big data with hadoop, spark and bigquery (google cloud next extended 2017 karachi)
TRANSCRIPT

Big Data with Hadoop, Spark and BigQuery Google Cloud Next Extended 2017Speaker: Imam Raza
Speaker.bio.toString()
Senior Software Architect @Folio3
Specialities:
Designing scalable Enterprise Software Architecture,
Designing scalable mobile app.
IBM Big Data certified professional.
MongoDB certified professional.

About this presentation
me.loveQuestion==true. Let's have interactive session.
The content is designed on basis of industry experience.
Would have some lab sessions
Switching the gear with interesting silicon valley facts.

Agenda
What is Big Data?
What is Big Data components?
What is hadoop?
What is spark
What is BigQuery?
Designing scalable Vs fashionable applications.

What is Big Data?
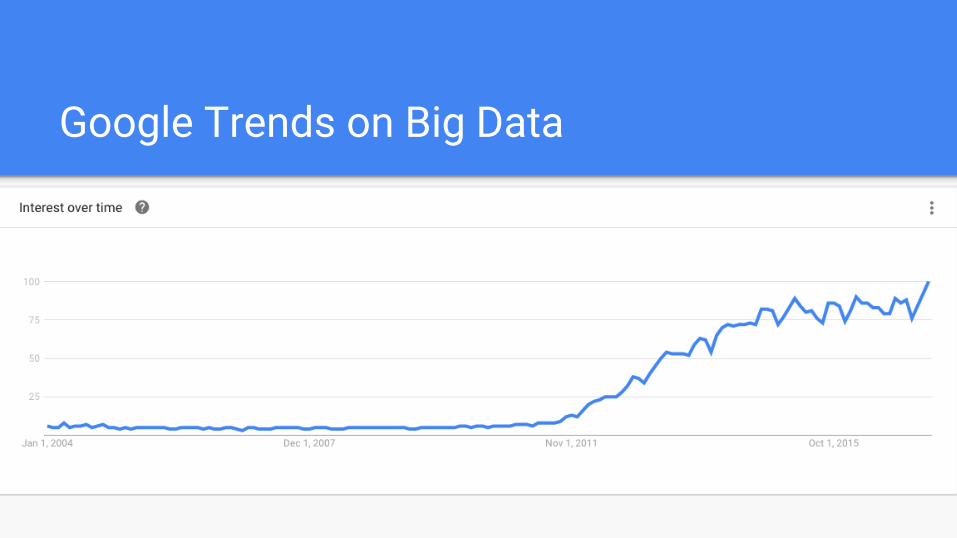
Google Trends on Big Data

Big Data Definition
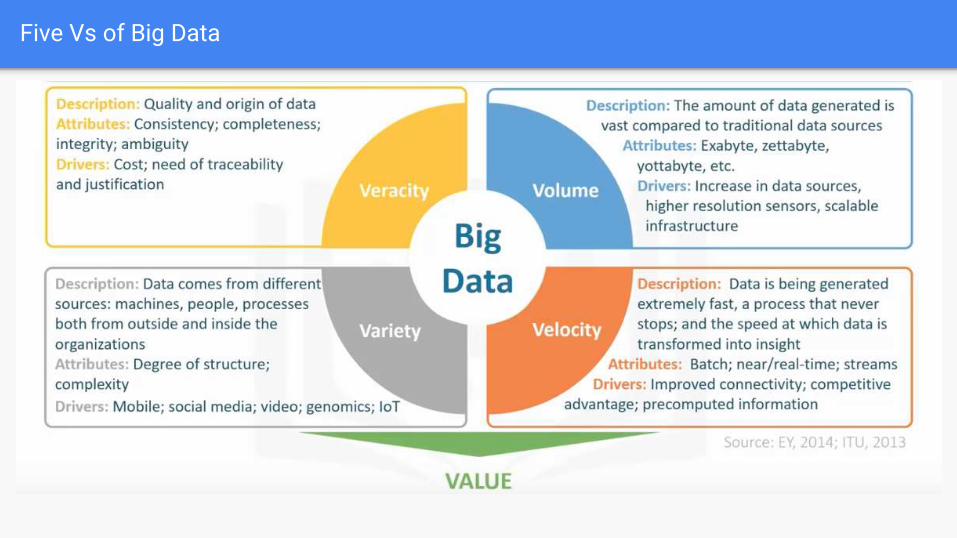
Five Vs of Big Data

1st V:Velocity

2nd V: Volume
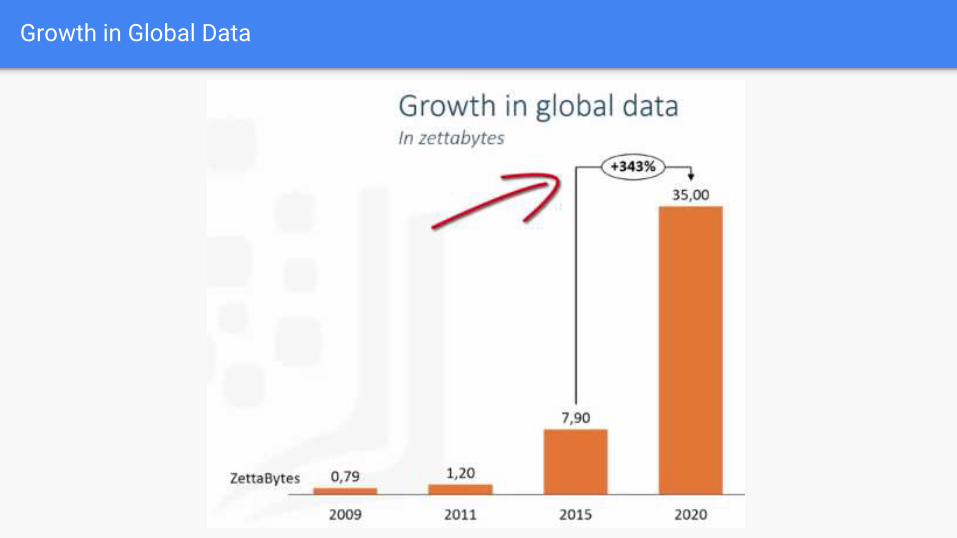
Growth in Global Data
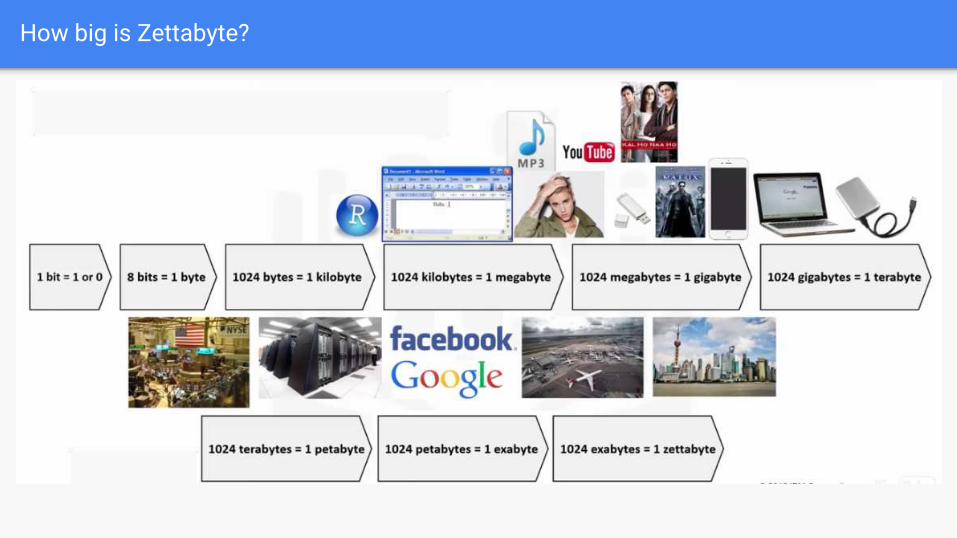
How big is Zettabyte?

3rd V: Variety

4th V: Veracity
5th V: Value
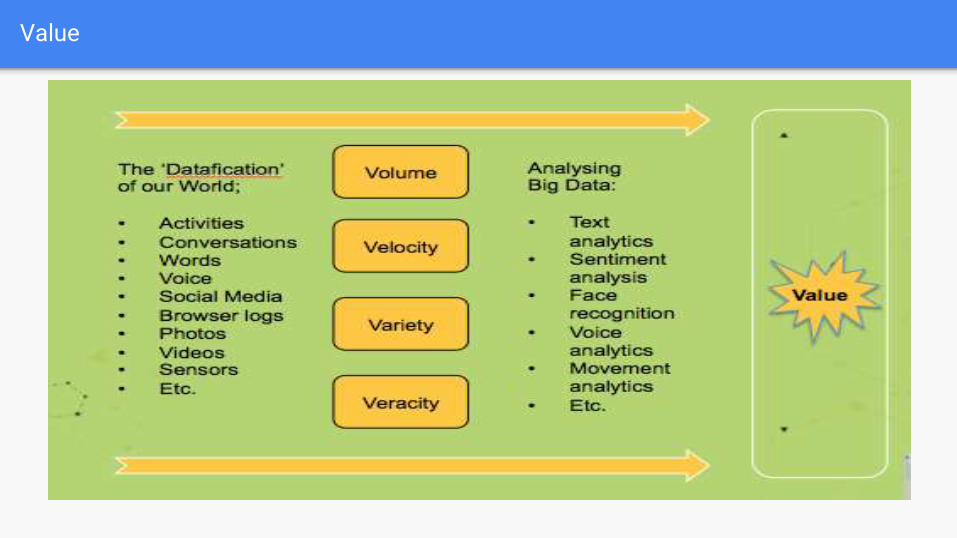
Value

Big Data Business implementation

Recommendation Engines

Netflix Show “House of Card” was an immediate hit

Big data business application
Better understand and target customers
Understand and optimize Business process
Improving Health
Improving security and Law enforcement
Improving sports performance
Improving and optimizing Cities and Countries

Types of Source of Big Data
Structured Data (RDBMS, Spreadsheets)
Unstructured Data (raw data)
Semi-Structured Data (XML,JSON)

Switching the gear
A mandatory books for silicon valley
graduates looking for jobs.

Big Data Ecosystem
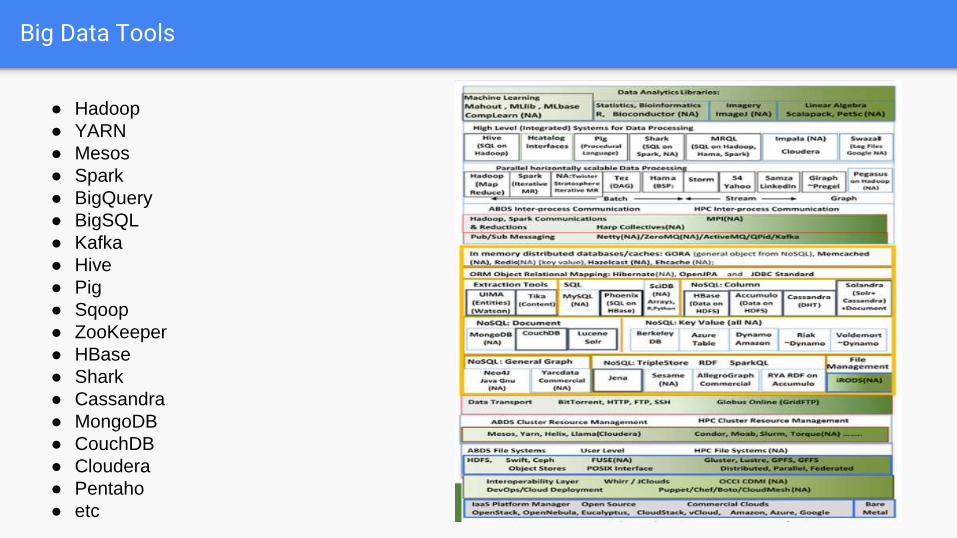
Big Data Tools
● Hadoop
● YARN
● Mesos
● Spark
● BigQuery
● BigSQL
● Kafka
● Hive
● Pig
● Sqoop
● ZooKeeper
● HBase
● Shark
● Cassandra
● MongoDB
● CouchDB
● Cloudera
● Pentaho
● etc

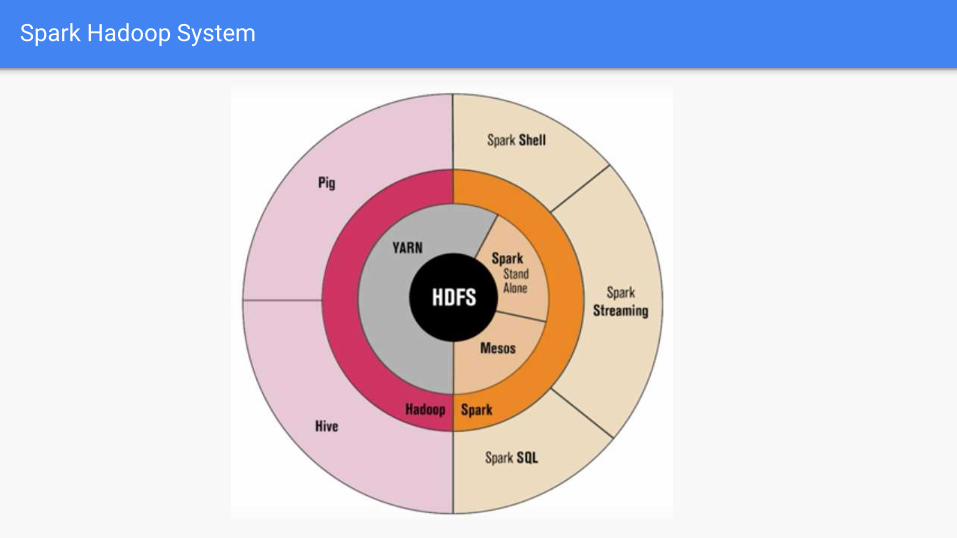
Spark Hadoop System

Hadoop
Hadoop is an open-source software framework that
supports data-intensive distributed applications
A Hadoop cluster is composed of a single master node
and multiple worker nodes

Hadoop Primary Components
HDFS – Hadoop Distributed File System.(Storing large
amounts of data)
MapReduce Programming Model- (Processing large
amounts of data)
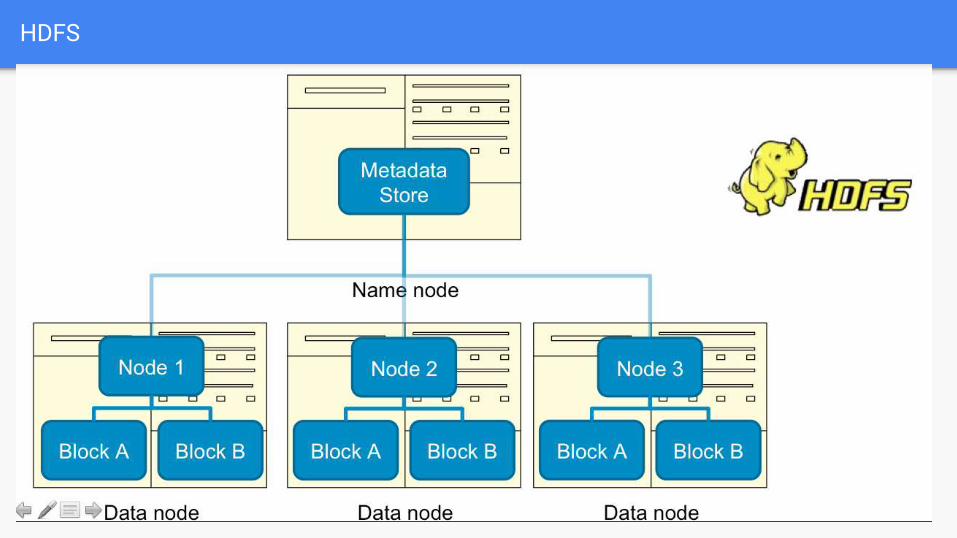
HDFS

Moving Code to Data Philosophy
If code and data are on different machines, one of them must be moved to
the other machine before the code can be executed on the data.
If the code is smaller than the data, better to send the code to the machine
holding the data than the other way around, if all the machines are equally
fast.
In the world of Big Data, the code is almost always smaller than the data.
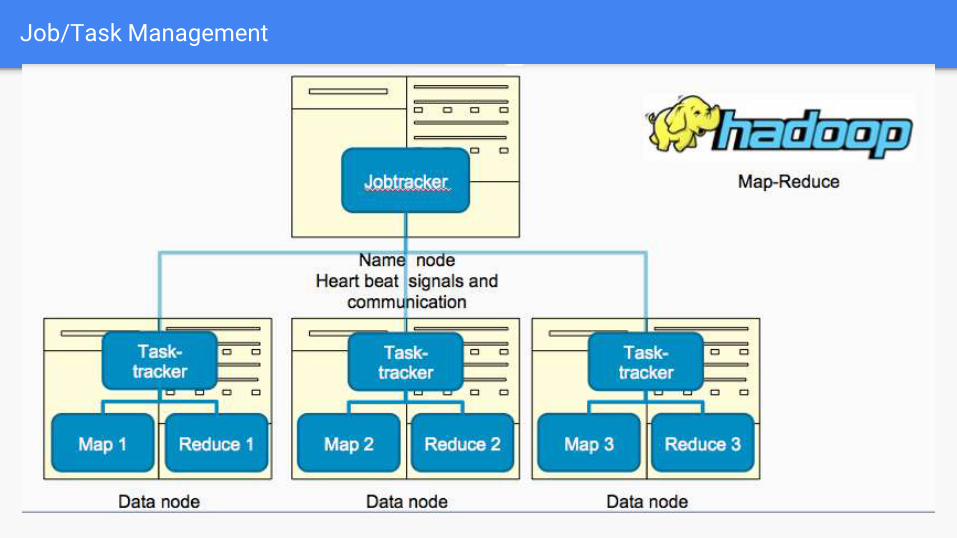
Job/Task Management
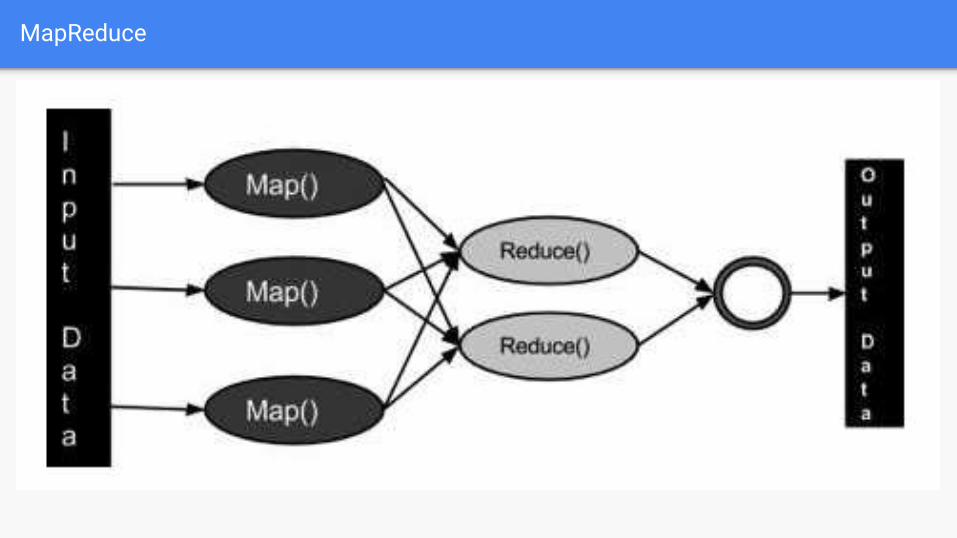
MapReduce
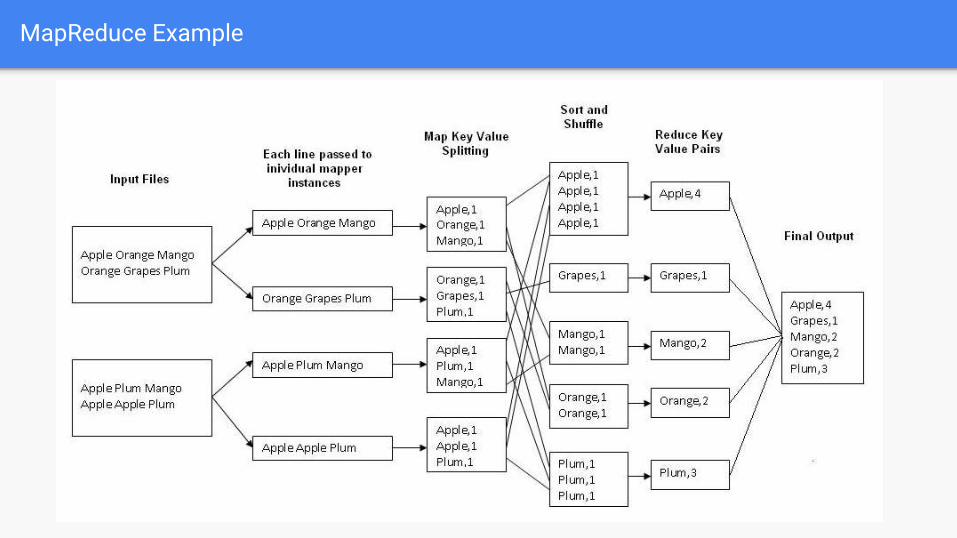
MapReduce Example
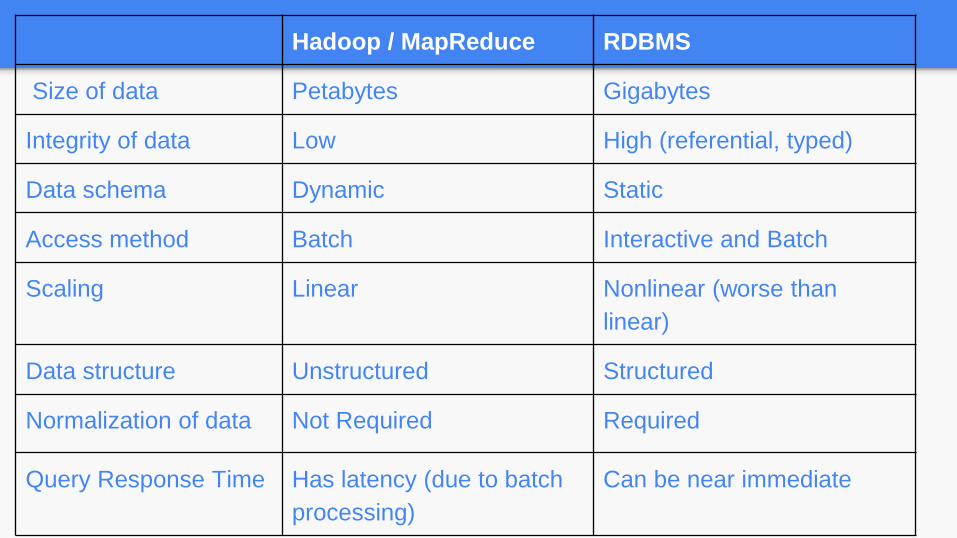
Hadoop / MapReduce RDBMS
Size of data Petabytes Gigabytes
Integrity of data Low High (referential, typed)
Data schema Dynamic Static
Access method Batch Interactive and Batch
Scaling Linear Nonlinear (worse than
linear)
Data structure Unstructured Structured
Normalization of data Not Required Required
Query Response Time Has latency (due to batch
processing)
Can be near immediate

Apache Spark
Apache Spark is a lightning-fast cluster computing technology,
designed for fast computation.
It is based on Hadoop MapReduce and it extends the MapReduce
model to efficiently use it for more types of computations,
which includes interactive queries and stream processing

Apache Spark features
Speed: Spark helps to run an application in Hadoop cluster, up to
100 times faster in memory, and 10 times faster when running
on disk.
Support Multi languages: provides built-in APIs in Java, Scala, or
Python
Advanced Analytics: Supports SQL queries, Streaming data,
Machine learning (ML), and Graph algorithms.
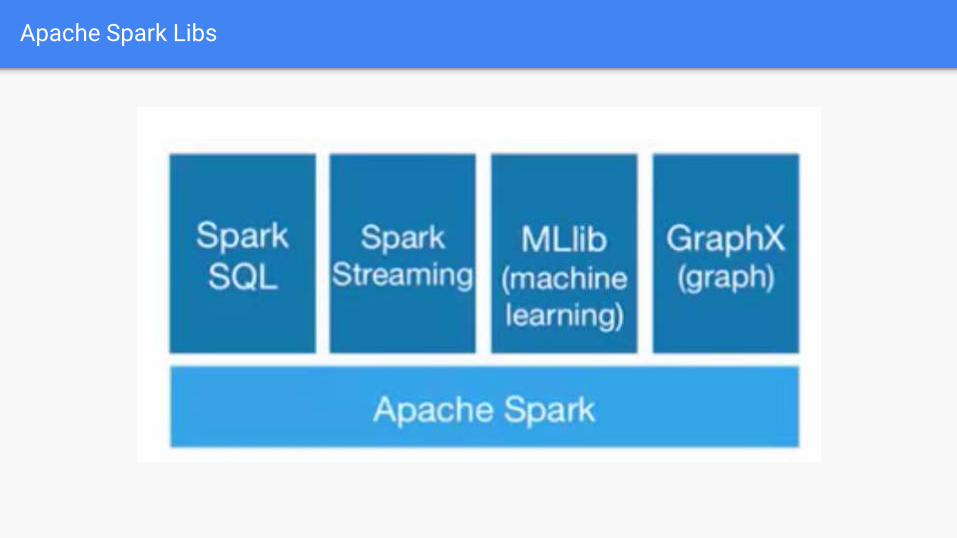
Apache Spark Libs

Apache Spark Lab SessionVia http://datascientistworkbench.com

Switching the gear
Silicon valley awakes early in the
morning

Big Query

BigQuery
A service that enables interactive analysis of massively large datasets
Based on Dremel, a scalable, interactive ad hoc query system for analysis
of read-only nested data
Working in conjunction with Google Storage
Has a RESTful web service interface.

BigQuery
You can issue SQL queries over big data
Interactive web interface
As small response time as possible
Auto scales under the hood
.
BigQuery
SaaS (/ PaaS)
Interfacing:
REST API
Web console
Command line tools
Language libraries
Insert only
.

BigQuery Lab SessionVia https://bigquery.cloud.google.com
Switching the gear
Zareen is a pakistani restaurant in
Google Mountain View.
1477 Plymouth Street, Suite C
Mountain View, CA 94043
http://www.zareensrestaurant.com/

Designing Scalable Vs Fashionable apps

References
https://cloud.google.com/bigquery/public-data/
https://bigquery.cloud.google.com
IBM BigData virtual Lab (https://datascientistworkbench.com/)
IBM Big data University (http://bigdatauniversity.com)
Questions