing the
usability dramatically at the cost of a more domain-specific workflow designer host but that should
be just okay.
Nevertheless, some basic knowledge of bindings will remain necessary for end-users in order to bind
one activity’s output to another activity’s input, for example to feed the output from a data retrieval
operation to a PrintXmlActivity. An alternative to make this more user friendly might be the
visualization of all PropertyBag and List<PropertyBag> objects in some other toolbox pane. Bindings
for activities’ default properties could be established then using simple drag-and-drop operations.
Such an approach visualizes the implicit dataflow present in workflow-based applications.
For example, a GatherDataActivity could have its Parameters property decorated with some custom
attribute that indicates it is the default input property. In a similar fashion, the Results property can
then be specified as the default output property. Using reflection, the tool can find out about those
default properties to allow for drag-and-drop based property binding. An early prototype of this
mechanism is shown in Figure 36, where green lines indicate inputs and red lines indicate outputs.
The list on the left-hand side shows all of the (lists of) PropertyBags that are present in the current
workflow, together with their bindings.
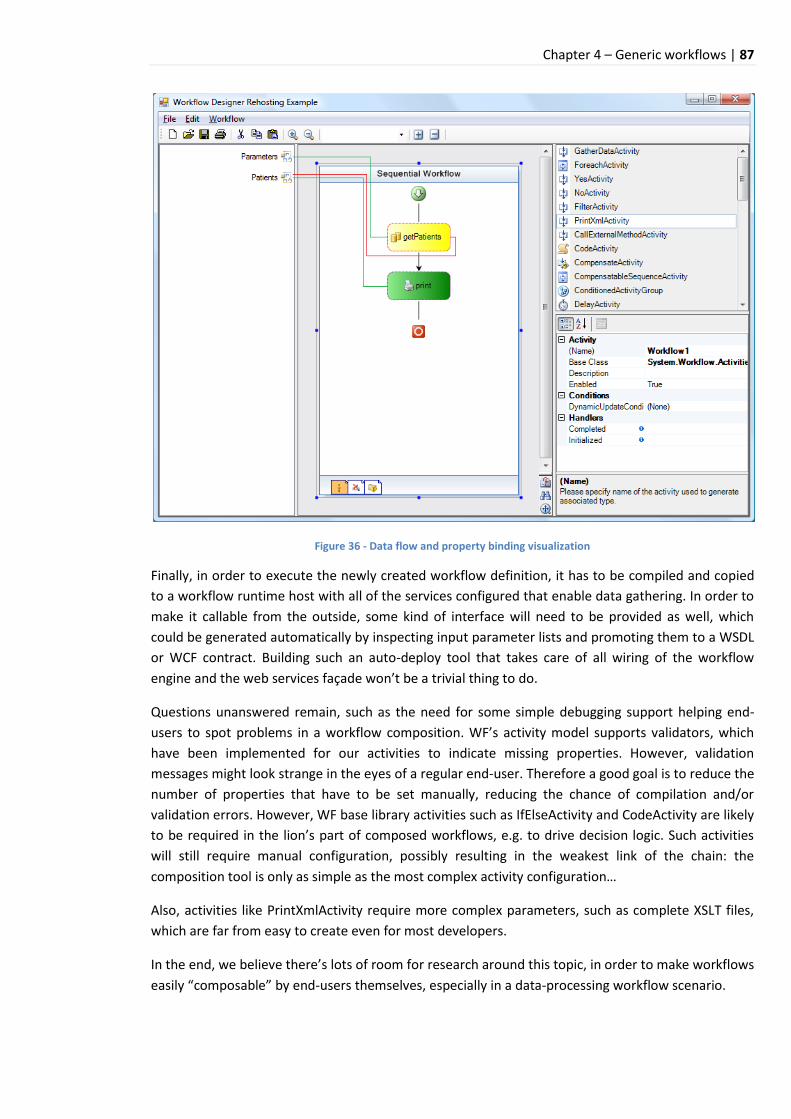
Chapter 4 – Generic workflows | 87
Figure 36 - Data flow and property binding visualization
Finally, in order to execute the newly created workflow definition, it has to be compiled and copied
to a workflow runtime host with all of the services configured that enable data gathering. In order to
make it callable from the outside, some kind of interface will need to be provided as well, which
could be generated automatically by inspecting input parameter lists and promoting them to a WSDL
or WCF contract. Building such an auto-deploy tool that takes care of all wiring of the workflow
engine and the web services façade won’t be a trivial thing to do.
Questions unanswered remain, such as the need for some simple debugging support helping end-
users to spot problems in a workflow composition. WF’s activity model supports validators, which
have been implemented for our activities to indicate missing properties. However, validation
messages might look strange in the eyes of a regular end-user. Therefore a good goal is to reduce the
number of properties that have to be set manually, reducing the chance of compilation and/or
validation errors. However, WF base library activities such as IfElseActivity and CodeActivity are likely
to be required in the lion’s part of composed workflows, e.g. to drive decision logic. Such activities
will still require manual configuration, possibly resulting in the weakest link of the chain: the
composition tool is only as simple as the most complex activity configuration…
Also, activities like PrintXmlActivity require more complex parameters, such as complete XSLT files,
which are far from easy to create even for most developers.
In the end, we believe there’s lots of room for research around this topic, in order to make workflows
easily “composable” by end-users themselves, especially in a data-processing workflow scenario.

Chapter 4 – Generic workflows | 88
9 Performance analysis
9.1 Research goal An important question when applying workflow as a replacement for procedural coding is the overall
performance impact on the application. Though performance degradations are largely overshadowed
in long-running workflows, applying workflows for short-running data processing operations can be
impacted by performance issues, especially when these operations are triggered through some
request-response RPC mechanism such as web services. This being said, efficient resource utilization
in long-running workflows matters as well.
In this paragraph we’ll investigate the impact of workflow-based programming on data processing
applications. More specifically we’ll take a look at the performance of the ForeachActivity and the
GatherDataActivity compared their procedural equivalents, the performance characteristics of per-
record based processing using individual workflow instances versus iterative workflows and the
impact of intra-workflow and inter-workflow parallelization.
9.2 Test environment All tests performed were conducted on a Dell Inspiron 9400 machine, with dual core Intel Centrino
Duo processor running at 2.16 GHz with an L1 cache of 32 KB and an L2 cache of 2 MB. The machine
has 2 GB of RAM and is running Windows Vista Ultimate Edition (32 bit). Tests were conducted with
persistence services disabled, with the workflow runtime hosted by a simple console application,
compiled in Release mode with optimizations turned on and started from the command-line without
a debugger attached.
The DBMS engine used throughout our tests is Microsoft SQL Server 2005 Developer Edition with
Service Pack 2, installed on the local machine. Connections to the database are using Windows
authentication and are established via named pipes using the ADO.NET built-in SqlClient. As a sample
database, the well-known Northwind database was installed [16]. We didn’t use the Sybase server in
our tests because of the network speed variance at the test location, possible influences caused by
the VPN network and because of unpredictable loads on the target database. However, tests can be
conducted again easily by putting another query manager in the test application and by replacing the
query definitions to match the target database schema.
Nevertheless, because data-driven workflows are highly dependent on the DBMS performance and
throughput as well as network traffic, we’ll model these processing delays in some of our tests as
outlined further on.
9.3 A raw performance comparison using CodeActivity It might look trivial but it’s interesting nevertheless: what about the performance of a simple “Hello
World!” application written in regular procedural coding versus the workflow-based equivalent? In
this scenario, we’re doing nothing more or less than wrapping one line of code in a CodeActivity
inside a workflow definition.
In order to reduce the effects of launching the workflow runtime, one runtime instance is created to
serve multiple workflow instances during testing (which is also the natural way of operating WF). The
code of the basic test is shown in Code 58, where Workflow1 is a trivial sequential workflow
definition with one CodeActivity.

Chapter 4 – Generic workflows | 89
class Program
{
static int N = 10000;
static void Main(string[] args)
{
Stopwatch sw = new Stopwatch();
sw.Start();
for (int i = 0; i < N; i++)
Console.WriteLine("Hello World!");
sw.Stop();
long l1 = sw.ElapsedMilliseconds;
sw.Reset();
sw.Start();
using(WorkflowRuntime workflowRuntime = new WorkflowRuntime())
{
AutoResetEvent waitHandle = new AutoResetEvent(false);
int n = 0;
workflowRuntime.WorkflowCompleted +=
delegate(object sender, WorkflowCompletedEventArgs e) {
if (++n == N)
waitHandle.Set();
};
for (int i = 0; i < N; i++)
{
WorkflowInstance instance =
workflowRuntime.CreateWorkflow(typeof(Workflow1));
instance.Start();
}
waitHandle.WaitOne();
}
sw.Stop();
Console.WriteLine(l1);
Console.WriteLine(sw.ElapsedMilliseconds);
}
}
Code 58 - Simple procedural performance measurement
Notice this piece of code isn’t thread-safe since the WorkflowCompleted event handler isn’t
synchronized. However, locking introduces a significant overhead that would affect the performance
results for a workflow-based application negatively. Therefore, we don’t fix this issue at the risk of
having a blocked test program when the counter ‘n’ doesn’t reach its final value because of
overlapped write operations. In such a case we simply restart the test application.
We measured results like the following:
Procedural: 1015 ms
Workflow: 3983 ms
So, the difference is about a factor four due to various mechanisms inside WF that are quite resource
hungry, especially the scheduler that has to schedule individual workflow instances as well as each
individual activity inside a workflow.
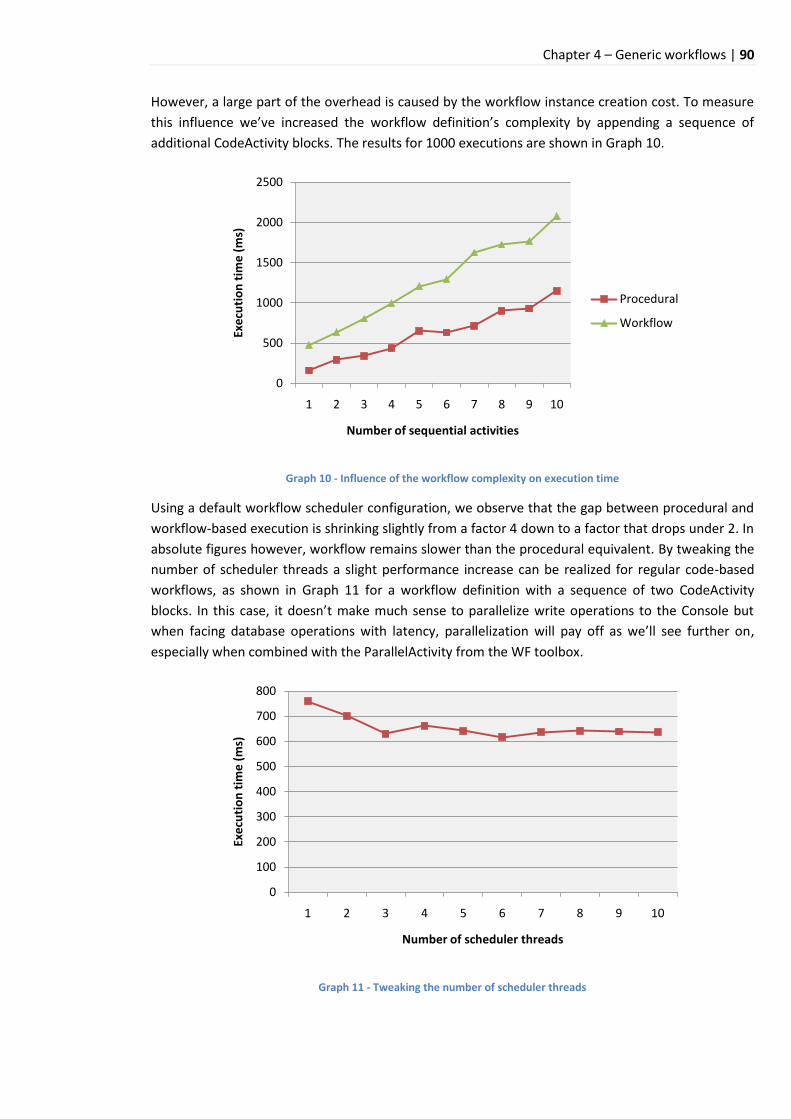
Chapter 4 – Generic workflows | 90
However, a large part of the overhead is caused by the workflow instance creation cost. To measure
this influence we’ve increased the workflow definition’s complexity by appending a sequence of
additional CodeActivity blocks. The results for 1000 executions are shown in Graph 10.
Graph 10 - Influence of the workflow complexity on execution time
Using a default workflow scheduler configuration, we observe that the gap between procedural and
workflow-based execution is shrinking slightly from a factor 4 down to a factor that drops under 2. In
absolute figures however, workflow remains slower than the procedural equivalent. By tweaking the
number of scheduler threads a slight performance increase can be realized for regular code-based
workflows, as shown in Graph 11 for a workflow definition with a sequence of two CodeActivity
blocks. In this case, it doesn’t make much sense to parallelize write operations to the Console but
when facing database operations with latency, parallelization will pay off as we’ll see further on,
especially when combined with the ParallelActivity from the WF toolbox.
Graph 11 - Tweaking the number of scheduler threads
0
500
1000
1500
2000
2500
1 2 3 4 5 6 7 8 9 10
Exe
cuti
on
tim
e (
ms)
Number of sequential activities
Procedural
Workflow
0
100
200
300
400
500
600
700
800
1 2 3 4 5 6 7 8 9 10
Exe
cuti
on
tim
e (
ms)
Number of scheduler threads

Chapter 4 – Generic workflows | 91
9.4 Calculation workflows with inputs and outputs An important aspect in our approach to data-driven workflows is performing calculations based on
input values that flow in to the workflow instance, producing output values during execution.
Therefore it is good to get an idea about the cost to create workflow instances that take in data and
produce data. To measure this cost, we’ve built a simple workflow that takes in two integer values
and calculates their sum. The code is trivial, consisting of three dependency properties and one
CodeActivity that calculates the sum. The result for 1000 calculations is:
Procedural: 2566 ticks (0 ms)
Workflow: 5728119 ticks (400 ms)
The cost of thousand integer operations can be neglected, giving us a good idea of the overhead
caused by workflow instance creation and input/output communication. To separate the costs of
workflow creation from the code execution inside, we measured the time it takes to create and
execute thousand instances of a void non-parameterized workflow, resulting in 287 ms. Based on
this, the remaining 133 ms can be considered an approximation for the input/output costs for the
three data values used in and produced by the workflow.
In addition we measured the cost associated with pushing the calculation logic outside the workflow
definition using Local Communication Services with a simple calculator as shown in Code 59.
[ExternalDataExchange]
interface ICalculator
{
int Sum(int a, int b);
}
class Calculator : ICalculator
{
public int Sum(int a, int b)
{
return a + b;
}
}
Code 59 - LCS service for a simple calculation
This time the result for 1000 instances is:
Workflow: 7416802 ticks (517 ms)
Subtracting the workflow instance creation cost results in a total processing cost of 230 ms where
the communication cost is the most significant due to the trivial cost for an addition operation. From
this we can conclude that LCS introduces a significant cost. Nevertheless, the flexibility of LCS is much
desired so one should be prepared to pay this cost to establish communication with the hosting
layer.
9.5 Iterative workflows In paragraph of 5.1 of this chapter we introduced a ForeachActivity to allow iterative workflow
definitions without having to rely on a more complex WhileActivity as available in WF directly. For
data-driven workflow definitions, the ability to iterate over a set of data seems an attractive solution

Chapter 4 – Generic workflows | 92
although a more fine-grained approach (e.g. a workflow instance for each individual patient that
requires data processing) might be desirable as pointed out previously.
In this section, a naïve workflow-based implementation is created that uses a ForeachActivity to
iterate over a sequence of numbers that are printed on the screen using the Console class. The goal
is to find out about the overhead introduced by the ForeachActivity when iterating over a sequence
of data, without counting in any cost to retrieve data (which is subject of subsequent analysis).
In Graph 12 the result for various iteration lengths is shown, comparing procedural code and the
workflow-based counterpart. From this test we can conclude that the cost of workflow-based
collection iteration grows faster in function of the number of iterations, compared to a classic
foreach loop. For 100 iterations the workflow variant is about 2.8 times more costly than procedural
code; for 2500 iterations this factor has grown to 3.7 already.
Graph 12 - Performance of the ForeachActivity
This growing gap between procedural and workflow can be explained by the nature of WF work
scheduling. Our ForeachActivity implementation uses the activity event model to schedule the
execution of the loop’s body. The core of the ForeachActivity implementation is shown in Code 60.
When the loop body finishes execution for an iteration, an event is raised that’s used to call the loop
body again as long there are items remaining in the source sequence. For the execution of the loop
body, the WF scheduler is triggered indirectly by calling the ExecuteActivity method on the
ActivityExecutionContext object. This scheduling overhead accumulates over time, causing the gap
between procedural and workflow-based iteration to grow.
Notice that this scheduling mechanism operates on the level of the workflow engine, across many
workflow instances. This means that individual workflow instances might be paused temporarily in
order to give other instances a chance to make progress. Because of this, the average execution time
of an individual workflow instance will increase. Strictly spoken, the ForeachActivity gives the WF
scheduler an opportunity to schedule another workflow instance every time it schedules the work for
the next iteration of the loop. One can compare this with voluntary yielding of threads in systems
with cooperative scheduling. Furthermore, such switching between instances can occur inside the
0
100
200
300
400
500
600
700
800
900
10
0
30
0
50
0
70
0
90
0
11
00
13
00
15
00
17
00
19
00
21
00
23
00
25
00
Exe
cuti
on
tim
e (
ms)
Number of iterations
Procedural
Workflow

Chapter 4 – Generic workflows | 93
loop’s body as well, each time a child activity has completed its work. Essentially, activities in WF are
atomic units of work, which can be subdivided in smaller work units again by using scheduling
mechanisms directly (e.g. through ActivityExecutionContext).
private int index = 0;
protected override ActivityExecutionStatus Execute(
ActivityExecutionContext context)
{
if (Input.Count != 0 && EnabledActivities.Count != 0)
{
ExecuteBody(context);
return ActivityExecutionStatus.Executing;
}
else
return ActivityExecutionStatus.Closed;
}
void ExecuteBody(ActivityExecutionContext context)
{
ActivityExecutionContextManager mgr
= context.ExecutionContextManager;
ActivityExecutionContext ctx
= mgr.CreateExecutionContext(EnabledActivities[0]);
IterationVariable = Input[index++];
Activity activity = ctx.Activity;
activity.Closed += ContinueAt;
ctx.ExecuteActivity(activity);
}
void ContinueAt(object sender, ActivityExecutionStatusChangedEventArgs e)
{
e.Activity.Closed -= this.ContinueAt;
ActivityExecutionContext context = sender as ActivityExecutionContext;
ActivityExecutionContextManager mgr = context.ExecutionContextManager;
ActivityExecutionContext ctx = mgr.GetExecutionContext(e.Activity);
mgr.CompleteExecutionContext(ctx);
if (this.ExecutionStatus == ActivityExecutionStatus.Executing
&& index < Input.Count)
ExecuteBody(context);
else
context.CloseActivity();
}
Code 60 - The ForeachActivity relies on the WF scheduler for loop body execution
At first glance, this loop mechanism seems to be a disadvantage from a performance point of view.
However, it really depends on the contents of the loop. If long-running operations inside the loop
construct are launched in an asynchronous manner, the scheduler can switch active execution to
another workflow instance or a parallel branch in the same workflow instance. When the background
work has been completed, the activity is rescheduled to allow activity execution completion.

Chapter 4 – Generic workflows | 94
9.6 Data processing Now that we’ve gained a better idea about the overall performance impact of workflow creation,
procedural code execution inside workflows, communication mechanisms and loop constructs, it’s
time to move our focus to the data processing side of the story. We’ll investigate a few different
options in detail to decide on the best possible approach to write workflow-based data processing
applications that inherit most of WF’s benefits such as suitability for human inspection, tracking
services, etc.
9.6.1 Iterative data processing
A first option is to leverage the power of our ForeachActivity in order to process a batch of records by
iterating over them. Despite the fact that this approach has some limitations on the field of tracking
(as discussed before in paragraph 5.1) it is a good candidate for agents that have to process a large
set of items resulting in an information aggregation. An example is a reporting engine that collects
data from various sources, iterates over these sources and presents aggregated information about all
of the processed records in a nice report.
To analyze the performance cost of such a construct, a simple one-loop workflow definition was
built, as shown in Figure 37. Data is retrieved from the Northwind sample database’s Products table
using a simple non-parameterized SELECT statement that retrieves a set of records using a TOP
clause.
Figure 37 - An iterative data processing workflow
The cost of the loop body is kept to a minimum, calculating the product of each product’s unit price
and the number of items still in stock. These values are summed up to result in a total product stock
value. Although such a data processing mechanism could be written in a much more efficient manner
by means of (server-side) DBMS features such as aggregates and cursors, a workflow-based variant
might be a better choice to clarify the processing mechanism by means of a sequential diagram. Of

Chapter 4 – Generic workflows | 95
course more advanced scenarios exist, for example where data is grabbed from the database as input
to much more complex processing, possibly in a distributed manner across multiple agents.
In order to have some ground to compare on, an alternative implementation was created using
regular procedural ADO.NET code, which is shown in Code 61.
using (SqlConnection conn = new SqlConnection(dsn))
{
decimal total = 0;
SqlCommand cmd = new SqlCommand(
"SELECT TOP " + N + " p.ProductID, p.ProductName, " +
"p.UnitsInStock, p.UnitPrice, p.SupplierID, p.CategoryID " +
"FROM Products AS p, Products AS p1", conn);
conn.Open();
SqlDataReader reader = cmd.ExecuteReader();
while (reader.Read())
{
total += (decimal)reader["UnitPrice"]
* (short)reader["UnitsInStock"];
}
}
Code 61 - Procedural coding equivalent for iterative data processing
Notice the little trick in the SELECT statement’s FROM clause that takes the Cartesian product of two
(identical) tables just to get a massive amount of rows so that the TOP row restriction clause doesn’t
run out of juice when measuring performance for large sets of data, exceeding the original table’s
row count.
For the query manager implementation that’s hooked up to the workflow engine we use the same
ADO.NET APIs as well as the same connection string. This causes data gathering to take place using
the same underlying connection technology and parameterization.
The results of the performance measurement are shown in Graph 13.
Graph 13 - Iterative data processing performance results
0
500
1000
1500
2000
2500
3000
10
0
30
0
50
0
70
0
90
0
11
00
13
00
15
00
17
00
19
00
21
00
23
00
25
00
Exe
cuti
on
tim
e (
ms)
Number of data records
Procedural
Workflow

Chapter 4 – Generic workflows | 96
We clearly see a much bigger cost associated with the workflow-based approach, accumulating a lot
of performance killers, for a large part caused by the fact that all data results are gathered in one
single operation, ruling out the high efficiency of the forward-only SqlDataReader, replacing it by a
more complex in-memory iteration mechanism. While the procedural code executes in only a few
milliseconds, workflow takes about 1 millisecond per iteration. Also the effects of putting data in a
PropertyBag and getting it out again shouldn’t be underestimated, even though these operations
have only O(1) complexity. This cycle of putting data in during the data gathering phase and getting it
back out is causing costly boxing/unboxing and casting operations to take place, due to our use of the
type “object” for values in the PropertyBag.
From this we can conclude that for easy data retrieval operations the raw ADO.NET reader-based
loop is unbeatable by far, at the cost of black-boxed code that doesn’t reflect the original intention
very well to end-users.
9.6.2 Nested data gatherings
Simple data retrieval operations as the one above don’t gain much benefit from a workflow-based
representation. Once things get more complex, e.g. when data gathering activities are nested in
another data gathering’s iteration mechanism, workflow becomes more and more attractive.
An example of such a structure is depicted in Figure 38. At the root level, products are retrieved
using a similar query as the one used in the previous section. As part of the processing of these
product records, other queries are launched in order to retrieve data from tables that have a
relationship with the parent table. In the Northwind database, each product has a foreign key
pointing to a category and another one pointing to the product’s supplier. These queries are
parameterized ones that take in the current product’s PropertyBag as a parameter, in order to obtain
the foreign key values for “relationship traversal”.
Notice that both nested queries are executed in parallel, creating a level of intra-workflow
parallelism without having to bother about thread safety ourselves. On the procedural side we didn’t
implement such a parallel data retrieval mechanism due to the complexity it imposes. The procedural
code used for performance comparison is shown in Code 62.
using (SqlConnection conn = new SqlConnection(dsn))
{
decimal total = 0;
SqlCommand cmd = new SqlCommand(
"SELECT TOP " + N + " p.ProductID, p.ProductName, " +
"p.UnitsInStock, p.UnitPrice, p.SupplierID, p.CategoryID " +
"FROM Products AS p, Products AS p1", conn);
conn.Open();
SqlDataReader reader = cmd.ExecuteReader();
while (reader.Read())
{
SqlCommand cmd2 = new SqlCommand(
"SELECT SupplierName FROM Suppliers " +
"WHERE SupplierID = @SupplierID", conn);
cmd2.Parameters.Add("@SupplierID", SqlDbType.Int).Value
= reader["SupplierID"];
SqlDataReader reader2 = cmd2.ExecuteReader();
while (reader2.Read())
;
SqlCommand cmd3 = new SqlCommand(

Chapter 4 – Generic workflows | 97
"SELECT CategoryName FROM Categories " +
"WHERE CategoryID = @CategoryID", conn);
cmd3.Parameters.Add("@CategoryID", SqlDbType.Int).Value
= reader["CategoryID"];
SqlDataReader reader3 = cmd3.ExecuteReader();
while (reader3.Read())
;
total += (decimal)reader["UnitPrice"]
* (short)reader["UnitsInStock"];
}
}
Code 62 - Nested data gathering using procedural code
Figure 38 - Nested data gathering operations
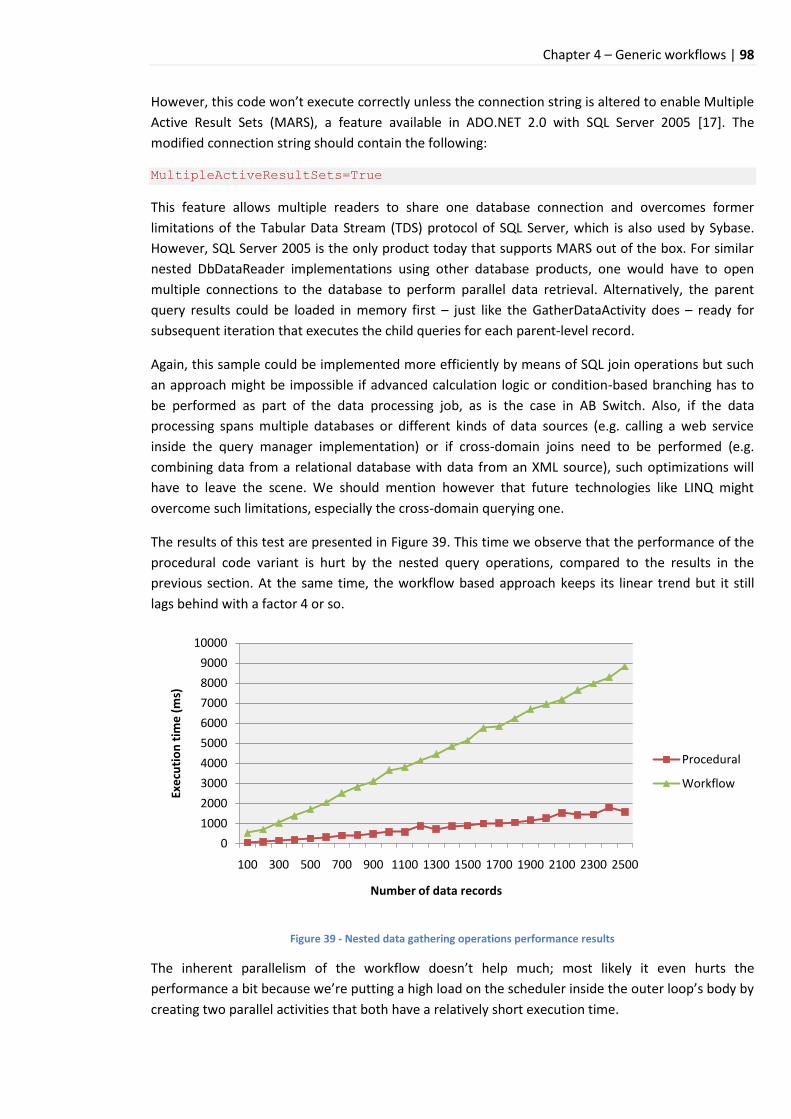
Chapter 4 – Generic workflows | 98
However, this code won’t execute correctly unless the connection string is altered to enable Multiple
Active Result Sets (MARS), a feature available in ADO.NET 2.0 with SQL Server 2005 [17]. The
modified connection string should contain the following:
MultipleActiveResultSets=True
This feature allows multiple readers to share one database connection and overcomes former
limitations of the Tabular Data Stream (TDS) protocol of SQL Server, which is also used by Sybase.
However, SQL Server 2005 is the only product today that supports MARS out of the box. For similar
nested DbDataReader implementations using other database products, one would have to open
multiple connections to the database to perform parallel data retrieval. Alternatively, the parent
query results could be loaded in memory first – just like the GatherDataActivity does – ready for
subsequent iteration that executes the child queries for each parent-level record.
Again, this sample could be implemented more efficiently by means of SQL join operations but such
an approach might be impossible if advanced calculation logic or condition-based branching has to
be performed as part of the data processing job, as is the case in AB Switch. Also, if the data
processing spans multiple databases or different kinds of data sources (e.g. calling a web service
inside the query manager implementation) or if cross-domain joins need to be performed (e.g.
combining data from a relational database with data from an XML source), such optimizations will
have to leave the scene. We should mention however that future technologies like LINQ might
overcome such limitations, especially the cross-domain querying one.
The results of this test are presented in Figure 39. This time we observe that the performance of the
procedural code variant is hurt by the nested query operations, compared to the results in the
previous section. At the same time, the workflow based approach keeps its linear trend but it still
lags behind with a factor 4 or so.
Figure 39 - Nested data gathering operations performance results
The inherent parallelism of the workflow doesn’t help much; most likely it even hurts the
performance a bit because we’re putting a high load on the scheduler inside the outer loop’s body by
creating two parallel activities that both have a relatively short execution time.
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
100 300 500 700 900 1100 1300 1500 1700 1900 2100 2300 2500
Exe
cuti
on
tim
e (
ms)
Number of data records
Procedural
Workflow
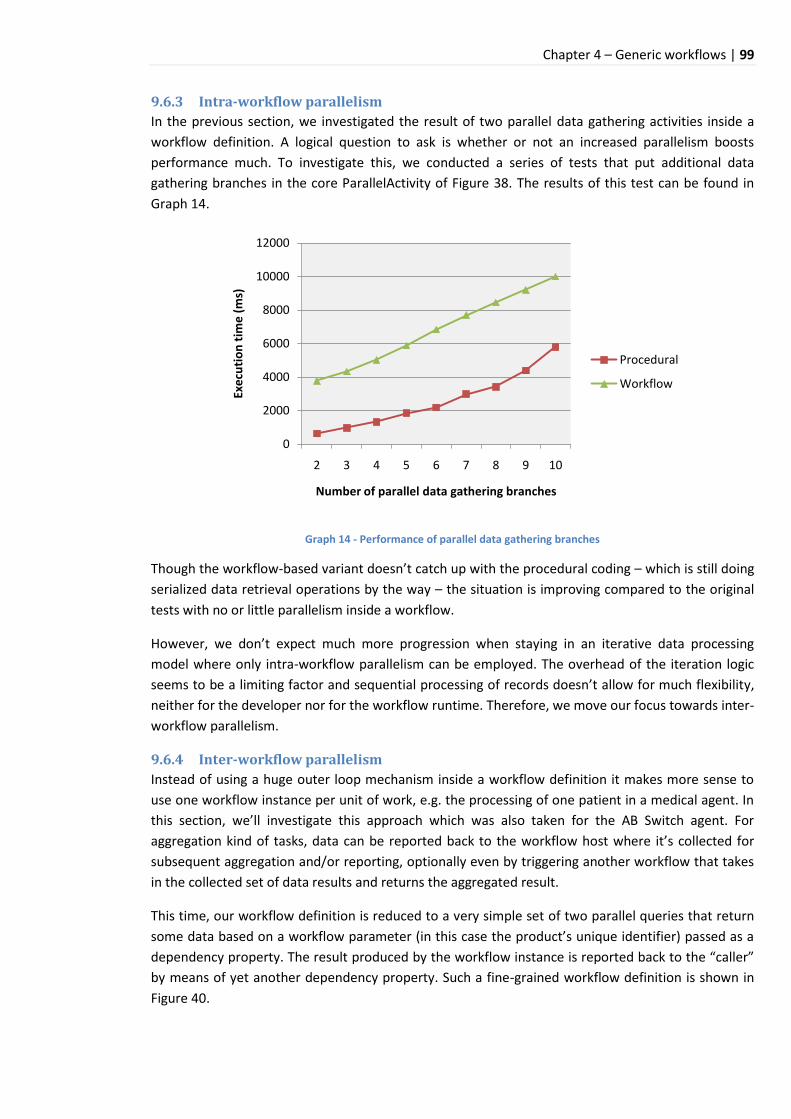
Chapter 4 – Generic workflows | 99
9.6.3 Intra-workflow parallelism
In the previous section, we investigated the result of two parallel data gathering activities inside a
workflow definition. A logical question to ask is whether or not an increased parallelism boosts
performance much. To investigate this, we conducted a series of tests that put additional data
gathering branches in the core ParallelActivity of Figure 38. The results of this test can be found in
Graph 14.
Graph 14 - Performance of parallel data gathering branches
Though the workflow-based variant doesn’t catch up with the procedural coding – which is still doing
serialized data retrieval operations by the way – the situation is improving compared to the original
tests with no or little parallelism inside a workflow.
However, we don’t expect much more progression when staying in an iterative data processing
model where only intra-workflow parallelism can be employed. The overhead of the iteration logic
seems to be a limiting factor and sequential processing of records doesn’t allow for much flexibility,
neither for the developer nor for the workflow runtime. Therefore, we move our focus towards inter-
workflow parallelism.
9.6.4 Inter-workflow parallelism
Instead of using a huge outer loop mechanism inside a workflow definition it makes more sense to
use one workflow instance per unit of work, e.g. the processing of one patient in a medical agent. In
this section, we’ll investigate this approach which was also taken for the AB Switch agent. For
aggregation kind of tasks, data can be reported back to the workflow host where it’s collected for
subsequent aggregation and/or reporting, optionally even by triggering another workflow that takes
in the collected set of data results and returns the aggregated result.
This time, our workflow definition is reduced to a very simple set of two parallel queries that return
some data based on a workflow parameter (in this case the product’s unique identifier) passed as a
dependency property. The result produced by the workflow instance is reported back to the “caller”
by means of yet another dependency property. Such a fine-grained workflow definition is shown in
Figure 40.
0
2000
4000
6000
8000
10000
12000
2 3 4 5 6 7 8 9 10
Exe
cuti
on
tim
e (
ms)
Number of parallel data gathering branches
Procedural
Workflow
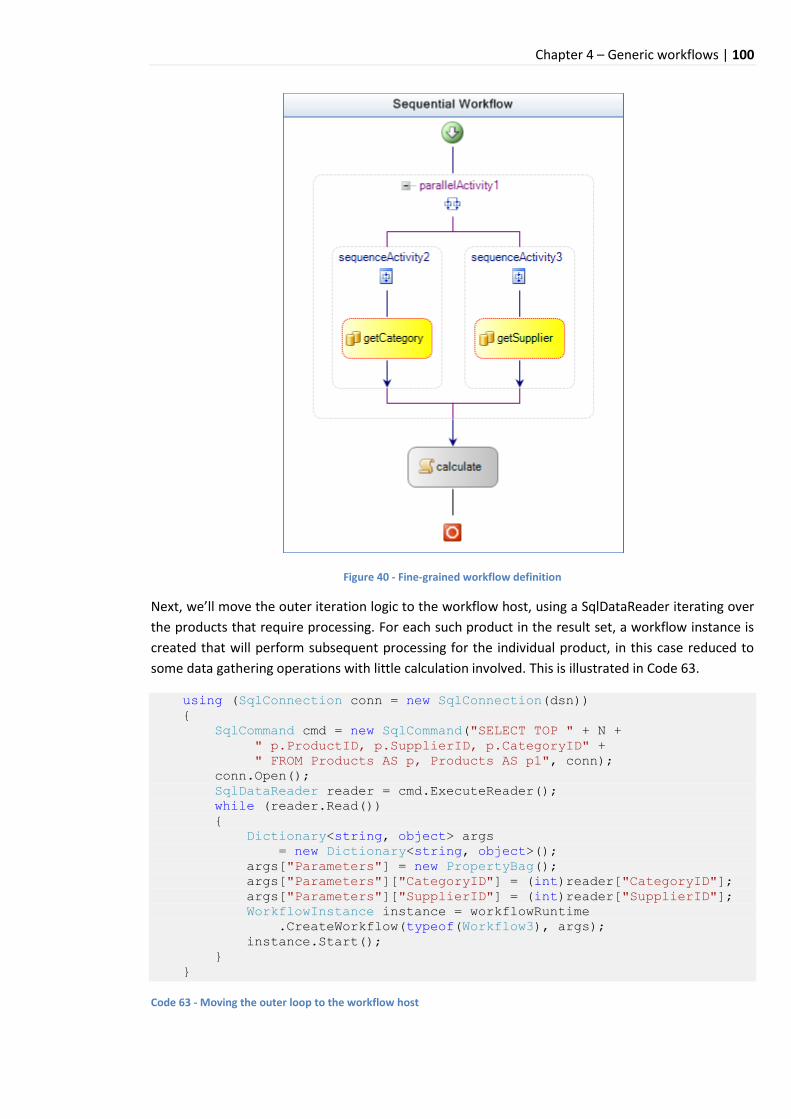
Chapter 4 – Generic workflows | 100
Figure 40 - Fine-grained workflow definition
Next, we’ll move the outer iteration logic to the workflow host, using a SqlDataReader iterating over
the products that require processing. For each such product in the result set, a workflow instance is
created that will perform subsequent processing for the individual product, in this case reduced to
some data gathering operations with little calculation involved. This is illustrated in Code 63.
using (SqlConnection conn = new SqlConnection(dsn))
{
SqlCommand cmd = new SqlCommand("SELECT TOP " + N +
" p.ProductID, p.SupplierID, p.CategoryID" +
" FROM Products AS p, Products AS p1", conn);
conn.Open();
SqlDataReader reader = cmd.ExecuteReader();
while (reader.Read())
{
Dictionary<string, object> args
= new Dictionary<string, object>();
args["Parameters"] = new PropertyBag();
args["Parameters"]["CategoryID"] = (int)reader["CategoryID"];
args["Parameters"]["SupplierID"] = (int)reader["SupplierID"];
WorkflowInstance instance = workflowRuntime
.CreateWorkflow(typeof(Workflow3), args);
instance.Start();
}
}
Code 63 - Moving the outer loop to the workflow host

Chapter 4 – Generic workflows | 101
Notice that the iteration logic on the host can be implemented manually or can call into the query
manager as well. In other words, the use of the query manager isn’t an exclusive right for
GatherDataActivity blocks, making it even more “generic” in the broad sense of the word because it
hasn’t tight bindings with WF.
The performance results of this workflow-based approach compared to a procedural equivalent are
shown in Graph 15. This time workflow clearly is the winner because of the inherent parallelism
between workflow instances. Although such parallelism could be created manually in procedural
code too, it’s much easier to do in a workflow-based design where one doesn’t have to worry about
thread safety and so on.
Graph 15 - Inter-workflow parallelism
9.6.5 Simulating processing overhead
The results shown so far do not take possible network delays and database processing latency into
account. After all, when facing delays on the arrival of data requested by a query, serial query
execution accumulates such delays really fast, bringing down the entire application’s scalability. The
inherent parallelism that can be realized using workflow seems an attractive escape from this issue,
so it’s the subject of this last performance analysis case.
In order to simulate such a delay, we apply a simple trick to the query definitions by means of a
WAITFOR construct from SQL Server. An altered query is shown in Code 64.
<Query Name="GetSupplier" Category="Demo">
<Statement>
SELECT CompanyName FROM Suppliers WHERE SupplierID = @SupplierID;
WAITFOR DELAY '00:00:01'
</Statement>
<Inputs>
<Parameter Name="@SupplierID" Type="int" />
</Inputs>
<Outputs>
<Column Name="CompanyName" Type="nvarchar" Nullable="No" />
</Outputs>
</Query>
Code 64 - Query with simulated data retrieval delay
0
200
400
600
800
1000
1200
1400
1600
1800
2000
10
0
30
0
50
0
70
0
90
0
11
00
13
00
15
00
17
00
19
00
21
00
23
00
25
00
Exe
cuti
on
tim
e (
ms)
Number of data records
Procedural
Workflow
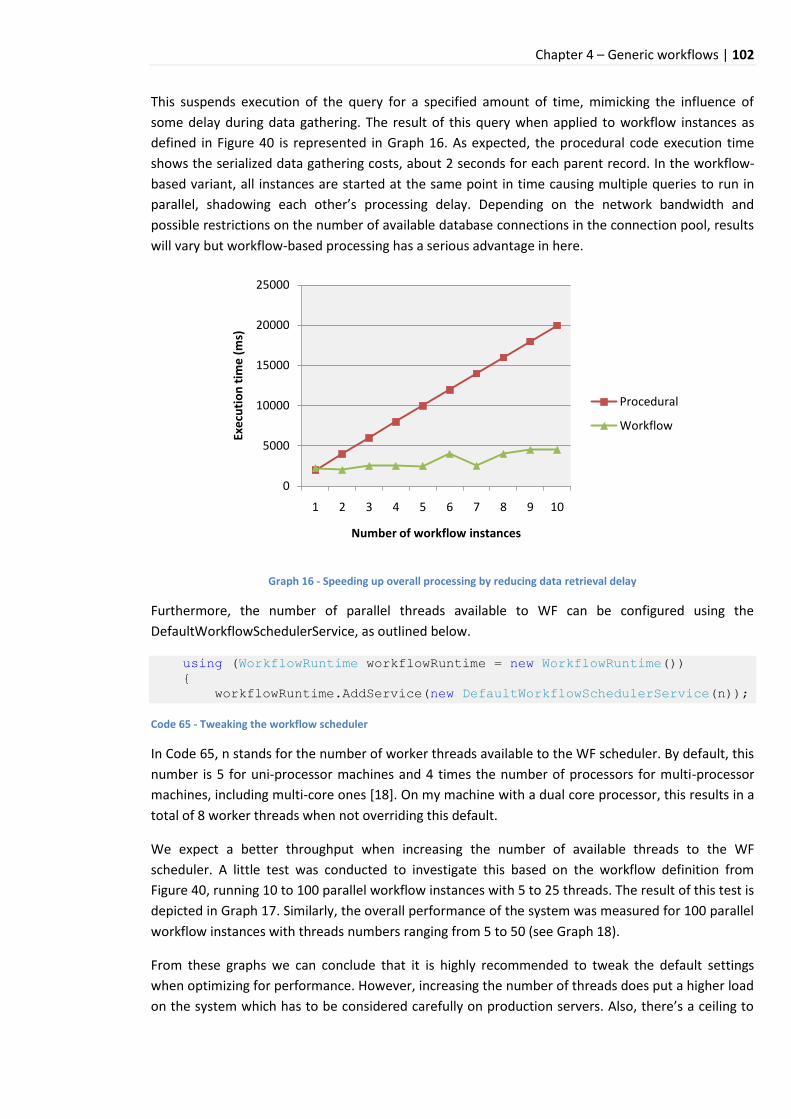
Chapter 4 – Generic workflows | 102
This suspends execution of the query for a specified amount of time, mimicking the influence of
some delay during data gathering. The result of this query when applied to workflow instances as
defined in Figure 40 is represented in Graph 16. As expected, the procedural code execution time
shows the serialized data gathering costs, about 2 seconds for each parent record. In the workflow-
based variant, all instances are started at the same point in time causing multiple queries to run in
parallel, shadowing each other’s processing delay. Depending on the network bandwidth and
possible restrictions on the number of available database connections in the connection pool, results
will vary but workflow-based processing has a serious advantage in here.
Graph 16 - Speeding up overall processing by reducing data retrieval delay
Furthermore, the number of parallel threads available to WF can be configured using the
DefaultWorkflowSchedulerService, as outlined below.
using (WorkflowRuntime workflowRuntime = new WorkflowRuntime())
{
workflowRuntime.AddService(new DefaultWorkflowSchedulerService(n));
Code 65 - Tweaking the workflow scheduler
In Code 65, n stands for the number of worker threads available to the WF scheduler. By default, this
number is 5 for uni-processor machines and 4 times the number of processors for multi-processor
machines, including multi-core ones [18]. On my machine with a dual core processor, this results in a
total of 8 worker threads when not overriding this default.
We expect a better throughput when increasing the number of available threads to the WF
scheduler. A little test was conducted to investigate this based on the workflow definition from
Figure 40, running 10 to 100 parallel workflow instances with 5 to 25 threads. The result of this test is
depicted in Graph 17. Similarly, the overall performance of the system was measured for 100 parallel
workflow instances with threads numbers ranging from 5 to 50 (see Graph 18).
From these graphs we can conclude that it is highly recommended to tweak the default settings
when optimizing for performance. However, increasing the number of threads does put a higher load
on the system which has to be considered carefully on production servers. Also, there’s a ceiling to
0
5000
10000
15000
20000
25000
1 2 3 4 5 6 7 8 9 10
Exe
cuti
on
tim
e (
ms)
Number of workflow instances
Procedural
Workflow
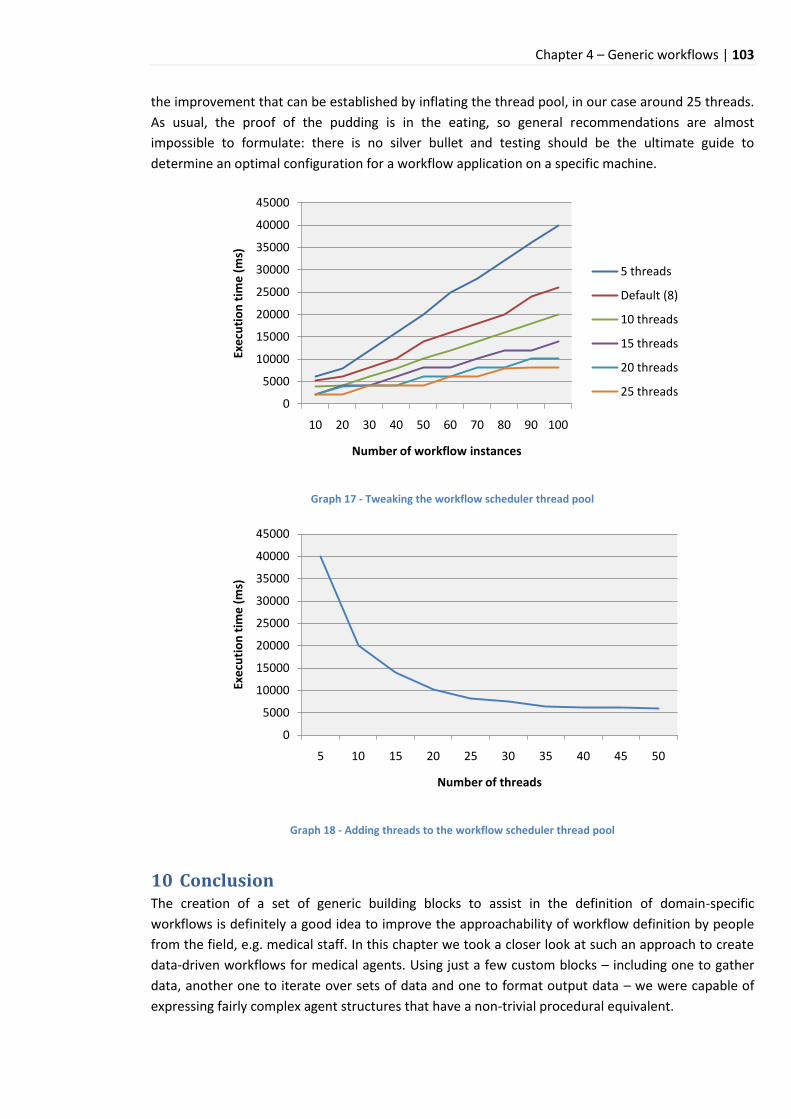
Chapter 4 – Generic workflows | 103
the improvement that can be established by inflating the thread pool, in our case around 25 threads.
As usual, the proof of the pudding is in the eating, so general recommendations are almost
impossible to formulate: there is no silver bullet and testing should be the ultimate guide to
determine an optimal configuration for a workflow application on a specific machine.
Graph 17 - Tweaking the workflow scheduler thread pool
Graph 18 - Adding threads to the workflow scheduler thread pool
10 Conclusion The creation of a set of generic building blocks to assist in the definition of domain-specific
workflows is definitely a good idea to improve the approachability of workflow definition by people
from the field, e.g. medical staff. In this chapter we took a closer look at such an approach to create
data-driven workflows for medical agents. Using just a few custom blocks – including one to gather
data, another one to iterate over sets of data and one to format output data – we were capable of
expressing fairly complex agent structures that have a non-trivial procedural equivalent.
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
10 20 30 40 50 60 70 80 90 100
Exe
cuti
on
tim
e (
ms)
Number of workflow instances
5 threads
Default (8)
10 threads
15 threads
20 threads
25 threads
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
5 10 15 20 25 30 35 40 45 50
Exe
cuti
on
tim
e (
ms)
Number of threads

Chapter 4 – Generic workflows | 104
However, at this point in time it is not possible to get rid of all procedural aspects of such an agent
application because of various reasons. For instance, calculation blocks are still to be written as
regular code, nested inside a CodeActivity or callable through Local Communication Services. Also,
the dataflow in a workflow-based application is realized through manual property bindings which
require a bit of code (though it can be auto-generated). Nevertheless, by black-boxing the remaining
pieces of code in custom activities, code in a workflow definition can be reduced to (IDE-supported)
property bindings and a minor amount of code for manipulation of PropertyBag objects where
appropriate.
Furthermore, having such a set of custom activities opens the door to composition by the end-user
using workflow designer re-hosting. More research has to be carried out to evaluate the feasibility of
this approach in practice but all required pieces of the puzzle are there to make it possible.
Using a generic approach to data, a big deal of flexibility can be realized because of the clean
separation between the query manager back-end and the GatherDataActivity front-end. Developers
can implement the query manager and query interfaces at will to match their needs, without
touching the inside of any workflow definition whatsoever. Our approach to query storage using XML
is minimalistic but sufficient for the scope of this work. Additional implementation efforts are likely
desirable in order to optimize performance or to store queries in some central query store. We
should also point at the possibilities for optimization by tuning the queries and by moving more
complex logic to the database tier. However, in the latter case we get trapped by procedural coding
again, this time on the database layer, until workflow extends its horizons to the DBMS.
Another important consideration when applying this approach in practice is the level of granularity of
workflow definitions. Using the ForeachActivity block it is possible to translate an entire agent into
just one single workflow definition, iterating over the gathered data to perform processing. However,
in various cases it makes more sense to make the workflow definition fine-grained, e.g. representing
the processing for one single patient record. Philosophically, this builds the bridge between workflow
instances and data records in a kind of workflow-relational “WR” mapping. Although this moves a bit
of database processing logic to the host layer (e.g. to iterate over the sequence of records to be
processed by workflow instances) this approach greatly benefits from WF’s inherent cross-workflow
instance parallelism, making the workflow-based agent outperform its procedural equivalent.
This granularity consideration also applies on the hosting level when considering a web services
façade. It’s perfectly possible to publish an entire workflow through a web service, optionally using
asynchronous one-way method call semantics for long-running workflows. However, one could also
wrap individual blocks, such as the GatherDataActivity block, inside web services. This can be done
either by encapsulating these blocks inside another workflow definition (kind of a “singleton”
workflow definition) or by bypassing WF completely, exposing the inner workings of the custom
activity directly to the outside world. The former approach is well-suited for blocks that have a long-
running nature, while the latter approach reduces load on the workflow engine.
Using WCF, the best of both worlds can be combined for (web) service publication. Workflows or
single activities can be exposed through services while on their turn consuming other services
internally. Because WCF is protocol-agnostic, wrapping an activity’s functionality in a service contract
shouldn’t hurt performance too much when being used on the same machine since fast inter-process
communication mechanisms can be used. We didn’t elaborate much on the WCF aspect of the story

Chapter 4 – Generic workflows | 105
in this work, so a more thorough investigation of WCF-based SOA architectures combined with WF
might be a good candidate for future research.
Performance-wise, workflow is much slower than procedural equivalents if one doesn’t exploit WF’s
rich capabilities such as parallel activities and inter-workflow parallelism. Therefore, replacing chunks
of complex procedural code by a workflow-equivalent doesn’t pay off unless some degree of
parallelism can be reached. A good level of workflow definition granularity combined with parallel
data gathering operations seems to be a good case where a workflow equivalent is beneficial. In such
a case, writing a multi-threaded procedural equivalent would be more costly and time-consuming to
get it right, while WF can provide parallelism out of the box.
Even if a workflow-equivalent for some system results in performance degradation, one shouldn’t
forget about additional advantages of WF such as long-running stateful processing mechanisms,
tracking services and the graphical representation of application logic. These could outweigh the
performance costs by far.
Putting the pieces together, generic building blocks make dynamic instrumentation as discussed in
the previous chapter even more approachable and useful. For example, when injecting inspection
blocks in a workflow dynamically in order to perform production debugging or state inspection, the
generic approach to data makes inspection (of PropertyBag objects) easier to do. Furthermore, such
an inspection point could be injected without any additional property bindings too, reflecting against
its predecessor and/or successor activity to grab a PropertyBag property for inspection. Such
methodology exploits the implicit dataflow of workflows by making an inspection point context
aware in a positional manner (e.g. an inspection point after a GatherDataActivity could report the
output data from its predecessor).
Finally, one should be extremely cautious when combining large data gathering operations with long-
running workflow instances. After all, GatherDataActivity stores the retrieved data in a property on
the workflow instance which might be subject of dehydration (i.e. persistence of workflow instance
state information) during a suspension operation, typically happening in long-running workflows.
This doesn’t only make the suspended workflow instance bigger in size; it also introduces the risk of
working with outdated information once the workflow instance is resumed. Therefore, lightweight
queries are more desirable and a fine granularity of workflow instances will help too. Otherwise, it’s
not unimaginable to build a workflow that creates copies of the source tables, causing performance
bottlenecks and possible side-effects. If the considered workflows are long-running by nature, it’s
best to avoid the storage of retrieved data inside a workflow instance altogether, replacing it by live
queries through LCS every time data is needed, avoiding outdated information to be read.

Chapter 5 - Conclusion | 106
Chapter 5 - Conclusion
In this work we investigated the Windows Workflow Foundation platform of the .NET Framework 3.0
on two fields: dynamic adaptation and its suitability as a replacement for procedural coding of data-
driven processing agents.
To support dynamic adaptation of workflow instances, we created an instrumentation engine layered
on top of the Dynamic Updates feature provided by WF. We distinguished between three update
types: the ones conducted from inside the workflow instance itself (internal modification), updates
applied to a workflow instance from the outside on the hosting layer (external modification) as well
as a combination of both, where external modification is used to inject an internal modification in a
workflow instance. Using this instrumentation mechanism, aspects can be injected in a workflow to
keep the workflow definition clean and smooth. Examples include logging, state inspection, time
measurement and authorization. It was found that the instrumentation engine provides enough
flexibility to adapt workflow instances in various ways and at various places. From a performance
point of view, internal modification outperforms the other options. On the other hand, external
modification is more flexible because of its direct access to contextual information from the host and
because workflows don’t have to be prepared for possible changes. Injection of adaptation logic
using the instrumentation framework combines the best of both worlds.
The second part of this work covered the creation of generic building blocks for easy composition of
data-driven processing agents, applied to the AB Switch agent which is used by the Intensive Care (IZ)
department of Ghent University (UZ Gent). It was shown that with a relatively low number of basic
building blocks a great level of expressiveness can be realized in a generic manner. The core block of
this design is without doubt the GatherDataActivity that retrieves data from some data source based
on a query manager that allows for flexible implementation. Such a set of building blocks also opens
up for granular publication through (web) services, for example using WCF. Other communication
mechanisms such as queue-based message exchange have been touched as well.
We should mention that WF is the youngest pillar of the .NET Framework 3.0 and maybe the most
innovative one for a general-purpose development framework. Till the advent of WF, most workflow
engines were tied to some server application like BizTalk that applies workflows in a broader context,
e.g. to allow business orchestrations. With WF, the concept of workflow-driven design has shifted to
all sorts of application types with lots of practical use case scenarios. Nevertheless it remains to be
seen how workflow will fit in existing application architectures, also in combination with SOA. One
could question WF’s maturity but to our humble opinion WF’s BizTalk roots contribute to this
maturity a lot. During the research, we saw WF transition out of the beta phase to the final release in
November 2006, each time with lots of small improvements.
To some extent, the impact of the introduction of workflow in a day-to-day programming framework
could be compared to the impact of other programming paradigms back in history, such as OO
design. With all such evolutions, the level of abstraction is raised. In the case of WF, things such as
persistence of long-running state and near real-time state tracking are introduced as runtime
services that free developers from the burden of implementing these manually. Nevertheless, one
has to gain some basic knowledge – and feeling over time – concerning how these runtime services

Chapter 5 - Conclusion | 107
impact the overall application’s performance and other quality attributes. It’s pretty normal to get
caught by these implications when facing a first set of application designs where workflow seems an
attractive solution. As developers gain more real-life experiences with the framework, the evaluation
process for workflow applicability will get sharper and more accurate.
Furthermore, some of WF’s runtime services will prove more valuable over time, such as the WF
scheduling service. This scheduler can be compared to the operating system scheduler, but applied
on another level: OS thread scheduling corresponds somewhat to activity scheduling in WF. In
today’s world of multi-core and many-core processors, the need for easier parallel programming
increases every day. WF can help to answer this need because of its inherent parallelism both inside
a workflow instance and across multiple workflow instances. Our performance analysis has shown
that such a statement is realistic, especially in data-driven workflows that gather data from various
data sources and that process records in parallel workflow instances.
In conclusion, one has to put all of the useful WF features on the balance to weigh them against
possible performance implications (or improvements), a different development methodology, etc. A
decision balance, containing the most crucial features and considerations, is depicted in Figure 41.
For long-running processing mechanisms, such as processes that require manual approval from
human beings or that have to wait for external services to provide responses that can suffer from
serious delays, workflow-based development should be a no-brainer. For short-running data
processing agents making a decision is more complex. In such a case, one should take performance
implications into account while considering advantages such as visual representation, runtime state
inspection and the possibility for easy dynamic adaptation and aspect cross-cutting using an
instrumentation engine.
Figure 41 - Workflow or not? A decision balance
WF features Considerations
Updates
Performance
Granularity
SOA
Persistence
Scheduling
Tracking
Designer

Appendix A – ICSEA’07 paper | 108
Appendix A – ICSEA’07 paper
The paper “Dynamic workflow instrumentation for Windows Workflow Foundation” is included on
the following pages. It was submitted to ICSEA’07 and accepted for publication and presentation at
the conference.
I want to thank K. Steurbaut, S. Van Hoecke, F. De Turck and B. Dhoedt for their support in writing
this paper and making it successful thanks to their contributions and incredible eye for detail.

Appendix A – ICSEA’07 paper | 109
Dynamic Workflow Instrumentation for Windows Workflow Foundation
Bart J.F. De Smet, Kristof Steurbaut, Sofie Van Hoecke, Filip De Turck, Bart Dhoedt
Ghent University, Department of Information Technology (INTEC), Gent, Belgium
{BartJ.DeSmet, Kristof.Steurbaut, Sofie.VanHoecke, Filip.DeTurck, Bart.Dhoedt}@UGent.be
Abstract
As the complexity of business processes grows, the
shift towards workflow-based programming becomes
more attractive. The typical long-running
characteristic of workflows imposes new challenges
such as dynamic adaptation of running workflow
instances. Recently, Windows Workflow Foundation
(in short WF) was released by Microsoft as their
solution for workflow-driven application development.
Although WF contains features that allow dynamic
workflow adaptation, the framework lacks an
instrumentation framework to make such adaptations
more manageable. Therefore, we built an
instrumentation framework that provides more
flexibility for applying workflow adaptation batches to
workflow instances, both at creation time and during
an instance’s lifecycle. In this paper we present this
workflow instrumentation framework and
performance implications caused by dynamic
workflow adaptation are detailed.
1. Introduction
In our day-to-day life we‟re faced with the concept
of workflow, for instance in decision making
processes. Naturally, such processes are also reflected
in business processes. Order processing, coordination
of B2B interaction and document lifecycle
management are just a few examples where workflow
is an attractive alternative to classic programming
paradigms. The main reasons to prefer the workflow
paradigm over pure procedural and/or object-oriented
development are:
Business process visualization: flowcharts are a
popular tool to visualize business processes;
workflow brings those representations alive. This
helps to close the gap between business people and
the software they‟re using since business logic is
no longer imprisoned in code.
Transparency: workflows allow for human
inspection, not only during development but even
more importantly during execution, by means of
tracking.
Development model: building workflows consists
of putting together basic blocks (activities) from a
toolbox, much like the creation of UIs using IDEs.
Runtime services free developers from the burden
of putting together their own systems for
persistence, tracking, communication, etc. With
workflow, the focus can be moved to the business
case itself.
Macroscopically, the concept of workflow can be
divided into two categories. First, there‟s human
workflow where machine-to-human interaction plays a
central role. A typical example is the logistics sector,
representing product delivery in workflow. The
second category consists of so-called machine
workflows, primarily used in B2B scenarios and inter-
service communication. On the technological side, we
can draw the distinction between sequential
workflows and state machine workflows. The
difference between them can be characterized by the
transitions between the activities. In the former
category, activities are executed sequentially, whilst
state machines have an event-driven nature causing
transitions to happen between different states. Many
frameworks that implement the idea of workflow
exist, including Microsoft‟s WF in the .NET
Framework 3.0. The architecture of WF is depicted in
Figure 1.
Figure 1. The architecture of WF [2]
A detailed overview of WF and its architecture can
be found in [1]. The WF framework allows developers
to create intra-application workflows, by hosting the
runtime engine in a host process. Windows
applications, console applications, Windows Services,
web applications and web services can all act as hosts
and façades for a workflow-enabled application. A
workflow itself is composed of activities which are the
atoms in a workflow definition. Examples of activities
include communication with other systems,
transactional scopes, if-else branches, various kinds of
loops, etc. Much like controls in UI development, one
can bring together a set of activities in a custom
activity that encapsulates a typical unit of work.
Finally, there‟s the workflow runtime that‟s
responsible for the scheduling and execution of
workflow instances, together with various runtime
services. One of the most important runtime services
is persistence, required to dehydrate workflow
instances becoming idle. This reflects the typical long-

Appendix A – ICSEA’07 paper | 110
running nature of workflow. Our research focuses on
building an instrumentation tool for WF, allowing
activities to be injected flexibly into an existing
workflow at the instance level.
This paper is structured as follows. In section 2,
we‟ll cover the concept of dynamic adaptation in more
detail. The constructed instrumentation framework is
then presented in section 3 and a few of its sample
uses in section 4. To justify this instrumentation
technique, several performance tests were conducted,
as explained in section 5.
2. Dynamic adaptation
2.1. Static versus dynamic: workflow
challenges
In lots of cases, workflow instances are long-lived:
imagine workflows with human interaction to approve
orders, or systems that have to wait for external
service responses. Often, this conflicts with ever
changing business policies, requiring the possibility to
adapt workflow instances that are in flight. Another
application of dynamic workflow adaptation is the
insertion of additional activities into a workflow. By
adding logic for logging, authorization, time
measurement, state inspection, etc dynamically, one
can keep the workflow‟s definition pure and therefore
more readable.
2.2. WF’s approach to dynamic adaptation
To make dynamic adaptation possible, WF has a
feature called “dynamic updates”. Using this
technique it‟s relatively easy to adapt workflow
instances either from the inside or the outside. We‟ll
refer to these two approaches by internal modification
and external modification respectively. A code
fragment illustrating a dynamic update is shown in
Figure 2. Internal modifications are executed from
inside a running workflow instance. An advantage is
having access to all internal state, while the main
drawback is the need to consider internal
modifications upfront as part of the workflow
definition design process. External modifications are
performed at the host layer where one or more
instances requiring an update are selected. Advantages
are the availability of external conditions the
workflow is operating in and the workflow definition
not needing any awareness of the possibility for a
change to happen. This flexibility comes at the cost of
performance because a workflow instance needs to be
suspended in order to apply an update. Also, there‟s
no prior knowledge about the state a workflow
instance is in at the time of the update.
WorkflowChanges changes = new WorkflowChanges(instance); // Add, remove, modify activities
changes.TransientWorkflow.Activities.Add(...);
foreach (ValidationError error in changes.Validate())
{ if (!error.IsWarning) { //Report error or fix it.}
}
instance.ApplyWorkflowChanges(changes);
Figure 2. Apply a dynamic update to an instance
3. An instrumentation framework for WF
3.1. Design goals
In order to make the instrumentation of workflow
instances in WF easier and more approachable, we
decided to build an instrumentation framework based
on WF‟s dynamic update feature. Our primary design
goal is to realize a framework as generic as possible,
allowing for all sorts of instrumentation. All
instrumentation tasks are driven by logic added on the
host layer where the workflow runtime engine is
hosted; no changes whatsoever are required on the
workflow definition level. This allows the
instrumentation framework to be plugged into existing
workflow applications with minimum code churn. It‟s
important to realize that instrumentations are
performed on the instance level, not on the definition
level. However, logic can be added to select a series of
workflow instances to apply the same instrumentation
to all of them. At a later stage, one can feed back
frequently performed instrumentations to the
workflow definition itself, especially when the
instrumentation was driven by a request to apply
functional workflow changes at runtime. This
feedback step involves the modification and
recompilation of the original workflow definition.
Another use of workflow instrumentation is to add
aspects such as logging to workflow instances. It‟s
highly uncommon to feed back such updates to the
workflow definition itself because one wants to keep
the definition aspect free. However, such aspects will
typically be applied to every newly created instance.
In order to make this possible, instrumentation tasks
can be batched up for automatic execution upon
creation of new workflow instances. The set of
instrumentation tasks is loaded dynamically and can
be changed at any time.
3.2. Implementation
Each instrumentation task definition consists of a
unique name, a workflow type binding, a parameter
evaluator, a list of injections and optionally a set of
services. We‟ll discuss all of these in this section. The
interface for instrumentation tasks is shown in Figure
3. The instrumentation tool keeps a reference to the
workflow runtime and intercepts all workflow
instance creation requests. When it‟s asked to spawn a
new instance of a given type with a set of parameters,
all instrumentation tasks bound to the requested
workflow type are retrieved. Next, the set of
parameters is passed to the parameter evaluator that

Appendix A – ICSEA’07 paper | 111
instructs the framework whether or not to instrument
that particular instance. If instrumentation is
requested, the instrumentation task is applied as
described below. The tool accepts requests to
instrument running instances too; each such request
consists of a workflow instance identifier together
with the name of the desired instrumentation task.
Filtering logic to select only a subset of workflow
instances has to be provided manually. When asked to
apply an instrumentation task to a workflow instance,
the instrumentation tool performs all injections
sequentially in one dynamic update so that all
injections either pass or fail. Every injection consists
of an activity tree path pointing to the place where the
injection has to happen, together with a before/after
indicator. For example, consider the example in Figure
4. In order to inject the discount activity in the right
branch, the path priceCheck/cheap/suspend1 (after)
will be used. This mechanism allows instrumentation
at every level of the tree and is required to deal with
composite activities. Furthermore, each injection
carries the activity that needs to be injected (the
subject) at the place indicated, together with
(optionally) a set of data bindings. Finally, every
instrumentation task has an optional set of services.
These allow injected activities to take advantage of
WF‟s Local Communication Services to pass data
from the workflow instance to the host layer, for
example to export logging messages. When the
instrumentation task is loaded in the instrumentation
tool, the required services are registered with the
runtime.
interface IInstrumentationTask {
// Parameter evaluator
bool ShouldProcess(Dictionary<string,object> args); // Instrumentation task name
string Name { get; }
// Type name of target workflow definition string Target { get; }
// Local Communication Services list
object[] Services { get; } // Set of desired injections
Injection[] Injections { get; } }
class Injection {
public string Path { get; set; }
public InjectionType Type { get; set; } public Activity Subject { get; set; }
public Dictionary<ActivityBind,DependencyProperty>
Bindings { get; set; } }
enum InjectionType { Before, After }
Figure 3. Definition of an instrumentation task
3.3. Design details
In order to apply workflow instrumentation
successfully, one should keep a few guidelines in
mind, as outlined below:
Instrumentations that participate in the dataflow of
the workflow can cause damage when applied
without prior validation. Invalid bindings, type
mismatches, etc might cause a workflow to fail or
worse, producing invalid results. Therefore, a
staging environment for instrumentations is highly
recommended.
Faults raised by injected activities should be
caught by appropriate fault handlers; dynamic
instrumentation of fault handlers should be
considered.
Dynamic loading of instrumentation tasks and
their associated activities should be done with care
since the CLR does not allow assembly unloading
inside an app domain. Therefore, one might extend
our framework to allow more intelligent resource
utilization, certainly when instrumentations are
applied on an ad hoc basis. More granular
unloading of (instrumented) workflow instances
can be accomplished by creating partitions for
(instrumented) workflow instances over multiple
workflow engines and application domains.
There‟s currently no support in our
instrumentation framework to remove activities
(injected or not) from workflow instances, which
might be useful to “bypass” activities. A
workaround is mentioned in 4.2.
When applying instrumentations on running
workflow instances, it‟s unclear at which point the
instance will be suspended prior to the
instrumentation taking place. Unless combined
with tracking services, there‟s no easy way to find
out about an instance‟s state to decide whether or
not applying certain instrumentations is valuable.
For example, without knowing the place where a
workflow instance is suspended, it doesn‟t make
sense to add logging somewhere since execution
might have crossed that point already. This
problem can be overcome using suspension points
as discussed in paragraph 4.2.
4. Sample uses of instrumentation
4.1. Authorization and access control
In order not to poison a workflow definition with
access control checks, distracting the human from the
key business process, authorization can be added
dynamically. Two approaches have been
implemented, the first of which adds “authorization
barriers” to a workflow instance upon creation. Such a
barrier is nothing more than an access denied fault
throwing activity. The instrumentation framework
uses the parameter evaluator to decide on the
injections that should be executed. For example, when
a junior sales member is starting a workflow instance,
a barrier could be injected in the if-else branch that
processes sales contracts over $ 10,000. This approach
is illustrated in Figure 4. An alternative way is to add

Appendix A – ICSEA’07 paper | 112
authorization checkpoints at various places in the
workflow, all characterized by a unique name
indicating their location in the activity tree. When
such a checkpoint is hit, an authorization service is
interrogated. If the outcome of this check is negative,
an access denied fault is thrown.
4.2. Dynamic adaptation injection
Using the instrumentation tool, internal adaptation
activities can be injected into a workflow instance.
This opens up for all of the power of internal
adaptations, i.e. the availability of internal state
information and the fact that a workflow doesn‟t need
to be suspended in order to apply an update.
Furthermore, we don‟t need to think of internal
adaptations during workflow design, since those can
be injected at any point in time. This form of
instrumentation has a Trojan horse characteristic,
injecting additional adaptation logic inside the
workflow instance itself, allowing for more flexibility.
However, internal modifications still suffer from the
lack of contextual host layer information. This can be
solved too, by exploiting the flexibility of dynamic
service registration to build a gateway between the
workflow instance and the host. Still, scenarios are
imaginable where external modifications are preferred
over injected internal modifications, for example when
much host layer state is required or when more tight
control over security is desirable. In order to allow this
to happen in a timely fashion, we can inject
suspension points in the workflow instance at places
where we might want to take action. When such a
suspension point is hit during execution, the runtime
will raise a WorkflowSuspended event that can be
used to take further action. Such an action might be
instrumentation, with the advantage of having exact
timing information available. As an example,
suspend1 is shown in Figure 4. This suspension point
could be used to change the discount percentage
dynamically or even to remove the discount activity
dynamically, as a workaround for the lack of activity
removal in our instrumentation framework. Notice that
the discount activity itself was also added
dynamically, exploiting the flexibility of dynamic
activity bindings in order to adapt the data in the
surrounding workflow, in this case the price.
4.3. Time measurement
Another instrumentation we created during our
research was time measurement, making it possible to
measure the time it takes to execute a section of a
workflow instance‟s activity tree, marked by a “start
timer” and “stop timer” pair of activities.
Instrumentation for time measurement of an order
processing system‟s approval step is depicted in
Figure 4. This particular case is interesting because of
a few things. First of all, both timer activity injections
have to be grouped and should either succeed or fail
together. This requirement can be enforced using
additional logic too, i.e. by performing a check for the
presence of a “start timer” activity when a “stop
timer” activity is added. However, it‟s more
complicated than just this. Situations can arise where
the execution flow doesn‟t reach the “stop timer”
activity at all, for instance because of faults. Another
problem occurs when the injections happen at a stage
where the “start timer” activity location already
belongs to the past; execution will reach the “stop
timer” activity eventually, without accurate timing
information being available. Implementing this sample
instrumentation also reveals a few more subtle issues.
When workflow instances become suspended,
persistence takes place. Therefore, non serializable
types as System.Diagnostics.Stopwatch can‟t be used.
Also, rehydration of a persisted workflow could
happen on another machine too, causing clock skews
to become relevant.
Instrumentation before (left) and after (right)
Figure 4. An example instrumentation
5. Performance evaluation of
instrumentation
5.1. Test methodology
To justify the use of workflow instrumentation, we
conducted a set of performance tests. More
specifically, we measured the costs imposed by the
dynamic update feature of WF in various scenarios. In
order to get a pure idea of the impact of a dynamic
update itself, we didn‟t hook up persistence and
tracking services to the runtime. This eliminates the
influences caused by database performance and
communication. In real workflow scenarios however,
services like persistence and tracking will play a
prominent role. For a complete overview of all factors
that influence workflow applications‟ performance,
see [3]. All tests were performed on a machine with a

Appendix A – ICSEA’07 paper | 113
2.16 GHz Intel Centrino Duo dual core processor and
2 GB of RAM, running Windows Vista. Tests were
hosted in plain vanilla console applications written in
C# and compiled in release mode with optimizations
turned on. To perform timings, the
System.Diagnostics.Stopwatch class was used and all
tests were executed without a debugger attached. For
our tests, we considered a workflow definition as
shown in Figure 4. One or more activities were
inserted in corresponding workflow instances, at
varying places to get a good image about the overall
impact with various injection locations. The injected
activity itself was an empty code activity in order to
eliminate any processing cost introduced by the
injected activity itself, also minimizing the possibility
for the workflow scheduler to yield execution in favor
of another instance. This way, we isolate the
instrumentation impact as much as possible.
5.2. Internal versus external modification
First, we investigated the relative cost of internal
versus external modification. Without persistence
taking place, this gives a good indication about the
impact introduced by suspending and resuming a
workflow instance when applying ad hoc updates to a
workflow instance from the outside. In our test, we
simulated different workloads and applied the same
dynamic update to a workflow both from the inside
using a code activity and from the outside. Each time,
the time required to perform one injection was
measured and best case, worst case and average case
figures were derived. The results of this test are shown
in Figure 5. The graphs show the time to apply the
changes as a function of the number of concurrent
workflow instances (referred to as N). One clearly
observes the much bigger cost associated with external
modification caused by the suspension-update-
resumption cycle, even when not accounting for
additional costs that would be caused by persistence
possibly taking place. Also, these figures show that
internal modification is hurt less by larger workloads
in the average case, while external modification is
much more impacted. These longer delays in the
external modification case can be explained by
workflow instance scheduling taking place in the
runtime, causing suspended workflows to yield
execution to other instances that are waiting to be
serviced. In the internal modification case, no
suspensions are required, so no direct scheduling
impact exists. However, one should keep in mind that
the suspension caused by external modification is only
relevant when applying updates to running workflow
instances. When applying updates at workflow
instance creation time, no suspension is required and
figures overlap roughly with the internal modification
case. Because of this, instrumentation at creation time
is much more attractive than applying ad hoc
injections at runtime.
a) Internal modification
b) External modification
Figure 5. Overhead of applying dynamic modifications to workflows
5.3. Impact of update batch sizes
Since instrumentation tasks consist of multiple
injections that are all performed atomically using one
dynamic update, we‟re interested in the relationship
between the update batch size and the time it takes to
apply the update. To conduct this test, we applied
different numbers of injections to a series of workflow
instances using external modification, mimicking the
situation that arises when using the instrumentation
framework. Under different workloads, we observed a
linear correspondence between the number of
activities added to the workflow instance (referred to
as n) and the time it takes to complete the dynamic
update. The result for a workload of 100 concurrent
workflow instances is shown in Figure 6. Based on
these figures, we decided to investigate the impact of
joining neighboring injections together using a
SequenceActivity and concluded that such a join can
impact the update performance positively. However,
designing an efficient detection algorithm to perform
these joins isn‟t trivial. Moreover, wrapping activities
in a composite activity adds another level to the
activity tree, which affects other tree traversal jobs but
also subsequent updates.
Figure 6. Impact of workfow update batch size
on update duration

Appendix A – ICSEA’07 paper | 114
5.4. The cost of suspension points
In order to get a better indication about the cost
introduced by the use of suspension points for exact
external update timing, we measured the time it takes
to suspend and resume a workflow instance without
taking any update actions in between. This simulates
the typical situation that arises when inserting
suspension points that are rarely used for subsequent
update actions. Recall that suspension points are just a
way to give the host layer a chance to apply updates at
a certain point during the workflow instance‟s
execution. The result of this test conducted for various
workloads (referred to as N) in shown in Figure 7. We
observe similar results to the external modification
case, depicted in Figure 5. From this, we can conclude
that the major contributing factor to external
modification duration is the suspend-resume cycle.
Naturally, it‟s best to avoid useless suspension points,
certainly when keeping possible persistence in mind.
However, identifying worthy suspension points is not
an exact science.
Figure 7. Workflow instance suspend-resume
cost for suspension points
5.5. Discussion
Based on these results, we conclude that ad hoc
workflow instance instrumentation based on external
modification has a significant performance impact,
certainly under heavy load conditions. Instrumentation
taking place at workflow instance creation time or
adaptation from the inside is much more attractive in
terms of performance. Injection of dynamic (internal)
adaptations as explained in section 4.2 should be taken
under consideration as a valuable performance booster
when little contextual information from the host layer
is required in the update logic itself. Overuse of
suspension points, though allowing a big deal of
flexibility, should be avoided if a workflow instance‟s
overall execution time matters and load on the
persistence database has to be reduced. These results
should be put in the perspective of typically long
running workflows. Unless we‟re faced with time-
critical systems that require a throughput as high as
possible, having a few seconds delay over the course
of an entire workflow‟s lifecycle shouldn‟t be the
biggest concern. However, in terms of resource
utilization and efficiency, the use of instrumentation
should still be considered carefully.
6. Conclusions
Shifting the realization of business processes from
pure procedural and object-oriented coding to
workflow-driven systems is certainly an attractive
idea. Nevertheless, this new paradigm poses software
engineers with new challenges such as the need for
dynamic adaptation of workflows without
recompilation ([4]), a need that arises from the long-
running characteristic of workflows and the ever
increasing pace of business process and policy
changes. To assist in effective and flexible application
of dynamic updates of various kinds, we created a
generic instrumentation framework capable of
applying instrumentations upon workflow instance
creation and during workflow instance execution. The
former scenario typically applies to weaving aspects
into workflows, while the latter one can assist in
production debugging and in adapting a running
workflow to reflect business process changes. The
samples discussed in this paper reflect the flexibility
of the proposed instrumentation framework.
Especially, the concept of suspension points allowing
external modifications to take place in a time-precise
manner opens up for a lot of dynamism and flexibility.
From a performance point of view, instrumentations
taking place at workflow instance creation time and
internal modifications are preferred over ad hoc
updates applied on running workflow instances. Also,
applying ad hoc updates is a risky business because of
the unknown workflow instance state upon
suspension. This limitation can be overcome by use of
suspension points, but these shouldn‟t be overused
7. Future work
One of the next goals is to make the
instrumentation framework easier and safer by means
of designer-based workflow adaptation support and
instrumentation correctness validation respectively.
Workflow designer rehosting in WF seems an
attractive candidate to realize the former goal but will
require closer investigation. Furthermore, our research
focuses on the creation of an activity library for
patient treatment management using workflow, in a
data-driven manner. Based on composition of generic
building blocks, workflow definitions are established
to drive various processes applied in medical practice.
Different blocks for data gathering, filtering,
calculations, etc will be designed to allow the creation
of data pipelines in WF. Our final goal is to combine
this generic data-driven workflow approach with the
power of dynamic updates and online instrumentation.
The need for dynamic adaptation in the health sector
was pointed out in [5]. This introduces new challenges
to validate type safety with respect to the dataflowing
through a workflow, under the circumstances of

Appendix A – ICSEA’07 paper | 115
activity injection that touches the data. Tools to assist
in this validation process will be required.
References
[1] D. Shukla and B. Schmidt, Essential Windows
Workflow Foundation. Addison-Wesley Pearson
Education, 2007.
[2] Windows SDK Documentation, MS Corp., Nov. 2006.
[3] M. Mezquita, “Performance Characteristics of WF,” on
the Microsoft Developer Network (MSDN), 2006.
[4] P. Buhler and J.M. Vidal. Towards Adaptive Workflow
Enactment Using Multiagent Systems. Information
Technology and Management Journal, 6(1):61--87,
2005.
[5] J. Dallien, W. MacCaull, A. Tien, “Dynamic Workflow
Verification for Health Care,” 14th Int. Symposium on
Formal Methods, August 2006.

Bibliography | 116
Bibliography
1. Microsoft Corporation. Windows SDK. Windows SDK. s.l. : Microsoft Corporation, 2006.
2. De Smet, Bart. WF - Working with Persistence Services. B# .NET Blog. [Online] October 14, 2006.
[Cited: April 12, 2007.]
http://community.bartdesmet.net/blogs/bart/archive/2006/10/14/4580.aspx.
3. De Smet, Bart. WF - Working with Tracking Services. B# .NET Blog. [Online] October 15, 2006.
[Cited: April 12, 2007.]
http://community.bartdesmet.net/blogs/bart/archive/2006/10/15/4582.aspx.
4. Richter, Jeffrey. CLR cia C# Second Edition. s.l. : Microsoft Press, 2006.
5. team, Microsoft's AzMan. Authorization Manager Team Blog. MSDN Blogs. [Online] Microsoft
Corporation. [Cited: May 28, 2007.] http://blogs.msdn.com/azman/.
6. De Smet, Bart. WF - Using the WorkflowMonitor in combination with Dynamic Updates. B# .NET
Blog. [Online] October 16, 2006. [Cited: April 27, 2007.]
http://community.bartdesmet.net/blogs/bart/archive/2006/10/16/4585.aspx.
7. Microsoft Corporation. Performance Characteristics of Windows Workflow Foundation. MSDN.
[Online] November 2006. [Cited: March 14, 2007.] http://msdn2.microsoft.com/en-
us/library/aa973808.aspx.
8. De Smet, Bart. Performance measurement in .NET 2.0 - The birth of Stopwatch. B# .NET Blog.
[Online] March 24, 2006. [Cited: May 17, 2007.]
http://community.bartdesmet.net/blogs/bart/archive/2006/03/24/3838.aspx.
9. Steurbaut, Kristof. Intelligent software agents for healthcare decision support - Case 1: Antibiotics
switch agent (switch IV-PO). Ghent : UGent - INTEC, 2006.
10. De Turck, F, et al. Design of a flexible platform for execution of medical decision support agents
in the Intensive Care Unit. Comput Biol Med. 37, 2007, 1.
11. Corp., Sybase. Adaptive Server Enterprise. Sybase. [Online] Sybase Corp. [Cited: May 21, 2007.]
http://www.sybase.com/products/databasemanagement/adaptiveserverenterprise.
12. Skeet, Jon. Why doesn't C# have checked exceptions? . MSDN Blogs. [Online] March 12, 2004.
[Cited: May 14, 2007.] http://blogs.msdn.com/csharpfaq/archive/2004/03/12/88421.aspx.
13. De Smet, Bart. WF - Introducing External Data Exchange, the CallExternalMethodActivity and
Local Communications Services. B# .NET Blog. [Online] October 17, 2006. [Cited: May 03, 2007.]
http://community.bartdesmet.net/blogs/bart/archive/2006/10/17/4584.aspx.

Bibliography | 117
14. Shukla, Dharma and Schmidt, Bob. Essential Windows Workflow Foundation. s.l. : Addison
Wesley, 2006.
15. Vihang Dalal. Windows Workflow Foundation: Everything About Re-Hosting the Workflow
Designer. MSDN. [Online] Microsoft, May 2006. [Cited: May 22, 2007.]
http://msdn2.microsoft.com/en-us/library/aa480213.aspx.
16. Corp., Microsoft. Northwind and pubs Sample Databases for SQL Server 2000. [Online] Microsoft
Corporation. [Cited: May 08, 2007.]
http://www.microsoft.com/downloads/details.aspx?familyid=06616212-0356-46a0-8da2-
eebc53a68034&displaylang=en.
17. Kleinerman, Christian. Multiple Active Result Sets (MARS) in SQL Server 2005. MSDN. [Online]
Microsoft Corp., June 2005. [Cited: May 24, 2007.] http://msdn2.microsoft.com/en-
us/library/ms345109.aspx.
18. Allen, Scott. Hosting Windows Workflow. OdeToCode.com. [Online] August 6, 2006. [Cited: May
24, 2007.] http://www.odetocode.com/Articles/457.aspx.
19. Microsoft Corporation. .NET Framework 3.0. .NET Framework 3.0. [Online] 2007. [Cited: March
26, 2007.] http://www.netfx3.com.
