assessing j4p projects: responding constructively to pervasive challenges michael woolcock...
TRANSCRIPT

Assessing J4P Projects:Responding constructively to
pervasive challenges
Michael WoolcockDevelopment Research Group
The World BankWashington, June 6, 2007

2
Overview
• Three challenges:– Allocating development resources– Assessing project effectiveness (in general)– Assessing J4P effectiveness (in particular)
• Discussion of options, strategies for assessing J4P pilots

3
Three challenges
• How to allocate development resources?
• How to assess project effectiveness (in general)?
• How to assess J4P effectiveness (in particular)?

4
1. Allocating development resources
• How to allocate finite resources to projects believed likely to have a positive development impact?
• Allocations made for good and bad reasons, only a part of which is ‘evidence-based’, but most of which is ‘theory-based’, i.e., done because of an implicit (if not explicit) belief that Intervention A will ‘cause’ Impact B in Place C net of Factors D and E for Reasons F and G.– E.g., micro-credit will raise the income of villagers in
Flores, independently of their education and wealth, because it enhances their capacity to respond to shocks (floods, illness) and enables larger-scale investment in productive assets (seeds, fertilizer)

5
Allocating development resources
• Imperatives of the prevailing resource allocation mechanisms (e.g., those of the World Bank) strongly favor one-size-fits-all policy solutions (despite protestations to the contrary!) that deliver predictable, readily measurable results in a short time frame– Roads, electrification, immunization
• Projects that diverge from this structure—e.g., J4P—enter the resource allocation game at a disadvantage. But the obligation to demonstrate impact (rightly) remains; just need to enter the fray well armed, empirically and politically…

6
2. How to Assess Project Effectiveness?
• Need to disentangle the effect of a given intervention over and above other factors occurring simultaneously– Distinguishing between the ‘signal’ and ‘noise’– Is my job creation program reducing unemployment, or is it just
the booming economy?
• Furthermore, an intervention itself may have many components– TTLs most immediately concerned about which aspect is the
most important, or the binding constraint?– (Important as this is, it is not the same thing as assessing impact)
• Need to be able to make defensible causal claims about project efficacy even (especially) when the apparent ‘rigor’ of econometric methods aren’t suitable/available– Thus need to change both the terms and content of debate

7
Impact Evaluation 101• Core evaluation challenge:
– Disentangling effects of people, place, and project (or policy) from what would have happened otherwise
– I.e., need a counterfactual (but this is rarely observed)• ‘Tin’ standard
– Beneficiary assessments, administrative checks• ‘Silver’
– Double difference: before/after, program/control• ‘Gold’
– Randomized allocation, natural experiments

8
Impact Evaluation 101• Core evaluation challenge:
– Disentangling effects of people, place, and project (or policy) from what would have happened otherwise
– I.e., need a counterfactual (but this is rarely observed)• ‘Tin’ standard
– Beneficiary assessments, administrative checks• ‘Silver’
– Double difference: before/after, program/control• ‘Gold’
– Randomized allocation, natural experiments• (‘Diamond’?)
– Randomized, triple-blind, placebo-controlled, cross-over• Alchemy?
– Making ‘gold’ with what you have, given prevailing constraints (people, money, time, logistics, politics)…
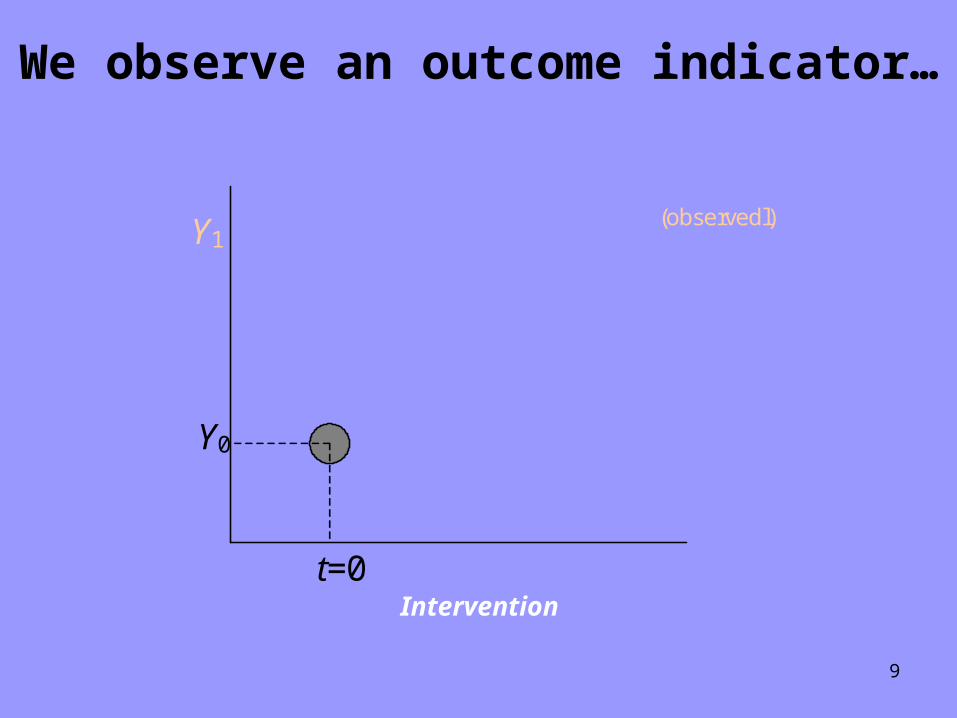
9
We observe an outcome indicator…
Y1 (observedl)
Y0
t=0 Intervention

10
…and its value rises after the program
Y1 (observedl)
Y0
t=0 t=1 time Intervention

11
However, we need to identify the counterfactual…
Y1 (observedl)
Y1
* (counterfactual)
Y0
t=0 t=1 time Intervention

12
… since only then can we determine the impact of the
intervention
Y1
Impact = Y1- Y1*
Y1
*
Y0
t=0 t=1 time

13
Problems when evaluation is not built in ex-ante
• Need a reliable comparison group
• Before/After: Other things may happen
• Units with/without the policy– May be different for other reasons than the policy (e.g.
because policy is placed in specific areas)

14
How can we fill in the missing data on the
counterfactual?• Randomization• Quasi Experiment:
• Matching• Propensity-score matching• Difference-in-difference• Matched double difference• Regression Discontinuity Design• Instrumental variables• Comparison group designs
• Designs pairing jurisdictions• Lagged start designs• Natural occurring comparison group

15
1. Randomization
“Randomized out” group reveals counterfactual
• Only a random sample participates• As long as the assignment is genuinely random, impact is revealed in expectation.• Randomization is the theoretical ideal, and the benchmark for non-experimental methods. Identification issues are more transparent compare with other evaluation technique.
• But there are problems in practice:• Internal validity: selective non-compliance• External validity: difficult to extrapolate results from a pilot experiment to the whole population

16
An example from Mexico
• Progresa: Grants to poor families (women), conditional on preventive health care and school attendance for children
• Mexican government wanted an evaluation; order of community phase-in was random
• Results: child illness down 23%; height increased 1-4cm; 3.4% increase in enrollment
• After evaluation: PROGRESA expanded within Mexico, similar programs adopted throughout other Latin American countries

17
• School-based de-worming: treat with a single pill every 6 months at a cost of 49 cents per student per year
• 27% of treated students had moderate-to-heavy infection, 52% of comparison
• Treatment reduced school absenteeism by 25%, or 7 percentage points
• Costs only $3 per additional year of school participation
An example from Kenya

18
2. Matching
Matched comparators identify counterfactual
Propensity-score matching: Match on the basis of the probability of participation
• Match participants to non-participants from a larger survey
• The matches are chosen on the basis of similarities in observed characteristics
• This assumes no selection bias based on unobservable heterogeneity (i.e., things that are not readily ‘measurable’ by orthodox surveys, such as ‘motivation’, ‘connections’)
• Validity of matching methods depends heavily on data quality

19
Collect baseline data on non-participants and (probable) participants before the program.
• Compare with data after the program. • Subtract the two differences, or use a regression with
a dummy variable for participant.• This allows for selection bias but it must be time-
invariant and additive.
3. Difference-in-difference (double difference)
Observed changes over time for non-participants
provide the counterfactual for participants.

20
The Assessing J4P Challenge• You’re a star in development if you devise a “best
practice” and a “tool kit”—i.e., a universal, easy-to-administer solution to a common problem
• There are certain problems for which finding such a universal solution is both desirable and possible (e.g., TB, roads for high rainfall environments)…
• But many key problems, such as those pertaining to local governance and law reform (e.g., J4P), inherently require context-specific solutions that are heavily dependent on negotiation and teamwork, not a technology (pills, bridges, seeds)– Not clear that if such a project works ‘here’ that it will
also work ‘there’, or that ‘bigger’ will be ‘better’– Assessing such complex projects is enormously difficult

21
Why are ‘complex’ interventions so hard to evaluate? A simple example• You are the inventor of ‘BrightSmile’, a new
toothpaste that you are sure makes teeth whiter and reduces cavities without any harmful side effects. How would you ‘prove’ this to public health officials and (say) Colgate?

22
Why are ‘complex’ interventions so hard to evaluate? A simple example• You are the inventor of ‘BrightSmile’, a new
toothpaste that you are sure makes teeth whiter and reduces cavities without any harmful side effects. How would you ‘prove’ this to public health officials and (say) Colgate?
• Hopefully (!), you would be able to:– Randomly assign participants to a ‘treatment’ and
‘control’ group (and then have then switch after a certain period); make sure both groups brushed the same way, with the same frequency, using the same amount of paste and the same type of brush; ensure nobody (except an administrator) knew who was in which group

23
Cf. Demonstrating ‘impact’ of BrightSmile vs. J4P projects
• Enormously difficult—methodologically, logistically and empirically—to formally identify ‘impact’; equally problematic to draw general ‘policy implications’, especially for other countries
• Prototypical “complex” CDD/J4P project:– Open project menu: unconstrained content of intervention– Highly participatory: communities control resources and
decision-making– Decentralized: local providers and communities given high
degree of discretion in implementation– Emphasis on building capabilities and the capacity for
collective action– Context-specific; project is (in principle) designed to respond
to and reflect local cultural realities– Project’s impact may be ‘non-additive’ (e.g., stepwise,
exponential, high initially then tapering off…) [DIAGRAM]

24
How does J4P work over time?(or, what is its ‘functional form’?)
Impa
ct
TimeIm
pact
Time
Impa
ct
Time
Impa
ct
Time
A
C
B
D
CCTs? ‘Governance’?
‘AIDS awareness’? Bridges?

25
How does J4P work over time?(or, what is its ‘functional form’?)
Impa
ct
TimeIm
pact
Time
Impa
ct
Time
Impa
ct
Time
?
G H
E F
Unknown… Unknowable?
‘Empowerment’?‘Pest control’?e.g., cane toads

26
Science, Complexity, and EvaluationPure Science Applied
ScienceHuman Dev (education, health) projects
J4P projects
Theory• Predictive precision• Cumulative knowledge• Subject/object gap
Hi
Mechanisms• # Causal pathways• # of ‘people-based’ transactions
Few
Outcomes• Plausible range• Measurement precision
Lo
Many
Wide Narrow

27
So, what can we do when…• Inputs are variables (not constants)?
– Facilitation/participation vs. tax cuts (seeds, pills, etc)– Teaching vs. text books– Therapy vs. medicine
• Adapting to context is an explicit, desirable feature?– Each context/project nexus is thus idiosyncratic
• Outcomes are inherently hard to define and measure?– E.g., empowerment, collective action, conflict mediation,
social capital

28
Using Mixed Methods to Make Causal Claims
Alternative Approaches to Understanding ‘Causality’• Econometrics: robustness tests on large N datasets;
controlling statistically for various contending factors• History: processes (‘process tracing’), conjunctures
shaping single/rare events• Anthropology: deep knowledge of contexts• Exploring inductive approaches
• cf. Courtroom lawyers: present various types and ‘quality’ of evidence (qualitative and quantitative) to test particular hypotheses about the efficacy of J4P
• The art of research/evaluation is knowing how to work within time, budgetary and human resource constraints to answer important problems, drawing on an optimal ‘package’ of data and the methods available to procure and interpret it

29
Practically all the techniques used in the social sciences, especially in statistics, can be used for evaluation.
Techniques, Tools, Instruments
• Interviews (individuals, key informants)• Discussion group• Literature search• Archive file review• Questionnaire survey• Case study• Aptitude or knowledge test• Opinion poll• Content analysis (e.g., of newspapers)

30
Be innovative on sampling• Can’t really take ‘random samples’, or assign
villagers to ‘treatment’ and ‘control’ groups (though one may be able to do this with specific aspects of projects—e.g., Olken)
• Comparative case study methods use theory (or knowledge of context!) to identify 2-3 factors deemed most likely to influence project impact—e.g., quality of local government, access to markets, etc
• “Control” for these contextual effects by selecting ‘high’ and ‘low’ areas of each variable, then use Propensity Score Matching methods, plus qualitative insights, to select matched ‘program’ and ‘comparison’ areas

31
Impact Evaluation Helps Us…
• To determine mean impact– Very important for policy decisions
• But provides little grounds for asking other key questions, for example:– Would a ‘scaled up’ project be even better?– Can the same results be expected elsewhere?– Where is there room for improvement?– Which aspects of a multi-faceted project are
most important (and/or the binding constraint?)