word weighting based on user’s browsing history yutaka matsuo national institute of advanced...
TRANSCRIPT

Word Weighting based on User’s Browsing History
Yutaka MatsuoNational Institute of Advanced Industrial Science and
Technology (JPN)
Presenter: Junichiro MoriUniversity of Tokyo (JPN)

Outline of the talk
• Introduction– Context-based word weighting
• Proposed measure
• System architecture
• Evaluation
• Conclusion

Introduction
• Many information support systems with NLP use tfidf to measure the weight of words.– Tfidf is based on statistics of word occurrence on a
target document and a corpus.
– It is effective in many practical systems including summarization systems and retrieval systems.
• However, a word that is important to one user is sometimes not important to others.
Introduction

Example• “Suzuki hitting streak ends at 23 games”
– Ichiro Suzuki is a Japanese MLB player, MVP in 2001.– Those who are greatly interested in MLB would thinks “hitting streak
ends” as important,– While a user who has no interest in MLB would note the words
“game” or “Seattle Mariners” as the informative, because those words would indicate that the subject of the article was baseball.
• If a user is not familiar with the topic, he/she may think general words related to the topic are important.
• On the other hand, if a user is familiar with the topic, he/she may think more detailed words are important.
Our main hypothesis
Introduction

Goal of this research
• This research addresses context-based word weighting, focusing on the statistical feature of word co-occurrence.
• In order to measure the weight of words more correctly, contextual information about a user (we call “familiar words”) is used.
Introduction

Outline of the talk
• Introduction– Context-based word weighting
• Proposed measure– Previous work– IRM (Interest Relevance Measure)
• System architecture• Evaluation• Conclusion

IRM• A new measure, IRM, is based on a word-
weighting algorithm applied to a single document.
– [Matsuo 03]: Keyword Extraction from a Single Document using Word Co-occurrence Statistical Information, FLAIRS 2003

We take a paper for example.COMPUTING MACHINERY AND INTELLIGENCE
A.M.TURING1 The Imitation Game I PROPOSE to consider the question, 'Can machines think?' This should begin with definitions of the meaning of the terms 'machine 'and 'think'. The definitions might be framed so as to reflect so far as possible the normal use of the words, but this attitude is dangerous. If the meaning of the words 'machine' and 'think 'are to be found by examining how they are commonly used it is difficult to escape the conclusion that the meaning and the answer to the question, 'Can machines think?' is to be sought in a statistical survey such as a Gallup poll. But this is absurd. Instead of attempting such a definition I shall replace the question by another, which is closely related to it and is expressed in relatively unambiguous words. The new form of the problem can be described' in terms of a game which we call the 'imitation game'. It is played with three people, a man (A), a woman (B), and an interrogator (C) who may be of either
Previous work [Matsuo03]

Distribution of frequent terms
00.050.10.150.20.250.30.350.4
probability
a b c d e f g h I j
term
Previous work [Matsuo03]

Next, count co-occurrences
・・・・・・・・・・・・・・・・The new form of the problem can be described' in terms of a
game which we call the `imitation game’.・・・・・・・・・・・・・・・・
stem, stop word elimination, phrase extraction
“new” and “form” co-occur once.“new” and “problem” co-occur once.….“call” and “imitation game” co-occur once.
Previous work [Matsuo03]

Co-occurrence matrix
“kind”
Frequent termsF
requ
ent
term
s
“make”
Previous work [Matsuo03]
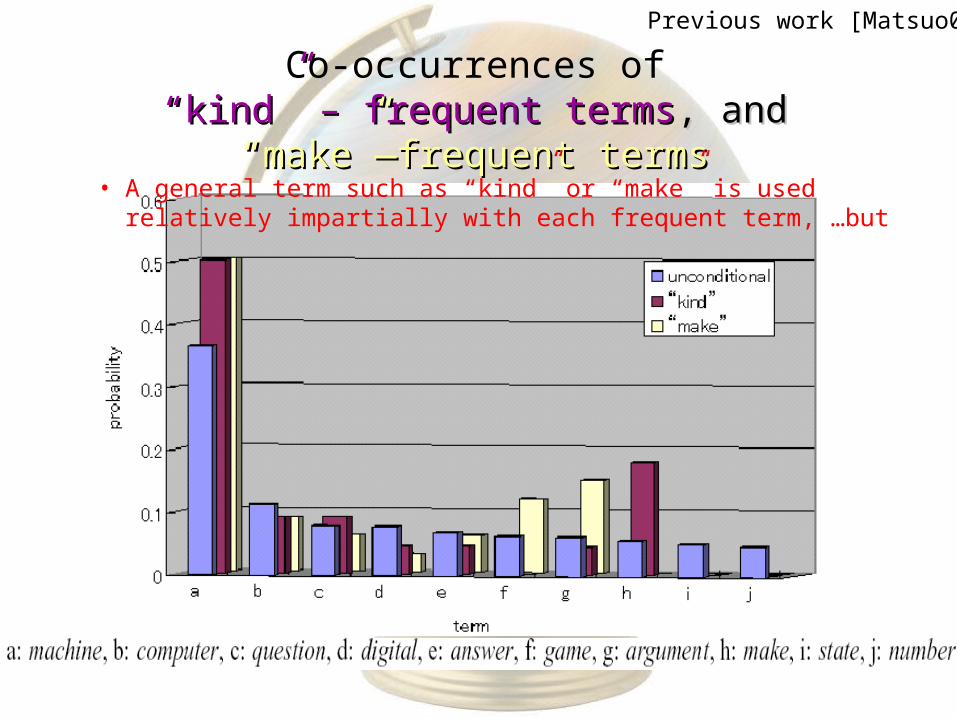
Co-occurrences of“kind” – frequent terms“kind” – frequent terms, and, and
“make”—frequent terms“make”—frequent terms• A general term such as “kind” or “make” is used relatively
impartially with each frequent term, …but
Previous work [Matsuo03]

Co-occurrence matrix
“imitation”
Frequent termsF
requ
ent
term
s
“digital computer”
Previous work [Matsuo03]

Co-occurrences of“imitation” – frequent terms, and
“digital computer”—frequent termswhile a term such as “imitation” or “digital
computer” shows co-occurrence especially with particular terms.
Previous work [Matsuo03]

Biases of co-occurrence
• A general term such as “kind” or “make” is used relatively impartially with each frequent tem,
while a term such as “imitation” or “digital computer” shows co-occurrence especially with particular terms.
• Therefore, the degree of biases of co-occurrence can be used as a surrogate of term importance.
Previous work [Matsuo03]

χ2-measure
• We use the χ2-test, which is very common for evaluating biases between expected and observed frequencies.
square
Expected co-occurrenceObserved co-occurrence
Gg g
g
pwf
pwfgwfreqw
)(
))(),(()(
22
G: Frequent termsfreq(w,g): Frequency of co-occurrence term w and term g.pg: unconditional probability (the expected probability) of g.f(w): The total number of co-oocurrence of term w and frequent terms G
Previous work [Matsuo03]
•Large bias of co-occurrence means importance of a word.

Sort by χ2-valueΧ2-
valueLabel Freq
1 593.7 digital computer 31
2 179.3 imitation game 16
3 163.1 future 4
4 161.3 question 44
5 152.8 internal 3
6 143.5 answer 39
7 142.8 input signal 3
8 137.7 moment 2
9 130.7 play 8
10 123.0 output 15
・・・
・・・ ・・・ ・・
・
551 1.0 slowness 2
552 1.0 unemotional channel 2
553 0.8 Mr. 2
554 0.8 sympathetic 2
555 0.7 leg 2
556 0.7 chess 2
557 0.6 Pickwick 2
558 0.6 scan 2
559 0.3 worse 2
560 0.1 eye 2
We can get important words based on co-occurrence information in a document.
Previous work [Matsuo03]

Outline of the talk
• Introduction– Context-based word weighting
• Proposed measure– Previous work– IRM (Interest Relevance Measure)
• System architecture• Evaluation• Conclusion

Personalize the calculation of word importance
• The previous method is useful for extracting reader-independent important words from a document.
• However, importance of words depends not only on the document itself but also on a reader.
IRM, proposed measure

If we change the columns to pick up…
a b c d e f g h i j total
a ― 30 26 19 18 12 12 17 22 9 165
b 30 ― 5 50 6 11 1 3 2 3 111
c 26 5 ― 4 23 7 0 2 0 0 67
d 19 50 4 ― 3 7 1 1 0 4 89
e 18 6 23 3 ― 7 1 2 1 0 61
f 12 11 7 7 7 ― 2 4 0 0 50
g 12 1 0 1 1 2 ― 5 1 0 23
h 17 3 2 1 2 4 5 ― 0 0 34
i 22 2 0 0 1 0 1 0 ― 7 33
j 9 3 0 4 0 0 0 0 7 ― 23
・・・
・・・
・・・
・・・
・・・
・・・
・・・
・・・
・・・
・・・
・・・
・・・
u 6 5 5 3 3 18 2 2 1 0 45
V 13 40 4 35 3 6 1 0 0 2 104
w 11 2 2 1 1 0 1 4 0 0 22
X 17 3 2 1 2 4 5 0 0 0 34
a: machine,b: computer,c: question,d: digital,e: answer,f: game,g: argument,h: make, i: state, j: number
u: imitation,v: digital computer,w:kind,x:make
k
9
13
0
4
2
0
5
0
7
6
・・・
0
2
4
0
IRM, proposed measure

If we change the columns to pick up…
word
196.9 imitation game
88.9 play
62.4 digital computer
60.1 card
57.1 future
50.4 logic
45.1 identification
44.4 universality
42.7 state
word
196.6 imitation game
88.5 play
84.4 logic system
62.2 digital computer
60.0 card
57.0 future
44.9 identification
44.2 proposition
43.9 limitation
word
196.2 imitation game
113.8 animal
88.2 play
62.0 digital computer
59.9 card
56.9 future
49.8 identification
44.7 woman
40.8 book
Frequent words Frequent terms “+ logic” Frequent terms+“God”
The relevant words to selected words have high χ2 value, because they co-occurs often.
IRM, proposed measure

Familiarity instead of frequency
• We focus on “familiar words” to the user, instead of “frequent words” in the document.
• [Definition] Familiar words are the words which a user has frequently seen in the past.
IRM, proposed measure

Interest Relevancy Measure (IRM)
where Hk is a set of familiar words for user k
kHh h
h
pwf
pwfhwfreqkwIRM
)(
))(),((),(
2
Gg g
g
pwf
pwfgwfreqw
)(
))(),(()(
22
IRM, proposed measure

IRM
• If the value of IRM is large, word wij is relevant to user’s familiar words. – The word is relevant to the user’s interests, so it
is a keyword for the user.
• Conversely, if the value of IRM is small, word wij is not specifically relevant to any of the familiar words.
IRM, proposed measure

Outline of the talk
• Introduction– Context-based word weighting
• Proposed measure– Previous work– IRM (Interest Relevance Measure)
• System architecture• Evaluation• Conclusion

Browsing support system
• It is difficult to evaluate IRM objectively because the weight of words depends on a user’s familiar words, and therefore varies among users.
• Therefore, we evaluate IRM by constructing a Web browsing support system. – Web pages accessed by a user are monitored by a proxy
server.
– The count of each word is stored in a database.

System architecture ofbrowsing support system
Proxy Server Keyword Extraction Module- Morphological analysis- Count word frequency- Query past word frequency-Compute IRM of words- Select keywords- Modify the HTML
-Keep word count for each user- Increment word count
Frequency Server
- Pass if non-text data - Send the body part of HTML - Receive the result and send to browser
query frequency in the history
Internet
Browser

Sample Screen shot


Outline of the talk
• Introduction– Context-based word weighting
• Proposed measure– Previous work– IRM (Interest Relevance Measure)
• System architecture• Evaluation• Conclusion

Evaluation
• For evaluation, ten people tried this system for more than one hour.
• Three methods are implemented for comparison.– (I) word frequency– (II) tf ・ idf– (III) IRM

Evaluation – Result(1)• After using each system (blind), we ask the following questions on a 5-
point Likert-scale from 1(not at all) to 5 (very much).
– Q1: Do this system help you browse the Web?• (I) 2.8 (II) 3.2 (III) 3.2
– Q2: Are the red color words (=high IRM words) interesting to you?• (I) 3.2 (II) 4.0 (III) 4.1
– Q3: Are the interesting words colored red?• (I) 2.9 (II) 3.3 (III) 3.8
– Q4: Are the blue color words (=familiar words) interesting to you?• (I) 2.7 (II) 2.5 (III) 2.0
– Q5: Are the interesting words colored blue?• (I) 2.7 (II) 2.5 (III) 2.4
(I) word frequency (II) tf ・ idf (III) IRM

Evaluation – Result(2)
• After evaluating all three system, we ask the following two questions.
– Q6: Which one helps your browsing the most?• (I) 1 people (II) 3 (III) 6
– Q7: Which one detects your interests the most?• (I) 0 people (II) 2 (III) 8
• Overall, IRM can detect words of the user’s interests the most.
(I) word frequency (II) tf ・ idf (III) IRM

Outline of the talk
• Introduction– Context-based word weighting
• Proposed measure– Previous work– IRM (Interest Relevance Measure)
• System architecture• Evaluation• Conclusion

Conclusion • We develop an context-based word weighting
measure (IRM) based on the relevance (i.e., the co-occurrence) to a user’s familiar words.– If a user is not familiar with the topic, he/she may think
general words related to the topic are important.
– On the other hand, if a user is familiar with the topic, he/she may think more detailed words are important.
• We implemented IRM to browsing support system, and showed the effect.