dark data and improving human rights in fulton county
TRANSCRIPT

Dark Data and Improving Human Rights in Fulton
CountyBob Baxley, Ph.D.
December 2016
1

How Anidata came to be
There are many people with both the Aptitude and Motivation to become data scientists
They are missing:
1) good data science mentors
2) exposure and experience working on real projects
We started Anidata as a 501c3 Nonprofit started to connect Professional and Aspiring Data Scientists with problems involving Social Good.
2

Guiding Principle #1: Mentorship
Make sure the professionals (data scientists) who come behind you end up better data scientists that you were, faster than you were able to get there

Guiding Principle #2: Community Improvement
Leave the community you live in better than how you found it

Pre-Hackathon: Human Trafficking Background
5

6
Potential Human Trafficking CSEC Cases
CSEC = Commercial Sexual Exploitation of Children

Building a Data Infrastructure to Fight Human Trafficking
7

Getting and organizing the data
This is often said to be 80% of a data scientist’s work and it can be messyApproach● Target adult web endpoints that are known to be channels for human trafficking● Write python code to scrape advertisements from these sites
○ We choose NOT to store or process any image data● Store in a database● Anonymize our data collection by using Tor and make requests look “human-like”● Focus on the southeast region, with Atlanta as a central anchor but extending as far as
Nashville, TN
After running for 2.5 months, we collected a database of approximately 230,000 ads
8
9
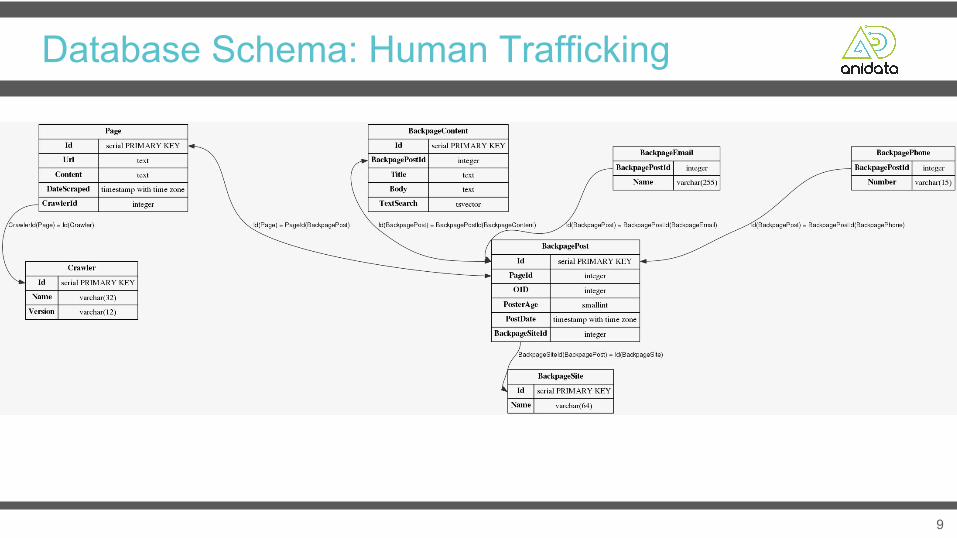
Database Schema: Human Trafficking

Jupyter Scraping Demo
10
https://github.com/gte620v/graph_entity_resolution/blob/master/201612_PyDataATL/Scaping_Talk.ipynb

Anidata Hackathon 1.0Pitch Your Product Idea and Find a
Product/Market FitMarch 5, 2016
11

Anidata 1.0 Human Trafficking Hackathon
Purpose: Develop one or more prototypes and/or data-focused product concepts that could lead to a measurable impact on preventing, prosecuting, investigating, or otherwise aiding the fight against human trafficking within the next 12 months.
Time: Saturday, March 5 from 7:30AM to 7:30PM
● Free food and caffeine all day● Invite-only to Anidata members
Judging: This is a non-competitive hackathon.
12

Collaborations
Data scientists
● We had 14 data scientists and aspiring data scientists
Law enforcement
● We had 12 volunteers from the District Attorney’s office○ Prosecutors, investigators, law-enforcement, victim interview specialists
13

14

15

Product-Market Fit Concept

Interview
Alice interviews Mary to discover Zed’s real identity:
Alias
Phone Number
17

Alice Creates a Profile with the Pimp Profiler
Legal Name: XXXXXXXX
Alias: Zed
Email IDs: XXXXXXX
Phone: (828) 280-2330 (This is a stolen phone)

Pimp Profiler Fetches Relevant E-mails
Legal Name: XXXXXXXX
Alias: Zed
Email IDs: '[email protected]', '[email protected]', '[email protected]', '[email protected]'
Phone: (828) 280-2330
19

Pimp Profiler Finds Associated Phone #s
Legal Name: XXXXXXXX
Alias: Zed
Email IDs: '[email protected]', '[email protected]', '[email protected]', '[email protected]'
Phone: (828) 280-2330
Alternate Phone Discovered: (828) 242-9969 (Zed’s personal phone number)
20

Zed’s Identity Discovered
Legal Name: Dan Michaels
Alias: Zed
Email IDs: '[email protected]', '[email protected]', '[email protected]', '[email protected]'
Phone: (828) 280-2330
Alternate Phone Discovered: (828) 242-9969 (Zed’s personal phone number)
21

JusticeServed

Anidata Hackathon 1.1:Building a Minimum Viable
DemonstrationHackweek
23

Stages of Innovation
MVD: “Minimum Viable Demonstration”● Not quite a prototype, more than a mockup, and something that can be shown in a simple demo
24

Anidata 1.1 Hackweek MVD Plan
● Goals○ Create polished demo○ Gain full stack skills○ Have fun collaboratively building a “product”○ Tighten up the cool work we did in Anidata 1.0
● What we hoped to create○ A mobile-responsive web UI that allows one to query the dataset and browse returned results○ A backend service that allows the web frontend to query the database for results○ Clean algorithm code that can be run on scraped data
■ Phone number cleaning■ Email type combing■ Phone-email-UID entity resolution (people graphs)
○ A mechanism to run everything and turn on the web service
25

Extract Transform Load - ETL
26
Extract
Scraper
Load
DB
Transform
Entity Resolution
Phone Number Reconciliation
Email Reconciliation

Problem Description
27
● I have a job I need to run every X hours
○ That job is composed of tasks
● These tasks have interdependencies○ E.g. Transform Step 2 comes after
Transform Step 1
● Each task interfaces with different external system
○ Google Cloud Storage (HDFS)○ Postgres Database○ Website (scraper)
● If a task breaks, I don’t want to have to re-run tasks that were successful
● I want an (email) alert when tasks fail

28

My Tool?
29
Maybe a Bash Script?
Or maybe a bit of Python?
Or maybe some sort of json schema that described my dependency graph?
Better Options

30
Basic Concepts
Where task is going to put output dataOutput filesystems are wrapped as luigi targets
What Tasks need to be complete for this task to runWe will access their outputs as part of this task
Task Name and type. Tasks are classes; luigi instantiates the classes to resolve dependencies and run task graph
Where work happens
Manually handle reading from input and writing to output

31
Simple Example
32
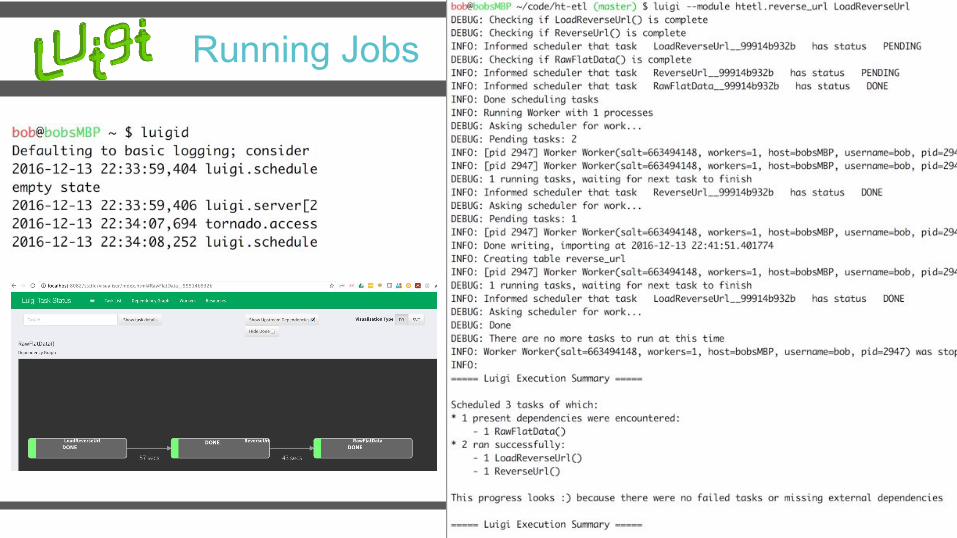
Running Jobs

Luigi Demo
33

34
Cool Feature: Target Abstraction
Mechanics of getting data from almost any system is abstracted away to an open() method

35
Cool Feature: Hadoop Streaming
Luigi pickles the mapper (and reducer) and sends them to hadoop streaming.
You can use Google dataproc or AWS EMR for your hadoop cluster.
See: http://rjbaxley.com/posts/2016/03/13/parallel_jobs_in_luigi.html

36
Cool Feature: PySpark
Luigi also has wrappers that start a pyspark session.
We can accomplish the hadoop task from the last slide using pyspark like so:

37
Cool Feature: Parallel Execution
If we don’t need a distributed cluster of machines, we can distribute the job across processes with

38

Hackweek MVD Architecture
Backpage DBScraper Webserver
ETL
39
https://github.com/anidata

“Connect-the-dots” Framework: Graph Theory
40
KeyEmail LinkPhone Number LinkBID Link

Jupyter Graph Clustering Demo
41
https://github.com/gte620v/graph_entity_resolution/blob/master/201612_PyDataATL/Graph_Talk.ipynb