building a real-time, self-service data analytics ecosystemmedia.computer.org/pdfs/arnold.pdf ·...
TRANSCRIPT

Building a real-time, self-service data analytics ecosystem
Greg Arnold, Sr. Director Engineering

“Self Service” at scale
1
2
3
5
6
4

? Relational?
MPP? Hadoop?

350M Members
4.8B Endorsements
2M Jobs
3.5M Active company profiles
25B Quarterly page views
Linkedin data
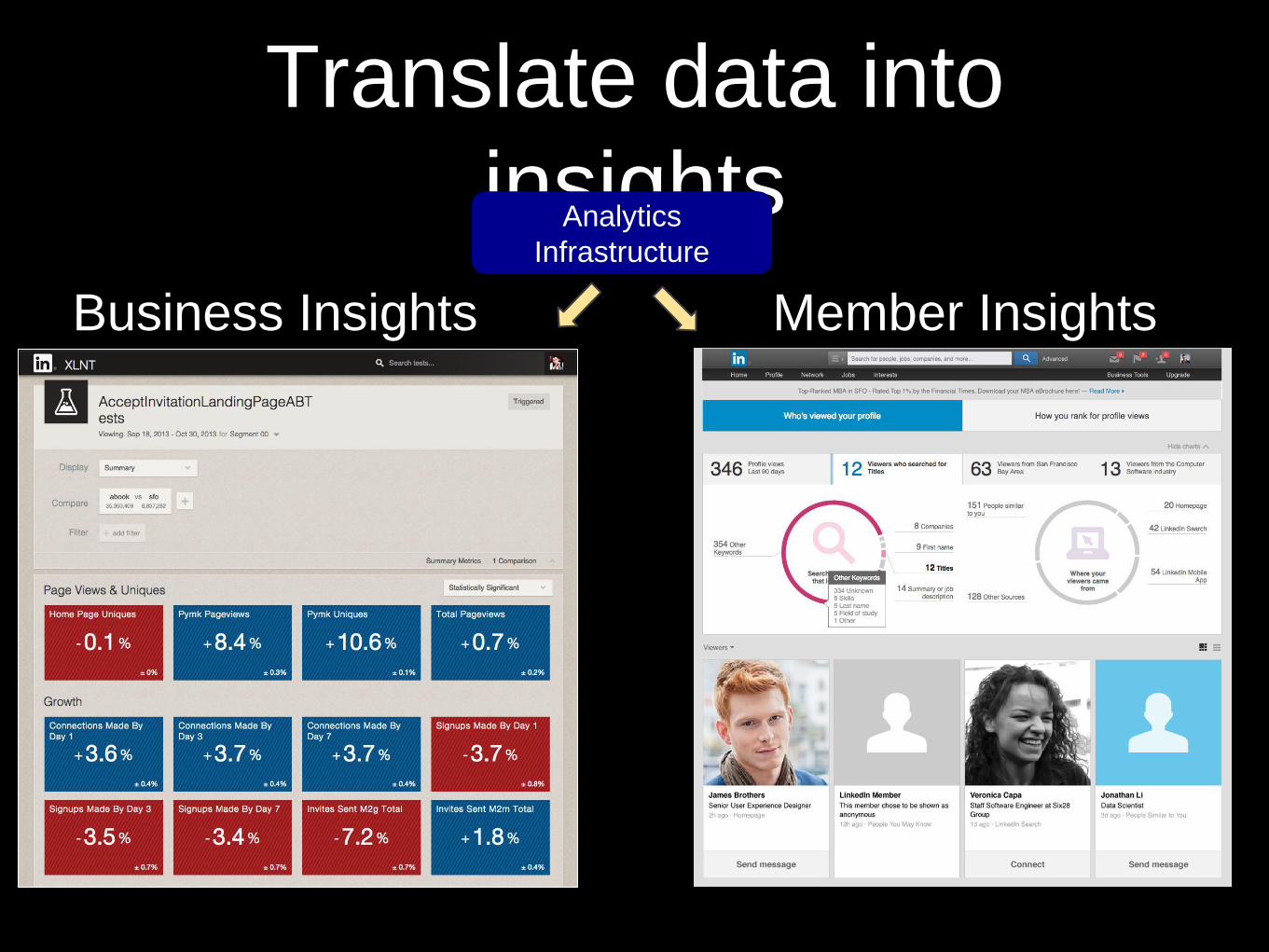
Translate data into
insights
Business Insights Member Insights
Analytics
Infrastructure

The Good Old Days

Data Flow@10000 ft

Scale Challenges
1. Human intervention
2. Long latencies to obtain
insights from data.
3. Complexity of integration
with increasing data
sources.

What does it take to
build a
self-service,
real-time,
democratic
analytics platform?
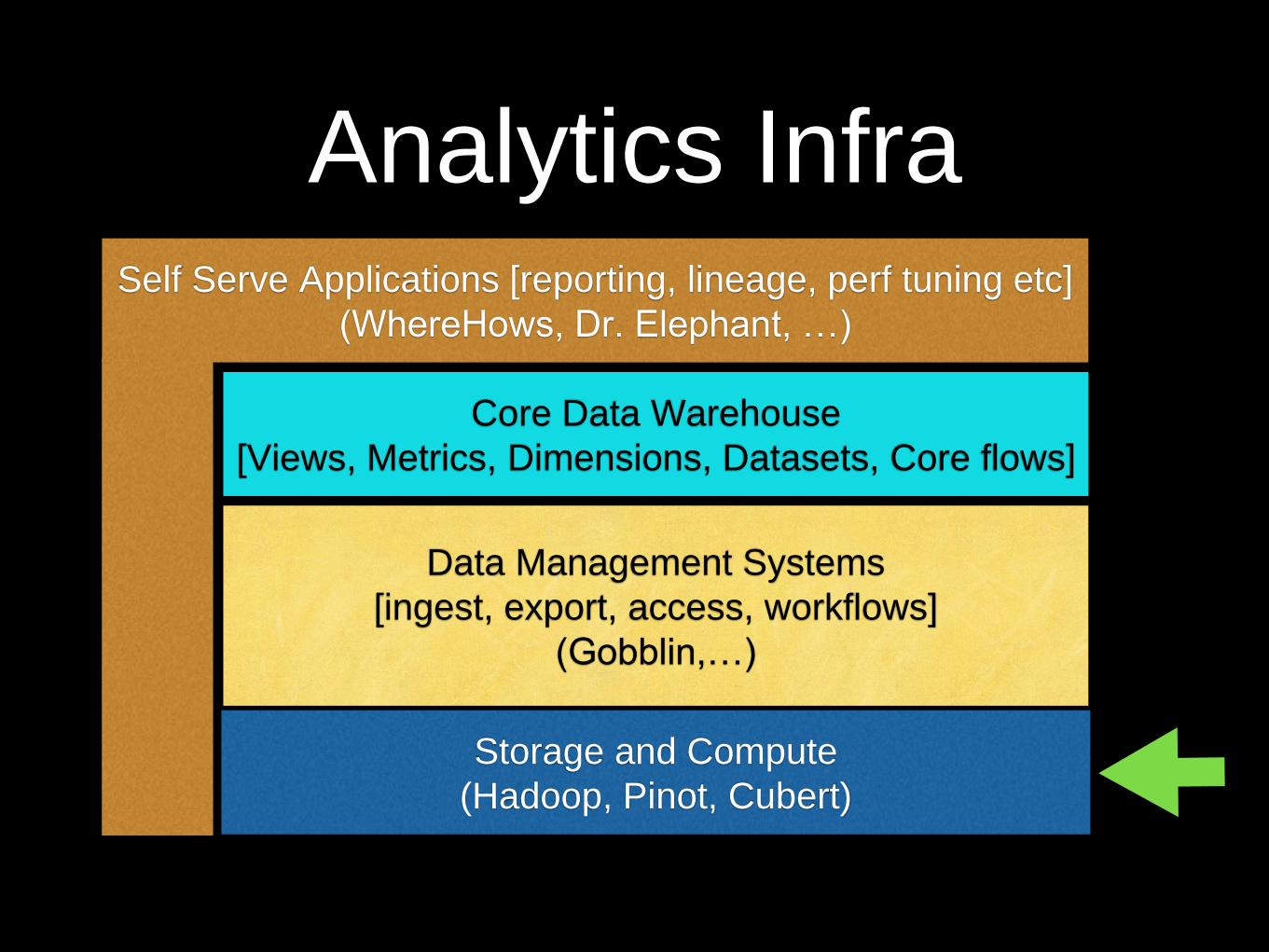
Analytics Infra
Storage and Compute
(Hadoop, Pinot, Cubert)
Data Management Systems
[ingest, export, access, workflows]
(Gobblin,…)
Self Serve Applications [reporting, lineage, perf tuning etc]
(WhereHows, Dr. Elephant, …)
Core Data Warehouse
[Views, Metrics, Dimensions, Datasets, Core flows]

Storage and Compute
Platforms
Hadoop
HDFS
Y
A
R
N
Map-Reduce Spark Tez
Pig Hive Cubert
Pinot
Scalding

Hadoop @ LinkedIn
• Deployment
• x Clusters (~x000 nodes)
• xx+ PB of data
• xxx k jobs / week
• xM compute hrs / month
ETL
R & D
PROD ETL
Online Data Serving
Ingest Export
R & D
PROD

Supporting > 1000
Hadoop users
• Development process
• do code, [review], deploy, while (! good);
• Hadoop is complex: lots of knobs, tuning helps
• Performance symptoms not easily identifiable: scattered evidence
• Performance implications of changes
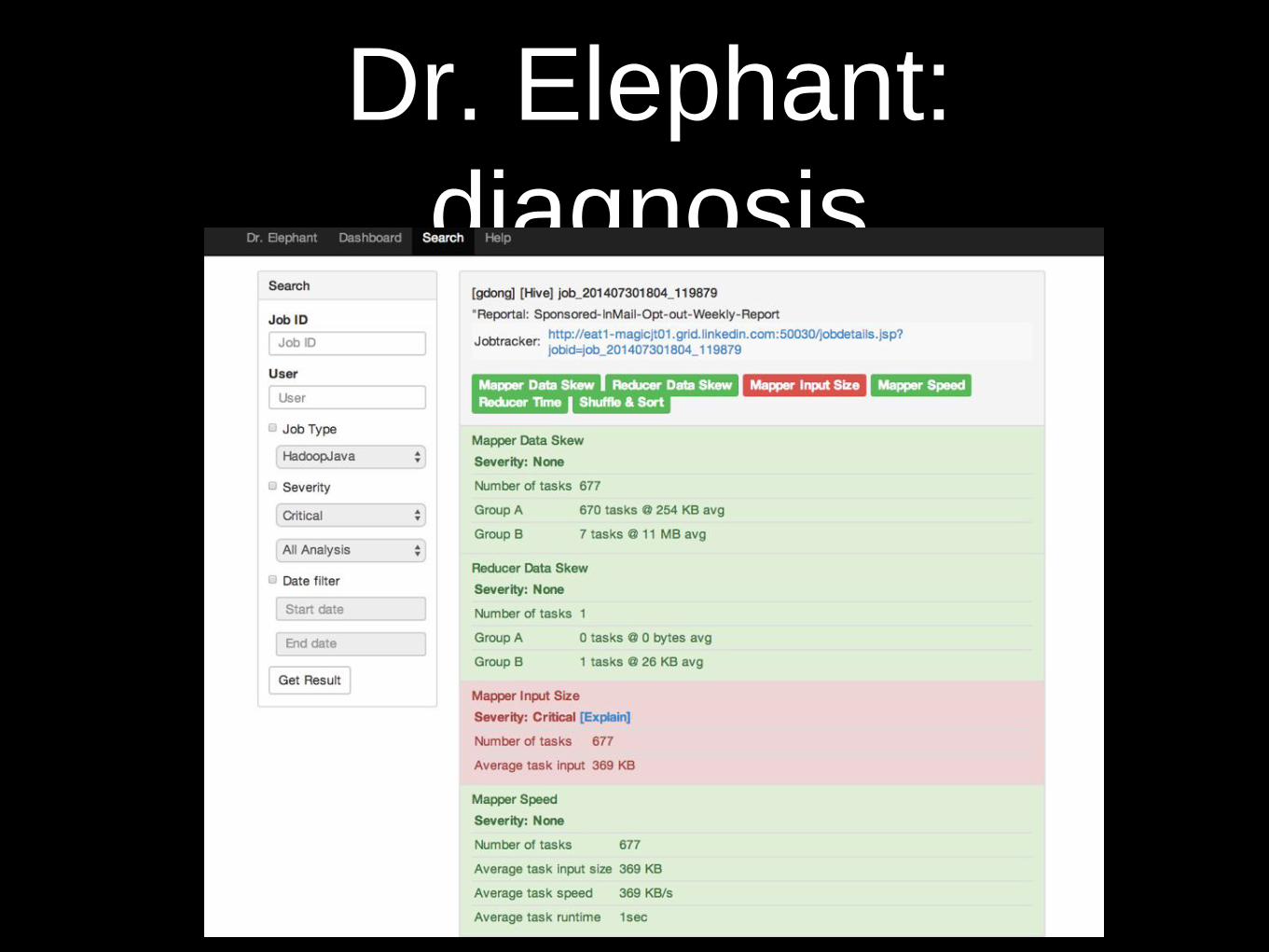
Dr. Elephant:
diagnosis

What about real-time
analytics?

Slow Queries

Solution
• Avoid joins at query time when possible.
• Denormalize data in Hadoop and load into a fast engine for slice-n-dice.

Real-time analytics
• A challenge for Hadoop
• Slice and dice billions of records, hundreds of dimensions
• End to end freshness of minutes not hours
• Sub-second query response times
• e.g. Which are top regions that contribute to my profile views? Which industries in those regions?

Pinot for realtime
analytics
g
• Distributed, fault-tolerant
• Compressed Columnar indexes
• Data ingestion from Kafka and Hadoop
• No joins, yet.
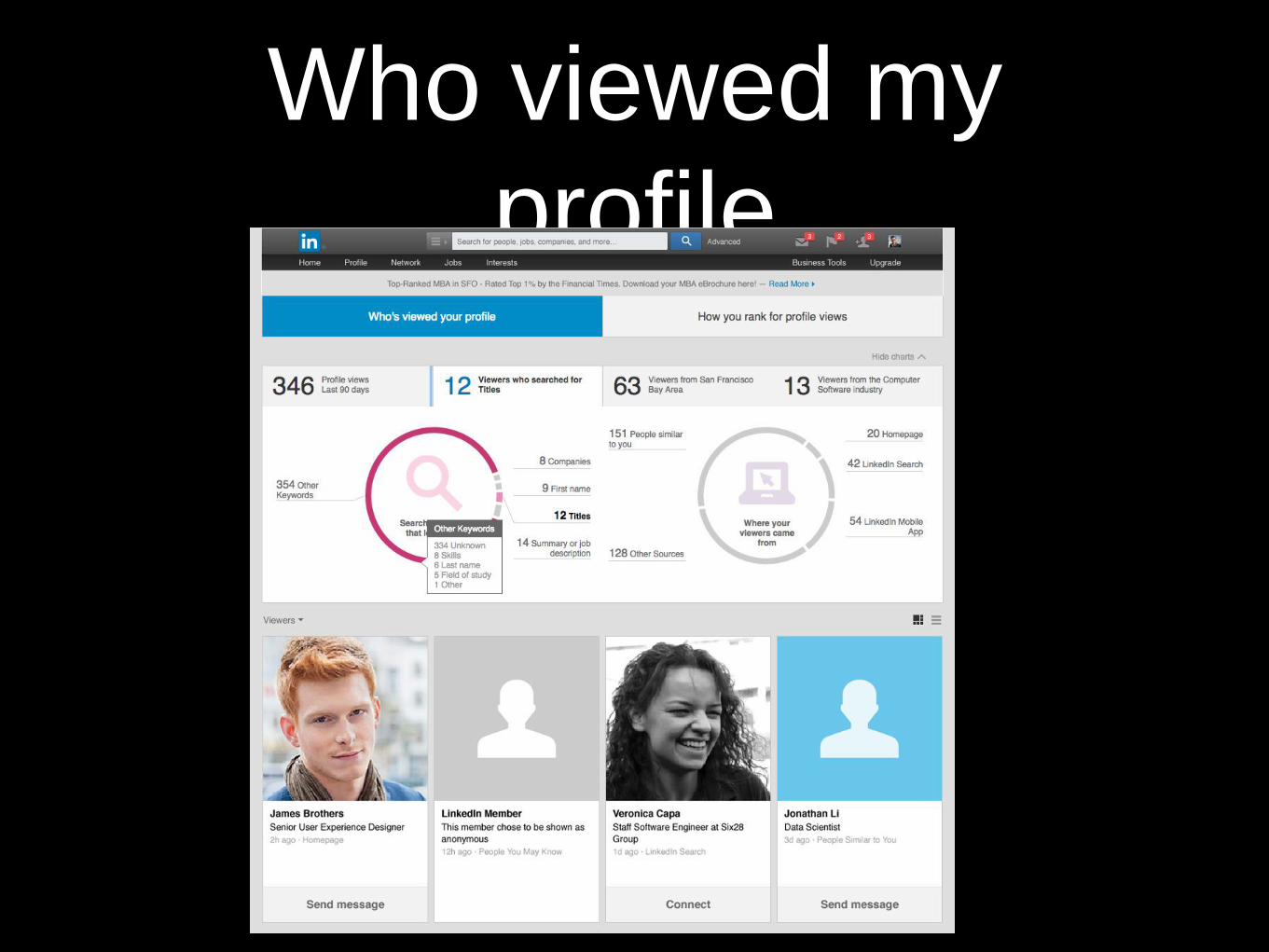
Who viewed my
profile
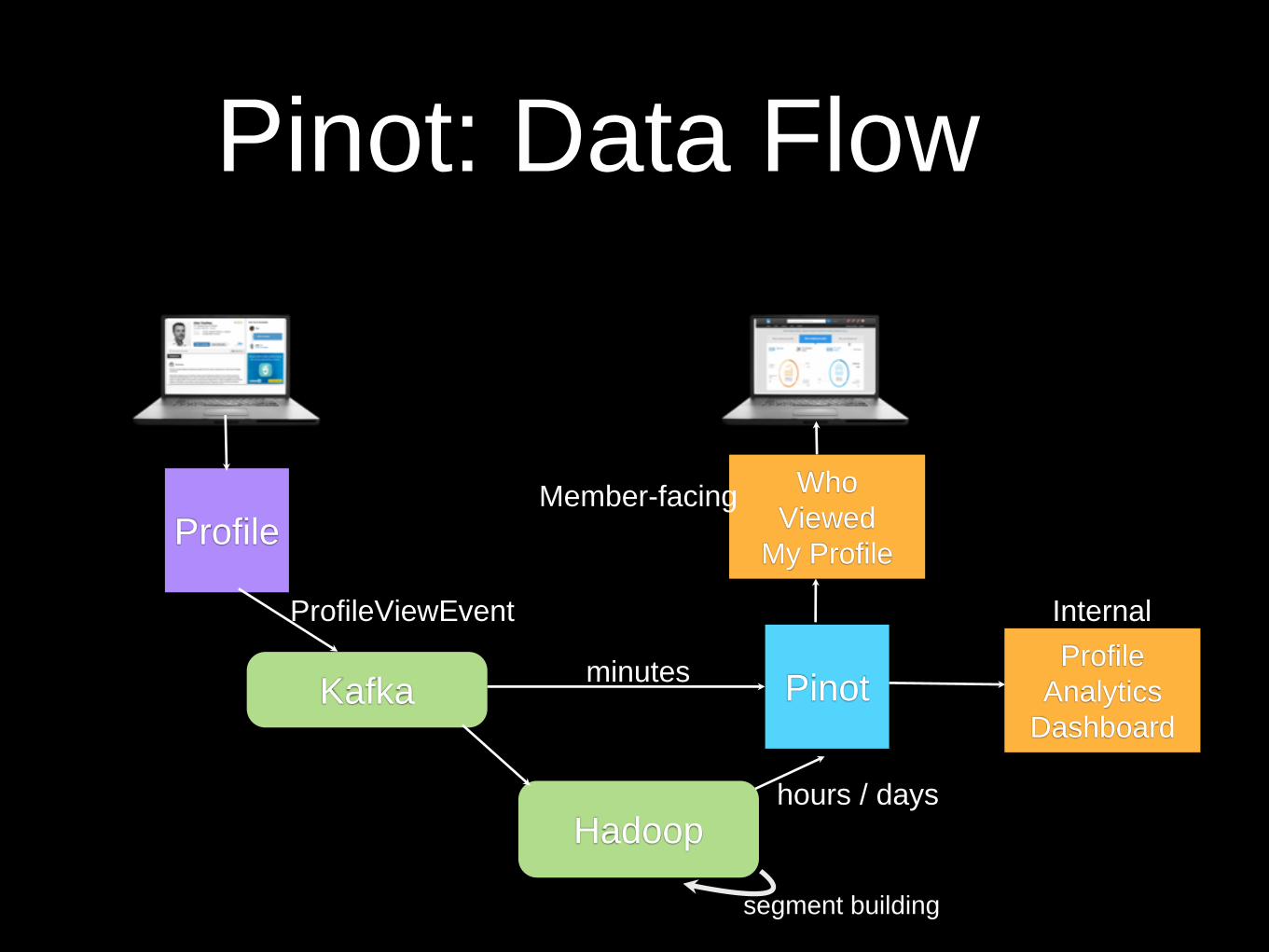
Pinot: Data Flow
Profile
Kafka
Hadoop
Pinot
Who
Viewed
My Profile
Profile
Analytics
Dashboard
Member-facing
Internal ProfileViewEvent
hours / days
minutes
segment building

Pig and Hive are
great but....
• Operate on individual records
• Re-compute scheduled batch ETL
jobs with full scans.
• Can do better by reorganization and
processing data in blocks

Cubert: Accelerating
Batch computation
0 hours
5 hours
10 hours
15 hours
20 hours
25 hours
30 hours
35 hours
40 hours
XLNT (Statistical) SPI (Graph) Plato (OLAP Cube)
Pig/Hive Cubert

Cubert Internals
•Organizes data in blocks
•Blocks created and transformed with
operators
•Cubert provides a scripting language
and a runtime to execute the operators
in Map-Reduce operations.

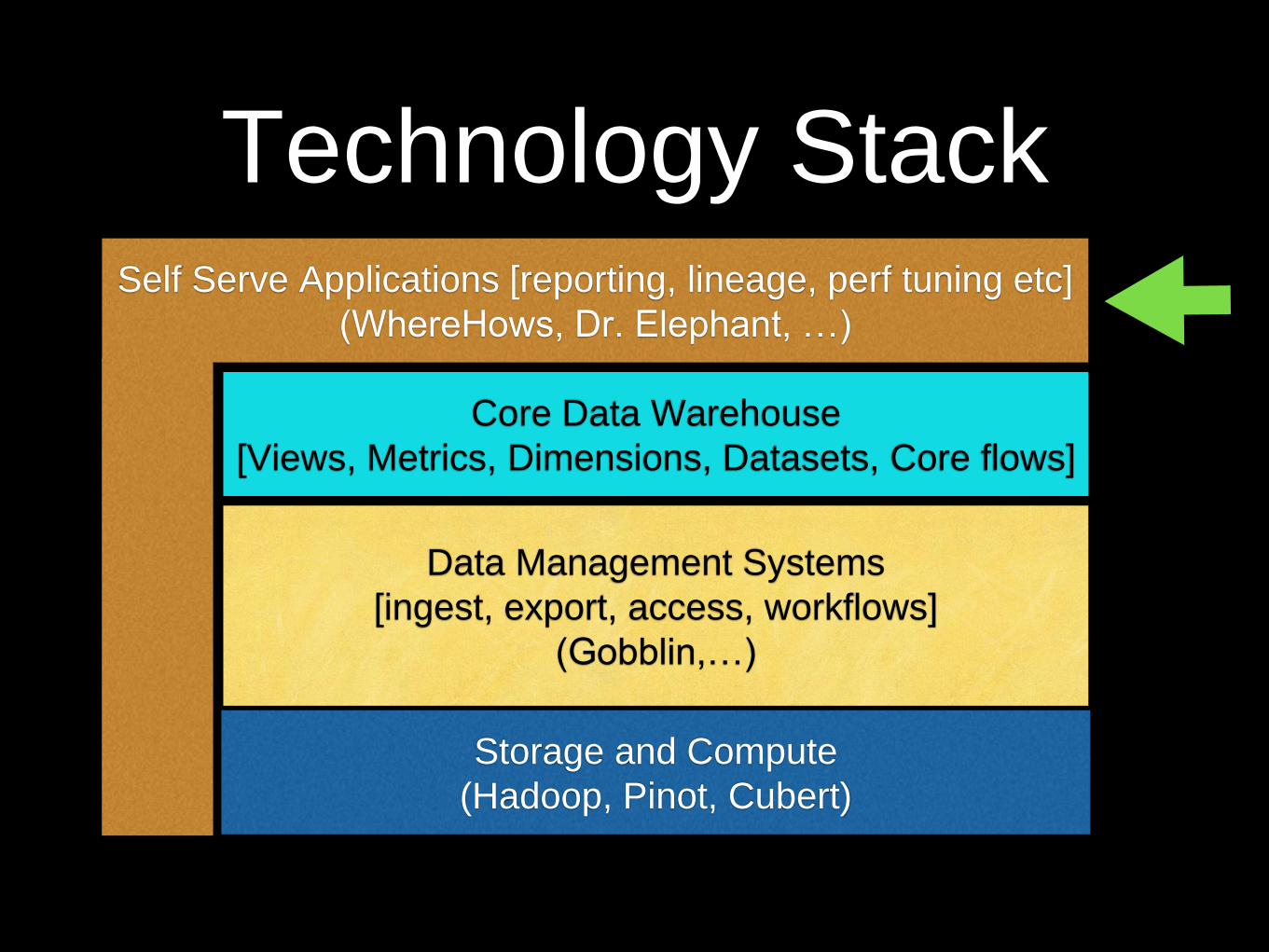
Technology Stack
Storage and Compute
(Hadoop, Pinot, Cubert)
Data Management Systems
[ingest, export, access, workflows]
(Gobblin,…)
Self Serve Applications [reporting, lineage, perf tuning etc]
(WhereHows, Dr. Elephant, …)
Core Data Warehouse
[Views, Metrics, Dimensions, Datasets, Core flows]

Perception
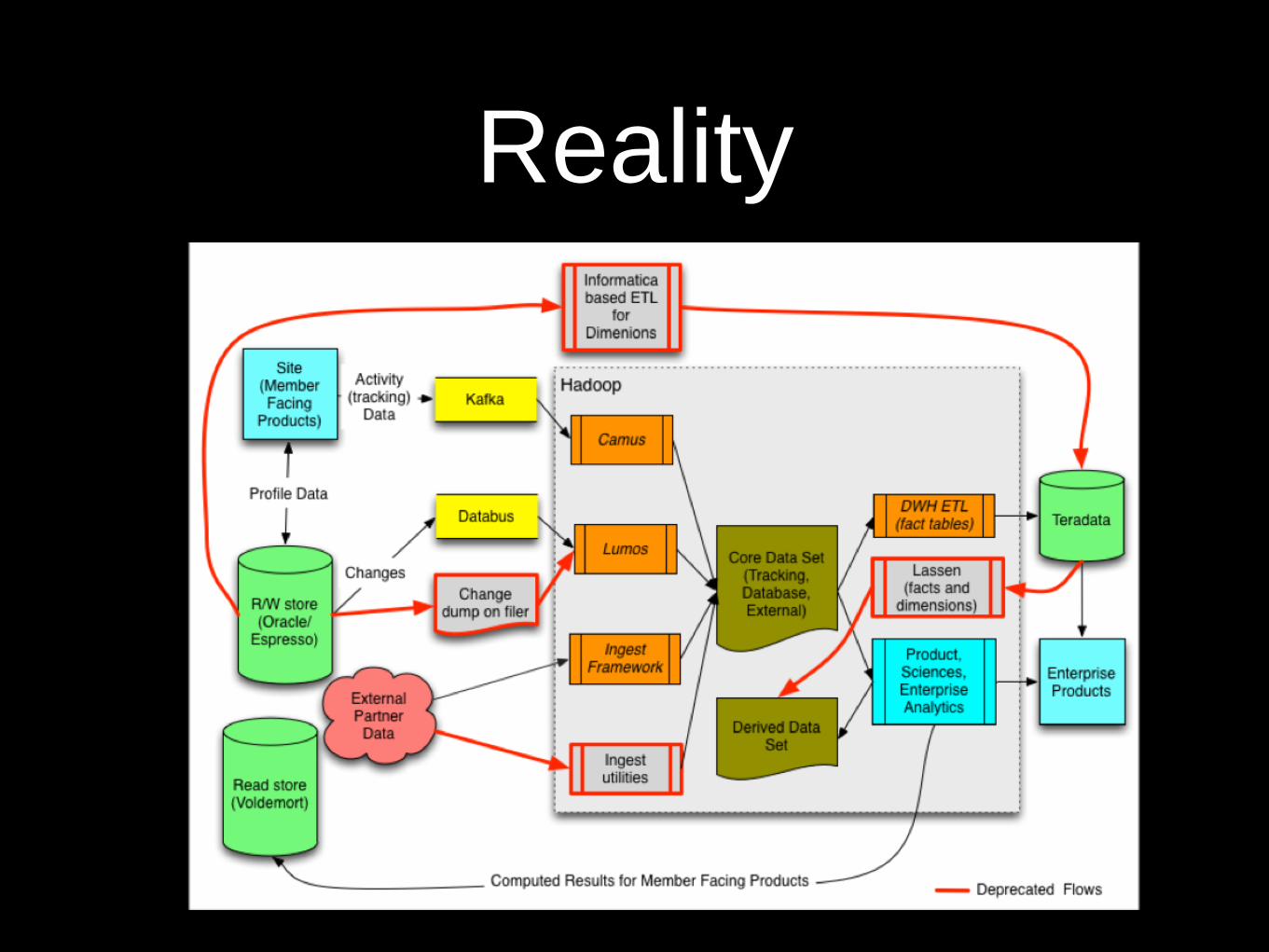
Reality

Unifying Ingress into Hadoop

Ingest operator chain

Gobblin: roadmap
• Open source in 2014
• Current work
• Continuous and batch ingest
• Data profiling, summarization
• Flexible deployment
• Resource utilization and sharing

Workflow
Management
Oozie
Azkaban EasyDat
a
Scheduling
Backend
Workflow
Mgmt Apps
Technology Stack
Storage and Compute
(Hadoop, Pinot, Cubert)
Data Management Systems
[ingest, export, access, workflows]
(Gobblin,…)
Self Serve Applications [reporting, lineage, perf tuning etc]
(WhereHows, Dr. Elephant, …)
Core Data Warehouse
[Views, Metrics, Dimensions, Datasets, Core flows]

“WhereHows” Data Exploration
• Discover datasets • Spread across storage systems (HDFS, TD, Kafka…)
• Murky semantics for data and columns
• Lineage to traverse relationships
• Discover processes • Spread across process execution engines (Azkaban, Ad-
hoc, Appworx, EasyData)
• See code and logic
• Correlate data and processes

WhereHows

Lineage in action

Reporting and
Visualization
1. Dashboards

Reporting and
Visualization
1. Dashboards
2. Curated
Exploration

Reporting and
Visualization
1. Dashboards
2. Curated
Exploration
3. Ad-hoc

Summary
Hadoop storage & compute
Pinot* for real-time querying
Dr. Elephant* for tuning Hadoop
Cubert* for batch M/R
Gobblin*: data ingest
WhereHows: explore data, lineage
Reporting: dashboards, curated exploration, ad-hoc
Workflow Mgmt
Hadoop
HDFS
Y
A
R
N Map-Reduce Spark Tez
Pig Hive Cubert Scalding
Oozie
Azkaban EasyDat
a
Pinot

Thanks!
Greg Arnold,
Sr. Director Engineering