an efficient cost-driven selection tool for microsoft sql server surajit chaudhurivivek narasayya...
TRANSCRIPT

An Efficient Cost-Driven Selection Tool for
Microsoft SQL Server
Surajit Chaudhuri Vivek Narasayya
Indian Institute of Technology Bombay
CS632 Course seminar by
Iyengar Suresh, CSE MTECH1

2
➢Indexes and materialized views are very important in physical design of a database.
➢They can significantly improve performance if used in the right manner.
➢The tool has been implemented in Microsoft SQL Server 7.0 and subsequent versions.
➢The technique developed was a part of the AutoAdmin project .
Introduction

3
➢ Make database systems self-tuning and self-administering.
➢ Enabling databases to track the usage of their systems and to gracefully adapt to application requirements.
➢ Databases actively auto-tunes itself to be responsive to application needs.
➢ Research work: Automating index and view selections, index merging, 'what-if' indexes, automating statistics management for Query Optimizers and many more.
AutoAdmin project

4
Indexes can be chosen based on
➢ Table columns
➢ Workload
➢ In harmony with the optimizer
How do we choose the indexes ?

5

6
Terminologies
Indexable column : Columns in a query that are potentially useful for indexing
Admissible index : Index that is on one or more (in case of a multi-column index) indexable columns
of the query.
Admissible index : An index that is an admissible index for (for a workload) one or more queries in the workload.

7
Cost evaluation
Basic method can is given M configurations and Q queries in the workload, optimize M*Q queries.
Atomic configuration C: For some query in the workload there is a possible execution of the query by the query engine that usesall indexes in C.
For select/update queries, for a non-atomic configuration C, there exists an atomic configuration C
i such that
Cost (Q, C) = Min {(Cost(Q, Ci)}

8
Cost evaluation contd...
For an insert/delete query, for a non-atomic configuration C
The cost can be divided into:
a) Cost of selection
b) Cost of updating the table and the indexes used for selection
c) Cost of updating indexes that do not affect the selection cost.

9
Cost evaluation contd...
Cost evaluation module can identify atomic configuration heuristically.
a) Restriction on the number of indexes per tableb) Restriction on the number of indexes referenced per query.
This can restrict the search space.
The technique implemented by the authors includes two indexes per table and also two indexes referenced per query. This is called single join atomic configuration.

10
Candidate Index Selection for a given workload
The number of admissible indexes for a given workload is very large.
Determine the best configuration for each query independently and then use these configurations for the further step.
Intuition: An index which is not a part of the best configuration for a single query is unlikely to be a part of best configuration for the entire workload.
This method is called query-specific-best-configuration candidate index selection.

11
1. For workload W that consists of n queries, generate 'n' workloads
each consisting of one query each, where Wi = { Q
i}
2. For each workload Wi, we use the set of indexable columns
Ii of the query in Wi as starting candidate indexes.
3. Let Ci be the configuration picked by index selection tool for W
i,
i.e., Ci = Enumerate (I
i,W
i).
4. The candidate index set for W is the union of all Ci's .
Candidate index selection

12
Problem with this approach...
Consider a query Q with indexable columns T1.C1 and T2.C2 such that the best configuration for Q is T1.C1 only.
Also, there is an insert query in the workload on T1.C1 with a high cost.
The enumeration phase would not consider T1.C2.
So, a general strategy can be consider even the second best configuration or the first 'k' best configurations.

13
The candidate index selection does perform well. Why ?
➢ Indexes that are part of 'next' best configuration of a query may appear as the best configuration for another query in the workload.
➢ Also, most of the indexes in the second best configuration do find their way into the best configuration.

14
Now we have 'n' candidate indexes and we want to pick k indexes.
A naïve method is to enumerate all the subsets.
However this is not practical as for realistic values of n and k. (e.g. n=40 and k=10.)
Enumeration

15
Greedy(m,k) enumeration approach
1. Let S = the best m index configuration using the naive enumeration algorithm. If m = k then exit.
2. Pick a new index I such that Cost (S U {I}, W) <= Cost(S U(I’}, W) for any choice of I’ != I
3. If Cost (S U {I}) >= Cost(S) then exit Else S = S U (I}
4. If size(S) = k then exit
5. Go to 2
A small value of 'm' leads to near optimal results.

16
Why Greedy algorithm performs well ??
Interaction between indexes.
For example, merge join with two clustered indexes.
If one of the indexed was picked during the 'm' phase of the above algorithm, its likely that the other will be picked during the 'k' phase as it will reduce the overall cost.

17
Multi-column Index Generation
➢ Considering all the multi-column indexes is not possible.
➢ This paper introduces an iterative approach for taking into account multi-column indexes of increasing width.
➢ First step is to find admissible two column indexes. This set along with the winning one-column indexes becomes the input for the second iteration.
➢ The strategy followed is for a two-column index to be desirable, a single column index on its leading column is also desirable.

18
Variants of this strategy
MC-LEAD : In (a,b), 'b' need not be an winning single column index
MC-ALL : Both a and b need to be winning single column indexes.

19
Experimental results

20

21
BEST-CONF-1: The winning indexBEST-CONF-2: The first two winning indexes.

22

23

24
➢Selecting candidate indexes
➢An algorithm for configuration enumeration
➢Multi-column index
Can these ideas be applicable to materialized views ??
Summary

25
Automated Selection of Materialized Views and Indexes for SQL Databases
Sanjay Agrawal Surajit Chaudhuri Vivek Narasayya

26
Indexes and Materialized views
➢Indexes can be considered as special materialized views.
➢Views have rich structure.
➢Space of potentially interesting materialized views for a given workload is very large.
➢The technique proposed deals with automate selection of materialized views in presence of:
a) Workload b) Indexes
c) Indexes on materialized views d) In sync with the optimizer

27
Indexed Views in SQL server
When a clustered index is created on the view, SQL Server immediately allocates storage space to store the results of the view.
Indexed View definition cannot contain the following
a) TOP b) DISTINCT c) MIN, MAX, COUNT, STDEV, VARIANCE, AVG d) Another view e) UNION f) Subqueries, outer joins, self joins g) Cannot include order by in view definition
and some more...
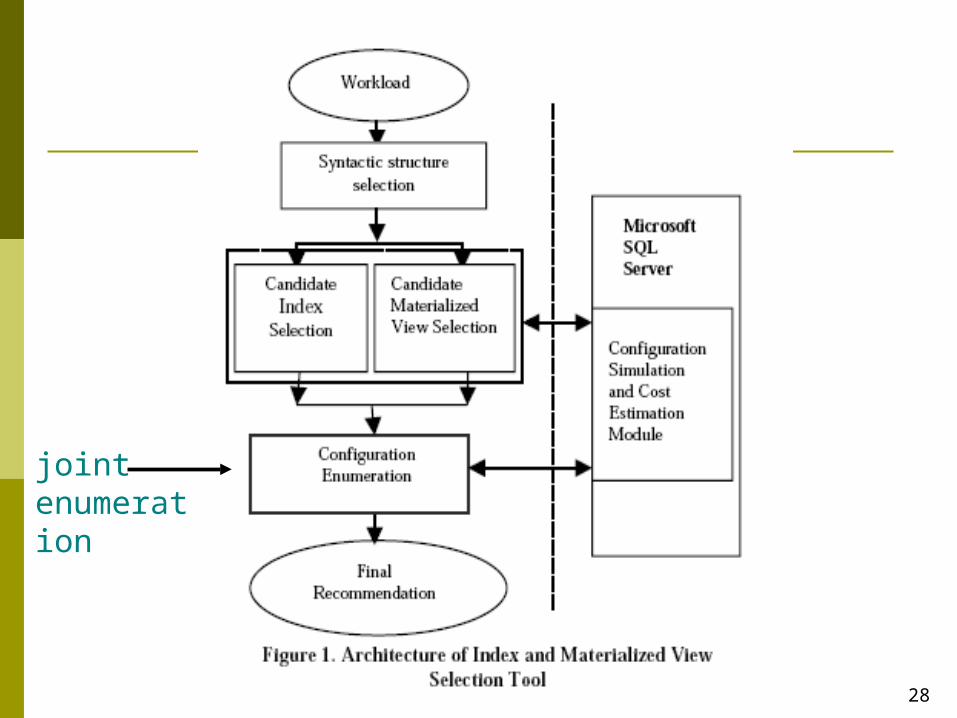
28
joint enumeration

29
Examples
Example 1. Workload consisting of 1000 queries of the form:
SELECT l_returnflag, l_linestatus, SUM(l_quantity) FROM lineitem WHERE l_shipdate BETWEEN <Date1> and <Date2> GROUP BY l_returnflag, l_linestatus
(Assume that each of the 1000 queries has different constants for <Date1> and <Date2> ).
MV that can service all 1000 queries
SELECT l_shipdate, l_returnflag, l_linestatus,SUM(l_quantity) FROM lineitem GROUP BY l_shipdate,l_returnflag, l_linestatus

30
Example 2: Workload of 100 queries whose total cost is 10,000 units. Let T be a table-subset that occurs in 25 queries whose combined cost is 50 units.
Then even if we considered all syntactically relevantmaterialized views on T, the maximum possible benefit ofthose materialized views for the workload is 0.5%.
Also, the number of rows matters. For example, tables lineitem and orders may have 6 million and 1.5 million rows respectively, but tables nation and region may be very small (25 and 5 rows respectively).

31
SQL Server 7.0 : Indexes Only, Thorough, 49%
SQL Server 2000 : Indexes Only, Fast, 37%
SQL Server 2000 : Indexes Only, Medium, 39%
SQL Server 2000 : Indexes and Indexed Views, Thorough, 79%
The Index Tuning Wizard in SQL Server 2000 supports the ability to randomly sample queries from a workload and restrict tuning to the sampled queries
Features(tuning mode, performance benefit)

32
Features
➢Index Usage Report
➢Query Cost Report
➢View-Table Relations Report
➢Workload Analysis Report
➢Maximum columns per index
➢Maximum space for the recommendation

33
Other References
AutoAdmin: Self-Tuning and Self-Administering Databaseshttp://research.microsoft.com/dmx/autoadmin/default.asp
➢Index tuning wizard http://www.microsoft.com/technet/prodtechnol/sql/2000/maintain/tunesql.mspx
➢Indexed Views in SQL server http://www.sqlteam.com/item.asp?ItemID=1015

34
Extra slides

35
Candidate materialized view selection
1) From the large space of all possible table-subsets forthe workload, we arrive at a smaller set of interestingtable-subsets.
2) Based on these, a) Propose a set of materialized views for each query in the workload b) From this set we select a configuration that is best for that
query.
3) View merging

36
Properties of Merged View
1. All queries answered using either of the parent views should be answerable using the merged view.
2. Prevent the merged view from becoming too large as compared to its parents based upon some threshold.

37
Metrics used
TS-Cost(T) = total cost of all queries in the workload (for the current database) where table-subset T occurs.
If all queries in the workload referenced the tables A, B, C and D together, then using the TS-Cost(T) metric, the table-subsets T1 = {A,B} would have the same importance as the table-subset T2 = {C,D}.
TS-Weight(T) = sum[ Cost(Qi)* (sum of sizes of tables in T)/
(sum of sizes of all tables referenced in Qi))
The summation is only over queries in the workload where T occurs.

38
Then, propose MV on these table sets. For a given query, take the view with minimum cost.

39
R= Materialized views returned by enumeration
While( | R | > 1) M' = Views returned by MergeView on each pair of R If M'={} return (R-M) R= R U M' For each view in M' remove both its parents
End While
Return (R-M)
Merging Views