
Hadoop at ContextWeb
Alex Dorman, VP Engineering
Paul George, Sr. Systems Architect
October 2009

2
ContextWeb: Traffic
ADSDAQ – Online Advertisement ExchangeTraffic –
up to 6,000 Ad requests per second. 7bln Ad requests per month 5,000+ Active Publisher and Advertiser accounts
Account reports are updated every 15 minutesAbout 50 internal reports for business users updated nightly

3
ContextWeb Architecture highlights
Pre – Hadoop aggregation framework Logs are generated on each server and aggregated in memory to 15
minute chunks Aggregation of logs from different servers into one log Load to DB Multi-stage aggregation in DB About 20 different jobs end-to-end Could take 2hr to process through all stages 200mln records was the limit

Hadoop Data Set
Up to 120GB of raw log files per day. 60GB compressed60 different aggregated data sets 25TB total to cover 1 year
(compressed) 50 different reports for Business and End UsersMajor data sets are updated every 15 minutes

Hadoop Cluster
40 nodes/320 Cores (DELL 2950)100TB total raw capacityCentOS 5.3 x86_64Hadoop 0.18.3-CH-0.2.1 (Cloudera), migrating to 0.20.xNameNode high availability using DRBD Replication.Log collection using custom scripts and Scribe

Hadoop Cluster
In-house developed Java framework on top of hadoop.mapred.*
PIG and Perl Streaming for ad-hoc reportsOpsWise scheduler~2000 MapReduce job executions per dayExposing data to Windows:
WebDav Server with WebDrive clients Reporting Application: Qlikview Cloudera support for Hadoop

7
Architectural Challenges
How to organize data set to keep aggregated data sets fresh. Logs constantly appended to the main Data Set. Reports and
aggregated datasets should be refreshed every 15 minutes
Mix of .NET and Java applications. (70%+ .Net, 30%- Java) How to make .Net application write logs to Hadoop?
Some 3rd party applications to consume results of MapReduce Jobs (e.g. reporting application) How make 3rd party or internal Legacy applications to read data from
Hadoop ?
Backward and forward compatibility of our data sets every month we are adding 3-5 new data points to our logs
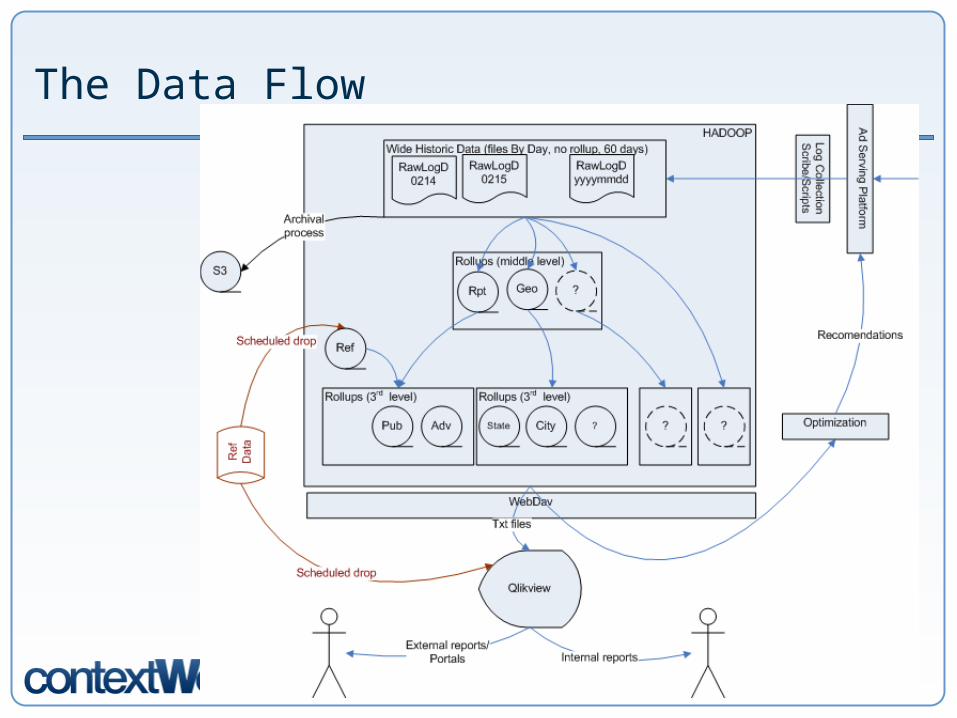
The Data Flow

9
Partitioned Data Set: Date/Time
Date/Time as main dimension for PartitioningSegregate results of MapReduce jobs into Monthly, Daily or
Hourly DirectoriesUse MultipleOutputFormat to segregate output to
different filesReprocess only what has changed – check DateTime in
filename to determine what is affected. Data Set is regenerated if input into MR job contains data for this Month/Day/Hour.
Use PathFilter to specify what files to process

10
Partitioned Data Set: Revisions
Need overlapping jobs: 12:00 -12:10 Job 1.1 A->B
12:10-12:20 Job 1.2 B->C 12:15-12:25 Job 2.1 A->B !!! Job 1.2 is still reading set B !!!
12:20-12:30 Job 1.3C->D 12:25-12:35 Job 2.2 B->C
12:35-12:45 Job 2.3 C->D
Use revisions:12:00 -12:10 Job 1.1 A.r1->B.r1
12:10-12:20 Job 1.2 B.r1->C.r1 12:15-12:25 Job 2.1 A.r2->B.r2
12:20-12:30 Job 1.3 C.r1->D.r1 12:25-12:35 Job 2.2 B.r2->C.r2
12:35-12:45 Job 2.3 C.r2->D.r2
Assign revision (timestamp) when generate output Use MultipleOutputFormat to segregate output to different files
Use highest available revision number when selecting input Use PathFilter to specify revisions to process
Clean up “old” revisions after some grace period
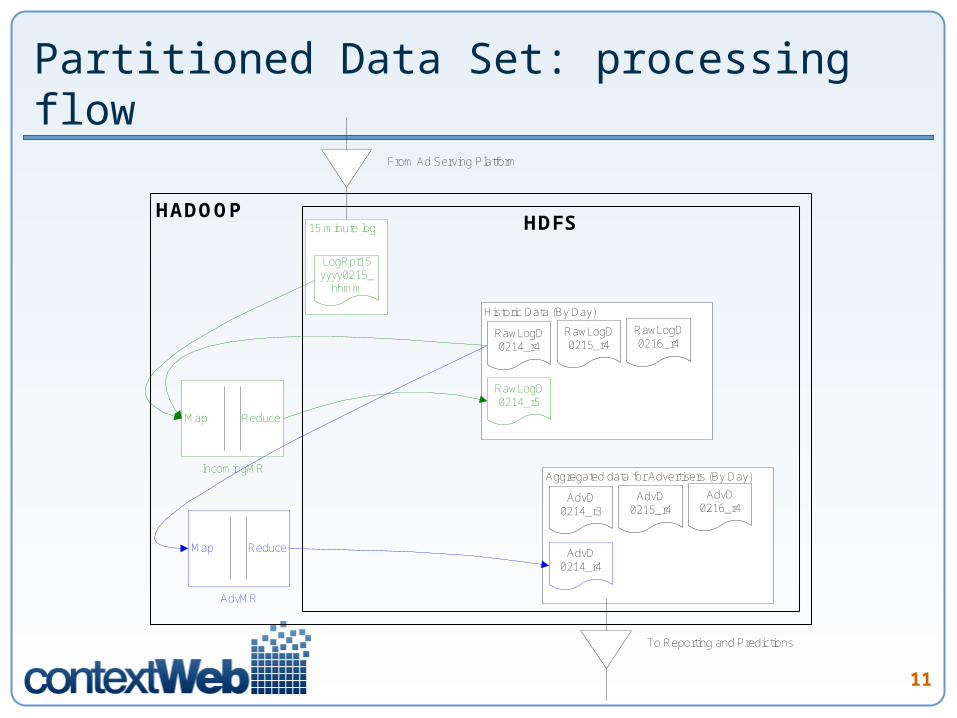
11
Partitioned Data Set: processing flow
HDFS
Historic Data (By Day)
RawLogD 0214_r4
RawLogD 0215_r4
RawLogD 0216_r4
HADOOP15 minute log
LogRpt15 yyyy0215_
hhmm
Map Reduce
RawLogD 0214_r5
Aggregated data for Advertisers (By Day)
AdvD 0214_r3
AdvD 0215_r4
AdvD 0216_r4
AdvD 0214_r4
Map Reduce
AdvMR
IncomingMR
From Ad Serving Platform
To Reporting and Predictions
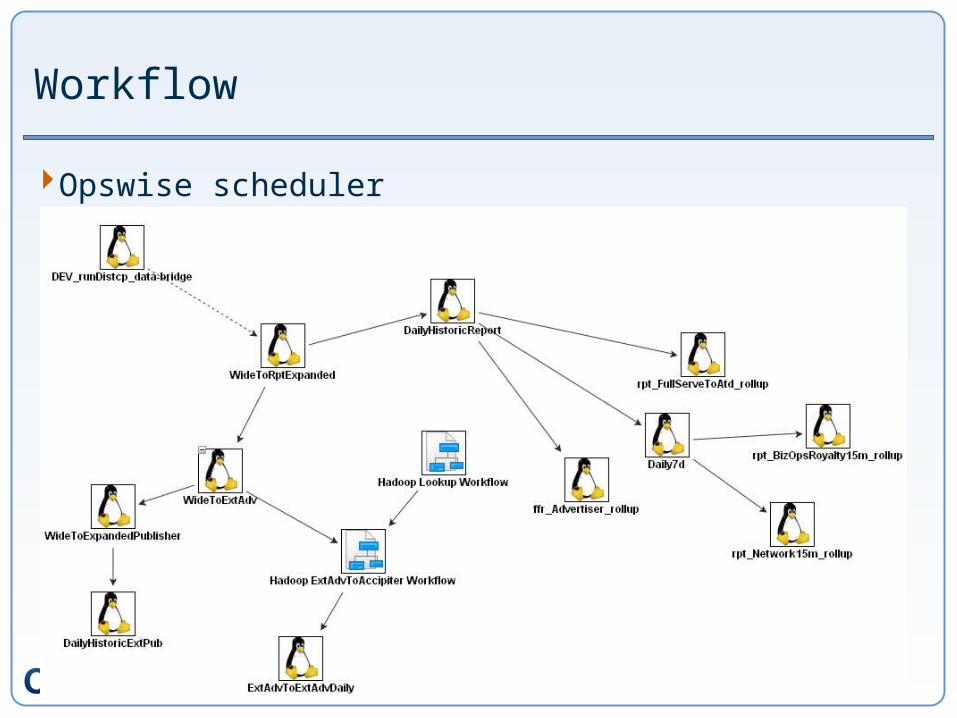
Workflow
Opswise scheduler

13
Logical Schemas and Headers
Meta data repository to define list of columns in all data setsEach file has headers as the first lineJob configuration files that define source and targetColumns are mapped dynamically based on the schema file
and header informationEach data set can have individual files of different formatNo need to modify source code if a new column is added or if
order of columns has changedSupport for default values if a column is missing in older fileEasy to export to external applications (DB, reporting apps)

14
Getting Data in and out
Mix of .NET and Java applications. (70%+ .Net, 30%- Java) How to make .Net application write logs to Hadoop?
Some 3rd party applications to consume results of MapReduce Jobs (e.g. reporting application) How make 3rd party or internal Legacy applications to read data from
Hadoop ?

15
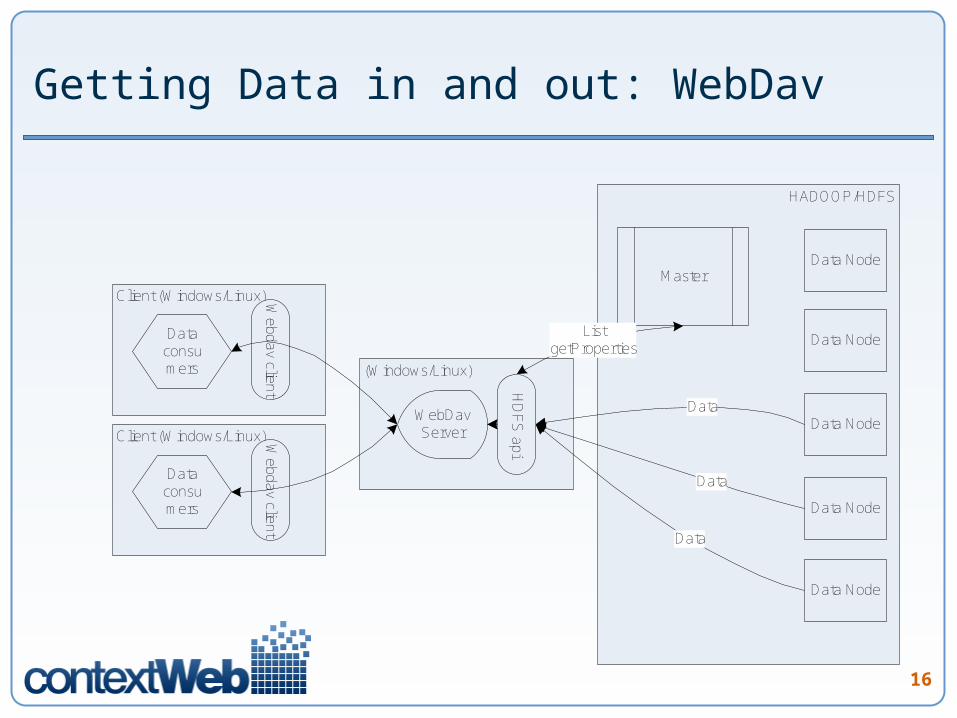
Getting Data in and out: WebDAV driver
WebDAV server is part of Hadoop source code tree Needed some minor clean up. Was co-developed with IponWeb.
Available http://www.hadoop.iponweb.net/Home/hdfs-over-webdav
There are multiple commercial Windows WebDav clients you can use (we use WebDrive) http://www.webdrive.com/
Linux Mount Modules available from http://dav.sourceforge.net/
16
Getting Data in and out: WebDav
(Windows/Linux)
HADOOP/HDFS
MasterData Node
Data Node
Data Node
Data Node
Data Node
Client (Windows/Linux)
WebDav Server
Data consumers
Webdav client
ListgetProperties
Data
Data
Data
HD
FS
apiClient (Windows/Linux)
Data consumers
Webdav client

QlikView Reporting Application
In-memory DBAJAX support for integration into WEB portals TXT files are supportedUnderstands headersWebDav allows to load data directly from HadoopComing soon: generation of Qlikview files as output of
Hadoop MR jobs

18
High Availability for NameNode/JobTracker
GoalsAvailability! (But not stateful)
Failed jobs resubmitted by workflow scheduler Target < 5 minutes of downtime per incident
Automatic fail over with no human action required. No phone calls, no experts required Alert that it happened, not that it needs to be fixed
Allow for maintenance windowsAvoid at all cost
Whenever possible, use redundancy inside of the box Disks (RAID 1), network bonding, dual power supplies

19
Redundant Network Architecture
• Use Linux bonding• See bonding.txt from Linux kernel docs.• Throughput advantage
– Observed at 1.76Gb/s
• We use LACP, aka 802.3ad, aka mode=4.– http://en.wikipedia.org/wiki/Link_Aggregation_Control_Protocol– Must be supported by your switches.
• On the data nodes, too. Great for rebalancing.
• Keep nodes on different switches• Use a dedicated cross over connection, too

20
Software Packages We Use for HA
Linux-HA Project’s Heartbeat (http://www.linux-ha.org) Default resource manager, haresources Manages multiple resources:
Virtual IP address DRBD Disk and file system Hadoop init scripts (from Cloudera’s distribution)
DRBD by LINBIT (http://www.drbd.org) “DRBD can be understood as network based raid-1.”

21
Replication of NameNode Metadata
DRBD Replication. Block level replication, file system agnostic File system is active on only one node at a time We use synchronous replication Move only the data that you need! (metadata, not the whole system) 2.6mm Files, 33k dirs, 60TB = 1.3GB meta data (not a lot to move) Still consider running your secondary namenode on another machine
and/or NFS dir! LVM snapshots /getimage?getimage=1 /getimage?getedit=1

In the Unlikely Event of a Water Landing
Order of Events, the magic of Heartbeat• Detect the failure (“deadtime” from ha.cf)• Virtual IP fails over.• DRBD system switches primary node. (/proc/drbd status)• File system fsck and mount at /hadoop.• Hadoop processes started via Cloudera init scripts.• Optionally, original master is rebooted (if it’s still alive)• End to end fail over time approximately 15 seconds.

In the Unlikely Event of a Water Landing
Order of Events, the magic of Heartbeat• Detect the failure (“deadtime” from ha.cf)• Virtual IP fails over.• DRBD system switches primary node. (/proc/drbd status)• File system fsck and mount at /hadoop.• Hadoop processes started via Cloudera init scripts.• Optionally, original master is rebooted (if it’s still alive)• End to end fail over time approximately 15 seconds.
Does it work?

In the Unlikely Event of a Water Landing
Order of Events, the magic of Heartbeat• Detect the failure (“deadtime” from ha.cf)• Virtual IP fails over.• DRBD system switches primary node. (/proc/drbd status)• File system fsck and mount at /hadoop.• Hadoop processes started via Cloudera init scripts.• Optionally, original master is rebooted (if it’s still alive)• End to end fail over time approximately 15 seconds.
Does it work?• Yes!! 6 failovers in the past 18 months

In the Unlikely Event of a Water Landing
Order of Events, the magic of Heartbeat• Detect the failure (“deadtime” from ha.cf)• Virtual IP fails over.• DRBD system switches primary node. (/proc/drbd status)• File system fsck and mount at /hadoop.• Hadoop processes started via Cloudera init scripts.• Optionally, original master is rebooted (if it’s still alive)• End to end fail over time approximately 15 seconds.
Does it work?• Yes!! 6 failovers in the past 18 months• (only 3 were planned)

Other Options to Consider
(or: How I Learned to Stop Worrying and Start Over From the Beginning) Explore additional resource management systems
• ie., OpenAIS + Pacemaker: N+1, N-to-N• Be resource aware, not just machine aware
Consider additional file system replication methods• ie., GlusterFS, Red Hat GFS• SAN/iSCSI backed
Virtualized solutions? Other things I don’t know about yet
• Solutions to the problem exist• Work with something you’re comfortable with
http://www.cloudera.com/blog/2009/07/22/hadoop-ha-configuration/
26







