big data, the community and the commons (may 12, 2014)
TRANSCRIPT

Big Data, The Community and The Commons
Robert Grossman University of Chicago
Open Cloud Consor?um
May 12, 2014 TCGA Third Annual Scien?fic Symposium

Outline
1. Big data and the problems it creates 2. Compu?ng over big data 3. Science clouds 4. Data analysis at scale 5. Genomic clouds 6. How might we organize?

Four ques?ons and one challenge

1. What is the same and what is different about big biomedical data vs big science data and vs big commercial data?
2. What instrument should we use to make discoveries over big biomedical data?
3. Do we need new types of mathema?cal and sta?s?cal models for big biomedical data?
4. How do we organize large biomedical datasets to maximize the discoveries we make and their impact on health care?

One Million Genome Challenge
• Sequencing a million genomes would likely change the way we understand genomic varia?on.
• The genomic data for a pa?ent is about 1 TB (including samples from both tumor and normal ?ssue).
• One million genomes is about 1000 PB or 1 EB • With compression, it may be about 100 PB • At $1000/genome, the sequencing would cost about $1B
• Think of this as one hundred studies with 10,000 pa?ents each over three years.
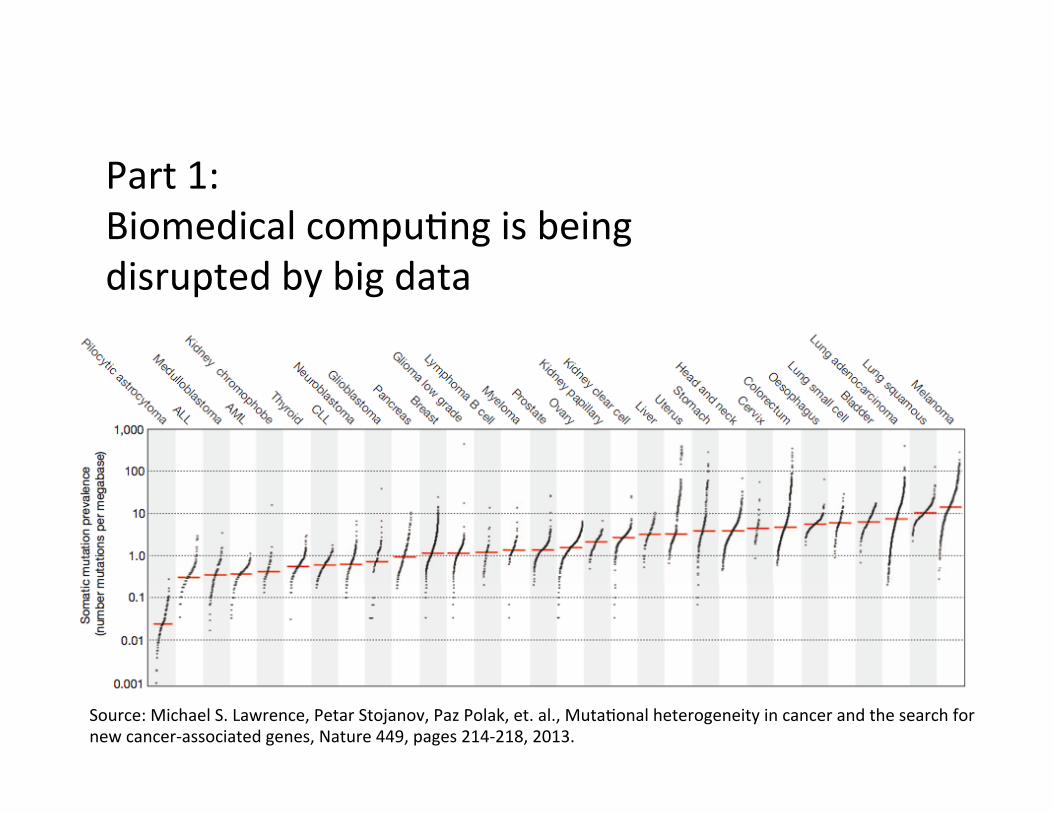
Part 1: Biomedical compu?ng is being disrupted by big data
Source: Michael S. Lawrence, Petar Stojanov, Paz Polak, et. al., Muta?onal heterogeneity in cancer and the search for new cancer-‐associated genes, Nature 449, pages 214-‐218, 2013.
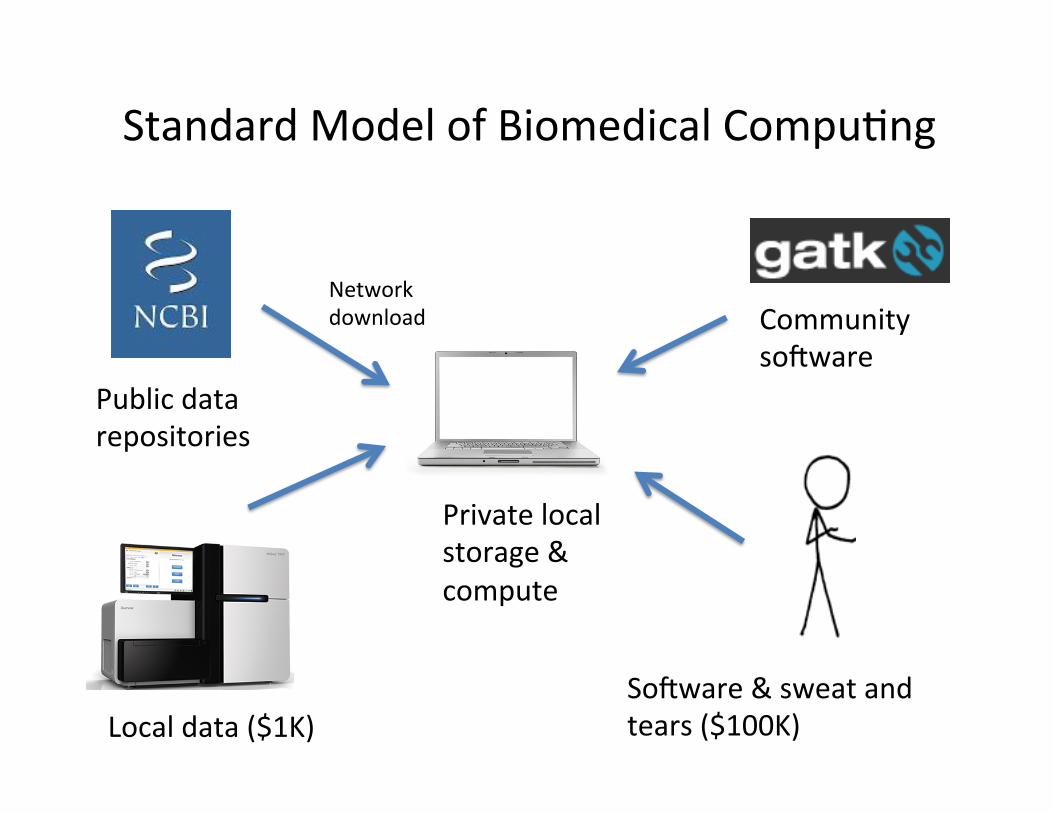
Standard Model of Biomedical Compu?ng
Public data repositories
Private local storage & compute
Network download
Local data ($1K)
Community soeware
Soeware & sweat and tears ($100K)

We have a problem …
Image: A large-‐scale sequencing center at the Broad Ins?tute of MIT and Harvard.
Growth of data New types of data
It takes over three weeks to download the TCGA data at 10 Gbps
Analyzing the data is more expensive than producing it

The Smart Phone is Becoming a Home for Medical & Environmental Sensors
Source: LifeWatch V from LifeWatch AG, www.lifewatchv.com.

Source: Interior of one of Google’s Data Center, www.google.com/about/datacenters/

Computa?onal Adver?sing and Marke?ng
• Computa?onal adver?sing finds the “best match” between a given user in a given context and a suitable adver?sement*.
• In 2011, over $100 billion was spent in online adver?sing (eMarketer es?mates)
• Contexts include: – Web search context (SERP adver?sing) – Web page content context (content match adver?sing and banners)
– Social media context – Mobile context
*Andrei Broder and Vanja Josifovski, Introduc?on to Computa?onal Adver?sing.

Why Do We Care?
• A modern adver?sing analy?c planorm: – Will build behavioral profiles on 100 million plus individuals
– Use full sta?s?cal models (not rules) for targe?ng – Re-‐analyze all of the data each night – Serve 10,000’s of ads per second using sta?s?cal models
– Respond < 100 ms (with analy?cs < 10 ms) – Use real ?me geoloca?on data – Do analy?cs at machine speed – Be driven by an analyst with only modest training
• More than pay for the data centers we just saw.
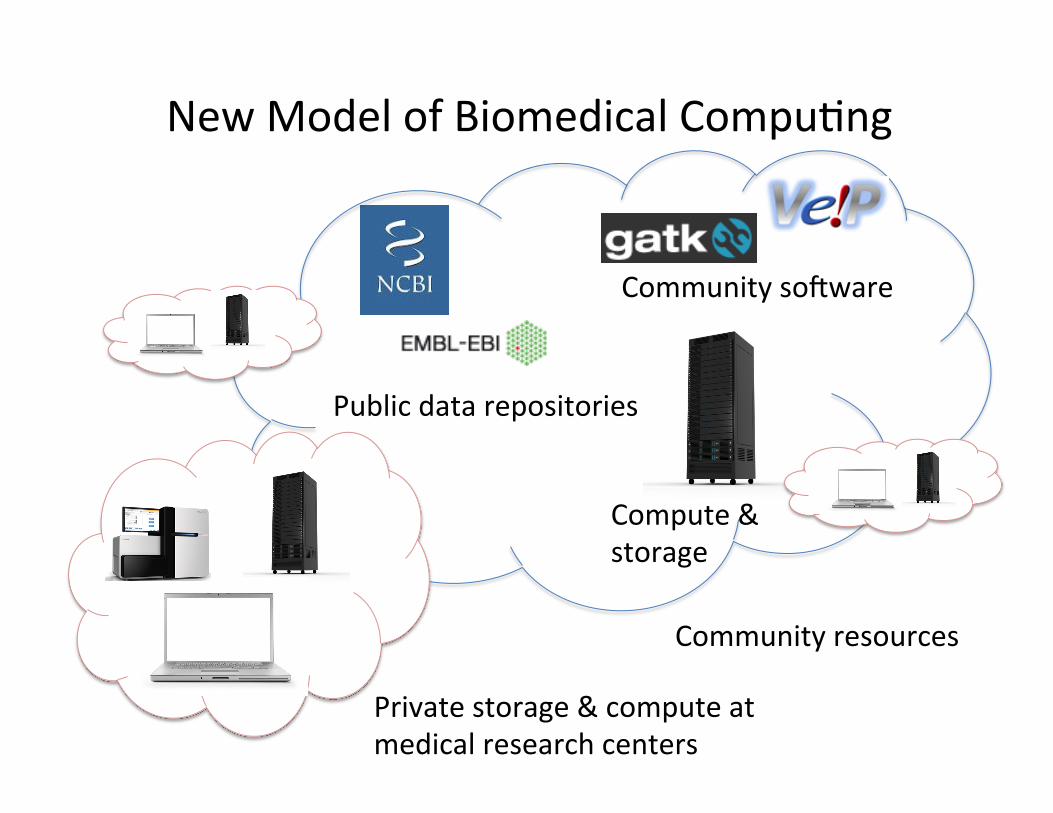
New Model of Biomedical Compu?ng
Public data repositories
Private storage & compute at medical research centers
Community soeware
Compute & storage
Community resources

The Tragedy of the Commons
Source: Garrep Hardin, The Tragedy of the Commons, Science, Volume 162, Number 3859, pages 1243-‐1248, 13 December 1968.
Individuals when they act independently following their self interests can deplete a deplete a common resource, contrary to a whole group's long-‐term best interests.

1. Create community commons of biomedical data. 2. Use a cloud compu?ng and automa?on to manage the commons and to compute over it.
3. Interoperate the data commons.

2005 -‐ 2015 Bioinforma)cs tools & their integra)on. Examples: Galaxy, GenomeSpace, workflow systems, portals, etc.
2010 -‐ 2020 ???
2015 -‐ 2025 ???

Part 2 Data Center Scale Compu?ng (aka “Cloud Compu?ng”)
Source: Interior of one of Google’s Data Center, www.google.com/about/datacenters/

What instrument do we use to make big data discoveries in cancer genomics and big data biology?
How do we build a “datascope?”

Source: Luiz André Barroso, Jimmy Clidaras and Urs Hölzle, The Datacenter as a Computer, Morgan & Claypool Publishers, Second Edi?on, 2013, www.morganclaypool.com/doi/pdf/10.2200/S00516ED2V01Y201306CAC024

Self Service Scale
Soeware stack that scales to a data center
Forgot cloud compu?ng. Focus on data centers & the soeware they run.
Use of automa?on

Sevng up and opera?ng large scale efficient, secure and compliant racks of compu?ng infrastructure is out of reach for most labs, but essen?al for the community.
This is not a cloud…

Commercial Cloud Service Provider (CSP) 15 MW Data Center
100,000 servers 1 PB DRAM
100’s of PB of disk
Automa?c provisioning and infrastructure management
Monitoring, network security and forensics
Accoun?ng and billing Customer
Facing Portal
Data center network
~1 Tbps egress bandwidth
25 operators for 15 MW Commercial Cloud

opencompute.org www.openstack.org
hadoop.apache.org
…

Open Science Data Cloud (Home of Bionimbus)
6 PB (OpenStack, GlusterFS, Hadoop)
Infrastructure automa?on & management
(Yates)
Compliance, & security (OCM)
Accoun?ng & billing
Customer Facing Portal (Tukey)
Data center network
~10-‐100 Gbps bandwidth
6 engineers to operate 0.5 MW Science Cloud
Science Cloud SW & Services

Why not just use (only) Amazon Web Services (AWS)?
Community science and biomedical clouds
• Scale / capacity • Simplicity of a credit card • Wide variety of offerings.
vs.
It is s?ll essen?al to interoperate with CSP whenever possible by compliance and security policies.
Commercial Cloud Service Providers (CSP)
• Lower cost (at medium scale)
• We can build specialized infrastructure for science.
• We can build specialized infrastructure for security & compliance.
• The data is too important to trust exclusively with a commercial provider.

Cost of a medium private/community cloud vs large public cloud.
Source: Allison P. Heath, Maphew Greenway, Raymond Powell, Jonathan Spring, Rafael Suarez, David Hanley, Chai Bandlamudi, Megan McNerney, Kevin White and Robert L Grossman, Bionimbus: A Cloud for Managing, Analyzing and Sharing Large Genomics Datasets, Journal of the American Medical Informa?cs Associa?on, 2014.
PB
Cost (thousands of $)

Reliability over Commodity Compu?ng Components Is Difficult as is Data Locality
• Hadoop enables reliable computa?on over thousands of low costs, unreliable compu?ng nodes.
• Hadoop efficiently computes over the data instead of moving the data.
• The programming model of Hadoop (MapReduce) is in prac?ce more efficient in terms of soeware development than the programming tradi?onally used by high performance compu?ng (message passing) (but usually does not fully u?lize the underlying hardware)

The Tail at Scale, Jeffrey Dean, Luiz André Barroso Communica?ons of the ACM, Volume 56 Number 2, Pages 74-‐80
Latency is Difficult

Call an algorithm and compu?ng infrastructure is “big-‐data scalable” if adding a rack of data (and corresponding processors) does not increase the ?me required to complete the computa?on but enables the computa?on to run on a rack more of data. Most of our community’s algorithms today fail this test.

2005 -‐ 2015 Bioinforma)cs tools & their integra)on. Examples: Galaxy, GenomeSpace, workflow systems, portals, etc.
2010 -‐ 2020 Data center scale science. Examples: Bionimbus/OSDC, CG Hub, Cancer Collaboratory, GenomeBridge, etc.
2015 -‐ 2025 ???
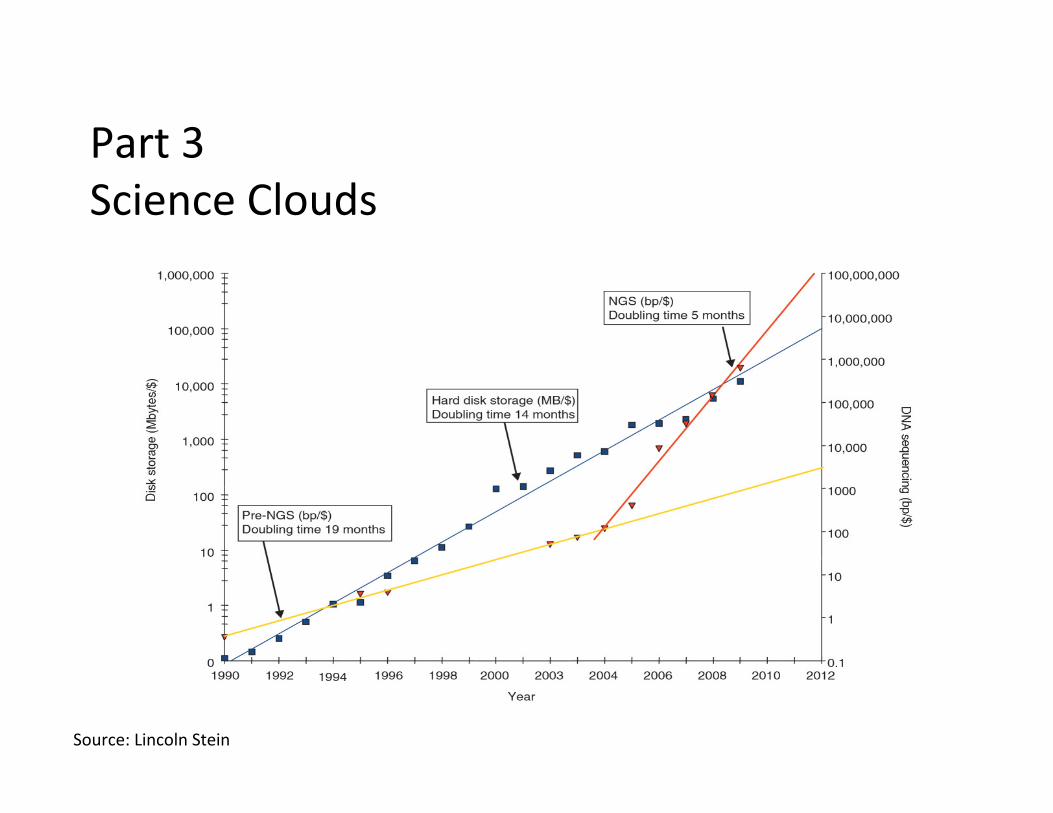
Part 3 Science Clouds
Source: Lincoln Stein
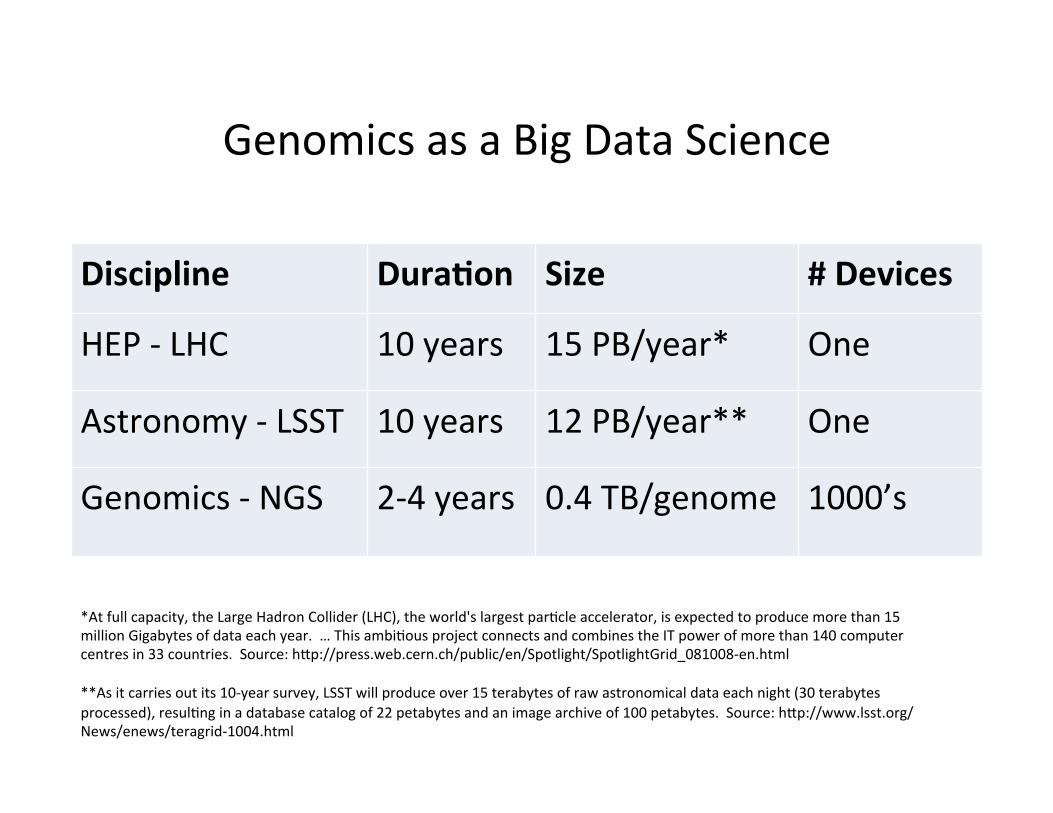
Discipline Dura)on Size # Devices
HEP -‐ LHC 10 years 15 PB/year* One
Astronomy -‐ LSST 10 years 12 PB/year** One
Genomics -‐ NGS 2-‐4 years 0.4 TB/genome 1000’s
Genomics as a Big Data Science
*At full capacity, the Large Hadron Collider (LHC), the world's largest par?cle accelerator, is expected to produce more than 15 million Gigabytes of data each year. … This ambi?ous project connects and combines the IT power of more than 140 computer centres in 33 countries. Source: hpp://press.web.cern.ch/public/en/Spotlight/SpotlightGrid_081008-‐en.html **As it carries out its 10-‐year survey, LSST will produce over 15 terabytes of raw astronomical data each night (30 terabytes processed), resul?ng in a database catalog of 22 petabytes and an image archive of 100 petabytes. Source: hpp://www.lsst.org/News/enews/teragrid-‐1004.html
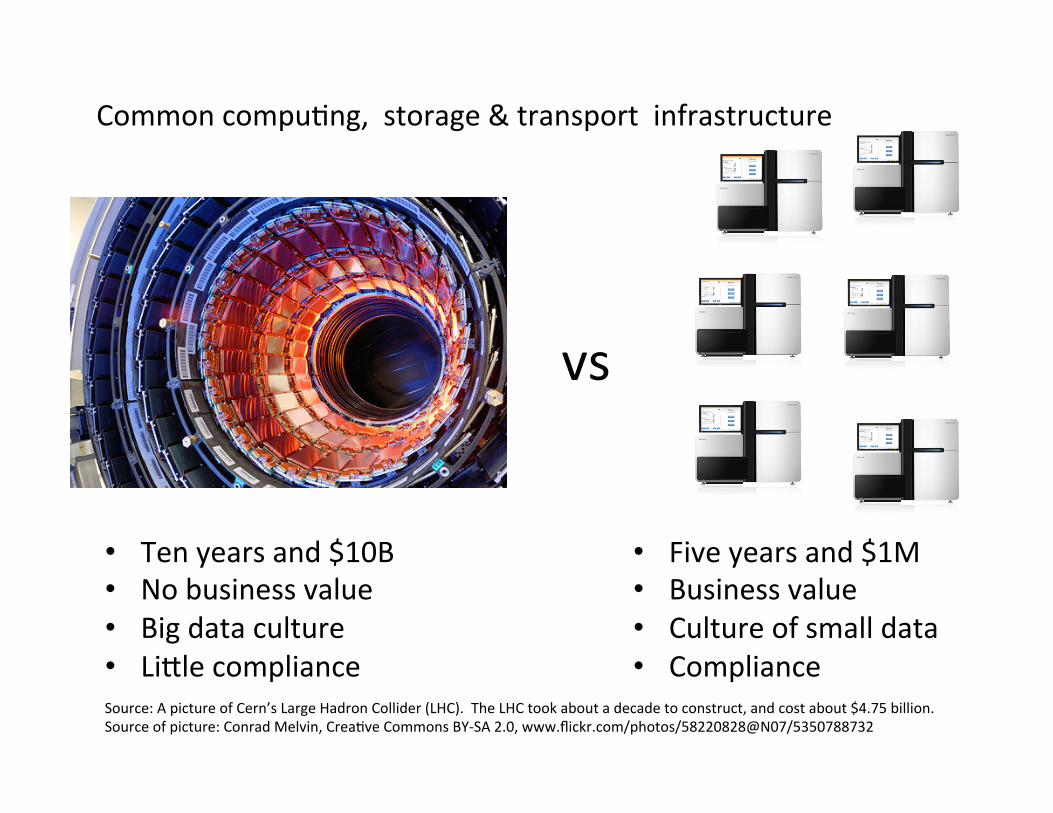
vs
Source: A picture of Cern’s Large Hadron Collider (LHC). The LHC took about a decade to construct, and cost about $4.75 billion. Source of picture: Conrad Melvin, Crea?ve Commons BY-‐SA 2.0, www.flickr.com/photos/58220828@N07/5350788732
• Ten years and $10B • No business value • Big data culture • Liple compliance
• Five years and $1M • Business value • Culture of small data • Compliance
Common compu?ng, storage & transport infrastructure

UDT Tuning: Buffers and CPUs
Configuration Change Observed Transfer Rate
Time to Transfer 1 TB (minutes)
UDT and Linux Defaults 1.6 Gbps 85
Setting buffers sizes to 64 MB 3.3 Gbps 41
Improved CPU on sending side with processor affinity
3.7 Gbps 36
Improved CPU on receiving side with processor affinity
4.6 Gbps 29
Improved CPU on both sides with processor affinity on both sides
6.3 Gbps 21
Turn off CPU frequency scaling and
set to max clock speed 6.7 Gbps 20

Science vs Commercial Clouds
Science CSP Commercial CSP Perspec?ve Democra?ze access to
data. Integrate data to make discoveries. Long term archive.
As long as you pay the bill; as long as we keep the our business model.
Data Data intensive compu?ng
Internet style scale out
Flows Large data flows in and out
Lots of small web flows
Lock in Data and compute portability essen?al
Lock in is good

A Key Ques?on
• Is biomedical compu?ng at the scale of a data center important enough for the research community to do or do we only outsource to commercial cloud service providers (certainly we will interoperate with commercial cloud service providers)?

Open Science Data Cloud

Part 4: Analyzing Data at the Scale of a Data Center
Source: Jon Kleinberg, Cornell University, www.cs.cornell.edu/home/kleinber/networks-‐book/
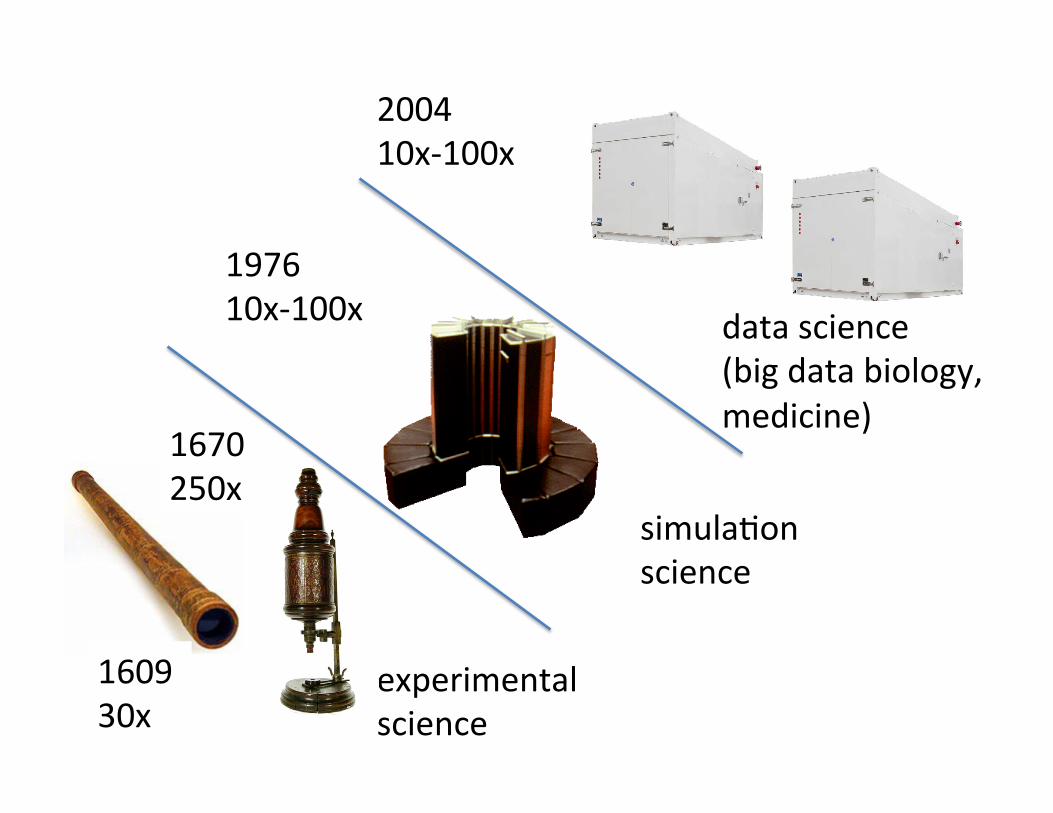
experimental science
simula?on science
data science (big data biology, medicine)
1609 30x
1670 250x
1976 10x-‐100x
2004 10x-‐100x

Is More Different? Do New Phenomena Emerge at Scale in Biomedical Data?

Complex models over small data that are highly manual.
Simpler models over large data that are highly automated.
Small data Medium data
GB TB PB
W KW MW

Several ac?ve voxels were discovered in a cluster located within the salmon’s brain cavity (Figure 1, see above). The size of this cluster was 81 mm3 with a cluster-‐level significance of p = 0.001. Due to the coarse resolu?on of the echo-‐planar image acquisi?on and the rela?vely small size of the salmon brain further discrimina?on between brain regions could not be completed. Out of a search volume of 8064 voxels a total of 16 voxels were significant.


Environmental Factors and Cancer

Building Models over Big Data
• We know about the “unreasonable effec?veness of ensemble models.” Building ensembles of models over computer clusters works well …
• … but, how do machine learning algorithms scale to data center scale science?
• Ensembles of random trees built from templates appear to work beper than tradi?onal ensembles of classifiers
• The challenge is oeen decomposing large heterogeneous datasets into homogeneous components that can be modeled.

New Ques?ons
• How would research be impacted if we could analyze all of the data each evening?
• How would health care be impacted if we could analyze of the data each evening?

2005 -‐ 2015 Bioinforma)cs tools & their integra)on. Examples: Galaxy, GenomeSpace, workflow systems, portals, etc.
2010 -‐ 2020 Data center scale science. Interoperability and preserva?on/peering/portability of large biomedical datasets. Examples: Bionimbus/OSDC, CG Hub, Cancer Collaboratory, GenomeBridge, etc.
2015 -‐ 2025 New modeling techniques. The discovery of new & emergent behavior at scale. Examples: What are the founda?ons? Is more different?
Part 5: Genomic Clouds
Cancer Genome Collaboratory (Toronto)
Cancer Genomics Hub (Santa Cruz)
Bionimbus Protected Data Cloud (Chicago)
(Cambridge)
(Mountain View)

bionimbus.opensciencedatacloud.org

Analyzing Data From The Cancer Genome Atlas (TCGA)
1. Apply to dbGaP for access to data.
2. Hire staff, set up and operate secure compliant compu?ng environment to mange 10 – 100+ TB of data.
3. Get environment approved by your research center.
4. Setup analysis pipelines. 5. Download data from CG-‐
Hub (takes days to weeks). 6. Begin analysis.
Current Prac)ce With Bionimbus Protected Data Cloud (PDC) 1. Apply to dbGaP for access
to data. 2. Use your exis?ng NIH grant
creden?als to login to the PDC, select the data that you want to analyze, and the pipelines that you want to use.
3. Begin analysis.

1. What scale is required for biomedical clouds? 2. What is the design for biomedical clouds? 3. What tools and applica?ons do users need to make
discoveries in large amounts of biomedical data? 4. How do different biomedical clouds interoperate?

6. How Do We Organize?

Cyber Condo Model
• Research ins?tu?ons today have access to high performance networks – 10G & 100G.
• They couldn’t afford access to these networks from commercial providers.
• Over a decade ago, they got together to buy and light fiber.
• This changed how we do scien?fic research.
• Cyber condos interoperate with commercial ISPs

Science Cloud Condos
• Build Science Cloud condo. • To provide a sustainable
home for large commons of research data (and an infrastructure to compute over it).
• “Tier 1” Science Clouds need to establish peering rela?onships.
• And to interoperate with CSPs • The Open Cloud Consor?um is
planning to develop a science cloud condo.

Some Biomedical Data Commons Guidelines for the Next Five Years
• There is a societal benefit when biomedical data is also available in data commons operated by the research community (vs sold exclusively as data products by commercial en??es or only offered for download by the USG).
• Large data commons providers should peer. • Data commons providers should develop standards for interopera?ng.
• Standards should not be developed ahead of open source reference implementa?ons.
• We need a period of experimenta?on as we develop the best technology and prac?ces.
• The details are hard (consent, scalable APIs, open vs controlled access, sustainability, security, etc.)

Source: David R. Blair, Christopher S. Lyple, Jonathan M. Mortensen, Charles F. Bearden, Anders Boeck Jensen, Hossein Khiabanian, Rachel Melamed, Raul Rabadan, Elmer V. Bernstam, Søren Brunak, Lars Juhl Jensen, Dan Nicolae, Nigam H. Shah, Robert L. Grossman, Nancy J. Cox, Kevin P. White, Andrey Rzhetsky, A Non-‐Degenerate Code of Deleterious Variants in Mendelian Loci Contributes to Complex Disease Risk, Cell, September, 2013
7. Recap

100,000 pa?ents 100 PB
1,000,000 pa?ents 1,000 PB
10,000 pa?ents 10 PB
1000 pa?ents
• What are the key common services & APIs?
• How do the biomedical commons clouds interoperate?
• What is the governance structure?
• What is the sustainability model?

2005 -‐ 2015 Bioinforma)cs tools & their integra)on. Examples: Galaxy, GenomeSpace, workflow systems, portals, etc.
2010 -‐ 2020 Data center scale science. Interoperability and preserva?on/peering/portability of large biomedical datasets. Examples: Bionimbus/OSDC, CG Hub, Cancer Collaboratory, GenomeBridge, etc.
2015 -‐ 2025 New modeling techniques. The discovery of new & emergent behavior at scale. Examples: What are the founda?ons? Is more different?
Thanks To My Colleagues & Collaborators
• Kevin White • Nancy Cox • Andrey Rzhetsky • Lincoln Stein • Barbara Stranger

Thanks to My Lab
Allison Heath
Ray Powell
Jonathan Spring
Renuka Ayra
David Hanley
Maria Paperson
Map Greenway
Rafael Suarez
Stu? Agrawal
Sean Sullivan
Zhenyu Zhang

Thanks to the White Lab
Jason Grundstad
Chaitanya Bandlamidi
Jason Pip
Megan McNerney

Ques?ons?
62

For more informa?on • www.opensciencedatacloud.org • For more informa?on and background, see Robert L.
Grossman and Kevin P. White, A Vision for a Biomedical Cloud, Journal of Internal Medicine, Volume 271, Number 2, pages 122-‐130, 2012.
• You can find some more informa?on on my blog: rgrossman.com.
• My email address is robert.grossman at uchicago dot edu.
Center forResearchInformatics

Major funding and support for the Open Science Data Cloud (OSDC) is provided by the Gordon and Bepy Moore Founda?on. This funding is used to support the OSDC-‐Adler, Sullivan and Root facili?es. Addi?onal funding for the OSDC has been provided by the following sponsors: • The Bionimbus Protected Data Cloud is supported in by part by NIH/NCI through NIH/SAIC Contract
13XS021 / HHSN261200800001E. • The OCC-‐Y Hadoop Cluster (approximately 1000 cores and 1 PB of storage) was donated by Yahoo!
in 2011. • Cisco provides the OSDC access to the Cisco C-‐Wave, which connects OSDC data centers with 10
Gbps wide area networks. • The OSDC is supported by a 5-‐year (2010-‐2016) PIRE award (OISE – 1129076) to train scien?sts to
use the OSDC and to further develop the underlying technology. • OSDC technology for high performance data transport is support in part by NSF Award 1127316. • The StarLight Facility in Chicago enables the OSDC to connect to over 30 high performance
research networks around the world at 10 Gbps or higher. • Any opinions, findings, and conclusions or recommenda?ons expressed in this material are those
of the author(s) and do not necessarily reflect the views of the Na?onal Science Founda?on, NIH or other funders of this research.
The OSDC is managed by the Open Cloud Consor?um, a 501(c)(3) not-‐for-‐profit corpora?on. If you are interested in providing funding or dona?ng equipment or services, please contact us at [email protected].