chapter 3: introduction to convolutional neural...
TRANSCRIPT

Chapter 3:
Introduction to Convolutional Neural Networks
Prepared by
Dr. Mohammed Taha El Astal
TMUL 3310
Artificial Intelligence
Winter 2019

Application of CNN:
• Applications of CNN is limitless
• CNN achieves state-of-art results in variety of problem areas, including voice-userinterfaces, NLP and computer-vision.
Link:https://deepmind.com/blog/wavenet-generative-model-raw-audio/
• Google made use of CNN in its recentlyreleased WaveNet model
• If you supply the algorithm with enoughsamples of your voice, it is possible to trainit to sound just like you
Link: http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/
• Although RNN is used more frequently in NLPthan CNN, CNN can also be used too.
• CNN can be used to extract information fromsentence, like if writer is happy or sad, is helike the movie or dislike it.
TEXT

Application of CNN:
• We’ll focus on computer-vision in using CNN.
Image classification Playing games
Know only the view and possible actions allowed, AI will
develop the strategy by itselfDigitizing handwritten text/number
Check samples of my group projects and games
https://www.facebook.com/groups/464625220715119/

• In general, CNNs can look at images as whole & learn to identify spatial patterns i.e.:
prominent colors and shapes or whether a texture is fuzzy or smooth and son on
• These patterns that define any image & any object in an image are called Features
• We’ll cover how a CNN can learn to identify these features and how a CNN can be
used for image classification
CNN concept:

CNN concept:
• we need this model (our objective), but dataset?
• you might notice that some digits are more legible
than others (38, 49!!)
• For us it is easy, and we need to design a model
that accurately distinguish between these numbers
• Using DL that can examine these images &
discover patterns that distinguish one number
from another
It was of the first databases used to prove
the usefulness ANN

How computer interprets images? Normalization
Normalization: Just divide each
pixel’s value by max (255),
why?
Answer: The reason we typically want normalized pixel values is because neural networks rely on gradientcalculations. These networks are trying to learn how important or how weighty a certain pixel should be indetermining the class of an image. Normalizing the pixel values helps these gradient calculations stayconsistent, and not get so large that they slow down or prevent a network from training.
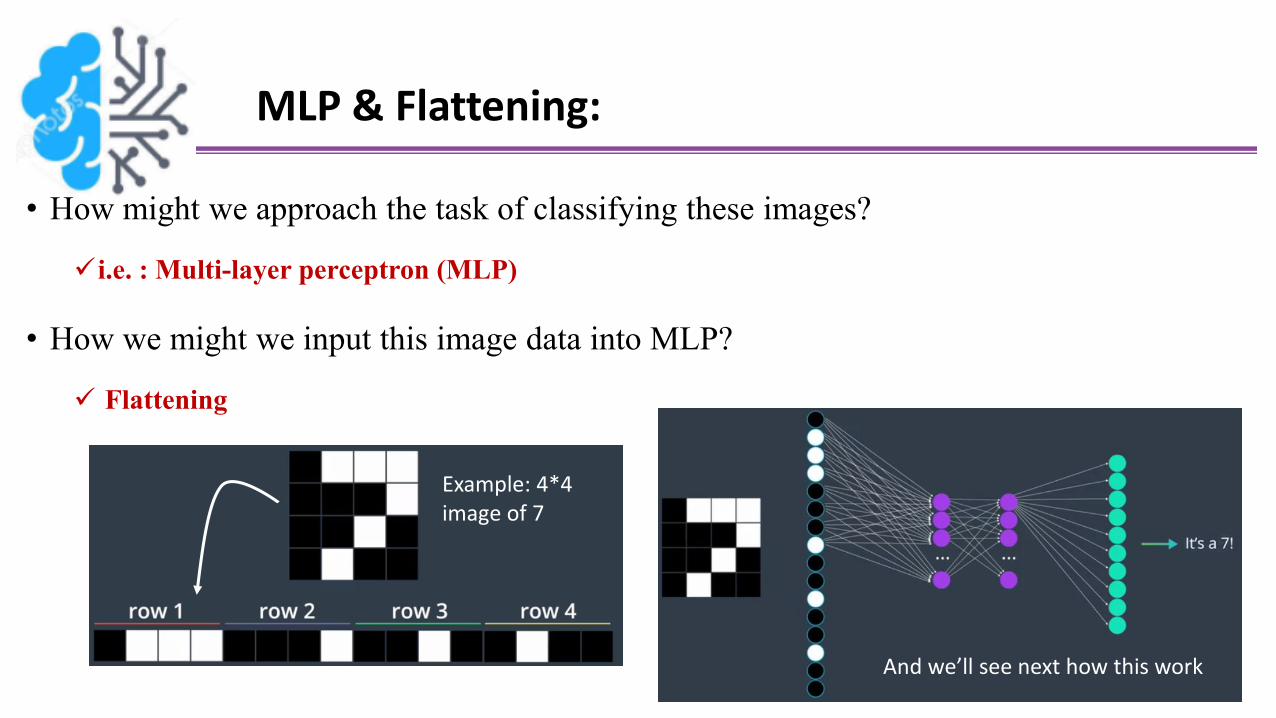
MLP & Flattening:
• How might we approach the task of classifying these images?
i.e. : Multi-layer perceptron (MLP)
• How we might we input this image data into MLP?
Flattening
Example: 4*4 image of 7
And we’ll see next how this work
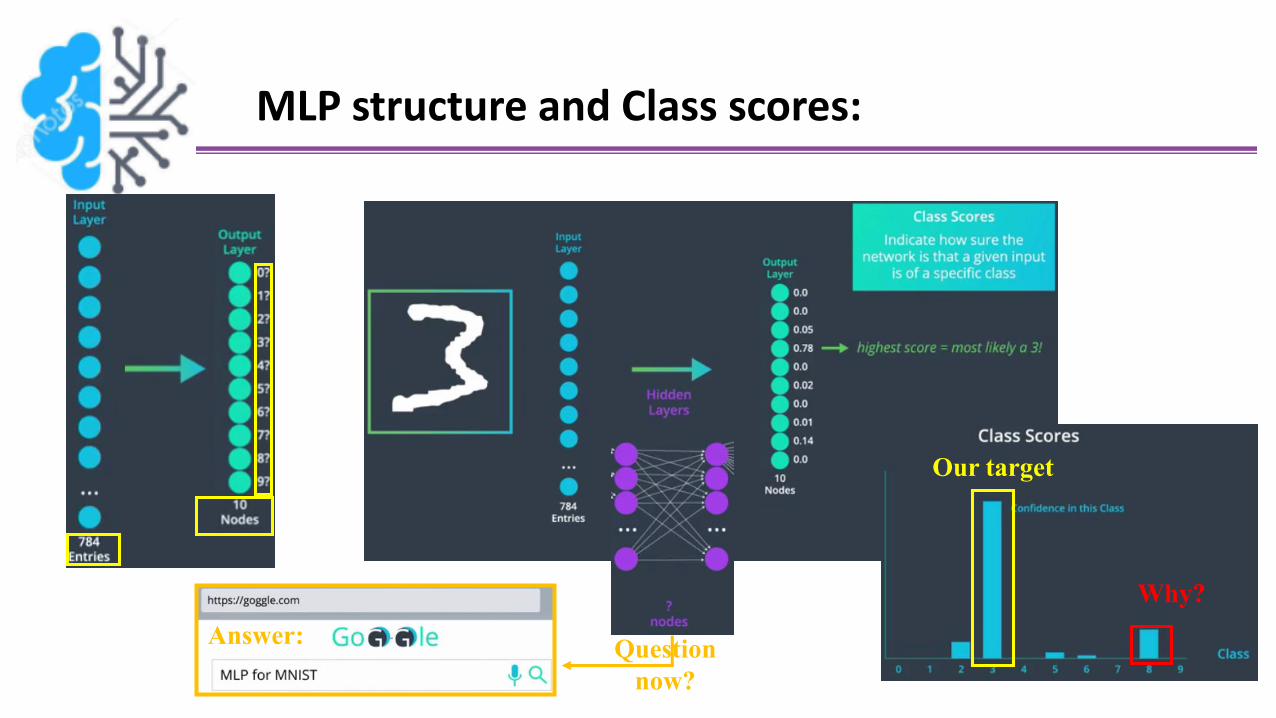
MLP structure and Class scores:
Example: 4*4 image of 7
And we’ll see next how this work
Why?
Our target
Question
now?
Answer:
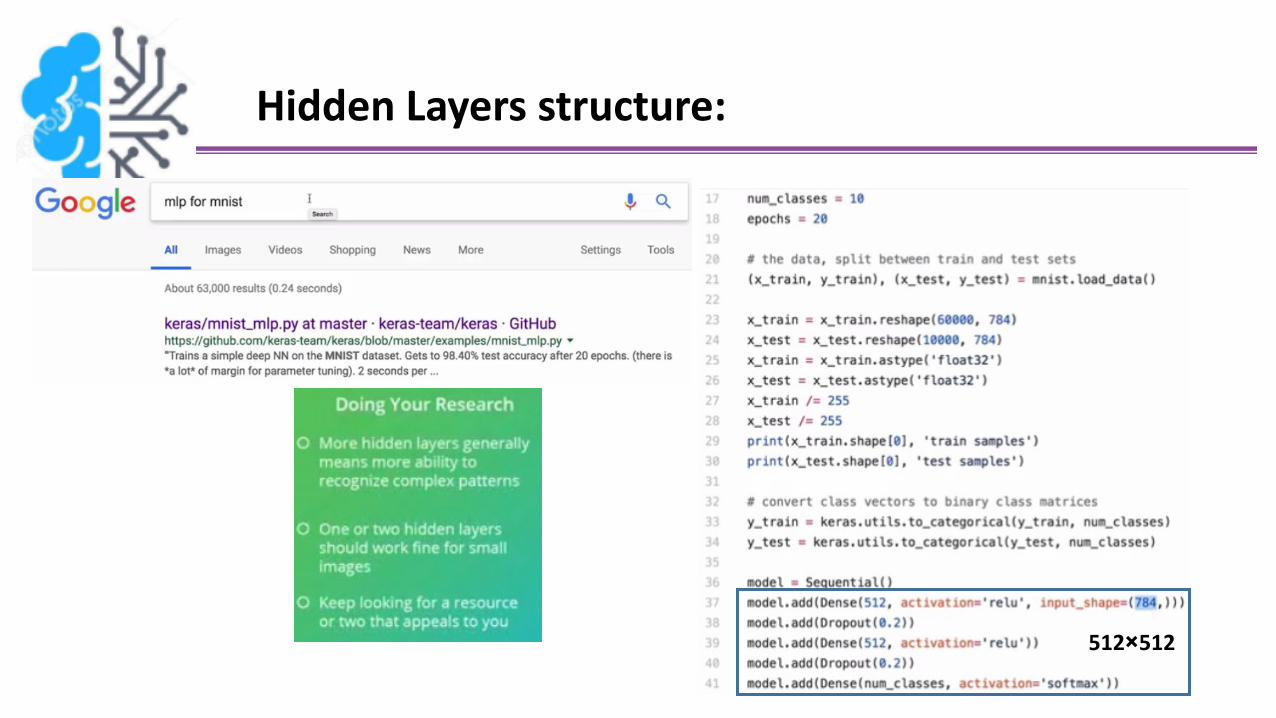
Hidden Layers structure:
512×512

Loss & Optimization
• After deciding the MLP structure, how it learn from MNIST database? What happens
when it actually see an input image (let assume it 2, see the figure)?
It believe that input is 8 but this is incorrect
• So, we need to let the MLP learn
from this mistake
𝝏ℓ
𝝏𝒘𝟏to determine which weight/s
are responsible for this mistakesUsing these calculation, go through
the negative of the gradient

Loss & Optimization
• Toward this goal, we need firstly to
make this outputs more interpretable
Do this math, the result is:
For sake of discussion, let assume it becomes:
Our goal as model training, find the weights that minimize the loss function
• So, a loss function & backpropagation give us a
way to quantify how bad a particular network
weight is, based on how close a predicted & the
true class label are from one another

Loss & Optimization
• Now, we need a way to calculate a better weight
value (in term of loss function)?
• To minimize the loss function, we need only find
a way to descend to the lowest value (the role of
optimizer). Standard method: Gradient descent
• There number of way to perform GD, and each
has it corresponding optimizer. Some do better
than others
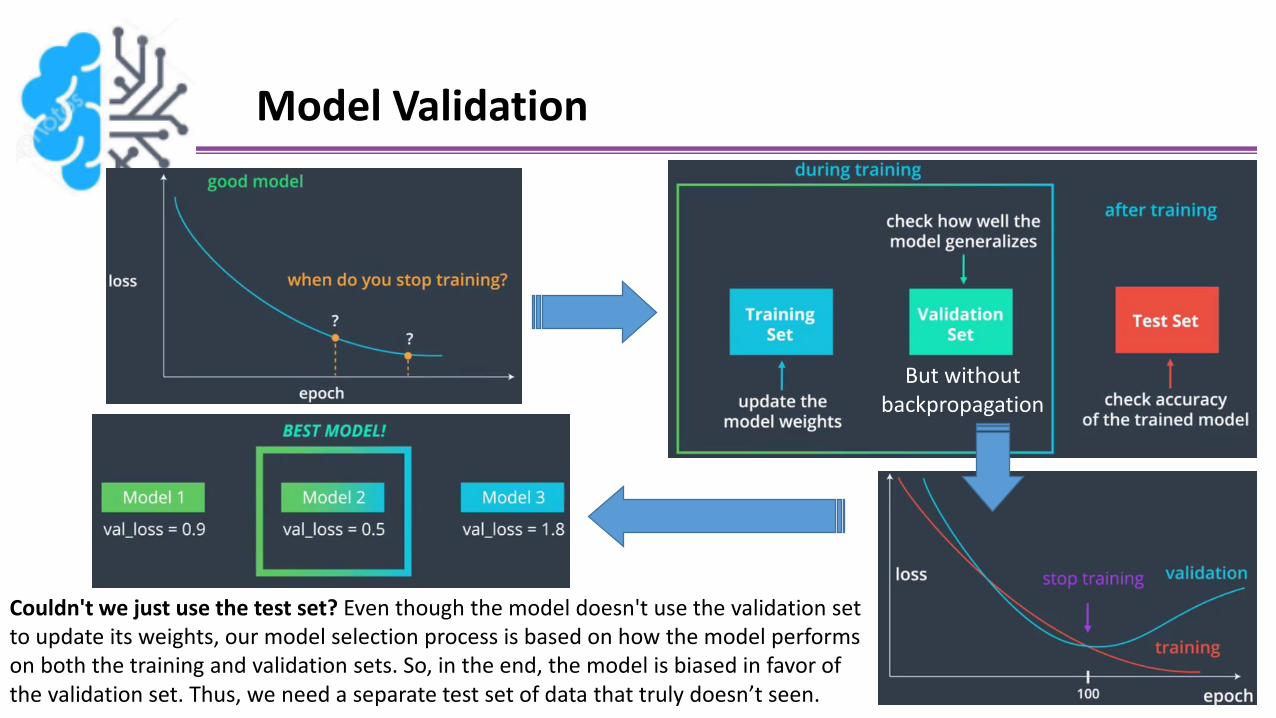
Model Validation
But without backpropagation
Couldn't we just use the test set? Even though the model doesn't use the validation set to update its weights, our model selection process is based on how the model performs on both the training and validation sets. So, in the end, the model is biased in favor of the validation set. Thus, we need a separate test set of data that truly doesn’t seen.

Image Classification Review (MLP):
Next, we’ll go with new architecture of network for image classification: CNN (better accuracy)

MLP vs CNN/others:
• For most of image classification tasks, CNN and MLP
don’t even compared. CNN do better
• MLP doesn’t have sense of inputs that were spatial
structure (after flattening), where CNN understand the fact
that image pixels that are closer in proximity to each other
are more heavily related than pixels that are far apart.
This challenge for MLP
http://yann.lecun.com/exdb/mnist/

Local Connectivity
All hidden nodes connected to all
inputs, is it necessary?
• In CNN, two important issues of MLP are resolved
1. MLP is only use fully connected layers
• i.e. 28×28 0.5 millions of parameters high
computations, what about 1024×1024 image?!?
2. Only accept vector, this means all spatial
information are lost
Each hidden node is responsible of gaining
understanding of a quarter of input image
(find patterns in only one portion of image),
but each is still reports to output layer
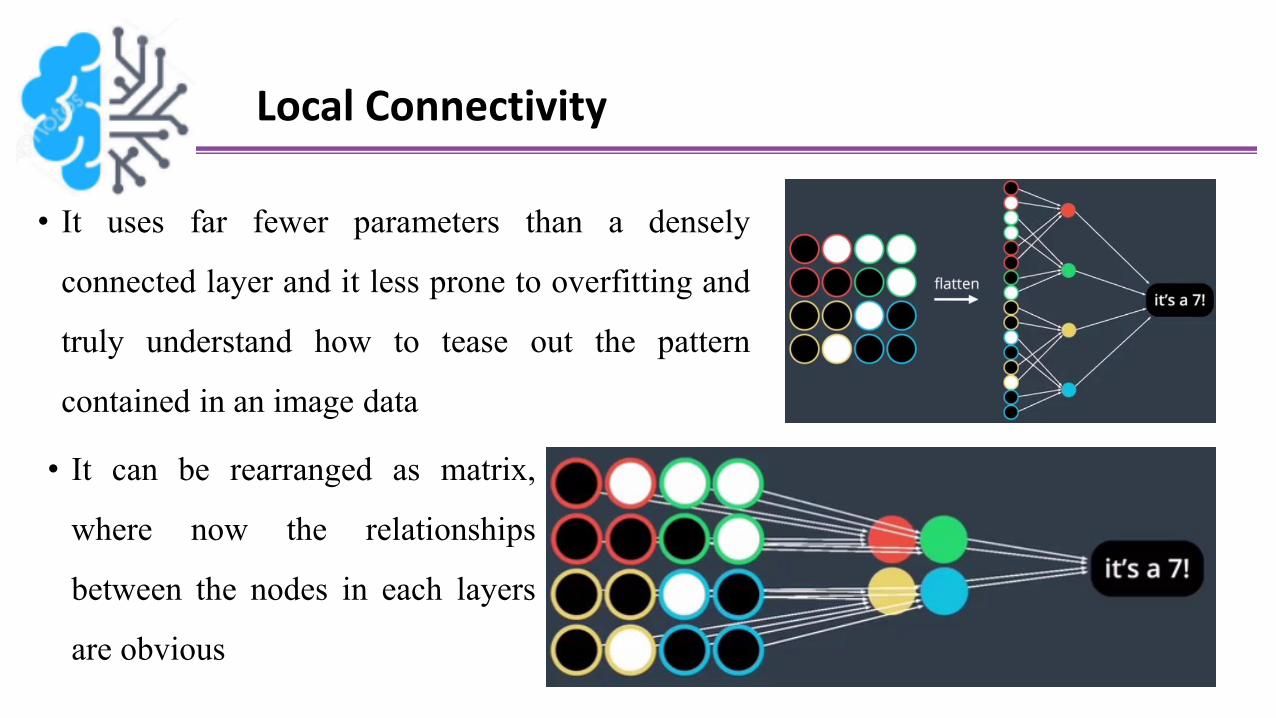
Local Connectivity
• It uses far fewer parameters than a densely
connected layer and it less prone to overfitting and
truly understand how to tease out the pattern
contained in an image data
• It can be rearranged as matrix,
where now the relationships
between the nodes in each layers
are obvious

Local Connectivity
• If you want to expand the number of pattern that can be
detected by adding more hidden layer/nodes. It means
you can discover more-complex pattern in data
• Weights sharing: it is behind the concept of object location independent
( it doesn’t matter if cat on left or right corner, it is still a cat

CNN
• CNN is special kind of ANN that can remember spatial information
• The key to preserving the spatial information is something called convolutional layer
• This layer applies a series of different image filter (known as convolution kernels ) to an
input image
• The filters may have extracted
features like the edges or the
distinguishable colors
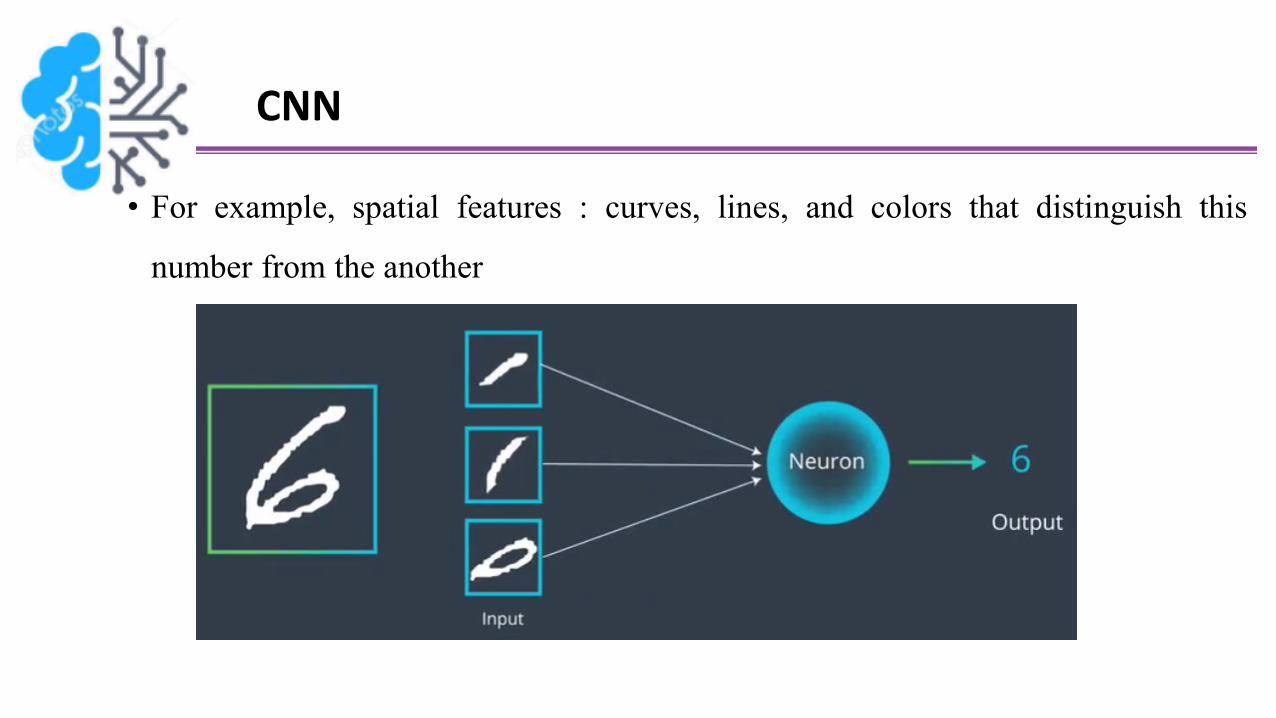
CNN
• For example, spatial features : curves, lines, and colors that distinguish this
number from the another

CNN
• Spatial pattern in image: shape or color (mostly)
• Shape can be thought of as pattern of intensity (is a measure of light and dark
(like brightness))in an image
i.e. a person in background of image: look at the contrast that occurs when the person ends and the
background begin to define a shape boundary that separates the two
Edge of object: look at the abrupt change in intensity (dark to light or vice versa)

High-pass filter:
• In image processing, filters are used to
filter out unwanted/irrelevant information in an image
amplify features, like object boundaries
• High –pass filter:
Sharpen an image
enhance high-frequency parts of image
Edges are areas in an image where intensity change very quickly and they
often indicate object boundaries

High-pass filter:
• These filters (convolution kernels) are in form of matrix contains numbers that
modifies an image
Because it is edge detection kernel, these
numbers should be added to zero
How applies the filter to an image??
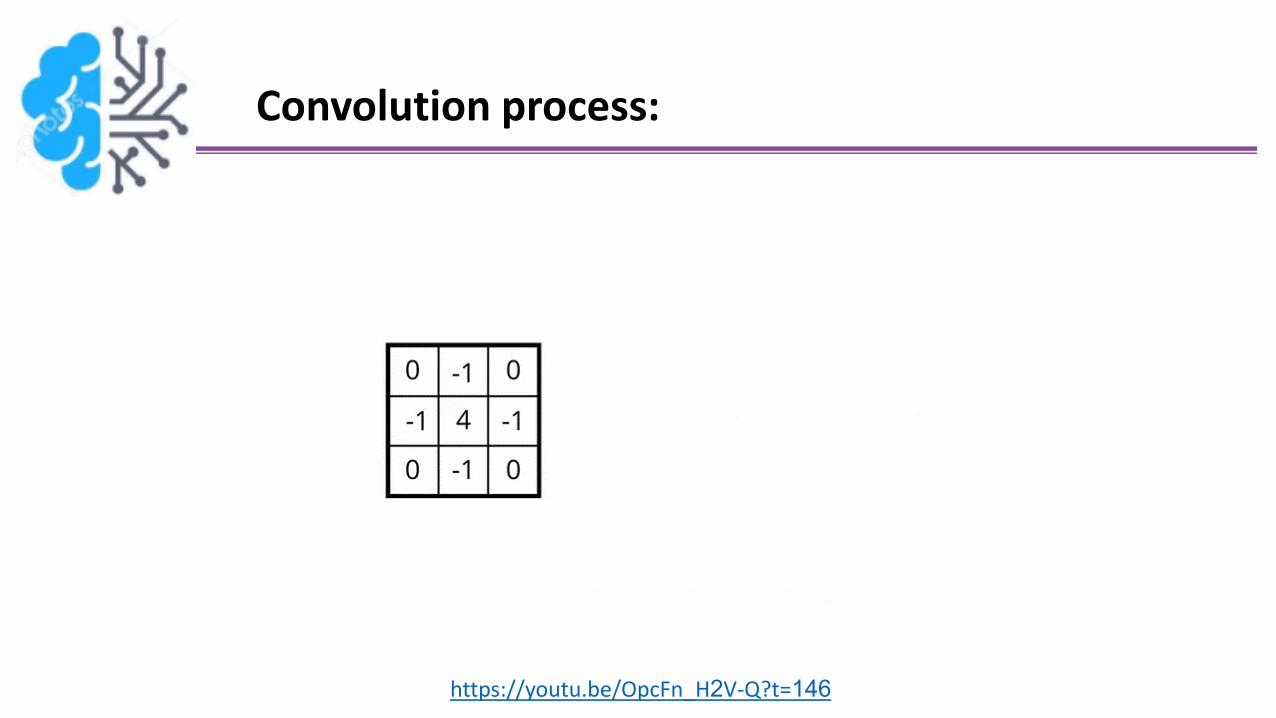

High-pass filter:
• A single region of image may have many different patterns needed to be
identified/detected, hence we need many filters for detecting all of these patterns
• In fact, it’s common to have tens to hundreds of these pattern collections

Perceptron:
Very dense-information & complicated input
Much simpler images with less information
Many kernel filters
Detect horizontal edgesDetect vertical edges

Perceptron (Cont.):
This applied to Gray-scale images (2-D matrix), what about colur images?
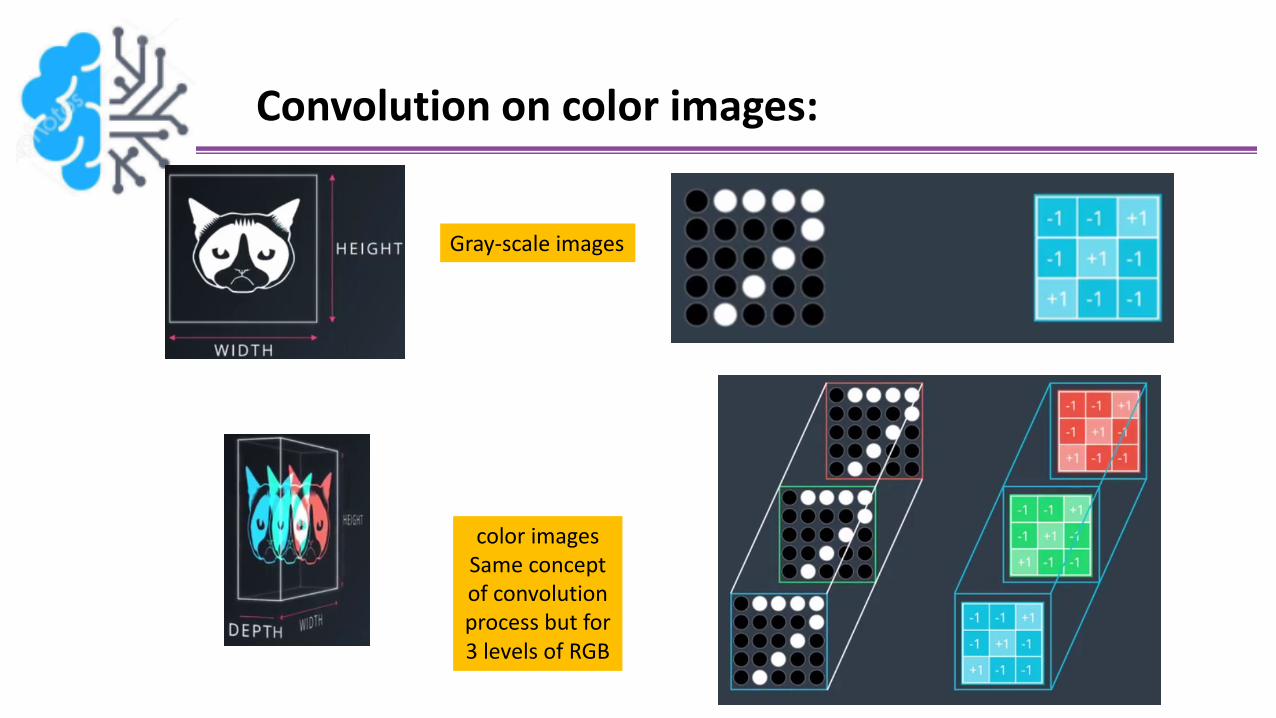
Convolution on color images:
Gray-scale images
color imagesSame concept of convolution process but for 3 levels of RGB
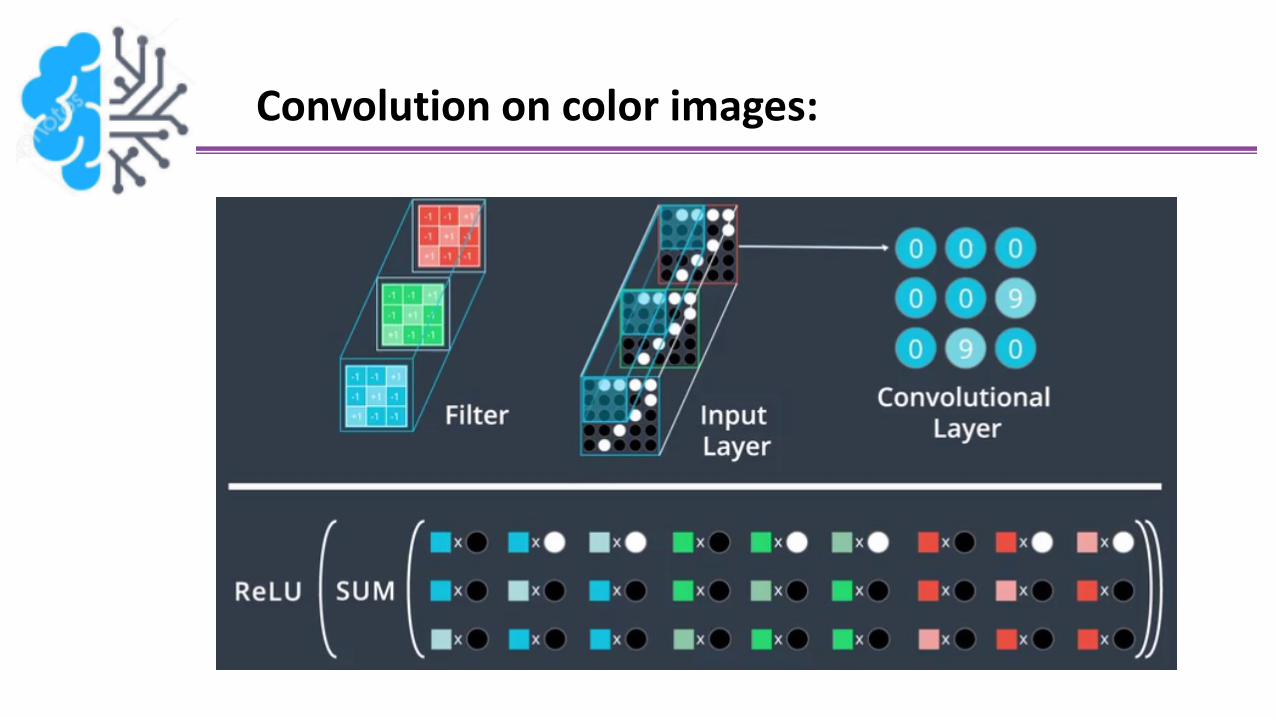
Convolution on color images:
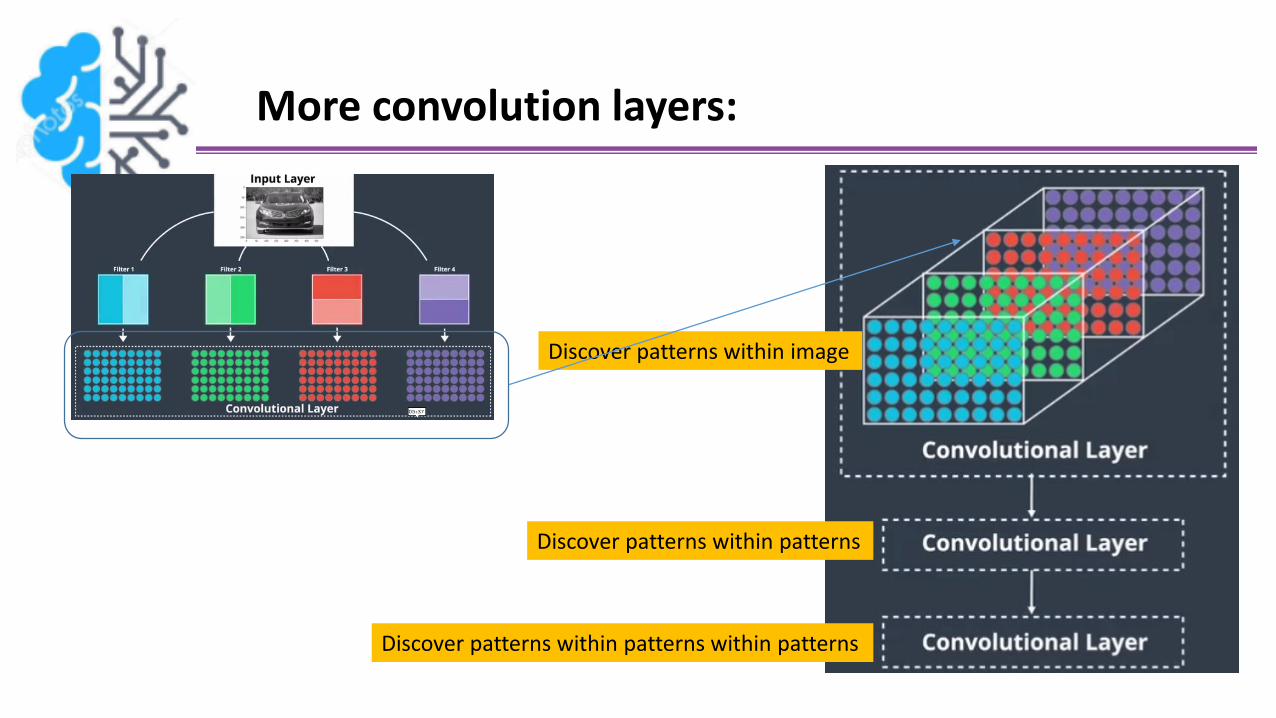
More convolution layers:
Discover patterns within patterns
Discover patterns within patterns within patterns
Discover patterns within image

• https://www.youtube.com/watch?v=OKYsDQ_WRDc
• https://www.youtube.com/watch?v=2-Ol7ZB0MmU
• https://www.youtube.com/watch?v=JB8T_zN7ZC0
More convolution layers:

Stride of the convolution layer:
• We’ve seen that you can control the behavior of a convolutional layer by specifying
the number of filters and the size of each filter
To increase the number of node in convolutional layer, you can increase the number of filters
To increase the size of detected patterns, you could increase the size of filter
• But there are even more hyper-parameters that you can do:
Stride of the convolution: is just the amount by which the filter slide over the image
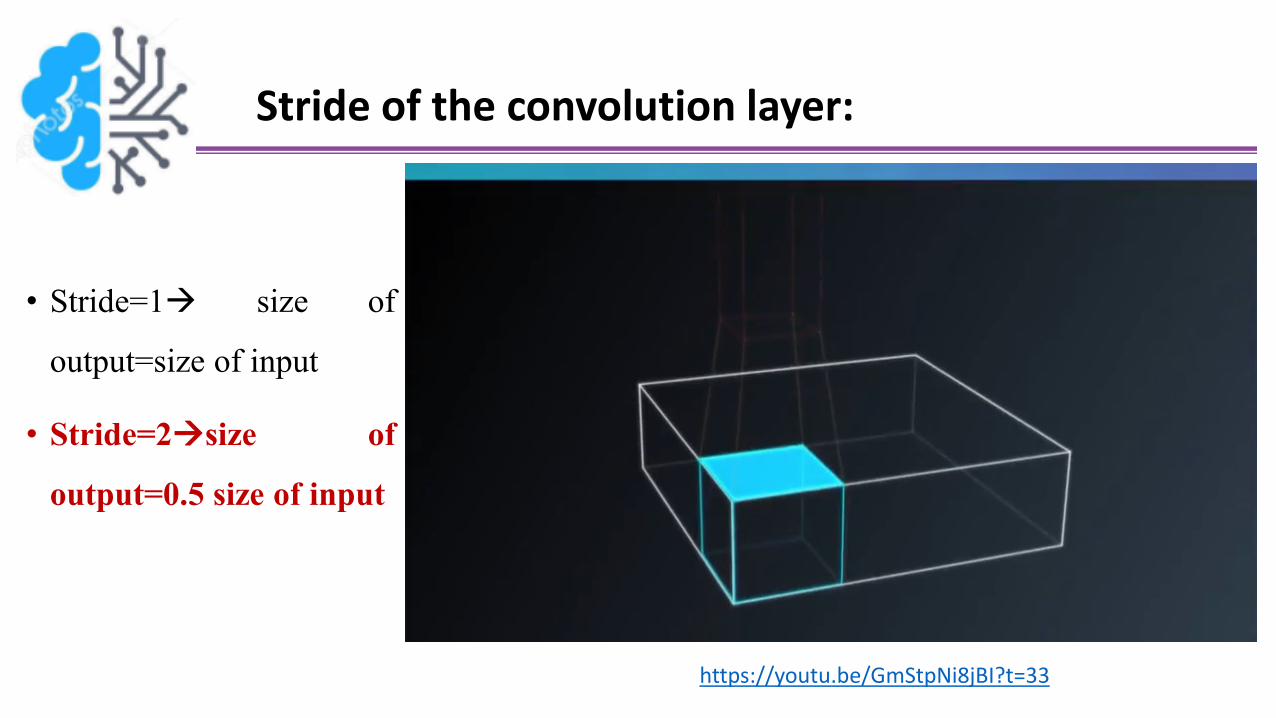
Stride of the convolution layer:
• Stride=1 size of
output=size of input
• Stride=2size of
output=0.5 size of input
https://youtu.be/GmStpNi8jBI?t=33

Padding:
• 1st option: just get ride of
them, this mean CNN
will not know about
some regions of image
• 1nd option: zero padding
to give CNN some spaces
to move and hence get
contribution of every
regions of image
https://youtu.be/GmStpNi8jBI?t=88

Pooling:
• A complicated dataset with many
different object categories will require a
large number of filters, each responsible
for finding a pattern in the image
• More filters mean a bigger stack, which
means that the dimensionality of our
convolutional layer can get quite large
• Higher dimensionality means, we’ll need
to use more parameters, which can lead
to overfitting
• Thus, we need method for reducing
this dimensionality?!
One feature map
for each filter
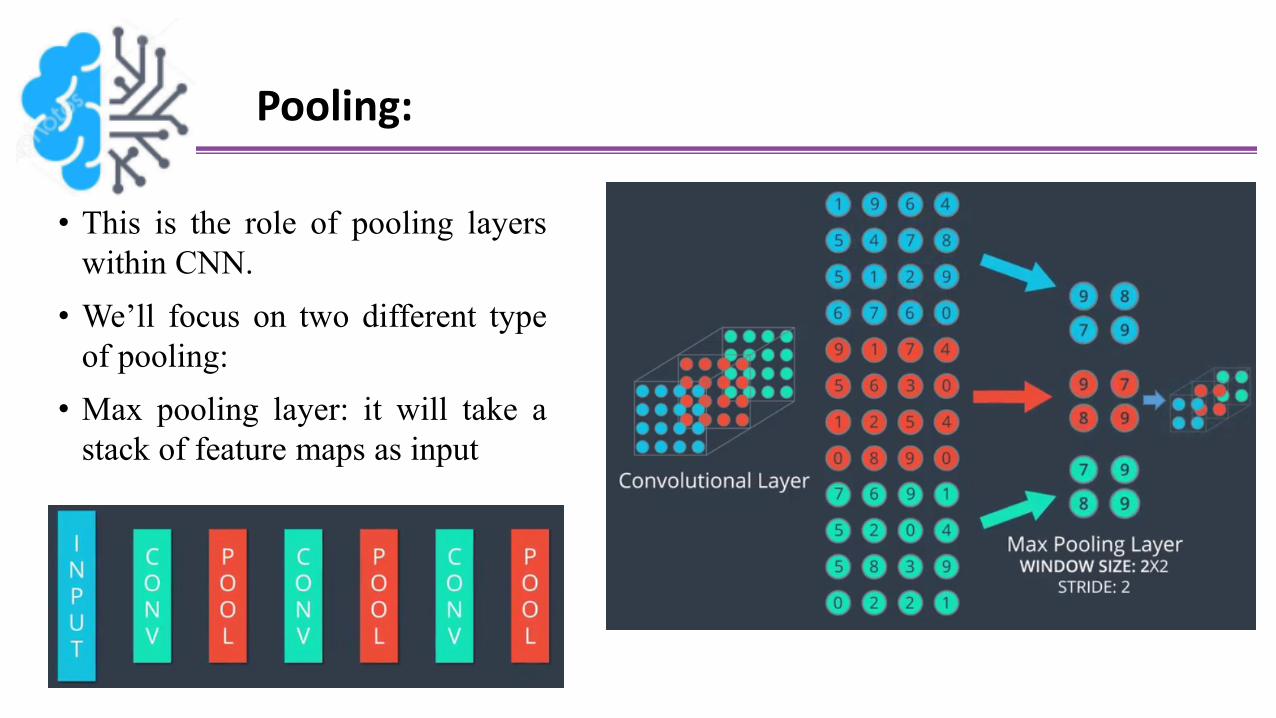
Pooling:
• This is the role of pooling layers
within CNN.
• We’ll focus on two different type
of pooling:
• Max pooling layer: it will take a
stack of feature maps as input

Numerous image size:
• We’ve investigated two new type
of layers:
Convolutional layer
Maxpooling layer
• In real life, images are with many
different sizes.
• These images should be resized
(another pre-processing step (like
normalization step)).
• It is very common to resize them
into square and 2^p size.

CNN for image classification:
• The height and width of input array are much
taller than depth, either in gray-scale images or
color images.
• CNN architecture will be designed with the goal
of taking that array and gradually making it
much deeper that it is tall or wide
• CNN makes the array deeper as it passes
through the network
• It actually extracting more and more
complex patterns and features and hence
discarding the useless information

Feature Vector
• The job of a convolutional NN is to discover patterns contained in an image.
• A sequence of layers is responsible for this discovery
• These layers in a CNN convert an input image array a representation that
encodes only the vital content of the image (Feature vector)
Feature vector:
Wheels?
Distinct light?
etc…
Irrelevant information
• Fancy design
• Color
• etc
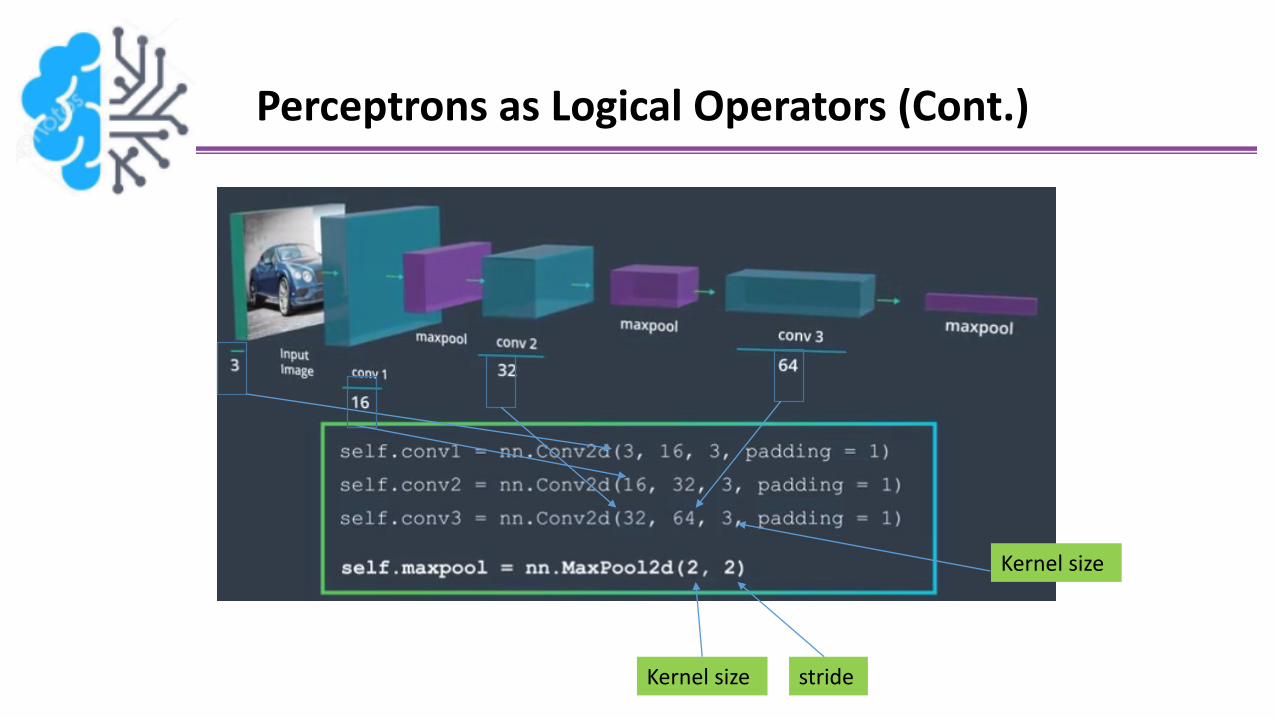
Perceptrons as Logical Operators (Cont.)
Kernel size stride
Kernel size
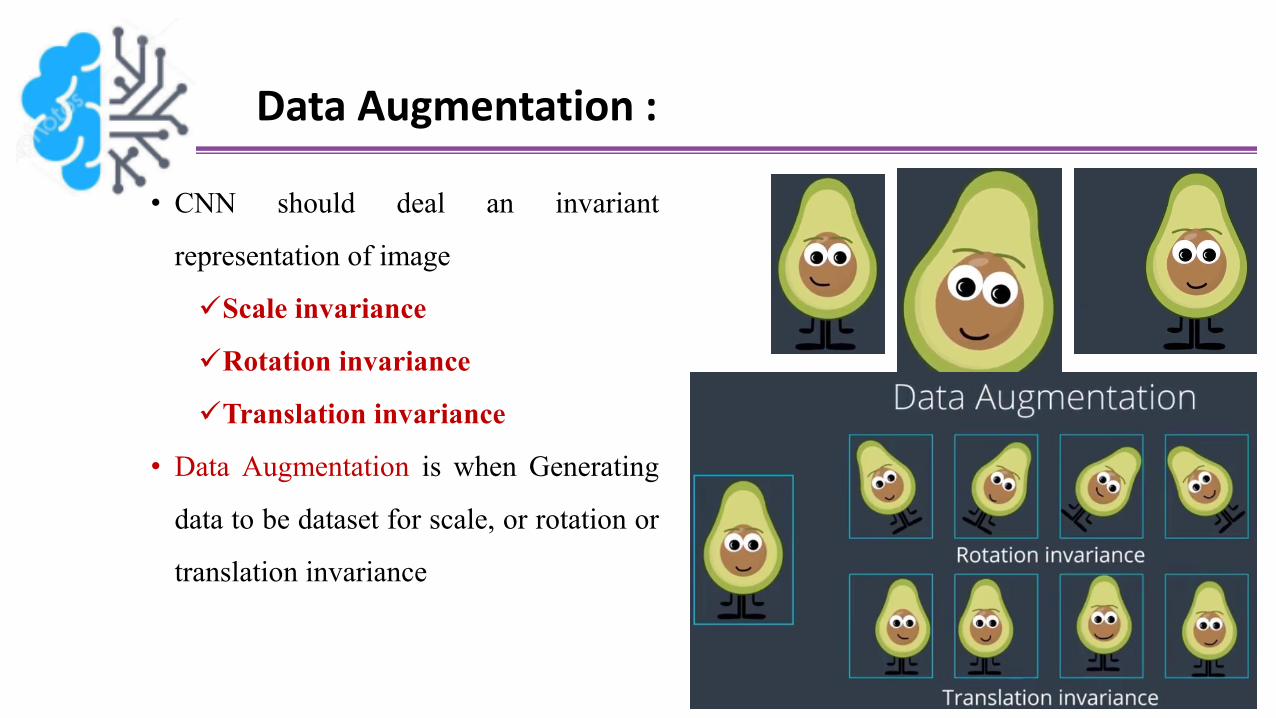
Data Augmentation :
• CNN should deal an invariant
representation of image
Scale invariance
Rotation invariance
Translation invariance
• Data Augmentation is when Generating
data to be dataset for scale, or rotation or
translation invariance

Groundbreaking CNN Architecture
• ImageNet is dataset of 10M labeled images with over 10K categories.
• Since 2010, the ImageNet project held competition and target is to build
best CNN for object recognition and classification

Groundbreaking CNN Architecture
• 1st breakthrough was in 2012, it is AlexNet and developed by a team at Toronto University
• Using GPU was available that days, the team trained the CNN in about a week

Groundbreaking CNN Architecture
• 2nd breakthrough was in 2014, it is VGG and developed by a team at Oxford University
• It has 2 versions, 16 and 19 that refered to the number of layers constructed.
• Simple construction of 3*3 convolutions where AlexNet use 11*11 window

Groundbreaking CNN Architecture
• 3rd breakthrough was in 2015, it is ResNet and developed by a team of Microsoft
• 152 layers, it something like repeating VGG
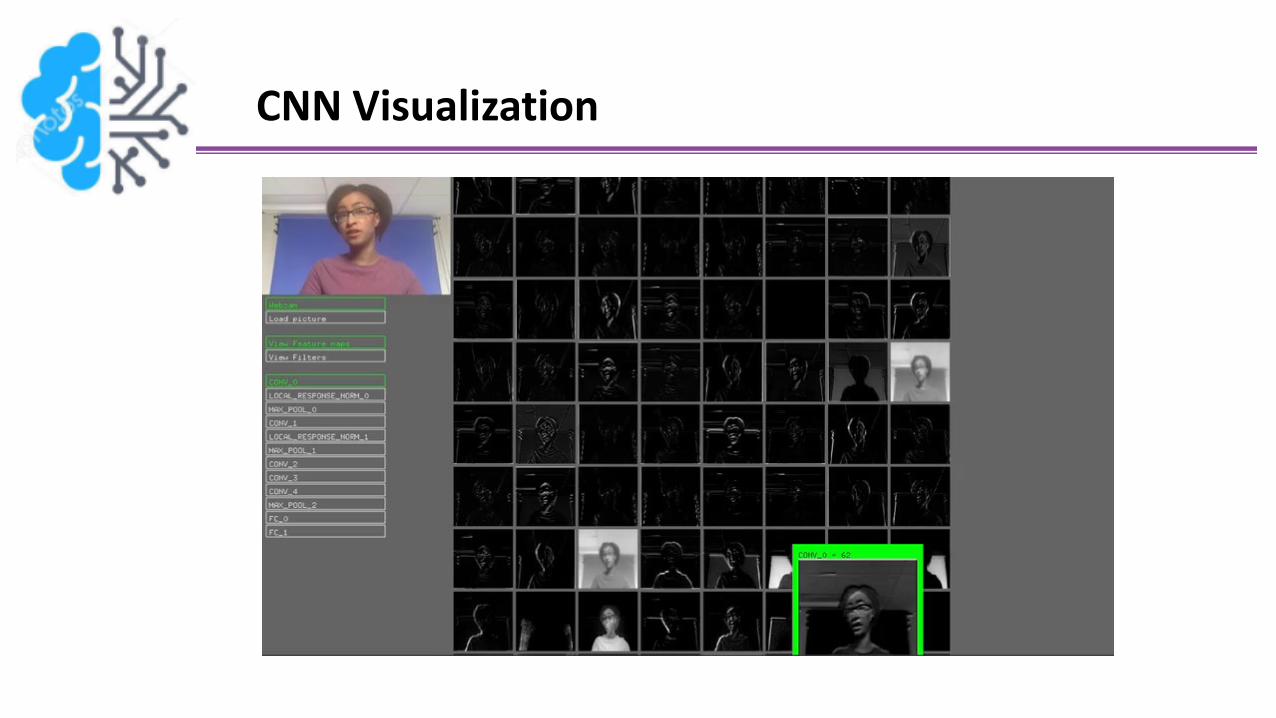
CNN Visualization

