chapter 2: introduction to neural networkssite.iugaza.edu.ps/mtastal/files/ch1-nn-all_parts.pdf ·...
TRANSCRIPT

Chapter 2:
Introduction to Neural Networks
Prepared by
Dr. Mohammed Taha El Astal
TMUL 3310
Artificial Intelligence
Winter 2019

Classification Problems:

Classification Problems (Cont.)
Does the student get accepted?
Answer: Yes, with some confidence

Classification Problems (Cont.)
• Yes, that’s correct! But how isthat?
Answer: You tried to find a classification
rule that most fil all previous data, then
you applied this rule for the new student
• This rule is commonly termed as“Model”. It is here modeled byLine.
• However, there are some pointsclassified incorrectly. Thistermed as “Model’s Accuracy”.
Now, the question is how to get this model??

Classification Problems (Cont.)
Discuss: Can you generalize the mentioned boundary?
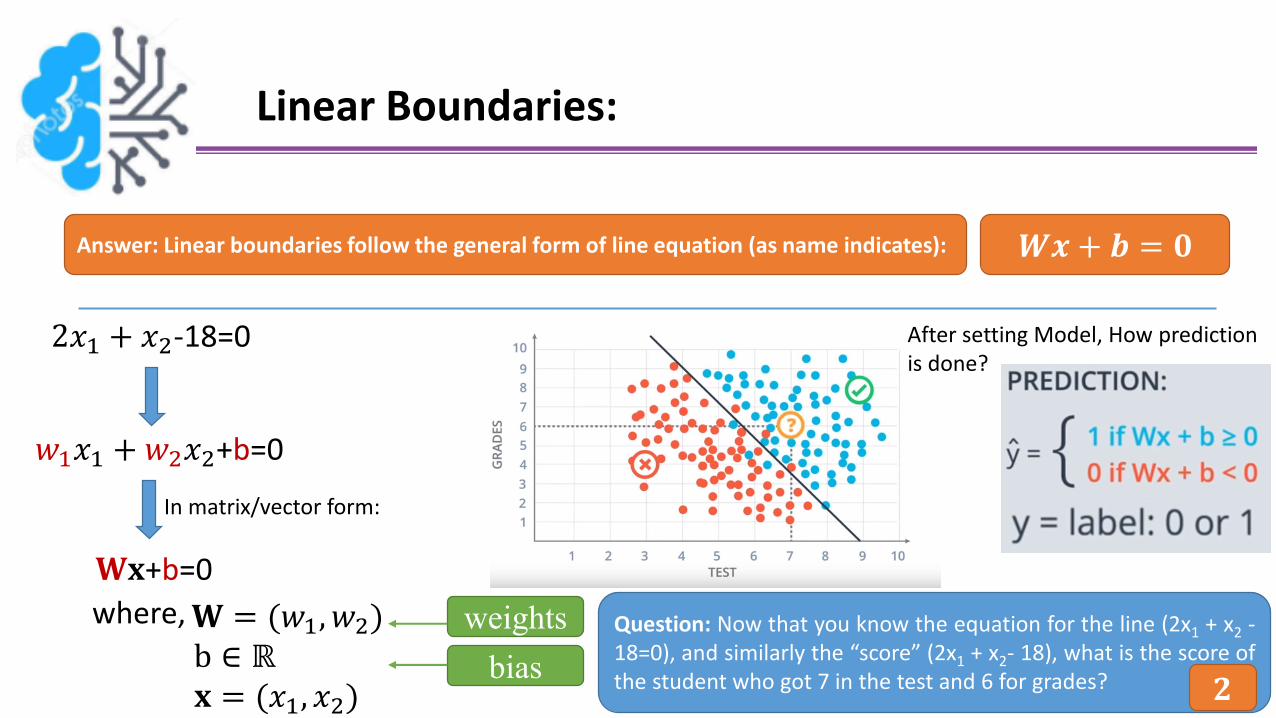
Linear Boundaries:
Answer: Linear boundaries follow the general form of line equation (as name indicates):
𝑤1𝑥1 +𝑤2𝑥2+b=0
𝑾𝒙+ 𝒃 = 𝟎
2𝑥1 + 𝑥2-18=0
𝐖𝐱+b=0
In matrix/vector form:
𝐖 = (𝑤1, 𝑤2)
𝐱 = (𝑥1, 𝑥2)
where, weights
biasb ∈ ℝ
After setting Model, How prediction is done?
Question: Now that you know the equation for the line (2x1 + x2 -18=0), and similarly the “score” (2x1 + x2- 18), what is the score ofthe student who got 7 in the test and 6 for grades? 𝟐

Linear Boundaries/Higher Dimensions:
• What do you suggest for a model “ boundary” ??, equation form??
Answer: A plan
𝑤1𝑥1 +𝑤2𝑥2 +𝑤3𝑥3+b=0
𝐖𝐱+b=0
In matrix/vector form:
𝐱 = (𝑥1, 𝑥2, 𝑥2)
where,
b ∈ ℝ
𝐖 = (𝑤1, 𝑤2, 𝑤3)

Linear Boundaries/Higher Dimensions (Cont.):
Question: Given the table in the video above, what would the dimensions be for input features (x), the weights (W), and the bias (b) to satisfy (Wx + b)?
Answer: W:1*n, x:1*n, and b:1*1

Perceptron:
Graphically
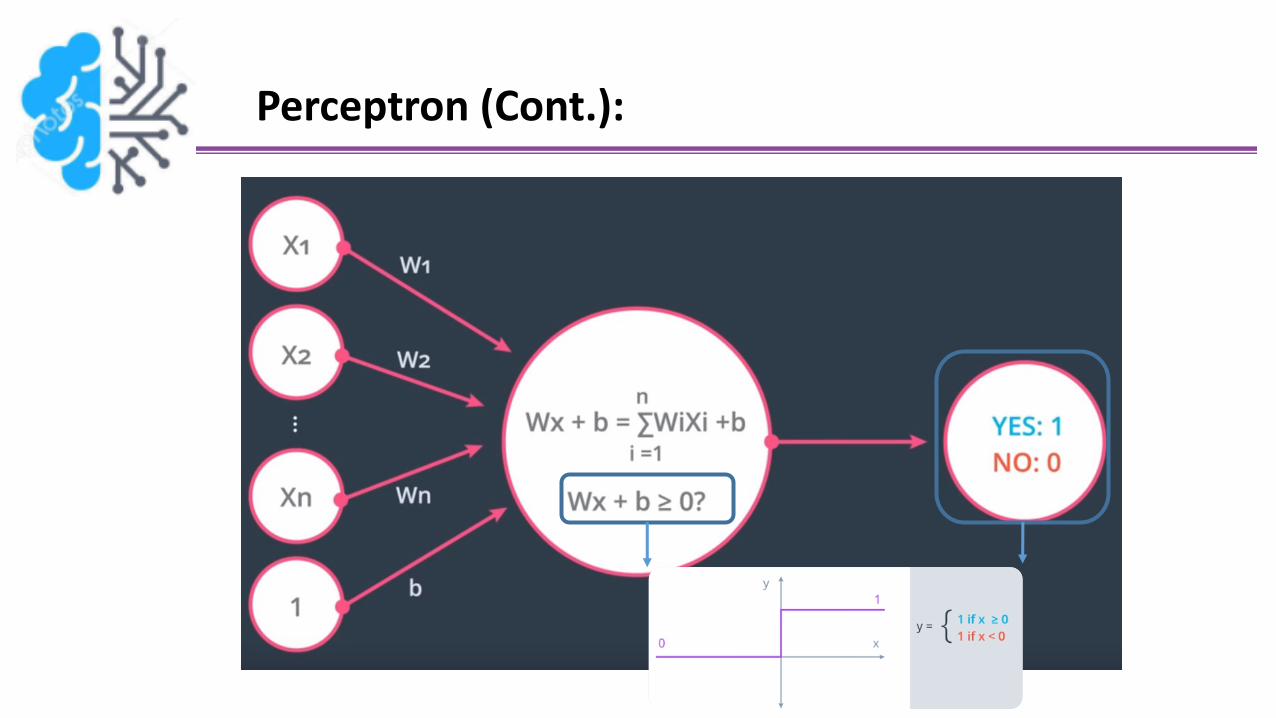
Perceptron (Cont.):
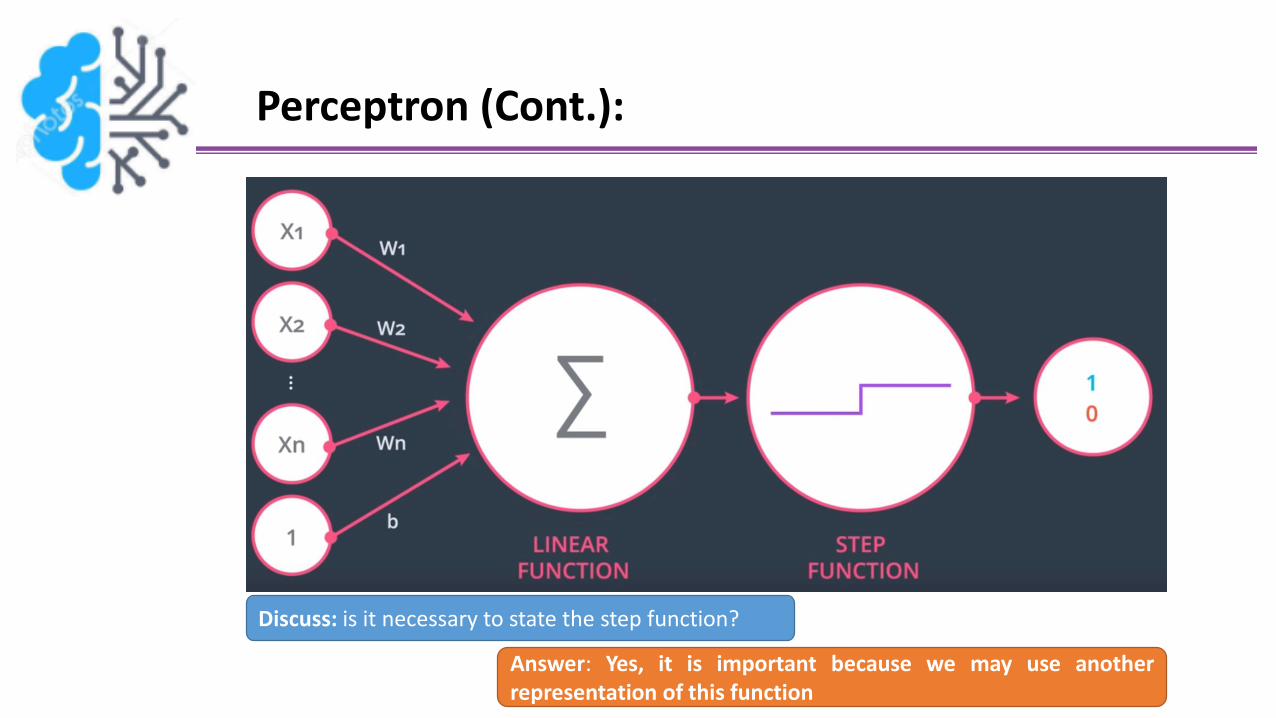
Perceptron (Cont.):
Discuss: is it necessary to state the step function?
Answer: Yes, it is important because we may use anotherrepresentation of this function
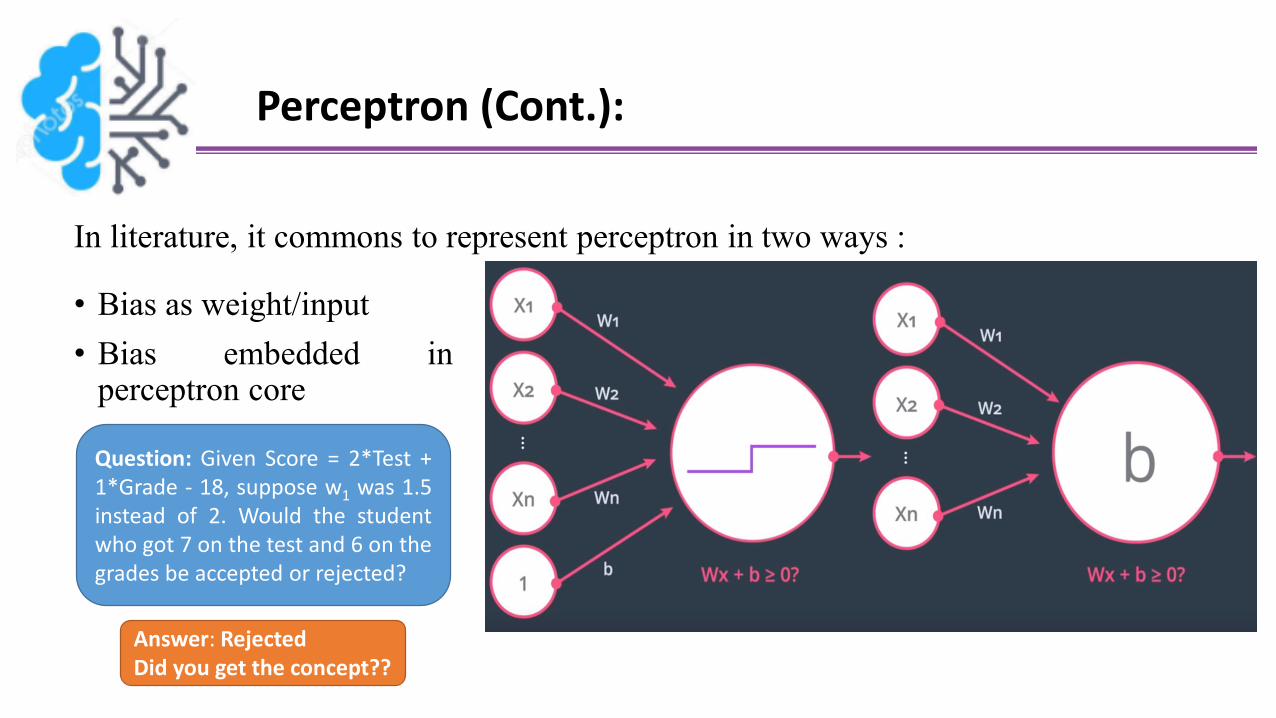
Perceptron (Cont.):
In literature, it commons to represent perceptron in two ways :
• Bias as weight/input
• Bias embedded inperceptron core
Question: Given Score = 2*Test +1*Grade - 18, suppose w1 was 1.5instead of 2. Would the studentwho got 7 on the test and 6 on thegrades be accepted or rejected?
Answer: RejectedDid you get the concept??
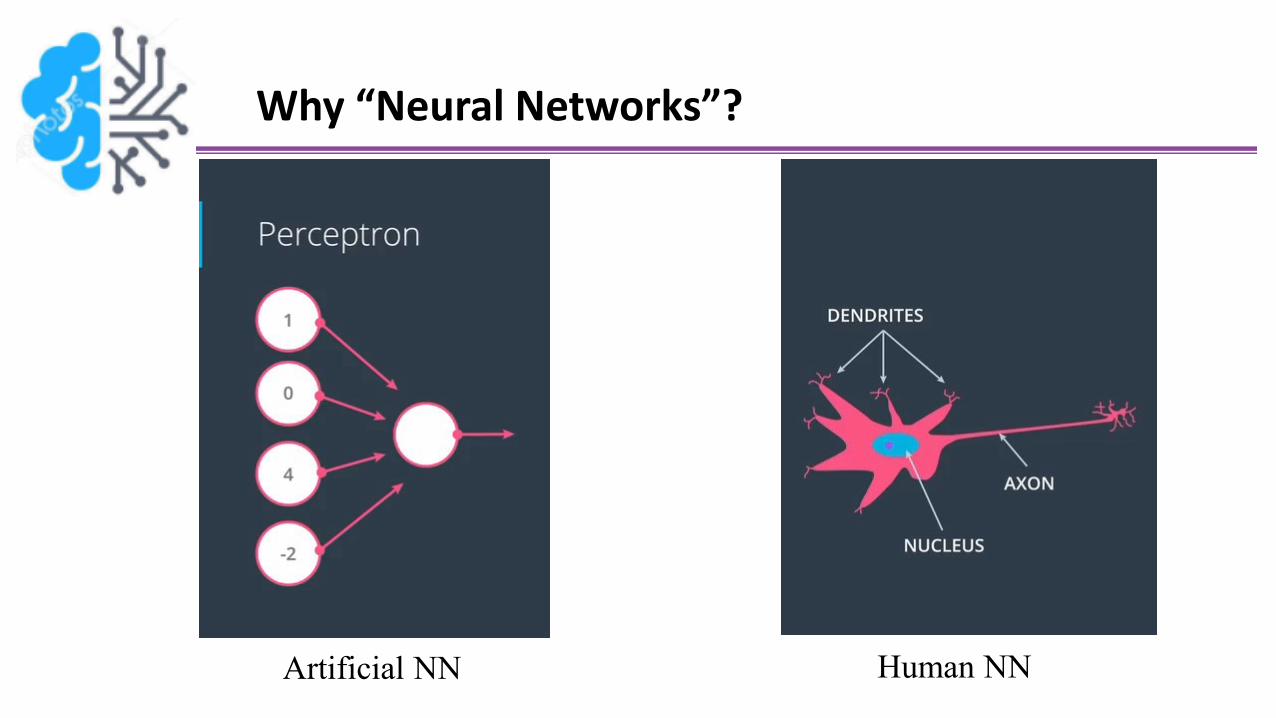
Why “Neural Networks”?
Artificial NN Human NN

Perceptrons as Logical Operators
What are the weights and bias for the ANDperceptron?
What are the weights and bias for the ORperceptron?
What are the weights and bias for the NOTperceptron?
Answer: w1=1, w2=1,b=-2
Answer: w1=1, w2=1,b=-1
Group work, 5 minutes only
Answer: w1=-2,b=+1
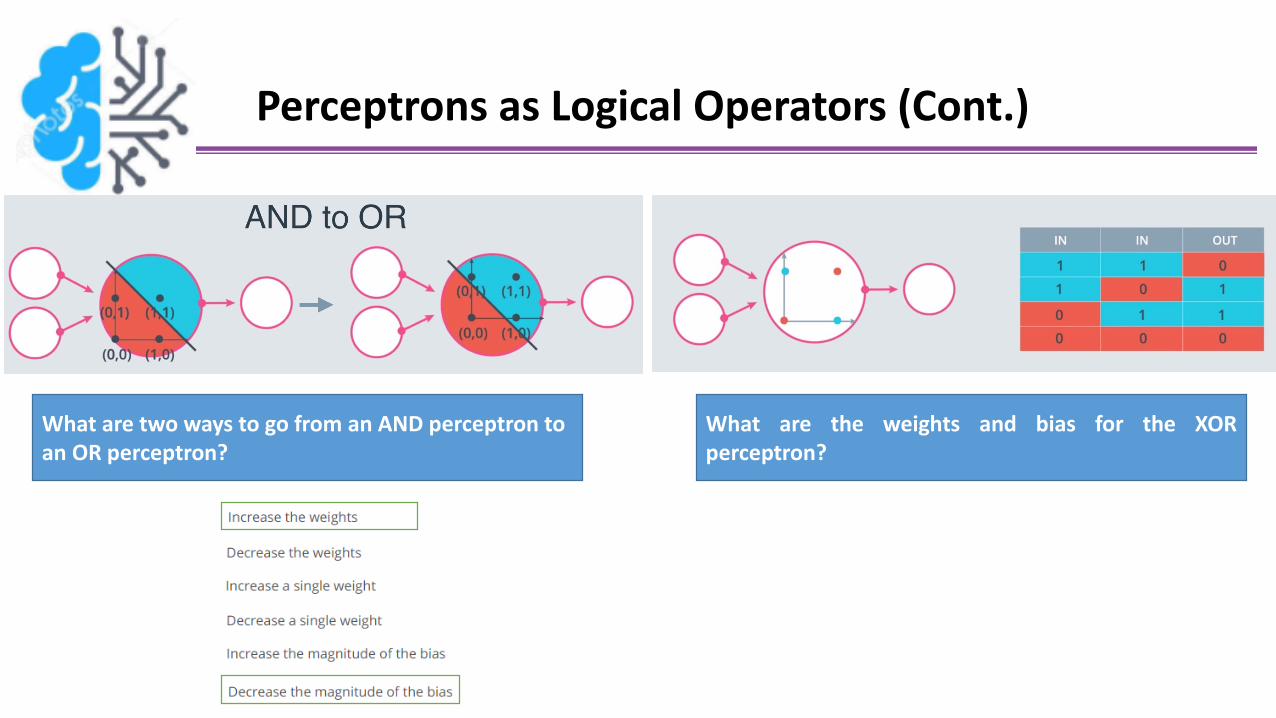
Perceptrons as Logical Operators (Cont.)
What are two ways to go from an AND perceptron to an OR perceptron?
What are the weights and bias for the XORperceptron?

Building Perceptrons:
In the last section you used your logic and your
mathematical knowledge to create perceptrons for
some of the most common logical operators. In real
life, though, we can't be building these perceptrons
ourselves. The idea is that we give them the
result, and they build themselves. How is that?
In simple words, set random weights and bias, then checkmisclassified points and come closer
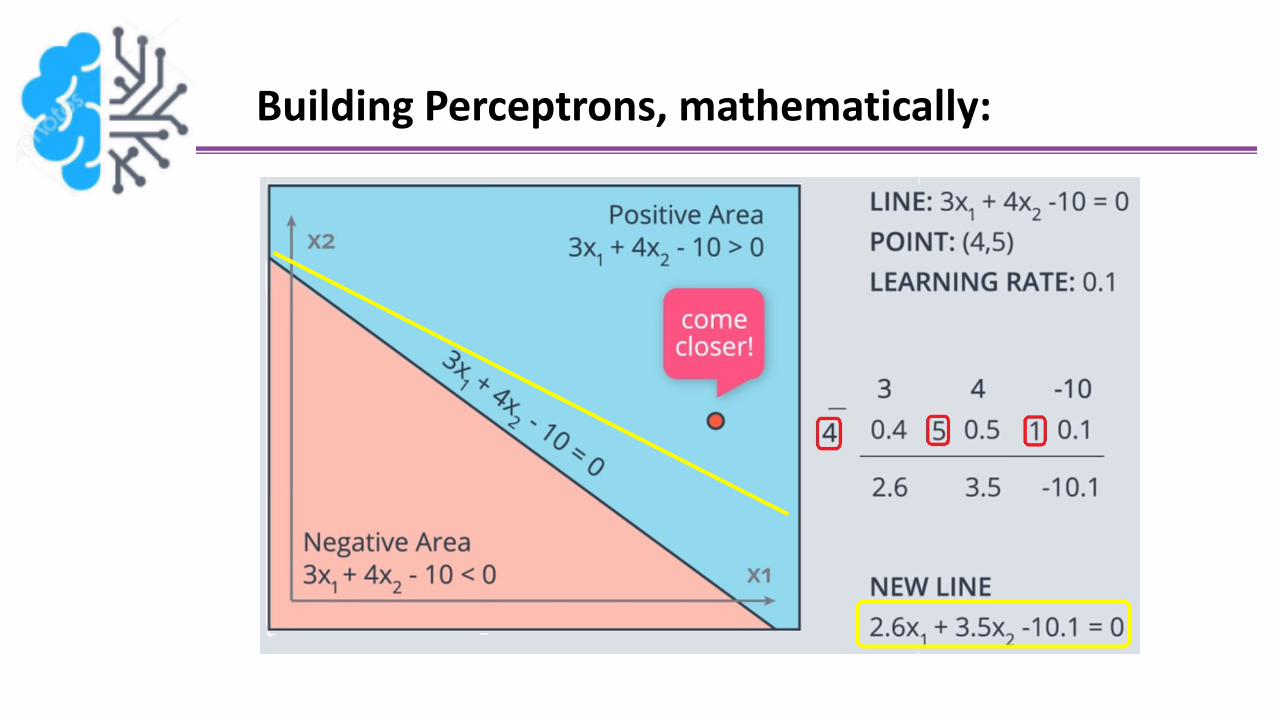
Building Perceptrons, mathematically:

Building Perceptrons, mathematically (Cont.):
For the second example, where the line is described by 3x1+ 4x2 - 10 = 0, if the learning rate was set to 0.1, how many timeswould you have to apply the perceptron trick to move the line to a position where the blue point, at (1, 1), is correctlyclassified?
Answer: 10
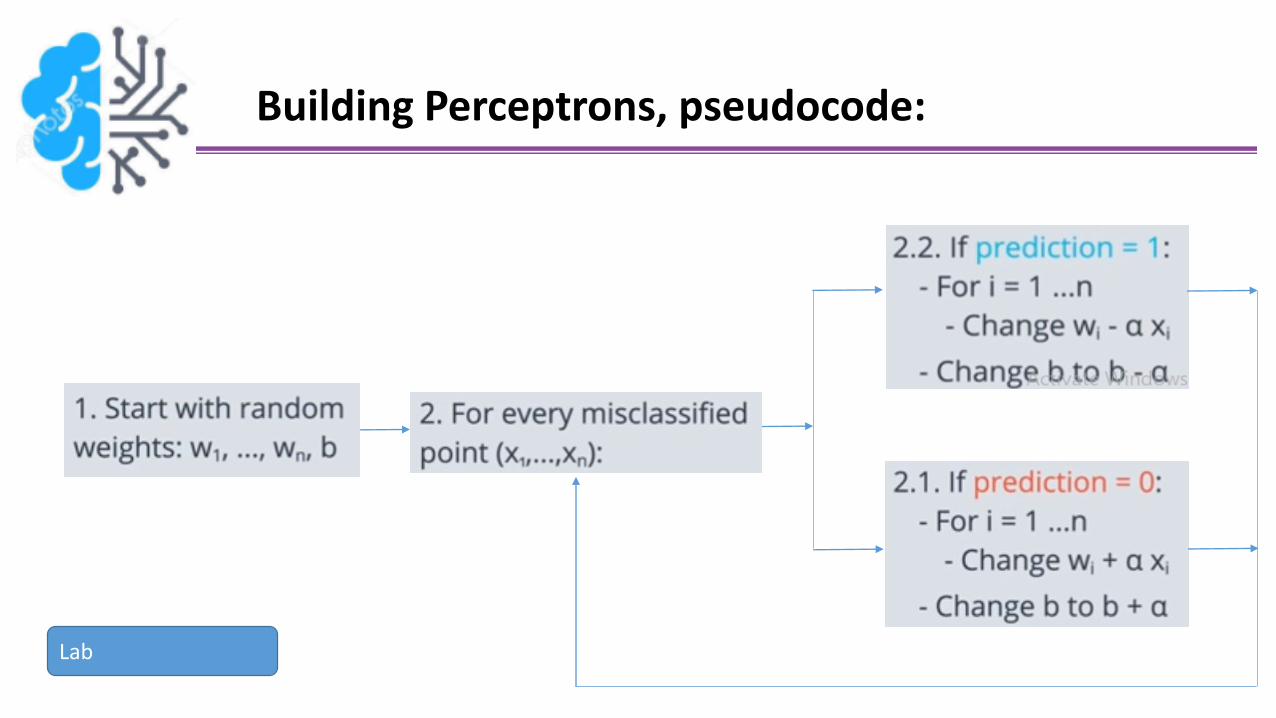
Building Perceptrons, pseudocode:
Lab
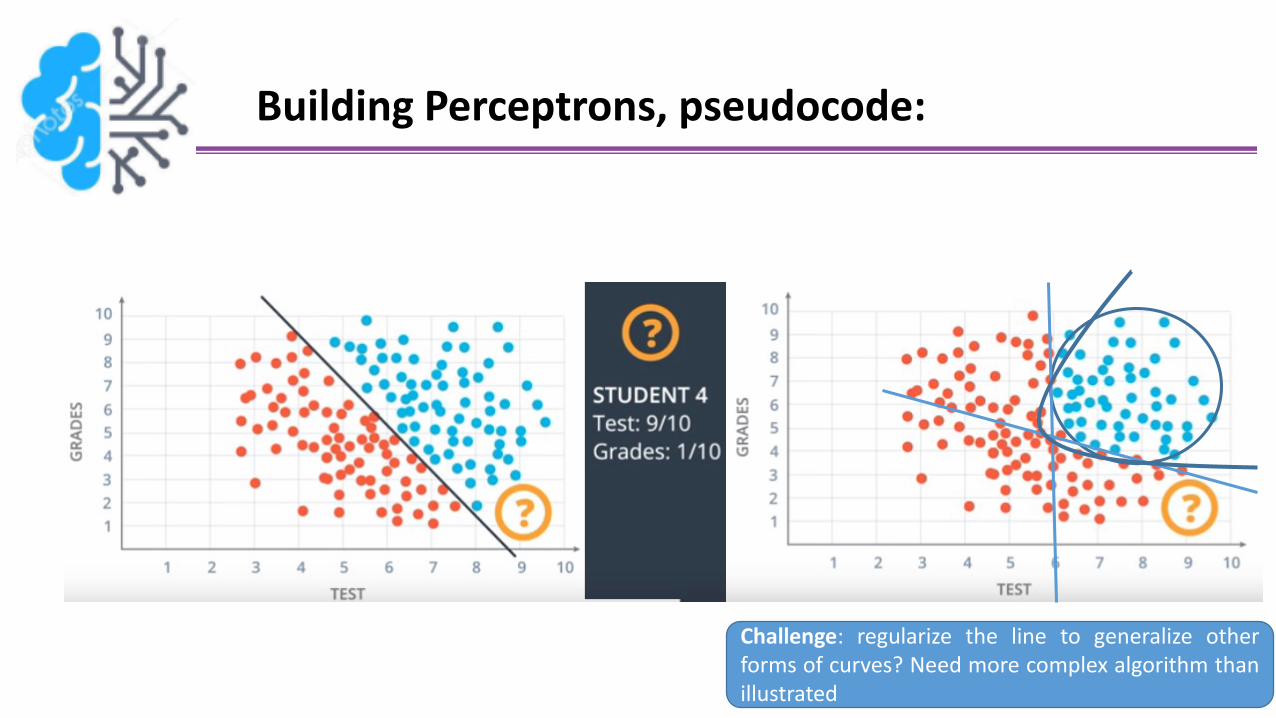
Building Perceptrons, pseudocode:
Challenge: regularize the line to generalize otherforms of curves? Need more complex algorithm thanillustrated

Error Function:
• Target: no misclassified points
• How? Start randomly, explore possibilities and then based on
error determined (here, is the # of misclassified points),
take your next step. Repeat until reach zero error/min Still Errors: 2, ?!!
• Problem: get lost, where to head. Is it the target or still
there is minimization (#). Also, It doesn’t reflect exactly the
situation (error in expectation with less confidence better
than that of same error but with higher confidence)
• Error function as Continuous fn is better than discrete inoptimization process.
1 2 3
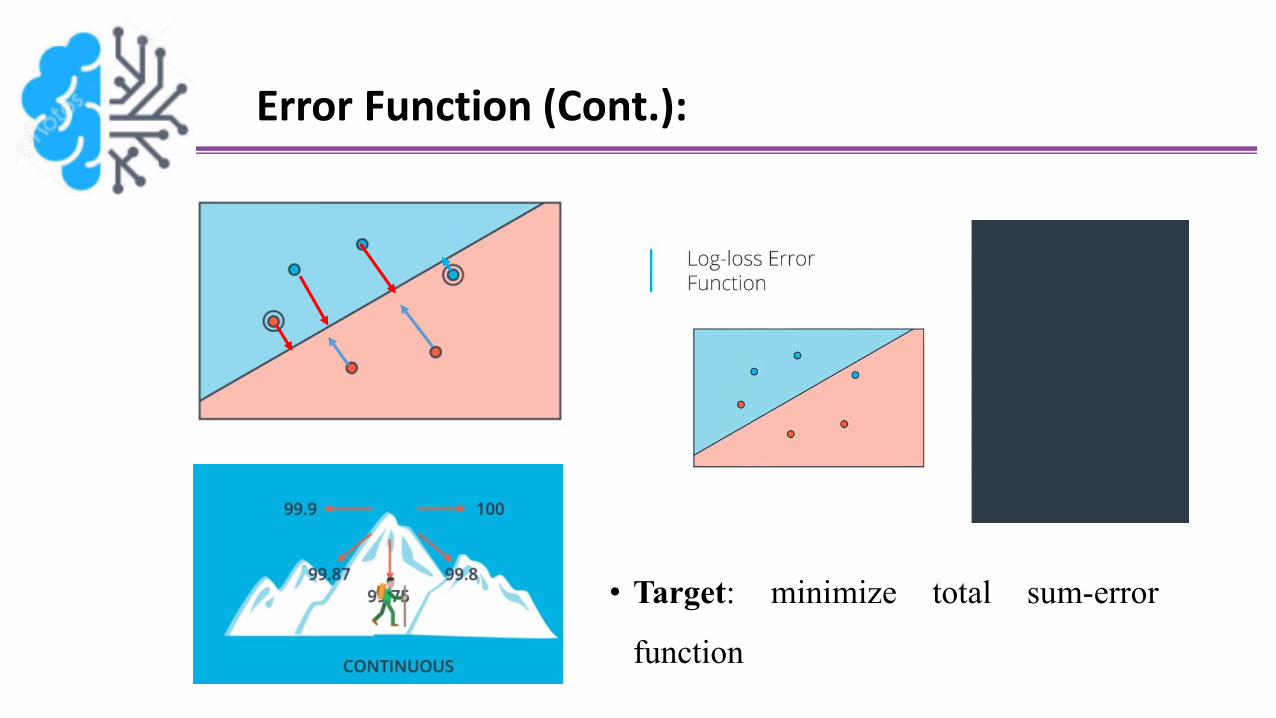
Error Function (Cont.):
• Target: minimize total sum-error
function

Error Function/Gradient Descent:
Challenge: How do we find this error-function?

Error Function/Discrete to Continuous:

Error Function/Discrete to Continuous (Cont.):
• Using Step-function:
• ≥ 𝟎 prediction=1 (blue point).
• < 𝟎 prediction=0 (red point).
• As mentioned, this doesn’t reflect the
situation exactly and it delete some
important data
• Using Sigmoid-function:
• Reflects the confidence of prediction,
0.6 means 60% is blue point
• It benefits from all data available

Error Function/Discrete to Continuous (Cont.):
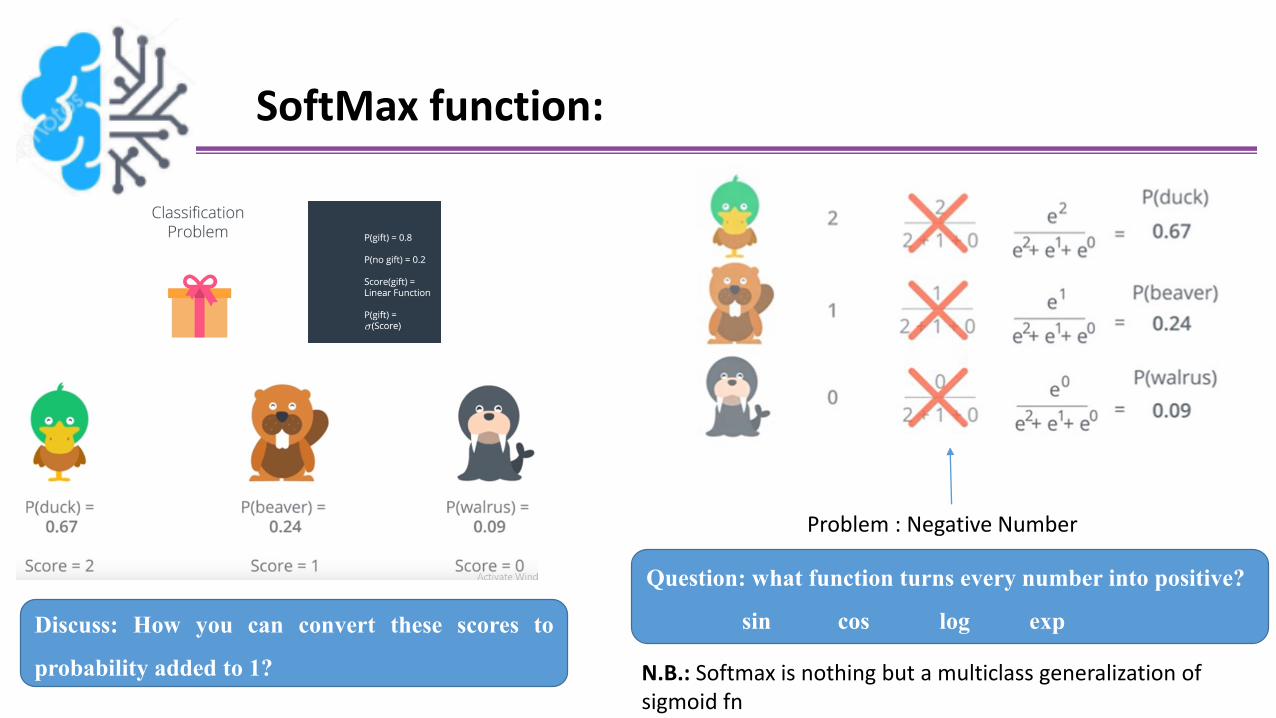
SoftMax function:
Discuss: How you can convert these scores to
probability added to 1?
Problem : Negative Number
Question: what function turns every number into positive?
sin cos log exp
N.B.: Softmax is nothing but a multiclass generalization of sigmoid fn
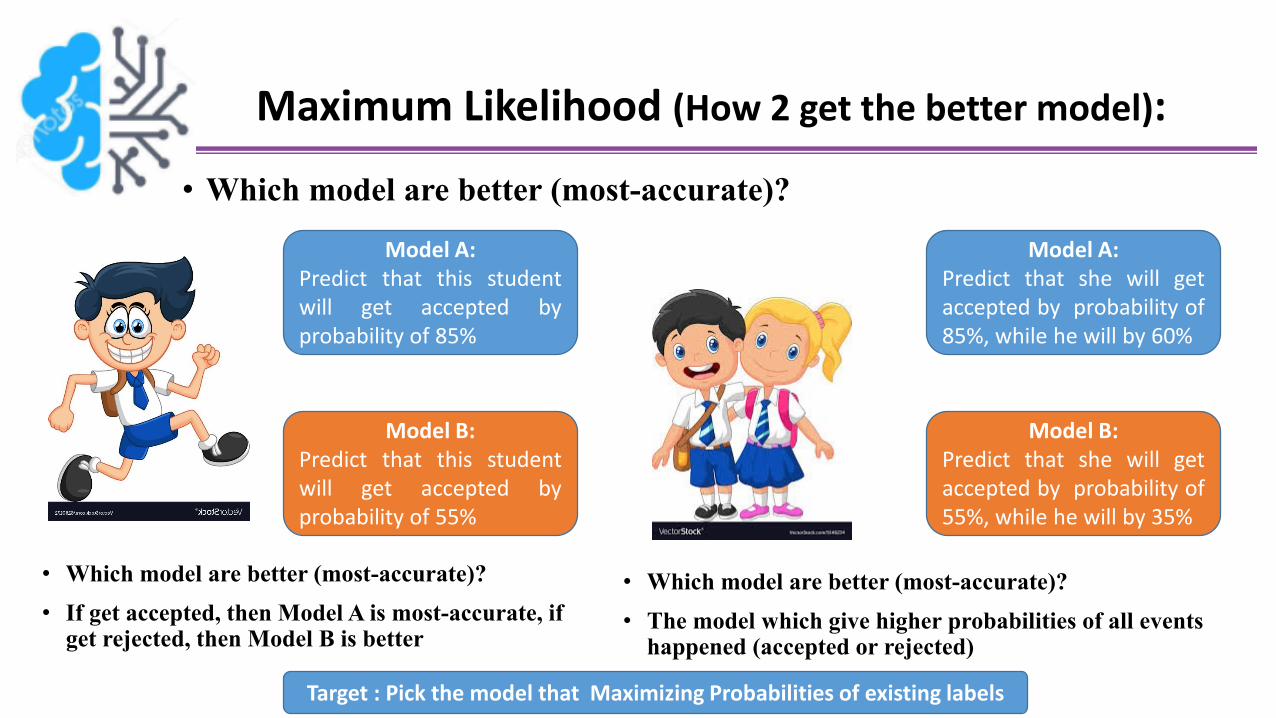
Maximum Likelihood (How 2 get the better model):
• Which model are better (most-accurate)?
• If get accepted, then Model A is most-accurate, if get rejected, then Model B is better
Model A:Predict that this studentwill get accepted byprobability of 85%
Model B:Predict that this studentwill get accepted byprobability of 55%
• Which model are better (most-accurate)?
• The model which give higher probabilities of all events happened (accepted or rejected)
Model A:Predict that she will getaccepted by probability of85%, while he will by 60%
Model B:Predict that she will getaccepted by probability of55%, while he will by 35%
• Which model are better (most-accurate)?
Target : Pick the model that Maximizing Probabilities of existing labels
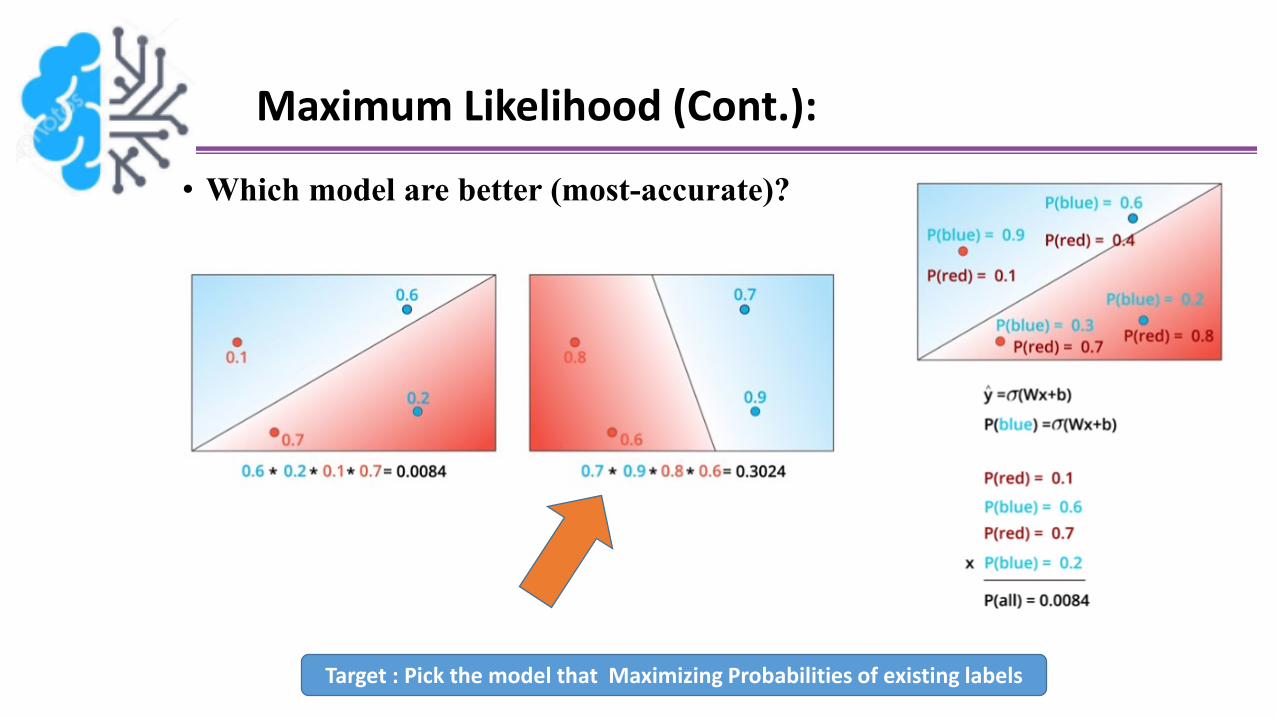
Maximum Likelihood (Cont.):
• Which model are better (most-accurate)?
Target : Pick the model that Maximizing Probabilities of existing labels

Maximum Likelihood (Cont.):
Target : Maximizing the Probabilities Target : minimize total sum-error function
Are they related/dependent?
• Yes, minimizing error fnmean results maximizingprobabilities;
• Problem: Usually, thesevalues are very tiny(0.00001) and they can bethousands of values. Thus,product is very bad and weneed something to be moreeasier


Cross-Entropy:
Cross-Entropy of model, need to minimize CE
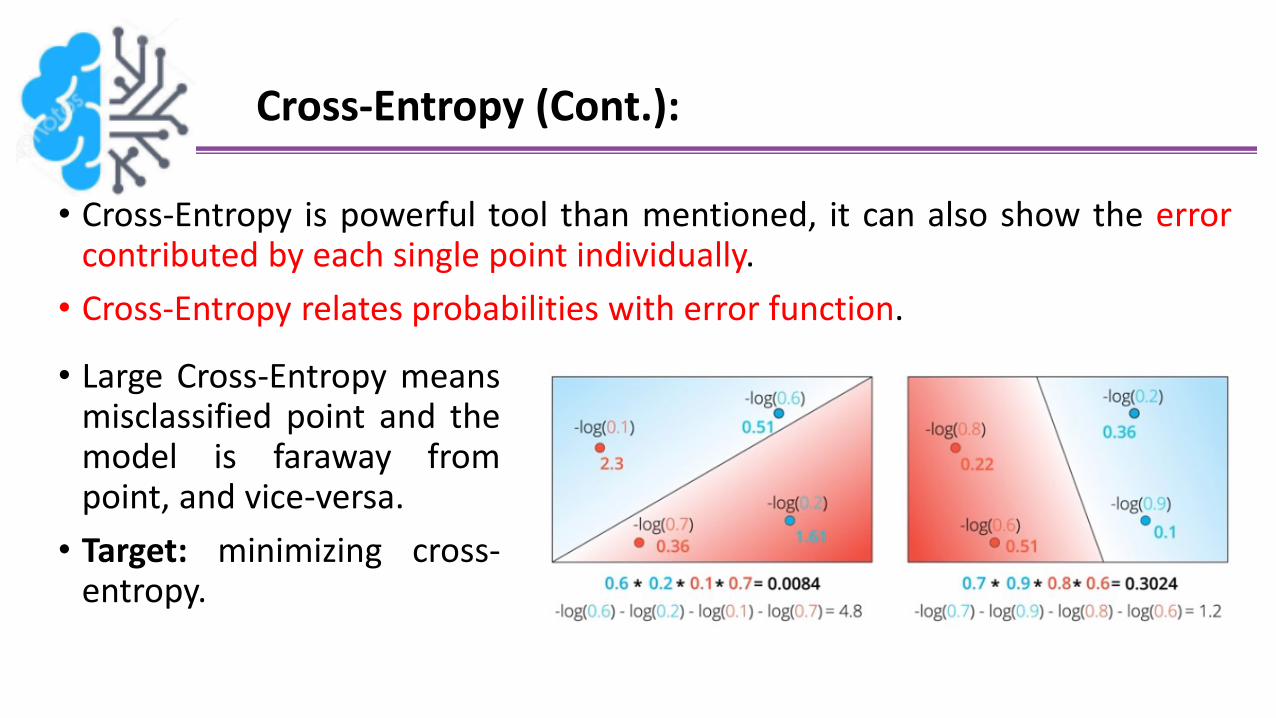
Cross-Entropy (Cont.):
• Cross-Entropy is powerful tool than mentioned, it can also show the errorcontributed by each single point individually.
• Cross-Entropy relates probabilities with error function.
• Large Cross-Entropy meansmisclassified point and themodel is faraway frompoint, and vice-versa.
• Target: minimizing cross-entropy.

Cross-Entropy (Cont.):
• Another Example (2 classes):
• Maximizing Probabilities
Minimizing Cross-Entropy
• See all values, it is not possible tomaximize unless it is correct !
• Cross-Entropy Formula derivation:
• Cross-Entropy tells us also how muchsimilar/different two vectors are, seeCE((1,1,0),(0.8,0.7,0.1) which means thatarrangement is likely to happen (0.69), whereCE((0,0,1),(0.8,0.7,0.1) is not likely happen (5.12)
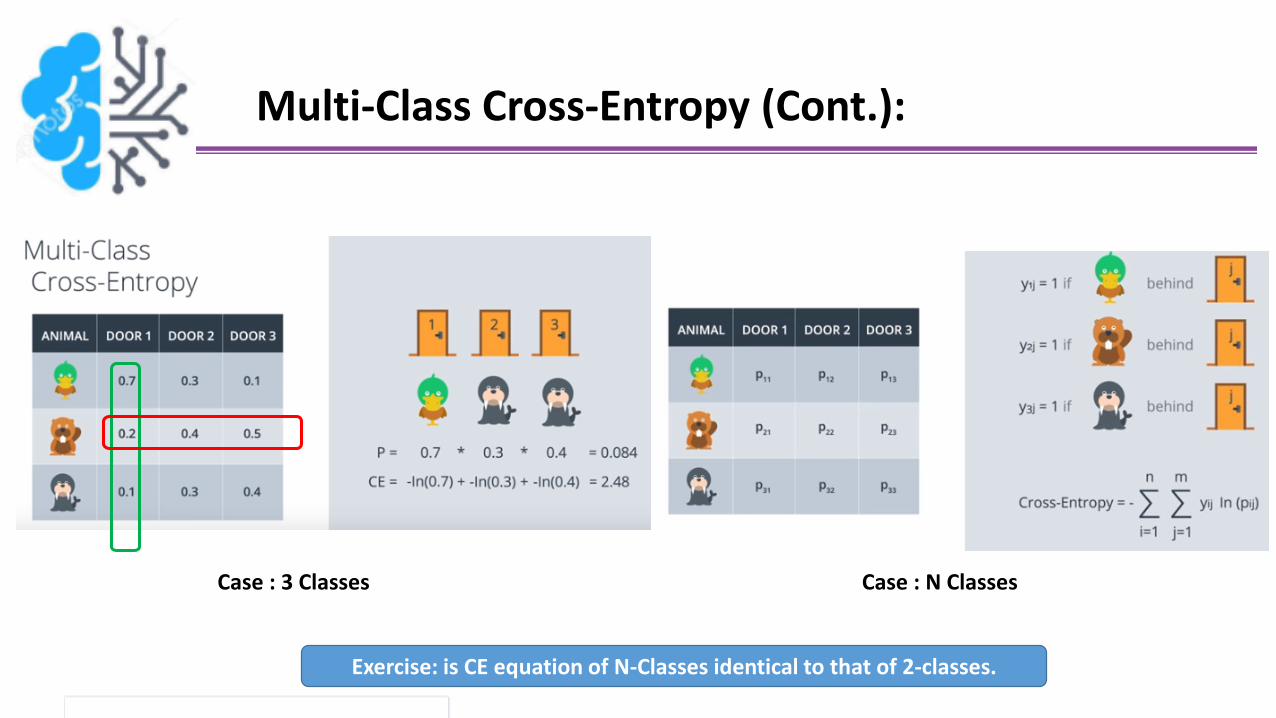
Multi-Class Cross-Entropy (Cont.):
Case : 3 Classes Case : N Classes
Exercise: is CE equation of N-Classes identical to that of 2-classes.

Logistic Regression:
• Now, we're finally ready for one of the most popular and useful algorithmsin Machine Learning, and the building block of all that constitutes DeepLearning.
• It basically goes like this: Take your data Pick a random model Calculate the error Minimize the error, and obtain a better model Enjoy!

Logistic Regression (Cont.):
Calculate the error:Let's dive into the details of how calculating error?
Goal: minimize this error (it is in term of W &b)
X & vice versa.
𝑦 = 𝑊𝑥 + 𝑏.

Logistic Regression (Cont.):
X & vice versa.
𝑦 = 𝑊𝑥 + 𝑏.Case : 2 Classes Case : N Classes
• Remember
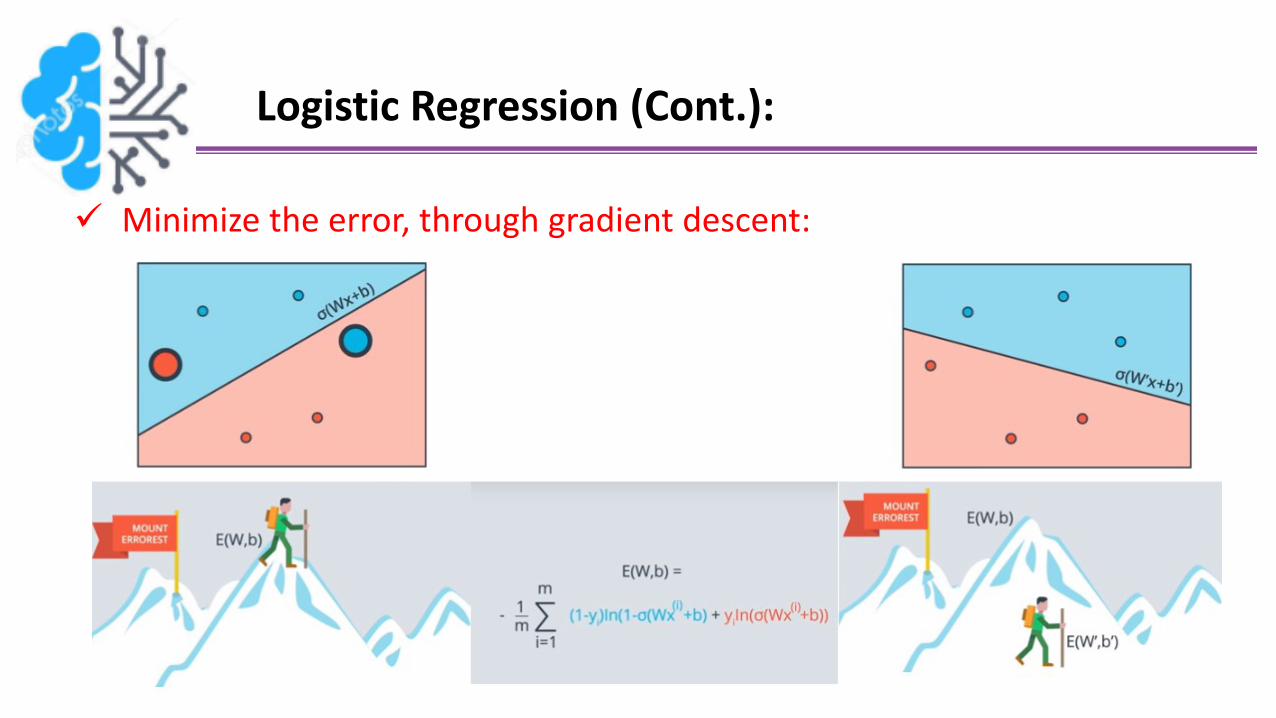
Logistic Regression (Cont.):
Minimize the error, through gradient descent:
X & vice versa.
𝑦 = 𝑊𝑥 + 𝑏.

Gradient Descent:
• Let learn the principles and math behind the gradient descent algorithm
X & vice versa.
𝑦 = 𝑊𝑥 + 𝑏.

Gradient Descent (Cont.):
• Gradient Calculation: refer to pdf file for details.
X & vice versa.
𝑦 = 𝑊𝑥 + 𝑏.

Gradient Descent Algorithm (PsuedoCode):
X & vice versa.
𝑦 = 𝑊𝑥 + 𝑏.epoch

Perceptron vs Gradient Descent:
X & vice versa.
𝑦 = 𝑊𝑥 + 𝑏.
• 𝒚 can be 𝟎 ≤ 𝒚 ≤ 𝟏 𝒚 can be either 𝟎 or 1 only

Perceptron vs Gradient Descent:
X & vice versa.
𝑦 = 𝑊𝑥 + 𝑏.

Neural Network Architecture:
X & vice versa.
𝑦 = 𝑊𝑥 + 𝑏.
Ok, so we're ready to put these building blocks together, and build great Neural Networks! (Or Multi-Layer Perceptrons)
Basic principle of combining regions
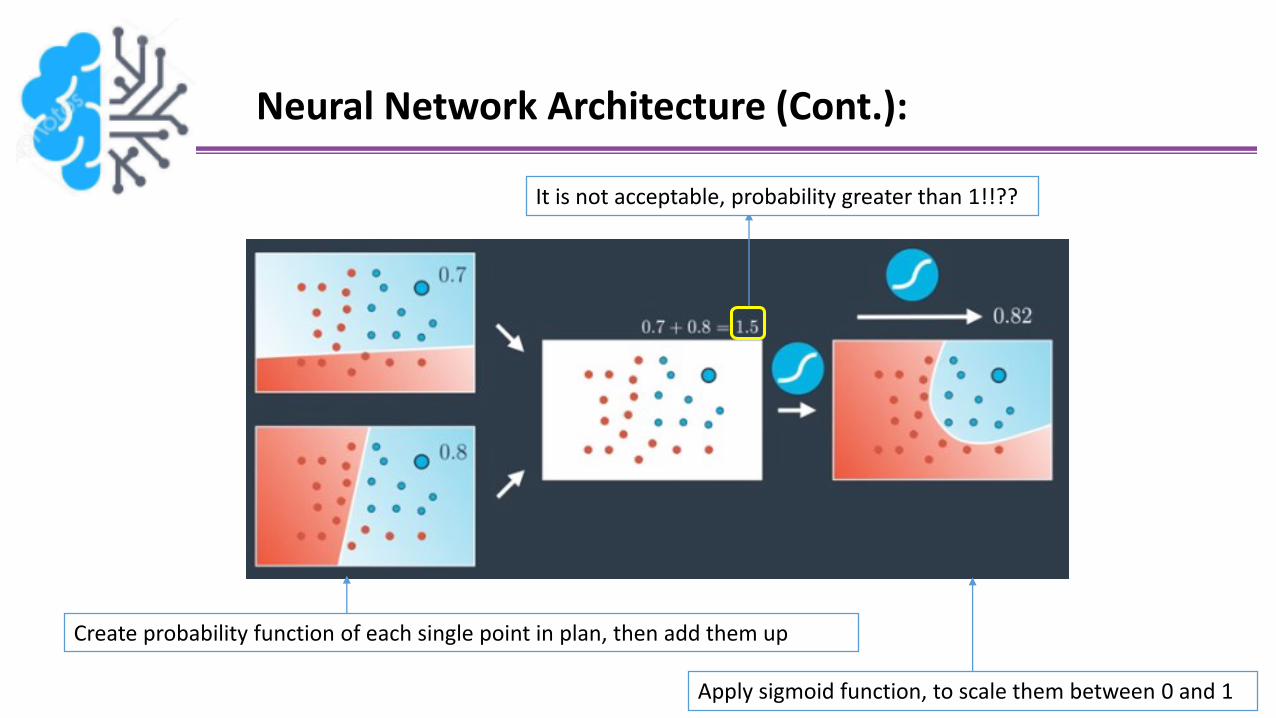
Neural Network Architecture (Cont.):
X & vice versa.
𝑦 = 𝑊𝑥 + 𝑏.
It is not acceptable, probability greater than 1!!??
Create probability function of each single point in plan, then add them up
Apply sigmoid function, to scale them between 0 and 1
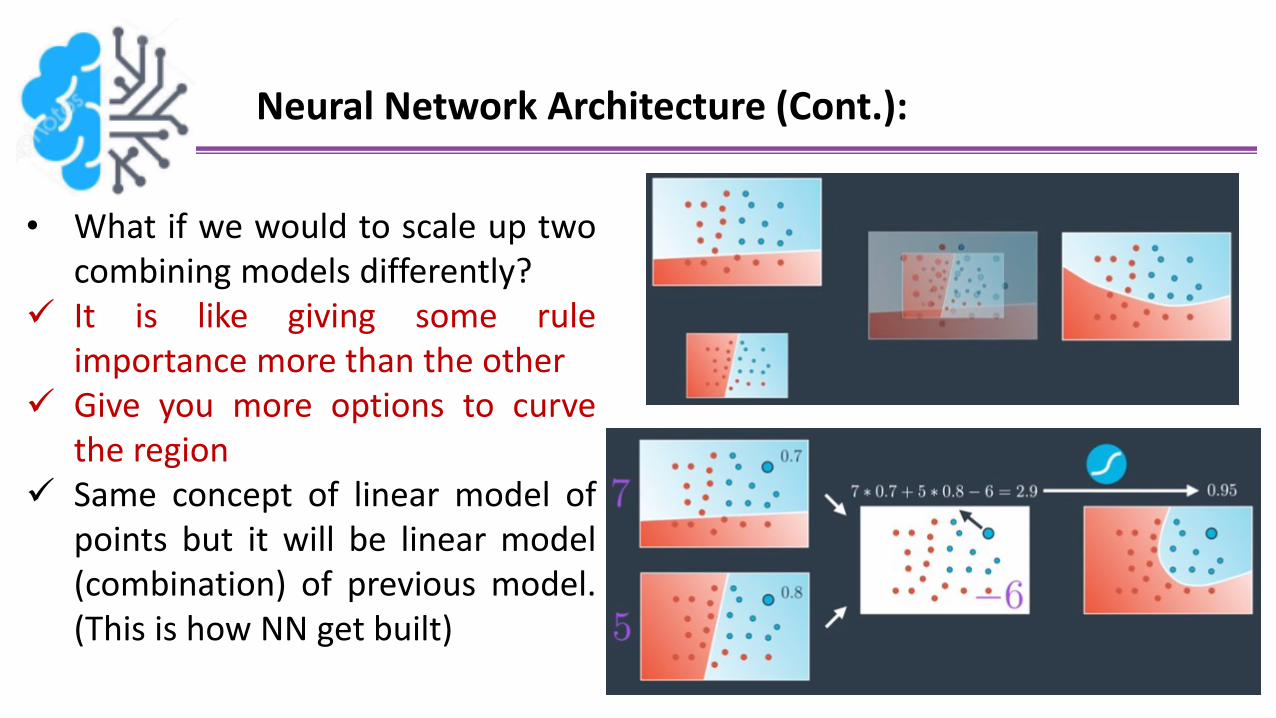
Neural Network Architecture (Cont.):
X & vice versa.
𝑦 = 𝑊𝑥 + 𝑏.
• What if we would to scale up twocombining models differently?
It is like giving some ruleimportance more than the other
Give you more options to curvethe region
Same concept of linear model ofpoints but it will be linear model(combination) of previous model.(This is how NN get built)
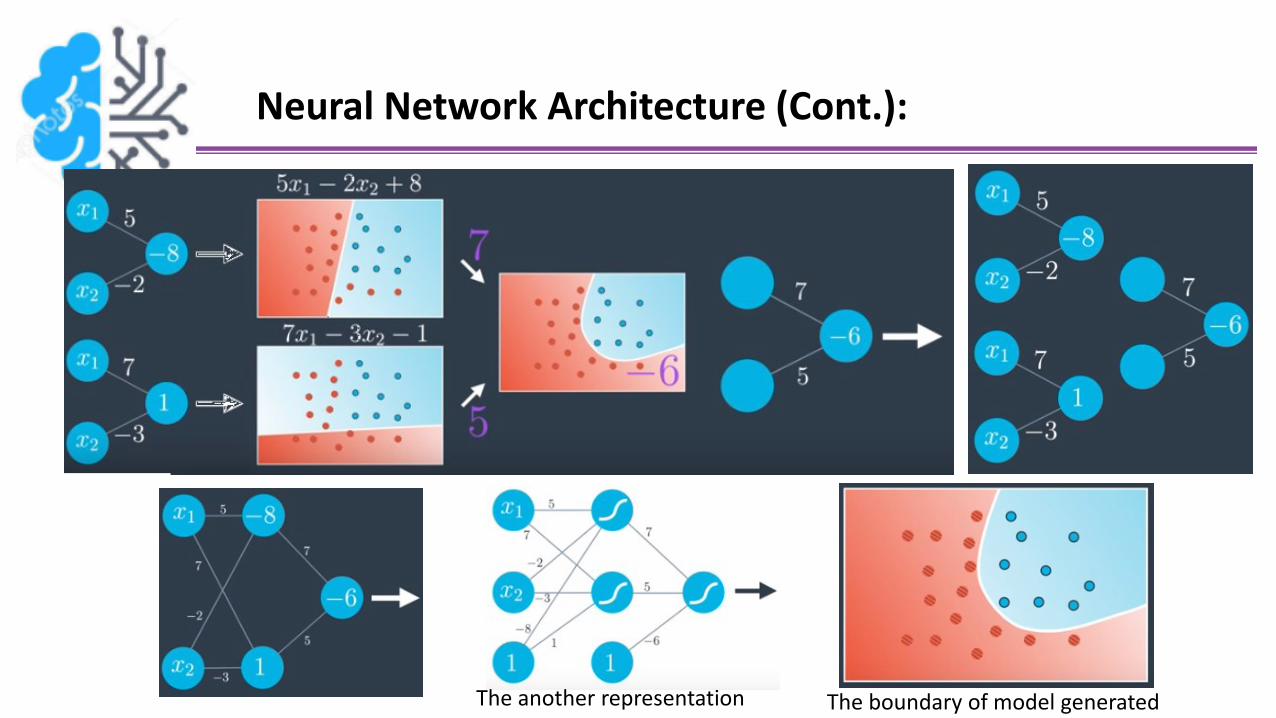
Neural Network Architecture (Cont.):
X & vice versa.
The another representation The boundary of model generated
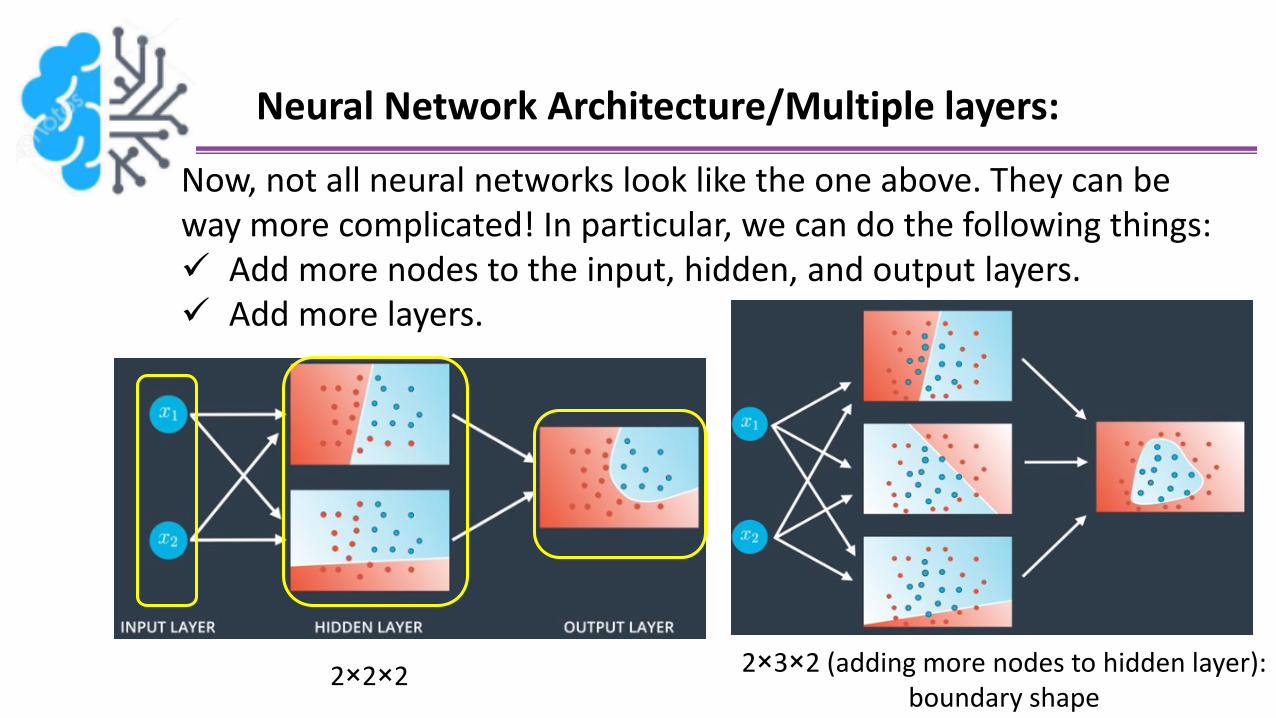
Neural Network Architecture/Multiple layers:
X & vice versa.
Now, not all neural networks look like the one above. They can be way more complicated! In particular, we can do the following things: Add more nodes to the input, hidden, and output layers. Add more layers.
2×2×2 2×3×2 (adding more nodes to hidden layer): boundary shape

Neural Network Architecture/Multiple layers (Conts.):
X & vice versa.
3×2×2 (adding more nodes to input layer: space dimension)
2×2×3 (adding more nodes to output layer: Multiclass classification)

Neural Network Architecture/Multiple layers (Conts.):
X & vice versa.
2×(2×2)×2 (adding more hidden-layer: deep NN: more complicated non-linear model)
N×(M×K)×1 (more & more complicated non-linear model but with binary
classification (i.e. gift or not))
Exercise: what about multi-class classification complicated non-linear problem.

Deep NN/Multi-class problem:
X & vice versa.
Soft-max
This would be over-kill
This is the right implementation
Discuss: How manynodes in the outputlayer would yourequire if you weretrying to classify allthe letters in theEnglish alphabet?
26
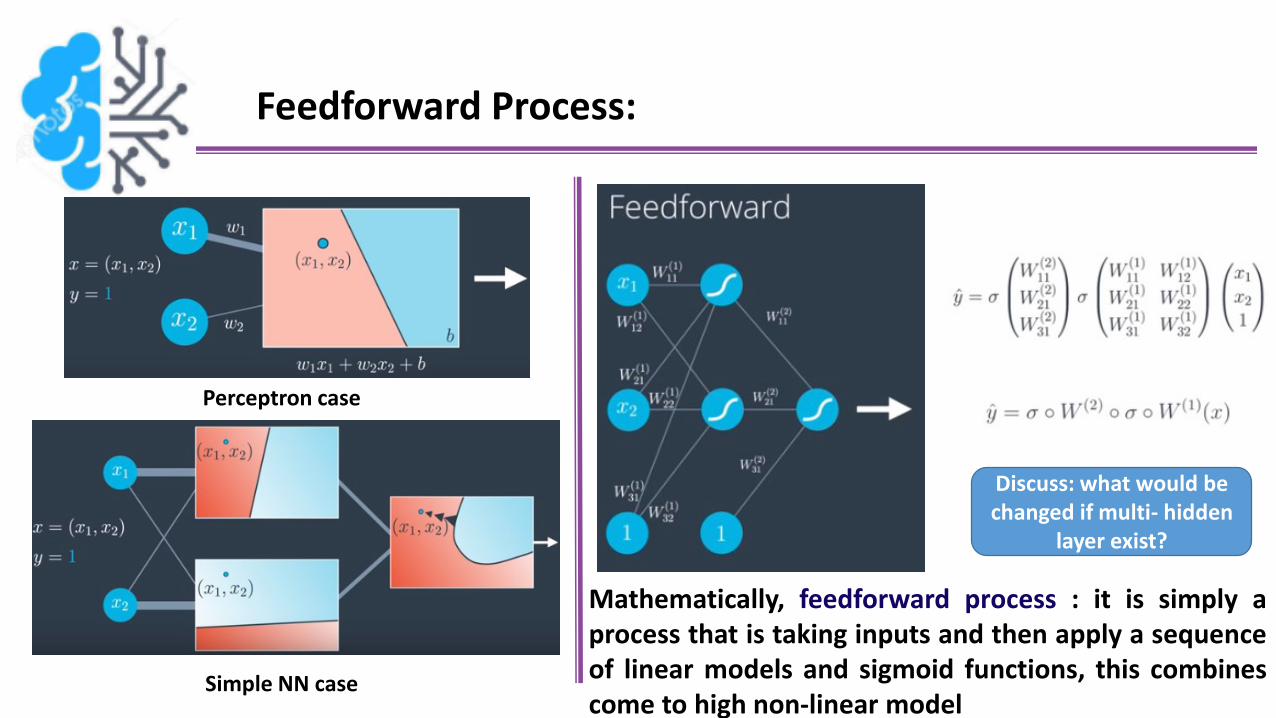
Feedforward Process:
X & vice versa.
Perceptron case
Simple NN case
Mathematically, feedforward process : it is simply aprocess that is taking inputs and then apply a sequenceof linear models and sigmoid functions, this combinescome to high non-linear model
Discuss: what would be changed if multi- hidden
layer exist?
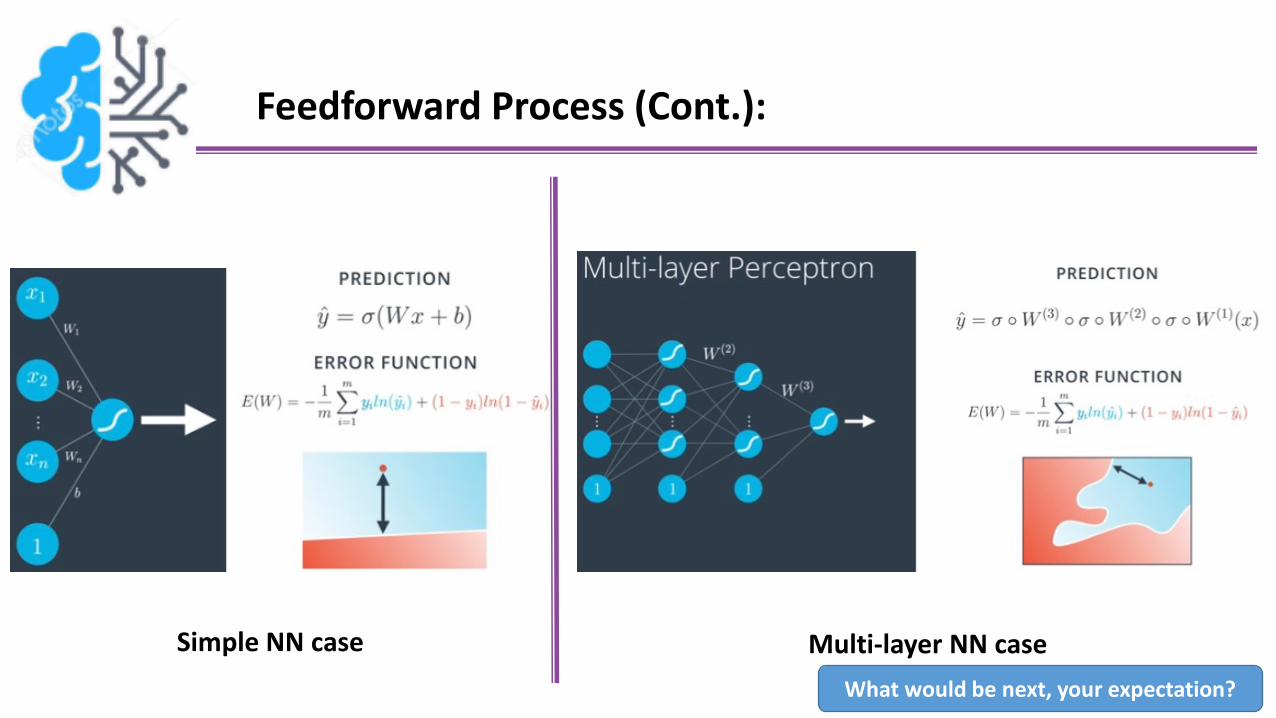
Feedforward Process (Cont.):
X & vice versa.
Simple NN case Multi-layer NN case
What would be next, your expectation?
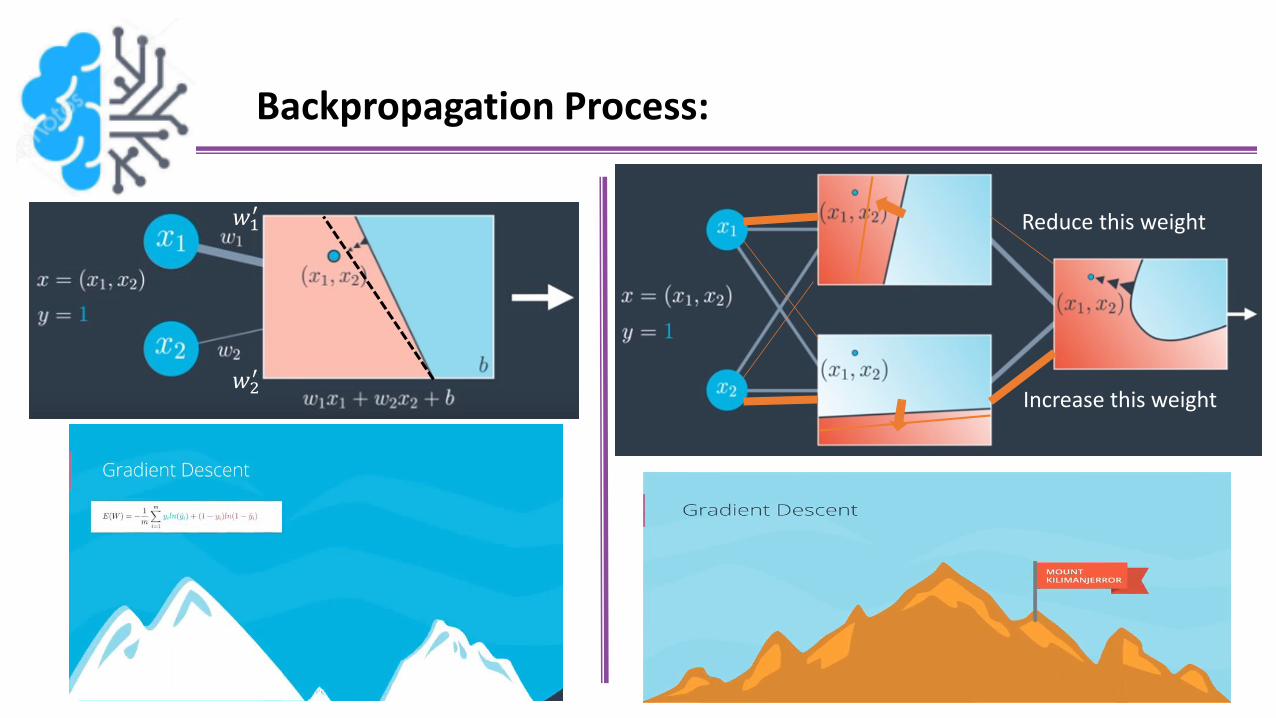
Backpropagation Process:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight

Backpropagation Process (Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
In a nutshell, backpropagation consists of:
Doing a feedforward operation.
Comparing the output of the model with the desired output.
Calculating the error.
Running the feedforward operation backwards
(backpropagation) to spread the error to each of the weights.
Use this to update the weights, and get a better model.
Continue this until we have a model that is good.

Backpropagation Process Math:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
Refer to pdf file

Training Optimization:
𝑤1′
𝑤2′
Reduce this weight
Increase this weightWhich model is better?Simple/ complexAccurate/less accurate
TO know which one is better, we introduce the concept of training and testing test
Train model with training test without looking on test set and then use test set to assess the model
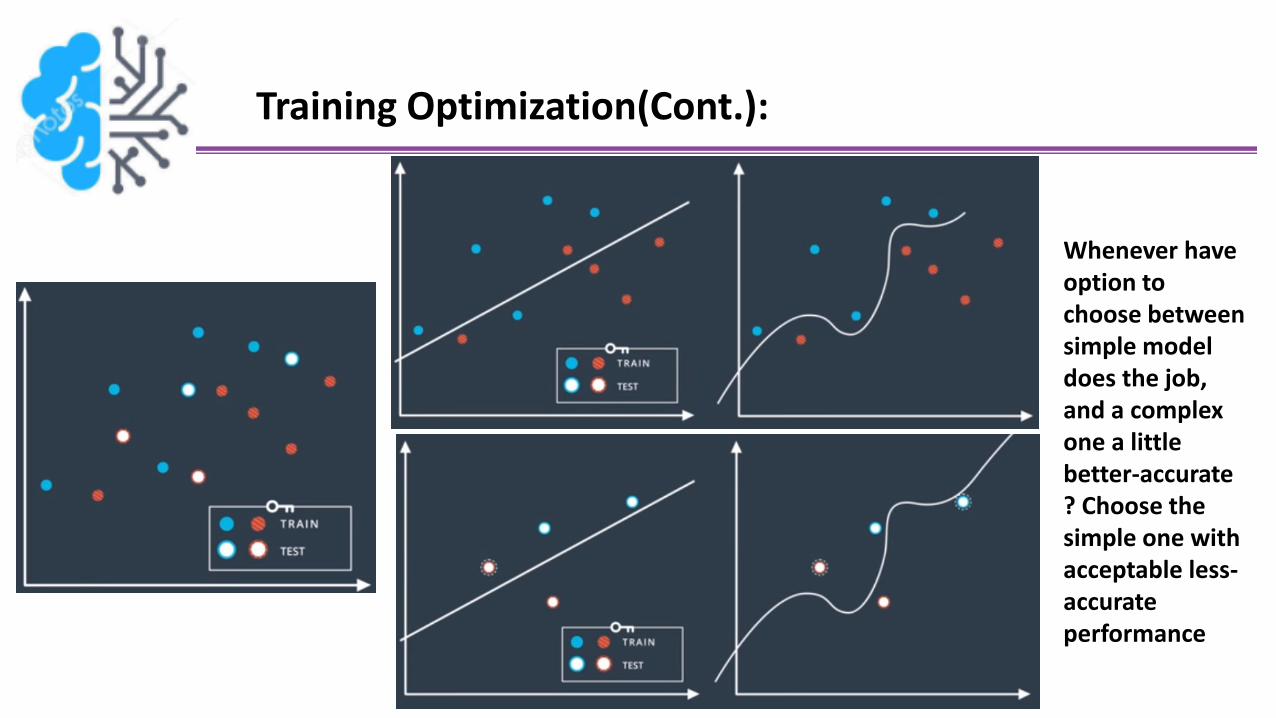
Training Optimization(Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
Whenever have option to choose between simple model does the job, and a complex one a little better-accurate ? Choose the simple one with acceptable less-accurate performance


Overfitting and Under-fitting:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
Type of Error in life:
Oversimplifying the problem It wouldn’t workML: under fitting
overcomplicated and resources waste, where simple tools would work ML: overfitting

Overfitting and Under-fitting (Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
Could you expect a proper-fit model?Dogs & not dog

Overfitting and Under-fitting (Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
Another example, like studying for exam:
Not studying well, under fitting, you’ll
fail in exam.
proper-fitting: studying well and doing
well in exam.
Memorizing the book word by word,
overfitting, this lead also to not
answer properly the exam’s question.
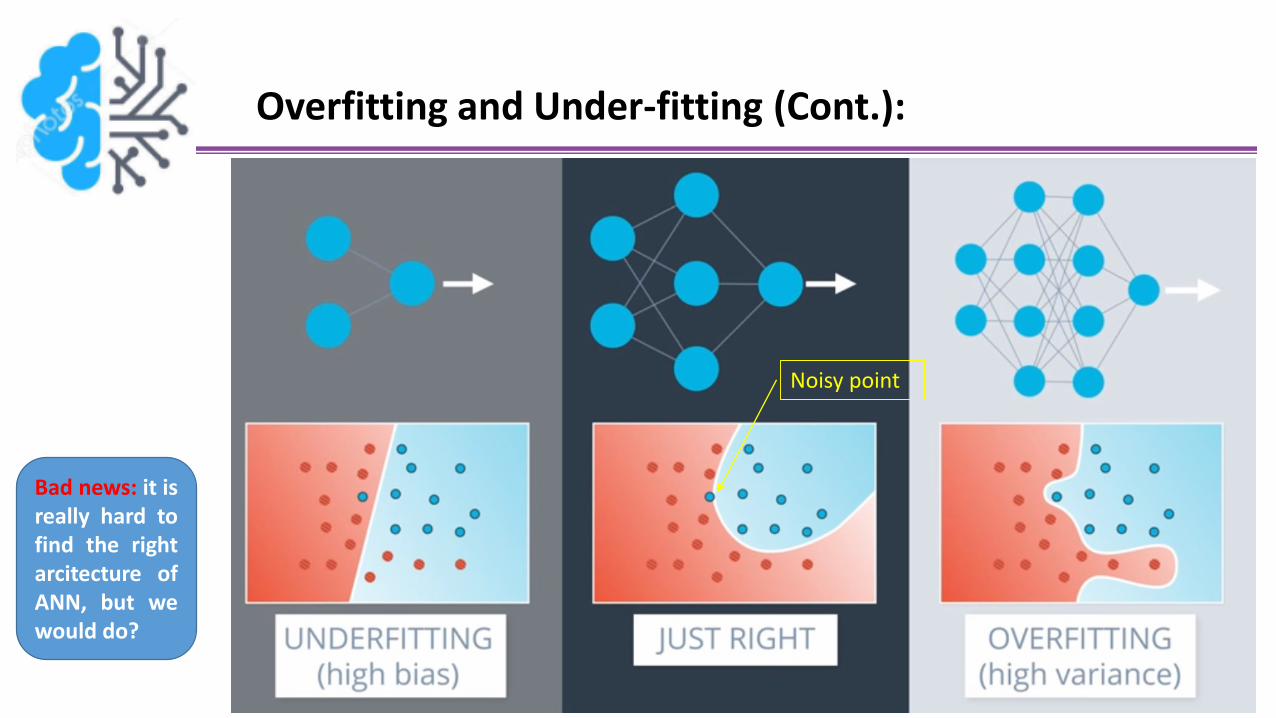
Overfitting and Under-fitting (Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
Bad news: it isreally hard tofind the rightarcitecture ofANN, but wewould do?
Noisy point

Overfitting and Under-fitting (Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
Start random, and then either:
It is Under-fitting model,
then go higher
It is Over-fitting model, then
go lower
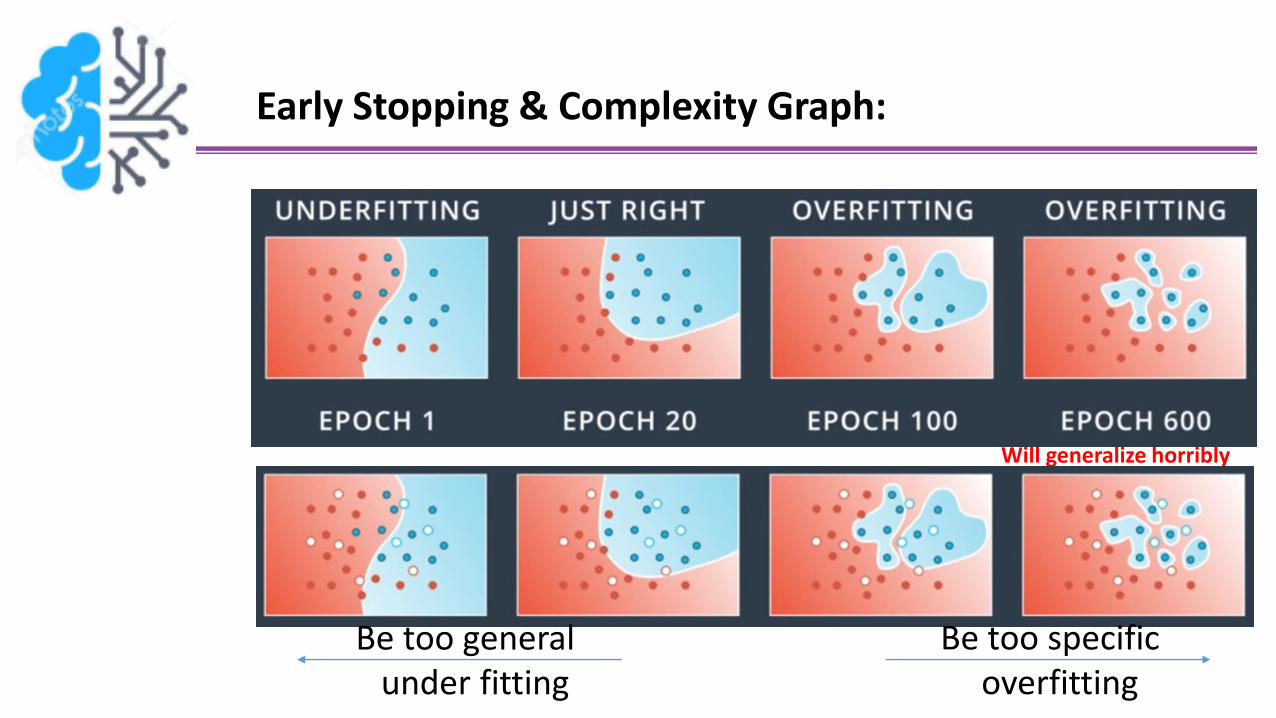
Early Stopping & Complexity Graph:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
Will generalize horribly
Be too specificoverfitting
Be too generalunder fitting

Early-stopping & Complexity Graph (Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
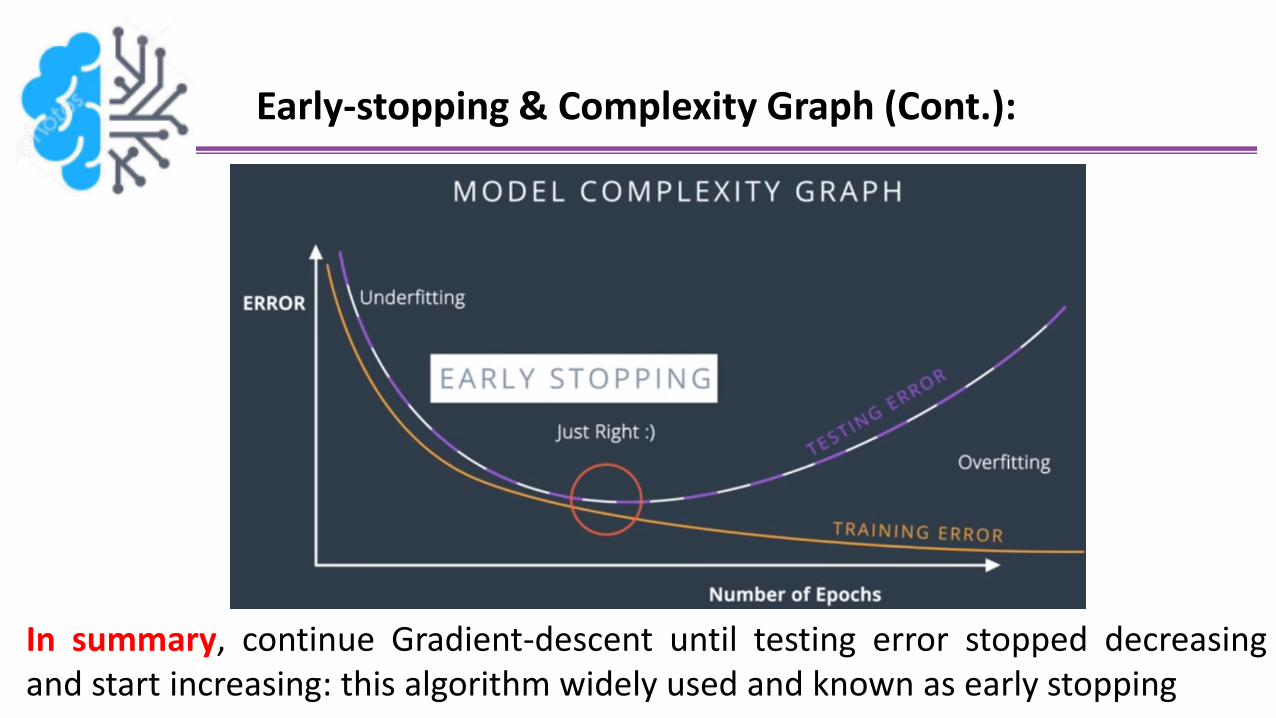
Early-stopping & Complexity Graph (Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
In summary, continue Gradient-descent until testing error stopped decreasingand start increasing: this algorithm widely used and known as early stopping

Regularization:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
This is better. Are you sure?, now, it is correct but in last of this section you may be bit reluctant
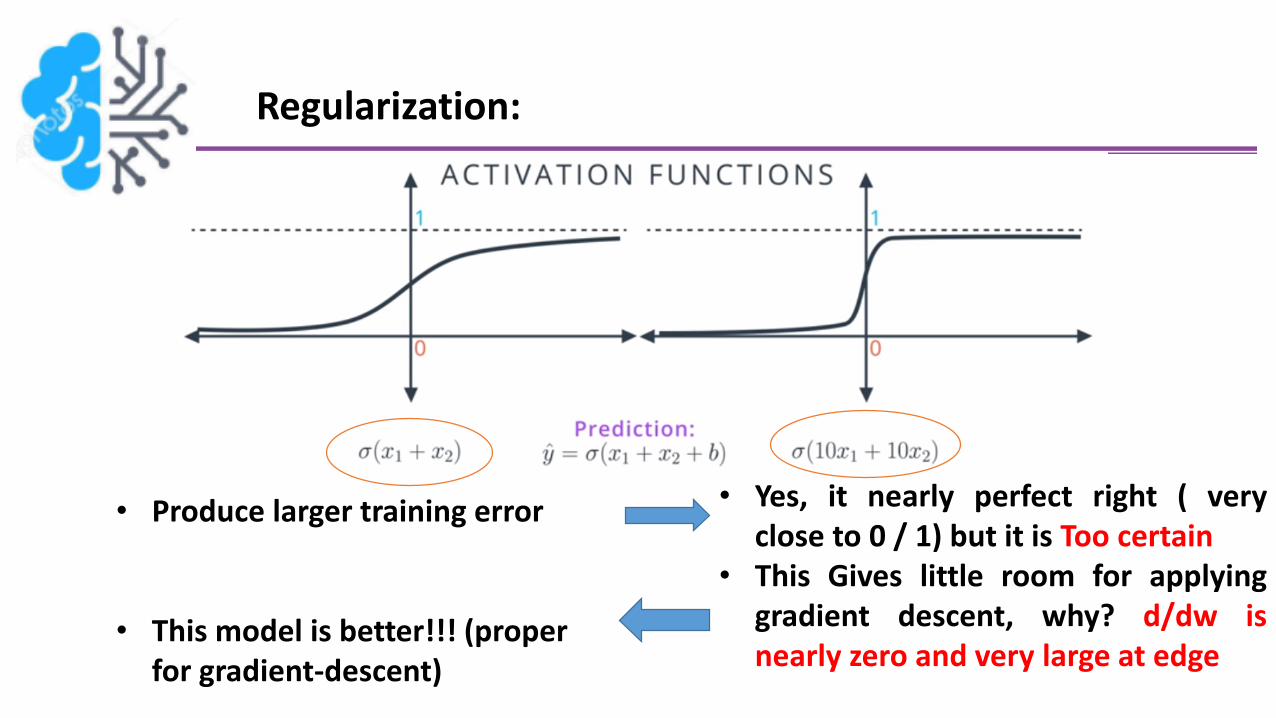
Regularization:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
• Yes, it nearly perfect right ( veryclose to 0 / 1) but it is Too certain
• This Gives little room for applyinggradient descent, why? d/dw isnearly zero and very large at edge
• Produce larger training error
• This model is better!!! (proper for gradient-descent)

Regularization (Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight

Regularization (Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
This factor determines the penalization amount

Regularization (Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
• Produces vectors with sparse weights. If we want to reduce # of weights & end
up with a small set If we have problem of hundreds of
features , L1 help in selecting which onesare important and it turns the rest tozeros
• It tends not to favour sparse vector since it tries to maintain all the weights homogenously small
Better for training Model It is mostly used.
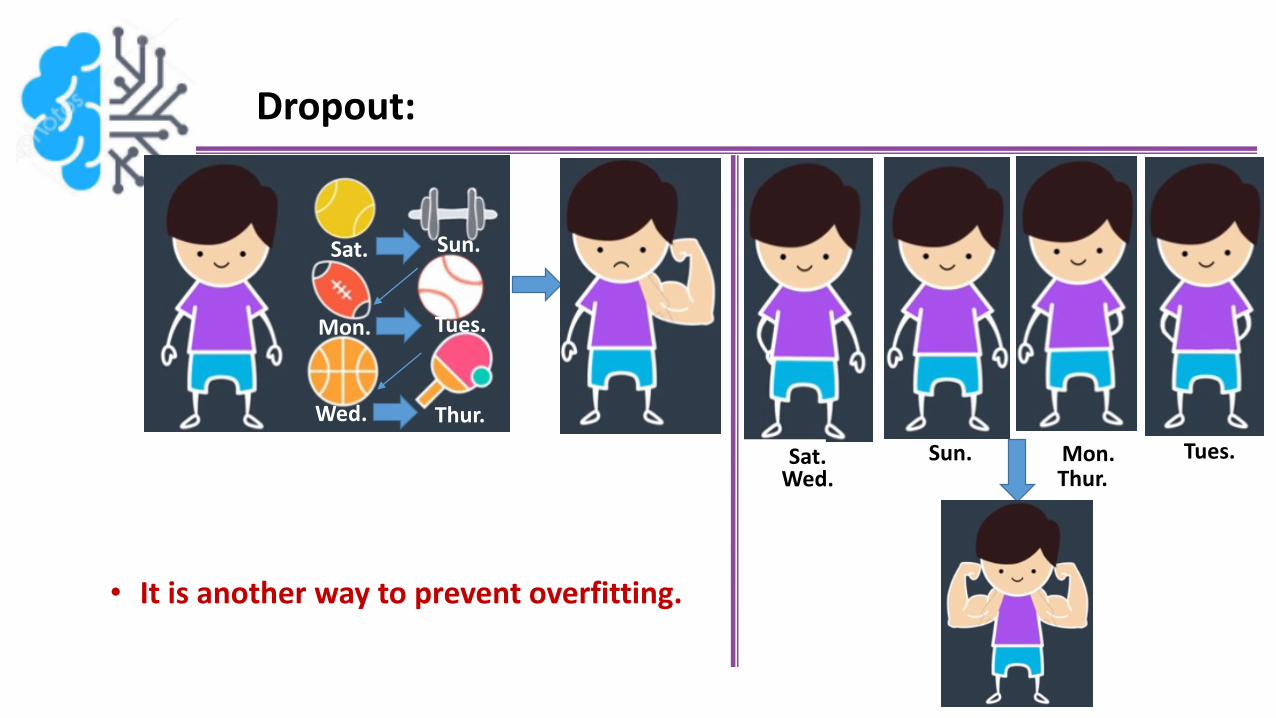
Dropout:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
• It is another way to prevent overfitting.
Sat. Sun.
Mon. Tues.
Wed. Thur.
Sat.Wed.
Tues.Thur.
Sun. Mon.
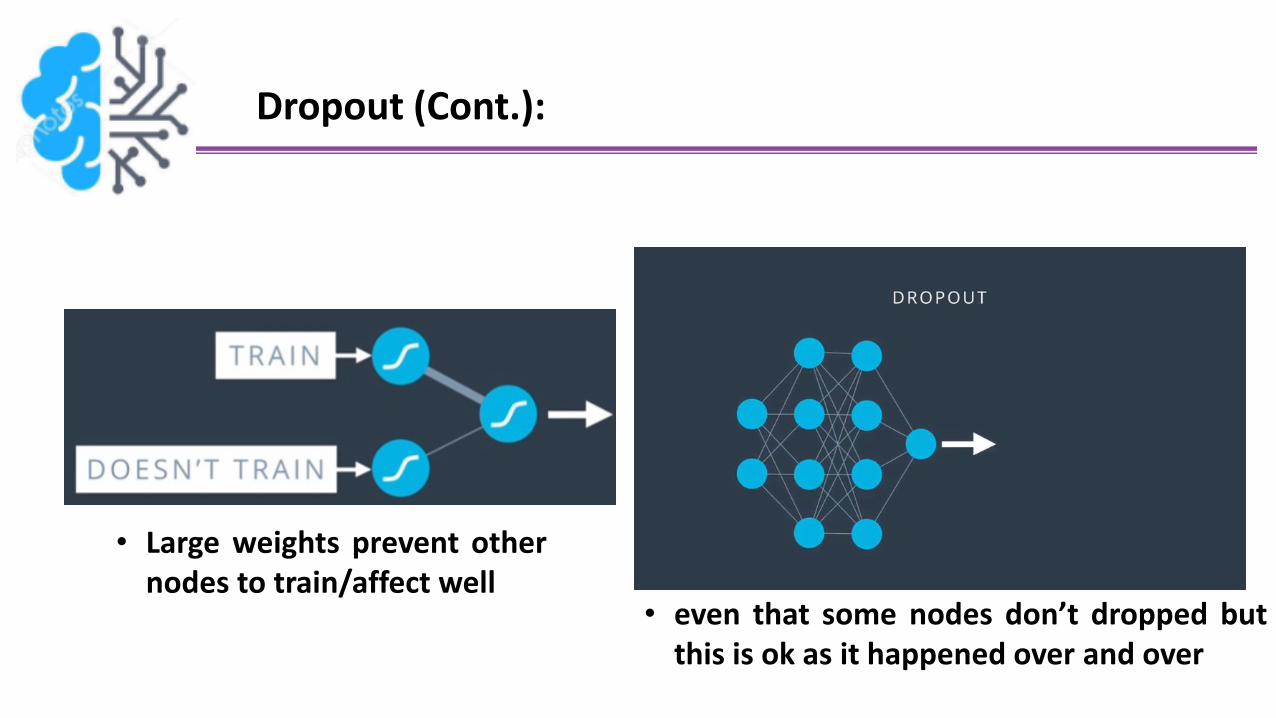
Dropout (Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
• Large weights prevent othernodes to train/affect well
• even that some nodes don’t dropped butthis is ok as it happened over and over

Local Minima/Random Start:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
Potential solution: random starts

Momentum:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
Even if it pushyou away but itturns back
Force you toskip the localminima

Vanishing Gradient:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
• Here is another problem can occur, where the gradient isvanishing.
• You can notice that the curve comes nearly flat at sides,hence derivative is almost zero, which is bad. This tells uswhere to move??.
• This comes worse in multi-layer model, see below whythis is becoming worse?
Very tiny steps, and then will never reachDiscuss: what would solve
this problem?
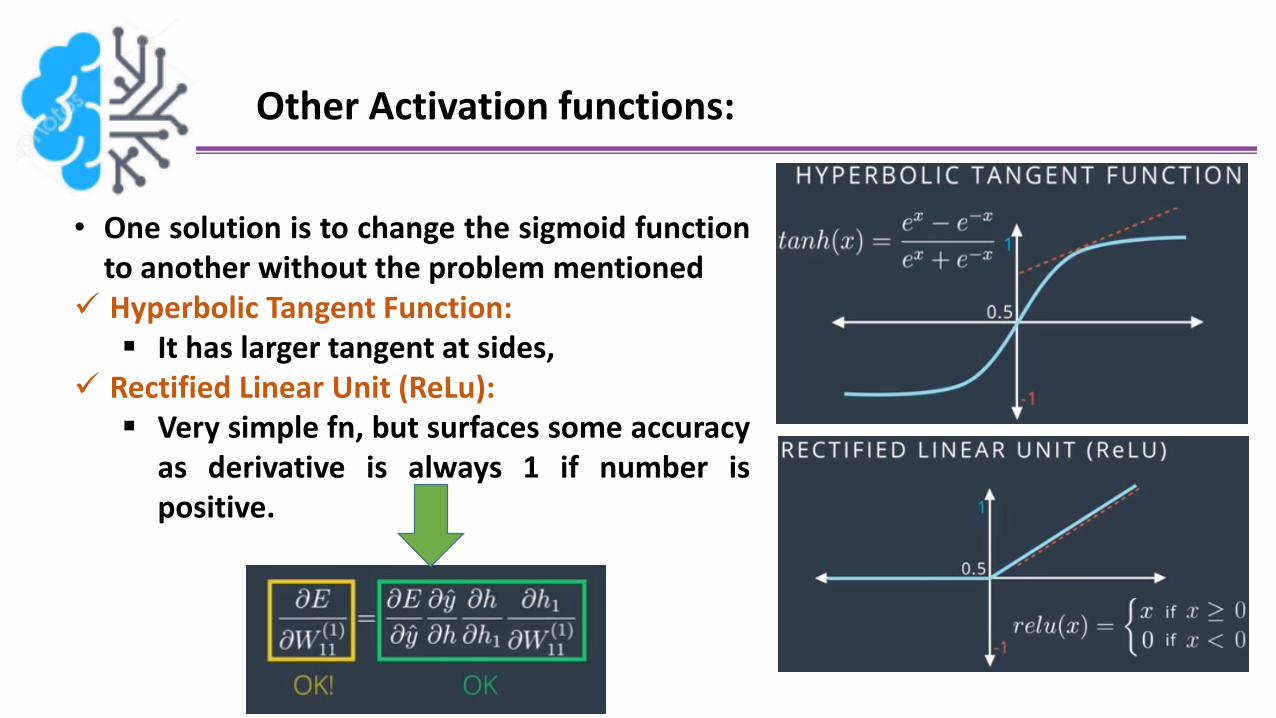
Other Activation functions:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
• One solution is to change the sigmoid functionto another without the problem mentioned
Hyperbolic Tangent Function: It has larger tangent at sides,
Rectified Linear Unit (ReLu): Very simple fn, but surfaces some accuracy
as derivative is always 1 if number ispositive.
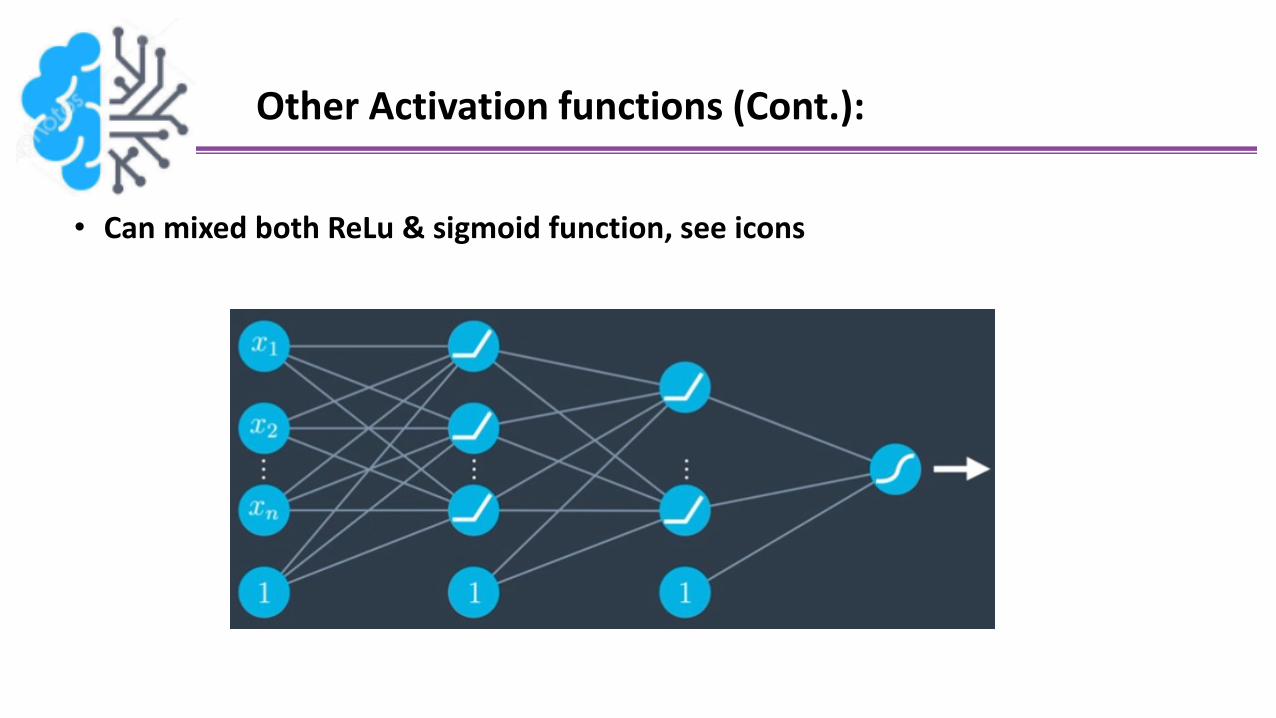
Other Activation functions (Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
• Can mixed both ReLu & sigmoid function, see icons
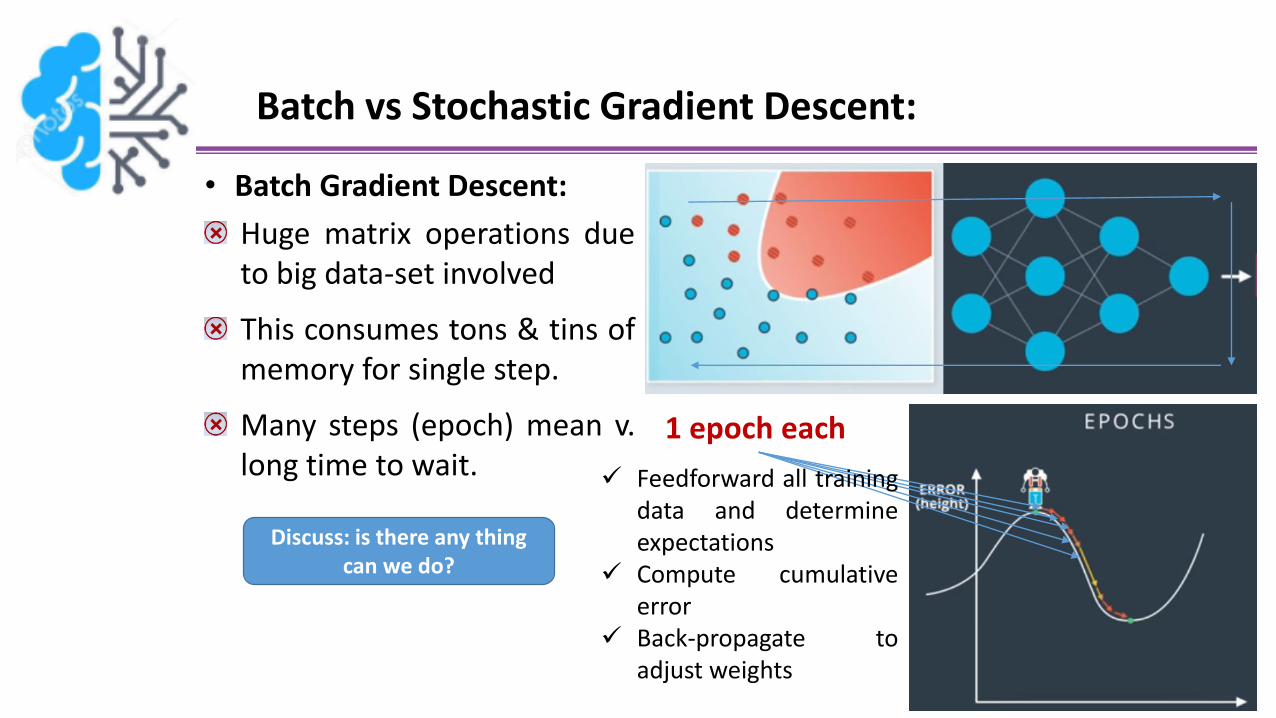
Batch vs Stochastic Gradient Descent:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
• Batch Gradient Descent:
Huge matrix operations dueto big data-set involved
This consumes tons & tins ofmemory for single step.
Many steps (epoch) mean v.long time to wait.
1 epoch each
Feedforward all trainingdata and determineexpectations
Compute cumulativeerror
Back-propagate toadjust weights
Discuss: is there any thing can we do?

Batch vs Stochastic Gradient Descent (Cont.):
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
• Stochastic Gradient Descent:
Divide data into parts
Train model for dataavailable (feedforward &backpropagation)
Turns into new epoch withnext data part and based onthe model trainedpreviously.
Not accurate but fast

Learning Rate:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
• High Learning Rate: Fast at beginning but
You may miss theminimum and keepgoing
Low Learning Rate:
Slow but has steadysteps and have betterchance to locate theminima
General Rule:if your model is not working, decrease your learning rate
Best Learning Rate: KERAS will do that

Error Functions around the world:
𝑤1′
𝑤2′
Reduce this weight
Increase this weight
Best Learning Rate: KERAS will do that
