adaptive locks: combining transactions and locks for efficient concurrency takayuki usui et all
Post on 22-Dec-2015
221 views
TRANSCRIPT

Adaptive Locks: Combining Transactions and Locks for
efficient Concurrency
Takayuki Usui et all

Introduction.
• Computing is more multi processor oriented.• Explicit multi threading is the most direct way to
program parallel system (monitor style programming).
• Flip side – – Interference between threads.– Hard to detect conditions such as deadlocks and
races.– Hard to get fine grained critical sections and course
grained critical sections reduces concurrency

Alternatives
• Transactional Memory.• Advantages
– Higher level programming model. No need to know which locks to acquire.
– No need of fine grained delineation of critical sections.
• Disadvantages– Livelocks, slower progress.– High Overhead.

Idea
• Try to combine the advantages of locks and transactional memory.
• How do the authors propose we do that?
• Adaptive Locks

What are adaptive locks.
• Synchronization mechanism combining locks and transactions.
• Programmer can specify critical sections which are executed as either mutex locks or atomically as transactions.

How?
atomic (l1)
{ code }
Is equivalent to
atomic{ code } when executing in
transactional mode or
lock (l1); code ; unlock(l1).

How do we decide if it should run as a transaction or as a mutex lock.• Let us throw out some terminology.
• Nominal contention.
• Actual contention.
• Transactional overhead.
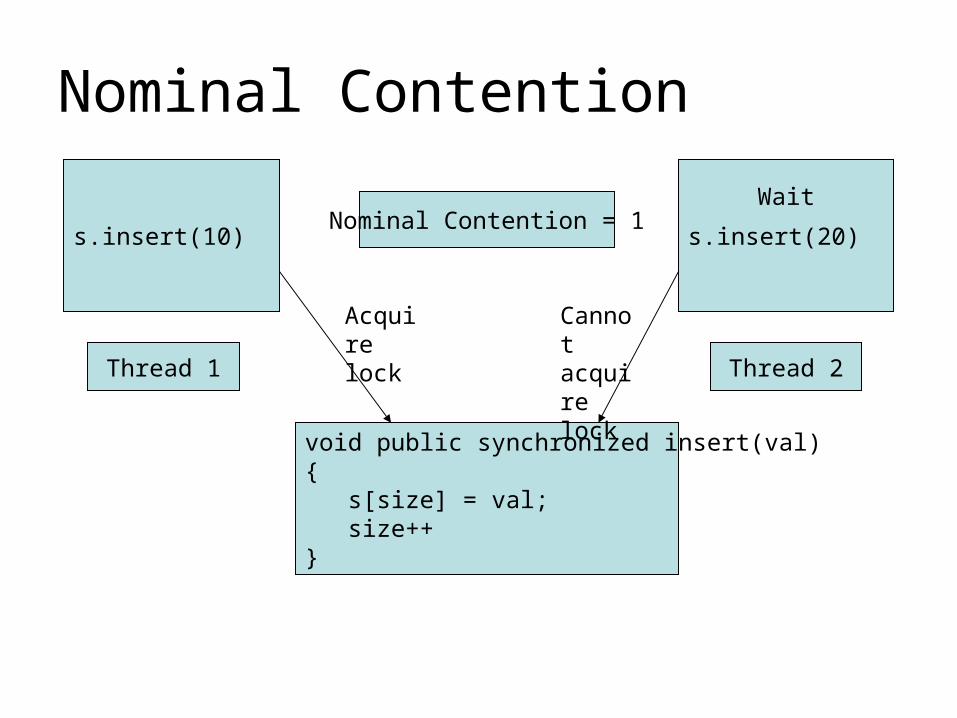
Nominal Contention
s.insert(10) s.insert(20)
void public synchronized insert(val){ s[size] = val; size++}
Acquire lock
Cannot acquire lockThread 1 Thread 2
Nominal Contention = 1Wait
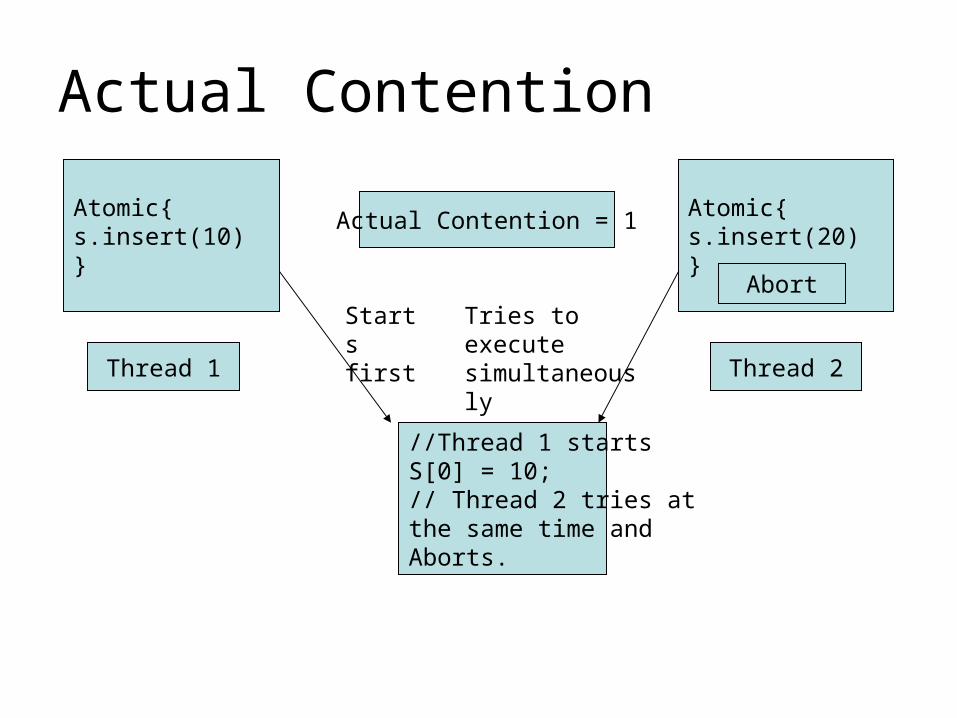
Actual Contention
Atomic{s.insert(10)}
Atomic{s.insert(20)}
//Thread 1 startsS[0] = 10;// Thread 2 tries atthe same time andAborts.
Starts first
Tries to execute simultaneously
Thread 1 Thread 2
Actual Contention = 1
Abort

Transactional Overhead.
• How much overhead is incurred when the critical section executes in transactional mode versus mutex mode.

How are these terms helpful
• The authors use these concepts to dynamically calculate which mode the critical section should be executed in.
• Wait .. Are locks and transactions interchangeable?
• No they are not .. But we will discuss how with certain high level correctness criteria this can be handled.

Contributions of this paper.
• Efficient and effective implementation of adaptive locks.– Trading some accuracy to make it faster and
reduce overhead.
• Define conditions under which transaction and mutex locks exhibit equivalent behavior.
• Evaluate adaptive locks with micro and macro benchmarks.

Programming with adaptive locks
• Adaptive locks introduce syntax for a labeled atomic sections.
al_t lock1;
atomic (lock1){
// critical section
}

Some rules for using adaptive locks
• Programmer has the burden to make sure that if all the instances of atomic(lock1) are replaced by mutex blocks (mutex mode) then the program is still correct.
• Programmer also has the burden to make sure that if all the critical sections are executed as transactions (transactional mode) then the program still runs correctly.

More rules ..
• All critical sections associated with the same lock should execute in the same mode.
• Mode of nested adaptive lock should be the same as that of the surrounding lock.
• Mode switching can also be done either for correctness (I/O operations = mutex mode) or for performance.

Cost benefit analysis
• Remember the terms that we talked about before– Nominal Contention– Actual Contention– Transactional Overhead
• The authors use these terms to come up with the decision making logic.

And the winner is
a.o >= c
• If this inequality holds then mutex mode is preferable.
• All these factors are computed separately for all of the locks dynamically.

Implementation and Optimizations
• Extension of the C language.
• Compiler translates it into 2 object code versions. One for mutex version and one for transactional version.
• Adaptive locks replace regular lock acquisition.
• The adaptive lock state is packed into a memory word.

What is contained in the state
• Number of threads executing in transactional mode = thrdsInStmMode
• Whether lock is in mutex mode = mutex mode
• Whether mutex lock is held = lockheld
• Whether we are currently in the process of changing modes = transition.
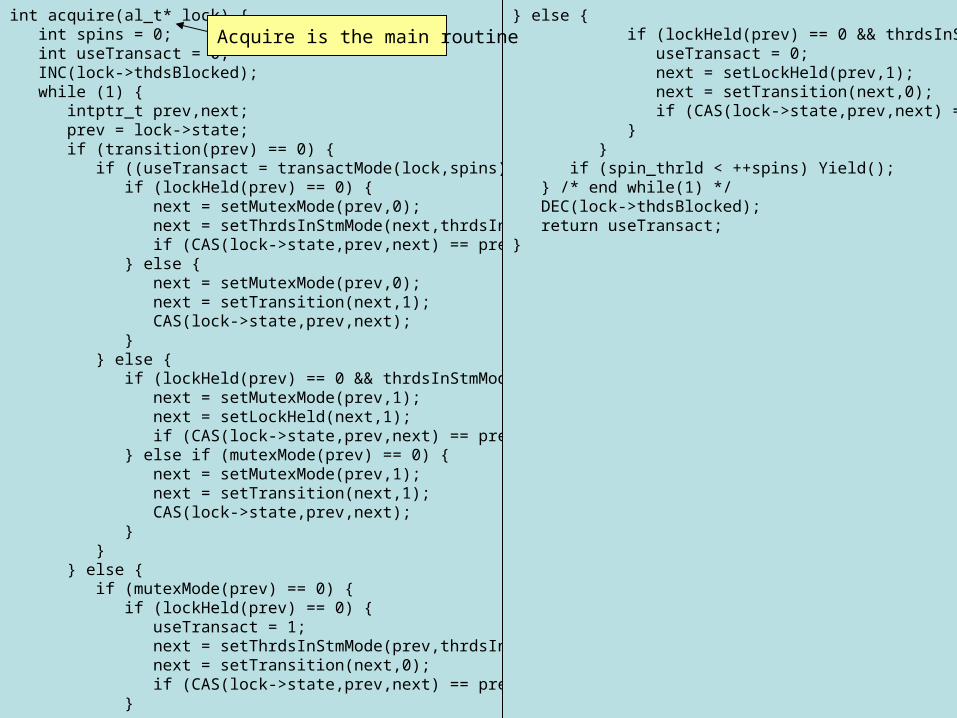
int acquire(al_t* lock) { int spins = 0; int useTransact = 0; INC(lock->thdsBlocked); while (1) { intptr_t prev,next; prev = lock->state; if (transition(prev) == 0) { if ((useTransact = transactMode(lock,spins))) { if (lockHeld(prev) == 0) { next = setMutexMode(prev,0); next = setThrdsInStmMode(next,thrdsInStmMode(next)+1); if (CAS(lock->state,prev,next) == prev) break; } else { next = setMutexMode(prev,0); next = setTransition(next,1); CAS(lock->state,prev,next); } } else { if (lockHeld(prev) == 0 && thrdsInStmMode(prev) == 0) { next = setMutexMode(prev,1); next = setLockHeld(next,1); if (CAS(lock->state,prev,next) == prev) break; } else if (mutexMode(prev) == 0) { next = setMutexMode(prev,1); next = setTransition(next,1); CAS(lock->state,prev,next); } } } else { if (mutexMode(prev) == 0) { if (lockHeld(prev) == 0) { useTransact = 1; next = setThrdsInStmMode(prev,thrdsInStmMode(prev)+1); next = setTransition(next,0); if (CAS(lock->state,prev,next) == prev) break; }
} else { if (lockHeld(prev) == 0 && thrdsInStmMode(prev) == 0) { useTransact = 0; next = setLockHeld(prev,1); next = setTransition(next,0); if (CAS(lock->state,prev,next) == prev) break; } } if (spin_thrld < ++spins) Yield(); } /* end while(1) */ DEC(lock->thdsBlocked); return useTransact;}
Acquire is the main routine

Performance Optimizations
• Threads need to update variables that keep count and calculate the various statistics for adaptive reasoning.
• Remember a (actual contention).• Instead of updating it all the time, threads do regular
writes to it. Then a shared update changes the global value.
• Of course this can give rise to write-write races but the authors seem to believe that sporadic inaccuracies in the statistics are not significant.
• Also to note, inaccuracies in statistics will not result in wrong program execution but choosing the other mode to execute the critical sections.

Performance Optimizations contd ..
• Atomic increment and decrement of variable locks->thdsBlocked is also avoided.
• The atomic increment and decrement of this variable is done only if there is real spinning else it is not done. This is contrary to the earlier code which was shown.

Performance Optimizations contd ..
int acquire(al_t* lock) { int spins = 0; ... INC(lock->thdsBlocked); while (1) { ... // try to acquire, // break if successful if (spin_thrld < ++spins) Yield(); } DEC(lock->thdsBlocked); ...}
int acquire(al_t* lock) { int spins = 0; ... while (1) { ... // try to acquire, // break if successful if (spins == 0) INC(lock->thdsBlocked); if (spin_thrld < ++spins) Yield(); } if (0 < spins) DEC(lock->thdsBlocked); ...}

Performance Optimizations contd ..
• o (optimization overhead) depends on shared memory updates.
• To keep the estimate of o realistic but inexpensive, – It is calculated at regular intervals.– The number of accesses to memory for that
transaction are noted and multiplied with a static estimate of much each transaction would take.

Reality Check ..
• But hey is interchanging between locks and transactions legal. Are they equivalent?
• Answer: No, they are not equivalent.• To be more specific, it depends on the
type of STM system. TL2 which is the STM used by the authors differentiates between locks and transactions when they are used interchangeably.

No more boring bullets. We are not MBA students
Thread 1 commits andIt removes the first item.
Thread 2 commits butDoes not copy the value to memory
Thread 2 eventually Update the value
By that time, r1 and r2Will see stale values.

So how can we fix this
• We can make a simple observation from this which is that there should be a lock for all the shared memory locations.
• Every access to these locations should be done with the lock held.
• This is the standard lockset well-formedness criteria for multi threaded programs.

Some results
• Tested with micro and macro benchmarks
• Tested with red black trees (STM), splay trees (mutex locks), fine grained hash tables – adaptive locks were as good as the better concurrency mechanism.
• Tested with (Stanford Transactional Applications for Multi-Processing).
Questions?