xia zhu – intel at mlconf atl
DESCRIPTION
Streaming and Online Algorithms for GraphX GraphX is a resilient distributed graph processing framework on Apache Spark. It is designed for, and is good at, analysis of static graphs. However, it does not support analysis on time evolving graphs yet. In this talk, I will present graph processing research on streaming enhancements for GraphX, which may be used in both pure stream processing or lambda architectures. I will describe an architecture design, and demonstrate how it works with three machine learning algorithms, with detailed evaluation and analysis on performance and scalability.TRANSCRIPT

Intel Confidential — Do Not Forward
Streaming and Online Algorithms for GraphX
Graph Analytics Team
Xia (Ivy) Zhu

Why Streaming Processing on Graph?
2
• New stores join
• New users join
• New users browse/clicks and buy items
• Old users browse/clicks and buy items
• New ads added
• …
• Recommend products based on users’ interest
• Recommend products based on users’ shopping habits
• Recommend products based on users’ purchasing capability
• Place ads which most likely will be clicked by users
• …
EverydayHowTo
Huge amount of relationships are created each day, Wisely utilize them is important

Alibaba Is Not Alone, Graphs are Everywhere
3
100B Neuron100T Relationships
1.23B Users160B Friendships
1 Trillion Pages100s T Links
Millions of Products and Users
50M Users1B hours/moth watch
Large Biological Cell Networks

… And Graphs Keep Evolving
4

Streaming Processing Pipeline
5
Data Stream
ETLCreation
GraphCreation
ML
Distributed Messaging System
• We are using Kafka for distributed messaging• GraphX as graph processing engine

6
• Graph processing engine on Spark
• Support Pregel-type vertex programming
• Unifies data-parallel and graph-parallel processing
Picture Source: GraphX team
What is GraphX

7
• GraphLab performs well, but standalone
• Giraph, open source, scales well, but performance is not good
• GraphX supports both table and graph operations
• On the same platform, Spark streaming provides basic streaming framework
Why GraphX
Spark
RDDs, Transformations, and Actions
Spark Streamingreal-time
SparkSQL
MLLibmachine learning
DStream’s: Streams of RDD’s
SchemaRDD’s RDD-BasedMatrices
GraphXgraph processing/machine learning
RDD-BasedGraphs
Picture Source: Databricks

8
Naïve Streaming Does not Scale• Current GraphX is designed for static graphs• Current Spark streaming provides limited types of state DStreams
• Naïve approach:• Merge table data before going to graph processing pipeline• Re-generate whole graph and re-run ML at each window• Minimal changes to GraphX and Spark Streaming• Straightforward, but does not scale well
0
20
40
60
80
100
120
140
160
180
1 2 3 4 5 6 7 8 9
Lat
en
cy(s
)
Sample Point
Throughput vs Latency of Naive Graph Streaming

Our solution
9
• Static algorithms -> Online algorithms
• Merge information at graph phase
• Efficient graph store for evolving graph• Better partitioning algorithms to reduce replicas
• Static index -> On the fly indexing method (ongoing)

Static vs Online Algorithms
10
• Static algorithms• Good for re-compute the whole graph at each time instance , and re-run ML
• Become increasingly infeasible in Big Data era, given the size and growth rate of graphs
• Online algorithms• Incremental machine learning is triggered by changes in the graph
• We designed delta updates based online algorithms• Page rank as an example• Same idea is applicable to other machine learning algorithms

Static vs Online Page Rank
11
Static_PageRank
// InitialVertexValue(0.0, 0.0)
// first messsageinitialMessage:
msg = alpha/(1.0-alpha)
// broadcast to neighborsSendMessage:
if (edge.srcAttr._2 > tol)Iterator((edge.dstId, edge.srcAttr_2 *
edge.attr))
//Aggregate Messages for each VertexmessageCombiner(a,b) :
sum = a+b
//Update VertexvertexProgram(sum) :updates = (1.0 - alpha) * sum(oldPR + updates, updates)
Online_PageRank
// Initialize vertex valuebase graph:
(0.0, 0.0)incremental graph:
old vertices:(lastWindowPR, lastWindowDelta)new vertices:(alpha, alpha)
// First MessageinitialMessage: base graph:
msg = alpha/(1.0-alpha)incremental graph:
none
// broadcast to neighborsSendMessage:oldSrc->newDst:Iterator((edge.dstId,(edge.srcAttr_1 – alpha) *
edge.attr)) newSrc->newDst or not converged: Iterator((edge.dstId,edge.srcAttr_2 * edge.attr))
//Aggregate Messages for each VertexmessageCombiner(a,b) :
sum = a+b
//Update VertexvertexProgram(sum) :updates = (1.0 - alpha) * sum(oldPR + updates, updates)

GraphX Data Loading and Data Structure
12
Edge lists
SrcIdSrcId
DstIdDstId
EdgeRDDEdgeRDD
DataData
IndexIndex
RoutingTablePartitionRoutingTablePartition
VertexRDDVertexRDD
RoutingTableMesssage
HasSrcIdHasSrcId
HasDstIdHasDstIdReplicated
VertexView
ReplicatedVertexView
GraphImplGraphImpl
EdgePartitionEdgePartition
VertexPartitionVertexPartition
MaskMask
VidVid
DataData
ShippableVertex
Partition
ShippableVertex
Partition
VertexPartitionVertexPartition
MaskMask
VidVid
DataData
Re-HashPartition

GraphX Data Loading and Data Structure
13
Edge lists
SrcIdSrcId
DstIdDstId
EdgeRDDEdgeRDD
DataData
Index
RoutingTablePartitionRoutingTablePartition
VertexRDDVertexRDD
RoutingTableMesssage
HasSrcIdHasSrcId
HasDstIdHasDstIdReplicated
VertexView
ReplicatedVertexView
GraphImplGraphImpl
EdgePartitionEdgePartition
VertexPartitionVertexPartition
MaskMask
VidVid
DataData
ShippableVertex
Partition
ShippableVertex
Partition
VertexPartitionVertexPartition
MaskMask
VidVid
DataData
Re-HashPartition
Static Index
Partitioning Algorithm can help reduce the replication factors

Partitioning Algorithm
14
• Torus-based partitioning• Divide overall partitions to A x B matrix• Vertex’s master partition is decided by Hash function• Replica set is in the same column as master partition (full column), and same row as
master partition ( � �⁄ + 1 elements starting from master partition)• The intersection between source replica set and target replica set decides where an
edge is placed
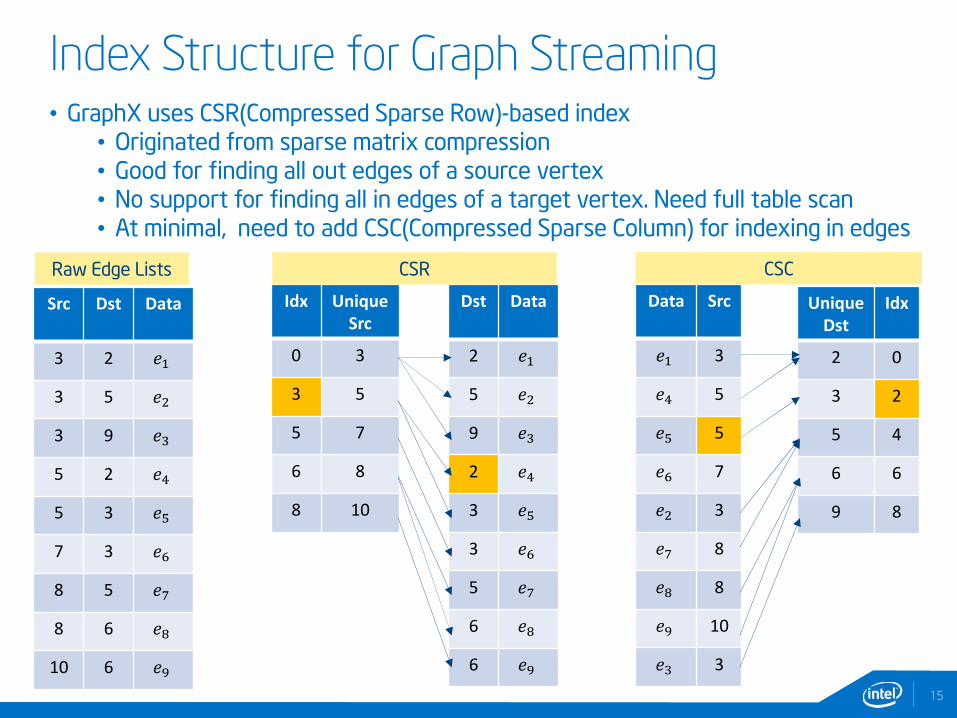
Index Structure for Graph Streaming
15
• GraphX uses CSR(Compressed Sparse Row)-based index• Originated from sparse matrix compression• Good for finding all out edges of a source vertex• No support for finding all in edges of a target vertex. Need full table scan• At minimal, need to add CSC(Compressed Sparse Column) for indexing in edges
Src Dst Data
3 2 ��
3 5 ��
3 9 ��
5 2 ��
5 3 ��
7 3 ��
8 5 ��
8 6 ��
10 6 ��
Raw Edge Lists
Dst Data
2 ��
5 ��
9 ��
2 ��
3 ��
3 ��
5 ��
6 ��
6 ��
Idx UniqueSrc
0 3
3 5
5 7
6 8
8 10
CSR
Data Src
�� 3
�� 5
�� 5
�� 7
�� 3
�� 8
�� 8
�� 10
�� 3
UniqueDst
Idx
2 0
3 2
5 4
6 6
9 8
CSC

Index Structure for Graph Streaming
16
• Both CSR and CSC need firstly sort edge lists and then create index.• Even better way is to build index on the fly
• For graph streaming, need to support both fast insert/write and fast search/read• HashMap
• Good for exact match, point search• Fast on insert and search• Good for graph with fixed/known size• Need to re-hash when size surpasses capacity
• Trees: B-Tree, LSM-Tree (Log Structured Merge Tree), COLA(Cache Oblivious Lookahead Array)• Support both point search and range search• B-Tree good for fast search, slow for insert• LSM-Tree good for fast insert, slow for search• COLA achieves good tradeoff: fast insert and good enough search
COLA based index for graph streaming

Putting Things Together: Our Streaming Pipeline
17
����
����
OML
������
��������
��������
OML
����������
��������
+
��������
��������
OML
����������
��������
+
��������
��������
OML
����������
��������
+
��������
��������
OML
����������
��������
+
…
����

Performance - Convergence Rate
18
0.0
0.2
0.4
0.6
0.8
1.0
1.2
Base +20% +40% +60% +80% +100% +150% +200%
No
rmal
ize
d N
um
be
r o
f It
era
tio
ns
Graph Size ( Num of Edges)
Converage Rate
Naive Incremental

Performance - Communication Overhead
19
0%
20%
40%
60%
80%
100%
120%
Base +20% +40% +60% +80% +100% +150% +200%
No
rmal
ize
d N
um
be
r o
f M
ess
age
s Se
nt
Graph Size (Num of Edges)
Communication Overhead
naive
Incremental

Ongoing & Future Work
20
• Working on online version of ML algorithms in different categories
• Performance evaluation on various online algorithms
• Complete on the fly indexing work
• Performance evaluation on different indexing methods

Intel Confidential — Do Not Forward