yelp data challenge - michelle9luo.com · yelp dataset challenge jie luo (michelle) | washignton,...
TRANSCRIPT

Yelp Dataset Challenge
Jie Luo (Michelle) | Washignton, DC
The challenge is a chance for students to conduct research or analysis on our data and share their discoveries with Yelp. Whether you're trying to figure out how food trends start or identify the impact of different connections from the local graph, you'll have a chance to win cash prizes for your work!

Natural Language Processing & Sentiment Analysis
What's in a review? Is it positive or negative? The Yelp’s reviews contain a lot of metadata that can be mined and used to infer meaning, business attributes, and sentiment.
What is the dataset challenge?
The challenge is a chance for students to conduct research or analysis on our data and share their discoveries with Yelp. Whether you're trying to figure out how food trends start or identify the impact of different connections from the local graph, you'll have a chance to win cash prizes for your
work!
Build a restaurant recommender based on user's past visits and ratings using collaborative filtering

Agenda
• Load and transform Yelp data challenge datasets into Pandas data frame. Cleaned data and join different data sets.
Exploratory Analysis
Clustering & PCA
NLP Study Recommendation & Conclusion
• Cluster users into groups by using unsupervised learning. Identify and understand the common user preference within each of the group by inspecting the cluster centroid.
• Convert user review data to vector space for Natural Language Processing study by using tokenization with stemming and lemmatization.
• Define the successfulness of a business entity by their rating and build different models to make predictions based on user tips and reviews.
• Build a restaurant recommender based on user's past visits and ratings by using collaborative filtering.
Jie Luo, Michelle | Washignton, DC

Data Distribution
The Challenge Dataset:
• 5.997M reviews and 1.2M tips by 1.5M users for 189K businesses • Over 1.4M business attributes, e.g., hours, parking availability, ambience. • Aggregated check-ins over time for each of the 186K businesses • 280,992 pictures from the included businesses
Cities:
• U.K.: Edinburgh • Germany: Karlsruhe • Canada: Montreal and Waterloo • U.S.: Pittsburgh, Charlotte, Urbana-Champaign, Phoenix, Las Vegas, Madison, Cleveland
Files:
• yelp_academic_dataset_business.json • yelp_academic_dataset_checkin.json • yelp_academic_dataset_review.json • yelp_academic_dataset_tip.json • yelp_academic_dataset_user.json • yelp_academic_dataset_photo.json
Notes on the Dataset:
• Each file is composed of a single object type, one json-object per-line.
Dataset Introduction
Yelp Dataset Challenge Dataset Last Updated:
July 26th, 2018
https://www.yelp.com/dataset_challenge
Jie Luo, Michelle | Washignton, DC
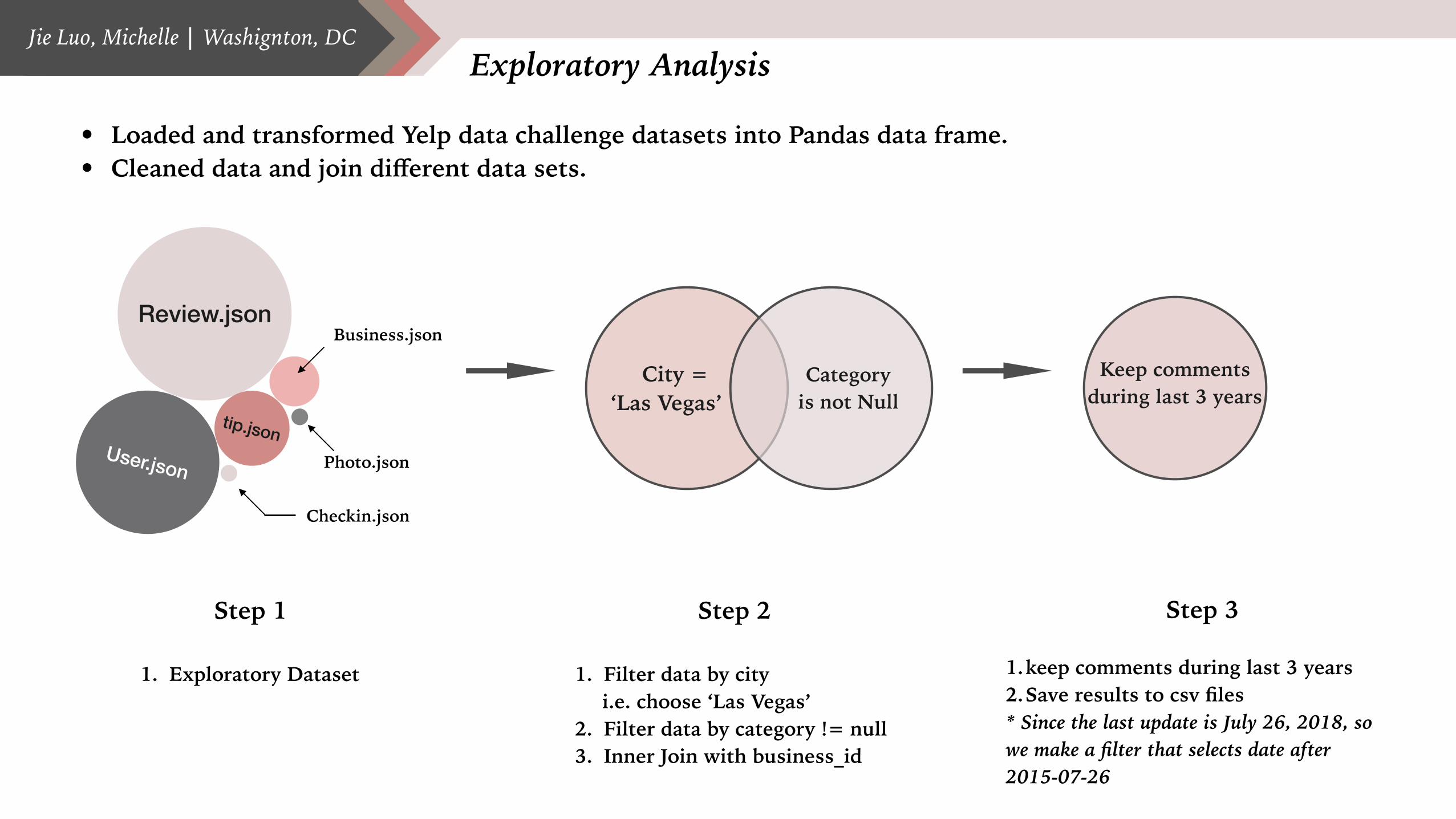
Exploratory Analysis
• Loaded and transformed Yelp data challenge datasets into Pandas data frame. • Cleaned data and join different data sets.
Step 1
1. Exploratory Dataset
Step 2
1. Filter data by city i.e. choose ‘Las Vegas’
2. Filter data by category != null 3. Inner Join with business_id
Step 3
1.keep comments during last 3 years 2.Save results to csv files * Since the last update is July 26, 2018, so we make a filter that selects date after 2015-07-26
City = ‘Las Vegas’
Category is not Null
Keep comments during last 3 years
Review.json
User.json
tip.json
Business.json
Checkin.json
Photo.json
Jie Luo, Michelle | Washignton, DC

Exploratory Analysis - Take a Glance at the Final Dataset
Freq
uenc
y
1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.00
50000
100000
150000
200000
Average_Stars (0 - 5.0)
The distribution of Average Rate
• The final dataset contains reviews of the restaurants in Las Vegas during last 3 years.
Business_id
• Count: 4929
• Each business_id corresponds to a specific restaurant name.
Review_count per Business_id
• Max_review_count: 4227
• Quantile: * 50%: 292 * 75%: 609 * 90%: 1289
Jie Luo, Michelle | Washignton, DC

Part II - NLP Study
• Convert user review data to vector space for Natural Language Processing study using tokenization with stemming and lemmatization.
• Define the successfulness of a business entity by their rating and build Naive-Bayes Model, Logistic Regression Classifier and Random Forest Classifier to make predictions based on user tips and reviews.
• Use cross validation to evaluate classifiers.
• Use grid methods to find best predictable classifier.

Similar Review Search Engine
• Stop words are words like “and”, “the”, “him”, which are presumed to be uninformative in representing the content of a text, and which may be removed to avoid them being construed as signal for prediction. Sometimes, however, similar words are useful for prediction, such as in classifying writing style or personality.
Tf-idf Vectorizer Model 1 Model 2
Stop Words = ‘English’
All tokens that appear in at least one document are used
max_features = 5000
2-gram of words
1
2
3
Fitting 2 models using different grams, the result of top 5 reviews seem to be unchanged.
The top5 reviews captures some key elements for the sample review, such as casino, service, decor, cleaning, etc.
However, the cosine similarity doesn't catch the meaning of sentence very well. For example, the sample review is a strong positive review using double negative formatting, however, the top 5 reviews are more on the negative side of the hotels/casino.
Jie Luo, Michelle | Washignton, DC

Classify Positive/Negative Review
• Define the successfulness of a business entity by their rating and build Naive-Bayes Model, Logistic Regression Classifier and Random Forest Classifier to make predictions based on user tips and reviews.
1. Comparing the three classifiers, logistic regression classier has highest accuracy and AUC for both train/test data.
2. For different models, the results from train sets and test sets are quite close.
Jie Luo, Michelle | Washignton, DC

Use Cross Validation to Evaluate Previous Models
•By partitioning the available data into train dataset and test dataset, we drastically reduce the number of samples which can be used for learning the model, and the results can depend on a particular random choice for the pair of (train, validation) sets.
•To solve this problem, we are going to use 5-fold cross-validation .
Jie Luo, Michelle | Washignton, DC

Use Grid Methods to Find Best Predictable Classifier
•The Grid Cross Validation instance implements the usual estimator API: when “fitting” it on a dataset all the possible combinations of parameter values are evaluated and the best combination is retained.
Jie Luo, Michelle | Washignton, DC

Part III - Clustering & PCA
• Cluster the review text data for all the restaurants by using unsupervised learning. Identify and understand the common user preference within each of the group by inspecting the cluster centroid.
• Cluster positive reviews.
• Cluster all the reviews of the most reviewed restaurant.
•Use PCA to reduce dimensionality and classifying positive/negative review with PCA preprocessing.
Yelp Dataset Chanllenge

Cluster the Review Text Data for All the Restaurants
• By using K-means methods, we cluster the review text data for all the restaurants.
• Split the data to training set and test set with 8:2 ratio.
• To identify and understand the common user preference within each of the group by inspecting the cluster centroid, the features for each cluster are found.
• For topics we are only really interested in the most present words, i.e. features/dimensions with the greatest representation in the centroid. In this case, the top 10 features for each cluster will be chosen.
Top 10 Features for Each Cluster
K is equal to 2Cluster 0 good food place like just time ordered order chicken really
Cluster 1 great food service place amazing good best love friendly vegas
K is equal to 5
Cluster 0 food order time just service minutes like came did place
Cluster 1 piazza crust good place great cheese slice best order Just
Cluster 2 great food service place amazing good friendly staff love definitely
Cluster 3 sushi rolls place roll ayce great good fresh service fish
Cluster 4 good place food chicken like best vegas delicious really Just
Jie Luo, Michelle | Washignton, DC

Cluster Positive Reviews
Top 10 Features for Each Cluster
K is equal to 2Cluster 0 place good Food best vegas delicious amazing time love just
Cluster 1 great food service place amazing good friendly Staff excellent awesome
K is equal to 5
Cluster 0 breakfast great place food good eggs service vegas coffee delicious
Cluster 1 love place food great good service amazing friendly staff time
Cluster 2 best vegas food las ve place service amazing restaurant time
Cluster 3 great food service place amazing good awesome friendly definitely excellent
Cluster 4 sushi place great roll rolls fresh ayce service good eat
• Define positive review when stars_value > 4
• Define imperfect review when 1<= starts <= 4 rating
• By using K-means methods, we cluster the text data for the positive reviews.
• For topics we are only really interested in the most present words, i.e. features/dimensions with the greatest representation in the cluster centroid. In this case, the top 10 features for each cluster will be chosen.
48%52%
Positive Review
Imperfect Review
Jie Luo, Michelle | Washignton, DC

Cluster All the Reviews of the Most Reviewed Restaurant
Top 10 Features for Each Cluster
K is equal to 2Cluster 0 crab buffet good legs food seafood dessert section really like
Cluster 1 food buffet vegas best wait great line time place worth
• Let's find the most reviewed restaurant and analyze its reviews.
• Define imperfect review when 1<= starts <= 4 rating
• By using K-means methods (k = 2), we cluster the text data for this restaurant’s reviews.
• For topics we are only really interested in the most present words, i.e. features/dimensions with the greatest representation in the cluster centroid. In this case, the top 10 features for each cluster will be chosen.
* The most reviewed restaurant of these datasets is the one named “Bacchanal Buffet”.
Jie Luo, Michelle | Washignton, DC

Classifying Positive/Negative Review with PCA Preprocessing
• Use PCA to Reduce Dimensionality
• Define the successfulness of a business entity by their rating and build Logistic Regression Classifier and Random Forest Classifier to make predictions based on user tips and reviews with PCA preprocessing.
1. In terms of running time, when using PCA preprocessing features to fit logistic model, it's much faster than non-PCA ones. The reason is that some data information is missing after PCA processing.
2. PCA results has larger gap between test and train. One way to explain is that the model is likely to be overfitting, and thus larger gap between training metric and testing metric.
Jie Luo, Michelle | Washignton, DC

Part IV - Restaurant Recommender
• Clean data and get rating data
• Item-Item similarity recommender
• Matrix Factorization recommender
Build a restaurant recommender based on user's past visits and ratings by using collaborative filtering.

Restaurant Recommender - Item-Item Similarity Recommender
• To make item-item similarity recommender, the ItemItemRecommender class derived from previous exercise is reused.
• Find neighborhoods. Here, we choose “neighborhood_size = 75”.
• Make a prediction for one lucky user. Here, we choose “user_id = 99”.
• Choose the top ten from the final recommendation.
Top Ten Recommendation from
The Final Results:
'Aloha Kitchen', "Pt's Gold",
"Freed's Bakery", 'Tiabi Coffee & Waffle',
'The Westin Las Vegas Hotel & Spa', 'Burger King',
"Rocco's NY Pizzeria", "Denny's",
'Yui Edomae Sushi', "Tony Roma's"
Jie Luo, Michelle | Washignton, DC

Restaurant Recommender - Matrix Factorization recommender
• To make matrix factorization recommender, two of the methods are going to be compared. One is NMF, and the other is UVD/SVD.
• Make a prediction for one lucky user. Here, we still choose “user_id = 99”.
• We compare the results on MSE, the average absolute error, and the absolute error for one particular user.
Top Ten Recommendation Based on NMF method:
'Pressed For Juice’, 'Good Fella Korean Bistro', 'Sambalatte', 'Veggie House',
'Outback Steakhouse', "Braddah's Island Style", 'Soho Sushi Burrito’, "Glazier's Food Marketplace",
'Greens and Proteins', 'Metro Diner'
Top Ten Recommendation Based on NMF method:
'Neighbors', 'Texas de Brazil', 'Me Gusta Tacos’, 'Yum Cha',
'Chabuya', 'JINYA Ramen Bar', 'Mr Mamas', 'Thai BBQ',
'Eat.', 'Bacon Bar'
Jie Luo, Michelle | Washignton, DC

Thank you
Jie Luo (Michelle) | Washignton, DC