dqn with differentiable memory architectures
TRANSCRIPT

DQN with Differentiable Memory Architectures
Okada Shintarou in SP team (Mentor: Fujita, Kusumoto)

What I Did in This Internship
- Implement the Chainer version DRQN, MQN, RMQN, FRMQN. (The original is implemented with Torch)
- DRQN has different mechanism from DQN to train
- MQN, RMQN, FRMQN have a Key-Value store memory
- Implement RogueGym
- 3D FPS based RL platform
- Scene images are available without OpenGL
- OpenAI Gym like Interface
- High customizability

Background and Problem
- DQN has been shown to successfully learn to play many Atari 2600 games (e.g. Pong).- However DQN is not good at some games where
- agents can not observe whole state of environment and- have to keep some memories to clear missions (e.g. I-Maze where agents
have to look an indicator tile and go remote correct goal tile.)
Whole of states are observable Partially observable

DeepQNetworks = Q-Learning + DNNs
- Q(s,a) is Quality function:
- Generally, Q(s,a) is approximated by a function because of combinatorial explosion of s and a.- In DQN, Q(s,a) is approximated by DNNs.
DNNs
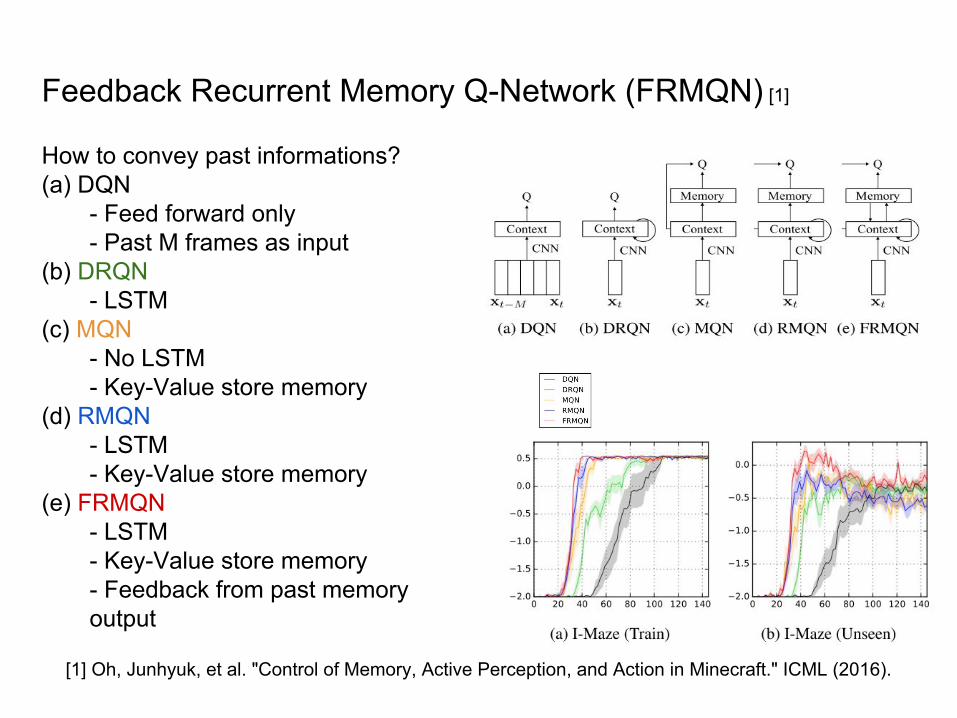
Feedback Recurrent Memory Q-Network (FRMQN) [1]
How to convey past informations?(a) DQN
- Feed forward only- Past M frames as input
(b) DRQN- LSTM
(c) MQN- No LSTM- Key-Value store memory
(d) RMQN- LSTM- Key-Value store memory
(e) FRMQN- LSTM- Key-Value store memory- Feedback from past memory output
[1] Oh, Junhyuk, et al. "Control of Memory, Active Perception, and Action in Minecraft." ICML (2016).

External Memory
Write:
Read:
Context:
CNNs to encode input
Retrieved memory
Context vector
Q(s,a)

Project Malmo[2]
- The original paper employed a Minecraft-based environment- So first, we tried using “Project Malmo” (a Minecraft-based RL platform developped by Microsoft)- But, Malmo
- Lacks of stability (Machine Learning turns into surprisingly difficult)- Uses OpenGL (Please tell me how to play Minecraft on Ubuntu16.04 servers with TitanX without any displays over SSH)- Is slow (It takes 4sec overhead per one episode of 30000 episodes)
[2] Johnson M., Hofmann K., Hutton T., Bignell D. (2016) The Malmo Platform for Artificial Intelligence Experimentation. Proc. 25th International Joint Conference on Artificial Intelligence, Ed. Kambhampati S., p. 4246. AAAI Press, Palo Alto, California USA. https://github.com/Microsoft/malmo

So I Developped RogueGym- RogueGym is a rogue-like environment for reinforcement learning inspired by Project Malmo- 3D scenes and types of surrounding blocks are available as agents' observations.
Agent's observation
World's state (top view)
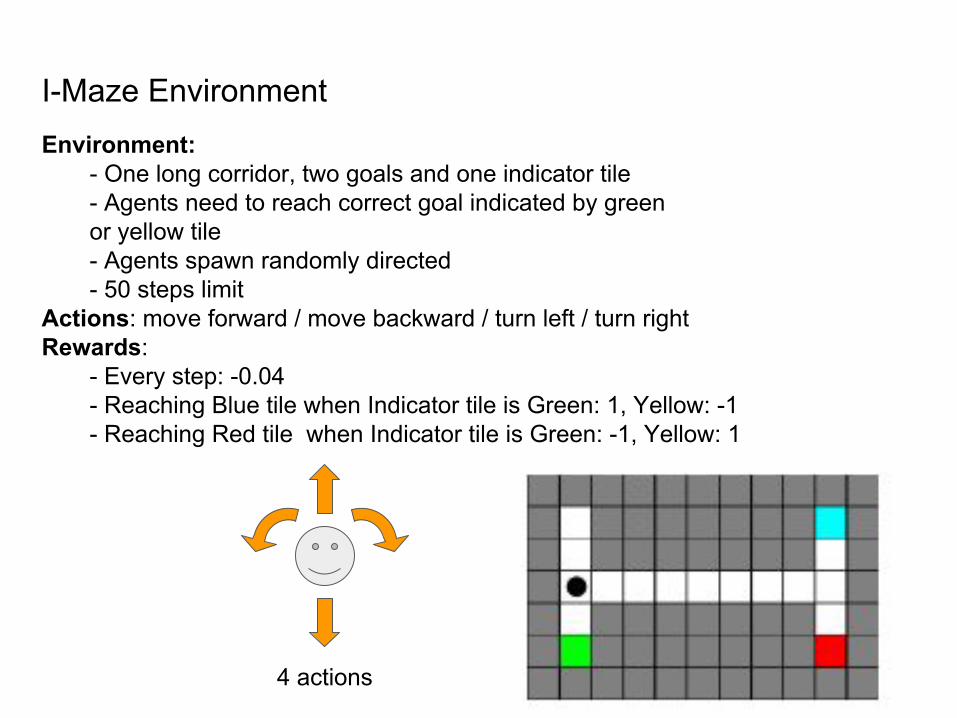
I-Maze EnvironmentEnvironment:
- One long corridor, two goals and one indicator tile- Agents need to reach correct goal indicated by green or yellow tile- Agents spawn randomly directed- 50 steps limit
Actions: move forward / move backward / turn left / turn rightRewards:
- Every step: -0.04- Reaching Blue tile when Indicator tile is Green: 1, Yellow: -1- Reaching Red tile when Indicator tile is Green: -1, Yellow: 1
4 actions
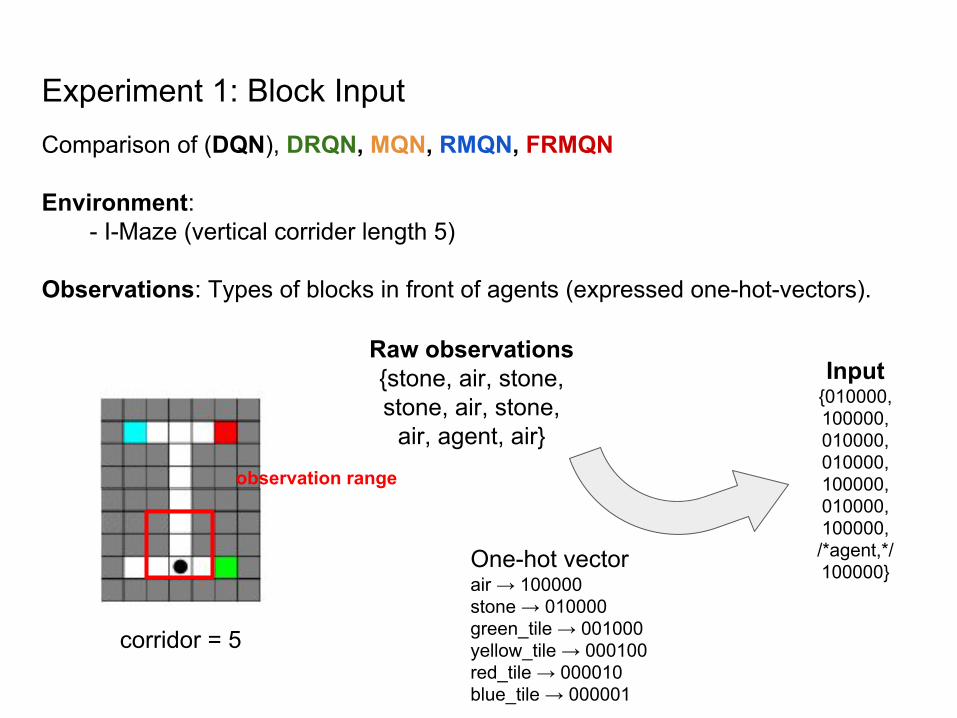
Experiment 1: Block InputComparison of (DQN), DRQN, MQN, RMQN, FRMQN
Environment:- I-Maze (vertical corrider length 5)
Observations: Types of blocks in front of agents (expressed one-hot-vectors).
corridor = 5
observation range
Raw observations{stone, air, stone, stone, air, stone,
air, agent, air}
One-hot vectorair → 100000stone → 010000green_tile → 001000yellow_tile → 000100red_tile → 000010blue_tile → 000001
Input{010000, 100000, 010000, 010000, 100000, 010000, 100000, /*agent,*/100000}
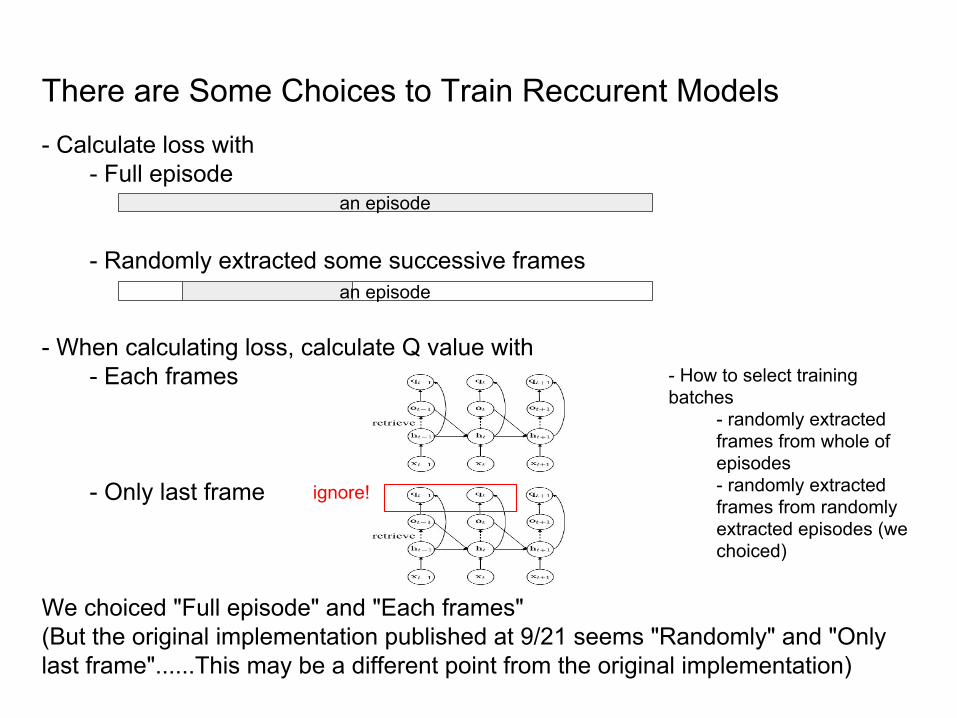
- Calculate loss with- Full episode
- Randomly extracted some successive frames
- When calculating loss, calculate Q value with- Each frames
- Only last frame
We choiced "Full episode" and "Each frames"(But the original implementation published at 9/21 seems "Randomly" and "Only last frame"......This may be a different point from the original implementation)
an episode
There are Some Choices to Train Reccurent Models
an episode
ignore!
- How to select training batches
- randomly extracted frames from whole of episodes - randomly extracted
frames from randomly extracted episodes (we choiced)
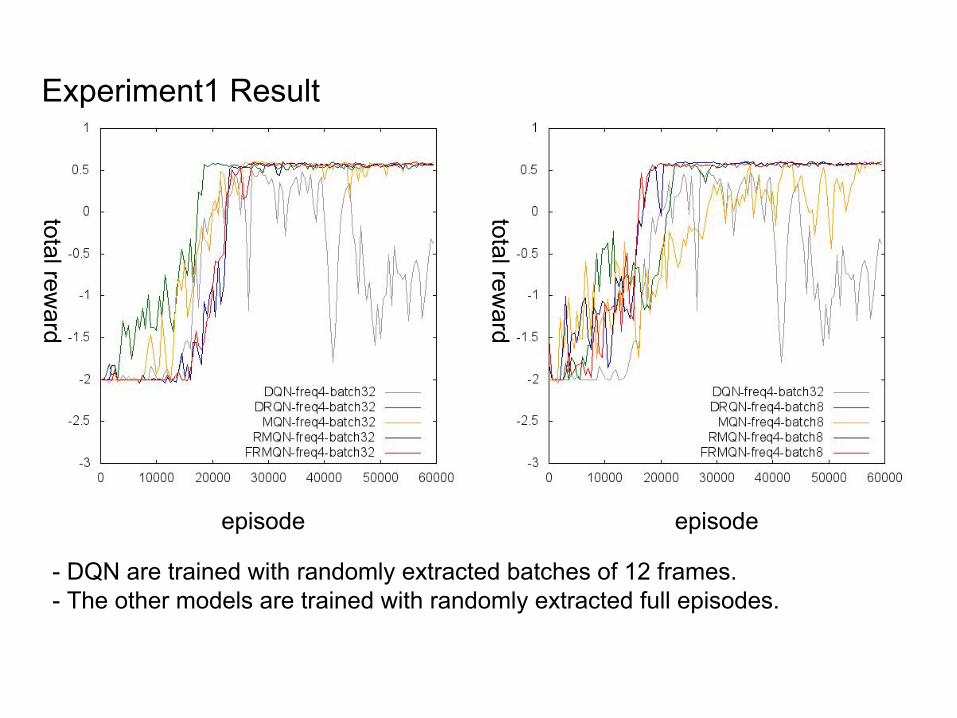
Experiment1 Result
episode
total reward
- DQN are trained with randomly extracted batches of 12 frames.- The other models are trained with randomly extracted full episodes.
episode
total reward

Generalization Performance
vertical corridor length
Total reward (average of 100 run)
- The memory limit are changed from 11 to 49- FRMQN does not lose performance on long vertical corridors.- DRQN fights well.

Conclusion
- FRMQN has high generalization performance
- Introduced differentiable Key-Value store memory module can be changed the size after trained
- DRQN is not so bad
- Recurrent Networks are useful for partially observable environment
- It is important that how to run iterations quickly
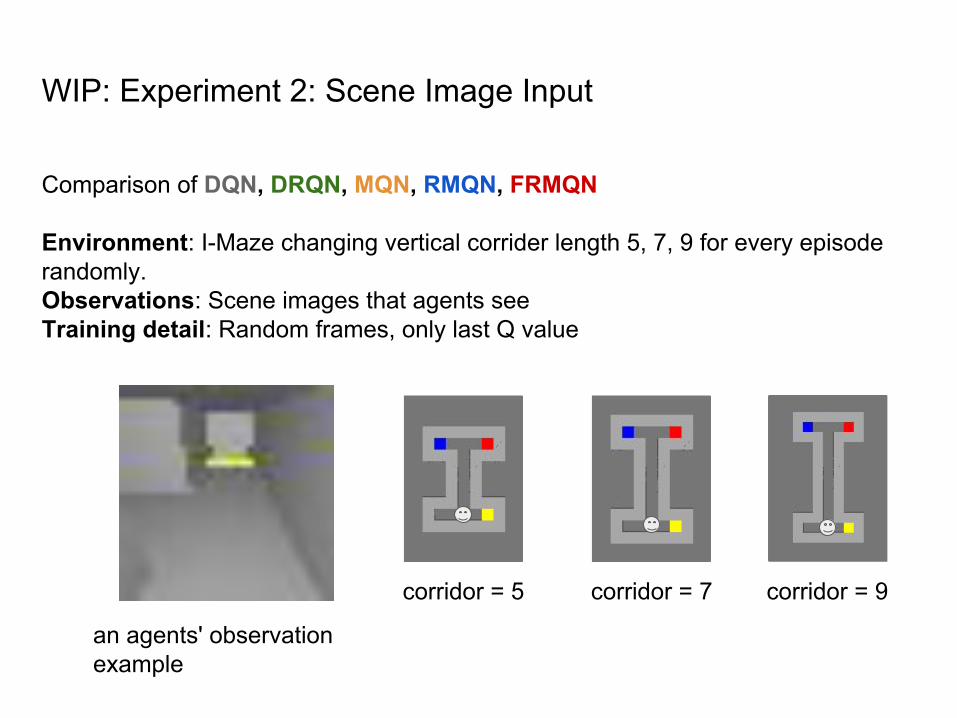
WIP: Experiment 2: Scene Image Input
Comparison of DQN, DRQN, MQN, RMQN, FRMQN
Environment: I-Maze changing vertical corrider length 5, 7, 9 for every episode randomly. Observations: Scene images that agents seeTraining detail: Random frames, only last Q value
corridor = 5 corridor = 7 corridor = 9
an agents' observation example