big data analysis using hadoop lecture 3 -...
TRANSCRIPT

2/13/19
1
Big Data Analysis using HadoopLecture 3
Part 2
Big Data Analysis using HadoopLecture 3

2/13/19
2
Last Week - Recap
• Driver Class
• Mapper Class
• Reducer Class
• Create our first MR process
• Ran on Hadoop
• Monitored on webpages
• Checked outputs using HDFS command line and web pages
In this Class
• Counters
• Combiners
• Partitionars
• Reading and Writing Data
• Chaining MapReduce Jobs (Workflows)
• Lab work
• Assignment

2/13/19
3
Counters
Passing information back to the driver
• Counters provide a way for Mappers or Reducers to pass aggregated values back to the driver after the job has completed.
• Framework provides built in counters:• Map-Reduce counters - e.g. number of input and output records for mapper,
reducers, time and memory statistics • File System counters - e.g. number of bytes read or written• Job counters - e.g. launched tasks, failed tasks, etc...
• Counters are visible from the JobTracker UI
• Counters are reported on the console when the job finishes

2/13/19
4
User Defined Counters
• User Defined Counters are a useful mechanism for gathering statistics about the job• e.g. quality control - track different types of input record types, e,g, ‘bad’ input records• Instrumentation of code
• Numbers of warnings• Number of errors • Number of …..
• Framework aggregates all user defined counters over all mappers, reducers and reports back on UI
• Counters are set up as Enums in Mapper or Reducer
• Counters are retrieved from the Context object which is passed to the Mapper and Reducer
• Increment or set the counter value:
context.getCounter(Enum<?> counterName);
setValue(long value);
increment(long incrementAmt);
enum GroupName { Counter1, Counter2,...}
Using Counters
• Set up the user-defined counters
• Increment the counter when necessary
public class WordMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
static enum MyCounters{Bad, Good, Missing}
public void map(LongWritable key, Text value, Context context)...
...if (<input data problem>) {
context.getCounter(MyCounters.Bad).increment(1);}...

2/13/19
5
Using Counters
• Print out the counters at the end of the Job in the Driver
...job.waitForCompletion(true)? 0 : 1;
System.out.println("Job is complete - printing counters now:");
Counters counters = job.getCounters();
Counter bad = counters.findCounter(MyMapper.MyCounters.Bad);System.out.println("Number of bad records is "+ bad.getValue());
...
1
2
3
4
5
6

2/13/19
6
1
2
3
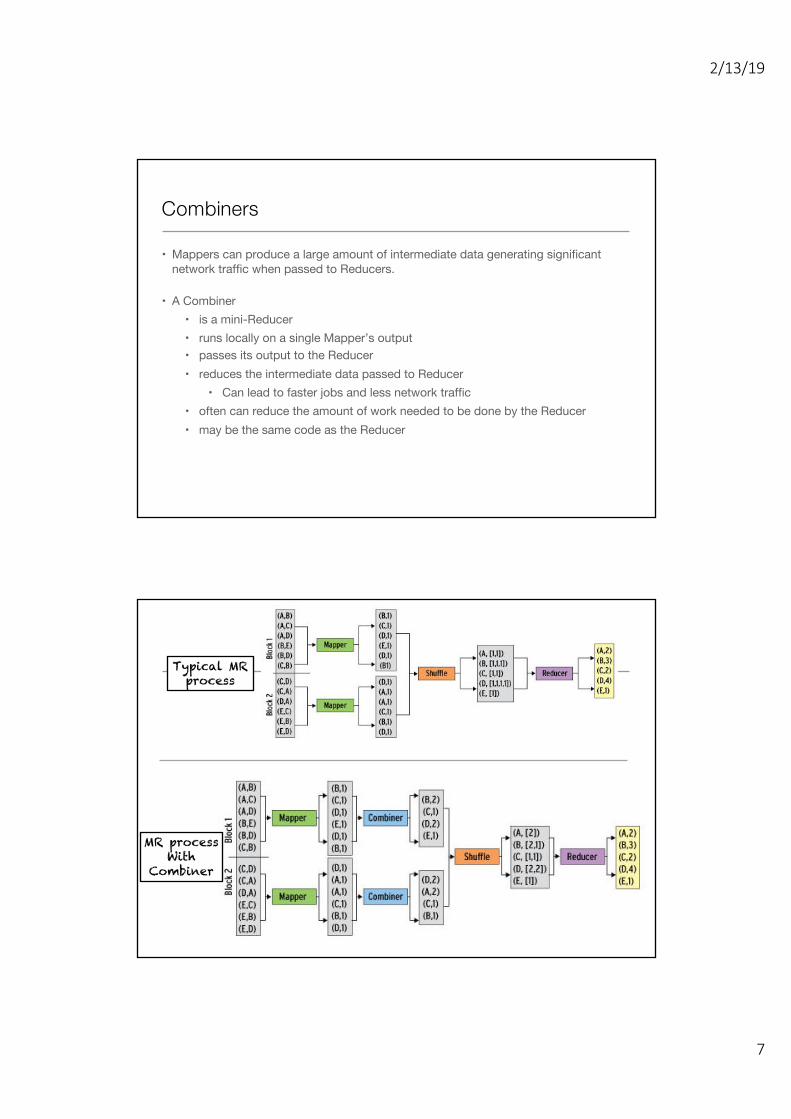
Combiners
2/13/19
7
Combiners
• Mappers can produce a large amount of intermediate data generating significant network traffic when passed to Reducers.
• A Combiner • is a mini-Reducer• runs locally on a single Mapper’s output• passes its output to the Reducer• reduces the intermediate data passed to Reducer
• Can lead to faster jobs and less network traffic• often can reduce the amount of work needed to be done by the Reducer• may be the same code as the Reducer
Typical MR process
MR processWith
Combiner

2/13/19
8
WordCount Example
• Input to the Mapper:(124, “this one I think is called a yink”)(158, “he likes to wink, he likes to drink”)(195, “he likes to drink and drink and drink”)
• Output from the Mapper:(this, 1) (one, 1) (I, 1) (think, 1) (is, 1) (called,1)(a, 1)(yink,1) (he, 1) (likes,1) (to,1) (wink,1) (he,1) (likes,1) (to,1) (drink,1) (he,1) (likes,1) (to,1) (drink 1) (and,1) (drink,1) (and,1) (drink,1)
Example Job – What happens with only a Reducer
(a, [1])(and,[1,1])(called, [1])(drink, [1,1,1,1])(he, [1,1,1]) (I, [1]) (is, [1])(likes, [1,1]) (one, [1])(think, [1])(this, [1]) (to, [1,1,1]) (wink, [1])(yink, [1] )
(a,1)(and,2)(called,1)(drink,4)(he,3) (I,1) (is,1)
(likes,2) (one,1)(think,1)(this,1) (to,3) (wink,1)(yink,1)
Intermediate data sent to the Reducer
• Reducer output

2/13/19
9
When we use a Combiner
(a, [1])(and,[2])(called, [1])(drink, [4])(he, [3]) (I, [1]) (is, [1])(likes, [2]) (one, [1])(think, [1])(this, [1]) (to, [3]) (wink, [1])(yink, [1] )
(a,1)(and,2)(called,1)(drink,4)(he,3) (I,1) (is,1)
(likes,2) (one,1)(think,1)(this,1) (to,3) (wink,1)(yink,1)
Output from Mapper Combiner output(a, [1])(and,[1,1])(called, [1])(drink, [1,1,1,1])(he, [1,1,1]) (I, [1]) (is, [1])(likes, [1,1]) (one, [1])(think, [1])(this, [1]) (to, [1,1,1]) (wink, [1])(yink, [1] )
Combiner Output
When we use a Combiner
(a, [1])(and,[2])(called, [1])(drink, [4])(he, [3]) (I, [1]) (is, [1])(likes, [2]) (one, [1])(think, [1])(this, [1]) (to, [3]) (wink, [1])(yink, [1] )
(a,1)(and,2)(called,1)(drink,4)(he,3) (I,1) (is,1)
(likes,2) (one,1)(think,1)(this,1) (to,3) (wink,1)(yink,1)
Intermediate data sent to the Reducer
Reducer outputCombiner output
Other Combiner outputs
2/13/19
10
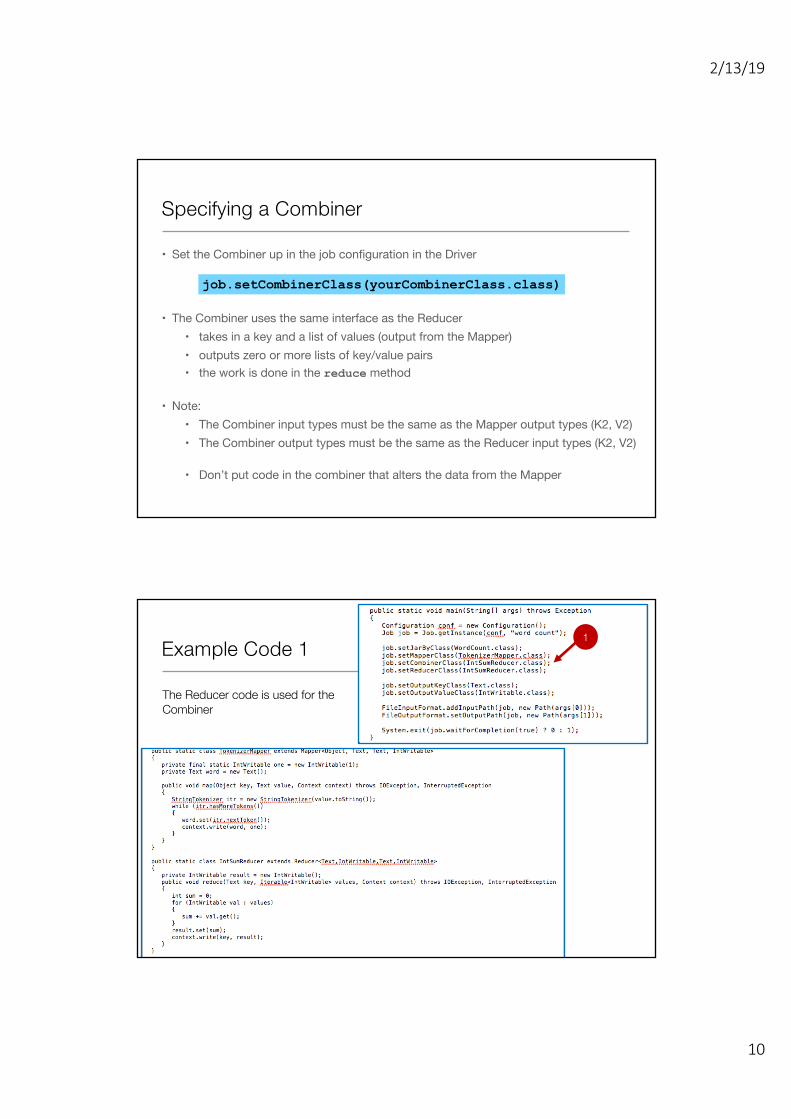
Specifying a Combiner
• Set the Combiner up in the job configuration in the Driver
• The Combiner uses the same interface as the Reducer• takes in a key and a list of values (output from the Mapper)• outputs zero or more lists of key/value pairs• the work is done in the reduce method
• Note:• The Combiner input types must be the same as the Mapper output types (K2, V2)• The Combiner output types must be the same as the Reducer input types (K2, V2)
• Don’t put code in the combiner that alters the data from the Mapper
job.setCombinerClass(yourCombinerClass.class)
Example Code 11
The Reducer code is used for the Combiner

2/13/19
11
Example Code 2
1
2
3
Sometimes the code can be slightly different between the Combiner and the Reducer
You need to be careful to maintain the input and output formats
Partitioners

2/13/19
12
Partitioners
• The number of Reducers that run is specified in the job configuration • the default number is 1
• The number of Reducers can be set when setting up the job
setNumReduceTasks(value)
job.setNumReduceTasks(10);
• No need to set this value if you just want one Reducer
• Partitioners implementation directs key-value pairs to a specific reducer• Number of Partitions = Number of Reducers• Default is to hash key the determine partition implemented HashPartitioner<K,V>
Shape = keyInner patterns = values
Note:• All keys go to the same
reducer• A reducer can handle
different keys• Reducers can have
different loads
Partitioners
Shuffle & Sort

2/13/19
13
Partitioners
• Partitioners determine which reducer the map output data is sent to in the shuffle & sort phase
• Normally determined using a hash function on the key value
• Important that the Partitioner will distribute the map output records evenly over the reducers
job.setNumReduceTasks(10);
… job.setPartitionerClass(CasePartitioner.class);…

2/13/19
14
Default Partitioner
• The default Partitioner is the HashPartitioner
• The key’s hash code is turned into a non negative integer by bitwise ANDing it with the largest integer value
• It is then reduced modulo the number of partitions to find the index of the partition (the reducer number) that the record belongs to
• Records distributed evenly across available reduce tasks
• Assuming good hashCode() function
• Records with same key will make it into the same reduce task
public int getPartition(K2 key, V2 value,int numPartitions) {
return (key.hashCode() & Integer.MAX_VALUE) % numPartitions;
}
Default Partitioner
Key Hashcode Modulo 3“This” 1 1
“is” 2 2“not” 3 0“my” 4 1
“office” 5 2“Colour” 6 0
“Pen” 7 1“Money” 8 2
Reducer 1
Reducer 2
Reducer 0

2/13/19
15
To Implement a Custom Partitioner...
• Set the number of reducers in the job configuration
• Create a custom Partitioner class by extending the Partitioner class
• implement the getPartition() method to return a number between 0 and the number of reducers indexing to which reducer that the key/value pair should be sent.
public class MyPartitioner extends Partitioner<KEY, VALUE> {
public int getPartition(KEY key, VALUE value, int numPartitions){
// put code here to decide based on the key which// reducer the map output should go to...
return partitionNumber;
}
}
Simple MapReduce Job

2/13/19
16
Complete MapReduce Job
Drawbacks
• Need to know the number of partitions/reducers at the start, not dynamic.
• Letting the application fix the number of reducers rather than the cluster can result in inefficient use of the cluster and uneven reduce jobs that can dominate the job execution time.
• See MultipleOutputs later on for an alternative solution

2/13/19
17
Partitioner – example code
1
2
3
Reading & Writing Data

2/13/19
18
InputSplit
FileBlock
Block
InputSplit
InputSplit
InputSplit
InputSplit
InputSplit
Mapper
RecordRecordRecordRecord
Mapper
Mapper
Mapper
Mapper
Mapper
map
RecordRecordRecordRecord
map
RecordRecordRecordRecord
map
RecordRecordRecordRecord
map
RecordRecordRecordRecord
map
RecordRecordRecord
map
Block
HDFS Physical locations
Logical split created by an InputFormat
Each split is processed by a single mapper -Data locality
Each record (key value pair) is processed by the map method

2/13/19
19
Input Data• The input data is split into chunks called input splits (logical division)
• split size is normally the size of a block - but is configurable
• The size of the splits determines the level of parallelisation• One input split ⇒ a mapper• All input data in one single split ⇒ no parallelisation• Small input split ⇒ useful for parallelisation of CPU bound tasks
• HDFS stores input data in blocks spread across the nodes (physical division)• One block ≈ one input split (very efficient for I/O bound tasks)• An input split may be split across blocks - Hadoop guarantees the processing of all
records but data-local mappers will need to access remote data infrequently.
Input Data
• Data input is supported by• InputFormat: indicates how the input files should be split into input splits• RecordReader: performs the reading of the data providing a key/value pair for
input to the mapper
• Hadoop provides predefined InputFormats• TextInputFormat : default input format• KeyValueTextInputFormat• SequenceFileInputFormat (normally used for chaining multiple MapReduce jobs)• NLineInputFormat
• The input format can be set in the job configuration in your driver, e.g.
job.setInputFormatClass(KeyValueTextInputFormat.class)

2/13/19
20
• To read input data in a way not supported by the standard InputFormat classes you can create a custom InputFormat
Output Data
• Each reducer writes its output to its own file normally named part-nnnnn, where nnnnn is the partition ID of the reducer
• Data output is supported by• OutputFormat • RecordWriter
• Hadoop provides predefined OutputFormats• TextOutputFormat : default output format• SequenceFileOutputFormat (normally used for chaining multiple MapReduce jobs)• NullOutputFormat
job.setOutputFormatClass(SequenceFileOutputFormat.class)

2/13/19
21
• MultipleOutputs allows you to write data to multiple files whose names are derived from the output keys and values
• Output file names are of the form name-x-nnnn• name is set by the code• x = m, for mapper output • x = r, for reducer output• nnnn is an integer designating the part number
Writing Multiple Files

2/13/19
22
Using MultipleOutputs
• Create an instance of MultipleOutputs in reducer or mapper where the output is being generated• normally done in the setup()
• Close the MultipleOutputs instance once finished with it• normally done in the cleanup()
protected void setup(Context context) throws IOException, InterruptedException{
multipleOutputs = new MultipleOutputs<KEY, VALUE>(context);}
protected void cleanup(Context context) throwsIOException,InterruptedException {
multipleOutputs.close();}
Using MultipleOutputs
• Write the output key value pair to the instance of MultipleOutputs
• where name identifies the base output path • name is interpreted relative to the output directory so it is possible to
create subdirectories by including file path separator characters in name
• Include logic to determine which output file to write to normally dependent on key and/or value• e.g. monthly reports, weekly reports, files identified by time periods• e.g. store or branch reports, files identified by store or branch, • or both.....
multipleOutputs.write(key, value, name );

2/13/19
23
Using MultipleOutputs
• MultipleOutputs delegates to the given OutputFormat• separate named outputs can be set up in the driver using
addNamedOutput each with its own OutputFormat and key value types
• A single record can be written to multiple output files
MultipleOutputs.addNamedOutput(job, name, OUTPUTFORMAT, KEY, VALUE );
Reading/Writing other types of data
• Reading to/from a database using JDBC• Can use the DBInputFormat and DBOutputFormat• DBInputFormat doesn’t have sharding capabilities so you have to be careful not
to overwhelm the database by reading with too many mappers• DBOutputFormat very useful for outputting data to a database
• Reading XML• Create a custom InputFormat to read a whole file at a time (see Chpt 7 in
Hadoop the Definitive Guide), suitable for small XML files, or • Use XMLInputFormat in Mahout (the machine learning library that is
implemented on Hadoop)

2/13/19
24
Chaining MapReduce Jobs
Chaining MapReduce Jobs
• We’ve looked at single MapReduce jobs.
• Not every problem can be solved with a MapReduce job.
• Map-Reduce can get very complex with multiple MR jobs.
• Many problems can be solved with MapReduce, by writing serval MapReduce steps which run in series, or parallel or both
• Can control these and get them to interact with each other (dependencies)• Gives better control and allows for greater computational capabilities

2/13/19
25
Chaining Jobs in a Sequence
• Run MapReduce jobs sequentially with the output of one job being the input of another
• Note: Watch intermediate file format... SequenceFileOutputFormat & SequenceFileInputFormat are useful for this.
• Remember: Sequence files are Hadoop’s compressed binary file format for storing key/value pairs.
• Set up a Job (job1) in the Driver - run job1;
• Then set up a new Job (job 2) in the driver, with the input path = the output path of job1 - run job2, etc....
MapReduce 1 | MapReduce 2 | MapReduce 3 |...
Useful code !

2/13/19
26
Chaining Jobs with Dependencies
• Dependencies can occur when tasks don’t run sequentially
• Use Job, ControlledJob & JobControl classes to setup and manage job dependencies
MapReduce 1
MapReduce 2
MapReduce 3
Setting up workflows
• JobControl is created to hold the workflow• Allows for the creation of simple workflows• Represents a graph of Jibs to run• Specify dependencies in code
• A ControlledJob is set up for each job in the workflow
• ControlledJob is a wrapper for Job• ControlledJob constructor can take in job dependencies
• Dependencies between jobs can also be setup using addDependingJob(),e.g. step2.addDependingJob(step1) means step2 will not start until step1 has finished
JobControl control = new JobControl("Workflow-Example");
ControlledJob step1 = new ControlledJob(job1, null);
List<ControlledJob> dependencies = new ArrayList<ControlledJob>();dependencies.add(step1);
ControlledJob step2 = new ControlledJob(job2, dependencies);

2/13/19
27
Setting up workflows
• Each ControlledJob is added to the JobControl object using addJob()
• The JobControl is executed in a thread• JobControl implements Runnable
...control.addJob(step1);control.addJob(step2);...
...
Thread workflowThread = new Thread(control,"Workflow-Thread");workflowThread.setDaemon(true);workflowThread.start();...
Setting up workflows
• Wait for JobControl to complete and report results
• JobControl has methods to allow monitoring and tracking of its jobs
...while (!control.allFinished()){Thread.sleep(500);
}
if (control.getFailedJobList().size() > 0 ){log.error(control.getFailedJobList().size() + " jobs failed!");for ( ControlledJob job : control.getFailedJobList()){
log.error(job.getJobName() + " failed");
}
} else {log.info("Success!! Workflow completed [" +
control.getSuccessfulJobList().size() + "] jobs");
}
...

2/13/19
28
Chaining preprocessing & postprocessing steps
• Preprocessing (and postprocessing) might require a number of Mappers to run sequentially, e.g. text preprocessing
• Sequential jobs (using identity Reducer) are inefficient
• Use ChainMapper and ChainReducer to implement modular pre- and post-processing steps
• each mapper is added with its own job configuration parameters to ChainMapper or ChainReducer
• each mapper can be run individually, useful for testing/debugging
[ map | reduce ]+ Sequential Jobs:
Modular Jobs: map+ | reduce | map
Programmer Control
• The ability to construct complex data structures as keys and values to store and communicate partial results
• The ability to execute user-specified initialisation code at the beginning of a map or reduce task, and the ability to execute user-specified termination code at the end of a map or reduce task.
• The ability to preserve state in both mappers and reducers across multiple input or intermediate keys.
• The ability to control the sort order of intermediate keys, and therefore the order in which a reducer will encounter particular keys.
• The ability to control the partitioning of the key space, and therefore the set of keys that will be encountered by a particular reducer.

2/13/19
29
2
3
1
4
5
6
7
8

2/13/19
30
User-defined types - examplepublic class TextPair implements WritableComparable<TextPair> {
private Text first;private Text second;
public TextPair() {set(new Text(), new Text());
}
public TextPair(String first, String second) {set(new Text(first), new Text(second));
}
public TextPair(Text first, Text second) {set(first, second);
}
public void set(Text first, Text second) {this.first = first;this.second = second;
}
public Text getFirst() {return first;
}
public Text getSecond() {return second;
}
...
@Overridepublic void write(DataOutput out) throws IOException {
first.write(out);second.write(out);
}
@Overridepublic void readFields(DataInput in) throws IOException {
first.readFields(in);second.readFields(in);
}
@Overridepublic int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);if (cmp != 0) {
return cmp;}return second.compareTo(tp.second);
}@Overridepublic int hashCode() {
return first.hashCode() * 163 + second.hashCode();}
@Overridepublic boolean equals(Object o) {
if (o instanceof TextPair) {TextPair tp = (TextPair) o;return first.equals(tp.first) && second.equals(tp.second);
}return false;
}
@Overridepublic String toString() {
return first + "\t" + second;}
}