big data & hadoop
TRANSCRIPT


Overview
Big Data
3 Vs of Big Data
Hadoop
HDFS
Map Reduce
Big Data Market Size
Big Data in India

oOrder Details for a store
oAll orders across 100s of stores
oA person’s stock portfolio
oAll stock transactions for Stock Exchange
Its data that is created very fast and is too big to be processed on a single machine .These data come from various sources in various formats.
What is BIG DATA ???

How 3 Vs define Big Data ???
Volume: Large volumes of data
Velocity: Quickly moving data
Variety: Structured, Unstructured, images, etc.

Volume
It is the size of the data which determines the value and potential of the data under consideration. The name ‘Big Data’ itself contains a term which is related to size and hence the characteristic.

VarietyData today comes in all types of formats: Structured, data in traditional databases. Unstructured text documents, email, stock ticker data and financial transactions and semi-structured data too.
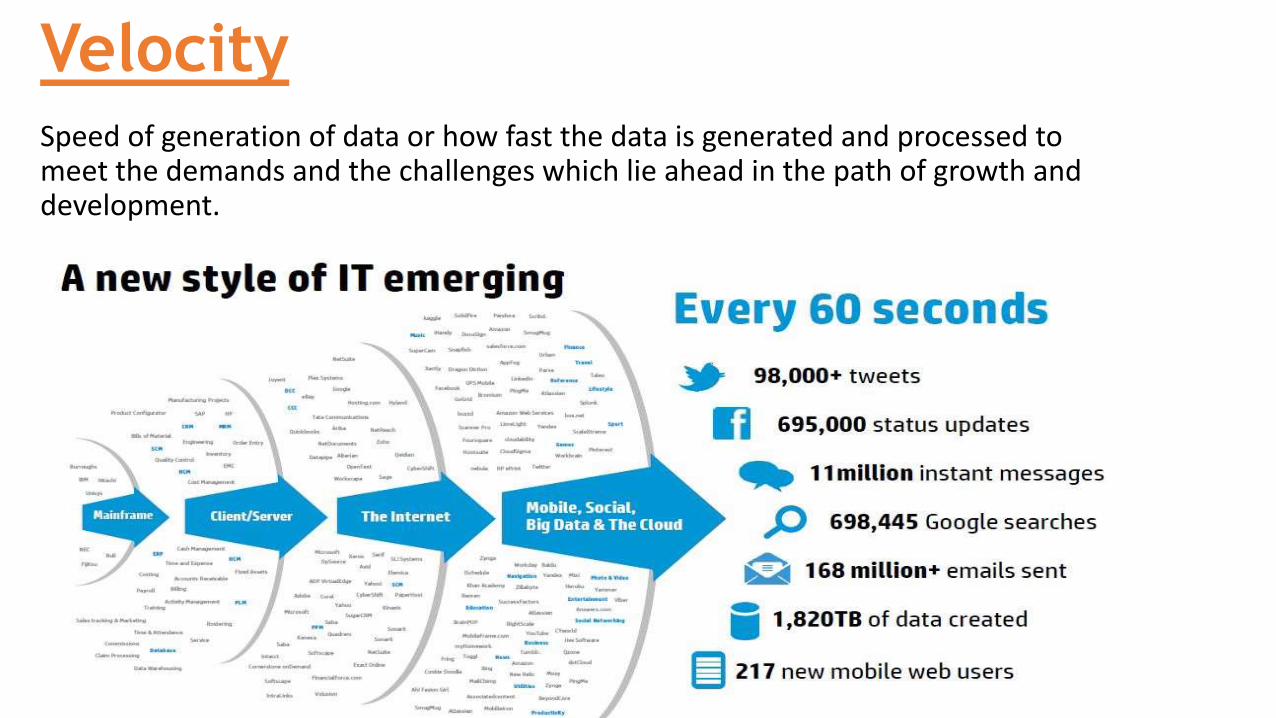
VelocitySpeed of generation of data or how fast the data is generated and processed to meet the demands and the challenges which lie ahead in the path of growth and development.

Why Big Data ?
The real issue is not that you are acquiring large amounts of data. It's what you do with the data that counts. The hopeful vision is that organizations will be able to take data from any source, harness relevant data and analyse it to find answers that enable
1) cost reductions
2) time reductions
3) new product development and optimized offerings
4) smarter business decision making

What is Hadoop?
Hadoop is a distributed file system and data processing engine that is designed to handle extremely high volumes of data in any structure.
Hadoop has two components: The Hadoop distributed file system (HDFS), which supports data in structured
relational form, in unstructured form, and in any form in between
The MapReduce programing paradigm for managing applications on multiple distributed servers
The focus is on supporting redundancy, distributed architectures, and parallel processing

Low cost: The open-source framework is free and uses commodity hardware to store large quantities of data.
Computing power: Its distributed computing model can quickly process very large volumes of data.
Scalability: You can easily grow your system simply by adding more nodes with little administration.
Storage flexibility: Unlike traditional relational databases, you don’t have to pre-process data before storing it. You can store as much data as you want .
Inherent data protection: Data and application processing are protected against hardware failure.

11
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It’s a scalable file system that distributes and stores data across all machines in a Hadoop cluster.
Hadoop Distributed File System

12
HDFS has a master/slave architecture
HDFS cluster consists of :
A single NameNode, a master server that manages the file system namespace and regulates access to files by clients.
A number of DataNodes, which manage storage attached to the nodes that they run on. Internally, a file is split into one or more blocks and these blocks are stored in DataNodes.
HDFS Architecture

Files in HDFS
13
HDFS supports a traditional hierarchical file organization. A user or an application can create directories and store files inside these directories. The NameNode maintains the file system namespace. Any change to the file system namespace or its properties is recorded by the NameNode.
The File System Namespace
Data Replication
HDFS is designed to reliably store very large files across machines in a large cluster. It stores each file as a sequence of blocks; all blocks in a file except the last block are the same size. The blocks of a file are replicated for fault tolerance. The block size and replication factor are configurable per file

HDFS Robustness
The primary objective of HDFS is to store data reliably even in the presence of failures. The common types of failures are DataNode failures and NameNode failures.
Data Disk Failure and Re-Replication
DataNodes may lose connectivity with the NameNode. The NameNode detects this condition, marks them as dead and does not forward any new IO requests to them. The NameNode constantly tracks block failures and initiates re-replication whenever necessary
Metadata Disk Failure
The FsImage and the EditLog are central data structures of HDFS. A corruption of these files can cause the HDFS instance to be non-functional. For this reason, the NameNode can be configured to support maintaining multiple copies of the FsImage and EditLog. Any update to either the FsImage or EditLog causes each of the FsImages and EditLogs to get updated synchronously.
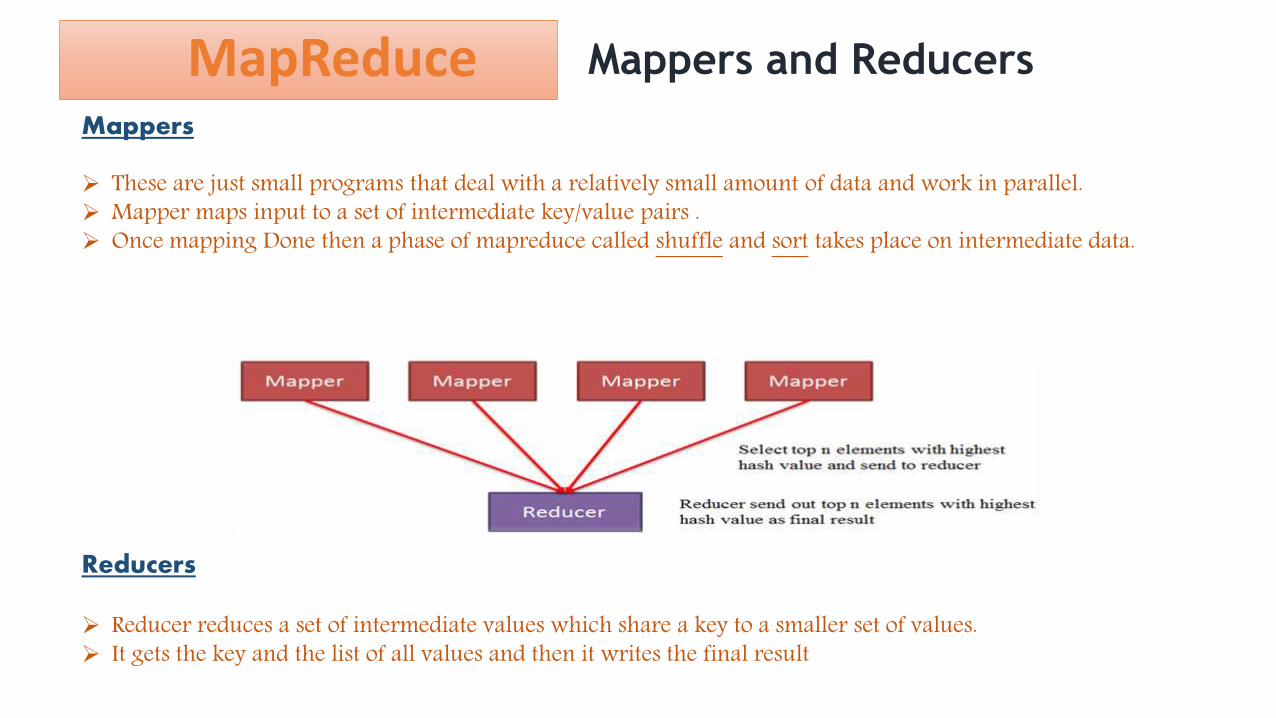
Mappers and Reducers
Mappers
These are just small programs that deal with a relatively small amount of data and work in parallel. Mapper maps input to a set of intermediate key/value pairs . Once mapping Done then a phase of mapreduce called shuffle and sort takes place on intermediate data.
Reducers
Reducer reduces a set of intermediate values which share a key to a smaller set of values. It gets the key and the list of all values and then it writes the final result
MapReduce

MapReduce
MapReduce applications typically implement the Mapper and Reducer interfaces to provide the map and reduce methods.
MapReduce divides workloads up into multiple tasks that can be executed in parallel
Why MapReduce ?
o It won’t work.
o We may run out of memory.
o Data processing may take long time.
The initial approach is to process data serially i.e. from top to bottom.

MapReduce in Action
Worker
WorkerWorker
Worker
Worker
Master(2) assign map
(2) assignreduce
(3) read (4) local write
(5) remote read
OutputFile 0
OutputFile 1
(6) write
Split 0
Split 1
Split 2
Input files
Mapper: split, read, emit intermediate Key-Value pairs
Reducer: repartition, emits final output
UserProgram
Map phaseIntermediate files
(on local disks)Reduce phase Output files

Market Size
Source: Wikibon Taming Big Data
By 2015 4.5 million IT jobs in Big Data ; 2 million is in US itself

In India
Gaining attraction
Huge market opportunities for IT services (82.9% of revenues) and analytics firms (17.1 % )
Market size by end of 2015 - $1 billion
India will require a minimum of 1 lakh data scientists in the next couple of years in addition to data analysts and data managers to support the Big Data space.


References
https://hadoop.apache.org
Cloudera (Introduction to HDFS & MapReduce)
CBT Nuggets Apache Hadoop
Hadoop- The Definitive Guide, 4th Edition
en.wikipedia.org
www.edureka.co/big-data-and-hadoop
https://www.udacity.com/
