1 locating application data across service discovery domains {csstrop,ben,muntz}@cs.ucla.edu...
TRANSCRIPT

1
Locating Application Data Across Service Discovery Domains
{csstrop,ben,muntz}@cs.ucla.edu{bisdik,parviz}@us.ibm.com{maria}@cs.columbia.edu
MobiCom’01
Byoungjip KimSSLab, EECS, KAIST
April 22, 2003

2
CONTENTS
• Introduction
• VIA Overview
• VIA Protocol Details
• Related Work
• Conclusions
• Critique

3
ITRODUCTION
• Mobile Computing• Pervasive Computing
• Thin Clients– PDAs, cellular telephones, sensors, etc.
• Service Discovery Architecture– To manage pervasive devices
– Ex. SLP, Jini, Salutation, UPnP
– service discovery protocol
– but, local (cell topology)
– service discovery domain

4
INTRODUCTION (contd.)
• Problem – how to share data across service discovery domains
• Approach– 1. Self-logging
• Client participation model• Not sharable
– 2. Centralized index• Infrastructure approach• Not scalable• Not reliable
– 3. Distributed indexes
• WASRV (1998, IETF)• SDS (Mobicom’99, Berkeley)• INS (OSR’99, MIT)

5
VIA OVERVIEW
• Gateways• Main Channel• Metadata Tags
– F1: (sslab)
– F2: (sslab,ppigy)
– F3: (sslab,bjkim)
– F4:
(sslab,piggy,p3.jpg)
• VIA– Verified Information Access
– “way” in LatinWell Known
Multicast Group
<user-group name=“sslab”>
<photographer name=“bjkim”>
<picture file-name=“b1.jpg”>
(sslab, piggy, p1.jpg)
(sslab, bjkim, b2.jpg)
(sslab, piggy, p2.jpg)
(sslab, bjkim, b3.jpg)
(sslab, yjsong, y1.jpg)
(sslab, piggy, p3.jpg)
G1
G2
G3
G4
PDA
G5
(sslab, piggy, p4.jpg)

6
VIA OVERVIEW (contd.)• Goal
– To reduce irrelevant queries to the gateways
• Features– Hierarchical Scheme
– Self-organizing of Gateways • based on the types of queries• depend on partial knowledge
– Semantic Filtering• get behind to avoid irrelevant queries
– Data Centric Heuristic
• Criteria for Aggregation/Split– Hit ration: H = Qres/Q
• Aggregation is triggered when H < T1.
– Filtering coefficient: F = Qc/Qroot
• Split is triggered when H>T1, F>T2
– Heuristic mechanisms

7
VIA PROTOCOL• Spanning Tree Operations
– Growth, Non-root failure, Root failure, and merging.
• Some basic notions– cluster table, edge set, rootside lin
k– Messages : JOIN, LINK, QUERY,
FAIL, ACCEPT, REFRESH
• Some useful technique– 1. 128-bit randomly generated ID– 2. proving (ping, RTT)– 3. REFRESH message : heartbeat
• good scheme for the autonomy.– 4. “token count”
• To avoid the congestion like “DOS” attack.

8
VIA PROTOCOL (Contd.)
• Basic– Failure recovery algorithms are based on the growth algorithm.
• Heartbeat (REFRESH message)– Is is useful to detect connection failure.

9
RELATED WORK
• Overlay Network– “test bed” “application-level infrastructure”
– Adaptive Network : Odyssey (Michigan, ’99), CANS (NYU, ’01), etc.
– Service Composition : Ninja (UCB, ’00), etc.
VIA Application-level multicast
P2P file sharing
Environment
Mobile, Pervasive
maybe Mobile, not Pervasive
maybe Mobile,not Pervasive
Goal Data Recovery, Sharing
Content Distribution, Delivery
Data Sharing
Data Structure
Tree Mesh, Tree DHT
Example WASRV (IETF, ’98)SDS (UCB, ’99)
Yoid (ACIRI, ’99)Scattercast (UCB, ’99) Narada (CMU, ’00)NICE (UMD, ’02)
Chord (MIT, ’01)Pastry (Rice, ’01)PAST (Rice, ’01)

10
CONCLUSIONS
• Problem – To locate application specific data across service discovery domains.
• Solution– Multicast + VIA
• Goal of VIA– To reduce irrelevant queries to a gateway.
• VIA features– Hierarchy Scheme
– Semantic Filtering
– Self-organizing Mechanism
– Data Centric Heuristic

11
CRITIQUE• Strong Points
– Simple means against the complex distribution algorithm • Proposal of Simple Self-organizing Mechanism• Using Semantic Data Model (proper heuristic)
• Weak Points– VIA clusters rely on global multicast to bootstrap the cluster creation
process.
– As in any hierarchical scheme, top-level nodes act as “martyrs”.• It must need a load balancing scheme for scalability.
– Experiments are vulnerable to be doubted.• There is no well-synthesized workload.
• New Idea– Collaboration based on “Reputation” of a node as another heuristic.

12
CRITIQUE (contd.)
• New Idea

13
Appendix 1• Metadata Tag Schema
• Query Example
14
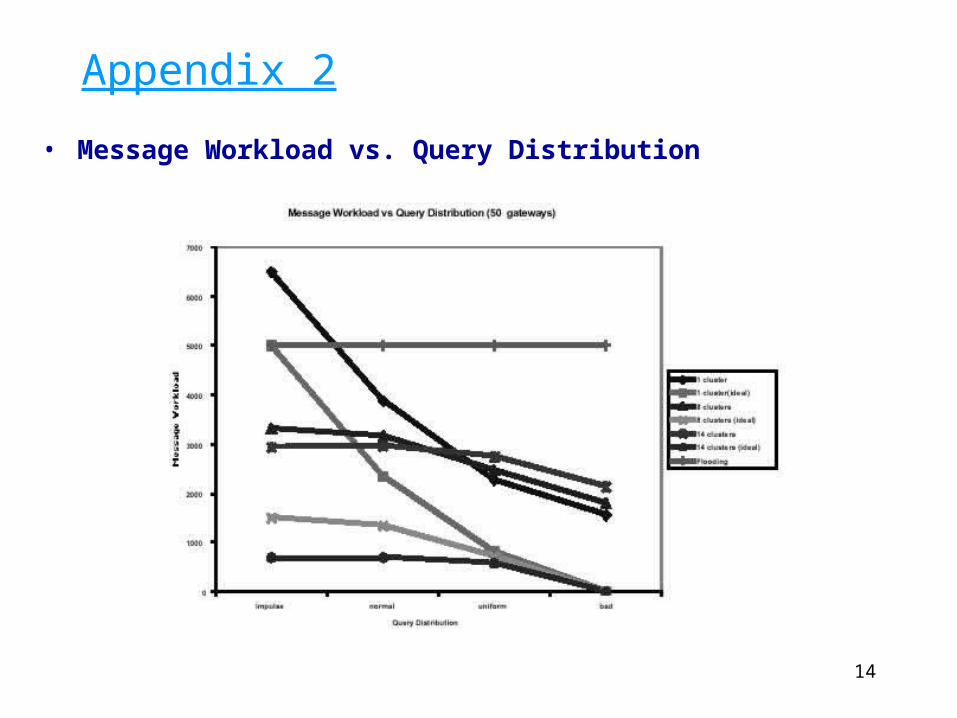
Appendix 2
• Message Workload vs. Query Distribution

15
Appendix 3
• Workload distribution for 24 gateways, 6 cluster system