redshift vs bigquery lessons learned at yahoo!
TRANSCRIPT

Redsh i f t vs B ig Query Lessons Lea rned
a t Yahoo !
P R E S E N T E D B Y J o n a t h a n R a s p a u d ⎪ J a n u a r y 2 n d , 2 0 1 7
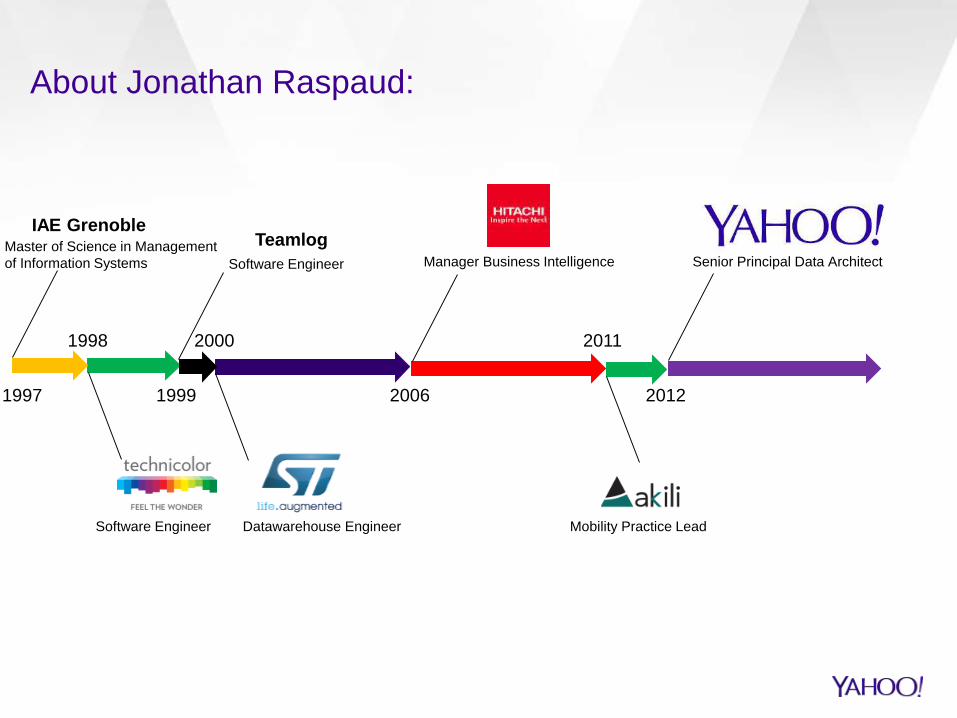
About Jonathan Raspaud:
1998 2000
2006
2011
2012
Senior Principal Data Architect
Mobility Practice Lead
Manager Business Intelligence
Datawarehouse EngineerSoftware Engineer
Software Engineer
Teamlog
1999
IAE GrenobleMaster of Science in Management
of Information Systems
1997
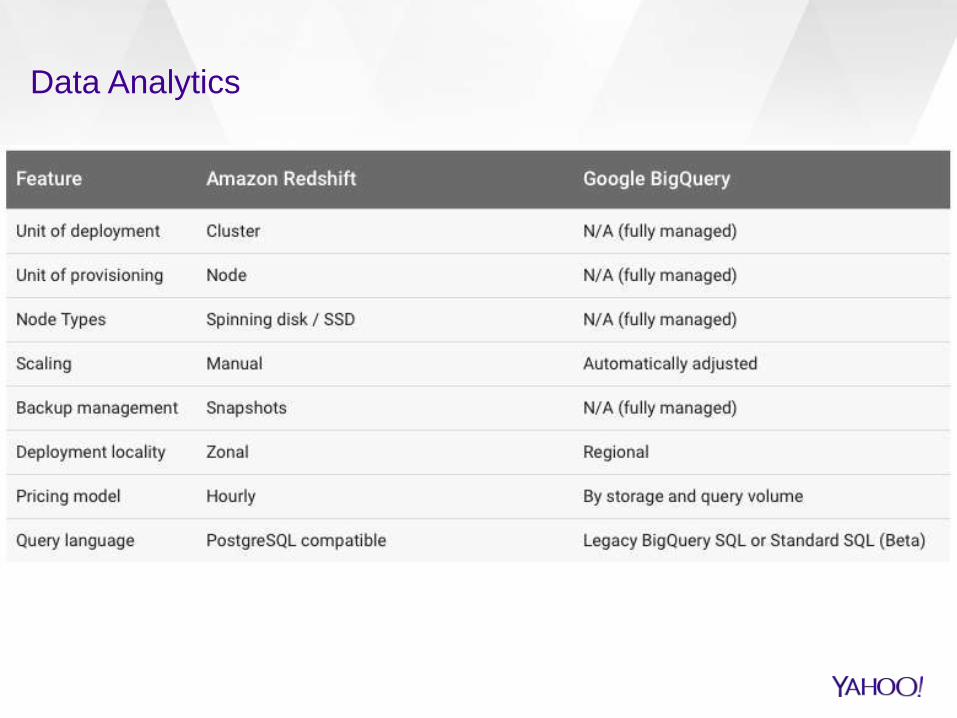
Data Analytics

Redshift vs BigQuery:
Amazon Redshift is a partially managed service. If Amazon Redshift users want to scale a cluster up or down— for example, to reduce costs during periods of low usage, or to increase resources during periods of heavy usage—they must do so manually. In addition, Amazon Redshift requires users to carefully define and manage their distribution and sort keys, and to perform data cleanup and defragmentation processes manually.
Amazon Redshift can scale from a single node to a maximum of either 128 nodes for 8xlarge node types or 32 nodes for smaller node types. These limits mean that Amazon Redshift has a maximum capacity of 2PB of stored data, including replicated data.

Redshift vs BigQuery (2):
To achieve good performance, the user must define their static distribution keys at the time of table
creation. These distribution keys are then used by the system to shard the data across the nodes so
that queries can be performed in parallel. Because distribution keys have a significant effect on query
performance, the user must choose these keys carefully. After the user defines their distribution keys,
the keys cannot be changed; to use different keys, the user must create a new table with the new
keys and copy their data from the old table.
In addition, Amazon recommends that the administrator perform periodic maintenance to reclaim lost
space. Because updates and deletes do not automatically compact the resident data on disk, they
can eventually lead to performance bottlenecks. For more information, see Vacuuming Tables in the
Amazon Redshift documentation.
Amazon Redshift administrators must manage their end users and applications carefully. For
example, users must tune the number of concurrent queries they perform. By default, Amazon
Redshift performs up to 5 concurrent queries. Because resources are provisioned ahead of time, as
you increase this limit—the maximum is 50—performance and throughput can begin to suffer. See the
Concurrency Levels section of Defining Query Queues in the Amazon Redshift documentation for
details.
Amazon Redshift administrators must also size their cluster to support the overall data size, query
performance, and number of concurrent users. Administrators can scale up the cluster; however,
given the provisioned model, the users pay for what they provision, regardless of usage.
Finally, Amazon Redshift clusters are restricted to a single zone by default. To create a highly
available, multi-regional Amazon Redshift architecture, the user must create additional clusters in
other zones, and then build out a mechanism for achieving consistency across clusters. For more
information, see the Building Multi-AZ or Multi-Region Amazon Redshift Clusters post in the Amazon
Big Data Blog.

Redshift vs BigQuery (3):
In contrast, BigQuery is fully managed. Users do not
need to provision resources; instead, they can simply push
data into BigQuery, and then query across the data. The
BigQuery service manages the associated resources
opaquely and scales them automatically as appropriate.
BigQuery has no practical limits on the size of a stored
dataset. Ingestion resources scale quickly, and ingestion
itself is extremely fast—by using the BigQuery API, you
can ingest millions of rows into BigQuery per second. In
addition, ingestion resources are decoupled from
query resources, so an ingestion load cannot degrade
the performance of a query load.

Redshift vs BigQuery (4):
BigQuery handles sharding automatically. Users do not
need to create and maintain distribution keys.
BigQuery is an on-demand service rather than a
provisioned one. Users do not need to worry about under
provisioning, which can cause bottlenecks, or
overprovisioning, which can result in unnecessary costs.
BigQuery provides global, managed data replication.
Users do not need to set up and manage multiple
deployments.
BigQuery supports up to 50 concurrent interactive
queries, with no effect on performance or throughput.

Cloud 2.0 vs 3.0 with GCP
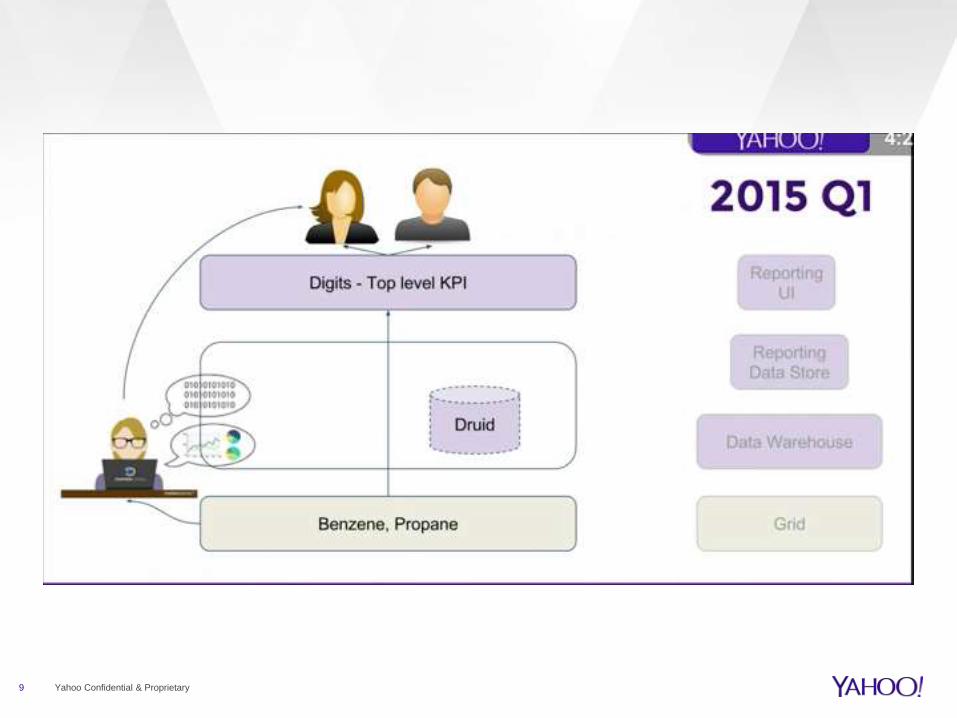
9 Yahoo Confidential & Proprietary

10 Yahoo Confidential & Proprietary
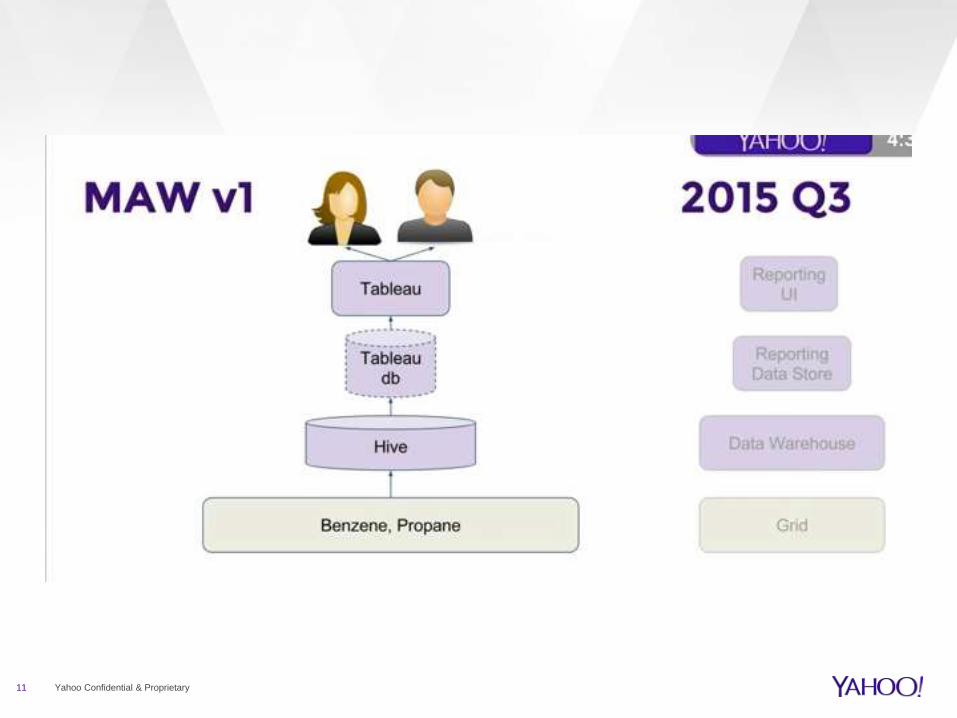
11 Yahoo Confidential & Proprietary

12 Yahoo Confidential & Proprietary

13 Yahoo Confidential & Proprietary
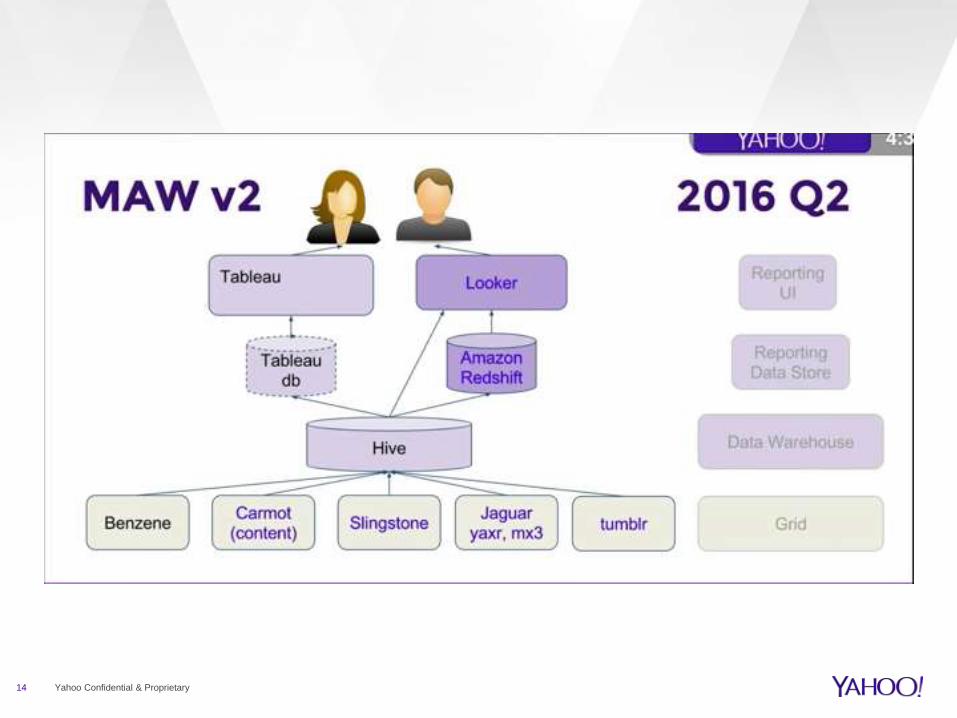
14 Yahoo Confidential & Proprietary

15 Yahoo Confidential & Proprietary

16 Yahoo Confidential & Proprietary
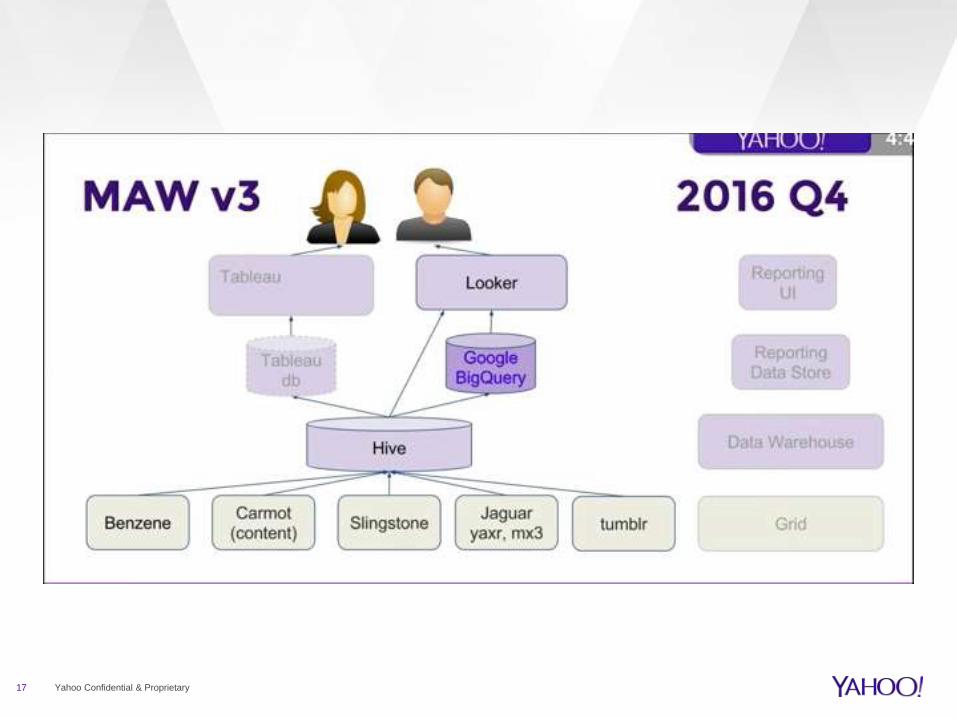
17 Yahoo Confidential & Proprietary

18 Yahoo Confidential & Proprietary

19 Yahoo Confidential & Proprietary

20 Yahoo Confidential & Proprietary
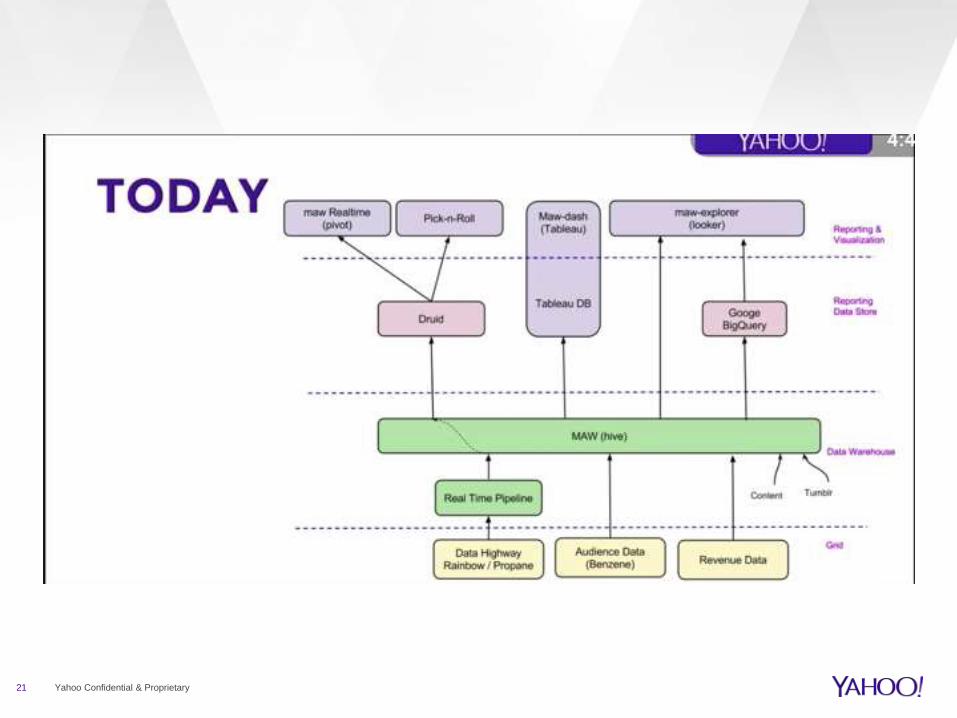
21 Yahoo Confidential & Proprietary