z research, inc. - openfabricsdownloads.openfabrics.org/media/ib_lowlatencyforum... · z research,...
TRANSCRIPT

© 2007 Z RESEARCH
Z RESEARCH
Z RESEARCH, Inc.Commoditizing Supercomputing and Superstorage
Massive Distributed Storage over InfiniBand RDMA

© 2007 Z RESEARCH
Z RESEARCH What is GlusterFS?
GlusterFS is a Cluster File System that aggregates multiple storage bricks over InfiniBand RDMA into one large parallel network file system
GlusterFS is MORE than making data available over a network or the organization of data on disk storage….
• Typical clustered file systems work to aggregate storage and provide unified views but….
- scalability comes with increased cost, reduced reliability, difficult management, increased maintenance and recovery time…. - limited reliability means volume sizes are kept small….- capacity and i/o performance can be limited…..
GlusterFS allows scaling of capacity and I/O using industry standard inexpensive modules!

© 2007 Z RESEARCH
Z RESEARCH GlusterFS Features
1. Fully POSIX compliant!2. Unified VFS!3. More flexible volume management (stackable features)!
4. Application specific scheduling / load balancing• roundrobin; adaptive least usage; non-uniform file access (NUFA)!
5. Automatic file replication (AFR); Snapshot! and Undelete!6. Striping for performance!7. Self-heal! No fsck!!!!8. Pluggable transport modules (IB verbs, IB-SDP)!9. I/O accelerators - I/O threads, I/O cache, read ahead and write
behind !10. Policy driven - user group/directory level quotas , access
control lists (ACL)

© 2007 Z RESEARCH
Z RESEARCH
GigE
GlusterFS Design
GlusterFS Clustered Filesystem on x86-64 platform
Storage ClientsCluster of Clients (Supercomputer, Data Center)
GLFS Client
Clustered Vol Manager
Clustered I/O Scheduler
GLFS Client
Clustered Vol Manager
Clustered I/O Scheduler
GLFS ClientClustered Vol Manager
Clustered I/O Scheduler
GLFS Client
Clustered Vol Manager
Clustered I/O Scheduler
GLFS Client
Clustered Vol Manager
Clustered I/O Scheduler
GLFS ClientClustered Vol Manager
Clustered I/O Scheduler
Storage Brick N
GLFSDVolumeGLFSDVolume
Storage Brick 1GLFSDVolume
Storage Brick 2GLFSDVolume
Storage Brick 3GLFSDVolume
GLFSDVolumeGLFSDVolume
Storage Brick 4GLFSDVolume
RDMA RDMA
Storage GatewayNFS/Samba
GLFS Client
Storage GatewayNFS/Samba
GLFS Client
Storage Gateway
NFS/Samba
GLFS Client
RDMA
Compatibility withMS Windows
and other Unices
InfiniBand / GigE / 10GigE
NFS / SAMBA over TCP/IP
Client
Sid
e
Serv
er S
ide

© 2007 Z RESEARCH
Z RESEARCH
GlusterFS Server
VFS
Stackable Design
Client
Server
I/O Cache
Unify
POSIX
Ext3 Ext3Ext3
TCPIP – GigE, 10GigE / InfiniBand - RDMA
POSIX POSIX
Brick 1
ServerServer
Glu
ster
FS
Client Client
GlusterF
S Clie
nt
Read Ahead
Brick 2 Brick n
GlusterFS Server GlusterFS ServerGlusterFS Server

© 2007 Z RESEARCH
Z RESEARCH GlusterFS Function - unify
Server/Head Node 1
Server/Head Node 2
Server/Head Node 3
Client ViewClient View (unify/roundrobin)../files/aaa../files/bbb
../files/aaa
../files/bbb
../files/ccc
../files/ccc

© 2007 Z RESEARCH
Z RESEARCH GlusterFS Function – unify+AFR
Server/Head Node 1
Server/Head Node 2
Server/Head Node 3
Client ViewClient View (unify/roundrobin+AFR)
../files/aaa../files/bbb
../files/aaa
../files/ccc
../files/aaa
../files/bbb
../files/bbb
../files/ccc
../files/ccc

© 2007 Z RESEARCH
Z RESEARCH GlusterFS Function - stripe
Server/Head Node 1
Server/Head Node 2
Server/Head Node 3
Client View (stripe)
../files/aaa../files/bbb../files/ccc
../files/aaa ../files/bbb../files/ccc
../files/aaa ../files/bbb../files/ccc
../files/aaa ../files/bbb../files/ccc

© 2007 Z RESEARCH
Z RESEARCH I/O Scheduling
1. Round robin
2. Adaptive least usage (ALU)
3. NUFA
4. Random
5. Custom
volume brickstype cluster/unifysubvolumes ss1c ss2c ss3c ss4coption scheduler aluoption alu.limits.min-free-disk 60GBoption alu.limits.max-open-files 10000option alu.order disk-usage:read-usage:write-usage:open-files-usage:disk-speed-usageoption alu.disk-usage.entry-threshold 2GB # Units in KB, MB and GB are allowedoption alu.disk-usage.exit-threshold 60MB # Units in KB, MB and GB are allowedoption alu.open-files-usage.entry-threshold 1024option alu.open-files-usage.exit-threshold 32option alu.stat-refresh.interval 10sec
end-volume

© 2007 Z RESEARCH
Z RESEARCH
Benchmarks

© 2007 Z RESEARCH
Z RESEARCHGlusterFS Throughput & Scaling Benchmarks
Benchmark Environment
Method: Multiple 'dd' of varying blocks are read and written from multiple clients simultaneously.
GlusterFS Brick Configuration (16 bricks)Processor - Dual Intel(R) Xeon(R) CPU 5160 @ 3.00GHzRAM - 8GB FB-DIMMLinux Kernel - 2.6.18-5+em64t+ofed111 (Debian)Disk - SATA-II 500GBHCA - Mellanox MHGS18-XT/S InfiniBand HCA
Client Configuration (64 clients)RAM - 4GB DDR2 (533 Mhz)Processor - Single Intel(R) Pentium(R) D CPU 3.40GHzLinux Kernel - 2.6.18-5+em64t+ofed111 (Debian)Disk - SATA-II 500GBHCA - Mellanox MHGS18-XT/S InfiniBand HCA
Interconnect Switch: Voltaire port InfiniBand Switch (14U)
GlusterFS version 1.3.pre0-BENKI

© 2007 Z RESEARCH
Z RESEARCH GlusterFS PerformanceAggregated I/O Benchmark on 16 bricks(servers) and 64 clients over IB Verbs transport.
Peak aggregated read throughput was 13 GBps.After a particular threshold, write performance plateaus because of disk I/O bottleneck. System memory greater than the peak load will ensure best possible performance. ib-verbs transport driver is about 30% faster than ib-sdp transport driver.
Peak aggregated read throughput was 13 GBps.After a particular threshold, write performance plateaus because of disk I/O bottleneck. System memory greater than the peak load will ensure best possible performance. ib-verbs transport driver is about 30% faster than ib-sdp transport driver.
13GBps!

© 2007 Z RESEARCH
Z RESEARCH Scalability
Performance improves when the number of bricks are increased
Throughput increases with corresponding increased in servers from 1 to 16

© 2007 Z RESEARCH
Z RESEARCH GlusterFS Value Proposition
A single solution for 10's of Terabytes to Petabytes
No single point of failure – completely distributed - no centralized meta-data
Non-stop Storage – can withstand hardware failures, self healing, snap-shots
Data easily recovered even without GlusterFSCustomizable schedulers
User Friendly - Installs and upgrades in minutes
Operating system agnostic!
Extremely cost effective – deployed on any x86-64 hardware!

© 2007 Z RESEARCH
Z RESEARCH
Thank You!
http://www.zresearch.comhttp://www.gluster.org

© 2007 Z RESEARCH
Z RESEARCH
Backup Slides

© 2007 Z RESEARCH
Z RESEARCHGlusterFS Vs Lustre Benchmark
Benchmark Environment
Brick Config (10 bricks)Processor - 2 x AMD Dual-Core Opteron™ Model 275 processorsRAM - 6 GBInterconnect - InfiniBand 20 Gb/s - Mellanox MT25208 InfiniHost III ExHard disk - Western Digital Corp. WD1200JB-00REA0, ATA DISK drive
Client Config (20 clients)Processor - 2 x AMD Dual-Core Opteron™ Model 275 processorsRAM - 6 GBInterconnect - InfiniBand 20 Gb/s - Mellanox MT25208 InfiniHost III ExHard disk - Western Digital Corp. WD1200JB-00REA0, ATA DISK drive
Software VersionOperation System - Redhat Enterprise GNU/Linux 4 (Update 3)Linux version - 2.6.9-42Lustre version - 1.4.9.1GlusterFS version - 1.3-pre2.3
© 2007 Z RESEARCH
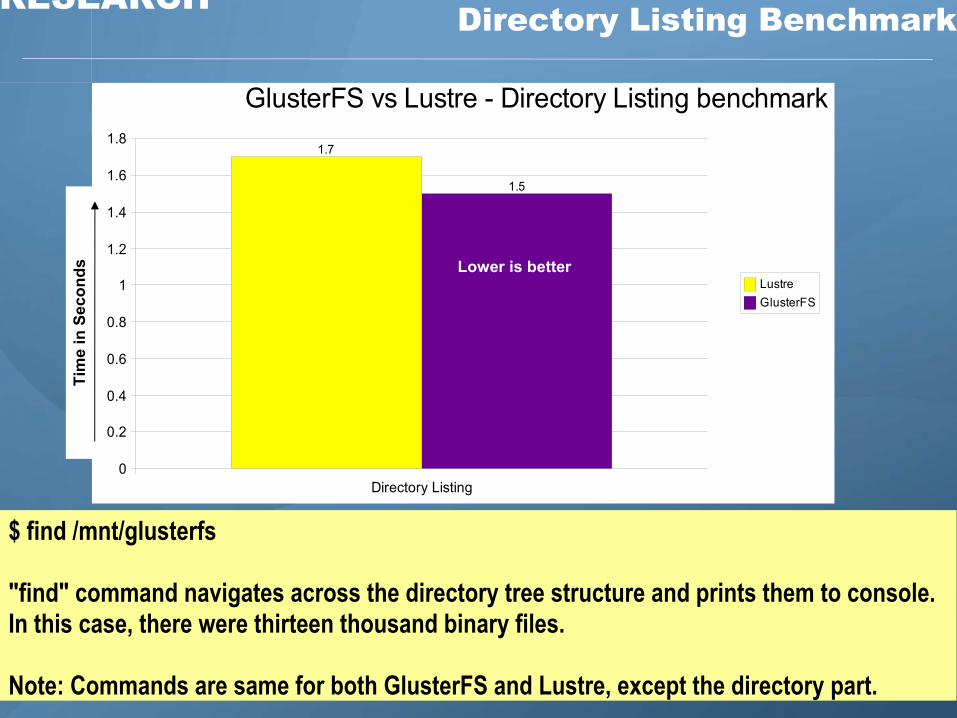
Z RESEARCH Directory Listing Benchmark
Directory Listing0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.81.7
1.5
GlusterFS vs Lustre - Directory Listing benchmark
LustreGlusterFS
Tim
e in
Sec
onds Lower is better
$ find /mnt/glusterfs
"find" command navigates across the directory tree structure and prints them to console. In this case, there were thirteen thousand binary files.
Note: Commands are same for both GlusterFS and Lustre, except the directory part.

© 2007 Z RESEARCH
Z RESEARCH Copy Local to Cluster File System
Copy Local to Cluster File System0
2.55
7.510
12.515
17.520
22.525
27.530
32.535
37.5 37
26
GlusterFS vs Lustre - Copy Local to Cluster File System
LustreGlusterFS
Tim
e in
Sec
onds
Lower is better
$ cp -r /local/* /mnt/glusterfs/
cp utility is used to copy files and directories.
Copy 12039 files (595 MB) were copied into the cluster file system.

© 2007 Z RESEARCH
Z RESEARCH Copy Local from Cluster File System
Copy Local from Cluster File System0
5
10
15
20
25
30
35
40
45 45
18
GlusterFS vs Lustre - Copy Local from Cluster File System
LustreGlusterFS
Tim
e in
Sec
onds
Lower is better
$ cp -r /mnt/glusterfs/ /local/*
cp utility is used to copy files and directories.
Copy 12039 files (595 MB) were copied from the cluster file system.
© 2007 Z RESEARCH
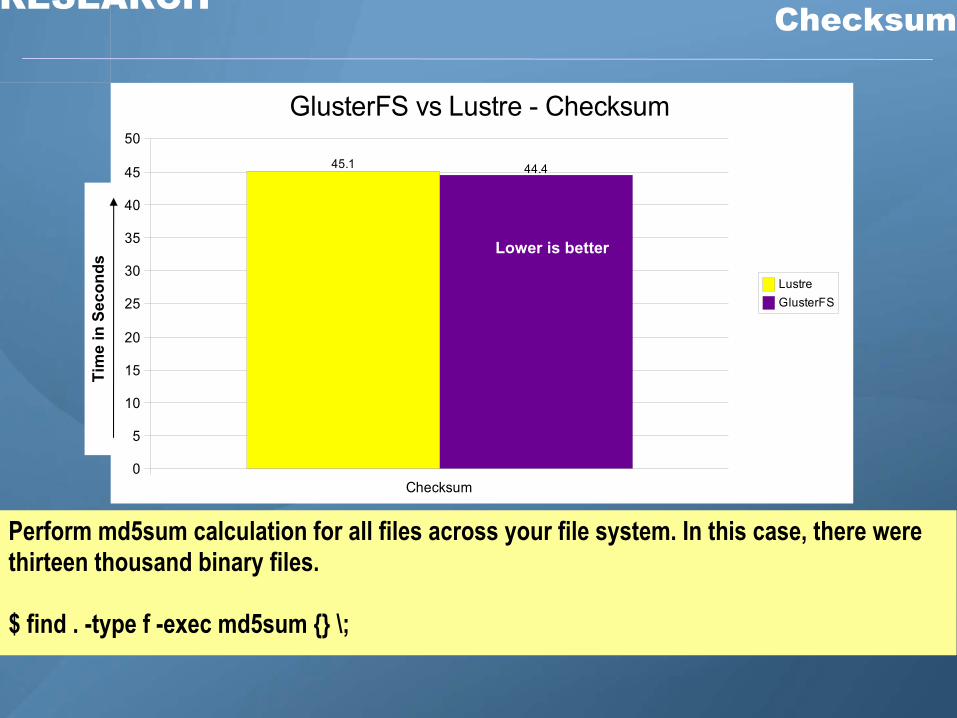
Z RESEARCH Checksum
Checksum0
5
10
15
20
25
30
35
40
45
50
45.1 44.4
GlusterFS vs Lustre - Checksum
LustreGlusterFS
Tim
e in
Sec
onds
Lower is better
Perform md5sum calculation for all files across your file system. In this case, there were thirteen thousand binary files.
$ find . -type f -exec md5sum {} \;

© 2007 Z RESEARCH
Z RESEARCH Base64 Conversion
Base64 Conversion0
2.5
5
7.5
10
12.5
15
17.5
20
22.5
25
27.525.7 25.1
GlusterFS vs Lustre - Base64 Conversion
LustreGlusterFS
Tim
e in
Sec
onds
Lower is better
Base64 is an algorithm for encoding binary to ASCII and vice-versa. This benchmark was performed on a 640 MB binary file.
$ base64 --encode big-file big-file.base64

© 2007 Z RESEARCH
Z RESEARCH Pattern Search
Pattern Search0
5
10
15
20
25
30
35
40
45
50
55 54.352.1
GlusterFS vs Lustre - Pattern Search
LustreGlusterFS
Tim
e in
Sec
onds
Lower is better
grep utility searches for a PATTERN on a file and prints the matching lines to console. This benchmark used 1GB ASCII BASE-64 file.
$ grep GNU big-file.base64
© 2007 Z RESEARCH
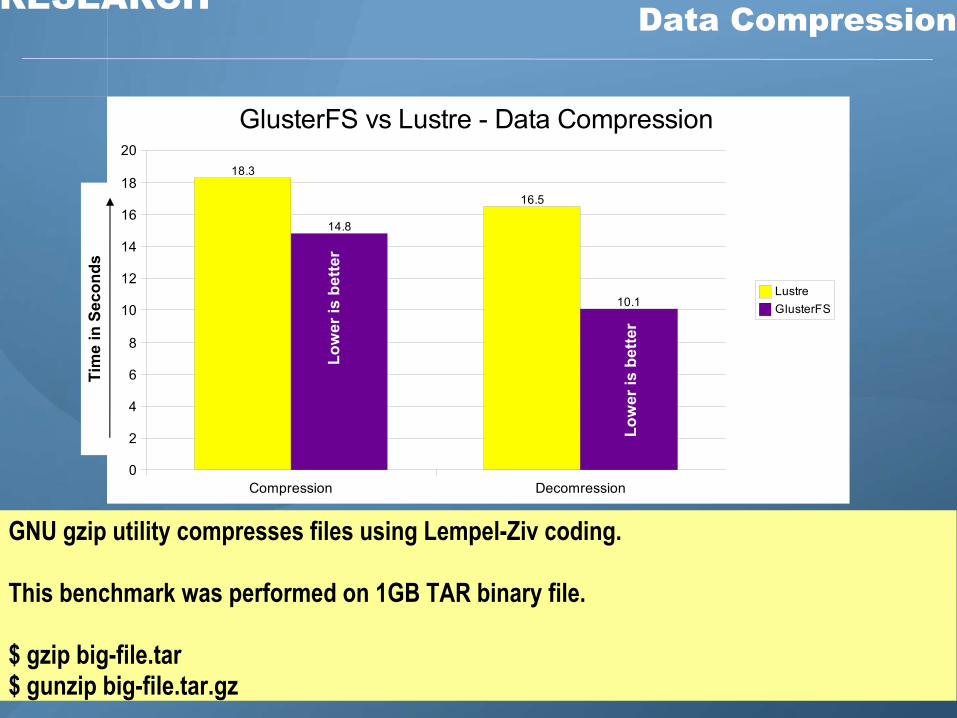
Z RESEARCH Data Compression
Compression Decomression0
2
4
6
8
10
12
14
16
18
2018.3
16.5
14.8
10.1
GlusterFS vs Lustre - Data Compression
LustreGlusterFS
Tim
e in
Sec
onds
Low
er is
bet
ter
GNU gzip utility compresses files using Lempel-Ziv coding.
This benchmark was performed on 1GB TAR binary file.
$ gzip big-file.tar$ gunzip big-file.tar.gz
Low
er is
bet
ter
© 2007 Z RESEARCH
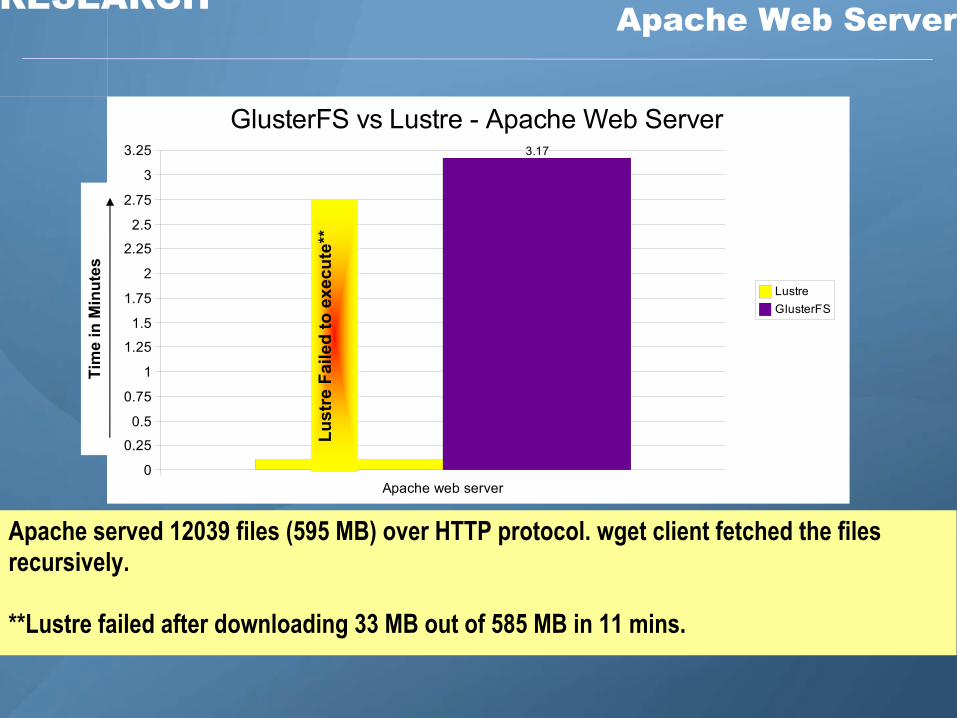
Z RESEARCH Apache Web Server
Apache web server0
0.25
0.5
0.75
1
1.25
1.5
1.75
2
2.25
2.5
2.75
3
3.25 3.17
GlusterFS vs Lustre - Apache Web Server
LustreGlusterFS
Tim
e in
Min
utes
Low
er is
bet
ter
Apache served 12039 files (595 MB) over HTTP protocol. wget client fetched the files recursively.
**Lustre failed after downloading 33 MB out of 585 MB in 11 mins.
Lust
re F
aile
d to
exe
cute
**

© 2007 Z RESEARCH
Z RESEARCH Archiving
Archive ceration Archive extraction0
5
10
15
20
25
30
35
40
4541
25
43
GlusterFS vs Lustre - ArchivingLustreGlusterFS
Tim
e in
Sec
onds
Low
er is
bet
ter
Archive Creationtar utility is used for archiving filesystem data.$ tar czf benchmark.tar.gz /mnt/glusterfs'tar utility created an archive of 12039 files (595 MB) served through GlusterFS.
Archive Extraction'tar utility extracted the archive on to GlusterFS filesystem.$ tar xzf benchmark.tar.gz
**Lustre Falied to Execute:-Tar extraction failed under Lustre with no space left on the device error. Disk-free (df -h) utility revealed lot of free space. It appears like I/O scheduler performed a poor job in distributing the data evenly.
tar: lib/libtdsS.so.1: Cannot create symlink to `libtdsS.so.1.0.0': No space left on device
tar: lib/libg.a: Cannot open: No space left on devicetar: Error exit delayed from previous errors
Lust
re F
aile
d to
exe
cute
**

© 2007 Z RESEARCH
Z RESEARCH Aggregated Read Throughput
4KB 16KB0
1
2
3
4
5
6
7
8
9
10
11
12
1.796
5.782
11.415 11.424
GlusterFS vs Lustre - Aggregated Read Throughput
LustreGlusterFS
Thro
ughp
ut in
Gig
a B
ytes
per
sec
ond
Multiple dd utility were executed simultaneously with different block sizes to read from GlusterFS filesystem.
Higher is Better
Data Sizes

© 2007 Z RESEARCH
Z RESEARCH Aggregated Write Throughput
4KB 16KB0
0.25
0.5
0.75
1
1.25
1.5
1.75
2
2.25
0.969
1.613
1.886
2.191
GlusterFS vs Lustre - Aggregated Write Throughput
LustreGlusterFS
Thro
ughp
ut in
Gig
a B
ytes
per
sec
ond
Multiple dd utility were executed simultaneously with different block sizes to write to GlusterFS Filesystem.
Higher is Better
Data Sizes