diffserv over network processors: implementation...
TRANSCRIPT

DiffServ over Network Processors: Implementation and Evaluation t
Ying-Dar Lin, Yi-Neng LinDepartment of Computer and Information
Science, National Chiao Tung University,Hsinchu, Taiwan
{ydlin, ynlin}@cis. nctu.edu.tw
Shun-Chin Yang, and Yu-Sheng Lin
Computer and Communications Laboratories,Industrial Technology Research Institute,
Hsinchu, Taiwan
{890047, 870932}@itri.org.tw
Abstract
Network processors are emerging as a programmablealternative to the traditional ASIC-based solutions inscaling up the data-plane processing of network services.This work. rather than proposing new algorithms,illustrates the process of, and examines the performanceissues in, prototyping a DifjServ edge router withIXP 1200. The external benchmarks reveal that though thesystem can scale to wire-speed of I.8Gbps in simple IPforwarding, the throughput declines to180Mbps-290Mbps when DifjServ is performed due tothe double bottlenecks of SRAM and microengines.Through internal benchmarks, the performance bottleneckwas found to be able to shift from one place to anothergiven different network services and algorithms. Most ofthe result reported here shall remain the same for otherNPs since they have similar architectures and
components.
I. Introduction
Increasing link bandwidth demands faster nodalprocessing, especially of data-plane traffic. Nodal data-plane processing ranges from routing table lookup tovarious classifications for firewall, DiffServ and Webswitching. The traditional general-purpose processorarchitecture is no longer sufficiently scalable for wire-speed processing, and some ASIC components or co-processors are commonly used to ofJload the data-planeprocessing, while leaving only control-plane processing tothe original processor.
Several ASIC-driven products have been announced inthe market, such as the acceleration cards forencryption/decryption, VPN gateways, Layer 3 switches,DiffServ routers and Web switches. While accelerating thedata-plane packet processing with special hardwareblocks, much wider memory buses, and faster executionprocesses, these ASICs lack the flexibility ofreprogrammability and have a long development cycle
usually of months or even years. The cost of possibledesign failures is also high.
Network processors are emerging as an alternativesolution to ASICs for providing reprogrammability whileretaining scalability for data-plane packet processing. Thisstudy employed the Intel IXPl200 [1] network processor,which consists of one StrongARM core and six co-processors, referred to as microengines, so that developerscan embed the control-plane and data-plane trafficmanagement modules into the StrongARM core andmicroengines, respectively. Scalability concerns in data-plane packet processing could be satisfied with the fourzero context switching overhead hardware contexts ineach of the six microengines and the instructionsspecifically for networking.
Spalink, Karlin, Peterson and Gottlieb [2] demonstratedand evaluated the IXPl200 in IP forwarding, concludingthat the SDRAM storing packets is the bottleneck.However, such results cannot be generalized to today'scomplex services which may need much SRAM tableaccesses and computing power. This work therefore aimsto implement a more sophisticated service, DifferentiatedServices (DiffServ), using two existing algorithms forclassification and scheduling, and identify scalabilityissues and possible performance bottlenecks in IXP1200.Two topics in benchmarking the implemented system areinvestigated. First, how well can this DiffServimplementation scale in terms of throughput for differentnumbers of classification rules? The reason we evaluatethe scalability in terms of the number of classificationrules is that since the number of classes in DiffServ islimited, it equals the number of flows, which is, in a sense,the number of classification rules. Second, where are thepotential bottlenecks and their causes? The exactbottleneck is anticipated to depend on the specific serviceand its algorithmic implementation.
The rest of this paper is organized as follows. Section IIbriefly reviews the architecture of IXP1200. Section IIIthen presents the design and implementation of DiffServ
t This work was supported in part by the MOE Program of Excellence
Research 89-E-FA04-1-4 and a grant &om Intel. The IXP 1200 platformwas donated by Intel for development and evaluation.
,...~COMPUTER
SOCIETYProceedings of the 10TH Symposium on High Performance Interconnects Hot Interconnects (Hotl'02)
0-7695-1650-5/02 $17.00 @ 2002 IEEE

over IXP1200. Next, Section IV illustrates the results ofexternal and internal benchmarks through experiment andsimulation, respectively. Conclusions are finally made inSection V.
microengines. The system is now ready to receive packets.When the Ready Bus Sequencer detects an incomingpacket in a MAC, it notifies the corresponding receiverthread to retrieve and store the packet in the RFIFO. Aftercompleting the routing table lookup, the receiver threadmoves the packet to SDRAM in order to wait to beforwarded. A transmitter thread of another microenginelater forwards the packet in SDRAM through TFIFO toanother MAC. Multiple receiver, transmitter, andscheduler threads may be distributed to six microengines,although some restrictions apply.
2. Architecture of IXP1200
3. Design and Implementation of DiffServ onIXP1200
This section briefly introduces DiflServ and thenexplains how to map DiflServ components onto anIXPl200 program, The implementation of two majorcomponents, classifier and scheduler, in DiflServ usingtwo algorithms, Multi-dimensional Range Matching andthe weighted form of Deficit Round Robin, respectively, isdescribed.
Closely examining the hardware architecture ofIXP1200, shown in Fig. 1, helps to elucidate our DiffServimplementation. The 32-bit, 200MHz StrongARM coregoverns the initialization of the whole system and part ofthe packet processing. A Memory Management Unit isalso included to translate virtual addresses into physicaladdresses and control memory access permission.
The six 200MHz microengines, supporting fourhardware contexts, i.e. threads, are primarily used toreceive, manipulate, and transmit packets. For networkingpurposes, microengines also support zero contextswitching overhead, single-cycle ALU with shifter, andother specifically designed instructions for bit, byte, and
longword operations.The SRAM is used for storing lookup tables and
pointers in scheduling queues for packet forwarding, whilethe SDRAM is used for storing mass data of packets. The64-bit IX bus Interface Unit is responsible for servicingMAC interface ports on the IX Bus, and moving data toand from the Receive and Transmit FIFOs. It provides a4.2Gbps (64bit at 66MHz) interface to MAC devices,meaning that it can afford 2.1 Gbps of the input ports and2.1Gbps of the output ports. In addition, two IXP1200network processors can be directly supported on the IXBus without additional support logic.
3.1. DiffServ Briefing
Differentiated Services (DiffServ) [3] mechanismsenable users to receive different levels of service from aprovider to support various types of applications.According to the service configuration in a DiffServ edgenode, packets are classified with multiple fields (MF),leaky bucket policed, and marked to receive a particularper-hop forwarding behavior (PHB), which defines howpackets with a particular behavior are treated at this node.Each predefined PHB is mapped to one DSCP (DiffServCode Point) value used in class-based scheduling, i.e.,Expedited Forwarding (EF) or one of four AssuredForwarding's (AF's).
The service differentiation of packets is often manifestas delay and loss rate. Packets of higher classes are morelikely to be scheduled before those of lower classes,resulting in lower latency and loss rate.
Fig. 2 illustrates the key components and the packetprocessing flow. The Ready Bus Sequencer periodicallypolls the MAC buffer and sets the receive flag in a globalrec-rdy register when a packet comes. Once the receiverthread responsible for the MAC port detects the flag, itasks the Receive State Machine to move the packet, inunits of 64-byte MAC packet, referred as MP which is abasic data unit in the system, from the MAC buffer intoRFIFO.
Fig. 1 Hardware architecture of IXP1200
The operations of IXP1200 hardware components,when handling packet-forwarding services, are describedbelow. At boot time, the StrongARM loads the boot imagefrom Boot ROM or via seriaVEthernet connection, andinitializes other functional units, including loading therouting table into SRAM and microcode into
IErf~
COMPUTER
SOCIETY
Proceedings of the 10TH Symposium on High Performance Interconnects Hot Interconnects (Hotl'02)
0-7695-1650-5/02 $17.00 @ 2002 IEEE

from I to 4, then skip to 9
Fig. 2. Detailed DiffServ packet flow in IXP1200
hJ!I::ThreadO ofMEO
SDRAM
ii policy rules "'
routinJ!I table I
SRAM
1J!,
--'--.B--IIII 7
:.:."j,:.;:.-1---
-"5~~ ~, f~ I,
r---~---",DRR riper-port U 10 per-po.; : 3 :]TFIFO RFI ~ O cdo:JrdY
L + 4 ReceiveI State} -Machine r-;:;;--;:l
~Iper-port jMAC buffe
3.3. Mapping DiffServ Components Otherwise, the thread examines the next queue for packetsto be sent, and the quanta.
The twenty four threads are equally divided into twogroups, eight lO/lOOM ports and one giga port. Eachgroup has twelve threads: eight of which are used asreceivers (assigned to two microengines), three of whichare used as transmitters and one as a scheduler (assignedto one microengine). Each lO/lOOM receiver thread isresponsible for a specific lO/lOOM port, while eight gigareceiver threads serve one giga port. The transmitterthreads, however, are not bound to specific ports. Theyoutput packets to ports according to assignments from thescheduler thread. Static task allocation, instead of dynamictask allocation, is employed for the following reasons.First, the lK Control Store of a microengine may not besufficiently large to hold microcode of two threads ofdifferent types, for example, receiver (1012 instructions)and transmitter (552 instructions), whose summed size ofinstructions exceeds the Control Store size. However, thetransmitter and scheduler (144 instructions), whosesummed size is below 1024, can co-exist in onemicroengine. Therefore, threads of the same type are bestgrouped in one microengine. Second, choosing dynamicallocation complicates the programming, and thecommunication overhead between threads or microengineswould be huge as tasks could not be clearly dividedamong threads.
Fig. 3 shows the software architecture of DifiServ andits corresponding task allocation on IXP1200. Sixmodules (the shaded blocks) are inserted into the originalsoftware of simple IP forwarding.
StrongARMreceiver thread 8 threads for 8
~ , 8 threads for I Giga port (microengine2.3)
ICP "~,,
nnt
j packet sto;;l..- I Imatch 1- j
1 threads for 10/100 ports (microengine 4)scheduler thread l-~!'!-"-~~-'-!!'.~-~-9-~~~-p-0.~-<.,!,j-c-,0.~!,-@!~-e-.51 ,
Tx ~ I Tx-ReadAssignment r-.1 Tx fill I j
.; ; ~ ~ ~ ;;; -i ~ ;~ -; ~ ~;~~d j -ihre-.- d s- f;; -'-i- O i ioo -p ~ rt-.-( ;;, i ~roe;, -g i~ -; 4) 3 threads for I Giga port (microengine 5)
Fig. 3 Data-plane architecture of DiffServ edge router
over IXP1200
The DiffServ processing is described below. Oncereceived at a transfer register from an RFIFO and verifiedas legal, a packet header is passed to the Range Matchingclassifier for the matching process. If the packet's headermatches one of the classification rules and is classified as,for example, EF traffic, it is admitted or discardedaccording to the policing bandwidth specified in theclassification rule. If admitted, it is marked with a DSCPin the header. After longest prefix matching in routingtable lookup, the packet is queued in the correspondingqueue of the output port, and waits to be scheduled; thatis, the packet's descriptor is enqueued in SRAM while thepacket itself is stored in SDRAM. The scheduler threadchooses one transmitter thread and assigns it a port, whichcontains six queues (I EF, 4 AF's and I BE), to serve. Thetransmitter thread examines the queue with the highestpriority to determine whether a packet is waiting to besent, and whether the queue has sufficient quanta ascredits for transmitting that packet in Deficit Round Robinscheduling. If having enough quanta, then the transmitterthread fetches the packet's descriptor in SRAM and thensends the entire packet in SDRAM to TFIFO for output.
3.4. Algorithm Adoption and Implementation
3.4.1. Related Works. Classification and scheduling havebeen two critical modules that influence the performanceof a DifiServ implementation. Several methods have beenproposed for the above two purposes, however, many ofthem are not practically applicable due to limitations ofthe platform, including memory size (2Mbytes of SRAM)and coding overhead. For example, Recursive FlowClassification [4] which has an unstable memory sizerequirement ranging from 1 Mbytes to lOOOMbytes;similar behavior can also be seen in Cross-Producting [5].
Another example is the Grid-of-Tries [5], which is alsoa classification algorithm and has a lower memory
""~COMPUTER
SOCIETY
Proceedings of the 10TH Symposium on High Performance Interconnects Hot Interconnects {Hotl'02)
0-7695-1650-5/02 $17.00@2002 IEEE
I. Poll MAC buffer and set the rec-rdyflag of the port
2. Poll rec-rdy of the port
3 Issue a reference to Rx State Machine
4. Move one MP to RFIFO
5. If SOP, move half of the MP(header)
to SRAM xfer regs for classification,half to SDRAM
6. Load rules into SRAM xfer regs
(classification iteration)
7. Policing, marking, routing table lookup
and enqueue (after classification)
8. Store the packet header to SDRAM
9. Store the rest of the MPs to SDRAM
10. DRR scheduling and then transmit to
TFIFO, MAC buffer
* If SOP, process from I to 8, otherwise

per-flow Leaky Bucket. A timer is implemented byStrongARM to determine timing information. Thelast-arrival-time is the arrival time of the previouspacket, and the token represents the number of quanta leftin the processing of the last packet and is available for thenext one. The total tokens available to the incomingpacket can thus be determined and a decision regarding itsadmission can be made.
requirement. Nontheless, the complexity of the algorithmmakes implementation with microcode difficult. Severalscheduling algorithms are not considered for the samereason, including, for example, Weighted Fair Queueing[6], which involves complex multiplications.
Multi-dimensional Range Matching [7] is thus used as aclassifier, to exploit its more stable and lower memoryrequirement, and efficiency in setting up flexibleclassification rules. The weighted form of Deficit RoundRobin [8] is adopted in the scheduler, which can be easilyimplemented (requiring only addition) and effectivelyensures weighted sharing among various flows. Thefollowing two subsections briefly describe theimplementation of these two algorithms.
3.4.3. Scheduler. The quantum size of each class can beset arbitrarily. Here, we set the ratio of quantum betweentwo adjacent classes in this system to two for simplicity. Apacket is represented as a queue descriptor when queuedin SRAM. Each queue descriptor contains the count MacPacket (MP) and points to a link list of buffer descriptors,which point to the MPs of the packet stored in theSDRAM. Once a packet is scheduled for transfer, thetransmitter thread uses the addresses of the bufferdescriptors and the buffer handle in the last bufferdescriptor to locate all MPs. The former are used to mapthe start addresses of the MPs (buf-des-addr*64 ), and thelatter is used to determine the number of valid bytes at theEOP (End of Packet).
3.4.2. Classifier. The concept of Multi-dimensional RangeMatching used to implement the classifier is describedbelow. The rules in a dimension form intervals, in whichmultiple rules may overlap. Each interval is associatedwith a BV (Bit Vector, which is 5l2-bit in thisimplementation and is stored in SRAM), which keepstrack of what rules overlap in this interval. The spacecomplexity is O(nA2), where n is the number ofclassification rules, since there are at most 2n-l intervals,and each of which keeps track of the n rules.
Fig. 4 presents an example of the matching process inthe source IP dimension. When a packet arrives, theclassifier searches the interval table of each dimension fora match with the corresponding field in the packet. Whenan interval is found for a dimension, the classifier retrievesthe corresponding BV in the BV table. If all six fields of apacket match an interval in six dimensions, the classifierANDs the BVs of the intervals, and the index of the firstnon-zero bit in the result vector becomes the index of thematched classification rule.
4. External and Internal Benchmarks
The performance of DiflServ has been evaluated in anumber of studies [9, 10, II, 12]. However, most of theseinvolve only simulations. Accordingly, this sectionconsiders two kinds of experiments, external and internalbenchmarks. Firstly, the aggregated throughput that can bescaled by the system, while conforming the PREs, isexarniend to determine scalability. A Linear Searchclassifier is also included for comparison with the RangeMatching classifier.
The internal benchmark involves simulations of twoDiflServ implementations on IXPl200 whose classifiersare implemented with Linear Search and Range Matching.The aim is to identify what cannot be seen in the externalbenchmarks, and the performance bottlenecks. Thenumber of classification rules is 64 with a worst caseconfiguration with respect to the number of classificationrule matching for both simulations.
Source IP rules ~
4.1. Scalability Test
Fig. 4. Example and relative tables for lookup inSource IP dimension 4.1.1. Traffic Load. The methodology for testing fairness
between input flows is described below. The maximumload, which is 58%, is first measured for a flow that yieldsno packet loss. The fairness of the system for more flowsis then obtained for input loads below or above 58%. Eachflow is set to have the same bandwidth, and the aggregatedbandwidth is 50% of the link. The input load is evenlydistributed over 500 flows in the following test.
After the classifier returns the index of the matchedclassification rule, the policer and marker use theinformation contained in the rule in further processing.Each rule is associated with two additional fields,last-arrival-time and token, which are used to maintain
IEFF~
COMPUTER
SOCIETY
Proceedings of the 10TH Symposium on High Performance Interconnects Hot Interconnects (Hotl'02)
0-7695-1650-5/02 $17.00 @ 20021EEE
thread cannot finish the processing of a packet in time toreceive later packets. In the test of four IOOMbps inputports, whose threads are all in the same rnicroengine, thebottleneck becomes the rnicroengine because of a lack ofcomputing power. However, in the test of the wholesystem throughput, the bottleneck is again the SRAM,since the aggregated throughput is not the sum of thethroughputs of eight looMbps ports and one gigabit port,although the computing power is doubled. The SRAM andrnicroengines are called double bottlenecks, because thesystem can still suffer from one bottleneck after the otheris solved.
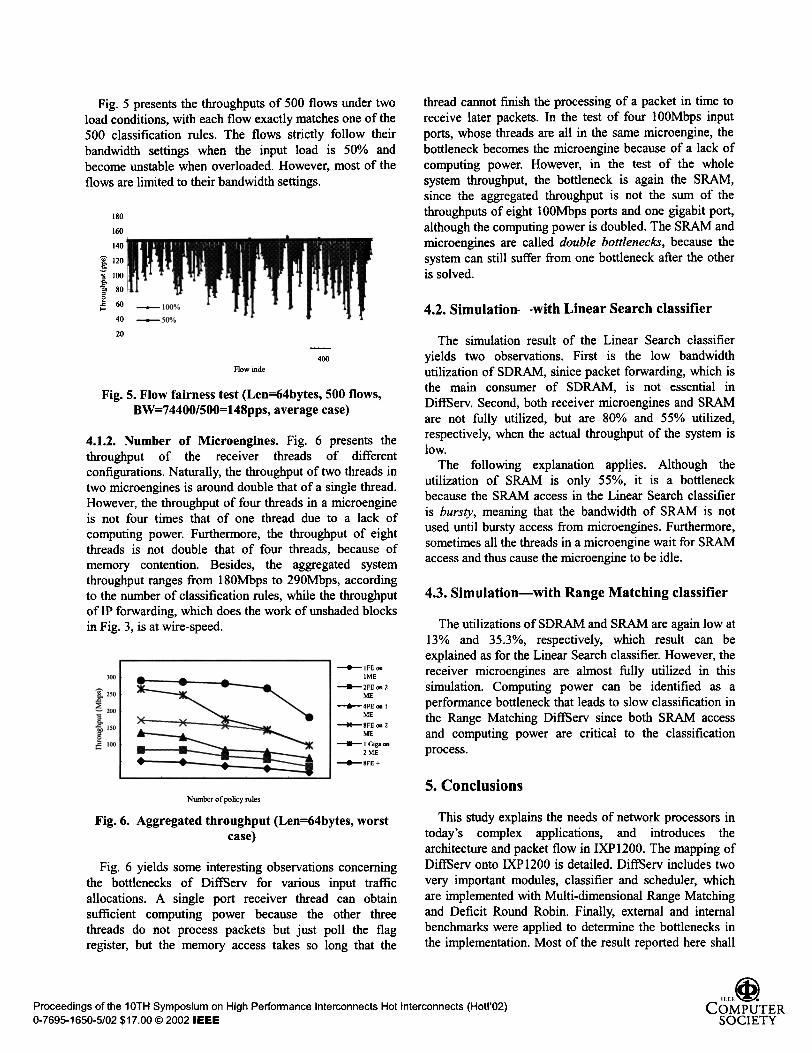
Fig. 5 presents the throughputs of 500 flows under twoload conditions, with each flow exactly matches one of the500 classification rules. The flows strictly follow theirbandwidth settings when the input load is 50% andbecome unstable when overloaded. However, most of theflows are liroited to their bandwidth settings.
180
160
140
R 1200.
~ 1000.
~ 80~o
.2 60..
40
20
-with Linear Search classifier4.2. Simulation-
400
flow inde
Fig. 5. Flow fairness test (Len=64bytes, 500 flows,
BW=74400/500=148pps, average case)
4.1.2. Number of Microengines. Fig. 6 presents thethroughput of the receiver threads of differentconfigurations. Naturally, the throughput of two threads intwo rnicroengines is around double that of a single thread.However, the throughput of four threads in a rnicroengineis not four times that of one thread due to a lack ofcomputing power. Furthermore, the throughput of eightthreads is not double that of four threads, because ofmemory contention. Besides, the aggregated systemthroughput ranges from 180Mbps to 290Mbps, accordingto the number of classification rules, while the throughputof IP forwarding, which does the work of unshaded blocksin Fig. 3, is at wire-speed.
The simulation result of the Linear Search classifieryields two observations. First is the low bandwidthutilization of SDRAM, sinice packet forwarding, which isthe main consumer of SDRAM, is not essential inDiftServ. Second, both receiver microengines and SRAMare not fully utilized, but are 80% and 55% utilized,respectively, when the actual throughput of the system islow.
The following explanation applies. Although theutilization of SRAM is only 55%, it is a bottleneckbecause the SRAM access in the Linear Search classifieris bursty, meaning that the bandwidth of SRAM is notused until bursty access from rnicroengines. Furthermore,sometimes all the threads in a microengine wait for SRAMaccess and thus cause the rnicroengine to be idle.
4.3. Simulation-with Range Matching classifier
The utilizations ofSDRAM and SRAM are again low at13% and 35.3%, respectively, which result can beexplained as for the Linear Search classifier. However, thereceiver microengines are almost fully utilized in thissimulation. Computing power can be identified as aperformance bottleneck that leads to slow classification inthe Range Matching Diffierv since both SRAM accessand computing power are critical to the classification
process.
-IFEoo
lME
-2FEoo2
ME
-4FEooi
ME
-8FEoo2
ME
-I Giga00
2ME
-8FE+
5. Conclusions
This study explains the needs of network processors intoday's complex applications, and introduces thearchitecture and packet flow in IXP1200. The mapping ofDiflServ onto IXP1200 is detailed. DiflServ includes twovery important modules, classifier and scheduler, whichare implemented with Multi-dimensional Range Matchingand Deficit Round Robin. Finally, external and internalbenchmarks were applied to determine the bottlenecks inthe implementation. Most of the result reported here shall
Number ofpolicy rules
Fig. 6. Aggregated throughput (Len=64bytes, worst
case)
Fig. 6 yields some interesting observations concerningthe bottlenecks of DiffServ for various input trafficallocations. A single port receiver thread can obtainsufficient computing power because the other threethreads do not process packets but just poll the flagregister, but the memory access takes so long that the
If[.~
COMPUTER
SOCIETY
Proceedings of the 10TH Symposium on High Performance Interconnects Hot Interconnects (Hotl'02)
0-7695-1650-5/02 $17.00 @ 2002 IEEE

remain the same for other NPs since they have similararchitectures and components.
The external benchmarks, which are in terms of numberof rules or flows, traffic load and number of microengines,have established that the implementation can well supportPHBs in DiffServ at an aggregated throughput of 568kpps.Both external and internal benchmarks identify the doublebottlenecks of both SRAM and microengines in the RangeMatching DiffServ-- the Range Matching DiffServ couldstill suffer from one bottleneck after the other is solved.Although the SDRAM is the bottleneck in IP forwarding,the bottleneck may shift from one functional unit toanother, depending on the specific service, algorithm andthe way input traffic is allocated to threads. Moreover, theSRAM bottleneck is found not necessarily to occur at100% utilization, but can even occur at 55% when theaccess is bursty.
Four methods are presented to solve thebottleneck of SRAM access that results in a lowutilization of receiver microengines. First, therouting table may be stored in SDRAM in the hopeof offioading SRAM. Second, one large SRAM maybe divided into many smaller banks at differentinterfaces, reducing the queuing delay of requests in
the command queue, if the requested addresses arein different memory banks. Even some redundantmemory modules may also be used, possibly with an
access arbitrator, to store many copies of the routingtable and classification rules to enhanceaccessibility. Third, a new memory architecture, forexample, QDR (Quad Data Rate) SRAM which hasa peak bandwidth of up to 1.6GBps per channel(which is two to three times that supported bySRAM), may be adopted. However, a new interfacebetween the memory and other functional units maybe required. Finally, an additional cache (or contentaddressable memory, CAM) can be used to reducethe number of times memory is accessed, becausetraffic in the same time period normally showslocality in lookups of classification rules and routingtables.
[4] P. Gupta, and N. McKeown, "Packet Classification onMultiple Fields", ACM SIGCOMM'99.[5] V. Srinivasan, G. Varghese, S. Suri, and M. Waldvogel,.'Fast and Scalable Layer Four Switching", ACM SIGCOMM'98.[6] A. Defiers, S. Keshav, and S. Shenker, "Analysis andSimulation ofa Fair Queuing Algorithm", ACM SIGCOMM'89.[7] T.V. Lakshman, and D. Stiliadis, '.High-Speed Policy-basedPacket Forwarding Using Efficient Multi-dimensional RangeMatching", ACM SIGCOMM'98.[8] M. Shreedhar, and G. Varghese, .'Efficient Fair QueuingUsing Deficit Round-Robin", IEEE/ACM Transactions onNetworking, June 1996, vol. 4, no.3, pp. 375-385.[9] L.V. Nguyen, T. Eyers, and J.F. Chicharo, .'DifferentiatedService Performance Analysis", Fifth IEEE Symposium onComputers and Communications, 2000, pp. 328 -333.[10] J.K. Muppala, T. Bancherdvanich, and A. Tyagi, '.VoIPPerformance on Differentiated Services Enabled Network",IEEE Internationa/ Conference on Network, 2000, pp. 419 -
423.[11] J. Harju, and P. Kivifiaki, "Co-operation and Comparisonof Diffserv and Intserv: performance measurements", 25thAnnua/ IEEE Conference on Loca/ Computer Networks, 2000,
pp.177-186.[12] Z. Di, and H.T. Mouftah, .'Performance Evaluation of Per-Hop Forwarding Behaviors in the DiffServ Internet", Fifth IEEESymposium on Computers and Communications, 2000, pp. 334-339.
6. Reference
[1] IXP1200 Data Sheet, Intel document number 278298-004,May 2000.[2] T. Spalink, S. Karlin, L. Peterson, and Y. Gottlieb, "Buildinga Robust Software-Based Router Using Network Processors",Proceedings of the 18th ACM Symposium on Operating Systems
Principles (SOSP).[3] S. Blake, D. Black, M. Carlson, E. Davies, Z. Wang, and W.Weiss, " An Architecture for Differentiated Services", RFC 2475 ,
Dec 1998.
Ir,,~COMPUTER
SOCIETY
Proceedings of the 10TH Symposium on High Performance Interconnects Hot Interconnects (Hotl'02)
0-7695-1650-5/02 $17.00 @ 20021EEE