chapter -ii approaches towards code mixing and code...
TRANSCRIPT

43
Chapter -II
Approaches towards Code Mixing and Code Switching
Sociolinguistics considers Code Mixing and Code Switching as the by-
products of bilingualism. In Code-Mixing, a fluent bilingual changes the
language by using words from other language without any change at all in
situation, whereas in Code Switching, anyone who speaks more than one
language chooses between them according to circumstances and according to
the language comprehensive to the persons addressed , the purpose is to get the
right effect of communication. With this primary understanding, we will
consider these phenomena in some detail.
2.1 Nature and Scope
2.1.1 Two Different Views
At the outset, it is necessary to mention that, as per the available literature
on CM and CS there are two different views about maintaining the distinction
between CM and CS. Some scholars like Kachru (1983), Annamali (1989),
Bokamba (1988), Sridhar and Sridhar (1980), Hamers and Blanc (1990), Bhatia
(1992), Poplack (1980) treat these phenomena as the distinct manifestations.
Some other scholars like Eastman (1992), Scotton (1992), however, consider
that there is no distinction between them.
2.1.1.1 In Favour of Maintaining Distinction
Kachru (1983:193) observes, “There is a distinction between CM and CS,
though they have been treated as the language contact phenomenon. The CS
entails the ability to switch from code A to code B. The alteration of codes is
determined by the function, the situation and the participants. It refers to
categorization of one‟s verbal repertoire in terms of functions and roles. The
CM, on the other hand, entails transferring linguistic units from one code into
another.”
Bokamba (1989), while maintaining difference in CM and CS, notes three
points:

44
1) The two phenomena must be distinguished, because each makes a different
linguistic and psycholinguistic claim. For instance, CS does not necessitate
the interaction of the grammatical rules of the language pair involved in the
speech event, whereas CM does.
2) CM exemplifies the most advanced degree of bilingualism to the extent that it
requires considerable competence in the simultaneous processing of the
grammatical rules of the language pair [cf. Kachru (1978, 1982 a), Sridhar
and Sridhar (1980), Poplack (1990), Sankoff and Poplack (1981) and
Bokamba (1988)]. Linguistically and perceptually, therefore, CS and CM
cannot be constructed as the co-variant phenomena. The degree of
bilingualism implied in the production of the code-mixed sentences suggests
that only highly proficient bi/multilingual can successfully engage in
sustained code-mixed production.
3) CM typically involves the use of two languages at a time, although
occasionally three are used. Regardless of the number of languages involved
in the discourse, the language that provides the grammatical structure into
which elements are inserted is referred to as the host while the other is termed
the guest language. (Sridhar and Sridhar, 1980).
2.1.1.2 Against Maintaining Distinction
According to Scotton (1992), the borrowed and code-switched forms
behave in the same way morphosyntactically in the matrix language, hence
should not be seen as distinct processes. Eastman (1992:1) notes that the urban
language contact phenomena do not distinguish CM, CS and Borrowing. The
urban settings where people from diverse linguistic and cultural backgrounds
regularly interact make it abundantly clear that in normal everyday conversation,
material from many languages may be embedded in a matrix language regularly
and unremarkably.
Though there are different views about the distinction between Code
Mixing and Code Switching, some linguists, have used CS as the cover term to
refer to these two phenomena. There are some others like Muysken (1997), who
use these terms interchangeably. Muysken (2000) uses CS for alteration; Bhatia

45
(1992) on the contrary, uses CM as cover term for CM and CS. Clyne (2003:75)
says, “We should reserve Code Switching for transference of individual lexical
items through to whole stretches of speech; but we should adopt different terms
like transversion for cases where the speaker crosses over completely into the
other language.”
Though, Code Switching, as Gardner-Chloros (2009) points out, has
gained wider currency in the language interaction phenomenon, on the whole,
among most of the linguists, there has been a general agreement on maintaining
the distinction. The discussion that follows further, elaborate this.
2.1.2 Definitions of Code Mixing
Many linguists and scholars have tried to define CM in their own way.
According to Mary W.J. Tay (1989:408), “Code-mixing involves the embedding
or mixing of various linguistics units, i.e. morphemes, words, phrases and
clauses from two distinct grammatical systems or sub-systems within the same
sentence and same speech situation.”
Kachru (1978:28) uses this concept to refer to “the use of one or more
languages for consistent transfer of linguistic units from one language into
another and by such a language mixture developing a new restricted or not
restricted code of linguistic interaction.” Bokamba (1989:278) notes, “Code
mixing is the embedding of various linguistic units such as affixes (bound
morphemes), words (unbound morphemes) phrases and clauses from two distinct
grammatical (sub) systems within the same sentence and speech event. That is,
CM is an intrasentential switching.” Weinreich (1963:1) uses the term
„Interference Phenomena‟ to imply the rearrangement of patterns that result from
the introduction of foreign elements into the more highly structured domains of
language, such as the bulk of the phonemic system a large part of the
morphology and syntax and some areas of vocabulary.
Crystal (1997:66), in „The Dictionary of Linguistics and Phonetics‟,
defines code-mixing as a linguistic behaviour that “involves the transfer of
linguistic elements from one language into another.” Gumperz Hermandez-

46
Chavez (1978) notes, “Code-mixing is a type of borrowing, where depending on
various linguistic factors speakers borrow items of various sizes.”
For Hudson (1996:53), CM takes place „where a fluent bilingual talking
to another fluent bilingual changes the language without any change at all in the
situation.‟ The purpose of CM seems to be to symbolize a somewhat ambiguous
situation for which neither language on its own would be quite right. To get the
right effect, the speakers balance the two languages against each other as a kind
of linguistic cocktail, a few words of one language, then a few words of the
other, then back to the first for a few more words and so on. The changes
generally take place more or less randomly as for as subject matter is concerned,
but they seem to be limited at structural level.
2.1.3 Definitions of Code Switching
Hudson (1996:53) discusses CS as the „inevitable consequences of
bilingualism, as any one who speaks more than one language chooses between
them according to circumstances.‟ Annamalai (1989:48) observed, “Switching is
normally done for the duration of a unit discourse. A bilingual speaker can
switch between mixed codes as he does between unmixed languages. Switching
is found only in a balanced and stable bilingual.”
Crystal (1995) states, “Code or language switching occurs when an
individual, who is bilingual, alternates between two languages during his or her
speech with another bilingual person.” Halliday (1978:65) defines CS as „code-
shift actualized as a process within the individual: the speaker moves from one
code to another and back, more or less rapidly, in course of a single sentence.‟
Verma (1976:156) focuses on Code Switching as „a verbal strategy used
by speakers in much the same way as creative artists switch styles and levels (i.e.
from sublime to the mundane or the serious to the comic or the vice versa) or the
ways in which monolinguals make selections from among vocabulary items‟ and
concludes, “Each type of coding or CS is appropriate to the topical and
situational features that give rise to it.” Weinriech (1953:73) elaborates, “The
ideal bilingual switches from one language to another according to appropriate

47
changes in speech situation, but not in unchanged speech situation and certainly
not within a single sentence.”
Bokamba (1989:278) considers CS as „the mixing of words, phrases and
sentences from two distinct grammatical (sub) systems across sentence
boundaries within the same speech event, in other words, intersentenstial
switching.‟ Ashok Kumar (1995:44) adds, “Code Switching which is influenced
by extra-linguistic factors such as topic, interlocutors, setting etc. is the alternate
use of lexical items, phrases, clauses and sentences from the non-native language
into the system of the native language.” Gardner Chloros (2009) is of the opinion
that CS may be used as „a general term covering all outcomes of contact between
two varieties whether or not there is evidence of conversions.‟ For her, Code
Switching refers to the use of several languages or dialects in the same
conversation or sentence by the bilingual people.
Regarding the precise definitions of CM and CS, it appears that it is
extremely difficult to maintain the difference between CM and CS for all
purposes. As CM/CS is a growth area in linguistics and as it is being studied
from several different perspectives, it may be said that, one definition covers
only one aspect/perspective of the huge phenomena of CM/CS. In this regard
one may agree with what Milroy and Muysken (1995 in Gardner Cholros
2009:12) noted in the introduction to One Speaker Two languages about the
confusing structure of CM/CS. They assert, “The field of CS research is replete
with a confusing range of terms descriptive of various aspects of phenomenon.
Sometimes referential scope of these terms overlaps and sometimes particular
terms are used in different ways by different writers.” One observation in this
regard is also right which reads, “CM/CS term distinction should be treated as
research tool while describing the data only.”
2.1.4 Code Mixing, Code Switching and Borrowing
CM and CS are further compared by linguists with Borrowing.
Borrowing is maintained as related to CM and CS, but also different from
them.
48
2.1.4.1 Borrowing as Different from CM/CS
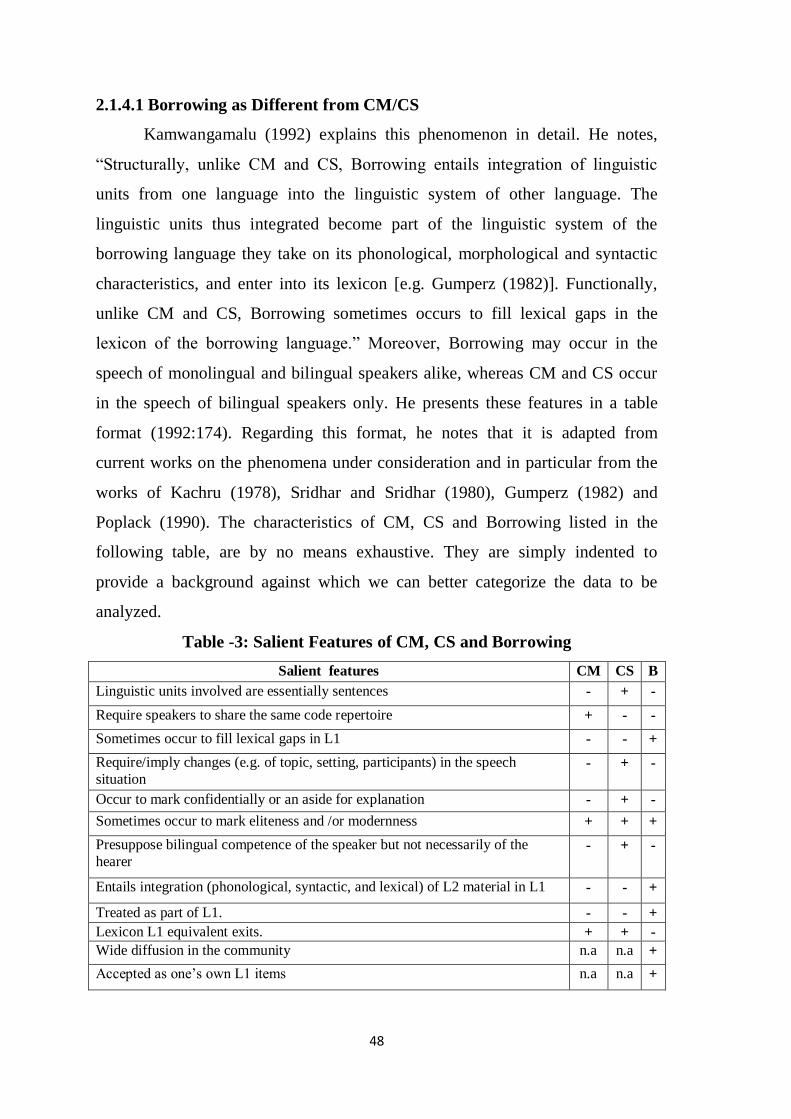
Kamwangamalu (1992) explains this phenomenon in detail. He notes,
“Structurally, unlike CM and CS, Borrowing entails integration of linguistic
units from one language into the linguistic system of other language. The
linguistic units thus integrated become part of the linguistic system of the
borrowing language they take on its phonological, morphological and syntactic
characteristics, and enter into its lexicon [e.g. Gumperz (1982)]. Functionally,
unlike CM and CS, Borrowing sometimes occurs to fill lexical gaps in the
lexicon of the borrowing language.” Moreover, Borrowing may occur in the
speech of monolingual and bilingual speakers alike, whereas CM and CS occur
in the speech of bilingual speakers only. He presents these features in a table
format (1992:174). Regarding this format, he notes that it is adapted from
current works on the phenomena under consideration and in particular from the
works of Kachru (1978), Sridhar and Sridhar (1980), Gumperz (1982) and
Poplack (1990). The characteristics of CM, CS and Borrowing listed in the
following table, are by no means exhaustive. They are simply indented to
provide a background against which we can better categorize the data to be
analyzed.
Table -3: Salient Features of CM, CS and Borrowing
Salient features CM CS B
Linguistic units involved are essentially sentences - + -
Require speakers to share the same code repertoire + - -
Sometimes occur to fill lexical gaps in L1 - - +
Require/imply changes (e.g. of topic, setting, participants) in the speech
situation - + -
Occur to mark confidentially or an aside for explanation - + -
Sometimes occur to mark eliteness and /or modernness + + +
Presuppose bilingual competence of the speaker but not necessarily of the
hearer - + -
Entails integration (phonological, syntactic, and lexical) of L2 material in L1 - - +
Treated as part of L1. - - +
Lexicon L1 equivalent exits. + + -
Wide diffusion in the community n.a n.a +
Accepted as one‟s own L1 items n.a n.a +

49
Hudson (1996) differentiates Borrowing from CM/CS on the basis of
speech and language systems. He notes, “Whereas Code Switching and Code
Mixing involved mixing language in speech, Borrowing involves mixing the
systems themselves because an item is „borrowed‟ from one language to become
part of other language. For example - words for foods, plants, instructions, music
and so on which most people can recognize as borrowings (or Loan –Words).”
SalMons (1990) uses four central criteria to distinguish Borrowing from
Code Switching, following Scotton (1988):
A. Frequency of occurrence is often the most central criterion. The frequent
items tend to be considered Borrowings, the infrequent ones more likely
represent code switches or nonce borrowings.
B. Phonological integration is taken as the indication of Borrowing and lack
of integration is understood as an indication of CS or nonce borrowings.
C. Syntactic integration, as with phonological integration, is taken as the
indication of Borrowing; with lack of syntactic integration, it is
understood as an indication of CS.
D. Lexically, Pfaff (1982:269-273) gives several directly relevant criteria for
drawing a distinction when dealing with items of unclear status.
The relation between Code Mixing, Code Switching and Borrowing is
extensively reviewed by Romaine (1989) and Myers-Scotton (1992) also.
Boschoten (1998) points out that though any aspect of a language including its
structures can be borrowed, the importance of this relation lies in the fact that
„single word code-switches/loans are the commonest kind of Code Switching in
many situations.‟ As Poplack, Sankoff and Miller (1988; 62) note, „within single
words, common nouns are the most frequency borrowed items.‟ This observation
is supported by three kinds of explanation. One is by Bynon (1977:231) who
views it as reflecting the size of grammatical categories concerned. Another is
suggested by Aitchison (2000:62), as the nouns are freer of syntactic restrictions
than other word-classes. The third, which is a more sociolinguistic one, is that
these are accessible to the bilinguals with any degree of competence, even

50
minimal, in the language from which the borrowing is taken (Gardner-Chloros,
2009).
2.1.4.2 Myers Scotton’s Views on Borrowing and Code Switching
Myers Scotton (1992) claims that CS and Borrowing are „universally
related process.‟ According to her Matrix Language Frame (MLF) Model, CS
occurs everywhere within a frame which is set by the matrix language. The term
matrix refers to the language in which the majority of morphemes in a given
conversation occur. The languages from which material enters a matrix language
are referred to as embedded. Central to MLF theory is the idea that content
(often nouns, verbs, etc.) and system (articles, inflections etc) morphemes in the
embedded language are accessed differently by the matrix language. Myers
Scotton is concerned with finding out which singly occurring embedded
language lexemes are borrowings and which are code-switches, in light of the
fact that both borrowed and code-switched forms behave the same way
morphosyntactically in the matrix language. Her MLF model posits structural
constraints which account for both borrowings and code switches.
She uses data from Kenya and Zimbabwe to explain her model. Swahili is
the matrix language of Kenya and Shona is the matrix language of Zimbabwe.
Her Matrix Language Frame Model provides a principled basis for considering
both Borrowing and Code Switching processes to be a part of a single
continuum. She explores four hypotheses:
1. Matrix language + embedded language [EL] constituents conform to
the morpheme order of the matrix language and in ML+EL
constituents articles and inflections (System morphemes with non-
lexical information) come from matrix language.
2. The EL content morphemes that are not congruent with stored lemmas
(lexical information in a mental lexicon are blocked from appearing in
ML+EL constituents. (This is called Blocking Hypothesis)
3. Embedded language forms which cannot be accounted for by the
blocking hypothesis are subject to an embedded language trigger
hypothesis.

51
4. The peripheral and formulaic embedded language constituents may
occur with relative freedom in a matrix language. ( This is called EL
Hierarchy Hypothesis)
On the continuum, the forms range from abrupt loans (e.g. the term
school fees as used in shone language) to core borrowings (e.g. the term weekend
in Swahili language), to actual instances of CS. According to Myers-Scotton,
frequency is the best criterion to use to link borrowings to the mental lexicon in
contrast to single form code switches. Yet, there is little reason to make a
distinction between the processes. Neither morphosyntactic nor phonological
integration criteria remain viable ways to decide whether embedded language
material is the result of borrowing or code switching. For example the word
shule (school) is a long established borrowing into Swahili (originally from
German); however, the verb stem-visit and the noun difference are considered
code switching forms, largely because they show no frequency of occurrence
and occur only in one conversation in a set of 40 of the data.
The MLF model of CS which can account for single form code switches
also accounts for borrowed lexical items. Single or multi-word code switches are
retained in the mental lexicon of the embedded language, are lemma entries
there, while borrowings continue to remain matrix language lexical items. All
code switches structurally represent material embedded into a matrix language
while all borrowings are matrix language material par excellence.
In accordance with this model, the English preposition at, for example, is
blocked from appearing in the Swahili sentence nilikuwa nataka kumpata
stadium which translates as „I wanted to find him stadium‟ rather than „I wanted
to find him at the stadium. At (or for that matter the as well) has no counterpart
in Swahili, so stadium „occurs as a bare form‟ making it look as much like a
borrowing as a code-switch. In contrast, other English prepositions do have
congruent forms in Swahili and may occur themselves as single code-switched
forms (kati ya and between so match).

52
2.1.4.3 Borrowing and CS as Continuum
Shaffer (1978), while dealing with the place of CS in linguistic contacts,
discusses „interlingual impact‟ defined and studied by Weinreich (1963), Clyne
(1967) and Haugen (1956). He accepts Haugen‟s three stages of diffusion,
namely CS, interference, and integration. As per this scheme, the switching
constitutes the alternate use of the distinct codes; interference constitutes
overlapping and integration constitutes interlingual impact only in historical
sense.
According to Haugen‟s scheme, interference and integration have in
common a certain degree of leveling in the structural distinctiveness of both
codes. By contrast, CS involves the stringing together of „unadopted‟ words and
phrases. [Haugen (1956:40), Haugen (1973:528)]. Interference is contrary to
contemporary norms, whereas integration is in harmony with current norms.
The acceptance of Haugen‟s diffusion concept is further modified by
different suggestions: Interference will be confined to imperfect second
language acquisition. So, interference will be recognized as restricting the
native-like distinctiveness of the two codes available to bilingual. Thus, there
appears to be a continuum between switching and borrowing. It also seems that
some times switches are gradually borrowed. There would then be roads to
lexical borrowing, instaneous borrowing (as in the case of sputnik, borrowed
from Russian overnight) and gradual integration of the lexical items used in
frequent switches.
2.1.4.4 Borrowing and CM/CS in Urban Setting
According to Eastman (1992:1), the multilingual phenomenon in urban
setting does not distinguish CM, CS and Borrowing. The urban settings where
people from diverse linguistic and cultural backgrounds regularly interact makes
it abundantly clear that in normal everyday conversation, material from many
languages may be embedded in a matrix language regularly and unremarkably.
At the same time, forms may be embedded noticeably. Where people use a
mixed language regularly, code switching represents the norm (an unmarked
choice after Myers Scotton 1983). Where people invoke another language is an

53
obvious way, position of relative social, political or economic strength is often
being negotiated and Code Switching represents a marked choice. In addition, it
is seen that the absence of CS in the multilingual urban contents may be
indicative of the tacit acceptance of political, social, and/or economic power
differences.
2.2 Syntactic Constraints
The syntactic constraints in CM/CS have been studied and commented
upon time to time by the linguists while dealing with CM/CS phenomena.
The formal and theoretical oriented studies on Code Mixing started
growing in the decade of 1970 with Tim (1975), McClure (1977), Lipski (1978),
Pfaff (1979), Poplack (1980) and others. In the decade of 1980, the systematic
attempts have been made by Wool Ford (1983) and Di Sciullo et al (1986) to
develop a formal model of code-mixing within transformational-generative and
government-binding frameworks, respectively. These models attempt to explain
why some syntactic elements are subject to code-mixing while others are
unlikely or impossible candidates for mixing. The models then go on to show
that either the shared portion of the participating grammars (phrase structure
rules etc.) or principles such as government set the stage for language mixing.
Bhatia‟s (1989) study on bilinguals‟ creativity and syntactic theory,
however, draws two conclusions. One, the conception of the grammar of CM
envisioned in the formal studies is too narrow in nature; and two, there is a
pressing need for reexamination of such notions as „hybrid rules‟ and „new
grammar ‟. Evidence has been presented which supports the conclusions that a
new grammar of Filmi-English is motivated by structural properties of Hindi and
English principles of Universal grammar, whereas the rule of „o’ insertion in the
derivation of infinitival verbs is motivated by the consideration of informal
discourse. An attempt has been made to present identifiable and distinguishing
properties of a hybrid grammatical system and a new grammatical system.
Finally, it was shown that code-mixing does not represent a surface level
phenomenon.

54
2.2.1 Possibility of Universal Constraints
Annamali (1989), in his research paper, „Language Factor in Code
Mixing‟, studies the universal constraints on CM and proposes that universal
constraints are likely to exist if CM is a universal phenomenon. He means to say
that any bilingual can mix his languages and any two languages can be mixed.
He assumes that the mixed code has the properties of a natural language. The
assumed linguistic properties of the mixed code, according to him, are- (a)
Mixing is governed by levels of units such as word level, clause level, and so on;
(b) It is sensitive to syntactic constituents like noun phrase, verb phrase, verb
phrase, etc. and (c) It is a variable with reference to word classes such as nouns ,
verbs, etc. In other words, it has organizational property, configuration property
and classificatory property. There are constraints which prohibit mixing within a
word or a phrase which illustrates. There are constraints which prohibit partial
mixing across constituents which illustrate. There are constraints which stipulate
that mixing will follow a hierarchy of word classes, which illustrates, a) for
example, if verbs are mixed, nouns would be mixed and mixing will include
more items in the noun class than in the verb class. Further, the distinction
between CM and CS is made in this study with regard to such constraints.
Mixing, for example, is the linguistic strategy for discourse functions primarily
involving social meanings and switching is a discourse strategy for linguistic
(verbal) communication reflecting language competence and preferred language
choice of the participants.
The switching is found only in a balanced and stable bilingual, while
mixing appears in incipient and attrited bilinguals as well. The mixing is largely
motivated by the need to fill gaps in the linguistic competence of the speaker.
The constraints on mixing are not likely to be the same in stable, incipient and
attrited bilinguals.
Further, by adopting the terminology such as MT for Mother Tongue and
OT for Other Tongue, the universal constraint of mixing in two types of
bilinguals is proposed. There are two types of bilinguals- balanced and
imbalanced. According to him, the balanced bilingual mixes his MT with OT

55
more than the imbalanced bilingual. The imbalanced bilingual mixes with low
frequency only with nouns.
Hudson (1996) is of the view that the syntactic categories used in
classifying linguistic items may be independent of their social descriptions. At
least some syntactic (and other) categories used in analyzing language are
universal rather than tied to particular languages. He firmly states that there is
no doubt that there are syntactic constraints; people who belong to code-mixing
communities can judge whether particular constructed code-mixed examples are
permitted or not, and these judgments are on the whole borne out by studies of
texts.
2.2.2 Bokamba’s Negative Views on Syntactic Constraints
Bokamba (1989) also treats this „Syntactic Constraint‟ aspect of CM.
According to him, “conceptually, the basic assumption underlying almost all
syntactic studies of CM is that the occurrence of code-mixed speech among bi
and multilingual is fundamentally differ from the occurrence of other speech
variants or registers. Hence, ungrammaticalities in the code-mixed speech are
best treated as violations of syntactic constraints of the language-pair involved in
the discourse rather than as violation of the morpho-syntactic rules governing
that particular dialect. The code-mixed speech is characteristically and
definitionally a dialect of the host language concerned and postulation of
Syntactic Constraints to account for such speech varieties is both inadequate and
misconceived.
This study claims that there are no general or universal surface syntactic
constraints on CM, because these changes are naturally called for by the very
nature of language as a linguistically structured and socio-psychologically rule –
governed means of communication. The failure to discover and establish such
constraints, it has been argued, is due to the narrow focus attributed to syntactic
research on CM where crucial socio-psychological factors are left out of
consideration. The postulation of the surface syntactic constraints, regardless of
the scope of their validity (e.g. language specific of putative universal), is not
only misguided but also unwanted at this stage of the research.

56
2.2.3 CS and Syntactic Constraints at Lexical level
Hussein (1993) studies the CS of Arabic-English bilinguals. It describes
various syntactic constraints that govern this phenomenon in their speech, the
susceptibility of particular sentence constituents to switching and the
determination of the matrix language in their linguistic performance.
CS among the Arabic-English bilinguals, like other language contact
situations, supports the fact that this phenomenon is not random but rule
governed. The verbal behavior of the respondents utilized for this study clearly
suggests certain linguistic constraints that not only determine the switches that
occur in their speech but also the acceptability of these switches by the
bilinguals.
While it is believed that extra-linguistic factors are the only means that
motivate bilinguals to switch code styles, or registers, this study has attempted to
deliberate syntactic restrictions in the speech of the Arabic English bilinguals.
Pronominal subjects, objects and their verbs are considered the main restrictions
against switching between Arabic and English; the pronominal subjects and
objects and their verbs are tightly linked in a way that they have to adhere to the
linguistic rules of a certain code rather than the mixture of two codes.
On the basis of the manner of CS experienced by the respondents, it is
observed that the Arabic, the mother tongue of these bilinguals, is invariably the
matrix language. In these sentences demonstrating CS, the matrix clause is in
Arabic. Moreover, the English constituents in Arabic clauses are deemed to
adapt to the morphological and phonological rules governing Arabic. Finally,
this study points to the fact that both languages are independent and are unlikely
to move towards merging; the linguistic constraints are, in fact, intrinsic to both
languages and this an overwhelming evidence that each language is keeping its
linguistic integrity at least for the foreseeable future.
Timm (1975) deals with the several constraints on Code Switching. The
first category deals with switching of pronominal subjects or objects that were
considered possible, although not common. It was noted, however, that
expressions such as they were chopeando, he was cahado, etc. and English

57
loanwords which had been morphologically adapted to fit Spanish paradigms
were possible.
Finally, within noun phrases, there is considerably more flexibility as
regards to the possibilities of CS, although certain restrictions do appear. The
data, which have been surveyed, suggest that the true model of bilingual
competence may lie somewhere between the two diametrically opposite poles,
being neither two completely distinct language systems nor one homogeneous
amalgam. Those bilingual speakers capable of engaging in spontaneous CS
apparently posses the ability to mentally compare equivalent sentences in the
two languages for degree of syntactic compatibility and to code-switch only in
those instances where such compatibility would be preserved.
2.2.4 Syntactic Constraints and Psychological Reasons
Sridhar and Sridhar (1980) investigate the syntax of Code Mixing in
psycholinguistic perspective. The syntactic constraints dealt by them have the
consequences for a psychological model of bilingual information processing.
They present the „Dual structure Principle‟ which is refinement of Poplack‟s
(1980) Equivalence Constraints and Hypothesis of Borrowing of Lipski
(1978).This principle is stated as follows:
Dual Structure Principle: The internal structure of the guest constituents
need not conform to the constituent‟s structure rules of the host language, so
long as its placement in the host sentence obeys the rules of the host language
(Sridhar and Sridhar 1980: 209).The authors arrive at the following conclusions
regarding its psycholinguistic aspects:
a) The entire rule system of both the languages, not just their respective
lexicons are simultaneously active when mixed sentence types are
produced. It rules out the possibility of a „single switch model‟ during
the code-mixing process.
b) The activation of one language system does not result in the non-
operation of the other.

58
c) The two languages systems are neither „merged‟ together, nor are they
totally independent of each other. Rather, they interact in complex
ways to produce complex code-mixed patterns.
2.2.5 Poplack’s Views on Syntactic Constraints
The paper by Sankoff and Poplack (1981) proposes a formal grammar of
CS, accepting at the same time that the complete understanding of CS could only
be achieved through combined ethnographic, attitudinal and grammatical study,
i.e. an integrated analysis not only of when people code-switch but also how
where and why (Sankoff and Poplack 1981:4).
Two constraints of language alteration between Spanish and English
(„free morphemes constraint‟ and „equivalence constraint‟) are posited. These
constraints serve as the basis for the formal description of the syntax of Spanish-
English Code Switching. The universality of these constraints is doubted, since it
is held, and rightly so, that they may not operate with reference to English and
some highly inflected or agglutinative language (e.g. Japanese and Turkish) or
language with an actively different word-order (e.g. Hindi), because the
constraints on CS are based on bilingual performance not transformationally
generated. The authors believe in direct generation of CS sentences by a context-
free grammar. The CS constraints are surface phenomena and can not naturally
be generated in deep structure. Phrase Structure Grammar of L1 and L2 can be
combined to from a Code Switching Grammar which generates grammatical
monolingual sentences as well as those containing only valid code-switches.
(Sankoff and Poplack 1981: 36).
2.2.6 Pfaff’s Views on Syntactic Rules in CM
Pfaff (1979) has considers the several aspects of Spanish/English
intrasentential mixing. She found that speakers who code-switch are competent
in the syntactic rules of both languages. She claims that the third grammar does
not exist to account for the utterances in which the languages are mixed. Instead,
the grammar of Spanish and English are meshed according to the given
constraints: functional and lexical constraints, structural constraints, semantic
constraints and discourse constraints.

59
2.3 Discourse Markers in CM/CS
Discourse Markers are the responses that indicate text as a conversation.
Generally, they are in one word or two words. They do not have independent
identity, but are very meaningful when they occur in conversation. O.K., Yes,
No, I mean, of course, yeah, ouch, woo, nei, weel, you know are such English
responses. In general, the educated Indian Speaker, while conversing in English,
uses these English responses. However, it is observed that most of the times, he
switches to his mother tongue only for the similar responses. For example,
„Come on yaar, do not take it seriously‟ or „we are going for shopping, you are
coming na?‟ In these examples, the speaker switches only for yaar and na. The
CS is essentially a product of bilingual or multilingual phenomena and one of
the major concerns of Sociolinguistics is to study the behavior of languages in
such phenomena.
2.3.1 Functions of Discourse Markers in Code Mixing and Code Switching
Discourse Markers are defined by Schifrin (1987) as „contextual
coordinates of talk‟. They display coherence; some markers have referential or
expressive meaning, others have interactional meaning and all markers may have
various functions in the text. Though Schifrin (1987) suggests that many
Discourse Markers are multifunctional, one can classify discourse markers
according to their primary function; of course, their specific function depends on
the context in which they are used. In her study, the Discourse Markers are
multifunctional. They fall into the following categories:
1) Participation category (Y’ know and I mean): They have little semantic
content serve as an interactional function.
2) Connectives (and and but) and markers of cause or result (because and
so), both of which have semantic content.
3) and and so functioning not as connectives or markers of a certain
relation between clauses, but as fillers and clause initiators and thus
with more interactive than semantic value.
Sal Mons (1990:453) reviews the role of Discourse Markers in code-
switching that changes into Borrowings. Discourse Markers such as „well’ and

60
„you know’ in English have been considered as „extra-sentenced or emblematic‟
code-switching (Poplack, 1982). In American German varieties spoken in central
Texas (and other areas), English markers are used in conversation to the normal
exclusion of the German discourse-marking system.
English Discourse Markers themselves do not represent proper code-
switching in his study, but instead have the status of borrowings (in line with
recent discussions of that distinction), while the discourse making systems of
German and English have undergone convergence, This conclusion is relevant to
other bilingual situations and could entail reclassifying such phenomena as
borrowings or convergence, where these have been assumed to represent
switches. His analysis also underscores the necessity of including „convergence‟
in addition to borrowings and code-switching in the study of
bilingual/multilingual communities.
Gumperz (1982) treats such kind of switching as an integration or
sentence filler. This occurs when languages merge into one another in language
contact situation.
The studies mentioned above help us to arrive at the conclusion that the
switched Discourse Markers are extra-sentenced, emblematic, sentence fillers,
contextual coordinates having participatory value. Most of the markers are
borrowed and become one with the common code. They are multifunctional and
their specific function depends on the context.
2.4 Functional Aspects
Several studies have dealt with the functions of CM and CS. These
functions vary as per the status of language pair involved, socio-cultural
divergences and the situation in which they occur. It is also noted that CS
functions as a symptom of quite opposite developments. It occurs in language
accommodations, in language divergence, in language maintenance and in
language shift. It reflects social differences and tendencies within the same
society and language combination. This aspect is dealt in the studies of Li
Wei,(1998a). On the contrary, in the studies of Poplack,(1988) and

61
McClure(1998), CS is dealt with social differences and tendencies between
different societies and different language combinations.
2.4.1 Gumperz’s Observations on Functions of CS
Gumperz (1982:75-76) mentions various types of functions of CS:
1) Quotations: In many instances, the code-switched passages are clearly
identifiable either as direct quotations or as reported speech. Where the
quotations were originally in a code-mixed variety, they also appear in reported
speech in the same variety.
2) Addressee specification: This function explains switches which serve to direct
the message to one of several possible addressees.
3) Integrations: According to this function, the code switch serves to mark an
integration or sentence filler. In the data from Singapore, numerous particles are
found in conversation irrespective of what is the predominant language used.
These are the results of various languages merging in contact with one another
and evolving a common code with a common vocabulary. To treat such
particles as mere interjections or sentence fillers seems counterintuitive.
4) Reiteration: Frequently, a message in one code is repeated in other code either
literally or in somewhat modified form. In some cases, such repetitions may
serve to clarify what is said but often they simply simplify or emphasis a
message.
5) Message qualification: A large group of switches consists of qualifying
constructions such as sentence and verb complements or predicates following a
copula. In such cases, the main message is in language X, whereas a
qualification of the message is given in language Y.
6) Personalization vs. objectivization: This dichotomy suggests a difference
between talk about action and talk as action, the degree of speaker‟s involvement
or distance from a message, whether a statement reflects personal opinion or
knowledge, or whether it refers to specific instances or has the authority of a
generally known fact.

62
2.4.2 CM as Mark of Modernization
Kamwangamalu (1989) demonstrates that CM is a cross-cultural
phenomenon. To support his claim, he considers the functional use of CM,
attitudes towards CM and the language change as the result of CM.
From a functional point of view, he focuses on CM as a mark of
modernization. The use of CM for modernization is attested to in a variety of
domains, for example, education, literature, science and technology. He points
out that the use of CM is a character feature of the speech of the elite group or
those who hold a higher socioeconomic status in their respective communities.
CM is both to these speakers and the aspiring masses a model of language use
with which to identify.
In attitudinal terms, it has been shown that, although CM proves to be the
norm of speech most observed in bilingual communities around the world, the
bilinguals do not always admit it. This is because CM is considered by some as a
„corrupt‟, an „impure‟ linguistic behavior. If such contact takes place, there will
be language change as a result of CM.
He further refers to Hymes‟ observation that “the fact that English, a
former immigrant language… has not prevented other immigrant language (e.g.
Italian, Spanish, French and German) from not only being spoken, but also
mixed with English. In that respect, CM sheds light on the current life of
language in bilingual communities around the world.”
2.4.3 Code Mixing as Communicative Strategy
Tay (1989) focuses on the use of CM and CS as a communicative strategy
in multilingual communities among proficient bilingual speakers. She uses the
spontaneous conversations which involve code-switching and mixing between
some of the major languages in Singapore, such as English, Mandarin, Hokkien.
She stresses that, the typical code switcher or mixer is usually not aware of why
he/she switches codes at certain points of the discourse; and, to try to evolve a
functional typology to fit all situations, would, therefore, seem futile. Instead, it
is suggested that total communicative impact created by the discourse should be
looked as discourse and ask questions such as: Is the speaker trying to establish

63
rapport or is he distancing himself? She emphasizes that the communicative
intent of the bilingual speakers is of „prime importance‟; once we get the
intention then, we might then be able to look at the various strategies used by
them and how codes are manipulated to achieve these purposes. According to
her, the effectiveness of a communicative strategy does not depend on the choice
of the code as such but considerations such as- which code has the most colorful,
expressive, shortest, most economic way of repeating or elaborating upon what
was said earlier.
With regard to the study of the new varieties of English, she notes that,
these varieties should not be treated as deviant forms of some native variety, but
as independent systems. She has observed in this study that the treatment of
Singaporean English as a learner variety is unsatisfactory, because it fails to
capture the essential difference in motivation between two very different types
of CM, one motivated by inadequate vocabulary on the part of genuine learner
and the other motivated by the desire to communicate as effectively and
expressively as possible on the part of the fluent bilingual. About Singaporean
English, her observation is that it is far richer than, for example, British English
because of its contact with other languages spoken in Singapore. Instead of
merely documenting purely formal or purely functional characteristics of
bilingual speech, there is the urgent need to look at bilingual speech as primarily
an act of communication. Thus, those functions which are „communicative‟
rather than act of communication (ritualistic) will be most relevant to the study
of bilingualism. Similarly, form is to be perceived as the outcome of
communication rather than the focus of bilingual speech.
2.4.4 Functions of Code Mixing in New Varieties of English
D‟Souza (1992) deals with the relationship between CM and the New
Varieties of English (NVEs). According to him, the NVEs are varieties of
English that have emerged as a result of the colonial experience. This fact is
important, because it contributes a great deal to making the NVE‟s what they
are. The NVEs have the following characteristics: They are the result of
colonization, are instutionalized, have range and depth, are nativized and stable,

64
have developed through the educational systems in bilingual context and are
creative.
Given these characteristics, one has to realize that in talking of an NVE one
is not talking of a monolith but of a code that encompasses several sub-varieties.
The NVEs then, like the Old Varieties of English, have a range of styles and
registers and regional variation. But in addition, they have code-mixed styles and
registers which are also so intrinsic to them that CM has to be added to the list of
characteristics that define the NVEs. CM may be used for the following reasons
in the NVEs:
a) To conceal speakers‟ regional caste/religious identity.
For example, Annamali (1978) notes that Tamil CM with English may
be used to conceal caste identity when the term „brother-in-law‟ is used
instead of „maccan’ or „attimbeer’.
b) For register identification
c) To impress one‟s interlocutors and force inferior status on others while
claiming prestige for oneself. In the NVE countries, English is the
language of Prestige and CM with English is used to impress.
d) To prove education, modernity urbanity etc. (Sridhar 1978:10)
e) As a neutralizing device: For example, in Kashmir, the word mond
carries the annotations that the English equivalent „widow‟ does not
(Kachru 1986).
D‟Souza questions the widespread assumption that CM is an essential
feature of the NVEs. It claims that CM is the result of bilingualism and
language contact and will be found in all such contexts even when English has
become a world language and one result of its spread is that it plays an important
part in mixing. The mixed varieties arise even in non-NVE contexts. To tie CM
to the study of the NVEs is to blind ourselves to many crucial aspects of both
phenomena and to claim that NVEs are in some essential way different from
other codes.

65
2.4.5 CS and Preference of the Speaker
Chengappa (2005) has attempted to relate the amount of CS to the
proficiency and preference of the speaker. The significance of the paper is in
that, it is prepared by using the Matrix Language Frame given by Myers Scotton
(1993 b). It makes distinction between the Western bilingualism and the Indian
bilingualism as it notes, “The bilingualism in the western world is not at a grass
root level as in India and the other Asian and African countries. So it is difficult
to generalize results obtaining from the western studies into the Indian Context.
The variety and the use of English spoken in India are also different and this
may in turn affect the CS evidenced in the Indian context. It is noted that the
operating mode of the speaker affects the amount and type of CS in the
experimental situation. The operating mode of the bilingual changes from one
instance to the other, depending on the community in which he is in.” Hence,
the study tries to correlate the speech mode of a bilingual with the amount of
CS seen. It also aims at comparing the CS across monolingual and the bilingual
communicative situations.
2.5 Socio-cultural and Pragmatic Factor
Most of the scholars are of the opinion that the sociolinguistic factor is
the key to understand why Code-switching takes the form it does in each
individual case. This sub-section summarizes the studies of the scholars
concentrating on the sociolinguistic and the pragmatic aspects of CM and CS.
2.5.1 Gardner-Chloros on CS and Sociolinguistic Factors
Gardner-Chloros (2009:42) discusses three types of factors contributing
to the form taken by CS in a particular instance:
1) The factors those are independent of particular speakers and
circumstances in which the varieties are used, which affect all the
speakers of the relevant varieties in particular community- e.g.
economic „market‟ forces- covert prestige, power relations, and the
associations of each variety, with a particular context or way of life.

66
2) The factors that are attached to the speakers, both as individual and as
members of a variety of subgroups- their competence, their social
networks and relationships, their attitudes and ideologies, their self
perception and perception of other.
3) The factors that are within the conversations where CS takes place.
CS provides bilinguals with tools to structure their discourse beyond
those available to the monolinguals.
The other three sociolinguistic determinants of CS pointed out by her are:
1) Conversational/Pragmatic Motivations:
Myres-Scotton (1993a:49) deals with the distinctions between the
allocational paradigm in which the social structure determines the
language behavior, and the interactional one in which individuals
make rational choices to achieve their goals.
Milroy and Gordon (2003) similarly make distinction between CS
which exploits the symbolism or connotations of each of the ends and
CS that purely exploits the context which the two varieties provide.
Gumperz (1982) makes the distinction between we code and they
code, While dealing with the pragmatic function of CS.
2) Socio-psychological influences:
Accommodation, attitude and audience design are the concepts used by
the socio-psycholinguists. CS is one of the possible ways of
accommodating to the interlocutors linguistic preferences. It can serve
as a compromise between two varieties, where these carry different
connotations or social meanings for speakers and in the locators.
This compromise function is not limited to the spontaneous
speech. It is also exploited by politicians in their speeches as comedians
in their jokes. Generally, it is used in the media which aim at
multilingual audiences for multiple functions.
3) Addresses Specification
Another major function of CS is what Gumperz called „addresses
specification‟. The use the appropriate language to address different

67
interlocutors allows the participants to continue the conversation
smoothly.
„Gender‟ is also considered as one of the most important
sociolinguistic categories. CS connects with gender issues.
2.5.2 CS Between Different Social Settings
Bloom and Gumperz (1972:409) have discussed the use of Ranamal (a
rural district variety in Northern Norway) and Bokmal (the standard variety) as
the symbols of local and national Norwegian social values. This study shows
that it is possible to find patterns in the phonological, grammatical and semantic
choices made by an individual, and predict their occurrence with the help of
certain social factors. Therefore, the claim that there is a constant relationship
between the linguistic and the social structures is not without basis. The authors
examine the linguistic repertoire of the Hemnesberget community and report the
formal and the functional distribution of the Ranamal and Bokmal. The analysis
proves that distinction with regard to the socio-economic status of
Hemnesbergests, their descent (local vs. non-local) and their use of and loyalty
towards the dialect or the standard, tend to operate simultaneously. CS, in this
setting, is considered to be narrowly constrained by the observable features of
the situation (locale, participants, etc.) and also as a linguistic force capable of
defining and altering that situation. The authors here make a basic distinction
between a „situational‟ type of CS which is governed by situational norms, and
„metaphorical‟ CS where alteration enriches a situation , allowing for allusions
to more than one social relationship within the situation.
Gumperz (1964:1117) studies Hindi–Punjabi CS and observes, “The need
for a number of individuals tends to reduce the language distance between codes.
Linguistic overlap is the greatest in those situations which favor inter-group
contact.” One reason for this distinctiveness is that, “they have coexisted with
the same linguistic area as part of the same cultural complex for several hundred
years”. The result, which Gumperz arrives at, indicates the differences in the
speech of Punjabi-Hindi bilinguals to be mostly grammatical.

68
2.5.3 Conversational Code Switching
Gumperz (1982) focuses on the central issues of the CS phenomenon. His
(1982) paper deals with „conversational Code Switching‟ involving three
language pairs: Spanish and English (Sp-E), Hindi and English (H-E): and
Slovenian and German (Sl-G) in South Western United States, Northern India
(Delhi) and Austria respectively. Gumperz here aims at investigating the
communicative aspects of CS and “to show how speakers and listeners utilize
sub-consciously internalized social and grammatical knowledge in interpreting
bilingual conversation” (63-64). In other words, the study implies a need for
exploring the strategies that determine the meaning potential of CS and the
connection that holds between them and the socio-linguistic knowledge that
speakers and listeners share among themselves. The important observations of
this paper are:
1) CS, as a type of speech variation, reflects the role of verbal signals in
human interactions;
2) CS signals contextual information equivalent to what in monolingual
settings is covered through prosody or other syntactic or lexical processes.
It generates the presuppositions in terms of which the content of what said
as decoded. The speakers‟ notion of a code is personalized and hence
differs from that of the linguist. The speakers depend on these notions to
relate their grammatical system to the extra-linguistic environment.
(Gumperz 1982:98)
2.5.4 CS and Extra-linguistic Factors
Weinreich (1963: 3) while discussing „Interference phenomenon‟ says,
“The precise effect of bilingualism on a person‟s speech varies with a great
many other factors, some of which might be called extra-linguistic because they
lie beyond the structural differences of the languages or even their lexical
inadequacies.” Among the non-structural factors, he notes that some are inherent
in the bilingual person‟s relation to the languages he brings into contact. These
factors are:

69
a) the speakers facilitating of verbal expression in general and his ability to
keep two languages apart,
b) the relative proficiency in each language,
c) the specialization in the use of each language by topics and interlocutors,
d) the manner of learning each language,
e) the attitudes toward each language- whether idiosyncratic or stereotyped,
f) the size of bilingual group and its socio-cultural homogeneity or
differentiation- its breakdown into sub-groups using one or the other
language as their mother tongue, demographic facts, social and political
relations between these sub-groups,
g) the prevalence of bilingual individuals with given characteristics of
speech behavior in several sub-groups,
h) the stereotyped attitudes towards each language „prestige‟, the indigenous
or immigrant status of the languages concerned,
i) the attitudes toward the culture of each language community,
j) the attitudes towards bilingualism as such,
k) the tolerance or intolerance with regard to mixing languages and to
incorrect speech in each language,
l) the relation between the bilingual group and each of two language
communities of which it is a marginal segment,
Weinreich believes that it is in broad psychological and socio-cultural
settings that the effects of bilingualism can best be understood.
2.5.5 Language Choice as per Situation
Hudson (1996) maintains the view that the choice of language is
controlled by the rules. The members of the community learn these rules from
their experience; so, these rules are the part of their total linguistic knowledge.
For example, according to Denison (1971), everyone in the village of Sauris, in
northern Italy, spoke German within the family, Saurian (a dialect of Italian)
informally within the village, and standard Italian to outsiders and in more
formal village settings (school, church, work). Because of this linguistic
division of labour, each individual could expect to switch codes (i.e.

70
languages) several times in the course of a day. This kind of code-switching is
called situational code-switching because the switches between languages
always coincide with changes from one external situation (for example, talking
to members of the family) to another (for example, talking to the neighbours).
The rules link the languages to different communities (homes, Sauris,
Italy), so each language also symbolizes that community. Speaking the
standard Italian at home would be like wearing a suit and the speaking German
in the village would be like wearing beach-clothes in church. In short, each
language has social functions which no other language could fulfill. These
social functions are less arbitrary results of history; but they are no less real for
that. The same seems to be typical of the bilingual communities in general.
The main reason for preserving the language is because of the social
distinctions that they symbolize. In clear cases, we can tell what situation we
are in just by looking around us; for example, if we are in lecture–room full of
people, or having breakfast with our family, classifying the situation is easy
and if language choice varies with the situation it is clearly the situation that
decides the language not the other way round.
2.5.6 CS as Identity Relationship with Language
McClure (1977) deals with CS in the bilingual Mexican American
children. He finds that the language alternation marks a shift in identity-
relationships. It is more common among the older children than the younger
ones mainly because “the former have access to more identities” (McClure 1977:
105). Their knowledge of English increases with age, thus bringing about an
increase in the number of identity relationships associated with English.
Regarding topic, McClure feels that it does not have as much an influence in the
choice of the code (Spanish/English), as do the participants: “The children are
able to and in fact do, converse about any thing in their experience in both
languages. When a topic which is habitually discussed in one language happens
to come up in a conversation in the other language, there is high incidence of
code-mixing and code-changing.”

71
2.6 Studies of CM/CS in Indian English
Most of the studies on CM in the Indian Context, concentrate on code-
mixing with English in Indian Languages which is a Pan Indian phenomenon
(Ashok kumar 1995, Annamali 1989, Kachru 1983, Verma 1976, Jyostna 1980,
Chengappa 2005, Agnihotri 1998). There are a few studies on code-mixing of
Indian languages into Indian English. (Shastri 1988, Kachru 1983, Malik 1994).
2.6.1 Kachru’s Studies of CM/CS
2.6.1.1 Speech Function
Kachru (1966) has studied the socially determined speech functions such
as modes of address or reference, greetings, blessings, prayers, abuses, curses as
being related to the Indian context of culture. In Indian languages, there are fixed
format exponents for these contexts; but these are sometimes transformed to the
L2 for those contextual units that are absent in the culture of the English
language. Further, Kachru (1978 a) argues that a linguistic divergence is a result
of CM. The divergence may take a more extreme form, as in Hindi and Urdu or
Dakkhini.
2.6.1.2 CM as Lexical Innovation
Kachru (1975: 62-63) makes a distinction between „lexical Innovation‟
which includes the use of single lexical items and hybridization items (in South
Asian English) and assimilated items or non–restricted items in the native
varieties of English. For him, however, hybridized item is simply a lexical item
which comprises of two or more elements at least one of which is from a South
East Asian language and one from English. This includes both open set and
closed system items of lexical and grammatical elements.
Kachru‟s study on code-shifting is restricted to lexis. His is a data–
oriented study and as such, both the data and the treatment are limited to some
twenty-two imaginative writings by ten writers and some press materials chosen
from twelve Indian Newspapers; the treatment is in terms mainly of
„hybridization‟ at the lexical level. He comes to the conclusion that „CM and CS
need to be studied in a functional-context, both cross-linguistically and cross-
culturally, and that „the Indian subcontinent provides a substantial data for the

72
study of code-mixing both diachronically and synchronically.‟‟ (Kachru 1983:
206)
2.6.1.3 Context of Situation
Kachru (1978) presents a theoretical framework which would relate the
formal and functional aspects of such „language-mixing‟ and view it in a
pragmatic perspective in terms of the linguistic needs of the speech community.
He follows mostly Firth‟s framework. In Firth (1957a and 1957 b) and later in
somewhat modified form in Mitchell (1957), Halliday (1959), Ellis (1966) and
Kachru (1966), a schema has been presented towards delimiting texts with
reference to their contextually relevant categories. Firth has suggested the
following categories for the context of situation of a text:
A. The relevant features of participants: persons, personalities.
i) Verbal actions of participants
ii) Non-verbal actions of participants.
B. The relevant objects
C. The effect of the verbal action.
The other features to be considered are –
i) Economic, religious and social structures to which participants
belong.
ii) Types of discourse : monologue, narrative
iii) Personal interchange: age of participants.
iv) Type of speech- social flattery, cursing, etc.
CM is a role–dependent and function–dependent linguistic phenomenon.
In terms of role, one has to ask who is using the language, and in terms of
function, one has to ask what is to be accomplished by the speech act. In terms
of role, then, the religious social, economic and religious characteristics of the
participant in a speech act are crucial. On the other hand, in terms of function,
the specialized uses to which the given language is being put determine the CM.
In a sense, then, in several linguistically relevant situations there is a mutual
expectancy between the formal characteristics of the language (in this case, a
code-mixed language and its function). Kachru (1978) discusses the

73
phenomenon of CM in the theoretical framework of the „context of situation‟.
The concept, context of situation, provides a framework for relating language
use and linguistic form to the „immediate‟ linguistically relevant situation and
also to the „wider‟ context of culture.
A „contextual‟ unit means those features of a text which contribute to its
being assigned to a particular function. These features may be termed the
contextual parameters of a text. These would comprise linguistically relevant
clues, such as the participants, their sex, their positions on the social, caste or
religious hierarchy.
In certain contextual units, a multilingual person has the possibility of
choice between code-mixed (say Hindi and English or Persian) or non-code,
mixed languages. In such situations, the selection of a particular „code‟ is
determined by the attitude of a person toward a language (or toward a certain
type of code-mixing) or the prestige which a language (or a type of code-mixing)
has in a speech community.
Formal appropriateness in CM may be judged by using the concept of
formal cohesion. In other words, a particular type of lexical and grammatical
cohesion is associated with a specific type of discourse or register. In linguistic
terms, CM involves functioning at least in diasystem and as a consequence,
developing another linguistic code comprising formal features of two or more
codes. A linguistic code developed in this manner then develops a formal
cohesion and functional expectancy.
One might then say that the function of the CM languages is between
what is termed „digloassia‟ and CS. In the „diglosssia‟ situation, there is a
situationally determined use of two codes, and the codes involved are
functionally mutually exclusive. In CS, on the other hand, the functional
domains of the languages involved are determined by linguistically pluratic
situations, for example- the Punjabi-Hindi Code-switching in Haryana.
2.6.1.4 Mixing of English and Indian Languages
Kachru (1983) has argued that CM once considered linguistic sin has now
come to be recognized as a historically and sociologically determined

74
phenomenon with well-defined linguistic, pragmatic and attitudinal functions.
Several mixed languages have developed as result of this process. He discusses
CM with English in Indian languages and proposes ways of structuring the
phenomenon (Kachru 1975, 1978, 1983).
As much of his work deals with lexical items, he uses CM as a cover term
for CM/CS expressions. According to him, there are four broad types of mixing
seen in Indian Languages: 1) Englishization 2) Sanskritization 3) Persianziation
4) Pidiginization.
Regarding the pragmatic functions of the code-mixed varieties in Indian
languages, he notes that CM in Indian languages shows register identification
(register-wise mixing), e.g. Englishization (mixing English words),
Persianization (Persian words mixed in legal register– in lower courts), Literary
Criticism and philosophical writing (Hindi-Sanskrit words mixed). It provides
formal clues for style identification (Sanskrit, Persian and English). It is used as
device for elucidation and interpretation. It is possible when terminologies of
that language have not been stabilized or have not received acceptance. A person
uses two linguistic sources in defying concepts or a term so as to avoid
vagueness or ambiguity. It is used to redefine in other language (English) what
has been already expressed in one language (Hindi). Sometimes mixed lexical
items do not provide contextual clues and thus, language is used to conceal
various types of identities. In order not to give away caste identity, a person
prefers the English Kinship term brother–in-law, for the Tamil maccan or
attimbeer. CM is a contextually determined device; therefore there is mutual
expectancy between the type of CM and the contextual unit in which it
functions.
With this explanation he further claims that in register identification and
style identification, CM functions as foregrounding, because it is used to attract
attention. On the other hand in neutralization, it is used for the opposite effect,
i.e. to conceal the identity.
While observing the attitudes towards the functions of the code-mixed
varieties, he points out that, in the multilingual settings, all the code-mixed

75
varieties do not evoke identical attitudinal responses. A multilingual person
seems to choose CM of various types, pragmatically and attitudinally. He
considers the attitudes towards four types of mixing mentioned above: 1) Code-
mixing with English is a Pan-South Asian phenomenon. In attitudinal functional
terms, it ranks the highest and cuts across language boundaries, religious
boundaries and caste barriers. It is a marker of 1) modernization 2) socio-
economic position 3) membership in the elite group. It makes deliberate style.
The widest register range is associated with CM in English. It continues to be
used in the contexts such as- to demonstrate authority, power and identity with
the establishment. The evidence of this attitude is seen in the parents‟ language
preference for their children. It is also seen the in the choice of preferred
language in the college. 2) The attitude towards sanskritization is seen in
oratorical style associated with the rightist–Arya Samaj, whereas attitude
towards desanskritaziation is seen in Dravid Communities‟ oratorical style 3)
Persianization spread in those parts of India that came under the Muslim domain,
is associated with the legal register of the lower courts. The attitude towards
Persianization varies from one part of India to another. CM with Persian is used
in educational system in Kashmir or north India by Hindu Kashmir is and by
Muslims. But CM with Persian in South India is different. In Karnataka, Sridhar
(1978) observes that the educated Kannada speaker mixes English in his
Kannada, and the illiterate (earthly) one mixes Perso-Arabic in his Kannada. 4)
Pidginization which is low on the hierarchy is an attempt toward simplification
of language used in situation. Here, the participants speak languages which are
not mutually intelligible. This mixed type variety is called Bazar Hindi, Butler
English or chi chi English (Kachru 1987 a).
The formal characteristic of CM texts is their lexis and lexical cohesion
(Halliday and Hassan 1976 in Kachru 1983) “A user of a code-mixed variety
intuitively applies the process of the first language to nativise the linguistic
elements of the other code. In Hindi-English code-mixing, most of the
productive grammatical processes of Hindi-Urdu are applied to English items.

76
For example, company-companiya, master-masterin, doctor-doctarin.” This also
applies to inflection assignment and other grammatical categories.
There is a type of cline in mixing which starts with lexical mixing and
then progressively extends to higher units, the maximum being an alternate use
of sentences from two codes. The mixing at lexical level may show a lexical
spread which is associated with a register (e.g. paragraph with Persian Lexical
items typical of legal register in Indian language) (Persian +Hindi); on the other
hand, there is almost an alternate use of units of Hindi and English (e.g.
paragraph with switching between Hindi and English).
2.6.1.5 Code Mixing vs. Odd Mixing
About unacceptable CM, Kachru (1978b) comments that CM is both
functionally and formally a rule governed phenomenon. It is not an open-ended
process, but has various collocational and grammatical constraints. There is a
point both in grammar and lexis when a user distinguishes between code-mixing
and odd-mixing, The responses to the code-mixed items by the users of such
varieties seem to vary from „yes, acceptable‟ to „no unacceptable‟ ,‟well
depends‟, and „I don‟t know‟.
2.6.1.6 Impact of CM on Hindi Syntax
There are several studies that concentrate on the phonological, lexical and
syntactic aspects of Hindi with mixing of the Persian words, Hindi with mixing
of the English words. Kachru (1983) summarizes the researches dealing with the
impact of CM and CS on Hindi syntax:
1) There is change in word order. The preferred word order of Hindi is
SOV as opposed to the SVO of English. In creative writing in Hindi and
newspaper register, we find example of SVO too. This may be due to the
influence of an English substratum (Mishra 1963 in Kachru 1983) and the
practice of fast translation from primarily English texts in journalism
broadcasting.
2) There is the introduction of indirect speech. In Hindi discourse,
traditionally, no distinction is made between direct and indirect speeches.

77
But modern Hindi prose construction such as „NP said that he will read’
as against „NP said that will read’
3) There is the use of impersonal constructions. For example,‘ it is said’ ,
‘it has been learnt’, ‘It is claimed’, type of constructions. In Hindi
newspaper, it is „kahajata hai’, - is now being used.
4) In the Indo–Aryan languages, in general, there is a tendency to delete the
agent in passive communications. In new Hindi, Dwara, Jariye, are used
because of the influence of English.
5) The use of post-head relative clause with „jo’ is also attributed to the
influence of English and by some to the influence of Persian. For
example, “Voh larka jo table par baitha hai mera bhai hai.” (That boy who
is sitting on the table is my brother).
6) There are two views regarding the use of the parenthetical clauses. For
some, they are the result of the English influence and for others; they are
typically Indo–Aryan constructions.
2.6.1.7 Exponents of ‘Mixing’
The formal exponents of „mixing‟, as stated in Kachru (1978 a), form a
hierarchy. In this hierarchy, mixing of simple lexical items rank the lowest and
the mixing of sentences rank the highest. They are NP insertion, VP insertion,
unit hybridization, sentence insertion, idioms and collocation insertion,
Inflection attachment and reduplication. This process includes the use of
reduplication of English items. In some south Asian languages, reduplication has
the function of marking identification, e.g. petrol vetrol , acting vekting, Taim
vaim , kar var.
2.6.2 Shastri’s Study of CM
Shastri‟s contribution to Indian English is worth noting, especially regard
to the compilation of the two corpora on Indian English: Kolhapur corpus of
Indian English (1988) and ICE-IND (2002). His research paper (1988) „Code
Mixing in the Process of Indianization of English‟ is based on Kolhapur Corpus
of Indian English. As our present study is based on CM and CS in Indian English

78
speech and as it is based on ICE-IND, we have considered his paper here in
some detail.
2.6.2.1 Code Mixing Process
Shastri (1988) considers CM of Indian languages into IE as an important
contributory factor in the process of Indianization of English. He considers
„hybridization‟, „absorption‟ and „assimilation‟ as distinct stages, in that order, in
the process of borrowing in languages. According to him, „absorption‟ is a
process of naturalization (the borrowed items which become stabilized by
gaining linguistic and socio-culture sanctions at the local or regional level). The
language speaking community tacitly accepts it. The term „assimilation‟ is used
for those that become part and parcel of the native varieties of English. The need
for assimilating Indian elements into English has once again arisen especially in
the Western World and in the fields of Fine Arts to cater for the desire for
International understanding though cultural sympathy. So, a number of register-
bound items have already found their way into standard British and American
dictionaries. More striking forms of assimilation are those that borrow the
abstract concepts of Indian socio-cultural phenomena and the Indian way of
conceptualizing reality through the Indian language items.
2.6.2.2 Functions of CM in Indian Context
Kachru (1983) has suggested the pragmatic and the attitudinal functions
of CM. The first manifests in the register-determined contexts and the second as
markers of the social status and attitudes. Shastri‟s (1988) study has revealed a
third aspect, i.e. a deliberate attempt to Indianize English, indicative of the
national aspiration typical of all the newly independent nations which expresses
itself in different ways in different nations. This deliberate attempt is more like
the early American efforts at the Americanization of English.
Moreover, it is a deliberate attempt not only at asserting the newly free
nation‟s distinct identity as strongly and emotionally as possible, but also at
adapting the English language so as to bring it within the reach of an average
educated Indian, a truly „socialistic motive‟. This may well be labeled as a
feature of pan-Indian English. Such attempts may range from genuinely

79
nationalistic to ridiculously parochial innovations. He gives a few examples:
Poorna-Swaraj, Azadi, Swadesh, Kala Parishad, Askashwani, Doordarshan,
Sangeet Natak Akademi, Shri Shrimati, and Sarvashri. There are quite a few
new items, the most talked about being- bundh, hartal, gherao, not to speak of
Dravida Munnetra Kazagam, Shiv Sena, Hindu Ekata etc. - the kind of which
have found their way into pan-Indian English, a kind of lingua franca typical
not only of the press but popular English literature in India and the bulk of
spoken English for everyday communication.
With regard to the formal treatment of CM, Shastri notes that, CM does
not confine itself to any particular level of language structure. It tends to affect
the code-mixed language at all levels. In phonology and morphology, it is most
obvious or transparent; but at the level of syntax and specially semantics, it
tends to be not so obvious or opaque. His corpus-based study deals with the
structural variety of CM in detail and also notes some examples of exponents
and constraints.
2.6.2.3 Structural Variety and Stylistic Motivation of CM
A) The details of the structural variety of CM marked in his study are as
follows:
1. Basic NPs
a. N +N Constructions in which the modifier N is an Indian item:
Tehsil level =level of the tehsil (administrative area) (All)
b. N+ N Constructions in which the head N is an Indian item:
Block Samiti= Committee to manage the block (All)
Here, the head nouns may be inflected the English way: as for example,
deeyas.
c. Adj=N Constructions in which the adjective is an Indian item:
Peria colony = big colony, really colony of the big (A09)
Here, too, the adjectives have their derivational affixes, swadesh, jirki
d. Quantifier + N constructions in which the head N is an Indian items. :
Ten thousand paras (measure) (KO1)
Notice the last phrase which is very English phrase.
2. Basic Coordinated NPs
N and N constructions in which either of the Ns is an Indian item:
AIR and Doordarshan (TV)(CO9)

80
3. Complex NPs with multiple premodification:
a. All modifier Ns :
Siasm sag timber (All)
b. Ns and Adjs
Purna Swaraj pledge (A10)
4. Complex NPs of sorts :
Badawar Tai (poor people’s mother) Indira Gandhi (A28)
5. Attributive constructions
a. N + Adj. constructions in which the N is an Indian item:
( mehandi-red (K10)
b. N + V-ed constructions in which the N is an Indian item:
Rishabha-based (CO2)
c. N+ V-ing constructions also as substantives in which the N element is an
Indian item.
Chappal- throwing (B22)
6. Inflected Forms : Indian items with English inflections :
A. Plurals in –s (simple forms)
By far the most productive English inflection used is the –s plural inflection:
Hamals (A09), harijans (A22)
B. Plurals in –s (complex forms)
Kabir panthis (A42)
C. Adjectives in –te and –ist
Baindavanite (CO5), harmonist (CO4)
D. Abstract nouns in –ism :
Brahmanism (B10), Hinduism (C10)
E. The –s Genitives :
a. Possessive Genitive : Prana‟s connection with Prajapati = Prana has
connection with prajapati (D05);
b. Group Genetive: raja of Dilwar’s cousin = the cousin of the raja of
Dilwar (KO5).
7. Prefixes and Suffixes : trans-Jamuna (A37), filmwalahs (L05)
Some of these features have no doubt been pointed out earlier by Kachru.
But the analysis presented here not only confirms some of his hypotheses, but
also indicates how CM in IE is a far more complex phenomenon affecting the
very fabric of the language at all levels of delicacy, for example- the structural
variety of the –s genitive in particular.
He uses the term stylistics in the broadest sense of the term to include what
the speaker wants to accomplish in a given context of situation.

81
B) Stylistically Motivated Code-Mixing:
Exponents of Code Mixing:
1. Single lexical items with restricted/extended meanings :
i) …mass sterilization camps… which are little more than melas. (B14)
ii) she would keep some of ….some of her charm for those …. who
might go on the line after the tamasha (minister’s visit to the slum) was
over. (K18)
No. i) is an illustration of exploitation of the associated meaning (-DESIRABLE)
of the item mela which literally means a „fair‟. No. ii) is an example of a
similar phenomenon, the item tamasha which could have an associated
component (+CONTEMPT) which otherwise literally means different things in
different Indian languages. The example seem to indicate that there is a need for
recognizing a fuller range of stylistic marking potential of the code-mixed items
even at the single lexical item level.
2. NP insertion
There are instances of Indian language NPs inserted into English with or
without English paraphrases. The writer‟s decision to supply or not to supply
paraphrase may be dictated by the audience readership he has in view or the
desire to compensate for the inadequacy of one of the phrases.
For example: The succeeding thumr ki bandish based on „khamaj’,
‘Adana’ and ‘Bahar’ and the final „dadra’ were all
redolent of the distinctive purab flavor (C04).
It Fills a gap in the receiving language, but could have been phrased as
the bandish of thumri; the motivation seems to be one of „Cohesion‟ or may be
of constraint.
3. Sentence Insertion
a. Without paraphrase:
Boja babuji? (Any load to carry Sir?) Those two words sent a shiver
through my body. „ Chalo, hamare sath’ ( Come with me) I
commanded her (K52)
b. With paraphrases :
Dramatic performance becomes, according to „Naatya Adriana’ an
art when it arouses sentiments in the minds of the audience (Sabha
yaanaam hridayam nartayati iti naatakam) (= That which makes the
audience’s heart dance is a drama)(C07).
4. Modes of address
i) „Yes, yes baba I am moving. I am moving’ and she tottered up the
aisle of the bus. (K50)
ii). „who is speaking? Jaydeep here. Yes Jaydeep, I am bit in a soup
dafa. Won‟t be able to come –yes.‟(L01)
These examples of address- baba (daddy, meaning any one who assumes
the role of one), Mai, ma (mother, one as good as mother), Beta (Son, one as
good as son), Deva (God-Hindu), Inshaalla (God-Muslim), Atte (aunty –regional
–Karnataka) suggest the wide range of modes of address with unmistakable
social function.

82
5. Interjections:
i) I bit a little pedha so that the remainder appeared, in my palm like
the moon a few days before becoming full. „Cha’ I cried, spitting
out what I had eaten. (K34)
ii) Choma heard the landlord‟s mother curse form inside the house
„Abba, the insolence of these holeyas‟. (K03)
The interjections Cha! Chee! Chee! are pan-Indian expressions of strong
disapproval: while Abba is limited to south Indian expressing shock at „temerity‟
– the limit.
6. Idioms and Proverbs:
This is all too common a phenomenon – the use of idioms, proverbs and
sayings which are culture-bound and, as rule, untranslatable. Occasionally,
parallel idioms occur in different languages. But the fact remains that these are
the surest markers of socio-cultural traits.
Regarding „constraints‟ on CM, this study suggests that there are two
kinds of constraints on CM: First, as discussed by Kachru (1978), the relevant to
the cline of acceptability, and the second, the language specific constraints. This
phenomenon seems to operate at the semantic level and, therefore, is likely to be
reflected in the processes of lexicalization and affixation or the realization of
open set items and closed-system terms.
Shastri refers also to the near absence of mixing of verbs in Indian
English. For example, Gherao (peaceful intimidation by crowding in on
person(s)), in Hindi is a noun, one has to add an operator karna to derive a verb
i.e. gherao karna . In the form gheraoed was obviously treating the item the
gherao is treated as verb with the English past –ed inflection. He observes that
there is a general tendency in Indian words to follow the English grammatical
processes of affixation for realizing grammatical meanings. Only in the case of
film-wallah, the affix wallah is from Hindi; but the root film itself is from
English and the item filmwallah is borrowed back into IE. Barring such
examples, he concludes surmises that the mixed items normally conform to the
morphological patterns of the receiving language.

83
2.6.3 Verma’s Study of Socio-cultural Factor in CS
Verma (1976), in his paper „Code-Switching: Hindi-English‟, begins with
a distinction between linguistic competence and communicative competence.
For him, “Linguistic competence does not necessarily mean communicative
competence; but communicative competence subsumes linguistic competence,
for it may be described as linguistic competence plus situational appropriateness.
Linguistic competence is abstract, context-free, rule governed linguistic
behavior; communicational competence is context-governed topic-oriented
externalization of linguistic competence.”
This paper attempts to illustrate certain aspects of Hindi-English CS
among the educated speakers of Hindi-English. English and Hindi have
coexisted within the same linguistic area as part of same socio-economic
complex for years. Both the codes have been serving important function in the
daily social interaction. These speakers use different varieties of their mother
tongue in various situations in life; but when they have to use the technical
register, they normally switch over to English. This kind of register-oriented
bilingualism is labeled as „registral bilingualism‟ (Verma 1969:302). In fact, the
situation is never as simple as this.
The chief regulations of Hindi-English CS or of mixture of Hindi-English
styles are related to the level of education and the topic of discourse. The higher
the level of education and more technical the topic of discourse the greater the
degree of mixture and frequency of switching. It may, therefore, be said that the
bilingual switching is patterned and predictable on the basis of topical and
situational feature. He explains the dominance of Hindi/English by way of cline.
At one end and in certain roles, these bilinguals use only English and at the other
end and in certain other roles, they use only Hindi. English is used in highly
formal situations to talk about technical topics; Hindi is used for intimate,
informal, personalized statements. In between these two extreme ends, we find
different degrees of English-dominated and Hindi-dominated mixtures.

84
The cline may be shown as:
English English dominated Hindi dominated Hindi
CS in multilingual settings is regulated by the topic of discourse and
stylistic (formal/informal) considerations. In this regard Fishman (1972: 439)
observes, “The fact that two individuals who usually speak to each other
primarily in X nevertheless switch to Y when discussing certain topics leads us
to consider topic per se as a regulator of language used in multilingual settings.
The implication of topical regulation of language choice is that certain topics are
somehow handled „better‟ or more appropriately in one language than in other in
particular multilingual contexts”. The speakers do not radically switch from one
style to another; but they build on the co-existence of alternative forms to create
meaning. Switching from one code to another is not a matter of free individual
choice. It is affected by topical and situational features, which determine the
speaker‟s choice from among a set of available codes.
Regarding the „context‟ in CS, Verma observes that the CS is context-
governed. If the interlocutors have a degree in English and use English as their
medium of lecturing or in their office work, they are likely to use information
carrying items of English and linkers of Hindi. If their topic of discourse is
technical, their registral items are likely to be from English and the grammatical
items from Hindi. CS, one might say, is a marked badge of educated, urban
bilinguals. The preponderance of a particular set of lexical items of a code, he
notes, also depends upon our emotional and intellectual attachments to the code.
2.6.4 Ashok Kumar’s Study of CS and Motivation
Ashok Kumar (1987) focuses on „motivation‟ for CS. He considers, apart
from the communicative necessity on the part of the bilingual, there are some
more reasons which are equally if not more effective in explaining this
phenomenon. These have either been superficially dealt with, or have been
totally ignored. His study of the Hindi-based bilinguals, both educated and
uneducated indicates that the alteration from Hindi to English is dictated also by
such considerations as a)Switching under emotional stress, b) Switching for

85
imposing authority, c) Switching for fashion, d) Inevitability, e) Technical CS, f)
Switching for business, g) Switching in creative writing and h)Euphemistic CS.
He deals with some of the important formal and functional features of
Hindi-English code-switching. The analysis of the linguistic aspects of Code-
switching refutes some of the code-switching constraints. The functions of code-
switching are more or less in line with Gumperz (1982), although they have been
dealt with more elaborately in his study.
2.6.5 Other Studies of CM/CS in Indian English
Malik Lalita (1994) discusses the role of Code-switching in the formation
of Indian English. On the basis of her investigation, she asserts that Code-
switching in bilingual or multilingual speech is not a „grammarless language
mixture‟. On the contrary, morphological, semantic and pragmatic analyses
show that there are marked linguistic, semantic and attitudinal functions of Code
Switching. The process of CS plays a major role in the formation of Indian
English; its contribution to the formation of IE is, no doubt, noteworthy. This
study traces also the educational implications of Code-switching in Indian
English.
Jyostna (1980) studies the formal functions of CM in Indian films. Her
study is based on the data collected from the spoken media. She argues that CM
may occur at a variety of grammatical levels. CM obeys certain syntactic
constraints. It is restricted by social aspects; however, as she insists, CM has
certain pragmatic advantages.
The work of Nirmale (2009) „A study of CS and CM in the selected
fictional works by Indian Writers in English‟, critically examines and investigate
the phenomenon of code mixing and code switching as manifested in Indian
writing in English in general and fictional work of M.K. Anand and Raja Rao,
Farukh Dhondi and Shobha De‟ in particular. The study probes into the process
of nativization which mainly operates through the mechanism of CM and CS.
To conclude the discussion on Code Mixing and Code Switching, it may
be observed that CM and CS have over years been the areas of great concern for
the linguists and the researchers. Their scope is not limited to one language or

86
medium, one region or community, one field of knowledge or communication.
In fact their scope is extended over to several languages and mass media used for
information and communication by users all over the world. A number of
linguistic, socio-cultural and pragmatic factors contribute to their formation and
usage. That also explains the researchers‟ keen interest in the study of CM and
CS in Indian English.