cda 5106 advanced computer architecture i...
TRANSCRIPT

School of Electrical Engineering and Computer Science
University of Central Florida
CDA 5106 Advanced Computer Architecture I
Thread-Level Parallelism

University of Central Florida 3
Resource Utilization (small instruction window)
time
Cache miss Cache miss repaired
…
…
…
…

University of Central Florida 4
Resource Utilization (large instruction window)
time
Cache miss Cache miss repaired

University of Central Florida 5
Resource Utilization (cont.)
• Limited instruction-level parallelism from single thread
• How about multiple threads? => multithreading

University of Central Florida 6
Multithreading
• Run multiple independent programs at same time
• Hardware support for multithreading
– Replicate some or all resources
• Fetch multiple programs
– Replicate state
• Each program needs its own context
• Context = register state + memory state
– Mechanism to switch context (?)

University of Central Florida 7
Multithreading on a Chip
• Two major alternatives
– Simultaneous multithreading (SMT)
– Chip multiprocessor (CMP)

University of Central Florida 8
SMT Motivation
• Wide superscalar is the way to go
– Must continue to improve single-program performance
• Multiple programs share fetch & issue bandwidth
– Thread-level parallelism (TLP) improves utilization of wide superscalar
– Can still exploit high ILP in a single program

University of Central Florida 9
CMP Motivation
• Wide superscalar not the way to go
– Trades fast clock for minor IPC gain
– Design and verification complexity
• Multiple simple processors (e.g., 2-way or 4-way superscalar)
– Exploit TLP
– Moderate ILP plus fast clock
– Use multiple cores to exploit single-thread ILP

University of Central Florida 10
thread 1
thread 2
thread 3
single-threaded
SMT
CMP

University of Central Florida 11
More multithreading architectures
CMP: IBM Power4
Fine-grain multi-threading (FGMT): CDC-6600
Coarse-grain multi-threading (CGMT): Northstar/Pulsar PowerPC
SMT: Intel Pentium 4

University of Central Florida 12
ISCA-23 SMT Paper
• D. Tullsen, S. Eggers, J. Emer, et. al., “Exploiting choice: instruction fetch and issue on an implementable simultaneous
multithreading processor”, ISCA-23, 1996
• Contributions
– Implementable SMT microarchitecture
• Leverage existing superscalar mechanisms
• Single-program performance almost unimpacted
– Exploit TLP better
• Basic fetch/issue policies exploit TLP poorly
– Utilization tops out at 50%
– Increasing number of threads beyond 5 doesn’t help
• Insight into fetch and issue bottlenecks
• Novel fetch/issue policies
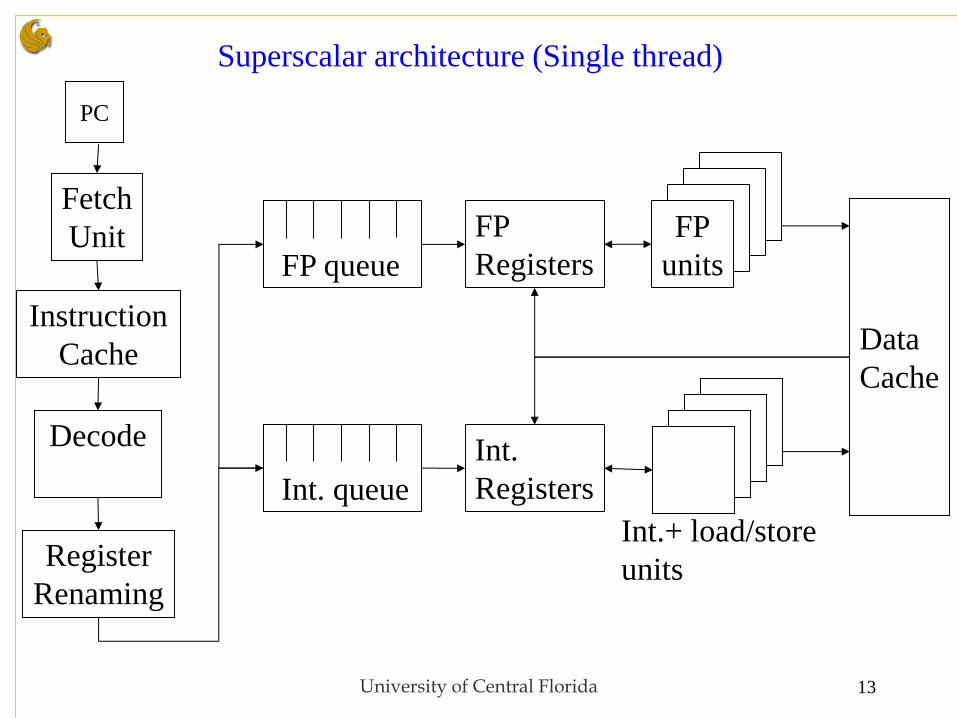
University of Central Florida 13
Fetch
Unit
Instruction
Cache
Decode
Register
Renaming
FP
Registers FP queue
Int. queue
Int.
Registers
FP
units
Int.+ load/store
units
Data
Cache
PC
Superscalar architecture (Single thread)

University of Central Florida 14
Fetch
Unit
PC
Instruction
Cache
Decode
Register
Renaming
FP
Registers FP queue
Int. queue
Int.
Registers
FP
units
Int.+ load/store
units
Data
Cache
Multiple PCs
• Multiple rename map tables
• Multiple ROBs
Selective
squash
Selective
squash
Replicate
architectural
state
Replicate
architectural
state
Per-thread
disambiguation
• Thread selection
• Replicate RAS
• BTB thread ids

University of Central Florida 15
Types of Changes
• Types of changes required for SMT support
– REP: Replicate hardware
– SIZE: Resize hardware
– CTL: Additional control
– ID: Thread identifiers needed

University of Central Florida 16
Instruction Fetch
• Multiple program counters (REP)
• Thread selection (CTL)
• Per-thread return address stacks (REP)
• Thread ids in BTB (ID)

University of Central Florida 17
Register File Management
• Per-thread rename map tables (REP)
• Per-thread ROB (REP)
– Simplifies retirement & squashing

University of Central Florida 18
Issue Queues
• Selective squash in queues (ID, CTL)
– Already implement selective squash due to arbitrary order in queue
– Augment selective squash with thread id

University of Central Florida 19
Load-Store Queue
• Options
– Per-thread load-store queues (REP)
-OR-
– Disambiguate using physical addresses instead of virtual addresses

University of Central Florida 20
Potential Problem Areas
• Predictor and cache pressure
• Claims from paper
– For chosen workload, predictor and cache conflicts not a problem
– Any extra mispredictions and misses are cushioned by abundant TLP
• Large benchmarks in practice
– Cache conflicts may cause slowdown w.r.t. running programs serially since serial execution exploits cache locality
– Slowdown due to contention on other shared resources, e.g., ROB.

University of Central Florida 21
Register File Impact
• Why is register file larger with SMT?
– 1 thread: Minimum of 1*32 integer registers
– 8 threads: Minimum of 8*32 integer registers
– I.e., need to store architectural state of all threads
– Note that amount of speculative state is independent of number of threads (depends only on total number of active instructions)
• Implication
– Don’t want to increase cycle time
– Expand register read stage into two stages; same with register write stage
– Performance impact?

University of Central Florida 22
Fetch Decode Rename Queue Reg Read Exec. Reg. Wrt. Commit
misfetch penalty 2 cycles
misprediction penalty 6 cycle minimum
register usage 4 cycle minimum
single bypass
may overlap
Fetch Decode Rename Queue Reg Read Exec. Reg. Wrt. Commit Reg Read
misfetch penalty 2 cycles
misprediction penalty 7 cycle minimum
double bypasses
Reg. Wrt.
register usage 6 cycle minimum

University of Central Florida 23
Methodology
8-way issue superscalar, 8 threads

University of Central Florida 24
Performance of Base SMT
• Positive results – Single-thread performance degrades only 2% due to additional pipe stages – SMT throughput is 84% higher than superscalar
• Negative results – Processor utilization still low at 50% (IPC = 4) – Throughput peaks at 5 or 6 threads (not 8)

University of Central Florida 25
SMT Bottlenecks
1. Fetch throughput
– Sustaining only 4.2 useful instructions per cycle!
– Base thread selection: Round-Robin, 1 thread at a time
– “Horizontal waste” due to single-threaded fetch stage
– Sources of waste include misalignment and taken branches

University of Central Florida 26
SMT Bottlenecks (cont.)
2. Lack of parallelism
– 8 independent threads should provide plenty of parallelism
– Perhaps have the wrong instructions in the issue queues!

University of Central Florida 27
Fetch Unit: in search of useful instructions
• Exploit choice
– SMT offers unique ability to improve fetch throughput by fetching from multiple threads at same time
– Just like we do for issue
– Misalignment, taken branches will have less impact

University of Central Florida 28
Fetch Unit (cont.)
• Fetch models
– Notation: alg.num1.num2
– alg => thread selection method (which thread(s) to fetch)
– num1 => # of threads that can fetch in 1 cycle
– num2 => max # of instructions fetched per thread per cycle
• There are 8 instruction cache banks and conflicts are modeled

University of Central Florida 29
Fetch Unit: Partitioning
• Keep thread selection (alg) fixed
– Round Robin (RR)
• Models
– RR.1.8
• Base scheme: 1 thread at a time, has full b/w of 8
– RR.2.4 and RR.4.2
• Total # of fetched instructions remains 8
• If num1 is too high, suffer thread shortage problem: too few threads to achieve 8 instr./cycle
– RR.2.8
• Eliminates thread shortage problem (each thread can fetch max b/w) while reducing horizontal waste

University of Central Florida 30
Throughput

University of Central Florida 31
Fetch Unit: Thread Choice
• Replace Round-Robin (RR) with more intelligent thread selection policies
– BRCOUNT
– MISSCOUNT
– ICOUNT

University of Central Florida 32
BRCOUNT
• Give high priority to those threads with fewest unresolved branches
• Attacks wrong-path fetching
• Also reduce pressure on shadow maps

University of Central Florida 33
MISSCOUNT
• Give priority to threads with fewest outstanding data cache misses
• Attacks IQ clog

University of Central Florida 34
ICOUNT
• Give priority to threads with fewest instructions in decode, rename, and issue queues
– Threads that make good progress => high priority
– Threads that make slow progress => low priority
• Attacks IQ clog generally

University of Central Florida 35
Throughput

University of Central Florida 36
Resource allocation
• STALL: build on top of ICOUNT (MICRO 34, 2001) – preventing the thread from fetching more instructions when a pending L2
miss is detected – Problem: L2 miss is detected too late
• FLUSH: flush all instructions from the thread with a pending L2 miss (MICRO34, 2001)
• Data Gating: Stall a thread on each L1 D-cache miss [HPCA 2003] – Problem: Not every L1 miss leads to an L2 miss
• Static partition (PACT 2003)
– Each thread has the equal share of resource
• Dynamically redistribute resources (MICRO37, 2004)
– Thread classification as either high LIP or memory intensive • Insight: threads without L2 misses require less resource
– Resource usage classification: active vs. inactive depending on with a type of resource is being used for following Y cycles
– Sharing model based on pre-calculated resource allocation values and the run-time thread & resource classification

University of Central Florida 37
Resource allocation (cont.)
• Resource impact for high ILP threads

University of Central Florida 38
Resource Sharing Model
• E = R / T – E is the number of the entries in a shared structure that each thread gets – R is the number of the entries in a shared structure – T is the number of threads
• Since slow threads require more resource than fast threads, we steal resource from fast threads
• Eslow = (1 + C * F) * R / T – Eslow is the number of entries in a shared – C is sharing factor: determines the amounts of resource each fast thread
offers. Empirically, C = 1 / (T + 4) gives good results – F: number of fast threads
• Taking into account that not all threads will require a particular type of resource
• Eslow = (1 + C * FA) * R / TA – TA = FA +SA (Fast active and slow active, thereby eliminating the
competition from non-active threads

University of Central Florida 39
Resource allocation (cont.)
• Pre-calculated resource sharing model

University of Central Florida 40
Resource allocation (cont.)
• Implementation

University of Central Florida 41
Methodology

University of Central Florida 42
Methodology (cont.)

University of Central Florida 43
Results

University of Central Florida 44
Results (cont.)

University of Central Florida 45
Results (cont.)

University of Central Florida 46
Sharing Caches among Multi-core Processors
• Last-Level Cache usually shared among multiple cores
• Issues for Shared Cache Design
– Layout
– Management
Shared Cache
C1 C2

University of Central Florida 47
Chip Layout for Multi-Core/Many-Core Processors
• Cache-in-middle surrounded by processor cores
• Non-Uniform Cache Access Time
– Line migration
• Shared lines present a problem
– Line replication
• Reducing the effective cache size
• Write-invalidation is required

University of Central Florida 48
Nahalal: Cache Organization for CMPs (CAL 2007)
• Inspired by a 19th century town design
• A central bank for shared
cache
- Key insight: sharing data is
relatively small

University of Central Florida 49
Cache Management [PACT’06]
• Capitalist: LRU
• Communist: Fairness (absolute vs. relative)
• Utilitarian: Overall system performance
• Aspects of cache partitioning policy
– Performance target
• Minimizing memory bandwidth
• Maximizing IPC
• Maximizing weighted IPC
– Evaluation metric
– Policy
– Policy metric

University of Central Florida 50
Methodology
• 1. Select performance targets
• 2. Obtain (Static) optimal cache allocation through off-line optimization analysis
• 3. Data analysis

University of Central Florida 51
Performance Targets
• Misses per access (MPA)
– Easy to measure online
– Not reflect to performance
• Miss per cycle (MPC)
– Bandwidth measure
• Instruction per cycle (IPC)
– May favor high IPC workloads at the cost of low IPC ones
– Solution: Weighted IPC = IPC / Baseline IPC
– Which baseline?
• Utilitarian or Communist

University of Central Florida 52
Performance Targets

University of Central Florida 53
Workload characteristics

University of Central Florida 54
Results
• Two types of applications (specweb and tpc-c) sharing the cache

University of Central Florida 55
Results (cont.) • Four types of applications sharing the cache
• General observation: optimal partition behavior varies widely and the impact of changing performance targets is not easy to predict (i.e., no general trends)

University of Central Florida 56
Communism vs. Utilitarian
Observation:
1. For most cases, Communist and Utilitarian metrics are comparable (i.e., optimizing
for one metric usually results near-optimal for the other)
2. However, there are tails in either distribution. In other words, there are exceptions
that when optimizing for one metric, it results in very poor performance in the other

University of Central Florida 57
The impact of the Baseline on Weighted Performance
Observation:
1. Utilitarian weighted IPC metrics are close
2. More variation observed from Communist metrics

University of Central Florida 58
Policy metrics: which on-line metric is useful
Observation:
1. MPA correlates poorly with all performance targets
2. MPC and IPC are relative good for Utilitarian targets
3. MPC and IPC are not good for Communist targets

University of Central Florida 59
Policy Evaluation
• Compare the optimal with LRU and even partition
Observation:
1. LRU is not close to optimal for most of the performance targets except raw IPC
2. Even partition is not good for either Communist or Utilitarian