11 1 anysp: anytime anywhere anyway signal processing mark woh 1, sangwon seo 1, scott mahlke...
TRANSCRIPT

11
1
AnySP: Anytime Anywhere Anyway Signal Processing
Mark Woh1, Sangwon Seo1, Scott Mahlke1,Trevor Mudge1,
Chaitali Chakrabarti2, Krisztian Flautner3
University of Michigan – ACAL1
Arizona State University2
ARM, Ltd.3

22
2
University of Michigan - ACAL
The Old Mobile PhoneThe Modern Mobile Phone
2
Video Recording
Video Editing
Higher Data Rates
Photos From - http://www.engadget.com/2009/06/10/iphone-3g-s-supports-opengl-es-2-0-but-3g-only-supports-1-1/http://www.apple.com/iphone
3D Rendering
Advanced Image Processing
• Future phones are becoming more complex• Richer applications require much more requirements
• How do phones handle this now?

33
3
University of Michigan - ACAL
Inside Today’s Smart Phones
3
Inside the OMAP3430 Application Processor
Inside the X-Gold 608 (Representation of QCOM)
• Modern phones are looking like Frankenchips!
• Some cores unused and functionality duplicated

44
4
University of Michigan - ACAL
Cost for Multi-System Support
Supporting multiple systems is reserved for the most expensive phones Cost is in supporting all the systems that may or may not be used at once
4
Programmable Unified Architectures Provide
Lower Cost Faster Time to Market Support for Multiple Applications (Current and Future) Bug Fixes After Manufacturing
So where do we start?
Data gathered from- Ramacher, U. 2007. Software-Defined Radio Prospects for Multistandard Mobile Phones. Computer 40, 10 (Oct. 2007)- Finchelstein, D.F.; Sze, V.; Sinangil, M.E.; Koken, Y.; Chandrakasan, A.P., "A low-power 0.7-V H.264 720p video decoder," Solid-State Circuits Conference, 2008. A-SSCC '08.

55
5
University of Michigan - ACAL
Power/Performance Requirements for Multiple Systems
5
Different applications have different power/performance characteristics!
We need to design keeping each application in mind!
(Not GPP but Domain Specific Processor)
1
10
100
1000
10000
0.1 1 10 100
Better
Pow
er Efficiency
1 Mops/mW
10 Mops/mW100 Mops/mW
1000 Mops/mW
SODA(65nm)
SODA (90nm)
TI C6X
Imagine
VIRAM Pentium M
IBM Cell
Pe
rfo
rma
nce
(G
op
s)
Power (Watts)
3G Wireless
4G Wireless
Mobile HDVideo

66
6
The Applications
Is there anything we can learn from the applications themselves?
6

77
7
University of Michigan - ACAL
H.264 Basics
7
Inverse Transform
Standard Basis Patterns
Residual Data
5
3 2
Basis Coefficients
“Past” FramesCurrentFrame
Future Frames
Motion Compensation
Form Prediction
ReconstructedMacroblock
Current Uncoded Block
Dec
od
ed B
lock
Decoded Block
Prediction Based on Neighbors
Intra-Prediction
ReconstructedMacroblock
Deblocking FilterModules
Entropy decoder
Inverse Transform
MotionCompensation
Intra Prediction
Deblocking Filter
Algorithms
Context-adaptive VLD
4x4 integer kernel
Power Profiling*
Half: 6-tap filterQuarter: 6-tap / bilinear filterEighth: 4-tap filter
Directional spatial prediction
In-loop adaptive filter
4%
29%
10%
34%
Misc Kernels 23%
T.-A. Liu, T.-M. Lin, S. -Z. Wang, et al. “A low-power dual-mode video decoder for mobile applications,” IEEE Communications Magazine, volume 44, issue 8, pp.119-126, Aug. 2006.

88
8
University of Michigan - ACAL
4G Wireless Basics
Three kernels make up the majority of the work FFT – Extract Data from Signals
STBC – Combine Data into More Reliable Stream
LDPC – Error Correction on Data Stream
8
Ant A/D
FFTSymbol Timing / Guard Detect
Channel Estimator
MIMODecoder
(STBC)
Channel Decoder(LDPC)
Recovered Data
Ant D/A IFFTGuard Insertion
Channel Encoder(LDPC)
S/PTransmitted
Data
Modulator
Demodulator

99
9
University of Michigan - ACAL
Mobile Signal Processing Algorithm Characteristics
9
Algorithms have different SIMD widths From very large to very small
Though SIMD width varies all algorithms can exploit it Large percentage of work can be SIMDized
Larger SIMD width tend to have less TLP
SIMD comes at a cost!•Register File Power
•Data Movement/Alignment CostSIMD architectures have to deal with this!

1010
10
University of Michigan - ACAL
Traditional SIMD Power Breakdown
Register File Power consumes a lot of power in traditional 32-wide SIMD architecture
SODA WCDMAMEM3%
REG37%
ALU+MULT11%
CONTROL38%
INTERCONNECT2%
SCALAR PIPE9%
MEM
REG
ALU+MULT
CONTROL
INTERCONNECT
SCALAR PIPE

1111
11
University of Michigan - ACAL
Register File Access
11
Many of the register file access do not have to go back to the main register file
Lots of power wasted on unneeded register file access!

1212
12
University of Michigan - ACAL
Instruction Pair Frequency
12
Like the Multiply-Accumulate (MAC) instruction there is opportunity to fuse other instructions
A few instruction pairs (3-5) make up the majority of all instruction pairs!
a) Intra- prediction and Deblocking Filter Combined
Instruction Pair Frequency1 multiply-add 26.71%2 add-add 13.74%3 shuffle-add 8.54%4 shift right-add 6.90%5 subtract-add 6.94%6 add-shift right 5.76%7 multiply-subtract 4.00%8 shift right-subtract 3.75%9 add-subtract 3.07%
10 Others 20.45%
b) LDPC
Instruction Pair Frequency1 shuffle-move 32.07%2 abs-subtract 8.54%3 move-subtract 8.54%4 shuffle-subtract 3.54%5 add-shuffle 3.54%6 Others 43.77%
c) FFT
Instruction Pair Frequency1 shuffle-shuffle 16.67%2 add-multiply 16.67%3 multiply-subtract 16.67%4 multiply-add 16.67%5 subtract-mult 16.67%6 shuffle-add 16.67%

1313
13
University of Michigan - ACAL
Data Alignment Problem!
H.264 Intra-prediction has 9 different prediction modes Each prediction mode requires a specific permutation
13
B C D
A B C D B C D A B C D A B C D
A B C D
A A A A B B B B C C C C D D D D
A B C D
A B C D B C D C
E
E D E
F G
GF D E F
A
A B C D E F G H I J
A B C D G H I JG H I J A B C D
A B C D E F G
A
A B C D E F G H I J
A B C D E F G H I J
A B C D E F G H I J
K L
K L
A B B C C D DD D D DE F F G G
CDE EF FG GHI J JK KLI
CE F G H I J KI J K L D E FD
F F FEG G HH I D E G C D E F0 1 2 3
4 5 6 7
8 9 10 11
12 13 14 15
16
164
4
16x16 luma MBprediction modes for each 4x4 block
a b c d
e f g h
i j k l
m n o p
I
J
K
L
A B C DX
Traditional SIMD machines take too long or cost too much to do this
Good news – small fixed number patterns per kernel
Intra-Prediction

1414
14
University of Michigan - ACAL
Summary
Conclusion about 4G and H.264 Lots of different sized parallelism
From 4 wide to 96 wide to 1024 wide SIMD
Which means many different SIMD widths need to be supported
Very short lived values
Lots of potential for instruction fusings
Limited set of shuffle patterns required for each kernel

1515
15
AnySP Design
15
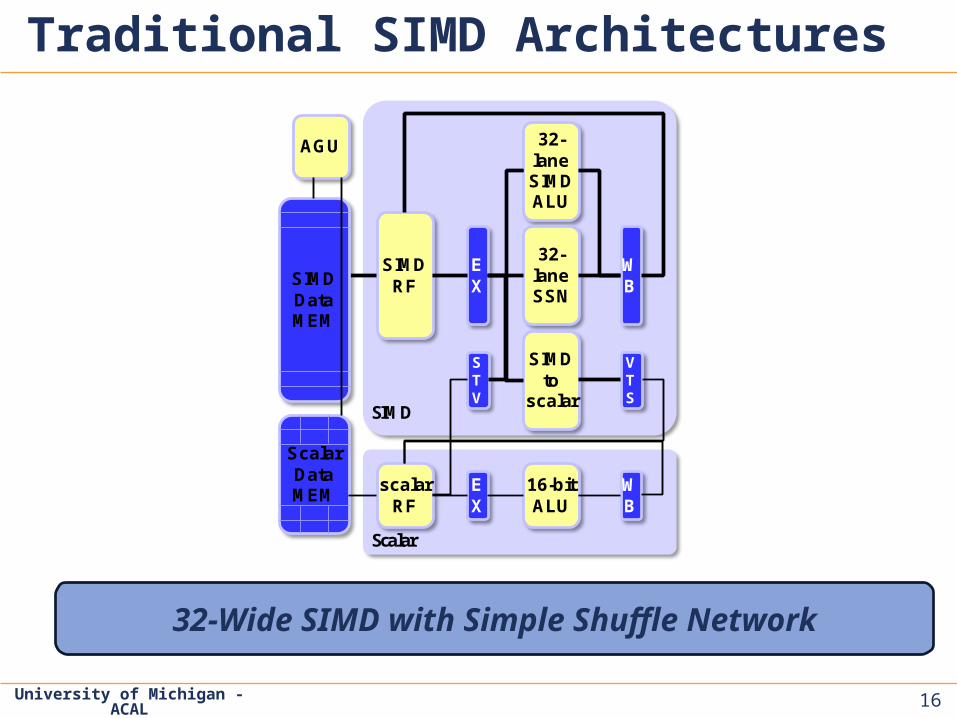
1616
16
University of Michigan - ACAL
Traditional SIMD Architectures
16
32-laneSIMDALU
SIMDRF
32-laneSSN
SIMDto
scalar
EX
WB
STV
VTS
scalarRF
16-bitALU
EX
WB
SIMDDataMEM
ScalarDataMEM
SIMD
Scalar
AGU
32-Wide SIMD with Simple Shuffle Network
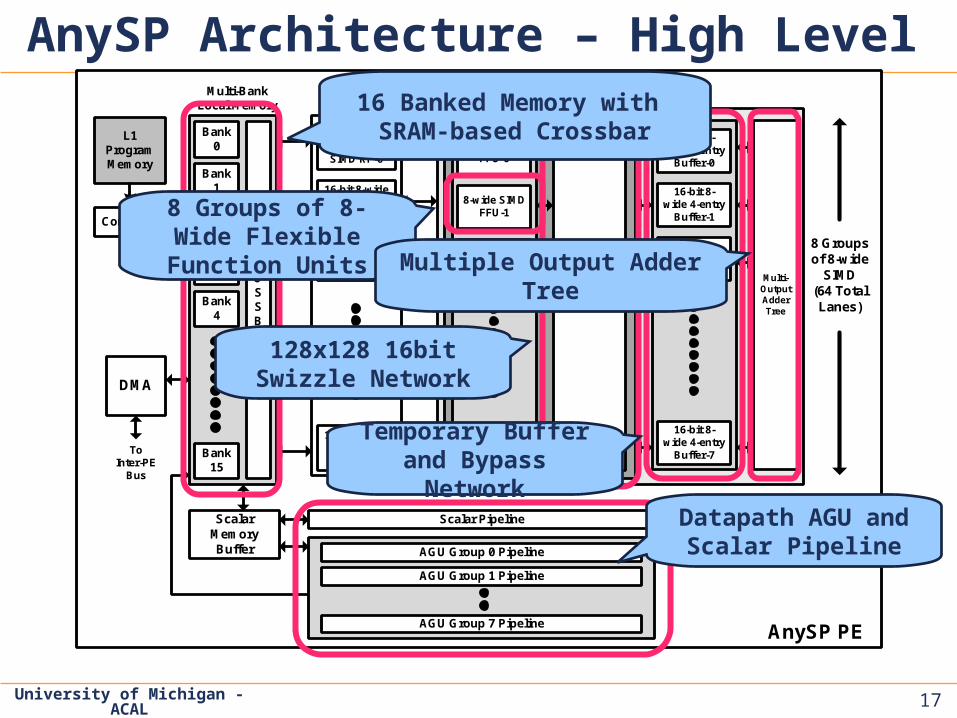
1717
17
University of Michigan - ACAL
CROSSBAR
Scalar Pipeline
Bank 0
Bank 1
Bank 2
Bank 15
L1ProgramMemory
Controller
Bank 3
Bank 4
16-bit 8-wide 16 entry
SIMD RF-0
16-bit 8-wide 16 entry
SIMD RF-1
16-bit 8-wide 16 entry
SIMD RF-2
16-bit 8-wide 16 entry
SIMD RF-7
Scalar Memory Buffer
Multi-SIMD Datapath
AGU Group 0 Pipeline
AGU Group 7 Pipeline
AGU Group 1 Pipeline
Multi-Bank Local Memory
DMA
To Inter-PE
Bus
8 Groups of 8-wide
SIMD(64 Total Lanes)
8-wide SIMD FFU-0
8-wide SIMDFFU-1
8-wide SIMDFFU-2
8-wide SIMD FFU-7
SwizzleNetwork
16-bit 8-wide 4-entry
Buffer-0
16-bit 8-wide 4-entry
Buffer-1
16-bit 8-wide 4-entry
Buffer-2
16-bit 8-wide 4-entry
Buffer-7
Multi-Output Adder Tree
AnySP PE
AnySP Architecture – High Level
17
8 Groups of 8-Wide Flexible Function
Units
128x128 16bit Swizzle Network
16 Banked Memory with SRAM-based Crossbar
Multiple Output Adder Tree
Temporary Buffer and Bypass Network
Datapath AGU and Scalar Pipeline

1818
18
University of Michigan - ACAL
Multi-Width Support
18
16-bit 8-wide 16 entry
SIMD RF-0
16-bit 8-wide 16 entry
SIMD RF-1
16-bit 8-wide 16 entry
SIMD RF-2
16-bit 8-wide 16 entry
SIMD RF-7
Multi-SIMD Datapath
AGU Group 0
AGU Group 7
AGU Group 1
8-wide SIMD FFU-0
8-wide SIMDFFU-1
8-wide SIMDFFU-2
8-wide SIMD FFU-7
SwizzleNetwork
16-bit 8-wide 4-entry
Buffer-0
16-bit 8-wide 4-entry
Buffer-1
16-bit 8-wide 4-entry
Buffer-2
16-bit 8-wide 4-entry
Buffer-7
Multi-Output Adder Tree
CROSSBAR
Bank 0
Bank 1
Bank 2
Bank 15
Bank 3
Bank 4
Multi-Bank Local Memory
16-bit 8-wide 16 entry
SIMD RF-3
8-wide SIMDFFU-3
16-bit 8-wide 4-entry
Buffer-3
AGU Group 2
AGU Group 3
Normal 64-Wide SIMD mode – all lanes share one AGU
16-bit 8-wide 16 entry
SIMD RF-0
16-bit 8-wide 16 entry
SIMD RF-1
16-bit 8-wide 16 entry
SIMD RF-2
16-bit 8-wide 16 entry
SIMD RF-7
Multi-SIMD Datapath
AGU Group 0
AGU Group 7
AGU Group 1
8-wide SIMD FFU-0
8-wide SIMDFFU-1
8-wide SIMDFFU-2
8-wide SIMD FFU-7
SwizzleNetwork
16-bit 8-wide 4-entry
Buffer-0
16-bit 8-wide 4-entry
Buffer-1
16-bit 8-wide 4-entry
Buffer-2
16-bit 8-wide 4-entry
Buffer-7
Multi-Output Adder Tree
CROSSBAR
Bank 0
Bank 1
Bank 2
Bank 15
Bank 3
Bank 4
Multi-Bank Local Memory
16-bit 8-wide 16 entry
SIMD RF-3
8-wide SIMDFFU-3
16-bit 8-wide 4-entry
Buffer-3
AGU Group 2
AGU Group 3
16-bit 8-wide 16 entry
SIMD RF-0
16-bit 8-wide 16 entry
SIMD RF-1
16-bit 8-wide 16 entry
SIMD RF-2
16-bit 8-wide 16 entry
SIMD RF-7
Multi-SIMD Datapath
AGU Group 0
AGU Group 7
AGU Group 1
8-wide SIMD FFU-0
8-wide SIMDFFU-1
8-wide SIMDFFU-2
8-wide SIMD FFU-7
SwizzleNetwork
16-bit 8-wide 4-entry
Buffer-0
16-bit 8-wide 4-entry
Buffer-1
16-bit 8-wide 4-entry
Buffer-2
16-bit 8-wide 4-entry
Buffer-7
Multi-Output Adder Tree
CROSSBAR
Bank 0
Bank 1
Bank 2
Bank 15
Bank 3
Bank 4
Multi-Bank Local Memory
16-bit 8-wide 16 entry
SIMD RF-3
8-wide SIMDFFU-3
16-bit 8-wide 4-entry
Buffer-3
AGU Group 2
AGU Group 3
Each 8-wide SIMD Group works on different memory locations of the same 8-wide code – AGU Offsets

1919
19
University of Michigan - ACAL
AnySP FFU Datapath
19
Flexible Functional Unit allows us to
1.Exploit Pipeline-parallelism by joining two lanes together2.Handle register bypass and the temporary buffer3.Join multiple pipelines to process deeper subgraphs4.Fuse Instruction Pairs

2020
20
AnySP Results
20

2121
21
University of Michigan - ACAL
Simulation Environment Traditional SIMD architecture comparison
SODA at 90nm technology
AnySP Synthesized at 90nm TSMC
Power, timing, area numbers were extracted
Performance and Power for each kernel was generated using synthesized data on in-house simulator
4G – based on a NTT DoCoMo 4G test setup
H.264 – 4CIF@30fps
21

2222
22
University of Michigan - ACAL
AnySP Speedup vs SIMD-based Architecture
For all benchmarks we perform more than 2x better than a SIMD-based architecture
22
0.0
0.5
1.0
1.5
2.0
2.5Baseline 64-Wide Multi-SIMD Swizzle Network Flexible Functional Unit Buffer + Bypass
No
rma
lized
Sp
eed
up
FFT 1024ptRadix-2
FFT 1024ptRadix-4
STBC LDPC H.264Intra
Prediction
H.264Deblocking
Filter
H.264Inverse
Transform
H.264Motion
Compensation

2323
23
University of Michigan - ACAL
AnySP Energy-Delay vs SIMD-based Architecture
More importantly energy efficiency is much better!
23
0.0
0.2
0.4
0.6
0.8
1.0
No
rma
lize
d E
ne
rgy
-De
lay SIMD- based Architecture AnySP
FFT 1024ptRadix-2
FFT 1024ptRadix-4
STBC LDPC H.264Intra
Prediction
H.264Deblocking
Filter
H.264Inverse
Transform
H.264Motion
Compenstation

2424
24
University of Michigan - ACAL
PE
System
Total
Components Units
SIMD Data Mem (32KB)SIMD Register File (16x1024bit)SIMD ALUs, Multipliers, and SSN
SIMD Pipeline+Clock+Routing
Intra-processor InterconnectScalar/AGU Pipeline & Misc.
ARM (Cortex-M3)Global Scratchpad Memory (128KB)
Inter-processor Bus with DMA
90nm (1V @300MHz)
4444
44
111
AreaAreamm2
Area%
9.76 38.78%3.17 12.59%4.50 17.88%1.18 4.69%
0.94 3.73%1.22 4.85%
0.6 2.38%1.8 7.15%1.0 3.97%
25.17 100%
Est.65nm (0.9V @ 300MHz) 13.1445nm (0.8V @ 300MHz) 6.86
4G + H.264 DecoderPower
mWPower
%
102.88 7.24%299.00 21.05%448.51 31.58%233.60 16.45%
93.44 6.58%134.32 9.46%
2.5 <1%10 <1%
1.5 <1%
1347.03 100%
1091.09862.09
SIMD Buffer (128B)SIMD Adder Tree
44
0.82 3.25%0.18 <1%
84.09 5.92%10.43 <1%
AnySP Power Breakdown
We estimate that both H.264 and 4G wireless can be done in under 1 Watt at 45nm
24

2525
25
University of Michigan - ACAL
Conclusion & Future Work Conclusion
We have presented an example architecture that could possibly meet the requirements of 100Mbps 4G and HD video on the same platform Under the power budget and meeting the performance at 45nm
Future and Ongoing Work Application-specific language
Larger class of algorithms for AnySP
Better utilization of resources for non-parallel kernels
Speedup sequential parts
25

2626
26
The End
26