1 xml indexing techniques 1.requirements 2.dataguide and variation 3.index fabric 4.adaptative path...
TRANSCRIPT

1
XML Indexing Techniques
1. Requirements
2. Dataguide and Variation
3. Index Fabric
4. Adaptative Path Index
5. Node Numbering scheme
6. Compact Structural Summary
7. Conclusion

2
Requirements
XML Queries involve navigating data using regular path expressions.(e.g., XPath) /Livre//Auteur[@specialite="informatique"]) Accessing all elements with same name string. Ancestor-descendant relationship between
elements. Content based access on values included in text.

3
Index Types
Structural index Accessing all elements of given name Ancestor-descendant and parent-child
relationship between elements
Content index Accessing elements containing given keywords Supporting most text search functionalities

4
Classical Content Index
Classically based on inverted lists
For each term, gives the doc.ID + localization
Several variations allows different search types
Offset, Relative, Proximity Generally stored in a B+-
Tree to optimize search for a given word
Size is an important issue Memory and Disk
(word, localization) Fixed entry (word repeated)
(word, Frequency, (localization)*)
Variable length entry
Words Localization
- t1 : doc1-100, doc1-300, doc3-200, …
- t2 : doc2-30, doc4-70, …
- t3 : doc4-87, doc5-754, …

5
Problem with XML
Support of element addressing
Doc.ID should include NodeId (Xpath) + Offset
Index size becomes very large
XPath are long Support of typed data
Integer, float, simple types of XML schema
Requires classical indexes for certain elements
Query processing Structural joins Text search Exact search
Support of updates Incremental updates
would be a plus

6
Evaluation Criteria
Identifiers Per node or per document
Descendant/Ancestor Search By join algo. By graph traversal By OID comparison
Keyword Search By element scan By B-tree traversal
Update Incremental
Index size Entry number Entry size
7
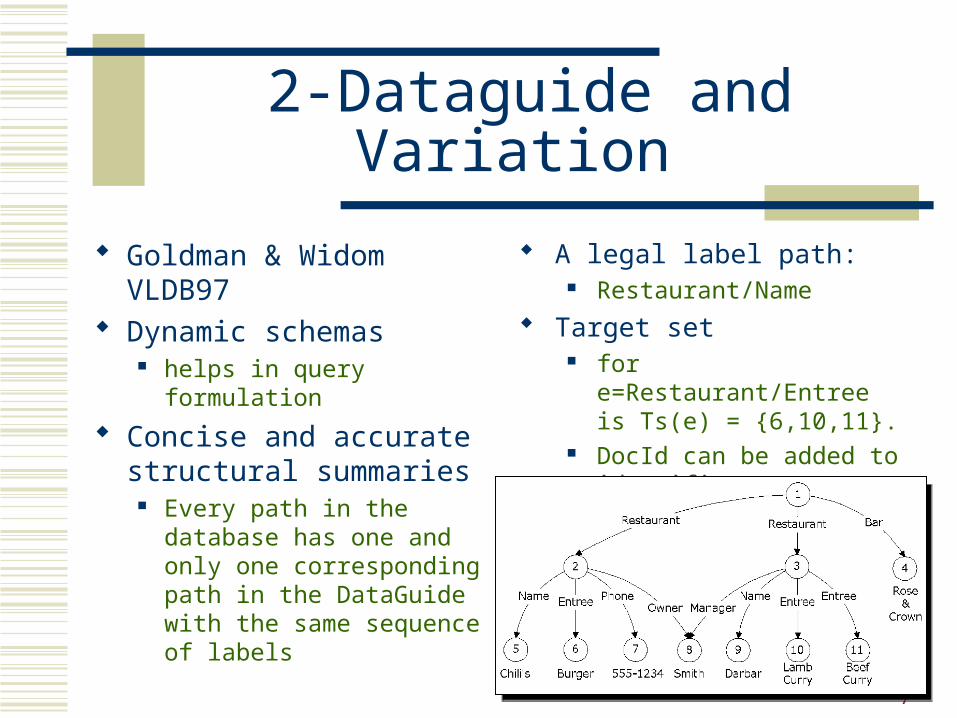
2-Dataguide and Variation
Goldman & Widom VLDB97
Dynamic schemas helps in query formulation
Concise and accurate structural summaries
Every path in the database has one and only one corresponding path in the DataGuide with the same sequence of labels
A legal label path: Restaurant/Name
Target set for e=Restaurant/Entree is Ts(e)
= {6,10,11}. DocId can be added to
identifiers

8
Dataguide Principle
To achieve conciseness a DataGuide describes every
unique label path of a source exactly once.
To ensure accuracy a DataGuide encodes no
label path that does not appear in the source.
And for convenience a DataGuide itself be an
object (OEM or XML).
2,3 4
5,9 6,10,11 7 8 8
Targeted dataguide

9
Dataguide Evaluation
Identifier One per node
Descendant/Ancestor Search By graph traversal
Keyword Search By element scan
Update Insertion is incremental Deletion is complex
Index size Entry number : Linear for tree; can be exponential in number of DB nodes Entry size : number of elements for a path

10
T-Index
[Milo & Suciu, LNCS 1997] T-index stands for Template-index A path template t has the form
T1 x1 T2 x2 … Tn xn where each Ti is either a regular path expression or one
of the following two place holders P (any Path) and F (any Formula)
//restaurant/ x P y /Address/City z F u A query path q is obtained from t by instantiating:
P by any path ; F by any formula

11
Principle
T-index indexes all sequences of objects connected by a sequence of path expressions defined by a template.
Particular cases : 1-index indexes = template any path P
Indexes all objects reachable through an arbitrary path expression P from a root:
two nodes are equivalent (same entry) if the set of paths into them from the root is the same.
1-index is a non-deterministic version of the strong data guide 2-index indexes = template P x P
all pairs of objects connected by an arbitrary path expression P

12
Building a T-index
Group objects into equivalence classes containing objects that are indistinguishable w.r.t to a class of paths defined by a path template
Finer equivallence classes are more efficient to construct using bi-simulation
Construct a non deterministic automaton states represent the equivalence classes transitions correspond to edges between objects in those classes.
T-index can be used to answer queries of more general forms than the template

13
3-Adaptative Path Index (APEX)
Adaptative Path Index for XML [Chung et.al. SIGMOD 2002]
Summarize paths that appear frequently in query workload
Maintain all paths of length 1 Efficient for partial match paths Incremental update of index

14
APEX details
Each node has an identifier (nid) Required paths for indexing ({label}+some
composed paths) APEX = Graph (structural summary) + hash tree
(incoming required paths to nodes of Graph) Hash tree is used to find nodes of graph for given
label path, also for incremental update Determine frequently used path from query
workload using sequential pattern mining

15
APEX Example
APEX Hash tree and Graph
XML data structure

16
APEX Evaluation
Identifiers One per node
Descendant/Ancestor Search Hash tree access if required or graph traversal or join
Keyword Search Not supported
Update Insertion is incremental
Index size (two structures) Entry number : Linear in number of nodes Entry size : number of elements for a path

17
4-Index Fabric
[Cooper et al. .A Fast Index for Semistructured Data.. VLDB, 2001]
Extension of dataguide for text search Keeps all label paths starting from the root Encode each label path with data value as a string Use efficient index for strings to store it (Patricia trie)
Perform queries on keywords for elements as string search
Does not keep information on non-terminal nodes

18
Patricia Trié
Trié : Key Value A Patricia trie is a simple form of compressed trie which merges single child nodes with their parents
More efficient for long keys (non-common postfix in one node)
Trie = A tree for storing strings in which there is one node for every common prefix. The strings are stored in extra leaf nodes.

19
Exemple
Doc 1:<invoice><buyer><name>ABC Corp</name><address>1 Industrial
Way</address></buyer><seller><name>Acme Inc</name><address>2 Acme
Rd.</address></seller><item count=3>saw</item><item count=2>drill</item></invoice>
Doc 2: <invoice><buyer><name>Oracle Inc</name><phone>555-1212</phone></buyer><seller><name>IBM Corp</name></seller><item><count>4</count><name>nail</name></item></invoice>

20
Patricia Trie

21
Search on Paths
Example of queries: /invoice/buyer/name/[ABC Corp] /invoice/buyer//[ABC Corp]
A key lookup operator search for the path key corresponding to the path expression.
If path expands to infinite number of tags start by using a prefix key lookup operator, then navigate through children to check the rest

22
Fabric Evaluation
Identifiers One per document
Descendant/Ancestor Search As string search; do not keep order of elements
Keyword Search By Patricia trie leaves if expanded; value index otherwise
Update Insertion is incremental Deletion is complex
Index size (index stored with document) Entry number : Linear for tree Entry size : number of elements for a path

23
5-Node Numbering Scheme
Used for indexing elements Node Identifier (NID) element The NID aims at replacing structural joins by
simple function computation: check parent & ancestor relationships
is_parent(NID1,NID2), is_ancestor(NID1,NID2) determine parent & children
get_parent(NID1), get_children(NID1)

24
Virtual nodes (1)
[Lee & Yoo Digital Libraries 99] Document structure mapped on a k-ary tree Node identifier assigned according to the level-
order tree traversalparent(i) = (i-2)/k + 1child(i,j) = k(i-1) + j + 1

25
Virtual nodes (2)
NID can be used to address elements in index of elements
Only certain nodes (e.g., leaves) have to be indexed as parent nodes can be determined by computation
Problems: arity of tree – may be variable and large determination of real existence of parent/child update when arity increases ?

26
XML trees node pre/post numbering
[Dietz82] Identification of nodes
Identifier = preorder rank||postorder rank
X ancestor of Y <=> pre(X) < pre(Y) and
post(X) > post(Y)
Example 1<5 and 7>3 => (1,7)
ancestor (5,3)
(1,7)
(2,4)
(3,1) (4,2) (5,3)
(6,6)
(7,5)

27
Interval encoding
[Li&Moon VLDB 2001] Identify each node by a pair of
numbers <order, size> as follows:
For a tree node y of parent x: order(x) < order(y) order(y)+size(y) =< order(x) +
size(x) For two sibling nodes x and y, if
x is the predecessor of y in preorder traversal then
order(x) + size(x) < order(y)
(1,100)
(10,30)
(11,5) (17,5)(25,5)
(41,10)
(45,5)
Size keeps space for updates

28
Relative Region Coordinates (1)
[Kha & Yoshikawa IEEE Data Engin. 2001] A RRC of a node n of an XML tree is a pair [sp-
sn,sp-en] of addresses in the region of parent, i.e., relative to parent start
Child
Parent
s
e

29
Relative Region Coordinates (2)
Absolute region coordinate (ARC) Relative to root begin (from byte Nth to Mth) Allow to extract the XML data Can be derived from RRCs of parents and self:
Begin = (parentsself)s –(k-1) End = (parents)s +e(self)–(k-1)
Advantages Updates are kept local to a region
To access parent-child efficiently A B-tree like structure is maintained (à la Natix).

30
Xyleme
Generate a form of dataguide per cluster Generalized DTD
Manage a label and value index (full index) Keep document ID and element ID Two forms of element ID:
Bit structured scheme: structure positionPrefix-postfix scheme: left-deep traversal
Stores XML DOM trees in pages NATIX (Mannheim Univ.) technology

31
Xyleme

32
6-Compact Structural Summary
[Bremer & Gertz Tech Report 2003] Compact addressing of words in XML doc. Encode XPath as reference to a path in a
document guide (path set, DTD or schema)

33
Managing a Compact Index
Naïve XML Indexing (Word,docId,(XPath)*)
Example book/chapter[2]/
resume/section[3] article/author/name
Difficulties: Index size ! Processing time !
Intersection of lists
Problem: How to memorize the
location of a word inside an element ?
Solution [Bremer & Gertz 02] Encode the XPath as a
reference to a path in a document guide (path sequence or schema)

34
db
articlearticletechreport
title text
sectsectsect
/db/article[1]/text/sect[3]
dbI
Article*II
techreportVI
titleIII
textIV
Sect*V
Document Guide
PID : (V, (1, 3))
XPath Encoding
XPath encoded as a path ID (PID) of structure (N,(p1,p2, ...) N being a node identifier in the guide (p1, p2, ...) being indices for repetitive ancestors from root to N

35
PID Ordering and Encoding
PID order : IV,(1))<(V,(1,2)) <(V,(1,3)).
Pre-order relationship X Parent Y PID(X) < PID(Y)
Compact PID encoding Path number
Integer (short) Repetitive node
log2(n) bits
Compact PID Encoding : (V, (1, 3)) /db/article[1]/text/sect[3]
db
articlearticletechreport
title text
sectsectsect
2 children : 1 bit
1 child : 0 bit
3 children : 2 bits
Total : 3 bits

36
Index Implementation
<livre> <titre>Les Misérables, Tome 1 : Fantine</titre> <auteur>Victor Hugo</auteur><histoire>1815. Alors que tous les aubergistes de la ville l'ont chassé, le bagnard Jean Valjean est hébergé par Mgr Myriel ( que les pauvres ont baptisé, d'après l'un de ses prénoms, Mgr Bienvenu). L'évêque de la ville de Digne, l'accueille avec bienveillance, le fait manger à sa table et lui offre un bon lit.….</histoire>
</livre>
Word PID – offset*
Valjean (PID; 15)
Ville (PID; 9, 36)
…
Entry Word (stem) || Address Address is :
PID || (offset in element)*
Example
City (V(1,3); (9, 36))

37
XQuery Text Evaluator
Normalize the query through thesaurus Translation Synonyms Conceptualization
Access to the text index Intersection, union, difference of PIDs
Access to the relevant elements from PIDs Verification of relevance

38
7-Conclusion
Various indexing techniques for XML Main dimensions of variations
Structural summary Dataguide, Schema guide, Generalized DTD
Identification of nodes (NID) Should keep parent-child relationship Should be stable to updates
Index of keywords Should be compact Should give NID and offset of instances

39
Classification
XMLIndexing Methods
GraphTraversal
TextSearch
NumberingScheme
Hierarchy Pre/PostOrder
Dataguide
FabricT-Index
APEX
RRC
IntervalEncoding

40
Index for XQuery Text
Facilitate the retrieval of: Non stop words Suffixes, prefixes Location of words in elements Relevant nodes for a search
Entries should focus on elements Word [(docId, NID)*]

41
Trreguide patterns
Author
@speciality
Book
Address
Category
City
Company
Author
@speciality
Book
Address
Category
City
Company
(a)(b)