differentiable sparse coding
DESCRIPTION
Differentiable Sparse Coding. David Bradley and J. Andrew Bagnell NIPS 2008. 100,000 ft View. Complex Systems. Joint Optimization. Cameras. Voxel Features. Voxel Classifier. Voxel Grid. Initialize with “cheap” data. Ladar. Column Cost. 2-D Planner. Y (Path to goal). - PowerPoint PPT PresentationTRANSCRIPT

1
Differentiable Sparse Coding
David Bradley and J. Andrew BagnellNIPS 2008

2
Joint Optimization
100,000 ft View• Complex Systems
VoxelFeatures
VoxelClassifier
2-DPlanner
Cameras
Ladar
Voxel Grid
ColumnCost
Y(Path to goal)
Initialize with “cheap” data

3
10,000 ft view
• Sparse Coding = Generative Model
• Semi-supervised learning• KL-Divergence Regularization• Implicit Differentiation
OptimizationUnlabeled Data Latent Variable
Classifierx w
Loss Gradient

4
Sparse Coding
Understand X

5
As a combination of factors
B

6
Sparse coding uses optimization
Projection (feed-forward):
)( Bxfw T
)( wBfx
Some vector
Want to useto classify x
Reconstructionloss function

7
Sparse vectors: Only a few significant elements

8
Example: X=Handwritten Digits
Basis vectors colored by w

9
Input Basis
Projection
Optimization vs. Projection

10
Input Basis
KL-regularized Optimization
Optimization vs. Projection
Outputs are sparse for each example

11
Generative Model
Latent variables are Independent
PriorLikelihood
Examples are Independent
i

12
PriorLikelihood
Sparse Approximation
MAP Estimate

13
Sparse Approximation
Distance between reconstruction and input
Distance between weight vector and prior mean
Regularization Constant
pwwBfxxP
||Prior)(||Loss)(log

14
Example: Squared Loss + L1
• Convex + sparse (widely studied in engineering)• Sparse coding solves for B as well (non-convex for now…)• Shown to generate useful features on diverse problems
Tropp, Signal Processing, 2006Donoho and Elad, Proceedings of the National Academy of Sciences, 2002Raina, Battle, Lee, Packer, Ng, ICML, 2007

15
L1 Sparse Coding
Shown to generate useful features on diverse problems
Optimize B over all examples

16
Differentiable Sparse Coding
Bradley & Bagnell, “Differentiable Sparse Coding”, NIPS 2008
Y
X
LearningModule (θ)
Loss Function
OptimizationModule (B)
UnlabeledData
Reconstruction Loss
LabeledData
X
W)(BWf
Sparse Coding
Raina, Battle, Lee, Packer, Ng, ICML, 2007

17
L1 Regularization is Not Differentiable
Bradley & Bagnell, “Differentiable Sparse Coding”, NIPS 2008
Y
X
LearningModule (θ)
Loss Function
OptimizationModule (B)
UnlabeledData
Reconstruction Loss
LabeledData
X
W)(BWf
Sparse Coding

18
Why is this unsatisfying?

19
Problem #1:Instability
L1 Map Estimates are discontinuous
Outputs are not differentiable
Instead use KL-divergenceProven to compete with L1 in online learning

20
Problem #2: No closed-form Equation
At the MAP estimate:
pwwBfxww
||Prior)(||Lossminargˆ
0||ˆPrior)ˆ(||Loss pwwBfx ww

21
Solution: Implicit DifferentiationDifferentiate both sides with respect to an element of B:
Since is a function of B: Solve for this
0||ˆPrior)ˆ(||Lossij
pwwBfxB ww

22
KL-Divergence
Example: Squared Loss, KL prior

23
Handwritten Digit Recognition
50,000 digit training set10,000 digit validation set10,000 digit test set

24
Handwritten Digit Recognition
Unsupervised Sparse Coding
L2 loss and L1 prior
Training Set
Step #1:
Raina, Battle, Lee, Packer, Ng, ICML, 2007

25
Handwritten Digit Recognition
Sparse Approximation
Step #2:Maxent
ClassifierLoss
Function

26
Handwritten Digit Recognition
Supervised Sparse Coding
Step #3:Maxent
ClassifierLoss
Function

27
KL Maintains Sparsity
Weight concentratedin few elements
Log scale

28
KL adds Stability
X
W (KL) W (backprop)
W (L1)
Duda, Hart, Stork. Pattern classification. 2001

29
Performance vs. Prior
0123456789
1,000 10,000 50,000
L1KLKL + Backprop
Number of Training Examples
Mis
clas
sific
atio
n E
rror
(%)
Bette
r

30
Classifier Comparison
0%
1%
2%
3%
4%
5%
6%
7%
8%
Maxent 2-layer NN SVM (Linear) SVM (RBF)
Mis
clas
sific
ation
Erro
r
PCAL1KLKL+backprop
Bette
r

31
Comparison to other algorithms
0.00%0.50%1.00%1.50%2.00%2.50%3.00%3.50%4.00%
50,000
Mis
clas
sific
ation
Erro
r
L1KLKL+backpropSVM2-layer NN
Bette
r

32
Transfer to English Characters
8
16
24,000 character training set12,000 character validation set12,000 character test set

33
Transfer to English Characters
Sparse Approximation
Step #1:
DigitsBasis
MaxentClassifier
Loss Function
Raina, Battle, Lee, Packer, Ng, ICML, 2007

34
Transfer to English CharactersStep #2:
MaxentClassifier
Loss Function
Supervised Sparse Coding

35
Transfer to English Characters
40%
50%
60%
70%
80%
90%
100%
500 5000 20000
Clas
sific
ation
Acc
urac
y
Training Set Size
RawPCAL1KLKL+backprop
Bette
r

36
Text ApplicationX
Unsupervised Sparse Coding
KL loss + KL prior
5,000 movie reviews
10 point sentiment scale1=hated it, 10=loved it
Step #1:
Pang, Lee, Proceeding of the ACL, 2005

37
Text ApplicationX
Sparse Approximation
5-fold Cross Validation
10 point sentiment scale1=hated it, 10=loved it
LinearRegression
L2 LossStep #2:

38
Text ApplicationX
10 point sentiment scale1=hated it, 10=loved it
5-fold Cross Validation
Step #3:
LinearRegression
L2 Loss
Supervised Sparse Coding
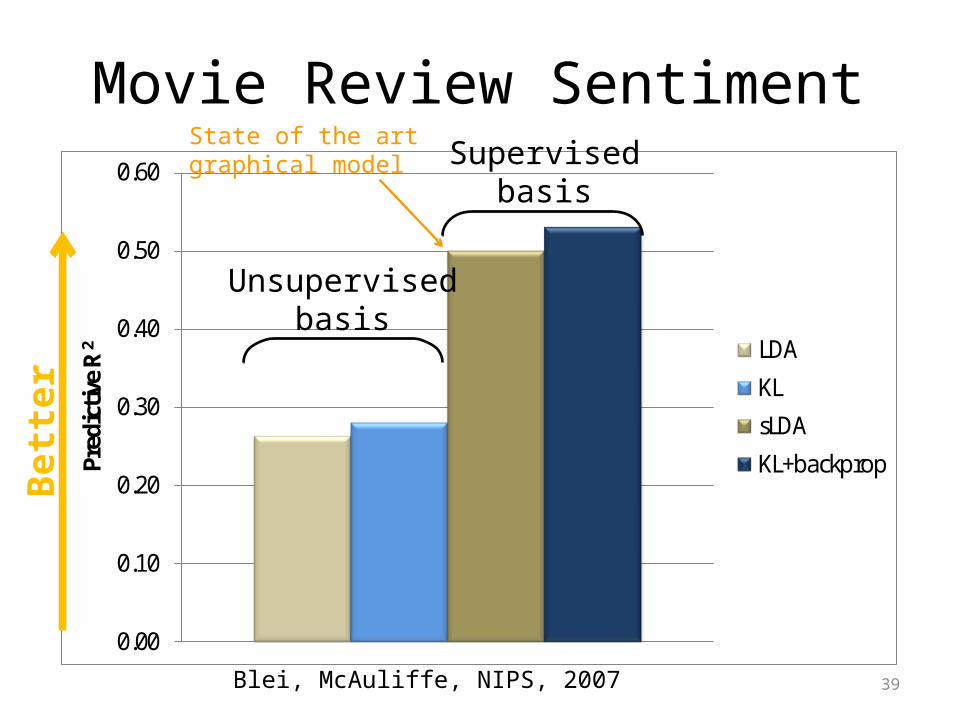
39
Movie Review Sentiment
0.00
0.10
0.20
0.30
0.40
0.50
0.60
Pred
ictiv
e R
2 LDAKLsLDAKL+backpropBe
tter
Unsupervisedbasis
Supervisedbasis
State of the artgraphical model
Blei, McAuliffe, NIPS, 2007

40
RGB Camera
NIR Camera
Ladar
Future Work
Sparse Coding
EngineeredFeatures Labeled
Training Data
Example Paths
VoxelClassifier
MMPCamera
Laser

41
Future Work: Convex Sparse Coding
• Sparse approximation is convex• Sparse coding is not because fixed-size basis is a
non-convex constraint• Sparse coding ↔ sparse approximation on
infinitely large basis + non-convex rank constraint– Relax to a convex L1 rank constraint
• Use boosting for sparse approximation directly on infinitely large basis
Bengio, Le Roux, Vincent, Dellalleau, Marcotte, NIPS, 2005Zhao, Yu. Feature Selection for Data Mining, 2005Riffkin, Lippert. Journal of Machine Learning Research, 2007

42
Questions?