architectural techniques for memory oversight in
TRANSCRIPT

Architectural Techniques for Memory Oversightin Multiprocessors
by
Arrvindh Shriraman
Submitted in Partial Fulfillment
of the
Requirements for the Degree
Doctor of Philosophy
Supervised by
Professor Sandhya Dwarkadas
Department of Computer ScienceArts, Sciences, and Engineering
Edmund A. Hajim School of Engineering and Applied Sciences
University of RochesterRochester, New York
2010

ii
To my family and friends

iii
Curriculum Vitae
Arrvindh Shriraman was born in Madras, India (now known as Chennai, although he always
liked the British version) and has walked this earth for ' 10,000 days. He graduated from
the University of Madras in 2004, with a Bachelor of Engineering degree in the area of Com-
puter Science. Arrvindh entered graduate studies at the University of Rochester in the Fall of
2004, pursuing research in computer architecture and systems, under the direction of Professor
Sandhya Dwarkadas. He received the Master of Science degree in Computer Science from Uni-
versity of Rochester in 2006. In the future, Arrvindh will seek to research ideas at Simon Fraser
University that his advisor considered too risky or half-baked when he was in graduate school.
Arrvindh loves fast cars, the Finger Lakes in Western New York, and fall weather.

iv
Acknowledgments
First and foremost, I would like to thank Sandhya Dwarkadas for helping me define and refine
the ideas in this dissertation. I was extraordinarily fortunate that she agreed to work with me,
and have grown and matured under her mentorship. I have stress tested Sandhya’s patience
many times over the years, but she has remained committed to my professional and personal
growth. It was great that she gave me the freedom to pursue my research ideas and go find my
own thing. These six years as her student have changed my life forever.
Michael Scott is the man, I continue to be amazed by his ability to google his brains for
major research works related to the topic of discussion, and then summarize them, all within a
few seconds. What is also obvious after a few minutes of conversation with him, is his startling
knowledge across a range of topics, which I have drawn upon often. Most of all, I would like to
thank him for helping me refine my half-baked ideas. He has been my virtual co-advisor.
Kai Shen impressed me with his eye for engineering details and his values as a researcher. I
learned a lot by just observing his dedication to work and his drive, which kept him a few hours
longer at work after I had retired for the night. I would also like to thank him for all the history
and politics lessons he taught me over dinner.
Engin Ipek, Chen Ding, and John B. Carter (thanks for agreeing to be on my thesis com-
mittee) were all very helpful during my job hunt season and provided valuable professional
consultancy at zero cost. I have tried to learn from Engin’s dedication to his students, Chen’s
drive to continuously to refine himself as a teacher, and John’s infectious enthusiasm.
Waran kickstarted my research career and motivated me to get a Ph.D. in the first place. He

v
helped me redefine my own limits and find work gears that I never knew existed to put in the
long hours.
My graduate studies have come to an end, but the relationships I have built at the UofR will
last a lifetime.
To Michael Spear, for teaching me how to work on collaborative projects and manage time.
Debugging RTM with him was a pleasure. I look forward to working with him in the future.
To Christopher Stewart, for lending me a comforting shoulder when I had paper rejections.
He has always heard my ideas, even before Sandhya did and helped me with his critical review-
ing skills.
To Virendra Marathe, whose is a treasure hoard of novel ideas.
To Bill Scherer and Luke Dalessandro, to whom I have always turned when I had trouble
with synchronization and C++.
To Hemayet Hossain and Hongzhou Zhao, for becoming part of the local GEMS hacker
community; they were also great architectural idea sounding boards.
More thanks to Kirk Kelsey, Xiao Zhang, Tongxin Bai, Xiaoming Gu, Amal Fahad, Stan
Park, Kostas Menychtas, and Bin Bao for being part of a fun systems group.
Thanks to everyone who spared a thought for me. I apologize, if I have not mentioned your
name; it was only because I ran out of space.
I would also like to thank my friends Gundi, KP, Rumbum, Harish, and Ninja for all the
good times and essentially being my extended family here in this country. I just tallied my cell
phone minutes and I averaged 45 mins every weekend in calls to these guys, over the last 4
years. The other part of the extended family consisted of the indian mafia at whipple park; this
thesis would not have been possible without their support.
The secretaries in our department have a thankless job; I would like to to acknowledge them
for letting me focus on my research and taking care of everything else.
Marty taught me everything I know about the north east and I personally owe all my great
summers in Rochester to her. She showed me how to maintain a sense of humor on the job and
helped me tide many a mini crisis (think spilling sour milk on one’s office carpet).

vi
JoMarie was my first contact within the department and she has taken care of all my logistics
over the years. I thank her for the countless letters she provided for the various visa procedures,
without ever asking why I needed it.
Eileen is really important, more so than most students realize. She ensured that I always got
paid on time.
To Pat, for making sense of all the pieces of conference receipts (and non-receipts) and
turning them into a kosher reimbursement form.
I would like to thank my parents, K.S.N.Sreeramen (yes!, south indians have 2–3 middle
names) and Sudha Sreeram, for always being there for me. My mother took an active hands-on
role in my education from the beginning and encouraged me be focused and at the same time
have an open mind. My dad always believed in me. To my grandmother for all the great muruku
(indian snack) she kept feeding me, when I was pouring over my middle school homework in
the summers. Lastly, I would like to thank my late thata (grandfather) and baba (uncle) for a
memorable childhood. Life was simple back then!
This material is based upon research supported by the National Science Foundation (grants
numbers: CNS-0411127, CAREER Award CCF-0448413, CNS-0509270, CNS-0615045,
CNS-0615139, CCF-0621472, CCF-0702505, ITR/IIS-0312925, CCR-0306473, and CNS-
0834451), the National Institutes of Health (5 R21 GM079259-02 and 1 R21 HG004648-01),
IBM Faculty Partnership Awards, and the University of Rochester. Any opinions, findings, and
conclusions or recommendations expressed in this material are those of the author(s) and do not
necessarily reflect the views of the above named organizations.

vii
Abstract
Computer architects have exploited the transistors afforded by Moore’s law to provide software
developers with high performance computing resources. Software has translated this growth in
hardware resources into improved features and applications. Unfortunately, applications have
become increasingly complex and are prone to a variety of bugs when multiple software mod-
ules interact. The advent of multicore processors introduces a new challenge, parallel program-
ming, which requires programmers to coordinate multiple tasks.
This dissertation develops general-purpose hardware mechanisms that address the dual chal-
lenges of parallel programming and software reliability. We have devised hardware mechanisms
in the memory hierarchy that shed light on the memory system and control the visibility of data
among the multiple threads. The key novelty is the use of cache coherence protocols to im-
plement hardware mechanisms that enable software to track and regulate memory accesses at
cache-line granularity. We demonstrate that exposing the events in the memory hierarchy pro-
vides useful information that was either previously invisible to software or would have required
heavyweight instrumentation.
Focusing on the challenge of parallel programming, our mechanisms aid implementations
of Transactional Memory (TM), a programming construct that seeks to simplify synchroniza-
tion of shared state. We develop two mechanisms, Alert-On-Update (AOU) and Programmable
Data Isolation (PDI), to accelerate common TM tasks. AOU selectively exposes cache events,
including those that are triggered by remote accesses, to software in the form of events. TM
runtimes use it to detect accesses that overlap between transactions (i.e., conflicts), and track a

viii
transaction’s status. Programmable-Data-Isolation (PDI) allows multiple threads to temporar-
ily hide their speculative writes from concurrent threads in their private caches until software
decides to make them visible. We have used PDI and AOU to implement two TM run-time
systems, RTM and FlexTM. Both RTM and FlexTM are flexible runtimes that permit software
control of the timing of conflict resolution and the policy used for conflict management.
To address the challenge of software reliability, we propose Sentry, a lightweight, flexible
access-control mechanism. Sentry allows software to regulate the reads and writes to memory
regions at cache-line granularity based on the context in the program. Sentry coordinates the
coherence states in a novel manner to eliminate the need for permission checks entirely for a
large majority of the program’s accesses (all cache hits), thereby improving efficiency. Sentry
improves application reliability by regulating data visibility and movement among the multiple
software modules present in the application. We use a real-world webserver, Apache, as a
case study to illustrate Sentry’s ability to guard the core application from vulnerabilities in the
application’s modules.

ix
Table of Contents
Appendices
Curriculum Vitae iii
Acknowledgments iv
Abstract vii
List of Figures xvi
List of Tables xix
Foreword 1
1 Introduction and Motivation 3
1.1 Transactional Memory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.1.1 Our Approach : Flexible Transactional Memory . . . . . . . . . . . . . 6
1.1.2 Monitoring : Alert-On-Update . . . . . . . . . . . . . . . . . . . . . . 7
1.1.3 Isolation : Programmable-Data-Isolation . . . . . . . . . . . . . . . . 7
1.1.4 Decoupling Conflict detection from Resolution . . . . . . . . . . . . . 8
1.2 Software Reliability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8

x
1.2.1 Problem and Motivation . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2.2 Our Approach : Sentry . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.3 Thesis Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.4 Dissertation Structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2 Background 13
2.1 Concurrency in Software Execution: Transactional Memory . . . . . . . . . . 13
2.1.1 Transactional Memory in a Nutshell . . . . . . . . . . . . . . . . . . . 14
2.1.2 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.1.3 Hardware support for small transactions . . . . . . . . . . . . . . . . . 17
2.1.4 Unbounded transactions . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.1.5 Classifying proposed TM systems . . . . . . . . . . . . . . . . . . . . 22
2.1.6 Our Approach : Flexible Transactional Memory . . . . . . . . . . . . . 24
2.2 Concurrency in Software Development :
Fine-grain Access Control . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.2.1 Modern processors : Paging and Segmentation . . . . . . . . . . . . . 25
2.2.2 Research Prototypes : Mondrian and Loki . . . . . . . . . . . . . . . . 26
2.2.3 Capabilities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.2.4 Tagged Memory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.2.5 Software-based Protection . . . . . . . . . . . . . . . . . . . . . . . . 28
2.2.6 Access Control for Debugging . . . . . . . . . . . . . . . . . . . . . . 28
2.2.7 Our Approach: Sentry . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3 Monitoring: Alert-On-Update 30
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.2 Current Monitoring Mechanisms . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.2.1 Design Space . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32

xi
3.3 Alert-On-Update . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.3.1 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.3.2 Observable events . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.3.3 Virtualization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.4 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.4.1 Informing Loads . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.4.2 Intel mark bits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.4.3 Signatures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.5 Application 1: AOU Assisted STMs . . . . . . . . . . . . . . . . . . . . . . . 41
3.5.1 RSTM : Indirection-Based STMs . . . . . . . . . . . . . . . . . . . . 42
3.5.2 LOCK : Lock-based STM . . . . . . . . . . . . . . . . . . . . . . . . 43
3.5.3 Challenges in STM . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.5.4 Using AOU to accelerate STMs . . . . . . . . . . . . . . . . . . . . . 45
3.5.5 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.6 Application 2: Accelerating Locks . . . . . . . . . . . . . . . . . . . . . . . . 54
3.6.1 Background : Transactional Mutex Locks . . . . . . . . . . . . . . . . 55
3.6.2 AOU Acceleration for Locks . . . . . . . . . . . . . . . . . . . . . . . 57
3.6.3 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.7 Application 3: Detecting Atomicity Bugs . . . . . . . . . . . . . . . . . . . . 59
3.8 Other Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
3.8.1 AOU for Fast User-space Mutexes . . . . . . . . . . . . . . . . . . . . 62
3.8.2 Debugging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.8.3 Code Security . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4 Isolation: Programmable Data Isolation 65
4.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66

xii
4.1.1 Previous Approaches to Data Isolation . . . . . . . . . . . . . . . . . . 67
4.1.2 Our Approach : Lazy Coherence . . . . . . . . . . . . . . . . . . . . . 68
4.2 Broadcast-based TMESI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.2.1 Bulk State Changes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.3 Directory-based TMESI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
4.3.1 Conflict Summary Tables . . . . . . . . . . . . . . . . . . . . . . . . . 76
4.4 Application of TMESI-Bcast : RTM Project . . . . . . . . . . . . . . . . . . . 77
4.4.1 RTM Transaction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
4.4.2 Fast-Path RTM Transactions . . . . . . . . . . . . . . . . . . . . . . . 80
4.4.3 Overflow RTM Transactions . . . . . . . . . . . . . . . . . . . . . . . 81
4.4.4 Latency of RTM Transactions . . . . . . . . . . . . . . . . . . . . . . 82
4.4.5 Hardware-Software Transactions . . . . . . . . . . . . . . . . . . . . . 86
4.5 Application of TMESI-Dir: FlexTM . . . . . . . . . . . . . . . . . . . . . . . 86
4.5.1 Bounded FlexTM Transactions . . . . . . . . . . . . . . . . . . . . . . 88
4.5.2 Mixed Conflict Resolution . . . . . . . . . . . . . . . . . . . . . . . . 91
4.6 Virtualizing of Cache Overflows in FlexTM . . . . . . . . . . . . . . . . . . . 92
4.6.1 Eviction of Transactionally Read Lines . . . . . . . . . . . . . . . . . 92
4.6.2 Overflow table (OT) Controller Design . . . . . . . . . . . . . . . . . 92
4.6.3 Handling Evictions with Fine-grain Translation . . . . . . . . . . . . . 94
4.6.4 Handling OS Page Evictions . . . . . . . . . . . . . . . . . . . . . . . 98
4.6.5 Context Switch Support . . . . . . . . . . . . . . . . . . . . . . . . . 99
4.7 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
4.7.1 Area Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
4.7.2 FlexTM Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
4.7.3 FlexTM vs. Hybrid TMs and STMs . . . . . . . . . . . . . . . . . . . 104
4.7.4 FlexTM vs. Central-Arbiter Lazy HTMs . . . . . . . . . . . . . . . . . 109

xiii
4.7.5 FlexTM-S vs. Other Virtualization Mechanisms . . . . . . . . . . . . . 111
4.8 Other Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
4.8.1 Profiling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
4.8.2 Garbage Collection . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
4.8.3 Concurrent Programming . . . . . . . . . . . . . . . . . . . . . . . . . 115
5 Conflict Management and Resolution in HTMs 116
5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
5.2 Conflict Resolution Primer . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
5.2.1 Conflict Resolution and Contention Management . . . . . . . . . . . . 119
5.2.2 Design Space . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
5.3 Effectiveness of Stalling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
5.3.1 Implementation Tradeoffs . . . . . . . . . . . . . . . . . . . . . . . . 124
5.3.2 Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
5.3.3 Effect of Wasted work . . . . . . . . . . . . . . . . . . . . . . . . . . 126
5.4 Interplay between Conflict Resolution and Management . . . . . . . . . . . . . 129
5.4.1 Wasted work in Eager and Lazy . . . . . . . . . . . . . . . . . . . . . 133
5.4.2 Concurrent Readers and Writers . . . . . . . . . . . . . . . . . . . . . 135
5.5 Mixed Conflict Resolution . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
5.5.1 Implementation Tradeoffs . . . . . . . . . . . . . . . . . . . . . . . . 137
5.5.2 Porting Mixed to other TMs . . . . . . . . . . . . . . . . . . . . . . . 139
5.6 Other studies on contention management . . . . . . . . . . . . . . . . . . . . . 140
5.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
6 Protection : Sentry 144
6.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
6.1.1 Access Control in the Memory Hierarchy . . . . . . . . . . . . . . . . 147

xiv
6.2 Sentry : Auxiliary Memory Access Control . . . . . . . . . . . . . . . . . . . 148
6.2.1 Metadata Hardware Cache (M-Cache) . . . . . . . . . . . . . . . . . . 149
6.2.2 Permission Cache Checks . . . . . . . . . . . . . . . . . . . . . . . . 151
6.2.3 Coherence-based Access Checks . . . . . . . . . . . . . . . . . . . . . 152
6.2.4 Exception Trigger . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
6.2.5 How is the M-cache filled ? . . . . . . . . . . . . . . . . . . . . . . . 153
6.2.6 Changing Permissions . . . . . . . . . . . . . . . . . . . . . . . . . . 154
6.3 Sentry Software . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
6.3.1 Foundations for Sentry’s Protection Models . . . . . . . . . . . . . . . 157
6.3.2 One Domain Per Process . . . . . . . . . . . . . . . . . . . . . . . . . 159
6.3.3 Intra-Process Compartments . . . . . . . . . . . . . . . . . . . . . . . 160
6.3.4 Ring Protection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
6.4 M-cache Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
6.4.1 Area, Latency, and Energy . . . . . . . . . . . . . . . . . . . . . . . . 164
6.4.2 Operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
6.5 Experimental System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
6.6 Application 1: Compartmentalizing Apache . . . . . . . . . . . . . . . . . . . 167
6.6.1 Compartmentalizing Code . . . . . . . . . . . . . . . . . . . . . . . . 168
6.6.2 Compartmentalizing Data . . . . . . . . . . . . . . . . . . . . . . . . 169
6.6.3 Performance Results . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
6.6.4 Process-based Protection vs. Sentry . . . . . . . . . . . . . . . . . . . 171
6.6.5 Lightweight Remote Procedure Call . . . . . . . . . . . . . . . . . . . 172
6.7 Application 2: Sentry-based Watchpoint Debugger . . . . . . . . . . . . . . . 173
6.7.1 Debugging Examples . . . . . . . . . . . . . . . . . . . . . . . . . . . 174
6.7.2 Comparison with Other Hardware . . . . . . . . . . . . . . . . . . . . 175
6.8 Extensions for address-translation . . . . . . . . . . . . . . . . . . . . . . . . 176
6.9 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177

xv
7 Summary and Future Work 178
7.1 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 178
7.1.1 Monitoring . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
7.1.2 Isolation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
7.1.3 Protection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181
7.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181
7.2.1 Transactional Memory . . . . . . . . . . . . . . . . . . . . . . . . . . 182
7.2.2 Fine-grain memory protection . . . . . . . . . . . . . . . . . . . . . . 183
7.3 Reflections . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184
7.3.1 Future of Transactional Memory . . . . . . . . . . . . . . . . . . . . . 184
7.3.2 Which one of your hardware mechanisms holds the most promise? . . . 186
7.3.3 How do you know your cache protocols work? . . . . . . . . . . . . . 187
A Supplement for Transactional Memory 189
A.1 Experimental Framework . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
A.2 Application Characteristics . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
A.3 Conflict Scenarios in Applications . . . . . . . . . . . . . . . . . . . . . . . . 193
B Coherence State Machine 196

xvi
List of Figures
1.1 Execution time breakdown in STM . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2 Concurrency in software development . . . . . . . . . . . . . . . . . . . . . . 9
1.3 Thesis contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.1 Loss of parallelism due to locks. [RaG01] . . . . . . . . . . . . . . . . . . . . 15
3.1 Coherence protocol support for Alert-on-update. . . . . . . . . . . . . . . . . . 37
3.2 STM Metadata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.3 Lock Stealing to make LOCK non-blocking . . . . . . . . . . . . . . . . . . . 46
3.4 Performance of STMs with AOU acceleration. . . . . . . . . . . . . . . . . . . 50
3.5 L1 cache miss rates across accelerated STMs . . . . . . . . . . . . . . . . . . 51
3.6 Timing breakdown for accelerated STMs . . . . . . . . . . . . . . . . . . . . . 52
3.7 Single-orec STM Algorithm. . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.8 Performance of Transactional-Mutex-Locks with AOU acceleration. . . . . . . 60
4.1 Example of data isolation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
4.2 TMESI Broadcast Protocol . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
4.3 TMESI Directory Protocol. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
4.4 RTM metadata. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79

xvii
4.5 RTM transaction execution time breakdown . . . . . . . . . . . . . . . . . . . 85
4.6 Interaction of RTM-F and RTM-O transactions . . . . . . . . . . . . . . . . . 87
4.7 FlexTM Architecture Overview . . . . . . . . . . . . . . . . . . . . . . . . . . 88
4.8 Pseudocode of BEGIN TRANSACTION and END TRANSACTION. . . . . . 90
4.9 Metadata for pages that have overflowed state . . . . . . . . . . . . . . . . . . 95
4.10 Software-metadata cache architecture . . . . . . . . . . . . . . . . . . . . . . 95
4.11 1 thread performance of FlexTM . . . . . . . . . . . . . . . . . . . . . . . . . 106
4.12 16 thread performance of FlexTM . . . . . . . . . . . . . . . . . . . . . . . . 107
4.13 FlexTM vs. Centralized hardware arbiters. . . . . . . . . . . . . . . . . . . . . 111
4.14 Comparing FlexTM-S (FlexTM-Streamlines) with other TMs . . . . . . . . . . 113
4.15 Effect of signature size on FlexTM performance . . . . . . . . . . . . . . . . . 114
5.1 Contention manager actions . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
5.2 Studying the effect of randomized-backoff on conflict management . . . . . . . 127
5.3 Interplay of conflict management and conflict resolution . . . . . . . . . . . . 132
5.4 Interaction of access patterns with conflict resolution . . . . . . . . . . . . . . 134
5.5 Interaction of Mixed resolution with Size contention manager. . . . . . . . . . . 138
5.6 Interaction of Mixed resolution with Age contention manager. . . . . . . . . . . 138
6.1 Software modules in Apache . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
6.2 Access control in the memory hierarchy . . . . . . . . . . . . . . . . . . . . . 148
6.3 Permissions metadata cache (M-cache) . . . . . . . . . . . . . . . . . . . . . . 150
6.4 Pseudocode for inserting a new M-cache entry. . . . . . . . . . . . . . . . . . 154
6.5 Changing Permissions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
6.6 Cross-domain call execution flow . . . . . . . . . . . . . . . . . . . . . . . . . 162
6.7 L1 miss rate in applications. . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
6.8 TLB vs. M-cache . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166

xviii
6.9 Performance of Sentry-protected Apache . . . . . . . . . . . . . . . . . . . . . 169
6.10 Comparing Sentry against process-based protection . . . . . . . . . . . . . . . 172
6.11 Sentry-Watcher vs. Binary instrumentation . . . . . . . . . . . . . . . . . . . 174
6.12 M-cache vs other hardware-based watchpoints . . . . . . . . . . . . . . . . . . 176
A.1 Conflict type breakdown . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
B.1 State Machine:Part 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
B.2 State Machine:Part 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200

xix
List of Tables
2.1 Virtualization in TM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.1 Classification of current monitoring mechanisms . . . . . . . . . . . . . . . . 33
3.2 Alert-on-update Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.3 Classification of proposed monitoring mechanisms . . . . . . . . . . . . . . . 40
3.4 Simulation Parameters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.5 Atomicity violation bugs defined by Lu et al. [LT06] . . . . . . . . . . . . . . 61
3.6 Execution time overhead for Atomicity violation detection . . . . . . . . . . . 62
4.1 Programmable Data Isolation API . . . . . . . . . . . . . . . . . . . . . . . . 69
4.2 Coherence state encoding for fast commits and aborts. . . . . . . . . . . . . . 72
4.3 Area overhead of FlexTM’s hardware mechanisms . . . . . . . . . . . . . . . 102
4.4 Experimental setup. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
5.1 Percentage of total (committed and aborted) txs that encounter a conflict. . . . 117
5.2 Interaction of contention manager and conflict resolution . . . . . . . . . . . . 120
5.3 Characteristics of aborted transactions . . . . . . . . . . . . . . . . . . . . . . 143
6.1 Permissions metadata cache (M-cache) API . . . . . . . . . . . . . . . . . . . 151

xx
6.2 Mapping coherence protocol states to permission checks . . . . . . . . . . . . 152
6.3 Design tradeoffs in M-cache design . . . . . . . . . . . . . . . . . . . . . . . 164
6.4 Application Characteristics . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174
A.1 Transactional Workload Characteristics . . . . . . . . . . . . . . . . . . . . . 195
B.1 TMESI L1 controller states . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201
B.2 TMESI L1 controller events . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
B.3 TMESI L1 controller messages . . . . . . . . . . . . . . . . . . . . . . . . . . 202
B.4 TMESI L1 cache controller actions . . . . . . . . . . . . . . . . . . . . . . . . 203

1
Foreword
While I am the author of this dissertation, the work in this dissertation would not have been
possible without the collaboration of various students and professors.
The monitoring mechanism in Chapter 3 was born out of discussions with Virendra Marathe
and Michael F. Spear about thread synchronization. I would like to thank Michael F. Spear for
incorporating my untested hardware mechanism within his reasonably stable (at least in com-
parison to my simulator) STM framework; our collaboration resulted in papers at ISCA’07,
SPAA’07, and TRANSACT’09. Hemayet Hossain provided valuable debugging support and
spent many hours stress testing our framework. Sandhya Dwarkadas and Michael Scott pro-
vided valuable suggestions and technical guidance throughout this project.
Programmable Data Isolation (PDI) described in Chapter 4, was first presented at the first
workshop on transactional memory (TRANSACT 2005). The cache coherence protocol for PDI
was developed by me with input from Sandhya Dwarkadas and Michael Scott. In published ma-
terial, PDI has been primarily used as as a mechanism to implement versioning in transactional
memory. We discuss two TM systems in this dissertation. The first, RTM (Section 4.4), was de-
veloped primarily by me in conjunction with Michael F. Spear. Virendra Marathe and Hemayet
Hossain provided valuable debugging support. The second, FlexTM (Section 4.5) was devel-
oped by me and designed in conjunction with Sandhya Dwarkadas and Michael Scott. The
contention management study for hardware-based TMs (Chapter 5.1) inherited the software
framework from RSTM.
The Sentry system described in Chapter 6 was designed and developed by me with advice

2
from Sandhya Dwarkadas and Kai Shen. Kai Shen helped me define the software interface and
protection models.
Finally, I would like to thank the Wisconsin GEMS members for providing the basic simu-
lation infrastructure upon which I developed the mechanisms described in this dissertation.

3
Chapter 1Introduction and Motivation
Computing systems have significantly evolved over the years and have come to occupy a major
part of our daily lives. Hardware designers have fueled this growth by doubling performance
every two years. Meanwhile, software has continued to include more features and has increased
in complexity. The advent of multicore processors is also an inflection point for software de-
velopment [Pat10]. Eight-core chips are available today, and if programmers can learn how to
take advantage of them, vendors will deliver hundreds of cores within a decade. However, de-
veloping correct, high performance, and reliable programs has become challenging. The major
source of bugs is the corruption of program memory state due to unexpected interaction be-
tween the different concurrently executing parts of the program [LP08]. Fine-grain intra-thread
events and inter-thread interactions via memory make it difficult for developers to comprehend
the synchronization required to enable correct programs.
In this dissertation, we seek to utilize the transistors afforded by Moore’s law to develop new
hardware mechanisms that lead to better software development tools and programming models.
The basic idea is to use hardware to expose information that enables a program to understand its
own execution and react to it. This will also help developers understand misbehaving software.
For example, if software could easily track the locations accessed by a program, it can use this
to detect concurrency bugs and check safety invariants. Similarly, if software was aware of the
cached locations, it could reorganize the code to overlap computation with cache misses and
improve performance.
It is possible to understand concurrent interactions with software-based techniques. One

4
possible approach is to use static program analyzers [NMW02]. Unfortunately, most static tools
require significant effort on the programmer’s side to annotate programs; limited information
available at compile-time also poses a challenge. Dynamic instrumentation-based tools can
extract information at run time that can detect concurrency bugs [SBN97; Cor] and track data
flow [NeS07]. Unfortunately, dynamic techniques impose significant performance overhead.
The work in this thesis focuses on mechanisms for the cache hierarchy, which holds a sig-
nificant fraction of a program’s execution state and serves as a medium of communication be-
tween the various parts of a program. Current hardware systems export a narrow interface to
memory (only read and write to words) and hide most of the data movement operations from
software. We believe that future memory systems should be designed in a manner that exposes
information about the hardware actions and events on memory locations. Our research pro-
poses hardware mechanisms that shed light on the memory system and expose information that
software can use for both self-diagnosis and improved programmability and reliability.
A key novelty in this dissertation is the utilization of cache coherence to develop general-
purpose hardware mechanisms that enable software to track and regulate memory accesses.
Current cache coherent systems already include a hardware framework to manage data commu-
nication; we show that it requires few extensions to enable software to observe the data accessed
by the various parts of the program. Cache coherent systems also include a state machine to
manipulate reads and writes and we demonstrate that software can exploit coherence states to
control accesses efficiently.
In this dissertation, we address the challenge of parallelism that manifests itself at multi-
ple. First, the introduction of multicore processors means future application now depend on
thread-level parallelism execution for improving performance. The implications for software
are profound: historically only the most talented programmers have been able to write good
parallel code; now everyone must do it. The core part of this dissertation addresses this chal-
lenge; we discuss this in detail in Section 1.1.
Second, we also address another challenging form of parallelism in Section 1.2; the paral-
lelism in software development. Modern software consist of collaborative artifacts with millions
of lines of code written by many developers concurrently. Fine-grain intra- and inter-thread in-
teractions via memory make it difficult for developers to track and validate the accesses arising

5
from the various software modules. We proposed the use of fine-granularity access control to
improve interaction among the various parts of an application.
1.1 Transactional Memory
Parallel programming is hard; even given a good division of labor among threads (something
that’s often difficult to find), mainstream applications are plagued by the need to synchronize
access to shared state. Transactional Memory (TM) aims to simplify synchronization by raising
the level of abstraction. As in the database world, the programmer or compiler simply marks
a block of code as atomic; the underlying system then promises to execute the block in an
“all-or-nothing” manner isolated from similar blocks (transactions) in other threads.
Any TM implementation based on speculation must perform the following tasks: detect
and resolve conflicts between transactions executing in parallel (conflict detection), keep track
of both old and new versions of data that are modified speculatively (version management),
and ensure that non-committed transactions never perform externally visible actions due to an
inconsistent view of memory.
The mechanisms required for conflict detection and version management can be im-
plemented in hardware (HTM) [HWC04; MBM06; HeM93; AAK05; RHL05], soft-
ware (STM) [HLM03b; FrH07; MSS05; SAH06; DSS06], or some hybrid of the two
(HyTM) [DFL06; KCH06; MTC07; DCW11].
Software-only implementations have the advantage of running on legacy machines, but it
is widely acknowledged that performance competitive with fine-grain locks will require hard-
ware support. Figure 1.1 shows the overhead of an STM system. In order to track conflicts
in the absence of special hardware, a software TM (STM) system must augment a program
with instructions that read and write some sort of metadata, which leads to high performance
overhead (20% – 350%). This overhead is embedded in every thread, cannot be amortized with
parallelism, and in fact tends to increase with processor count, due to contention for metadata
access.
Once regarded as impractical, in part because of limits on the size and complexity of 1990s
caches, TM in the 2000s has enjoyed renewed attention. Unfortunately, it is not yet clear to

6
Useful work Metadata Checks Versioning
0
1
2
3
4
5
6
Bayes Delaunay Genome Intruder Kmeans Labyrinth Vacation
Norm
aliz
ed E
xecu
tion T
ime
Single-thread runs of a TL2-like STM [DSS06] system on applications from STAMP (see Appendix A). Uninstru-
mented code run time = 1.
Figure 1.1: Execution time breakdown in STM
us that proposed hardware TMs will provide the most practical, cost-effective, or semantically
acceptable implementation of transactions. A key limitation with current hardware TM propos-
als is their rigidity in conflict management policy. Key policy choices that have a first order
effect on TM performance are conflict resolution time (when to manage conflicts) and conflict
management policy (how to arbitrate amongst conflicting transactions). Proposed hardware
TMs employ fixed choices for eagerness of conflict resolution, strategies for conflict arbitration
and back-off, and eagerness of versioning. They embed conflict resolution and management
in silicon—policies for which current evidence suggests that no one static approach may be
acceptable and which are likely to change with the emergence of new applications.
1.1.1 Our Approach : Flexible Transactional Memory
We strive to leave policy decisions on when and how to resolve conflicts under software control,
while using hardware mechanisms to accelerate both bounded and unbounded transactions. This
strategy allows the choice of policy to be tuned to the current workload. It also allows the TM
system to reflect system-level concerns such as thread priority. The key insight that enables pol-
icy flexibility is that information gathering and decision making can be decoupled. In particular,

7
data versioning, access tracking, and conflict detection can be supported as decoupled/separable
mechanisms that do not embed policy.
The first TM runtime system we developed in 2005, RTM, is a hardware-software TM.
RTM promotes policy flexibility by decoupling version management from conflict detection
and management—specifically, by separating data and TM runtime metadata, and performing
conflict detection only on the latter. Software can choose (by controlling the timing of metadata
inspection and updates) when to abort concurrent conflicting transactions. Software can also use
various parameters to choose which transaction needs to be aborted. We show in this dissertation
that the software control on conflict management has a first-order impact on performance. RTM
included two forms of hardware support : (1) Monitoring of cache lines, which can reduce the
overheads of conflict detection and (2) Isolation for keeping transaction updates invisible from
other concurrent transactions.
1.1.2 Monitoring : Alert-On-Update
Alert-On-Update selectively exposes cache coherence events to software and enables an appli-
cation to track accesses from the various threads in the system. Alert-On-Update enables fast
event-based notification on addresses marked by software and serves two related roles in RTM:
it provides low overhead conflict detection and informs software, which can then manage the
conflict and it also tracks the status of the transaction and ensures a transaction is immediately
informed when it is aborted. Overall, it eliminates a large fraction of the cost for the metadata
checks shown in Figure 1.1.
1.1.3 Isolation : Programmable-Data-Isolation
To accelerate data versioning in TM, we proposed Programmable Data Isolation (PDI). PDI
allows selective use of processor-private caches as a buffer for speculative writes or for read-
ing/caching the current version of locations being speculatively written remotely. Multiple
transactions can speculatively read or write the same location enabling lazy conflict resolution.
RTM allows us to experiment with a wide variety of policies for conflict detection, con-
tention management, deadlock, livelock avoidance, and virtualization. RTM falls back to a

8
software-only implementation of transactions in the event of overflow. Unfortunately, metadata
management imposes significant performance costs since even bounded transactions that use
hardware support need software instrumentation to inter-operate with overflow transactions.
1.1.4 Decoupling Conflict detection from Resolution
In 2008, based on the lessons we learnt from RTM, we proposed FlexTM to minimize the
software bookkeeping overheads of RTM. The key insight that enables policy flexibility is that
information gathering and decision making can be decoupled. RTM left both these in software
while FlexTM employs hardware to gather information and leaves software still in charge of
the policy. FlexTM decouples conflict detection from resolution time, with a monitoring mech-
anism we call conflict summary tables (CSTs). CSTs record the occurrence of conflicts without
necessarily forcing immediate resolution. More specifically, CSTs indicate the transactions that
conflict, rather than the locations on which they conflict. This information concisely captures
what a TM system needs to know in order to resolve conflicts at some potentially future time.
Software can choose when to examine the tables and can use whatever other information it
desires (e.g., priorities) to drive its resolution policy.
1.2 Software Reliability
1.2.1 Problem and Motivation
Software bugs in production environments lead to as much as 40% of computer system fail-
ures [MaS0.]. Modern applications are large software projects and are rapidly evolving with
the collaboration of many developers. For example, the popular firefox browser involves a large
number of concurrent developers (see Figure 1.2). To sustain this growth, most software sys-
tems employ a modular approach (or plugins) to provide extensibility to the core kernels of
large software systems. For example, internet browsers (e.g. firefox) support a general plugin
interface to enable additional functionality; the linux kernel has an elaborate module system for
device drivers and kernel sub systems; In most modern shared memory systems, each process
has a separate, linear, demand-paged virtual address space. Most current software systems use

9
a single address space and link in the modules into the same space. Using a single address
space provides fast flexible shared memory based communication but compromises safety. For
example, vulnerabilities in Adobe’s pdf plugin enabled attackers to inject arbitrary code into
the browser [PaF06]. Modular boundaries can only be enforced by programmer convention
and not by the runtime system. Defending against memory corruption and dirty reads requires
inspecting every load, store, and instruction fetch. There is considerable complexity and per-
formance penalty associated with doing this entirely in software due to the cost of instrumenta-
tion [NeS07] and source level modifications [NMW02]. Ideally, we would want the underlying
runtime to sandbox the module and control the accesses by the application’s modules based on
system-specified rules.
Number of concurrent developers on Firefox. X axis: Firefox release years. Y axis: Number of developers.
Source : [Tro10]
Figure 1.2: Concurrency in software development

10
1.2.2 Our Approach : Sentry
We propose an architectural mechanism for access control that will enable software to track,
regulate accesses, and deliver a more robust application. We investigate Sentry, a hardware
framework that enables software to enforce protection policies at run time. The core developer
annotates the program to define the policy and then the system ensures the privacy and integrity
of a module’s private data (no external reads or writes), the safety of inter-module shared data
(by enforcing permissions specified by the application), and adherence to the module’s interface
(controlled function call points). From the software’s perspective, Sentry is a pluggable access
control mechanism for application-level fine-grain protection. The key novelty in Sentry is
the lightweight low-cost manner in which permissions are enforced. Sentry’s permissions tags
intercept only L1 misses and reuse the L1 cache coherence states to enforce permissions and
elide checks on L1 hits. Overall, this results in significant saving in the dynamic energy needed
to implement permission checks and provides design flexibility.
1.3 Thesis Contributions
Thesis Statement: As we move into the multicore era, software development is being hindered
by the need to develop and maintain parallel programs. Hardware mechanisms in the memory
hierarchy that provide support for tracking, isolating, and controlling memory accesses can help
software effectively manage program state. The required architectural support can be efficiently
implemented by exploiting the cache subsystem and coherence protocol.
Figure 1.3 provides a pictorial representation of our contributions.
1. We developed Alert-On-Update for selectively monitoring cache coherence events. We
demonstrate the usage of this mechanism in speeding up locks, event-based communica-
tion, and accelerating transactions.
2. We developed Programmable-Data-Isolation for allowing multiple software threads to
concurrently issue speculative writes and to effectively control the visibility of writes.
We demonstrate the usage of this mechanism in accelerating versioning in TM.

11
3. To demonstrate the utility of the proposed hardware mechanisms, we develop two TM
runtime systems. The first, RTM, uses hardware support for only bounded transactions
and reverts to software TM for transactions that overflow hardware resources. The sec-
ond, FlexTM, manages conflicts with very low overhead and adds hardware support for
virtualization. Both RTM and FlexTM, support flexible software-based policies for con-
flict resolution and management.
4. We developed Sentry, a ligtweight access control framework that can be used for im-
proving software reliability by setting up fine-grain protection domains to encapsulate
the modules in an application.
Shared memory Multicore
Monitoring(Alert-On-Update)
Isolation(Prog. Data Isolation)
Protection(Sentry)
Synch. Debugger Transactional MemoryThread-level Speculation
SoftwareSafety ...... } Applications
} HardwareMechanisms
Top Row: Software application case studies developed in the thesis. Middle Row: Proposed hardware mechanisms.
Bottom Row: System
Figure 1.3: Thesis contributions
1.4 Dissertation Structure
Chapter 2 provides background on the work in this dissertation. It provides an overview of trans-
actional memory and discusses the support required for both small and large transactions. It also
provides an overview of access control mechanisms and their usage in debugging and software
protection. Chapter 3 presents our monitoring mechanism, Alert-On-Update, and demonstrates
its application in speeding up locks, improving TM performance, and debugging data races.
Chapter 4 describes Programmable-Data-Isolation (PDI) and includes details on the additions
required to the coherence protocol. It also compares and contrasts the techniques that can be
used to virtualize hardware resources. Finally, it demonstrates the use of PDI in RTM and

12
FlexTM. In Chapter 5, we use the FlexTM framework to study the various conflict management
strategies in hardware-based TMs. We also suggest policies that various TM systems should
adopt based on application characteristics. Chapter 6 deals with Sentry and includes details on
the hardware and software framework. It also showcases applications of Sentry in protecting
a webserver and in watchpoint-based debugging. Chapter 7 concludes with a discussion on
possible directions for future research.

13
Chapter 2Background
In this dissertation, we tackle problems with concurrency at two levels: managing the concur-
rency that arises out of multiple threads in a program and managing the concurrency present
in a multi-programmer, multi-modular application. In Section 2.1, we provide an overview of
Transactional Memory (TM), which seeks to enable programmers to tackle the concurrency in
programming. We commence with a discussion on the hardware support proposed to support
small transactions, discuss the software and hardware techniques to virtualize transactional re-
sources, and finally conclude with a classification of proposed TM systems. In Section 2.2, we
discuss the use of fine-grain access control to address the challenges of safety in modularized
applications with concurrent developers. We then discuss access control mechanisms proposed
in both commercial and research prototypes, and describe access control in the context of mem-
ory protection and debugging.
2.1 Concurrency in Software Execution: Transactional Memory
For more than 40 years, Moore’s Law has packed twice as many transistors on a chip every
18 months. Between 1974 and 2004, hardware vendors used those extra transistors to equip
their processors with ever-deeper pipelines, multi-way issue, aggressive branch prediction, and
out-of-order execution, all of which served to harvest more instruction-level parallelism (ILP).
Because the transistors were smaller, vendors were also able to dramatically increase the clock

14
rate. All of that ended in the 2000s, when microarchitects ran out of independent things to do
while waiting for data from memory, and when the heat generated by faster clocks reached the
limits of fan-based cooling. Future performance improvements must now come from multicore
processors, which depend on thread-level parallelism.
Sadly, parallel programming is hard. Historically it has been limited mainly to servers, with
“embarrassingly parallel” workloads, and to high-end scientific applications, with enormous
data sets and enormous budgets. Applications need to set up synchronization on access to shared
state. For this, programmers have traditionally relied on mutual exclusion locks, but these suffer
from a host of problems, including the lack of composability (one cannot nest two lock-based
operations inside a new critical section without introducing the possibility of deadlock) and
the tension between concurrency and clarity: Coarse-grain lock-based algorithms are relatively
easy to understand (grab the One Big Lock, do what needs doing, and release it), but they
preclude any significant parallel speedup; Fine-grain lock-based algorithms allow independent
operations to proceed in parallel, but they are notoriously difficult to design, debug, maintain,
and understand. Transactional Memory (TM) aims to simplify synchronization by raising the
level of abstraction for critical sections.
2.1.1 Transactional Memory in a Nutshell
With transactions, software has only to mark a block of code as “atomic”; the underlying system
then promises to execute the block in an “all-or-nothing” manner isolated from similar blocks
(transactions) in other threads. The implementation is typically based on speculation: it guesses
that transactions will be independent and executes them in parallel, but watches their memory
accesses just in case. If a conflict arises (two concurrent transactions access the same location,
and at least one of them tries to write it), the implementation aborts one of the contenders, rolls
back its execution, and restarts it at a later time. In some cases it may suffice to delay one of the
contending transactions, but this does not work if, for example, each transaction tries to write
something that the other has already read.
While TM systems vary in how they handle various subtle semantic issues, all are based
on the notion of serializability: regardless of implementation, transactions appear to execute

15
Thread 1 Thread 2
lock(hash tab.mutex) lock(hash tab.mutex)var = hash tab.lookup(X); var = hash tab.lookup(Y);if(!var) if(!var)
hash tab.insert(X); hash tab.insert(Y);unlock(hash tab.mutex) unlock(hash tab.mutex)
Figure 2.1: Loss of parallelism due to locks. [RaG01]
in some global serial order. The writes by transaction A must never become visible to other
transactions until A commits, at which time all of its writes must be visible. Moreover, writes
by other transactions must never become visible to A partway through its own execution, even
if A is doomed to abort (otherwise A might perform some logically impossible operation with
externally visible effects). Some TM systems relax the latter requirement by sandboxing A so
that any erroneous operations it may perform do no harm to the rest of the program.
The principal motivation for TM is to simplify the synchronization of state in parallel pro-
gramming. In some cases (e.g., if transactions are used in lieu of coarse-grain locks), it may
also lead to performance improvements. An example appears in Fig. 2.1: if X6=Y, it is likely
that the critical sections of Threads 1 and 2 can execute safely in parallel. Because locks are a
low-level mechanism, they preclude such execution. TM, however, allows it. If we replace the
lock. . . unlock pairs with atomic{. . . } blocks, the typical TM implementation will execute the
two transactions concurrently, aborting and retrying one of the transactions only if they actually
conflict.
TM can be implemented in hardware, in software, or in some combination of the two.
Software-only implementations have the advantage of running on legacy machines, but it is
widely acknowledged that performance competitive with fine-grain locks will require hardware
support [SAH06; YBM07; CBM08]. This section aims to describe what the hardware might
look like, and briefly describe their policy choices. Section 2.1.3 describes several ways in
which brief, small-footprint transactions can be implemented entirely in hardware. Section 2.1.4
considers extension to transactions that overflow on-chip hardware resources, or must survive a
context switch.

16
2.1.2 Implementation
Any TM implementation based on speculation must perform the following three tasks: it must
(1) detect and resolve conflicts between transactions executing in parallel; (2) keep track of
both old and new versions of data that are modified speculatively; and (3) ensure that running
transactions never perform erroneous, externally visible actions due to an inconsistent view of
memory.
Many researchers (e.g., [MSS05; MBM06]) have conceived conflict resolution to be either
eager or lazy. An eager system detects and resolves conflicts as soon as a pair of transactions
have performed (or are about to perform) operations that preclude committing them both. A
lazy system delays conflict resolution (and possibly detection as well) until one of the trans-
actions is ready to commit. The losing transaction L may abort immediately or, if it is only
about to perform its conflicting operation (and has not done so yet), it can wait for the winning
transaction W to either abort (in which case L can proceed) or commit (in which case L may
be able to occur after W in logical order).
Lazy conflict resolution exposes more concurrency by permitting both transactions in a
pair of concurrent read-write conflicting transactions to commit so long as the reader commits
(serializes) before the writer. Lazy conflict resolution also helps in ensuring that the conflict
winner is likely to commit: if we defer to a transaction that is ready to commit, it will generally
do so, and the system will make forward progress. Eager conflict resolution avoids investing
effort in a transaction L that is doomed to abort, but may waste the work performed so far if
it aborts L in favor of W and W subsequently fails to commit due to conflict with some third
transaction T . Recent work, suggests that eager management is inherently more performance-
brittle and livelock-prone than lazy management [SDM09; ShD09]. The performance of eager
systems can be highly dependent on the choice of contention management (arbitration) policy
used to pick winners and losers, and the right choice can be application-dependent [ScS05].
Version management typically employs either direct update, in which speculative values are
written to shared data immediately, and undone on abort using an undo-log, or deferred update,
in which speculative values are written to a log and redone (written to shared data) on commit.
Direct update may be somewhat cheaper if—as we hope—transactions commit more often than

17
they abort. Systems that perform lazy conflict resolution, however, must generally use deferred
update, to enable parallel execution of (i.e., speculation by) conflicting writers.
2.1.3 Hardware support for small transactions
On modern processors, locks and other synchronization mechanisms tend to be implemented
using compare-and-swap (CAS) or load-linked/store-conditional (LL/SC) instructions. Both
of these options provide the ability to read a single memory word, compute a new value, and
update the word, atomically. Transactional memory was originally conceived as a way to extend
this capability to multiple locations.
Herlihy & Moss [HeM93] The term “transactional memory” was coined by Herlihy and
Moss in 1993. In their proposal (“H&M TM”), a small “transactional cache” holds specula-
tively accessed locations, including both old and new values of locations that have been written.
Conflicts between transactions appear as an attempt to invalidate a speculatively accessed line
within the normal coherence protocol, and cause the requesting transaction to abort. A transac-
tion commits if it reaches the end of its execution while still in possession of all speculatively
accessed locations. A transaction will always abort if it accesses more locations than will fit in
the special cache, or if its thread loses the processor due to preemption or other interrupts.
Oklahoma Update [SSH93] In modern terminology, H&M TM called for eager conflict res-
olution. A contemporaneous proposal by Stone et al. envisioned lazy resolution, with a conflict
detection and resolution protocol based on two-phase commit. Dubbed “Oklahoma Update”
(after the Rogers and Hammerstein song “All er Nothin’ ”), the proposal included a novel solu-
tion to the doomed transaction problem: as part of the commit protocol, an Oklahoma Update
system would immediately restart any aborted competing transactions, by branching back to a
previously saved address. By contrast, H&M TM required that a transaction explicitly poll its
status (to see if it were doomed) prior to performing any operation that might not be safe in the
wake of inconsistent reads.

18
AMD ASF [DiH08] Recently, researchers at AMD have proposed a multiword atomic update
mechanism as an extension to the x86-64 instruction set. Their “Advanced Synchronization
Facility” (ASF), though not a part of any current processor roadmap, has been specified in
considerable detail. As H&M TM does, it uses eager conflict resolution, but with a different
contention management strategy: where H&M TM resolves conflicts in favor of the transaction
that accessed the conflicting location first, ASF resolves it in favor of the one that accessed it last.
This “requester wins” strategy fits more easily into standard invalidation-based cache coherence
protocols, but may be somewhat more prone to livelock. As Oklahoma Update does, ASF
includes a provision for immediate abort. Most importantly ASF provides a strong progress
guarantee that a transaction that does not write more than four unique locations will eventually
commit.
Sun Rock [TrC08] Prior to Oracle’s acquisition of Sun, the next generation UltraSPARC
processor [TrC08] included a thread-level speculation (TLS) mechanism that could be used to
implement transactional memory. Like H&M TM and ASF, Rock uses eager conflict manage-
ment; it resolves conflicts in favor of the requester. Like Oklahoma Update and ASF, it provides
immediate abort. In a significant advance over these systems, however, ROCK implements true
processor checkpointing; on abort, all processor registers revert to the values they held when
the transaction began. Moreover, all memory accesses within the transaction (not just those
identified by special load and store instructions) are considered speculative.
Stanford TCC [HWC04] While still limited (in its original form) to small transactions, the
Transactional Coherence and Consistency (TCC) proposal of Hammond et al. represented a
major break with traditional concepts of memory access and communication. Where traditional
threads (and processors) interact via individual loads and stores, TCC expresses all interaction
in terms of transactions.
Like the multilocation commits of Oklahoma Update, TCC transactions are lazy. Individual
writes within the transaction are delayed (buffered) and propagated to the rest of the system in
bulk at commit time. Commit-time conflict detection and resolution employs either a central
hardware arbiter or a distributed two-phase protocol. As in Rock, doomed transactions suffer

19
an immediate abort and roll back to a processor checkpoint.
Discussion A common feature of the systems described in this section is the careful leveraging
of existing hardware mechanisms. Eager systems (H&M TM, ASF, and Rock) leverage existing
coherence protocol actions to detect transaction conflicts. In all five systems, hardware avoids
most of the overhead of both conflict detection and versioning. At the same time, transactions
in all five can abort simply because they access too much data (overflowing hardware resources)
or take too long to execute (suffering a context switch). While the systems differ in both the
eagerness of conflict resolution and choice of conflict winner, in all cases these policy choices
are embedded in the hardware; they cannot be changed in response to programmer preference
or workload characteristics.
2.1.4 Unbounded transactions
Small transactions are not sufficient if TM becomes a generic programming construct that can
interact with other system modules (e.g., file systems and middleware) that have much more
state than the typical critical section. It also seems unreasonable to expect programmers to
choose transaction boundaries based on hardware resources. While the usage model for “un-
bounded transactions” is not proven yet, we do not want to discourage their deployment. Hence,
what is needed are low overhead “unbounded” transactions that hide hardware resource limits
and persist across system events (e.g., context switches, system calls, and device interrupts).
To support unbounded transactions, a TM system must virtualize both conflict detection and
versioning. In both cases, the obvious strategy is to move transactional state from hardware to
a metadata structure in virtual memory. Concrete realizations of this strategy vary in hardware
complexity, degree of software intervention, and flexibility of conflict detection and contention
management policy.
Transactional memory is a very active area of research. Larus and Rajwar [HLR10] provide
an excellent summary up to Fall 2010. We first categorize the design space for both versioning
and conflict detection mechanisms. Hardware-based TMs need to address two requirements: (1)
a conflict detection mechanism to track concurrent accesses and conflicts for locations evicted
out of the caches and coherence framework and (2) a versioning mechanism to maintain the

20
new and old values of data for an unbounded number of locations. The implementation for
these tasks is governed by performance targets, the conflict resolution policy supported, and the
hardware complexity.
Conflict Detection
The implementation choices can be broadly classified as:
Software Instrumentation: To handle large transactions, TM runtime systems system can
augment a program with instructions that read and write some sort of metadata. If pro-
gram data are read more often than written (as is often the case), it is generally undesirable
for readers to modify metadata, since that tends to introduce high performance overhead.
As a result, readers are invisible to writers in most STM systems, and bear full responsi-
bility for detecting conflicts with writers. This task is commonly rolled into the problem
of validation—ensuring that the data read so far are mutually consistent.
State-of-the-art STM systems perform validation on every nonredundant read [SMP08;
SMS09; DSS06]. The supporting metadata vary greatly: In some systems, a reader in-
spects a modification timestamp or writer (owner) id associated with the location it is
reading. In other systems, the reader inspects a list of Bloom filters that capture the
write sets of recently committed transactions [SMP08]. In addition to the instrumen-
tation overhead that limits gains from concurrency, the software instrumentation add to
cache pressure since they access additional metadata on each memory access. Overall,
transactions with the software instrumentation can experience slowdowns on the order of
2–3× compared to transactions thathave hardware support.
Hardware Acceleration: Hardware support can remove the bottlenecks associated with soft-
ware instrumentation by using hardware metadata to track accesses. There are trade-
offs associated with different tracker hardware: Bloom filter based signatures [CTC06;
YBM07] can concisely summarize a large set of addresses with a fixed amount of space.
Bloom filters require support only at the processor but are prone to false-positive based
performance bugs. Error checking codes [BGH08] are extra metadata that are stored

21
along with data blocks. Such metadata can also be used to encode transactional metadata
and are precise. Unfortunately, this requires modifications to the various caches in the
memory hierarchy and requires the coherence protocol to interact with off-chip metadata.
Metadata added to cache tags are simple to implement but have space limitations; they
either require a software algorithm [DFL06] or a complex hardware controller [AAK05]
to handle cache evictions.
Virtual Memory: OS page tables include protection bits per-page entry to implement pro-
cesses. TM runtime can exploit these protection bits to set up read-only and read/write
permissions at a page granularity and trap concurrent accesses to detect conflicts [CNV06;
CMM06]. The major performance overhead involved is the TLB shootdowns and OS
intervention required when modifying the protection bits which occur frequently on non-
redundant accesses within a transaction.
Versioning
The conflict resolution policy in some ways critically governs the choice of versioning mecha-
nism. Lazy allows concurrent transactions to read or write a shared location thus necessitating
a redo-log in order to avoid irreversible actions while Eager detects conflicts prior to the ac-
cess, thereby accommodating both forms of logging. The undo-log is used to restore values if
a transaction aborts while the redo-log is used to copy-update the original locations on commit;
these actions need to occur in an atomic manner for all the locations in the log. Most impor-
tantly, since a redo-log buffers new values, it needs to intervene on all other accesses to check
if it needs to supply the data; this dictates the data structure used to maintain the new values
(typically a hash table). An undo-log approach can make do with a simpler data structure (e.g.,
dynamically resizable array or vector) and typically does not need to optimize the access cost
since it is traversed only on an abort.
Similar to conflict detection, versioning can be implemented either with (1) Software han-
dlers, (2) Hardware acceleration, or (3) Virtual memory (i.e., translation information in the
page tables). The performance and complexity tradeoffs are similar to conflict detection. The
software approach adds handlers to all writes (to set up the log data structures) and possibly

22
to all reads (needed to pass values if they are buffered in a redo-log) and leads to significant
degradation in performance. The hardware approach adds significant complexity, including
new state machines that interact in a non-trivial manner with the existing memory hierarchy.
The VM approach reuses existing hardware and OS support, but suffers the performance over-
heads of having to perform page granularity cloning and buffering. An important difference be-
tween the mechanisms that implement versioning and conflict detection is that versioning deals
with data values (no false positives or negatives) and cannot trade off precision for complexity-
effectiveness like conflict detection (e.g., signatures).
2.1.5 Classifying proposed TM systems
This dissertation primarily focuses on the hardware support required for accelerating TMs. We
refer readers interested in STM systems to Michael Spear’s Ph.d dissertation [Spe09]; we use the
term STM to refer to TM systems that rely only on software instrumentation to implement the
TM runtime. In this section, we study the design of proposed hardware TM systems. Table 2.1
lists the mechanism used by various hardware-based TMs based on the classification scheme
discussed previously. We specify three features of each TM system: the conflict resolution
supported, the type of conflict detection mechanism, and the versioning scheme.
Table 2.1: Virtualization in TMSystem Conflict Resolution Conflict Detection Versioning
UTM [AAK05] Eager H (controller) H (undo-log)VTM [RHL05] Eager H (microcode) S (redo-log)
LogTM-SE [YBM07] Eager H (Signature) H (undo-log)XTM [CMM06] Lazy (Eager?) VM VM (redo-log)
PTM-Select [CNV06] Eager H (controller) VM (undo-log)TokenTM [BGH08] Eager H (ECC) H (undo-log)
Hybrid SystemsSigTM [MTC07] Eager (Lazy?) H (signature) S (redo-log)
UFO TM [BNZ08] Eager H (ECC) S (undo-log)HyTM [DFL06] Eager S S (undo-log)
H - Hardware Acceleration S - Software Instrumentation VM - Virtual Memory ? - Can supportconflict resoultion but limits policy choices.Hybrids (other than SigTM) use a best-effort HTM for small transactions.
The Bulk system of Ceze et al. [CTC06] decouples conflict detection from cache tags by
summarizing read/write sets in Bloom filter signatures [Blo70]. To commit, a transaction broad-
casts its write signatures, which other transactions compare to their own read and write signa-

23
tures to detect conflicts. Conflict management (arbitration) is first-come-first-served, and re-
quires global synchronization in hardware to order commit operations.
LogTM-SE [YBM07] integrates the cache-transparent eager versioning mechanism of
LogTM [MBM06] with Bulk style signatures. It supports efficient virtualization (i.e., con-
text switches and paging), but this is closely tied to eager versioning (undo logs), which in turn
requires Eager to avoid inconsistent reads. Since LogTM does not allow transactions to abort
one another, it is possible for running transactions to “convoy” behind a suspended transaction.
Like LogTM-SE, TokenTM [BGH08] use undo-logs to implement versioning but implement
conflict detection using a hardware token scheme.
UTM [AAK05] and VTM [RHL05] both perform lazy versioning using virtual memory. On
a cache miss in UTM, a hardware controller walks an uncacheable in-memory data structure that
specifies access permissions. VTM employs tables maintained in software and uses software
routines to walk the table only on cache misses if an overflow signature indicates that the block
has been speculatively modified. Like LogTM, both VTM and UTM require eager resolution
of conflicts.
Both XTM [CMM06] and PTM [CNV06] use the virtual memory mechanisms (i.e., protec-
tion and translation) present in existing operating systems to enable TM virtualization. These
virtual memory mechanism are coarse-grained and add significant performance overhead to the
TM runtime.
Hybrid TMs [DFL06; KCH06] allow hardware to handle common-case bounded transac-
tions and fall back to software for transactions that overflow time and space resources. Hybrid
TMs must maintain metadata compatible with the fallback STM and use policies compatible
with the underlying HTM. SigTM [MTC07] employs hardware signatures for conflict detec-
tion but uses an (always on) TL2 [DSS06] style software redo-log for versioning. Like hybrid
systems, it suffers from per-access metadata bookkeeping overheads. It restricts conflict man-
agement policy (specifically, only self aborts) and requires expensive commit time arbitration
on every speculatively written location.

24
2.1.6 Our Approach : Flexible Transactional Memory
Published papers [MSS05; ScS05; SDM09; ShD09; BMV07] reveal performance differences
across applications of '10× in each direction for different approaches to contention manage-
ment, and eagerness of conflict detection (i.e., write-write sharing). It is clear that no one knows
the “right” way to do these things; it is likely there is no one right way. We propose, therefore,
that hardware serve simply to optimize the performance of transactions that are controlled fun-
damentally by software. This allows us, in almost all cases, to cleanly separate policy and
mechanism. The former is the province of software, allowing flexible policy choice; the latter
is supported by hardware in cases where we can identify an opportunity for significant perfor-
mance improvement. We present two TM systems, RTM and FlexTM that embody our design
principles.
2.2 Concurrency in Software Development :
Fine-grain Access Control
In this section, we discuss the approaches to address the challenges associated with collabora-
tive multi-programmer multi-module software projects. Modern software are complex artifacts
consisting of millions of lines of code written by many developers. Developing correct, high
performance, and reliable code has thus become increasingly challenging. As one example,
consider the development framework of the Apache webserver. The system designers define a
software interface that specifies the set of functions and data that are private and/or exported to
other modules. For the sake of programming simplicity and performance, current implementa-
tions of Apache run all modules in a single process and rely on adherence to the module API to
enforce protection. A bug or safety problem in any module could potentially (and does) affect
the whole application.
The prevalence of multicore processors, resulting in the need for multiple threads of control
in order to harness the available compute power, has increased the burden on software develop-
ers. Fine-grain intra- and inter-thread interactions via memory make it difficult for developers
to track, debug, and validate the accesses arising from the various software modules. Architec-

25
tural features for access control that will enable software to track, regulate accesses, and deliver
a more robust application, are highly desirable. We first commence with a discussion on access
control for software protection.
2.2.1 Modern processors : Paging and Segmentation
Page-based protection Page-based protection introduced in 1961 [BCD72], has virtually
been adopted by nearly every major OS and hardware vendor. Essentially each user-process
has a separate, linear address space which also represents a unique protection domain (a pro-
cess). Every thread in the system belongs to only a single process for its lifetime. Furthermore,
pages also represent the minimum granularity of sharing between address spaces and only sup-
port coarse-grain protection. This design makes it difficult for setting up protected sharing and
performing access control between the various modules in an application. Pages can have dif-
ferent permissions only when they map to separate address spaces. Even then, all words in the
page need to have the same permissions for a process. Further, if data pointers are passed across
processes, both processes need to map the shared page to same virtual address region in their
respective address spaces or require the use of non-trivial pointer swizzling techniques [Wil92].
Finally, the overhead of context switches and OS intervention required for inter process com-
munication impose significant limits to their usage.
Improvements to page-based protection Some architectures provide support for pages
shared between groups of processes. Ultrasparc and MIPS both tag TLB entries with ASID
(address space identifiers). A group of pages shared between processes can share an ASID (and
TLB entry). A key restriction is that each process can only see the same permissions for each
shared page.
Efforts were made to separate the protection mechanisms from the address space by the
proposal of a protection lookaside buffer [KCE92] and protection identifiers in HP’s PA-
RISC [WiS92]. Such systems specify the permissions for a tag (as opposed to a page) and then
associate the tag with each page that expects the same type of permissions. This introduces an
extra-level of indirection when looking up the permissions. Although, bulk permission changes
can be accomplished easily since since changing a tag’s permissions, effectively updates the

26
permissions of all pages associated with the tag. These systems require that collection of pages
shared between the various processes have a fixed set of permissions, but each process could
choose whether to subscribe to those fixed permissions. Another key challenge is coarse-grain
protection, all designs are confined to page-granularity (typically 4/8 KB) protection manage-
ment and cannot provide the finer granularity of control required for the protection needs of
today’s modularized software.
Segmentation Segments was first introduced in Burroughs [HaD68] as a technique to manage
virtual memory space as variable granularity regions. It could also support fine-grain protected
sharing amongst processes. Segments are base and bounds information which describe variable
granularity memory regions. Every process (or address space) is described using a table of
segments. Every instruction or data access in the processor refers this table for the protection
information. Segments (like pages) can be shared between processes. Segment based protection
is more flexible than page based protection since it can describe variable fine granularity regions.
There are two main drawbacks of segments: the hardware structures required to cache segment
information are complex since the lookups need to check if address falls within a segment region
and cross-segment data and instruction accesses require special instructions, which exposes
hardware limits to applications.
Segments are well suited to describe coarse grain mutually exclusive regions which do not
change often. This feature has been exploited to enable sandboxing between modules of an
application [CVP99]. While this enables separation of the modules and isolation of faults it is
hard to enable protected sharing of data between modules. In most cases, the applications have
to be modified significantly to take advantage of segments.
2.2.2 Research Prototypes : Mondrian and Loki
Recently, Mondriaan [WCA02] decoupled protection from a conventional paging framework
and implemented it using segments. An application’s address space is described by a collec-
tion of a variable sized segments, each capable of supporting byte granularity. This flexibility
comes at the cost of additional hardware and operating system modifications. This work re-
places the existing protection framework (TLB) with a new permissions-lookaside-buffer (PLB)

27
that checks all accesses in the pipeline and needs add-ons (e.g., sidecar registers) to reduce the
performance overheads. Furthermore, it introduces new layers in the operating system to imple-
ment all protection (intra-process and inter-process) based on the PLB approach. This requires
every application to communicate its policy to the low-level supervisor.
Loki [ZKD08] adopted a different tagging strategy, choosing to tag physical memory with
labels that further map to a set of permission rules. Loki allows system software to translate
application security policies into memory tags. Threads must have the corresponding entry
in the permissions cache in order to be granted access permission. If the threads need to be
segregated into separate domains, then this would require software support to convert inter-
thread function calls into cross-domain call gates. Permission cache modifications must be
performed within the operating system. Permission revocation in the case of page swapping
would require a sweep of all process/thread’s permissions caches.
2.2.3 Capabilities
Capability systems [CKD94; Lev84; CCL81; SSF99] augment object reference pointers to in-
clude information on access control. The capabilities shared between threads are marshaled
by the OS and can support generalized protection models. Typical capability implementations
change the layout of memory and fatten pointers. Software developers need to be aware of the
modified layout and typically need code rewrites, which lessens their appeal.
More importantly, the relatively large management cost for a capability (e.g., when revok-
ing access rights) makes it ill-suited for protecting fine-grain data elements. Rather, typical
capability-protected objects are external resources like files and printers, or memory segments
at page or larger granularity.
2.2.4 Tagged Memory
The memory hierarchy in tagged architectures [Feu73] carry a few additional bits per data block
to store metadata information. The hardware typically manipulates the tags in parallel with the
data and calls in to the software, if needed. Tagged architectures have been used in the the
past for setting up access control for type safety [ScT89], supporting capabilities [Lev84], and

28
debugging. The IBM System 360 [GiS87] tagged memory locations with 4 bit protection keys.
Only processes that owned specific protection keys could access the data and unauthorized ac-
cesses would raise an exception. While general purpose tagged architectures have not penetrated
mass market processors, there has been recent interest in exploiting them for access control for
debugging, garbage collection, and watchpoints.
2.2.5 Software-based Protection
Several approaches specifically target protection within the operating system, but lack the flex-
ibility to support application-level protection. For instance, SPIN takes advantage of type-safe
languages in constructing safe operating system extensions [BSP95]. The required use of certain
type-safe languages is too restrictive for general application development. As another example,
Nooks manages specific kernel to device driver interactions to guard against bugs [SBL03]. Un-
fortunately, these schemes require programmers to modify the applications and in some cases
change the programming model.
2.2.6 Access Control for Debugging
Hardware support for debugging is an active research area [QLZ05; ZQL04; TAC08; VRS07],
which primarily focuses on reducing the performance overhead of the access control mecha-
nism. These proposals can conveniently ignore the manageability concerns since debuggers
are typically deployed in the development phase. Space overheads are also inherently minimal
since debuggers are interested in only a limited subset of locations. Given that the number of
locations is small, debuggers typically try to provide word-granularity watchpoints.
When used for debugging applications, the space and performance overheads are directly
proportional to the number of locations being watched. Prior proposals mainly focus on reduc-
ing the overhead of intercepting memory operations and manipulating some debugger-specific
metadata. This capability is sufficient to detect a variety of memory bugs [NeS07].
The main commonality among the various acceleration proposals is the software-transparent
interception of memory accesses and the use of hardware state bits to track the watchpoint
metadata. A common feature of all these works is that they intercept all loads and stores in

29
the processor pipeline. They also share the metadata among different threads, which makes it
difficult to set up thread-specific access control. The main differences arise in the hardware
implementation: bloom filters [TAC08], additional cache-tag bits [NeZ07], ECC bits [ZQL04;
QLZ05], or separate lookaside structures [VRS07]; which have varying levels of false positives
and coverage characteristics. They also vary in whether the hardware semantics are hardcoded
for a specific tool [ZLL04] or support a general-purpose state machine [VRS07].
2.2.7 Our Approach: Sentry
While we share the goals of Mondriaan and Loki to allow more flexible protection models, Sen-
try employs an auxiliary protection architecture. Specifically, Sentry’s hardware is implemented
entirely outside the processor core subordinate to the existing TLB mechanism. Sentry’s design
is based on the key observation that permission checks do not change often; we intercept only
L1 misses and completely eliminate permission checks for L1 hits. Sentry intercepts a minimal
number of accesses, which enables us to save energy for the permission checks. Compared
to Mondriaan and Loki, Sentry reduces the changes required to the core hardware and oper-
ating system software. It enables flexible, low-cost protection within individual applications.
No changes are made to the existing process-based protection and the intra-process protection
models may be implemented at the user level. Finally, it incurs space or time overhead only
when auxiliary intra-application protection is needed.

30
Chapter 3Monitoring: Alert-On-Update
In this chapter, we begin with a description of shared memory multicore processors. We then
introduce the design space of mechanisms to monitor memory accesses and classify existing
monitoring mechanisms (Section 3.2.1). Section 3.3 describes the Alert-On-Update (AOU)
mechanism, its implementation, and the type of memory system events that can be monitored.
We demonstrate AOU’s generality by using it to accelerate STMs (Section 3.5), improve locks
(Section 3.6), and in detecting concurrency bugs (Section 3.7).
3.1 Introduction
Multicore processors are typically based on the shared memory paradigm. A conventional
shared memory multicore processor partitions the physical memory across multiple memory
banks and includes multiple levels of low latency private caches for each processor backed up
by a large shared cache. Shared memory systems employ additional hardware to provide the
programmer the illusion of a single unified address space. These systems partition the physical
address space into blocks (i.e. cache lines) and manage caching and block transfers.
Allowing processors to cache memory blocks means that a logically unique single block of
physical memory may reside in multiple physical locations scattered across the cache levels.
A coherence protocol is required to define the interaction between the processors, the various
caches, and memory. The coherence protocol controls the block permissions when the various

31
system components read or write the contents of a memory block. The invalidation scheme
is the dominant mechanism for implementing cache coherence protocols. Hardware-based co-
herence protocols enforce the following invariants: (1) only one processor in the system may
obtain write permissions to a cache block and (2) more than one processor is allowed to obtain
a copy for reading and all these copies are implicitly cleaned up on a write. The hardware needs
to track the cached copies of a memory block to efficiently satisfy a processor accesses and gen-
erate invalidations. This tracking is typically implemented using either a snoopy bus broadcast
[ArB84] or through a directory-based coherence [ASH88] mechanism.
3.2 Current Monitoring Mechanisms
The introduction of multicore processors has increased the burden on software developers–
multiple threads of control are needed to harness the available compute power. Fine-grain
intra-thread events and inter-thread interactions via memory make it difficult for developers
to comprehend and debug programs. Hence, there is a need to utilize at least some of the extra
transistors afforded by Moore’s law toward architectural features that help monitor programs
efficiently. Monitoring a process’s memory accesses, whether for passive observation or active
regulation of reads and writes, forms the basis of many program analysis techniques, debugging
tools, and sandboxing mechanisms.
Broadly defined, a Memory Monitoring mechanism tracks shared memory accesses that
arise from the various threads and possibly informs software about accesses to locations specif-
ically marked by software. Current general purpose processors incorporate three forms of hard-
ware support for memory monitoring: a memory management unit (TLB) that combines address
translation with access control for pages, watchpoint registers that support access monitoring
for words, and performance counters that passively count memory events. The TLB is managed
by heavyweight OS routines, affords only coarse-grain access monitoring. Watchpoint registers
are very few in number (e.g., 4 on the x86), which deters widespread use. Finally, performance
counters typically summarize/count only local events (e.g., cache misses).
It is possible to implement memory monitoring entirely in software by instrumenting mem-
ory accesses. Instrumentation can be set up with either compiler support [NMW02] or dynamic

32
runtime instrumentation [NeS07]. Unfortunately, static instrumentation requires programmer
effort to annotate programs and requires access to source code. Dynamic instrumentation,
typically adds significant overhead due to lack of type information about the data structures
and runtime interposition needed on the entire program. Software-based instrumentation has
been widely employed for tools like detecting concurrency bugs [SBN97; Cor] and security
violations [CPM98], although reducing the performance overheads with hardware support is
appealing even in such cases.
3.2.1 Design Space
In this section, we describe our design space for classifying memory monitoring mechanisms
and study the monitoring mechanisms of current processors. The typical software environment
employs multiple threads of control, each of which issue sequences of memory accesses (loads
and stores). We use the term “local” to refer to the thread performing the access and “remote”
to refer to other threads in the system with potentially concurrent reads and writes to the same
location.
1. Access visibility refers to whether memory operations by the “local” thread are visible
to the memory monitoring mechanism at either the “local” or “remote” end. Options:
“local”, “remote” or “local and remote”
2. Event location specifies where an event handler is triggered. The thread hardware could
choose to pass the information gathered about a memory operation. Typically this entails
stopping the thread’s operation and triggering a handler.
Options: “local” or “remote”
3. Event time refers to when (and if) the handler is triggered to enable software to be syn-
chronously notified when the event occurs. Options: Break (handler triggered before ac-
cess), Report (handler triggered after access), Record (no handlers, software is expected
to poll)
4. Monitor Visibility: It is obvious that to track accesses, they need to be visible to memory
monitoring mechanism. Monitoring visibility is the complementary of Acccess visibility;

33
it specifies whether the monitoring mechanism provides a response to inform the access
about its presence.
Options: “local” or “remote” refers to whether a monitoring mechanism set up locally or
remotely is visible
5. Accuracy specifies the precision of the monitoring mechanism. In the interest of
complexity-effectiveness, hardware primitives might introduce false-positives (events
even in the absence of operations) or false-negatives (lose some of the tracked opera-
tions).
In Table 3.1 we classify monitoring primitives that current processors support. An evident
limitation is the restriction of monitoring to local events only, which limits their benefits to
multithreaded code that have fine-grain inter-thread interactions. Furthermore, implementations
provide limited support (e.g., x86 has 4 watchpoint registers) and/or introduce high overhead
(e.g., TLB protection changes) on software.
Table 3.1: Classification of current monitoring mechanismsAccessVisibility
Event lo-cation
EventTime
Monitor -Visibility
Accuracy
TLB Local Local Break Local False +WatchpointRegs.
Local Local Break/Rep. Local -
PerformanceCounters
Local Local Record Local False +/-
Accuracy: “-” 100% accurate. Rem. - Remote, Rep. - Report.
3.3 Alert-On-Update
We propose a simple technique to selectively expose cache events to user programs. Using our
technique, threads register an alert handler and then selectively mark lines of interest as alert-
on-update (AOU). When a cache controller detects an event of interest, it notifies the local
processor, effecting a spontaneous subroutine call to the current thread’s alert handler.
A traditional advantage of shared-memory multiprocessors is their ability to support very
fast implicit communication: if thread A modifies location D, thread B will see the change as

34
soon as it tries to read D; no explicit receive is required. There are times, however, when B
needs to know ofA’s action immediately. Event-based programs and condition synchronization
are obvious examples, but there are many others. As an example, consider a program which uses
a lock L for synchronization. Typically, if L is already acquired, then a threadA that desires the
lock has to repeatedly poll the the status of L to detect the release of the lock. Interprocessor
interrupts are the standard alternative to polling in shared-memory multiprocessors, but they are
typically triggered by the operating system and have prohibitive latencies. This cost is truly
unfortunate, since most of the infrastructure necessary to inform remote threads of a change
to location L is already present in the cache coherence protocol. Alert-on-update provides an
effective way to reflect write notices up to user-level code.
3.3.1 Implementation
Alert-on-update can be implemented on top of any cache coherence protocol: coherence re-
quires, by definition, that a controller be notified when the data cached in a local line is written
elsewhere in the machine. The controller also knows of conflict and capacity evictions. AOU
simply alerts the processor of these events when they occur on marked lines. The alert includes
the address of the affected line and the nature of the event. Perhaps the most obvious way to
deliver a notification is with an interrupt, which the OS can transform into a user-level signal.
The overhead of signal handling, however, makes this option unattractive. We propose, there-
fore, that interrupts be used only when the processor is already running in kernel mode. If the
processor is running in user mode, an alert takes the form of a spontaneous, hardware-effected
subroutine call. Alert traps require simple additions to the processor pipeline. Modern pro-
cessors already include trap signals between the Load-Store-Unit (LSU) and Trap-Logic-Unit
(TLU) [KAO05]. AOU adds an extra message to this interface.
Note that with AOU, the thread performing the access itself is completely oblivious of
whether the cache line was AOUd, unless the accessor thread also requested notification of
local accesses. Simply put, AOU is used as a way for a thread to glean information on events
on lines that are locally cached. AOU can be implemented entirely with modifications to the
local cache controller and a single additional “A” bit in tag of the private L1, without requiring
any modifications to the coherence protocol itself. Since AOU relies on tag bits, it can not

35
monitor a line if it is not cached. On eviction of an AOUd line, the hardware conservatively
traps to software to indicate that the line will no longer be tracked. The “A” bits are valid only
as long as the thread that set them is active on the processor; they are flash-cleared on context
switches. Subsequently, the OS wakes up the thread in its alert handler to inform that the AOU
was terminated.
An application enables AOU by using an instruction to register a handler. It then indicates
its interest in individual lines using aload (alert-load) instructions. One variety of aload
requests alerts on remote writes only; another requests alerts on any write, including local
ones. Both varieties also generate alerts on capacity and conflict misses. Hardware provides
set_handler, aload, clear_handler, and arelease instructions; special registers
to hold the handler address, the PC at the time an alert is received, and a description of the alert;
and two bits per cache line to indicate interest in local and/or remote operations. For simplicity,
we implement the alert bits in a non-shared level of the memory hierarchy (the L1 cache). If the
L1 were shared we would need separate bits for each local core or thread context.
Table 3.2: Alert-on-update InterfaceRegisters%aou_handlerPC: address of handler to be called on a user-space alert%aou_oldPC: PC immediately prior to call to %aou_handlerPC%aou_alertType (4 bits) remote read, remote write, local write, and local read
lost alert, or capacity/conflict eviction%alert_enable (1bit): set if alerts are to be delivered; unset when they are maskedInstructionsset_handler %r move %r into %aou_handlerPCclear_handler clear %aou_handlerPC and flash-clear alert bits for all cache linesaload %r set alert bit for cache line containing the address in %r; set overflow
condition code to indicate whether the bit was already setarelease %r unset alert bit for line containing the address in %rClearAlerts flash-clear alert bits on all cache linesenable_alerts set the alert-enable bit
Cacheone extra bit per line, orthogonal to the usual sta te bits
We make no assumptions about the calling conventions of AOU-based code. Typically, our
alert handlers consist of a subroutine bracketed by code reminiscent of a signal trampoline. Ad-
ditional alerts are masked until the handler re-enables them. A status register allows the handler
to determine whether masked alerts led to lost information. Capacity/conflict alerts, likewise,

36
indicate that the local cache has lost the ability to precisely track a line. Moreover, exclusive
loads and prefetches, failed atomic operations, silent stores, and false sharing within lines may
all lead to “spurious” alerts. For these reasons user software must treat alerts conservatively: any
change to a marked line will result in an alert, but not all alerts provide precise information or
correspond to interesting changes. We expect the overhead of spurious alerts to be significantly
less than that of fruitless polling.
Alert States
Figure 3.3.1 shows the coherence protocol support required for Alert-on-update. Processor read
and write operations are represented by Rd and Wr respectively; alert operations are represented
as ARd and AWr. To indicate a write operation (alert or not) we use [A]Wr; we use a similar
convention for reads with the [A]Rd. Dashed boxes enclose the MESI and Alert subsets of the
state space. Notation on transitions is conventional: the part before the slash is the triggering
message; after is the ancillary action (‘–’ means none). “Flush” indicates writing the line to
the bus. S indicate signals on the “shared” bus line. It indicates the signals that accompany the
response to a BusRd request; an overbar means “not signaled”. The “Release” transition from
the Alert state space to the MESI state space occur only on the corresponding cache line. “Bus-
Rdx” invalidate the cache-line and transition the corresponding cache line to I. “ClearAlerts”
flash-clears the alert bit and reverts all the AOUd lines in the cache to their respective MESI
counterparts.
Note that the response to processor and bus operations of the alert states mirror those of their
respective MESI counterparts. This ensures that we can implement Alert-on-update without any
addition to the transition state space. Infact while the coherence protocol shows a separate set
of alert states to describe the transitions, the alert bit is completely orthogonal to the coherence
protocol. Its sole purpose is to monitor cache coherence events and does not impact the protocol
responses or transitions.

37
M
E
Wr/--
I
Wr /BusRdx
S
Wr /BusRdx
Rd /BusRd (S)-
Rd/--
Rd/--
Wr,Rd / --
BusRdX/Flush
BusRdX/ --
BusRd/ --
BusRdX/ --
BusRd/ --
Rd /BusRd (S)
MESI States
[A]Wr/--
[A]Wr /BusRdx
[A]Rd/--
[A]Rd/--
[A]Wr, [A]Rd / --
BusRd/ --
BusRd/ --
Alert States
AM
AE
AS
AWr /BusRdx
ARd /BusRd (S)
ARd /BusRd (S)
AWr/BusRdX
ARd/BusRd (S)
ARd/BusRd (S)
Release or BusRdx
ClearAlerts
Figure 3.1: Coherence protocol support for Alert-on-update.
3.3.2 Observable events
A key design choice in AOU is the type of events that are observable at the cache controller.
Alert bits can obviously observe all local accesses (writes and reads) from the processor. The
cache coherence protocol also guarantees that remote writes are observable at all cached copies.
Remote reads are trickier since they are only observable if the local processor has performed a
write and holds the only valid copy i.e., remote reads are only observable if the line is locally
cached in the AM state (see Figure 3.3.1). Also note that in the case of remote accesses, only the
first remote access is visible. Subsequent accesses will not be seen either because the alerted
line is lost (remote write) or coherence protocol filtered out remote reads by choosing to supply
the line from another copy. Finally, the cache controller has to inform software of evictions
(either capacity or confict) to software that can use this alert to enable software-based tracking.
Another important design choice that critically impacts the implementation, is the capability
to allow multiple types of monitoring to be activated simultaneously. To indicate whether a

38
cache line requires to monitor any combination of the four type of events (i.e., local read, local
write, remote write, and remote read) would require four separate alert bits per cache line. To
minimize the modifications required to the critical L1 data cache, our current design decouples
this design choice from the cache line. It provides a set of four configuration bits for the entire
L1 cache to specify the type of events and requires a single Alert bit per cache line to switch
on/off alerts. All cache lines set up for alerts to monitor the same type of events.
3.3.3 Virtualization
When exposing hardware primitives to user-level applications there is a critical need to vir-
tualize resources to free applications from the burden of reasoning about low-level hardware
resources. When aloaded lines are evicted from the cache there are two challenges that need
to be addressed: First, alert bits are available only in the cache and second, the appropriate
thread contexts that requested the alert need to be tracked. The former can possibly be ad-
dressed by extending alert bits throughout the memory hierarchy. The latter is a hard challenge
since a AOUd cache line implicitly identified the thread that requested the alert, but maintaining
this information for an arbitrary swapped out number of threads would require extensive hard-
ware resources and would further complicate system software support. For our base design,
we adopted a simple approach to virtualization. We assume that all aloaded lines belong to
the active thread. Thread and process schedulers must execute clearhandler (which also
areleases all aloaded cache lines) on context switches.
When a thread is inactive, the cache line associated with the thread could possibly change
without notifying the thread. When the thread is re-activated it must perform a conservative
polling operation to check if a previously AOUd line has changed. The polling can be imple-
mented in an application-specific manner by either examining values or version numbers. For
example, our AOU-accelerated STMs utilize version numbers (see Section 3.5 for details).
Another challenge that we have to deal with is the possibility of multiple alerts arising at the
same time. As with any other form of hardware interrupt, we coalesce multiple alerts. Only the
first alert has detailed information saved in the registers. When the alert handler is triggered it
disables alerts until it has saved the alert registers on the stack; any further alerts that arise in the

39
meantime are reflected back to software by using a flag register to indicate missed alerts. We
use existing virtualizing mechanisms like version numbers to detect alerts that may have been
missed. More details on how STMs use software validation to detect missed alerts is discussed
in Section 3.5.
Finally, we need to define the behavior when a code-region that is using AOU invokes sys-
tem calls. To ensure simple system calls and many common interrupts do not enforce conser-
vative polling the OS does not execute clear_handler when returning to the most recently
executing user thread. If an event occurs on an aloaded line while the processor is executing
in the kernel, the alert will be delivered as an interrupt. The interrupt handler simply remembers
the contents of the AOU registers (see Table 3.2), and if control eventually returns to user space
without a context switch, the kernel effects a deferred call to the user-level handler. Moreover
kernel routines themselves can use alert-on-update, so long as the interrupt handler is able to
distinguish between user and kernel lines, and so long as all the kernel lines are areleased
before returning to user space.
3.4 Related Work
Table 3.3 classifies proposed monitoring mechanisms and alert-on-update on the design space
discussed in Section 3.2.1. Overall, AOU is more flexilble than other proposed mechanisms; it
can track both remote and local accesses, trigger events at either the remote processor or local
processor, and can operate in either break, report or record mode. We compare and contrast
with each of the proposed mechanisms in detail below.
3.4.1 Informing Loads
More than a decade ago, Horowitz et al. [HMM96] proposed a set of memory operations that
enables software to directly observe cache misses and react to it. Their proposal was to enable
runtime optimizations through fine-grain profiling of non-uniform data access latencies. They
propose informing memory instructions, which essentially couple conventional memory opera-
tions with a branch operation. If the memory operation misses in the primary L1 cache, then the
hardware transfers control to a specified handler. AOU is data centric and its seeks to monitor

40
Table 3.3: Classification of proposed monitoring mechanismsAccessVisibility
EventLocation
EventTime
Monitor -Visibility
Accuracy
Informing Loads [HMM96] Local Local Break Local -Intel Mark bits [SAJ06] Local Local/-
RemoteRecord Local -
Signature [CTC06] Local/-Remote
Local Break Local/-Remote
False +
Alert-on-update Local/-Remote
Local/Remote
Break,Report orRecord
Local -
Accuracy: “-” 100% accurate. Rem. - Remote, Rep. - Report. Signatures can only be usedin record mode for remote accesses.
accesses (both local and remote) to a given location, while informing loads detect cache (hit or
miss) for the specific memory access. Unlike informing loads, alert operations are decoupled
from the instruction that informs the cache itself i.e., the handler is triggered on subsequent
operations.
3.4.2 Intel mark bits
Alert-on-update was originally introduced in a 2005 technical report and a paper at TRANS-
ACT’06 [SMD06]. Researchers in the McRT group at Intel subsequently published a variant
of AOU that uses polling instead of events to detect cache line evictions. Their HASTM sys-
tem [SAJ06] proposed a set of mark bits in the cache which software can set up for specifically
monitoring remote writes. Unlike AOU, which can operate in break or report mode, Intel’s mark
bits operate only in record mode (see Table 3.3). On remote write operations or (cache line evic-
tions) the hardware sets a flag register which software polls to detect if any of the marked lines
were evicted. Expecting software to frequently poll and check the status of the cache line intro-
duces performance penalty due to noticeable increase in instructions and requires extra memory
fences in the program to order the polling of the flag register and memory operations. Alert op-
erations are aysnchronous events which completely eliminate polling and significantly reduce
the overheads.

41
3.4.3 Signatures
In 2006, Ceze et al. [CTC06] introduced bloom filter based hardware signatures that record the
addresses read and written by a thread. The signature performs a membership test on coher-
ence requests and memory accesses; on a membership hit a handler is triggered on the accessor.
Unfortunately, bloom filters have false positives i.e., they represent a superset of the addresses
marked by the program. False positives, while a performance issue can be handled in appli-
cations like transactional memory or debugging [TAC08] which require alert handlers only on
the accessor. Triggering handlers on remote processors is a challenge in the presence of false
positives, since you could have spurious alerts showing up on completely unrelated threads in
the system. False positives are not acceptable for applications such as event-based communica-
tion or accelerating locks (see Section 3.6). Signatures also modify the coherence protocol to
inform the thread making the access about the monitoring mechanism i.e., signatures detect an
access and provide feedback to the accessor about the thread that set up the signature. However
Aload, makes no modifications to the coherence response messages and remote accessors are
not informed about AOU.
3.5 Application 1: AOU Assisted STMs
In this section, we examine in detail the value that alert-on-update offers in accelerating a soft-
ware transactional memory system. We focus on a two specific STM systems, (1) RSTM,
an indirection-based nonblocking STM system, and (2) LOCK, a lock-based STM similar
to Transactional Locking II [DSS06]. AOU can also be used to accelerate other STMs like
McRT [SAH06], Microsoft’s Bartok STM [HPS06], and the Ennals’ LibTx system [Enn06].
Pure software implementations of transactional memory (STM) can be divided into two
main camps: those that use locks under the hood (hidden from the user) and those that are non-
blocking (typically obstruction-free [HLM03a; HLM03b]). Several groups have found lock-
based implementations to be faster in practice [Enn06; DSS06; SAH06; HPS06], but nonblock-
ing implementations have other advantages: they are immune to priority inversion in event-
based code, and to performance anomalies caused by inopportune preemption or page faults.

42
Finally, nonblocking implementations ensure consistency even if a thread can die in the middle
of a transaction.
In Section 3.5.1 and Section 3.5.2, we briefly describe the internals of two STM systems,
RSTM and LOCK. In Section 3.5.3, we discuss the challenges associated with improving per-
formance of STMs. Section 3.5.4 describes the use of AOU in accelerating STMs. Finally,
Section 3.5.5 quantifies the performance improvements obtained when incorporating AOU sup-
port in STMs.
3.5.1 RSTM : Indirection-Based STMs
Indirection-based nonblocking STM systems include DSTM [HLM03b], ASTM [MSS05], and
RSTM [SMS06]; in this dissertation we focus on RSTM. The two principal metadata structures
in RSTM (see Figure 3.2a) are the transaction descriptor and the object header. The descriptor
contains an indication of whether the transaction is active, committed, or aborted. The header
contains a pointer to the descriptor of the most recent transaction to modify the object, together
with pointers to old and new versions of the data. If the most recent writer committed in soft-
ware, the new version is valid; otherwise the old version is valid. Indirection-based STMs
typically introduce an extra level of pointer lookup through the metadata on every data access.
All modifications to objects are performed on private copies. Before it can commit, a trans-
action must acquire the headers of any objects it wishes to modify, by making them point at its
descriptor. By using a CAS instruction to change the status word in the descriptor from active
to committed, a transaction can then, in effect, make all its updates valid in one atomic step.
Prior to doing so, it must also verify that all the object clones it has been reading are still valid.
The indirection of nonblocking systems ensures that committing and aborting are both
lightweight operations, and that objects read during a transaction are immutable. Unfortunately,
the extra indirection also increases both capacity and coherence misses in the cache, by increas-
ing the number of lines required to represent an object and the number of lines that are modified
when changes to an object are committed. Ennals et al. [Enn06] and of Dice et al. [DiS06], find
these cache misses to be a major source of overhead in indirection-based STMs.

43
Header
new version
of data
Txn descriptor
Owner
Old Data
old version
of data
(a) RSTM Metadata
Version#/Owner/LockRedo Log (Clone)
Master Copyof Object
Old Version#Master CopyIn-Progress
Modifications(“Log”)
(b) LOCK Metadata
(a) In RSTM, all references go through the indirection pointer (header), which is easily changedto install a new version. (b) In LOCK, readers can directly reference the location but need tocheck to ensure that the read value is consistent.
Figure 3.2: STM Metadata
3.5.2 LOCK : Lock-based STM
The RSTM indirection header is unnecessary. Pointers to shared objects need not pass through
the header to mediate conflicts and indicate acquisition. Instead we can pack lock status, version
number, and acquisition status into a single-word in the object itself. Figure 3.2b depicts the per-
object metadata for the LOCK STM. Every object contains two header words, which we modify
only using atomic double word compare-and-swap (CAS) instructions. In the common
case, an object is not owned: its redo log pointer is null and its version number is odd. In this
case, the object contents can be read directly, so long as the version number has not changed
since the first time the object was accessed by the current transaction.
As in RSTM, LOCK transactions perform all speculative writes on private object clones.
Each clone serves, in effect, as a “redo log”, to be applied to the master copy in the wake of a
successful commit. A thread must perform this copy-back before it can start a new transaction.
In the absence of hardware support, log application is performed under the protection of per-
object locks. Threads that desire the lock can do so eagerly (at the time of the first access) or
lazily (just before commit). If a transaction attempts to read a locked object, it must wait. After
completing a log application, a thread zeros the redo log pointer and updates the version number
word and releases the lock.
A metadata in the acquired state contains a pointer to the owner in the first header field, and
a pointer to the redo log in the second. Because objects are updated in place, a transaction is not

44
guaranteed that the (copy of an) object it reads is immutable. To ensure that all reads come from
the same consistent version of the object, we need a version number to each object. The first
word of the redo log contains the old version number of the object. The second word contains
a back-pointer to the public version of the object. Reading transactions ensure the consistency
of the version number before using any field read from an object.
3.5.3 Challenges in STM
Validation
Since many transactions can read a shared object simultaneously, STMs tend to permit “invisible
reads”, in which transactions that read an object O but make no modification to O’s metadata.
This behavior prevents metadata from bouncing between cache lines when several threads read
O simultaneously, but in the event that a transaction modifies O while O is being read, then all
transactions TR who have read O are responsible for detecting the change to O and aborting
themselves. To validate a single object, a Tr need only ensure that the object’s header still
references the same version of the object that TR has seen in all previous accesses. Since
acquisition and locking both modify the same header field, it is straightforward for a transaction
to ensure that an object has not changed; it need only compare the first word of the header to a
private copy of that field that was read the first time the object was accessed. However, every
time TR opens a new object, it must re-validate all previously read objects. Thus if TR reads
N objects, it must perform N(N−1)2 = O(N2) comparisons. This validation overhead is on the
critical path for both RSTM and LOCK.
Bookkeeping
An additional cost that many STMs face is that of bookkeeping. Clearly, in the case of invisible
reads it is necessary for a transaction to maintain a list of all objects read. Furthermore, in STMs
for non-garbage-collected languages, it is likely that transactions reuse their descriptor objects.
In this case, the O(n) storage and time overhead for tracking all reads is necessary even with
visible reads. In STMs that frequently search through their read sets, list structures may be
inappropriate, resulting in greater algorithmic and storage complexity.

45
Delayed Aborts
STMs cannot tightly bound the delay between when a transaction becomes destined to abort
and when it actually aborts. In the case of invisible reads, the thread must first validate its read
set to detect that it must abort, but even for visible reads, the system may not be able to bound
the time that a transaction spends outside of library code. In library-based STMs where abort
and rollback mechanisms are never initiated in user-provided code even when globally-visible
information dictates that a transaction must abort, it still might spend considerable time doing
useless work.
3.5.4 Using AOU to accelerate STMs
To keep the discussion simple, we only describe the details in incorporating AOU in LOCK.
We present a two-step evolution of STM systems characterized by increasing reliance on AOU.
LOCK can use a single aloaded line per thread to guarantee nonblocking progress. LOCK
can also use one aloaded line per object to avoid the performance overheads associated with
validation.
Restoring Nonblocking Guarantees
The sole purpose of the per-object lock in LOCK to ensure that as soon as one thread has
completed the copyback of a redo log, no other thread continues attempting to apply that log.
The use of lock for the copyback causes the STM to satisfy obstruction freedom. We can restore
nonblocking guarantees by making the lock revocable. Using AOU we can construct a simple
special-purpose revocable lock. We do not expect the use of a single alert-on-update
to significantly increase performance; the code is equivalent in complexity of the base LOCK
system.
If all threads agree on the set of locations to be written (a condition guaranteed by the redo
log), then the lock can be stolen as long as the previous lock holder is certain not to continue
writing once the lock is lost. Figure 3.3 demonstrates how the redo lock can be stolen using
AOU. The AcquireRevocableLock() operation can either lock an unlocked object, or
overwrite the lock of a locked object. In the latter case, the current lock holder will receive an

46
#define LOCKED 2bool success = truetry
set_handler({throw Alert()})if (log = o->HasRedoLog)
aload(o->lock);if (o->AcquireRevocableLock(log))
o->ApplyRedoLog(log)o->ReleaseLockAndClearLog()
arelease(o->lock)clear_handler
catch (Alert)success = false
AcquireRevocableLock(log):v = versionNumberif (v == copyback_needed() && backoff() < THRESHOLD)
goto AcquireRevocableLockreturn CASX(this, <v, log>, <LOCKED, log>)
A single aloaded line suffices to steal responsibility for applying a redo log to object o.
Figure 3.3: Lock Stealing to make LOCK non-blocking
immediate alert, ensuring that if the new lock holder completes, no other threads are writing the
object. To avoid pathological behavior, AcquireRevocableLock() waits for a bounded
period of time before attempting to steal the lock. Since threads never hold more than one lock,
and since that lock is used only to protect log application, a single aloaded line suffices to
restore obstruction freedom.
Reducing Validation Costs
We now focus on a more pervasive use of AOU to dramatically improve performance. As in
the previous subsection, we use AOU to implement revocable locks. However, we also use AOU
to eliminate both quadratic-time inter-object validation and per-access intra-object validation in
the common case.
In the common case, a transaction reads and writes only a small number of objects. If all
transaction headers fit in cache, then once an object O is read, its header ought to remain in
the cache until the transaction completes. Barring pathological cache overflows, invalidation of
O’s header implies that O has been acquired by another transaction and the current transaction

47
should abort. If the transaction registers an alert handler that immediately aborts, and then each
object header is initially loaded using alert-on-update, all validation can be elided: An
alert is certain to precede any modification to relevant metadata, and all forms of validation fail
only if some relevant metadata is modified. In effect, the alert mechanism transforms the cache
into a self-validating read set.
Our proposal is somewhat idealized, since the capacity of a cache is limited. If we have
abundant but finite lines that can be tagged alert-on-update, then we may tag up to K
objects (where K is based on the cache size) and then fall back to explicit incremental and
per-access validation for the remaining R − K objects in the read set.In our implementation,
transactions estimate K and decrease it when they are alerted due to overflow (detected through
the %aou_alertType register).
The runtime sometimes requires that a set of related metadata updates be allowed to com-
plete, i.e., that the transaction not be aborted immediately. This is accomplished by setting a
“do not abort me” flag. If an alert occurs while the flag is set, the handler defers its normal ac-
tions, sets another flag, and returns. When the runtime finishes its updates, it clears the first flag,
checks the second, and jumps back to the handler if action was deferred. This “deferred abort”
mechanism is also available to user applications, where it serves as a cheap, non-isolated ap-
proximation of open nested transactions [Mos06]. We us this interface to interact with external
memory allocator libraries.
3.5.5 Evaluation
In this section we present experimental results that measure the impact of
alert-on-update on TM performance. We consider both throughput and the cache
miss rate, which we use as a measure of the benefit of removing indirection. Detailed
performance graphs appear in an appendix. All results were obtained through full-system
simulation.

48
Simulator Framework
We simulate a 16-way chip multiprocessor (CMP) using the GEMS/Simics infrastruc-
ture [MSB05]. Simulation parameters are listed in Table 3.4.
Table 3.4: Simulation Parameters
16-way CMP, Private L1, Shared L2Processor Cores 1.2GHz in-order, single issue,
ideal IPC=1L1 Cache 64KB 4-way split, 64-byte
blocks, 1 cycle latency, VictumBuffer:32 entries
L2 Cache 8MB, 8-way unified, 64-byteblocks, 4 banks, 20 cycle la-tency
Memory 2GB, 250 cycle latencyInterconnect 4-ary totally ordered hierarchi-
cal tree, 2 cycle link latency,64-byte links
Benchmarks
We consider the following five benchmarks, HashTable, RBTree, LFUCache, LinkedList-
Release and Randomgraph, designed to stress different aspects of software TM. Appendix A
includes a detailed description of the benchmarks. In all benchmarks, we execute a fixed num-
ber of transactions in single-thread mode to advance the data structure to a steady state. We then
execute a fixed number of transactions concurrently in multiple threads to evaluate scalability
and throughput. During the timed trial, we also monitor L1 cache misses (read and write), as
we expect them to decrease in systems without indirection.
Runtime Systems Evaluated
We compare a total of 7 systems. As baselines, we consider RSTM (RSTM) and RSTM with
our global commit counter heuristic (RSTM+C) [SMS06]. The commit counter is a global count
of the number of transactions that have attempted to commit. When a transaction acquires an
object, it sets a local flag indicating that it must increment the counter before attempting to

49
commit. Now when opening a new object, a reader can skip validation if the global commit
counter has not changed since the last time the reader checked it.
We also evaluate the acceleration of LOCK using AOU. The first, LOCK-AOU_1, uses a
single AOU line to eliminate indirection; the second, LOCK-AOU_N, uses one AOU line per ob-
ject to eliminate validation. For LOCK-AOU_1, we also consider a variant that uses the global
commit counter (LOCK_AOU_1+C). Lastly, we consider a variant of RSTM (RSTM-AOU_N)
that uses AOU to avoid validation overheads (like LOCK-AOU_N) but without eliminating indi-
rection. This library does not incur per-access validation, but has increased cache pressure. The
graphs also include results for the (LOCK) STM of Section 3.5.2 . Its performance is within 5%
of LOCK_AOU_1 on average, which is unsurprising, since LOCK-AOU_1 differs from LOCK
only when locks are stolen; we do not discuss LOCK further here.
To ensure a fair comparison, we use the same benchmark code, memory manager, and con-
tention managers in all systems. For contention management we use the Polka manager [ScS05]
and all TMs use eager conflict detection.
Eliminating Read-Set Validation
By leveraging abundant AOU lines, both RSTM-AOU_N and LOCK-AOU_N are able to im-
prove TM performance by 1.4–2× in HashTable, RB-Tree, LinkedList-Release, and LFUCache.
Single-thread RandomGraph improves by a factor of 5. Not only do these systems outperform
their unaccelerated counterparts (RSTM and LOCK-AOU_1, respectively) at all thread levels,
they also outperform our commit-counter heuristic in almost all cases.
In previous work, we showed that the commit counter entails a tradeoff: in return for a
constant-time indication of whether any transaction has committed, all transactions must seri-
alize on a single global counter. For HashTable, where transactions tend not to conflict, this
forced serialization is a bottleneck that slows performance. However, both RSTM-AOU_N and
LOCK-AOU_N avoid serializing on a counter while still enabling validation calls to be skipped.
As a result, we see HashTable improve by over 20%, whereas the commit counter actually
degrades performance with respect to RSTM.
In LFUCache, where transactions conflict with high likelihood and consequently do

50
HashTable
0
2
4
6
8
10
12
1 2 4 8 16Threads
Norm
aliz
ed T
hrou
ghpu
tRBTree
0
2
4
6
8
10
12
14
16
1 2 4 8 16Threads
Norm
aliz
ed T
hrou
ghpu
t
LinkedListRelease
0
2
4
6
8
10
12
14
16
18
1 2 4 8 16Threads
Norm
aliz
ed T
hrou
ghpu
t
LFUCache
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1 2 4 8 16Threads
Norm
aliz
ed T
hrou
ghpu
t
RandomGraph
0
1
2
3
4
5
6
7
1 2 4 8 16Threads
Norm
aliz
ed T
hrou
ghpu
t
RSTM
RSTM+C
RSTM-AOU_N
LOCK-AOU_1
LOCK-AOU_1+C
LOCK-AOU_N
Results are normalized to RSTM, 1 thread. Using alert-on-update to eliminate valida-tion improves performance by as much as a factor of 2 (a factor of 5 in RandomGraph), andoutperforms the global commit counter heuristic.
Figure 3.4: Performance of STMs with AOU acceleration.

51
0
0.25
0.5
0.75
1
1.25
1.5
1.75
RST
M
LOC
K
LOC
K-A
OU
_1
LOC
K-A
OU
_N
RST
M
LOC
K
LOC
K-A
OU
_1
LOC
K-A
OU
_N
RST
M
LOC
K
LOC
K-A
OU
_1
LOC
K-A
OU
_N
RST
M
LOC
K
LOC
K-A
OU
_1
LOC
K-A
OU
_N
RST
M
LOC
K
LOC
K-A
OU
_1
LOC
K-A
OU
_N
HashTable RBTree LinkedList-Release LFUCache RandomGraph
Nor
mal
ized
L1
Cac
he M
isse
s Wr Misses
Rd Misses
0
0.25
0.5
0.75
1
1.25
1.5
1.75
RST
M
LOC
K
LOC
K-A
OU
_1
LOC
K-A
OU
_N
RST
M
LOC
K
LOC
K-A
OU
_1
LOC
K-A
OU
_N
RST
M
LOC
K
LOC
K-A
OU
_1
LOC
K-A
OU
_N
RST
M
LOC
K
LOC
K-A
OU
_1
LOC
K-A
OU
_N
RST
M
LOC
K
LOC
K-A
OU
_1
LOC
K-A
OU
_N
HashTable RBTree LinkedList-Release LFUCache RandomGraph
Nor
mal
ized
L1
Cac
he M
isse
s
Top:L1 cache misses per transaction at 1 thread. Bottom:L1 cache misses at 16 threads. Resultsare normalized to RSTM, 1 thread.
Figure 3.5: L1 cache miss rates across accelerated STMs
not admit scalability, we still see that removing validation without adding an expensive
fetch-and-increment enables an improvement of almost 40%. Furthermore, since AOU
decreases the time required to commit a transaction, performance degrades less at higher thread
levels. With faster transactions, the window of conflict is smaller.
In RBTree and LinkedList, the counter is not a bottleneck, but it is imprecise. When a
writing transaction increments the counter and commits, all active transactions are forced to
validate, even if they do not conflict with the writer. Thus for longer transactions and moderate
concurrency (T threads), a transaction is likely to validate T−12 = O(T ) times, even if there
are no conflicts. Since AOU precisely tracks conflicts, it is not victim to false-positive events,
and thus it improves performance by a much larger amount. For RBTree at 16 threads, AOU

52
0
0.2
0.4
0.6
0.8
1
1.2
CG
L
RST
M
LOC
K
RST
M-A
OU
_N
LOC
K-A
OU
_1
LOC
K-A
OU
_N
CG
L
RST
M
LOC
K
RST
M-A
OU
_N
LOC
K-A
OU
_1
LOC
K-A
OU
_N
CG
L
RST
M
LOC
K
RST
M-A
OU
_N
LOC
K-A
OU
_1
LOC
K-A
OU
_N
CG
L
RST
M
LOC
K
RST
M-A
OU
_N
LOC
K-A
OU
_1
LOC
K-A
OU
_N
CG
L
RST
M
LOC
K
RST
M-A
OU
_N
LOC
K-A
OU
_1
LOC
K-A
OU
_N
Hash RBTree LinkedList-Release LFUCache RandomGraph
Nor
mal
ized
Exe
cutio
n Ti
me
Abort
Copy
Validation
CM
MM
Bookkeeping
App Non-Tx
App Tx
Figure 3.6: Timing breakdown for accelerated STMs
increases throughput by 70%, whereas the commit counter improves throughput by less than
10%. LinkedList-Release sees a 2× speedup with AOU, and only a 10% speedup with the
counter. The imprecision and false positives induced by the counter mask the concurrency of
these benchmarks.
As in other benchmarks, RandomGraph single-thread performance is slightly higher with
AOU than with the counter, since AOU does not require an expensive CAS operation. However,
the counter enables reorderings that approximate mixed invalidation [Sco06; SMS06], which
dramatically improves throughput in RandomGraph. Briefly, the counter defers detection of
conflicts between a reader and a subsequent writer of an object until the writer commits. If
the reader commits first, the conflict is ignored. This behavior is not present when using AOU,
since the writer’s acquisition will immediately alert the reader. Since the window of contention
is long in RandomGraph, and since the counter shrinks this window considerably, the commit
counter delivers substantially better throughput than AOU.
Analysis of cache misses identifies an interesting trend: When read set validation is avoided,
cache misses decrease. This is a direct result of the reduced bookkeeping afforded by AOU.
Since the transaction relies on the cache for notification of conflicts, it is not necessary to main-
tain a large list of all objects read in order to enable validation. Additionally, there is no costly
validation step that pulls metadata into the cache, possibly at the expense of objects read transac-
tionally. By reducing bookkeeping, AOU reduces cache pressure and avoids capacity evictions,
decreasing the overall miss rate. The commit counter has a similar, but less pronounced effect.

53
Latency and Overhead
Figure 3.6 quantifies the overheads incurred by our various TM systems in single-thread execu-
tion. Among the principle overheads, only validation and bookkeeping vary significantly across
systems; other overheads are either negligible (due to the lack of conflicts in single-threaded
code) or constant. Single-thread latency measurements are an effective way to gauge the fixed
overheads of the STM instrumentation that cannot be overcome with concurrency.
Our latency measurements reflect some instrumentation artifacts. As in HASTM [WCW07],
since object metadata is located within data objects, the cost of pulling an object into the cache
is represented as bookkeeping rather than real work (App Tx). In RSTM, this results in one level
of indirection being assigned to App Tx and the other to metadata manipulation (Bookkeeping),
as desired. However, for LOCK this artificially inflates bookkeeping. Secondly, since per-
access validation is only a three-instruction sequence (cache hit, compare, branch), we treat that
overhead as App Tx rather than as validation, in order to limit the instrumentation cost. This
incorrectly adds all per-access validation in the LOCK-based systems to App Tx overhead.
The combination of these effects paints a surprising picture. Indirection and per-access val-
idation overheads are roughly equal, resulting in a slight slowdown in LOCK for most bench-
marks despite the removal of indirection. Furthermore, in the absence of validation we see that
metadata bookkeeping is the dominant overhead. In our systems, this overhead is the cost of
flexibility and obstruction freedom: we must bookkeep eager and lazy writes separately, result-
ing in higher constant overhead per transaction, and we must execute multiple branches when
reading any object, in order to choose between visible and invisible reads (in RSTM) and eager
or lazy acquire. We also collect extensive statistics to drive contention management and adaptive
policies (not employed here) that choose between eager and lazy acquire, and between visible
and invisible readers. To support obstruction freedom and flexible contention management, our
systems must obey a protocol for stealing ownership, stealing locks, and aborting competitors
that places tens of instructions on the critical path. For large transactions, this per-object cost is
an obstacle to good performance.

54
Sensitivity to Cache Size
Our benchmarks present a best-case scenario for LOCK-AOU_N and RSTM-AOU_N. Even Ran-
domGraph fits entirely in the L1 cache, and thus despite hundreds of transactional objects, AOU
can still be leveraged to avoid all incremental validation overhead. Under more taxing condi-
tions (such as cache associativity constraints or read sets dramatically larger than the number
of cache lines and victim-buffer entries), the relative benefit of AOU will decrease. Assuming
no commit counter, for R >> C objects, where C is the cache size (in lines), the expected
validation overhead is O((R − C)2). Compared to the validation overhead of RSTM or LOCK
(O(R2)), the cost will be less in practice, though still quadratic. For such workloads, combining
AOU and the commit counter would appear to be an attractive option.
3.6 Application 2: Accelerating Locks
For TRANSACT 2009, I collaborated with Michael F. Spear to propose the use of AOU in ac-
celerating transactional mutex locks (TML), a scalable reader-writer lock. In shared memory
applications, locks are the most common mechanism for synchronizing access to shared mem-
ory. While transactional memory (TM) research has identified novel techniques to replace some
lock-based critical sections, these techniques suffer from many problems [MAK01]. Funda-
mentally, TM’s speculative nature does not appear to be suitable for small but highly contended
critical sections, such as those common in operating systems and language runtimes, where low
latency is critical. From an engineering perspective, modern STM runtimes typically require
significant amounts of global and per-thread metadata. This space overhead may be prohibitive
if TM is not used widely within the language runtime.
Of course, it is possible to improve the scalability of a lock-based critical section with-
out abandoning locks altogether. In particular, reader/writer (R/W) locks, read-copy-update
(RCU) [McK04],1 and sequence locks [Lam05]2 all permit multiple read-only critical sections
1RCU writers create a new version of a data structure that will be seen by future readers. Cleanup of the oldversion is delayed until one can be sure (often for application-specific reasons) that no past readers are still active.
2Sequence lock readers can “upgrade” to write status so long as no other writer is active, and can determine,when desired, whether a writer has conflicted with their activity so far. Readers must be prepared, however, to backout manually and retry on conflict.

55
to execute in parallel. Each of these mechanisms comes with significant strengths and limita-
tions: R/W locks allow the broadest set of operations within the critical section, but typically
require static knowledge of whether a critical section might perform writes; RCU ensures no
blocking in a read-only operation, but constrains the behavior allowed within a critical section
(such as permitting only forward traversal of a doubly-linked list); and sequence locks forbid
both function calls and any traversal of linked data structures. Furthermore, the performance
characteristics of these mechanisms (such as the two atomic operations required for a R/W
lock), or their programmer overhead (e.g., the manual instrumentation overhead for rollback
of sequence locks) make it troublesome to use them, even in situations where these techniques
appear appropriate.
The nature of many critical sections in systems software suggests an approach that spans
the boundary between locks and transactions: specifically, we may be able to leverage TM
research to create a more desirable locking mechanism. Transactional Mutex Lock (TML), a
scalable locking mechanism was developed by Michael F. Spear. TML offers the generality of
mutex locks and the read-read scalability of sequence locks, while avoiding the atomic oper-
ation overheads of R/W locks or the usage constraints of RCU and sequence locks. We used
AOU to enable event-based communication between lock acquirer (writer) and current holders
(readers). This enables threads to detect lock-related operations without any polling (which
improves performance) and simplifies the memory management issues since threads are imme-
diately informed when the lock is stolen.
3.6.1 Background : Transactional Mutex Locks
TML is built atop an STM with minimal storage and instrumentation overheads. In contrast
to previous “lightweight” STMs, we explicitly limit both programming features and potential
scalability. In turn, TML can operate with as little as one word of global metadata, two words
of per-thread metadata, and low per-access instrumentation.
The most straightforward STM API consists of four functions: TMBegin and TMEnd mark
the boundaries of a lexically scoped transaction, and TMRead and TMWrite are used to read
and write shared locations, respectively. Compared to STMs, TML institutes several simplifica-

56
TMBegin:1 while (true)2 lOrec = gOrec3 if (isEven(lOrec))4 break
TMEnd:1 if (isOdd(lOrec))2 gOrec++
TMRead(addr)1 tmp = *addr2 if (gOrec != lOrec)3 throw aborted()4 return tmp
TMWrite(addr, val)1 if (isEven(lOrec))2 if (!cas(&gOrec, lOrec, lOrec + 1))3 throw aborted()4 lOrec++5 *addr = val
Figure 3.7: Single-orec STM Algorithm.
tions. Any writing transaction is inevitable (will never be rolled back). Inevitability precludes
the use of condition synchronization after a transaction’s first write (for simplicity, we omit
self-abort altogether). At the same time, it means that writes can be performed in place without
introducing the possibility of out-of-thin-air reads in concurrent readers.
Figure 3.7 lists the algorithm. A single word of global metadata (gOrec) provides all
concurrency control. When odd, it indicates that a writer is active; when even, zero or more
readers may be active. A single words of metadata is stored per transaction: a local copy of the
global orec (lOrec). Instrumentation is also low. The single global orec (gOrec) is sampled
at transaction begin, and stored in transaction-local lOrec. To write, a transaction attempts
to atomically increment gOrec to lOrec + 1. Reads postvalidate to ensure that gOrec and
lOrec match (which is trivially true for transactions that have performed any writes), and the
commit sequence entails only incrementing gOrec in writing transactions. For simplicity, any
memory management operation (malloc or free) is treated as a write, and is prefixed with
the instrumentation of TMWrite lines 1–4.

57
With only one orec, the runtime does not support parallelism in the face of any writes, but
the per-write instrumentation can be simplified: no mapping function is called on each access,
and the read log has a single entry. If every transaction is expected to read at least one location
(a reasonable assumption under most, but not all transactional semantics [MBS08]), then it is
correct to hoist and combine all “prevalidate” operations to a single operation at the beginning
of the transaction. The algorithm is livelock-free: once W increments gOrec, it is guaranteed
to commit (it cannot abort due to conflicts, nor can it self-abort).
3.6.2 AOU Acceleration for Locks
AOU eliminates the need for read instrumentation within TML transactions. With AOU the
alerted processor immediately jumps to a handler that can either (a) validate the transaction,
re-mark the line, and continue, or (b) roll back and restart.
The changes to Figure 3.7 are trivial: in TMBegin, the transaction must use an aload] to
sample gOrec, and must install a handler (which may be as simple as throw aborted()).
In TMEnd (or upon first TMWrite), the transaction must unmark the line holding gOrec. De-
pending on the implementation of AOU, writes may (in the best case) acquire gOrec with a
simple store, or (in the worst case) they may require an atomic read-modify-write. Transaction
behavior is unchanged from the baseline, except that a read-only transaction does not poll for
changes to gOrec. If its processor loses the line holding gOrec, it will be notified immedi-
ately.
Virtualization support is straightforward: on a context switch, the AOU mark is discarded
from all lines. When a preempted thread resumes, the OS provides a signal, so that the thread
can test gOrec and abort if necessary. Additionally, writers must not be preempted between
lines 2 and 4 of TMWrite. Alternatively, they may briefly store a per-thread identifier in gOrec
during TMWrite.
By detecting alerts immediately at the time when a write is acquired, AOU eliminates all
read instrumentation. If read-only transaction T is traversing a linked data structure, and writer
transaction W will modify that data structure, then so long as W acquires gOrec before per-
forming any free() calls, T will be guaranteed to take an immediate alert (caused by the

58
acquisition of gOrec) before the free() can return memory to the operating system.
A key challenge with speculative critical sections like in TML is the memory allocator. If
a writer acquires the lock and deallocates a memory location (like it can do with mutex locks),
readers could potentially be dereferencing illegitimate data, which can lead to dangerous side-
effects. By providing immediate aborts, AOU ensures that concurrent readers’ are immediately
stopped and their alert handlers are invoked. This ensures that transactions can employ conven-
tional memory allocator libraries within critical sections.
3.6.3 Evaluation
We evaluate four run-time systems. The runtimes are configured as follows. The optimizations
in variants of TML were all performed by hand. We use the simulation parameters listed in
Table 3.4.
• TML – The default TML implementation, with transaction metadata accessed via thread-
local storage, and setjmp/longjmp for rollback.
• TML-tls – Removes thread-local storage overhead from TML. TM implementations typ-
ically store per-thread metadata on the heap. Every transactional access requires the
address of the calling thread’s metadata, and rather than add an extra parameter to ev-
ery function call to provide a reference to this metadata, we rely on thread-local storage
(TLS). With OS support, TLS is almost free; otherwise, an expensive pthread API
call provides TLS. Avoiding TLS overhead is a well-understood optimization [WCW07];
TML merely makes it simpler.
• TML-pwi – Builds upon TML by adding the PWI (Post-write-instrumentation) optimiza-
tion. When a transaction issues its first write to shared memory, via TMWrite, it becomes
inevitable and cannot abort. Other concurrent transactions are also guaranteed to abort,
and to block until the writer completes completes. Thus once a transaction performs its
first write, instrumentation is not required on any subsequent read or write. For any call to
TMRead that occurs on a path that has already called TMWrite, lines 2–3 can be skipped.
Similarly, for any call to TMWrite that occurs on a path that has already called TMWrite,

59
lines 1–4 can be skipped. Thus after the first write the remainder of a writing transaction
will execute as fast as one protected by a single mutex.
• TML-aou – Adds AOU support, as well as PWI optimizations, to TML. AOU eliminates
all read instrumentation, since by design any change to the lock variable will trigger an
alert at the treader end. PWI is used to optimize for write instrumentation.
Results appear in Figure 3.8; all performance numbers are normalized to coarse-grain locks.
The ability to remove all read instrumentation has a substantial impact on the list and tree
benchmarks. The list is particularly interesting, since PWI offers little benefit. Additionally, the
impact is noticeable even on the counter, for which our compiler optimizations had little effect
on the Niagara. However, AOU introduces an unfortunate tradeoff: since AOU is modeled as a
spontaneous subroutine call, we require setjmp for rollback. This leads to noticeable overhead
on the SPARC, in part due to register windows and in part due to the single-issue cores. Best-
effort hardware TM systems [TrC08] have also proposed micro-architecture support for register
checkpointing; this support would have a clear beneficial impact on TML-aou performance.
3.7 Application 3: Detecting Atomicity Bugs
Data-race bugs occur when there are concurrent accesses to the same piece of shared-data, and
at least one of the accesses is a write. Flanagan and Qadeer [FlQ03] introduced the notion
of atomicity violation and distinguished it from a data race. They are a specific class of con-
currency bugs that occur due to runtime interleaving between memory accesses from different
threads that break the atomicity expectations of the programmer. Atomicity violations typically
occur when the software (or programmer) annotates the program incorrectly due to which two
accesses that are expected to fall in the same critical section (or atomic region) are interleaved
by an external access.
At ASPLOS 2006 Lu et al. [LT06] proposed the use of an access invariant to detect such
bugs. The access invariant is held by an instruction if the access pair, composed of itself and
its preceding local access to the same location, is never unserializably interleaved. The thread
whose atomicity is disrupted is the local thread (its accesses are called local accesses) and
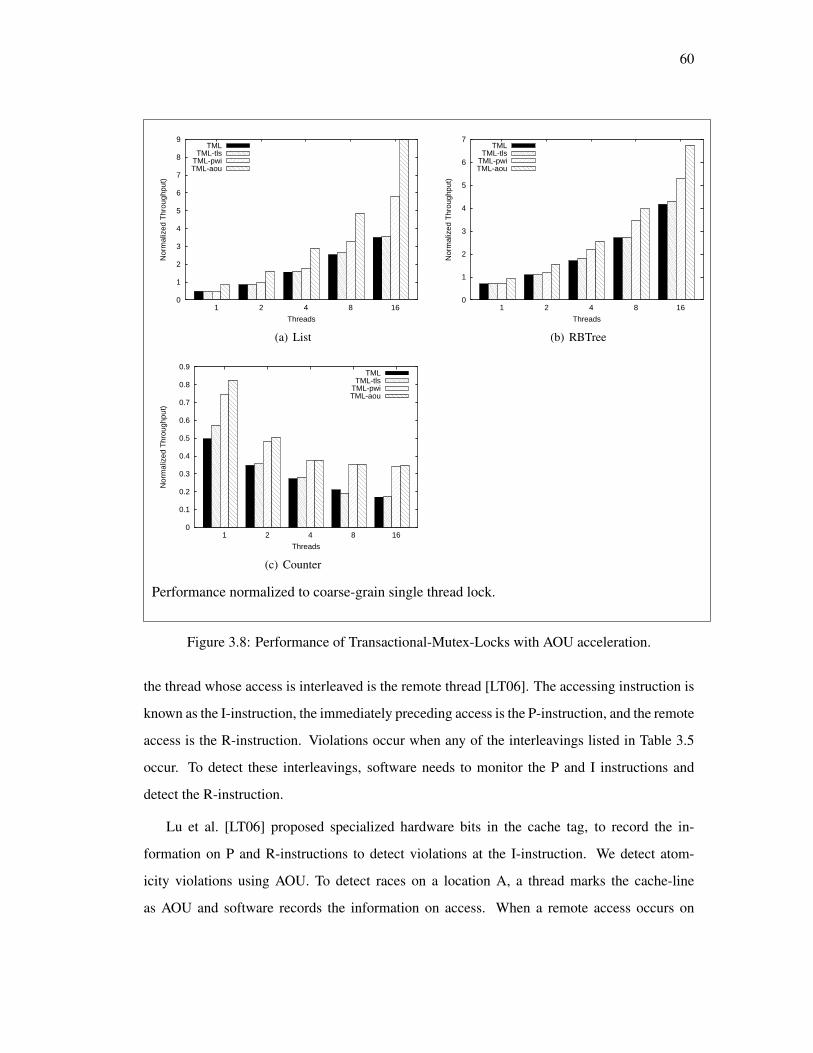
60
0
1
2
3
4
5
6
7
8
9
168421
Nor
mal
ized
Thr
ough
put)
Threads
TMLTML-tls
TML-pwiTML-aou
(a) List
0
1
2
3
4
5
6
7
168421
Nor
mal
ized
Thr
ough
put)
Threads
TMLTML-tls
TML-pwiTML-aou
(b) RBTree
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
168421
Nor
mal
ized
Thr
ough
put)
Threads
TMLTML-tls
TML-pwiTML-aou
(c) Counter
Performance normalized to coarse-grain single thread lock.
Figure 3.8: Performance of Transactional-Mutex-Locks with AOU acceleration.
the thread whose access is interleaved is the remote thread [LT06]. The accessing instruction is
known as the I-instruction, the immediately preceding access is the P-instruction, and the remote
access is the R-instruction. Violations occur when any of the interleavings listed in Table 3.5
occur. To detect these interleavings, software needs to monitor the P and I instructions and
detect the R-instruction.
Lu et al. [LT06] proposed specialized hardware bits in the cache tag, to record the in-
formation on P and R-instructions to detect violations at the I-instruction. We detect atom-
icity violations using AOU. To detect races on a location A, a thread marks the cache-line
as AOU and software records the information on access. When a remote access occurs on

61
Table 3.5: Atomicity violation bugs defined by Lu et al. [LT06]P-Inst I-inst R-inst Atomicity violation
R R W(RR
)←W Reads not consistent within atomic section
W R W(WR
)←W Write in atomic section overwritten by external thread;
read does not get correct value.
W W R(WW
)← R Writes in atomic section are not atomic; earlier write
visible to remote read before later write has propa-gated.
R W W(RW
)←W Writes in atomic section may not be consistent with
read in atomic section; remote write dependent on theread may view external write.
R - Read; W-Write. Operations in brackets indicate atomic operation needed. All opera-tions show in tabular operate on a single variable.
the line, the thread alert handler records the %aou alertType register (R-instruction informa-
tion), %aou alertAddress (location), %alert alertState (P-instruction information). At the I-
instruction, AOU will generate another trigger since its set up to monitor local accesses as well.
Using the %aou alertType register (I-instruction information) and the previously recorded in-
formation the system can flag violations.
To measure the overheads we used the benchmarks provided by Lu et al. [LT06] and com-
pare the AOU and AVIO scheme with a software binary-instrumentation scheme (Valgrind3).
The main difference between AOU violation detection and the AVIO [LT06] is that AOU
records information in software, while AVIO uses extra hardware bits to record without dis-
rupting the program. As can be seen from Table 3.6, the software handlers do add overhead
over AVIO, but are still significantly better than an all-software approach. The overheads seem
acceptable, given that AOU is also general purpose (e.g., RPC calls).
Multi-variable Atomicity Violations
While in this section, we discussed atomicity violations on a single variable, AOU can be easily
extended to support multi-variable atomicity violation detection as well. Multi-variable viola-
tions occur when the P-instruction and the I-instruction access different variables. With AOU,
the detection of the violation itself occurs in software which can lookup the list of accesses
3Valgrind is not compatible with SPARC. Hence we measure its overheads on the real x86 machine.

62
Table 3.6: Execution time overhead for Atomicity violation detectionApplication AOU AVIO Valgrind
Apache 2.1 1.15 2567Mysql 2.3 1.2 3215lu-cont 1.3 1.05 589radix 1.5 1.07 209
Base application execution time=1. Valgrindoverheads measured on real x86 hardware3.3Ghz,16MB L2 Core2duo machine. AOUand AVIO overheads measured on simulator.
and check if an earlier P-instruction (to a different address) was affected by a remote operation.
AVIO [LT06] performs detection in hardware and hence would find it challenging to check all
other caches lines for the occurence of a P-instruction.
3.8 Other Applications
3.8.1 AOU for Fast User-space Mutexes
The low latency of alert signals shifts the tradeoff between spinning and yielding on lock ac-
quisition failure, especially in the case of user-level thread packages. Let us consider the ideal
behavior of a user-level mutex: a thread T will yield immediately when it fails to acquire lock
L, and will wake immediately when L is released. To approximate this behavior, we need only
prefix the acquire attempt with an aload of the lock. Then, on lock failure T can yield, and on
an alert we yield the current thread and switch back to T . In this manner no cycles are wasted
spinning on an unavailable lock, and no bus traffic is generated by multiple unsuccessful acquire
attempts.
For optimal performance, the thread package may specify that the alert handler attempts
to acquires L on T ’s behalf when an alert is given. This ensures the lowest latency between
the release of L and its acquisition by T . Additionally, if L is acquired by T ′ before the alert
handler can acquire it for T , the thread switch to T can be avoided. Furthermore, since alerts are
also generated by local events, this method is appropriate regardless of whether the lock holder
and failing acquirer reside on the same processor or separate processors. This technique is also
general to multithreaded code independent of whether that code uses transactions, and thus is

63
more general (and carries less overhead due to transaction rollback) than a similar proposal by
Zilles and Baugh [ZiB06].
3.8.2 Debugging
Modern microprocessors currently provide limited support for debuggers through watchpoint
registers. On the X86 there are 4 debug registers which are used by GDB to maintain memory
regions. These debug registers can watch regions of 1,2 or 4bytes long. However, GDB has to
maintain reference count for these debug registers to allow multiple watchpoints to share these
registers. With pervasive parallelism, four debug watchpoints registers will probably be insuf-
ficient. The alert-on-update allows the debugger to set watchpoints at only coarser cache-line
granularity but supports larger number of watchpoints, upto primary cache size. It is possible
for the debugger with feedback parameter from the alert signal indicating the address being
alerted on, to provide finer granularity watchpoints up to word level in software.
3.8.3 Code Security
Due to the fine granularity of the alert-on-update mechanism, it is suitable for reacting to mem-
ory corruption in some settings where page-based detection mechanisms are either too expen-
sive or too space-inefficient. We do not consider AOU to be a fine-grained replacement for all
or even most page-based memory protection techniques: page protection traps causes before
memory is modified modification, whereas AOU alerts occur after modification to a location,
making AOU clearly unsuitable for tasks such as garbage collection [ApL91].
Buffer Overflows In order to detect buffer overflows in legacy code, a program could aload
portions of its stack. A particularly appealing technique, inspired by DieHard, is to use random-
ization across installations of an application: the compiler could choose a random number of
cache lines of buffering between stack frames at compile time, and then aload those empty lines
as part of the function prologue. Since the size of the padding is known at compile time, pa-
rameter passing via the stack would not be compromised, but the randomization of the padding
across builds of the program would increase the likelihood that an attacker could not attack

64
multiple installations of a program with the same input. To do so would very likely result in an
alert-based detection for at least one installation, thereby revealing the buffer vulnerability.
Notification on Dynamic Code Modification Another appealing use of aload is to permit
fine-grained protection of code pages. Although the majority of applications do not require the
ability to dynamically modify their code, and are well served by using page-level protection,
thereq is no mechanism by which applications who modify their own code pages can ensure
that malicious code does not tamper make unauthorized modifications.
With aload, however, a program could mark the alert bits of code pages, and then use a
private signature field to indicate to the alert handler when the application is making a safe
modification to its code. If the alert handler is invoked and the private signature matches a hash
of the address causing the alert, the handler can safely assume that the alert was caused by a
trusted operation. If the alert handler detects a signature conflict, it can assume that the code
pages are being modified by an untrusted agent, and can raise an appropriate exception.

65
Chapter 4Isolation: Programmable Data Isolation
In this chapter, we elaborate on programmable-data-isolation (PDI), a hardware mechanism
that enables software to have fine-grain control over the propagation of write operations in
a multiprocessor system. Section 4.1 motivates the need for a data isolation mechanism in
shared-memory systems and briefly introduces the notion of lazy cache coherence. Section 4.2
introduces a lazy coherence protocol based on broadcast networks, TMESI-Bcast, and discusses
the coherence encoding that allows bulk state manipulations on isolated data. Section 4.3 dis-
cusses a directory-based version of TMESI and introduces a mechanism for detecting specula-
tive sharing between processors to optimize bulk state manipulations. Finally, Section 4.4 and
Section 4.5 discuss two flexible transactional memory systems, RTM and FlexTM, that exploit
TMESI to implement transactional isolation. We use these TM systems to also illustrate var-
ious techniques to virtualize data isolation when the cache runs out of space. RTM explores
a software-only approach (Section 4.4.3), while FlexTM explores two hardware techniques: a
hardware overflow controller (Section 4.6.2) and fine-grain translation hardware (Section 4.6.3).
Finally, Section 4.8 concludes with a discussion on other applications that could possibly benefit
from PDI.

66
4.1 Motivation
In shared-memory systems, coherence guarantees that a write operation in software is implic-
itly visible to all threads that share that data. While this implicit propagation of writes pro-
vides fast flexible communication, it is not often always desired. For example, vulnerabilities
in Adobe’s pdf plugin enables attackers to make changes that are immediately visible to the
browser [PaF06]. Shared memory systems do not provide any mechanism to hide a plugin’s
updates from the core application. Once a write operation is issued, the software does not have
any control over the communication of the value to other copies in the system.
In emerging programming aids like Thread-Level-Speculation [SBV95; SCZ00] and Trans-
actional Memory (TM) [HWC04; MBM06; AAK05; RaG02; MaT02], software marked code
regions perform speculative memory operations that are assumed to be not visible to concurrent
tasks until the end of the speculation region. Isolation of memory state is required to guarantee
the atomicity of such tasks.
Finally, online software testing is another application that requires low-overhead data iso-
lation capability. In vivo (IV) testing of software applications [CMK08; TXZ09; MKC07] is
a recently proposed approach, in which microbenchmarks test deployed software at specific
points. To enable isolated online testing we need to provide each test case with its own sep-
arate snapshot of memory that can sandbox updates and test cases. Currently, online tests are
sandboxed within heavyweight OS processes; an alternative light weight isolation mechanism
would enable us to run more stringent tests frequently.
In this dissertation, we propose a hardware mechanism, Programmable-Data-Isolation
(PDI), that enables software to control the transparency of writes in shared memory. Soft-
ware can use PDI to (1) decouple the execution of a write from its propagation, i.e. execute
a write operation, make it immediately visible to the local thread, but hide the write operation
from remote threads until specified by software, (2)atomically make visible the set of isolated
memory blocks to other threads in the system, and (3)atomically “undo” isolated blocks and
restore coherency with the rest of the memory system.
We use the sample execution in Figure 4.1 to illustrate PDI. The example involves three
threads, T1 and T3, both of which execute speculative, isolated code regions, and T2, which

67
performs non-isolated loads and stores. PDI seeks to make transparent the stores marked for
isolation within the speculative tasks, T1 and T3 i.e., Stores while visible to subsequent local
accesses are not visible to accesses in other threads. When a speculative region commits it
propagates its modifications, from which point future accesses (either local or remote) can view
the new value. As shown, the updates from T1 are visible to the second load in T2. At T1’s
commit, T3 aborts the isolated region to ensure coherence and that subsequent accesses receive
the up-to-date values.
Store X,1
Load X (1)
Begin_Isolation
Commit
T1
Load X (0)
Initially X = 0
Load X (1)
T2
Store X,2
Load X (2)
Begin_Isolation
Abort
T3
Time
T1, T2 and T3 indicate threads. The code regions marked for isolation are speculative. The store addr,value indicates
value written to addr. The load addr (value) indicates value read from addr.
Figure 4.1: Example of data isolation.
4.1.1 Previous Approaches to Data Isolation
To implement data isolation, the memory system needs to support multiple versions of a cache
block. Caches inherently provide data buffering, but coherence protocols normally propa-
gate modifications as soon as possible to all copies. Hardware transactional memory pro-
posals investigated versioning mechanisms to support transaction isolation. Most HTM pro-
posals [AAK05; RHL05; MBM06; HWC04; CTC06] allow a thread to delay this propaga-
tion while executing speculatively, and then to make the entire set of written blocks visible to
other threads atomically. Previous research have adopted two alternative approaches. Some

68
proposals track data (new and old) at the granularity of words and individual write opera-
tions, which leads to extra storage buffers and overheads proportional to length of specula-
tion [GFV99; RPA97; WAF07]. Furthermore, this also increases the cost of either rollback or
commit since these operations need to be performed at a fine-granularity on individual loca-
tions. Another body of work seek to amortize the cost of speculative state and their associated
coherence operations across multiple cache lines. They enable speculation at the granularity
of chunks (groups of memory operations), and at commit attempt to acquire coherence store
permissions for all cache lines speculatively written in that chunk [HWC04; CTM07]. These
designs require an aggressive memory system with support for bulk coherence operations and
global commit arbitration.
4.1.2 Our Approach : Lazy Coherence
The main challenges associated with supporting data isolation are: First, we need a memory
system where the speculatively written values and the non-speculative current values can be
maintained simultaneously in the memory hierarchy. The speculative values while transparent
to remote tasks need to be accessible within the speculative task. Second, conventional co-
herence protocols maintain the single-writer or multiple-reader invariant. Speculative memory
operations can be enabled across multiple processors which leads to multiple copies of the same
cache line being concurrently read and written. Finally, coherence protocol operations need to
logically appear to happen on groups of memory addresses, to preserve a mutually consistent
view.
To address these challenges we propose the notion of lazy coherence in which coherence
messages are eagerly sent out at each memory operation (speculative or non-speculative) but the
coherence state changes are performed lazily (under software control) to enable isolation. We
use a level of cache close to the processor to hold the new speculative copy of data, and rely on
shared lower levels of the memory hierarchy to hold the current values of the cache line. This
design results in many benefits: we can employ a standard memory hierarchy with conventional
cache lines being used as a buffer to hold the speculative data. Since the speculative data value
is already drained into the caches, when a speculative chunk commits (or aborts) the new values
can be published with a few simple operations on the local cache state.

69
Table 4.1: Programmable Data Isolation APIRegisters%t_in_flight: a bit to indicate that a isolated task is currently executingInstructionsbegin_t set the %t_in_flight register to indicate the start of a speculative
regiontstore [%r1], %r2 write the value in register %r2 to the word at address %r1; isolate the
line (TMI state)tload [%r1], %r2 read the word at address %r1, place the value in register %r2, and tag
the line as transactionalabort discard all isolated (TMI or TI) lines; clear all transactional tags and
reset the %t_in_flight registercas-commit [%r1], %r2, %r3 compare %r2 to the word at address %r1; if they match, commit all
isolated writes (TMI lines) and store %r3 to the word; otherwise dis-card all isolated writes; in either case, clear all transactional tags, dis-card all isolated reads (TI lines), and reset the %t_in_flight reg-ister
Lazy coherence also forwards coherence messages similar to traditional cache coherence,
at the time of the individual memory operations. We reuse the actions that already exist in a
conventional cache coherence protocol. The coherence messages on speculative operations are
noted down at the the remote cache, but the remote processor is allowed to continue accessing
the cached copy. When a subsequent remote chunk commits we invalidate the state of the cache
lines for which speculative memory operations were intercepted. This can also be achieved with
a few completely local state change operations.
4.2 Broadcast-based TMESI
In this section, we describe the first generation transactional-MESI which was developed as
part of the RTM transactional memory project (see Section 4.4). This protocol was designed
assuming a broadcast interconnect linked the processor-private L1s with the shared L2 in a
multicore; like traditional broadcast protocols it implements processors responses using shared
wired-OR lines.
Table 4.1 presents the processor interface for data isolation. Speculative reads and writes
use TLoad and TStore instructions. Since PDI was first developed in the context of transac-
tional memory the api uses the terms “transactional” to refer to speculative instructions. These
instructions are interpreted as speculative when the transactional bit (%t_in_flight) is set.

70
As described in Section 4.4, this allows the same code path to be used by by speculative blocks
that use hardware support for speculation and those that employ software support when the
cache resources are overflown. TStore is used for writes that require isolation. TLoad is used
for reads that can safely be cached despite remote TStores.
Speculative reads and writes employ two new coherence states: TI and TMI. These states
allow a software policy, if it chooses, to activate lazy coherence and permits multiple speculative
tasks to share cache blocks for reading and writing in a transparent manner. A conflict occurs
between two copies of a cache block when two concurrent tasks both access the block and
at least one of the accesses is a write. Hardware helps in the detection task by piggybacking
a threatened (T) signal/message, analogous to the traditional shared (S) signal/message, on
responses to read-shared bus requests whenever the line exists in TMI state somewhere in the
system. The T signal warns a reader of the existence of a speculative writer.
TMI serves to buffer speculative local writes. Regardless of previous state, a line moves to
TMI in response to a PrTWr (the result of a TStore). The first TStore to a modified cache line
results in a writeback prior to transitioning to TMI to ensure that lower levels of the memory
hierarchy have the latest non-speculative value. A TMI line then reverts to M on commit and
to I on abort. Software must ensure that among any concurrent speculative chunks which have
written, at most one commits, and if a conflicting reader and writer both commit, the reader does
so first from the point of view of program semantics. Lines in TMI state threaten any remote
reads, resulting in the remote reader loading the cache in TI state. A line in TMI state threatens
read requests and suppresses its data response, allowing lower levels of the hierarchy to supply
the non-speculative version of the data.
TI allows continued use of data that have been read by the current transaction, but may have
been speculatively written by a concurrent transaction in another thread. An I line moves to
TI when threatened during a TLoad; an M, E, or S line moves to TI when written by another
processor while tagged transactional (indicating that a TLoad has been performed by the current
transaction). A TI line must revert to I when the current transaction commits or aborts, because
a remote processor has made speculative changes which, if committed, would render the local
copy stale. No writeback or flush is required since the line is not dirty.
The CAS-Commit instruction performs the usual function of compare-and-swap. In addi-

71
BusRd/S
BusTRdX,UpgrTX/Flush
PrTWr/Flush
PrTRd/−
PrTRd/−
PrRd,PrTRd/−
PrTWr/−
PrRd,PrTRd/−
PrTWr/ BusTRdX
PrWr
X/–
PrRd/−
PrWr
PrRd /
BusRd,X/–
PrRd/−
PrRd /
/ BusRdX
PrRd&¬t_in_flight/ BusRd(T)
PrRd,PrWr/−
PrWr/−
PrRd&t_in_flight/BusRd(T)
PrTRd/BusRd(S,T)
/ UpgrX
/ UpgrX
E
M
I
S
PrTWr/–
X/–
X/Flush
BusRd TMI
TS
PrTWr
TE
TM
TI
PrTWr/ UpgrTX
PrRd,PrTRd/−
/ Flush
BusTRdX, UpgrTX/–
BusRd/Flush
PrRd,PrTRd,PrTWr,BusTRdX,UpgrTX/– BusRd/T
BusTRdX, UpgrTX/–
PrTRd/BusRd(S,T)
MESI States
TMESI States
PrTRd/−
BusRd/S
CAS−Commit
ABORTPrRd,PrTRd,BusRd,BusTRdX,UpgrTX/−
/ FlushPrTWr
PrTWr/ UpgrTX
BusRd/S
BusRd/S
BusRd(S,T)
BusRd(S,T)
PrTRd/BusRd(T)
PrWr,BusRdX,UpgrX/ ABORT state, MESI action;if TMI, alert processor
Dashed boxes enclose the MESI and TMESI subsets of the state space. On a CAS-Commit, TM, TE, TS, and TI
revert to M, E, S, and I, respectively; TMI reverts to M if the CAS succeeds, or to I if it fails. Notation on transitions
is conventional: the part before the slash is the triggering message; after is the ancillary action (‘–’ means none). X
stands for the set {BusRdX, UpgrX, BusTRdX, UpgrTX}. “Flush” indicates writing the line to the bus. S and T
indicate signals on the “shared” and “threatened” bus lines respectively. Plain, they indicate assertion by the local
processor; parenthesized, they indicate the signals that accompany the response to a BusRd request. An overbar
means “not signaled”. For simplicity, we assume that the base protocol prefers memory–cache transfers over cache–
cache transfers. The dashed transition from the TMESI state space to the MESI state space indicates that actions
occur only on the corresponding cache line. “ABORT state” is the state to which the line would transition on abort.
The solid “CAS-Commit” and “ABORT” transitions from the TMESI state space to the MESI state space operate on
all transactional lines.
Figure 4.2: TMESI Broadcast Protocol
tion, if the CAS succeeds, speculatively written (TMI) lines revert to M, thereby making the
data visible to other readers through normal coherence actions. If the CAS fails, TMI lines are
invalidated, and software branches to an abort handler. In either case, speculatively read (TI)

72
Table 4.2: Coherence state encoding for fast commits and aborts.T A MESI C/A M/I State0 — 0 0 — —0 — 1 1 0 1
}I
0 — 0 1 — — S0 — 1 0 — — E0 — 1 1 1 —0 — 1 1 0 0
}M
1 — 0 0 — — TI1 — 0 1 — — TS1 — 1 0 — — TE1 — 1 1 — 0 TM1 — 1 1 — 1 TMI
T Line is (1) / is not (0) transactionalA Line is (1) / is not (0) alert-on-updateMESI 2 bits: I (00), S (01), E (10), or M (11)C/A Most recent txn committed (1) or aborted (0)M/I Line is/was in TMI (1)
lines revert to I and any transactional tags are flashed clear on M, E, and S lines.The motivation
behind CAS-Commit is simple: software TM systems invariably use a CAS or its equivalent to
commit the current transaction; we overload this instruction to make buffered transactional state
once again visible to the coherence protocol. The Abort instruction clears the transactional state
in the cache in the same manner as a failed CAS-Commit.
TMESI-Bcast enforces the single-writer or multiple-reader invariant for non-transactional
lines. For transactional lines, FlexTM also enforces (1) TStores can only update lines in TMI
state and (2) TLoads that are threatened can only cache the block in TI state. Software is
expected to ensure that at most one of the speculation with overlap commits. It can restore
coherence to the system by triggering an Abort on the remote speculation’s cache, without
having to re-acquire exclusive access to store sets [HWC04; CTC06].
4.2.1 Bulk State Changes
A cache line can be in any one of the four MESI states (I, S, E, M), the speculative states (TI,
TMI), or transactionally tagged variants of M, E, and S. If the protocol were implemented as a
pure automaton, this would imply a total of 9 stable states, compared to 4 in the base protocol.
To allow fast commits and abort of speculative state, our cache tags can be encoded in six
bits, as shown in Table 4.2.
At commit time, based on the outcome of the CAS in CAS-Commit, we pulldown (broadcast
a 0 on abort) the C/A bit line of transactional lines for which the T bit has been conditionally en-

73
abled. The conditional pull down is achieved by adding two separate series pull down transitors
to the C/A bit. The two transistors form a logical and between an external conditional enable
signal and the adjacent T bit; the C/A bit of lines with the T bit set are pulled down in bulk when
the conditional enable is asserted. Following this, we flash-clear the A and T bits. Flash clear
can be achieved with a single pull-down transitor enabled by a flash clear signal. Ken Mai’s
thesis discusses the circuit for conditional flash clear and flash clear in detail [Mai05] For TM,
TE, TS, and TI the flash clear alone would suffice, but TMI lines must revert to M on commit
and I on abort. We use the C/A bit to distinguish between these: when the line is next accessed,
M/I and C/A are used to interpret the state before being reset. If T is 0, the MESI bits are 11,
C/A is 0, and M/I is 1, the cache line state is invalid and the MESI bits are changed to reflect
this. In all other cases, the state reflected by the MESI bits is valid.
Note that, when the T bit is set we can ignore the C/A bit when interpreting the coherence
state. We can possibly eliminate the C/A bit, by adding three pull-down transistors to the
MESI’s state. The pull down transistors would logically and the conditional enable signal,
the T bit, and the M/I bit. On a conditional enable, if the T bit and M/I bit are set, the MESI
state will drop to I.
4.3 Directory-based TMESI
A key challenge with TMESI-Bcast is the addition of five stable states to the basic MESI pro-
tocol. TMESI-Dir adapts PDI to a directory protocol and extends it to incorporate signatures
(Section 3.4.3). It also simplifies the management of speculative reads, adding only two new
stable states to the base MESI protocol, rather than the five employed in RTM [SSH07]. Details
appear in Figure 4.3.
It would be possible to eliminate the transactionally tagged TM ,TE, and TS states entirely,
at the cost of some extra reloads in the event of read-write sharing. Suppose thread T1 has read
line X speculatively at some point in the past. The transactional tag indicates that X was
TLoaded as part of the current speculative region. A remote write toX (appearing as a BusRdX
protocol message) can moveX to I, because software (or other hardware like signatures) will be
tracking potential conflicts. If TLoads are replaced with normal loads and/or the transactional
tags eliminated, T1 will need to drop X to I, but a subsequent load will bring it back to TI.

74
Coherence Protocol
M
E
S
TMI
TI
I
X /INV-ACK
X /INV-ACK
GETS /Flush
X / Flush
TStore /Flush
TStore /—
TStore /TGETX
TStore /TGETX
TStore /TGETX
GETX / INV-ACK
TGETX / EXP-RD;GETS / S
TLoad /GETS(T)
Store /GETX
Store /GETX
Store /—
GETS / S
Load / GETS(T);X / INV-ACK; GETS /—
Load,Store,TLoad /—
Load,TLoad,TStore /—;TGETX,GETX,GETS / T
Load,TLoad /GETS(S
_,T_
)
Load,TLoad /GETS(S,T
_)
Load,TLoad /—
Load,TLoad /—
PDI States
COMMIT
ABORT
Dashed boxes enclose the MESI and PDI subsets of the state space. Notation on transitions is conventional: the part
before the slash is the triggering message; after is the ancillary action (‘–’ means none). GETS indicates a request for
a valid sharable copy; GETX for an exclusive copy; TGETX for a copy that can be speculatively updated with TStore.
X stands for the set {GETX, TGETX}. “Flush” indicates a data block response to the requestor and directory. S
indicates a Shared message; T a Threatened message. Plain, they indicate a response by the local processor to the
remote requestor; parenthesized, they indicate the message that accompanies the response to a request. An overbar
means logically “not signaled”.
State EncodingM bit V bit T bit
I 0 0 0S 0 1 0M 1 0 0E 1 1 0
TMI 1 0 1TI 0 0 1
Responses to requests that hit in Wsig or Rsig
Hit in Wsig Hit in Rsig
Request Msg Response Msg Response MsgGETX Threatened Invalidated
TGETX Threatened Exposed-ReadGETS Threatened Shared
Figure 4.3: TMESI Directory Protocol.

75
The TMESI-Dir base cache protocol for private L1s and a shared L2 is an adaptation of
the SGI ORIGIN 2000 [LaL97] directory-based MESI, with a full-map directory maintained at
the L2. TMESI-Bcast uses the coherence states to detect speculative sharing and specify the
coherence responses. With TM,TE, and TS states eliminated an alternative mechanism is re-
quired to track the read locations within a speculative region. Inspired by hardware TM systems
like Bulk [CTC06] and LogTM-SE [YBM07], TMESI2 uses Bloom filter signatures [Blo70]
to summarize the read and write sets of transactions in a concise but conservative fashion (i.e.,
false positives but no false negatives). Local L1 controllers use these signatures to respond to
both the directory and the requestor (response to the directory is used to indicate whether the
cache line has been dropped or retained). Requestors make three different types of requests:
GETS on a read (Load/TLoad) miss in order to get a copy of the data, GETX on a normal write
(Store) miss/upgrade in order to get exclusive permissions as well as potentially an updated
copy, and TGETX on a transactional store (TStore) miss/upgrade.
A TStore results in a transition to the TMI state in the private cache (encoded by setting the
T bit and dirty bit in conventional MESI. A TMI line reverts to M on commit (propagating the
speculative modifications) and to I on abort (discarding speculative values). To the directory,
the local TMI state is analogous to the conventional E state. The directory realizes that the
processor can transition to M (silent upgrade) or I (silent eviction), and any data request needs
to be forwarded to the processor to detect the latest state. The only modification required at
the directory is the ability to support multiple owners. We accommodate this need by adding
a mechanism similar to the existing support for multiple sharers. We track owners when they
issue a TGETX request and ping all of them on other requests. In response to any remote request
for a TMI line, the local L1 controller sends a Threatened response, analogous to the Shared
response to a GETS request on an S or E line.
In addition to transitioning the cache line to TMI, a TStore also updates the Wsig. A Wsig
lookup is performed to threaten remote requestors (readers and writers alike, represented as (T)
in Figure 4.2). TLoad likewise updates the Rsig.
TLoads when threatened (i.e., concurrent remote writer) move to the TI state (encoded by
setting the T bit when in the I (invalid) state). (Note that a TLoad from E or S can never be
threatened; the remote transition to TMI would have moved the line to I.) TI lines must revert

76
to I onz commit or abort, because if a remote processor commits its speculative TMI block, the
local copy could go stale. The TI state appears as a conventional sharer to the directory.
On forwarded L1 requests from the directory, the local cache controller tests the signatures
and appends the appropriate message type to the response message. On a miss in the Wsig,
the result from testing the Rsigis used; on a miss in both, the L1 cache responds as in normal
MESI. The local controller also piggybacks a data response if its deemed necessary (M state).
Signature-based response types are shown in Figure 4.2. Threatened indicates a write shar-
ing (hit in the Wsig), Exposed-Read indicates a read sharing (hit in the Rsig), and Shared or
Invalidated indicate no conflict.
Hits to Wsig always threaten the requestor, indicating a speculative writer. Hits to Rsig on a
TGETX respond with “Exposed-Read” to indicate a reader conflict with the transactional writer.
If the cache state is M, then a data response is piggybacked on all response messages. Hits to
either Rsig or Wsig result in a Shared (S) message to the directory in order to continue to be
perceived as a sharer and receive future requests for access checks.
4.3.1 Conflict Summary Tables
A challenge with TMESI-Bcast is the commit operation; remote copies of cache lines which
have been locally modified and committed need to be invalidated. The TMESI protocol arranges
for such lines to be in the TI state at the time of the speculative write; but the commit process
needs to arrange for the line on the remote cores to transition to I when an abort is issued. To
trigger the aborts, the committer needs information about the specific remote processors with
which it shares cache lines speculatively. TMESI-Dir addresses this challenge by gathering
information about sharers of conflicting speculative cache lines. A conflicting cache line is
shared between two or more processors where at least one of the processors has written the
line speculatively. It exposes this information to software which can then take the appropriate
decision about which processor to trigger the abort on.
We devise a bitmap structure, conflict summary tables (CSTs) to record the occurrence of
speculatively shared cache lines between processors. CSTs indicate that speculative regions on
two processors that conflict, instead of the locations on which they conflict. This information

77
concisely captures what software needs to know in order to resolve conflicts at the time of
its choosing. Software can choose when to examine the tables, and can use whatever other
information it desires (e.g., priorities) to drive its choice of which speculative chunk can commit.
Specifically, each processor has three Conflict Summary Tables (CSTs), each of which con-
tains one bit for every other processor in the system. Named R-W, W-R, and W-W, the CSTs
indicate that a local read (R) or write (W) has conflicted with a read or write (as suggested by
the name) on the corresponding remote processor. The W-R and W-W list at a processor P rep-
resent the speculative task that might need to be aborted when the speculative task at P wants to
commit. The R-W list helps disambiguate abort triggers; if an abort is initiated by a processor
not marked in the table, then software can safely ignore the message (i.e, not a conflicting spec-
ulative task). On each coherence request, the controller reads the local Wsig and Rsig, sets the
local CSTs accordingly, and includes information in its response that allows the requestor to set
its own CSTs to match. When it sends a Threatened or Exposed-Read message, the responder
sets the bit corresponding to the requestor in its R-W, W-W, or W-R CSTs, as appropriate. The
requestor likewise sets the bit corresponding to the responder in its own CSTs, as appropriate,
when it receives the response. In Section 4.5, we show that CSTs when exposed to software
enable flexible software-controlled TM confilct resolution policies.
4.4 Application of TMESI-Bcast : RTM Project
In this section, we use TMESI-Bcast to develop a flexible hardware-software TM, RTM
(Rochester Transactional Memory). RTM [SSH07] promotes policy flexibility by decoupling
version management from conflict detection and management—specifically, by separating data
and metadata, and performing conflict detection only on the latter. While RTM’s conflict detec-
tion mechanism enforces immediate conflict resolution, software can choose (by controlling the
timing of metadata inspection and updates) when conflicts are resolved. We permit, but do not
require, read-write and write-write sharing, with delayed detection of conflicts. We also employ
a software contention manager [ScS05] to arbitrate conflicts and determine the order of com-
mits. RTM also illustrates the use of software to virtualize the proposed hardware mechanisms.
The RTM runtime is based on the open-source RSTM system [MSH06], a C++ library that

78
runs on legacy hardware. RTM uses alert-on-update and programmable data isolation to avoid
copying and to reduce bookkeeping and validation overheads, thereby improving the speed of
“fast path” transactions. When a transaction’s execution time exceeds a single quantum, or
when the working set of a transaction exceeds the ALoad or TStore capacity of the cache, RTM
restarts the transaction in a more conservative “overflow mode” that supports unboundedness in
both space and time. We use the RTM to illustrate how cache evictions can be handled entirely
in software.
4.4.1 RTM Transaction
Transactions are lexically scoped, and delimited by BEGIN_TRANSACTION and
END_TRANSACTION macros. The first of these sets the alert handler for a transaction and
configures per-transaction metadata. The second issues a CAS-Commit.In order to access fields
of an object, a thread must obtain read or write permission by performing an open_RO or
open_RW call.
Every RTM transaction is represented by a descriptor (Figure 4.4) containing a serial num-
ber and a word that indicates whether the transaction is currently ACTIVE, COMMITTED, or
ABORTED. The serial number is incremented every time a new transaction begins.
Every transactional object is represented by a header containing five fields: a pointer to
an “owner” transaction, the owner’s serial number, pointers to valid (old) and speculative(new)
versions of the object, and a bitmap listing overflow transactions currently reading the object. 1
Open_RO returns a pointer to the most recently committed version of the object. Typi-
cally, the owner/serial number pair indicates a COMMITTED transaction, in which case the New
pointer is valid if it is not NULL; otherwise the Old pointer is valid. If the owner/serial number
pair indicates an ABORTED transaction, then the Old pointer is always valid. When the owner
is ACTIVE, there is a conflict.
Open_RW returns a pointer to a writable copy of the object. At some point between its
open_RW and commit time, a transaction must acquire every object it has written. The acquire
1The reader list is a software bitmap very similar to the sharer list associated with cache lines in a directoryprotocol. The reader list informs the writer of all the current transactions actively reading the object.

79
Serial Number
Status
Serial Number
Status
Txn−1 Descriptor
Old Writer
Old Version
Data Object −Clone
Txn−2 Descriptor
New Writer
Object Header
Owner
Old Object
New Object
Serial Number
Overflow Readers
Data Object −
Here a writer transaction is in the process of acquiring the object, overwriting the Owner pointer and Serial Number
fields, and updating the Old Object pointer to refer to the previously valid copy of the data. A fast-path transaction
will set the New Object field to null; an overflow transaction will set it to refer to a newly created clone. Several
overflow transactions can work concurrently on their own object clones prior to acquire time, just as fast-path
transactions can work concurrently on copies buffered in their caches.
Figure 4.4: RTM metadata.
operation first gets permission from a software contention manager [HLM03b; ScS05] to abort
all transactions in the overflow reader list. It then writes the owner’s ID, the owner’s serial
number, and the addresses of both the last valid version and the new speculative version into the
header using a Wide-CAS(not shown in Table 4.1) instruction.2 Finally, it aborts any transactions
in the overflow reader list of the freshly acquired object.
At the end of a transaction, a thread issues a CAS-Commit to change its state from ACTIVE
to COMMITTED. If the CAS fails because another thread has set the state to ABORTED, the
transaction is retried.
2As in Itanium’s cmp8xchg16 instruction [Int06], if the first two words at location A match their “old” values,all words are swapped with the “new” values (loaded into contiguous registers). Success is detected by comparingold and new values in the registers.

80
4.4.2 Fast-Path RTM Transactions
Eliminating Data Copying
A fast-path transaction calls begin_hw_t inside the BEGIN_TRANSACTION macro. Subse-
quent TStores will be buffered in the cache; their data will remain invisible to other threads until
the transaction commits (at the hardware level, of course, the existence of lines to which TStores
have been made is visible in the form of “threatened” signals/messages). For fast-path transac-
tions this is the valid version that would be returned by open_RO; updates will be buffered in
the cache. Programmable data isolation thus avoids the need to create a separate writable copy,
as is common in software TM systems (RSTM among them). When a fast-path transaction
acquires an object, it writes a NULL into the New pointer, since the old pointer is both the last
and next valid version. A newly arriving transaction that sees mismatched serial numbers will
read the appropriate version.
Reducing Bookkeeping and Validation Costs
In most software TM systems a transaction must verify that all its previously read objects are
still valid before it performs any dangerous operation. ALoad allows validation to be achieved
essentially for free (see Section 3.5). Whenever an object is read (or opened for writing lazily),
the transaction uses ALoad to mark the object’s header in the local cache. Since transactions
cannot commit changes to an object without modifying the object header first, the remote ac-
quisition of a locally ALoaded line results in an immediate alert to the reader transaction. Freed
of the need to explicitly validate previously opened objects, software can also avoid the book-
keeping overhead. Best of all, perhaps, a transaction that acquires an object implicitly aborts
all fast-path readers of that object simply by writing the header: fast-path readers need not
add themselves to the list of readers in the header, and the O(t) cost of aborting the readers is
replaced by the invalidation already present in the cache coherence protocol. An RTM trans-
action aborts and retries in overflow mode to such an event, or to invalidation or eviction of an
A-tagged or TMI line.

81
4.4.3 Overflow RTM Transactions
Fast-path RTM transactions are bounded in space and time; they cannot ALoad or TStore more
lines than the cache can hold, and they cannot execute across a context switch.To accommodate
larger or longer transactions, RTM employs an overflow mode with only one hardware require-
ment: that the transaction’s ALoaded descriptor remain in the cache whenever the transaction is
running. Since committing a fast-path writer updates written objects in-place, we must ensure
that a transaction in overflow mode also notices immediately when it is aborted by a competitor.
We therefore require that every transaction ALoad its own descriptor. If a competitor CAS-es
its status to ABORTED, the transaction will suffer an immediate alert. It also writes itself into
the Overflow Reader list of every object it reads; this ensures it will be explicitly aborted by
writers.
While only one ALoaded line is necessary to ensure immediate aborts and to handle valida-
tion, using a second ALoad can improve performance when a an overflow transaction clones an
object.If the overflow writer is cloning an object when the fast-path writer commits, the clone
operation may return an internally inconsistent object. If the transaction ALoaded the header
and then clone the object. We assume in our experiments that the hardware is able (with a small
victim cache) to prefer non-ALoaded lines for eviction, and to keep at least two in the cache.
In the overflow mode the transaction leaves the %hardware_t bit clear, instructing the
hardware to interpret TLoad and TStore instructions as ordinary loads and stores. This conven-
tion allows the overflow transaction to execute the exact same user code as fast-path transac-
tions; there is no need for a separate version. Without speculative stores, open_RW calls in the
overflow transaction must clone to-be-written objects. At acquire time, the WCAS instruction
writes the address of the clone into the New field of the metadata. When open_RO calls en-
counter a header whose last Owner is committed and whose New field is non-null, they return
the New version as the current valid version.
Context Switches
To support transactions that must be preempted, we require two actions from the operating
system. When it swaps a transaction out, the operating system flash clears all the A tags. In

82
addition, for transactions in fast-path mode, it executes the abort instruction to discard iso-
lated lines. When it swaps the transaction back in, it starts execution in a software-specified
restart handler (separate from the alert handler). The restart handler aborts and retries if the
transaction was in fast-path mode or was swapped out in mid-clone; otherwise it re-ALoads the
transaction descriptor and checks that the transaction status has not been changed to ABORTED.
If this check succeeds, control returns as normal; otherwise the transaction jumps to its abort
code.
4.4.4 Latency of RTM Transactions
In this section we study the latency characteristics of RTM transactions and investigate the
overheads of the various TM runtime components. The RTM system evaluated in this disserta-
tion is an object based system in which applications need to declare the shared data and use the
specified interface. We evaluate RTM with six microbenchmarks, HashTable, RBTree, RBTree-
Large, LinkedList-Release, LFUCache and RandomGraph with varied transaction characteris-
tics. Appendix A provides a detailed description of the microbenchmarks.
We evaluate each benchmark with two RTM configurations: RTM-F always executes fast-
path transactions to extract maximum benefit from the hardware; RTM-O always executes over-
flow transactions to demonstrate worst-case throughput. We also compare RTM to RSTM and
to the RTM-Lite runtime which only uses AOU described in Chapter 3. Like a fast-path RTM
transaction, an RTM-Lite transaction ALoads the headers of the objects it reads; it does not per-
form any validation. Since PDI not available, however, it must version every acquired object.
Every RTM-Lite transaction keeps an estimate of the number of lines it can safely ALoad. If it
opens more objects than this, it keeps a list of the extra objects and validates them incremen-
tally, as RSTM does. If it suffers a “no more space” alert, it reduces its space estimate, aborts,
and restarts. As a baseline best-case single-thread execution, we compare against a coarse-
grain locking library (CGL), which enforces mutual exclusion by mapping the BEGIN_ and
END_TRANSACTION macros to acquisition and release of a single coarse-grain test-and-test-
and-set lock.

83
To ensure a fair comparison, we use the same benchmark code, memory manager, and con-
tention manager (Polka [ScS05]) in all systems. Briefly, Polka performs exponential backoff
when a transaction aborts and increases the stall time based on the difference between the num-
ber of read accesses performed by the conflicting transactions. To avoid the need for a hook
on every load and store, we modify the memory manager to segregate the heap and to place
shared object payloads at high addresses (metadata remains at low addresses). The simulator
then interprets memory operations on high addresses as TLoads and TStores.
Figure 4.5 presents a breakdown of transaction latency at 1 thread and 8 threads. App Tx
represents time spent in user-provided code between the BEGIN_ and END_TRANSACTION
macros; time in user code outside these macros is App Non-Tx. Validation records any time
spent by the runtime explicitly validating its read set; Copy is the time spent cloning objects;
MM is memory management; CM is contention management. Fine-grain metadata and book-
keeping operations are aggregated in Bookkeeping. For single-thread runs, the time spent in
statistics collection for contention management is merged into bookkeeping; for multi-thread
runs, Abort is the sum of all costs in aborted transactions.
We make the following overall conclusion.
Result: Seperating the metadata tracking conflicts from the shared data that needs version-
ing makes them amenable for hardware acceleration and enables flexible software controlled
TMs. However, this separation of data and metadata can cause excessive bookkeeping over-
heads due to the indirection required on every data access. The interoperability of concurrent
hardware and software transactions complicates the critical path of hardware transactions.
On a single thread, RTM-F exploits PDI the shorter code path to attain a maximum speedup
of 8.7× on RandomGraph and a geometric-mean speedup of 3.5× across all the benchmarks.
Figure 4.5 shows that bookkeeping is the dominant overhead in RTM-F relative to CGL. One
source of overhead is RTM’s use of indirection to access an object. This in turn stems from our
choice of metadata organization. RTM decouples metadata cache blocks on which conflicts are
detected using AOU from the data cache blocks which are made invisible to the shared memory
system. Access to shared data lines incur an extra pointer access on the critical path through the
metadata.

84
While this supports flexible conflict resolution it also add up to a significant number of
instructions executed by hardware transactions (22 extra instructions in open RO, 38 extra in-
structions in open RW, 47 extra instructions in begin transaction, and 22 in end transaction)
compared to optimal path of other hardware TMs (e.g., HASTM [SAJ06]). Bookeeping over-
heads minimize the gains that RTM-F can obtain for these benchmarks. Here, we also tried to
optimize the runtime to elide the per-access instrumentation for transactions that are guaranteed
to run in single-thread mode (i.e., no other active transactions). In Section 4.5 we demonstrate
a more streamlined HTM that exploits the full potential of AOU and PDI.
As the breakdowns show, RTM and RTM-Lite successfully leverage ALoad to eliminate
RSTM’s validation overhead. RTM-F also eliminates copying costs. Due to the small object
sizes in benchmarks other than RBTree-Large, this gain is sometimes compensated for by dif-
ferences in metadata structure and corresponding bookkeeping overhead. Similar analysis at 8
threads (Figure 4.5) continues to show these benefits, although increased network contention
and cache misses, as well as limited concurrency in some benchmarks, cause increased latency
per transaction.
HashTable exhibits embarrassing parallelism since transactions are short (5 cache lines read
and 2 cache lines written) and conflicts are rare. These properties prevent the hardware from
offering much additional benefit. In single thread mode, the cost of copying is 4.3% of trans-
action latency in RSTM. Since the read set is small the cost of validation is 16.8%. RTM-F
eliminates the validation overhead and reduces bookkeeping to improve transaction latency by
X%. In single-thread mode, RTM-F minimizes bookkeeping over RTM-Lite by 2.2× due to
single-thread optimizations. However, memory management and bookkeeping account for 52%
of RTM-F’s transaction latency. Furthermore, these costs increase with number of threads; at 8
threads, the bookkeeping cost increases by 2.5×.
LinkedList-Release has a high cost for metadata manipulation and bookkeeping. Together,
they account for 88% of the transaction latency of an RSTM transaction. RTM-F removes the
validation overhead and reduces RSTM’s bookkeeping overheads by 2.8×. However, it still
incurs 58% overhead over CGL. RTM-Lite performs slightly better than RTM-F at more than 1
thread since RTM-F has 11% higher bookkeeping compared to RTM-Lite at > 1 thread. This
increase in bookkeeping outweighs the benefits obtained from eliminating the copying.

85
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
CG
L
RS
TM
RT
M-L
ite
RT
M-F
CG
L
RS
TM
RT
M-L
ite
RT
M-F
CG
L
RS
TM
RT
M-L
ite
RT
M-F
CG
L
RS
TM
RT
M-L
ite
RT
M-F
CG
L
RS
TM
RT
M-L
ite
RT
M-F
CG
L
RS
TM
RT
M-L
ite
RT
M-F
Hash RBTree LinkedList-Release LFUCache RandomGraph RBTree-Large
Nor
mal
ized
Exe
cutio
n T
ime
Abort
Copy
Validation
CM
Bookkeeping
MM
App Non-Tx
App Tx
0
0.5
1
1.5
2
2.5
RS
TM
RT
M-L
ite
RT
M-F
RS
TM
RT
M-L
ite
RT
M-F
RS
TM
RT
M-L
ite
RT
M-F
RS
TM
RT
M-L
ite
RT
M-F
RS
TM
RT
M-L
ite
RT
M-F
RS
TM
RT
M-L
ite
RT
M-F
Hash RBTree LinkedList-Release LFUCache RandomGraph RBTree-Large
Nor
mal
ized
Exe
cutio
n T
ime
Abort
Copy
Validation
CM
Bookkeeping
MM
App Non-Tx
App Tx
9.2 6.7 Livelock5.7
Breakdown of per transaction latency for 1 thread (top) and 8 threads (bottom). All results are normalized to 1-thread
RSTM.
Figure 4.5: RTM transaction execution time breakdown
Tree rebalancing in RBTree gives rise to conflicts. By deferring to transactions that have
invested more work, and by backing off before retrying, the Polka [ScS05] contention manager
keeps aborts to within 5% of the total transactions committed. At 8 threads, transactions spend
∼10% of the time in contention management. As shown in Figure 4.5, validation is a signifi-
cant overhead in RSTM transactions (40% of transaction latency); both RTM-F and RTM-Lite
eliminate the validation cost. Despite this, in single-thread mode, bookkeeping for RTM-F
transactions is 17× higher compared to optimal critical path fn CGL. In RBTree-Large RTM-F
is able to leverage TLoad and TStore to eliminate long latency copy operations. RTM-F reduces
latency by another 19% by eliminating the copy overhead. At 8 threads, '58% of RTM-F’s
transaction latency is bookkeeping..
LFUCache has little concurrency and all TM systems experience very high latencies at 8
threads due to the wasted work in aborts. At 8 threads, RSTM transactions take 9.2× as long

86
as they do on a single thread, and aborts account for 75% of total time. Commit latency in a
transaction increases by 2.4× compared to a single thread. At 8 threads,, RTM-F eliminates
copying and validation, and reduces bookkeeping, resulting in 2.5× reduction in latency over
RSTM. LFUCache’s small transactions stress RTM’s bookkeeping. Even with single thread
optimizations, RTM has 2.2× increased latency compared to CGL. At 8 threads, the increased
complexity of the code path when there are multiple threads) and absence of single-thread
optimization means bookkeeping increases by 3× compared to a single thread.
Transactions in RandomGraph are complex and conflict with high probability. Validation is
expensive and aborts are frequent. In RSTM, validation dominates single thread latency, con-
tributing to 79% of overall execution time. Leveraging ALoad to eliminate validation enables
RTM-F improves performance by a factor of 8.7× compared to RSTM. With the validation
overheads eliminated the bookkeeping overheads are clearly noticeable; 60% of a transaction’s
time is spent in bookkeeping. When there is any concurrency, the choice of eager acquire causes
all TMs to livelock in RandomGraph with the Polka contention manager. 3
4.4.5 Hardware-Software Transactions
The previous subsections analyzed the performance of RTM fast-path (RTM-F) transactions.
Figure 4.6 presents average transaction latency as the fraction of fast-path transactions is varied
from 0–100%, normalized to latency in the all-fast-path case. The figure shows a linear increase
in latency as the percentage of overflow transactions is increased, with the fraction of time
spent in overflow mode being directly proportional to this percentage. Overflow transactions
do not block or significantly affect the performance of fast-path transactions when executed
concurrently.
4.5 Application of TMESI-Dir: FlexTM
In this section, we develop a TM system, FlexTM, which uses Conflict Summary Tables for
demonstrating low-overhead and flexible conflict resolution between transactions. FlexTM
3We have tagged the top of the breakdown plots for 8 threads as “livelock” since almost 99% of transaction timeis spent in aborts. This livelocking behavior can be avoided even with eager acquire by using a Greedy contentionmanager [GHP05a].

87
0
0.5
1
1.5
2
100%
F75
%F
-50
%F
-25
%F
-10
0%O
100%
F75
%F
-50
%F
-25
%F
-10
0%O
100%
F75
%F
-50
%F
-25
%F
-10
0%O
100%
F75
%F
-50
%F
-25
%F
-10
0%O
100%
F75
%F
-50
%F
-25
%F
-10
0%O
100%
F75
%F
-50
%F
-25
%F
-10
0%O
HashTable RBTree LinkedList-Release
LFUCache RandomGraph RBTree-Large
Nor
mal
ized
Tra
nsac
tion
Lat
ency Tx-O
Tx-F
Breakdown of time spent in fast-path and in overflow mode, normalized to the all-fast-path execution (16 threads).
Figure 4.6: Interaction of RTM-F and RTM-O transactions
(FLEXible Transactional Memory) [SDS08] separates conflict detection from resolution and
management, and leaves software in charge of the latter. Simply put, hardware always detects
conflicts eagerly during the execution of a transaction and records them in the CSTs, but soft-
ware chooses when to notice and what to do about it.
A key contribution of FlexTM is a commit protocol that arbitrates between transactions in a
distributed fashion, allows parallel commits of an arbitrary number of transactions, and imposes
performance penalty proportional to the number of transaction conflicts. It enables lazy conflict
resolution without commit tokens [HWC04], broadcast of write sets [HWC04; CTC06], or
ticket-based serialization [CCC07]. To our knowledge FlexTM is the first hardware TM in
which the decision to commit or abort can be an entirely local operation, even when performed
lazily by an arbitrary number of threads in parallel.
FlexTM deploys four hardware primitives (1) Bloom filter signatures (as in Bulk [CTC06]
and LogTM-SE [YBM07]) to track and summarize a transaction’s read and write sets; (2) con-
flict summary tables (CSTs) to concisely capture conflicts between transactions; (3) the version-
ing system of RTM (programmable data isolation—PDI), simplified and adapted to directory-

88
based coherence, and augmented with an overflow mechanism and (4) Alert-On-Update mech-
anism to help transactions detect their status. Figure 4.7 shows the hardware additions.
User Registers
DataSharer ListStateTag
Processor Core
L2$
Signatures
RS
WSsig
sig
WsigRsig
Cores Summary
Tag State A T Data
L1 D$
Private L1 Cache ControllerOverflow Table Controller
MissL1
Shared L2 Cache Controller
Context Switch Support
R−W
W−R
W−W
CSTs
AOU Control
PDI Control
CMPC AbortPC
Thread IdOsigOver. CountComm./Spec.
V. BaseP. Base# Sets# Ways
Figure 4.7: FlexTM Architecture Overview
4.5.1 Bounded FlexTM Transactions
A FlexTM transaction is represented by a software descriptor (Table 4.4). This descriptor
includes a status word, space for buffering the hardware state when paused (CSTs, Signatures,
and Overflow control registers), pointer to the abort (AbortPC) and contention management
handlers (CMPC), and a field to specify the conflict resolution mode of the transaction.
A transaction is delimited by BEGIN_TRANSACTION and END_TRANSACTION macros
(see Figure 4.8). BEGIN_TRANSACTION establishes the conflict and abort handlers for the
transaction, checkpoints the processor registers, configures per-transaction metadata, sets the
transaction status word (TSW) to active, and ALoads that word (for notification of aborts).
Some of these operations are not intrinsically required and can be set up for the entire lifetime of
a thread (e.g., AbortPC and CMPC). END_TRANSACTION aborts conflicting transactions and
tries to atomically update the status word from active to committed using CAS-Commit.

89
Within a transaction, the processor issues TLoads and TStores when it expects transactional
semantics, and conventional loads and stores when it wishes to bypass those semantics. TLoads
and TStores are interpreted as speculative when the hardware transaction bit (%hardware_t)
is set. This convention facilitates code sharing between transactional and non-transactional
program fragments. Ordinary loads and stores can be requested within a transaction; these could
be used to implement escape actions, update software metadata, or reduce the cost of thread-
private updates in transactions that overflow cache resources. In order to avoid the need for
compiler generation of the TLoads and TStores, our prototype implementation follows typical
HTM practice and interprets ordinary loads and stores as TLoads and TStores when they occur
within a transaction.
Transactions of a given application can employ either Eager or Lazy conflict resolution. In
Eager mode, when conflicts appear through response messages (i.e., Threatened and Exposed-
Read), the processor effects a subroutine call to the handler specified by CMPC. The conflict
manager either stalls the requesting transaction or aborts one of the conflicting transactions. The
remote transaction can be aborted by atomically CASing its TSW from active to aborted,
thereby triggering an alert (since the TSW is always ALoaded). FlexTM supports a wide va-
riety of conflict management policies (even policies that desire the ability to synchronously
abort a remote transaction). When an Eager transaction reaches its commit point, its CSTs
will be empty, since all prior conflicts will have been resolved. It attempts to commit by ex-
ecuting a CAS-Commit on its TSW. If the CAS-Commit succeeds (replacing active with
committed), the hardware flash-commits all locally buffered (TMI) state. The CAS-Commit
will fail leaving the buffered state local if the CAS does not find the expected value (a remote
transaction managed to abort the committing transaction before the CAS-Commit could com-
plete).
In Lazy mode, transactions are not alerted into the conflict manager. The hardware simply
updates requestor and responder CSTs. To ensure serialization, a Lazy transaction must, prior to
committing, abort every concurrent transaction that conflicts with its write-set. It does so using
the END TRANSACTION() routine shown in Figure 4.8.
All of the work for the END TRANSACTION() routine occurs in software, with no need
for global arbitration [CTC06; CCC07; HWC04], blocking of other transactions [HWC04], or

90
BEGIN TRANSACTION()1. clear Rsig and Wsig
2. set Abort PC3. set CMPC
4. TSW[my id] = active5. Aload(TSW[my id])6. begin t
END TRANSACTION() /* Non-blocking, pre-emptible */1. if (TSW[my id] == active) goto Abort PC2. copy-and-clear W-R and W-Wregisters3. foreach i set in W-R or W-W4. abort id = manage conflict(my id, i)5. if (abort id 6= NULL) // not resolved by waiting6. CAS(TSW[abort id], active, aborted)7. CAS-Commit(TSW[my id], active, committed)8. if (TSW[my id] == active) // failed due to nonzero CST9. goto 1
Figure 4.8: Pseudocode of BEGIN TRANSACTION and END TRANSACTION.
special hardware states. The routine begins by using a copy and clear instruction (e.g., clruw
on the SPARC) to atomically access its own W-R and W-W. In lines 3–6 of Figure 4.8, for
each of the bits that was set, transaction T aborts the corresponding transactionR by atomically
changing R’s TSW from active to aborted. Transaction R, of course, could try to CAS-
Commit its TSW and race with T , but since both operations occur on R’s TSW, conventional
cache coherence guarantees serialization. After T has successfully aborted all conflicting peers,
it performs a CAS-Commit on its own status word. If the CAS-Commit fails and the failure can
be attributed to a non-zero W-R or W-W (i.e., new conflicts), the END TRANSACTION() routine
is restarted. In the case of a R-W conflict, no action is needed since T is the reader and is about
to serialize before the writer (i.e., the two transactions can commit concurrently). Software
mechanisms can be used to disambiguate conflicts and avoid spurious aborts when the writer
commits.
The contention management policy (line 4) in the commit process is responsible for pro-
viding various progress and performance guarantees. The TM system can choose to plug in an
application-specific policy. For example, if we used a Timestamp manager [ScS05], then it will
ensure livelock freedom. More recently, EazyHTM [TPK09] has exploited CST-like bitmaps to
accelerate a pure-HTM’s commit, but does not allow pluggable contention management poli-
cies. FlexTM’s commit operation is entirely in software and its latency is proportional to the
number of conflicting transactions — in the absence of conflicts there is no overhead. Even in
the presence of conflicts, aborting each conflicting transaction consumes only the latency of a
single CAS operation (at most a coherence operation).

91
4.5.2 Mixed Conflict Resolution
While Lazy generally provides the best performance [ShD09] with its ability to exploit concur-
rency and ensure progress, it does introduce certain challenges. Lazy requires a multiple-writer
and/or multiple reader protocol, that makes notable additions to a basic MESI protocol. Multi-
ple L1’s need to be able to concurrently cache a block and be able to read and write the block
(quite different from the basic “’S” and “M” states). This is a source of additional complexity
over an Eager system and could prove to be a barrier to adoption.
Furthermore, allowing write-write sharing seems to introduce non-trivial performance chal-
lenges. Write-Write conflicts need to be conservatively treated as dueling read-write and write-
read conflicts since a transaction that obtains permissions for writing a block can also read it.
It is not possible to allow both transactions to concurrently commit (one of them has to abort).
Commit-time conflict resolution in Lazy does try to ensure progress but the workload charac-
teristics could lead to significant levels of wasted work on delayed aborts and handicap the
performance benefits from concurrency (see effect on STMBench7 workload in [ShD09]).
A possible way to address Lazy’s challenges is to disallow multiple-writer sharing since it
does not seem to be prevalent in the first generation of TM workloads (see Appendix A). We
extend FlexTM to support the Mixed mode proposed previously [Sco06; ShD09]. In Mixed
mode, when write-write conflicts appear (TStore operation receives a threatened response) the
processor effects a call to the contention manager. On read-write or write-read conflicts the
hardware records the conflict in the CSTs and allows the transaction to proceed. When the
transaction reaches its commit point, it needs to take care of only W-R conflicts (algorithm
similar to Figure 4.8) as its W-W CST will be empty. Mixed tries to save wasted work on write-
write conflicts (where allowing concurrent execution does not help) and exploit parallelism
present in W-R and R-W conflicts.
Mixed has modest versioning requirements compared to Lazy. A system that supports only
Mixed (can also support Eager) can simplify the coherence protocol and overflow mechanisms.
Briefly, Mixed maintains the single writer and/or multiple reader invariant: it allows only one
writer for a cache block (unlike Lazy) although the writer can co-exist with concurrent readers
(unlike Eager). At any given instant, there is only one speculative copy accessed by the single

92
writer and/or a non-speculative version accessed by the concurrent readers. This simplifies the
design of the TMI state in the TMESI protocol–only one of the L1 caches in the system can
have the line in TMI (not unlike the “M” state in MESI).
4.6 Virtualizing of Cache Overflows in FlexTM
To provide the illusion of unbounded space, FlexTM must provide mechanisms to handle trans-
actional state evicted from the L1 cache. Cache evictions must be handled carefully. First,
signatures rely on forwarded requests from the directory to trigger lookups and provide con-
servative conflict hints (Threatened and Exposed-Read messages). Second, TMI lines holding
speculative values need to be buffered and cannot be merged into the shared level of the cache.
We first describe our approach to handling coherence-based conflict detection for evicted lines,
followed by two alternative schemes for versioning of evicted TMI lines in Section 4.6.2 and
Section 4.6.3.
4.6.1 Eviction of Transactionally Read Lines
Conventional MESI performs silent eviction of E and S lines to avoid the bandwidth overhead of
notifying the directory. In FlexTM, silent evictions of E, S, and TI lines also serve to ensure that
a processor continues to receive the coherence requests it needs to detect conflicts. (Directory
information is updated only in the wake of L1 responses to L2 requests, at which point any
conflict is sure to have been noticed.) When evicting a cache block in M, FlexTM updates the
L2 copy but does not remove the processor from the sharer list. Processor sharer information
can, however, be lost due to L2 evictions. To preserve the access conflict tracking mechanism,
L2 misses result in querying all L1 signatures in order to recreate the sharer list. This scheme
is much like the sticky bits used in LogTM [MBM06].
4.6.2 Overflow table (OT) Controller Design
This design has been adopted by FlexTM and employs a per-thread overflow table (OT) to buffer
evicted TMI lines. The OT is organized as a hash table in virtual memory. It is accessed both by

93
software and by an OT controller that sits on the L1 miss path. The latter implements (1) fast
lookups on cache misses, allowing software to be oblivious to the overflowed status of a cache
line, and (2) fast cleanup and atomic commit of overflowed state.
The controller registers required for OT support appear in Figure 4.7. They include a thread
identifier, a signature (Osig) for the overflowed cache lines, a count of the number of such lines,
a committed/speculative flag, and parameters (virtual and physical base address, number of sets
and ways) used to index into the table.
On the first overflow of a TMI cache line, the processor traps to a software handler, which
allocates an OT, fills the registers in the OT controller, and returns control to the transaction.
To minimize the state required for lookups, the current OT controller design requires the OS to
ensure that OTs of active transactions lie in physically contiguous memory. If an active transac-
tion’s OT is swapped out, then the OS invalidates the Base-Address register in the controller. If
subsequent activity requires the OT, the hardware traps to a software routine that re-establishes
a mapping. The hardware needs to ensure that new TMI lines are not evicted during OT set-up;
the L1 cache controller could easily support this by ensuring that at least one entry in the set is
free for non-TMI lines.
On a subsequent TMI eviction, the OT controller calculates the set index using the physical
address of the line, accesses the set tags of the OT region to find an empty way, and writes the
data block back to the OT instead of the L2. The controller tags the line with both its physical
address (used for associative lookup) and its virtual address (used to accommodate page-in at
commit time; see below). The controller also adds the physical address to the overflow signature
(Osig) and increments the overflow count.
The Osig provides quick lookaside checks for entries in the OT. Reads and writes that miss
in the L1 are checked against the signature. Signature hits trigger the L1-to-L2 request and
the OT lookup in parallel. On OT hits, the line is fetched from the OT, the corresponding OT
tag is invalidated, and the L2 response is squashed. This scheme is analogous to the speculative
memory request issued by the home memory controller before snoop responses are all collected.
When a remote request hits in the Osig of a committed transaction, the controller could perform
lookup in the OT, much as it does for local requests, or it could NACK the request until copy-
back completes. Our current implementation does the latter.

94
In addition to functions previously described, the CAS-Commit operation sets the Commit-
ted bit in the controller’s OT state. This indicates that the OT content should be visible, acti-
vating NACKs or lookups. At the same time, the controller initiates a microcoded copy-back
operation. To accommodate page-evictions of the original locations, OT tags include the virtual
addresses of cache blocks. These addresses are used during copy-back, to ensure automatic
page-in of any nonresident pages.
There are no constraints on the order in which lines from the OT are copied back to their
natural locations. This stands in contrast to time-based logs [MBM06], which must proceed in
reverse order of insertion. Remote requests need to check only committed OTs (since specula-
tive lines are private) and for only a brief span of time (during OT copy-back). On aborts, the
OT is returned to the operating system. The next overflowed transaction allocates a new OT.
When an OT overflows a way, the hardware generates a trap to the OS, which expands the OT
appropriately.
Although we require that OTs be physically contiguous for simplicity, they can themselves
be paged. In particular, it makes sense for the OS to swap out the OTs of descheduled threads.
A more ambitious FlexTM design could allow physically non-contiguous OTs, with controller
access mediated by more complex mapping information. With the addition of the OT controller,
software is involved only for the allocation and deallocation of the OT structure. Indirection
to the OT on misses, while unavoidable, is performed in hardware rather than in software,
thereby reducing the resulting overheads. Furthermore, FlexTM’s copyback is performed by
the controller and occurs in parallel with other useful work on the processor.
4.6.3 Handling Evictions with Fine-grain Translation
The OT controller mechanism described in the previous section requires a hardware state ma-
chine to maintain a write-buffer that is scattered across multiple levels in the memory hierarchy.
There is implementation complexity associated with the state machine that searches (writes
back and reloads) and accesses data blocks without any help from software.
In this section, we propose a more streamlined mechanism. We move the actions of main-
taining the data structure and performing the redo on commit to software, replacing the hash

95
table with buffer pages and introducing a metadata cache that enables hardware to access the
buffer pages without software intervention. Figure 4.9 shows the per-page software metadata,
which specifies the buffer-page address and for each cache block, the writer transaction id
(Tx id) and a “V/I” bit to indicate if the buffer block is buffering valid data. To convey the
metadata information to hardware and accelerate repeated block accesses, we install a metadata
cache (SM-cache) on the L1 miss path (see Figure 4.10).
Tx IdBuffer V. addr V/IData
V. addr.
Page-Granularity Metadata1st cache line Nth cache line
Writer Tx andValid bit
Tx Id V/I...
Buffer-page is in virtual memory. V/I bit is set/unset by hardware on cache-eviction/reload respectively. The
(V/I,Tx Id) pair denotes the following semantics when accessed by transaction T: (0,don’t care) buffer-page cache
block empty; (1,X) X6=T. T conflicts with writer transaction X; (1,T). T has speculatively written the block and
evicted it in the past.
Figure 4.9: Metadata for pages that have overflowed state
Processor Core
Tag State A T Data
Private L1 Cache
Tag1 Data Tag2Metadata P. addr
Data V. addrMetadata
SM-CacheInsert /
Remove entry
Coherence
Overflow Wsig
L1 miss /writeback
Simplified overflow support with SM-cache. Dashed lines surround new extension that replaces the OT controller
(see Figure 4.7)
Figure 4.10: Software-metadata cache architecture
When a speculatively written cache line is evicted, the cache controller looks up the SM-
cache for the metadata and uses the buffer page address to index into the TLB (for the buffer-

96
page’s physical address) for writeback redirection. Multiple transactions that are possibly writ-
ing different cache blocks on the same page can share the same buffer-page.4 A miss in the
SM-cache triggers a software handler that allocates the buffer-page metadata and reloads the
SM-cache. To provide the commit handler with the virtual address of the cache block to be
written back, every SM-cache entry includes this information and is virtually indexed (note
that the data cache is still physically indexed). While the entire buffer-page is allocated when
a single cache-block in the original page is evicted, the individual buffer-page cache blocks
are used only as and when further evictions occur. This ensures that the overflow mechanism
adds overhead proportional to the number of cache blocks that are evicted (similar to the OT
controller mechanism). In contrast to this design, other page-based overflow mechanisms (e.g.,
XTM [CMM06] and PTM [CNV06]) clone the entire page if at least a single cache block on
the page is evicted.
With data buffered, L1 misses now need to ensure that data is obtained from the appropriate
location (buffer-page or original). Similar to the OT controller design, we use an overflow
signature (Osig) to summarize addresses of evicted blocks and elide metadata checks. L1 misses
check the Osig, and signature hits require a metadata check. If the metadata indicates that
transaction T accessing the location had written the block (i.e., V/I bit is 1 and Tx Id=T), then
hardware fetches the buffer block and over-rides the L2 response. It also unsets the V/I bit to
indicate that the buffer block is no longer valid (block is present in the cache). Otherwise, the
coherence response message dictates the action.
On eviction of a speculatively written cache line that another transaction has written and
overflowed as well (i.e., V/I bit is 1 and Tx Id=X, X 6=T), a handler is invoked that either al-
locates a new buffer-page and refills the SM-cache or resolves the conflict immediately. The
former design supports multiple writers to the same location (and enables Lazy conflict resolu-
tion), while the latter forces eager write-write conflict resolution, but enables a simpler design.
The Tx Id field supports precise detection of writer conflicts (see the FlexTM-S design below).
When a transaction commits, it copy-updates the original locations using software routines.
To ensure atomicity, the transaction updates its status word to inform concurrent accesses to
4Virtual page synonyms are cases where multiple virtual pages point to the same physical frame and a thread canaccess the same location with different virtual addresses. To resolve these, since software knows about the pagesthat are synonyms it ensures that the SM-cache is loaded with the same metadata for all the virtual synonym pages.

97
hold off until the copy-back completes. It then iterates through the metadata of the various
buffer-pages in the working set and copies back the cache blocks that it has written.
SM-Cache
The SM-cache stores metadata which hardware can use to accelerate block access and cache
evictions without software intervention. It resides on the L1 miss path and operates in parallel
with the L2 lookup (see Figure 4.10). SM-cache misses are handled entirely by software
handlers that index into it using the virtual page address. The L1 controller also uses a similar
technique to obtain metadata for redirecting evictions and for block reloads.
The metadata may be concurrently updated if different speculative cache-blocks in the page
are evicted at multiple processor sites. To ensure metadata consistency, the SM-cache partic-
ipates in coherence using the physical address of the metadata. This physical address tag is
inaccessible to software and is automatically filled by the hardware when an entry is allocated.
The dual-tagging of the SM-cache introduces the possibility that the two tags (virtual address
of page and physical address of metadata) might not map to the same set index. We solve this
with tag array pointers [Goo87] as in virtually-indexed caches.
FlexTM-S Transactions
FlexTM-S To evaluate the performance of the SM-cache approach, we developed FlexTM-S.
For bounded transactions, it operates similar to FlexTM, but supports Mixed in lieu of conflict
resolution.
Compared to FlexTM, FlexTM-S (1) simplifies hardware support for the versioning mecha-
nism by trading in FlexTM’s overflow hardware controller for an SM-cache (software metadata
cache) and (2) allows precise detection of conflicting writers. By restricting support to Mixed
and Eager modes, i.e., allowing only one speculative writer, the coherence protocol is also
simplified.
To ensure low overhead for detecting conflicting readers, FlexTM-S uses the Rsig for both
overflowed and cached state. To identify writer transactions, it uses a two-level scheme: if
the speculative state resides in the cache, the response message from the conflicting processor

98
identifies the transaction (the CST bits will identify the conflicter’s id). If the speculative state
has been evicted then the Osig membership tests will indicate the possibility of a conflict. This
type of conflict is also encoded in the response message. If an Osig conflict is indicated, the
requester checks the metadata for precise disambiguation, thereby eliminating false positives.
Since a block can be written by only one transaction (Mixed/Eager invariant), the Tx id in the
metadata precisely identifies the writer. If the metadata indicates no conflict, software loads
the SM-cache, instructing hardware to ignore the Osig response and allows the transaction to
proceed. Thus the metadata for versioning helps to disambiguate writer transactions which
(1) helps identify the conflicting writer precisely and (2) allows progress of non-conflicting
transactions, which would have otherwise required contention management (in Eager mode)
due to signature false-positives.
4.6.4 Handling OS Page Evictions
The challenges that need to be considered are (1) when a page is swapped out and its frame is
reused for a different page in the application, and (2) when a page is re-mapped to a different
frame. Since signatures are built using physical addresses, (1) can lead to false positives, which
can cause spurious aborts but not correctness issues. In a more ambitious design, we could
address these challenges with virtual address-based conflict detection for non-resident pages.
For (2) we adapt a solution first proposed in LogTM-SE [YBM07]. At the time of the
unmap, active transactions are interrupted both for TLB entry shootdown (already required)
and to flush TMI lines to the OT. When the page is assigned to a new frame, the OS interrupts
all the threads that mapped the page and tests each thread’s Rsig, Wsig, and Osig for the old
address of each block. If the block is present, the new address is inserted into the signatures.
Finally, there are differences between the support required from the paging mechanism for the
OT controller approach and the SM-Cache approach. The former indexes into the overflow table
using the physical address and requires the paging mechanism to update the tags in the table
entries with the new physical address. The latter needs no additional support since it uses the
virtual address of the buffer-page and at the time of writeback indexes into the TLB to obtain
the current physical address.

99
4.6.5 Context Switch Support
STMs provide effective virtualization support because they maintain conflict detection and ver-
sioning state in virtualizable locations and use software routines to manipulate them. For com-
mon case transactions, FlexTM uses scalable hardware support to bookkeep the state associated
with access permissions, conflicts, and versioning while controlling policy in software. In the
presence of context switches, FlexTM detaches the transactional state of suspended threads from
the hardware and manages it using software routines. This enables support for transactions to
extend across context switches (i.e., to be unbounded in time [AAK05]).
Ideally, only threads whose actions overlap with the read and write set of suspended trans-
actions should bear the software routine overhead. Both FlexTM and FlexTM-S handle context
switches in a similar manner. To track the accesses of descheduled threads, FlexTM maintains
two summary signatures, RSsig and WSsig, at the directory of the system. When suspending a
thread in the middle of a transaction, the OS unions (i.e., ORs) the signatures (Rsig and Wsig) of
the suspended thread into the current RSsig and WSsig installed at the directory. FlexTM updates
RSsig and WSsig using a Sig message that uses the L1 coherence request network to write the
uncached memory-mapped registers. The directory updates the summary signatures and returns
an ACK on the forwarding network. This avoids races between the ACK and remote requests
that were forwarded to the suspending thread/processor before the summary signatures were
updated.
Once the RSsig and WSsig are up to date, the OS invokes hardware routines to merge the
current transaction’s hardware state into virtual memory. This hardware state consists of (1) the
TMI lines in the local cache, (2) the overflow hardware registers, (3) the current Rsig and Wsig,
and (4) the CSTs. After saving this state (in the order shown), the OS issues an abort instruction,
causing the cache controller to revert all TMI and TI lines to I, and to clear the signatures, CSTs,
and overflow controller registers. This ensures that any subsequent conflicting access will miss
in the private cache and generate a directory request. In other words, for any given location,
the first conflict between the running thread and a local descheduled thread always results in
an L1 miss. The L2 controller consults the summary signatures on each such miss, and traps
to software when a conflict is detected. A TStore to a line in M state generates a write-back

100
(see Figure 4.2) that also tests the RSsig and WSsig for conflicts. This resolves the corner case
in which a suspended transaction TLoaded a line in M state and a new transaction on the same
processor TStores it.
On summary signature hits, a software handler mimics hardware operations on a per-thread
basis, testing signature membership and updating the CSTs of suspended transactions. When
using the SM-cache design, the software metadata from versioning can be used to precisely
identify the writer conflict. No special instructions are required, since the CSTs and signa-
tures of descheduled threads are all visible in virtual memory. Nevertheless, updates need to
be performed atomically to ensure consistency when multiple active transactions conflict with a
common descheduled transaction and update the CSTs concurrently. The OS helps the handler
distinguish among transactions running on different processors. It maintains a global conflict
management table (CMT), indexed by processor id, with the following invariant: if transac-
tion T is active, and has executed on processor P , irrespective of the state of the thread (sus-
pended/running), the transaction descriptor will be included in P ’s portion of the CMT.
The handler uses the processor ids in its CST to index into the CMT and to iterate through
transaction descriptors, testing the saved signatures for conflicts, updating the saved CSTs (if
running in lazy mode), or invoking conflict management (if running in eager mode). Similar
perusal of the CMT occurs at commit time if running in lazy mode. As always, we abort a
transaction by writing its TSW. If the remote transaction is running, an alert is triggered since it
would have previously ALoaded its TSW. Otherwise, the OS virtualizes the AOU operation by
causing the transaction to wake up in a software handler that checks and re-ALoads the TSW.
The directory needs to ensure that sticky bits are retained when a transaction is suspended.
Along with RSsig and WSsig, the directory maintains a bitmap indicating the processors on
which transactions are currently descheduled (the “Cores Summary” register in Figure 4.7).
When the directory would normally remove a processor from the sharers list (because a response
to a coherence request indicates that the line is no longer cached), the directory refrains from
doing so if the processor is in the Cores Summary list and the line hits in RSsig or WSsig. This
ensures that the L1 continues to receive coherence messages for lines accessed by descheduled
transactions. It will need these messages if the thread is swapped back in, even if it never reloads
the line.

101
When re-scheduling a thread, if the thread is being scheduled back to the same processor
from which it was swapped out, the thread’s Rsig, Wsig, CST, and OT registers are restored on
the processor. The OS then re-calculates the summary signatures for the currently swapped
out threads with active transactions and re-installs them at the directory. Thread migration is a
little more complex, since FlexTM performs write buffering and does not re-acquire ownership
of previously written cache lines. To avoid the inherent complexity, FlexTM adopts a simple
policy for migration: abort and restart.
Unlike LogTM-SE [YBM07], FlexTM is able to place the summary signature at the di-
rectory rather than on the path of every L1 access. This avoids the need for inter-processor
interrupts to install summary signatures. Since speculative state is flushed from the local cache
when descheduling a transaction, the first access to a conflicting line after re-scheduling is
guaranteed to miss, and the conflict will be caught by the summary signature at the directory.
Because it is able to abort remote transactions using AOU, FlexTM also avoids the problem of
potential convoying behind suspended transactions.
4.7 Evaluation
4.7.1 Area Analysis
In this section, we summarize the area overheads of our hardware mechanisms; area estimates
appear in Table 4.7.1. We consider processors from a uniform (65nm) technology generation
to better understand microarchitectural tradeoffs. Processor component sizes were estimated
using published die images. We used CACTI 6 to estimate the area overheads of the storage.
Only for the 8-way multithreaded Niagara-2 do the Rsig and Wsig have a noticeable area im-
pact: 2.2%; on Merom and Power6 they add only ∼0.1%. CACTI indicates that the signatures
should be readable and writable in less than the L1 access latency. These results appear to be
consistent with those of Sanchez et al. [SYH07]. The CSTs for their part are full-map bit-vector
registers (as wide as the number of processors), and we need only three per hardware context.
We do not expect the extra state bits in the L1 to affect the access latency because (a) they have
minimal impact on the cache area and (b) the state array is typically accessed in parallel with
the higher latency data array.

102
Finally, we compare the OT controller to the metadata cache (SM-cache) approach. While
the SM-cache is significantly more area hungry than the controller, it is a regular memory struc-
ture rather than a state machine. The SM-cache needs a separate hardware cache to store the
metadata while the OT controller’s metadata (i.e., hash-table index entries) contend with regular
data for L2 cache space. Overall, the OT controller adds less than 0.5% to core area. Its state
machine is similar to Niagara-2’s [KAO05] TLB walker. Niagara-2 with its 16-byte data cache
line presents a worst-case design point for the SM-cache. The small cache line leads to high
overhead in page-level metadata, since there are more cache blocks per page (4× more than
Merom or Power6) and per-cache line metadata, since the per-cache line entry (17 bits) is a
significant fraction of cache line size (16 bytes). Straightforward optimizations that would save
area include organizing the metadata to represent a larger than cache line region.
Overall, with either FlexTM (which includes the OT controller) or FlexTM-S (which in-
cludes the SM-cache) the overheads imposed on out-of-order CMP cores (Merom and Power6)
are well under 1-2%. In the case of Niagara-2 (high core multithreading and small cache lines),
FlexTM add-ons require a∼2.6% area increase while FlexTM-S’s add-ons require a∼10% area
increase.
Table 4.3: Area overhead of FlexTM’s hardware mechanismsProcessor Merom [SYM07] Power6 [FMJ07] Niagara-2 [Inc05]
Actual DieSMT (threads) 1 2 8Feature Size 65nm 65nm 65nmDie (mm2) 143 340 342
Core (mm2) 31.5 53 11.7L1 D (mm2) 1.8 2.6 0.4
line size (bytes) 64 128 16L2 (mm2) 49.6 126 92
CACTI PredictionRsig + Wsig (mm2) .033 .066 0.26
RSsig + WSsig (mm2) .033 .033 0.033CSTs (registers) 3 6 24Extra state bits 2 (T A) 3 (T A, ID) 5 (T A ID)
% Core increase 0.6% 0.59% 2.6%% L1 Dcache increase 0.35% 0.29% 3.9%OT controller (mm2) 0.16 0.24 0.035
32 entry SM-Cache (mm2) 0.27 0.96ID — SMT context of ‘TMI’ line

103
Table 4.4: Experimental setup.16-way CMP, Private L1, Shared L2
Processor Cores 16 1.2GHz in-order, single issue; non-memory IPC=1L1 Cache 32KB 2-way split, 64-byte blocks, 1 cycle,
32 entry victim buffer,2Kbit signature [CTC06, S14]
L2 Cache 8MB, 8-way, 4 banks, 64-byte blocks, 20 cycleMemory 2GB, 250 cycle latency
Interconnect 4-ary tree, 1 cycle, 64-byte links,Central Arbiter (Section 4.7.4)
Arbiter Lat. 30 cycles [CTM07]Commit Msg. Lat. 16 cycles/linkCommit messages also use the 4-ary tree.
4.7.2 FlexTM Evaluation
We evaluate FlexTM through full system simulation of a 16-way chip multiprocessor (CMP)
with private L1 caches and a shared L2 (see Table 4.4(a)), on the GEMS/Simics infrastruc-
ture [MSB05].
We evaluate FlexTM using the benchmarks listed in Appendix A. Workload set 1 is a set
of microbenchmarks obtained from the RSTM package [10a] and Workload set 2 consists of
applications from STAMP [MTC07] and STMBench7 [GKV07]. Kmeans and Labyrinth spend
60—65% of their time in transactions; for all other applications spend over 98% of time in
transactions. In the microbenchmark tests, we execute a fixed number of transactions in a single
thread to warm up the structure, then fork off threads to perform the timed transactions. In Bayes
and Labyrinth we added padding to a few data structures to eliminate frequent false conflicts.
As Table A.1 in Appendix A shows, the workloads we evaluate have varied dynamic charac-
teristics. Delaunay and Genome perform a large amount of work per memory access and repre-
sent workloads in which time spent in the TM runtime is small compared to overall transaction
latency. Kmeans is essentially data parallel and along with the HashTable microbenchmark rep-
resents workloads that are highly scalable with no noticeable level of conflicts. Intruder also has
small transactions but there is a high level of conflicts due to the presence of dueling write-write
conflicts. The short transactions in HashTable, KMeans, and Intruder suggest that TM runtime
overheads (if any) may become a significant fraction of total transaction latency. LFUCache and
Randomgraph have a large number of conflicts and do not scale; any pathologies introduced by
the TM runtime itself [BGH08] are likely to be exposed. Bayes, Labyrinth, and Vacation have

104
moderate working set sizes and significant levels of read-write conflicts due to the use of tree-
like data structures. RBTree is a microbenchmark version of Vacation. STMBench7 is the most
sophisticated application in our suite. It has a varied mix of large and small transactions with
varying types and levels of conflicts [GKV07].
Evaluation Dimensions
We have designed the experiments to address the following questions
• How does FlexTM perform relative to hybrid TMs, hardware-accelerated STMs, and
STMs?
• How does FlexTM’s CST-based parallel commit compare to a centralized hardware ar-
biter design?
• How do the virtualization mechanisms deployed in FlexTM and FlexTM-S compare to
previously proposed software instrumentation (SigTM [MTC07]) and virtual memory-
based implementations [CMM06]?
4.7.3 FlexTM vs. Hybrid TMs and STMs
Result 1: Separable hardware support for conflict detection, conflict tracking, and versioning
can provide significant acceleration for software controlled TMs; eliminating software book-
keeping from the common case critical path is essential to realizing the full benefits of hardware
acceleration.
Runtime systems
We evaluate FlexTM and compare it against two different sets of Hybrid TMs and STMs with
two different sets of workloads.
Workload set 1 (WS1) interfaces with three TM systems: (1) FlexTM; (2) RTM-F [SSH07],
a hardware accelerated STM system; and (3) RSTM [MSH06], a non-blocking STM for legacy

105
hardware (configured to use invisible readers, with self validation for conflict detection). Work-
load set 2 (WS2), which uses a different API, interfaces with (1) FlexTM, (2) TL2, a blocking
STM for legacy hardware [DSS06], and (3) SigTM [MTC07], a hybrid TM derived from TL2
that uses signatures to track accesses to accelerate conflict detection and a software write-buffer
to version data locations. Every read or write is instrumented to insert the address into the sig-
nature and cross-reference the write-buffer to check if a new local version exists. FlexTM, the
hybrids (SigTM and RTM-F), and the STMs (RSTM and TL2) have all been set up to perform
Lazy conflict resolution.
We use the “Polka” conflict manager [ScS05] in FlexTM, RTM-F, SigTM, and RSTM. TL2
limits the choice of contention manager and uses a timestamp manager with backoff. While all
runtime systems execute on our simulated hardware, RSTM and TL2 make no use of FlexTM’s
extensions. RTM-F uses only PDI and AOU and SigTM uses only the signatures (Rsig and
Wsig). FlexTM uses all the presented mechanisms. Average speedups reported are geometric
means.
Results
Figure 4.11 shows the performance (transactions/sec) normalized to sequential thread perfor-
mance for 1 thread runs. This demonstrates that the overheads of FlexTM are minimal. For
small transactions (e.g., Hashtable) there is some overhead ('15%) for the checkpointing of
processor registers, which FlexTM performs in software — it could take advantage of check-
pointing hardware if it exists.
We study scaling and performance with 16 thread runs (Figure 4.12). To illustrate the use-
fulness of CSTs (see the table in Figure 4.12), we also report the number of conflicts encoun-
tered and resolved by an average transaction—the number of bits set in the W-R and W-W CST
registers.
The performance of both STMs suffer from the bookkeeping required to track data versions,
detect conflicts, and guarantee a consistent view of memory (validation). RTM-F exploits AOU
and PDI to eliminate validation and copying overhead, but still incurs bookkeeping that accounts
for 40–50% of execution time. SigTM uses signatures for conflict detection but performs ver-

106
FlexTM RTM-F RSTM(a) Workload Set 1
0
0.2
0.4
0.6
0.8
1
Has
hTa
ble
RBTr
ee
LFU
Cac
he
Ran
dom
Gra
phNorm
aliz
ed T
hro
ughput
FlexTM SigTM TL2
(b) Workload Set 2
0
0.2
0.4
0.6
0.8
1
Bay
es
Del
aunay
Gen
om
e
Intr
uder
Km
eans
Labyr
inth
Vac
atio
n
STM
Ben
ch7
Norm
aliz
ed T
hro
ughput
Å
Throughput (transactions/106 cycles), normalized to sequential thread. All performance barsuse 1 thread.
Figure 4.11: 1 thread performance of FlexTM
sioning entirely in software. On average, the overhead of software-based versioning is smaller
than that of software-based conflict detection, but it still accounts for as much as 30% of exe-
cution time for on some workloads (e.g.,STMBench7). Because it supports only lazy conflict
detection, SigTM has simpler software metadata than RTM-F. RTM-F tracks conflicts for each
individual transactional location and could varies the eagerness on a per-location basis.
FlexTM’s hardware tracks conflicts, buffers speculative state, and ensures consistency in a
manner transparent to software, resulting in single thread performance close to that of sequen-
tial thread performance. FlexTM’s main overhead, register checkpointing, involves spilling of

107
FlexTM RTM-F RSTM
(a) Workload Set 1
0
2
4
6
8
10
Has
hTa
ble
RBTr
ee
LFU
Cac
he
Ran
dom
Gra
phNorm
aliz
ed T
hro
ughput 10.1
FlexTM SigTM TL2
(b) Workload Set 2
0
2
4
6
8
10
12
Bay
es
Del
aunay
Gen
om
e
Intr
uder
Km
eans
Labyr
inth
Vac
atio
n
STM
Ben
ch7
Norm
aliz
ed T
hro
ughput
Throughput (transactions/106 cycles), normalized to sequential thread. All performance barsuse 16 threads.
Figure 4.12: 16 thread performance of FlexTM
local registers into the stack and is nearly constant across thread levels. Eliminating per-access
software overheads (metadata tracking, validation, and copying) allows FlexTM to realize the
full potential of hardware acceleration, with an average speedup of 2× over RTM-F and 5.5×
over RSTM on WS1. On WS2, FlexTM has an average speedup of 1.7× over SigTM and 4.5×
over TL2.
HashTable and RBTree both scale well and have significant speedup over sequential thread
performance, 10.3× and 8.3× respectively. In RSTM, validation and copying account for 22%
of execution time in HashTable and 50% in RBTree; metadata management accounts for 40%

108
and 30%, respectively. RTM-F manages to eliminate the validation cost and copying cost but
unfortunately the metadata management hinders performance improvement. FlexTM stream-
lines transaction execution and provides 2.8× and 8.3× speedup over RTM-F and RSTM re-
spectively.
LFUCache and RandomGraph do not scale (no performance improvement compared to
sequential thread performance). In LFUCache, conflict for popular keys in the Zipf distribu-
tion forces transactions to serialize. Stalled writers lead to extra aborts with larger numbers
of threads, but performance eventually stabilizes for all TM systems. In RandomGraph, larger
numbers of conflicts between transactions updating the same region in the graph cause all TM
systems to experience significant levels of wasted work. The average RandomGraph transaction
reads ∼60 cache lines and writes ∼9 cache lines. In RSTM, read-set validation accounts for
80% of execution time. RTM-F eliminates this overhead, after which per-access bookkeeping
accounts for 60% of execution time. FlexTM eliminates this overhead as well, to achieve 2.7×
the performance of RTM-F.
In applications with large access set sizes (i.e., Vacation, Bayes, Labyrinth, and STM-
Bench7), TL2 suffers from the bookkeeping required prior to the first read (i.e., for checking
write sets), after each read, and at commit time (for validation) [DSS06]. This instrumentation
accounts for '40% of transaction execution time. SigTM uses signatures-based conflict detec-
tion to eliminate this overhead. Unfortunately, both TL2 and SigTM suffer from another source
of overhead: given lazy conflict resolution, reads need to search the redo log to see previous
writes by their own transaction. Furthermore, the software commit protocol needs to lock the
metadata, perform the copyback, and then release the locks. FlexTM eliminates the cost of ver-
sioning and conflict detection and improves performance significantly, averaging 2.1× speedup
over SigTM and 4.8× over TL2.
Genome and Delaunay are workloads with a large ratio between the transaction size and
the number of accesses. TL2’s instrumentation on the reads does add significant overhead
and affects its scalability—only 3.4× and 2.1× speedup (at 16 threads) over sequential thread
performance for Genome and Delaunay respectively. SigTM eliminates the conflict detection
overhead and significantly improves performance—an average of 2.4× improvement over TL2.
FlexTM, in spite of the additional hardware support, improves performance by 22%, since the

109
versioning overheads account for a smaller fraction of overall transactional execution.
Finally, Kmeans and Intruder have unusually small transactions. Software handlers add
significant overhead in TL2. In Kmeans, SigTM eliminates conflict detection overhead to im-
prove performance by 2.7× over TL2. Since the write sets are small, eliminating the versioning
overheads in FlexTM only improves performance a further 24%. Intruder has a high level of
conflicts, and does not scale well, with a 1.6× speedup for FlexTM over sequential thread per-
formance (at 16 threads). Both SigTM and FlexTM eliminate the conflict detection handlers
and streamline the transactions, which leads to a change in the conflict pattern (fewer conflicts).
This improves performance significantly—3.3× and 4.2× over TL2 for SigTM and FlexTM
respectively. As in Kmeans, the versioning overheads are smaller and FlexTM’s improvement
over SigTM is restricted to 23%.
4.7.4 FlexTM vs. Central-Arbiter Lazy HTMs
Result 2: CSTs are useful: transactions do not often conflict and even when they do the num-
ber of conflicts per transaction is less than the total number of active transactions. FlexTM’s
distributed commit demonstrates better performance than a centralized arbiter.
As shown in Table 4.4(b), the number of conflicts encountered by a transaction is small
compared to the total number of concurrent transactions in the system. Even in workloads that
have a large number of conflicts (LFUCache and RandomGraph) a transaction typically en-
counters conflicts only about 30% of the time. Scalable workloads (e.g., Vacation, Kmeans)
encounter essentially no conflicts. This clearly suggests that global arbitration and serialized
commits will not only waste bandwidth but also restrict concurrency. CSTs enable local arbi-
tration and the distributed commit protocol allows parallel commits thereby unlocking the full
concurrency potential of the application. Also, a transaction’s commit overhead in FlexTM is
not a constant, but rather proportional to the number of conflicting transactions encountered.
In this set of experiments, we compare FlexTM’s distributed commit against two schemes
with centralized hardware arbiters: Central-Serial and Central-Parallel. In both schemes, in-
stead of using CSTs and requiring each transaction to ALoad its TSW, transactions forward their
Rsig and Wsig to a central hardware arbiter at commit time. The arbiter orders each commit

110
request, and broadcasts the Wsig to other processors. Every recipient uses the forwarded Wsig
to check for conflicts and abort its active transaction; it also sends an ACK as a response to the
arbiter. The arbiter collects all the ACKs and then allows the committing processor to complete.
This process adds 97 cycles to a transaction, assuming unloaded links and arbiter (latencies are
listed in Table 4.4(a)). The Serial version services only one commit request at a time (queuing
up any others); the Parallel services all non-conflicting transactions in parallel (assuming infi-
nite buffers in the arbiter). Central arbiters are similar in spirit to BulkSC [CTM07], but serve
only to order commits; they do not interact with the L2 directory.
We present results (see Figure 4.13) for all our workloads and enumerate the general trends
below:
• Arbitration latency for the Central commit scheme is on the critical path of transactions.
This gives rise to noticeable overhead in the case of short transactions (e.g., HashTable, RBTree,
LFUCache, Kmeans, and Intruder). CSTs simplify the commit process: in the absence of
conflicts, a commit requires only a single memory operation on a transaction’s cached status
word. On these workloads, CSTs improve performance by an average of 25% even over the
aggressive Central-Parallel, which only serializes a transaction commit if it conflicts with an
already in flight commit.
• Workloads that exhibit inherent parallelism with Lazy conflict resolution (all except
LFUCache and RandomGraph) suffer from serialization of commits in Central-Serial. Cen-
tral-Serial essentially queues up transaction commits and introduces the commit latency of even
other non-conflicting transactions onto the critical path. The serialization of commits could also
change the conflict pattern. In some workloads (e.g., Intruder, STMBench7), in the presence
of reader-writer conflicts as the reader transaction waits for predecessors to release the arbiter
resource, the reader could be aborted by the conflicting writer. In a system that allows paral-
lel commits the reader could finish earlier and elide the conflict entirely. CST-based commit
provides an average of '50% and a maximum of 112% (HashTable) improvement over Cen-
tral-Serial. Central-Parallel removes the serialization overhead, but still suffers from commit
arbitration latency.
• In benchmarks with high conflict levels (e.g., LFUCache and RandomGraph) that do not
inherently scale, Central’s conflict management strategy avoids performance degradation. The

111
transaction being serviced by the arbiter always commits successfully, ensuring progress and
livelock freedom. The current distributed protocol allows the possibility of livelock. However,
the CSTs streamline the commit process, narrow the vulnerability window (to essentially the
interprocessor message latency), and eliminate the problem as effectively as Central. Lazy
conflict resolution inherently eliminates livelocks as well. [ShD09; SDM09]
At low conflict levels, a CST-based commit requires mostly local operations and its per-
formance should be comparable to an ideal Central-Parallel (i.e., zero message and arbitration
latency). At high conflict levels, the penalties of Central are lower compared to the overhead
of aborts and workload inherent serialization. Finally, the influence of commit latency on per-
formance is dependent on transaction latency (e.g., reducing commit latency helps Central-
Parallel approach FlexTM’s throughput in HashTable but has negligible impact on Random-
Graph’s throughput).
FlexTM Central-Parallel Central-Serial
0
2
4
6
8
10
12
Bay
es
Del
aunay
Gen
om
e
Intr
uder
Km
eans
Labyr
inth
Vac
atio
n
STM
Ben
ch7
Has
hTa
ble
RBTr
ee
LFU
Cac
e
Ran
dom
Gra
phN
orm
aliz
ed T
hro
ughput
(1 t
hre
ad=
1)
Throughput (transactions/106 cycles), normalized to sequential thread. All performance bars use 16 threads.
Figure 4.13: FlexTM vs. Centralized hardware arbiters.
4.7.5 FlexTM-S vs. Other Virtualization Mechanisms
To study TM virtualization mechanisms, we downgrade our private L1 caches to 32KB 2-way.
This ensures that in spite of the moderate write set sizes in our workloads they experience

112
overflows due to associativity constraints. Every L1 has access to a 64 entry SM-cache. Each
metadata entry is 136 bytes.
We use five benchmarks in our study: Bayes, Delaunay, Labyrinth, and Vacation from the
STAMP suite, and STMBench7. As Table 4.4(b) shows, these benchmarks have the largest
write sets and are most likely to generate L1 cache overflows, enabling us to highlight tradeoffs
among the various virtualization mechanisms. The fraction of total transactions that experience
overflows in Bayes, Delaunay, Labyrinth, Vacation and STMBench7 is 11%, 8%, 25%, 9% and
32% respectively.
We compare FlexTM-S’s performance against the following Lazy TM systems:(1) FlexTM,
which employs a hardware controller for overflowed state and signatures for conflict detection,
(2) XTM [CMM06], which uses virtual memory to implement all TM operations; (3) XTM-
e, which employs virtual memory support for versioning but performs conflict detection using
cache-line granularity tag bits; and (4) SigTM [MTC07], which uses hardware signatures for
conflict detection and software instrumentation for word-granularity versioning. All systems
employ the Polka [ScS05] contention manager.
Result 1: A software maintained metadata cache is sufficient to provide virtualization sup-
port with negligible overhead.
As shown in Figure 4.14, FlexTM-S imposes modest performance penalty (10%) com-
pared to FlexTM. This is encouraging since it is vastly simpler to implement the SM-cache
than the controller in FlexTM. The SM-cache miss and copyback handlers are the main con-
tributors to the overhead. Unlike FlexTM and FlexTM-S, which version only the overflowed
cache lines, XTM and XTM-e suffers from the overhead of page-granularity versioning. XTM’s
page-granularity conflict detection also leads to excessive aborts. XTM and XTM-e both rely
on heavyweight OS mechanisms; by contrast, FlexTM-S requires only user-level interrupt han-
dlers. Finally, SigTM incurs significant overhead due to software lookaside checks to determine
if an accessed location is being buffered.
We also analyzed the influence of signature false positives. In FlexTM-S, write signature
false positives can lead to increased handler invocation for loading the SM-cache, but the soft-
ware metadata can be used to disambiguate and avoid abort penalty. In FlexTM, signature

113
FlexTM FlexTM-S XTM-e SigTM XTM(a) Bayes
0
0.2
0.4
0.6
0.8
1
Nor
mal
ized
Thr
ough
put
(b) Delaunay
0
0.2
0.4
0.6
0.8
1
Nor
mal
ized
Thr
ough
put
(c) Labyrinth
0
0.2
0.4
0.6
0.8
1
Nor
mal
ized
Thr
ough
put
(d) Vacation
0
0.2
0.4
0.6
0.8
1
Nor
mal
ized
Thr
ough
put
(e) STMBench7
0
0.2
0.4
0.6
0.8
1
Nor
mal
ized
Thr
ough
put
Throughput at 16 threads for FlexTM-S vs. other TMs, normalized to FlexTM.
Figure 4.14: Comparing FlexTM-S (FlexTM-Streamlines) with other TMs
responses are treated as true conflicts, and causes contention manager invocations that could
lead to excessive aborts. We set the Wsig and Osig to 32 bits (see Figure 4.15) to investigate the
performance penalties of small write signatures.

114
Result 4: As Figure 4.15 shows, FlexTM-S’s use of software metadata to disambiguate
false positives helps reduce the needed size of hardware signatures while maintaining high
performance.
FlexTM (32bit Wsig) FlexTM-S (32bit Osig and OWsig)
0
0.2
0.4
0.6
0.8
1
Bayes Labyrinth Delaunay STMBench7
Nor
mal
ized
Thr
ough
put
Performance normalized to FlexTM with 2048-bit Wsig)
Figure 4.15: Effect of signature size on FlexTM performance
4.8 Other Applications
Programmable-Data-Isolation essentially provides support for capturing a snapshot of the cache
blocks. Threads can make updates to private isolated blocks without worrying about remote
threads and always obtain the up-to-date version for read-only blocks. Memory snapshots can be
used to improve concurrency in many applications where multiple threads need to sift through
the program state as the program is executing.
4.8.1 Profiling
A number of profling tools (e.g., memory profiling, call-graph profiling [FMF05]) rely on a
separate profiling thread to traverse and assimilate information as the application is concurrently
executing. In such cases, the program objects referenced by the profiling thread are also being
concurrently modified by the application. Locking can be used to ensure correct interaction.
However, the profiling thread has been developed by a third-party, and ensuring correctness
and high performance is a challenge. Note that any consistent snapshot of the memory suffices

115
for the profiling thread (and does not necessarily need the up-to-date values). PDI effectively
supports profiling; the profiling thread has to only execute in an isolated block and prefetch the
data it needs to profile in speculative exclusive mode.
4.8.2 Garbage Collection
Similar to profiling a common application of separate threads iterating over program state is
garbage collection. Fast garbage collectors try to improve concurrency between mutators and
collectors with complex synchronization operations. Snapshots of memory will help the collec-
tors assimilate the dead objects [DFH04] without having to worry about the object references
being modified by the application.
4.8.3 Concurrent Programming
Most recently Burkhardt et al. [BBL10] have proposed using isolated versions of shared data
(revisions in Burkhardt’s terminology) to reason about concurrency as an alternative to critical-
section (TM or locks) based synchronization. Revision-based concurrency control relies on
maintaining a separate isolated copy of the shared data per concurrent task. These concurrent
tasks (non-speculative) make updates to the private copies of the data, which are propagated
when the task completes; all conflicts are resolved without aborts using program-level seman-
tics. Revisions need isolation without conflict detection. Software-only implementations of
revisions requires custom GET and PUT functions per field of a data object. PDI could elimi-
nate these handlers and provide a low overhead mechanism to implement revisions in both typed
and untyped languages. Our current implementation of PDI only supports a single task per L1
cache that requires isolation. Future work could potentially investigate extensions to PDI for
supporting multiple lightweight tasks per L1.

116
Chapter 5Conflict Management and Resolution in
HTMs
This chapter seeks to analyze the interaction between TM conflict management and conflict res-
olution policies, while taking into consideration both performance and implementation trade-
offs. In Section 5.1, we introduce the various types of conflict scenarios and motivate the need
for studying conflict management and resolution policies. Section 5.2 defines the basic termi-
nology and discusses the options available to a contention manager based on when it is invoked
to resolve a specific conflict scenario. Following this, we incorporate contention management
heuristics in a step-by-step fashion. In Section 5.3, we analyze the influence of introducing
backoff (stalling) into the contention manager. Section 5.4 studies the interaction between con-
tention manager heuristics with conflict resolution time (Eager and Lazy). In Section 5.5, we
implement and evaluate a mixed conflict resolution policy (the semantics of which were defined
in [Sco06]). Finally, Section 5.6 includes a discussion on related work.
5.1 Introduction
Currently, there is very little consensus on the right way to implement transactions. Hardware
proposals are more rigid than software proposals with respect to the conflict resolution poli-
cies supported. However, this stems in large part not from a clear analysis of the tradeoffs,

117
but rather from a tendency to embed more straightforward policies in silicon. In general, TM
research has tended to focus on implementation tradeoffs, performance issues, and correctness
constraints while assuming conflicts are infrequent. This assumption does not seem to hold for
the first wave of TM applications that employ coarse-grain transactions (Table 5.1). Conflicts
are common with “tries” and linked-list data-structures prevalent in these workloads. In such
data structures, typically, insertion proceeds bottom-up while searching moves top-down, which
leads to non-trivial interaction and overlap between the associated writer and reader transac-
tions. Furthermore, conservative programming practices that encapsulate large regions within
a single atomic block might lead to unnecessary conflicts due to the juxtaposition of unrelated
data with different conflict properties.
Hardware support for TM seems inevitable and has already started to appear [TrC08]. How-
ever, there seems to be very little understanding and analysis of TM policies in a HTM context.
Our work seeks to remedy this situation. In the absence of conflicts, policy decisions take a
backseat and most systems perform similarly. In the presence of conflicts, performance varies
widely (orders of magnitude, see Section 4.7.2) based on policy. We focus on the interaction
between two policy decisions that affect performance in the presence of conflicts: conflict reso-
lution time and contention management policy. We informally describe these two critical design
decisions below.
Table 5.1: Percentage of total (committed and aborted) txs that encounter a conflict.
Benchmark % Conf. tx Benchmark % Conf. TxBayes 85% Labirynth 81%Delaunay 85% Vacation 73%Genome 11% STMBench7 68%Intruder 90% LFUCache 95%Kmeans 15% RandomGraph 94%
See Appendix A for workload description. These experiments are for 16 thread runs with Lazyconflict resolution and a “committer wins” contention manager.
A conflict detection mechanism is needed to detect conflicts so that the system can ensure
that transactions do not perform erroneous externally visible actions as a result of an inconsis-
tent view. The conflict resolution time decides when the detected conflicts (if they still persist)
are managed — Eager systems (pessimistic) detect and resolve a conflict when a transaction

118
accesses a location. In Lazy systems (optimistic), the transaction that reaches its commit point
first will resolve the resulting conflict (although it may detect the conflict earlier). Most systems
tend to conflate detection and resolution and perform both at the same time. Here, we separate
the concepts and refer to the mechanism implemented in hardware or software as conflict detec-
tion and the policy choice of when to react when a conflict is detected as the conflict resolution
time. At the time of conflict resolution, the TM system invokes a contention manager to deter-
mine the response action. The contention manager employs a set of heuristics to decide which
transaction has to stall/retry and which can progress. The job of a good contention manager is
to mediate access to conflicting locations and maximize throughput while ensuring some level
of fairness. A contention manager’s policy is also influenced by conflict resolution time — in
Eager it is invoked before the access and could potentially elide the conflict while in Lazy it is
invoked after an access (when a conflict becomes unavoidable) and the contention manager has
to try to choose the appropriate transaction to abort.
We use FlexTM developed in Chapter 4:Section 4.5 as our experimental framework.
FlexTM allows software the flexibility to control both the conflict resolution time and contention
management policy. This allows us to analyze the policy tradeoffs within a common framework.
We use a diverse set of workloads from STAMP [MTC07] and STMBench7 [GKV07] that have
varied transaction parameters and conflict characteristics. Appendix A provides more details on
our experimental set up and workloads. Interestingly, while conflicts are commonplace in most
applications (Table 5.1), most conflicts (average over 90%) are between reader and writer trans-
actions, which can possibly be elided with the appropriate conflict resolution and management
policy as we demonstrate.
In this chapter, we conduct the following three studies. First, we analyze the influence of
introducing backoff (stalling) into the contention manager and how it helps with livelock issues.
Second, we implement and compare a variety of contention manager heuristics and evaluate
their interaction with conflict resolution time (Eager and Lazy). We analyze the access patterns
and transaction interleaving in our applications that lead to performance differences between
Eager and Lazy — specifically, the wasted work due to aborts and concurrency between reader
and writer transactions. Finally, we implement and evaluate a mixed conflict resolution policy
(the semantics of which were defined in [Sco06]) in the context of a hardware-accelerated TM.

119
The mixed policy resolves write-write conflicts eagerly to save wasted work and resolves read-
write conflicts lazily to exploit concurrency. Finally, we also briefly discuss the implementation
challenges and feasibility of modifying other HTMs to use the Mixed mode.
5.2 Conflict Resolution Primer
5.2.1 Conflict Resolution and Contention Management
The contention manager (CM) is called on any conflict and has to choose from a range of actions
based on conflict resolution time. Assuming deadlock freedom is a property of the underlying
TM system, the additional goals of the runtime, broadly defined, are to try to avoid livelock
(ensure that some transaction makes progress) and starvation (ensure that a specific transaction
that has been aborted often makes progress). It also needs to exploit as much parallelism as
possible, ensuring that transactions execute and commit concurrently (whenever possible). The
contention manager is decentralized and is invoked by the transaction that detects the conflict,
which we’ll label the attacking transaction (Ta), using the terminology introduced in [GHP05a].
The conflicting transaction that must participate in the arbitration is labeled the enemy transac-
tion (Te) (as opposed to the victim [GHP05a], since Te might actually win the arbitration). On
detecting a conflict, Ta invokes its contention manager, which decides the order it wants to se-
rialize the transactions based on some heuristic: Tabefore−−−−→ Te or Te
before−−−−→ Ta. The actions
carried out by the contention manager may also depend on when it was invoked, i.e., the conflict
resolution time.
The two main conflict resolution modes that have been been explored by previous HTM
designs is Eager and Lazy. They exploit varying levels of application parallelism based on
their approach to concurrent accesses. Eager enforces the single-writer rule and allows only
multiple-readers while Lazy permits multiple writers and multiple readers to coexist until a
commit. Transactions need to acquire exclusive permission to the written locations sometime
prior to commit. Eager acquires this permission at access and blocks out other transaction
workers for the duration of the transaction while Lazy delays this to commit allowing concurrent
work. There is, of course, a sliding scale between access and commit time, but we have chosen
the two end points for evaluation.

120
With Lazy, it is possible for readers to commit concurrently with a potential writer enemy
if they reach and finish their commits earlier than the writer. This form of conflict-awareness
where potentially conflicting transactions are allowed to concurrently execute and commit un-
covers more parallelism than Eager. This parallelism tradeoff is completely orthogonal to the
contention management that typically focuses on improving progress and fairness. Eager can
possibly save more wasted work via early detection of conflicts but only if the winner commits;
if the winner of the conflict aborts, more work will be wasted. Fundamentally, Eager tries to
handle potential conflicts at access and finds it difficult to make optimal decisions about which
transaction has a higher likelihood of committing in the future. Since Lazydoes not resolve
conflicts until the commit point (by which time a conflict becomes unavoidable) it allows the
contention manager to do a better job of choosing the appropriate winner (one that is likely
to commit) in a conflict. Lazy reduces the window of vulnerability (where a transaction could
abort its enemies only to find itself aborted later) to the commit window. In Eager the window
extends from the point at which the conflict was detected and the resulting contention managed
(access time) to the transaction commit time.
Figure 5.1 shows the generic set of options available to a contention manager. We now
discuss in detail the option exercised for a specific conflict type. Table 5.2 summarizes the
details. Any transaction can encounter three types of conflicts: Read-Write, Write-Read1, and
Write-Write.
Table 5.2: Interaction of contention manager and conflict resolutionObjective Te
before−−−−→ Ta Tabefore−−−−→ Te
E L E LR(Ta)-W(Te) WAITa : Ta WAITc : Ta ABrem : Te COself : Ta
W(Ta)-R(Te) WAITa : Ta WAITc : Ta ABrem : Te ABrem : Te
W(Ta)-W(Te) WAITa : Ta WAITc : Ta ABrem : Ta ABrem : Ta
R(tx) - Tx has read the location; W(tx) - Tx has written locationTa - Attacking transaction; Te - Enemytransaction
Read-Write: Read-Write conflicts are noticed by reader transactions, where the reader
plays the role of the attacker. If in Eager mode, the contention manager can try to avoid the
1Read-Write and Write-Read conflicts are the converse of each other. They vary based on the transaction thatnotices the conflict; when a transaction T1 reads a location being concurrently accessed by T2 for writing, theconflict is classified as Read-Write at T1’s end and Write-Read at T2’s end.

121
AA Write location Read locationXact_Begin
Stall ActiveAbortXXact_Commit
Te Ta
A
A
Tim
e
(a) WAITa
A
TaTe
A
(b) WAITc
Te Ta
AA
X
(c) ABrem
Te Ta
AA
X
(d) ABself
WAITa - Backoff on conflict in Eager systemsWAITc - Backoff before commit in Lazy systemsABrem - Abort remote transactionABself - Self abortCOself - Commit the transaction
Figure 5.1: Contention manager actions
conflict by waiting and allowing the enemy transaction to commit before it reads. Alternatively,
it could take the action of either ABself (self abort, see Figure 5.1 to release isolation on other
locations it may have accessed or ABrem on the writer in-order to make progress. With Lazy
systems, when the reader reaches the commit point, the reader can commit without conflict.
Write-Read: A Write-Read conflict at the high level is the same as Read-Write, except that
the writer is the attacker. If the contention manager decides to commit the reader before the
writer then the writer has to stall irrespective of the conflict resolution scheme (Eager or Lazy
). Eager systems would execute a WAITa while Lazy systems would execute a WAITc only
if the reader has not committed prior to the writer’s commit. If the writer is to serialize ahead
of the reader, the only option available is to abort the reader. In this scenario aborting early in
Eager systems might potentially save more wasted work.
Write-Write: True write-write conflicts are serializable even if concurrent transactions
commit; but, due to constraints with coherence-based conflict detection, such implementations
need to conservatively also treat write-write conflicts as dueling read-write, write-read conflicts.
There is no serial history in which both transactions can concurrently commit. One of them has

122
to abort. However, since Eager systems manage conflicts before access, they can WAITa until
the conflicting transaction commits. Lazy systems have no such option and in this case will
waste work. Both Eager and Lazy may also choose to abort either transaction.
5.2.2 Design Space
As described in [GHP05a], each contention manager exports notification and feedback meth-
ods. Notification methods inform the contention manager about transaction progress. In order
to minimize overhead, unlike the STM contention managers in [GHP05a], we assume explicit
methods exist only at transaction boundary events — transaction begin, abort, commit, and stall.
Any information on access patterns is gleaned via hardware performance counters/registers.
Feedback methods indicate to the transaction, based on who the enemy and attacker are, the
information the contention manager has on their progress, and what type of conflict is detected
(R-W, W-R, or W-W), what action must be taken among aborting the enemy transaction, abort-
ing itself, or stalling in order to give the enemy more time to complete.
Exploring the design spectrum of contention manager heuristics is not easy since the objec-
tives are abstract. In some sense, the contention manager heuristic has the same goals as the
heuristics that arbitrate a lock. Just as a lock manager tries to maximize concurrency and pro-
vide progress guarantees to critical sections protected by the lock, the contention manager seeks
to maximize transaction throughput while guaranteeing some level of fairness. We have tried to
adopt an organized approach: a five dimensional design space guides the contention managers
that we develop and analyze. We enumerate the design dimensions here while describing the
specific contention managers in our evaluation Section 4.7.2.
1. Conflict type: This dimension specifies whether the contention manager distinguishes
between various types of conflict. For example, with a write-write conflict the objective
might be to save wasted work while with read-write conflicts the manager might try to
optimize for higher throughput.
Options: Read-Write, Write-Read, or Write-Write
2. Implementation (I): The contention manager implementation is a tradeoff between con-
currency and implementation overheads. For example, each thread could invoke its own

123
instance of the contention manager (as we have discussed in this paper) or there could be a
centralized contention manager that usually closely ties both conflict detection and com-
mit protocol (e.g., lazy HTM systems [HWC04]). The latter enables global consensus
and optimizations while the former imposes less performance penalty and is potentially
more scalable.
Options: Centralized or De-centralized
3. Conflict Resolution: This controls when the contention manager is invoked,
Options: Eager, Lazy, or Mixed (see Section 5.5)
4. Election: This indicates the information used to arbitrate among transactions. There are a
number of heuristics that could be employed, such as timestamps, read-set and write-set
sizes, transaction length, etc. Early work on contention management [ScS05] explored
this design axis. In this paper, we limit the information used in a tradeoff between re-
duced implementation complexity and statistics collection overhead, and throughput in
the presence of contention.
Options: Timestamp, Read/Write set size, etc.
5. Action: Section 5.2 included a detailed discussion of the action options available to a
contention manager when invoked under various conflict scenarios. These have a critical
influence on progress and fairness properties. A contention manager that always only
stalls is prone to deadlock while one that always aborts the enemy is prone to livelock.
A good option probably lies somewhere in between. We show in our results that aside
from progress guarantees, waiting a bit before making any decision is important to overall
throughput.
Options: abort enemy, abort self, stall, increase/decrease priority, etc.
Since we are focused on the influence of software policy decisions, we only investigate
the de-centralized manager implementation. We investigate three types of conflict resolution:
Eager, Lazy, and Mixed. We study the interaction of conflict resolution with various election
strategies, with varying progress guarantees (e.g., Timestamp vs. Transaction progress). With
all these design choices, the contention manager can exercise the full range of actions.

124
5.3 Effectiveness of Stalling
There are many different heuristics that can be employed for conflict resolution and contention
management. To better understand the usefulness of each heuristic, we analyze them in a step-
by-step fashion, targeting specific objectives. We show that livelock is a problem mainly in
Eager systems and analyze the effectiveness of randomized backoff in alleviating the prob-
lem. Our results corroborate earlier findings [ScS05] that randomized-backoff is an effective
solution. We further note that the timing of backoff (whether prior to access or after aborting)
is important. We also quantify the average wasted work that can be attributed to an aborted
transaction and the work wasted cumulatively due to all aborts.
Randomized backoff is perhaps best known in the context of the Ethernet framework. In the
context of transactional memory, it is a technique used to either (1) stall a transaction restart to
mitigate repeated conflicts with another or (2) stall an access prior to actual conflict and thereby
potentially elide it entirely. There seems to be a general consensus that backoff is useful – most
STM contention managers use it [ScS05] and some Eager HTMs embed it into hardware as
their default[MBM06].
We study three contention managers,Reqwin,Reqlose, andComwin, with and without back-
off. Reqwin and Reqlose are access-time schemes compatible with Eager In Reqwin the at-
tacker always wins and aborts the enemy while in Reqlose the attacker always loses, aborting
itself. Comwin is the simple committer always-wins policy in Lazy. Reqwin and Reqlose when
combined with backoff (+B systems), wait a bit, retrying the access a few times (until the av-
erage latency of a transaction) before falling back to their default action. Reqwin and Reqlose
strategies were first studied by Scherer [ScS05] in the context of STMs. Recently, Bobba et
al. [BMV07] studied similar schemes as part of a pathology exploration in fixed-policy HTMs.
5.3.1 Implementation Tradeoffs
There are significant challenges involved in integrating even these simple managers within the
existing framework. Reqwin requires no modifications to the coherence protocol but is prone to
livelock, while Reqlose requires the support of coherence NACKs to inform the requestor that
its access must be aborted. Comwin in previous Lazy systems [HWC04; CTC06] has required

125
the support of a global arbiter. In FlexTM [SDS08], it requires a software commit protocol to
collect the ids of all the enemies from the conflict bitmaps and abort them.
Stalling a transaction in the midst of its execution after discovering a conflict is not easy.
The backoff needs to occur logically prior to the access in order to avoid the conflict but it
should occur only on conflicting accesses lest it waste time unnecessarily. Hence, backoff oc-
curs after the coherence requests for an access have been sent out to find out if the access does
conflict. Therein lies the problem: coherence messages typically update metadata along the
cache hierarchy to indicate access; if backoff is invoked, the metadata needs to be cleaned up
since logically the access did not occur. This requires extra messages and states in the coher-
ence protocol. Furthermore, continually stalling without aborting can lead to deadlock (e.g.,
transactions waiting on each other). The coherence extensions needed to conservatively check
for deadlock (e.g., with timestamps on coherence messages [MBM06]) introduce verification
challenges. In FlexTM, since transactions can use alerts [SSH07] to abort remote transactions
explicitly, we use a software-based timestamp scheme similar to the greedy manager [GHP05b]
to detect deadlocks. Eliminating the need for backoff prior to an access would arguably make
the TM implementation simpler.
5.3.2 Analysis
Figure 5.2 shows the performance plots. The Y-axis plots normalized speedup compared to
sequential execution. Each bar in the plot represents a specific contention manager.
Result 1a: Backoff is an effective technique to elide conflicts and randomization ensures
progress in the face of conflicts. The introduction of backoff in existing contention managers
can significantly improve Eager’s performance. Lazy’s delayed commit inherently serves as
backoff.
Implication: HTM systems that rely on coherence protocols for conflict resolution should
include a mechanism to stall and retry a memory request when a conflict is detected. STMs
should persist with the out-of-band techniques that permit stalling.
At anything over moderate levels of contention (benchmarks other than Kmeans and
Genome (see Table A.1 in Appendix A) both Reqlose and Reqwin perform poorly (see Fig-

126
ure 5.2). Reqlose’s immediate aborts on conflicts does serve as backoff, but in these bench-
marks it ends up wasting more work. Bobba et al. [BMV07] observed this same trend for
other SPLASH2 workloads. Introducing backoff helps thwart these issues (see Figures 5.2
(a),(b),(f),(g)): waiting a bit prevents us from making the wrong decision and also tries to en-
sure someone makes progress. Bobba’s EL system [BMV07] is similar to Reqwin. In both of
them the requester wins the conflict but they vary in their utilization of backoff; Reqwin ap-
plies it to the requester logically prior to access whereas the EL system applies backoff to the
restart of the enemy transaction after aborting it. This leads to different levels of wasted work
compared to the Reqlose system (comparable to Bobba’s EE system); Bobba’s work reports
significant wasted work and futile stalls in the EL compared to EE while here Reqwin performs
similarly to Reqlose.
Comwin performs well even without backoff. In benchmarks with no concurrency (e.g.,
RandomGraph) Lazy ensures that the transaction aborting enemies at commit-time usually fin-
ishes successfully (i.e., some transaction makes progress). In other benchmarks (e.g., Bayes
and Vacation) it exploits concurrency (allows readers and writers to execute concurrently and
commit). Backoff improves the chance of concurrent transactions committing. With read-write
conflicts, it stalls the writer at the commit point and tries to ensure the reader’s commit oc-
curs earlier, eliding the conflict entirely (see Figure 5.1(b)). There is noticeable performance
improvement in workloads with read-write sharing such as Bayes and Vacation.
We did observe that randomizing backoff at transaction start time can help avoid convoying
that arises in irregular workloads such as STMBench7. There are many short-running concur-
rent writer transactions that desire to update the same location and when one of them commits
the rest abort, restart, and the phenomenon repeats. This is akin to the “Restart Convoy” ob-
served by Bobba et al [BMV07] in their microbenchmarks.
5.3.3 Effect of Wasted work
A significant fraction of the performance differences between Eager and Lazy can be attributed
to the wasted work due to aborted transactions. Since Lazy resolves conflicts later than Eager it
would be expected that the work lost when a transaction is aborted is larger. The amount of extra

127
Req. wins Req. Wins + B Req. losesReq. loses + B Commit wins Commit Wins + B
(a) Bayes
0
2
4
6
8
10
16 threads
Norm
aliz
ed T
hro
ughput
(b) Delaunay
0
2
4
6
8
16 threads
Norm
aliz
ed T
hro
ughput
(c) Genome
0
2
4
6
8
10
12
16 threads
Norm
aliz
ed T
hro
ughput
(d) Intruder
0
2
4
6
8
16 threads
Norm
aliz
ed T
hro
ughput
(e) Kmeans
0
2
4
6
8
10
12
14
16 threads
Norm
aliz
ed T
hro
ughput
(f) Labyrinth
0
2
4
6
8
10
12
14
16 threads
Norm
aliz
ed T
hro
ughput
(g) Vacation
0
2
4
6
8
10
16 threads
Norm
aliz
ed T
hro
ughput
(h) STMBench7
0
2
4
6
16 threads
Norm
aliz
ed T
hro
ughput
(i) LFUCache
0
0.2
0.4
0.6
0.8
1
1.2
16 threads
Norm
aliz
ed T
hro
ughput
(j) RandomGraph
0
0.2
0.4
0.6
0.8
1
16 threads
Norm
aliz
ed T
hro
ughput
Y-axis: Normalized throughput, 1 thread throughput = 1. +B: with randomized Backoff
Figure 5.2: Studying the effect of randomized-backoff on conflict management
work wasted when a transaction aborts is dependent on the time elapsed between the access that
caused the conflict (which is when Eager would have aborted the enemy) and the commit point

128
(which is when Lazy aborts the enemy). Table 5.3 lists the statistics for four systems: Reqlose,
Reqlose+B, Comwin and Comwin+B. The Lazy systems (Comwin policies) waste more work
on an aborted transaction (7–68%). However, the work wasted on an abort is limited since a
conflict is discovered and handled as soon as a conflicting writer reaches the commit point. As
Table A.1 in Appendix A indicates(see Wr1 and Wrn metrics) transactions typically finish up
soon after they start writing.
Furthermore, the performance loss due to wasted work is also dependent on the number
of aborts in the system (see Ab/Ct metric in Table 5.3). This is already visible when compar-
ing Reqlose with Reqlose+B—Reqlose+B performs 1.7× better than Reqlose by aborting fewer
transactions (6.6× fewer). This is despite the average aborted transaction wasting 40% more
work inReqlose+B since a transaction always performs backoff prior to aborting. A similar pat-
tern is visible when comparing Comwin+B with Reqlose+B—-Comwin+B wastes 31% more
work per aborted transaction but aborts an average 1.6× fewer transactions (maximum 5.4×
fewer transactions) compared to Reqlose+B. Finally, it is also important to consider that while
Eager can save wasted work, the resulting available resources must be utilized for other useful
work in order to reap any benefit. Most TM systems do not allow fast context switching to other
useful work and the resources are essentially left idle during a backoff, resulting in no overall
improvement in performance.

129
5.4 Interplay between Conflict Resolution and Management
In this section, we focus on the tradeoffs between the various software arbitration heuristics
(e.g., timestamp, transaction size) that prioritize transactions and try to avoid starvation. We
analyze the influence of these policies on the varying concurrency levels of Eager and Lazy. All
managers in this section include backoff to eliminate performance variations due to livelocking.
Note that backoff does not help a specific transaction make progress (i.e., starvation-freedom).
Election/arbitration heuristics help achieve this goal (refer to Section 5.2.2). Election deals with
fairness issues by increasing the priority of the starving transaction over others, letting it win
and progress on conflicts. Here, we investigate three heuristics: transaction age, read-set size,
and number of aborts; under both Eager and Lazy conflict resolution. The plots also include
Reqlose+B and Comwin+B as a baseline.
• Age: The Age manager helps with scenarios where a transaction is repeatedly aborted. It
also helps with increasing the likelihood of a transaction committing if it aborts someone.
Every transaction obtains a logical timestamp by incrementing a shared counter at the
start. If the enemy is older the attacker waits, hoping to avoid the conflict, and then aborts
after a fixed backoff period. If the enemy is younger it is aborted immediately. The
timestamp value is retained on aborts and no two transactions have the same age, which
guarantees that at least one transaction in the system makes progress.
• Size: The Size manager tries to ensure that (1) a transaction that is making progress
and is closer to committing does not abort and (2) read sharing is prioritized to improve
overall throughput. This heuristic approximates transaction progress by the number of
read accesses made by the transaction. It uses this count to arbitrate between conflicting
transactions.
This manager uses a performance counter to estimate the number of reads.2 Finally,
Size also considers the work done before the transaction aborted. Hence, transactions
restart with the performance counter value retained from previous aborts (similar to
Karma [ScS05]).
2When arbitrating, software would also need to read performance counters on remote processors to compareagainst. For this, we use a mechanism similar to the SPARC %ASI registers.

130
• Aborts: The Abs manager tries to help with transactions that are aborted repeatedly.
Transactions accumulate the number of times a transaction has been aborted. On a con-
flict the manager uses this count to make a decision. Unlike Size it does not need a
performance counter since abort events are infrequent and can be counted in software.
Abs has weaker progress guarantees compared to Age; two dueling transactions can end
up with the same abort counter and kill each other. Similar to Age and Size it always waits
a bit before making the decision.
Figure 5.3 shows the results of our evaluation of the above policies. ’-E’ refers to eager
systems and ’-L’ refers to Lazy systems. We have removed Kmeans and Genome from the plots
since they have very low conflict levels, with all policies demonstrating good scalability.
Result 2a: Conflict resolution mode seems to be more important than contention manage-
ment heuristic. Lazy’s ability to allow concurrent readers and writers finds more parallelism
compared to any Eager system and this helps with overall system throughput.
Result 2b: Starvation and livelock can be practically avoided with software-based priority
mechanisms (like Age). They should be selectively applied to minimize their negative impact
on concurrency. With Lazy there is typically at least one transaction at commit point, which
manages to finish successfully, ensuring practical livelock-freedom.
Overall, Lazy exploits reader-writer sharing and allows concurrent transactions to commit
while Eager systems are inherently pessimistic, which limits their ability to find parallelism.
Also, a Lazy transaction aborts its enemies only when it reaches its commit phase, at which
point it has a better likelihood of finishing. This helps with overall useful work in the system.
Note that multi-programmed workloads could change the tradeoffs [SSH07]. Currently, on an
abort, the transaction keeps retrying until it succeeds; if the resources were to be yielded to
other independent computation, Eager could be a better choice. Power and energy constraints
could also constrain Lazy’s speculation limits, which would affect the concurrency that can be
exploited for performance.
As shown in Figure 5.3, a specific contention manager may help some workloads (by help-
ing prevent starvation) while they hurt the performance in others (serializing unnecessarily).

131
We have observed that Size performs reasonably well across all the benchmarks. It seems
to have a similar effect on Eager and Lazy alike. Size maximizes concurrency and tries to
help readers commit early, thereby eliding the conflict entirely without aborting the writer (e.g.,
vacation); orthogonally, Size also helps with writer progress since typically writers that are
making progress have higher read counts and win their conflicts. Note that the number of reads
is also a good indication of the number of writes since most applications read locations before
they write them.
Age helps transactions avoid starvation in workloads that have high contention (LFUCache
and RandomGraph). Age’s timestamps ensure that a transaction gets the highest priority in a
finite time and ultimately makes progress. On other benchmarks, Age hurts performance when
interacting with Eager. This is due to the following dual pathologies: In Eager mode, (1)
Age can lead to readers convoying and starving behind a older long running writer; in Lazy
mode, since reads are optimistic, no such convoying results. (2) Age can also result in wasteful
waiting behind an older transaction that gets aborted later on (akin to “FriendlyFire” [BMV07]);
with Lazy the likelihood is that the transaction that reaches the commit point first (the one
that would wait) is also older and therefore makes progress and avoids waiting once again.
Bobba [BMV07] explored hardware prefetching mechanisms to prioritize starving writers in a
rigid-policy HTM that prioritized enemy responders. We have shown that similar effects can be
achieved with Age; we can also explore writer priority in a more straightforward manner since
the control of when and which transaction aborts is in software.
As for the Abs manager, its performance falls between Size and Age. This is expected, since
it does not necessarily try to help with concurrency and throughput like Size but does not hurt
them with serialization like Age.
The “Serialized commit” pathology observed by others [BMV07] does not arise with our
optimized Lazy implementation, which allows parallel arbitration and commits. Lazy exhibits
a significant performance boost compared to even contention management optimized Eager
systems. Although the contention manager can help eliminate pathologies, it does not affect
the concurrency exploited. In general, Lazy exploits more concurrency (reader-writer overlap),
avoids conflicts, and ensures better progress (some transaction is at the commit stage) than Ea-
ger. Combining Lazy with selectively invoking the Age manager (to help starving transactions

132
L-Abs E-Abs Comwin+B Reqlose+BL-Age E-Age L-Size E-Size
(a) Bayes
0
2
4
6
8
10
16 threads
Norm
aliz
ed T
hro
ughput
(b) Delaunay
0
2
4
6
8
10
16 threads
Norm
aliz
ed T
hro
ughput
(c) Intruder
0
2
4
6
8
16 threads
Norm
aliz
ed T
hro
ughput
(d) Labyrinth
0
2
4
6
8
16 threadsN
orm
aliz
ed T
hro
ughput
(e) Vacation
0
2
4
6
8
10
16 threads
Norm
aliz
ed T
hro
ughput
(f) STMBench7
0
2
4
6
8
16 threads
Norm
aliz
ed T
hro
ughput
(g) LFUCache
0
0.2
0.4
0.6
0.8
1
1.2
16 threads
Norm
aliz
ed T
hro
ughput
(h) RandomGraph
0
0.2
0.4
0.6
0.8
1
16 threads
Norm
aliz
ed T
hro
ughput
L-Lazy, E-Eager conflict resolution. Y axis: Normalized throughout, 1 thread throughput = 1
Figure 5.3: Interplay of conflict management and conflict resolution
get priority) and with backoff (to avoid convoying) would lead to an optimized system that can
handle various workload characteristics.

133
Finally, for some workloads (e.g., STMBench7), the conflict resolution modes and con-
tention management policies explored above do not seem to have any noticeable impact on
their performance. We analyze the reasons and propose solutions in the next section.
5.4.1 Wasted work in Eager and Lazy
To analyze the performance variations between Eager and Lazy we explore the access pat-
terns and transaction interleaving prevalent across the applications we study. We focus on
two aspects: (1) the performance loss due to wasted work in aborted transactions Earlier
works [MBM06; BMV07] have commonly argued that since Lazy resolves a conflict later in
a transaction’s execution (i.e., at commit) doomed enemies discover their status later and end
up wasting more work compared to Eager. Figure 5.4(a) sketches the scenario for a read-write
conflict. A transaction T1 reads a location A that is subsequently written by a concurrent writer
T2 that commits earlier. All of T1’s work is wasted regardless of whether a Lazy or Eager sys-
tem is used. There is extra work wasted in Lazy since T1 is not notified until T2’s commit point.
This extra work is proportional to the interval between T2’s write and commit. Since in most
transactions the writes occur in a more clustered manner than reads and towards the end of the
transaction, this extra wasted work can be expected to be limited.
The statistics in Table 5.3 indicate that Eager in fact tends to waste more cumulative work
than Lazy. This contradicts Eager’s design philosophy: detect and abort conflicting transactions
as early as possible to save wasted work. The primary reason for this is futile aborts — while in
Lazy each individual aborted transaction may waste more work (than Eager), overall, Eager can
lead to a higher number of aborts, wasting cumulatively more work than Lazy. Figure 5.4(b)
sketches the access pattern prevalent across most applications with moderate levels of conflict
(e.g., Bayes, Intruder, Labyrinth and Vacation). In Eager, transaction T1 aborts in favor of T2,
while T2 subsequently does not commit. The work in both both T1 and T2 is wasted. Conversely,
if T2 aborted itself in favor of T1, it is possible that T1 is aborted subsequently leading to a
similar wastage of work. These scenarios occur because of a fundamental design principle in
Eager — address potential conflicts early even before they are confirmed (e.g., here the conflict
between T1 and T2 is confirmed only when T1 attempts to commit before T2). Essentially, on

134
a conflicting access, Eager expects the contention manager to speculate on which transaction is
likely to commit and this is a difficult task with multiple concurrent operations.
AA Write location Read locationXact_Begin
Stall ActiveAbortXXact_Commit
(a) Wasted Work
AAAbort
X
Was
ted
work
AA
AbortX
Was
ted
work
Eager Lazy
time
(b) Futile Aborts
A
A
B
BAbort
X
Tx1 Tx2 Tx3
A
A
B
BAbort
X
Tx1 Tx2 Tx3Eager Lazy
XAbort
(c) Read-Write Sharing
AA
AAbortX
Abort
X
AA
A
Tx1 Tx2 Tx3 Tx1 Tx2 Tx3Eager Lazy
(a) Wasted work due to aborts. Lazy wastes more work than Eager proportional to the time duration between the
write and the commit. (b) Futile abort. Eager can cause aborts in favor of an attacker that itself does not commit, Lazy
reduces the likelihood of this. (c) Concurrency between readers and writer transactions. Lazy permits conflicting
transactions to concurrently execute and commit, Eager does not support this pattern.
Figure 5.4: Interaction of access patterns with conflict resolution
Lazy allows concurrent execution between even conflicting transactions and eliminates these
problems. Since T2 does not abort T1 until the commit stage, it reduces the likelihood of a third
transaction intervening to cause T2’s victory over T1 to be futile. When a transaction (T1)
aborts in favor of a transaction (T2), the likelihood of the winner (T2) committing is higher than
in Eager. The primary reason is the window of vulnerability: the time between the point at
which a transaction aborts its enemy to its commit point. During this time, it could be aborted
by other transactions, which would render the earlier abort of the enemies futile. In the case of
Eager this window extends from the point of the access that causes the abort to the commit. In

135
the case of Lazy, it is limited to the duration of the commit phase, which is negligible in most
workloads.
Another problem with Eager is that it does not permit both T1 and T2 to concurrently ex-
ecute. If the contention manager chooses T2 as the transaction likely to succeed, the only
option for T1 would be backoff the write to A. Note that this backoff could itself lead to an-
other problem; possible cascading of a third transaction T3 behind T1 (access to location B
in Figure 5.4(b)). This kind of cascaded stalls could potentially lead to deadlock and hence
backoff has to be finite: if the conflict persists eventually one of the transactions will have to
abort. Compared to this, Lazy permits concurrency between T1 and T2, and does not require
any contention management until T2 has finished all the work and reaches the commit point.
5.4.2 Concurrent Readers and Writers
An important benefit of Lazy is the support for concurrent readers and writers to the same lo-
cation. Read-Write (and its converse Write-Read) sharing is an access pattern prevalent across
most transaction workloads (see Table A.1 in Appendix A). Conflicts between reader and writer
transactions (R-W or W-R conflicts) is the dominant type (see Figure A.1 in Appendix A). Most
of the workloads (in our suite) use transactions to operate on pointer-based data structures like
trees. All transactions, irrespective of the sub-tree they are interested in, access the higher levels
in the tree (e.g., root node) to get to the sub-tree. Writer operations typically re-organize the
tree, modify the higher levels in the tree, and conflict with reader transactions. Note that modifi-
cations to the root would not in most cases affect the safety of the readers, which once they have
traversed to the sub-tree do not care about the root. Typically, the writer transaction also con-
flicts with multiple concurrent readers (e.g., Bayes, Labyrinth, Vacation). Figure 5.4(c) shows
an illustration of this conflict pattern. Both T1 and T2 read a location A, which is subsequently
written by T3. In an Eager system, if T3 is prioritized, then it needs to abort both T1 and T2 and
ends up wasting work from both transactions. However, Lazy permits all three transactions to
continue execution until T3 needs to commit. This provides a window of opportunity between
the write to A to T3’s commit point to allow other concurrent reader transactions to complete.
This allows Lazy to achieve more commits than Eager — in this case three compared to Eager’s
one.

136
5.5 Mixed Conflict Resolution
As shown in Figure 5.3, none of the contention managers seem to have any noticeable positive
impact on STMBench7’s scalability. Despite the high level of conflicts, both Eager and Lazy
perform similarly. STMBench7 has an interesting mix of transactions: unlike other workloads,
it has a mix of transactions of varying length. It has long running writer transactions interspersed
with short readers and writers. This presents an unhappy tradeoff between the desire to allow
more concurrency and avoid high levels of wasted work on abort. Eager cannot exploit the
concurrency since the presence of the long running writer blocks out other transactions. With
Lazy the abort of long writers by other potentially short (or long) writers starves them and
wastes useful work. We evaluate a new conflict resolution mode in HTM systems, Mixed, which
detects read-write and write-read conflicts lazily while detecting write-write conflicts eagerly. 3
For Write-Write conflicts, there is no valid execution in which two writers can concur-
rently commit. Mixed uses eager resolution to abort one of the transactions and thereby avoid
wasted work, although it is possible to elect the wrong transaction as the winner (one that will
subsequently be aborted). For Read-Write conflicts, if the reader’s commit occurs before the
writer’s then both transactions can concurrently commit. Mixed postpones conflict resolution
and contention management to commit time, trying to exploit any concurrency inherent in the
application.
Figures 5.5 and 5.6 plot the performance of Mixed against Eager and Lazy. To isolate
and highlight the performance variations due to conflict resolution, we plot different contention
managers on different plots— Figure 5.5 uses the Size contention manager and Figure 5.6 used
the Age contention manager (see description of contention managers in Section 5.4).
Result 3: Mixed combines the best features of Eager and Lazy. It can save wasted work on
write-write conflicts and uncover parallelism prevalent with read-write sharing.
As the results (see Figure 5.5 and Figure 5.6) demonstrate, Mixed is able to provide a sig-
nificant boost to STMBench7 over both Eager and Lazy. In STMBench7, which has a mix of
long running writers conflicting with short running writers, resolving write-write conflicts early
3In FlexTM [SDS08], this requires minor changes to the conflict detection mechanism. In Lazy mode, where thehardware would have just recorded the conflict in the W-W list, it now causes a trigger to the contention manager.

137
reduces the work wasted when the long writer aborts. Similar to Lazy it also exploits more
reader-writer concurrency compared to Eager.
When there is significant reader-writer overlap (Bayes, Delaunay, Intruder, Labyrinth, and
Vacation), Mixeds performance is comparable to the Lazy system. In Section 5.4, we saw that
for the STAMP workloads and STMBench7, Size was the best performing contention manager.
Comparing the plots of the STAMP workloads and STMBench7 between Figure 5.5 and Fig-
ure 5.6, the performance order between Size and Age carries over to Mixed as well.
On LFUCache, Mixed with the Size contention manager performs badly due to dueling
writer transactions. Trying to exploit reader-writer parallelism does not help since all trans-
actions seek to upgrade the read location causing a write-write conflict; Furthermore, a writer
could abort another transaction only to find itself aborted later (cascaded aborts). This leads
to an overall fall in throughput. On RandomGraph, Mixed livelocks with the Size contention
manager, similar to Eager. Switching the contention manager to Age which provides stronger
progress guarantees, helps both Eager and Mixed achieve higher performance. Further, Mixed’s
ability to exploit read-write sharing helps it exploit more concurrency than Eager and improve
performance.
In summary, Mixed saves some of Lazys wasted work in the case of write-write conflicts
while continuing to exploit read-write concurrency as in LazyThe inability to exploit read-
write concurrency is a fundamental design limitation of EagerHowever, Mixed may suffer from
progress problems similar to Eager but as in Eager this can be solved with the appropriate
contention manager.
5.5.1 Implementation Tradeoffs
There is a general assumption that Eager is easier to implement in hardware compared to Lazy
because of its more modest versioning requirements. Eager conflict mode maintains the “Sin-
gle writer or Multiple reader” invariant. There are a maximum of two versions that must be
maintained for a specific memory block: a single writer’s speculative version and the non-
speculative original version. At any given instant, either multiple readers are allowed to access
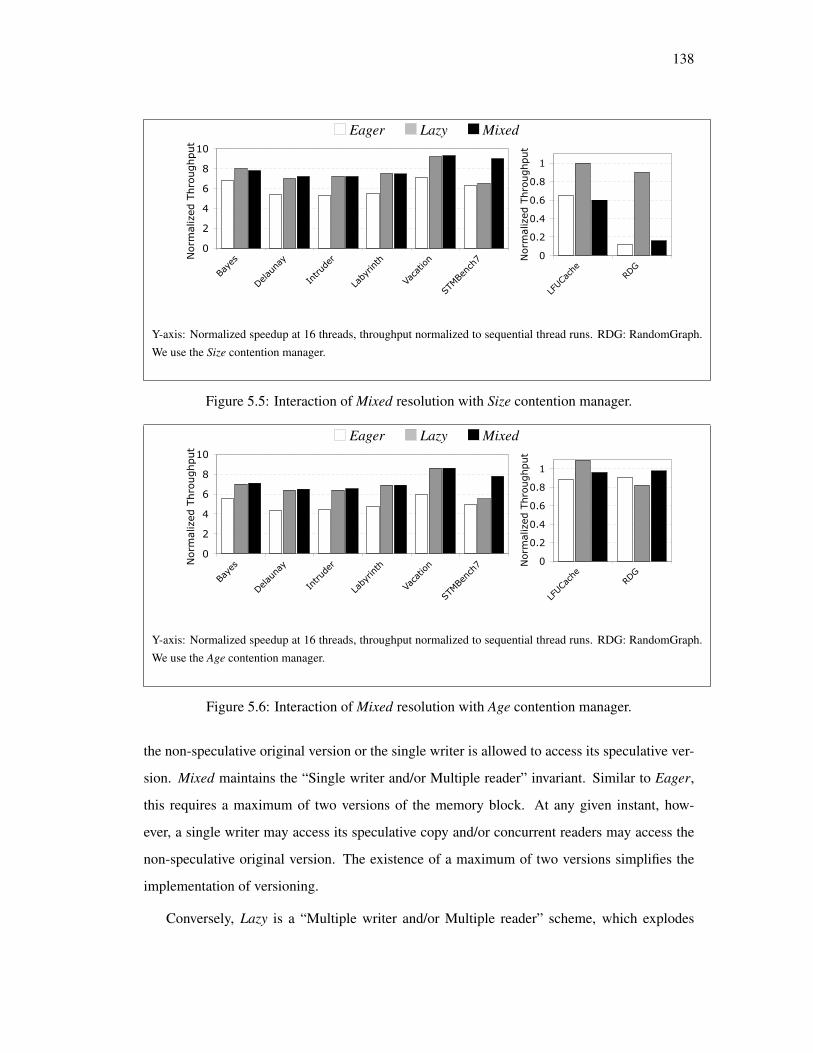
138
Eager Lazy Mixed
0
2
4
6
8
10
Baye
s
Delau
nay
Intru
der
Laby
rinth
Vaca
tion
STMBe
nch7
Norm
aliz
ed T
hro
ughput
0
0.2
0.4
0.6
0.8
1
LFUC
ache
RDG
Norm
aliz
ed T
hro
ughput
Y-axis: Normalized speedup at 16 threads, throughput normalized to sequential thread runs. RDG: RandomGraph.
We use the Size contention manager.
Figure 5.5: Interaction of Mixed resolution with Size contention manager.
Eager Lazy Mixed
0
2
4
6
8
10
Baye
s
Delau
nay
Intru
der
Laby
rinth
Vaca
tion
STMBe
nch7
Norm
aliz
ed T
hro
ughput
0
0.2
0.4
0.6
0.8
1
LFUC
ache
RDG
Norm
aliz
ed T
hro
ughput
Y-axis: Normalized speedup at 16 threads, throughput normalized to sequential thread runs. RDG: RandomGraph.
We use the Age contention manager.
Figure 5.6: Interaction of Mixed resolution with Age contention manager.
the non-speculative original version or the single writer is allowed to access its speculative ver-
sion. Mixed maintains the “Single writer and/or Multiple reader” invariant. Similar to Eager,
this requires a maximum of two versions of the memory block. At any given instant, how-
ever, a single writer may access its speculative copy and/or concurrent readers may access the
non-speculative original version. The existence of a maximum of two versions simplifies the
implementation of versioning.
Conversely, Lazy is a “Multiple writer and/or Multiple reader” scheme, which explodes

139
the number of possible data versions required, potentially requiring as many as the number of
speculative writer transactions in addition to the one non-speculative version required by the
readers. Thus, taking implementation costs into consideration, Mixed offers a good tradeoff
between performance and complexity-effective implementation.
5.5.2 Porting Mixed to other TMs
Given Mixed’s benefits, it would be interesting to consider the changes required to adopt it
in other HTMs. Any HTM system that desires to implement Mixed’s “Single writer and/or
Multiple reader” model needs to implement the following: (1) a versioning mechanism that
allows one transaction to speculatively write a block and allow other concurrent readers to
access the non-speculative copy and (2) a conflict detection mechanism that detects and resolves
writer-write conflicts at access time and resolves read-write (or conversely, write-read) conflicts
at commit time.
Existing Lazy HTM systems (Bulk [CTC06], TCC [HWC04]) could support Mixed with
minimal changes. Adapting the versioning mechanism to support Mixed is trivial since the
system already allows multiple writers and readers to share a cache block. Changes would be
need only in the conflict detection mechanism. Lazy systems other than FlexTM (Bulk [CTC06]
and TCC [HWC04]) implement conflict detection using a centralized arbitration mechanism
that intervenes on transaction commits. Such systems implement implicit transactions in which
processors communicate with the shared memory at the granularity of transactions rather than
individual memory operations. At commit time, a transaction broadcasts its write-set so that
other transactions can compare their access sets against it and detect conflicts. Mixed would
need to augment this with a more traditional coherence framework in which individual writes
are sent out at access time. Hence, a transaction write initiates coherence requests, which other
transactions use to detect conflicts with their write-sets. Commit-time write-sets also need to be
sent out to detect conflicts with the read-set of other transactions. Since these systems combine
detection and resolution, changes are needed to detect some conflicts (write-write) eagerly and
some (read-write and write-read) lazily. FlexTM always detects conflicts eagerly but leaves the
choice of resolution to software, which can then choose to resolve the conflict eagerly or lazily
based on the conflict type.

140
Porting other Eager HTM systems (e.g., LogTM-SE [YBM07]) to support Mixed is more
challenging when compared to Lazy. Eager systems allow only a single writer for a cache block
at any given instant and preclude other transactions from sharing the same block. They imple-
ment versioning using an undo-log which writes new speculative values in-place and stores the
old values in an undo-log (to be restored on commit). Like Eager, Mixed allows only one block
to write a line but unlike Eager it requires multiple concurrent readers to be able to access the
block. This means Eager systems which typically implement an undo-log (old values in log,
new values in memory location) need to provide concurrent readers the current committed value
from the undo-log. For conflict detection, Eager HTMs piggyback on the coherence framework
— they maintain the “single writer or multiple reader” invariant. This proves sufficient for
Mixed as well since it resolves write-write conflicts eagerly at access-time. The remaining
challenges to address is Mixed’s requirement for delayed commit-time resolution of read-write
conflicts. Possible implementations include either support for bulk coherence operations or the
use of conflict summary tables as in FlexTM [SDS08], which allow lazy resolution of multiple
conflicts in parallel without centralized hardware structures.
5.6 Other studies on contention management
The seminal DSTM paper by Herlihy et al. [HLM03b] introduced the concept of “contention
management” in the context of STMs. They postulated that obstruction-free algorithms enable
the separation of correctness and progress conditions (e.g., avoidance of livelock), and that a
contention manager is expected to help only with the latter. Scherer et al. [ScS05] investigated
a collection of arbitration heuristics on the DSTM framework. Each thread has its own con-
tention manager and on conflicts, transactions gather information (e.g., priority, read/write set
size, number of aborts) to decide whether aborting enemy transactions will improve system
performance. This study did not evaluate an important design choice available to the con-
tention manager: that of conflict resolution time (i.e., Eager or Lazy). Shriraman et al. [SSH07]
and Marathe et al. [MSS04] observed that laziness in conflict resolution can significantly im-
prove the throughput for certain access patterns. However, these studies did not evaluate con-
tention management. In addition, evaluation in all these studies was limited to microbench-

141
marks. Scott [Sco06] presents a classification of possible conflict resolution modes, including
the mixed mode, but does not discuss or evaluate implementations. Contention management can
also be viewed as a scheduling problem. Yoo et al. [YoL08] and CAR-STM [DHS08] use cen-
tralized queues to order and control the concurrent execution of transactions. These queueing
techniques preempt conflicts and save wasted work by serializing the execution of conflicting
transactions. Yoo et al. [YoL08] use a single system-wide queue and control the number of
transactions that run concurrently based on the conflict rate in the system. Dolev et al. [DHS08]
use per-processor transaction issue queues to serially execute transactions that are predicted to
conflict. While they can save wasted work, these centralized scheduling mechanisms require
expensive synchronization and could unnecessarily hinder existing concurrency. Furthermore,
the existing scheduling mechanisms serialize transactions on all types of conflict. Serializing
transactions that only have read-write overlap significantly hurts throughput and could lead to
convoying [SDS08; BMV07].
Most recently, Spear et al. [SDM09] have performed a comprehensive study of contention
management policy in STMs. Though limited to microbenchmarks, they analyze the perfor-
mance tradeoffs under various conflict scenarios and conclude that Lazy removes the need for
sophisticated contention managers in STMs. Our analysis reveals a similar trend in HTMs as
well, indicating that hardware designers must pay attention to the policies embedded in hard-
ware in order to avoid losing the benefits of hardware acceleration.
It would be fair to say that hardware supported TM systems have mainly focused on im-
plementation tradeoffs and have largely ignored policy issues. Bobba et al. [BMV07] were the
first to study the occurrence of performance pathologies due to specific conflict detection, man-
agement, and versioning policies in HTMs. Their hardware enhancements targeted progress
conditions (i.e., practical starvation-freedom, livelock-freedom) and did not focus on the con-
currency tradeoffs between Eager and Lazy (see Section 5.2). Furthermore, they limited their
study to three points in the design space, which does not fully capture the interaction between
the various other contention managers and conflict resolution policies. Baugh et al. [BNZ08]
and Ramadan et al. [RRP07] compare a limited set of previously proposed STM contention
managers in the context of Eager systems.
Most recently, Ramadan et al. [RRW08] have proposed dependence-aware transactions as

142
an alternative conflict resolution model. Instead of resolving conflicts, they forward data be-
tween speculative transactions and tie their destinies together (requiring support for potential
rollback of multiple dependent transactions) with the goal of uncovering more concurrency.
It is not yet clear that performance improvements promised by dependence-awareness merit
the hardware complexity. We demonstrate here that Lazy is sufficient to uncover most of the
parallelism prevalent in the application.
5.7 Summary
We presented a comprehensive study of the interplay between policies on “when to detect” (con-
flict resolution) and “how to manage” (conflict management) conflicts in hardware-accelerated
TM systems. Although the results were obtained on a HTM framework, the conclusions and
recommendations are applicable to any type of TM: hardware, software, or hybrid, and are
corroborated by those in Spear et al. [SDM09].
Our first set of experiments corroborated recent studies that randomized Backoff is an essen-
tial heuristic and is best applied before conflict management in order to potentially side-step the
conflict. We then demonstrated that Lazy provides higher performance than Eager by exploit-
ing reader-writer concurrency prevalent in many applications and by narrowing the window of
conflict. Finally, we evaluated a Mixed conflict resolution mode in the context of HTMs. Mixed
mode retains most of the concurrency benefits of lazy and outperforms it (by saving wasted
work) in workloads dominated by write-write conflicts.

143
Tabl
e5.
3:C
hara
cter
istic
sof
abor
ted
tran
sact
ions
Ben
chm
ark
Eag
er-R
eqw
ins
Laz
y-C
omm
iterw
ins
w/o
back
off
w/b
acko
ffw
/oba
ckof
fw
/bac
koff
Ab-
Tx
Size
Ab
/Ct
Ab-
Tx
Size
Ab
/Ct
Ab-
Tx
Size
Ab
/Ct
Ab-
Tx
Size
Ab
/Ct
(%C
tSiz
e)(%
CtS
ize)
(%C
tSiz
e)(%
CtS
ize)
Bay
es35
5.1
430.
5649
0.45
520.
31D
elau
nay
393.
146
0.41
510.
2455
0.2
Gen
ome
330.
0145
0.01
510.
0158
0.01
Intr
uder
2012
293.
141
0.8
490.
78K
mea
ns60
0.02
750.
0279
0.02
810.
02L
abyr
inth
1914
313.
668
0.65
790.
59V
acat
ion
304.
240
1.6
540.
2854
0.25
STM
Ben
ch7
327.
145
1.05
740.
6580
0.54
LFU
Cac
he45
—51
2389
12.9
9011
Ran
dom
grap
h35
—49
—48
18.3
5619
Ab-
Tx
Size
(%C
tsiz
e)-L
engt
hof
Avg
.abo
rtT
xas
a%
ofco
mm
itT
x’s
dura
tion.
Ab/
Ct-
Avg
.num
bero
fabo
rts
perc
omm
it.—
:Liv
eloc
k

144
Chapter 6Protection : Sentry
In this chapter, we describe the Sentry system that we proposed at ISCA 2010 [ShD10]. Sen-
try enables software developers to set up intra-application protection domains. Section 6.1
discusses the reliability challenges encountered by large applications that consist of multiple
modules and motivates the need for an access control mechanism. In Section 6.1.1, we dis-
cuss the design tradeoffs in the implementation of access control hardware and summarize the
limitations of current approaches. Section 6.2 presents the Sentry architecture and describes
the use of cache coherence states to implement access control. Section 6.3 presents the soft-
ware framework and compares the various intra-application protection models supported by
Sentry. In Section 6.6, we use Sentry to implement a protection model for the modules of the
Apache webserver and demonstrate that this can be achieved with moderate performance over-
head ('13%). We also develop a watchpoint debugger using Sentry and compare it against
other hardware-based watchpoint mechanisms in Section 6.7.
6.1 Motivation
Modern applications are complex artifacts consisting of millions of lines of code written by
many developers. Developing correct, high performance, and reliable code has thus become
increasingly challenging. The prevalence of multicore processors, resulting in the need for mul-
tiple threads of control in order to harness the available compute power, has increased the burden

145
Apache Core
1. Http request() 2. Allocator()3. Utilities()
D1 (M1:R/W)D2 (M1:R/W)
M1
Private data
...................
Mod_Cachecache root()insert_entry()
D3 (M2:R/W)D4 (M2:R/W)
M2
Private data
...................
D5 (M1:R/W) (M2:R)D6 (M1:R) (M2:R)setcache_size()get_request_packet()
Mod_log
D6 (M3:R/W)D7 (M3:R/W)
M3
Private data
...................
...................
log_bytes()log_filter()...................
D8 (M1,M3:R/W) (M2,R)log_config()insert_log()
Example of software modules in Apache. M1,M2,M3 — modules, D1...D8 — data elements. Dashed lines indicateshared data and function interface between modules. Tuple D: (M:P) indicates module M has permission P on thememory location D.
Figure 6.1: Software modules in Apache
on software developers. Intra- and inter-thread interactions to shared data make it difficult for
developers to track, debug and validate the accesses arising from the various software modules.
Figure 6.1 presents a high-level representation of the developers’ view of Apache [10b] at
design time. The system designers define a software interface that specifies the set of functions
and data that are private and/or exported to other modules. For the sake of programming sim-
plicity and performance, current implementations of Apache run all modules in a single process
and rely on adherence to the module API to enforce protection. A bug or safety problem in any
module could potentially (and does) affect the whole application.
There are two main aspects to enforcing the protection of a specific datum or object: (1)
the domain, referring to the environment or context, typically the module, that a thread is ex-
ecuting in; and (2) the access privileges, the set of permissions available to a domain, for the
object [Lam71]. Access control enforces the permissions specified for the domain and object.
An instance of this use is enforcing the rule that a plug-in should not have access to the appli-
cation’s data or another plug-in’s data, while the application should have unrestricted access to
all data. Access control can also be used for program debugging in order to intercept accesses

146
or detect violations of specific access invariants, such as accesses to uninitialized or unallocated
locations, dangling references, unexpected write values, etc. Tracking memory bugs is an in-
tensive task and it is especially complicated in modularized collaborative applications where
accesses to memory regions are split across codes developed independently.
In this section, we describe Sentry, a hardware framework that enables software to enforce
flexible application-specific protection policies at runtime. The core developer annotates the
program to define the policy and then the system ensures the privacy and integrity of a module’s
private data (no external reads or writes), the safety of inter-module shared data (by enforcing
permissions as described in the annotations), and adherence to the module’s interface (con-
trolled function call access points as in Multics [Org72]).
Sentry is a light-weight, multi-purpose access control mechanism that is independent of
and subordinate to (enforced after) the page protection in the Translation-Lookaside-Buffer
(TLB). We implement Sentry using a permissions metadata cache (M-cache) that intercepts
only L1 misses and resides entirely outside the processor core. It reuses the L1 cache coherence
states in a novel manner to enforce permissions and elide checks on L1 hits. This enables
a simpler design and places fewer constraints on the pipeline cycle compared to per-access
in-core checks [WCA02]. Since checks are less frequent and on higher latency L1 misses,
Sentry up to 100× less energy than required by the in-processor option. The M-cache also has
a novel dual-tag organization that transparently maintains metadata coherence and simplifies
management (no need for heavy-weight interprocessor interrupts).
From the software’s perspective, Sentry is a pluggable access control mechanism for
application-level memory watching and protection. It works as a supplement (not a replace-
ment) to OS process-based protection. These models are orthogonal to existing process-based
protection and provide varying degrees of flexibility with which applications can set up and en-
force access protection contracts. Applications that desire fine-grain protection annotate mem-
ory (code and data) regions and specify permissions. No other changes to the programming
model or language are required.

147
6.1.1 Access Control in the Memory Hierarchy
Access control must essentially provide a way for software to express permissions to a given
location, for the active threads. Hardware is expected to intercept the accesses, check them
against the expected permissions, and raise an exception if the thread does not have appropriate
rights. Current processors typically implement a physical memory hierarchy through which
an access traverses looking for data. Accesses can be intercepted at any level in the memory
hierarchy: within the processor core, in the L1 miss path (Sentry design), or any other level.
Here, we analyze the design tradeoffs between intercepting these accesses at the various levels.
Most protection schemes (Mondriaan [WCA02], Loki [ZKD08], Page-protection in the
TLB) adopt the logically simple option of intercepting all memory accesses within the pro-
cessor, even before they are visible to the memory system. After the access is intercepted, they
use the address in the access to perform a lookup into an hardware table which caches the per-
missions information. Since every access is intercepted it enables support for access control at
word-level granularity of memory operations, although hardware may choose to increase the
granularity of protection to reduce the overheads of the permissions metadata. Unfortunately,
checking permissions on every access induces significant energy cost. The permissions cache
requires additional structures in highly optimized stages of the processor pipeline. Since the
access control hardware is consulted in parallel with L1 access on every load and store, the
hardware design is constrained to complete the checks before the loaded value becomes visi-
ble to other instructions. To achieve this, high-performance transistor technology will likely be
employed, leading to a noticeable energy and area budget.
Placement of access control outside the processor in the memory hierarchy is challenging.
The lower levels of the cache system are shared between the multiple processors and this makes
it challenging to implement different permissions for each thread. Permission changes need to
also be handled carefully compared to the in-processor approach since cached data could poten-
tially overlook the new permissions. In the past, access control at the lower levels of the memory
hierarchy has been explored only to implement software-based cache coherence [SFL94]
Figure 6.2 summarizes qualitatively the tradeoffs between placing the hardware access-
control cache at the various levels in the memory hierarchy. As we locate the permissions

148
CPU
L1$
L2$
LN$
.....
2-3
ns
20-3
0 ns
Perm.$
Red
uced
# o
f che
cks
Fine
r gra
nula
rity
chec
ks
Mor
e de
sign
flex
ibilit
y
Figure 6.2: Access control in the memory hierarchy
cache closer to the processor it can intercept finer-granularity accesses and can support up to
word granularity checks. However, storing permissions at the granularity of words poses a
significant challenge in terms of space overhead and requires complex encoding of the entries
in the permission cache [WCA02]. As we move the permission cache away from the processor
to lower levels in the memory hierarchy it intercepts needs to intercept fewer accesses since
the higher levels cache hits filter out many accesses. This results in significant dynamic energy
savings. If the permissions cache is located in the lower levels in the memory hierarchy it can
afford better design tradeoffs. For instance, a permissions cache located between the processor
and L1 needs to complete the checks within the L1 access latency (typically 2-3ns) whereas if
it is located between the L1 cache and L2 cache it can complete it within the L2 access latency
(typically 20-30ns). This allows it to possibly use more energy efficient transistors to conserve
both dynamic energy and static power. Placing the access control hardware further from the
processor complicates the processor interface (e.g., propagating exceptions back to software).
6.2 Sentry : Auxiliary Memory Access Control
In Sentry, we place the access checks on the L1 miss path and transparently reuse the coherence
states of the L1 to implicitly check the accesses. The L1 cache filters out cache hits and the

149
permissions cache needs to be accessed only by L1 hits. The L1 miss rate in most applications
is considerably lower than the total accesses — PARSEC (1-4%), SPLASH2 (4-9%), Apache
(16%). This results in fewer lookups compared to the in-processor permissions cache and a
corresponding savings in dynamic energy. Another benefit is the design flexibility; since the
checks occur only in parallel with L2 accesses (which can take 20—30ns), we have a longer
time window to complete the checks and can trade performance for energy. Employing energy-
optimized transistor technology [MBJ07] can save leakage and dynamic power. Using LOP
transistor technology [Ass07] increases latency to 1ns, which is still well below the critical path
of the L2 access but enables 33% reduction in dynamic energy and a 10× reduction in static
power.
Our design choice to intercept L1 misses implies that the smallest protection granularity we
support is an L1 cache line. Sub-cache-line granularity can be supported at the cost of additional
bits in the cache. To accommodate L1 cache line granularity monitoring (typically 16 - 64
bytes) the memory allocator can be modified to create cache-line-aligned regions with the help
of software annotations (compiler or programmer). Software can also further disambiguate an
access exception to implement word granularity monitoring if necessary.
6.2.1 Metadata Hardware Cache (M-Cache)
In Sentry, we maintain the invariant that a thread is allowed to access the L1 memory cache
without requiring any checks i.e., L1 accesses are implicitly validated. To implement this we
include a metadata cache (M-cache) that controls whether data is allowed into the L1.
Figure 6.3 shows the M-cache positioned in the L1 miss path outside the processor core.
Each entry in the M-cache provides permission metadata for a specific virtual page. The per-
page metadata varies based on the intended protection model (see Section 6.3). In general, it
is a bitmap data structure that encodes 2 bits of access permission (read-only, read/write, no
access, execute) per cache line. Note that these are auxiliary to the OS protection scheme since
the access has to pass the TLB checks before getting to the memory system. This ensures that
the M-cache’s policies do not interfere with the OS protection scheme. An M-cache entry is
tagged on the processor side using the virtual address (VA) of the page using the metadata for

150
User Registers
Processor Core
Tag State Data
Private L1 Cache
Tag1 Data Tag2Metadata
Physical addrData
Virtual addrMetadata
M-Cache
Fwd. Coherence Request
L1 miss
L1-Shared L2Interface
VA PA attr Owner Dom. F V
TLB Entry
MetadataDom.
C
Thread Domain
Dark lines enclose add-ons. Every TLB includes three fields: ’F’ bit to indicate if the page desires fine-grainprotection, ’Domain’ field which specifies the owner domain (see Section 6.3 for details), and ’V’ which indicatesif L1 hits may need verification. The cache includes a
Figure 6.3: Permissions metadata cache (M-cache)
permission checks. Using virtual addresses allows user-level examination and manipulation of
the M-cache entries and, avoids the need to purge the M-cache on a page swap. The domain
id fields included in the processor register, TLB entry, and M-cache implement the protection
domain (we discuss this in more detail in the following Section 6.3).
In addition to the processor-side tags, the M-cache contains a network-side tag consisting of
the physical address of the metadata (MPA) to ensure entries are invalidated if the metadata is
changed. In Section 6.2.6, we discuss the need for these tags in detail. The dual side addressing
of the cache does introduce an interesting challenge — the VA, the data address using the access
control metadata, and the MPA, the metadata word’s physical address, may index into different
positions in their respective tag arrays. We need to ensure that when the entry in one of the
tag arrays is invalidated (VA due to processor action or MPA due to network message), the
corresponding entry in the other tag array is also cleaned up. To solve this issue, we include
forward and back pointers similar to those proposed by Goodman [Goo87] — a VA tag includes
a pointer (set index and way position) to the corresponding entry in the MPA array and the MPA
tag entry includes a back pointer. Table 6.1 lists the ISA interface of the M-cache.

151
Table 6.1: Permissions metadata cache (M-cache) APIRegisters%mcache_handlerPC: address of the handler to be called on a user-space alert%Domain1_Handler: address of handler to be called within user-level supervisor (see Sec-
tion 6.3.3)%mcache_faultPC: PC prior to the fault instruction%mcache_faultAddress virtual address that experienced the access exception%mcache_faultIns: local write or local read%mcache_faultType: M-cache miss or permission exception%mcache_entry: per-page metadata; 2 bits per cache line to represent access permissions
(Read-only, Read/Write, Execute, No Access)%mcache_vindex specifies the vaddr position in the M-cache.
Instructionsget_entryvaddr,%mcache_index
get an entry for vaddr and store its index in %mcache_index. Hard-ware specified LRU eviction policy.
inv_entry vaddr,%mcache_index
evict vaddr’s metadata from M-cache and return its position in%mcache index
LD vaddr,%mcache_index
load vaddr into M-cache position pointed to by %mcache_index
LL vaddr,%mcache_index
Load Linked version of the above.
LD_MPA vaddr,%mcache_index
load physical address of cache block corresponding to vaddr into MPAand set up the pointer to the vaddr tags
ST %mcache_index,%mcache_entry
store the data in %mcache_entry into the M-cache entry pointed toby %mcache_index
SC %mcache_index,%mcache_entry
Store-Conditional version of the above.
switch_call %R1,%R2
Effects a subroutine call to the address in %R1 and changes threaddomain to that specified in %R2
The %Domain1 Handler register and switch call instruction are needed for implementing protectiondomains and are discussed in detail in Section 6.3.3
6.2.2 Permission Cache Checks
Sentry requires access checks only on L1 misses. Even then, metadata must only be created
when an application requires fine-grain or user-level access control. We use an unused bit
in the page-table entry to encode an “F” bit (Fine-grain) to ensure that metadata is employed
only when necessary. If the software does not need the checks, it leaves the ‘F” bit unset and
hardware bypasses the M-cache for accesses to the page. 1 If the bit is set, on an L1 miss, the
M-cache is indexed using the virtual address of the access to examine the metadata. The virtual
address of the L1 miss is available at the load-store unit.
1We also use this technique to prevent accesses on the permissions metadata from having to look for metadata.

152
6.2.3 Coherence-based Access Checks
Once a block is loaded into the processor’s L1 cache, we use coherence states to transparently
enforce permissions (i.e., cache hits do not check the M-cache). The coherence states guarantee
that the corresponding cache block experiences a cache hit only if the specific type of access
occurs. Without any modifications to the coherence protocol, M or E can check read/write
permissions, S can enforce read-only, and I can check any permission type. An attempt to
access data without the appropriate coherence state will result in an L1 miss, which checks the
M-cache. As shown in Table 6.2), other coherence protocol states can also be mapped on to
the basic permission types, no-access, read-only, and read/write. In this dissertation, we only
implement the basic MESI coherence protocol.
Table 6.2: Mapping coherence protocol states to permission checksM Read/WriteE Read/WriteO Read/WriteS Read-only or Read/Write
F [MHS09] Read-only or Read/WriteI No-access, Read-only, or Read/Write
Data persistence in caches does introduce a challenge; data fetched into the L1 by one
thread continues to be visible to other threads on the processor. Essentially, if two threads
have different access permissions, the L1 hits could circumvent the access control mechanism.
Consider two threads T1 and T2, which the application has dictated to have read-write and
read-only rights to location A. T1 runs on a processor, stores A, and caches it in the “M” state.
Subsequently, the OS switches in T2 to the same processor. Now, if T2 was allowed to write
A, the permission mechanism would be circumvented. To ensure complexity-effectiveness, we
need to guard against this without requiring that all L1 hits check the M-cache. We employ two
bits, a “V” (Verify) bit in the page-table to indicate whether the page has different permissions
for different threads and “C” (checked) bit in the cache tag, which indicates if the cache block
has already been verified (1 yes, 0 no). All accesses (hit or miss) check permissions if the TLB
entry’s “V” bit is set and the “C” bit in the L1 cache tag is unset, indicating first access within
the thread context. Once the first access verifies permissions, the “C” bit is set. This ensures
that subsequent L1 hits to the cache line need not access the M-cache. The “C” bit of all cached
lines is flash-cleared on context switches.

153
6.2.4 Exception Trigger
When an access does not have appropriate rights, the hardware triggers a permission exception,
which should occur logically before the access. To implement this, we reuse the existing ex-
ception mechanism on modern processors. The permissions checks do not need to be enforced
until instruction retirement. The M-cache response marks the instruction as an exception point
in the reorder-buffer. When the instruction is about to be committed, the exception is checked
and the software handler is triggered, if needed. The permission check, which is performed by
looking up either the L1 cache state on a hit or the M-cache metadata on a miss, has potential
impact only at the back end of the pipeline in the case of a miss. Pipeline critical paths and
therefore cycle time consequently remain unaffected.
On a permission exception, the M-cache provides the following information in registers:
the program counter of the instruction that failed the check (%mcache faultPC) , the address ac-
cessed (%mcache faultAddress), and the type of instruction (%mcache faultInstruction). There
are separate sets of registers for kernel and user-mode exceptions.
6.2.5 How is the M-cache filled ?
The M-cache entries can be indexed and written under software control similar to a software
TLB. Allowing software to directly write M-cache entries (1) allows maintenance of the meta-
data in virtual memory regions using any data structure and (2) permits flexibility in setting
permission policies. Hardware never updates the M-cache entries and it is expected that soft-
ware already has a consistent copy. Hence, any evictions from the M-cache are silently dropped
(no writebacks). Since no controller is required to handle refills or eviction, the implementation
is simplified.
The ISA extensions (see Table 6.1) required are similar to the software-loaded TLB found
across many RISC architectures (e.g., SPARC, Alpha, MIPS). There are separate load and store
instructions that access the metadata using an index into the M-cache. In addition, to fill the
MPA (not typically found in the TLB) we use an instruction (LD MPA) that specifies the virtual
address of the physical address for which a tag needs to be set up in the MPA. 2 The MPA is
2Hardware also sets up pointer to the virtual address tags so that invalidations can cleanup entries consistently in

154
used by the hardware to ensure the entry is cleaned up if the metadata changes, i.e., when a
store occurs anywhere in the system to the MPA address. Typically, the metadata is maintained
in the virtual address space of the application. Figure 6.4 shows the pseudo code for the insert
routine: lines 1 — 2 get an entry from the M-cache and sets up the virtual address of the data
to be protected, lines 3 — 5 set up the permissions metadata in the corresponding entry, and the
final two instruction 6 — 7 try to update the metadata in the M-cache entry. An exception event
between 1 and 6 (e.g., context switch) will cause line 6 to fail and the insert routine is restarted.
M-Cache Fill Routine()/*X: Virtual address of data */
1. get_entry X,%mcache_index2. LL X,%mcache_index3. P = get_permissions(X)4. LD P,%mcache_entry5. LD_MPA P,%mcache_index6. SC %mcache_index,%mcache_entry7. if failed(SC) goto 1;
Figure 6.4: Pseudocode for inserting a new M-cache entry.
The software fill routine has control over the address chosen to be the MPA of an entry. One
option is to use the physical address of the metadata as the MPA, but in reality software can
set up any address to ensure the coherence of the M-cache entry. It is even valid and useful to
have multiple M-cache entries managed by the same MPA. For example, locations A, B, and C
could each have an entry in the M-cache where the VA is tagged with the page addresses of A,
B, and C while each of their corresponding MPA entries could be tagged with MPA X. When
X is written, a lookup in the MPA array would match three entries each with a back pointer to
the corresponding VA entries of A, B, and C, which can then be invalidated — an efficient bulk
invalidation scheme.
6.2.6 Changing Permissions
The permissions metadata structure is in virtual memory space and this allows software to di-
rectly access and modify it. When changes to the access permissions (metadata) are made, we
need to ensure that subsequent accesses to the data locations are performed only when allowed
both tag arrays

155
by the new metadata. For example, assume there are two threads T1 and T2 on processors P1
and P2 that have write permissions on location A. If T1 decides to downgrade permissions to
read-only, we need to ensure that (1) the old metadata entry in P2’s M-cache is invalidated and
(2) since P2 could have cached a copy of A in its L1 before the permissions changed, this copy
is also invalidated. Both actions are necessary to ensure that P2 obtains new permissions on the
next access. We deal with these in order.
Shooting down M-cache entries
This operation is simplified by the MPA field in the M-cache, which is used by hardware to
ensure consistency of the cached metadata. This set of tags snoop on coherence events and any
metadata updates result in invalidations of the corresponding M-cache entry. Hence all software
has to do is update the metadata and the resulting coherence operations triggered will clean up
all M-cache entries. Action 1 in Figure 6.5 illustrates this operation. Most previously proposed
permission lookaside structures (e.g., TLB, Mondriaan [WCA02]) typically use interprocessor
interrupts and sophisticated algorithms to shootdown the entry [TKS88].
Checks of future accesses
Sentry allows L1 hits to proceed without any intervention. Hence, when permissions are down-
graded, the appropriate data blocks need to be evicted from all the L1 caches to ensure future
accesses trigger permission checks. To cleanup the blocks from the L1 level, software can per-
form prefetch-exclusives to invalidate the cache block at remote L1s and then evict the cache
line from the local L1 (e.g., using PowerPC’s dcb-flush instruction). Action 2 in Figure 6.5
illustrates the cleaning up of the cached data from the L1s. A final issue to consider is that the
cleanup races with other concurrent accesses from processors and the system needs to ensure
that these accesses get the new permissions. To solve this problem, software must order the per-
mission changes (including cleaning up remote M-cache entries) before the L1 cache cleanup
so that subsequent accesses will reload the new permissions.

156
Processor Core 1
Tag DataX_Phys
Private L1 Cache
Tag1 Data Tag2P_Phys X
Private M-Cache
1. Store P; 2. Store X; Flush X
Processor Core 2
Tag DataX_Phys
Private L1 Cache
Tag1 Data Tag2P_Phys X
Private M-Cache
2
1
2
Shootdown of M-cache entries and cleanup of L1 cache lines using cache coherence. X: Address of data; P: Perm.metadata of X. X Phys, P Phys: physical addresses. Actions 1 shows a store operation shooting down the metadatain the M-cache. Action 2 illustrates the cleaning up of the cached data from the L1s.
Figure 6.5: Changing Permissions
6.3 Sentry Software
In this section, we develop the software infrastructure required to support Senty and discuss
the various types of protection models. Sentry is a pluggable access control mechanism which
supplements OS process-based protection and this leads to three main advantages. First, it
incurs space and time overhead only when additional intra-application protection is needed as
otherwise existing page-based access control can be used. Second, the software runtime that
manages the intra-application protection can reside entirely at the user level and can operate
without much OS intervention, making the system both efficient and attractive to mainstream
OS vendors. Third, within the same system, applications using the Sentry protection framework
can co-exist with applications that do not require Sentry’s services.
When developing a protection framework, the design decisions that need to be addressed are
(1) Where is the software that regulates the access control mechanism located (e.g., user-level
or OS) ? and (2) How do applications that do not take advantage of the protection framework
co-exist with code that requires it.

157
Conventional systems are critically dependent on hiding the protection metadata from ma-
nipulation by user applications. For example, the TLB and protection systems such as Mon-
driaan and Loki [WCA02; ZKD08] are exclusively managed in privileged mode by low-level
operating system software. In order to utilize the mechanism to achieve application-specific
protection, every application in the system must cross protection boundaries via well-defined
(system call) interfaces and abstractions to convey its protection policy to system software.
Furthermore, all applications in the system need to adopt the same framework to implement
protection, whether they desire it or not. The need to satisfy each application’s requirements
usually complicates the protection framework design.
In contrast, Sentry supplements the existing process-based protection provided by the TLB.
Our objective is to support low-cost and flexible protection models, with the emphasis on
application-controlled intra-process protection. Leaving the existing process-based framework
untouched allows us to relocate all the software that manages the access control mechanism to
the user level (within each application itself). This eliminates the challenge of porting a new
protection framework to the OS and reduces the risk of an application’s policy affecting another
application. Each application can independently choose whether to use the Sentry framework
or not. User-level management also allows application-specific optimizations.
6.3.1 Foundations for Sentry’s Protection Models
Sentry’s protection models are realized by regulating the M-cache access control mechanism.
A key concept in realizing the various models is the protection domain — the context of a
thread that determines the access permissions to each data location [Lam71]. Every executing
thread at any given instant belongs to exactly one protection domain and multiple threads can
belong to the same protection domain. Furthermore, a thread can dynamically transition be-
tween different protection domains if the system policy permits it. The M-cache entries for a
particular protection domain can be thought of as a capability list—they specify the data access
permissions for a thread running in the domain. The ability to dynamically change a thread’s
protection domain context allows software to easily perform permissions changes over large
regions without changing per-entry permissions.

158
Domain 0 and 1
Sentry uses integer values to identify protection domains. Domain 0 is reserved for the oper-
ating system while domain 1 and larger identifiers are used by applications. Within a process,
different application domains must carry different identifiers, but domains in different processes
may share the same identifier. Sentry is focused on intra-application protection and M-cache
entries are flushed on address space (process) context switches.
Domain 1 serves as an application-level supervisor, with the main thread of execution at
the time of process creation being assigned to this domain. Specifically, Domain 1 enjoys the
following privileges:
1. Page Ownership: Domain 1 controls page (both code and data) ownership; all requests
for ownership change must be directed to the operating system via Domain 1.
2. Thread Domain: Domain 1 handles the tasks of adding, removing, and changing the
domain of a thread during its lifetime.
3. M-cache manipulation by non-owner domains: M-cache exceptions (e.g., no metadata
entry) triggered on accesses to non-owner locations (addresses owned by a different do-
main) are handled by Domain 1.
4. Cross-Domain Calls: Domain 1 ensures cross-domain calls (instruction addresses that are
in pages owned by a different domain) can occur only at specific entry points (according
to application-specified policies registered with Domain 1).
Sentry requires the support of a few tasks from the operating system. First, the OS saves
and restores thread state registers associated with Sentry. Second, the OS stores the domain
ownership in the page tables and has them loaded into the processor TLB. It also handles
ownership changes (which must be recorded in the page table) from domain 1. Finally, to ensure
the application supervisor’s control over all process memory space, the OS restricts access to
certain memory space-related system calls (including mmap and sbrk) so that they can only
be made from domain 1.

159
Hardware Metadata
Several hardware elements play key roles in such realization of Sentry’s protection models.
They include a global %Thread_Domain register, a per-entry Metadata_Domain field
in the M-cache, and a per-entry Owner_Domain field in the TLB (all illustrated earlier in
Figure 6.3). Below we define their specific functions.
The M-cache needs to recognize the current thread’s protection domain and distinguish data
permission information for different domains. %Thread_Domain is a new CPU register that
identifies the protection domain of the current executing thread. Metadata_Domain is a
per-entry field in the M-cache identifying the protection domain that the entry’s access permis-
sion information applies to. On an M-cache check, the %Thread_Domain register and the
access address are both used to index into the M-cache. The M-cache entry with matching
Metadata_Domain and virtual-address tag is identified and its access permission informa-
tion is then checked.
The privilege of filling M-cache entries must be carefully regulated. If the M-cache were
allowed to be modified by any domain, then a thrqead would be able to grant itself arbitrary
permissions to any location. We introduce a per-entry Owner_Domain field in the TLB,
which identifies the domain that “owns” the page corresponding to that entry. Only a thread
in the page’s owner domain or the exception handler in domain 1 can fill the M-cache for the
locations in that page. The hardware enforces this by guaranteeing that an M-cache entry can be
filled only when the %Thread_Domain register matches the target page’s Owner_Domain3 or when the %Thread_Domain is 1. Note that the ownership is maintained at a coarser page
granularity while the access control mechanism is managed at cache line granularity.
6.3.2 One Domain Per ProcessIn this model, the existing process-based protection domain boundaries are inherited without
any further refinement. Sentry’s primary benefit is to support flexible cache-line granularity
access control. In this case, all application-level threads within a process belong to protection
domain 1. The domain identifiers of 0 and 1 differentiate operating system and application
3The page table entry for the filled address needs to be in the TLB when filling the M-cache. We ensure that anM-cache fill instruction (see Table 6.1) triggers a TLB reload for the filled address.

160
executions. Sentry supports two modes of access control. In the first mode, the operating
system retains the privileges of filling the M-cache content, managing M-cache misses, and
handling permission exceptions. In the second mode, the application threads can directly per-
form these tasks. Both modes of control can co-exist in a system on a page by page basis. The
mode is determined by each page’s owner domain (0 or 1) loaded into the page table entry’s
Owner_Domain field.
The application-managed model incurs much less overhead than the OS-managed model.
For instance, the cost of permission exception handling appears as an unconditional jump in the
instruction stream (10s of cycles). In comparison, an OS-level exception needs switching of
privilege level and saving of register state, which mirrors the cost of a privilege switch (100s of
cycles). For an application-managed M-cache, the access permission metadata is visible to all
threads within a process and any thread can set up the permissions for its use. The M-cache is
flushed on process context switches to ensure that permissions metadata does not leak beyond
the process boundary. Existing process-based protection isolates data access permissions across
different processes. It is useful for supporting cache-line-grain watchpoints. Reads and writes
to specific locations can be trapped by setting appropriate M-cache permissions. The low-
cost, cache-line-grain watchpoints can help with detecting various buffer overflow and stack
smashing attacks, as well as with debugging code [ZQL04; QLZ05]. This model has weak
protection semantics since any part of the application can modify the M-cache.
The OS-managed M-cache allows safer protected sharing across the different domains. For
example, in remote procedure calls (RPCs), the argument stack can be mapped between a RPC
client and the server process with different permissions (at a page granularity on current hard-
ware [BAL90]). Further, a safe kernel-user shared memory can eliminate expensive memory
copies between the operating system and applications. Sentry supports such protected sharing
at the cache line granularity.
6.3.3 Intra-Process Compartments
This model supports multiple protection domains within a single process. A real-world use of
this model is the Apache application (see Figure 6.1) that supports various features (like caching

161
pages fetched from the disk) in modules loaded into the web server’s address space. The core
set of developers sets the interface between the various code and data segments. Isolating these
modules into separate domains and enforcing the interface between them (data and functions)
can improve reliability and safety.
In the compartment model, each domain owns a set of data and executable code regions.
Threads in a protection domain can set up the permissions, execute code, and access the data
owned by the domain. They are responsible for handling M-cache misses and filling it. An
owner thread may want to do this to set up application-specific monitoring, like watchpoints.
This case is akin to the application-managed model described in Section 6.3.2.
Cross-Domain Data Accesses and Code Invocation
In some cases, threads in a protection domain may need to access data that is not owned by the
domain and we call these non-owner data accesses. For instance, a web server module accesses
some request data structure from the core application in order to apply output filters. Threads
in a domain may also want to call functions that are not owned by the domain and we call
them cross-domain calls. Applications set up specific permissions for authorizing non-owner
accesses but they must be carefully checked for safety.
One of our key design objectives is to minimize the role of the operating system and al-
low much of the management tasks to be performed directly by the application. This affords
the most flexibility in terms of application-specific protection policies. It also incurs low man-
agement cost, since the operating system does not need to be invoked on policy changes. We
designate domain 1 in each process as a user-level supervisor. Domain 1 takes the primary
responsibility for coordinating cross-domain data accesses and code invocation. It is implicitly
given the ownership role for all memory in the process address space, including the ability to
fill M-cache content and handle M-cache permission exceptions. Domain 1 can also dynam-
ically change the domain (anything other than domain 0) of a running thread by modifying
the %Thread_Domain register. Given its privileges, domain 1 guards its own data and code
against unauthorized accesses by other domains by owning those pages and setting up the ap-
propriate permissions.

162
Domain X: Caller Domain Y: Callee
Domain 1: User Level Supervisor
Domain 0: Operating System
Call Y_PC Return
1 2 34
Steps of a cross-domain call when a thread in domain X invokes a function whose code is owned by domain Y:
1. Domain X tries to jump into a code region that it does not own. The hardware intercepts the call by recogniz-ing a mismatch between the %Thread_Domain register and the Owner_Domain field in the TLB entryassociated with the instruction. The function entry address Y_PC is then saved. The hardware then effects anexception into Domain1_Handler while assuming the context of supervisor domain 1.
2. The domain 1 exception handler marshals the arguments on the stack, grants the appropriate data accesspermissions to the callee domain, and invokes the function through a special switch_call instruction.The instruction jumps into Y_PC and changes the protection domain context (%Thread_Domain) to Y.
3. On return, the function tries to jump back to the caller. Since the return target is owned by domain X, anexception is triggered into domain 1 and the return target address is saved.
4. Domain 1 finally executes switch_call back to X.
Figure 6.6: Cross-domain call execution flow
Non-owner data accesses that trigger M-cache miss exceptions (i.e., no M-cache entry) need
to be handled carefully. The thread itself lacks the privilege to set up the metadata. Hence, these
operations are handled by domain 1. The address to this exception handler in domain 1 is located
in a CPU register (%Domain1_Handler), which is managed exclusively by domain 1. On
a non-owner M-cache exception, hardware changes the domain context (i.e., %Thread Domain
register) to domain 1 and traps to the %Domain1_Handler. Based on application specific
policies, the domain 1 exception handler can let the non-owner data access progress (finish or
raise an exception) by filling the appropriate M-cache entry. When the miss handler has finished
its operations, domain 1 reverts back to the original domain context to continue execution.
Subsequent accesses to the same location (from the non-owner domain) can proceed without
interruption.
Cross-domain calls are registered with domain 1, according to the application policies. A
cross-domain call and its return are redirected and managed by domain 1 in a four-step process
illustrated in Figure 6.6.

163
The indirection through domain 1 for cross-domain calls does impose a minor performance
penalty. Unlike earlier work that speeds up cross-address space calls by using shared-memory
segments [BAL90], our cross-domain call remains in the same address space and the complete
execution flow utilizes the same stack. This allows us to achieve efficiencies comparable to a
standard function call.
6.3.4 Ring Protection
The M-cache access control mechanism is highly flexible and can support different protection
models with small changes. We briefly discuss its ability to support another popular protection
model, a Ring [Org72]. In this model, threads in domains 1, 2, · · · , k−1 can directly access data
and code owned by domain k. This model would be appropriate for workloads like Transaction
processing, which typically involve multiple layers of middleware stack [IsS99], and a web
browser client, which includes support for multiple plug-in levels that depend on each other. To
realize the ring protection model, we can tune the M-cache mechanism to expand the concept of
ownership of a memory region. Specifically, for a page owned by domain k, domains 1 through
k−1 all assume the owner’s privileges, such as directly filling the M-cache content for data in
the page. Cross-domain data accesses and code executions that do not fall into this expanded
concept of ownership will still need to go through the supervisor indirection.
Hierarchical protection rings were introduced in Multics [SCS77]. Hardware metadata
could be set up to regulate the instructions and memory state that can be accessed at any given
ring and restrict the points of control flow between the various ring levels (i.e., call gates). A
challenge with the system is that a program needs to be aware of the hardware protection. For
example, when using function pointers the compiler or programmer needs to specify whether
the callee points to an intra-ring or inter-ring address.

164
6.4 M-cache Design
6.4.1 Area, Latency, and Energy
The M-cache area implications are a function of its size and organization. All known cache
and TLB optimizations apply (banking, associativity, etc.). Most importantly, the M-cache
intercepts only L1 misses, thereby reducing its impact on the processor critical path. While
dual-tagged, each tag array is single-ported. The virtual tag is accessed only from the processor
side (for checking permissions and filling M-cache entries) and the MPA is accessed only from
the network side (for snoop-based coherence). We used CACTI 6 [MBJ07] to estimate cycle
time for a 256-entry M-cache (4KB, 4 way, 16 bytes per entry) that provides good coverage
(fine-grain permissions for a 1MB working set). We estimate that in 65 nm high-performance
technology (ITRS HP), the M-cache can be indexed within 0.5ns (1 processor cycle using our
parameters). Furthermore, since the M-cache is located outside the processor core and is ac-
cessed in parallel with a long latency L1 miss we can trade latency for energy benefits. Ta-
ble 6.3 shows a few of the possible designs when locating the permissions cache on the L1 miss
path. If we use the low power transistor technology from ITRS (see Design-2 in Table 6.3),
the access latency increases by 4× (to ∼4 cycles) compared to high-performance transistor
technology (ITRS HP). However, there is a significant energy reduction: an M-cache designed
with ITRS [Ass07] LOP consumes 1% of the leakage power and 33% of the dynamic access
power of an M-cache employing ITRS HP transistors. On average (geometric mean), across the
PARSEC, SPLASH2, and Apache workloads, the M-cache with ITRS LOP consumes 0.029nJ,
0.037nJ, and 0.27nJ respectively per memory access; in comparison a TLB with the same num-
ber of entries consumes 3nJ.
Table 6.3: Design tradeoffs in M-cache designDesign Latency (cycles) Dynamic energy (cycles) Static power (mW)
In-Processor 1 30 20Sentry Design-1 2 21 2.3Sentry Design-2 4 9 0.21

165
6.4.2 Operation
The energy required by the hardware cache used to maintain protection information needs to be
considered carefully. Word-granularity checks require larger permission caches and also require
the permissions M-cache to intervene on each memory access. In comparison, Sentry intervenes
only on L1 misses and its dynamic energy savings are directly proportional to the number of
accesses it has to check (L1 misses). Figure 6.7 shows the miss rate of workloads. Overall
the miss rate varies between 1.4% — 16% for SPLASH2, and 0.1% — 4% for PARSEC. Even
in commercial workloads like Apache with large working sets the number of L1 misses is 6×
lower than the total number of accesses.
(a) SPLASH2 and Apache
02468
1012141618
Bar
nes
Cho
lesk
y
FFT
LU
MP3
D
Oce
an
Rad
ix
Wat
er
Apa
cheL1
mis
s rat
e %
(mis
ses/
acce
sses
)
(b) PARSEC
0
1
2
3
4
5
Bla
cksc
hole
s
Bod
ytra
ck
Can
neal
Ded
up
Face
sim
Ferr
et
Flui
dani
mat
e
Freq
min
e
Stre
am
Swap
atio
ns
Vip
s
x264
L1 m
iss r
ate
% (m
isse
s/ac
cess
es)
Y-axis: Average number of L1 misses per 100 accesses per thread.
Figure 6.7: L1 miss rate in applications.
The management costs associated with any hardware protection mechanism are the latency
of switching to the privilege level that can manipulate permissions and the cost of maintaining
the coherence of the cached copies of the metadata. The M-cache can be managed entirely
at user level. In addition, the metadata physical address (MPA) tag allows the M-cache to
exploit coherence to propagate metadata invalidations to remote processors. This simplifies
the software protocol required to manage the M-cache and improves performance compared to
existing protection mechanisms that use the interprocessor interrupt mechanism.
We compare the cost of changing the metadata associated with the M-cache against the cost
of manipulating page-attribute protection bits in the TLB. We set up a microbenchmark that

166
TLB M-cache 1 M-cache 16
M-cache 64 M-cache Parallel 64
1.E+00
1.E+01
1.E+02
1.E+03
1.E+04
1.E+05
1 8 16Threads
Exec
. Cyc
les (
log
scal
e)
M-cache N measures execution cycles for changing permissions on N cache lines. L1 handles stores in order. In
M-cache Parallel 64, the L1 can sustain 64 concurrent misses.
Figure 6.8: TLB vs. M-cache
creates K threads (varied from 1—16) on the machine, and every 10,000 instructions a random
thread is picked to make permission changes. To test the TLB, we change permissions for a
page, and to test the M-cache we change permissions for N cache lines within a page. Overall,
modifying permissions with the M-cache is 10—100× faster than TLB shootdowns (see Fig-
ure 6.8). The dominant cost with the M-cache is that of purging the data from the L1 caches (see
Section 6.2.6). The routine needs to prefetch the data cache blocks in exclusive mode in order
to invalidate all L1s, and this typically results in coherence misses. In our design, each L1 cache
allows only one outstanding miss and hence the invalidation of each cache line directly appears
on the critical path. The latency of the permission change is directly proportional to the number
of cache blocks that are invalidated (M-cache 1, M-cache 16 and M-cache 64 bars). We also
evaluate performance when 64 outstanding L1 prefetches are allowed (M-cache Parallel 64)
and show that overlapping the latency of multiple misses is sufficient to significantly reduce
permission change cost.
Teller et al. [TKS88] discuss hardware support to keep TLBs coherent and recently, con-
current with our work, UNITD [RLS10] explored the performance benefits of coherent TLBs.
Both these works mainly seek to reduce the overheads of conventional OS TLB management
routines while Sentry employs user-level software routines to manage the M-cache.

167
6.5 Experimental System
Our base hardware is a 16-core chip (2 GHz clock frequency), which includes private L1 in-
struction and data write-back caches (32KB, 4-way, 1 cycle) and a banked, shared L2 (8MB,
8-way, 30 cycle), with a memory latency of 300 cycles. The cores are connected to each other
using a 4 × 4 mesh network (3 cycle link latency, 64 byte links). The L2 is organized on one
side of this mesh and the cores interface with the 16-banked L2 over a 4× 16 crossbar switch.
The L1s are kept coherent with the L2 using a MESI directory protocol. This coherence proto-
col is based on the SGI ORIGIN 3000 3-hop scheme with silent evictions. Our infrastructure
is based on the full-system GEMS-Simics framework. We faithfully emulate the Sentry hard-
ware/software interface and model the latency penalty of the software handlers from within the
simulator. We simulate all memory references made by the handler and use instruction counts
to estimate the latency of non-memory instructions.
6.6 Application 1: Compartmentalizing Apache
In this section, we use Sentry’s intra-process compartment protection model (see Section 6.3.3)
to enforce a safety contract between a web server (Apache) and its modules. Apache includes
support for a standard interface to aid module development; the “Apache Portable Runtime”
(APR) [10b] exports many services including support for memory management, access to
Apache’s core data structures (e.g., file stream), and access to intercept fields in the web re-
quest. Apache’s modules are typically run in the same address space as the core web server
in the interest of efficiency and the desire to maintain a familiar programming model (conven-
tional procedure calls between Apache and the module). A module therefore has uninhibited
access to the web server’s data structures, resulting in the system’s safety relying on the module
developers’ discipline.
Our goal is to (1) isolate each module’s code and data in a separate domain and ensure that
the APR is enforced. This protects the web server’s data and ensure that modules can access the
web server’s data only through the exported routines; and (2) achieve this isolation with simple
annotations in the source code without requiring any source revisions. While the definition

168
of a module may be abstract, here we use the term to refer to the collection of code that the
developers included to extend the functionality of the web server. To enable protection, Sentry
annotates the source to perform the following tasks: (1) specify the ownership (domain) of code
and data regions, (2) assign permissions to the various data regions for the different domains,
and (3) assign domains to preforked threads that wait for requests. To simplify our evaluation,
we set up the core Apache code (all folders other than module/ ) to directly execute in domain 1
and emulate all the actions required by domain 1 (those that would be provided in the form of
a library) for cross-domain calls from within the simulator. The only modifications required to
Apache’s source code were the instructions that set up the domains and permissions.
The modules we compartmentalized are mod_cache and mod_mem_cache, which work
in concert to provide a caching engine that stores pages in memory that were previously fetched
from disk. “mod cache” consists of two parts: (1) module-Apache interface (mod_cache.c)
and (2) the cache implementation (cache_cache.c[.h],cache_hash.c[.h], and
cache_pqueue.c[.h]). “mod cache” also needs to interface with a storage engine,
for which we use mod_mem_cache (cache_storage.c, mod_mem_cache.c). We
compiled the modules into the core web server and compartmentalized the storage engine
(mod mem cache) into domain 2 and the cache engine (mod cache) into domain 3, respectively.
6.6.1 Compartmentalizing Code
Our primary goal was to enforce the APR interface and ensure that module domains cannot
call into non-APR functions. First, we compiled in the modules and did a static object code
analysis to determine the module boundaries. We then added routines to the core Apache web
server that (1) registered the APR code regions as owned by Apache and set up read-write
permissions for Apache (domain 1) and read-only permissions for the modules and (2) de-
clared the individual module code regions as owned by the appropriate domains. The modules
expose only a subset of the functions to other modules (e.g., the storage module exports the
cache_create_entity() to the cache module as read-only while it hides the internal
cleanup_cache_mem, which is used for internal memory management). The module’s en-
tire code is accessible to the Apache web server. Finally, the pre-forked worker threads are
started in domain 1. When the threads call into a module’s routines, the exception handler in

169
Baseline ApacheApache with storage and cache modulesApache with Sentry-protected storage moduleApache with Sentry-protected storage and cache modules
0
400
800
1200
1600
160 Clients 320 Clients
Req
ues
ts /
s
Figure 6.9: Performance of Sentry-protected Apache
domain 1 transitions the thread to the appropriate domain if the call is made to the module’s
exported APR. Non-APR calls from the module would be caught by Sentry.
Since memory ownership is assigned at the page granularity, we have to ensure that code
from two different modules or the core web server are not linked into the same page. While
current compilers do not provide explicit support for page alignment, it is fortunate that our
compiler (gcc) allows code generated from an individual source file to remain contiguous in
the linked binary. Given the contiguity of each module’s code segment, we added appropriate
padding in the form of no-ops (asm volatile nops) to the end of the source (.h and .c
files) to page align each module.
6.6.2 Compartmentalizing Data
Assigning ownership to data regions proved to be a simpler task. The
core web server and modules all use the APR provided memory allocator
(srclib/apr/memory/unix/apr_pools.c). With this allocator, it was possible
to set up different pools of memory regions and request allocation from a specific pool.
We specified separate pools for each of the domains: Apache web server (domain 1),
mod mem cache module (domain 2), and mod cache module (domain 3). We then assigned

170
ownership of the pool to the domain that it served. The allocator itself is part of the APR
interface (domain 1). The permissions rules we set up were (1) Apache’s core (domain 1)
can read/write all memory in the program, (2) each module can read/write any memory in
their pool, and (3) a module has read-only access to some specific variables exported by other
external modules — this is where fine-grain permission assignment was useful. In some cases,
a variable exported by a module (read-only for remote domains) was located in the same
page as a local variable (no permissions). For example, the cache object in the storage engine
(mem cache object) contained two different sets of fields, those that described the page being
cached (e.g., html headers) and those that described the actual storage (e.g., position in the
cache). The former needs to be readable from the cache engine, while the latter should be
inaccessible.
Structure-fields also constituted a challenge. Consider two collocated words A and B, with
permission specifications read-only and read-write, respectively. Since A and B fall in the same
cache line, our runtime system would downgrade B to read-only as well and then deal with false
permission exceptions. Interestingly, this case did not occur often since it appears that develop-
ers when writing code seem to collocate declaration for variables with similar semantics. In the
few cases, where this was an issue we were also able to re-organize the fields in the structure
after source inspection. This ensured that variables with similar permission specification were
allocated to the same cache line.
6.6.3 Performance Results
We now estimate the overheads of compartmentalizing the modules in Apache. In this exper-
iment, we pre-compiled modules into the core kernel, disabled logging, and used POSIX mu-
texes for synchronization. The specific configuration we used is -with-mpm=worker -enable-
proxy -disable-logio -enable-cgi -enable-cgid -enable-suexec –enable-cache. We configured
the Surge client for two different loads: 10 or 20 threads per processor (total of 160 or 320
threads) and set the think time to 0ms. Our total webpage database size was 1GB with the
file sizes following a Zipf distribution (maximum file size of 10 MB). We warmed up the soft-
ware data structures (e.g., OS buffer cache) for 50,000 requests and measured performance for
10,000 requests. Sentry permits incremental adoption of compartment-based protection. In our

171
experiments we protect apache’s modules in two stages: we first moved mod_mem_cache
into a separate domain leaving mod_cache within domain 1 (along with the core webserver).
Subsequently, we moved both mod_mem_cache and mod_cache out of domain 1, each into
a separate domain.
Figure 6.9 shows the relative performance. Sentry protection imposes an overhead of'13%
when compartmentalizing both mod_cache and mod_mem_cache and a '6% when com-
partmentalizing just the mod_mem_cache. The primary overheads with Sentry are the exe-
cution of the handlers required to set up data permissions in the M-cache and the indirection
through domain 1 needed for cross-domain calls. Approximately 20% of the functions invoked
by the module are APR routines, which involve a domain crossing. We believe the overhead is
acceptable given the safety guarantees and the level of programmer effort needed.
6.6.4 Process-based Protection vs. SentryTo evaluate the protection schemes afforded by OS process-based protection, we develop
mod case (a module that changes the case of ASCII characters in the webpage) using process-
based protection and compare it against Sentry’s compartment model. To employ process-
based protection we needed to make significant changes to the programming model and reor-
ganize the code and data. We had to implement a mod case specific shim (implemented as
an Apache module) that communicates with mod case through IPC (inter-process communi-
cation), requiring a shared-memory segment. All interaction between Apache and mod case
passes through the shim, which converts the function calls between Apache and mod case into
IPC. Although Apache’s APR helps with setting up shared-memory segments between the shim
and the mod case process, the shim and the module still needed to write explicit memory rou-
tines (for each interface function) to copy from and to the shared argument passing region. The
conversion of even this simple module to use IPC was frustrated by the inability to pass data
pointers directly between the processes and the need to use a specific interface between the
shim and the module itself. As Figure 6.10 shows, the process-based protection adds significant
overhead (33%) compared to Sentry (7%). To summarize, we believe the programming rigidity,
need to customize the interface for individual modules, and performance overheads are major
barriers to the adoption of process-based protection.

172
We briefly compare Sentry’s cross domain calls against existing IPC mechanisms. Despite
considerable work to reduce the cost of IPC [Lie93; KEG97; BAL90], it is still 103 slower than
an intra-process function call. In contrast, Sentry focuses on functions calls between protection
domains established within a process. They have lower overheads since they share the OS
process context and crossing domains does not involve address-space switches. The indirection
through the user-level supervisor domain 1 adds 2 call instructions (to jump from caller→ to
domain 1 and then into callee) and 9 instructions to align the parameters to a cache line boundary
and set appropriate permissions to the stack for the callee domain (i.e., permissions to access
only the parameters and its own activation records). The overhead at runtime varies between 20
and 30 cycles (compared to 5 cycles required for a typical function call).
0
200
400
600
800
1000
1200
Base
Proc
ess-
Prot
ectio
n
Sent
ry-
Prot
ectio
n
Requ
ests
/ s
Performance normalized to mod case with no protection
Figure 6.10: Comparing Sentry against process-based protection
6.6.5 Lightweight Remote Procedure Call
RPC is a form of inter-process communication where the caller process invokes a handler ex-
ported by a callee process. We first describe the scheme used to implement RPC in current
OS kernels (e.g., Solaris): (1) The caller copies arguments into a memory buffer and generates
a trap into the OS. (2) The OS copies the buffer content into the address space of the callee.

173
It then context switches into the callee. (3) To return, the callee traps into the kernel, which
unblocks the caller process. The main overhead is due to the four privilege switches (two from
user→kernel space and two from kernel→user space) and the memory copy required. Earlier
proposals [BAL90] have optimized RPC by using a shared memory segment (i.e., shmem()) to
directly pass data between the caller and callee process. The minimum size of the shared mem-
ory segment is a page and a copy is still needed from the argument location to the shared page.
More recently, Mondrian[WCA02] postulated that word granularity permission and translation
can eliminate the argument passing region.
We use the M-cache to provide fine-grain access control of the locations that need to be
passed from the the caller to the callee process and eliminate the copying entirely. The caller
process must align the arguments to a cache line boundary and request the kernel to map the
argument memory region into the callee’s address space (requiring a user-kernel and kernel-
user crossing). We experiment with a client that makes RPC calls to a server periodically (every
30,000 cycles). The server is passed a 2 KB random alphabet string that it reverses while switch-
ing the case of characters. We compare the cost of argument passing using several approaches
— Sentry, the implementation in the Solaris RPC library, and an optimized implementation that
uses page sharing [BAL90]. Our results indicate that completely eliminating the copying pro-
vides a (∼9–10×) speedup compared to the optimized page sharing approach. The unoptimized
RPC implementation has 103–104 × higher latency.
6.7 Application 2: Sentry-based Watchpoint Debugger
We developed Sentry-Watcher, a C library that applications call into for watchpoint support.
A watchpoint is usually set by the programmer to monitor a specific region of the memory
and when an access occurs to this region, it raises an exception. Sentry-Watcher employs
the one-domain per process model and operates in the application mode (permissions meta-
data and M-cache managed by a library in the application space). It exports a simple inter-
face: insert_watchpoint(), delete_watchpoint(), and set_handler(), with
which the programmer can specify the range to be monitored, the type of accesses to check, and
the exception handler.

174
Apart from fine granularity watchpoints, there are three additional benefits with Sentry-
Watcher: (1) it supports flexible thread-specific monitoring, allowing different threads to set up
different permissions to the same location 4, (2) it supports multi-threaded code efficiently since
the hardware watchlist can be propagated in a consistent manner across multiple processors at
low overhead (also supported by MemTracker [VRS07]), and (3) it effectively virtualizes the
watchpoint metadata and allows an unbounded number of watchpoints.
Table 6.4: Application CharacteristicsBenchmark Mallocs/1s Heap Size Heap Access % Bug Type
BC 810K 60KB 75% BONcom 2 8B 0.6% SSGzip 0 0 0% BO,IVGO 10 294B 1.9% BOMan 350K 210KB 89% BO,SSPoly 890 11KB 27% BO
Squid 178K 900KB 99.5% MLB-Bytes, KB-Kilobytes, MB-MegabytesBO-Buffer Overflow SS-Stack Smash, ML-Memory Leak,IV-Invariant Violation. Squid is multi-threaded.
M-cache (256 entries) Discover
0
0.5
1
1.5
2
2.5
3
BC
NCO
M GO
GZI
P1
GZI
P2
Man
Poly
Squi
dNor
mal
ized
Slo
wdo
wn
(App
=1) 4x75x 50x 18x 35x 65x 6x
N/A
N/A -Discover is not compatible with multi-threaded code. Gzip1 detects Buffer-Overflowbugs. Gzip2 detects memory leak, buffer overflow, and stack smash bugs.
Figure 6.11: Sentry-Watcher vs. Binary instrumentation
6.7.1 Debugging Examples
Generic unbounded watching of memory can help widen the scope of debugging. Here, we use
the system to detect four types of bugs: (1) Buffer Overflow — this occurs when a process ac-
4Since all threads run in the same domain, this would require a flush of the M-cache on a thread switch.

175
cesses data beyond the allocated region. To detect it we pad all heap buffers with an additional
cache line and watch the padded region. (2) Stack Smashing — A specific case of buffer over-
flow where the overflow occurs on a stack variable and manages to modify the return address;
we watch the return addresses on the stack. Dummy arguments need to be passed to the func-
tions to set up the appropriate padding and eliminate false positives. (3) Memory Leak — We
monitor all heap allocated objects and update a per-location timestamp on every access. Any
location with a sufficiently old access timestamp is classified as a potential memory leak. (4)
Invariant Violation—Monitor application-specific variables and check specified assertions. We
demonstrate the prototype on the benchmark suite provided with iWatcher [ZQL04] — Table 6.4
describes the benchmark properties. We compare the performance of Sentry-Watcher against
Discover (a SPARC binary instrumentation tool [10c]). Sentry-Watcher is evaluated on our sim-
ulator. Discover is set up on the Sun T1000. Compared to the binary instrumentation technique,
Sentry-Watcher provides 6–75× speedup. Sentry still incurs noticeable overhead compared to
the original applications—varying between 3–50% for most applications. At worst, we en-
counter up to ∼2× overhead on the memory-leak detector experiments, which instrument all
heap accesses (see Squid in Figure 6.11).
6.7.2 Comparison with Other Hardware
To understand the performance overheads of Sentry-Watcher, we further compared it against
the performance of MemTracker [VRS07], a hardware mechanism tuned for debugging, and
Mondrian [WCA02], a fine- and variable-grain flexible protection mechanism placed within the
processor pipeline.
In MemTracker, a software-programmable hardware controller maintains the metadata,
fetching and operating on it in parallel with the data access. To emulate the controller’s opera-
tions, we assign a 0 cycle penalty for all operations other than the initial setup of the metadata.
This is an optimistic assumption since typically metadata misses in MemTracker also add to the
overhead. In Mondrian, setting up or changing the metadata require privilege mode switches
into and out of the operating system kernel. To estimate the cost of a fast privilege switch, we
measure the latency of an optimized low overhead call (e.g., gethrtimer()) on three widely
available microarchitectures (SPARC, x86, and PowerPC). We observed 280 cycles (SPARC),

176
MemTracker Sentry Mondrian
0
5
10
15
20
25
per
lben
ch
mcf
asta
r
gobm
k
xala
nc
h264
oce
an
wat
er
dat
amin
e
tsp
mp3dPe
rform
ance
Ove
rhea
d (
%)
Effect of software handlers and cost of manipulating metadata in the OS.
Figure 6.12: M-cache vs other hardware-based watchpoints
312 cycles (x86) and 450 cycles(PowerPC). To emulate Mondrian, we add a penalty of 300
cycles to every permission exception and metadata modification; we assign a 0 cycle penalty to
metadata operations. To limit the number of variables, we keep the metadata cache size fixed
across all the systems (256 entries). For this comparison, we implemented the debugger tool
discussed by the MemTracker paper [VRS07], which checks for heap errors, buffer overflow,
and stack smashing. The workloads we use are from the SPECCPU 2006 suite [Sta06]. We also
include the SPLASH2 benchmarks to verify that our findings are valid for multi-threaded work-
loads. Figure 6.12 shows that the overhead of Sentry-Watcher averages 6.2%, compared to the
idealized MemTracker’s 2.6% and Mondrian’s 14%. Since MemTracker requires a hardware
controller to fetch and manipulate the metadata while we leave all such operations in software,
we believe that our system is more complexity-effective.
6.8 Extensions for address-translation
Sentry’s M-cache entries can also include other metadata. The M-cache associates software
permissions metadata with cache-line granularity address regions. We discussed another form
of software metadata in Section 4.6.3, which associated fine-grain translation information with
cache-line granularity regions. The key difference between the metadata cache structures de-
signed in Section 4.6.3 and here, is the hardware interpretation of the metadata. In the case of the

177
fine-grain translation, hardware uses the metadata to isolate data blocks in transactional mem-
ory and redirect misses and writebacks. Here, hardware simply checks the permission bitmap
against the type of miss and raises an exception. In both the metadata caches, the hit path for
the cache is left untouched; astute readers will also observe the similarities of the organization
and tag design of both the metadata caches. This is encouraging from a hardware complexity
perspective since these designs can be essentially fused, giving rise to a single general-purpose
metadata cache, which can store translation and permissions metadata. Note that, the data array
design does not need to change; it only needs to become wider to accommodate the additional
metadata.
6.9 Discussion
Our results demonstrate that fine-grain auxiliary access control can enable lightweight protec-
tion models and can support watchpoint-based debuggers. However, these results do not reflect
on the tradeoff between programmability and granularity of protection. Word-granularity pro-
tection provides maximal flexibility and requires few program changes. Since a word is the
smallest granularity of datum in the system it enables application developers to specify permis-
sions without having to worry about collocated words. However, there is inherent complexity
associated with intercepting word-granularity accesses. Software-based systems require instru-
mentation on every access, which adds significant performance overhead. Word-granularity
accesses need to be intercepted within the processor itself and require modifications to the crit-
ical processor pipeline.
We increased the basic granularity of protection to simplify the implementation but main-
tained it at L1 cache line granularity (typically 8–16 words) to provide flexibility to the appli-
cation developers. We have demonstrated that a cache-line granularity interception provides
significant energy benefits and reduces complexity of the access control hardware. We also
ported a few modules in a widely-used webserver to use intra-application protection and dis-
cussed the challenges when using our framework. The two key challenges we had to address
were the memory allocator and structure fields. Overall, we find our intermediate approach quite
promising and think it makes the appropriate tradeoff between implementation complexity and
protection requirements.

178
Chapter 7Summary and Future Work
In this chapter, I summarize the contributions of the dissertation and present directions for future
work. I also reflect back on my research work and comment on it with the benefit of hindsight.
7.1 Summary
Multicore processors are the only game in town and are an inflection point for software
development [Pat10]. Multicore processors have exacerbated the challenges for software
development—algorithms, languages, and operating systems have all been forced to adopt par-
allelism, which increases the likelihood of concurrency bugs. In this dissertation, we have
utilized the transistors afforded by Moore’s law to develop hardware mechanisms that aid soft-
ware development. The dissertation focused on the memory system, which plays an important
role in a program’s lifetime and contains a wealth of information. I proposed hardware mech-
anisms that shed light on the memory system and expose information that software can use for
both self-diagnosis and control of data flow using higher level semantics, such as transactions.
Specifically, I developed mechanisms for Monitoring, Isolation, and Protection of memory.
These mechanisms have been designed to support fine-grain cache block regions (typically 10s
of bytes), which simplifies the interface with software. A key novelty is the use of cache coher-
ence mechanisms and caches to implement the proposed hardware mechanisms in a lightweight
manner. Modern memory hierarchies already include the requisite mechanisms for managing

179
data and we demonstrate that few extensions are needed to enable software to track and control
data transfers in the memory hierarchy. Here, we summarize the contribution of each mecha-
nism.
7.1.1 Monitoring
Many program analysis tasks required for debugging, performance optimization, and specu-
lative threading need to track a program’s accesses dynamically and insert instrumentation to
record information about the accesses. We investigated hardware-based monitoring to help ex-
pose the data movement in the cache hierarchy to software and reduce this overhead. We track
the coherence events that occur in shared memory and enable software to track the various
data accesses in the system. In Chapter 3, we proposed Alert-On-Update (AOU), a lightweight
mechanism which triggers a software handler on coherence events and provides information
about the event such as address and type. Specifically, we monitor lines marked by software in
the L1 cache and trigger a handler when remote (or local) events occur on such lines. Software
controls the use of and reaction to the event, and can relate the event information to program
semantics in various ways.
Using AOU, we proposed the first hardware-accelerated software-based transactional mem-
ory system (Section 3.5), which boosts the performance of software transactions while main-
taining their policy flexibility. We demonstrated that AOU-acceleration can boost the perfor-
mance of STMs by 1.4-2×. In this dissertation, we also demonstrated the use of AOU in thread
synchronization, accelerating locks, and detecting concurrency bugs.
7.1.2 Isolation
In Chapter 4, we introduced the notion of data isolation, which refers to a thread’s capabil-
ity to hide modifications from other threads of the application and then expose or revoke the
modifications in bulk.
Our hardware mechanism, Programmable-Data-Isolation, is based on the observation that
the multiple levels of caching in the memory system can be designed to hold the different
versions of data. We adapt the processor private L1 caches to hold the thread-private specula-

180
tive version, while maintaining the globally consistent data version at the shared L2. Multiple
processors can concurrently isolate and read the same location. This scheme supports low over-
head commit and revocation of isolated data. We propose the notion of lazy coherence, in
which coherence messages are eagerly sent out at each memory operation (speculative or non-
speculative) but the coherence state changes are performed lazily (under software control) to
enable isolation. The overall coherence state design for isolation is independent of the proto-
col type and we develop both snoopy and directory protocols. The dissertation also explores
the tradeoffs between the use of hardware and software based approaches to virtualizing and
extending isolated state beyond processor caches.
Our application case study for isolation is transactional memory. A noteworthy feature of
programmable data isolation is that it permits multiple new versions of a location, allowing
different software tasks to isolate the same location concurrently. We used this feature to ac-
celerate two different TM systems: RTM, a hardware-software TM that handles large and long
transactions entirely in software, and FlexTM, a scalable flexible Lazy HTM system that does
not require centralized arbitration. While RTM accelerate STM systems by '2.5×, it still suf-
fered performance overheads due the software bookeeping needed to interact between hardware
and software transactions. FlexTM includes a more streamlined runtime system and improves
performance by '2× relative to RTM. We demonstrated that FlexTM’s distributed commit
demonstrates '25% better performance than an aggressive hardware-based centralized arbiter
design (which can handle an unbounded number of parallel commits).
Both RTM and FlexTM support flexible software-defined policies for contention manage-
ment and conflict resolution laziness. In Chapter 5, using FlexTM, we investigate the interaction
between conflict management and resolution for different types of conflict scenarios and make
recommendations on what policies need to be adopted. Overall, Lazy outperformed Eager by up
to 2× with an average of 40%. In some cases Lazy’s wasted work limits performance improve-
ment to 20%. We evaluated an intermediate Mixed approach that limits the negative effects of
failed speculation and improves performance by up to 40% over Lazy.

181
7.1.3 Protection
In Chapter 6, we developed Sentry, a flexible memory protection mechanism that helps to im-
prove the reliability and debugging of modular software. Sentry allows software to enforce
protection among a program’s modules. Sentry ensures the integrity of a module’s private data
(no external accesses), the safety of inter-module shared data (enforce the permissions speci-
fied), and adherence to the module’s interface (regulate function invocation). The key hardware
innovation is a lightweight permissions cache that only intercepts L1 cache misses and reuses
the coherence states to implicitly validate L1 cache hits. This design is based on the observa-
tion that the permissions metadata do not change often and hence can be checked infrequently,
possibly only when they change. We use the fact that a location is in the cache to indicate that
its permissions have not changed and elide checks for the cache hits.
Sentry provides a protection framework using virtual memory tagging that is completely
subordinate to the existing OS-TLB framework. It realizes intra-application protection mod-
els with predominantly user-level software, requires very little OS intervention, and makes no
changes to process-based protection. We developed an intra-application compartment protec-
tion model and used it to isolate the modules of a popular web server application (Apache),
thereby protecting the core web server from buggy modules. Our evaluation demonstrated
that Apache’s module interface can be enforced at low overhead ('13%), with few application
annotations, and in an incremental fashion. Finally, we also investigated the use of memory
protection in watchpoint-based debuggers.
7.2 Future Work
Given the broad range of problems that we tackled in this dissertation, we summarize future
work on the two main applications we explored (1) Transactional memory and (2) Memory
protection.

182
7.2.1 Transactional Memory
In this dissertation, we made a case for making TM implementations more flexible to deal
with the various conflict scenarios that arise in applications. We explored policy decisions in
the context of FlexTM. The hardware-software TM, RTM, is more appealing since it requires
changes to only the on-chip cache hierarchy and handles large and long transactions entirely in
software. Future work could explore conflict scenarios in more detail with the RTM system,
which would introduce new challenges such as the conflict between software and hardware
transactions. We would need to port benchmark suites (e.g., STAMP in Appendix A) to RTM.
This task could be made a lot easier by porting the Intel compiler [Int] recently released for
STMs. As part of this exercise, one of the key challenges that needs to be addressed is the
cache-line alignment restriction.
A general limitation of HTMs that buffer speculative data in the cache is that they do not
allow speculatively written data and non-speculatively written data to reside in the same cache
line. Most HTMs track speculative locations at the granularity of cache lines and throw an
exception when a speculatively written cache line is subsequently written non-speculatively.
This could give rise to spurious aborts when two program level objects that do not have a race
happen to be co-located. We would need extensions to the compiler and memory allocator
to ensure this limitation is invisible to the programmer. An alternative would be to make the
non-speculative stores write-through to the shared cache, but the performance effects of such
write-through operations need to be investigated.
A key design decision that we made early on was to not consider support for closed or
open nesting. It was not clear to us then whether any form of support other than simple flat-
tening was needed. Furthermore, a workable solution based entirely on software has been pro-
posed [LeM08]. One could possibly revisit this assumption in light of new applications and
study the support needed for constructs like nested parallelism [VWA09]. The study would
have to also consider performance implications for the various approaches to nesting. Perhaps
the biggest challenge in hardware support is that each nesting level may need separate support
for conflict detection and versioning.
Finally, isolation is a key property which enables transactions to run independently of other

183
threads in the program. This feature is useful in applications like testing, debugging, and sand-
boxing. Future work could explore the interface that TM runtime systems need to support to
enable these applications. We may also need to extend the underlying TM mechanism itself
to support these new uses. For example, software testing requires the isolation mechanism to
enable software to query both the new and old versions of a location.
7.2.2 Fine-grain memory protection
In Chapter 6, we demonstrated that access control can be implemented efficiently if we take
into consideration that the permissions of many locations do not change frequently. Based on
this observation, we exploited cache states to implicitly check accesses and elide the actual per-
mission checks for the majority of the accesses. The observation about the temporal stability
of permissions can also be used to drive a software virtual-machine-based implementation of
Sentry. A virtual-machine-based design is attractive since it requires few changes in the appli-
cation and no changes to the hardware. It would also allow the development of library support
and applications before the Sentry hardware is available.
The key challenge in software-based implementations is the performance overhead of in-
strumentation that is needed on every access. This overhead can be elided by using hardware-
based access control available on current microprocessors. Current microprocessors provide
support in the form of small number of watchpoint registers and coarse-grain page protection.
The virtual machine could dynamically utilize the hardware support for frequently and recently
accessed data where possible, while inserting run time checks for other data in the application.
For example, if all entries in a large array had the same permissions, then we can protect it using
page protection and elide instrumentation for accesses to the array. We could also dynamically
detect the most frequently used words and assign them watchpoint registers [LH10].
As part of Sentry’s design, we presented four different protection models and demonstrated
Sentry on a few modules of the Apache webserver. Future work, could investigate the pro-
tection models in a more formal setting and investigate more applications; an attractive study
could be the Firefox web browser. Languages such as C# and Java also provide type informa-
tion and one could potentially investigate techniques to extract protection models, and insert

184
permission annotations in an automated fashion. Part of this project could also devise new
pragmas and annotations to allow programmers to indicate permissions with higher level spec-
ifications [WSC10].
7.3 Reflections
In this section, I reflect on my dissertation research with the benefit of hindsight, experience of
working with memory hierarchies for over five years, and the freedom to state my my opinion.
7.3.1 Future of Transactional Memory
Based on the researcher, TM is either nothing more than a research toy [CBM08], or it could
potentially ease the task of writing parallel programs. Why the stark difference of opinion
among academic researchers of reason? Well, it depends on how you view the experiments
set up by the different research groups or in Mark Moir’s words — All short statements about
TM are wrong! [Moi10]. Concurrency control mechanisms in general are notoriously hard to
evaluate due to the influence of subtle interactions between threads; speculative techniques in
TM only add further pandemonium. As we showed in Chapter 5, introducing a simple backoff
mechanism on a conflict can change the timing of events and lead up to 10× improvement or
loss in throughput.
TM evaluation has been largely driven by simple benchmarks and small application kernels.
In my opinion, this does not necessarily prove or disprove anything about the usefulness of TM
as the impact on a real application could possibly be minimal due to the fraction of the appli-
cation using transactions. Most researchers do understand that software-only TMs will suffer
from inherent overheads due to the instrumentation needed. However, STMs have reasonable
scalability and it may be possible to use extra cores in the system to improve programmability at
the expense of reduced performance efficiency. More work is needed to convince ourselves that
TM improves programmability. The appearance of a somewhat open standard [ACC11], mod-
ern compilers [Int], spectrum of runtime systems [10a], and system support [PHR09] will all
aid in getting TM into mainstream applications and investigating the programmability question.

185
Overall, in my opinion TM provides a clean atomic abstraction that can help programmers
avoid the difficult tradeoffs associated with locking conventions and avoid the possibility of
deadlock. In many cases, programmers appear to commit fewer mistakes with TM than they do
with locks. TM also allows the implementation to transparently employ speculative execution
to concurrently execute atomic actions and recover performance, when the conditions are right.
I see best-effort hardware support for TMs as being fundamental to pave the way for TM
adoption. HTMs help in tackling the uneasy tradeoffs among the scalability, latency, and live-
ness of many existing parallel programs. I am not convinced that we need anything more than
best-effort HTMs, given that most transactions tend to be small in current applications and that
there is no clear usage case for unbounded transactions in general. Best-effort HTM transac-
tions clearly help with applications such as concurrent data structures, memory allocators, and
lock elision; we only need a real system to ensure the benefits continue to hold in the real world.
It has the potential to simplify the writing and debugging of these complex parallel programs,
while improving performance in many cases.
Unfortunately, the first iteration of HTMs, ROCK, has proven to be too frustrating, with
transaction failures caused by low-level hardware conditions, which are difficult to diagnose
and even harder to resolve in a satisfactory manner. The lack of clear feedback to software has
also not helped. Going forward, I think that best-effort HTMs need to make some guarantees
about the ultimate progress of small transactions, similar to the compare-and-swap instruction.
To encourage software developers, best-effort HTMs need to streamline transactions and im-
prove performance over STMs as much as possible by providing support for tasks like register
checkpointing, even though it can be performed in software. Perhaps most importantly, best-
effort HTMs need to recognize the value of flexibility in conflict management. As we showed
in Chapter 5, to ensure scalability and freedom from pathological conditions, TM systems need
to delay choosing the winner in the event of a conflict and even then carefully make the choice.
Policies like eager requestor-wins conflict management, while directly compatible with cache
coherence, introduce significant performance problems. Care needs to be taken that we do not
hardwire policies in the HTM that cause poor performance and lead to software developers
blaming TM in general.
Finally, a key question that needs to be answered is what should best-effort HTMs look

186
like. While everyone agrees that it should involve minimal modifications to existing hardware,
there is less consensus on what the support should look like. Many research HTM systems (in-
cluding our own) have recognized that conflict detection constitutes the dominant overhead in
STM systems. This suggests that HTM systems should begin by including support for tracking
accesses in a transaction and detect conflicts against remote writes in the system. I particularly
think that we should avoid support for versioning in a best-effort TM because (1) it does not
constitute the dominant overhead in TMs, (2) supporting lazy conflict resolution would require
versioning to make changes that change the invariants of a traditional coherence protocol, and
(3) eager versioning can only support eager conflict resolution, which could introduce perfor-
mance pathologies. We demonstrated the value of decoupling conflict detection from resolution
in Chapter 5; we believe supporting flexible conflict resolution is an important goal.
Overall, I think that we should start with a system that includes alert-on-update (or bloom-
filter based access signatures) for detecting conflicts and adds conflict-summary-tables (Sec-
tion 4.3.1 in Chapter 4) to provide more information to software about conflicts. This would
allow the system to support both eager and lazy conflict resolution and allow flexible con-
tention managers to deal with pathological scenarios in applications. This design requires min-
imal changes to the coherence protocol and can be implemented with extra metadata bits at the
cores.
7.3.2 Which one of your hardware mechanisms holds the most promise?
In computer architecture, it has become increasingly hard to directly influence real micropro-
cessors due to their general complexity. Industry vendors need to be assured of many different
aspects and application cases, before they can incorporate “your favorite idea” in a future prod-
uct. Given this status, over the years, I have tried to be mindful of design complexity when
working on my research ideas. I first invented Alert-On-Update back in 2005 — it was a design
that was born out of the need for a way to let a transaction in an STM system know when it has
been aborted. All AOU requires is a single bit per cache-line (in some cases we can make do
with one bit for the entire cache) and few status registers. It requires no changes to the cache
coherence protocol itself and our design only detects events at the cores in the coherence proto-

187
col. I see Alert-On-Update as probably the mechanism that holds the most promise and offers
the potential for impacting industry and academia.
AOU started with the simple question: “What could software do, if it were aware of the
coherence events?”. Over the years, I have been pleasantly surprised at the number of possible
answers to this question: we have used AOU to speed up multiple TM systems, improve locks,
and enable watchpoint-based debugging. Other researchers have used extended versions of
AOU, which can also permit software to control coherence response messages, to enable thread-
speculation and software-based replay tools [NaG09]. The key to AOU’s usability has been the
design decision not to fix the semantics for an alert in hardware. The response actions to an
alert are entirely controlled in software, which significantly improves its versatility. AOU also
had well-defined behavior when interacting with regular memory operations and this enabled
us to incrementally incorporate it in applications.
The key challenge left in moving AOU into mainstream processors is virtualization. Per-
mitting multiple applications to simultaneously use the cache requires the addition of extra
metadata to the cache. To provide guarantees about the minimum number of AOU lines that
will not experience overflows requires additional logic in the cache replacement algorithms. It
would also be useful to investigate generalized techniques to handle cache overflows; in the
dissertation (Section 3.5) we investigated the use of software version numbers to handle missed
alerts in STMs.
7.3.3 How do you know your cache protocols work?
Finally, I reflect on the development and evaluation process used in my dissertation research.
Over the years, I have received multiple conference reviews posing questions about the com-
plexity and correctness of our protocols. Evaluating ideas that define the coherence protocol
interactions between multiple cores requires significant manpower and expenditure even for in-
dustry, and it is a large undertaking for a student. The SLICC language developed as part of the
GEMS tool chain [MSB05] is a boon: it allowed me to specify the protocol with varying levels
of transient states and verify system behavior with a random tester. The table-based specifica-
tion allowed me to carefully visualize the protocol’s operations and reason about the correctness

188
and invariants. SLICC has empowered even graduate students to actively research areas such
as coherence protocols with reasonable fidelity. I think it is the next best thing to full blown
formal verification, which has its own challenges. One of the key features that got me hooked
on to SLICC was being able to design tests and rapidly catch obvious mistakes such as missing
transitions and events. Using a tool such as SLICC has its disadvantages: the specification may
contain latent bugs that may not be caught by random testing. SLICC also makes it hard to
specify circuit-level optimizations like broadcast networks or to directly manipulate coherence
state bits.

189
Appendix ASupplement for Transactional Memory
A.1 Experimental Framework
We evaluated the TM systems discussed in Chapter 3 and Chapter 4 through full system simu-
lation of a 16-way chip multiprocessor (CMP) with private split L1 caches and a shared L2. We
use the GEMS/Simics infrastructure [MSB05], a full system functional simulator that faithfully
models the SPARC architecture. GEMS itself underwent multiple revisions during my Ph.D;
the work described in Chapter 3 and Chapter 4 used GEMS 1.2 and the work in Chapter 6 used
GEMS 2.0. The move to a new version of the simulator was necessitated since Simics 2.2.X
licenses expired in December 2009.
The instructions specified for the Alert-On-Update and Programmable-Data-Isolation
mechanisms interface with the TM runtime systems using the standard Simics “magic instruc-
tion” mechanism. We implemented support for the TMESI protocol and AOU mechanism using
the SLICC [MSB05] framework to encode all the stable and transient states in the system. We
employ GEMS’s network model for interconnect and switch contention and use 64 byte links.
Simics allows us to run an unmodified Solaris 9 kernel on our target system with the “user-
mode-change” and “exception-handler” interface enabling us to trap user-kernel mode cross-
ings. On crossings, we suspend the current transaction context and allow the OS to handle TLB
misses, register-window overflow, and other kernel activities required by an active user context
in the midst of a transaction. On transfer back from the kernel we deliver any exception signals

190
received during the kernel routine, triggering any user-level handlers if required. We used such
handlers for managing the interaction between hardware and software transactions in the RTM
system.
A.2 Application Characteristics
While microbenchmarks help stress-test an implementation and identify pathologies, de-
signing and understanding policy requires a comprehensive set of realistic workloads.
In this study, we have assembled seven benchmarks from the STAMP workload suite
v0.9.9 [MCK08], STMBench7 [GKV07], a CAD database workload, and two microbench-
marks from RSTMv3.3 [MSH06]. We briefly describe the benchmarks, where transactions are
employed, and present their runtime statistics (see Table A.1). Our runtime statistics include
transaction length, read/write set sizes, read and write event timings, and average conflict levels
(number of locations on which and the number of transactions with which conflicts occur). We
have also included information on the number of conflicting transactions and type of conflicts
(i.e., Read-Write or Write-Write) in order to analyze the behavior of the applications. We corre-
late this information with the influence of contention manager heuristics and measure the ability
of Eager/Lazy to uncover parallelism in Chapter 5.
Bayes: The bayesian network is a directed acyclic graph that tries to represent the relation
between variables in a dataset. All operations (e.g., adding dependency sub-trees, splitting
nodes) on the acyclic graph occur within transactions. There is plenty of concurrency but the
data is accessed in a fine-grain manner, resulting in potential for conflict.
Read/Write Set: Large Contention: High
Input: -v32 -r1024 -n2 -p20 -s0 -i2 -e2
Delaunay: There have been multiple variants of the Delaunay benchmark that have been re-
leased [SSD07; KCP06]. This version is from the STAMP suite and implements the Delaunay
mesh refinement [Rup95]. There are primarily two data structures: (1) a Set for holding mesh
segments and (2) a graph that stores the generated mesh triangles. Transactions protect access
to these data structures. The operations on the graph (adding nodes, refining nodes) are complex

191
and involve large read/write sets, which leads to significant contention.
Read/Write Set: Large Contention: Moderate
Input: -a20 -i inputs/633.2
Genome: This benchmark implements a gene sequencing algorithm that reconstructs the gene
sequence from shorter known fragments of a larger gene (short strings of alphabets A,T,C,G).
It uses transactions for (1) eliminating duplicates by inserting the fragments into a hash-set and
(2) matching segments in parallel using a string matching algorithm to find the longest match.
In general, the application is highly parallel and contention free.
Read/Write Set: Moderate Contention: Low
Input: -g256 -s16 -n16384
Intruder: This benchmark parses a set of packet traces using a three stage pipeline. There
are also multiple packet-queues that try to use the data-structures in the same pipeline stage.
Transactions are used to protect the FIFO queue in stage 1 (capture phase) and the dictionary in
stage 2 (reassembly phase).
Read/Write Set: Moderate Contention High
Input: -a10 -l16 -n4096 -s1
Kmeans: This workload implements the popular clustering algorithm that tries to organize data
points into K clusters. This algorithm is essentially data parallel and can be implemented with
only barrier-based synchronization. In the STAMP version, transactions are used to update the
centroid variable, for which there is very little contention.
Read/Write Set: Small Contention: Low
Input: -m10 -n10 -t0.05 -i inputs/random2048-d16-c16.txt
Labyrinth: This implements a route finding algorithm in a three-dimensional grid. Multiple
threads are set up to find an optimized route, each with their own copy of the grid. They update a
separate globally shared grid that stores the best routes. All the work including the route finding
with the private copy of the grid is enclosed in a transaction, leading to a large working set. The
contention on the shared grid is also high with many transactions desiring simultaneous access
to check and update the best route.
Read/Write Set: Large Contention High

192
Input: -i inputs/random-x32-y32-z32 -n96
Vacation: Implements a travel reservation system. Client threads interact with an in-memory
database that implements the database tables as a Red-Black tree. Transactions are used during
all operations on the database.
Read/Write Set: Moderate Contention: Moderate
Input: -n4 -q45 -u90 -r1048576 -t4194304
STMBench7: STMBench7 [GKV07] was designed to mimic a transaction processing CAD
database system. Its primary data structure is a complex multi-level tree in which internal nodes
and leaves at every level represent various objects. It exports up to 45 different operations with
varying transaction properties. It is highly parametrized and can be set up for different levels
of contention. Here, we simulate the default read-write workload. This benchmark has high
degrees of fine-grain parallelism at different levels in the tree.
Read/Write Set: X-Large Contention: High
Input: Reads-60%, Writes-40%. Short Traversals-40%. Long Traversals 5%, Ops. - 45%,
Mods. 10%.
µbenchmarks: We chose four data structure benchmarks from RSTMv3.3 [10a]
a) HashTable: Transactions use a hash table with 256 buckets and overflow chains to lookup,
insert, or delete a value in the range 0 . . . 255 with equal probability. At steady state, the table
is 50% full. b) RBTree: In the red-black tree (RBTree) benchmark, transactions attempt to
insert, remove, or delete values in the range 0 . . . 4095 with equal probability. At steady state
there are about 2048 objects, with about half of the values stored in leaves. c) LFUCache:
LFUCache uses a large (2048) array based index and a smaller (255 entry) priority queue to
track the most frequently accessed pages in a simulated web cache. When re-heapifying the
queue, transactions always swap a value-one node with a value-one child; this induces hysteresis
and gives each page a chance to accumulate cache hits. Pages to be accessed are randomly
chosen using a Zipf distribution: p(i) ∝ Σ0<j≤ij−2. d) RandomGraph The RandomGraph
benchmark requires transactions to insert or delete vertices in an undirected graph represented
with adjacency lists. Edges in the graph are chosen at random, with each new vertex initially
having up to 4 randomly selected neighbors.

193
A.3 Conflict Scenarios in Applications
We also profiled the conflict patterns present in the applications and categorized conflicts into
three types: Read-Write, Write-Read or Write-Write (see Figure A.1). Read-Write and Write-
Read conflicts vary based on which transaction notices the conflict — in Read-Write the reader
notices the conflict and in Write-Read the writer notices the conflict. Read-Write conflicts can
be resolved amicably between the transactions if the reader commits before the writer since the
conflict is elided entirely. Write-Write conflicts are problematic since both transactions can’t
commit concurrently (see footnote 2 on page 6). Bayes, Delaunay, Labyrinth, STMBench7, and
Vacation all employ “trie”-like data structures extensively and transactions are primarily used
to protect the “trie” operations. There are an extensive number of conflicts arising between
transactions that perform lookups on the tree and writer transactions that perform rotations and
balancing. The primary cause of conflicts is read-write sharing (which Lazy can exploit) and
account for '97% of the conflicts. The working set size is also moderate to high due to the
prevalence of pointer chasing. Intruder has small transactions but has a conflict pattern similar
to Delaunay (Read-Write and Write-Read together represent over 99% of the conflicts) Kmeans
and Genome are essentially data parallel, and have a negligible fraction of conflicts (<15%).
Finally, LFUCache and RandomGraph are both stress tests — they have small, highly contended
working sets; a significant fraction of the conflicts are write-write (87% in LFUCache and 29%
in RandomGraph) and it is not possible to avoid wasted work.

194
R-W W-R W-W
0%
20%
40%
60%
80%
100%
Baye
s
Delau
nay
Genom
e
Intru
der
Kmea
ns
Laby
rinth
Vaca
tion
STMBe
nch7
LFUC
ache
Rand
omGra
ph
Conflic
t Ty
pe
%
R-W: Read-Write conflict. Reader accesses location before Writer. W-R: Write-Read conflict. Writer accesses
location before reader. W-W: Write-Write conflicts. Represents true write-write conflicts and upgrade conflicts in
which the reader in a R-W or W-R conflicts writes the location. All conflicts estimated for a Lazy system.
Figure A.1: Conflict type breakdown

195
Tabl
eA
.1:T
rans
actio
nalW
orkl
oad
Cha
ract
eris
tics
Ben
chm
ark
Inst
/txW
r set
Rd
set
Wr 1
Rd1
Wr N
Rd
NC
STco
nflic
tspe
r-tx
Avg
.pe
r-tx
W-W
Avg
.pe
r-tx
R-W
Bay
es70
K15
022
50.
60.
050.
80.
953
01.
7D
elau
nay
12K
9017
80.
50.
120.
850.
91
0.1
1.1
Gen
ome
1.8K
949
0.55
0.09
0.99
0.85
00
0In
trud
er41
041
140.
50.
040.
990.
82
01.
4K
mea
ns13
04
190.
650.
10.
990.
70
00
Lab
yrin
th18
0K19
016
00.
570.
010.
990.
94
02
Vac
atio
n5.
5K12
890.
750.
020.
990.
81
01.
6ST
MB
ench
715
5K31
059
00.
40
0.85
0.9
30.
53.
6H
ash
110
13
0.96
0.1
0.96
0.95
00
0R
BTr
ee2K
225
0.9
0.01
0.99
0.8
10
1.1
LFU
Cac
he12
51
20.
990
0.99
0.78
60.
80.
8R
ando
mG
raph
11K
960
0.6
00.
90.
995
0.6
3Se
tup:
16th
read
sw
ithla
zyco
nflic
tres
olut
ion;
Inst
/Tx-
Inst
ruct
ions
pert
rans
actio
n.K
-Kilo
Wr s
et(R
dset):
Num
bero
fwri
tten
(rea
d)ca
che
lines
Wr
1(W
rN
):Fi
rst(
last
)wri
teev
entt
ime;
Mea
sure
das
frac
tion
oftx
exec
utio
ntim
e.R
d-R
ead
CST
confl
icts
per
tx:N
umbe
rofC
STbi
tsse
t.M
edia
nnu
mbe
rofc
onfli
ctin
gtr
ansa
ctio
nsen
coun
tere
dW
-W(R
-W):
-Avg
(N
o.of
confl
icts
/txN
umbe
rofs
etC
STbi
ts/tx
).A
vg.n
umbe
rofc
onfli
ctin
glo
catio
nssh
ared
betw
een
txs.

196
Appendix BCoherence State Machine
This chapter shows detailed specification for the L1 cache controllers of the broadcast version
of the TMESI protocol. We use the 2-state TMESI protocol discussed in Section 4 to keep the
discussion simple. The transition table split across Figure B.1 and Figure B.2 was generated
using the SLICC parser from the GEMS toolchain. These tables provide a clear and concise
representation of the protocol, including all the transient states and detailed actions that occur
on specific transitions. This methodology provides a clear illustration of the additional actions
and events introduced by the TMESI states.
The row of each table corresponds to the states that the cache controller can be in. The columns
correspond to events triggered that cause the cache controller to take actions and move to state
indicated in the cell. Events are typically triggered as the result of a processor access or when a
message is received on the interconnect. The table entries indicate a set of actions performed in
an atomic fashion when the state change is triggered by an event.
Table B.1 indicates the states of our L1 cache controller — it includes the stable states M,E,S,I,
and TM. In this broadcast based system, the L1 controller interfaces with three logical networks,
Address network (which handles L1 broadcasts and L2 forwarded invalidations), Data response,
and Snoop response. Table B.3 enumerates the type of messages sent out on these network.
GETS, UPGRADE, GETX, TGETX, and TUPGRADE all use the address network. The snoop
response messages corresponding to ACKs are sent out on the snoop response queue. The
shared-L2 collects the snoop responses and forwards the final response on the address queue

197
to indicate request completion. The data messages, DATA, travel on a separate logical data
network; writebacks (WB) from the L1 to the shared-L2 also use the same network. The logical
networks, data and address, share the same physical network and contend for bandwidth, while
the snoop response queue uses a separate physical network. In SLICC, the separate physical
network for the snoop response can be implemented by instantiating a seperate queue in the
chip class.
Table B.2 list the events that trigger state changes in the L1 controller: we add six new events,
TStore, TLoad, and T TLoad from the processor side. Other TGETX, Other TUPGRADE,
and ACK Threat from the network side compared to the basic MESI protocol. Table B.4 list the
actions of the coherence protocol. To illustrate a sample transition, consider a cache line in state
I which receives the trigger Load; it performs the actions ggets, c, a, k (refer Table B.4)
and moves to the state ISAD indicated by the slash (/).
Every miss handler register (MSHR) include three single bit fields: a) Abort, which indicates
that the abort handler should be invoked when the request completes, b) Alert, which indicates
if the memory operation in flight is an alert memory operation. It detects racy remote writes and
sets the Abort field, if necessary, and c) Trans, which indicates transactional operation in flight.
It detects racy non-transactional writes for aborts. It sets the T bit in the cache line if threatened
(ACK Threat). Every cache line includes two bits: a) Alert, which indicates if the cache line
has been tagged as alert-on-update, and b) Trans, which tags the transactional states.
We use the Trans in each cache line to encode the TI state, and eliminate the separate state
shown in our state machine diagram (Figure 4.3 in Chapter 4). TI’s transitions mirrors I for
all events except the processor TLoad event, in which case TI returns a hit, while I initiates
miss activity. Hence, within the SLICC specification we can eliminate the separate state by
including a new event type, T_Load to handle the case where a TLoad is issued to a TI line;
other processor events do not distinguish between TI and I. Table B.1 also shows the transient
states part of the L1 cache controller. Note that the majority of the transient states are part of
the basic MESI coherence protocol. We add 11 new transient states, ITMAD, ITMD, ITMA,
ITMADI , STMUAD, STMD, STMDI , STMA, MTMA, andMTMAI . Interestingly, the
transitions from I and S into the TM state, which include the ITM [∗] and STM [∗] states are
similar to the transient states IM [∗] and SM [∗], which move to the M state. Although, there

198
are extra states in this representation, the number of unique transitions for which the actions
differ is small. For example, when a core issues a TStore to the cache controller in State
I, it broadcasts a TGETX message and transitions to ITMAD. The other cache controllers
will provide a snoop response, which is collected by the L2. Let us assume that there were
no other sharers, in which case the L2 supplies the DATA message and sends a separate ACK
message. Based on the order in which these messages are received, ITMAD transitions to
ITMA, ITMD, and finally into TM . Now when the core issues a Store to the cache controller
in I , it broadcasts a GETX and transitions to IMAD and its counterparts; essentially the IM [∗]
states mirror the ITM [∗] states. We could potentially eliminate all the ITM [∗] transient states
by including checks in the final transitions to detect if the transient states were initiated by a
TStore or a Store, and then transitioning to TM orM based on this check. This would reduce
the readability of the protocol since these checks would need more events and modifications to
the controller that triggers the events. However, it reduces the number of states in the protocol
and may potentially reduce the verification complexity.
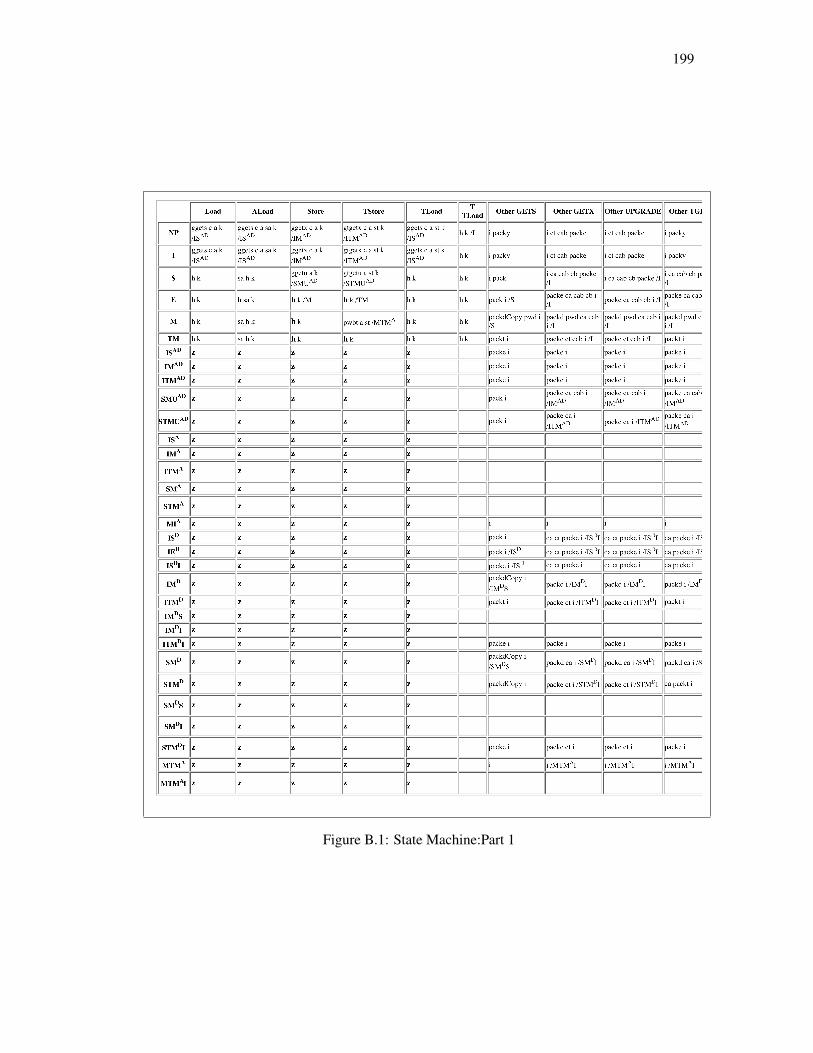
199
Figure B.1: State Machine:Part 1

200
Note that the states are listed in the last column.
Figure B.2: State Machine:Part 2

201
Table B.1: TMESI L1 controller states
NP Default state. Not PresentI InvalidS SharedE OwnedM ModifiedTM Transactionally modifiedISAD Invalid,issued GETS, have not seen GETS ACK or Data yetIMAD Invalid, issued GETX, have not seen GETX ACK or Data yetITMAD Invalid, issued TGETX, have not seen TGETX ACK or Data yetSMUAD Shared, issued Upgrade, have not seen upgrade yetSTMUAD Invalid, issued TUpgrade, have not seen Upgrade ACK or Data yetISA Invalid, issued GETS, have not seen GETS ACK, have seen DataIMA Invalid, issued GETX, have not seen GETX ACK, have seen DataITMA Invalid, issued TGETX, have not seen TGETX ACK, have seen DataSMA Shared, issued GETX, have not seen GETX ACK, have seen DataSTMA shared, issued TUPGRADE, have not seen TUPGRADE ACK, have seen DataMIA Modified, issued WB, have not seen WB ACK yetISD Invalid, issued GETS, have seen GETS, have not seen Data yetIED Invalid, issued GETS, have seen Ack exclusive, have not seen Data yetISDI Invalid, issued GETS, have seen GETS, have not seen Data, then saw other GETX. Move
to Invalid after receiving data.IMD Invalid, issued GETX, have seen GETX, have not seen Data yetITMD Invalid issued TGETX have seen ACK. have not see Data yetIMDS Invalid, issued GETX, have seen GETX, have not seen Data yet, then saw other GETSIMDI Invalid, issued GETX, have seen GETX, have not seen Data yet, then saw other GETXITMDI Invalid, issued TGETX, have seen TGETX, have not seen Data yet, then saw other GETX.
Abort TransactionSMD Shared, issued GETX, have seen GETX, have not seen Data yetSTMD Shared, issued TUPGRADE, have seen TUPGRADE, have not seen Data yetSMDS Shared, issued GETX, have seen GETX, have not seen Data yet, then saw other GETSSMDI Shared, issued GETX, have seen GETX, have not seen Data yet, then saw other GETX. On
Data, drain store and then supply the updated cache block.STMDI Shared, issued TUPGRADE, have seen TUPGRADE, have not seen Data yet, then saw
other GETX. Abort transaction.MTMA Modified, issued threatened WB. Not seen ACKMTMI Modified, issued threatened WB, then saw another GETX before ACK. Abort transaction.

202
Table B.2: TMESI L1 controller events
Processor EventsLoad Load request from the processorALoad ALoad request from the processorStore Store request from the processorTStore Transactional Store from the processorTLoad Transactional Load from the processorT TLoad Represents TLoad to a cache line with T state set
Address queue eventsOther GETS Occurs when we observe a GETS request from another processorOther GETX Occurs when we observe a GETX request from another processorOther UPGRADE Occurs when we observe a Upgrade request from another processorOther TGETX Occurs when we observe a TGETX request from another processorOther TUPGRADE Occurs when we observe a TUPGRADE request from another processorOwn Request Occurs when we observe our own request in global orderInv L2 sent invalidation requestAck Occurs when it indicates a AckWB Ack Occurs when it indicates a Writeback AckAck Threat Occurs when it indicates a Ack ThreatAck Upgrade Occurs when we observe an Ack UPGRADE; no data neededAck Exclusive Occurs when it indicates a Ack Exclusive; can move to E state if data
received without any intervening GET
Table B.3: TMESI L1 controller messages
Coherence messagesMessage Description Source→DestinationGETX Get exclusive. L1 Request→broadcastTGETX Transactional GETX L1 Request→broadcastUPGRADE Upgrade to exclusive L1 Request→broadcastTUPGRADE Transactional Upgrade to exclusive L1 Request→broadcastGETS Get shared copy L1 Request→broadcastINV INValidate L2 eviction→ L1ACK Generic ack to L1 L2 ack→ L1ACK THREAT Generic Threatened ACK L2 ack→ L1ACK EXCLUSIVE Exclusive Copy, data response L2 ack→ L1ACK UPGRADE Exclusive copy for upgrade, no data response L2 ack→ L1WB ACK writeback ack L2 ack→ L1
L1 coherence response messagesDATA Data response to forwarded coherence message L1→L2 on data networkACK Invalidation response L1→L2 on snoop responseACK THREAT Threat ack; L1 has line in TM L1→L2 on snoop responseACK Exclusive Exclusive copy returned L1→L2 on snoop responseWB Writeback data L1→L2 on data network

203
Table B.4: TMESI L1 cache controller actions
a Allocate MSHR with Trans=false, Alert=false, and Abort=false.cab Abort handlerc Set L1 Dcache tag equal to tag of block B.ca Check A Bitct Check T Bit.cc Commit handlerchka Check for abort handlercb Clear A bitctb Clear T bitsa Set Alert bit.st Set Trans bitd Deallocate MSHR.ggets Issue GETS.ggetu Issue Upgrade.ggetx Issue GETX.gtgetu Issue transactional UPGRADE.gtgetx Issue transactional GETX.h Notify sequencer the load or store completed.i Pop incoming address queue.j Pop incoming data queue.k Pop mandatory queue.m Deallocate L1 cache block.packdCopy Issue Ack Data Copypackd Issue Data-ACKpacke Issue Exclusive-ACK.pack Issue Ack.packt Issue threatened ACK.packy Issue specific Ack type based on response from remote cores.pwd Issue data.pwb Issue writeback.pwbt Issue threatened writeback.qtbe Write data from the cache into the MSHR.sca Save data into cache.z Recyle mandatory queue from processor. Can’t handle access in this cycle.

204
Bibliography
[ACC11] Ali-Reza Adl-Tabatabai, Calin Cascaval, Steve Clamage, Robert Geva, Victor Luchangco,Virendra Marathe, Maged Michael, Mark Moir, Ravi Narayanaswamy, Clark Nelson, Yang Ni,Daniel Nussbaum, Tatiana Shpeisman, Raul Silvera, Xinmin Tian, Douglas Walls, Adam Welc,Michael Wong, and Peng Wu. Draft Specification (v3.0) of Transactional Language Constructs forC++. June 2011. http://groups.google.com/group/tm-languages.
[ASH88] Anant Agarwal, Richard Simoni, John Hennessy, and Mark Horowitz. An Evaluation of Di-rectory Schemes for Cache Coherence. In Proc. of the 15th Intl. Symp. on Computer Architecture,pages 280-289, Honolulu, HI, June 1988.
[AAK05] C. Scott Ananian, Krste Asanovic, Bradley C. Kuszmaul, Charles E. Leiserson, and Sean Lie.Unbounded Transactional Memory. In Proc. of the 11th Intl. Symp. on High Performance ComputerArchitecture, pages 316-327, San Francisco, CA, Feb. 2005.
[ApL91] A. W. Appel and K. Li. Virtual Memory Primitives for User Programs. In Proc. of the 4thIntl. Conf. on Architectural Support for Programming Languages and Operating Systems, pages96-107, Santa Clara, CA, Apr. 1991.
[ArB84] J. Archibald and J.-Loup Baer. An Economical Solution to the Cache Coherence Problem. InProc. of the 11th Intl. Symp. on Computer Architecture, pages 355-362, 1984.
[Ass07] Semiconductor Industries Association. Model for Assessment of CMOS Technologies andRoadmaps (MASTAR). 2007. http://www.itrs.net/models.html.
[BNZ08] Lee Baugh, Naveen Neelakantan, and Craig Zilles. Using Hardware Memory Protection toBuild a High-Performance, Strongly Atomic Hybrid Transactional Memory. In Proc. of the 35thIntl. Symp. on Computer Architecture, Beijing, China, June 2008.
[BCD72] A. Bensoussan, C. T. Clingen, and R. C. Daley. The MULTICS Virtual Memory: Conceptsand Design. Comm. of the ACM, 15(5), May 1972.
[BAL90] B. N. Bershad, T. E. Anderson, E. D. Lazowska, and H. M. Levy. Lightweight Remote Pro-cedure Call. ACM Trans. on Computer Systems, 8(1):37-55, Feb. 1990. Originally presented at the12th ACM Symp. on Operating Systems Principles, Dec. 1989.
[BSP95] Brian N Bershad, Stefan Savage, Przemysław Pardyak, Emin Gun Sirer, Marc Fiuczynski,David Becker, Susan Eggers, and Craig Chambers. Extensibility, Safety and Performance in theSPIN Operating System. In Proc. of the 15th ACM Symp. on Operating Systems Principles, CopperMountain, CO, Dec. 1995.
[Blo70] Burton H. Bloom. Space/Time Trade-Off in Hash Coding with Allowable Errors. Comm. of theACM, 13(7):422-426, July 1970.

205
[BMV07] Jayaram Bobba, Kevin E. Moore, Haris Volos, Luke Yen, Mark D. Hill, Michael M. Swift,and David A. Wood. Performance Pathologies in Hardware Transactional Memory. In Proc. of the34th Intl. Symp. on Computer Architecture, pages 32-41, San Diego, CA, June 2007.
[BGH08] Jayaram Bobba, Neelam Goyal, Mark D. Hill, Michael M. Swift, and David A. Wood. To-kenTM: Efficient Execution of Large Transactions with Hardware Transactional Memory. In Proc.of the 35th Intl. Symp. on Computer Architecture, Beijing, China, June 2008.
[BBL10] Sebastian Burckhardt, Alexandro Baldassion, and Daan Leijen. Concurrent Programming withRevisions and Isolation Types. In Proc. of the 2010 OOPSLA, 2010.
[CKD94] Nicholas P. Carter, Stephen W. Keckler, and William J. Dally. Hardware Support for FastCapability-Based Addressing. In Proc. of the 6th Intl. Conf. on Architectural Support for Program-ming Languages and Operating Systems, pages 319-327, San Jose, CA, Oct. 1994.
[CBM08] Calin Cascaval, Colin Blundell, Maged Michael, Harold W. Cain, Peng Wu, Stefanie Chiras,and Siddhartha Chatterjee. Software Transactional Memory: Why Is It Only a Research Toy?Queue, 6:46–58, 5, September 2008.
[CTC06] Luis Ceze, James Tuck, Calin Cascaval, and Josep Torrellas. Bulk Disambiguation of Spec-ulative Threads in Multiprocessors. In Proc. of the 33rd Intl. Symp. on Computer Architecture,Boston, MA, June 2006.
[CTM07] Luis Ceze, James Tuck, Pablo Montesinos, and Josep Torrellas. BulkSC: Bulk Enforcementof Sequential Consistency. In Proc. of the 34th Intl. Symp. on Computer Architecture, San Diego,CA, June 2007.
[CCC07] Hassan Chafi, Jared Casper, Brian D. Carlstrom, Austen McDonald, Chi Cao Minh, WoongkiBaek, Christos Kozyrakis, and Kunle Olukotun. A Scalable, Non-blocking Approach to Trans-actional Memory. In Proc. of the 13th Intl. Symp. on High Performance Computer Architecture,Phoenix, AZ, Feb. 2007.
[CVP99] Tzicker Chiueh, Ganesh Venkitachalam, and Prashant Pradhan. Integrating Segmentation andPaging Protection for Safe, Efficient and Transparent Software Extensions. In Proc. of the 17thACM Symp. on Operating Systems Principles, Charleston, SC, Dec. 1999.
[CMK08] Matt Chu, Christian Murphy, and Gail Kaiser. Distributed in vivo testing of software applica-tions. In Proc. of the 1st International Conference on Software Testing, Verification, and Validation,2008.
[CNV06] Weihaw Chuang, Satish Narayanasamy, Ganesh Venkatesh, Jack Sampson, Michael Van Bies-brouck, Gilles Pokam, Brad Calder, and Osvaldo Colavin. Unbounded Page-Based TransactionalMemory. In Proc. of the 12th Intl. Conf. on Architectural Support for Programming Languages andOperating Systems, pages 347-358, San Jose, CA, Oct. 2006.
[CMM06] JaeWoong Chung, Chi Cao Minh, Austen McDonald, Travis Skare, Hassan Chafi, Brian D.Carlstrom, Christos Kozyrakis, and Kunle Olukotun. Tradeoffs in Transactional Memory Virtual-ization. In Proc. of the 12th Intl. Conf. on Architectural Support for Programming Languages andOperating Systems, pages 371-381, San Jose, CA, Oct. 2006.
[CCL81] S. Colley, G. Cox, K. Lai, J. Rattner, and R. Swanson. The Object-Based Architecture of theIntel 432. In Proc. of the IEEE COMPCON Spring ’81, Feb. 1981.
[Cor] Intel Corporation. Intel thread checker. http://developer.intel.com/software/products/threading/tcwin.
[CPM98] Crispin Cowan, Calton Pu, Dave Maier, Heather Hinton, Peat Bakke, Steve Beattie, AaronGrier, Perry Wagle, and Qian Zhang. StackGuard: Automatic Adaptive Detection and Preventionof Buffer-Overflow Attacks. In In Proceedings of the 7th USENIX Security Symposium, 1998.

206
[DCW11] L. Dalessandro, F. Carouge, S. White, Yossi Lev, Mark Moir, Michael L. Scott, and MichaelF. Spear. Hybrid Transactional Memory. In Proc. of the 16th Intl. Conf. on Architectural Supportfor Programming Languages and Operating Systems, Mar. 2011.
[DFL06] Peter Damron, Alexandra Fedorova, Yossi Lev, Victor Luchangco, Mark Moir, and Dan Nuss-baum. Hybrid Transactional Memory. In Proc. of the 12th Intl. Conf. on Architectural Support forProgramming Languages and Operating Systems, San Jose, CA, Oct. 2006.
[DFH04] David Detlefs, Christine Flood, Steve Heller, and Tony Printezis. Garbage-first garbage col-lection. In Proc. of the 4th Intl. Symp. on Memory Management, 2004.
[DSS06] Dave Dice, Ori Shalev, and Nir Shavit. Transactional Locking II. In Proc. of the 20th Intl.Symp. on Distributed Computing, pages 194-208, Stockholm, Sweden, Sept. 2006.
[DiS06] Dave Dice and Nir Shavit. What Really Makes Transactions Fast? In Proc. of the 1st ACMSIGPLAN Workshop on Transactional Computing, Ottawa, ON, Canada, June 2006.
[DiH08] Stephan Diestelhorst and Michael Hohmuth. Hardware Acceleration for Lock-Free Data Struc-tures and Software-Transactional Memory. In Workshop on Exploiting Parallelism with Transac-tional Memory and other Hardware Assisted Methods (EPHAM), Boston, MA, Apr. 2008. Inconjunction with CGO.
[DHS08] Shlomi Dolev, Danny Hendler, and Adi Suissa. CAR-STM: Scheduling-Based CollisionAvoidance and Resolution for Software Transactional Memory. In Proc. of the 27th ACM Symp. onPrinciples of Distributed Computing, Toronto, Canada, Aug. 2008.
[Enn06] Robert Ennals. Software Transactional Memory Should Not Be Lock Free. Technical ReportIRC-TR-06-052, Intel Research Cambridge, 2006.
[Feu73] Edward A. Feustel. On The Advantages of Tagged Architecture. IEEE Transactions on Com-puters, 22(11):644-656, 1973.
[FlQ03] C. Flanagan and S. Qadeer. A Type and Effect System for Atomicity. In Proc. of the 2003 Conf.on Programming Language Design and Implementation, June 2003.
[FrH07] Keir Fraser and Tim Harris. Concurrent Programming Without Locks. ACM Trans. on Com-puter Systems, 25(2):article 5, May 2007.
[FMJ07] J. Friedrich, B. McCredie, N. James, B. Huott, B. Curran, E. Fluhr, G. Mittal, E. Chan, Y.Chan, D. Plass, S. Chu, H. Le, L. Clark, J. Ripley, S. Taylor, J. Dilullo, and M. Lanzerotti. Designof the Power6 Microprocessor. In Proc. of the Intl. Solid State Circuits Conf., pages 96-97, SanFrancisco, CA, Feb. 2007.
[FMF05] Nathan Froyd, J. Mellor-Crummey, and R. Fowler. Low-overhead call path profiling of un-modified, optimized code. In Proc. of the 19th ACM Intl. Conf. on Supercomputing, 2005.
[GiS87] D. Gifford and A. Spector. Case Study: IBM’s System/360-370 Architecture. Comm. of theACM, 30(4):291-307, Apr. 1987.
[GFV99] Chris Gniady, Babak Falsafi, and T. N. Vijaykumar. Is SC + ILP = RC? In Proc. of the 26thIntl. Symp. on Computer Architecture, pages 162-171, Atlanta, GA, May 1999.
[Goo87] J. R. Goodman. Coherency for Multiprocessor Virtual Address Caches. In Proc. of the 2ndIntl. Conf. on Architectural Support for Programming Languages and Operating Systems, pages72-81, Palo Alto, CA, Oct. 1987.
[GHP05a] Rachid Guerraoui, Maurice Herlihy, and Bastian Pochon. Polymorphic Contention Manage-ment in SXM. In Proc. of the 19th Intl. Symp. on Distributed Computing, Cracow, Poland, Sept.2005.
[GHP05b] Rachid Guerraoui, Maurice Herlihy, and Bastian Pochon. Toward a Theory of Transactional

207
Contention Managers. In Proc. of the 24th ACM Symp. on Principles of Distributed Computing,Las Vegas, NV, Aug. 2005.
[GKV07] Rachid Guerraoui, Michal Kapalka, and Jan Vitek. STMBench7: A Benchmark for SoftwareTransactional Memory. In Proc. of the 2nd EuroSys, Lisbon, Portugal, Mar. 2007.
[HWC04] Lance Hammond, Vicky Wong, Mike Chen, Ben Hertzberg, Brian Carlstrom, ManoharPrabhu, Honggo Wijaya, Christos Kozyrakis, and Kunle Olukotun. Transactional Memory Co-herence and Consistency. In Proc. of the 31st Intl. Symp. on Computer Architecture, Munchen,Germany, June 2004.
[HPS06] Timothy Harris, Mark Plesko, Avraham Shinnar, and David Tarditi. Optimizing MemoryTransactions. In Proc. of the SIGPLAN 2006 Conf. on Programming Language Design and Im-plementation, pages 14-25, Ottawa, ON, Canada, June 2006.
[HLR10] Tim Harris, James R. Larus, and Ravi Rajwar. Transactional Memory (2nd edition), SynthesisLectures on Computer Architecture. Morgan & Claypool, 2010.
[HaD68] E. A. Hauck and B. A. Dent. Burroughs’ B6500/B7500 Stack Mechanism. Proc. of the AFIPSSpring Joint Computer Conf., 32:245-251, 1968.
[HLM03a] Maurice Herlihy, Victor Luchangco, and Mark Moir. Obstruction-Free Synchronization:Double-Ended Queues as an Example. In Proc. of the 23rd Intl. Conf. on Distributed ComputingSystems, Providence, RI, May 2003.
[HLM03b] Maurice Herlihy, Victor Luchangco, Mark Moir, and William N. Scherer III. SoftwareTransactional Memory for Dynamic-sized Data Structures. In Proc. of the 22nd ACM Symp. onPrinciples of Distributed Computing, pages 92-101, Boston, MA, July 2003.
[HeM93] M. Herlihy and J. E. Moss. Transactional Memory: Architectural Support for Lock-Free DataStructures. In Proc. of the 20th Intl. Symp. on Computer Architecture, pages 289-300, San Diego,CA, May 1993. Expanded version available as CRL 92/07, DEC Cambridge Research Laboratory,Dec. 1992.
[HMM96] Mark Horowitz, Margaret Martonosi, Todd C. Mowry, and Michael D. Smith. InformingMemory Operations: Providing Memory Performance Feedback in Modern Processors. In Proc. ofthe 23rd Intl. Symp. on Computer Architecture, Philadelphia, PA, May 1996.
[Inc05] Sun Microsystems Inc. OpenSPARC T2 Core Microarchitecture Specification. July 2005.
[Int] Intel. Intel(R) C++ STM Compiler, Prototype Edition. http://software.intel.com/en-us/articles/intel-c-stm-compiler-prototype-edition/.
[Int06] Intel Corporation. Intel Itanium Architecture Software Developer’s Manual. Revision 2.2, Jan.2006.
[IsS99] Haruna R. Isa and William R. Shockley. A Multi-threading Architecture for Multilevel SecureTransaction Processing. In Proc. of the IEEE Symp. on Security and Privacy, May 1999.
[KEG97] Frans Kaashoek, Dawson Engler, Greg Ganger, Hector Briceno, Russel Hunt, David Mazieres,Tom Pinckney, Robert Grimm, and Ken Mackenzie. Application Performance and Flexibility onExokernel Systems. In Proc. of the 16th ACM Symp. on Operating Systems Principles, St. Malo,France, Oct. 1997.
[KCE92] Eric J. Koldinger, Jeffrey S. Chase, and Susan J. Eggers. Architectural Support for SingleAddress Space Operating Systems. In Proc. of the 5th Intl. Conf. on Architectural Support forProgramming Languages and Operating Systems, pages 175-186, Boston, MA, Oct. 1992.
[KAO05] Poonacha Kongetira, Kathirgamar Aingaran, and Kunle Olukotun. Niagara: A 32-Way Mul-tithreaded SPARC Processor. In IEEE Micro, pages 21-29, Mar.-Apr. 2005.

208
[KCP06] Milind Kulkarni, L. Paul Chew, and Keshav Pingali. Using Transactions in Delaunay MeshGeneration. In Workshop on Transactional Memory Workloads, Ottawa, ON, Canada, June 2006.
[KCH06] Sanjeev Kumar, Michael Chu, Christopher J. Hughes, Partha Kundu, and Anthony Nguyen.Hybrid Transactional Memory. In Proc. of the 11th ACM Symp. on Principles and Practice ofParallel Programming, New York, NY, Mar. 2006.
[Lam05] Christoph Lameter. Effective Synchronization on Linux/NUMA Systems. In Proc. of the 2005Gelato Federation Meeting, 2005.
[Lam71] B. W. Lampson. Protection. In Proc. of the 5th Princeton Symp. on Information Sciences andSystems, pages 437-443, Mar. 1971. Reprinted in ACM SIGOPS Operating Systems Review 8:1(Jan. 1974), pp. 18-24.
[LaL97] James Laudon and Daniel Lenoski. The SGI Origin: A ccNUMA Highly Scalable Server. InProc. of the 24th Intl. Symp. on Computer Architecture, Denver, CO, June 1997.
[LeM08] Yossi Lev and Jan-Willem Maessen. Split Hardware Transaction: True Nesting of TransactionsUsing Best-effort Hardware Transactional Memory. In Proc. of the 13th ACM Symp. on Principlesand Practice of Parallel Programming, Salt Lake City, UT, Feb. 2008.
[Lev84] H. M. Levy. Capability-Based Computer Systems. Digital Press, Bedford, MA, 1984.
[LH10] Xin Li, Michael C. Huang, Kai Shen, and Lingkun Chu. A Realistic Evaluation of MemoryHardware Errors and Software System Susceptibility. In Proc. of the USENIX 2010 TechnicalConf., Jan. 2010.
[Lie93] J. Liedtke. Improving IPC by Kernel Design. In Proc. of the 14th ACM Symp. on OperatingSystems Principles, Ashville, NC, Dec. 1993.
[LT06] Shan Lu, Joseph Tucek, Feng Qin, and Yuanyuan Zhou. AVIO: Detecting Atomicity Violationsvia Access Interleaving Invariants. In Proc. of the 12th Intl. Conf. on Architectural Support forProgramming Languages and Operating Systems, San Jose, CA, Oct. 2006.
[LP08] Shan Lu, Soyeon Park, Eunsoo Seo, and Yuanyuan Zhou. Learning from Mistakes — A Com-prehensive Study on Real World Concurrency Bug Characteristics. In Proc. of the 13th Intl. Conf.on Architectural Support for Programming Languages and Operating Systems, Mar. 2008.
[Mai05] Ken Mai. Design and Analysis of Reconfigurable Memories. Ph. D. dissertation, StanfordUniv., June 2005.
[MSS04] Virendra J. Marathe, William N. Scherer III, and Michael L. Scott. Design Tradeoffs in Mod-ern Software Transactional Memory Systems. In Proc. of the 7th Workshop on Languages, Com-pilers, and Run-time Systems for Scalable Computers, Houston, TX, Oct. 2004.
[MSS05] Virendra J. Marathe, William N. Scherer III, and Michael L. Scott. Adaptive Software Trans-actional Memory. In Proc. of the 19th Intl. Symp. on Distributed Computing, Cracow, Poland, Sept.2005.
[MSH06] Virendra J. Marathe, Michael F. Spear, Christopher Heriot, Athul Acharya, David Eisenstat,William N. Scherer III, and Michael L. Scott. Lowering the Overhead of Software TransactionalMemory. In Proc. of the 1st ACM SIGPLAN Workshop on Transactional Computing, Ottawa, ON,Canada, June 2006. Expanded version available as TR 893, Dept. of Computer Science, Univ. ofRochester, Mar. 2006.
[MaS0.] E. Marcus and H. Stern. Blueprints for high availability. In John Willey and Sons,, 2000.
[MaT02] Jose F. Martınez and Josep Torrellas. Speculative Synchronization: Applying Thread-LevelSpeculation to Explicitly Parallel Applications. In Proc. of the 10th Intl. Conf. on ArchitecturalSupport for Programming Languages and Operating Systems, pages 18-29, San Jose, CA, Oct.

209
2002.
[MSB05] Milo M. K. Martin, Daniel J. Sorin, Bradford M. Beckmann, Michael R. Marty, Min Xu,Alaa R. Alameldeen, Kevin E. Moore, Mark D. Hill, and David A. Wood. Multifacet’s GeneralExecution-driven Multiprocessor Simulator (GEMS) Toolset. In ACM SIGARCH Computer Archi-tecture News, Sept. 2005.
[MAK01] P. E. McKenney, J. Appavoo, A. Kleen, O. Krieger, R. Russel, D. Sarma, and M. Soni. Read-Copy Update. In Proc. of the Ottawa Linux Symp., July 2001.
[McK04] Paul E. McKenney. Exploiting Deferred Destruction: An Analysis of Read-Copy-UpdateTechniques in Operating System Kernels. Ph.D. dissertation, Dept. of Computer Science and En-gineering, Oregon Graduate Institute, July 2004.
[MBS08] Vijay Menon, Steven Balensiefer, Tatiana Shpeisman, Ali-Reza Adl-Tabatabai, Richard L.Hudson, Bratin Saha, and Adam Welc. Practical Weak-Atomicity Semantics for Java STM. InProc. of the 20th ACM Symp. on Parallelism in Algorithms and Architectures, pages 314-325,Munich, Germany, June 2008.
[MTC07] Chi Cao Minh, Martin Trautmann, JaeWoong Chung,, Austen McDonald, Nathan Bronson,Jared Casper, Christos Kozyrakis, and Kunle Olukotun. An Effective Hybrid Transactional MemorySystem with Strong Isolation Guarantees. In Proc. of the 34th Intl. Symp. on Computer Architecture,San Diego, CA, June 2007.
[MCK08] Chi Cao Minh, JaeWoong Chung, Christos Kozyrakis, and Kunle Olukotun. STAMP: Stan-ford Transactional Applications for Multi-Processing. In Proc. of the 2008 IEEE Intl. Symp. onWorkload Characterization, Seattle, WA, Sept. 2008.
[Moi10] Mark Moir. All Short Sentences about Transactional Memory are Wrong! In TransactionalMemory Workshop (TMW) 2010, Apr. 2010.
[MHS09] Daniel Molka, Daniel Hackenberg, Robert Schone, and Matthias S. Muller. Memory Perfor-mance and Cache Coherency Effects on an Intel Nehalem Multiprocessor System. In Proc. of the18th Intl. Conf. on Parallel Architectures and Compilation Techniques, Sep, 2009.
[MBM06] Kevin E. Moore, Jayaram Bobba, Michelle J. Moravan, Mark D. Hill, and David A. Wood.LogTM: Log-based Transactional Memory. In Proc. of the 12th Intl. Symp. on High PerformanceComputer Architecture, Austin, TX, Feb. 2006.
[Mos06] J. Eliot B. Moss. Open Nested Transactions: Semantics and Support. In Proc. of the 4th IEEEWorkshop on Memory Performance Issues, Austin, TX, Feb. 2006. Held in conjunction with HPCA2006.
[MBJ07] Naveen Muralimanohar, Rajeev Balasubramonian, and Norm Jouppi. Optimizing NUCA Or-ganizations and Wiring Alternatives for Large Caches With CACTI 6.0. In Proc. of the 40th Intl.Symp. on Microarchitecture, December 2007.
[MKC07] C. Murphy, G. Kaiser, and M. Chu. Towards in vivo testing of software applications. Techni-cal Report cucs-038-07, Columbia University, 2007.
[NaG09] V. Nagarajan and R. Gupta. ECMon: Exposing Cache Events for Monitoring. In Proc. of the36th Intl. Symp. on Computer Architecture, June 2009.
[NMW02] George C. Necula, Scott McPeak, and Westley Weimer. CCured: type-safe retrofitting oflegacy code. In Proc. of the 29th ACM Symp. on Principles of Programming Languages, 2002.
[NeZ07] Naveen Neelakantam and Craig Zilles. UFO: A General-Purpose User-Mode Memory Protec-tion Technique for Application Use. Technical Report, UIUCDCS-R-2007-2808, Jan 2007.
[NeS07] Nicholas Nethercote and Julian Seward. Valgrind: A Framework for Heavyweight Dynamic

210
Binary Instrumentation. In Proc. of the SIGPLAN 2007 Conf. on Programming Language Designand Implementation, June 2007.
[Org72] E. I. Organick. The Multics System: An Examination of Its Structure. MIT Press, Cambridge,MA, 1972.
[PaF06] Stefano Di Paola and Giorgio Fedon. Subverting Ajax. In Proc. of the 23rd Chaos Communi-cation Congress, 2006.
[Pat10] David Patterson. The Trouble with Multicore. In IEEE Spectrum, July, 2010.
[PHR09] Donald E. Porter, Owen S. Hofmann, Christopher J. Rossbach, Alex Benn, and EmmettWitchel. Operating System Transactions. In Proc. of the 22nd ACM Symp. on Operating SystemsPrinciples, October 2009.
[QLZ05] Feng Qin, Shan Lu, and Yuanyuan Zhou. SafeMem: Exploiting ECC-Memory for DetectingMemory Leaks and Memory Corruption During Production Runs. In Proc. of the 10th Intl. Symp.on High Performance Computer Architecture, Feb. 2005.
[RaG01] Ravi Rajwar and James R. Goodman. Speculative Lock Elision: Enabling Highly ConcurrentMultithreaded Execution. In Proc. of the 34th Intl. Symp. on Microarchitecture, Austin, TX, Dec.2001.
[RaG02] Ravi Rajwar and James R. Goodman. Transactional Lock-Free Execution of Lock-Based Pro-grams. In Proc. of the 10th Intl. Conf. on Architectural Support for Programming Languages andOperating Systems, pages 5-17, San Jose, CA, Oct. 2002.
[RHL05] Ravi Rajwar, Maurice Herlihy, and Konrad Lai. Virtualizing Transactional Memory. In Proc.of the 32nd Intl. Symp. on Computer Architecture, Madison, WI, June 2005.
[RRP07] Hany E. Ramadan, Christopher J. Rossbach, Donald E. Porter, Owen S. Hofmann, AdityaBhandari, and Emmett Witchel. MetaTM/TxLinux: Transactional Memory For An Operating Sys-tem. In Proc. of the 34th Intl. Symp. on Computer Architecture, San Diego, CA, June 2007.
[RRW08] Hany E. Ramadan, Christopher J. Rossbach, and Emmett Witchel. Dependence-Aware Trans-actional Memory for IncreasedConcurrency. In Proc. of the 41ST Intl. Symp. on Microarchitecture,Dec 2008.
[RPA97] Parthasarathy Ranganathan, Vijay S. Pai, Hazim Abdel-Shafi, and Sarita V. Adve. The Inter-action of Software Prefetching with ILP Processors in Shared-Memory Systems. In Proc. of the24th Intl. Symp. on Computer Architecture, Denver, CO, June 1997.
[RLS10] Bogdan F. Romanescu, Alvin R. Lebeck, Daniel J. Sorin, and Anne Bracy. UNified Instruc-tion/Translation/Data (UNITD) Coherence: One Protocol to Rule Them All. In Proc. of the 16thIntl. Symp. on High Performance Computer Architecture, January 2010.
[Rup95] J. Ruppert. A Delaunay Refinement Algorithm for Quality 2-Dimensional Mesh Generation.In Journal of Algorithms, pages 548-555, May, 1995.
[SAJ06] Bratin Saha, Ali-Reza Adl-Tabatabai, and Quinn Jacobson. Architectural Support for SoftwareTransactional Memory. In Proc. of the 39th Intl. Symp. on Microarchitecture, pages 185-196, Dec.2006. Orlando, FL.
[SAH06] Bratin Saha, Ali-Reza Adl-Tabatabai, Richard L. Hudson, Chi Cao Minh, and BenjaminHertzberg. McRT-STM: A High Performance Software Transactional Memory System for a Multi-Core Runtime. In Proc. of the 11th ACM Symp. on Principles and Practice of Parallel Program-ming, pages 187-197, New York, NY, Mar. 2006.
[SYM07] N. Sakran, M. Yuffe, M. Mehalel, J. Doweck, E. Knoll, and A. Kovacs. The Implementationof the 65nm Dual-Core 64b Merom Processor. In Proc. of the Intl. Solid State Circuits Conf., pages

211
106-107, San Francisco, CA, Feb. 2007.
[SYH07] Daniel Sanchez, Luke Yen, Mark D. Hill, and Karu Sankaralingam. Implementing Signaturesfor Transactional Memory. In Proc. of the 40th Intl. Symp. on Microarchitecture, Chicago, IL, Dec.2007.
[SBN97] Stefan Savage, Michael Burrows, Greg Nelson, Patrick Sobalvarro, and Thomas Anderson.Eraser: A Dynamic Data Race Detector for Multithreaded Programs. ACM Trans. on ComputerSystems, 15(4):391-411, Nov. 1997. Earlier version presented at the 16th ACM Symp. on OperatingSystems Principles, Oct. 1997.
[ScS05] William N. Scherer III and Michael L. Scott. Randomization in STM Contention Management(poster paper). In Proc. of the 24th ACM Symp. on Principles of Distributed Computing, Las Vegas,NV, July 2005.
[ScT89] David L. Schleicher and Roger L. Taylor. System Overview of the Application System/400.IBM Systems Journal, 28(3):360-375, 1989.
[SFL94] Ioannis Schoinas, Babak Falsafi, Alvin R. Lebeck, Steven K. Reinhardt, James R. Larus, andDavid A. Wood. Fine-grain Access Control for Distributed Shared Memory. In Proc. of the 6thIntl. Conf. on Architectural Support for Programming Languages and Operating Systems, pages297-306, San Jose, CA, Oct. 1994.
[SCS77] M. D. Schroeder, D. D. Clark, and J. H. Saltzer. The Multics Kernel Design Project. In Proc. ofthe 6th ACM Symp. on Operating Systems Principles, pages 43-56, West Lafayette, IN, Nov. 1977.
[Sco06] Michael L. Scott. Sequential Specification of Transactional Memory Semantics. In Proc. of the1st ACM SIGPLAN Workshop on Transactional Computing, Ottawa, ON, Canada, June 2006.
[SSD07] Michael L. Scott, Michael F. Spear, Luke Dalessandro, and Virendra J. Marathe. DelaunayTriangulation with Transactions and Barriers. In IEEE Intl. Symp. on Workload Characterization,Boston, MA, Sept. 2007. Benchmarks track.
[SSF99] Jonathan S. Shapiro, Jonathan M. Smith, and David J. Farber. EROS: a Fast Capability System.In Proc. of the 17th ACM Symp. on Operating Systems Principles, Charleston, SC, Dec. 1999.
[SMD06] Arrvindh Shriraman, Virendra J. Marathe, Sandhya Dwarkadas, Michael L. Scott, DavidEisenstat, Christopher Heriot, William N. Scherer III, and Michael F. Spear. Hardware Accelerationof Software Transactional Memory. In Proc. of the 1st ACM SIGPLAN Workshop on TransactionalComputing, Ottawa, ON, Canada, June 2006. Expanded version available as TR 887, Dept. ofComputer Science, Univ. of Rochester, Dec. 2005, revised Mar. 2006.
[SSH07] Arrvindh Shriraman, Michael F. Spear, Hemayet Hossain, Sandhya Dwarkadas, and MichaelL. Scott. An Integrated Hardware-Software Approach to Flexible Transactional Memory. In Proc.of the 34th Intl. Symp. on Computer Architecture, San Diego, CA, June 2007. Earlier but expandedversion available as TR 910, Dept. of Computer Science, Univ. of Rochester, Dec. 2006.
[SDS08] Arrvindh Shriraman, Sandhya Dwarkadas, and Michael L. Scott. Flexible Decoupled Transac-tional Memory Support. In Proc. of the 35th Intl. Symp. on Computer Architecture, Beijing, China,June 2008.
[ShD09] Arrvindh Shriraman and Sandhya Dwarkadas. Refereeing Conflicts in Hardware TransactionalMemory. In Proc. of the 2009 ACM Intl. Conf. on Supercomputing, June 2009.
[ShD10] Arrvindh Shriraman and Sandhya Dwarkadas. Sentry: An Auxilliary Memory Access Control.In Proc. of the 37th Intl. Symp. on Computer Architecture, June 2010.
[SBV95] Guri Sohi, Scott Breach, and T. N. Vijaykumar. Multiscalar Processors. In Proc. of the 22ndIntl. Symp. on Computer Architecture, Santa Margherita Ligure, Italy, June 1995.

212
[SMS06] M. F. Spear, V. J. Marathe, W. N. Scherer III, and M. L. Scott. Conflict Detection and Valida-tion Strategies for Software Transactional Memory. In Proc. of the 20th Intl. Symp. on DistributedComputing, pages 179-193, Stockholm, Sweden, Sept. 2006.
[SMP08] Michael F. Spear, Maged M. Michael, and Christoph von Praun. RingSTM: Scalable Trans-actions with a Single Atomic Instruction. In Proc. of the 20th ACM Symp. on Parallelism in Algo-rithms and Architectures, pages 275-284, Munich, Germany, June 2008.
[SDM09] Michael F. Spear, Luke Dalessandro, Virendra Marathe, and Michael L. Scott. A Comprehen-sive Strategy for Contention Management in Software Transactional Memory. In Proc. of the 14thACM Symp. on Principles and Practice of Parallel Programming, Mar. 2009.
[Spe09] Michael F. Spear. Fast Software Transactions. Ph. D. dissertation, Univ. of Rochester, June2009.
[SMS09] Michael Spear, Maged Michael, Michael Scott, and Peng Wu. Reducing Memory OrderingOverheads in Software Transactional Memory. In Proc. of the Intl. Symp. on Code Generation andOptimization, March 2009.
[Sta06] Standard Performance Evaluation Corporation. SPEC CPU06 Benchmarks. Mar. 2006. Avail-able at http://www.spec.org/cpu2006/.
[SCZ00] J. Gregory Steffan, Christopher Colohan, Antonia Zhai, and Todd Mowry. A Scalable Ap-proach to Thread-Level Speculation. In Proc. of the 27th Intl. Symp. on Computer Architecture,Vancouver, BC, Canada, June 2000.
[SSH93] Janice M. Stone, Harold S. Stone, Philip Heidelberger, and John Turek. Multiple Reservationsand the Oklahoma Update. IEEE Parallel and Distributed Technology, 1(4):58-71, Nov. 1993.
[SBL03] Michael M. Swift, Brian N. Bershad, and Henry M. Levy. Improving the Reliability of Com-modity Operating Systems. In Proc. of the 19th ACM Symp. on Operating Systems Principles,Bolton Landing (Lake George), NY, Oct. 2003.
[TKS88] P. J. Teller, R. Kenner, and M. Snir. TLB Consistency on Highly-Parallel Shared-MemoryMultiprocessors. In Proc. of the 21st Hawaii Intl. Conf. on System Sciences, pages 184-192, Kailua-Kona, HI, Jan. 1988.
[TPK09] Sasa Tomic, Cristian Perfumo, Chinmay Kulkarni, Adria Armejach, Adrian Cristal, OsmanUnsal, Tim Harris, and Mateo Valero. EazyHTM, Eager-Lazy Hardware Transactional Memory.In Proc. of the 42nd Intl. Symp. on Microarchitecture, New York, New York, Dec. 2009.
[TrC08] M. Tremblay and S. Chaudhry. A Third-Generation 65nm 16-Core 32-Thread Plus 32-Scout-Thread CMT. In Proc. of the Intl. Solid State Circuits Conf., San Francisco, CA, Feb. 2008.
[Tro10] Trollaxor. Firefox has too many developers. 2010. http://www.trollaxor.com/2009/12/firefox-has-too-many-developers.html.
[TXZ09] Joseph Tucek, Weiwei Xiong, and Yuanyuan Zhou. Efficient online validation with deltaexecution. In Proc. of 14th Intl. Conf. on Architectural Support for Programming Languages andOperating Systems, 2009.
[TAC08] James Tuck, Wonsun Ahn, Luis Ceze, and Josep Torrellas. SoftSig: software-exposed hard-ware signatures for code analysis and optimization. In Proc. of the 13th Intl. Conf. on ArchitecturalSupport for Programming Languages and Operating Systems, Seattle, WA, Mar. 2008.
[VRS07] Guru Venkataramani, Brandyn Roemer, Yan Solihin, and Milos Prvulovic. MemTracker: Ef-ficient and Programmable support for Memory Access Monitoring and Debugging. In Proc. of the13th Intl. Symp. on High Performance Computer Architecture, Feb. 2007.
[VWA09] Haris Volos, Adam Welc, Ali-Reza Adl-Tabatabai, Tatiana Shpeisman, Xinmin Tian, and

213
Ravi Narayanaswamy. NePalTM: design and implementation of nested parallelism for transac-tional memory systems. In Proc. of the 14th ACM Symp. on Principles and Practice of ParallelProgramming, 2009.
[WCW07] Cheng Wang, Wei-Yu Chen, Youfeng Wu, Bratin Saha, and Ali-Reza Adl-Tabatabai. CodeGeneration and Optimization for Transactional Memory Constructs in an Unmanaged Language.In Proc. of the Intl. Symp. on Code Generation and Optimization, San Jose, CA, Mar. 2007.
[WAF07] Thomas F. Wenisch, Anastassia Ailamaki, Babak Falsafi, and Andreas Moshovos. Mecha-nisms for store-wait-free multiprocessors. In Proc. of the 34th Intl. Symp. on Computer Architec-ture, San Diego, CA, June 2007.
[WiS92] J. Wilkes and B. Sears. A Comparison of Protection Lookaside Buffers and the PA-RISCProtection Architecture. HLP-92-55, Hewlett Packard Laboratories, Mar. 1992.
[Wil92] P. R. Wilson. Pointer Swizzling at Page Fault Time: Efficiently and Compatibly SupportingHuge Address Spaces on Standard Hardware. In Proc. of the Intl. Workshop on Object Orientationin Operating Systems, pages 364-377, Paris, France, Sept. 1992.
[WCA02] Emmett Witchel, Josh Cates, and Krste Asanovic. Mondrian Memory Protection. In Proc. ofthe 10th Intl. Conf. on Architectural Support for Programming Languages and Operating Systems,pages 304-316, San Jose, CA, Oct. 2002.
[WSC10] Benjamin P. Wood, Adrian Sampson, Luis Ceze, and Dan Grossman. Composable Specifica-tions for Structured Shared-Memory Communication. In OOPSLA 2010 Conf. Proc., 2010.
[YBM07] Luke Yen, Jayaram Bobba, Michael R. Marty, Kevin E. Moore, Haris Valos, Mark D. Hill,Michael M. Swift, and David A. Wood. LogTM-SE: Decoupling Hardware Transactional Mem-ory from Caches. In Proc. of the 13th Intl. Symp. on High Performance Computer Architecture,Phoenix, AZ, Feb. 2007.
[YoL08] Richard M. Yoo and Hsien-Hsin S. Lee. Adaptive Transaction Scheduling for TransactionalMemory Systems. In Proc. of the 20th ACM Symp. on Parallelism in Algorithms and Architectures,pages 169-178, Munich, Germany, June 2008.
[ZKD08] Nickolai Zeldovich, Hari Kannan, Michael Dalton, and Christos Kozyrakis. Hardware En-forcement of Application Security Policies. In Proc. of the 8th Symp. on Operating Systems Designand Implementation, Dec. 2008.
[ZLL04] Pin Zhou, Wei Liu, Fei Long, Shan Lu, Feng Qin, Yuanyuan Zhou, Sam Midkiff, and JosepTorrellas. AccMon: Automatically Detecting Memory-Related Bugs via Program Counter-basedInvariants. In Proc. of the 37th Intl. Symp. on Microarchitecture, Dec. 2004.
[ZQL04] Pin Zhou, Feng Qin, Wei Liu, Yuanyuan Zhou, and Josep Torrellas. iWatcher: Efficient Archi-tecture Support for Software Debugging. In Proc. of the 31st Intl. Symp. on Computer Architecture,Munchen, Germany, June 2004.
[ZiB06] Craig Zilles and Lee Baugh. Extending Hardware Transactional Memory to Support Non-Busy Waiting and Non-Transactional Actions. In Proc. of the 1st ACM SIGPLAN Workshop onTransactional Computing, Ottawa, ON, Canada, June 2006.
[10a] The Rochester Software Transactional Memory Runtime. 2010.www.cs.rochester.edu/research/synchronization/rstm/.
[10b] Apache Project. In http://April.apache.org/, 2010.
[10c] Cool Tools. In http://cooltools.sunsource.net/, 2010.