1 comp541 sequencing – iii (sequencing a computer) montek singh april 9, 2007
Post on 20-Dec-2015
239 views
TRANSCRIPT

1
COMP541COMP541
Sequencing – IIISequencing – III(Sequencing a Computer)(Sequencing a Computer)
Montek SinghMontek Singh
April 9, 2007April 9, 2007

2
Test 2Test 2 On April 17On April 17 Covers Covers
MemoriesMemories ArithmeticArithmetic DatapathsDatapaths SequencingSequencing

3
Design Reviews: Last Week of Design Reviews: Last Week of ClassesClasses Individual meetings during class time next Individual meetings during class time next
week (and maybe one more day)week (and maybe one more day) 20 minutes20 minutes Please prepare a presentationPlease prepare a presentation
Not necessarily a PPT, but don’t make up your Not necessarily a PPT, but don’t make up your description on the flydescription on the fly

4
Chapter 10-7Chapter 10-7 Simple computer architectureSimple computer architecture
Not unlike MIPS, except 16 bitsNot unlike MIPS, except 16 bits
Single-cycle hardwired controlSingle-cycle hardwired control Multicycle microprogrammed controlMulticycle microprogrammed control

5
Instruction FormatsInstruction Formats Register-type instructionsRegister-type instructions
Only 8 registers (3 bits)Only 8 registers (3 bits)

6
ImmediateImmediate
Only 3 bits for the immediate value (Op)Only 3 bits for the immediate value (Op) Mostly useful for typical increments/decrementMostly useful for typical increments/decrement
Or just as an exampleOr just as an example

7
BranchingBranching PC relative branchingPC relative branching
The 6 bits are sign extended to 16The 6 bits are sign extended to 16 Opcode might specify branch on zero, if Opcode might specify branch on zero, if
register SA is zeroregister SA is zero

8
Example InstructionsExample Instructions

9
Contrast to MicrooperationsContrast to Microoperations Although appear similar, they’re notAlthough appear similar, they’re not Computer instructions fetched using PCComputer instructions fetched using PC Branching much more generalBranching much more general Decoding of computer instructions usually Decoding of computer instructions usually
more complexmore complex

10
ResourcesResources Book implies Harvard Book implies Harvard
architecturearchitecture Separate I and DSeparate I and D They treat I memory as They treat I memory as
ROMROM AsynchronousAsynchronous

11
Single-Cycle ControlSingle-Cycle Control Datapath is same as example we used in Datapath is same as example we used in
datapath topicdatapath topic Next slide shows for reviewNext slide shows for review
First look at overall controlFirst look at overall control Then look at instruction decoderThen look at instruction decoder

12
Datapath & Control WordDatapath & Control Word
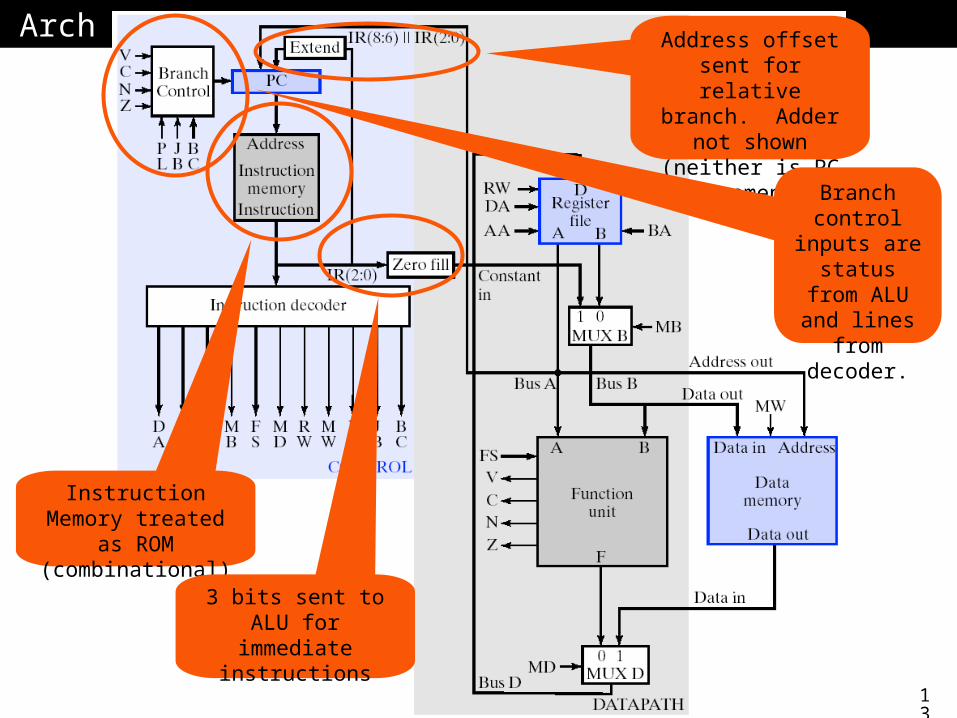
13
ArchArch
Instruction Memory treated as ROM (combinational)
3 bits sent to ALU for immediate instructions
Address offset sent for relative branch. Adder not shown
(neither is PC increment).
Branch control inputs
are status from ALU and
lines from decoder.

14
Instruction DecoderInstruction Decoder Many lines (the Many lines (the
three regs) need three regs) need no logicno logic RISC StyleRISC Style
Architecture Architecture tailored so parts of tailored so parts of inst. correspond to inst. correspond to control linescontrol lines

15
ControlControl Not much more to sayNot much more to say
Simple, partly because decoding so straightforwardSimple, partly because decoding so straightforward DrawbacksDrawbacks
Some instructions, like multi-cycle shifts, can’t be Some instructions, like multi-cycle shifts, can’t be implemented w/o complex datapathimplemented w/o complex datapath
Two memories (essentially a ROM and an async data Two memories (essentially a ROM and an async data memory)memory)Two cycles needed to use one memoryTwo cycles needed to use one memory
Biggest problem is delayBiggest problem is delay

16
Delay in Single-Cycle ControlDelay in Single-Cycle Control Worst case delay with reasonable componentsWorst case delay with reasonable components
Say, total 17nsSay, total 17ns Could only clock at about 50 MHzCould only clock at about 50 MHz
Pipelining is a solutionPipelining is a solution First let’s look at multi-cycle controlFirst let’s look at multi-cycle control

17
Multi-Cycle Hardwired ControlMulti-Cycle Hardwired Control GoalsGoals
Support more complex instructionsSupport more complex instructions Use single memoryUse single memory
Not necessarily coupled with multi-cycleNot necessarily coupled with multi-cycle
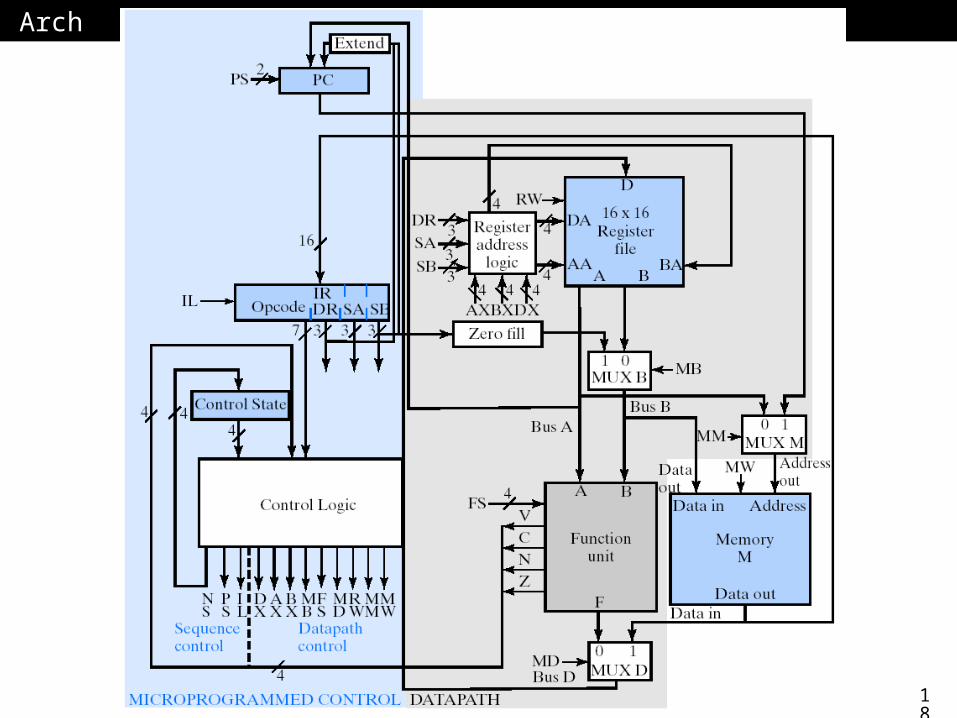
18
ArchArch

19
Instruction RegisterInstruction Register
IL – load IL – load signal for IRsignal for IR
PS, for PC PS, for PC controlcontrol Hold value Hold value
multiple multiple cycles, cycles, increment, increment, load, etc.load, etc.

20
Single MemorySingle Memory
PC addresses PC addresses memorymemory
Mux M gates Mux M gates addressaddress
MM signal to MM signal to select select program/data program/data addressaddress
Inst. stored in Inst. stored in IRIR

21
Added Temporary RegsAdded Temporary Regs
Now 16x16Now 16x16 8 not visible 8 not visible
to userto user New signals New signals
to address to address the registersthe registers

22
Sequence ControlSequence Control

23
Control WordControl Word

24
Control DesignControl Design Not hard to specify state diagramNot hard to specify state diagram
Derived from definition of ISADerived from definition of ISA
Hard to design logic manuallyHard to design logic manually If didn’t have logic synthesis, would probably If didn’t have logic synthesis, would probably
use microprogramminguse microprogramming

25
Two-Cycle InstructionsTwo-Cycle Instructions Simplest instructions have 2 cyclesSimplest instructions have 2 cycles
Fetch (instruction)Fetch (instruction) ExecuteExecute
This is minimum necessaryThis is minimum necessary They assume async memoryThey assume async memory
Don’t need extra clock cyclesDon’t need extra clock cycles

26
Basic Inst.Basic Inst.

27
BranchBranch Test and modify PCTest and modify PC

28
Next StepNext Step Make a table or write Verilog from ASM Make a table or write Verilog from ASM
diagram and instruction descriptionsdiagram and instruction descriptions Tedious, but not hardTedious, but not hard Same as you’ve done, with more detailsSame as you’ve done, with more details
State machine easy for these instructionsState machine easy for these instructions

29
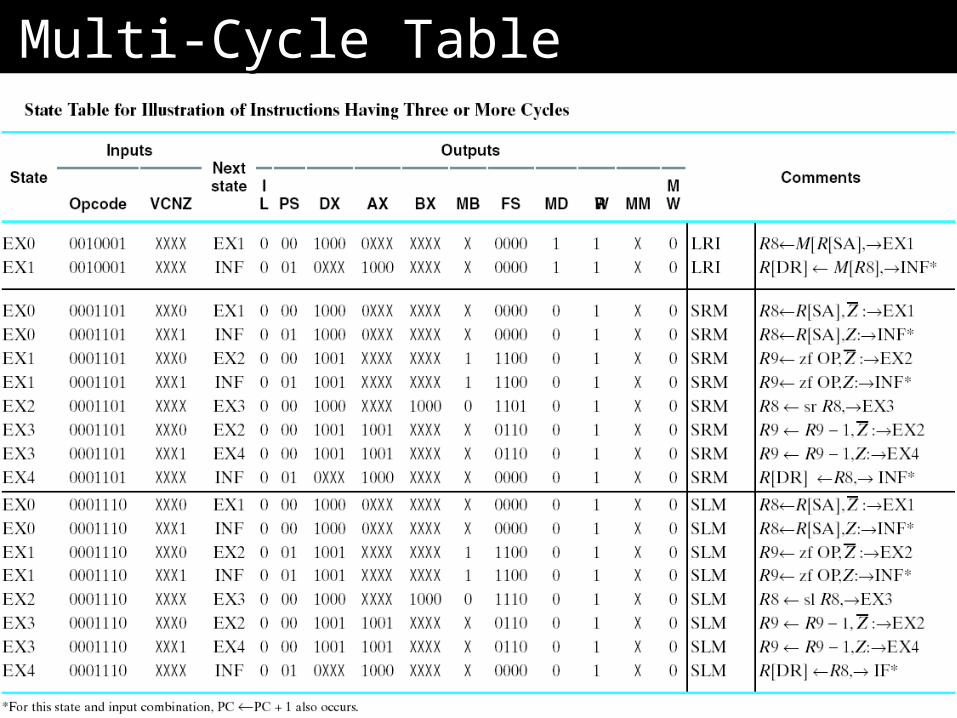
Table from ISA and ASMTable from ISA and ASM
30
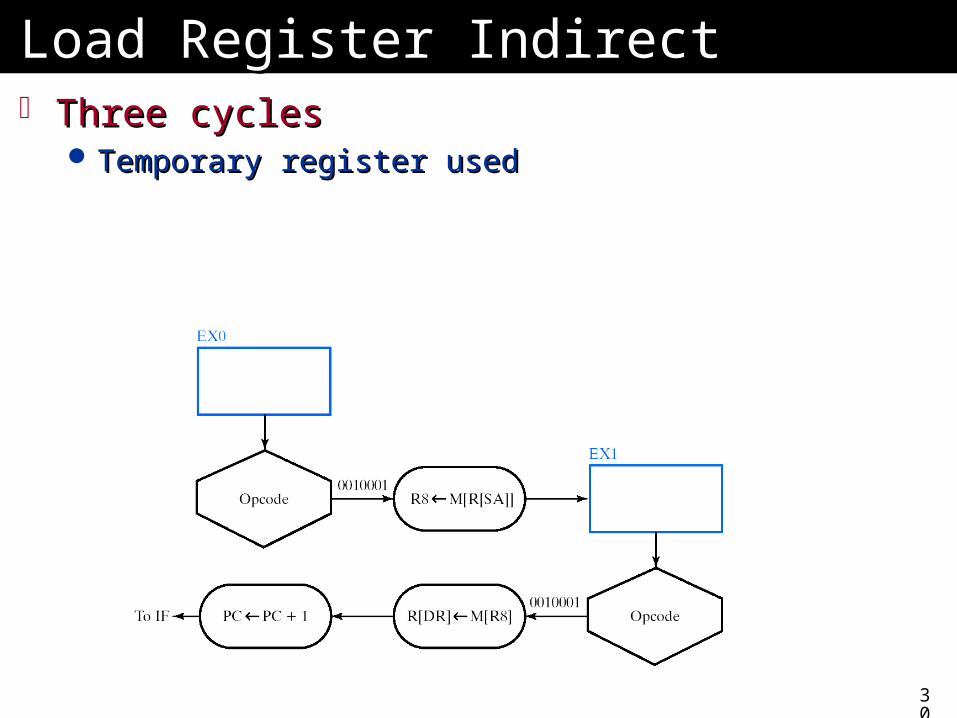
Load Register IndirectLoad Register Indirect Three cyclesThree cycles
Temporary register usedTemporary register used

31
ShiftShift Shift right/left multipleShift right/left multiple R[SA] to be shiftedR[SA] to be shifted First tested for 0First tested for 0 R9 loaded with shift lengthR9 loaded with shift length
32
Multi-Cycle TableMulti-Cycle Table

33
Summary – multi-cycleSummary – multi-cycle Multi-cycle computer enables more complex Multi-cycle computer enables more complex
instructionsinstructions May also be fasterMay also be faster We’ll also briefly look at We’ll also briefly look at pipelinedpipelined computers – computers –
more parallelism but more complex controlmore parallelism but more complex control

34
Limits to Clock PeriodLimits to Clock Period Conventional datapathConventional datapath 12 ns delay, so maximum is 83 12 ns delay, so maximum is 83
MHz clockMHz clock Maybe have even tighter Maybe have even tighter
constraints due to control logicconstraints due to control logic

35
PipeliningPipelining Break datapath into stagesBreak datapath into stages Add registers between stagesAdd registers between stages Like production line – book Like production line – book
uses car wash exampleuses car wash example Wash, rinse, dryWash, rinse, dry

36
Latency vs ThroughputLatency vs Throughput LatencyLatency, the amount of time it takes to , the amount of time it takes to
execute an instruction, does not improveexecute an instruction, does not improve In fact, typically increasesIn fact, typically increases
Throughput, the number of instructions Throughput, the number of instructions executed per second, increasesexecuted per second, increases By almost the number of pipeline stagesBy almost the number of pipeline stages

37
Expected PerformanceExpected Performance Longest stage is 5nsLongest stage is 5ns So clock can be 200 MHzSo clock can be 200 MHz Not 3 x 83 MHz. Why?Not 3 x 83 MHz. Why?
Latency is 15nsLatency is 15ns Also extra hardwareAlso extra hardware

38
DatapathDatapath 3 Stages3 Stages
Operand FetchOperand Fetch ExecuteExecute Write BackWrite Back
Note that WB register is the Note that WB register is the register file (same as at top)register file (same as at top)

39
Pipelined ExecutionPipelined Execution
Note pipeline fill and emptyNote pipeline fill and empty Efficiency is not 100%Efficiency is not 100% Important to not Important to not stallstall pipeline pipeline