data engineering for data scientists
TRANSCRIPT

Data Engineering for Data Scientists
Jonathan Lacefield – Solution Architect
DataStax

Introduction
• Jonathan Lacefield
– Solutions Architect, DataStax
– Former Dev, DBA, Architect, reformed PM
– Email: [email protected]
– Twitter: @jlacefie
– LinkedIn: www.linkedin.com/in/jlacefield

DataStax Introduction1. Commercial Provider of Apache Cassandra
2. Provider of Proprietary Software Built on Apache Cassandra
3. Deliverer a linearly scalable, “always-on” Data Platform on the foundation of Apache Cassandra and the integration of:
1. Apache Spark
2. Apache SOLR
3. Apache Hadoop
4. TitanDB

DataStax, What we Do (Use Cases)
• Fraud Detection• Personalization• Internet of Things• Messaging• Lists of Things (Products, Playlists, etc)• Smaller set of other things too!
We are all about working with temporal data sets at large volumes with high transaction counts (velocity).

“One believes things because one has been conditioned to believe them.”
― Aldous Huxley, Brave New World

After today, you will have enough knowledge to walk into any organization and communicate with Data Engineers, in their terms, to effectively design Analytical solutions based on modern technologies.

Agenda • Background and Context
– From 1 Database to Distributed, Polyglot Persistence Data Stores
• Data Engineering Concepts 101
– The CAP Theorem and it’s Variants
• Data Engineering Concepts 102
– Deeper into CAP
• The Data Stores You Will (Probably) Use
• The Architectures in Which You Will Participate

What’s Happened in the Last 10 Years
OLTP
Web Application Tier
OLAP
Statistical/Analytical Applications
ETL
2005

Ahh….2005
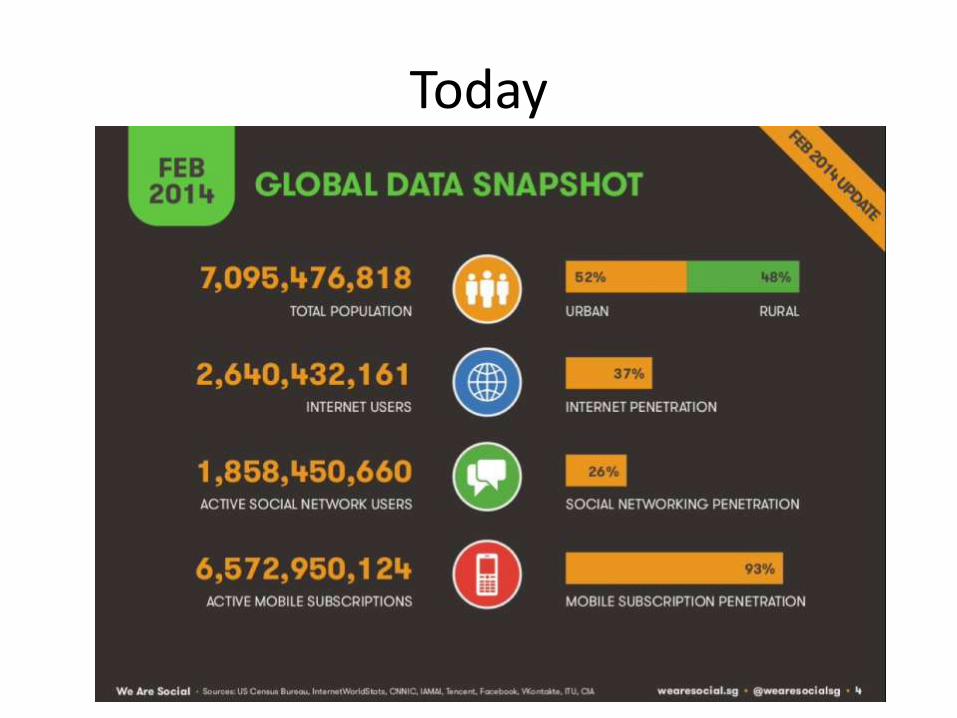
Today
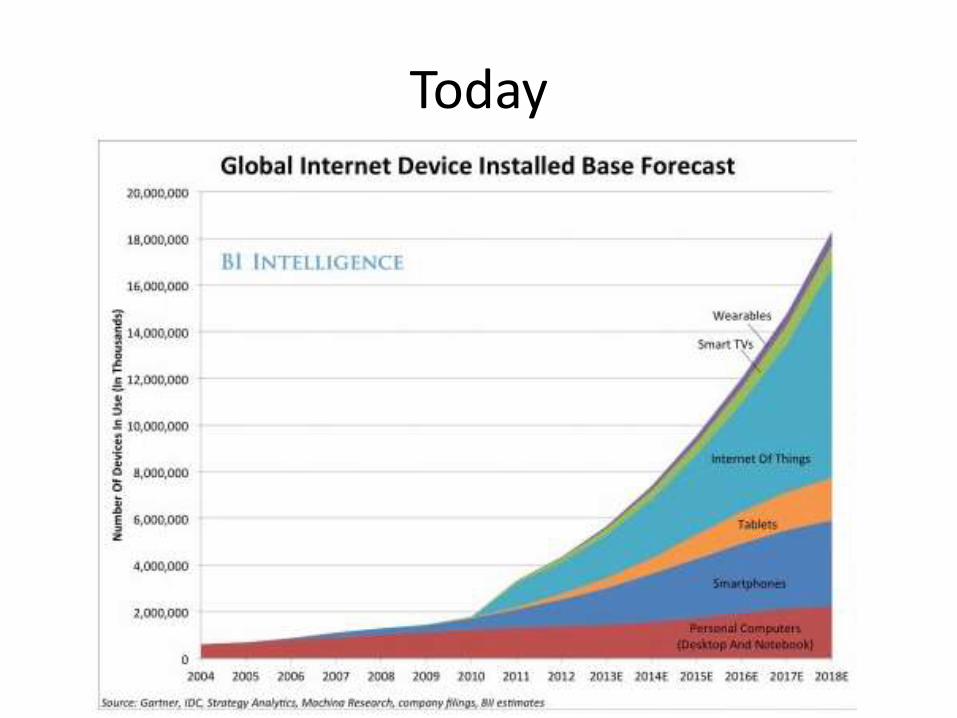
Today

2015
OLTP
Web Application Tier
OLAP
Statistical/Analytical Applications
ETL

Innovations in Data Engineering• 2000 – Eric Brewer’s Cap Theorem, proved in 2002
– http://en.wikipedia.org/wiki/CAP_theorem
• 2004 – Google MapReduce– http://research.google.com/archive/mapreduce.html
• 2006 – Google Big Table– http://static.googleusercontent.com/media/research.google.com/en/us/archive/
bigtable-osdi06.pdf
• 2007 – Amazon Dynamo– http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
• 2008 – Polyglot Persistence– https://www.altamiracorp.com/blog/employee-posts/polyglot-persistence
• 2009 – NoSQL (in modern terms) Introduced – http://en.wikipedia.org/wiki/NoSQL
• 2012 – Berkley Spark– https://amplab.cs.berkeley.edu/wp-content/uploads/2012/01/nsdi_spark.pdf
• …
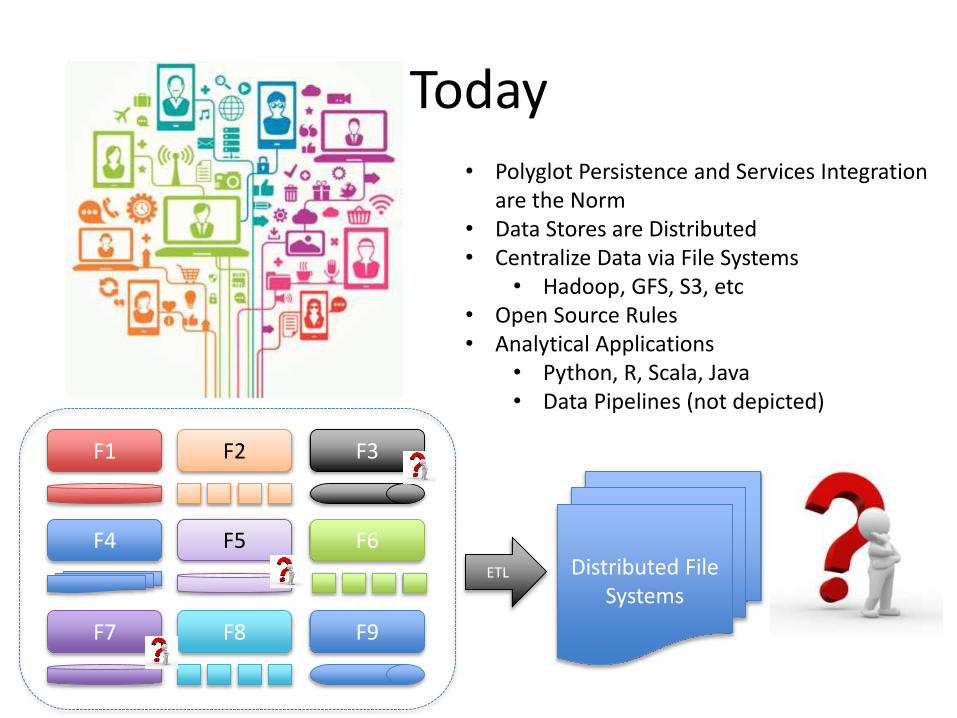
Today
F1 F2 F3
F4 F5 F6
F7 F8 F9
Distributed File Systems
ETL
• Polyglot Persistence and Services Integration are the Norm
• Data Stores are Distributed• Centralize Data via File Systems
• Hadoop, GFS, S3, etc• Open Source Rules• Analytical Applications
• Python, R, Scala, Java• Data Pipelines (not depicted)

SO WHAT?
WHO CARES?

To succeed you must thrive in this
environment!
1 + 1 = 2 Only Sometimes

CAP Theorem (The Foundation)
It is impossible for a distributed computer system to simultaneously provide all three of the following guarantees:
• Consistency (all nodes see the same data at the same time)
• Availability (a guarantee that every request receives a response about whether it succeeded or failed)
• Partition tolerance (the system continues to operate despite arbitrary message loss or failure of part of the system)

Consistency
Add nodes in a system see the same data at the same time.
V1 V1 V1 V1
V1

Availability
A guarantee that every request receives a response about whether it succeeded or failed.
V1 V1 V1 V1
Request Response

Partition Tolerance
The system continues to operate despite arbitrary message loss or failure of part of the system.
Graphic and following example, borrowed from here –http://www.slideshare.net/YoavFrancis/cap-theorem-theory-implications-and-practices

CAP an Example
V0 V0 V0 V0

CAP an Example
V1 V0 V0 V0
V1

CAP an Example
V1 V1 V1V1

CAP an Example
V1 V1 V1 V1
V1

CAP an Example
V1 V1 V1 V1
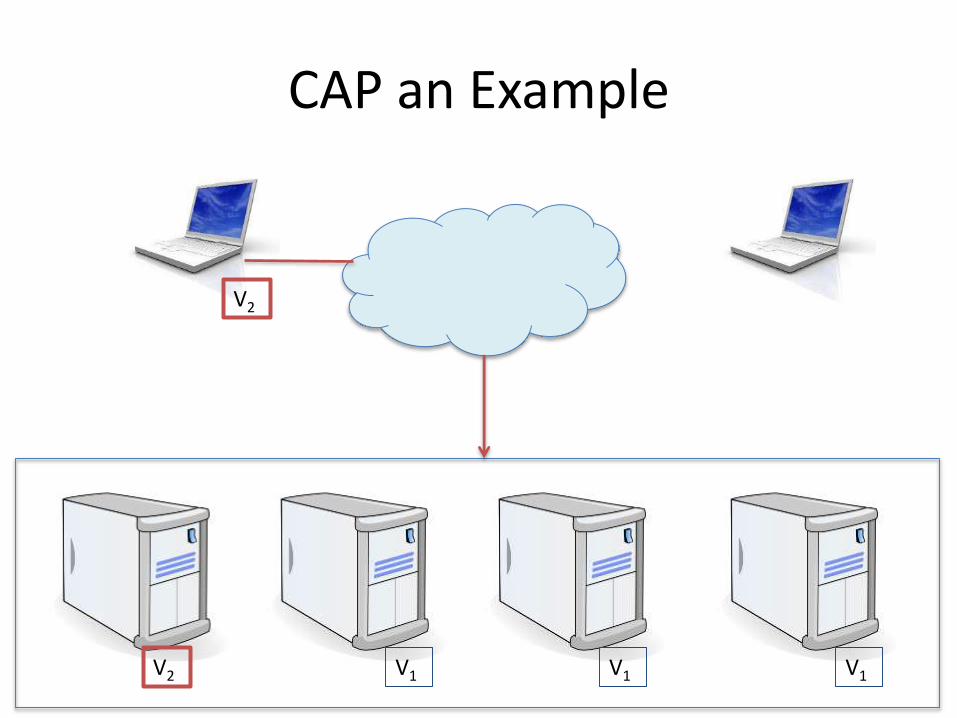
CAP an Example
V2 V1 V1 V1
V2

CAP an Example
V2 V2V2 V1
Partition

CAP an Example
V2 V2 V2 V1
V1
Partition

In a Distributed Environment, one must trade availability, consistency,
or partition tolerance.

Availability TechniquesEither a system is available in the face of any failure or it is not.
Leader | Follower
Leader
FollowerFollower
Peer – to - Peer
Availability Vulnerability Availability Resilient*


I’m biased, but to me…
Truly Available Systems MUST BE Distributed Across
Geographical Boundaries.

Availability Technique Examples
Leader | Follower Peer Based
RDBMS (particularly sharded) Cassandra
MongoDB Riak*
Hadoop (and Ecosystem) DynamoDB
Spark S3
Most Analytical-Oriented Data Stores Favor the Leader | Follower Approach of Availability.

Consistency Techniques
• Systems that are Leader | Follower based are typically consistent
• Peer based, or other non Leader | Follower based systems are vulnerable to consistency.
– These types of systems are typically called Eventually Consistent because they do tend to become consistent over a period of time.

Highlighted Consistency TypesConsistency Type Definition Example
Strict A shared-memory system is said to support the strict consistency model if the value returned by a read operation on a memory address is always the same as the value written by the most recent write operation to that address, irrespective of the locations of the processes performing the read and write operations. That is, all writes instantaneously become visible to all processes.
Sequential(all nodes appear to see the same order)
The result of any execution is the same as if the (read and write) operations by all processes on the data store were executed in some sequential order and the operations of each individual process appear in this sequence in the order specified by its program.
Linearizable(also known as atomic consistency)
An execution is linearizable if each operation taking place in linearizable order by placing a point between its begin time and its end time and guarantees sequential consistency.
Casual(order may not be observed)
Writes that are potentially causally related must be seen by all processes in the same order. Concurrent writes may be seen in a different order on different machines.
For more, go here - http://en.wikipedia.org/wiki/Consistency_modelAnd here - http://en.wikipedia.org/wiki/Linearizability

Highlighted Consistency Protocolsfor Eventually Consistent Systems
Protocol Definition
CRDT(Convergent Replicated Data Types)
Used to enable abstract functionality in EC Systems. sets, lists, counters that require additional functionality to ensure they are accurate in eventually consistent distributed system. https://vimeo.com/43903960
CRDT – Last Write Win Implementation of CRDT where timestamps are stored in cellvalues and the system only returns the replica with the latesttimestamp.
CRDT – Vector Clocks Implementation of CRDT where the system stores and returns a merged set of all writes. Typically requires a read-before-writestyle operation.
Paxos(2 Phase Commits)
Used to provide strong consistency in an EC system at the cost of performance for the transaction. The coordinator gets agreement from participants that the coordinator’s message will be the only accepted mutation during the operation. Typically require 4 RTT’s
RAMP New Theoretical protocol to provide strong consistency, like Paxos, at half or better the cost. Writes typically take 2 RTTs and reads typically take 1-2 RTTs.

Partition Tolerance
• Technically, Partition Tolerance relates to networking, but it is vague.
• Technically, if the System can withstand a network partition, then it is tolerant to Partition.
Note: My interpretation of Partition Tolerance is controversial as the CAP Theorem is very vague on the meaning of “Working” when defining Partition Tolerance.

Trade Offs
In practicality, each “service” chooses to trade Availability for Consistency.
F1 F2 F3
F4 F5 F6
F7 F8 F9
Lets Say F1, F3, F5, F6, F9 are Leader | Follower based
Lets Say F2, F4, F7, F8 are Peer based
What does this mean?

Systems by CAP Classification
AP CP AC
Cassandra Hadoop and EcoSystem RDBMS
Riak Spark Vertica
Dynamo Mongo
CouchDB Couchbase

Can your Analytical solution tolerate data sourced from an non always available system, i.e. holes in data?
Can your Analytical solution tolerate data sourced from an eventually consistent system, i.e. different results at different times?
What if your data comes from both types of systems?
What if you are processing your data on one or the other system?
Practical CAP

Reference Architectures
Here are some views of “standard” architectures
• Lambda
• Kappa
• “Data Lake”

Lambda
http://lambda-architecture.net/
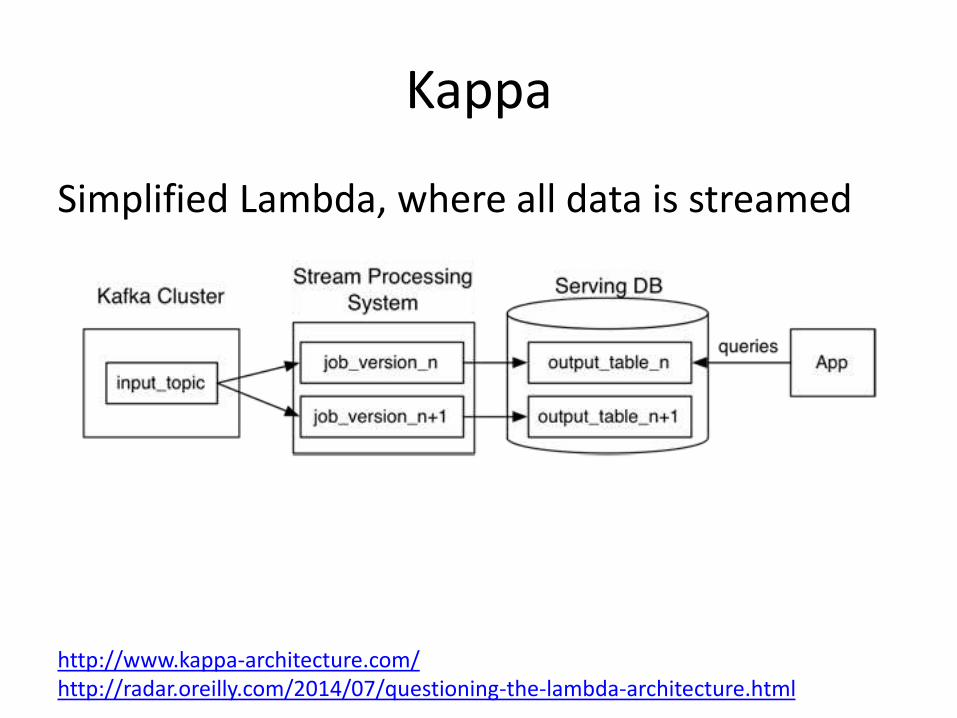
Kappa
Simplified Lambda, where all data is streamed
http://www.kappa-architecture.com/http://radar.oreilly.com/2014/07/questioning-the-lambda-architecture.html

Data Lake
My view – Data Lake is Marketicture
• Pivotal - http://www.informationweek.com/big-data/software-platforms/pivotal-subscription-points-to-real-value-in-big-data/d/d-id/1174110
• Hortonworks -http://www.slideshare.net/hortonworks/modern-data-architecture-for-a-data-lake-with-informatica-and-hortonworks-data-platform
• Cloudera - http://vision.cloudera.com/the-enterprise-data-hub/
http://www.gartner.com/newsroom/id/2809117

Summary
• Data Scientists will require working knowledge of Data Engineering
• CAP
– Consistency
– Availability
– Partition Tolerance
• Architectures in the New World
