
Reinforcement Learning for Mobile Robots
Reinforcement Learning for
Mobile Robots
Ali Hosseiny [email protected] University of TehranComputer Engineering and IT FacultyDec 26

Reinforcement Learning for Mobile Robots
Agenda
Introduction
Machine learning
Reinforcement learning
Learning system for robots
Comparison
Conclusion
References

Reinforcement Learning for Mobile Robots
Introduction
1. Programming robot is extremely time-consuming process.
2. It is difficult to specify in detail how the robot accomplish tasks. robot code control is full of “magic numbers” that must be painstakingly set for each environment that robot must operate in.
3. Specifying low-level mapping from sensors to actuators is prone to misconception and takes many iterations to fine-tune.
4. Debugging pre-mentioned mapping is tedious. Recreating the exact same state over several debugging runs is almost impossible.
Idea :Having a robot learn how to accomplish a task, rather that being told explicitly. Programmer easily and intuitively specify what the robot should be doing and robot learn details of how to do that.

Reinforcement Learning for Mobile Robots
Agenda
Introduction
Machine learning
Reinforcement learning
Learning system for robots
Comparison
Conclusion
References

Reinforcement Learning for Mobile Robots
Machine Learning
What is learning ?
any process by witch a system improves its performance.
Why is machine learning necessary?
learning is the hallmark of intelligence; many would argue that a system that cannot learn is not intelligent.
Why is learning possible?
Because there are regularities in the world.

Reinforcement Learning for Mobile Robots
Machine Learning
Different Varieties of Machine Learning
• Concept Learning
• Clustering Algorithms
• Connectionist Algorithms
• Genetic Algorithms
• Explanation based Learning
• Transformation based Learning
• Reinforcement Learning
• Case based Learning
• Macro Learning
• Evaluation Functions
• Cognitive Learning Architectures
• Constructive Induction
• Discovery Systems

Reinforcement Learning for Mobile Robots
Machine Learning-Classes of learning
based on its interaction with environment
• Static
information flow form environment to system, like classification.
• Dynamic
information flow is bidirectional, like robot control.

Reinforcement Learning for Mobile Robots
Machine Learning-Classes of learning
Environment
Learning System
I
O
Static environment
Environment
Learning System
I
O
Dynamic environment

Reinforcement Learning for Mobile Robots
Machine Learning-Classes of learning
based on level of supervision
Supervised learning ( with a teacher)
Fast, In known environments
Unsupervised learning
extract regularities and statistical properties from input, like SOM
Learning with a critic( Reinforcement methods)

Reinforcement Learning for Mobile Robots
Machine Learning-Classes of learning
Learning with a teacher
Environment
I
O
Teacher
Agent
T
Static environment
Environment
IO
Teacher
Agent
T
Dynamic environment

Reinforcement Learning for Mobile Robots
Machine Learning-Classes of learning
Environment
IO
Learning with a critic (Reinforcement Learning)
Critic
Agent
r
Critic’s evaluation : reinforcement signal r

Reinforcement Learning for Mobile Robots
Machine Learning
Learning with a critic example: Inverted Pendulum
Learning to balance a pole hinged to a cart that is running on a track of finite length.
State: x(t),x’(t), θ (t), θ’(t)Action: Force F Signal r: signals failure when pole fall over or cart hit the end of track.

Reinforcement Learning for Mobile Robots
Agenda
Introduction
Machine learning
Reinforcement learning
Learning system for robots
Comparison
Conclusion
References

Reinforcement Learning for Mobile Robots
Reinforcement Learning (RL)
A set of states : S
A set of actions : A
A reward function :R : S x A R
A state transition function: T: S x A ∏ ( S)
T (s,a,s’): probability of transition from s to s’ using action a
A1
A2
A3
+2034
A1
A2
10

Reinforcement Learning for Mobile Robots
RL
1. Agent senses world
2. Agent takes action
3. Agent goes new state and receives reward
4. Repeat
Goal : finding a mapping from states to actions that maximize the total reward
1. STATE
3. REWARD
2. ACTION

Reinforcement Learning for Mobile Robots
Characteristics 1. Based on trial and error
2. Delayed reward( temporal credit assignment)
3. Exploration vs. exploitation
RL

Reinforcement Learning for Mobile Robots
RL
Basic RL Definitions
Value Function:
Bellman – Equation:
Action-Value Function (Q-Function):

Reinforcement Learning for Mobile Robots
RL
Value Iteration Algorithm
We don’t know and
Instead use the following :
model free learning

Reinforcement Learning for Mobile Robots
RL
The quality of feedback
A feedback from a teacher is specific, it tells answer
A feedback from a critic is qualitative, it tells how good is answer
Immediacy of feedback:
• Immediate answer for each input-output pairs
• Delayed feedback (temporal credit assignment problem)
biggest problem facing a RL robot

Reinforcement Learning for Mobile Robots
RL
RL Mechanisms for
“temporal credit assignment problem”
1. Agent have an internal reward estimation
2. Eligibility traces
• Rrecency heuristic
• Frequency heuristic
• Both of them

Reinforcement Learning for Mobile Robots
Agenda
Introduction
Machine learning
Reinforcement learning
Learning system for robots
Comparison
Conclusion
References

Reinforcement Learning for Mobile Robots
Learning System for robots
History • RL for games (formal rules, simulation, consistent with RL model)
tic-tac-toe ,checkers ,backgammon,…
• RL for robot control
Robot navigation , Box-pushing, Inserting a peg in hole, Balancing a ball on a beam, Kicking a ball into goal,...
Elevator dispatching control : 4 elevators , 10 floor
goal : minimization passenger's waiting time.
Result : 70% better than best found algorithm (heuristic) and 50% progress in contrast to common elevator control method.

Reinforcement Learning for Mobile Robots
Learning System for robots
Difficulties in using RL for robot control1. Discrete state space
2. Needs many experiences (trial and error) for good learning
impossible learn in in real world and simulation is unavoidable
Solutions for problem 1• Discretizing the state space
Value-function Approximation
replace the tabular representation of the Q-value function with a general-purpose function approximator.
• Modifying the standard model to accepting continuous inputs
using Multi-Layer Feed-Forward Neural Nets, Genetic algorithms,..

Reinforcement Learning for Mobile Robots
Learning System for robots
Inverted Pendulum
State: x(t),x’(t), θ (t), θ’(t)4-Dimensional
* Partitioning the space into hyper-rectangles
* Human analysis used in Partitioning. Fine control was needed in central regions.

Reinforcement Learning for Mobile Robots
Learning System for robots
Solutions for problem2RL Need many trials and errors and takes too long to achieve
good results.
In standard RL for each discrete state in environment learns responses independently (Q-Learning). If the sate space is large, the structural credit assignment problem – learning actions for states that maybe encountered rarely-becomes paramount
Idea : If there is some similarities between environment states, we can make some assumptions that allow for more rapid learning. If some states are similar we can treat them the same.

Reinforcement Learning for Mobile Robots
Learning System for robots
Basic learning systemConsist of two primary components, each of them can be neural
Network, input network and output network.
Input network : Classify input vectors with competition.
Output network : Using classification, select responsible unit. RL using output network units to learn appropriate control responses.

Reinforcement Learning for Mobile Robots
the The system forms a mapping from input space to output space
Learning System for robots
Basic learning system

Reinforcement Learning for Mobile Robots
Truck-backing ProblemSpace: (goal angle, hitch angle) 2- D
Output : wheel angle 1-D
Success : rear of trailer reaches the goal
Failure : goal angle or hitch angle exceed 90
Each trial and ends in success or failure status.
Learning System for robots

Reinforcement Learning for Mobile Robots
Learning System for robots
Input classification Input spaces is partitioned uniformly in each dimension. Each unit of
input network associated with a weight vector v=(v1,v2,…,vd). Unit’s Weight vector is set equal to the middle point of correspond partition.
On each time step input vector x is given to input net and we use Manhattan distance to select winning unit (s) .
Similarity measure :
Then the correspond unit in output net is chosen to response learning.

Reinforcement Learning for Mobile Robots
Learning System for robots
Response learningNeurons become more amenable to change when they fire. This plasticity
reduces with time.
Eligibility trace has been used in reinforcement learning as one of the mechanisms to deal with the temporal credit assignment problem. Determines which action deserve credit for success and which deserve blame for failure, when reward and punishment signals are depend on multiple actions taken over some period of time.
Associate with each unit an eligibility value. At the start of each trial, all units are given a eligibility value of zero. When an output unit fires, its eligibility value is increased by default value (base eligibility value). Eligibility value decays exponentially with time.

Reinforcement Learning for Mobile Robots
Learning System for robots
Eligibility trace•Replacing trace
•Accumulating trace
•Saturating trace

Reinforcement Learning for Mobile Robots
Learning System for robots
A replacing eligibility trace
An accumulating eligibility trace
A saturating eligibility trace

Reinforcement Learning for Mobile Robots
Learning System for robots
When reward or punishment occurs, all output weights are updated.
T : trial number
e : eligibility value
σ(T) : scaling function , for our problem σ(T) = 1/(1+(T-1)/10)
f : feedback signal

Reinforcement Learning for Mobile Robots
Learning System for robots
Simulating truck-backing problem
Start point : rear of trailer with 6 feet from the goal
Goal angle initial value: uniformly in [-45,45]
Hitch angle initial value: uniformly in [-15,15]
Partitioning : 8 bye 8
*without using of human analysis of the problem and let robot partitioned it by itself

Reinforcement Learning for Mobile Robots
Average performance for 100 runs of 500 trials each using the basic learning system with a uniform 8 by 8 partitioning on the truck-backing task.
Learning System for robots

Reinforcement Learning for Mobile Robots
A random starting point
The movement of the rig, shown every tenth time step
The final position of the rig at the goal
Typical trail
Learning System for robots

Reinforcement Learning for Mobile Robots
Learning System for robots
Q :Would it be possible for the system to achieve equally good performance using fewer neural units?
A :try it.
Average performance for 100 runs of 500 trials each using the basic learning system with a uniform 6 by 6 partitioning on the truck-backing task.

Reinforcement Learning for Mobile Robots
Learning System for robots
A 6 by 6 network of units witch an eight-connected neighborhood relation, showing neighborhood of width zero, two, four around unit (3,3).
Input partitioning learning
For unsupervised partition learning, we use SOM concept.

Reinforcement Learning for Mobile Robots
Learning System for robotsAt the starting of each run , units initialized randomly instead of uniformly partitioned.
The input vectors for each time step are recorded and at the end of the trial are again presented to network for input-space partition learning. As each input vector is re-presented to the input network, a winning unit is determined as before. Now the weights of winning unit and all other units in its neighborhood are updated according to :
T: trial number
α : α(T)=1/T
Gamma :all trial are weighted equally regardless of their length gamm(tfinal)=1/ tfinal
tfinal :number of time steps of this trial
f’ : variation of feedback signal
Neighborhood definition :

Reinforcement Learning for Mobile Robots
Learning System for robots
Goal angle
Hitch
angle
A initial random placement of a six by six network of input units in input space at the start of the run. Neighborhood topology shown as lines connecting units.

Reinforcement Learning for Mobile Robots
Learning System for robots
Hitch angle
Goal angle
The placement of input units in input space after 50 trials. The neighborhood topology is shown lines connecting units.

Reinforcement Learning for Mobile Robots
Learning System for robots
Hitch angle
Goal angle
The arrangement of input units in input space after 500 trials. The neighborhood topology is shown lines connecting units.

Reinforcement Learning for Mobile Robots
Learning System for robots
Hitch angle
Goal angle
The arrangement of input units in input space after 500 trials with voronoi diagram that correspond to the partition regions.
In weight update rule, units compete to being winner and then winning unit cooperates with its neighbors.
As W(T) , neighbor hood size, and α(T) , gain parameter, both decrease to zero the network converges to a set of input weights that specify the final partitioning of the input space.

Reinforcement Learning for Mobile Robots
Learning System for robots
Average performance for 100 runs of 500 trials each using a 6 by 6 input network learning
A direct partitioning on the truck-backing task.
Performance
90% success with 36 units
* Basic system requires 64 units

Reinforcement Learning for Mobile Robots
Learning System for robots
A random starting position
The movement of the rig, shown every tenth time step
The final position of the rig at the goal
Typical trail

Reinforcement Learning for Mobile Robots
Learning System for robots
Cooperative response learningDefine a topological arrangement of units in output network. As before we se eight-connected
neighborhood relation.
After a success or failure is signaled and each unit’s weight is updated according to its eligibility, for inter neural cooperation, units updating their weights a second time, this time based on the weight values of the other units in their neighborhood.
Updating rule :
Ni : neighborhood of unit i
m : number of units in Ni
β : scaling factor , for this problem β(T)=1/(2+(T-1)/10)

Reinforcement Learning for Mobile Robots
Learning System for robots
Average performance for 100 runs of 500 trials each using cooperative response learning with a uniform 8 by 8 partitioning on the truck-backing task.
Fixed input 8 by 8 partitioning
* 95% success 50 trials
* 100% success in 250 trials

Reinforcement Learning for Mobile Robots
Learning System for robots
performance of cooperative response learning with a fixed input partitioning is analyzing good on the task given but the system is somewhat brittle.
It depends on initial conditions. If we give the system a more difficult version of the same basic task, the results may be much worse.

Reinforcement Learning for Mobile Robots
Learning System for robots
Goal angle value in [-18-,+180]
•The additional failure condition needed

Reinforcement Learning for Mobile Robots
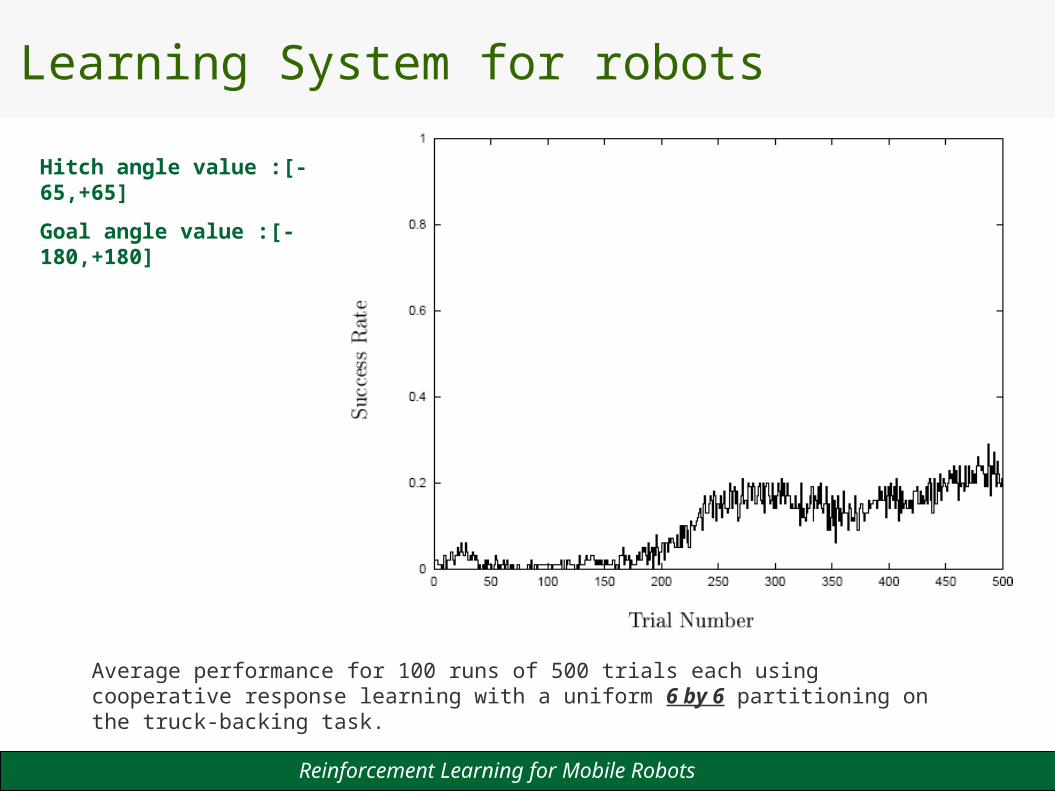
Learning System for robots
Hitch angle value :[-65,+65]
Goal angle value :[-180,+180]
Average performance for 100 runs of 500 trials each using cooperative response learning with a uniform 8 by 8 partitioning on the truck-backing task.
Reinforcement Learning for Mobile Robots
Learning System for robots
Hitch angle value :[-65,+65]
Goal angle value :[-180,+180]
Average performance for 100 runs of 500 trials each using cooperative response learning with a uniform 6 by 6 partitioning on the truck-backing task.

Reinforcement Learning for Mobile Robots
Learning System for robots
Combining input partitioning learning and cooperative response learning
When an input vector is given to input network, it classifies it and select correspond unit in output network to updating based on its eligibility.
At the end of each trial, the input weights are adjusted to give a new partitioning and output weights are adjusted cooperatively.

Reinforcement Learning for Mobile Robots
Learning System for robots
Average performance for 100 runs of 500 trials each using cooperative response learning while learning a direst partitioning with a 36 units in the input and output network.
Hitch angle value :[-65,+65]
Goal angle value :[-180,+180]

Reinforcement Learning for Mobile Robots
Learning System for robots
A random starting position
The movement of the rig, shown every 15th time step
The final position of the rig at the goal
Other variations Input space : 3D
Hitch1 : [-6,+6]
Hitch1 : [-6,+6]
Goal : [-6,+6]

Reinforcement Learning for Mobile Robots
Agenda
Introduction
Machine learning
Reinforcement learning
Learning system for robots
Comparison
Conclusion
References

Reinforcement Learning for Mobile Robots
Comparison
Complexity Input : number of weights in the input Net.
Output : number of weights in the input Net.
Log : is the need for the log of input states?
Class. : computational time needed for classification
Part. : computational time needed for adjusting the input partitioning
Coop. : computational time needed for cooperative response learning
W(T) : width of neighborhood for cooperative response learning
η : number of neural units per dimension of input space
dI : number of dimensions in input space

Reinforcement Learning for Mobile Robots
Agenda
Introduction
Machine learning
Reinforcement learning
Learning system for robots
Comparison
Conclusion
References

Reinforcement Learning for Mobile Robots
Conclusion
Four versions of learning systems
1.Fixed & individual 2.Fixed & cooperative
3.Direct & individual 4.Direct & cooperative
Response Learning
Partition Learning

Reinforcement Learning for Mobile Robots
Conclusion
Learning system version
Neural units per
dimension
Ultimate success rates for the learning systems on simulation case 1.
Hitch angle value :[-15,+15]
Goal angle value :[-45,+45]

Reinforcement Learning for Mobile Robots
Conclusion
Learning system version
Neural units per
dimension
Ultimate success rates for the learning systems on simulation case 2.
Hitch angle value :[-65,+65]
Goal angle value :[-180,+180]

Reinforcement Learning for Mobile Robots
Conclusion
Learning system version
Neural units per
dimension
Ultimate success rates for the learning systems on simulation case 3.
Goal angle value :[-6,+6]
Hitch1 angle value :[-6,+6]
Hitch2 angle value :[-6,+6]

Reinforcement Learning for Mobile Robots
Value-function approximation
Two learning phase

Reinforcement Learning for Mobile Robots
Value-function approximation

Reinforcement Learning for Mobile Robots
Value-function approximation

Reinforcement Learning for Mobile Robots
[1] dean Ferederick Hougen, “Connectionist reinforcement learning for control of robotic systems”, University of Minnesota, PHD Thesis, October 1998.
[2] Sandra Pinto Clara do Carmo Gadanho, “Reinforcement learning in autonomous robots ”, University of Edinburgh, PHD Thesis, June 1999.
[3] William D. Smarta ,Leslie Pack Kaelblingb, “Reinforcement Learning for Robot Control”, Department of Computer Science, Washington University in St. Louis, Artificial Intelligence Laboratory MIT,1992,Prentice Hall.
[4] Lisa A. Meeden, James B. Marshall, Douglas Blank, “Self-Motivated, Task-Independent Reinforcement Learning for Robots”
[5] Jan Peters, Sethu Vijayakumar, Stefan Schaal, “Reinforcement Learning for Humanoid Robotics”, Third IEEE-RAS International Conference on Humanoid Robots, Karlsruhe, Germany, Sept.29-30,2003.
[6] Leslie Pack kaelbling, Michael L. Littman, Andrew W. More, “Reinforcement learning : a survey”, Journal of artificial intelligence research,1995.
References







