a tighter weave – how yarn changes the data quality game
TRANSCRIPT

Grab some coffee and
enjoy the
pre-show
banter
before the top of the
hour!

H T Technologies of 2014

HOST: Eric Kavanagh

THIS YEAR is…

ANALYST:
David Loshin President, Knowledge Integrity
ANALYST:
David Raab Principal, Raab Associates
GUEST:
George Corugedo CTO, RedPoint Global TH
E LINE UP

INTRODUCING
David Loshin

© 2014 Knowledge Integrity, Inc. www.knowledge-integrity.com
(301) 754-6350
7
Big Data Quality
David Loshin Knowledge Integrity, Inc.
www.knowledge-integrity.com
7

A Conventional Approach to “Big Data Quality” p Immediate thoughts:
n “lots of data” means “lots of errors” means “lots of cleansing” n “big data quality” = prepending “big” onto “data quality”
p However, conventional processes associated with manufacturing quality are less applicable in a big data world:
© 2014 Knowledge Integrity, Inc. www.knowledge-integrity.com
(301) 754-6350
8
DQ Directive Challenge for Repurposing
“Process management” Business function-based data development intends data for specific purposes
“Customer requirements”
Desire to assert customer requirements at point of creation or acquisition conflicts with expectation to use data in different ways
“Supplier management” Often, the source of the data is way beyond the organization’s administrative control or is completely unknown
“Control” There is opacity regarding the data flow processes and lineage, so control is limited to execution at the point of use
“Continuous improvement”
Transitory nature of streamed data

Drivers of Quality of Big Data
p Rampant data repurposing n For data scientists, the data sets are demanded in raw form, free
from the shackles of dimensional models n Simultaneously, analytical results need to be integrated with
existing data warehouse and business intelligence architecture p Content in addition to structure
n Scanning and parsing text must go beyond validation against known formats to ascertain meaning in context
p Value of discrete pieces information varies in relation to content type, precision, timeliness, overall volume
p Information Utility n The onus of ensuring usability (and “quality”) is on the data
consumer, not the data producer
© 2014 Knowledge Integrity, Inc. www.knowledge-integrity.com
(301) 754-6350
9

Assessing Big Data Quality and Utility
Temporal Consistency
Completeness
Precision Consistency
Currency
Unique Identifiability
Timeliness
Semantic Consistency
✔
✔
✔
✔
✔
✔
✔
© 2014 Knowledge Integrity, Inc. www.knowledge-integrity.com
(301) 754-6350
10

Characteristics of Applications Suited for Hadoop
p Adapting existing solutions to improve performance
p Algorithms or solutions exhibit one or more of these characteristics: n Large data volumes n Significant data variety n Performance impacted by data
latency n Computational performance
throttled n Amenable to parallelization
p Enabling or improving solutions whose requirements exceed existing resource capabilities
© 2014 Knowledge Integrity, Inc. www.knowledge-integrity.com
(301) 754-6350
11

Leveraging Performance Computing for Data Quality
p Hadoop’s parallel and distributed computing enables scalability in deploying key data quality tasks
p Each of these activities exhibits the characteristics of applications amenable to Hadoop: n Data validation that uses data quality and business rules for
validating consistency, completeness, timeliness, etc. n Identity Resolution that uses advanced techniques for entity
recognition and identity resolution from structured and unstructured sources
n Data cleansing, standardization, enhancement that applies parsing and standardization rules within context of end-use business analyses and applications
n Inspection, Monitoring, and Remediation to empower data stewards to monitor quality and take proper actions for ensuring big data utility
© 2014 Knowledge Integrity, Inc. www.knowledge-integrity.com
(301) 754-6350
12

Check Out These Resources!
p www.knowledge-integrity.com p www.dataqualitybook.com p If you have questions,
comments, or suggestions, please contact me David Loshin 301-754-6350 [email protected]
© 2014 Knowledge Integrity, Inc. www.knowledge-integrity.com
(301) 754-6350
13

INTRODUCING
David Raab


What’s New about Big Data?
• Comprehensive details on all customers • Near-‐immediate updates • High-‐speed detecJon, assessment, response
• (Almost) always reachable

What’s It Good For?
• PersonalizaJon • MarkeJng measurement • Real Jme bidding • Web prospecJng

What Are the Challenges? (Technical)

What Are the Challenges? (Business)

INTRODUCING
George Corugedo

YARN Changes the Data Quality Game August 2014

22 © RedPoint Global Inc. 2014 Confidential
Overview – Challenges to Adoption
• Severe shortage of MR skilled resources
• Very expensive resources and hard to retain
• Inconsistent skills lead to inconsistent results
• Under uJlizes exisJng resources
• Prevents broad leverage of investments across enterprise
Skills Gap
• A nascent technology ecosystem around Hadoop
• Emerging technologies only address narrow slivers of funcJonality
• New applicaJons are not enterprise class
• Legacy applicaJons have built short term capabiliJes
Maturity & Governance
• Data is not useful in its raw state, it must be turned into informaJon
• Benefit of Hadoop is that same data can be used from many perspecJves
• Analysts must now do the structuring of the data based on intended use of the data
Data Into InformaJon

23 © RedPoint Global Inc. 2014 Confidential
Overview - What is Hadoop/Hadoop 2.0
Lower cost scaling
No need for structure
Ease of data capture
Hadoop 1.0 • All operaJons based on Map Reduce
• Intrinsic inconsistency of code based soluJons
• Highly skilled and expensive resources needed
• 3rd party applicaJons constrained by the need to generate code
Hadoop 2.0 • IntroducJon of the YARN:
“a general-‐purpose, distributed, applicaJon management framework that supersedes the classic Apache Hadoop MapReduce framework for processing data in Hadoop clusters.”
• Mature applicaJons can now operate directly on Hadoop
• Reduce skill requirements and increased consistency

24 © RedPoint Global Inc. 2014 Confidential
RedPoint Data Management on Hadoop
ParJJoning AM / Tasks
ExecuJon AM / Tasks Data I/O Key / Split
Analysis
Parallel SecJon (UI)
YARN
MapReduce

25 © RedPoint Global Inc. 2014 Confidential
Key features of RedPoint Data Management
Master Key Management
ETL & ELT Data Quality
Web Services IntegraJon
IntegraJon & Matching
Process AutomaJon & OperaJons
• Profiling, reads/writes, transformaJons
• Single project for all jobs
• Cleanse data • Parsing, correcJon • Geo-‐spaJal analysis
• Grouping • Fuzzy match
• Create keys • Track changes • Maintain matches over Jme
• Consume and publish • HTTP/HTTPS protocols • XML/JSON/SOAP formats
• Job scheduling, monitoring, noJficaJons
• Central point of control
All func(ons can be used on both TRADITIONAL and BIG DATA
Creates clean, integrated, ac/onable data – quickly, reliably and at low cost

26 © RedPoint Global Inc. 2014 Confidential
RedPoint Functional Footprint
Monitoring and Management Tools
AMBARI
MAPREDUCE
REST
DATA REFINEMENT
HIVE PIG
HTTP
STREAM
STRUCTURE
HCATALOG (metadata services)
Query/Visualization/ Reporting/Analytical
Tools and Apps
SOURCE DATA
- Sensor Logs - Clickstream - Flat Files - Unstructured - Sentiment - Customer - Inventory
DBs
JMS Queue’s
Files Fil
es Files
Data Sources
RDBMS
EDW
INTERACTIVE
HIVE Server2
LOAD
SQOOP
WebHDFS
Flume
NFS
LOAD SQOOP/Hive
Web HDFS
YARN
� � � � � � � � � �
� � � � � � � � � � �
� � � � � � � � � � �
� �
� �
� n
HDFS
1 � � � � � � � � � � � �
�
� � � � � � � � � � � � �
� � � � � � � � � � � � �
� � � � � � � � � � � � �

27 © RedPoint Global Inc. 2014 Confidential
RedPoint
Benchmarks – Project Gutenberg
Map Reduce Pig
Sample MapReduce (small subset of the entire code which totals nearly 150 lines): public static class MapClass extends Mapper<WordOffset, Text, Text, IntWritable> { private final static String delimiters = "',./<>?;:\"[]{}-=_+()&*%^#$!@`~ \\|«»¡¢£¤¥¦©¬®¯±¶·¿"; private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(WordOffset key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer itr = new StringTokenizer(line, delimiters); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
Sample Pig script without the UDF: SET pig.maxCombinedSplitSize 67108864 SET pig.splitCombination true A = LOAD '/testdata/pg/*/*/*'; B = FOREACH A GENERATE FLATTEN(TOKENIZE((chararray)$0)) AS word; C = FOREACH B GENERATE UPPER(word) AS word; D = GROUP C BY word; E = FOREACH D GENERATE COUNT(C) AS occurrences, group; F = ORDER E BY occurrences DESC; STORE F INTO '/user/cleonardi/pg/pig-count';
>150 Lines of MR Code ~50 Lines of Script Code 0 Lines of Code
6 hours of development 3 hours of development 15 min. of development
6 minutes runtime 15 minutes runtime 3 minutes runtime
Extensive optimization needed User Defined Functions required prior to running script
No tuning or optimization required

28 © RedPoint Global Inc. 2014 Confidential
Attributes of Information
RELEVANT InformaJon must pertain to a specific problem. General data must be connected to reveal relevance of the informaJon.
COMPLETE ParJal informaJon is oien worse than no informaJon. ParJal informaJon frequently leads to worse conclusions than if no data had been used at all.
ACCURATE This one is obvious. In a context like health care, inaccurate data can be fatal. Precision is required across all applicaJons of informaJon.
CURRENT As data ages, it becomes less accurate. MulJple research studies by Google and others show the decay in the accuracy of analyJcs as data becomes stale.
ECONOMICAL There has to be a clear cost benefit. This requires work to idenJfy the realizable benefit of informaJon but this is also what rives the use if successful

29 © RedPoint Global Inc. 2014 Confidential
Big Data Can Become Big Information

30 © RedPoint Global Inc. 2014 Confidential
Big Data Can Become Big Information
" IngesJon of all data available from any source, format, cadence, structure or non-‐structure
" ELT and data refinement
" GeospaJal processing and geocoding
" Data profiling, lineage and metadata management
" Data parsing, quality, validaJon and hygiene
" IdenJty resoluJon and persistent keying
" EnJty profile management
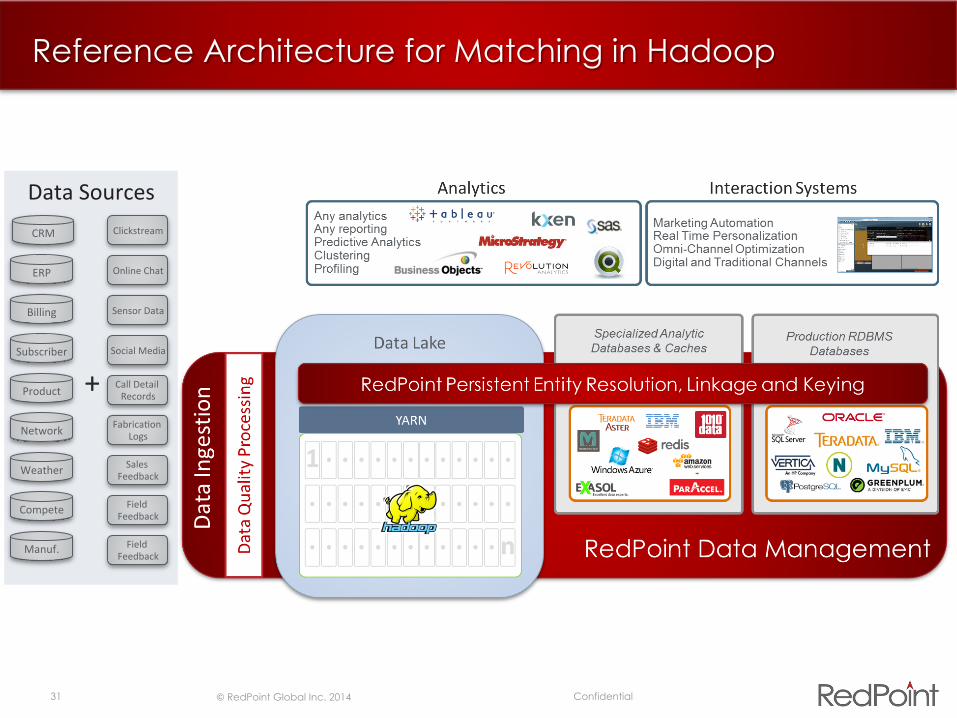
31 © RedPoint Global Inc. 2014 Confidential
Reference Architecture for Matching in Hadoop
Data Sources CRM
ERP
Billing
Subscriber
Product
Network
Weather
Compete
Manuf.
Clickstream
Online Chat
Sensor Data
Social Media
Call Detail Records
FabricaJon Logs
Sales Feedback
Field Feedback
Field Feedback
+

32 © RedPoint Global Inc. 2014 Confidential
Key Points to Cover Today
" Broad functionality across data processing domains
" Validated ease of use, speed, match quality and party data superiority
" Hadoop 2.0/YARN certified – 1 of first 17 companies to do so
" Not a repackaging of Hadoop 1.0 functionality. RedPoint Data Management is a pure YARN application (1 of only 2 in the initial wave of certifications)
" Building a complex job in RPDM takes a fraction of the time that it takes to write the same job in Map Reduce and none of the coding or java skills.
" Big functional footprint without touching a line of code
" Design model consistent with data flow paradigm
" RPDM has a “Zero-Footprint” install in the Hadoop cluster
" The same interface and functionality is available for both structured and unstructured databases. Thus it is seamless to work across both from a users perspective.
" Data quality done completely within the cluster


The Archive Trifecta: • Inside Analysis www.insideanalysis.com • SlideShare www.slideshare.net/InsideAnalysis • YouTube www.youtube.com/user/BloorGroup
THANK YOU!