cs b 553: a lgorithms for o ptimization and l earning temporal sequences: hidden markov models and...
TRANSCRIPT

CS B553: ALGORITHMS FOR OPTIMIZATION AND LEARNINGTemporal sequences: Hidden Markov Models and Dynamic Bayesian Networks

MOTIVATION
Observing a stream of data Monitoring (of people,
computer systems, etc) Surveillance, tracking Finance & economics Science
Questions: Modeling & forecasting Unobserved variables

TIME SERIES MODELING
Time occurs in steps t=0,1,2,… Time step can be seconds, days, years, etc
State variable Xt, t=0,1,2,… For partially observed problems, we see
observations Ot, t=1,2,… and do not see the X’s X’s are hidden variables (aka latent variables)

MODELING TIME
Arrow of time
Causality => Bayesian networks are natural models of time series
Causes Effects
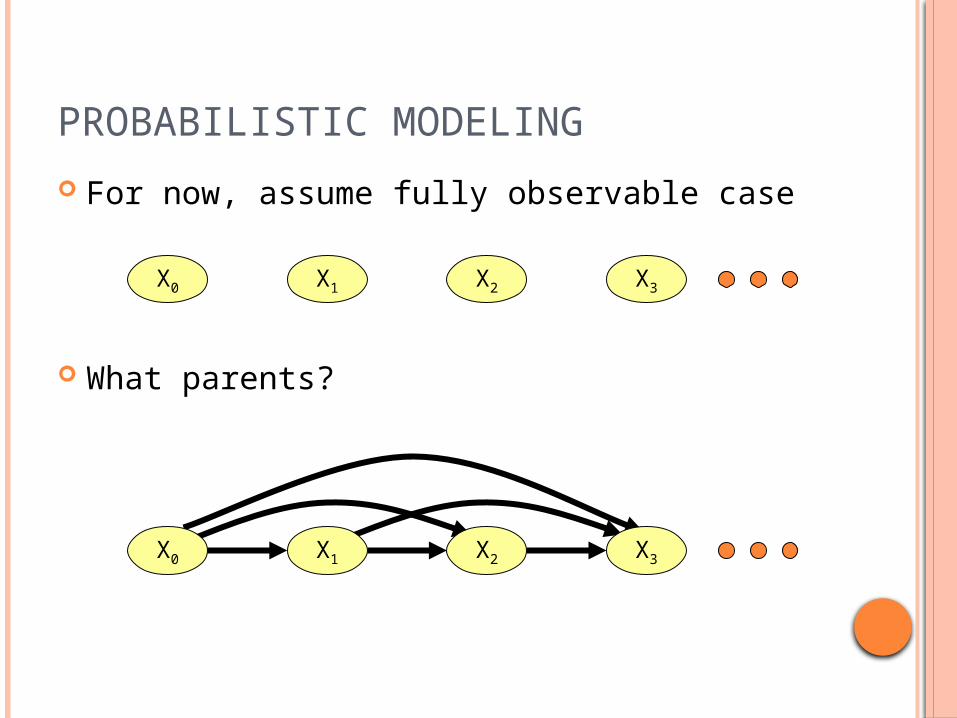
PROBABILISTIC MODELING
For now, assume fully observable case
What parents?
X0 X1 X2 X3
X0 X1 X2 X3

MARKOV ASSUMPTION
Assume Xt+k is independent of all Xi for i<tP(Xt+k | X0,…,Xt+k-1) = P(Xt+k | Xt,…,Xt+k-1)
K-th order Markov Chain
X0 X1 X2 X3
X0 X1 X2 X3
X0 X1 X2 X3
X0 X1 X2 X3
Order 0
Order 1
Order 2
Order 3

1ST ORDER MARKOV CHAIN
MC’s of order k>1 can be converted into a 1st order MC on the variable Yt = {Xt,…,Xt+k-
1} So w.o.l.o.g., “MC” refers to a 1st order MC
Y0 Y1 Y2 Y3
X0 X1 X2 X3
X0 X1’ X2’ X3’
X1 X2 X3 X4

INFERENCE IN MC
What independence relationships can we read from the BN?
X0 X1 X2 X3
Observe X1
X0 independent of X2, X3, …
P(Xt|Xt-1) known as transition model

INFERENCE IN MC
Prediction: the probability of future state?
P(Xt) = Sx0,…,xt-1P (X0,…,Xt)
= Sx0,…,xt-1P (X0) Px1,…,xt P(Xi|Xi-1)
= Sxt-1P(Xt|Xt-1) P(Xt-1)
Approach: maintain a belief state bt(X)=P(Xt), use above equation to advance to bt+1(X) Equivalent to VE algorithm in sequential order
[Recursive approach]


BELIEF STATE EVOLUTION
P(Xt) = Sxt-1P(Xt|Xt-1) P(Xt-1) “Blurs” over time, and (typically) approaches
a stationary distribution as t grows Limited prediction power Rate of blurring known as mixing time

STATIONARY DISTRIBUTIONS
For discrete variables Val(X)={1,…,n}: Transition matrix Tij = P(Xt=i|Xt-1=j) Belief bt(X) is just a vector bt,i=P(Xt=i) Belief update equation: bt+1 = T*bt
A stationary distribution b is one in which b = Tb => b is an eigenvector of T with eigenvalue 1 => b is in the null space of (T-I)

HISTORY DEPENDENCE
In Markov models, the state must be chosen so that the future is independent of history given the current state
Often this requires adding variables that cannot be directly observed
Are these people walking toward you or away from you?
What comes next?
“the bare”
minimum
essentials
market
wipes himselfwith the rabbit

PARTIAL OBSERVABILITY
Hidden Markov Model (HMM)
X0 X1 X2 X3
O1 O2 O3
Hidden state variables
Observed variables
P(Ot|Xt) called the observation model (or sensor model)

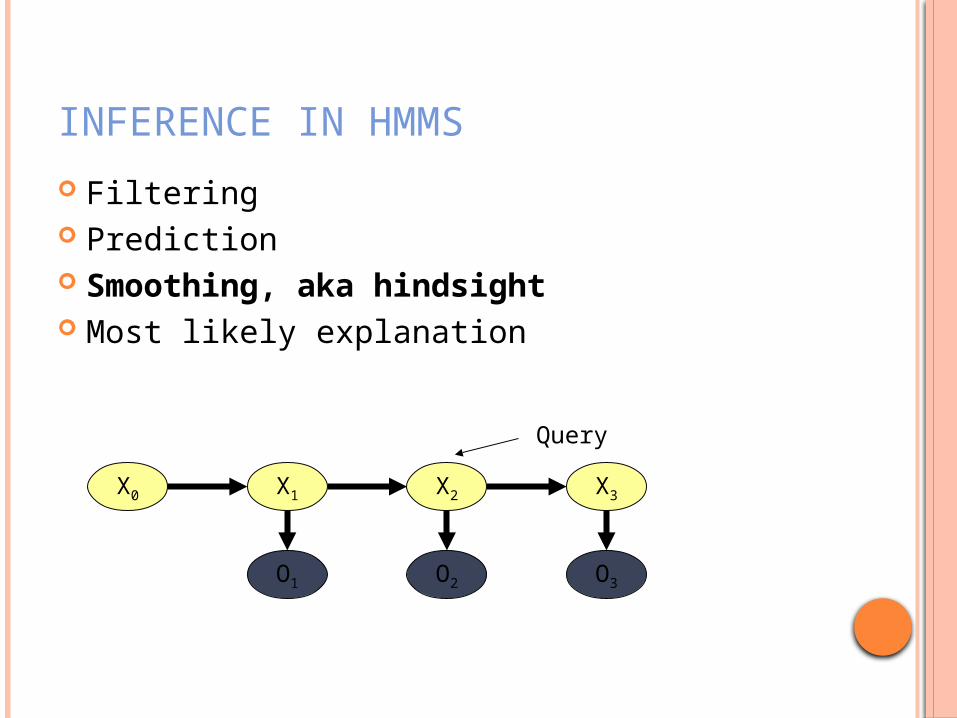
INFERENCE IN HMMS
Filtering Prediction Smoothing, aka hindsight Most likely explanation
X0 X1 X2 X3
O1 O2 O3

INFERENCE IN HMMS
Filtering Prediction Smoothing, aka hindsight Most likely explanation
X0 X1 X2
O1 O2
Query variable

FILTERING
Name comes from signal processing
P(Xt|o1:t) = Sxt-1 P(xt-1|o1:t-1) P(Xt|xt-1,ot)
P(Xt|Xt-1,ot) = P(ot|Xt-1,Xt)P(Xt|Xt-1)/P(ot|Xt-1)= a P(ot|Xt)P(Xt|Xt-1)
X0 X1 X2
O1 O2
Query variable

FILTERING
P(Xt|o1:t) = a Sxt-1P(xt-1|o1:t-1) P(ot|Xt)P(Xt|xt-1) Forward recursion If we keep track of belief state bt(X) = P(Xt|o1:t)
=> O(|Val(X)|2) updates for each t!
X0 X1 X2
O1 O2
Query variable

PREDICT-UPDATE INTERPRETATION
Given old belief state bt-1(X) Predict: First compute MC update
bt’(Xt)=P(Xt|o1:t-1) = a Sxbt-1(x) P(Xt|Xt-1=x) Update: Re-weight to account for observation
probabilities: bt(x) = bt’(x)P(ot|Xt=x)
X0 X1 X2
O1 O2
Query variable

INFERENCE IN HMMS
Filtering Prediction Smoothing, aka hindsight Most likely explanation
X0 X1 X2 X3
O1 O2 O3
Query

PREDICTION
P(Xt+k|o1:t)
2 steps: P(Xt|o1:t), then P(Xt+k|Xt) Filter to time t, then predict as with standard
MC
X0 X1 X2 X3
O1 O2 O3
Query
INFERENCE IN HMMS
Filtering Prediction Smoothing, aka hindsight Most likely explanation
X0 X1 X2 X3
O1 O2 O3
Query
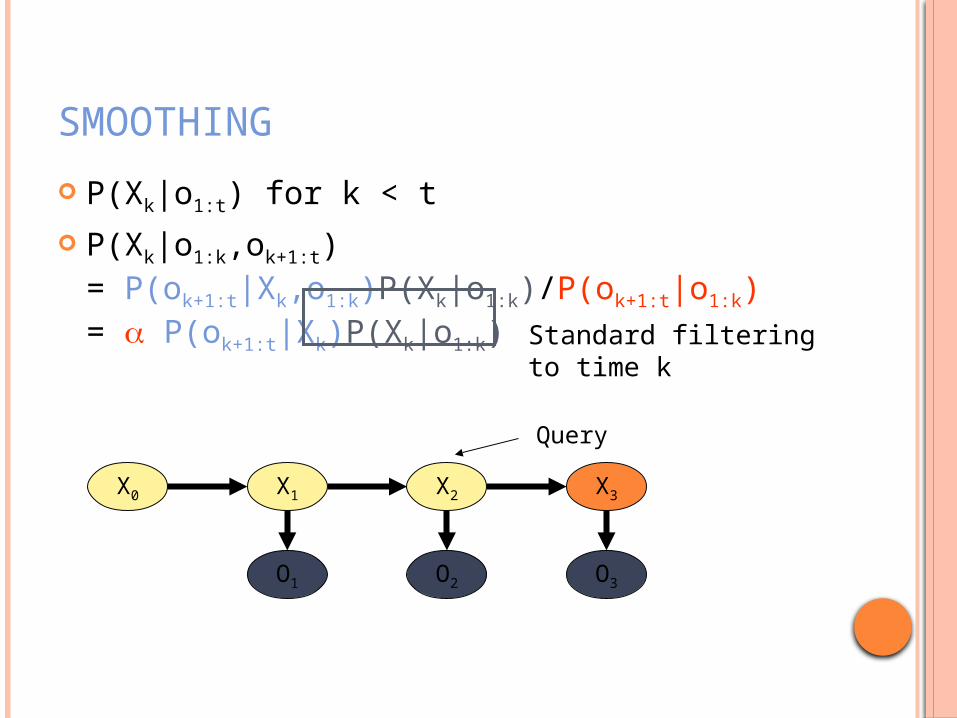
SMOOTHING
P(Xk|o1:t) for k < t
P(Xk|o1:k,ok+1:t)= P(ok+1:t|Xk,o1:k)P(Xk|o1:k)/P(ok+1:t|o1:k)= a P(ok+1:t|Xk)P(Xk|o1:k)
X0 X1 X2 X3
O1 O2 O3
Query
Standard filtering to time k

SMOOTHING
Computing P(ok+1:t|Xk)
P(ok+1:t|Xk) = Sxk+1P(ok+1:t|Xk,xk+1) P(xk+1|Xk)
= Sxk+1P(ok+1:t|xk+1) P(xk+1|Xk)
= Sxk+1P(ok+2:t|xk+1)P(ok+1|xk+1)P(xk+1|Xk)
X0 X1 X2 X3
O1 O2 O3
Given prior states
What’s the probability of this sequence?
Backward recursion

INTERPRETATION
Filtering/prediction: Equivalent to forward variable elimination / belief
propagation Smoothing:
Equivalent to forward VE/BP up to query variable, then backward VE/BP from last observation back to query variable
Running BP to completion gives the smoothed estimates for all variables (forward-backward algorithm)

INFERENCE IN HMMS
Filtering Prediction Smoothing, aka hindsight Most likely explanation
Subject of next lecture
X0 X1 X2 X3
O1 O2 O3
Query returns a path through state space x0,…,x3

APPLICATIONS OF HMMS IN NLP
Speech recognition Hidden phones
(e.g., ah eh ee th r) Observed, noisy acoustic
features (produced by signal processing)

PHONE OBSERVATION MODELS
Phonet
Signal processing
Features(24,13,3,59)
Featurest
Model defined to be robust over variations in accent, speed, pitch, noise

PHONE TRANSITION MODELS
Phonet
Featurest
Good models will capture (among other things):
Pronunciation of wordsSubphone structureCoarticulation effects Triphone models = order 3 Markov chain
Phonet+1

WORD SEGMENTATION Words run together when
pronounced Unigrams P(wi)
Bigrams P(wi|wi-1)
Trigrams P(wi|wi-1,wi-2)
Logical are as confusion a may right tries agent goal the was diesel more object then information-gathering search is
Planning purely diagnostic expert systems are very similar computational approach would be represented compactly using tic tac toe a predicate
Planning and scheduling are integrated the success of naïve bayes model is just a possible prior source by that time
Random 20 word samples from R&N using N-gram models

WHAT ABOUT MODELS WITH MANY VARIABLES? Say X has n binary variables, O has m binary variables Naively, a distribution over Xt may be intractable to
represent (2n entries) Transition models P(Xt |Xt-1) require 22n entries
Observation models P(Ot |Xt) require 2n+m entries
Is there a better way?

EXAMPLE: FAILURE DETECTION
Consider a battery meter sensor Battery = true level of battery BMeter = sensor reading
Transient failures: send garbage at time t Persistent failures: send garbage forever

EXAMPLE: FAILURE DETECTION
Consider a battery meter sensor Battery = true level of battery BMeter = sensor reading
Transient failures: send garbage at time t 5555500555…
Persistent failures: sensor is broken 5555500000…

DYNAMIC BAYESIAN NETWORK
Template model relates variables on prior time step to the next time step (2-TBN)
“Unrolling” the template for all t gives the ground Bayesian network
BMetert
BatterytBatteryt-1
BMetert ~ N(Batteryt,s)

DYNAMIC BAYESIAN NETWORK
BMetert
BatterytBatteryt-1
BMetert ~ N(Batteryt,s)
P(BMetert=0 | Batteryt=5) = 0.03Transient failure model

RESULTS ON TRANSIENT FAILUREE
(Bat
tery
t)
Transient failure occurs
Without model
With model
Meter reads 55555005555…

RESULTS ON PERSISTENT FAILUREE
(Bat
tery
t)
Persistent failure occurs
With transient model
Meter reads 5555500000…

PERSISTENT FAILURE MODEL
BMetert
BatterytBatteryt-1
BMetert ~ N(Batteryt,s)
P(BMetert=0 | Batteryt=5) = 0.03
Brokent-1 Brokent
P(BMetert=0 | Brokent) = 1

RESULTS ON PERSISTENT FAILUREE
(Bat
tery
t)
Persistent failure occurs
With transient model
Meter reads 5555500000…
With persistent failure model

HOW TO PERFORM INFERENCE ON DBN? Exact inference on “unrolled” BN
E.g. Variable Elimination Typical order: eliminate sequential time steps so
that the network isn’t actually constructed Unrolling is done only implicitly
BM1
Ba1Ba0
Br0 Br1
BM2
Ba2
Br2
BM3
Ba3
Br3
BM4
Ba4
Br4

ENTANGLEMENT PROBLEM After n time steps, all n variables in the belief
state become dependent! Unless 2-TBN can be partitioned into disjoint
subsets (rare) Lost sparsity structure

APPROXIMATE INFERENCE IN DBNS
Limited history updates Assumed factorization of belief state Particle filtering

INDEPENDENT FACTORIZATION
Idea: assume belief state P(Xt) factors across individual attributes P(Xt) = P(X1,t)*…*P(Xn,t)
Filtering: only maintain factored distributions P(X1,t|O1:t),…,P(Xn,t|O1:t)
Filtering update: P(Xk,t|O1:t) = Sxt-1P(Xk,t|Ot,Xt-1) P(Xt-1|O1:t-1) = marginal probability query over 2-TBN
X1,t-1
Xn,t-1
X1,t
Xn,t
O1,t
Om,t

NEXT TIME
Viterbi algorithm Read K&F 13.2 for some context
Kalman and particle filtering Read K&F 15.3-4