artificial intelligence and computer games john laird eecs 494 university of michigan
TRANSCRIPT

Artificial Intelligence and Computer Games
John Laird
EECS 494
University of Michigan

Different Practices of AI• The study of “rational” behavior and processing.
• The study of human behavior and cognitive processing.
• The study of other approaches: neural, evolutionary.
• Computational models of component processes: knowledge bases, inference engines, search techniques, machine learning techniques.
• Understanding the connection between domains & techniques.• Computational constraints vs. desired behavior.
• Application of techniques to real world problems.

Roles of AI in Games• Opponents
• Teammates
• Strategic Opponents
• Support Characters
• Autonomous Characters
• Commentators
• Camera Control
• Plot and Story Guides/Directors

Goals of AI action game opponent• Provide a challenging opponent
• Not always as challenging as a human -- Quake monsters.• What ways should it be subhuman?
• Not too challenging.• Should not be superhuman in accuracy, precision, sensing, ...
• Should not be too predictable.• Through randomness.• Through multiple, fine-grained responses.• Through adaptation and learning.

AI Agent in a Game• Each time through control loop, “tick” each agent.
• Define an API for agents: sensing and acting.
• Encapsulate all agent data structures.• And so agents can’t trash each other or the game.• Share global data structures on maps, etc.
Agent 1
Agent 1
Player
Game

Structure of an Intelligent Agent• Sensing: perceive features of the environment.
• Thinking: decide what action to take to achieve its goals, given the current situation and its knowledge.
• Acting: doing things in the world.
Thinking has to make up for limitations in sensing and acting.
The more accurate the models of sensing and acting, the more realistic the behavior.

Why not just C code?• Doesn’t easily localize tests for next action to take.
• Hard to add new variables and new actions
• End up retesting all variables every time through.

Sensing Limitations & Complexities• Limited sensor distance
• Limited field of view:• Must point sensor at location and keep it on.
• Obstacles
• Complex room structures• Detecting and computing paths to doors
• Noise in sensors
• Different sensors give different information and have different limitations.• Sound: omni-directional, gives direction, distances, speech, ...• Vision: limited field of view, 2 1/2D, color, texture, motion, ...• Smell: omni-directional, chemical makeup.Need to integrate different sources to build complete picture.

Simple Behavior• Random motion
• Just roll the dice to pick when and which direction to move
• Simple pattern• Follow invisible tracks: Galaxians
• Tracking• Pure Pursuit: Move toward agent’s current position
• Head seeking missile
• Lead Pursuit: Move to position in front of agent• Collision: Move toward where agent will be• Weave: Every N seconds move X degree off opponent’s bearing• Spiral: Head 90-M degrees off of opponent’s bearing
• Evasive – opposite of any tracking
• Delay in sensing gives different effects

Random

Simple Patterns

Pure Pursuit

Lead Pursuit

Collision

Moving in the World: Path Following
• Just try moving toward goal.
Source
Goal

Problem
Source
Goal

Create Avoidance Regions
Source
Goal

Indoors - Nodes
Pickup
Die
Run
Attack

Path Planning• Find a path from one point to another using an internal
model
• Satisficing: Try to find a good way to achieve a goal
• Optimizing: Try to find best way to achieve goal
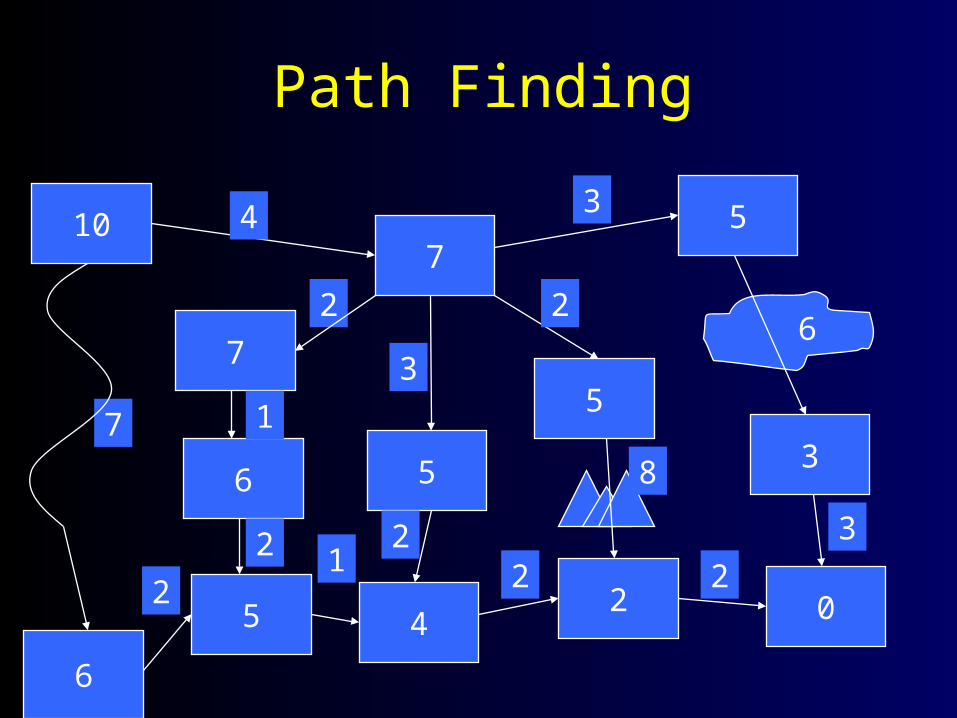
Path Finding
107
6
5
5
5
24
3
0
4
62
2
3
3
7
2
8
3
2
7
2
6
5
1
2 12

Analysis• Find the shortest path through a maze of rooms.
• Approach is A*:• At each step, calculate the cost of each expanded path.• Also calculate an estimate of remaining cost of path.• Extend path with the lowest cost + estimate.
• Cost can be more than just distance:• Climbing and swimming are harder (2x)• Monster filled rooms are really bad (5x)• Can add cost to turning – creates smoother paths• But must be a numeric calculation.• Must guarantee that estimate is not an overestimate.
• A* will always find shortest path.

Goals for Tutorial• Exposure to AI on tactical decision making
• Not state-of-the-art AI, but relevant to Computer Game• Concepts not code• Analysis of strengths and weaknesses• Pointers to more detailed references• Enough to be “dangerous”
• What’s missing?• Sensing models• Path planning and spatial reasoning• Scripting languages• Teamwork, flocking, …• Personality, emotion, …• How all of these pieces fit together

Plan for the Tutorial• Cover a variety of AI decision-making techniques
1. Finite-state Machines 2. Decision Trees3. Neural Networks4. Genetic Algorithms5. Rule-based Systems6. Fuzzy Logic7. Planning Systems8. Maybe Soar
• Describe within the context of a simple game scenario
• Describe implementation issues
• Evaluate their strengths and weaknesses

Which AI techniques are missing?• Agent-based approaches
• A-Life approaches
• Bayesian, decision theoretic …
• Blackboards
• Complex & partial-order planning
• Logics
• Prolog & Lisp
• Also not covering scripting

Types of Behavior to Capture• Wander randomly if don’t see or hear an enemy.
• When see enemy, attack
• When hear an enemy, chase enemy
• When die, respawn
• When health is low and see an enemy, retreat
• Extensions:• When see power-ups during wandering, collect them.

Execution Flow of an AI Engine
Sense
Think
Act
En
vironm
ent
Finite-state machines
Decision trees
Neural nets
Fuzzy logic
Rule-based systems
Planning systems
Can be extremely expensive
Can be modulated by “think”

Dimensions of Comparison• Complexity
• Execution• Specification
• Expressiveness• Propositional• Predicates and variables

Complexity• Complexity of Execution
• How fast does it run as more knowledge is added?• How much memory is required as more knowledge is added?
• Complexity of Specification• How hard is it to write the code?• As more “knowledge” is added, how much more code needs
to be added?
• Memory of prior events

Expressiveness of Specification• What can easily be written?
• Propositional: • Statements about specific objects in the world – no variables• Jim is in room7, Jim has the rocket launcher, the rocket
launcher does splash damage.• Go to room8 if you are in room7 through door14.
• Predicate Logic:• Allows general statement – using variables• All rooms have doors• All splash damage weapons can be used around corners• All rocket launchers do splash damage• Go to a room connected to the current room.

Memory• Can it remember prior events?
• For how long?
• How does it forget?

General References• AI
• Winston: Artifical Intelligence, 3rd Edition, Addison Wesley, 1992
• Russell and Norvig: Artificial Intelligence: A Modern Approach, Prentice Hall, 1995.
• Nilsson, Artificial Intelligence: A New Synthesis, Morgan Kaufmann, 1998.
• AI and Computer Games• LaMothe: Tricks of the Windows Game Programming
Gurus, SAMS, 1999, Chapter 12, pp. 713-796.• Deloura, Game Programming Gems, Charles River Media,
2000, Section 3, pp. 219-350.• www.gameai.com• www.gamedev.net/• Chris Miles

Finite State Machines
John Laird and Michael van Lent
University of Michigan
AI Tactical Decision Making Techniques

Example FSM
Events:
E=Enemy Seen
S=Sound Heard
D=Die
SpawnD
Wander-E, -S, -D
D
-E
E
-S
AttackE, -D
E
-E
ChaseS, -E, -D
S
D
E
D
S
Action (callback) performed when a transition occurs
Code
…
…

Example FSM
Events:
E=Enemy Seen
S=Sound Heard
D=Die
SpawnD
Wander-E, -S, -D
D
-E
E
-S
AttackE, -D
E
-E
ChaseS, -E, -D
S
D
E
D
S
Problem: No transition from attack to chase

Example FSM - Better
Events:
E=Enemy Seen
S=Sound Heard
D=Die
Attack-SE, -D, S
S
-E
-S
S
E
-S
AttackE, -D, -S
E
-E
SpawnD
Wander-E, -S, -D
D
-E
ChaseS, -E, -D
D
D
S
ED

Example FSM with Retreat
SpawnD
(-E,-S,-L)
Wander-E,-D,-S,-L
E
-SAttack-EE,-D,-S,-L
E
Chase-E,-D,S,-L
S
D
S
D
Events:E=Enemy SeenS=Sound HeardD=DieL=Low Health
Each feature with N values can require N times as many statesD
Retreat-EE,-D,-S,L
L
-E
Retreat-S-E,-D,S,L
Wander-L-E,-D,-S,L
Retreat-ESE,-D,S,L
Attack-ESE,-D,S,-L
E
E-E
-L
S
-S
L
-E E
L-L
-L
-L
L
D

Extended FSM: Save Values
SpawnD
(-E,-S,-L)
Wander-E,-D,-S
E
AttackE, -L
E
ChaseS,-L
D
S
D
D
LRetreat
L-L
L
Events:E=Enemy SeenS=Sound HeardD=DieL=Low Health
Maintain memory of current values of all events – transition event on old events
-E
D
-E
S
E
-S

Augmented FSM: Action on Transition
SpawnD
(-E,-S,-L)
Wander-E,-D,-S
E
AttackE, -L
E
ChaseS,-L
D
S
D
D
LRetreat
L-L
L
Events:E=Enemy SeenS=Sound HeardD=DieL=Low Health
Execute action during transition
-E
D
-E
S
E
-S
Action

Hierarchical FSM• Expand a state into its own FSM
Wander
Die
S/-S
E/-E
Attack
Chase
Spawn
StartTurn Right
Go-throughDoor
Pick-upPowerup

Non-Deterministic HierarchicalFSM (Markov Model)
Attack
Die
No enemy
Wander
Start
Start
Approach
Aim & Jump &Shoot
Aim & Slide Left& Shoot
Aim & Slide Right
& Shoot .3.3
.4
.3.3
.4

Simple Implementation• Compile into an array of state-name, event
• state-name := array[state-name] [event]
• Uses state-name to call execution logic
• Add buffers to queue up events in case get simultaneous events
event
state
• Hierarchical• Create array for every FSM• Have stack of states
• Classify events according to stack• Update state which is sensitive to current event

Extended & Augmented• Use C++ class for states
• Methods for actions and transitions

FSM Evaluation• Advantages:
• Very fast – one array access• Can be compiled into compact data structure
• Dynamic memory: current state• Static memory: state diagram – array implementation
• Can create tools so non-programmer can build behavior• Non-deterministic FSM can make behavior unpredictable
• Disadvantages:• Number of states can grow very fast
• Exponentially with number of events: s=2e
• Number of arcs can grow even faster: a=s2
• Hard to encode complex memories• Propositional representation
• Difficult to put in “pick up the better weapon”, attack the closest enemy

References• Web references:
• www.gamasutra.com/features/19970601/build_brains_into_games.htm• csr.uvic.ca/~mmania/machines/intro.htm• www.erlang/se/documentation/doc-4.7.3/doc/design_principles/fsm.html• www.microconsultants.com/tips/fsm/fsmartcl.htm
• Deloura, Game Programming Gems, Charles River Media, 2000, Section 3.0 & 3.1, pp. 221-248.

Decision Trees
John Laird and Michael van Lent
University of Michigan
AI Tactical Decision Making Techniques

Classification Problems• Task:
• Classify “objects” as one of a discrete set of “categories”
• Input: set of facts about the object to be classified• Is today sunny, overcast, or rainy• Is the temperature today hot, mild, or cold• Is the humidity today high or normal
• Output: the category this object fits into• Should I play tennis today or not?• Put today into the play-tennis category or the no-tennis
category

Example Problem• Classify a day as a suitable day to play tennis
• Facts about any given day include:• Outlook = <Sunny, Overcast, Rain>• Temperature = <Hot, Mild, Cool>• Humidity = <High, Normal>• Wind = <Weak, Strong>
• Output categories include:• PlayTennis = Yes• PlayTennis = No
• Outlook=Overcast, Temp=Mild, Humidity=Normal, Wind=Weak => PlayTennis=Yes
• Outlook=Rain, Temp=Cool, Humidity=High, Wind=Strong => PlayTennis=No
• Outlook=Sunny, Temp=Hot, Humidity=High, Wind=Weak => PlayTennis=No

Classifying with a Decision Tree
Outlook?
Sunny Overcast Rain
NoTemp? Wind?
Hot CoolMild
No Yes Yes
WeakStrong
Yes No

Decision Trees• Nodes represent attribute tests
• One child for each possible value of the attribute
• Leaves represent classifications
• Classify by descending from root to a leaf• At root test attribute associated with root attribute test• Descend the branch corresponding to the instance’s value• Repeat for subtree rooted at the new node• When a leaf is reached return the classification of that leaf
• Decision tree is a disjunction of conjunctions of constraints on the attribute values of an instance

Decision Trees are good when:• Inputs are attribute-value pairs
• With fairly small number of values• Numeric or continuous values cause problems
• Can extend algorithms to learn thresholds
• Outputs are discrete output values• Again fairly small number of values• Difficult to represent numeric or continuous outputs
• Disjunction is required• Decision trees easily handle disjunction
• Training examples contain errors• Learning decision trees• More later

Decision-making as Classification• How does classification relate to deciding what to do in
a situation?
• Treat each output command as a separate classification problem• Given inputs should walk => <forward, backward, stop>• Given inputs should turn => <left, right, none>• Given inputs should run => <yes, no>• Given inputs should weapon => <blaster, shotgun…>• Given inputs should fire => <yes, no>

Decision-making w/ Decision Trees• Separate decision tree for each output
• Poll each decision tree for current output• Poll each tree multiple times a second• Event triggered like FSM
• Need current value of each input attribute/value• All sensor inputs describe the state of the world
• Store the state of the environment • Most recent sensor inputs• Constantly update this state• Constantly poll the decision trees to decide on output• Constantly send outputs to be executed

Sense, Think, Act Cycle• Sense
• Gather input sensor changes• Update state with new values
• Think• Poll each decision tree
• Act• Execute any changes to actions
Sense
Think
Act

Example FSM with Retreat
SpawnD
(-E,-S,-L)
Wander-E,-D,-S,-L
E
-SAttack-EE,-D,-S,-L
E
Chase-E,-D,S,-L
S
D
S
D
Events:
E=Enemy
S=Sound
D=Die
L=Low Health
Each new feature can double number of states
D
Retreat-EE,-D,-S,L
L
-E
Retreat-S-E,-D,S,L
Wander-L-E,-D,-S,L
Retreat-ESE,-D,S,L
Attack-ESE,-D,S,-L
E
E-E
-L
S
-S
L
-E E
L-L
-L
-L
L
D

Decision Tree for Quake• Input Sensors: E=<t,f> L=<t,f> S=<t,f> D=<t,f>
• Categories (actions): Attack, Retreat, Chase, Spawn, Wander
D?
Spawn E?
L? S?
WanderRetreat Attack L?
t
t
t t
f
f
f f
Retreat Chase
t f

Learning Decision Trees• Decision trees are usually learned by induction
• Generalize from examples• Induction doesn’t guarantee correct decision trees
• Bias towards smaller decision trees• Occam’s Razor: Prefer simplest theory that fits the data• Too expensive to find the very smallest decision tree
• Learning is non-incremental• Need to store all the examples
• ID3 is the basic learning algorithm• C4.5 is an updated and extended version

Induction• If X is true in every example X must always be true
• More examples are better• Errors in examples cause difficulty• Note that induction can result in errors
• Inductive learning of Decision Trees• Create a decision tree that classifies the available examples• Use this decision tree to classify new instances• Avoid over fitting the available examples
• One root to node path for each example• Perfect on the examples, not so good on new instances

Induction requires Examples• Where do examples come from?
• Programmer/designer provides examples• Capture a human’s decisions
• # of examples need depends on difficulty of concept• More is always better
• Training set vs. Testing set• Train on most (75%) of the examples• Use the rest to validate the learned decision trees

ID3 Learning Algorithm
ID3(examples,attributes)if all examples in same category then
return a leaf node with that categoryif attributes is empty then
return a leaf node with the most common category in examplesbest = Choose-Attribute(examples,attributes)tree = new tree with Best as root attribute testforeach value vi of best
examplesi = subset of examples with best == vi
subtree = ID3(examplesi,attributes – best)
add a branch to tree with best == vi and subtree beneath
return tree
• ID3 has two parameters• List of examples
• List of attributes to be tested
• Generates tree recursively• Chooses attribute that best divides the examples at each step

Entropy• Entropy: how “mixed” is a set of examples
• All one category: Entropy = 0• Evenly divided: Entropy = log2(# of examples)
• Given S examples Entropy(S) = Σ –pi log2 pi
where pi is the proportion of S belonging to class i• 14 days with 9 in play-tennis and 5 in no-tennis
• Entropy([9,5]) = 0.940
• 14 examples with 14 in play-tennis and 0 in no-tennis• Entropy ([14,0]) = 0

Information Gain• Information Gain measures the reduction in Entropy
• Gain(S,A) = Entropy(S) – Σ Sv/S Entropy(Sv)
• Example: 14 days: Entropy([9,5]) = 0.940• Measure information gain of Wind=<weak,strong>
• Wind=weak for 8 days[6,2]• Wind=strong for 6 days: [3,3]• Gain(S,Wind) = 0.048
• Measure information gain of Humidity=<high,normal>• 7 days with high humidity: [3,4]• 7 days with normal humidity: [6,1]• Gain(S,Humidity) = 0.151
• Humidity has a higher information gain than Wind• So choose humidity as the next attribute to be tested

Learning Example• Learn a decision tree to replace the FSM
• Four attributes: Enemy, Die, Sound, Low Health• Each with two values: true, false
• Five categories: Attack, Retreat, Chase, Wander, Spawn
• Use all 16 possible states as examples• Attack(2), Retreat(3), Chase(1) Wander(2), Spawn(8)
• Entropy of first 16 examples (max entropy = 4)• Entropy([2,3,1,2,8]) = 1.953

Example FSM with Retreat
SpawnD
(-E,-S,-L)
Wander-E,-D,-S,-L
E
-SAttack-EE,-D,-S,-L
E
Chase-E,-D,S,-L
S
D
S
D
Events:
E=Enemy
S=Sound
D=Die
L=Low Health
Each new feature can double number of states
D
Retreat-EE,-D,-S,L
L
-E
Retreat-S-E,-D,S,L
Wander-L-E,-D,-S,L
Retreat-ESE,-D,S,L
Attack-ESE,-D,S,-L
E
E-E
-L
S
-S
L
-E E
L-L
-L
-L
L
D

Learning Example (2)• Information gain of Enemy
• 0.328
• Information gain of Die• 1.0
• Information gain of Sound• 0.203
• Information gain of Low Health• 0.375
• So Die should be the root test

Learned Decision Tree
• 8 examples left [2,3,1,2] = 1.906
• 3 attributes remaining: Enemy, Sound, Low Health
• Information gain of Enemy• 0.656
• Information gain of Sound• 0.406
• Information gain of Low Health• 0.75
D?
Spawn
t f

Learned Decision Tree (2)
• 4 examples on each side: t = 0.811; f = 1.50
• 2 attributes remaining: Enemy, Sound
• Information gain of Enemy (L = f)• 1.406
• Information gain of Sound (L = t)• .906
D?
Spawn
t f
L?
t f

Learned Decision Tree (3)D?
Spawn
t f
L?
t f
S?
t f
E?
t f
Retreat E?
t f
Attack S?
t f
Retreat Wander WanderChase

Decision Tree Evaluation• Advantages
• Simpler, more compact representation• State = Memory
• Create “internal sensors” – Enemy-Recently-Sensed
• Easy to create and understand• Can also be represented as rules
• Decision trees can be learned
• Disadvantages• Decision tree engine requires more coding than FSM• Need as many examples as possible• Higher CPU cost• Learned decision trees may contain errors

References• Mitchell: Machine Learning, McGraw Hill, 1997.• Russell and Norvig: Artificial Intelligence: A Modern Approach, Prentice Hall, 1995.
• Quinlan: Induction of decision trees, Machine Learning 1:81-106, 1986.
• Quinlan: Combining instance-based and model-based learning,10th International Conference on Machine Learning, 1993.

Neural Networks
John Laird and Michael van Lent
University of Michigan
AI Tactical Decision Making Techniques

Inspiration• Mimic natural intelligence
• Networks of simple neurons• Highly interconnected• Adjustable weights on connections• Learn rather than program
• Architecture is different• Brain is massively parallel
• 1011 neurons
• Neurons are slow• Fire 10-100 times a second
• Brain is much faster• 1014 neuron firings per second for brain• 106 perceptron firings per second for
computer

Simulated Neuron• Inputs (aj) from other perceptrons with weights (Wi,j)
• Learning occurs by adjusting the weights
• Perceptron calculates weighted sum of inputs (ini)
• Threshold function calculates output (ai)• Step function (if ini > t then ai = 1 else ai = 0)• Sigmoid g(a) = 1/1+e-x
• Output becomes input for next layer of perceptron aj Wi,j
aiΣ Wi,j aj = ini
ai = g(ini)

Network Structure• Single perceptron can represent AND, OR not XOR
• Combinations of perceptron are more powerful
• Perceptron are usually organized on layers• Input layer: takes external input• Hidden layer(s)• Output player: external output
• Feed-forward vs. recurrent• Feed-forward: outputs only connect to later layers
• Learning is easier
• Recurrent: outputs can connect to earlier layers or same layer• Internal state

Neural network for Quake• Four input perceptron
• One input for each condition
• Four perceptron hidden layer• Fully connected
• Five output perceptron • One output for each action• Choose action with highest output• Probabilistic action selection
Enemy
Sound
Dead
Low Health
Attack
Retreat
Wander
Chase
Spawn

Back Propagation• Learning from examples
• Examples consist of input and correct output
• Learn if network’s output doesn’t match correct output• Adjust weights to reduce difference• Only change weights a small amount (η)
• Basic perceptron learning• Wi,j = Wi,j + ΔWi,j
• Wi,j = Wi,j + η(t-o)aj
• If output is too high (t-o) is negative so Wi,j will be reduced
• If output is too low (t-o) is positive so Wi,j will be increased
• If aj is negative the opposite happens

Neural Net Example• Single perceptron to represent OR
• Two inputs• One output (1 if either inputs is 1)• Step function (if weighted sum > 0.5 output a 1)
10.1
Σ Wj aj = 0.1
g(0.1) = 0
0
0
0.6
• Error so training occurs

Neural Net Example• Wj = Wj + ΔWj
• Wj = Wj + η(t-o)aj
• W1 = 0.1 + 0.1(1-0)1 = 0.2
• W2 = 0.6 + 0.1(1-0)0 = 0.60
0.2Σ Wj aj = 0.6
g(0.6) = 0
1
1
0.6
• No error so no training occurs

Neural Net Example
• Error so training occurs
• W1 = 0.2 + 0.1(1-0)1 = 0.3
• W2 = 0.6 + 0.1(1-0)0 = 0.6
10.2
Σ Wj aj = 0.2
g(0.2) = 0
0
0
0.6
10.3
Σ Wj aj = 0.9
g(0.9) = 1
1
1
0.6

Neural Networks Evaluation• Advantages
• Handle errors well• Graceful degradation• Can learn novel solutions
• Disadvantages• “Neural networks are the second best way to do anything”• Can’t understand how or why the learned network works• Examples must match real problems• Need as many examples as possible• Learning takes lots of processing
• Incremental so learning during play might be possible

References• Mitchell: Machine Learning, McGraw Hill, 1997.
• Russell and Norvig: Artificial Intelligence: A Modern Approach, Prentice Hall, 1995.
• Hertz, Krogh & Palmer: Introduction to the theory of neural computation, Addison-Wesley, 1991.
• Cowan & Sharp: Neural nets and artificial intelligence, Daedalus 117:85-121, 1988.

Genetic Algorithms
John Laird and Michael van Lent
University of Michigan
AI Tactical Decision Making Techniques

Inspiration• Evolution creates individuals with higher fitness
• Population of individuals• Each individual has a genetic code
• Successful individuals (higher fitness) more likely to breed• Certain codes result in higher fitness• Very hard to know ahead which combination of genes = high fitness
• Children combine traits of parents• Crossover• Mutation
• Optimize through artificial evolution• Define fitness according to the function to be optimized• Encode possible solutions as individual genetic codes• Evolve better solutions through simulated evolution

Genetic Algorithminitialize population p with random genesrepeat
foreach pi in pfi = fitness(pi)
repeatparent1 = select(p,f)parent2 = select(p,f)child1, child2 = crossover(parent1,parent2)if (random < mutate_probability)
child1 = mutate(child1)if (random < mutate_probability)
child2 = mutate(child2)add child1, child2 to p’
until p’ is fullp = p’
• Fitness(gene): the fitness function
• Select(population,fitness): weighted selection of parents
• Crossover(gene,gene): crosses over two genes
• Mutate(gene): randomly mutates a gene

Genetic Operators• Crossover
• Select two points at random• Swap genes between two points
• Mutate• Small probably of randomly changing each part of a gene

Representation• Gene is typically a string of symbols
• Frequently a bit string• Gene can be a simple function or program
• Evolutionary programming
• Every possible gene must encode a valid solution• Crossover should result in valid genes• Mutation should result in valid genes
• Intermediate genes = intermediate fitness values• Genetic algorithm is a hill climbing technique• Smooth fitness functions provide a hill to climb

Example FSM with Retreat
SpawnD
(-E,-S,-L)
Wander-E,-D,-S,-L
E
-SAttack-EE,-D,-S,-L
E
Chase-E,-D,S,-L
S
D
S
D
Events:
E=Enemy
S=Sound
D=Die
L=Low Health
Each new feature can double number of states
D
Retreat-EE,-D,-S,L
L
-E
Retreat-S-E,-D,S,L
Wander-L-E,-D,-S,L
Retreat-ESE,-D,S,L
Attack-ESE,-D,S,-L
E
E-E
-L
S
-S
L
-E E
L-L
-L
-L
L
D

Representing rules as bit strings• Conditions
• Enemy = <t,f>: bits 1 and 2• 10: Enemy = t; 01: Enemy = f; 11: Enemy = t or f; 00: Enemy has no value
• Sound = <t,f>: bits 3 and 4• Die = <t,f>: bits 5 and 6• Low Health = <t,f>: bits 7 and 8
• Classification• Action = <attack,retreat,chase,wander,spawn>• Bits 9-13: 10000: Action = attack
• 1111101100001: If dead=t then action=spawn
• Encode 1 rule per gene or many rules per gene
• Fitness function: % of examples classified correctly

Genetic Algorithm Example• Initial Population
10 11 11 11 11010: E => Attack or Retreat or Wander11 10 10 11 10100: S D => Attack or Chase01 00 01 10 01100: -E -D L => Retreat or Chase10 10 10 11 00010: E S D => Wander...
• Parent Selection10 11 11 11 11010: Sometimes correct11 10 10 11 10100: Never correct01 00 01 10 01100: Sometimes correct10 10 10 11 00010: Never correct...

• Crossover10 11 11 11 11010: Sometimes correct01 00 01 10 01100: Sometimes correct
10 10 01 10 01010: E S -D L => Retreat or Wander01 01 11 11 11100: -E -S => Attack or Retreat or Chase
• Mutate10 10 01 10 01000: E S -D L => Retreat 01 01 11 11 11100: -E -S => Attack or Retreat or Chase
• Add to next generation10 10 01 10 01000: Always correct01 01 11 11 11100: Never correct...
Genetic Algorithm Example

Cloak and Dagger DNA• Simple turn-based strategy game
• Genes encode programs to play the game• 12 simple instructions
• Fitness measures success of programs• Fitness measured against rest of population• Play members of population against each other
• Crossover and mutation create new programs• Crossover: combine the first n instructions from parent 1
with the last m instructions from parent 2• Child can have more or less instructions than the parents
• Mutation: replace an instruction with a random instruction

Genetic Algorithm Evaluation• Advantages
• Powerful optimization technique• Can learn novel solutions• No examples required to learn
• Disadvantages• “Genetic algorithms are the third best way to do anything”• Finding correct representation can be tricky• Fitness function must be carefully chosen• Evolution takes lots of processing
• Can’t really run a GA during game play
• Solutions may or may not be understandable

References• Mitchell: Machine Learning, McGraw Hill, 1997.
• Holland: Adaptation in natural and artificial systems, MIT Press 1975.
• Back: Evolutionary algorithms in theory and practice, Oxford University Press 1996.
• Booker, Goldberg, & Holland: Classifier systems and genetic algorithms, Artificial Intelligence 40: 235-282, 1989.

Rule-based Systems(Production Systems)
John Laird and Michael van Lent
University of Michigan
AI Tactical Decision Making Techniques

History of Rule-based Systems• Originally developed by Allen Newell and Herb Simon
• To model human problem solving: PSG
• Followed by OPS languages (OPS1-5, OPS-83) and descendants: CLIPS, ECLIPS, …
• Used extensively in building “expert systems” and knowledge-based systems.
• Used in psychological modeling.• Act-R, Soar, EPIC, …
• Actively used in many areas of AI Applications• Less used in research (except by us!).

Newell and Simon

Rule-Based Systems Structure
Rule Memory
Working Memory
Program
Procedural Knowledge
Long-term Knowledge
Data
Declarative Knowledge
Short-term Knowledge
Match
ConflictResolution
Act

Basic Cycle
Match
ConflictResolution
Act
Changes to Working Memory
Selected
Rule
Rule instantiations that match working memory

Complete Picture
Sensors
Actions
Match
ConflictResolution
Act
Changes to WM

Simple Approach• No rules with same variable in multiple conditions.
• Restricts what you can write, but might be ok for simple systems.

Limits of Simple Approach• Can’t use variables in condition
• Can’t pick something from a set• If the closest enemy is carrying the same weapon that
I am carrying, then …
• Must have pre-computed data structures or function calls for comparisons• More work for sensor module

Picking the rule to fireSimple approach
• Run through rules one at a time and test conditions• Pick the first one that matches• Time to match depends on:
1. Number of rules2. Complexity of conditions3. Number of rules that don’t match

Creating Efficient Rule-based Systems
• Where does the time go?• 90-95% goes to Match
• Matching all rules against all of working memory each cycle is way too slow.
• Key observation• # of changes to working memory each cycle is small
Match
ConflictResolution
Act
Changes to Working Memory
Selected
Rule
Rule Instantiations

Picking the next rule to fire• If only simple tests in conditions,
compile rules into a match net.
• Process changes to working memory: hash into tests
R1: If A, B, C, then …A B C
R1
Conflict Set
Bit vectors for rules if all bits are set, add to conflict set
R2: If A, B, D, then …
D
R2
Expected cost: Linear in the number of changes to working memory

More Complex Rule-based Systems• Allow complex conditions with multiple variables
• Function calls in conditions and actions• Can compute many relations using rules
• Examples:• OPS5, OPS83, CLIPS, ART, ECLIPS, Soar, EPIC, …

OPS5 Working Memory Syntax
• Set of working memory elements (WME) records• WME: class name and list of attribute value pairs
(self ^health 100 ^weapon blaster)(enemy ^visible true ^name joe ^range 400)(item ^visible true ^name small-health ^type health ^range 500)(command ^action ^arg1 ^arg2)

Literalize(literalize self health weapon ammo heading)
• Declares the legal attributes for a class
• OPS5 assigns positions in record for attributes:
• Working memory objects are a complete record• If one attribute modified, delete and add in new record
Health weapon ammo heading

Example Initial Working Memory(self ^health 1000 ^x 230 ^y 34 ^weapon blaster ^ammo full)(enemy ^visible true ^name joe ^range 400)(command)
Each WME has a unique timetag associated with it.

Prototype Ops5 Rule(p name (condition …) …--> (actions))
(p name (condition …) …--> (actions))
(p name (condition …) …--> (actions))
(p name (condition …) …--> (actions))
(p name (condition …) …--> (actions))
(p name (condition …) …--> (actions))
(p name (condition …) …--> (actions))

OPS5 Rule Syntax(p attack (enemy ^visible true ^name <name>) (command)--> (modify 2 ^action attack ^arg1 <name>))

OPS5 Rule Syntax(p attack (enemy ^visible true ^name <name>) (command)--> (modify 2 ^action attack ^arg1 <name>))
Working memory(self ^health 1000 ^x 230 ^y 34 ^weapon blaster)(enemy ^visible true ^name joe ^range 400)(command)
<name> = joe
Changes to working memory:
Remove: (command)
Add: (command ^action attack ^arg1 joe)

OPS5 Rule Matching(p get-item (item ^visible true ^type <type>) (command)--> (modify 2 ^action get-item ^arg1 <type>))
Working memory(self ^health 1000 ^x 230 ^y 34 ^weapon blaster)(item ^visible true ^type health ^range 400) (item ^visible true ^type hyperblaster ^range 500)(command)Two matches:
(item ^visible true
^type health)
(item ^visible true
^type hyperblaster)

Even More Rules; If ammunition is low and see weapon in room : that is same as current weapon, go get it
(p get-weapon-ammo-low (self ^ammo low ^weapon <weapon>) (item ^visible true ^type <weapon>) (command)--> (modify 3 ^action get-item ^arg1 <weapon>)
Both occurrences of <weapon> must match same value.

Summary of OPS5 Syntax• Conditions
• Variables: <x>• Negation: -(object ^type monkey)• Predicates: > <x>• Conjunctive tests: { <> <y> <x> }• Disjunctive tests: << monkey ape >>• [Many languages allow function calls in conditions.]
• Actions• Add, Delete, Modify Working Memory• Function calls

Conflict Resolution• Which matched rule that should fire?
• Which instantiation of a rule should fire?• Separate instantiation for every match of variables in rules
Match
ConflictResolution
Act
Changes to Working Memory
Selected
Rule
Rule Instantiations

Conflict Resolution FiltersSelect between instantiations based on filters:
1. Refractory Inhibition: • Don’t fire same instantiation that has already fired
2. Data Recency:• Select instantiations that match most recent data
3. Specificity:• Select instantiations that match more working memory
elements
4. Random• Select randomly between the remaining instantiations

Data Recency: Lexical graphic Ordering
R1: 1, 5, 8
R2: 1, 5, 6, 7
R3: 2, 5, 9
R4: 1, 6, 7, 8
R4: 1, 5, 5, 7
R5: 2, 5, 9
R6: 5, 9
R3: 9, 5, 2
R5: 9, 5, 2
R6: 9, 5
R4: 8, 7, 6, 1
R2: 8, 5, 1
R1: 7, 6, 5, 1
R4: 7, 5, 5, 1

Specificity• Pick the rule instantiation based on more “tests”
• Only invoked when two rules match the same WMEs• More reasons to do this action
(p get-weapon-ammo-low (self ^ammo high ^weapon <weapon>) (item ^visible true ^type { <> <weapon> <nweapon> }) (command)--> (modify 3 ^action get-item ^arg1 <nweapon>)
(p get-item (self ^name <name>) (item ^visible true ^type <type>) (command)--> (modify 3 ^action get-item ^arg1 <type>))

Other Conflict Resolution Strategies(not in OPS5)
• Rule order – pick the first rule that matches• In original PSG• Makes order of loading important – not good for big systems
• Rule importance – pick rule with highest priority• When a rule is defined, give it a priority number• Forces a total order on the rules – is right 80% of the time• Decide Rule 4 [80] is better than Rule 7 [70]• Decide Rule 6 [85] is better than Rule 5 [75]• Now have ordering between all of them – even if wrong

Creating Efficient Rule-based Systems
• Where does the time go?• 90-95% goes to Match
• Matching all rules against all of working memory each cycle is way too slow.
• Key observation• # of changes to working memory each cycle is small Match
ConflictResolution
Act
Changes to Working Memory
Selected
Rule
Rule Instantiations

Basic Idea of Efficient MatchingOnly process the changes to working memory
1. Save intermediate match information (RETE)• Compile rules into discrimination network• Share intermediate match information between rules• Recompute intermediate information for changes• Requires extra memory for intermediate match information• Scales well to large rule sets
2. Recompute match for rules affected by change (TREAT)• Check changes against rules in conflict set• Less memory than Rete• Doesn’t scale as well to large rule sets
Both make extensive use of hashing

RETE Network(p pickupobject
(goal ^status active
^type holds
^object <w>)
(object ^name <w>)
-(monkey ^holds <w>)
-->
(goal ^status active
^type pickup
^object <w>))
A0
Test “goal”Test “active”Test “holds”
A2
Test “Monkey”A1
Test “Object”
B1
JoinAND3=1
B2
JoinNAND
3=3
Add “pickup object” to CS
Alpha nodes
Beta Nodes

Sharing in RETE Network(p pickupobject
(goal ^status active
^type holds
^object <w>)
(object ^name <w>)
-(monkey ^holds <w>)
-->
…
A0
Test “goal”Test “active”Test “holds”
A2
Test “Monkey”A1
Test “Object”
B1
JoinAND3=1
B2
JoinNAND
3=3
Add “pickup object” to CS
B3
JoinAND3=1
Add “Remove pickup goal”
(p quitpickupobject
(goal ^status active
^type holds
^object <w>)
(monkey ^holds <w>)
-->

RETE Network(p pickupobject
(goal ^status active
^type holds
^object <w>)
(object ^name <w>)
-(monkey ^holds <w>)
-->
(goal ^status active
^type pickup
^object <w>))
A0
Test “goal”Test “active”Test “holds”
A2
Test “Monkey”A1
Test “Object”
B1
JoinAND3=1
B2
JoinNAND
3=3
Add “pickup object” to CS
Add (goal ^status active …)
[(goal ^status active ^type holds ^name banana)]
Add (object ^name lamp …)
[(object ^name lamp)]
Add (object ^name banana …)
[(object ^name banana)]
[(goal ^status active ^type holds ^name banana) (object ^name banana)]]
[(goal ^status active ^type holds ^name banana) (object ^name banana)]]
Add (monkey ^holds banana …)
[(monkey ^holds banana)]

Rule-based System Evaluation• Advantages
• Corresponds to way people often think of knowledge• Very expressive• Modular knowledge
• Easy to write and debug compared to decision trees• More concise the FSM
• Disadvantages• Can be memory intensive• Can be computationally intensive• Sometimes difficult to debug

References• RETE
• Forgy, C. L. Rete: A fast algorithm for the many pattern/many object pattern match problem. Artificial Intelligence, 19(1) 1982, pp. 17-37.
• TREAT:• Miranker, D. TREAT: A new and efficient match algorithm
for AI production systems. Pittman/Morgan Kaufman, 1989.

Fuzzy Logic
John Laird and Michael van Lent
University of Michigan
AI Tactical Decision Making Techniques

Fuzzy Logic
• Philosophical approach• Ontological commitment based on “degree of truth”• Is not a method for reasoning under uncertainty
• See probability theory and Bayesian inference
• Crisp Facts – distinct boundaries• Fuzzy Facts– imprecise boundaries• Example – Scout reporting an enemy
• “Two to three tanks at grid NV 123456“ (Crisp)• “A few tanks at grid NV 123456” (Fuzzy)• “The water is warm.” (Fuzzy)• “There might be 2 tanks at grid NV 54 (Probabilistic)

Fuzzy Rules
• If the water temperature is cold and water flow is low then make a positive bold adjustment to the hot water valve.
• If position is unobservable, threat is somewhat low, and visibility is high then risk is low.
Fuzzy Variable
Fuzzy Value represented as a fuzzy set
Fuzzy Modifier or Hedge

Fuzzy Sets
• Classical set theory• An object is either in or not in the set.
• Sets with smooth boundary• Not completely in or out – somebody 6” is 80% tall
• Fuzzy set theory• An object is in a set by matter of degree• 1.0 => in the set• 0.0 => not in the set• 0.0 < object < 1.0 => partially in the set
• Provides a way to write symbolic rules but “add numbers” in a principled way

Apply to Computer Game• Can have different characteristics of entities
• Strength: strong, medium, weak• Aggressiveness: meek, medium, nasty• If meek and attacked, run away fast.• If medium and attacked, run away slowly.• If nasty and strong and attacked, attack back.
• Control of a vehicle• Should slow down when close to car in front• Should speed up when far behind car in front
• Provides smoother transitions – not a sharp boundary

Fuzzy Variable
Aggressiveness
Membership (Degree of Truth)
1.0
0.0
-1 1 0 0.5
Medium NastyMeek

Fuzzy Set OperationsIntersection (AND) = Min
Medium
If meek and medium strong then …
Membership
Units
1.0
0.0
Meek
Meek AND Medium

Fuzzy Set OperationsUnion (Or) = Max
Membership
Units
1.0
0.0
Meek
Medium
If meek or medium strong then …
Meek or Medium

Fuzzy Inference
• Fuzzy Matching• Calculate the degree to which given facts (WMES)
match rules – pick rule with best match
• Inference• Calculate the rule’s conclusion based on its
matching degree.
• Combination• Combine conclusions inferred by all fuzzy rules’
into a final conclusion
• Defuzzification• Convert fuzzy conclusion into a crisp
consequence.
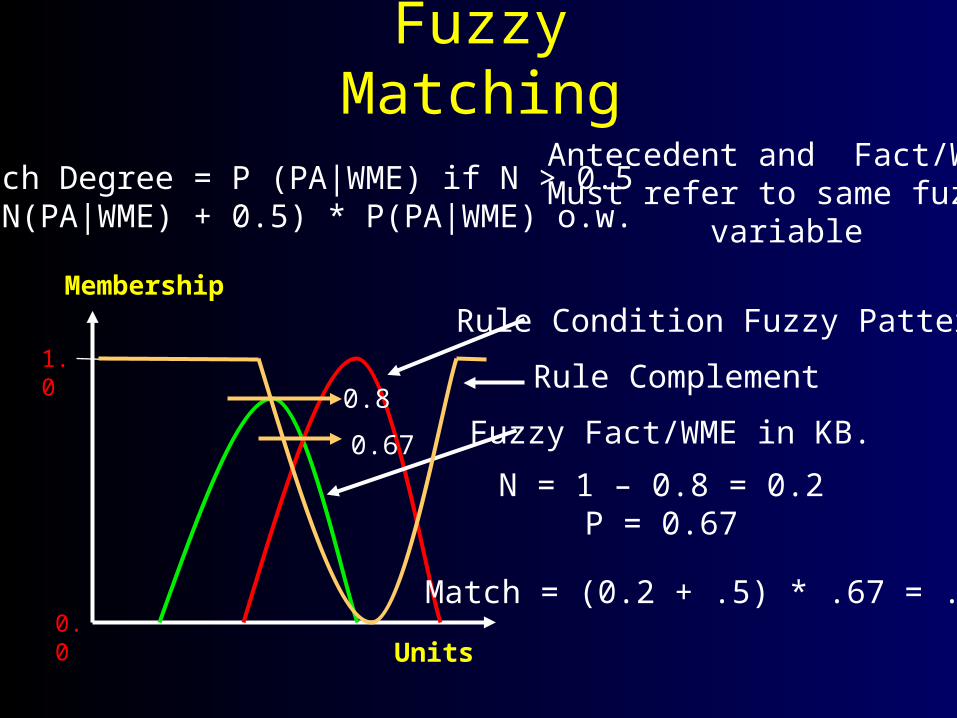
Fuzzy Matching
Membership
Units
1.0
0.0
Rule Condition Fuzzy Pattern
Fuzzy Fact/WME in KB.
Antecedent and Fact/WME Must refer to same fuzzy
variable
Rule Complement
Match Degree = P (PA|WME) if N > 0.5= (N(PA|WME) + 0.5) * P(PA|WME) o.w.
0.8
0.67
N = 1 – 0.8 = 0.2P = 0.67
Match = (0.2 + .5) * .67 = .467

Fuzzy Inference
Membership
Units
1.0
0.0
Fuzzy Consequence
Clipping MethodMatch Degree = .467
.467
Fuzzy Set added to WM

Fuzzy Combination
• Why? • More than one rule may match because of
overlapping fuzzy sets• May trigger multiple fuzzy rules
• Example of Multiple Rule Match• if shower is cold then turn hot valve up boldly.• if shower is somewhat warm then turn hot valve
up slightly
• Union of all the calculated fuzzy consequences in Working Memory.

Defuzzification
• Why? • May require a crisp value for output to
environment.• May trigger multiple fuzzy rules
• Two Methods• Mean of Maximum (MOM)• Center of Area (COA)

Defuzzification
Membership
Units
1.0
0.0
Mean of MaximumMethod
.467
Fuzzy Set added to WM
Crisp Result

Evaluation of Fuzzy Logic• Does not necessarily lead to non-determinism
• Advantages• Allows use of numbers while still writing “crisp” rules• Allows use of “fuzzy” concepts such as medium• Biggest impact is for control problems
• Help avoid discontinuities in behavior
• Disadvantages• Sometimes results are unexpected and hard to debug• Additional computational overhead• Change in behavior may or may not be significant

References• Nguyen, H. T. and Walker, E. A. A First Course in
Fuzzy Logic, CRC Press, 1999.
• Rao, V. B. and Rao, H. Y. C++ Neural Networks and Fuzzy Logic, IGD Books Worldwide, 1995.
• McCuskey, M. Fuzzy Logic for Video Games, in Game Programming Gems, Ed. Deloura, Charles River Media, 2000, Section 3, pp. 319-329.

Planning
John Laird and Michael van Lent
University of Michigan
AI Tactical Decision Making Techniques

What is Planning?• Plan: sequence of actions to get from the current
situation to a goal situation• Higher level mission planning• Path planning
• Planning: generate a plan• Initial state: the state the agent starts in or is currently in• Goal test: is this state a goal state• Operators: every action the agent can perform
• Also need to know how the action changes the current state
• Note: at this level planning doesn’t take opposition into account

Two Approaches• State-space search
• Search through the possible future states that can be reached by applying different sequences of operators
• Initial state = current state of the world• Operators = actions that modify the world state• Goal test = is this state a goal state
• Plan-space search• Search through possible plans by applying operators that
modify plans• Initial state = empty plan (do nothing)• Operators = add an action, remove an action, rearrange actions• Goal test = does this plan achieve the goal

Two Approaches
State-space Search
Plan-space Search

Traditional planning and combat simulations
• Combat simulations are difficult for traditional AI planning• Opponent messes up the plan• Environment changes messing up the plan• “Goal state” is hard to define and subject to change• Lots of necessary information is unavailable• Too many steps between start and finish of mission
• Some applications of traditional AI planning• Path planning
• State-space search algorithms like A*
• Game theoretical search• State-space search algorithms with opponents like min-max and alpha-beta

What concepts are useful?• Look-ahead search
• Internal state representation
• Internal action representation
• State evaluation function
• Opponent model
• Means-ends analysis

What should I do?
Shoot?Pickup? Pickup?

Look-ahead search• Try out everything I could do and see what works best
• Looking ahead into the future• As opposed to hard-coded behavior rules
• Can’t look-ahead in real world• Don’t have time to try everything• Can’t undo actions
• Look-ahead in an internal version of the world• Internal state representation• Internal action representation• State evaluation function

Internal State Representation• Store a model of the world inside your head
• Simplified, abstracted version
• Experiment with different actions internally• Simple planning
• Additional uses of internal state• Notice changes
• My health is dropping, I must be getting shot in the back
• Remember recent events• There was a weak enemy ahead, I should chase through that door
• Remember less recent events• I picked up that health pack 30 seconds ago, it should respawn soon

Internal State for Quake IISelf
Current-healthLast-health
Current-weaponAmmo-left
Current-roomLast-room
Current-armorLast-armor
Available-weapons
EnemyCurrent-weaponCurrent-roomLast-seen-timeEstimated-health
PowerupTypeRoomAvailableEstimated-spawn-time
MapRoomsHallsPaths
Current-time
Random-number
Parameters
Full-health
Health-powerup-amount
Ammo-powerup-amount
Respawn-rate

Internal Action Representation• How will each action change the internal state?
• Simplified, abstracted also
• Necessary for internal experiments• Experiments are as accurate as the internal representation
• Internal actions are called operators (STRIPS-style)• Pre-conditions: what must be true so I can take this action• Effects: how action changes internal state
• Additional uses of internal actions• Update internal opponent model

Pick-up-health operator• Preconditions:
• Self.current-room = x• Self.current-health < full-health• Powerup.current-room = x• Powerup.type = health• Powerup.available = yes
• Effects:• Self.last-health = self.current-health• Self.current-health = current-health + health-powerup-amount• Powerup.available = no• Powerup.estimated-spawn-time = current-time + respawn-rate

State Evaluation Function• What internal states are good and bad?
• Way to compare states and decide which is better• Traditional planning talks about goal states• Desirable state properties
• Internal experiments find good states and avoid bad

State Evaluation for Quake II• Example 1: Prefer states with higher self.current-health
• Always pick up health powerup• Self.current-health = 99% and Enemy.current-health = 1%
• Example 2: Prefer lower enemy.current-health• Always shoot enemy• Self.current-health = 1% and Enemy.current-health = 99%
• Example 3: Prefer higher self.health – enemy.health
• More complex evaluations• If self.health > 50% prefer lower enemy.health else higher self.health• If self.health > low-health prefer lower enemy.health else higher self.health

Look-ahead Search• Simple limited depth state-space search
• One step look-ahead searchfor each operator with matching pre-conditions
apply operator to current stateevaluate resulting state
choose “real” action that looked best internally
• Searching deeper• Longer, more elaborate plans• More time consuming• More space consuming• More chances for opponent or environment to mess up plan• Simplicity of internal model more likely to cause problems

What should I do?
Shoot?Pickup? Pickup?
Self.current-health = 20 Enemy.estimated-health = 50 Powerup.type = health-pak
Self.current-weapon = blaster Powerup.available = yes
Powerup.type = Railgun
Powerup.available = yes
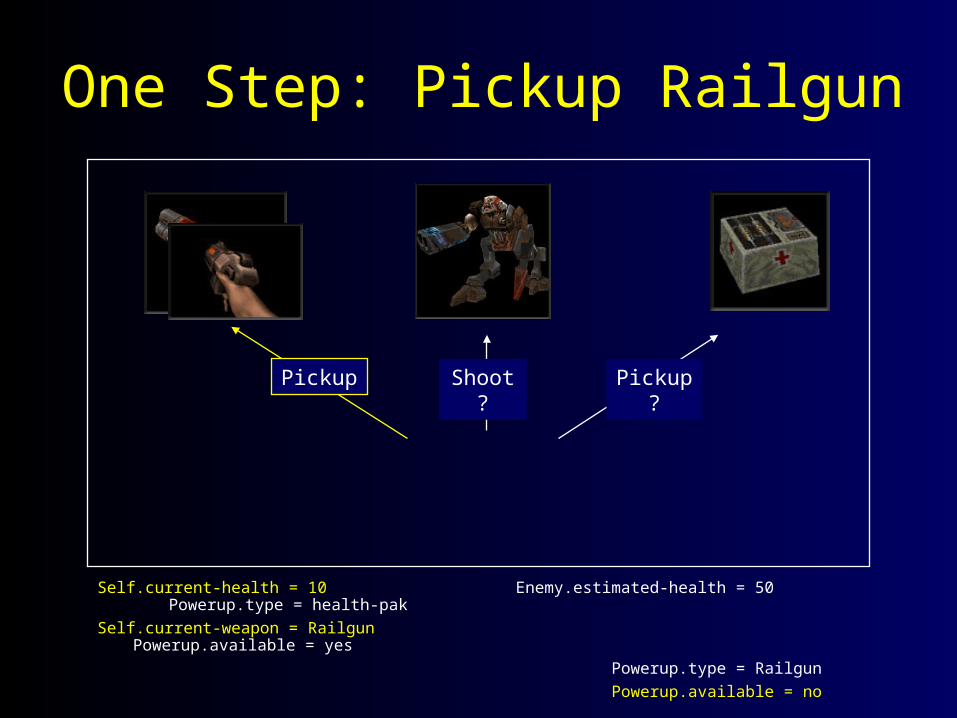
One Step: Pickup Railgun
Shoot?Pickup Pickup?
Self.current-health = 10 Enemy.estimated-health = 50 Powerup.type = health-pak
Self.current-weapon = Railgun Powerup.available = yes
Powerup.type = Railgun
Powerup.available = no

One Step: Shoot
ShootPickup? Pickup?
Self.current-health = 10 Enemy.estimated-health = 40 Powerup.type = health-pak
Self.current-weapon = blaster Powerup.available = yes
Powerup.type = Railgun
Powerup.available = yes

One Step: Pickup Health-pak
Shoot?Pickup? Pickup
Self.current-health = 90 Enemy.estimated-health = 50 Powerup.type = health-pak
Self.current-weapon = blaster Powerup.available = no
Powerup.type = Railgun
Powerup.available = yes

Two Step
Shoot
Pickup
Self.current-health = 80 Enemy.estimated-health = 40 Powerup.type = health-pak
Self.current-weapon = blaster Powerup.available = no
Powerup.type = Railgun
Powerup.available = yes

Three Step Look-ahead
Pickup
Pickup
Self.current-health = 100 Enemy.estimated-health = 0 Powerup.type = health-pak
Self.current-weapon = Railgun Powerup.available = no
Powerup.type = Railgun
Powerup.available = no
Shoot

Opponent: New problems
Shoot?Pickup? Pickup?
Pickup? Pickup?
Self.current-health = 20 Enemy.estimated-health = 50 Powerup.type = health-pak
Self.current-weapon = blaster Enemy.current-weapon = blaster Powerup.available = yes
Powerup.type = Railgun
Powerup.available = yes

Opponent Model• Need to know what opponent will do
• Accurate internal state update• Actions can interfere
• Solution 1: Assume the worst• Opponent does what would be worst for you• Game tree search• Exponential increase in number of state evaluations
• Solution 2: What would I do?• Opponent does what you would in the same situation
• Solution 3: Internal model of opponent• Remember what they did last time or like to do

Means-ends Analysis• What’s the difference between the current situation and the goal?
• Goal is represented by a target state or target conditions• Compare current state and target state
• What reduces the differences?• Match differences up with operator effects
• Can I perform these operators?• Try to achieve operator pre-conditions• Match pre-conditions up with other operator’s effects
• Searching backwards from the goal is sometimes cheaper• Many operators to perform at any time• Few operators achieve the goal conditions

Goal Situation
Self.current-health = 100 Enemy.estimated-health = 0

Current Situation
Self.current-health = 20 Enemy.estimated-health = 50 Powerup.type = health-pak
Self.current-weapon = blaster Powerup.available = yes
Powerup.type = Railgun
Powerup.available = yes

Differences
Self.current-health = 20 not 100 Enemy.estimated-health = 50 not 0

What can reduce the differences?
Self.current-health = 20 not 100 Enemy.estimated-health = 50 not 0
Pickup
Shoot

Can I perform these operators?
Pickup
Shoot
Self.current-health = 20 Enemy.estimated-health = 50 Powerup.type = health-pak
Self.current-weapon = Railgun Powerup.available = yes
Powerup.type = Railgun
Powerup.available = yes

Intermediate Goal Situation
Self.current-health = 20 Enemy.estimated-health = 50 Powerup.type = health-pak
Self.current-weapon = Railgun Powerup.available = yes
Powerup.type = Railgun
Powerup.available = yes

How can I reduce the differences?
Self.current-health = 20 Enemy.estimated-health = 50 Powerup.type = health-pak
Self.current-weapon = Railgun Powerup.available = yes
Powerup.type = Railgun
Powerup.available = yes
Pickup

Are there ordering conflicts?
Self.current-health = 20 Enemy.estimated-health = 50 Powerup.type = health-pak
Self.current-weapon = Railgun Powerup.available = yes
Powerup.type = Railgun
Powerup.available = yes
Pickup
Shoot
Pickup

Final Plan
Self.current-health = 100 Enemy.estimated-health = 0 Powerup.type = health-pak
Self.current-weapon = Railgun Powerup.available = no
Powerup.type = Railgun
Powerup.available = no
Pickup
Shoot
Pickup

Planning Evaluation• Advantages
• Less predictable behavior• Can handle unexpected situations
• Disadvantages• Less predictable behavior• Planning takes processor time• Planning takes memory• Need simple but accurate internal representations

References• Russell and Norvig: Artificial Intelligence: A Modern Approach, Prentice Hall, 1995.
• Fikes and Nilsson: STRIPS: a new approach to the application of theorem proving to problem solving, Artificial Intelligence 2(3-4): 189-208, 1971.
• Korf: Optimal path finding algorithms, chapter 7 in Search in Artificial Intelligence, Springer-Verlag, 1988.

Soar
John Laird and Michael van Lent
University of Michigan
AI Tactical Decision Making Techniques
Computer Game 2001
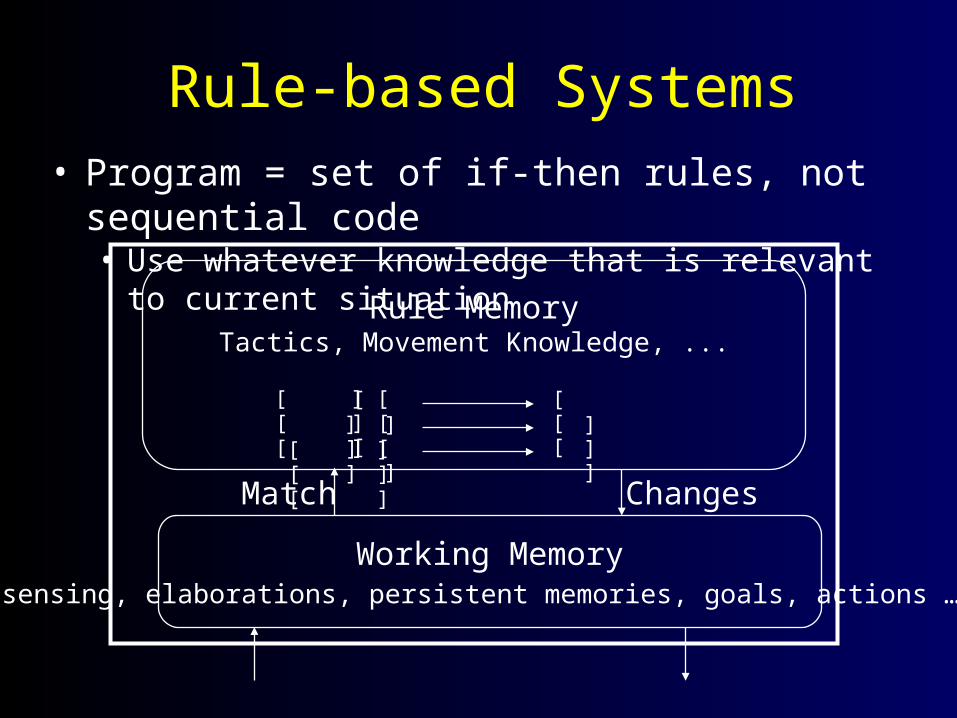
Rule-based Systems• Program = set of if-then rules, not sequential code
• Use whatever knowledge that is relevant to current situation
Working Memorysensing, elaborations, persistent memories, goals, actions …
Rule MemoryTactics, Movement Knowledge, ...
[ ][ ] [ ][ ]
[ ]
[ ][ ][ ]
Match Changes
[ ] [ ][ ]
[ ] [ ][ ]

Which Rule(s) Should Fire?
• Matching finds which rules can fire in current situation.
• Conflict resolution picks which rules actually fire.• Based only on syntactic features of rules and data.• Must engineer rules so correct rule is selected each time.• Should select action based on current situation and knowledge
RuleMemory
WorkingMemory
[ ] [ ] [ ] [ ][ ] [ ] [ ] [ ]
[ ] [ ]
[ ] [ ]
[ ] [ ]
[ ] [ ]
Rule Instantiations
?Conflict resolution
Match

Soar’s Approach• Fire all matched rules in parallel until quiescence
• Sequential operators generate behavior• Turn, adjust-radar, select-missile, climb• Provides trace of behavior comparable to human actions
• Rules select, apply, terminate operators• Select: create preferences to propose and compare operators• Apply: modify the current situation, send motor commands• Terminate: determine that operator is finished
Inpu
t
Elaboration(propose operators)
Decide(select operator)
Elaboration(apply operator)
Out
put
Inpu
t
Env
iron
men
t
Dec
ide
Elaboration(propose)

Execution Flow of Soar Engine
Elaboration
Propose Operators
Evaluate Proposed Operators
Select One Operator
Perform Operator Actions
Sense
Think
Act
G
A
M
E
Soar
10x/second
~40x/second

TacAir-Soar
ModSAF:Sensors, Weapons, Vehicle,
Communication
Soar-ModSAF-Interface
WorkingMemory
TacAirRules
Soar
WorkingMemory
TacAirRules
Soar
WorkingMemory
TacAirRules
Soar
Other Simulators
Other Simulators
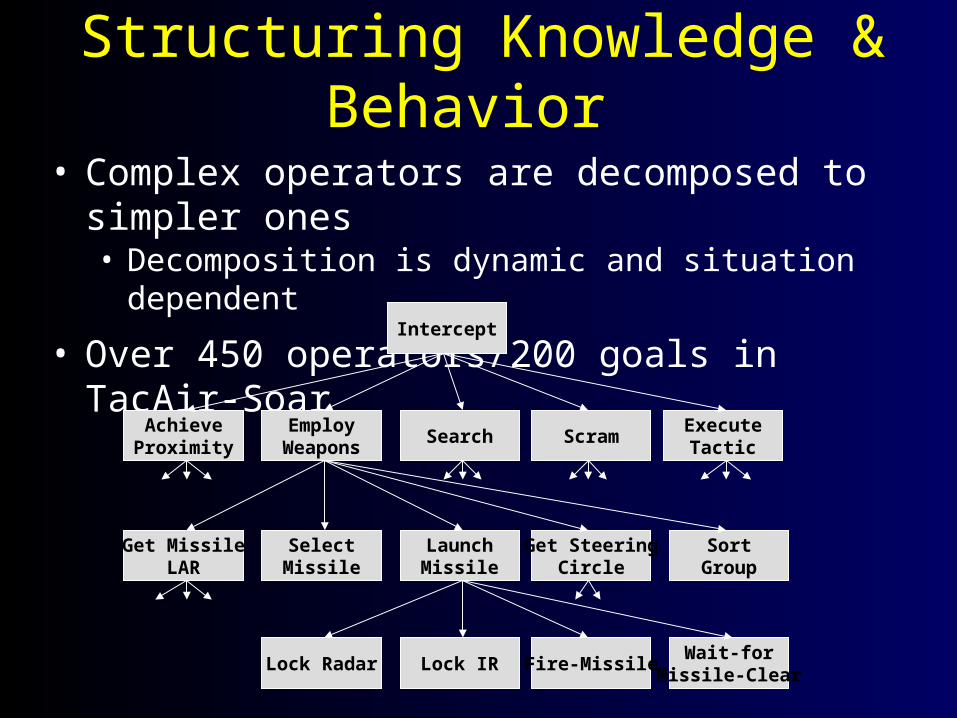
Structuring Knowledge & Behavior • Complex operators are decomposed to simpler ones
• Decomposition is dynamic and situation dependent
• Over 450 operators/200 goals in TacAir-SoarIntercept
AchieveProximity
EmployWeapons
SearchExecuteTactic
Scram
Get MissileLAR
SelectMissile
Get SteeringCircle
SortGroup
LaunchMissile
Lock Radar Lock IR Fire-MissileWait-for
Missile-Clear

Example Trace of Goals1770: Intercept-bogey1771: Achieve-proximity1772: Turn-toward-bogey1773: wait...1795: wait ...1810: Employ-weapons1811: Select-missile1812: Get-missile-launch-acceptability-region (LAR)1813: Cut-to-lateral-separation1814: wait...1830: Launch-missile1831: Lock-radar1832: Fire-missile 1833: Wait-for-missile-to-clear

Evaluation of Soar• Disadvantages
• Not a commercial product• Can be memory and compute intensive
• Advantages• Development tools• Easy to add knowledge• Natural way to represent and organize knowledge• Basic control structure can be used in other systems

AI for Strategic Games• Possible way to do Warcraft
• Define top goals such as kill enemy, mine gold, build buildings.
• Weight the goals and pick most important one that is not achieved and we are not working on.
• Determine what needs to be done to achieve this goal• Get more gold, get men closer to enemy, ...
• Select operators to achieve goal.• Some operators may involve complex actions like walking to the goal mine --
use specialized planning approaches for these: A*.• Some operators may manipulate multiple pieces at once: teams.
• Once resources assigned to a goal, go to next goal in list and see if any resources available to achieve it.

Why aren’t AI’s better?• Don’t have realistic models of sensing.
• Not enough processing time to plan ahead.
• Space of possible actions too large to search efficiently (too high of branching factor).
• Single evaluation function or predefined subgoals makes them predictable.• Only have one way of doing things.
• Too hard to encode all the relevant knowledge.
• Too hard to get them to learn.

References• Laird, J. E., Newell, A., and Rosenbloom, P. S. (1987), Soar: An architecture
for general intelligence. Artificial Intelligence, 33(3), 1-64.
• Laird, J. E. (2000) It Knows What You're Going to Do: Adding Anticipation to a Quakebot. AAAI 2000 Spring Symposium Series: Artificial Intelligence and Interactive Entertainment, March 2000: AAAI Technical Report SS-00-02.
• ai.eecs.umich.edu/soar/
• ai.eecs.umich.edu/people/laird