wing.comp.nus.edu.sgwing.comp.nus.edu.sg/~antho/w/w00/w00-17.pdfwing.comp.nus.edu.sg
TRANSCRIPT

Semantic Annotation and Intelligent Content
Proceedings of the Workshop
Supported by SIGLEX, the ACL Special Interest Group
on the Lexicon
Paul Buitelaar, Kôiti Hasida
Editors
August 5th/6th, 2000
Centre Universitaire
Luxembourg
COLING 2000


iii
Topics and Motivation
SEMANTIC ANNOTATION is augmentation of data to facilitate automaticrecognition of the underlying semantic structure. A common practice in this respect islabeling of documents with thesaurus classes for the sake of document classificationand management. In the medical domain, for instance, there is a long-standingtradition in terminology maintenance and annotation/classification of documentsusing standard coding systems such as ICD, MeSH and the UMLS meta-thesaurus.Semantic annotation in a broader sense also addresses document structure (title,section, paragraph, etc.), linguistic structure (dependency, coordination, thematic role,co-reference, etc.), and so forth. In NLP, semantic annotation has been used inconnection with machine-learning software trainable on annotated corpora forparsing, word-sense disambiguation, co-reference resolution, summarization,information extraction, and other tasks. A still unexplored but important potential ofsemantic annotation is that it can provide a common I/O format through which tointegrate various component technologies in NLP and AI such as speech recognition,parsing, generation, inference, and so on.
INTELLIGENT CONTENT is semantically structured data that is used for a widerange of content-oriented applications such as classification, retrieval, extraction,translation, presentation, and question-answering, as the organization of such dataprovides machines with accurate semantic input to those technologies. Semanticallyannotated resources as described above are typical examples of intelligent content,whereas another major class includes electronic dictionaries and inter-lingual orknowledge-representation data. Some ongoing projects along these lines are GDA(Global Document Annotation), UNL (Universal Networking Language) and SHOE(Simple HTML Ontology Extension), all of which aim at motivating people tosemantically organize electronic documents in machine-understandable formats, andat developing and spreading content-oriented application technologies aware of suchformats. Along similar lines, MPEG-7 is a framework for semantically annotatingaudiovisual data for the sake of content-based retrieval and browsing, among others.Incorporation of linguistic annotation into MPEG-7 is in the agenda, becauselinguistic descriptions already constitute a main part of existing metadata. In short,semantic annotation is a central, basic technology for intelligent content, which inturn is a key notion in systematically coordinating various applications of semanticannotation. In the hope of fueling some of the developments mentioned above andthus promoting the linkage between basic researches and practical applications, theworkshop invites researchers and practitioners from such fields as computationallinguistics, document processing, terminology, information science, and multimediacontent, among others, to discuss various aspects of semantic annotation andintelligent content in an interdisciplinary way.
Paul Buitelaar, Kôiti Hasida

iv
Organisation and Invited Talks
Organisers
Paul BuitelaarKôiti Hasida
Program Committee
Amit Bagga, GE Corporate R&D, USAPaul Buitelaar, DFKI-LT, Germany (Co-Chair)Gregor Erbach, FTW, AustriaChristiane Fellbaum, Princeton University, USAWolfgang Giere, ZINFO, University of Frankfurt, GermanyNicola Guarino, Ladseb-CNR Padova, ItalyKôiti Hasida, ETL, Japan (Co-Chair)Boris Katz, AI Laboratory, MIT, USAAdam Kilgarriff, University of Brighton, UKElizabeth Liddy, Syracuse University, USAKatashi Nagao, IBM TRL, JapanHiroshi Nakagawa, University of Tokyo, JapanHwee Tou Ng, DSO, SingaporeMartha Palmer, University of Pennsylvania, USAVirach Sornlertlamvanich, NECTEC, ThailandSteffen Staab, University of Karlsruhe, GermanyHenry Thompson, Edinburgh University, UKHiroshi Uchida, United Nations University, JapanRémi Zajac, CRL, New Mexico State University, USA
Invited Talks
In-depth Utilization of Natural Language Processing for Rich Semantic AnnotationElizabeth Liddy, Syracuse University, USA
MindNet as a Framework for Semantically Structuring TextBill Dolan, Microsoft, USA
UNL: Interlingua as Intelligent ContentHiroshi Uchida, United Nations University, Japan
GDA: Semantically Annotated Documents as Intelligent ContentKoiti Hasida, ETL, Japan

v
Table of Contents
Topics and Motivation ............................................................................................................. iiiOrganisation and Invited Talks ................................................................................................ ivTable of Contents ..................................................................................................................... v
Workshop Papers
SECTION 1 : Semantic Annotation of Word Class and Dependency Structure ............. 1
Semantic Annotation of a Japanese Speech CorpusJohn Fry, Francis Bond .............................................................................................. 3
Exploring Automatic Word Sense Disambiguation with Decision Lists and the WebEneko Agirre, David Martinez ................................................................................... 11
Improving Natural Language Processing by Linguistic Document AnnotationHideo Watanabe, Katashi Nagao, Michael McCord, Arendse Bernth ........................ 20
Building an Annotated Corpus in the Molecular-Biology DomainYuka Tateisi, Tomoko Ohta, Nigel Collier, Chikashi Nobata, Jun-ichi Tsujii ........... 28
SECTION 2 : Semantic Annotation of Discourse Structure ............................................. 35
Semantic Annotation for Generation: Issues in Annotating a Corpus to Develop and EvaluateDiscourse Entity Realization Algorithms
Massimo Poesio .......................................................................................................... 37An Environment for Extracting Resolution Rules of Zero Pronouns from Corpora
Hiromi Nakaiwa ......................................................................................................... 44Discourse Structure Analysis for News Video
Yasuhiko Watanabe, Yoshihiro Okada, Sadao Kurohashi, Eiichi Iwanari ................. 53
SECTION 3 : Semantic Annotation of Document Segments ............................................ 61
Alignment of Sound Track with Text in a TV DramaSeigo Tanimura, Hiroshi Nakagawa ........................................................................... 63
Semantic Transcoding: Making the WWW More Understandable and Usable with ExternalAnnotations
Katashi Nagao, Shingo Hosoya, Yoshinari Shirai, Kevin Squire ............................... 70From Manual to Semi-Automatic Semantic Annotation: About Ontology-Based TextAnnotation Tools
Michael Erdmann, Alexander Maedche, Hans-Peter Schnurr, Steffen Staab ............ 79

vi

1
SECTION 1
Semantic Annotation of Word Class andDependency Structure

2

Semantic annotation of a Japanese speech corpus
John FryLinguistics Dept. & CSLIStanford University
Stanford CA 94305-2150 [email protected]
Francis Bond∗
Machine Translation Research GroupNTT Communication Science Laboratories2-4 Hikari-dai, Kyoto 619-0237 [email protected]
Abstract
This paper describes the semantic annotationswe are performing on theCallHome Japanesecorpus of spontaneous, unscripted telephoneconversations (LDC, 1996). Our annotationsinclude (i) semantic classes for all nouns andverbs; (ii) verb senses for all main verbs; and(iii) relations between main verbs and theircomplements in the same utterance. Our se-mantic tagset is taken from NTT’s Goi-Taikeisemantic lexicon and ontology (Ikehara et al.,1997). A pilot study demonstrates that theverb sense tagging can be efficiently performedby native Japanese speakers using computer-generated HTML forms, and that good inter-annotator reliability can be obtained in the rightconditions.
1 Introduction
Semantic annotations have proved valuable fora variety of NLP tasks, including parsing, wordsense disambiguation, coreference resolution,summarization, and information retrieval andextraction. The most challenging domain forall these tasks is spontaneous spoken language,which tends to be more terse, less grammati-cal, less structured, and more ambiguous thanplanned or written text. For this reason, theannotation of spoken language corpora with ac-curate, high-quality linguistic tags has becomea topic of great interest recently (Dybkjær etal., 1998; Ide, 1998; Core et al., 1999).The target of our semantic annotations is
the CallHome Japanese (CHJ) corpus (LDC,1996). The CHJ corpus consists of digi-tized speech data and text transcriptions of120 spontaneous, unscripted telephone conver-sations in Japanese. Each transcript is en-
∗ Visiting CSLI, Stanford University (1999-2000).
coded in EUC-format Japanese characters andcovers a contiguous 5 or 10 minute segmenttaken from a recorded conversation lasting upto 30 minutes. To illustrate, a brief frag-ment (the first three utterances) of a CHJ tran-script is given in Figure 1 (an English glossappears below the fragment). Each utterancein a transcript is analyzed into individual mor-phemes, with transcriber comments in brack-ets. The speaker (A or B) and the startand end times of each utterance (i.e. speakerturn) are also provided in the transcripts. The120 conversations in the CHJ corpus containa total of about 340,000 word/morpheme to-kens, 12,000 unique word/morpheme types, and39,000 speaker turns.The CHJ corpus was originally created for re-
search in large vocabulary speech recognition.However, we hope to make the corpus useful forother types of NLP research (by ourselves andothers) by supplementing it with a variety oflinguistic annotations. When finished, we planto make the annotated CHJ corpus available tothe research community through the LDC.We are annotating the CHJ corpus with
a variety of syntactic, semantic, and acous-tic/prosodic tags. In this paper we focus on oursemantic annotations, which include the follow-ing:
• Semantic classes for all verbs and nouns.
• Verb senses for each main verb.
• Predicate-argument relations betweenmain verbs and their explicitly mentionedverb complements, labeled with thematicroles.
By way of example, Table 1 shows the endtime boundary te (i.e. duration), POS, pronun-ciation, canonical form (including verb sense

120.20 123.35 A:���
@ � [[ ����� ,col]] � ������������������� � �123.26 123.70 B: !#"$�124.28 128.50 A: %'&)(+* ,.-0/1�325476��38:9;� @ <=9 [[ �0")9 ,col]] >=���?� @A !7BDC����?E�F � @ � [[ � �1� ,col]] �3G0H*JI=K+8 {laugh} �Translation:
A:�$�Uso,Lie,
�atashiI
shokuemployment
-ganom
�;�L�nakutenot-have
�say’know
���nihonJapan
�-nidat
���M�kaettareturned
� �-ra.if.
‘No way. Having no employment, y’know, maybe I should return to Japan?’
B: !�"��Un.
‘Uh-huh.’
A: %N&0(ToniiTony
*-nogen
,o-hon
-0/��tanjoubibirthday
2=4kugatsuSept.
6��futsuka2nd
8dais
9;�karabecause
<=9nankasomething
>=���kattebuy
��@age-give
A !youvol
B-tocomp
C����omottathink
E�F �kedo,but,
�atashiI
�say’know
G)mushokujobless
*-nogen
IOKningenperson
8$�da.am.
‘Tony’s birthday is Sept. 2 so I want to buy him something, but I’m unemployed.’
Figure 1: Fragment from CHJ transcript 0696
ID Word te (s) POS Phonetic Canonical Class Arguments003 � �1� 0.810 pro atasi � c0008004 1.060 noun syoku c1939005 1.180 part ga006 �;�L� 1.580 v-neg,te nakute GQP (3) v0003 N1:003,N2:004007 � 1.840 part sa008 �#� 2.134 prop nihoN �#� c0385,c0463,p0030009 � 2.250 part ni010 ���M� 2.610 v-r5 kaeqta ��R (2) v0014 N1:003,N5:008011 � 2.940 cond2 ra
Table 1: Sample annotations from the first utterance of 0696
number), semantic class, and argument indexesfor most of the first utterance from Figure 1.Our current plan is to provide our annota-
tions in the simple tabular text format shownin Table 1, rather than in one of the of thenumerous annotation frameworks currently incontention.1 If a reliable and widely-acceptedXML encoding framework emerges before werelease our annotations, then we will consider
1For example, 53 annotation frameworks arelisted at http://morph.ldc.upenn.edu/annotation/.For speech corpora, notable contributions in-clude the Corpus Encoding Standard (CES,http://www.cs.vassar.edu/CES/), MATE (Dybkjær etal., 1998), and the ‘annotation graph’ approach of Birdand Liberman (1998).
adopting that scheme. However, our primaryaim is to provide simple, accurate, low-level an-notations (upon which other, higher-level an-notations might be based) so that language re-searchers can use the corpus more flexibly andwith greater confidence.Some of the annotations which we have al-
ready completed, or nearly completed, but willnot discuss in this paper include the following:
• Phonetic transcriptions, in Romancharacters (kunreisiki transliteration), ofall 120 conversations.
• POS tags using the LDC’s existing inven-tory of 60 syntactic and morphological tagsfor Japanese.

• Raw acoustic data from theESPS/waves+ speech processing software,including f0 (fundamental frequency)and power (root-mean-square amplitude)measurements at 10ms intervals.
• The duration of each word, based on semi-automatic word segmentation of the speechdata.
The remainder of this paper is organized asfollows. In Section 2 we describe NTT’s Goi-Taikei semantic dictionary, which is the sourceof our semantic tagset. Section 3 describes ourtagging methodology and our pilot study of theverb sense annotation task. Finally, Section 4describes our browser-based annotation appli-cation.
2 Goi-Taikei
As a base for our tags, we are using the Goi-Taikei (GT) Japanese lexicon (Ikehara et al.,1997), a 400,000-word lexicon and ontology de-veloped by NTT for machine translation (MT)applications.We decided that GT is an appropriate re-
source for our semantic annotation task forthree reasons. First, semantic information fromGT has already proved valuable in a variety ofNLP applications in Japan, including parsing,morphological analysis, text-to-speech, proof-reading, and MT (Ikehara et al., 1994; Shi-rai et al., 1995; Akiba et al., 1995; Oku,1996; Nakaiwa and Seki, 1999; Baldwin et al.,1999; Baldwin and Tanaka, 1999; Yokoyamaand Ochiai, 1999). Secondly, the GT lexi-con and ontology, at 400,000 words, is signifi-cantly larger than earlier dictionaries, such asthe 260,000-word EDR Dictionary (EDR, 1996)and the 2,000-word IPAL lexicon (IPA, 1987;IPA, 1990; IPA, 1996). GT also contains de-tailed valency information for 16,000 predicatesenses, which makes it more suited to our taskthan the Kadokawa thesaurus (Hamanishi andOno, 1990). Finally, GT is available in bookand CD-ROM format at a price (around US$750) that is several times lower than EDR.GT consists of three main components: (i) an
ontology, (ii) a semantic word dictionary, and(iii) a semantic structure dictionary which in-cludes subcategorization frames for verbs andadjectives.
2.1 Ontology
GT’s ontology classifies concepts to use in ex-pressing relationships between words. Themeanings of common nouns are given in termsof a semantic hierarchy of 2,710 nodes. Most ofthe top four levels of the semantic hierarchy areshown in Figure 2, with two examples of deepernodes. Each node represents a semantic class.Edges in the hierarchy represent is-a or has-a relationships, so that the child of a semanticclass related by an is-a relation is subsumed byit. For example, nation is-a organization. Inaddition to the 2,710 classes (12-level tree struc-ture) for common nouns, there are 200 classes(9-level tree structure) for proper nouns and 108classes (5-level tree structure) for predicates.
2.2 Semantic Word Dictionary
The GT semantic dictionary includes 100,000common nouns, 200,000 proper nouns, 70,000technical terms and 30,000 other words: 400,000words in all.Figure 3 shows a simplified example of one
record of the Japanese semantic word dictio-nary. Each record specifies an index form, pro-nunciation, canonical form, syntactic informa-tion and a set of semantic classes. The syn-tactic information includes the part of speech,inflectional class, detailed parts of speech, con-junctive conditions and so on. Each word canhave up to five common noun semantic classesand ten proper noun semantic classes. Thenumbering system gives common-noun seman-tic classes a prefix of c, proper-noun classes aprefix of p, and predicate classes a prefix of v.In Figure 3, for example, the word
���nihon
“Japan” belongs to the common-noun classesc0385 nation (⊂ organization) and c0463territory (⊂ place), and to proper-noun classp0030 country (⊂ place name). More exam-ples of semantic classes for the nouns and verbsfrom the annotated CHJ fragment in Table 1are listed in that table under the column labeled‘Class’.
2.3 Semantic Structure Dictionary
The basic structure of a clause comes fromthe relationship between the main verb andnouns. GT’s structure transfer dictionary, de-signed for MT applications, provides this basicclause structure. GT provides 10,000 patternsin its common structure transfer dictionary and

personagent organization nation
facilityconcrete place region territory
natural placeobject animate
noun inanimatemental state
abstract thing actionhuman activity
abstract event phenomenonnatural phenomenon
relation [etc.]
Figure 2: GT’s Semantic Hierarchy (top 4 levels)
Index Form �#�Pronunciation /nihon/
Canonical Form �#�Part of Speech noun
Semantic Classes
[
common noun nation (c0385), territory (c0463)
proper noun country (p0030)
]
Figure 3: Japanese Lexical Entry for noun� �nihon “Japan”
5,000 patterns in its idiomatic structure trans-fer dictionary. The common structure transferdictionary contains an average of 2.3 patternsfor each verb.Figure 4 gives an example from the common
structure transfer dictionary. Each predicate isassociated with one or more arguments labeledN1, N2, . . . . Each case-slot contains informa-tion such as grammatical function, case-marker,case-role, semantic restrictions on the filler anddefault order (not all features are shown in theexample). The arguments correspond betweenJapanese and English, thus giving the backboneof the transfer.
2.3.1 Case Roles
Case-elements in the valency dictionary are as-sociated with particular case roles (also knownas thematic roles, θ-roles, or deep cases). Thecurrent set of case roles is given in Table 2, alongwith the most commonly associated case mark-ers2 in Japanese, and prepositions or grammat-ical functions (gf) in English. The annotatedCHJ fragment in Table 1 shows some specific
2Japanese case markers (also known as ‘particles’) arepostpositions, and are similar to English prepositions inmany ways.
case-role fillers under the column labeled ‘Ar-guments’. For example, word 008,
� �nihon
“Japan”, serves as the goal argument (N5) of theverb
�����kaetta “returned (home)” in that
utterance.There seems to be no consensus among lin-
guists on what the best set of case roles is,or even whether case roles should be replacedby more abstract primitives or more concreteparticipant-roles. In any case, case roles havein practice proved extremely useful for NLP andare used in most MT systems (Bond and Shirai,1997).
3 Tagging methodology
We are annotating the CHJ corpus with (i) se-mantic classes for all nouns and verbs; (ii) verbsenses for all main verbs; and (iii) predicate-argument relations between main verbs andtheir complements in the same utterance. Ourtagging of verb senses and predicate-argumentrelations relies on the browser-based annota-tion application described in Section 4. Thepredicate-argument tags, based on GT’s seman-tic structure dictionary (Section 2.3), provide abasic dependency structure for each utterance.

Pattern-ID -0002-00-
Semantic Class (action)
Japanese
pred� R toru (verb)
N1
[
case-marker ga “nom” (Agent)restriction agent
]
N2
[
case-marker � o “acc” (Object-1)restriction lodging, room, vehicle, ...
]
English
pred reserve (verb)
N1[
function subject (nominative)]
N2[
function direct-object (accusative)]
Figure 4: Part of the common structure transfer dictionary for one sense of ��� toru “take”
Label Name Case-marker English Label Name Case-marker English
N1 Agent ga (kara, towa) Subj (gf) N8 Locative ni, o, de, e, kara in/at/onN2 Object-1 o (nituite) Obj (gf) N9 Comitative to withN3 Object-2 ni (. . . ) I-Obj (gf) N10 Quotative toN4 Source kara, yori from N11 Material kara, yori, de with, fromN5 Goal ni, e, made to (until) N12 Cause kara, yori, de forN6 Purpose ni for N13 Instrument de withN7 Result ni, to as N14 Means de by
Table 2: Case-roles
Although spontaneous utterances like those inthe CHJ corpus are often fragmentary and un-grammatical, rendering full syntactic parsingimpractical, the basic relations between pred-icates and their arguments still hold.
3.1 Tagging semantic classes
We assign GT semantic classes to individualCHJ nouns and verbs by automatic table lookupon their GT canonical form. In both GT andthe CHJ lexicon, the canonical forms of wordsare generally in Chinese characters (kanji). Forexample, the annotated CHJ fragment in Ta-ble 1 shows some canonical forms under the col-umn labeled ‘Canonical’. For the verbs in Ta-ble 1, the canonical (dictionary) form includesthe GT verb sense number.In the majority of cases, the GT canonical
form of a verb or noun is identical to the canoni-cal form which appears in the CHJ lexicon. Thesmall percentage of cases where the canonicalforms differ are corrected by hand. For the ap-proximately 700 nouns in the CHJ corpus thatare not covered in the GT lexicon (mainly per-
sonal names), we assign the closest available GTclass(es) by hand.We are marking each noun and verb in the
corpus with all of its GT semantic classes, eventhose which might be inappropriate for the wordin its particular utterance context. For exam-ple, in the annotated CHJ fragment in Table 1,the noun
� �nihon “Japan” is marked with
all three of its GT classes: c0385 nation (⊂organization), c0463 territory (⊂ place),and p0030 country (⊂ place name). Natu-rally, it would preferable to exclude those se-mantic classes which are inappropriate for agiven noun or verb in its particular context ofuse in the CHJ corpus. However, this wouldrequire human coders to classify hundreds ofthousands of word tokens based on the per-ceived context in the conversation. In addition,it would be hard to obtain high inter-annotatorreliability, given the context-dependent natureof the task and the amount of overlap in thesemantic classes.

3.2 Tagging verb senses and arguments
We are providing human-tagged verb sense andverb argument annotations for each main verbin the corpus. Auxiliary verbs and other formsof verb morphology are ignored, except in caseslike the passive and causative in which the va-lence of the main verb is altered. In those cases,special passive or causative senses are provided.Our plan is to annotate the GT verb senses
and argument indexes according to the major-ity judgments of three native-speaker studentassistants. The students will make the annota-tions by clicking on menu choices in a web ap-plication that we generate automatically fromthe GT dictionary files and CHJ transcript files(Section 4).
3.3 A pilot study
In preparation for the verb sense taggingproject, we conducted a pilot study in whichwe asked five native speakers to select GT verbsenses and identify intrasentential argumentsfor all 110 main verbs in one five-minute CHJtranscript.Our initial results showed that pairwise inter-
annotator agreement on verb senses was 0.68.When chance agreement is taken into accountvia the kappa statistic, the result, κ = 0.63,shows that annotator agreement was not reli-able (Carletta, 1996). However, we discoveredthat this result was largely attributable to theannotators’ selection of the category “none (ofthe above),” which the five judges picked withhighly variable frequency ({7, 11, 22, 25, 26}, s =8.6). For 51 of the 110 verb tokens (46%),“none” was selected by one or more judges, andagreement was low (0.48, κ = 0.42). Whenthe “none” answers were disregarded, pair-wise agreement on those verbs rose consider-ably (to 0.67, κ = 0.64). For the remaining59 verb tokens (54%), “none” was never cho-sen and pairwise agreement was very reliable(0.84, κ = 0.82). For the second task, identify-ing the intrasentential arguments to verbs, pair-wise agreement was also very high: 0.89 amongannotators who chose the same verb sense.We then examined more closely those cases
in which the low agreement was attributable toinconsistent use of the category “none”. Wefound that most of these cases involved verycommon, ‘light’ verbs such as
� � suru “do”
and � � naru “become”. As it turned out, GTwas lacking some common colloquial senses forthese verbs. For example, the verb
� � suru“do” was often used as in utterance (1).
(1) �atoafter
�����ni-shuu-kan2-weeks-long
� �shitadid
raif
‘in about two weeks’
This sense of� � suru “do” does not appear in
theGT lexicon. In written Japanese suru wouldnot normally be used in this way; rather, a morespecialized verb such as �� tatsu “pass” wouldbe preferred.In sum, the results of our pilot study lead us
to conclude that we are likely to obtain reliableinter-annotator agreement on the verb sensetask, provided the following steps are taken:
• The highly general, spoken-language sensesof certain common ‘light’ verbs need to beadded to GT.
• The conditions under which the coders areto use the category “none (of the above)”need to be carefully delineated. In partic-ular, “none” should only be selected whenthere is a particular, standard, well-definedsense of the verb in question that clearlyshould be listed in the lexicon but is not.
We are encouraged in this regard by the re-sults of Kilgarriff and Rosenzweig (1999) whowere able, using careful experimental methodol-ogy, to achieve replicable agreement on Englishword senses (albeit by lexicographers, not stu-dents) of 95% in the Senseval project. Ourexperience echoes the observation of Kilgarriff(1998) that annotators should be given the op-portunity to offer feedback to the lexicogra-phers, including information such as inadequateor missing verb senses.
4 The annotation application
We developed a browser-based semantic anno-tation application specifically for this project.The application is implemented using HTMLforms within a web browser (Figure 5). Wewrote Perl scripts to generate the annotationforms automatically, using the CHJ transcripts,CHJ lexicon, and GT database as input.

Figure 5: Screen shot of verb sense diambiguation application
The left frame of the application displaysthe transcript of a CHJ conversation. NPs inthe transcript are enclosed in square brackets,and main verbs are underlined and hyperlinked.Clicking on a main verb in the transcript (leftframe) brings up a verb sense menu for that verbin the right frame.For example, in Figure 5, the verb sense menu
for a token of the verb��� � hazimaru “begin”
(fourth utterance in the left frame) has beenbrought up in the right frame. The four GTsenses of hazimaru are listed as menu choices.Each sense is assigned a unique subcategoriza-tion frame, including the case roles (N1, N2,etc.; cf. Table 2). The subcategorized-for se-mantic categories are also underlined and hy-perlinked to a diagram of the complete GT on-tology (cf. Figure 2), so that the coders can seeexamples of each category and how that cate-gory fits into the broader semantic framework.Finally, an English gloss of each verb sense
(from the GT transfer component) is given atthe end of each subcategorization frame.Once a coder selects the correct verb sense for
the verb token in question (in the case of Fig-ure 5, it is the first sense listed), the coder thenselects that verb’s NP complements (case-rolefillers), if any, from within the same utterance.For example, in Figure 5, the coder has selectedthe first verb sense for
��� � hazimaru “begin”,which subcategorizes for the NP arguments N1(subject) and N3 (start time). Separate menuforms are displayed for both N1 and N3, with allNPs in the utterance listed as possible fillers. Inthis case the coder selected ��� gakkou “school”as the subject and ���� � sanjuuichinichi “the31st” as the start time. If no NP in the utter-ance fills a given role, the zero option is selected(this is the default choice). Finally, the coderclicks ‘Submit’ and then moves on to the nextverb in the transcript (left frame).

Acknowledgments
This project is supported by U.S. National Sci-ence Foundation grant BCS-0002646, and bya dissertation grant in Japanese studies to thefirst author from Stanford University’s Institutefor International Studies.
References
Y. Akiba, M. Ishii, H. Almuallim, and S.Kaneda. 1995. Learning English verb selec-tion rules from hand-made rules and trans-lation examples. Sixth International Confer-ence on Theoretical and Methodological Issuesin Machine Translation: TMI-95, pp. 206–220, Leuven, July.
T. Baldwin and H. Tanaka. 1999. Argumentstatus in Japanese verb sense disambiguation.TMI-99, pp. 196–206, Chester, UK, August.
T. Baldwin, F. Bond, and B. Hutchinson. 1999.A valency dictionary architecture for machinetranslation. TMI-99, pp. 207–217, Chester,UK, August.
S. Bird and M. Liberman. 1998. Towards a for-mal framework for linguistic annotations. IC-SLP’98, Sydney.
F. Bond and S. Shirai. 1997. Practical and ef-ficient organization of a large valency dictio-nary. NLPRS-97 Workshop on MultilingualInformation Processing, Phuket. (handout).
J. Carletta. 1996. Assessing agreement on clas-sification tasks: the kappa statistic. Compu-tational Linguistics, 22(2):249–254.
M. Core, M. Ishizaki, J. Moore, C. Nakatani, N.Reithinger, D. Traum, and S. Tutiya. 1999.Report of the third workshop of the DiscourseResource Initiative. Technical Report CC-TR-99-1, Chiba Corpus Project, Chiba U.
L. Dybkjær, N. Bernson, H. Dybkjær, D. McK-elvie, and A. Mengel. 1998. The MATEmarkup framework. MATE Deliverable D1.2,LE Telematics Project LE4–8370, Denmark.http://mate.nis.sdu.dk/.
EDR. 1996. EDR Electronic Dictionary Ver-sion 1.5. Japan Electronic Dictionary Re-search Institute, Ltd. http://www.iijnet.or.jp/edr/.
M. Hamanishi and S. Ono, editors. 1990.Ruigo Kokugo Jiten [Japanese Synonym Dic-tionary]. Kadokawa Shoten, Tokyo.
N. Ide. 1998. Encoding linguistic corpora. Pro-
ceedings of the Sixth Workshop on Very LargeCorpora, pp. 9–17, Montreal.
S. Ikehara, S. Shirai, and K. Ogura. 1994.Criteria for evaluating the linguistic qualityof Japanese to English machine translations.Journal of Japanese Society for Artificial In-telligence, 9(4):569–579. (In Japanese).
S. Ikehara, M. Miyazaki, S. Shirai, A.Yokoo, H. Nakaiwa, K. Ogura, Y. Ooyama,and Y. Hayashi. 1997. Goi-Taikei — AJapanese Lexicon. Iwanami Shoten, Tokyo.5 volumes. http://www.kecl.ntt.co.jp/icl/mtg/resources/GoiTaikei.
IPA. 1987. IPAL Lexicon of Basic Verbs.Software Technology Center, Information-Technology Promotion Agency (IPA), Tokyo.(In Japanese).
IPA. 1990. IPAL Lexicon of Basic Adjectives.IPA, Tokyo. (In Japanese).
IPA. 1996. IPAL Lexicon of Basic Nouns. IPA,Tokyo. (In Japanese).
A. Kilgarriff and J. Rosenzweig. 1999. Sen-seval: Report and results. NLPRS’99, pp.362–367, Beijing, November.
A. Kilgarriff. 1998. Gold standard datasetsfor evaluating word sense disambiguationprograms. Computer Speech and Language,12(4):453–472.
LDC. 1996. Callhome Japanese corpus. Lin-guistic Data Consortium, University of Penn-sylvania. http://www.ldc.upenn.edu.
H. Nakaiwa and K. Seki. 1999. Automaticaddition of verbal semantic attributes to aJapanese-to-English valency transfer dictio-nary. TMI-99, pp. 185–195, Chester, UK.
M. Oku. 1996. Analyzing Japanese double-subject construction having an adjectivepredicate. COLING-96, pp. 865–870.
S. Shirai, S. Ikehara, A. Yokoo, and H. Inoue.1995. The quantity of valency pattern pairsrequired for Japanese to English machinetranslation and their compilation. NLPRS-95, pp. 443–448, Seoul.
S. Yokoyama and T. Ochiai. 1999. Aimai-nasuryoshi-o fukumu meishiku-no kaisekiho [amethod for analysing noun phrases with am-biguous quantifiers]. ANLP-99, pp. 550–553.(In Japanese).

Exploring automatic word sense disambiguationwith decision lists and the Web
Eneko AgirreIxA NLP group.
649 pk.Donostia, Basque Country, E-20.080
David MartínezIxA NLP group.
649 pk.Donostia, Basque Country, E-20.080
Abstract
The most effective paradigm for word sensedisambiguation, supervised learning, seems tobe stuck because of the knowledge acquisitionbottleneck. In this paper we take an in-depthstudy of the performance of decision lists ontwo publicly available corpora and anadditional corpus automatically acquired fromthe Web, using the fine-grained highlypolysemous senses in WordNet. Decision listsare shown a versatile state-of-the-arttechnique. The experiments reveal, amongother facts, that SemCor can be an acceptable(0.7 precision for polysemous words) startingpoint for an all-words system. The results onthe DSO corpus show that for some highlypolysemous words 0.7 precision seems to bethe current state-of-the-art limit. On the otherhand, independently constructed hand-taggedcorpora are not mutually useful, and a corpusautomatically acquired from the Web isshown to fail.
Introduction
Recent trends in word sense disambiguation (Ide& Veronis, 1998) show that the most effectiveparadigm for word sense disambiguation is that ofsupervised learning. Nevertheless, currentliterature has not shown that supervised methodscan scale up to disambiguate all words in a textinto reference (possibly fine-grained) wordsenses. Possible causes of this failure are:1. Problem is wrongly defined: tagging withword senses is hopeless. We will not tackle thisissue here (see discussion in the Senseval e-maillist – [email protected]).2. Most tagging exercises use idiosyncraticword senses (e.g. ad-hoc built senses, translations,thesaurus, homographs, ...) instead of widelyrecognized semantic lexical resources (ontologieslike Sensus, Cyc, EDR, WordNet, EuroWordNet,
etc., or machine-readable dictionaries likeOALDC, Webster's, LDOCE, etc.) which usuallyhave fine-grained sense differences. We chose towork with WordNet (Miller et al. 1990).3. Unavailability of training data: current hand-tagged corpora seem not to be enough for state-of-the-art systems. We test how far can we go withexisting hand-tagged corpora like SemCor (Milleret al. 1993) and the DSO corpus (Ng and Lee,1996), which have been tagged with word sensesfrom WordNet. Besides we test an algorithm thatautomatically acquires training examples from theWeb (Mihalcea & Moldovan, 1999).
In this paper we focus on one of the mostsuccessful algorithms to date (Yarowsky 1994), asattested in the Senseval competition (Kilgarriff &Palmer, 2000). We will evaluate it on bothSemCor and DSO corpora, and will try to testhow far could we go with such big corpora.Besides, the usefulness of hand tagging usingWordNet senses will be tested, training on onecorpus and testing in the other. This will allow usto compare hand tagged data with automaticallyacquired data.
If new ways out of the acquisition bottleneckare to be explored, previous questions aboutsupervised algorithms should be answered: howmuch data is needed, how much noise can theyaccept, can they be ported from one corpus toanother, can they deal with really fine sensedistinctions, performance etc. There are few in-depth analysis of algorithms, and precision figuresare usually the only features available. Wedesigned a series of experiments in order to shedlight on the above questions.
In short, we try to test how far can we go withcurrent hand-tagged corpora, and explore whetherother means can be devised to complement hand-tagged corpora. We first present decision lists andthe features used, followed by the method toderive data from the Web and the design of theexperiments. The experiments are organized inthree sections: experiments on SemCor and DSO,

cross-corpora experiments, and tagging SemCorusing the Web data for training. Finally someconclusions are drawn.
1 Decision lists and the features used
Decision lists (DL) as defined in (Yarowsky,1994) are simple means to solve ambiguityproblems. They have been successfully applied toaccent restoration, word sense disambiguation andhomograph disambiguation (Yarowsky, 1994;1995; 1996). It was one of the most successfulsystems on the Senseval word sensedisambiguation competition (Kilgarriff andPalmer, 2000).
The training data is processed to extract thefeatures, which are weighted with a log-likelihoodmeasure. The list of all features ordered by thelog-likelihood values constitutes the decision list.We adapted the original formula in order toaccommodate ambiguities higher than two:
))|Pr(
)|Pr((),(∑
≠
=
ijkj
kiki featuresense
featuresenseLogfeaturesenseweight
Features with 0 or negative values were are notinserted in the decision list.
When testing, the decision list is checked inorder and the feature with highest weight that ispresent in the test sentence selects the winningword sense. An example is shown below.
The probabilities have been estimated usingthe maximum likelihood estimate, smoothed usinga simple method: when the denominator in theformula is 0 we replace it with 0.1.
We analyzed several features alreadymentioned in the literature (Yarowsky, 1994; Ng,1997; Leacock et al. 1998), and new features likethe word sense or semantic field of the wordsaround the target which are available in SemCor.Different sets of features have been created to testthe influence of each feature type in the results: abasic set of features (section 4), several extensions(section 4.2).
The example below shows three senses of thenoun interest, an example, and some of thefeatures for the decision lists of interest thatappear in the example shown.
Sense 1: interest, involvement => curiosity, wonderSense 2: interest, interestingness => power, powerfulness, potencySense 3: sake, interest => benefit, welfare
.... considering the widespread interest in the election ...
2.99 ’#3 lem_50w win 2 2’1.54 ’#2 big_wf_-1 interest in 14 17’1.25 ’#2 big_lem_-1 in 14 18’
We see that the feature which gets the highestweight (2.99) is "lem_50w win" (the lemma winoccurring in a 50-word window). The lemma winshows up twice near interest in the training corpusand always indicates the sense #3. The next bestfeature is " big_wf_-1 interest in" (the bigram"interest in") which in 14 of his 17 apparitionsindicates sense #2 of interest. Other featuresfollow. The interested reader can refer to thepapers where the original features are described.
2 Deriving training data from the Web
In order to derive automatically training data fromthe Web, we implemented the method in(Mihalcea & Moldovan, 1999). The informationin WordNet (e.g. monosemous synonyms andglosses) is used to construct queries that are laterfed into a web search engine like Altavista. Fourprocedures can be used consecutively, indecreasing order of precision, but with increasingamounts of examples retrieved. Mihalcea andMoldovan evaluated by hand 1080 retrievedinstances of 120 word senses, and attested that91% were correct. The method was not used totrain a word sense disambiguation system.
In order to train our decision lists, weautomatically retrieved around 100 documents perword sense. The html documents were convertedinto ASCII texts, and segmented into paragraphsand sentences. We only used the sentence aroundthe target to train the decision lists. As the glossor synonyms were used to retrieve the text, wehad to replace those with the target word.
The example below shows two senses ofchurch, and two samples for each. For the firstsense, part of the gloss, group of Christians wasused to retrieve the example shown. For thesecond sense, the monosemous synonyms churchbuilding was used.
’church1’ => GLOSS ’a group of Christians’Why is one >> church << satisfied and the other oppressed ? :
’church2’ => MONOSEMOUS SYNONYM ’church building’The result was a congregation formed at that place, and a>> church << erected . :
Several improvements can be made to the process,like using part-of-speech tagging andmorphological processing to ensure that thereplacement is correctly made, discardingsuspicious documents (e.g. indexes, too long ortoo short) etc. Besides (Leacock et al., 1998) and(Agirre et al., 2000) propose alternative strategiesto construct the queries. We chose to evaluate themethod as it stood first, leaving the improvementsfor the future.

3 Design of the experiments
The experiments were targeted at three differentcorpora. SemCor (Miller et al., 1993) is a subsetof the Brown corpus with a number of textscomprising about 200.000 words in which allcontent words have been manually tagged withsenses from WordNet (Miller et al. 1990). It hasbeen produced by the same team that createdWordNet. As it provides training data for allwords in the texts, it allows for all-wordevaluation, that is, to measure the performance allthe words in a given running text. The DSOcorpus (Ng and Lee, 1996) was differentlydesigned. 191 polysemous words (nouns andverbs) and an average of 1000 sentences per wordwere selected from the Wall Street Journal andBrown corpus. In the 192.000 sentences only thetarget word was hand-tagged with WordNetsenses. Both corpora are publicly available.Finally, a Web corpus (cf. section 2) wasautomatically acquired, comprising around 100examples per word sense.
For the experiments, we decided to focus on afew content words, selected using the followingcriteria: 1) the frequency, according to the numberof training examples in SemCor, 2) the ambiguitylevel 3) the skew of the most frequent sense inSemCor, that is, whether one sense dominates.
The two first criteria are interrelated (frequentwords tend to be highly ambiguous), but there areexceptions. The third criterion seems to beindependent, but high skew is sometimes relatedto low ambiguity. We could not find all 8combinations for all parts of speech and thefollowing samples were selected (cf. Table 1): 2adjectives, 2 adverbs, 8 nouns and 7 verbs. These19 words form the test set A.
The DSO corpus does not contain adjectives oradverbs, and focuses on high frequency words.Only 5 nouns and 3 verbs from Set A werepresent in the DSO corpus, forming Set B of testwords.
In addition, 4 files from SemCor previouslyused in the literature (Agirre & Rigau, 1996) wereselected, and all the content words in the file weredisambiguated (cf. section 4.7).
The measures we use are precision, recall andcoverage, all ranging from 0 to 1. Given N,number of test instances, A, number of instanceswhich have been tagged, and C, number ofinstances which have been correctly tagged;precision = C/A, recall = C/N and coverage =A/ NIn fact, we used a modified measure of precision,equivalent to choosing at random in ties.
The experiments are organized as follows:• Evaluate decision lists on SemCor and DSOseparately, focusing on baseline features, otherfeatures, local vs. topical features, learning curve,noise, overall in SemCor and overall in DSO(section 4). All experiments were performed using10-fold cross-validation.• Evaluate cross-corpora tagging. Train on DSOand tag SemCor and vice versa (section 5).• Evaluate the Web corpus. Train on Web-acquired texts and tag SemCor (section 6).
Because of length limitations, it is not possibleto show all the data, refer to (Agirre & Martinez,2000) for more comprehensive results.
4 Results on SemCor and DSO data
We first defined an initial set of features andcompared the results with the random baseline(Rand) and the most frequent sense baseline(MFS). The basic combination of featurescomprises word-form bigrams and trigrams, partof speech bigrams and trigrams, a bag with theword-forms in a window spanning 4 words leftand right, and a bag with the word forms in thesentence.
The results for SemCor and DSO are shown inTable 1. We want to point out the following:• The number of examples per word sense isvery low for SemCor (around 11 for the words inSet B), while DSO has substantially more trainingdata (around 66 in set B). Several word sensesoccur neither in SemCor nor in DSO.• The random baseline attains 0.17 precisionfor Set A, and 0.10 precision for Set B.• The MFS baseline is higher for the DSOcorpus (0.59 for Set B) than for the SemCorcorpus (0.50 for Set B). This rather highdiscrepancy can be due to tagging disagreement,as will be commented on section 5.• Overall, decision lists significantlyoutperform the two baselines in both corpora:for set B 0.60 vs. 0.50 in SemCor, and 0.70 vs.0.59 on DSO, and for Set A 0.70 vs. 0.61 onSemCor. For a few words the decision liststrained on SemCor are not able to beat MFS(results in bold), but in DSO decision listsovercome in all words. The scarce data inSemCor seems enough to get some basicresults. The larger amount of data in DSOwarrants a better performance, but limited to0.70 precision.• The coverage in SemCor does not reach 1.0,because some decisions are rejected when the log

likelihood is below 0. On the contrary, the richerdata in DSO enables 1.0 coverage.
Regarding the execution time, Table 3 showstraining and testing times for each word inSemCor. Training the 19 words in set A takesaround 2 hours and 30 minutes, and is linear tothe number of training examples, around 2.85seconds per example. Most of the training time isspent processing the text files and extracting allthe features, which includes complex windowprocessing. Once the features have been extracted,training time is negligible, as is the test time(around 2 seconds for all instances of a word).Time was measured on CPU total time on a SunSparc 10 (512 MB of memory at 360 MHz).
4.1 Results in SemCor according to thekind of words: skew of MFS counts
We plotted the precision attained in SemCor foreach word, according to certain features. Figure 1shows the precision according to the frequency ofeach word, measured in number of occurrences inSemCor. Figure 2 shows the precision of eachword plotted according to the number of senses.Finally, Figure 3 orders the words according tothe degree of dominance of the most frequentsense. The figures show the precision of decisionlists (DL), but also plot the difference of
performance according to two baselines, random(DL-Rand) and MFS (DL-MFS). These lastfigures are close to 0 whenever decision listsattain results similar to those of the baselines. Weobserved the following:• Contrary to expectations, frequency andambiguity do not affect precision (Figures 1 and2). This can be explained by interrelation betweenambiguity and frequency. Low ambiguity wordsmay seem easier to disambiguate, but they tend tooccur less, and SemCor provides less data. On thecontrary, highly ambiguous words occur morefrequently, and have more training data.• Skew does affect precision. Words with highskew obtain better results, but decision listsoutperform MFS mostly on words with low skew.
Overall decision lists perform very well(related to MFS) even with words with very fewexamples (“duty”, 25 or “account”, 27) or highlyambiguous words.
4.2 Features: basic features are enough
Our next step was to test other alternativefeatures. We analyzed different window sizes (20words, 50 words, the surrounding sentences), andused word lemmas, synsets and semantic fields.We also tried mapping the fine-grained part ofspeech distinctions in SemCor to a more general
SemCor DSOWord PoS Senses Rand # Examples Ex. Per sense MFS DL # Examples Ex. Per senses MFS DLAll A 2 .50 211 105.50 .99 .99/1.0Long A 10 .10 193 19.30 .53 .63/.99Most B 3 .33 238 79.33 .74 .78/1.0Only B 7 .14 499 71.29 .51 .69/1.0Account N 10 .10 27 2.70 .44 .57/.85Age N 5 .20 104 20.80 .72 .76/1.0 491 98.20 .62 .73/1.0Church N 3 .33 128 42.67 .41 .69/1.0 370 123.33 .62 .71/1.0Duty N 3 .33 25 8.33 .32 .61/.92Head N 30 .03 179 5.97 .78 .88/1.0 866 28.87 .40 .79/1.0Interest N 7 .14 140 20.00 .41 .62/.97 1479 211.29 .46 .62/1.0Member N 5 .20 74 14.80 .91 .91/1.0 1430 286.00 .74 .79/1.0People N 4 .25 282 70.50 .90 .90/1.0Die V 11 .09 74 6.73 .97 .97/.99Fall V 32 .03 52 1.63 .13 .34/.71 1408 44.00 .75 .80/1.0Give V 45 .02 372 8.27 .22 .34/.78 1262 28.04 .75 .77/1.0Include V 4 .25 144 36.00 .72 .70/.99Know V 11 .09 514 46.73 .59 .61/1.0 1441 131.0 .36 .46/.98Seek V 5 .20 46 9.20 .48 .62/.89Understand V 5 .20 84 16.80 .77 .77/1.0
Avg. A 5.82 .31 202.00 34.71 .77 .82/1.0Avg. B 5.71 .20 368.50 64.54 .58 .72/1.0Avg. N 9.49 .19 119.88 12.63 .69 .80/.99Avg. V 20.29 .10 183.71 9.05 .51 .58/.92
Set A
Overall 12.33 .17 178.21 14.45 .61 .70/.97Avg. N 10.00 .16 125.00 12.50 .63 .77/.99 927.20 92.72 .56 .72/1.0Avg. V 29.33 .06 312.67 10.66 .42 .49/.90 137.33 46.72 .61 .67/.99Set BOverall 17.25 .10 195.38 11.33 .50 .60/.94 1093.38 63.38 .59 .70/1.0
Table 1: Data for each word and results for baselines and basic set of features.
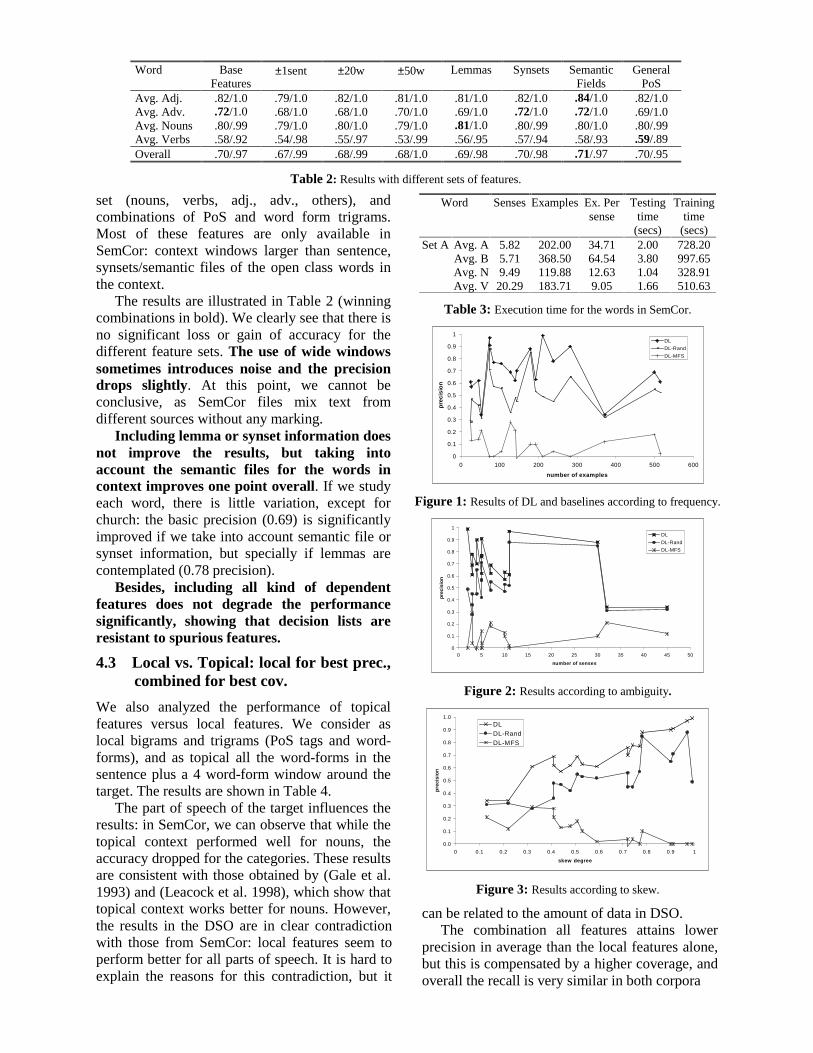
set (nouns, verbs, adj., adv., others), andcombinations of PoS and word form trigrams.Most of these features are only available inSemCor: context windows larger than sentence,synsets/semantic files of the open class words inthe context.
The results are illustrated in Table 2 (winningcombinations in bold). We clearly see that there isno significant loss or gain of accuracy for thedifferent feature sets. The use of wide windowssometimes introduces noise and the precisiondrops slightly. At this point, we cannot beconclusive, as SemCor files mix text fromdifferent sources without any marking.
Including lemma or synset information doesnot improve the results, but taking intoaccount the semantic files for the words incontext improves one point overall. If we studyeach word, there is little variation, except forchurch: the basic precision (0.69) is significantlyimproved if we take into account semantic file orsynset information, but specially if lemmas arecontemplated (0.78 precision).
Besides, including all kind of dependentfeatures does not degrade the performancesignificantly, showing that decision lists areresistant to spurious features.
4.3 Local vs. Topical: local for best prec.,combined for best cov.
We also analyzed the performance of topicalfeatures versus local features. We consider aslocal bigrams and trigrams (PoS tags and word-forms), and as topical all the word-forms in thesentence plus a 4 word-form window around thetarget. The results are shown in Table 4.
The part of speech of the target influences theresults: in SemCor, we can observe that while thetopical context performed well for nouns, theaccuracy dropped for the categories. These resultsare consistent with those obtained by (Gale et al.1993) and (Leacock et al. 1998), which show thattopical context works better for nouns. However,the results in the DSO are in clear contradictionwith those from SemCor: local features seem toperform better for all parts of speech. It is hard toexplain the reasons for this contradiction, but it
can be related to the amount of data in DSO.The combination all features attains lower
precision in average than the local features alone,but this is compensated by a higher coverage, andoverall the recall is very similar in both corpora
Word Senses Examples Ex. Persense
Testingtime
(secs)
Trainingtime
(secs)Avg. A 5.82 202.00 34.71 2.00 728.20Avg. B 5.71 368.50 64.54 3.80 997.65Avg. N 9.49 119.88 12.63 1.04 328.91
Set A
Avg. V 20.29 183.71 9.05 1.66 510.63
Table 3: Execution time for the words in SemCor.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 100 200 300 400 500 600
number of examples
pre
cisi
on
DL
DL-Rand
DL-MFS
Figure 1: Results of DL and baselines according to frequency.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 5 10 15 20 25 30 35 40 45 50
number of senses
pre
cisi
on
DL
DL-Rand
DL-MFS
Figure 2: Results according to ambiguity.
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
skew degree
pre
cisi
on
DLDL-RandDL-MFS
Figure 3: Results according to skew.
Word BaseFeatures
±1sent ±20w ±50w Lemmas Synsets SemanticFields
GeneralPoS
.82/1.0 .79/1.0 .82/1.0 .81/1.0 .81/1.0 .82/1.0 .84/1.0 .82/1.0
.72/1.0 .68/1.0 .68/1.0 .70/1.0 .69/1.0 .72/1.0 .72/1.0 .69/1.0
.80/.99 .79/1.0 .80/1.0 .79/1.0 .81/1.0 .80/.99 .80/1.0 .80/.99
Avg. Adj.Avg. Adv.Avg. NounsAvg. Verbs .58/.92 .54/.98 .55/.97 .53/.99 .56/.95 .57/.94 .58/.93 .59/.89Overall .70/.97 .67/.99 .68/.99 .68/1.0 .69/.98 .70/.98 .71/.97 .70/.95
Table 2: Results with different sets of features.

4.4 Learning curve: examples in DSOenough
We tested the performance of decision lists withdifferent amounts of training data. We retainedincreasing amounts of the examples available foreach word: 10% of all examples in the corpus,20%, 40%, 60%, 80% and 100%. We performed10 rounds for each percentage of training data,choosing different slices of data for training andtesting. Figures 4 and 5 show the number oftraining examples and recall obtained for eachpercentage of training data in SemCor and DSOrespectively. Recall was chosen in order tocompensate for differences in both precision andcoverage, that is, recall reflects both decreases incoverage and precision at the same time.
The improvement for nouns in SemCor seemto stabilize, but the higher amount of examples inDSO show that the performance can still grow upto a standstill. The verbs show a steady increase inSemCor, confirmed by the DSO data, whichseems to stop at 80% of the data.
4.5 Noise: more data better for noise
In order to analyze the effect of noise in thetraining data, we introduced some random tags inpart of the examples. We created 4 new samplesfor training, with varying degrees of noise: 10%of the examples with random tags, %20, %30 and40%.
Figures 6 and 7 show the recall data forSemCor and DSO. The decrease in recall is steadyfor both nouns and verbs in SemCor, but it israther brusque in DSO. This could mean thatwhen more data is available, the system ismore robust to noise: the performance is hardlyaffected by %10, 20% and 30% of noise.
4.6 Coarse Senses: results reach .83 prec.
It has been argued that the fine-grainedness of thesense distinctions in SemCor makes the task moredifficult than necessary. WordNet allows to makesense distinctions at the semantic file level, that is,the word senses that belong to the same semanticfile can be taken as a single sense (Agirre &Rigau, 1996). We call the level of fine-grainedoriginal senses the synset level, and the coarsersenses form the semantic file level.
In case any work finds these coarser sensesuseful, we trained the decision lists with themboth in SemCor and DSO. The results are shownin Table 5 for the words in Set B. At this level theresults on both corpora reach 83% of precision.
4.7 Overall Semcor: .68 prec. for all-word
In order to evaluate the expected performance ofdecision lists trained on SemCor, we selected four
SemCor DSOPoS Local Topical Comb. Local Topical Comb.A .84/.99 .81/.89 .82/1.0B .74/1.0 .64/.96 .72/1.0N .78/.96 .81/.87 .80/.99 .75/.97 .71/.98 .72/1.0V .61/.84 .57/.72 .58/.92 .70/.96 .66/.91 .67/.99
Ov. .72/.93 .68/.84 .70/.97 .73/.96 .69/.95 .70/1.0
Table 4: Local context Vs Topical context.
0,3
0,4
0,5
0,6
0,7
0,8
12 43 72 103
133
164
194
225
256
286
number of examplesre
call
N
Overall
V
Figure 4: Learning curve in SemCor.
0,600,620,640,660,680,700,720,74
92 214
336
457
579
701
822
944
1066
1187
1309
number of examples
reca
ll
N
Overall
V
Figure 5: learning curve in DSO.
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0% 10% 20% 30% 40%amount of noise
reca
ll
N
Overall
V
Figure 6: Results with noise in SemCor.
0.4
0.5
0.6
0.7
0.8
0% 10% 20% 30% 40%amount of noise
reca
ll
N
Overall
V
Figure 7: Results with noise in DSO.

files previously used in the literature (Agirre &Rigau, 1996) and all the content words in the fileswere disambiguated. For each file, the decisionlists were trained with the rest of SemCor.
Table 6 shows the results. Surprisingly,decision lists attain a very similar performance inall four files (random and most frequent baselinesalso show the same behaviour). As SemCor is abalanced corpus, it seems reasonable to say that68% precision can be expected if any running textis disambiguated using decision lists trained onSemCor. The fact that the results are similar fortexts from different sources (journalistic, humor,science) and that similar results can be expectedfor words with varying degrees of ambiguity andfrequency (cf. section 4.1), seems to confirm thatthe training data in SemCor allows to expect for asimilar precision across all kinds of words andtexts, except for highly skewed words, where wecan expect better performance than average.
4.8 Overall DSO: state-of-the-art results
In order to compare decision lists with other stateof the art algorithms we tagged all 191 words inthe DSO corpus. The results in (Ng, 1997) onlytag two subsets of all the data, but (Escudero et al.2000a) implement both Ng’s example-based (EB)approach and a Naive-Bayes (NB) system and testit on all 191 words. The same test set is also usedin (Escudero et al. 2000b) which presents aboosting approach to word sense disambiguation.The features they use are similar to ours, but notexactly. The precision obtained, summarized onTable 7 show that decision lists provide state-of-the-art performance. Decision list attained 0.99coverage.
5 Cross-tagging: hand taggers need to becoordinated
We wanted to check what would be theperformance of the decision lists training on onecorpus and tagging the other. The DSO andSemCor corpora do not use exactly the same wordsense system, as the former uses WordNet version1.5 and the later WordNet version 1.6. We wereable to easily map the senses form one to the otherfor all the words in Set B. We did not try to mapthe word senses that did not occur in any one ofthe corpora.
A previous study (Ng et al. 1999) has used thefact that some sentences of the DSO corpus arealso included in SemCor in order to study theagreement between the tags in both corpora. Theyshowed that the hand-taggers of the DSO and
SemCor teams only agree 57% of the time. This isa rather low figure, which explains why theresults for one corpus or the other differ, e.g. thedifferences on the MFS results (see Table 1).
Considering this low agreement, we were notexpecting good results on this cross-taggingexperiment. The results shown in Table 8confirmed our expectations, as the precision isgreatly reduced (approximately one third in bothcorpora, but more than a half in the case of verbs).Teams of hand-taggers need to be coordinatedin order to produce results that areinterchangeable.
6 Results on Web data: disappointing
We used the Web data to train the decision lists(with the basic feature set) and tag the SemCorexamples. Only nouns and verbs were processed,as the method would not work with adjectives andadverbs. Table 9 shows the number of examplesretrieved for the target words, the random baselineand the precision attained. Only a few words getbetter than random results (in bold), and foraccount the error rate reaches 100%.
These extremely low results clearly contradictthe optimism in (Mihalcea & Moldovan, 1999),where a sample of the retrieved examples wasfound to be 90% correct. One possibleexplanation of this apparent disagreement couldbe that the acquired examples, being correct onthemselves, provide systematically misleadingfeatures. Besides, all word senses are trained with
SemCor DSOPOS # Syns # SFs Synset SF Synset SFN 50 29 .77/.99 .78/.00 .72/1.0 .76/1.0V 88 19 .51/.90 .87/.96 .67/.99 .91/1.0Ov. 138 48 .62/.94 .83/.98 .70/1.0 .83/1.0
Table 5: Results disambiguatingfine (synset) vs. coarse (SF) senses.
File POS # Senses # Examples Rand MFS DLbr-a01 6.60 792 .26 .63 .68/.95br-b20 6.86 756 .24 .64 .66/.95br-j09 6.04 723 .24 .64 .69/.95br-r05 7.26 839 .24 .63 .68/.92
A 5.49 122.00 .28 .71 .71/.92B 3.76 48.50 .34 .72 .80/.97N 4.87 366.75 .28 .66 .69/.94V 10.73 240.25 .16 .54 .61/.95
average
Ov. 6.71 777.50 .25 .63 .68/.94
Table 6: Overall results in SemCor.
PoS MFS EB NB Boosting Decision ListsN .59/1.0 .69 .68 .71 .72/.99V .53/1.0 .65 .65 .67 .68/.98Ov .56/1.0 .67 .67 .70 .70/.99
Table 7: Overall results in DSO.
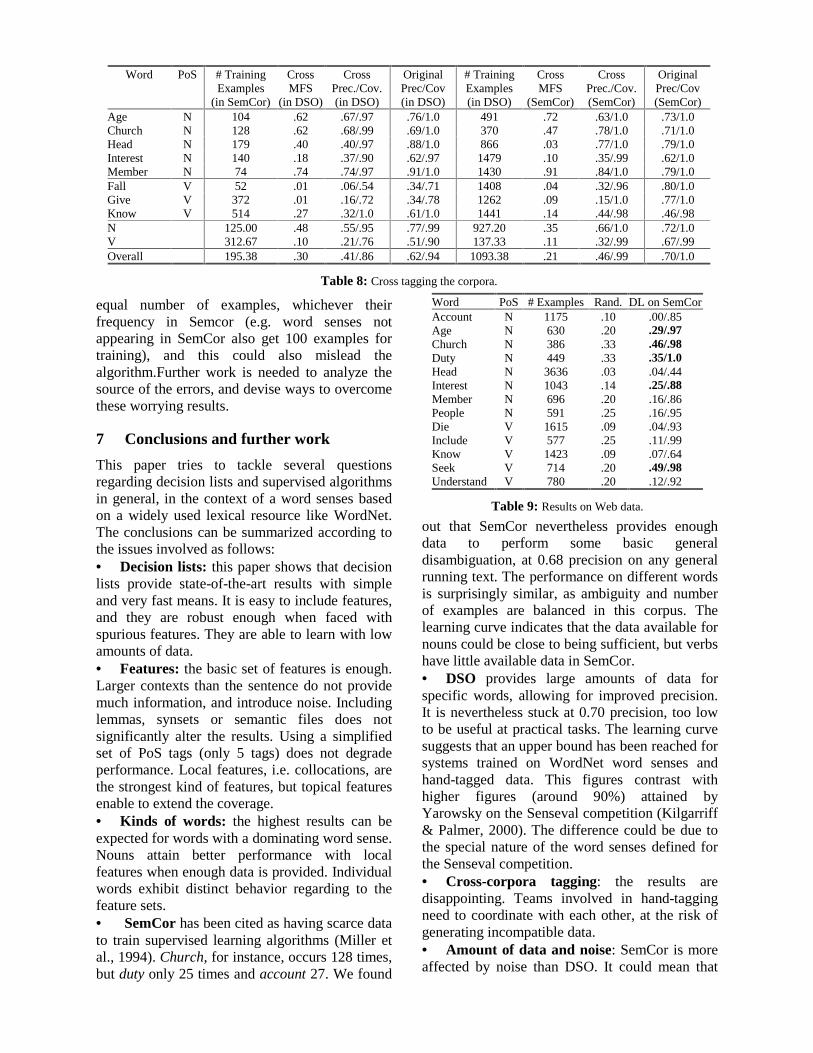
equal number of examples, whichever theirfrequency in Semcor (e.g. word senses notappearing in SemCor also get 100 examples fortraining), and this could also mislead thealgorithm.Further work is needed to analyze thesource of the errors, and devise ways to overcomethese worrying results.
7 Conclusions and further work
This paper tries to tackle several questionsregarding decision lists and supervised algorithmsin general, in the context of a word senses basedon a widely used lexical resource like WordNet.The conclusions can be summarized according tothe issues involved as follows:• Decision lists: this paper shows that decisionlists provide state-of-the-art results with simpleand very fast means. It is easy to include features,and they are robust enough when faced withspurious features. They are able to learn with lowamounts of data.• Features: the basic set of features is enough.Larger contexts than the sentence do not providemuch information, and introduce noise. Includinglemmas, synsets or semantic files does notsignificantly alter the results. Using a simplifiedset of PoS tags (only 5 tags) does not degradeperformance. Local features, i.e. collocations, arethe strongest kind of features, but topical featuresenable to extend the coverage.• Kinds of words: the highest results can beexpected for words with a dominating word sense.Nouns attain better performance with localfeatures when enough data is provided. Individualwords exhibit distinct behavior regarding to thefeature sets.• SemCor has been cited as having scarce datato train supervised learning algorithms (Miller etal., 1994). Church, for instance, occurs 128 times,but duty only 25 times and account 27. We found
out that SemCor nevertheless provides enoughdata to perform some basic generaldisambiguation, at 0.68 precision on any generalrunning text. The performance on different wordsis surprisingly similar, as ambiguity and numberof examples are balanced in this corpus. Thelearning curve indicates that the data available fornouns could be close to being sufficient, but verbshave little available data in SemCor.• DSO provides large amounts of data forspecific words, allowing for improved precision.It is nevertheless stuck at 0.70 precision, too lowto be useful at practical tasks. The learning curvesuggests that an upper bound has been reached forsystems trained on WordNet word senses andhand-tagged data. This figures contrast withhigher figures (around 90%) attained byYarowsky on the Senseval competition (Kilgarriff& Palmer, 2000). The difference could be due tothe special nature of the word senses defined forthe Senseval competition.• Cross-corpora tagging: the results aredisappointing. Teams involved in hand-taggingneed to coordinate with each other, at the risk ofgenerating incompatible data.• Amount of data and noise: SemCor is moreaffected by noise than DSO. It could mean that
Word PoS # TrainingExamples
(in SemCor)
CrossMFS
(in DSO)
CrossPrec./Cov.(in DSO)
OriginalPrec/Cov(in DSO)
# TrainingExamples(in DSO)
CrossMFS
(SemCor)
CrossPrec./Cov.(SemCor)
OriginalPrec/Cov(SemCor)
Age N 104 .62 .67/.97 .76/1.0 491 .72 .63/1.0 .73/1.0Church N 128 .62 .68/.99 .69/1.0 370 .47 .78/1.0 .71/1.0Head N 179 .40 .40/.97 .88/1.0 866 .03 .77/1.0 .79/1.0Interest N 140 .18 .37/.90 .62/.97 1479 .10 .35/.99 .62/1.0Member N 74 .74 .74/.97 .91/1.0 1430 .91 .84/1.0 .79/1.0Fall V 52 .01 .06/.54 .34/.71 1408 .04 .32/.96 .80/1.0Give V 372 .01 .16/.72 .34/.78 1262 .09 .15/1.0 .77/1.0Know V 514 .27 .32/1.0 .61/1.0 1441 .14 .44/.98 .46/.98N 125.00 .48 .55/.95 .77/.99 927.20 .35 .66/1.0 .72/1.0V 312.67 .10 .21/.76 .51/.90 137.33 .11 .32/.99 .67/.99Overall 195.38 .30 .41/.86 .62/.94 1093.38 .21 .46/.99 .70/1.0
Table 8: Cross tagging the corpora.
Word PoS # Examples Rand. DL on SemCorAccount N 1175 .10 .00/.85Age N 630 .20 .29/.97Church N 386 .33 .46/.98Duty N 449 .33 .35/1.0Head N 3636 .03 .04/.44Interest N 1043 .14 .25/.88Member N 696 .20 .16/.86People N 591 .25 .16/.95Die V 1615 .09 .04/.93Include V 577 .25 .11/.99Know V 1423 .09 .07/.64Seek V 714 .20 .49/.98Understand V 780 .20 .12/.92
Table 9: Results on Web data.

higher amounts of data provide more robustnessfrom noise.• Coarser word senses: If decision lists aretrained on coarser word senses inferred fromWordNet itself, 80% precision can be attained forboth SemCor and DSO.• Automatic data acquisition from the Web:the preliminary results shown in this paper showthat the acquired data is nearly useless.
The goal of the work reported here was toprovide the foundations to open-up the acquisitionbottleneck. In order to pursue this ambitious goalwe explored key questions regarding theproperties of a supervised algorithm, the upperbounds of manual tagging, and new ways toacquire more tagging material.
According to our results hand-tagged materialis not enough to warrant useful word sensedisambiguation on fine-grained reference wordsenses. On the other hand, contrary to currentexpectations, automatically acquisition of trainingmaterial from the Web fails to provide enoughsupport.
In the immediate future we plan to study thereasons for this failure and to devise ways toimprove the quality of the automatically acquiredmaterial.
Acknowledgements
The work here presented received funds fromprojects OF319-99 (Government of Gipuzkoa),EX1998-30 (Basque Country Government) and2FD1997-1503 (European Commission).
Bibliography
Agirre E. and Rigau G. Word Sense Disambiguationusing Conceptual Density. Proceedings ofCOLING’96, 16-22. Copenhagen (Denmark). 1996.
Agirre, E., O. Ansa, E. Hovy and D. MartinezEnriching very large ontologies using the WWW.ECAI 2000, Workshop on Ontology Learning.Berlin, Germany. 2000.
Agirre, E. and D. Martinez. Exploring automatic wordsense disambiguation with decision lists and theWeb. Internal report. UPV-EHU. Donostia, BasqueCountry. 2000.
Escudero, G., L. Màrquez and G. Rigau. Naive Bayesand Exemplar-Based approaches to Word SenseDisambiguation Revisited. Proceedings of the 14thEuropean Conference on Artificial Intelligence,ECAI 2000. 2000.
Escudero, G., L. Màrquez and G. Rigau. BoostingApplied to Word Sense Disambiguation. Proceedingsof the 12th European Conference on MachineLearning, ECML 2000. Barcelona, Spain. 2000.
Gale, W., K. W. Church, and D. Yarowsky. A Methodfor Disambiguating Word Senses in a Large Corpus,Computers and the Humanities, 26, 415--439, 1993.
Ide, N. and J. Veronis. Introduction to the Special Issueon Word Sense Disambiguation: The State of the Art.Computational Linguistics, 24(1), 1--40, 1998.
Kilgarriff, A. and M. Palmer. (eds). Special issue onSENSEVAL. Computer and the Humanities, 34 (1-2).2000
Leacock, C., M. Chodorow, and G. A. Miller. UsingCorpus Statistics and WordNet Relations for SenseIdentification. Computational Linguistics, 24(1),147--166, 1998.
Mihalcea, R. and I. Moldovan. An Automatic Methodfor Generating Sense Tagged Corpora. Proceedingsof the 16th National Conference on ArtificialIntelligence. AAAI Press, 1999.
Miller, G. A., R. Beckwith, C. Fellbaum, D. Gross, andK. Miller. Five Papers on WordNet. Special Issue ofInternational Journal of Lexicography, 3(4), 1990.
Miller, G. A., C. Leacock, R. Tengi, and R. T. Bunker,A Semantic Concordance. Proceedings of the ARPAWorkshop on Human Language Technology, 1993.
Miller, G. A., M. Chodorow, S. Landes, C. Leacockand R. G. Thomas. Using a Semantic Concordancefor Sense Identification. Proceedings of the ARPA.1994.
Ng, H. T. and H. B. Lee. Integrating MultipleKnowledge Sources to Disambiguate Word Sense:An Exemplar-based Approach. Proceedings of the34th Annual Meeting of the Association forComputational Linguistics. 1996.
Ng, H. T. Exemplar-Based Word SenseDisambiguation: Some Recent Improvements.Proceedings of the 2nd Conference on EmpiricalMethods in Natural Language Processing, 1997.
Ng, H. T., C. Y. Lim and S. K. Foo. A Case Study onInter-Annotator Agreement for Word SenseDisambiguation. Proceedings of the Siglex-ACLWorkshop on Standarizing Lexical Resources. 1999.
Yarowsky, D. Decision Lists for Lexical AmbiguityResolution: Application to Accent Restoration inSpanish and French’, in Proceedings of the 32ndAnnual Meeting of the Association forComputational Linguistics, pp. 88--95. 1994.
Yarowsky, D. Unsupervised Word SenseDisambiguation Rivaling Supervised Methods.Proceedings of the 33rd Annual Meeting of theAssociation for Computational Linguistics.Cambridge, MA, pp. 189-196, 1995.
Yarowsky, D. Homograph Disambiguation in Text-to-speech Synthesis. J Hirschburg, R. Sproat and J. VanSanten (eds.) Progress in Speech Synthesis,Springer-Vorlag, pp. 159-175. 1996.

������������ ��������������������� �� �!�"�$#&%'���)(*#,+�+-�� ���.0/1�2�� ��$����+����3(54��)(,���6#7 $�8 � ��9�:�����3�;
<�=?>�@BADCFEHGIEKJLENM7@PO�Q:R!ENGIEKSUTV=W�EKXYEKA�OYQ:Z[=?\ITVEK@B]_^�`,Z[\�^aAcbd>,OcODENJV>[e�bd@fJV>VSd@hga@fbdJYGiT7OKO
j_kmlLnpo,qsrtq�uwvyx{zN|B}K~U���i~"o,qsrtq�uwvyx{z)�NuU��~Uv{u3�y~Uvt��s�i�w�w�y�s�0� zf���;~U�yrt�fvy�f� u�|I��uU� u3�y~f|� uU�BuU�du��Vu �w�i�3���i�w�i� |��iuU�BuU�
�Vuw�{uw��uU��q��7�tvy� � ���B�¡� xs~�� ¢m�N|���uU�duU~i�7�tvy� � ���B�¡� xs~�� ¢m�
jUj_kmlVn£}*���f��¤¥uw�yrt~U�¡o,qsrtq�uwvyx{z§¦�qs�I�yq¨vo,~d���yq ���w� |B��~Uvy�I�y~��:�a©7qs���dzI�yrs|
ª � ���i�w«d� |�¬ ���;xs�;xsx¨~Uv{®��*�frs� �¯�f�¡� xs~d�¡|�u3vyqs��®�rtq3�*�Brs� ���B�¡� xs~U�
°²±"³�´�µP¶L·K´¸_¹�º¼»P½s¹�¾�¾¿¹�ÀPÁ�»H¹�Á�ÂVÃP½¨Ä�Å3ÂUƨƼÇÈÀPÁ;É�¸_Ê-Ë*ÌKÃP½¨Ä�Á�½s¹�Í)Æc¹�½¨Â
ÅwÄ�À�Î ½¨Ä�ÀBº¼ÂdÏ'ÐÇȺ¼ÑÓÒI¹�½¼Ç¿Ä�»HÆÔÏ�ǯէÅw»P¾¯º¨ÇÈÂdÆ!Ç¿ÀÓÃP½¨Ä�ÅwÂUƨÆ{Ç¿ÀPÁÖ�×Ø!Ê£¹�ÀNÏÚÙ�Ø!ÊÛÏ�Ä�Å3»PÍ¡ÂwÀBºsÆwÜa¹�ÀHÏÚÑH¹iÒfÂ2º¼ÑPÂ�ÃNÄ�ݺ¨ÂwÀBº¼ÇÞ¹�¾;º¨ÄßÃP½¨Ä�Ï�»HÅ3ÂDàKÂ3º¼º¼ÂU½Ô½¨ÂUƼ»P¾¯ºsÆ¥ÇÈΧ¾ÈÇ¿ÀPÁ�»HÇ¿Æ{º¼ÇÞÅ2ÇÈÀPÝÎ Äf½¼Í)¹Iº¨ÇÈÄfÀáÇÞÆa¹�ÀPÀPÄ�º¨¹Iº¨ÂUÏâÇÈÀ²Æ{Äf»P½sÅ3§º¨Â3ã�º¨ÆUäáåæÂ�ÑH¹iÒ�º¨ÑPÂw½¨Â3Î Äf½¼Â,ÏPÂwÒ�ÂU¾ÈÄfÃNÂdÏ"º¼ÑPÂ*Ê�Ç¿ÀPÁ�»HÇ¿Æ{º¼ÇÞÅ,ç_ÀPÀPÄ�ºs¹Iº¨ÇÈÄfÀ$Ê-¹�À�ÝÁf»H¹�ÁfÂÔÉ Äf½aÊ�ç_Ê�Ì3ÜLÐÑPÇÞÅsÑáÇ¿Æ¡¹�ÀâÙ�ØÔÊYÝtÅ3Ä�Í¡ÃP¾¿ÇÞ¹�ÀBº$ºs¹�ÁƼÂ3ºaÎ Ä�½§¹fƼƼǿÆ{º¼Ç¿ÀPÁæÀH¹Iº¨»P½s¹�¾è¾¿¹�ÀPÁ�»N¹�Á�Â�ÃP½¨Ä�ÅwÂUƨÆ{Ç¿ÀPÁhÃP½¼Ä�ÝÁf½¨¹�Í¡ÆUäFémº!Å3Ä�ÀNÆ{ÇÞÆyºsÆ�Ä�Î$¾¿ÇÈÀPÁf»PÇÞÆyº¨Ç¿ÅæÇ¿À�Î Ä�½¨Í)¹Iº¼Ç¿Ä�Àߺ¨¹�ÁBÆƼ»HÅsѲ¹�Æaº¨¹�ÁfÆ)ƼÃNÂdÅ3ÇÈÎ ê�ÇÈÀPÁDÐ*Ä�½sÏNëIÃPÑP½s¹�ƨ¹�¾*àNÄf»PÀHÏP¹�½¼Ç¿ÂUÆUܹ�ÀHÏDºs¹�ƼìfÝtÏ�ÂUÃNÂUÀHÏ�ÂwÀBº)Ç¿ÀHÆyº¨½¼»NÅ�º¼Ç¿Ä�À�º¨¹�ÁfơƼ»HÅsÑ�¹fÆ0º¨¹�ÁBÆÏ�ÂwíHÀPÇ¿ÀPÁ9º¼ÑHÂ_ƼÅwÄ�ÃKÂèÄ�Îcº¼½s¹�ÀHƼ¾Þ¹Iº¼Ç¿Ä�À0Î Ä�½,Í¡¹fÅsÑPÇ¿ÀPÂ*º¼½s¹�ÀHÆ{ݾ޹Iº¨ÇÈÄfÀ�ÃP½¨Ä�Áf½¨¹�Í)ÆwäVåæÂ;ÑH¹iÒ�Â;¹�¾ÞƼÄaÏ�ÂUÒ�ÂU¾ÈÄfÃNÂdÏ�¹�À¥Ê-ç_Ê�ݹ�ÀPÀPÄ�ºs¹Iº¨ÇÈÄfÀîÂdÏ�ÇȺ¼Ä�½!º¼ÄïÎð¹fÅ3Ç¿¾ÈÇȺ¨¹�º¼ÂD»HƼÂw½sÆ�º¼Ä[¹�ÀPÀPÄ�º¨¹�º¼ÂÏ�Ä�Åw»PÍ¡ÂwÀBº¨ÆèÐÇȺ¼ÑPÄf»�º_ƼÂwÂwÇ¿ÀPÁaº¨¹�ÁfÆUä
ñ òfó ´�µPôõ_ö�·K´�÷{ô ó×èÑPÂ�½¨¹�ÃPÇ¿Ï2Âwã�ÃH¹�ÀHƼǿÄ�ÀDÄ�κ¨ÑPÂ�étÀBº¨Âw½¨ÀPÂ3ºaÑH¹�Æ0¹�ÅwÅwÂw¾ÈÝ
ÂU½¨¹�º¼ÂUÏ'º¼ÑHÂDÃP½¼Äf¾ÈÇÈÎ Âw½s¹Iº¨ÇÈÄfÀ'Ä�ΡÏ�Ä�Åw»PÍ¡ÂwÀBº¨Æ�н¨Ç¯º¼º¼ÂUÀîÇ¿ÀÖ�×Ø!ʲ¹�ÀHÏæÙ�ØÔÊ:ä�Ë:½¨Ä�Áf½¨¹�Í)Æ�Î Äf½;ÃNÂU½{Î Äf½¼Í¡Ç¿ÀPÁ�ÀH¹Iº¨»�ݽs¹�¾f¾¿¹�ÀPÁ�»H¹�Á�Â7ÃP½¼Ä�ÅwÂUƨÆ{Ç¿ÀPÁ$ÉðÄ�½V¸_Ê-Ë*ÌYºs¹�Ƽì�Æ�Ƽ»HÅsÑ$¹fÆ-ìfÂwêBÝÐ*Ä�½sÏ_Âwã�º¼½s¹�Å�º¨ÇÈÄfÀ�ÜU¹�»�º¼ÄfÍ)¹Iº¼ÇÞÅ�º¼Âwã�º�Æ{»HÍaÍ)¹�½¼Ç¿øU¹�º¼Ç¿Ä�À�Üd¹�ÀHÏÍ)¹�ÅsÑHÇÈÀPÂ�º¼½s¹�ÀHƼ¾Þ¹Iº¼Ç¿Ä�ÀâÑH¹iÒ�Â)º¨ÄhàKÂ�¹�àP¾¿Â�º¨ÄhÏ�Âd¹�¾èÐÇȺ¼ÑƼ»HÅsÑ�étÀfº¨Âw½¨ÀPÂ3º_ÏPÄ�Åw»PÍ¡ÂwÀBº¨ÆUä7Ö_ÄIÐ7ÂUÒ�ÂU½UÜBº¼ÑHÂw½¨Â ¹�½¨Â"ÒI¹�½¼ÇÈÝÄf»HÆVÄ�àHÆ{º¨¹fÅ3¾¿ÂUÆ�º¨ÑH¹Iº:Í)¹�ìfÂèǯº7ÏPǯէÅ3»H¾¯º:Î Äf½Vº¼ÑPÂUÍùº¨Ä9ÃP½¼Ä�ÝÏ�»NÅ3Â�ÁfÄBÄ�Ïa½¨ÂUƼ»P¾¯ºsÆwä�émº7ÇÞÆLº¨½¼»Hº¼ÑH¹�º7¸_Ê�Ë2º¼ÂdÅsÑPÀPÄf¾ÈÄfÁ�Ç¿ÂUƹ�½¼Â¡ÀPÄ�º ÃNÂU½{Î ÂdÅ�ºUÜ�àP»�ºaÆ{ÄfÍa¡Ä�Î7º¨ÑPÂ�Ï�ÇÈÕ§Å3»P¾Èº¼Ç¿ÂUÆ$½¼ÂdÆ{»P¾ÈºÎ ½¨Ä�ÍúÃP½¨Ä�àP¾¿ÂwÍ)Æ�Ç¿À[Ö_×ØÔÊ:ä�ûP»H½{º¨ÑPÂw½dÜ_Ç¿À[ÁfÂwÀPÂU½¨¹�¾�Ü_ǯξ¿ÇÈÀHÁ�»PÇÞÆyº¨Ç¿Å$ÇÈÀPÎ Ä�½¨Í¡¹�º¼Ç¿Ä�À!ÇÞÆ9¹�ÏPÏPÂUϥǿÀh¹�Æ{Äf»P½sÅ3Â;º¨Â3ã�ºUÜYÇȺÁf½¼Âd¹Iº¼¾¿ê"ÑPÂw¾¿ÃHÆV¸_Ê�Ë!ÃP½¨Ä�Áf½¨¹�Í¡ÆYº¼Ä"ÃP½¼Ä�Ï�»NÅ3Â7¹_àNÂwº{º¨Âw½V½¼ÂwÝƼ»P¾ÈºUä_ü7Ä�ÀHƼÇÞÏ�Âw½º¨ÑPÂ;Î Äf¾È¾¿ÄIÐÇÈÀHÁ§Æ{ÇȺ¼»H¹�º¼Ç¿Ä�ÀHÆUäèåïÑPÂwÀ¥êfÄ�»»HƼÂ�¹!ƼÂU¹�½¨ÅsÑæÂwÀHÁ�Ç¿ÀPÂ�ÜVê�Äf»á¹�½¨Â)Ä�Îýº¨ÂwÀD½¨Â3º¼»H½¼ÀPÂdÏD¹¥¾¿Ç¿Æ{ºÄ�Î_º¼ÑHÄ�»Hƨ¹�ÀHÏHÆ)Ä�Î;Ï�Ä�Å3»PÍ¡ÂUÀfºsÆ)Í)¹IºsÅsÑPÇÈÀHÁæêfÄ�»P½§þB»PÂU½¼êfäØ¥ÄBÆyº:Ä�ÎYº¼ÑPÂ�Å3»P½¨½¼ÂUÀBº7Æ{Âd¹�½sÅsÑ0ÂUÀPÁ�Ç¿ÀPÂdÆYÿy»HÆ{º7»HƼÂ_Ƽ»PÃKÂw½¼íPÝÅwÇ¿¹�¾�Ç¿À�Î Ä�½¨Í)¹Iº¼Ç¿Ä�À;Ƽ»HÅsÑ ¹�Æ-ì�ÂUêBÐ*Ä�½sÏPÆUäYémÎHÆ{Âd¹�½sÅsÑ9ÂwÀPÁfÇÈÀPÂdÆ»HƼÂUϧ½¼ÇÞÅsÑPÂw½*¾¿ÇÈÀPÁf»PÇÞÆyº¨Ç¿Å�ÇÈÀPÎ Ä�½¨Í¡¹�º¼Ç¿Ä�À�Ƽ»HÅsÑ�¹�Æ*Æ{ê�ÀBº¨¹fÅ�º¼ÇÞÅÆ{º¼½¨»HÅ�º¨»P½¨ÂUÆUÜ-º¨ÑPÂwêæÐ7Äf»P¾ÞÏ2àNÂ�¹�àP¾¿Â)º¼ÄÔÃP½¼ÄIÒ�ÇÞÏ�§¹¥Í¡Ä�½¨Â¹�ÃPÃP½¨Ä�ÃP½¨Ç¿¹�º¼Â�½¨¹�ÀPì�ÇÈÀPÁ¡Ä�Î�½¨Â3º¼½¨Ç¿ÂwÒ�ÂdÏ�ÏPÄ�Åw»PÍ¡ÂwÀBº¨ÆUäåïÑPÂUÀÓê�Ä�»îÁ�ÂUÀPÂw½s¹Iº¨ÂD¹�Ƽ»PÍ¡Í)¹�½¨êßÄ�Î)¹�ÀÓÖ�×Ø!Ê
Ö_×Ø!Ê���Äf»P½sÅ3Âé*»HƼÂUÏ�º¼ÑHÂ"Ñ��aº¨¹�Áaº¨ÄaÂUÍ¡ÃPÑH¹�ƼǿøwÂ�� Ñ����mº¨ÑPÇ¿Æ�ÃH¹�½¼º�mëiÑ�����ä
ÂwÀNÏ�Âw½¨ÇÈÀHÁaétÍ)¹�Á�Âé*»HƼÂUÏ�º¼ÑHÂ"Ñ��aº¨¹�Áaº¨ÄaÂUÍ¡ÃPÑH¹�ƼǿøwÂ��� ����������äû�Ç¿Á�»P½¨Â�����ç_À0ÂwãP¹�Í¡ÃP¾¿Â7Ä�ÎHн¼ÄfÀPÁ_»NƼ¹�Á�Â*Ä�ÎNÖ�×Ø!Ê�º¨¹�Á
ÃN¹�Á�Â�à�êD»HƼÇÈÀHÁ2¹�À�¹�»�º¼ÄfÍ¡¹�º¼ÇÞÅ�Æ{»PÍ¡Í)¹�½¨êDÁ�ÂUÀPÂw½s¹Iº¨ÇÈÄfÀÃH½¼ÄfÁ�½s¹�Í�ÜP¹)Å3ÄfÃBê�½¨ÇÈÁfÑBºèÀHÄ�º¼ÇÞÅ3Â;ÇÞÆ�ƼÄ�Í¡Â3º¨ÇÈÍ¡ÂdÆÇÈÀNÅ3¾¿»HÏ�ÂUÏÇ¿À�º¼ÑPÂ!Ƽ»PÍ¡Í)¹�½¨ê2º¼ÂwãBºdäßØ¥ÄfÆ{º)Ä�Î�º¼ÑPÂ!Åw»P½¼½¨ÂwÀBº)¹�»�º¨Ä�ÝÍ)¹�º¼ÇÞÅ0Ƽ»PÍ¡Í)¹�½¨ê�ÃH½¼ÄfÁ�½s¹�Í)Æ�ƼÇÈÍ¡ÃP¾¿ê!Æ{ÂU¾ÈÂdÅ�º9ÇÈÍ¡ÃKÄ�½¼º¨¹�ÀfºÆ¼ÂwÀBº¨ÂwÀHÅwÂUÆ*Ä�À�º¼ÑPÂ9àH¹fÆ{ÇÞÆ*Ä�Î�Ƽ»P½¼Îð¹�Å3Â"Å3¾¿»PÂUÆƼ»HÅsÑ�¹�Æ7ì�ÂwêBÝÐ*Ä�½sÏPÆ�¹�ÀHÏïƼÂwÀBº¼ÂUÀHÅ3Âh¾ÈÄ�ÅU¹Iº¼Ç¿Ä�ÀïÇ¿À'¹áÏPÄ�Åw»PÍ¡ÂwÀBºUä ç_ƹ�½¨ÂUƼ»P¾ÈºUÜ-º¼ÑPÂUêhƼÄ�Í¡Â3º¨ÇÈÍ¡ÂUÆ$Æ{ÂU¾ÈÂdÅ�º$¹�Å3ÄfÃBê�½¨ÇÈÁfÑBº"ÀPÄ�º¼ÇÞÅ3¾¿Ä�Åw¹�º¼ÂUÏæ¹Iº"º¼ÑHÂaÂUÀHÏhÄ�Î7¹�Ï�Ä�Å3»HÍaÂUÀBºUÜ�ƼÇÈÀHÅwÂ)Æ{ÂUÀfº¨ÂwÀHÅwÂUƾ¿Ä�Åw¹�º¼ÂUÏ�¹Iºaº¼ÑPÂ�ÂwÀNÏPÆaÄ�Î�Ï�Ä�Åw»PÍ¡ÂwÀBº¨Æ0º¼ÂUÀHÏDº¨ÄhàKÂ�ÇÈÍaÝÃKÄ�½¼º¨¹�ÀBºUä_×èÑPÇÞÆ�ÃH½¼ÄfàP¾ÈÂUÍ�ÅU¹�À¥àKÂ0¹iÒfÄ�ÇÞÏ�ÂUÏ�ÇÈÎLº¼ÑPÂ0Í¡¹�ÇÈÀÃN¹�½¼º�Ä�Î�ÏPÄ�Åw»PÍ¡ÂwÀBº�ÇÞÆèÂ3ã�ÃP¾¿Ç¿Åwǯº¨¾Èê�Ï�ÂUÅw¾¿¹�½¼ÂdÏYäûH»P½¼º¼ÑPÂU½UÜ�ÐÑPÂwÀDêfÄ�»2»HƼÂ�¹�åæÂwàáÃH¹�Á�Âaº¼½s¹�ÀNÆ{¾Þ¹Iº¨ÇÈÄfÀ
ÃH½¼ÄfÁ�½s¹�Í�Ü9ê�Ä�»ÓƼÄ�Í¡Â3º¨ÇÈÍ¡ÂdÆ!Æ{ÂUÂDн¼ÄfÀPÁ²º¼½s¹�ÀNÆ{¾Þ¹Iº¨ÇÈÄfÀHÆwäØ!ÄfÆ{ºèÄ�Î�º¨ÑPÂwÍ�¹�½¨Â�ÁfÂwÀPÂU½¨¹�º¼Âdϧà�ê)º¼ÑHÂ;ÇÈÀHÅwÄ�Í¡ÃP¾¿Â3º¨ÂwÀPÂdƼÆÄ�ÎKØ!×ẼÂdÅsÑPÀPÄ�¾¿Ä�Áfê�ÜIàP»PºLƼÄ�Í¡Âè¹�½¨Â7ÁfÂwÀPÂU½¨¹�º¼ÂdÏ à�ê;ÃP½¨Ä�à�ݾ¿ÂwÍ)Æ7ÇÈÀ�ÒfÄ�¾¿ÒBÇ¿ÀPÁ$Ö�×Ø!ÊÔ¹�ÀHÏ)Ù"Ø!Ê!ºs¹�Á »NƼ¹�Á�Â�äVûPÄf½,Ç¿À�ÝÆ{º¨¹�ÀHÅ3ÂfÜNн¨ÇȺ¼Âw½sÆÄ�Îýº¼ÂwÀÔÍaÇÞƼ»HÆ{ º¨¹�ÁBƺ¨Ä§Ä�à�ºs¹�Ç¿À!Å3ÂU½{ºs¹�Ç¿ÀÆ{ºyê�¾ÈÇÞÆ{º¼ÇÞÅ�Â��KÂdÅ�º¨ÆUäDûPÄf½aÇ¿ÀHÆ{º¨¹�ÀHÅ3ÂfÜ:Æ{ÄfÍaÂ�н¼ÇȺ¼ÂU½¨Æ0»HƼÂ�¹ÑHÂU¹�ÏPÇÈÀPÁ¡ºs¹�Á¡º¨Ä)Ä�à�ºs¹�Ç¿À�¾Þ¹�½¨Á�Â�Î Ä�ÀBº�¹�ÀHÏ�àNÄf¾¿Ï�Æ{ºyê�¾ÈÂfÜH¹�ÆƼÑPÄIÐÀhÇÈÀ2û�ÇÈÁNä���äaØ¥ÄfÆ{º;Í)¹�ÅsÑPÇ¿ÀPÂ0º¼½s¹�ÀHƼ¾¿¹�º¼Ç¿Ä�À�ÉðØ!×�ÌÂUÀPÁ�Ç¿ÀPÂdÆ�ÅsÑH¹�ÀPÁ�Â�º¼ÑHÂ!º¼½s¹�ÀNÆ{¾Þ¹Iº¨ÇÈÄfÀ�¾¿Ä�ÁfÇ¿Å�ÐÑPÂUÀß¹áƼÂwÀ�ݺ¨ÂwÀHÅw§ÇÞÆ;¹�º¼ÇȺ¼¾¿Â�ÜVÆ{Ä�º¼ÑHÇ¿Æ;н¨Ä�ÀHÁ�»NÆ{Â)Ä�Î*ÑPÂd¹�Ï�Ç¿ÀPÁ�º¨¹�ÁfÆƼÄ�Í¡Âwº¼Ç¿ÍaÂdÆ,ÅU¹�»HƼÂUÆ7¹;н¼ÄfÀPÁ"º¼½s¹�ÀHƼ¾Þ¹Iº¼Ç¿Ä�À)½¨ÂUƼ»P¾ÈºUäVÖ�ÄIÐèÝÂUÒ�ÂU½UÜ�º¼ÑPÂ�¾ÈÇ¿ì�ÂU¾ÈÇ¿ÑPÄ�Ä�Ï2Ä�Î*º¼ÑPÇÞÆ ÐÇ¿¾È¾èÏ�ÂdÅ3½¨ÂU¹�Ƽ¡ǯÎ�¹!Æ{ºyê�¾ÈÂƼÑPÂUÂ3º�Í¡ÂdÅsÑH¹�ÀPÇÞÆ¼Í ÇÞƧÐÇÞÏ�ÂU¾Èêï¹�ÅUÅ3ÂUÃ�º¼ÂdÏïà�ê�åæÂwà[¹�»�ݺ¨ÑPÄ�½sÆèÇ¿À�º¨ÑPÂ9Î »�º¨»P½¼Âfäç_ÀPÄ�º¨ÑPÂw½�Â3ãP¹�ÍaÃH¾ÈÂæÄ�Î$Ö�×Ø!Ê�ëIÙ�Ø!Ê ÃP½¨Ä�àP¾¿ÂwÍ)ƧÇÞÆ
º¨ÑPÂ*½¼ÂdÅ3Ä�ÁfÀPÇȺ¼Ç¿Ä�À;Ä�ÎH¹�Æ{ÂUÀBº¼ÂwÀNÅ3Â�ä�×èÑPÂw½¨Â7¹�½¼Â7Í)¹�À�ê"ÅU¹�ƼÂUÆÇ¿À¥ÐÑPÇÞÅsÑ¥¹aƼÂwÀBº¨ÂwÀHÅwÂ;Ç¿Æ*º¨Âw½¨ÍaÇ¿ÀH¹�º¼ÂUÏ�ÀPÄ�º�à�ê�¹aÃNÂU½¼Ç¿Ä�ÏYÜàH»�º,Í¡Âw½¨Âw¾¿ê à�ê$¹�� àP½ ��º¨¹�ÁHÜIÎ Äf½LÇÈÀNÆyºs¹�ÀHÅwÂ�Ü�Ç¿À)¹�À¡Ö_×Ø!ʺs¹�àP¾¿Â�ÂUÀ�ÒBÇ¿½¨Ä�ÀPÍ¡ÂwÀBºdä!ç_Æ$ƼÑPÄIÐÀDÇ¿Àâû�ÇÈÁNä"!�ÜL¹¥Ð½¨Ç¯º¨Âw½

�ýºs¹�àP¾¿Â��ýº¨½ ��ýºsÏ���ð¹¡ÑP½¨Â3Î ��� äÈä¿ä � �tétÀBº¨Âw½¨ÀPÂ3º ��ÑPÄfÃHÆ �mëI¹�� � àH½ ��ð¹¡ÑP½¨Â3Î ��� äÈä¿ä � �¼ü7Ä�Äf¾ ��ǯº¨ÂUÆ�?ëI¹�� �ðàP½ ��ð¹¡ÑP½¨Â3Î ��� äÈä¿ä � �tåïÑN¹Iº�� Æè¸�ÂUÐ�� �mëI¹ ��?ëiº¨Ï���?ëiº¼½ ��?ëiº¨¹�àH¾ÈÂ��
û�Ç¿Á�»P½¨Â !��:ç�À�Âwã�¹�Í¡ÃP¾ÈÂ9Ä�Î�»HƼǿÀPÁ � àP½ �7º¨¹�ÁfÆ*ÇÈÀ¥¹aºs¹�àP¾¿Â
ƼÄ�Í¡Â3º¨ÇÈÍ¡ÂdÆ_Ç¿ÀBº¼ÂwÀNÏPÆ9ÂU¹fÅsÑÔ¾¿ÇÈÀPÂaÇ¿Àæ¹�Å3ÂU¾È¾VÄ�Î*¹§ºs¹�àP¾¿Â$º¨ÄÂwã�ÃH½¼ÂdƼÆè¹)ƼÂwÀBº¼ÂUÀHÅ3ÂfÜPÂwÒfÂwÀ�ǯÎ�º¼ÑHÂw½¨Â;Ç¿ÆÀHÄ)ÃP»PÀHÅ3º¼»H¹�º¼Ç¿Ä�À¹�º�º¨ÑPÂÂwÀHÏ0Ä�ÎNº¼ÑP¾¿Ç¿ÀPÂ�äV×èÑPÂØ!×áÃH½¼ÄfÁ�½s¹�ÍÓÅw¹�ÀPÀPÄ�ºVº¨Âw¾¿¾ÐÑPÂwº¼ÑPÂU½)ÂU¹fÅsÑ�¾¿ÇÈÀH¥ǿÆ)¹DƼÂwÀBº¼ÂUÀHÅ3Â�Äf½)ÐÑPÂ3º¨ÑPÂw½¡º¨ÑPÂUƼº¨ÑP½¼ÂUÂ9¾ÈÇ¿ÀPÂUÆÎ Ä�½¨Í£Ä�ÀPÂ;ƼÂwÀBº¼ÂUÀHÅ3ÂfäétÀæÁ�ÂwÀHÂw½s¹�¾?ÜNÇȺ;Ç¿Æ"Ò�ÂU½¼ê�ÑPÂU¾ÈÃPÎ »P¾VÎ Ä�½9Í)¹�ÅsÑPÇ¿ÀPÂ$º¼½s¹�ÀHÆ{Ý
¾Þ¹Iº¨ÇÈÄfÀaÃH½¼ÄfÁ�½s¹�Í)Æ�º¼Ä ì�ÀPÄIÐ�àNÄf»PÀHÏP¹�½¼Ç¿ÂUÆLÇ¿À)Í)¹�À�ê$¾¿ÂwÒfÂw¾ÞÆÉ�Æ{»HÅsÑa¹�ÆVƼÂwÀBº¼ÂUÀHÅ3ÂfÜIÃPÑP½s¹�ƼÂUÆUÜi¹�ÀHÏ Ð*Ä�½sÏPÆsÌ-¹�ÀHÏ;º¨Ä�ì�ÀPÄIÐÐ*Ä�½sÏ�Ý?º¼Ä�ÝmÐ*Ä�½sÏ¥Ï�ÂwÃKÂwÀHÏPÂwÀHÅwêÔ½¨Âw¾Þ¹Iº¼Ç¿Ä�ÀNÆwä¡ûPÄf½;ÇÈÀHÆ{º¨¹�ÀHÅ3ÂfÜÇ¿ÀﺼÑHÂ!Î Ä�¾¿¾¿ÄIÐÇÈÀPÁâÂ3ãP¹�Í¡ÃP¾¿Â�Ü � �BºUä � ÑN¹�Æ)ºyÐ*ÄâÃKÄfƨƼÇÈàP¾¿ÂÍ¡ÂU¹�ÀPÇ¿ÀPÁfÆ � � Æ{º¼½¨ÂwÂwº � ¹�ÀNÏ � Ƽ¹�ÇÈÀBºdä � ×èÑPÂU½¼ÂwÎ Ä�½¨Â�Ü�Ð*Â�Åw¹�À�ÝÀPÄ�º_Ï�Â3º¨Âw½¨Í¡ÇÈÀPÂ$ÐÑPÂ3º¨ÑPÂw½º¨ÑPÂ;Î Äf¾È¾¿ÄIÐÇÈÀHÁ)Â3ãP¹�Í¡ÃP¾¿Â Å3ÄfÀ�ÝƼǿÆ{º¨ÆèÄ�Î�ÄfÀPÂ;Ä�½*ºyÐ*ġƼÂwÀBº¨ÂwÀHÅwÂUÆèÐÇȺ¼ÑPÄf»�º�ÃH¹�½sƼÇÈÀPÁaÇȺUä
é,Ð*ÂwÀBº7º¨Äa¸_ÂwÐ'ç_½¼ì �BºUä:ËL¹�»P¾N¾¿Ç¿Ò�ÂUϧº¼ÑPÂU½¼ÂÇÈÀ�ºyÐ*ÄaêfÂU¹�½¨Æè¹�ÁfÄHä
ç_Æ�¹�ÀHÄ�º¼ÑHÂw½�ÂwãP¹�Í¡ÃP¾¿Â�Ü躼ÑHÂ!Î Ä�¾¿¾¿ÄIÐÇÈÀPÁ�Æ{ÂUÀfº¨ÂwÀHÅwÂ!ÇÞƹ�Í$àPÇ¿Á�»PÄf»HƧƼÄ2º¼ÑH¹�º�º¨ÑPÂw½¨ÂÔ¹�½¨Â¥ºyÐ*ÄáÇ¿Àfº¨Âw½¨ÃP½¨Â3º¨¹�º¼Ç¿Ä�ÀHÆ��ÄfÀPÂ�Ç¿ÀBº¼Âw½¨ÃP½¨Â3ºs¹Iº¼Ç¿Ä�ÀâÇ¿Æ0º¼ÑN¹Iº¡ÐÑH¹Iº¡ÑPÂ�¾ÈÇ¿ì�ÂdÆ$ÇÞÆaÃNÂUÄ�ÃP¾¿Â¹�ÀHÏ!º¨ÑPÂ)Ä�º¨ÑPÂw½$ÇÈÀBº¼ÂU½¼ÃH½¼Âwº¨¹Iº¨ÇÈÄfÀÔÇÞÆ9º¼ÑN¹Iº ÐÑH¹�º ÑPÂ)¾ÈÇ¿ì�ÂdÆÇÞÆ�¹�ÅUÅ3ÄfÍaÍ¡Ä�ÏP¹�º¼Ç¿ÀPÁHäLémÎ�º¼ÑPÂU½¼Â ¹�½¼Â9ºs¹�ÁBÆèÇÈÀHÏPÇ¿ÅU¹Iº¼Ç¿ÀPÁ¡º¨ÑPÂÏ�Ç¿½¨ÂUÅ�º¼Ý?Äfà�ÿyÂUÅ3º�Í¡Ä�ÏPǯíHÂU½_Ä�ÎLº¼ÑPÂ0Ð7Äf½¨Ï � ¾¿Ç¿ì�Â�Ü � º¼ÑHÂwÀ¥º¨ÑPÂÅwÄ�½¨½¼ÂdÅ�ºèÇÈÀBº¼ÂU½¼ÃH½¼Âwº¨¹Iº¨ÇÈÄfÀ�ÇÞÆÃKÄfƨÆ{Ç¿àP¾¿Â�ä
Ö�Â;¾¿ÇÈìfÂUƹ�ÅUÅ3ÄfÍaÍ¡Ä�ÏP¹�º¼Ç¿ÀPÁ0ÃKÂwÄfÃP¾¿Â�äç_Æ_º¼ÑHÂ$¹�àKÄIÒ�Â;Âwã�¹�Í¡ÃP¾ÈÂdÆ_ƼÑPÄIÐ;ÜN¸�Ê-Ëß¹�ÃPÃP¾¿Ç¿ÅU¹Iº¨ÇÈÄfÀHÆ
Ï�ÄæÀPÄ�º¡¹fÅsÑPÇÈÂUÒ�Â�º¼ÑPÂUÇȽ¡Î »P¾¿¾ÃKÄ�º¼ÂUÀBº¼ÇÞ¹�¾?Ü,Ä�À�¹�ÅUÅ3Ä�»HÀfºaÄ�ÎÃP½¨Ä�àH¾ÈÂUÍ¡Æ:»PÀP½¨Âw¾Þ¹Iº¼ÂdÏ0º¼Ä;º¨ÑPÂ�ÂUƨƼÂwÀBº¼ÇÞ¹�¾H¸�Ê-ËDÃH½¼Ä�Å3ÂdƼƼÂUÆUäémÎBº¨¹�ÁfÆYÂwã�ÃH½¼ÂdƼƼÇÈÀHÁ*¾¿Ç¿ÀPÁ�»PÇÞÆ{º¼ÇÞÅVÇÈÀ�Î Äf½¼Í)¹�º¼Ç¿Ä�À;¹�½¨ÂVÇÈÀHƼÂw½¼º¼ÂdÏÇ¿ÀBº¼ÄáƼÄ�»P½sÅ3Â¥Ï�Ä�Å3»HÍaÂUÀBº¨ÆUÜ7º¨ÑPÂwê�ÑPÂw¾¿Ã߸_Ê�ËFÃP½¨Ä�Á�½s¹�Í)ƽ¨ÂUÅwÄ�Á�ÀHÇÈøUÂ�Ï�Ä�Å3»PÍ¡ÂwÀBº¹�ÀHϧ¾ÈÇ¿ÀPÁ�»HÇ¿Æ{º¼ÇÞÅ_Æ{º¼½¨»HÅ�º¨»P½¨ÂUÆ:ÃH½¼ÄfÃ�ÝÂU½¼¾¿ê�Ü�¹�¾È¾¿ÄIÐÇÈÀHÁ�º¼ÑHÂ*ÃH½¼ÄfÁ�½s¹�Í)ÆYº¨Ä�ÃP½¨Ä�Ï�»HÅwÂ*Í0»HÅsÑ$àKÂ3º¼º¼ÂU½½¨ÂUƼ»P¾Èº¨ÆUä�ç*ºLº¼ÑHÂ�Ƽ¹�ÍaÂ*º¨ÇÈÍ¡Â�Üfǯº:ÇÞÆ�º¼½¨»PÂ躨ÑH¹Iº:¸_Ê�Ë溼ÂdÅsÑ�ÝÀPÄf¾ÈÄfÁ�Ç¿ÂUÆ9¹�½¨ÂaÇÈÀHÅwÄ�Í¡ÃP¾¿Â3º¨Â�Ü-àH»�º;º¼ÑPÂUÇȽ ÏPÂ3íNÅwÇÈÂUÀHÅ3Ç¿ÂUÆ ÅU¹�ÀƼÄ�Í¡Â3º¨ÇÈÍ¡ÂdÆ-àKÂ*ÅwÇȽsÅ3»HÍ$Ò�ÂUÀBº¼ÂUÏ;º¼ÑP½¨Ä�»PÁfÑ º¨ÑPÂ7»NÆ{Â*Ä�ÎNƼ»HÅsѺs¹�ÁfÆUä0×èÑHÂw½¨Â3Î Ä�½¨Â�Ücº¨ÑPÇÞÆ;ÃH¹�ÃKÂw½9ÃP½¨Ä�ÃKÄfƼÂUÆ9¹�ƼÂ3º;Ä�Î7º¨¹�ÁBÆÎ Äf½,ÑPÂU¾ÈÃPÇ¿ÀPÁ$¸�Ê-ËâÃP½¼ÄfÁ�½s¹�Í)ÆUÜ�Åw¹�¾È¾¿ÂUÏ)Ê-ÇÈÀPÁf»PÇÞÆyº¨Ç¿Å�ç�ÀPÀPÄ�ݺs¹Iº¼Ç¿Ä�À�Ê-¹�ÀPÁ�»N¹�Á�Â¡É Äf½�Ê-ç�Ê�Ì�ä
� ÷ ó� ö_÷{³f´P÷{·ï° ó�ó ôL´�¶�´P÷yô ó� ¶ ó ö�¶ ������� ��� � ������ � ����� � � �Ê-ÇÈÀHÁ�»PÇÞÆyº¨Ç¿Å;ç_ÀPÀPÄ�º¨¹Iº¨ÇÈÄfÀ�Ê�¹�ÀPÁf»H¹�ÁfÂaÉðÄ�½�Ê�ç_Ê�Ì*ÇÞÆ�¹�À
Ù"Ø!ÊYÝtÅ3ÄfÍ¡ÃP¾ÈÇÞ¹�ÀBº"º¨¹�Á�ƼÂ3ºdä;émº"Ðè¹�Æ9Ï�ÂdÆ{Ç¿Á�ÀPÂdÏ¥ÐÇȺ¼Ñhº¼ÑPÂÎ Äf¾È¾¿ÄIÐÇ¿ÀPÁ)Å3Ä�ÀNÆ{ÇÞÏ�Âw½s¹Iº¨ÇÈÄfÀHÆ �
! ��Ç¿Í¡ÃP¾ÈÇÞÅ3ÇȺyê �)ç�¾Èº¼ÑPÄf»PÁ�ÑDÐ*Â�Å3ÄfÀHƼǿÏ�ÂU½ º¨ÑH¹Iº0Ê�ç_ʺ¨¹�ÁfÆ;ƼÑPÄ�»H¾¿ÏæàK§¹�Æ;ƼÇÈÍ¡ÃP¾¿Â§¹�Æ9ÃKÄfƨÆ{Ç¿àP¾¿Â§Æ{Ä�º¨ÑH¹IºÑ�»PÍ)¹�ÀHÆÔÐÇȾ¿¾$Ðè¹�ÀBº¥º¨Äﺼ½¨ê[¹�ÀPÀPÄ�ºs¹Iº¨ÇÈÀPÁ[Ï�Ä�Å3»�ÝÍ¡ÂwÀBº¨Æ�Í)¹�À�»H¹�¾¿¾¿ê�Ü*Ð7Â¥Í0»HÆyº�Ä �cÂw½�¹�À²¹fƼƼÇÞÆyº¨ÇÈÀPÁº¼Ä�Äf¾�Î Ä�½"¹�ÀPÀHÄ�º¨¹�º¼Ç¿Ä�À�Ç¿À¥ÃP½¨¹fÅ�º¨Ç¿ÅwÂ�ä×èÑPÂ$ƼÇÈÍ¡ÃP¾¿ÇÞÅ�ÝÇȺyê¥Ç¿Æ9¹�¾ÞƼħÇÈÍ¡ÃKÄ�½¼º¨¹�Àfº"º¼Ä�Í)¹�ìfÂ0¹�ÀÔÂU¹�ƼêBÝ�º¨Ä�Ým»HƼ¹�ÀHÀPÄ�ºs¹Iº¼Ç¿Ä�À¡º¨Ä�Ä�¾?ÜBƼÇÈÀNÅ3Â_ÇÈÎ-Ð*Â�»HƼÂ�¹ Î ÂU¹Iº¨»P½¨Â3Ým½¼ÇÞÅsѺ¨¹�Á¥Æ{ÂwºUÜ�¹�»HƼÂw½9Í0»HÆyº$ÅsÑHÂUÅsì¥Í)¹�À�êÔ¹�ÀPÀPÄ�ºs¹Iº¨ÇÈÄfÀÇȺ¼ÂwÍ)ÆUä:×èÑPÂw½¨Â3Î Äf½¼ÂfÜBº¼ÑPÂ;Í)¹�Ç¿À�ÃH¹�½¼ºÄ�ÎLÊ-ç_Ê2ÅwÄ�À�ÝƼǿÆ{º¨ÆèÄ�Î�ƼêBÀBºs¹�Å�º¨Ç¿Å9¹�ÀPÀPÄ�ºs¹Iº¨ÇÈÄfÀ�ºs¹�ÁfÆ7Î Äf½�Æ{ÃKÂUÅwǯΠêBÝÇ¿ÀPÁ_àKÄ�»PÀNÏP¹�½¨ÇÈÂdÆ-¹�º�Í)¹�À�ê9¾ÈÂUÒ�ÂU¾¿ÆUÜI¹�ÀHÏ;¾¿Ç¿ÍaÇȺ¼ÂdÏ$ƼÂ3ÝÍ)¹�ÀBº¼ÇÞÅ_¹�ÀPÀPÄ�º¨¹Iº¨ÇÈÄfÀ¡º¨¹�ÁfÆLÎ Äf½*ƼÃKÂUÅ3ÇÈÎ ê�ÇÈÀHÁ$¾¿ÇÈÍ¡ÇȺ¼ÂUÏƼÂwÍ)¹�ÀBº¼ÇÞÅ2Ç¿À�Î Ä�½¨Í)¹Iº¼Ç¿Ä�À-ä étÀÓÃP½s¹�Å3º¼ÇÞÅ3Â�Ü;àKÄ�»HÀHÏ�ݹ�½¨ê0ƼÃKÂUÅ3ÇÈíNÅU¹Iº¼Ç¿Ä�À)ÐÇȺ¼Ñ)¾¿Ç¿ÍaÇȺ¼ÂdÏ)¾¿ÇÈÀPÁf»PÇÞÆyº¨Ç¿ÅÇ¿À�Î Äf½{ÝÍ)¹Iº¨ÇÈÄfÀæÅU¹�ÀDÅ3ÄIÒfÂw½9Í¡ÄfÆ{º;¸�Ê-ËÚÃP½¨Ä�àH¾ÈÂUÍ¡ÆUÜ-ƼÄ�ǯºÇÞÆ0Ƽ»�Õ§Å3Ç¿ÂwÀBº¼¾¿ê2 �cÂUÅ3º¼Ç¿Ò�Â)Î Äf½a¸�Ê-ËÓÃP½¨Ä�Áf½¨¹�Í)Æ;ÇÈÀº¼ÂU½¼Í)ÆèÄ�Î�Ç¿ÀHÅ3½¨ÂU¹fÆ{Ç¿ÀPÁ¡¹�ÅUÅ3»P½s¹�Åwê�ä
! ç_ƨƼǿÆ{º¨¹�ÀHÅ3¡ÐÇȺ¼ÑD¸_Ê�ËÓ×�¹fÆ{ì�Æ �9×èÑHÂ)Í¡¹�ÇÈÀ2ÃP»H½{ÝÃKÄfƼÂ�Ä�Î-Ê�ç_Ê¥ÇÞÆ:º¨Ä ÑPÂU¾ÈÃ�¸�Ê-ËDÃH½¼ÄfÁ�½s¹�Í)Æ�º¼Ä0ÃNÂU½{ÝÎ Ä�½¨Í º¨ÑPÂwÇ¿½ ºs¹�Ƽì�Æ9Í$»HÅsÑ2àKÂ3º{º¨Âw½dä�×èÑHÂw½¨Â3Î Ä�½¨Â�Ü�ÇÈÀ¹�ÏHÏ�ǯº¨ÇÈÄfÀ�º¼Ä¡ºs¹�ÁfÆÎ Ä�½_¾¿Ç¿ÀPÁ�»PÇÞÆ{º¼ÇÞÅ9ÇÈÀ�Î Äf½¼Í)¹�º¼Ç¿Ä�À�ÜNǯºÆ¼ÑPÄ�»P¾ÞÏ9Å3ÄfÀfºs¹�Ç¿À"º¨¹�ƼìBÝmÏPÂwÃKÂwÀHÏ�ÂUÀBº�ÇÈÀHÆ{º¼½¨»HÅ3º¼Ç¿Ä�À"º¨¹�ÁfÆƼ»HÅsÑ�¹fƹ0º¨¹�Á¡Ç¿ÀHÏ�ÇÞÅw¹�º¼Ç¿ÀPÁ¡º¼½s¹�ÀHƼ¾Þ¹Iº¼Ç¿Ä�À�ƼÅwÄ�ÃKÂ�ä
Ê�ç_ʲºs¹�ÁBÆ ¹�½¨Â)»HƼ»H¹�¾¿¾ÈêhÂ3ã�ÃP½¨ÂUƨÆ{ÂdÏæàBêh»HƼÇÈÀPÁÔÙ�Ø!ÊÀN¹�Í¡ÂUƼÃH¹�ÅwÂUÆUä�×èÑHÂwÇ¿½$Ù�ØÔÊïÀH¹�Í¡ÂdÆ{ÃH¹fÅ3Â)ÃP½¨Â3íHãæÇÞÆ ���"� ä��ÇÈÀHÅw§¾¿ÇÈÀPÁf»PÇÞÆyº¨Ç¿Å)Ç¿À�Î Äf½¼Í)¹Iº¨ÇÈÄfÀD¹�ÀPÀPÄ�º¨¹�º¼Ç¿Ä�À2ÇÈÀHÑPÂw½¨ÂwÀBº¼¾¿êÑN¹�Æ�ÏPÇ �cÂw½¨ÂwÀBº�¹�ÀPÀPÄ�º¨¹Iº¨ÇÈÄfÀßÏ�Ç¿½¼ÂdÅ�º¼Ç¿Ä�ÀNÆwÜ辿ÇÈÀPÁf»PÇÞÆyº¨Ç¿Åh¹�À�ÝÀHÄ�º¨¹�º¼Ç¿Ä�À溨¹�ÁfÆ9Í)¹iê!ÄIÒfÂw½¨¾¿¹�ÃÔÐÇȺ¼Ñ2Ä�º¨ÑPÂw½ Ö�×Ø!Êï¹�ÀHÏÙ"Ø!Êhº¨¹�ÁfÆUä�étÀ�º¼ÑHÇ¿ÆèÅw¹fÆ{ÂfÜ�Ê-ç_Êhºs¹�ÁfÆ*¹�½¨Â"Â3ã�ÃP½¨ÂUƨÆ{ÂdÏ)ÇÈÀº¨ÑPÂ9Î Ä�½¨Í Ä�Î-º¨ÑPÂ;ÃP½¨Ä�ÅwÂUƨÆ{Ç¿ÀPÁaÇÈÀNÆyº¨½¼»HÅ3º¼Ç¿Ä�ÀHÆUä���#� $&%'$)( �*���Ê�ç_Êߺ¨¹�ÁBÆ0¹�½¼Â�Å3¾Þ¹�ƨÆ{ÇÈíHÂUÏ2Ç¿ÀBº¼Äh¾ÈÇ¿ÀPÁ�»HÇ¿Æ{º¼ÇÞŧǿÀ�Î Ä�½¨Í)¹IÝ
º¨ÇÈÄfÀ$ºs¹�ÁBÆ�¹�ÀHÏ;ºs¹�ƼìfÝtÏ�ÂUÃNÂUÀHÏ�ÂwÀBºVÇÈÀNÆyº¨½¼»HÅ3º¼Ç¿Ä�À0º¨¹�ÁfÆUä-Ê�Ç¿À�ÝÁf»PÇÞÆyº¨Ç¿Å)Ç¿À�Î Äf½¼Í)¹Iº¨ÇÈÄfÀ溨¹�ÁBÆ ¹�½¨ÂaÎ »P½¼º¼ÑPÂU½0Å3¾Þ¹�ƨƼǯíHÂdÏæÇÈÀBº¼ÄƼê�ÀBº¨¹�Å3º¼ÇÞŹ�ÀHÏ)ƼÂwÍ)¹�Àfº¨Ç¿Å7ºs¹�ÁfÆUä +,¹�ÅsÑ0ºyê�ÃNÂ_Ä�ÎYÊ-ç_Ê¥º¨¹�ÁÇÞÆ�Ï�ÂdƼÅw½¼Ç¿àKÂUÏ�àNÂU¾ÈÄIÐ;ä���#����� ,.- � ��"� � ��0/1�3254��76 ��� 849� ( �"���×èÑHÇ¿Æ7Åw¹Iº¨ÂwÁfÄ�½¨ê ÑH¹�ÆLº¨¹�ÁBÆVÎ Ä�½7Æ{ÂUÀfº¨ÂwÀHÅwÂUÆUÜ�Ð*Ä�½sÏPÆUÜ�¹�ÀHÏ
ÃHÑP½¨¹fÆ{ÂdÆwä¥×èÑPÂdÆ{§º¨¹�ÁBÆ ¹�½¨Â)Í)¹�Ç¿ÀP¾¿êh»HƼÂUÏ溨ÄÔƼÃNÂdÅ3ÇÈÎ ê2¹Æ¨Å3ÄfÃNÂ9Î Äf½ÂU¹fÅsÑ�»PÀHǯºdä
,:� � � � ��� ��; ×èÑP¡Æ{ÂUÀfº¨ÂwÀHÅwÂ$ºs¹�Á � ÇÞÆ�»HÆ{ÂdÏ¥º¨Ä�ƼÃNÂdÅ3ÇÈÎ ê¹)ƼÂwÀBº¨ÂwÀHÅwÂ9ƨÅ3ÄfÃNÂfä
� ¾Þ¹�¾ � Æ �{×èÑPÇ¿Æ�ǿƧº¼ÑPÂ!íH½¨Æ{º�ƼÂwÀBº¼ÂUÀHÅ3Âfä �mëi¾Þ¹�¾ � Æ �� ¾Þ¹�¾ � Æ �{×èÑPÇ¿Æ�Ç¿Æ�º¼ÑPÂ:ƼÂUÅwÄ�ÀHÏ9ƼÂwÀBº¼ÂUÀHÅ3Âfä �mëi¾Þ¹�¾ � Æ �

×èÑPÂ�¹Iº¼º¼½¨ÇÈàP»Pº¼Â ����������� ���� Í¡Âd¹�ÀHÆ$º¼ÑH¹�º0º¨ÑPÂ�Æ{ÂUÀ�ݺ¨ÂwÀHÅwÂ"ÇÞÆ�¹0º¼ÇȺ¼¾¿Â;Ä�½ÑHÂU¹�ÏPÂw½dä
� 4���� ; ×èÑPÂ�Ð7Äf½¨Ïaºs¹�Á�� ÇÞÆ7»HÆ{ÂdÏ¡º¼ÄaÆ{ÃKÂUÅwǯΠ꧹ Ð7Äf½¨ÏƨÅ3ÄfÃNÂfä émºhÅw¹�ÀÚÑH¹iÒ�ÂD¹Iº¼º¼½¨ÇÈàH»�º¼ÂdÆ�Î Ä�½Ô¹fÏPÏ�ÇȺ¼Ç¿Ä�ÀH¹�¾;ÇÈÀPÝÎ Äf½¼Í)¹Iº¨ÇÈÄfÀ�Ƽ»HÅsÑï¹�Æ¡àN¹�ƼÂ3Ý?Î Ä�½¨Í É�� ��� Ì�ÜÃH¹�½{º¼Ý?Ä�ÎýÝmƼÃKÂwÂUÅsÑÉ � ��� Ì3ÜYÎ ÂU¹�º¼»P½¨ÂUÆaÉ�� ����� Ì�Ü-¹�ÀHÏÔƼÂwÀNÆ{Â�É ���! ���� Ì�Ä�Î*¹§Ð*Ä�½sÏYä×èÑPÂ9ÒI¹�¾¿»PÂdÆ7Ä�Î-º¨ÑPÂUƼÂ;¹Iº{º¨½¼Ç¿àP»�º¨ÂUƹ�½¼Â"¾¿¹�ÀPÁ�»N¹�Á�Â"Ï�ÂwÃKÂwÀPÝÏ�ÂUÀBºUÜ7¹�ÀHÏâ¹�½¼Â�ÀPÄ�º¡Ï�ÂdƼÅw½¼Ç¿àKÂUÏ�ÇÈÀ�º¼ÑPÇÞÆaÃH¹�ÃKÂw½§ÏP»PÂ�º¨Äº¨ÑP Æ{ÃN¹�Å3Â"¾¿ÇÈÍ¡ÇȺ¨¹Iº¨ÇÈÄfÀ�ä
� ¾Þ¹�¾ � Æ �� ¾Þ¹�¾ � Ðæ¾ÈÂwã ��� º¼ÑHÇ¿Æ � ÃNÄBÆ ��� Ï�Â3º � �{×èÑPÇ¿Æ�?ëI¾¿¹�¾�� Ð �� ¾Þ¹�¾ � Ðæ¾ÈÂwã ��� àK � ÃKÄfÆ ��� Ò�ÂU½¼à � Îýº¼½ ��� ƼÁHÜ ��½sÏ � �tÇÞÆ�?ëi¾Þ¹�¾ � Ð �� ¾Þ¹�¾ � Ðî¾ÈÂwã ��� ¹ � ÃNÄBÆ ��� Ï�Â3º � �{¹��?ëI¾¿¹�¾�� Ð �� ¾Þ¹�¾ � Ðæ¾ÈÂwã ��� ÃKÂwÀ � ÃKÄfÆ ��� ÀPÄf»PÀ � Îýº¼½ ��� ƼÁHÜ Å3Äf»PÀBº � �ÃNÂUÀ �?ëI¾¿¹�¾�� Ð ��?ëi¾Þ¹�¾ � Æ �
×èÑP¡Ï�ÂwÃKÂwÀNÏ�ÂwÀHÅwêáÉ Äf½�Ð*Ä�½sÏ�Ý?º¼Ä�ÝmÐ*Ä�½sÏ�Í¡Ä�Ï�ÇÈíNÅw¹�º¼Ç¿Ä�À½¨Âw¾Þ¹Iº¨ÇÈÄfÀHÆ{ÑHÇÈÃNÌ*ÅU¹�À�àNÂ;Âwã�ÃP½¼ÂdƼƼÂUÏ�à�ê�»HƼǿÀPÁaº¼ÑPÂ#" � ¹�ÀHÏ$ ��� ¹�º{º¼½¨Ç¿àP»�º¼ÂdÆaÄ�Î"¹hÐ*Ä�½sÏ2º¨¹�ÁHÜLº¨ÑH¹Iº)ÇÞÆwÜ7ÂU¹�ÅsÑâÐ7Äf½¨ÏÅU¹�ÀÔÑN¹iÒ�Â0¹�ÀÔé�%FÒI¹�¾¿»PÂaÄ�Î,ÇȺ¨Æ9Í¡Ä�Ï�ÇÈíHÂw¡ǿÀh¹�Í¡Ä�Ïæ¹Iº¼Ýº¨½¼Ç¿àP»�º¨Â�ä_×èÑPÂ0é�%ùÒI¹�¾È»PÂ0Ä�Î:¹)Í¡Ä�Ï!¹Iº¼º¼½¨ÇÈàH»�º¼Â0Í$»HÆ{º�àK¹�ÀÔé�%pÒI¹�¾¿»P¡Ä�Îè¹�Ð*Ä�½sÏ!Äf½ ¹�ƼÂwÁ�º¨¹�ÁHä¡ûPÄf½;ÇÈÀHÆ{º¨¹�ÀHÅ3Âfܺ¨ÑP ΠÄf¾È¾¿ÄIÐÇÈÀHÁ�Â3ãP¹�ÍaÃH¾ÈÂaÅ3Ä�ÀBºs¹�Ç¿ÀHÆ_¹�º{º¼½¨Ç¿àP»�º¼ÂdÆ9Æ{ÑPÄIÐÇ¿ÀPÁº¨ÑH¹IºVº¼ÑHÂÐ7Äf½¨Ï � ÐÇȺ¼Ñ � Í¡Ä�ÏPǯíHÂdÆVº¼ÑHÂ*Ð*Ä�½sÏ � Ƽ¹iÐ;Ü � ¹�ÀHÏÐÑPÇÞÅsÑ�ÍaÂd¹�ÀHÆ*º¨ÑH¹Iº � Æ{ÑH � ÑH¹�ƹ0º¨Âw¾¿ÂUƨÅ3Ä�ÃKÂ�ä
��ÑP �𾿹�¾�� Ð�ÇÞÏ ��� Ð � � ¾ÈÂwã ��� Æ{ÂU � ÃKÄfÆ ��� Ò �Æ{ÂUÀHÆ{ ��� ƼÂw � � �{Ƽ¹iÐ �mëi¾Þ¹�¾ � Ð �*¹�Í¡¹�À �𾿹�¾�� ÐÍaÄ�Ï ��� Ð � � �tÐÇȺ¼Ñ �mëi¾Þ¹�¾ � Ð �7¹aº¼ÂU¾ÈÂdƼÅwÄ�ÃKÂ�ä
×èÑP �&� �-¹�º{º¼½¨Ç¿àP»�º¼ÂèÑH¹fÆ�º¼ÑPÂèé�%²ÒI¹�¾¿»PÂ*Ä�ÎHº¨ÑPÂè½¼ÂwÎ Âw½¨ÂwÀBºÄ�Î-º¼ÑHÂ$Å3»P½¨½¨ÂwÀBºÐ7Äf½¨ÏYä:×èÑHÇ¿Æ�ÅU¹�À�àNÂ$»HÆ{ÂdÏ�º¼Ä)Æ{ÃKÂUÅwǯΠê�¹ÃP½¨Ä�ÀHÄ�»PÀ�½¼ÂwÎ Âw½¨ÂwÀBºUÜ�Î Äf½ÇÈÀHÆ{º¨¹�ÀHÅ3 �
� ¾Þ¹�¾ � Æ �yÖ_Â:àNÄf»PÁ�ÑBº-¹èÀPÂUÐ �𾿹�¾�� Ð2Ç¿Ï ��� Ð � � �yÅU¹�½�?ëi¾Þ¹�¾ � Ð �*ê�ÂUÆ{º¼ÂU½¨ÏH¹iê�ä �?ëi¾Þ¹�¾ � Æ �� ¾Þ¹�¾ � Æ � ��ÑHÂæÐè¹�Æ�ÒfÂw½¨ê²Æ¼»P½¨ÃP½¨Ç¿Æ¼ÂUÏߺ¼Ä²¾ÈÂd¹�½¨Àº¼ÑH¹�º � ¾Þ¹�¾ � Ð潨Â3Î ��� Ð � � �yǯº��?ëi¾Þ¹�¾ � Ð �HÐè¹�ÆcÒfÂw½¨êÂ3ã�ÃNÂUÀHƼÇÈÒfÂ�ä �?ëi¾Þ¹�¾ � Æ �
� ��� � � ��; ×èÑPÂÔÃPÑP½s¹�ƼÂ�º¨¹�Á � � � ÇÞƧ»HƼÂUÏ�º¨ÄâÆ{ÃKÂUÅwǯΠê¹�ÃPÑH½¨¹fÆ{Â)ƨÅ3Ä�ÃKÂ)Ç¿Àá¹�À�ê!¾¿ÂwÒ�ÂU¾�ä�×èÑPÂ)Î Äf¾È¾¿ÄIÐÇÈÀHÁ�ÂwãP¹�ÍaÝÃP¾¿Â ƼÃNÂdÅ3ÇÈíHÂUÆ�º¼ÑP ƨÅ3ÄfÃN Ä�ÎV¹¡ÀHÄ�»PÀ¥ÃPÑH½¨¹fÆ{ � ¹¡Í)¹�Àæä¿ä¿ä¹�º¼ÂU¾ÈÂdƼÅwÄ�ÃKÂ�Ü � ¹�ÀHÏ!º¨ÑPÇÞÆ;¹�¾ÞÆ{Ä�ÇÈÍ¡ÃP¾¿Ç¿ÂUÆ"º¼ÑN¹Iº ¹�ÃH½¼ÂUÃNÄBÆ{ÇÈݺ¨ÇÈÄfÀH¹�¾èÃPÑP½s¹�Ƽ � Ðǯº¨Ñ�¹Ôº¼ÂU¾ÈÂdƼÅwÄ�ÃK � Í¡Ä�ÏPǯíHÂdÆ¡¹ÔÀPÄf»PÀÃPÑH½¨¹fÆ{ � ¹aÍ)¹�À�ä �
��ÑPÂ,ƨ¹iÐ �𾿹�¾�� Æ{ÂUÁ��{¹7Í)¹�À;Ðǯº¨Ñ ¹*º¼Âw¾¿ÂUƨÅ3ÄfÃNÂ��?ëI¾¿¹�¾�� Æ{ÂUÁ��3äétÀâ¹fÏPÏ�ÇȺ¼Ç¿Ä�ÀDº¨ÄÔàKÄ�»PÀHÏH¹�½¨ê2ƼÃKÂUÅ3ÇÈíNÅU¹Iº¼Ç¿Ä�À-Ü�êfÄ�»âÅU¹�À
ƼÃNÂdÅ3ÇÈÎ ê§Æ{ê�ÀBº¨¹fÅ�º¨Ç¿Å"Åw¹�º¼ÂwÁfÄ�½¨ê$Î Äf½¹$ÃPÑH½¨¹fÆ{Â"à�ê)»HÆ{Ç¿ÀPÁ¡¹�ÀÄfÃ�º¼Ç¿Ä�ÀH¹�¾�¹�º{º¼½¨Ç¿àP»�º¼Â('�) � äp×èÑPÂhÒI¹�¾È»PÂæÄ�Î;º¨ÑPÂ2Åw¹Iº¥¹Iº¼Ýº¨½¼Ç¿àP»�º¨Â:Ç¿Æ�¹�¾ÞƼÄ�Ï�ÂwÃKÂwÀHÏPÂwÀBº�ÄfÀ;¾¿¹�ÀPÁ�»N¹�Á�ÂdÆY¹�ÀHÏ$Æ{ê�Æ{º¼ÂwÍ)ÆUä×èÑPÂ�Î Äf¾È¾¿ÄIÐÇÈÀHÁhÂwã�¹�Í¡ÃP¾È¥ƼÃNÂdÅ3ÇÈíHÂUÆaº¨ÑH¹Iº§¹æÃPÑP½s¹�Ƽ � ¹Í)¹�À�ÐÇȺ¼Ñ¥¹0º¼Âw¾¿ÂUƨÅ3ÄfÃN � Ç¿Æ�¹aÀPÄf»PÀ�ÃPÑP½s¹�ƼÂ�ä
Ö�Â"Ƽ¹iÐ � ¾Þ¹�¾ � Æ{ÂUÁ Åw¹Iº ��� ÀPà � �y¹9Í)¹�À)Ðǯº¨Ñ�¹º¼ÂU¾ÈÂdƼÅwÄ�ÃK �mëi¾Þ¹�¾ � ƼÂwÁ ��ä×èÑH§¹Iº{º¨½¼Ç¿àP»�º¨Â � ) � ) �!�*�+�� Í¡Âd¹�ÀHÆ9º¨ÑH¹Iº;º¨ÑPÇÞÆ Æ{ÂUÁ�Ý
Í¡ÂUÀfº"¹�¾ÞÆ{Ä)Í¡ÂU¹�ÀHÆ�¹)ƨÅ3ÄfÃNÂ;Ä�ÎLÅwÄ�Ä�½sÏ�ÇÈÀN¹Iº¼Ç¿Ä�À-ä,×èÑPÂ;Î Äf¾¯Ý¾¿ÄIÐÇ¿ÀPÁ)Â3ãP¹�Í¡ÃP¾¿Â$ƼÑPÄIÐ�Æ躨ÑH¹Iº�¹¡Ð*Ä�½sÏ � ƼÄ�ÎýºyÐè¹�½¨Â � ¹�ÀHϹ¡Ð*Ä�½sÏ � ÑH¹�½sÏ�Ðè¹�½¨Â � ¹�½¨Â"ÅwÄBÄf½¨ÏPÇÈÀH¹�º¼ÂdÏYä
×èÑPÇÞÆ�Å3ÄfÍ¡ÃH¹�À�ê�ÏPÂU¹�¾ÞÆcÐÇȺ¼Ñ � ¾Þ¹�¾ � Æ{ÂUÁ�Åw¹Iº ��� ÀPà �ÃH¹�½¨¹ ��� ê�ÂdÆ � �yƼÄ�ÎýºyÐè¹�½¨Â�¹�ÀHÏ9ÑN¹�½sÏ�Ð*¹�½¼Â��?ëI¾¿¹�¾�� Æ{ÂUÁ��Ä�ÎLÅ3ÄfÍ¡ÃP»�º¼ÂU½Uä���#���#� ,�� 6 � �"� � �� / ��254�� 6 ��� �4�� ( �"� �Ê�ç_Ê)ÑN¹�ÆKº¼ÑHÂLÎ Ä�¾¿¾ÈÄIÐÇ¿ÀPÁ辿ÇÈÍ¡ÇȺ¼ÂUÏ$Æ{ÂUÍ¡¹�ÀBº¼ÇÞÅ-ºs¹�ÁBÆYÐÑPÇÞÅsÑ
¹�½¼Â;ƼÂw¾¿ÂUÅ3º¼ÂUÏ�ƼÇÈÀNÅ3Â"º¼ÑPÂdÆ{Â;Âwã�ÃP½¼ÂdƼƼǿÄ�ÀHÆ*¹�½¨Â9Ä�Îýº¼ÂUÀ�»HÆ{ÂdÏYä×èÑH ��� 4�� � � ºs¹�ÁÇÞÆY»HƼÂUÏ�º¼Ä�ƼÃNÂdÅ3ÇÈÎ ê"¹èÃH½¼ÄfÃNÂU½�ÀH¹�Í¡ÂfÜ
¹�ÀHÏ�ǯºÑH¹fÆ*º¼ÑP ������� ¹Iº¼º¼½¨ÇÈàP»Pº¼Â;Æ{ÃKÂUÅwǯΠê�Ç¿ÀPÁ§¹¡Æ{»Hà�ÝmÅw¾¿¹fƼÆÄ�Î:¹)ÃP½¨Ä�ÃKÂw½�ÀH¹�Í¡Â�ÜNƼ»HÅsÑ¥¹�Æ�ÃNÂU½¨Æ¼Ä�À�ÜNÃP¾Þ¹�Å3ÂfÜHÄf½¼ÁB¹�ÀPÇ¿øU¹�ݺ¨ÇÈÄfÀ�ÜPÄf½�Å3Ä�»HÀfº¨½¼êfä
� ¾Þ¹�¾ � ÃP½¼ÄfÃNÂU½cºyê�ÃN ��� Å3Äf»PÀBº¼½¨ê � �yÊ-»�ã�ÂwÍ0àNÄf»P½¼Á�?ëI¾¿¹�¾�� ÃP½¨Ä�ÃKÂw½ �
×èÑHÇ¿Æ�ÇÈÀPÎ Ä�½¨Í¡¹�º¼Ç¿Ä�À!ÇÞÆ" �cÂUÅ3º¼Ç¿Ò� ΠÄf½_º¨½¨¹�ÀHƼ¾¿¹�º¼Ç¿Ä�À�ÜNÎ Ä�½Ç¿ÀHÆ{º¨¹�ÀHÅ3ÂfÜ�º¼Ä)Æ{ÂU¾ÈÂdÅ�º¹�À�¹�ÃPÃH½¼ÄfÃP½¼ÇÞ¹Iº¨Â�º¨½¨¹�ÀHÆ{¾Þ¹Iº¨ÇÈÄfÀ§Ð*Ä�½sÏÄ�Î�¹0Ò�ÂU½¼à�ÐÑPÇ¿ÅsÑ�Í)¹iê)àNÂ9ÅsÑH¹�ÀHÁ�ÂUÏ�ǯÎV¹0Ƽ»Pà�ÿyÂdÅ�ºèÄ�Î�º¼ÑPÂÒfÂw½¨à�ÑN¹�ƹaÑ�»PÍ)¹�À�ÃP½¨Ä�ÃKÂw½¼ºyê�Ü�Â3ºsÅ�ä
,:Äf»hÅU¹�ÀÔ¹�¾¿Æ¼Ä�»HƼ �*� � 49� - 6 ¹�ÀHÏ �.-/-�� ÂU¾ÈÂUÍaÂUÀBº¨ÆÏPÂ3íHÀPÂdÏïÇ¿ÀßÖ_×Ø!Ê º¼ÄâƼÃNÂdÅ3ÇÈÎ ê�¹�Àß¹�Åw½¼ÄfÀBê�Í ¹�ÀHÏï¹�À¹�àPàP½¨ÂwÒ�ÇÞ¹Iº¼Ç¿Ä�À�º¨Âw½¨Í¡ÆUäè×èÑPÂwê�¹�½¨Â ¹¡¾ÈÇȺ{º¨¾ÈÂ0àPǯº�Â3ã�º¼ÂUÀHÏ�ÂUϺ¨Ä ÑH¹iÒfÂ7º¨ÑPÂ�Âwã�ÃN¹�À)¹Iº¼º¼½¨ÇÈàP»Pº¼Â躼Ä0Æ{ÃKÂUÅwǯΠêa¹�À)Â3ã�ÃH¹�ÀHÏ�ÂdÏÎ Äf½¼Í Ä�ÎL¹�àPàP½¨ÂwÒ�ÇÞ¹Iº¼Ç¿Ä�À�Äf½�¹�Åw½¼ÄfÀ�êBÍ ¾ÈÇ¿ì�Â;º¨ÑPÂ0¹�àPàP½_º¨¹�ÁÄ�ÎV× +,é&0
� ¾Þ¹�¾ � ¹�Å3½¨Ä�À�ê�ÍßÂwã�ÃN¹�À ��� étÀfº¨Âw½¨ÀH¹Iº¨ÇÈÄfÀH¹�¾21*»HƼǯÝÀPÂdƼÆØ!¹fÅsÑPÇ¿ÀPÂUÆ � �yé�1*Ø �?ëi¾Þ¹�¾ � ¹�Å3½¨Ä�À�ê�Í �
×èÑH ����� � ºs¹�Á�ÇÞÆ;»HƼÂUÏhº¼Ä!ƼÃNÂdÅ3ÇÈÎ êæ¹¥ÏH¹Iº¼Â)Âwã�ÃP½¼ÂdÆyÝƼǿÄ�À�ÜiÐÑPÂU½¼Âd¹�ÆUÜ3º¼ÑH � 86 � ºs¹�Á�ÇÞÆ�»HƼÂUÏ"º¨Ä_ƼÃNÂdÅ3ÇÈÎ ê"¹èº¨ÇÈÍ¡ÂÂwã�ÃP½¼ÂdƼƼǿÄ�À�äV×èÑPÂ43�)��65 � ¹Iº¼º¼½¨ÇÈàP»Pº¼Â_ÇÞÆ:»NÆ{ÂdÏ$º¨Ä$ƼÃNÂdÅ3ÇÈΠ꡹ÀHÄ�½¨Í¡¹�¾ÈÇ¿øwÂdÏ�Î Ä�½¨Í Ä�Î,¹�ÏP¹�º¼ÂaÄ�½�º¼Ç¿Ía¡Ï�ÂwíHÀPÂUÏÔà�ê¥é ��78�9*: �<; =2>mä
� ¾Þ¹�¾ � ÏP¹Iº¨ÂLÒi¹�¾È»H ��� ! :*:�: Ý : �3Ý : � � �@?f¹�À�ä ��Ü�! :�:*:�?ëI¾¿¹�¾�� ÏP¹�º¼Â�� ¾Þ¹�¾ � º¼Ç¿ÍaÂ,Òi¹�¾È»H ��� �2=�� :*: � � ��� :�: Ë,Ø �?ëi¾Þ¹�¾ � º¼Ç¿ÍaÂ��
×èÑH �BA�6 º¨¹�Á_Ç¿Æ-»HÆ{ÂdÏ9º¼Ä"Æ{ÃKÂUÅwǯΠê;¹À�»PÍ0àNÂU½�Âwã�ÃP½¼ÂdÆyÝƼǿÄ�ÀßÉ Âfä ÁNäÈÜ�ºyÐ*Ä�Í¡Ç¿¾È¾¿Ç¿Ä�Àá¹�ÀNÏæºyÐ7ÂUÀfºyêBÝmÄ�ÀPÂiÌ�ä�×èÑH �������¹�ÀHÏC3�)��65 � ¹�º{º¼½¨Ç¿àP»�º¼ÂdÆ�¹�½¼Â;»NÆ{ÂdÏ�º¼Ä�Æ{ÃKÂUÅwǯΠꥹ§ÀHÄ�½¨Í¡¹�¾¯ÝÇ¿øwÂdÏæÎ Ä�½¨Í Ä�Î7º¨ÑPÂ)À�»PÍ$àKÂw½ Âwã�ÃP½¼ÂdƼƼǿÄ�À�ä§ûH»P½{º¨ÑPÂw½dÜ�º¼ÑPÂ6 49� � - ºs¹�Á ÇÞÆ7»HÆ{ÂdÏ¡º¼Ä0Æ{ÃKÂUÅwǯΠê)Í¡Ä�ÀHÂwêaÂ3ã�ÃP½¨ÂUƨÆ{Ç¿Ä�À�ÜfÇÈÀÃN¹�½¼º¼ÇÞÅ3»P¾Þ¹�½dÜ�º¼Ä)¹�ÏHÏ�Í¡ÄfÀPÂ3ºs¹�½¨ê)»PÀPÇȺ_ÇÈÀPÎ Ä�½¨Í¡¹�º¼Ç¿Ä�À�ä
D&E�F+GIHJF�KMLMNOLQPSR�T+UBV�R�W!H/P�V2HXUSR�GIHJY�R�GIHOR�UZP�V[F+U�HX\2H^]�Y[H@\_ Ya`[b�H^W _ F+c[UdH^e*F+b�P�UfU�c[gSV<R�UfhjilkSmnU _ Y2g�HpoBHq\[FrY2F�Pts _vu HdP�F _ Y[wP�b�F�\2c[g@HtY2H^oxP�R�TIY�R�GIH�U&m[bSR�P�V2H�b&m[oZF+c2sv\ys _vu H/P�FIb�H�c2U�HfH^z _ U{P _ Y2TY�R�GIH�U _ KMP�V2HtGIH@R�Y _ Y2T _ UjP�V2HtUSR�GIH+|

� ¾Þ¹�¾ � À�»PÍ[ºyê�ÃN ��� Åw¹�½¨ÏPÇÈÀH¹�¾ � ÒI¹�¾¿»P ��� !�� � �mºyÐ*ÂwÀBºyêÄ�ÀPÂ��?ëi¾Þ¹�¾ � ÀB»HÍ��� ¾Þ¹�¾ � Í¡Ä�ÀHÂwê_»HÀPǯº ��� »HÆ¨Ï � � � ¾Þ¹�¾ � À�»PÍîÒI¹�¾¿»P ��� � :*:�: � �Ä�ÀPÂVº¨ÑPÄ�»Hƨ¹�ÀNÏ��mëi¾Þ¹�¾ � À�»PÍ �cÏ�Äf¾È¾Þ¹�½sÆ �?ëI¾¿¹�¾�� Í¡Ä�ÀPÂUê �
���#����� ( � ����� ��� � � �O� � � � / ��� ����A�� � �4�� ( �"� �� �*��� �� � ( � �"��� � ��� �4�� ; ûHÄ�½èÍ)¹�ÅsÑPÇ¿ÀPÂ"º¼½s¹�ÀHƼ¾Þ¹Iº¼Ç¿Ä�ÀÄ�Î,Ö_×Ø!ÊâÄ�½"Ù�Ø!Ê�Ï�Ä�Å3»PÍ¡ÂwÀBºsÆwÜcÐ*Â$ÀPÂUÂUÏ!»HÀPÇ¿þB»PÂa¹�¾ÈÝÁfÄ�½¨Ç¯º¨ÑPÍ)ÆVº¼ÄaÏ�Â3º¨ÂUÅ�º*ÐÑPÇÞÅsѧÆ{ÂUÁ�Í¡ÂwÀBº¨Æ7¹�½¨Âº¼Ä$àNÂ_º¼½s¹�ÀHÆ{ݾ޹Iº¨ÂUÏ9¹�ÀHÏ9ÐÑHÇ¿ÅsÑ ¹�½¼ÂLÀPÄ�ºUä�étÀ;ÃH¹�½¼º¼ÇÞÅ3»P¾Þ¹�½dÜwÙ"Ø!ʧÅU¹�À9ÇÈÀPݺ¨½¼Ä�Ï�»HÅwÂÀPÂwÐ�ºs¹�ÁfÆUÜ�ÐÑHÄfƼÂ�Æ{ÂUÍ¡¹�ÀBº¼ÇÞÅwÆLÐ*ÂÁ�ÂUÀPÂw½s¹�¾¿¾ÈêaÏ�ÄÀPÄ�ºìBÀHÄIÐ;ä,×èÑPÂw½¨Â3Î Äf½¼ÂfÜ�Ð7Â;ÀPÂUÂUÏ�¹�À�Ç¿ÀHÆ{º¼½¨»HÅ�º¨ÇÈÄfÀH¹�¾cºs¹�Áº¨Ä�Ç¿À�Î Ä�½¨Í ¹�Í)¹�ÅsÑPÇ¿ÀPÂaº¼½s¹�ÀHƼ¾Þ¹Iº¼Ç¿Ä�ÀhÃP½¨Ä�Á�½s¹�Í�ÐÑPÂwº¼ÑPÂU½Äf½*ÀHÄ�º_¹0º¼ÂwãBº_ƼÂwÁfÍ¡ÂwÀBºÇ¿Æ*º¨Ä)àNÂ9º¨½¨¹�ÀHÆ{¾Þ¹Iº¨ÂUÏYäémÎ-¹�À§ØÔײÃP½¼ÄfÁ�½s¹�Í ÂUÀHÅ3Äf»PÀBº¼ÂU½¨Æ �𾿹�¾�� º¼½s¹�À �Bº¼ÄfÃKë �3ÜfÇȺ
ÃH¹fƼƼÂUÆ7ÄIÒ�ÂU½*º¼ÑPÂ;Ƽ»PàHƼÂUþB»PÂwÀBºèº¼Âwã�ºè»HÀfº¨ÇȾ-ǯºÂwÀNÅ3Ä�»HÀfº¨Âw½sÆ�𾿹�¾�� º¼½s¹�À���º¨¹�½¼º�ë���ä
( ��� � , A36 6 ��� ��� 849� ; ç_»�º¼ÄfÍ¡¹�º¼ÇÞÅ�º¼Â3ã�º�Ƽ»PÍ¡Í¡¹�ݽ¨ÇÈød¹Iº¨ÇÈÄfÀ;ÃP½¼ÄfÁ�½s¹�Í)ÆYÑH¹iÒfÂ,ÃP½¨Ä�àH¾ÈÂUÍîÇ¿À$ÑN¹�ÀHÏ�¾¿Ç¿ÀPÁ�Ö�×Ø!ʺ¨Â3ã�º¨Æ)ÐÇȺ¼Ñ�º¨ÑPÂ¥½¼ÂdÆ{»H¾¯º)º¨ÑH¹Iº§»PÀHÇÈÍ¡ÃKÄ�½¼º¨¹�ÀBº�ƼÂwÀBº¼ÂUÀHÅ3Âdƹ�½¼ÂæÇÈÀNÅ3¾¿»HÏ�ÂUÏîÇ¿ÀÑPÂáƼ»PÍ¡Í)¹�½¨êﺼÂwãBºsÆwä ×èÑPÇ¿Æ�ÃH½¼Äfà�ݾ¿ÂwÍúÄ�ÅwÅw»P½¨Æ�àNÂdÅw¹�»HÆ{ÂÔº¼ÑPÂæÃP½¨Ä�Áf½¨¹�Í Â3ã�º¨½¨¹fÅ�º¨Æ�ÇÈÍ¡ÃKÄ�½¼Ýºs¹�ÀBº§Æ{ÂUÀfº¨ÂwÀHÅwÂUÆ¡ÐÑPÄBÆ{Â�Ç¿Í¡ÃNÄf½{ºs¹�ÀHÅwÂ�ÇȺ�Åw¹�¾¿Åw»P¾Þ¹Iº¼ÂdÆ¡Ä�Àº¨ÑPÂèàH¹�ƼǿÆVÄ�ÎHº¨ÑPÂÀ�»PÍ$àKÂw½LÄ�ÎNÇ¿ÍaÃKÄ�½¼º¨¹�ÀBºVìfÂwê�Ð*Ä�½sÏPÆwÜdº¨ÑP¾¿Ä�Åw¹Iº¨ÇÈÄfÀáÇ¿À�¹Ôº¼Â3ã�ºdÜ7¹�ÀNÏâƼÄÔÄ�À ; � 9 >mäâ×èÑ�»HÆwÜ7¹hƼ»PÍaÝÍ)¹�½¨ê$ÃH½¼ÄfÁ�½s¹�ÍùÍ)¹iêaÆ{ÂU¾ÈÂdÅ�º7»HÀPÇÈÍ¡ÃKÄ�½¼º¨¹�Àfº*Æ{ÂUÀfº¨ÂwÀHÅwÂUÆ,ǯÎÇȺ:Ï�Ä�ÂUÆVÀPÄ�º:ìBÀHÄIÐDº¼ÑPÂÍ)¹�ÇÈÀaº¼Âwã�ºL¹�½¼Âd¹_Ç¿À)¹9Ï�Ä�Å3»PÍ¡ÂwÀBºdäç ºyê�ÃPÇÞÅw¹�¾,Ö_×Ø!ÊﺼÂ3ã�º$ÑN¹�Æ;½¨Âw¾Þ¹Iº¨ÂUÏæÇÈÀPÎ Ä�½¨Í¡¹�º¼Ç¿Ä�ÀD¹�½¼ÝÂd¹�Æ_Ƽ»HÅsÑÔ¹fÆ_¹�¾ÈÇÞÆyº9Ä�Î:½¨Âw¾Þ¹Iº¨ÂUÏ�¾¿ÇÈÀHì�ÆUÜKº¼ÑPÂaÀH¹�ÍaÂ0Ä�ÎLº¨ÑP½¨ÂwÃKÄ�½¼º¼ÂU½UÜY¹�ÀNÏÔ¹�Å3Ä�Ã�ê�½¨ÇÈÁfÑfº"ÀPÄ�º¨Ç¿ÅwÂ�ÜYÇ¿ÀÔº¨ÑPÂaàNÂUÁ�Ç¿ÀPÀPÇ¿ÀPÁ¹�ÀHÏ ÂUÀHÏ�Ç¿ÀPÁ"¹�½¼Âd¹PÜ�¹�ÀHÏ;º¨ÑPÂUƼ¹�½¨ÂU¹�Æ�Åw¹�À0ÅU¹�»HƼÂ7¹"н¨Ä�ÀPÁƼ»PÍ¡Í)¹�½¨ê�º¼Ä�àNÂ7Á�ÂUÀPÂw½s¹Iº¨ÂUÏYä-×èÑHÂw½¨Â3Î Ä�½¨Â�ÜdÐ*Â:ÀPÂwÂdÏ ¹èºs¹�Áº¨ÑH¹Iº9Æ{ÃKÂUÅwǯíHÂdÆ"ÐÑPÇ¿ÅsÑhÆ{ÂUÁ�Í¡ÂwÀBº¨Æ�Æ{ÑHÄ�»P¾ÞÏ!àKÂ$ÃP½¨Ä�Å3ÂdƼƼÂUÏÇ¿À�Äf½¨ÏPÂw½èº¼Ä¡ÁfÂwÀPÂU½¨¹�º¼Â9¹)Æ{»PÍ¡Í)¹�½¨ê)Ä�ÎL¹¡Ï�Ä�Å3»PÍ¡ÂUÀfºdäémÎP¹Æ{»HÍaÍ)¹�½¼ê�ÃH½¼ÄfÁ�½s¹�ÍßÂUÀHÅ3Äf»PÀBº¼Âw½sÆ � ¾Þ¹�¾ � Æ{Í¡½¨ê�ÅU¹�¾ÞÅ �Bº¨Ä�ÃKë���Ü
ÇȺ!Æyº¨Ä�ÃHƥƼ»PÍ¡Í)¹�½¨êßÅw¹�¾ÞÅ3»H¾¿¹�º¼Ç¿Ä�À'»HÀfº¨ÇȾ$ǯº¥ÂwÀNÅ3Ä�»HÀfº¨Âw½sÆ�𾿹�¾�� Æ{Í¡½¨ê�Åw¹�¾ÞÅ ��º¨¹�½¼º�ë���ä ×èÑPÂU½¼ÂwÎ Ä�½¨Â�Ü�¹fÏPÏ�ÇȺ¼Ç¿Ä�ÀH¹�¾_Ç¿À�Î Ä�½¼ÝÍ)¹Iº¨ÇÈÄfÀÓÃH¹�½¼º¨ÆhÆ{»NÅsÑ ¹�ÆÔ¹'Å3Ä�Ã�ê�½¨ÇÈÁfÑfº!ÀHÄ�º¼ÇÞÅ3ÂfÜ0¹�ÀHÏ ¹Ð½¨Ç¯º¨Âw½ � Æ0Æ{Ç¿Á�ÀN¹Iº¼»H½¼ÂfÜ:Æ{ÑPÄf»P¾ÞÏáÀPÄ�ºaàKÂ�Ç¿ÀHÅw¾È»HÏPÂUÏáÇ¿ÀẨÑPÇÞÆƼ»PÍ¡Í)¹�½¨ê§Åw¹�¾ÞÅ3»H¾¿¹�º¼Ç¿Ä�À�ƼÅwÄ�ÃKÂ�ä
� ° � ¶��2¶Vµ ��� ���� µPô µH¶��F³åæÂ,ÑH¹iÒfÂLÍaÄ�Ï�ÇÈíHÂdÏ Æ{ÄfÍ¡Â,¸_Ê�Ë!Æ{ê�Æ{º¼ÂUÍ¡Æ�º¼Ä�àNÂ*Ê-ç_Ê�Ý
¹iÐè¹�½¨Â��iä+ ��� ;���Ü 8 >*Ç¿Æa¹�À +,ÀPÁ�¾¿Ç¿Æ¼Ñ2ÃH¹�½sƼÇÈÀPÁ!Ƽê�Æyº¨ÂwÍ&Ï�ÂwÒfÂw¾ÈÝ
ÄfÃNÂdÏßà�ê²é�1*Ø åæ¹�º¨Æ¼Ä�À ÂUƼÂU¹�½¨ÅsÑîü7ÂUÀBº¼Âw½dÜ_¹�ÀHÏß»PÃPÝÏP¹�º¼ÂdÏ!º¨Ä!¹�ÅwÅwÂwÃ�º ¹�ÀHÏæÁ�ÂwÀHÂw½s¹Iº¼Â¡Ê-ç�ÊYÝt¹�ÀPÀHÄ�º¨¹�º¼ÂdÏ +,À�ÝÁf¾ÈÇÞÆ{Ñ-äV×èÑHÇ¿ÆÊ�ç_ÊYÝt¹iÐè¹�½¨Â_Ò�ÂU½¨Æ¼Ç¿Ä�À�Ä�Î�+ ���ÓÇÞÆè»HƼÂUÏ�¹�ƹàH¹fÅsì�ÂUÀHÏ)ÃP½¨Ä�Å3ÂUƨÆ7º¼Ä¡Æ{ÑHÄIÐß»HƼÂw½sÆ*¹�À�Ç¿ÀBº¼ÂU½¼ÃP½¨Â3ºs¹Iº¨ÇÈÄfÀ§Ä�ι�Ƽê�Æ{º¼ÂUÍ Ä�ι�Á�Ç¿Ò�ÂUÀ +,ÀPÁ�¾¿Ç¿Æ¼ÑhƼÂwÀBº¨ÂwÀHÅwÂ)ÇÈÀ溼ÑH§Ê-ç_Ê�ݹ�ÀPÀPÄ�ºs¹Iº¨ÇÈÄfÀ�ÂUÏPǯº¨Ä�½�Ï�ÂdƼÅw½¼Ç¿àNÂdÏ�ÇÈÀ�º¼ÑHÂ;ÀPÂ3ã�º�Æ{ÂdÅ�º¨ÇÈÄfÀ�ä
� hjV2H�� U�c2`2`�F+b{PZF+Y2s � U ��Y�P�R�g^P _ g _ Y�K F+b�G R�P _ F+Y P�R�T+UZg�c2b�b�H�Y�P�s �!mR�Y2\ro _ svs*U�c2`[`*F+b{PJF�P�V2H�bJPSR�T+UJs6R�P�H�b@|
!;¸�Ë ; 9 >VÇ¿Æ"¹ ?B¹�ÃN¹�ÀPÂdÆ{Â$ÏPÂwÃKÂwÀHÏ�ÂUÀHÅ3ê¥ÃN¹�½sÆ{Ç¿ÀPÁ�Ƽê�Æyݺ¨ÂwÍÓÏ�ÂUÒ�Âw¾¿Ä�ÃKÂUÏ"à�ê"!9êfÄ�º¨Ä$#_ÀPÇ¿Ò�Âw½sƼǯºyêfä�åhÂ7ÑH¹iÒ�ÂLÏ�ÂUÒ�ÂU¾¯ÝÄfÃNÂdÏ!¹§ÃKÄfÆ{º{ÝmÃP½¨Ä�Å3ÂUƨƽ¨Ä�»�º¨ÇÈÀH º¼Ä�Å3ÄfÀBÒfÂw½¼º%!;¸_Ë'ÃH¹�½sÆyÝÇ¿ÀPÁ�½¼ÂdÆ{»P¾Èº_Ç¿ÀBº¼Ä�Ê�ç_Ê2Î Äf½¼Í)¹�ºUä_×èÑPÇÞÆ�ÇÞÆ"¹�¾ÞÆ{Ä)»HƼÂUÏÔ¹�Æ_¹àN¹�Åsì�ÂUÀHÏhÃP½¼Ä�ÅwÂUƨÆ_º¨Ä!Æ{ÑHÄIÐ º¼ÑHÂaÇ¿ÀPÇȺ¼ÇÞ¹�¾:Ç¿ÀBº¼ÂU½¼ÃP½¨Â3ºs¹Iº¨ÇÈÄfÀÄ�ÎH¹Á�Ç¿Ò�ÂUÀQ?f¹�ÃH¹�ÀPÂdÆ{Â:ƼÂwÀBº¨ÂwÀHÅwÂ:ÇÈÀ º¼ÑPÂ,Ê�ç_Ê�Ým¹�ÀPÀPÄ�ºs¹Iº¨ÇÈÄfÀÂdÏ�ÇȺ¼Ä�½däûH»P½¼º¼ÑPÂU½UÜiÐ*Â:ÑH¹iÒ�Â,ÍaÄ�Ï�ÇÈíHÂdÏ;é�1èØ � Æ3+:ÀPÁf¾ÈÇÞƼÑ9º¼Ä"�"ÂU½{Ý
Í)¹�À�Ü�ûH½¼ÂUÀHÅsÑ�Ü ��ÃH¹�ÀPǿƼÑ�Ü�¹�ÀHÏæémº¨¹�¾ÈÇÞ¹�À溨½¨¹�ÀHÆ{¾Þ¹Iº¨ÇÈÄfÀhÂUÀ�ÝÁfÇÈÀHÂUÆy; 8 Ü'&PÜ�� : >Y¹�ÀNÏ +:ÀPÁf¾ÈÇÞƼѡº¼Äa?B¹�ÃH¹�ÀPÂUƼÂ躼½s¹�ÀNÆ{¾Þ¹Iº¨ÇÈÄfÀÂUÀPÁ�Ç¿ÀP ; � ��Ü �)(PÜ �*��>�º¨Äá¹�ÅwÅwÂwÃ�º�Ê�ç_Ê�Ým¹�ÀPÀPÄ�ºs¹Iº¨ÂUÏ +:À�ÝÁf¾ÈÇÞƼÑ�Ö�×Ø!Ê2Ç¿ÀPÃP»�ºdäétÀ�¹�ÏPÏPǯº¨ÇÈÄfÀ�ÜfÐ*Â_ÑN¹iÒ�Â�ÏPÂwÒ�ÂU¾ÈÄfÃNÂdÏ)¹�À�¹�¾¿Á�Ä�½¨ÇȺ¼ÑPÍ Î Ä�½
¹fÅwÅwÂw¾¿Âw½s¹Iº¼Ç¿ÀPÁ_ü*û+��ÝmÃH¹�½¨Æ¼ÇÈÀHÁÃP½¼Ä�ÅwÂUƨÆcàBê"»HƼÇÈÀHÁ�Ê-ç_Ê)º¨¹�ÁÇ¿À�Î Äf½¼Í)¹Iº¨ÇÈÄfÀ�,I; ��&�>mÜi¹�ÀHÏ�º¼ÑHÇ¿Æ�¹�¾¿Á�Ä�½¨ÇȺ¼ÑPÍßÇÞÆYÇ¿Í¡ÃP¾ÈÂUÍ¡ÂwÀBº¼ÂdÏÇ¿À)º¨ÑP +:ÀHÁ�¾¿Ç¿Æ¼Ñ�Ý?º¼Ä�Ý^?B¹�ÃH¹�ÀPÂUƼÂ,º¨½¨¹�ÀHƼ¾¿¹�º¼Ç¿Ä�À¡ÂwÀPÁfÇÈÀHÂÍaÂUÀ�ݺ¨ÇÈÄfÀPÂUÏ�¹�àNÄIÒfÂ�ä
- ° .� ° ó�ó ôL´�¶�´P÷yô ó0/ õ_÷y´�ô:µ��ÇÈÀHÅwÂ9ÇÈÀHƼÂw½¼º¼Ç¿ÀPÁaº¨¹�ÁfÆ*Ç¿Àfº¨Ä)Ï�Ä�Å3»PÍ¡ÂwÀBºsÆèÍ¡¹�À�»H¹�¾¿¾Èê)ÇÞÆ
ÀHÄ�º Á�ÂUÀPÂw½s¹�¾¿¾¿ê!¹�À2ÂU¹fÆ{ê�ºs¹�Ƽì¥Î Ä�½ ÂUÀHÏæ»HƼÂw½sÆwÜ�ÇȺ ÇÞÆ9ÇÈÍaÝÃKÄ�½¼º¨¹�ÀBº7º¨ÄaÃH½¼ÄIÒ�ÇÞÏ�Â�¹1�.#�émÝmàH¹�ƼÂUÏ�¹�ÀPÀHÄ�º¨¹�º¼Ç¿Ä�À�ÂUÏ�ÇȺ¼Äf½UäétÀhÏ�ÂwÒfÂw¾¿Ä�ÃPÇ¿ÀPÁ�Ƽ»HÅsÑ!¹�ÀÔÂUÏ�ÇȺ¼Äf½UÜNÐ7Â;º¨Ä�Ä�ì�ÇÈÀBº¨Ä�Å3ÄfÀHÆ{ÇÞÏ�ÝÂU½¨¹�º¼Ç¿Ä�À�º¼ÑPÂ9Î Äf¾È¾¿ÄIÐÇ¿ÀPÁ¡ÃNÄfÇÈÀBº¨Æ �
! #_ƼÂw½sÆƼÑPÄ�»P¾ÞÏ�ÀPÄ�º�ÑH¹iÒfÂ_º¨Ä§Æ{ÂUÂ;¹�À�ê)º¨¹�ÁfÆUä! #_ƼÂw½sÆ Æ¼ÑPÄ�»H¾¿ÏæÀPÄ�º ÑH¹iÒ�Âaº¼ÄhÆ{ÂUÂ)ÇÈÀBº¼ÂU½¼ÀN¹�¾:½¨ÂwÃP½¨Â3ÝƼÂwÀBº¨¹�º¼Ç¿Ä�ÀHÆèÂwã�ÃH½¼ÂdƼƼÇÈÀHÁ0¾¿ÇÈÀHÁ�»PÇÞÆyº¨Ç¿Å"Ç¿À�Î Ä�½¨Í)¹Iº¨ÇÈÄfÀ�ä
! #_ƼÂw½sÆèÆ{ÑHÄ�»P¾ÞÏ�àKÂ;¹�àP¾¿Â�º¼Ä¡Ò�ÇÈÂUÐ'¹�ÀHÏ�Í¡Ä�Ï�ǯΠê�¾ÈÇ¿À�ÝÁ�»HÇ¿Æ{º¼ÇÞÅVÇÈÀPÎ Ä�½¨Í¡¹�º¼Ç¿Ä�À;Ƽ»HÅsÑ;¹�ÆcÎ Âd¹Iº¼»H½¼ÂLÒI¹�¾¿»PÂdÆwÜdàP»�ºÄ�ÀH¾Èê§ÇÈÎ�º¼ÑPÂUê�Ðè¹�ÀBºUä
åïÇȺ¼Ñ)½¨ÂUƼÃKÂUÅ�ºVº¨Ä�º¨ÑPÂ�¹�àKÄIÒ�ÂèÃKÄ�Ç¿ÀBº¨ÆUÜ�Ð7ÂÑN¹iÒ�Â7Î Ä�»PÀHϺ¨ÑH¹Iº�Í¡ÄfÆ{º�Ä�Î;º¼ÑPÂæÂw½¨½¼Äf½¨Æ§Í¡¹fÏ�ÂÔà�êï¸_Ê�Ë£ÃP½¨Ä�Áf½¨¹�Í)ƽ¨ÂUƼ»P¾Èº_Î ½¨Ä�Í�º¼ÑHÂwÇ¿½�Îð¹�Ç¿¾¿»P½¼Â$º¼Ä�½¼ÂdÅ3Ä�ÁfÀPÇ¿øwÂ9º¼ÑHÂ$¾¿ÇÈÀPÁf»PÇÞÆyº¨Ç¿ÅÆ{º¼½¨»HÅ3º¼»P½¨ÂUÆÄ�ÎVƼÂwÀBº¨ÂwÀHÅwÂUÆUä:×èÑPÂw½¨Â3Î Äf½¼ÂfÜ�º¼ÑPÂ$Ê�ç_Ê2ÂdÏ�ǯº¨Ä�½Æ¼ÑPÄIÐ�Æ$Ä�ÀP¾¿êD¹ÔÆ{º¼½¨»HÅ�º¨»P½¨¹�¾,Ò�Ç¿ÂwÐpÄ�Î_¹!Á�Ç¿Ò�ÂwÀ�Æ{ÂUÀfº¨ÂwÀHÅw �Ä�º¼ÑPÂU½LÇÈÀPÎ Ä�½¨Í¡¹�º¼Ç¿Ä�ÀaÇ¿ÆLƼÑPÄIÐÀ0Ä�ÀP¾¿ê ÇÈÎNº¨ÑP»HƼÂw½V½¼ÂdþB»PÂUÆ{º¨ÆÇȺUä×èÑHÂ*Ç¿Í¡ÃNÄf½{ºs¹�ÀBºLǿƨƼ»PÂèÑPÂw½¨ÂèÇ¿ÆVÑPÄIÐ⺼Ä9½¨ÂwÃP½¨ÂUƼÂwÀBº�º¼ÑPÂ
Ƽê�ÀBº¨¹�Å3º¼ÇÞÅ;Æyº¨½¼»NÅ�º¼»H½¼Â;Ä�ÎV¹)ƼÂwÀBº¼ÂUÀHÅ3Â9º¨Ä¡º¼ÑPÂ;»NÆ{ÂU½Uä*¸_Ê-ËÃH½¼ÄfÁ�½s¹�Í)Æ*ÀPÄ�½¨Í)¹�¾¿¾Èê§Ï�Âd¹�¾YÐÇȺ¼Ñ¥¹a¾ÈÇ¿ÀPÁf»PÇ¿Æ{º¼ÇÞÅ;Æ{º¼½¨»HÅ�º¨»P½¼Âà�ê�Í¡ÂU¹�ÀHÆ�Ä�Î,¹§Æ{ê�ÀBº¨¹fÅ�º¨Ç¿Å º¼½¨ÂwÂ�ÜKàP»�º9Æ{»NÅsÑ!¹�Æ{º¼½¨»HÅ�º¨»P½¼ÂÇÞÆ7ÀPÄ�º*ÀPÂUÅwÂUƨƼ¹�½¼Ç¿¾ÈêaÂU¹fÆ{ê0Î Ä�½7ÂwÀHÏ�»HƼÂw½sÆLº¼Ä0»PÀHÏ�ÂU½¨Æ{º¨¹�ÀHÏYäûHÄ�½;Ç¿ÀHÆ{º¨¹�ÀNÅ3Â�Ü�û�ÇÈÁNä ��ƼÑPÄIÐ�Æ�º¼ÑH§Ï�ÂwÃKÂwÀHÏPÂwÀHÅwêhÆ{º¼½¨»HÅ�ݺ¨»P½¨ÂæÄ�Î$º¨ÑP +:ÀPÁf¾ÈÇÞÆ{ÑîÆ{ÂUÀBº¼ÂwÀNÅ3 � é�1èØ ¹�ÀPÀPÄf»PÀHÅ3ÂdÏ[¹ÀHÂwÐ[ÅwÄ�Í¡ÃP»�º¨Âw½Æ¼ê�Æ{º¼ÂUÍpÎ Ä�½ÅsÑPÇ¿¾ÞÏ�½¼ÂUÀ�ÐÇȺ¼Ñ�Ò�ÄfÇ¿ÅwÂ_Î »PÀNÅ�ݺ¨ÇÈÄfÀ�ä � ×èÑPÇ¿Æ,Ï�ÂwÃKÂwÀHÏPÂwÀHÅwê0Æ{º¼½¨»HÅ�º¨»P½¼ÂÇÞÆLÀPÄ�ºLÂU¹�Ƽê;º¨Ä;»PÀ�ÝÏPÂw½sÆyºs¹�ÀHÏ�Î Ä�½)ÂUÀHϲ»HƼÂw½sÆwÜ*ÃH¹�½{º¨¾ÈêáàKÂUÅU¹�»HƼ¥ÇȺ§Ç¿Æ§ÏPǯաÝÅw»P¾Èº*º¨Ä¡½¼ÂUÍaÇ¿ÀHϧº¼ÑPÂ9Ä�½¨Ç¿Á�Ç¿ÀH¹�¾cÆ{ÂUÀBº¼ÂwÀNÅ3Â;þB»PÇ¿Åsì�¾¿ê§Ï�»PÂ�º¼Ä
2 hjV _ U \2F�H@U Y2F�P \2H�`�H�Y2\ F+Y LnN/L m bSR�P�V2H�b _ P _ U R<T+H�Y2H�bSR�sR�svT+F+b _ P�V2G R�`2`[s _ g&R43[svHZK F+b�5�6�7Ow `2R�b�U _ Y[TOoJV2H�YqR�Y8�d\2H�`*H�Y2\[H@Y[g9�_ Y[K F+b�G R�P _ F+Y _ UjT _ W!H�Yn|

ÀPÄ�º�ì�ÂUÂwÃPÇ¿ÀPÁ)º¨ÑPÂ$Ƽ»P½{Îð¹fÅ3Â;Ð*Ä�½sÏ�Ä�½sÏ�Âw½Ç¿À!¹)Á�Ç¿Ò�ÂUÀ¥Æ{ÂUÀ�ݺ¨ÂwÀHÅwÂ)ÇÈÀ2º¨ÑPÇ¿Æ$Æyº¨½¼»HÅ3º¼»P½¨Â � ä�×èÑPÂU½¼ÂwÎ Ä�½¨Â�ÜYº¨ÑP§ÀPÂdÅ3ÂdƼƨ¹�½¨êÃP½¨Ä�ÃKÂw½¼ºyê§Ä�ÎV¹¡¾¿ÇÈÀHÁ�»PÇÞÆyº¨Ç¿Å;Æ{º¼½¨»HÅ3º¼»P½s¹�¾YÒ�Ç¿ÂwÐîÇ¿Æ�Î Ä�½»HƼÂw½sƺ¨Ä!ÂU¹fÆ{Ç¿¾Èêh½¼ÂdÅ3ÄfÀHÆyº¨½¼»NÅ�º º¨ÑP§Ä�½¨Ç¿Á�Ç¿ÀH¹�¾,Ƽ»P½¼Îð¹�ÅwÂ�Æ{ÂUÀBº¼ÂwÀNÅ3ÂÆ{º¼½¨ÇÈÀHÁHä
û�Ç¿Á�»P½¨Â���� ç�À2Â3ãP¹�ÍaÃH¾È¡Ä�Î7º¼½¨ÂwÂ)Æ{º¼½¨»HÅ�º¨»P½¼Â¡Ä�Îè¹�À +,À�ÝÁf¾ÈÇÞÆ{Ñ�ƼÂwÀBº¼ÂUÀHÅ3Âü7Ä�ÀNÆ{ÇÞÏ�Âw½¨Ç¿ÀPÁ*º¼ÑPÇÞÆ�½¨ÂUþB»PÇ¿½¼ÂUÍ¡ÂwÀBºUÜUÐ7Â:ÑN¹iÒ�ÂLÏ�ÂwÒfÂw¾¿Ä�ÃKÂUÏ
¹�À!¹�¾¿Á�Ä�½¨ÇȺ¼ÑPÍÛº¼Ä�Æ{ÑPÄIÐÚ¾¿ÇÈÀHÁ�»PÇÞÆyº¨Ç¿Å0Ï�ÂwÃKÂwÀNÏ�ÂwÀHÅwê¥Æyº¨½¼»HÅ3ݺ¨»P½¼ÂDÐÇȺ¼ÑÓìfÂwÂUÃPÇÈÀHÁ²º¼ÑPÂáƼ»P½¼Îð¹�Å3ÂDÐ*Ä�½sÏ[Ä�½sÏ�Âw½¥ÐÑPÇÞÅsÑƼÑPÄIÐ�ÆÏ�ÂUÃNÂUÀHÏ�ÂwÀNÅ3Ç¿ÂUÆ�à�ê�ÇÈÀNÏ�ÂwÀBº¨¹�º¼Ç¿Ä�ÀHÆUäèû�Ç¿ÁHäI=¡Æ¼ÑPÄIÐ�ÆÂwã�¹�Í¡ÃP¾ÈÂdÆ)Ä�Î9¾¿ÇÈÀPÁf»PÇÞÆyº¨Ç¿Å!Æ{º¼½¨»HÅ3º¼»P½s¹�¾�Ò�Ç¿ÂwÐ à�êẨÑPÇ¿Æ�¹�¾ÈÝÁfÄ�½¨Ç¯º¨ÑPÍ�ä�étÀ¥º¨ÑPÂUƼÂaÂ3ãP¹�Í¡ÃP¾¿ÂUÆUÜcê�Ä�»hÅw¹�ÀÔÂU¹�Ƽǿ¾Èê�½¨ÂUÅ3ÄfÀ�ÝÆ{º¼½¨»HÅ�ºVº¨ÑPÂÆ{»P½¼Îð¹�ÅwÂÆ{ÂUÀfº¨ÂwÀHÅwÂÆyº¨½¼Ç¿ÀPÁ"àBê�ÿy»HÆyº:¾¿Ä�Ä�ì�Ç¿ÀPÁ"¹�ºÐ*Ä�½sÏPÆ"Î ½¨Ä�Í º¨Ä�Ã溼ÄÔàNÄ�º{º¼ÄfÍ ¹�ÀHÏhÎ ½¼ÄfÍ ¾¿Â3Îýº0º¼Ä¥½¨ÇÈÁfÑfºdܹ�ÀHÏaÂU¹�Ƽǿ¾Èê ì�ÀPÄIвÏ�ÂUÃNÂUÀHÏ�ÂwÀNÅ3Ç¿ÂUÆLÄ�ÎKÐ*Ä�½sÏPÆL¹IºLº¨ÑPÂ_ƨ¹�͡º¨ÇÈÍ¡Â�ä×èÑPÂ�ÀPÂwãBº§Ç¿Í¡ÃNÄf½{ºs¹�ÀBº¡Ç¿Æ¨Æ{»HÂ�ÇÞÆaº¼ÑN¹Iº)ÑPÄIÐ Âd¹�ƼÇȾ¿êá¹
»HƼÂw½hÅw¹�ÀÚ»PÀNÏ�Âw½sÆyºs¹�ÀHÏ[º¨ÑPÂáÄIÒ�ÂU½¨¹�¾È¾9¾¿ÇÈÀHÁ�»PÇÞÆyº¨Ç¿ÅâÆyº¨½¼»HÅ3ݺ¨»P½¼Âfä émÎ*¹�»HƼÂw½9ÇÞÆwÜ-¹�º�íN½¨Æ{ºUÜYÃP½¨ÂUƼÂwÀBº¨ÂUÏ!ÐÇȺ¼Ñ2Ï�Âwº¨¹�Ç¿¾¿ÂUϾ¿ÇÈÀHÁ�»PÇÞÆyº¨Ç¿Å�Æyº¨½¼»NÅ�º¼»H½¼Â"ÇÈÀ�º¼ÑPÂ"Ð*Ä�½sÏ¡¾ÈÂUÒ�Âw¾?ÜBº¼ÑPÂUÀ�ÇȺ*ÇÞÆèÏ�ÇÈÎýÝíNÅw»P¾Èº_º¼Ä�Á�½s¹�ƼÃ�º¼ÑPÂaÇ¿ÍaÃKÄ�½¼º¨¹�ÀBº�¾¿ÇÈÀPÁf»PÇÞÆyº¨Ç¿Å0Æ{ìfÂw¾¿Â3º¼ÄfÀ¥Ä�ι§Æ¼ÂwÀBº¨ÂwÀHÅwÂ�ä_×èÑPÂU½¼ÂwÎ Ä�½¨Â�ÜK¹�ÀPÄ�º¼ÑPÂU½_ÀPÂdÅ3ÂUƨƨ¹�½¨ê§ÃP½¨Ä�ÃKÂw½¼ºyêÇÞÆVº¼Ä$Á�Ç¿Ò�Âè»HƼÂw½sÆ:¹9Ò�ÇÈÂUÐ�Ç¿À)ÐÑPÇÞÅsÑaº¼ÑPÂ�ÄIÒfÂw½s¹�¾¿¾PÆ{ÂUÀBº¼ÂwÀNÅ3ÂÆ{º¼½¨»HÅ�º¨»P½¨Â"ÇÞÆèÂU¹fÆ{Ç¿¾¿ê§½¼ÂdÅ3ÄfÁ�ÀPÇ¿øwÂdÏYä×�Ä�Æ{»PÕ)Åw º¨ÑPÇ¿Æ_½¼ÂdþB»PÇȽ¨ÂwÍ¡ÂUÀfºdÜHÐ* ÑH¹iÒf ÇÈÀBº¨½¼Ä�Ï�»HÅwÂUÏ
ºyÐ*ħÃP½¨ÂUƼÂwÀBº¨¹�º¼Ç¿Ä�À�Í¡Ä�Ï�ÂUÆ �躼ÑPÂ0½¼ÂdÏ�»HÅwÂUÏ�ÃP½¨ÂUƼÂwÀBº¨¹�º¼Ç¿Ä�ÀÒ�Ç¿ÂwÐ ¹�ÀHÏhº¼ÑPÂ)Âwã�ÃH¹�ÀHÏPÂUÏæÃP½¨ÂUƼÂwÀBº¨¹�º¼Ç¿Ä�ÀÔÒ�Ç¿ÂwÐ;ä§étÀ溨ÑP½¨ÂUÏ�»NÅ3ÂUÏÚÃH½¼ÂdÆ{ÂUÀfºs¹Iº¨ÇÈÄfÀîÒ�Ç¿ÂwÐ;Üa¹ïÍ)¹�Ç¿ÀÓÒ�Âw½¨à ¹�ÀNÏÚǯºsÆÍ¡Ä�Ï�ÇÈíHÂw½sÆ�¹�½¼Â0àH¹�ƼÇÞÅ »PÀPÇȺ¨Æ"Î Äf½�ÃH½¼ÂdÆ{ÂUÀfº¨ÇÈÀHÁ�Ï�ÂUÃNÂUÀHÏ�ÂwÀPÝÅwÇÈÂdÆwÜ�¹�ÀHϲº¼ÑHÂwê²¹�½¨Â!¾ÈÄ�ÅU¹Iº¼ÂdϲÇÈÀ[Ï�Ç �cÂw½¨ÂwÀBº�¾ÈÇ¿ÀPÂUÆ�ÐÇȺ¼ÑìfÂwÂwÃHÇÈÀPÁẼÑPÂæÆ{»P½¼Îð¹�ÅwÂÔÄf½¨Ï�ÂU½Uä û�Ç¿ÁHä =ïÉ�¹fÌ�Æ{ÑPÄIÐ�Æ�¹�ÀÂwã�¹�Í¡ÃP¾ÈÂ9Ä�Î�º¨ÑPÇ¿Æ_½¼ÂdÏ�»HÅwÂUÏ�ÃP½¨ÂUƼÂwÀBº¨¹�º¼Ç¿Ä�À�Ò�Ç¿ÂwÐ;ä7étÀ�º¨ÑPÇÞÆÒ�Ç¿ÂwÐ;ÜiÆ{Ç¿ÀHÅ3ÂVº¨ÑPÂ:ÄfàBÒ�Ç¿Ä�»HÆYÏPÂwÃKÂwÀHÏ�ÂUÀHÅ3Ç¿ÂUÆYÎ Ä�½�ÀH¹�º¼Ç¿Ò�Â:ƼÃNÂd¹�ìBÝÂU½¨Æ)ÉðÂ�ä ÁHä � ¹ � ¹�ÀHÏ � ÅwÄ�Í¡ÃP»�º¨Âw½ � Ì ¹�½¨Â)ÀPÄ�º$Ï�ÇÞƼÃP¾¿¹iêfÂUÏÂwã�ÃH¾ÈÇÞÅ3ÇȺ¼¾¿ê�Ü�¹�»HƼÂw½;Åw¹�ÀhÅ3ÄfÀHÅ3ÂUÀBº¼½s¹Iº¼Â0Ä�ÀæÏ�ÂwÃKÂwÀHÏPÂwÀHÅwÇÈÂdÆàKÂ3ºyÐ*ÂwÂUÀ!ì�ÂUê�»HÀPǯºsÆ¡É Ä�½"ÃPÑP½s¹�ƼÂUÆsÌ�ä9émÎ7¹�»HƼÂw½�íHÀHÏÔ¹�À�ê
��� F+cIG c[U�PZ`�H�b�K F+b�G R�Y _ Y[F+b�\2H�b P�b�H�HOoBR�s u P�Fpb�H@g�F+Y2U{P�b�c2g^PJRU�c2b{K R�g�HXU�H�Y�P�H�Y2g�HpU{P�b _ Y2T2|
ÏPÂwÃKÂwÀHÏ�ÂUÀHÅ3ê2ÂU½¼½¨Ä�½sÆ"ÇÈÀ2º¨ÑP§½¨ÂUÏ�»HÅwÂUÏ2Ò�Ç¿ÂwÐ;Ü�ÑP§Ä�½ ƼÑPÂÅU¹�ÀîÂwÀBº¼ÂU½�º¼ÑPÂDÂwã�ÃH¹�ÀHÏPÂUÏ[ÒBÇ¿ÂwÐ Í¡Ä�ÏPÂæÇ¿ÀîÐÑPÇ¿ÅsÑÓ¹�¾È¾Ð*Ä�½sÏPÆ�¹�½¨Â àH¹�ƼÇÞÅ »PÀPÇȺ¨Æ_Î Ä�½"ÃP½¨ÂUƼÂwÀBº¼Ç¿ÀPÁ�ÏPÂwÃKÂwÀHÏ�ÂUÀHÅ3Ç¿ÂUÆUäû�Ç¿ÁHät=aÉ àNÌV¹�ÀHÏ�ÉðÅUÌVƼÑPÄIÐ�ÆVÂwã�¹�Í¡ÃP¾ÈÂdÆ�Ä�ÎKº¼ÑPÇÞÆLÂ3ã�ÃH¹�ÀHÏ�ÂdÏÒ�Ç¿ÂwÐ;ä� LMF�g&R�P�HfP�V[Hfb�F�F�P/R�P/R�Y R�`[`2b�F+`2b _ R�P�Hf`�F+U _ P _ F+Y��� N/\2\ P�V2Htb�F�F�PJP�F�� ������� �������� oJV _ svH��� ��� ��� ��������! #"$ % &(')& �*���,+ b�H�GIF&W!H^w ]2b�U�P{w H�svH�GIH�Y�P -.�� ������� ������/��0 % &(' � �����1+ P�V2Htb�F&o F�K % &(')& �*�2���3 NO\2\ `2b�H�w GIF�\ _ ]2H@b�UtF�K % &(')& �*���ZP�F546 ����� �2���BR�Y2\
U�F+b�P _ P+38�yP�V2Ht\ _ U{PSR�Y2g�Hto _ P�V % &(')& �*�2� _ YrP�V2HdR�U{wg�H�Y2\ _ Y2TIF+b�\2H�b��7 oJV _ svH�4���8��� �����1��! 9": 46 ��+ b�H�GIF&W!H^w ]�b�U�P{w H�svH�GIH@Y!P -.4���8��� ������/��; k KnP�V2H/K F+b�ojR�b�\IGIF�\ _ ]2g&R�P _ F+Y _ UZG R�<{F+b _ YqP�V2H
g@c[b�b�H�Y!Pds6R�Y2T+c�R�T+H+m=46 � _ UfP�V2H Y2H@R�b�H�U�Pp`2b�H�wGIF�\ _ ]2H@b@mJR�Y2\ P�V2H�b�H _ U Y2F<oBF+b�\2U%3*H^P oBH�H�Y46 �pR�Y[\ %�&>')& �*��� m[P�V2H�Y "� ? LMF�g@R�P�H@46 �=<�c2U{P 3�H�K F+b�H % &(')& �*�2���
�8� A H�svU�H "� � k Y2U�H@b{PBRfY2H^o b�F&o9<{c2U�P 3�H^K F+b�HJP�V2HJb�F&o F�KP�V2H %�&(' � �2���@m�R�Y2\rG R u H _ P %�&>' � �������
� � LMF�g@R�P�HB4��� _ Y % &(' � �2��� R�PqP�V2H g�F+svc2GIYR�K�P�H�bpP�V�R�P _ Y<oJV _ gSV<P�V2H s6R�U�PpgSV�R�bSR�g^P�H�bF�K %�&>')& �*��� _ UjsvF�g&R�P�H�\n|
� $ A� 0 A� 3 % &(' � �����1+ P�V2Htb�F&o F�K % &(')& �*�2���� 7 NO\2\y`�F+U�P{w GIF�\ _ ]�H�b�UJF�K %�&>')& �*���nP�FC46 ����� �2���.R�Y2\U�F+b�P _ P+38�yP�V2Ht\ _ U{PSR�Y2g�Hto _ P�V % &(')& �*�2� _ YrP�V2HdR�U{wg�H�Y2\ _ Y2TIF+b�\2H�b��� : oJV _ svH�4���8��� �����1��! 9"� ; 46 ��+ b�H�GIF&W!H^w ]�b�U�P{w H�svH�GIH@Y!P -.4���8��� ������/���8? k KXP�V[H.3�R�g u ojR�b�\ GIF�\ _ ]�g@R�P _ F+Y _ UqG R�<�F+b _ Y
P�V2Hyg@c[b�b�H�Y!P s6R�Y2T+c�R�T+H+mD46 � _ UqP�V[H Y2H@R�b�H�U�P`*F+U{P�w GIF�\ _ ]2H@b@mJR�Y2\ P�V2H�b�H _ U Y2F<oZF+b�\2U 3�H^wP oBH�H@YE46 �pR�Y[\ %�&>')& �*��� m[P�V2H�Y "�(� LMF�g@R�P�H@46 �=<�c2U{PJR�K P�H�b % &(')& �*�2���
�8� A H�svU�H "�8� k Y2U�H@b{PtRIY2H^o b�F&oF<�c2U{PfR�K�P�H�b/P�V2Hpb�F&o F�KP�V2H %�&(' � �2���@m�R�Y2\rG R u H _ P %�&>' � �������
� $ LMF�g@R�P�HB4��� _ Y % &(' � �2��� R�PqP�V2H g�F+svc2GIYR�K�P�H�bpP�V�R�P _ Y<oJV _ gSV<P�V2H s6R�U�PpgSV�R�bSR�g^P�H�bF�K %�&>')& �*��� _ UjsvF�g&R�P�H�\n|
�80 A�83 A� 7 A�8: hjV2Hjb�F�F�PZc2Y _ P R�Y2\ _ P�U \ _ b�H�g�PlGIF�\ _ ]�H�b�UlR�b�HJR�\G<{c2U�P�H�\
P�F 3*HfsvF�g@R�P�H�\ _ Y P�V2HtUSR�GIHXg�F+svc2GIYn|
û�Ç¿Á�»P½¨Â (��Vç�¾¿Á�Äf½¼ÇȺ¼ÑHÍ Î Ä�½,ÃP½¼ÂdÆ{ÂUÀBº¼Ç¿ÀPÁ9¾ÈÇ¿ÀPÁ�»HÇ¿Æ{º¼ÇÞÅ�Æ{º¼½¨»HÅ�ݺ¨»P½¨Â×èÑHÂ,¹�¾¿Á�Äf½¼ÇȺ¼ÑPÍßÎ Ä�½�ÃP½¨ÂUƼÂwÀBº¨ÇÈÀPÁ辿ÇÈÀHÁ�»PÇÞÆyº¨Ç¿ÅLÆ{º¼½¨»HÅ3º¼»P½¨ÂUÆ
Ð*Â_ÑN¹iÒ�Â_Ï�ÂUÒ�ÂU¾ÈÄfÃNÂdÏ)Ç¿Æ*ƼÑPÄIÐÀ)ÇÈÀ�û�ÇÈÁNä (Nä�étÀ§º¼ÑPÇÞÆè¹�¾¿Á�Ä�ݽ¨ÇȺ¼ÑPÍ�ÜBÃP¾ÈÂd¹�ƼÂÀPÄ�º¨Â躼ÑH¹�º,Í)¹�Ç¿À¡Ò�Âw½¨àHÆ:¹�ÀHÏaǯºsÆLÍ¡Ä�Ï�ǯíNÂw½Åw¾¿¹�»HƼÂUÆ�¹�½¨Â!»HƼÂUÏï¹�Æ�ÃP½¨ÂUƼÂwÀBº¨¹�º¼Ç¿Ä�Àï»PÀHǯºsÆhÉðÍaÄ�Ï�ÇÈíHÂUÂUƹ�ÀHÏ�Í¡Ä�ÏPǯíHÂU½¨ÆsÌ*Ç¿À�º¼ÑPÂ;½¨ÂUÏ�»NÅ3ÂUÏ�Ò�Ç¿ÂwÐ;ÜH¹�ÀHÏ�Ð7Äf½¨ÏPƹ�½¼Â»NÆ{ÂdÏ�¹fÆèÃP½¨ÂUƼÂwÀBº¨¹�º¼Ç¿Ä�À�»HÀPǯºsÆÇ¿À�º¨ÑPÂ;Â3ã�ÃH¹�ÀHÏ�ÂdÏ�Ò�Ç¿ÂwÐ;äåæÂ:ÑH¹iÒfÂLÏ�ÂwÒfÂw¾¿Ä�ÃKÂUÏ9¹ �.#�émÝmàH¹�ƼÂUÏ9Ê�ç_ÊYÝt¹�ÀHÀPÄ�ºs¹Iº¼Ç¿Ä�À
ÂdÏ�ÇȺ¼Ä�½�º¨ÑH¹Iº¥ÃP½¨ÄIÒ�Ç¿ÏPÂUÆ�¹�Æ{º¼½¨»HÅ3º¼»P½s¹�¾9Ò�ÇÈÂUÐ�Æ�à�êß»HƼÇÈÀPÁº¨ÑPÂ�¹�àNÄIÒfÂá¹�¾¿Á�Äf½¼ÇȺ¼ÑPÍ�ä5û�Ç¿ÁHä =ïƼÑPÄIÐ�ÆÔƨÅ3½¨ÂwÂUÀÚÇÈÍaÝ

¹�Á�ÂUÆ_Ä�Î:º¨ÑPÂaÂUÏ�ÇȺ¼Äf½Uä9étÀ!º¨ÑPÂa½¼ÂdÏ�»HÅ3ÂdÏ¥Ò�ÇÈÂUÐ Éð¹fÆ�ƼÑPÄIÐÀÇ¿ÀùÉð¹BÌ{Ì3Ü_¹�ÀïÂUÀHÏï»HƼÂw½�Åw¹�ÀïÂU¹�Ƽǿ¾Èê�Á�½s¹�ƼÃ�º¼ÑPÂhÄIÒ�Âw½s¹�¾¿¾Æ{º¼½¨»HÅ�º¨»P½¨Â9ƼÄaº¼ÑH¹�º � é�1èØ � Í¡Ä�Ï�ǯΠê � ¹�ÀPÀPÄ�»HÀHÅ3ÂdÏYÜ � º¨ÑPÂÃPÑH½¨¹fÆ{ � ¹¡ÀHÂwÐÓÅ3ÄfÍaÃH»�º¼ÂU½ � Í¡Ä�Ï�ÇÈíHÂUÆ ÉðÄ�½�ÇÞÆ_¹�À¥Ï�ÇȽ¨ÂUÅ3ºÄfà�ÿyÂUÅ3º-Ä�Î¨Ì � ¹�ÀPÀPÄf»PÀHÅ3ÂdÏYÜ � ¹�ÀHÏ9º¨ÑPÂ,ÃHÑP½¨¹fÆ{ � ÐÇȺ¼Ñ ÒfÄ�ÇÞÅ3½¨ÂUÅwÄ�Á�ÀHǯº¨ÇÈÄfÀïÎ »PÀHÅ3º¼Ç¿Ä�À � Í¡Ä�Ï�ÇÈíHÂUÆ � ¹�ÀPÀPÄf»PÀHÅwÂUÏYÜ � Âwº¨Å�äétÀ¥º¨ÑPÇÞÆ�ÅU¹�ƼÂ�ÜNƼǿÀHÅ3Â$º¼ÑPÂaÏ�ÂwÃKÂwÀHÏPÂwÀHÅwÇÈÂdÆ_àKÂ3ºyÐ*ÂwÂUÀ � Î Äf½ �¹�ÀHÏ � ¹�ÀPÀPÄ�»HÀHÅ3ÂdÏYÜ � ¹�ÀHÏ � ÐÇȺ¼Ñ � ¹�ÀHÏ � ¹�ÀPÀPÄf»PÀHÅwÂUÏ �¹�½¼Â2н¨Ä�ÀPÁNÜ9¹ß»HÆ{ÂU½ÔÅsÑH¹�ÀPÁ�ÂdÆ�º¼ÑPÂáÍ¡Ä�Ï�Â2º¨ÄﺼÑPÂâÂ3ã�ÝÃH¹�ÀHÏ�ÂdÏ0Ò�Ç¿ÂwÐÓÉð¹fÆ:ƼÑPÄIÐÀ¡ÇÈÀ!ÉðàNÌ{Ì3äLétÀ¡º¼ÑPÇÞÆ:Ò�Ç¿ÂwÐ;Ü�¹9»HÆ{ÂU½ÅU¹�À§ÅsÑH¹�ÀPÁ�Â�Ï�ÂUÃNÂUÀHÏ�ÂUÀHÅ3Ç¿ÂUÆ7à�êaÏ�½s¹�ÁfÁ�Ç¿ÀPÁ;¹;Í¡Ä�Ï�ǯíNÂw½:º¨Äº¨ÑP Å3Äf½¼½¨ÂUÅ3ºèÍ¡Ä�Ï�ÇÈíHÂwÂ;»NÆ{Ç¿ÀPÁ§¹¡Í¡Ä�»HƼÂ�ä7×èÑP Å3Äf½¼½¨ÂUÅ3º¼ÂUÏÏ�ÂUÃNÂUÀHÏ�ÂUÀHÅ3ê�Æyº¨½¼»HÅ3º¼»P½¨Â9Ç¿ÆƼÑPÄIÐÀ�ÇÈÀDÉ�ÅUÌ�äû�ÇÈÁNä 9 ƼÑPÄIÐ�Æ�º¼ÑP§Äf»�º¼ÃH»�º Ä�ÎÊ-ç�ʲÂUÏ�ÇȺ¼Äf½;Î Ä�½9º¨ÑPÂ
¹�àNÄIÒfÂ�+,ÀPÁ�¾¿Ç¿Æ¼Ñ�Æ{ÂUÀfº¨ÂwÀHÅwÂ�ä×èÑPÇÞÆ0¹�¾ÈÁfÄ�½¨Ç¯º¨ÑPÍ Ç¿Æ0¾¿¹�ÀPÁ�»N¹�Á�ÂwÝ?Ç¿ÀHÏ�ÂUÃNÂUÀHÏ�ÂUÀfº0Â3ãPÅ3ÂUÃ�º
Î Äf½�ÏPÂ3º¼ÂU½¼Í¡Ç¿ÀPÇ¿ÀPÁïǯÎ0Î Ä�½¨Ð*¹�½¨Ï'Í¡Ä�ÏPǯíNÅU¹Iº¨ÇÈÄfÀ[Äf½¥àH¹�ÅsìBÝÐè¹�½sÏ�Í¡Ä�Ï�ÇÈíNÅw¹�º¼Ç¿Ä�À�ÇÞÆ�Í)¹IÿyÄf½Uä*û�Ç¿ÁHä �¡Æ¼ÑPÄIÐ�ƹ)ƼÅw½¼ÂUÂwÀÇ¿Í)¹�Á�Â�Ä�Î�º¨ÑPÂ¥Ê-ç�Ê'ÂdÏ�ǯº¨Ä�½aÎ Ä�½¡¹ ?f¹�ÃH¹�ÀPÂdÆ{Â�Æ{ÂUÀBº¼ÂwÀNÅ3ÂÐÑPÇÞÅsÑßÇÞÆ�¹áº¨½¨¹�ÀHÆ{¾Þ¹Iº¨ÇÈÄfÀßÄ�Î$º¼ÑPÂ2¹�àKÄIÒ� +:ÀPÁf¾ÈÇÞÆ{Ñ[Æ{ÂUÀ�ݺ¨ÂwÀHÅwÂ�ä
� � ÷{³�·Yö�³B³�÷{ô ó×èÑPÂU½¼ÂhÑH¹iÒ�Â!àKÂwÂUÀ[ƼÂwÒfÂw½s¹�¾_Â��KÄf½{ºsÆ)º¨Ä�Ï�ÂwíHÀPÂÔº¨¹�ÁBÆ
Î Äf½*Ï�ÂdƼÅw½¼Ç¿àPÇ¿ÀPÁ$¾Þ¹�ÀHÁ�»H¹�Á�Â�½¨ÂUƼÄ�»P½sÅ3ÂdÆwÜBÆ{»NÅsÑ�¹�Æ,º¼ÑPÂ9×�Â3ã�º+,ÀHÅ3Ä�Ï�Ç¿ÀPÁ"étÀPǯº¨Ç¿¹�º¼Ç¿Ò�ÂQ; �[=[>mÜn7�ÃKÂwÀH×�¹�Á ; � �+>mÜ�ü7Ä�½¨ÃP»HÆ +,À�ÝÅwÄ�ÏPÇÈÀPÁ��Bº¨¹�ÀHÏP¹�½sÏ; �+>?Üiº¨ÑP +:ã�ÃNÂU½{º�ç�Ï�Ò�ǿƼÄ�½¨ê �"½¼Äf»PÃ;Ä�ÀÊ�¹�ÀPÁf»H¹�Áf +:ÀHÁ�Ç¿ÀPÂwÂU½¼Ç¿ÀPÁ �Bº¨¹�ÀHÏP¹�½¨ÏPÆ ; !2>mÜ �"¾¿Ä�àH¹�¾t%_Ä�Å3Ý»PÍ¡ÂUÀfº!ç_ÀPÀPÄ�ºs¹Iº¨ÇÈÄfÀ ÉðÄ�½ � %�ç"Ì ; �2>mä ×èÑPÂDÍ)¹�Ç¿À'Î Ä�ÝÅw»HÆaÄ�Î_º¨ÑPÂUƼÂ� �cÄ�½¼º¨ÆaÄ�º¨ÑPÂw½aº¨ÑH¹�À � %�ç ÑH¹fÆ0àKÂwÂUÀ⺨ÄƼÑH¹�½¨Âa¾ÈÇ¿ÀPÁ�»HÇ¿Æ{º¼ÇÞÅ¡½¼ÂdÆ{Äf»P½sÅ3ÂUÆ�à�êÔÂwã�ÃH½¼ÂdƼƼÇÈÀHÁ�º¨ÑPÂwÍ ÇÈÀD¹Æ{º¨¹�ÀHÏP¹�½sϲºs¹�Á�ƼÂ3ºdÜ�¹�ÀHÏﺨÑPÂw½¨Â3Î Äf½¼ÂÔº¼ÑPÂUêßÏ�Â3íHÀHÂæÒfÂw½¨êÏ�Âwº¨¹�ÇȾ¿ÂUÏh¾ÈÂUÒ�ÂU¾¿Æ"Ä�Î7º¨¹�ÁfÆ�Î Ä�½;Âwã�ÃH½¼ÂdƼƼÇÈÀHÁ�¾¿ÇÈÀPÁf»PÇÞÆyº¨Ç¿Å)Ï�Âwݺs¹�Ç¿¾¿ÆUä � %�ç ÑN¹�Æ¡¹�¾¿Í¡ÄfÆ{º$º¼ÑHÂ�ƨ¹�Í¡Â�ÃH»P½¼ÃKÄfƼÂUÆ0àP»�º)ÇȺÑH¹fÆ;¹�¾ÞÆ{Ä¥Ï�ÂwíHÀPÂdÏhÒfÂw½¨êÔÅ3ÄfÍ¡ÃP¾ÈÂwã!º¨¹�Á¥Æ{ÂwºUä�×èÑPÇÞÆ ÅwÄ�ÍaÝÃP¾¿Â3ã�ÇȺyê;Ï�ǿƨÅ3Äf»P½s¹�Á�ÂdÆ�ÃKÂwÄfÃP¾ÈÂ7Î ½¨Ä�ÍÚ»HƼÇÈÀPÁ�º¼ÑHÂUƼÂ:º¨¹�Á"ƼÂ3ºsÆÐÑPÂUÀ2н¼ÇȺ¼Ç¿ÀPÁÔÏ�Ä�Åw»PÍ¡ÂwÀBº¨ÆUÜ�¹�ÀHÏæǯº0àNÂdÅ3Ä�Í¡ÂdÆ$Ï�ÇÈÕ§Å3»P¾Èºº¨Ä�Í)¹�ìfÂa¹�Àæ¹fƼƼÇÞÆyº¨ÇÈÀPÁ�º¼Ä�Äf¾�Î Äf½ ¹�ÀPÀHÄ�º¨¹�º¼Ç¿ÀPÁ�º¼ÑPÂaº¨¹�ÁfÆUäÖ_ÄIÐ7ÂUÒ�Âw½dÜfÊ�ç_ÊæÇÞÆèÀPÄ�ºèÄ�ÃPÃKÄfƼÂUÏ�º¼Ä0º¼ÑHÂUƼÂ"ÃH½¼ÂUÒBÇ¿Ä�»NÆ,ÂwÎýÝÎ Äf½{ºsÆwÜdàP»�º-½s¹Iº¨ÑPÂw½-ÃP½¼ÄfÃNÄBÆ{ÂdÆY¹Å3ÂU½{ºs¹�Ç¿À;¾ÈÂUÒ�Âw¾�Ä�ÎPÆ{»HàHÆ{Âwº�Ä�κ¨ÑPÂLº¨¹�ÁfÆ�º¼ÑH¹�º�Åw¹�À;àNÂ7»HƼÂUÏ9ÐÇÞÏ�Âw¾¿ê�ä�étÀ ¹�ÏPÏPǯº¨ÇÈÄfÀ;º¼Äº¨ÑPÇÞÆÄfà�ÿyÂUÅ3º¼Ç¿Ò�Â�Ü�¹fÆ7Í¡ÂUÀfº¨ÇÈÄfÀPÂUÏ�ÂU¹�½¼¾¿Ç¿Âw½dÜ�Ê�ç_Ê&� Æ*Í)¹�Ç¿À�Äfà�ÿyÂUÅ3ݺ¨ÇÈÒf ǿÆ�º¼Ä§ÑHÂw¾¿Ã!Í)¹�ì� ¸�Ê-ËïÃH½¼ÄfÁ�½s¹�Í)ÆèÒ�ÂU½¼ê�¹�ÅUÅ3»P½s¹Iº¨Â�ä×èÑPÂU½¼ÂwÎ Ä�½¨Â�Ü�Ê-ç�Ê2ÇÈÀNÅ3¾¿»HÏ�ÂUÆ*ºs¹�ƼìBÝmƼÃNÂdÅ3ÇÈíNÅ9¹�ÀPÀHÄ�º¨¹�º¼Ç¿Ä�ÀHÆUä×èÑPÂU½¼ÂÑH¹fÆLàKÂwÂwÀ§Æ¼Ä�Í¡Â�Ï�ÇÞƨÅ3»HƨÆ{Ç¿Ä�ÀNÆL¹�àKÄ�»�ºLº¨ÑPÂ�Í¡Âw½¼Ý
ÇȺ¨Æ0Ä�Î�¾¿ÇÈÀHÁ�»PÇÞÆyº¨Ç¿Å�¹�ÀPÀHÄ�º¨¹�º¼Ç¿Ä�À2ºs¹�ÁfÆ$Î Ä�½0Ä�½sÏ�Ç¿ÀH¹�½¨êhÃKÂwÄ�ÝÃP¾¿Â�ä7ûPÄ�½Ç¿ÀHÆ{º¨¹�ÀHÅ3ÂfÜHÖ_¹fÆ{ÑPÇÞÏP¹ ; (�>�Æ{º¨¹�º¼ÂUÏ�º¼ÑN¹Iº_ÐÇÞÏ�Â;»HÆ{ݹ�Á�Â9Ä�Î:Ƽ»HÅsÑ�º¨¹�ÁBÆÐ*Ä�»P¾ÞÏ�Á�½¨ÂU¹Iº¨¾Èê�ÇÈÍ¡ÃP½¨ÄIÒ�Â"º¨ÑP ½¨ÂUƼ»P¾¯ºsÆÄ�Î�¸_Ê�Ë�ÃP½¼ÄfÁ�½s¹�Í)ÆLÎ Äf½�¹�ÃPÃH¾ÈÇÞÅw¹�º¼Ç¿Ä�ÀHÆèƼ»HÅsÑ�¹fÆèÍ)¹�ÅsÑPÇ¿ÀPº¨½¨¹�ÀHÆ{¾Þ¹Iº¨ÇÈÄfÀ�Ü-Ç¿À�Î Äf½¼Í)¹Iº¨ÇÈÄfÀD½¼Âwº¼½¨ÇÈÂUÒI¹�¾?Ü�Ç¿À�Î Ä�½¨Í)¹Iº¨ÇÈÄfÀDÂ3ã�ݺ¨½¨¹fÅ�º¼Ç¿Ä�À-Ü9Ƽ»PÍ¡Í)¹�½¨ÇÈød¹Iº¨ÇÈÄfÀ�Ü;þf»HÂUÆ{º¼Ç¿Ä�À�Ýt¹�ÀHƼÐ*Âw½¨ÇÈÀPÁ�Æ{ê�Æ{ݺ¨ÂwÍ�Ü_Âwã�¹�Í¡ÃP¾ÈÂwÝ?àN¹�ƼÂUϲ½¨ÂU¹�ƼÄ�ÀHÇÈÀPÁNܹ�ÀHÏßÏH¹Iº¨¹âÍ¡ÇÈÀPÇ¿ÀPÁNܹ�ÀHÏ¥º¨ÑH¹Iº9º¼ÑHÇ¿Æ9Ð*Ä�»P¾ÞÏ!ÂUÀHÅ3Äf»P½s¹�Á�Â0Ä�½sÏ�Ç¿ÀH¹�½¨ê�ÃNÂUÄ�ÃP¾¿Â$º¨Ä»HƼÂL¾¿ÇÈÀPÁf»PÇÞÆyº¨Ç¿ÅL¹�ÀPÀPÄ�ºs¹Iº¨ÇÈÄfÀ�ºs¹�ÁBÆwä���Ä�Í¡Â:¸_Ê�Ë�½¼ÂdÆ{Âd¹�½sÅsÑPÂw½sÆ
Âwã�ÃNÂdÅ�º9º¼ÑH¹�º Æ{Ç¿ÀHÅ3¡Í)¹�À�ꥻHƼÂw½sÆ9Å3½¨ÂU¹�º¼Â0Ö�×Ø!Ê�ÃH¹�ÁfÂUÆÂUÒ�ÂUÀ�ÐÇȺ¼ÑHÄ�»�º�Ö�×Ø!ÊDÂdÏ�ǯº¨ÇÈÀHÁ¡º¼Ä�Ä�¾ÞÆwÜNÆ{»HÅsÑ¥»NÆ{ÂU½¨ÆèÍ)¹i꺨ÑPÂw½¨Â3Î Äf½¼ÂL»NÆ{ÂL¾¿ÇÈÀHÁ�»PÇÞÆyº¨Ç¿Å,¹�ÀPÀPÄ�º¨¹�º¼Ç¿Ä�À�º¨¹�ÁBÆ�¹�ÆcÐ*Âw¾¿¾?ä�Ö�ÄIÐèÝÂUÒ�ÂU½UÜIÇȺ�ÑN¹�ÆV¹�¾ÞÆ{Ä�àNÂUÂwÀ0Ä�àHƼÂw½¨Ò�ÂdÏ9º¼ÑH¹�º�Äf½¨ÏPÇÈÀH¹�½¼ê"ÃKÂwÄ�ÃH¾ÈÂн¨ÇȺ¼Â�Ö_×ØÔÊ¥ÃH¹�ÁfÂUÆVàKÂUÅU¹�»HƼÂ*º¼ÑPÂU½¼ÂÇÞÆ:¹;Ï�Ç¿½¼ÂdÅ�º,¹fÏ�ÒI¹�À�ݺs¹�ÁfÂVº¼Äº¨ÑPÂwÍîÇÈÀ9àKÂwÇ¿ÀPÁ_¹�àP¾ÈÂVº¨Ä�Å3½¨ÂU¹�º¼Â:¹Iº¼º¼½s¹�Å3º¼Ç¿Ò�ÂVÃH¹�ÁfÂUƹ�ÀHÏ)¹�À)Ç¿ÀHÏ�Ç¿½¨ÂUÅ�ºè¹�Ï�ÒI¹�Àfºs¹�ÁfÂ7º¨ÑH¹Iº7º¼ÑPÂ_ÍaÄf½¼Â�¹�º{º¨½¨¹fÅ�º¼Ç¿Ò�º¨ÑPÂwÇ¿½"ÃH¹�ÁfÂUÆUÜ�º¼ÑPÂ$ÍaÄf½¼Â � ÑPÇȺ¨Æ � º¼ÑPÂUê�ÐÇ¿¾¿¾�ÁfÂ3ºUäèétÀ!ÅwÄ�À�ݺ¨½¨¹fÆyºdÜf¾¿Ç¿ÀPÁ�»PÇÞÆ{º¼ÇÞÅ�¹�ÀPÀHÄ�º¨¹�º¼Ç¿Ä�À¡ºs¹�ÁfÆ:Ä �cÂw½,Äf½¨ÏPÇÈÀH¹�½¼ê0ÃNÂUÄ�ÝÃH¾ÈÂ)ÄfÀP¾ÈêhÇÈÀNÏ�ÇȽ¨ÂUÅ3º ¹�Ï�ÒI¹�ÀBºs¹�Á�ÂdÆwä)×èÑPÂU½¼ÂwÎ Ä�½¨Â�ÜYº¨Ä�ÃNÄfÃP»�ݾ޹�½¨Ç¿øw§º¨ÑPÂUƼÂ�º¨¹�ÁBÆwÜLÇȺ¡Ç¿ÆaÇ¿ÍaÃKÄ�½¼º¨¹�ÀBº$º¼ÄæÍ¡ÇÈÀHÇÈÍ¡Ç¿øwÂ�º¼ÑPÂÐ*Ä�½¨ì�¾ÈÄB¹�ÏaÄ�Î�¹fÏPÏ�Ç¿ÀPÁ ¾¿ÇÈÀPÁf»PÇÞÆyº¨Ç¿Å�¹�ÀPÀPÄ�º¨¹�º¼Ç¿Ä�Àaº¨¹�ÁfÆ���º¨ÑH¹IºÇÞÆ;º¨Ä!Ƽ¹iêfÜ-Ð*§Í$»NÆyº ÃP½¨ÄIÒ�Ç¿ÏPÂ)ÂU¹�ƼêBÝ�º¨Ä�Ým»HƼÂa¹�ÀPÀPÄ�ºs¹Iº¨ÇÈÄfÀº¨Ä�Ä�¾ÞÆwä:×èÑPÂ"ì�ÂUê)ÃNÄfÇÈÀBºsÆèÇÈÀ�Í)¹�ì�ÇÈÀHÁaƼ»HÅsѧº¨Ä�Ä�¾ÞÆèÂU¹�Ƽêaº¼Ä»NÆ{Â"¹�½¨Â�Üf¹fÆLÍ¡ÂwÀBº¼Ç¿Ä�ÀHÂUÏ)Âd¹�½¨¾ÈÇ¿Âw½dÜ�Í¡ÇÈÀHÇÈÍ0»PÍFÇÈÀBº¼ÂU½¨¹fÅ�º¨ÇÈÄfÀ¹�ÀHÏ0 �cÂUÅ�º¨ÇÈÒfÂèÃP½¼ÂdÆ{ÂUÀBº¨¹Iº¨ÇÈÄfÀ�ä�×�Ä9Ƽ¹�º¼ÇÞÆyÎ ê;º¨ÑPÂUƼÂè½¼ÂdþB»PÇȽ¨Â3ÝÍ¡ÂUÀfºsÆwÜVÇȺ0ÇÞÆ;Ç¿ÍaÃKÄ�½¼º¨¹�ÀBº º¼ÄÔÏPÂ3íHÀPÂ�¹!Å3ÄfÍaÃH½¼ÂUÑPÂwÀHƼǿÒ�Â�ÜƼǿÍaÃH¾È ƼÂ3º�Ä�Î�¹�ÀHÀPÄ�ºs¹Iº¼Ç¿Ä�À�º¨¹�ÁfÆUä
� � ô ó ·��{ö�³�÷yô óétÀ9º¨ÑPÇÞÆYÃH¹�ÃKÂw½dÜdÐ7ÂLÑH¹iÒfÂVÃP½¼ÄfÃNÄBÆ{ÂdÏ9¹�À9Ù�Ø!Ê�ÝmÅwÄ�Í¡ÃP¾¿Ç¿¹�ÀBº
ºs¹�Á2Æ{ÂwºaÅU¹�¾¿¾ÈÂdÏâÊ�Ç¿ÀPÁf»PÇ¿Æ{º¼ÇÞÅ�ç�ÀPÀPÄ�º¨¹�º¼Ç¿Ä�ÀâÊ�¹�ÀPÁf»H¹�Áf§Ä�½Ê�ç_Ê,ÜwÐÑPÇÞÅsÑ9ÑPÂw¾¿ÃHÆ-¸�Ê-Ë�ÃP½¨Ä�Áf½¨¹�Í)ÆNÃKÂw½¼Î Ä�½¨Íߺ¨ÑPÂwÇ¿½Yºs¹�Ƽì�ÆÍ¡Äf½¼Â9Å3Äf½¼½¨ÂUÅ3º¼¾¿ê�äVÊ-ç_ÊæÇÞÆèÏ�ÂUƼÇÈÁfÀPÂUϧº¼ÄaàNÂ;¹fÆ7ƼÇÈÍ¡ÃP¾¿Â;¹�ÆÃKÄfƨƼÇÈàP¾¿Â�Æ{ÄÔº¼ÑH¹�ºaÑ�»PÍ)¹�ÀNÆaÅU¹�Àá»NÆ{Â�ǯº)ÐÇȺ¼Ñ�ÍaÇ¿ÀPÇ¿Í)¹�¾ÑHÂw¾¿ÃÔÎ ½¨Ä�Í ¹�ƨƼǿÆ{º¼Ç¿ÀPÁ§º¨Ä�Ä�¾ÞÆwä9åæÂ0ÑH¹iÒfÂ0¹�¾¿Æ¼Ä�Ï�ÂUÒ�ÂU¾ÈÄfÃNÂdϹ �.#_émÝ?àH¹fÆ{ÂdÏ$Ê�ç_Ê�¹�ÀPÀHÄ�º¨¹�º¼Ç¿Ä�À0ÂUÏ�ÇȺ¼Äf½Uä�åhÂèÑPÄfÃNÂ*º¨ÑH¹IºÐÇÞÏ�¹�ÅUÅ3ÂUÃ�º¨¹�ÀHÅ3Â7Ä�ÎNÊ�ç_Ê�ÐÇȾ¿¾�Í)¹�ì�Â*ÇȺ�ÃKÄfƨÆ{Ç¿àP¾¿Â,º¨Ä�»NÆ{ÂÍ¡Äf½¼Â9Ç¿Àfº¨Âw¾¿¾ÈÇ¿Á�ÂUÀBº�étÀfº¨Âw½¨ÀPÂ3ºèº¨ÄBÄf¾¿Æ¹�ÀHÏ�Æ{ÂU½¼Ò�ÇÞÅ3ÂdÆwä
� ��� � µ �-ó · � ³ �� 5BiZE*m ��5BF+b�`2c2U ilY2g�F�\ _ Y[T E�P�R�Y2\�R�b�\ - 5BiZE /Sm
- V!P�P�`�� ���&ojojot| g@U@| W+R�U�USR�b&| H�\2c�� 5BiZE��8/ �� i N+7/LMiBE�m ��ilz�`*H�b{P N/\�W _ U�F+b � 7/b�F+c2`
F+Y L.R�Y2T+c�R�T+H i Y2T _ Y2H�H�b _ Y[T E!PSR�Y2\2R�b�\2U@m - V!P�P�`�� ���&ojojot| _ svg!| ` _ | g@Y[b&| _ P���i N+7/LMiBE���V2F+GIH+| V�P�GIs�/
�� 7��JNdm ��7/svF 32R�s �/F�g�c2GIH�Y�P N/Y2Y2F�P�R�P _ F+Ynm - V!P�P�`�� ���&ojojot| H�P�s | T+F2| <{`���H^P�s���Y2s���T+\2R��8/
$ �� F _ gSV _�� R�U�V _ \�R[m � R�P�R�U�V _! R�T!R�F2m4H^P&| R�s m" �# b�F+T+b�H�U�UR�Y2\$# b�F+U�`�H@g^PF�K 7/svF 3�R�s��/F�g�c2GIH�Y!PN/Y[Y2F�PSR�P _ F+Ynm - _ Y% R�`2R�Y2H�U�H�/&# b�F�g+|�F�K $ P�V N/Y[Y�c�R�s(' H�H�P _ Y2T�F�KXP�V[H N/U�U�F�wg _ R�P _ F+Y F�K R�P�c2bSR�sJL.R�Y2T+c2R�T+H�# b�F�g�H�U�U _ Y[T2mB`2`n| 3(� :*)>38�(� m� ;8;8:
0� ���XR�PSRIH�svH�GIH�Y�P�UXR�Y2\ _ Y�P�H�b�gSV�R�Y[T+HpK F+b�G R�P�U ) k Y[K F+b�G R�P _ F+Y_ Y�P�H�b�gSV�R�Y[T+H ),+ H�`2b�H�U�H�Y�P�R�P _ F+Y�F�Kl\�R�P�H@UtR�Y[\4P _ GIH�U&m Ik{E�-:838?(� � � ;8:8: |
3��� c2b�F+V�R�U _ mjE*|vmBR�Y2\ R�T!R�F2m.'<|vm/��N E)��Y�P�R�g^P _ g4NOY�R�s �[U _ U' H�P�V2F�\<F�KjLMF+Y[T % R�`�R�Y2H�U�HrE�H�Y!P�H�Y2g�H�U 3�R�U�H�\ F+YaP�V2H0�/H^wP�H�g^P _ F+Y F�K'5ZF+YG<{c2Y2g^P _ W!HXE!P�b�c2g^P�c2b�H�U&m %5ZF+GI`2c[P�R�P _ F+Y2R�s�L _ Y[wT+c _ U�P _ g�U&m�1lF+s | �8? m F2| $ m � ;8; $ |
7 ' g 5ZF+b�\nm�5/|�'<|vm2�^E�svF�P�7/bSR�GIG R�b�U@m 5ZF+GI`2c[P�R�P _ F+Y�R�s�L _ Y[wT+c _ U�P _ g�U&m�1lF+s | 3 m[`2`n| �(��) $ � m � ;8:8? | :� ' g 5ZF+b�\nm 5X|3'<|vm4�^E�svF�P 7/b�R�GIG R�b*� N(E)��U�P�H�G K F+bqE _ Gqw`2svH�b�5ZF+Y2U{P�b�c2g^P _ F+YIF�K5# b�R�g�P _ g@R�s R�P�c2bSR�s�LMR�Y2T+c�R�T+H 7/b�R�Gqw
G R�b�U&m _ Y - H�\�/ + |�E�P�c2\2H�b@m R�P�c2b�R�s�L.R�Y[T+c�R�T+HdR�Y2\rLnF+T _ g��k Y�P�H�b�Y�R�P _ F+Y�R�s E�g _ H@Y!P _ ]�g#E)��GI`�F+U _ c2G mJLMH�g^P�c[b�H F�P�H�U _ Y5BF+GI`[c[P�H�bOE�g _ H�Y2g�H+m�`2`n| �8� :*)�� $ 0 m�E�`2b _ Y2T+H�b�1 H�b�s6R�T2m � ;8;8? |

�������;���iq¨vyrt��~d��� � � � ;qs�Bx¨~�®f���B���d¬ �I��è� ¦�ktk� ����ý�¯uw����ý�¯uw��� r,�¯®��d�¯® � ��ý�¯uw��� ���¯®��d�¯® �¨�y� ;�;~�®��d�¯® �¼�m� 9��~dr��U�B~U�B��"�¯q����UkmlLn���¿�tvyr��drt��| �fvy~d�f����?kmlLn����w�¯uU��� ����ý�¯uw��� ���¯®��d�¯® �¨�?� ;��~Ur����iq¨vy��9��q����iuw�B�B~U�B�fxsq� �muw�B�f~d�B�fxsq�® ���w�¯uU��� ����ý�¯uw��� ���¯®��d�¯® �¨��� ;�;~�®��d�¯® �¼�m� 9��~dr��d®fq¨�!"�¯q����du"#�È�tvyr��drt�" �mu$���w�¯uU��� ����ý�¯uw��� ���¯®��d�¯® �¨�ð� ;�;~�®��d�¯® �¼�m� 9��~dr��dud®3¢%;��q����d�fq¨�& �?�fq¨�'���w�¯uU��� ����ý�¯uw��� ���¯®��d�¯® �¨�?� ;�;~�®��d�¯® �¼�m� 9��~dr��U�B~U�B��"�¯q����Uxs~d�;�f�f�yq¨v!(�¿�tvyr��Urt�f| xs����?xs~d�;�f�f�yq¨v(���3�Èuw��� ����ý�¯uw��� ���¯®��d�¯® �¨��� ;�;~�®��d�¯® �¼�m� 9��~dr��U�fvyqs��9��q����"�¿~Uv! ���¿~Uv#���w�¯uU��� ����ý�¯uw��� ���¯®��d�¯® �¨�*) ;�;~�®��d�¯® �¼�?� 9��~dr��U�B~U�B��"�¯q����Ux¼zf���È®+ �?x{zB���¯®�vyqs�,���w�¯uU��� ����ý�¯uw��� ���¯®��d�¯® �¨��� ;�;~�®��d�¯® �¼�m� 9��~dr��U�fvyqs��9��q����U�:� �yz�����:� �yz-���w�¯uw��� ����ý�¯uw��� ���¯®��d�¯® �¨��« ;�;~�®��d�¯® �¼�{�s� 9��~Ur��d�f~d�B��9��q������i~U��xsq� �*�d~d��xsq.���w�¯uU��� ����ý�¯uw��� ���¯®��d�¯® �¨�y��� ;�;~�®��d�¯® �¨�y�d� 9��~dr��U�B~d�f��9��q����wvyqsxs~d�U�B� �y��~d�� ��vyqsxs~U�d�f���y��~U�-���w�¯uw��� ����ý�¯uw��� ���¯®��d�¯® �¨�y�d� ;�;~�®��d�¯® �¨��� 9��~Ur��d�f~d�B��9��q����"�¿�B�Bx¼�y�¯~U������Þ�B�fx¨�y��~d�/���w�¯uU��� ����0 �3�¯uU��� r�����3�¯uU�1�
û�Ç¿Á�»P½¨Â 9 ��+:ã�¹�Í¡ÃP¾ÈÂ"Ä�ÎLÊ-ç�ÊDç�ÀPÀHÄ�º¨¹�º¼Ç¿Ä�À 7�»�º¼ÃH»�º
;� ' g 5ZF+b�\nm 5/|3'<|vm � � H�c2b _ U{P _ g�UdK F+b�2Zb�F!R�\[w 5BF@W!H�bSR�T+H R�P{wc2b�R�sOL.R�Y[T+c�R�T+H�#�R�b�U _ Y[T2m # b�F�g+|ZF�KXP�V2HQN + #*N � c2G R�YL.R�Y2T+c2R�T+Hdh.H�gSV[Y2F+svF+T4�#3aF+b u U�V[F+`nm � ;8;8� |
� ?� ' g 5ZF+b�\nm 5/|�'<|vm[R�Y2\42ZH�b�Y!P�Vnm�Np|vm(��hjV2HtL ' h h.b�R�Y2U�K F+b�wG R�P _ F+Y�R�slE)�[U{P�H�G m #lb�F�g+|nF�K�#lb�F�g�H@H�\ _ Y[T+UdF�KZN�' h.NOw ;8: m`2`n| � $8$ )>�8080 m � ;8;8: |
�8�� -/`*H�Y2h R�T2m ��N E�P�R�Y2\�R�b�\ ilz�P�bSR�g^P _ F+Y���N 32U{P�b�R�g�P _ F+Yh.H^z�P06�F+b�G R�P K F+b h.bSR�Y2U�s6R�P _ F+Y R�Y2\ L # h.F�F+svU@m - V�P{P�`5� ���&oJojot| F+`�H�Y�P�R�T2| F+b�T �8/
� �� E 7�' L m5��k{E�- ��k i�5 :8: 7 ; w � ;8:83 - i /^|�k Y[K F+b�G R�P _ F+Yq`2b�F�g�H�U�U{w_ Y2T ) h.H�z�P<R�Y2\ -65Ig�H E)��U�P�H�GIU ) E�PSR�Y[\�R�b�\ 7/H�Y2H�b�R�s w_87 H�\ 'QR�b u c[`aLMR�Y2T+c�R�T+HC- E 7�' L /S|�6 _ b�U{PXil\ _ P _ F+Y )E� ;8:83 w� ? w � 0 | k Y!P�H�b�Y�R�P _ F+Y2R�s(-/b�T!R�Y _87 R�P _ F+Y K F+bpE�P�R�Y2\�R�b�\ _87 R�P _ F+Ynm � ;8:83 |
� �� h R u H@\2R[m � |vm � #�R�P{P�H�b�Y[w�2BR�U�H�\ 5ZF+Y�P�H^z�P{w 6�b�H@H 7/bSR�GIG R�b�UK F+b�'QR�gSV _ Y2HXh.b�R�Y2U�s6R�P _ F+Ynm !# b�F�g+|�F�K � $ P�VrN+5BLlm[`2`�| � $8$ )� 0(� m % c2Y2H � ;8;83 |
� $ h R u H@\2R[m � |vm � #�R�P�P�H�b�Y[w�2BR�U�H�\$'QR�gSV _ Y2H#h.bSR�Y[U�s6R�P _ F+Ynm # b�F�g+|�F�K � 3 P�V 5�-/LMk 7pm�1lF+s | � m*`2`n| �8� 080*)��8� 08: mMNOc2T+c2U�P� ;8;83 |
� 0� hJilkSm ��h.H^z�P i Y[g@F�\ _ Y2T k Y _ P _ R�P _ W!H - hji k /Sm - V�P{P�`5� ���&oJojot| c _ g+| H�\2c�� :8? ��F+b�T+U��&P�H _ �8/
� 3� 3<R�P�R�Y�R43�H+m � |vm.��N ' H^P�V2F�\ K F+bBN+32U�P�bSR�g^P _ Y2T H�oJU�`�R�`�H@bN/b{P _ g�svH�U 38�.9OU _ Y2TQE�c[b�K R�g@H$5Zsvc2H�U&m #lb�F�g!|�F�K � 3 P�V<k Y!P�H�b{wY�R�P _ F+Y�R�s 5ZF+Y[K H�b�H�Y2g�H F�K+5BF+GI`[c[PSR�P _ F+Y�R�sZL _ Y2T+c _ U�P _ g�U&m.`[`n|; 7�$ )>; 7 ; m�N/c[T2| $ w ; m � ;8;83 |
� 7 3<R�P�R�Y�R43�H+m � |vm�R�Y2\rh R u H@\2R[m � |vm.��N #�R�P�P�H�b�Y[w 3�R�U�H�\ 'QR�wgSV _ Y[Hqh.bSR�Y2U�s6R�P _ F+Y�E)��U�P�H�G i�z�P�H�Y2\2H�\138�Qilz[R�GI`2svH^w 3�R�U�H�\# b�F�g�H�U�U _ Y2T2m 4# b�F�g+|*F�K P�V2H �83 P�V4N+5BL;: � 7 P�V 5�-/LMk 7pm1lF+s | � m2`[`n| � �838; w � � 7 � m � ;8;8: |
� :� 3<R�P�R�Y�R43�H+m � |vm ��L _ Y2T+c _ U�P _ gZNOY2Y2F�P�R�P _ F+YqLMR�Y2T+c�R�T+H ) hjV2H'QR�b u c2`pL.R�Y2T+c�R�T+HjK F+b�N/U�U _ U{P _ Y2T L #a`2b�F+T+bSR�GIU ) m Ik�2�'+ H@U�H@R�b�gSV + H�`�F+b�P + h ?8�8� $ m � ;8;8; |
� ;� 3<R�P�R�Y�R43�H+m � |vm ��N ' H�P�V2F�\ K F+baN/g�g�H�svH�bSR�P _ Y2T 5�6 7Ow#�R�b�U _ Y2T 3)�<9OU _ Y2T!�/H�`�H@Y[\2H�Y2g��#k Y[K F+b�G R�P _ F+Y�m # b�F�g+| F�K� : P�V 5�-/LMk 7pm �8?8?8? |
�8?�(= ' L m ��ilz�P�H�Y2U _ 32svH 'QR�b u c2` L.R�Y2T+c�R�T+H - = ' L /Sm - V�P{P�`5� ���&oJojot| o � | F+b�T ��h + ��# + w z[GIs w ; 7 � �8?8: /^m 3aF+b�sv\3 _ \2H>3aH 3 5BF+Y[U�F+b�P _ c2G m��/H�g+| : m � ;8; 7 |
�(��#= ' L E*m � R�GIH�U�`�R�g�H�U _ Y = ' L m - V!P�P�`�� ���&ojojot| o � | F+b�T ��h + � � ;8;8: ��3 �Ow z�GIs w Y�R�GIH�U�w� ;8;8:8?8�8� 7 /^m?3aF+b�sv\@3 _ \2H43aH93 5ZF+Y2U�F+b�P _ c2G m('QR�b�gSV � 7 m� ;8;8: |

Éð¹BÌ ÂUÏ�»NÅ3ÂUÏ���ÇÈÂUÐ
É àNÌ�+Lã�ÃH¹�ÀNÏ�ÂUÏ��_Ç¿ÂwÐ É àKÂ3Î Ä�½¨Â Å3Äf½¼½¨ÂUÅ3º¼Ç¿Ä�ÀNÌ
ÉðÅdÌ +Lã�ÃH¹�ÀHÏ�ÂdÏ��_Ç¿ÂwÐFÉð¹�Îýº¼ÂU½_Å3Äf½¼½¨ÂUÅ3º¼Ç¿Ä�ÀNÌ
û�Ç¿Á�»P½¨Âa=�� ��Å3½¨ÂwÂUÀ¥étÍ¡¹�Á�Â;Ä�ÎLÊ�ç_Ê +7Ï�ÇȺ¼Ä�½_Î Ä�½ +,ÀPÁ�¾¿ÇÞÆ{ÑƼÂwÀBº¼ÂUÀHÅ3Â
û�Ç¿Á�»P½¨Â%� � ��Å3½¨ÂwÂUÀ$étÍ)¹�ÁfÂ7Ä�ÎKÊ-ç�Ê +,Ï�ÇȺ¼Äf½�Î Äf½t?f¹�ÃH¹�ÀHÂUƼÂƼÂwÀBº¨ÂwÀHÅwÂ

Building an Annotated Corpus in the Molecular-Biology Domain
Yuka Tateisi, Tomoko Ohta, Nigel Collier, Chikashi Nobata, Jun-ichi TsujiiDepartment of Information Science
Graduate School of ScienceUniversity of Tokyo,
7-3-1 Hongo, Bunkyo-ku, Tokyo 113-0033, Japan
Abstract
Corpus annotation is now a key topic for all ar-eas of natural language processing (NLP) andinformation extraction (IE) which employ su-pervised learning. With the explosion of re-sults in molecular-biology there is an increasedneed for IE to extract knowledge to supportdatabase building and to search intelligently forinformation in online journal collections. Tosupport this we are building a corpus of an-notated abstracts taken from National Libraryof Medicine’s MEDLINE database. In this pa-per we report on this new corpus, its ontologi-cal basis, and our experience in designing theannotation scheme. Experimental results areshown for inter-annotator agreement and com-ments are made on methodological considera-tions.
1 Introduction
In the field of molecular biology there have re-cently been rapid advances that have motivatedresearchers to construct very large databases inorder to share knowledge about biological sub-stances and their reactions. A large part of thisknowledge is only available in unformalized re-search papers and information extraction (IE)from such sources is becoming crucial to helpsupport timely database updating and to helpresearchers avoid problems associated with in-formation overload.
For this purpose, various NLP techniqueshave been applied to extract substance namesand other terms (Ohta et al., 1997; Fukuda etal., 1998; Proux et al., 1998; Nobata et al., 1999)as well as information concerning the natureand interaction of proteins and genes (Sekimizuet al., 1998; Blaschke et al., 1999; Hamphrayset al., 2000; Thomas et al., 2000; Rindfleschet al., 2000). The nomenclatures of genes and
associated proteins for model organisms suchas S. Cerevisiae (yeast) and D. Melanogaster(fruit fly) are established so that good dictio-naries for those names have been constructed.However nomenclatures for humans are not yetavailable as the whole picture of the humangenome has yet to be revealed, this results inarbitrary names being used by researchers whoidentified the structure of proteins and genes,so dictionary-based approaches might not beas effective as in the case of model organisms.Thus many of the previous researchers eitherlimit their scope to extracting information onsubstances like enzymes which have establishednaming conventions (Hamphrays et al., 2000)or extracting information on ‘substance’ givingup the distinction between the class of sub-stance like protein and DNA (Fukuda et al.,1998; Proux et al., 1998; Sekimizu et al., 1998;Thomas et al., 2000).
Term identification and classification meth-ods based on statistical learning seem to bemore generalizable to new knowledge types andrepresentations than the methods based on dic-tionaries and hand-constructed heuristic rules.We think that a corpus-based, machine-learningapproach is quite promising, and to supportthis we are building a corpus of annotated ab-stracts taken from National Library of Medicine(NLM)’s MEDLINE database.
Corpus annotation is now a key topic for allareas of natural language processing and lin-guistically annotated corpus such as treebanksare now established. In information extractiontask, annotated corpora have been made mainlyfor the judgment set of information extractioncompetitions such as MUC (Chinchor, 1998).We think that technical terms of a scientificdomain share common characteristics with the“Named Entities” and the tasks we attempt in-

volve recognition and classification of the namesof substances and their locations, just as namedentity recognition task in MUC conferences. Wetherefore try to model our annotation task afterthe definition of “EnameX” (Chincor, 1998a)of MUC conferences. Unlike in MUC confer-ences, we don’t make a precise definition of howthe recognized names are used in further infor-mation extraction task such as event identifica-tion, because we want the recognition technol-ogy to be independent of the further task. Ourwork is also compared to word-sense annotation(e.g.,(Bruce and Wiebe, 1998)) where instancesof words that have multiple senses are labelledfor the sense it denotes according to a certaindictionary or thesaurus.
We first built a conceptual model (ontology)of substances and sources (substance location),and designed a tag set based on the ontologywhich conforms to SGML/XML format. Us-ing the tag set, we annotated the entities suchnames that appears in the abstracts of researchpapers taken from the MEDLINE database. Inthis paper we report on this new corpus, its on-tological basis, and our experience in designingthe annotation scheme. Experimental resultsare shown for inter-annotator agreement andcomments are made on methodological consid-erations.
2 Design of The Tag Set
2.1 Underlying Ontology
The task of annotation can be regarded as iden-tifying and classifying the names that appearsin the texts according to a pre-defined classifi-cation. For a reliable classification, the classifi-cation must be well-defined and easy to under-stand by the domain experts who annotate thetexts. To fulfill this requirement, we create aconcrete data model (ontology) of the biologi-cal domain on which the tag sets are based.
Ontologies have been developed in thebiomedical sciences for several applications.Such ontologies include conceptual hierarchiesfor databases covering diseases and drug names.Construction of a more general ontology e.g.(Baker et al., 1999) is being attempted byseveral groups interested in interconnectingdatabases under a uniform view.
We start from a taxonomy illustrated in Fig-
ure 11. In this taxonomy, we classify sub-stances according to their chemical character-istics rather than their biological role. Thisis unlike other existing ontologies in the biol-ogy field (Baker et al., 1999; Schulze-Kremer,1998), which mix the classification by biologicalrole and by chemical structure. The reason thatwe have adopted this approach is that we con-sider mixing two criteria prevents the mutuallyexclusive classification and thus makes the an-notated task more complicated by introducingnested tag structures and context dependent se-mantic tags. In our initial annotation work wetherefore chose to simplify the classification byconcentrating on the chemical structure.
Chemical classification of substances is quiteindependent of the biological context in whichit appears, and is therefore more stably defined.For example, the chemical characteristics of aprotein can be easily defined, but its biologicalrole may vary depending on the biological con-text, e.g., it may work as an enzyme for onespecies but a poison for others. Therefore, inour model we do not classify substance as en-zymes, transcription factors, genes, etc. butas proteins, DNAs, RNAs, etc. They are fur-ther classified into families, complexes, individ-ual molecules, subunits, domains, and regions,because these super- and sub- structures oftenhave separate names. This classification is non-controversial among biologists and can be easilyexpanded into other ontologies.
Sources are biological locations where sub-stances are found and their reactions take place,such as human (an organism), liver (a tissue),leukocyte (a cell), membrane (a sub-location ofa cell) or HeLa (a cultured cell line). Organismsare further classified into multi-cell organisms,mono-cell organisms other than viruses, andviruses. Organism, tissue, cell, sub-locationsare interrelated with part-of relation but thatrelation is not shown in Figure 1. Based on thisdomain model, we annotate the names of pro-teins, DNAs, RNAs, and sources using the tagsshown in Table 1.
An example of an annotated text is shownin Figure 2: the UI number is a unique iden-tifier of the abstract in MEDLINE assigned by
1In Figure 1 the concepts represented in bold arereflected in the tag set and the concepts represented initalic are reflected in the attributes.

other
peptide
amino acid monomer
nucleic
RNA
DNA
nucleic acid monomer
other polymer of nucleic acid
DNA family/group
DNA molecule
domain/region of DNA
RNA family/group
RNA molecule
domain/region of RNA
substance amino PROTEIN protein family/group
protein complex
protein molecule
protein substructure
subunit of protein complex
domain/region of protein
SOURCE organism
sub-location of cells
multi-cell organism
mono-cell organism
virus
natural
tissue
cell type
cultured cell line
Figure 1: The taxonomy used as a domainmodel of our tagging scheme
Table 1: Tags and their target objectstag object<PROTEIN> the names of proteins, in-
cluding protein groups, fam-ilies, molecules, complexes,and substructures
<DNA> the names of DNAs, includingDNA molecules, DNA groups,DNA regions, and genes
<RNA> the names of RNAs, includingDNA molecules, RNA groups,RNA regions, and genes
<SOURCE> the sources of substances, i.e.,the names of organisms, tis-sues, cells, sub-locations ofcells, and cell lines
the National Library of Medicine, TI is the ti-tle, and AB is the abstract text. The unsure
attribute shown in the text is optional. This isused when annotators are unsure about whethera name should be tagged or whether the bound-ary of the tagged name is correct, and when theannotator was sure about the instance of themarkup, unsure attribute can be omitted (orcan be assigned the value ok).
3 Tagging Task
Before beginning the tagging process we madea preliminary experiment by tagging 100 ab-
UI - 91012785
TI - <PROTEIN unsure=ok>Lymphotoxin</PROTEIN>
activation by <SOURCE subtype=cl unsure=ok>human
T-cell leukemia virus type I-infected cell
lines</SOURCE>: role for <PROTEIN unsure=ok>NF-kappa
B</PROTEIN>. AB - <SOURCE subtype=cl
unsure=ok>Human T-cell leukemia virus type
I (HTLV-I)-infected T-cell lines</SOURCE>
constitutively produce high levels of biologically
active <PROTEIN unsure=ok>lymphotoxin</PROTEIN>
(<PROTEIN unsure=ok>LT</PROTEIN>; <PROTEIN
unsure=ok>tumor necrosis factor-beta</PROTEIN>)
protein and <RNA unsure=ok>LT mRNA</RNA>.
To understand the regulation of <PROTEIN
unsure=ok>LT</PROTEIN> transcription by <SOURCE
subtype=vi unsure=ok>HTLV-I</SOURCE>, we analyzed
the ability of a series of deletions of the
<DNA unsure=ok>LT promoter</DNA> to drive the
<DNA unsure=ok>chloramphenicol acetyltransferase
(CAT) reporter gene</DNA> in <SOURCE subtype=cl
unsure=ok>HTLV-I-positive MT-2 cells</SOURCE>. The
smallest <DNA unsure=ok>LT promoter fragment</DNA>
(-140 to +77) that was able to drive CAT activity
contained a site that was similar to the <DNA
unsure=ok>immunoglobulin kappa-chain NF-kappa
B-binding site</DNA>.
Figure 2: Example of Annotated Text
stracts. The abstracts were 116 words long onaverage. One of the authors, who has a doctor-ate in molecular biology, manually tagged theabstracts. The process took about 40 hours.2125 proteins, 358 DNAs, 30 RNAs, and 801SOURCEs are tagged.
Ten abstracts out of the 100 were randomlychosen and three other volunteers, two medicalscience researchers and one biology researcher,were asked to annotate them with our taggingscheme. We gave a brief explanation on the tag-ging task and scheme to each annotator. Theannotators were asked to annotate the text in-dependently in one weeks’ time.
After the annotation was done, we sent aquestionnaire to annotators to ask for their com-ments on the tagging task and the guide. Fromthe feedback of the questionnaire, we learnedthat the annotators felt the task to be relativelyeasy, but there are several cases where the theywere unsure about which tags to be assignedwhere. The cases include:
• where two or more names are conjoinedwith and or or, e.g., IRF-1 mRNA and
protein
• the ambiguity in some papers concerning

Table 2: The percentage of inter-annotator agreement on 10 abstracts
T1 T2 T3 T4 T5 T6 T7 T8 T9 T10 MeanA0-A1 100.00 69.05 38.18 82.76 69.81 83.87 74.07 83.33 88.31 91.67 77.29A0-A2 100.00 60.98 66.13 67.65 80.49 72.31 72.73 90.11 84.21 71.43 76.78A0-A3 95.24 59.09 57.63 96.55 86.05 83.82 69.64 79.55 85.71 84.91 78.44A1-A2 100.00 83.78 41.18 60.61 62.00 67.21 83.02 77.65 80.82 78.72 72.55A1-A3 95.24 52.50 66.67 78.57 61.54 76.56 77.78 70.73 79.73 76.47 72.76A2-A3 95.24 51.28 47.27 63.64 85.00 76.12 85.45 82.02 83.56 65.38 73.85Mean 97.62 62.78 52.84 74.96 74.15 76.65 77.16 80.57 83.72 78.10 75.85
whether names denote DNAs, RNAs orproteins,
The annotators also said that the concrete ex-ample of tagged texts are more useful thandescriptions and more examples should be in-cluded in the manual.
Two-way agreement rate is scored accord-ing to the scheme used in MUC confer-ences(Chincor, 1998b). This scoring schemeuses the F -measure derived from recall and pre-cision. Recall R and precision P are given by:
R = |X ∩ Y |/|X| (1)
and
P = |X ∩ Y |/|Y | (2)
where X is the set of ‘correct’ objects and Y isthe set of ‘retrieved’ objects. The F -measure isthe harmonic mean of R and P given by
F = 1/(1/P + 1/R) = 2 × |X ∩ Y |/(|X |+ |Y |)(3)
and this F can be used to measure the agree-ment of two sets of objects neither of which areconsidered ‘correct’ (note that F is symmetricwith regards to X and Y ).
The F -measures multiplied by 100 to showthe percentage of the agreement between anno-tators for the 10 abstracts are shown in Table 2.In Table 2, T1, ..., T10 denotes the abstractsand A0, ..., A3 denotes annotators. The ta-ble shows that the agreement rate, comparableto man-machine agreement of systems partici-pated in MUC, is not good for inter-annotatoragreement rate. The disagreement indicate thatthere are several problems in the definition ofthe target and the description in the manual,
some of which seem to be specific to this do-main2.
We investigate into the case of disagreementby aligning the tagged text and examining thedisagreed parts by hand. We found that the dis-agreement could be classified into several pat-terns enlisted below. The numbers in the paren-theses in the items are the number of the occur-rence of the disagreement in total 10 texts. SeeTable 3 for examples3.
Division (27): The cases where a same partof a text is tagged as one by some annotatorsbut divided into two (or more) parts by others.They were further classified into the followingcases.
D-1 (13) parenthesized abbreviations, fullforms, and synonyms
D-2 (3) appositive phrasesD-3 (6) names of a substance which includes
SOURCE namesD-4 (2) names of a complexD-5 (3) conjoined names
Part (60): The cases where a part of phrasesis included between <TAG> and </TAG> by someannotators but not by others. They were fur-ther classified into the following cases.
P-1 (30) the cases where the substances des-ignated by the tagged part are changed bywhether the words following a name aretagged together or not: in 10 cases, dif-ferent tags are used by the annotators; in
2Though it may not be directly compared, inter-annotator agreement for the judgment set of IREXconference on Japanese information extraction(Sekine,1999) is reported to be around 97% in F-measure.
3Attributes are omitted in the examples.

Table 3: Examples of disagreement
Cases Examples
D-1 <SOURCE>Mycobacterium avium complex (MAC)</SOURCE><SOURCE>Mycobacterium avium complex</SOURCE> (<SOURCE>MAC</SOURCE>)
D-2 <SOURCE>U937, a human monocytoid cell line</SOURCE><SOURCE>U937</SOURCE>, <SOURCE>a human monocytoid cell line</SOURCE>
D-3 <PROTEIN>Human erythroid 5-aminolevulinate synthase</PROTEIN><SOURCE>Human erythroid</SOURCE> <PROTEIN>5-aminolevulinatesynthase</PROTEIN>
D-4 <PROTEIN>p50-p65</PROTEIN><PROTEIN>p50</PROTEIN>-<PROTEIN>p65</PROTEIN>
D-5 <RNA>ferritin or transferritin receptor mRNAs</RNA><PROTEIN>ferritin</PROTEIN> or <RNA>transferritin receptor mRNAs</RNA>
P-1(differenttags)
<DNA>AP-2 consensus binding sequences</DNA><PROTEIN>AP-2</PROTEIN> consensus binding sequences
P-1(same tags)
<PROTEIN>IRF-2 repressor</PROTEIN><PROTEIN>IRF-2</PROTEIN> repressor
P-2 <PROTEIN>Stat91 protein </PROTEIN><PROTEIN>Stat91</PROTEIN> protein
P-3 <RNA>housekeeping ALAS mRNA</RNA>housekeeping <RNA>ALAS mRNA</RNA>
P-4 <PROTEIN>transcription factor AP-2</PROTEIN>transcription factor <PROTEIN>AP-2</PROTEIN>
P-5 <DNA>the terminal protein 1 gene promoter</DNA>the <DNA>terminal protein 1 gene promoter</DNA>
Class <RNA>TAR</RNA><DNA>TAR</DNA>
Missing <DNA>21 bp repeats</DNA>21 bp repeats
the other 20 cases, the same tags are usedby the annotators.
P-2 (18) the cases where the substances des-ignated by the tagged part are not affectedby whether the words following a name aretagged together or not
P-3 (6) the preceding attributive phrase thatnarrows the meaning of the phrase
P-4 (5) the preceding appositive phraseP-5 (1) determiners
Class (19): The same part of text is taggedwith different tags
Missing (25): A part of text is tagged by someannotators but not by others
The result shows that most of disagreementinvolves recognizing the names, i.e., identifyingthe range of words in sentence that are part of
the names. On the other hand, there are rela-tively few cases where classification of the namesalone is the problem.
The disagreement involving abbreviation andsynonym (case D-1) will be simply solved byexplicitly giving an instruction as to whether afull form and its abbreviation (or a name and itssynonym) should be separated or not. The caseof appositives (cases D-2 and P-5) and deter-miners are also easy to solve by giving explicitinstruction, though the distinction between ap-positives or determiners and other attributivephrases (case P-4) must be carefully stated inthe instruction. The cases involving words thatfollow a name that do not affect the substancethe name designates (P-2) should be handledsimilarly with a careful description of such casesin the instruction.
The cases that involve the source names (caseD-3) and the following words that modify the

meaning of the phrase (P-1) are more difficult,because the names with or without the modi-fying phrases are recognized by the annotators.One solution would be to allow nesting tags, butthis might complicate the tagging scheme andbe the cause of another type of error. Simpleheuristics of ‘taking the longest phrase’ mightwork here, but in the case of preceding modi-fiers (P-3) the heuristic is not desirable, becausemost of the preceding modifiers are just descrip-tion of a characteristics of a substance.
The names tagged by some annotators butnot by others (case M) were mostly the termsthat describes the parts of a gene as in the ex-ample above, or the terms that denotes a familyor a class of substances. Such parts or familiesare considered to be the ‘substance’ by someannotators but not by others. Incorporatingthe distinction between families, individual sub-stances, and parts of the substance would helpto make the classification of names clearer andresult in more consistent annotation.
One of the difficulties of this task comparedto MUC named entity extraction is that ourtargets are inherently unique names of classes,whereas the targets of MUC named entity ex-traction are names of unique entities. Whenwe refer to a specific protein or DNA, we don’trefer to a specific molecule, but rather a classof molecules that have the same characteris-tics. As the name of a class, when a researcherfinds a new substance, the substance is oftennamed after the combination of its function, lo-cation, etc. For example, “B-cell specific tran-scription factor” is a name of a protein (thereis an entry in the SwissProt database). This re-sults in the difficulty of distinguishing the namesof substances from general description of thesubstance. In cases such as “Human erythroid5-aminolevulinate synthase”, some researchersrecognize it as a name but some only recog-nize “5-aminolevulinate synthase” as a nameand “Human erythroid” as just a descriptionand separate the part as different entity. Alsothe prenominal modifiers are recognized or notrecognized as a part of the name depending onwhether the names with or without the modify-ing phrases are recognized by the annotators.
The classification error, though relatively few,also might be from the nature of this domain.Most of the inconsistency are suspected to be
from conventional use of the protein names todenote the genes that transcribe the protein.For example, NF-kappa B gene is a name ofa gene that transcribe the protein NF-kappaB, and the authors often omit the word gene
where they think it is clear from the contextthat the particular occurrence of NF-kappa B
denotes the DNA. This require the annotatorsgood background knowledge and careful read-ing, and sometimes the cause of annotation er-rors. Even the participated annotators, who arequalified specialist of the domain, are sometimesunsure about the target, according to the ques-tionnaire. This might be resolved if the full pa-per could be referenced in the process of anno-tation.
4 Conclusion and Future Work
We are in the process of developing a high-quality tagging scheme for semantic annotationof substances and their sources which play animportant role in molecular-biology events. Wehave shown the results of initial inter-annotatoragreement tests using the current scheme. Af-ter the initial experiment, we revised the tag-ging manual to give more precise definitionsand more examples, and also added attributesto denote the distinction of whether the pro-tein (DNA, RNA) is a molecule, complex, sub-structure, region, etc. We tagged 500 abstractsaccording to the revised manual and tagging-scheme, which are in the process of cross-checking and cleaning up the errors. When theyare done we plan to make the corpus availableto the public along with the tagging manual.
Establishing the training process of annota-tors, including communication between anno-tators to get agreement on tagging strategies,which is reported to improve the agreement rate(Dan Melamed, 1998; Wiebe et al., 1999) shouldalso be necessary to help them make consist an-notation.
One of the concerns that we have is that ourtarget task is more difficult than the traditionalnamed entity recognition task, because of thenaming convention (or the lack of it) of themolecular-biology domain and because the taskrequires very precise knowledge of the special-ist. To solve this problem, tagging tools thatincorporates the reference function to the exter-nal sources such as substance databases, on-line

glossaries, and full-text of the paper should alsobe of great help.
The preliminary corpus, though it may be‘noisy’, can be useful as a training set for recog-nition program of biological names and terms.The preliminary corpus can also be used to gainthe knowledge of how the tagged names are re-lated to each other and other names, in orderto give feedback to the annotators and enhancethe domain model and enables us to annotatemore rich information such as biological roles.
References
P. G. Baker, C. A. Goble, S. Bechhofer, N. W.Paton, R. Stevens, and A. Brass. 1999.An ontology for bioinformatics applications.15:510–520.
C. Blaschke, M. A. Andrade, C. Ouzounis,and A. Valencia. 1999. Automatic extractionof biological information from scientific text:protein-protein interactions. In Proc. 7th In-
ternational conference on Intelligent Systems
for Molecular Biology, pages 60–67.R. Bruce and J. Wiebe. 1998. Word sense dis-
tinguishability and inter-coder agreement. InProc. 3rd Conference on Empirical Methods
in Natural Language Processing, pages 53–60.N. Chinchor. 1998. Overview of MUC-
7. In Proceedings of 7th Message Un-
derstanding Conference. available athttp://www.muc.saic.com/proceedings.
N. Chincor. 1998a. MUC-7 named en-tity task definition version 3.5. InProceedings of 7th Message Under-
standing Conference. available athttp://www.muc.saic.com/proceedings.
N. Chincor. 1998b. MUC-7 test scores in-troduction. In Proceedings of 7th Mes-
sage Understanding Conference. available athttp://www.muc.saic.com/proceedings.
I Dan Melamed. 1998. Manual annota-tion of translation equivalence:the blinkerproject. Technical Report IRCS-98-07, IRCS,University of Pennsylvania. available atftp://ftp.cis.upenn.edu/pub/ircs/tr/98-07/.
K. Fukuda, T. Tsunoda, A. Tamura, andT. Takagi. 1998. Towards information ex-traction: Identifying protein names from bi-ological papers. In Proc. 3rd Pacific Symoi-
sium of Biocomputing, pages 707–718.K. Hamphrays, G. Demetriou, and
R. Gaizauskas. 2000. Two applicationsof information extraction to biological sci-ence journal articles: Enzyme interactionsand protein structures. In Proc. 5th Pacific
Symoisium of Biocomputing, pages 72–80.C. Nobata, N. Collier, and J. Tsujii. 1999.
Automatic term identification and classifica-tion in biology texts. In Proc 5th Natural
Language Processing Pacific Rim Symoisium,pages 369–374.
Y. Ohta, Y. Yamamoto, T. Okazaki, andT. Takagi. 1997. Automatic construction ofknowledge base from biological papers. InProc. 5th International Conference on Intel-
ligent Systems for Molocular Biology, pages218–225.
D. Proux, F. Rechenmann, L. Julliard, V. Pillet,and B. Jacq. 1998. Detecting gene symbolsand names in biological texts: A first steptoward pertinent information extraction. InGenome Informatics, pages 72–80. UniversalAcademy Press.
T. C. Rindflesch, L. Tanabe, J. N. Weinstein,and L. Hunter. 2000. Edgar: Extraction ofdrugs, genes and relations from the biomedi-cal literature. In Proc. 5th Pacific Symposium
on Biocomputing, pages 514–525.S. Schulze-Kremer. 1998. Ontologies for molec-
ular biology. In Proc. 3rd Pacific Symposium
on Biocomputing, pages 695–706.T. Sekimizu, H. S. Park, and J. Tsujii. 1998.
Identifying the interaction between genes andgene products based on frequently seen verbsin MEDLINE abstracts. In Genome In-
formatics, pages 62–71. Universal AcademyPress.
S. Sekine. 1999. Analysis of the answerof named entity extraction. In Proceedings
of the IREX workshop, pages 129–132. inJapanese.
J. Thomas, D. Milward, C. Ouzounis, S. Pul-man, and M. Carroll. 2000. Automatic ex-traction of protein interactions from scientificabstracts. In Proc. 5th Pacific Symposium onBiocomputing, pages 538–549.
J. Wiebe, R. Bruce, and T. O’Hara. 1999. De-velopment and use of a gold standard data setfor subjectivity classifications. In Proceedings
of the 37th Meeting of ACL, pages 246–253.

35
SECTION 2
Semantic Annotation of Discourse Structure

36

Semantic Annotation for Generation: Issues in annotating a corpus todevelop and evaluate discourse entity realization algorithms
Massimo PoesioUniversity of Edinburgh
HCRC and Informatics�Massimo.Poesio � @ed.ac.uk
Abstract
We are annotating a corpus with information rele-vant to discourse entity realization, and especiallythe information needed to decide which type of NP
to use. The corpus is being used to study correla-tions between NP type and certain semantic or dis-course features, to evaluate hand-coded algorithms,and to train statistical models. We report on the de-velopment of our annotation scheme, the problemswe have encountered, and the results obtained sofar.
1 MOTIVATIONS
The goal of the GNOME project is to develop NP
generation algorithms that can be used by real sys-tems, with different architectures, and operating inrealistic domains. As part of the project, we havebeen annotating a corpus with the syntactic, seman-tic and discourse information that is needed for dif-ferent subtasks of NP realization, including the taskof deciding on the most appropriate NP type to beused to realize a certain discourse entity (propername, definite description, pronoun, etc.), and thetask of organizing the additional information to beexpressed with that discourse entity. We are usingthe annotated corpus to extract information useful tothe development of hand-coded algorithms for thesubtasks of NP realization we are focusing on, todevelop statistical models of these subtasks, and toevaluate both types of algorithms. Conversely, wehave been using the results of this evaluation to ver-ify the completeness of our annotation scheme andto identify modifications. The annotation schemeused in our first corpus annotation exercise was dis-cussed in (Poesio et al., 1999b); in this paper wepresent the modified annotation scheme that we de-veloped as a result of that preliminary work, anddiscuss the problems we encountered when tryingto annotate semantic and discourse information.
2 APPLICATIONS AND DATA
The systems we are working with are the ILEX sys-tem developed at HCRC, University of Edinburgh(Oberlander et al., 1998),1 and the ICONOCLAST
system (Scott et al., 1998), developed at ITRI, Uni-versity of Brighton. The ILEX system generatesWeb pages describing museum objects on the ba-sis of the perceived status of its user’s knowledgeand of the objects she previously looked at; ICON-OCLAST supports the creation of pharmaceuticalleaflets by means of the WYSIWYM technique inwhich text generation and user input are interleaved.
The corpus we have collected for GNOME in-cludes texts from both the domains we are studying.It contains texts in the museum domain, extendingthe corpus collected by the SOLE project (Hitzemanet al., 1998); and texts from the corpus of patientinformation leaflets collected for the ICONOCLAST
project. The initial GNOME corpus (Poesio et al.,1999b) consisted of two subsets of about 1,500 NPseach; since then, the corpus has been extended andcurrently includes about 3,000 NPs in each domain.We are also adding texts from a third domain, tuto-rial dialogues.
3 DEVELOPING A SCHEME FOR NPREALIZATION
The traditional approach to surface realization inNLG (as exemplified, say, by NIGEL / KPML (Hen-schel et al., 1999)) assumes (systemic functional)grammars that make decisions on the basis of theanswer to queries asked to the knowledge base anddiscourse model. Typical examples of such queriesare:
� whether a given discourse entity is IDENTIFI-ABLE;
1The latest version of the system can be found athttp://www.cstr.ed.ac.uk/cgi-bin/ilex.cgi.

� whether the object denoted is GENERIC or not;� whether that entity is IN FOCUS, or more gen-
erally what is its ACCESSIBILITY (Gundel etal., 1993)
� what is the ONTOLOGICAL STATUS of the ob-ject, i.e., its position in a taxonomy.
These systems have typically been used only bytheir developers, or by researchers working in closecollaboration with them. In order to make themmore generally usable, three questions have to beaddressed. The first question is whether anybodyother than the developers of these grammars can un-derstand queries such as those just listed enough toimplement them in their systems. The second iswhether real systems have enough information toanswer these queries, or whether instead approxi-mations have to be implemented. The final questionis how well the implementation is going to perform,especially if only approximations are implemented.
In GNOME we have been studying these questionsby means of corpus annotation studies. We havebeen trying to identify which of the queries used bysystems such as KPML for NP realization can be gen-erally understood by asking subjects to annotate theNPs in our corpus with the information needed to an-swer these queries, and we have then used the result-ing annotation to train statistical models to evaluatethe completeness of a given set of features. Weuse to measure agreement the K statistic discussedby Carletta (1996). A value of K between .8 and 1indicates good agreement; a value between .6 and .8indicates some agreement.
4 SEMANTIC AND DISCOURSEFEATURES THAT MAY AFFECT NPTYPE DETERMINATION
Even if in this first phase we focused on realiz-ing discourse entities only, we still need to knowfor each NP in the corpus its semantic type. Nounphrases appear in a text as the realization of at leastthree different types of logical form constituents:
� terms, which include referring expressions, asin Jessie M. King or the hour pieces here , butalso non-referring terms such as jewelry or dif-ferent types of creative work. Terms are calledDISCOURSE ENTITIES in Discourse Represen-tation Theory.
� quantifiers, as in quite a lot of different typesof creative work or nearly every day
� nominal predicates, such as an illustrator inShe was an illustrator.
Noun phrases can be coordinated, as in The patchesalso contain oestradiol and norethisterone acetateor the inventory givesneither the name of the maker nor its original location;we finesse the many issues raised by coordinationby assuming a fourth type of logical form objects,coordinations.
Two features generally acknowledged to play animportant role in determining the type of the NP tobe used to realize a discourse entity are COUNT-ABILITY and GENERICITY. These features are es-pecially important when bare-NPs are going to beused. One of the conditions under which (singu-lar) bare NPs are used is when the object denotedis mass (cfr. *a gold/a jewel vs. gold/*jewel); theother is when the NP is used to express a generic ref-erence, as in The cabinets de curiosites containednatural specimens such as shells and fossils.
Much work on NP generation has been devotedto studying the discourse factors that determinewhether a given discourse entity should be real-ized by a definite or an indefinite NP (Prince, 1992;Loebner, 1987; Gundel et al., 1993). Among thediscourse properties of a discourse entity claimed toaffect its form are
� Whether it is discourse new or old (Prince,1992): e.g., a new jewel would be introducedby means of the indefinite a jewel, whereas foran already mentioned one the definite descrip-tion the jewel would be used. This simple no-tion of familiarity was refined by Prince herselfas well by Gundel et al. (Gundel et al., 1993).
� Whether it’s hearer-new or hearer-old (Prince,1992).
� Whether it is referring to an object in the visualsituation or not: if so, a demonstrative NP maybe used, as in this jewel.
� Whether it’s currently highly salient or not,which may prompt the use of a pronoun. Prop-erties that have been claimed to affect thesalience of a discourse entity include: whetherit’s the current CENTER (CB) or not (Grosz etal., 1995), or more generally whether that en-tity is the TOPIC of the current discourse (Rein-hart, 1981; Garrod and Sanford, 1983); itsgrammatical function; whether it’s animated or

not; its role; its proximity. (For a discussion ofthe effect of these and other factors on saliencesee (Poesio and Stevenson, To appear)).
According to Loebner (Loebner, 1987), the distin-guishing property of definites is not familiarity (adiscourse notion), but whether or not the predicatedenoted by the head noun is functional or, more gen-erally, UNIQUE. This seems to be the closest formalspecification of the notion of ‘identifiability’ used inKPML.
5 THE ANNOTATION SCHEMEOur first scheme, and the results we obtained withit, are discussed in (Poesio et al., 1999b). We arecurrently in the process of reannotating the corpusfrom scratch according to a new annotation schemedeveloped to address the limitations of the schemediscussed there (reliability and/or incompleteness ofinformation). The new scheme also includes infor-mation to study another aspect of NP realization,NP modification; this aspect of the new annotationwon’t be discussed here. For reasons of space, onlya brief discussion is possible - in particular, wewon’t be able to discuss in detail the instructionsgiven to annotators; the complete instructions areavailable at http://www.hcrc.ed.ac.uk/
�gnome/anno manual.html.
Markup LanguageOur annotation scheme is XML-based. The basis forour annotation are a rather minimal set of layouttags, identifying the main divisions of texts, theirtitles, figures, paragraphs, and lists. Also, as a resultof the reliability studies discussed below and of ourfirst annotation effort, we decided to also mark upunits of text that may correspond to rhetorical unitsin our second annotation, using the tag
�unit � .
An important feature of the scheme is that the in-formation about NPs is split among two XML ele-ments, as in the MATE scheme for coreference (Poe-sio et al., 1999a). Each NP in the text is tagged withan
�ne � tag, as follows:
(1) <ne ID="ne07" ... >Scottish-born, Canadian based jew-eller,Alison Bailey-Smith</ne>...<ne ID="ne08"> <ne ID="ne09">Her</ne>materials</ne>
the instructions for identifying the�ne � markables
are derived from those proposed in the MATE project
scheme for annotating anaphoric relations (Poesioet al., 1999a), which in turn were derived from thoseproposed by Passonneau (Passonneau, 1997) and inMUC-7 (Chinchor and Sundheim, 1995).
Anaphoric relations are annotated by means ofa separate
�ante � element specifying relations be-
tween�ne � s, also as proposed in MATE. An
�ante �
element includes one or more�anchor � element,
one for each plausible antecedent of the current dis-course entity (in this way, ambiguous cases can bemarked). E.g., the anaphoric relation in (1) betweenthe possessive pronoun with ID ="ne09" and theproper name with ID ="ne07" is marked as fol-lows:
(2) <ante current="ne09"><anchor ID="ne07" rel="ident" ... >
</ante>
(Discourse) Units
One difference between the annotation scheme weare using and the one discussed in (Poesio et al.,1999b) is that the problems we encountered try-ing to annotate centering information, proximity,and grammatical function (see also below) led usto mark up sentences and potential rhetorical units /centering theory utterances before marking up cer-tain types of information about NPs such as gram-matical function. The instructions for marking upunits were in part derived from (Marcu, 1999); foreach
�unit � , the following attributes were marked:
� utype: whether the unit is a main clause, a rel-ative clause, appositive, a parenthetical, etc.
� verbed: whether the unit contains a verb ornot.
� finite: for verbed units, whether the verb is fi-nite or not.
� subject: for verbed units, whether they have afull subject, an empty subject (expletive, as inthere sentences), or no subject (e.g., for infini-tival clauses).
The agreement on identifying the boundaries ofunits was K = .9; the agreement on features was fol-lows:
Attribute K Valueutype .76
verbed .9finite .81
subject .86

This part of the annotation has now been completed.The main difficulties we observed had to do with as-signing an utterance type to parenthetical sentences.
NEsAfter marking up units as discussed above, allNPs are marked up, together with a number of at-tributes. During our first round of experimentationwe found that marking ‘topics’ in general was toodifficult (K=.37), as was marking up thematic roles(K=.42); so although we haven’t completely aban-doned the idea of trying to annotate this informa-tion, in this second round we concentrated on im-proving the reliability for the other attributes. Afew other attributes used in the previous schemewere dropped because they could be inferred auto-matically: among these are the feature disc speci-fying whether the discourse entity is discourse-newor discourse-old (redundant once antecedent infor-mation was marked up) and the feature cb usedto mark whether the discourse entity is the currentCB (Grosz et al., 1995) (which could be automati-cally derived from the information about grammat-ical function and units). We separated off informa-tion about the logical form type of an NP (quantifier,term, etc) from the information about genericity. Fi-nally, new attributes were introduced to specify in-formation which we found missing on the basis ofour first evaluation: in particular, we decided to an-notate information about the abstractness or con-creteness of an object, and about its semantic plu-rality or atomicity. The revised list of informationannotated for each NP includes:
� The output feature, cat, indicating the type ofNP (e.g., bare-np, the-np, a-np).
� The other ‘basic’ syntactic features, num, per,and gen (for GENder).
� A feature gf specifying its grammatical func-tion;
� The following semantic attributes:
– ani: whether the object denoted is ani-mate or inanimate
– count: whether the object denoted ismass or count
– lftype: one ofquant,term,pred,coord
– generic: whether the object denoted is ageneric or specific reference
– onto: whether the object denoted is con-crete, an event, a temporal reference, oranother abstract object
– structure: whether the object denoted isatomic or not
� The following discourse attributes:
– deix: whether the object is a deictic refer-ence or not
– loeb: whether the description used allowsthe reader to characterize the object asfunctional in the sense of Loebner (i.e.,whether it denotes a single object, as inthe moon, or at least a functional concept,like father)
A number of NP properties (e.g., familiarity) can bederived from the annotation of anaphoric informa-tion (below); in addition, a few properties of NPsare automatically derived from other sources of in-formation - e.g., the type of layout element in whichthe NP occurs (in titles, bare-nps are often used) andwhether a particular NP has uniquely distinguishingsyntactic features in a given unit. All of these fea-tures can be annotated reliably, except for generic-ity; the results that we do have are as follows:
Attribute K Valuecat .9gen .89num .84per .9gf .85ani .91
count .86lftype .82onto .80
structure .82deix .81loeb .80
(One interesting point to note here is that agreementon lftype is actually quite high (90%), but becauseTERMs are so prevalent, chance agreement is alsovery high.)
We should point out that even though we reacheda good level of agreement on all of these features,not in all cases it was easy to do so. The only fea-tures that are truly easy to annotate are NP type, per-son, and animacy. Good instructions are needed forgender, number, logical form, multiplicity, deixis,and uniqueness–e.g., for the case of gender one has

to decide what to do with second person pronounssuch as you, and for deixis the instructions haveto specify what to do with objects that are not inthe picture although appear to be visible. Finally,the count/mass distinction proved to be very diffi-cult, as did the abstract / concrete distinction (e.g.,are diseases abstract or concrete?). We did intro-duce a number of ‘underspecified’ values, but thisdid not lead to results as good as including in theinstructions a number of examples (which suggestsour scheme may not transport well to other applica-tions).
Antecedent InformationPrevious work, particularly in the context of theMUC initiative, suggested that while it’s fairly easyto achieve agreement on identity relations, markingup bridging references is quite hard; this was con-firmed, e.g., by (Poesio and Vieira, 1998). The onlyway to achieve a reasonable agreement on this typeof annotation, and to contain somehow the annota-tors’ work, is to limit the types of relations anno-tators are supposed to mark up, and specify prior-ities. We are currently experimenting with mark-ing up only four types of relations, a subset ofthose proposed in the ‘extended relations’ versionof the MATE scheme (Poesio et al., 1999a) (which,in turn, derived from Passonneau’s DRAMA scheme(Passonneau, 1997): identity (IDENT), set member-ship (ELEMENT), subset (SUBSET), and ‘general-ized possession’, including part-of relations.
In addition, given our interests we had to bequite strict about the choice of antecedent: whereasin MUC it is perfectly acceptable to mark an ‘an-tecedent’ which follows a given anaphoric expres-sion, in order, e.g., to compute the CB of an utter-ance it is necessary to identify the closest previousantecedent.
As expected, we are achieving a rather goodagreement on identity relations. In our most recentanalysis (two annotators looking at the anaphoric re-lations between 200 NPs) we observed no real dis-agreements; 79.4% of these relations were markedup by both annotators; 12.8% by only one of them;and in 7.7% of the cases, one of the annotatorsmarked up a closer antecedent than the other. Onthe other hand, only 22% of bridging referenceswere marked in the same way by both annotators;although our current scheme does limit the disagree-ments on antecedents and relations (only 4.8% rela-tions are actually marked differently) we still findthat 73.17% of relations are marked by only one or
the other annotator.
6 EVALUATION
In order to evaluate the complenetess of ourschemes, we have been using the corpus annotatedwith the reliable features to build statistical modelsof the process of NP type determination - i.e., theprocess by which the value of cat is chosen on thebasis of the values of the other features. We triedboth the Maximum Entropy model (Berger et al.,1996) as implemented by Mikheev (Mikheev, 1998)and the CART model of decision tree construction(Breiman et al., 1984); the results below were ob-tained using CART. The models are evaluated bycomparing the label it predicted on the basis of thefeatures of a given NP with the actual value of catfor that NP, performing a 10-fold cross-validation.
The models discussed in (Poesio et al., 1999b)achieved a 70% accuracy, against a baseline of 22%(if the most common category, BARE-NP, is chosenevery time.), training on a corpus of 3000 NPs. Weare still in the process of evaluating the models builtusing our second corpus, but partial tests (trainedon about 1,000 NPs) suggest that the using the newannotation scheme an accuracy of about 80% can beachieved.
The most complex problem to fix is that ofTHIS-NPs. The reason for the misclassification isthat THIS-NPs are used in our texts not only to re-fer to pictures or parts of them, but also to refer toabstract objects introduced by the text, as in the fol-lowing examples:
(3) a. A great refinement among armorialsignets was to reproduce not onlythe coat-of-arms but the correct tinc-tures; they were repeated in colouron the reverse side and the crystalwould then be set in the gold bezel.Although the engraved surface couldbe used for impressions, the colourswould not wear away. The signet-ringof Mary, Queen of Scots (beheaded in1587) is probably the most interestingexample of this type;
b. The upright secretaire began to bea fashionable form around the mid-1700s, when letter-writing became apopular past-time. The marchands-merciers were quick to respond tothis demand,

The problem is that such references are difficult toannotate reliably.
7 DISCUSSION
There are some pretty obvious omissions in thework done so far. Even if we only consider the taskof NP type determination, there are a number of fea-tures whose impact we haven’t been able to studyso far, in some cases because they proved very hardto annotate. We already discussed two such exam-ples, topichood and thematic roles; another poten-tially important source of information about the de-cision to pronominalize, rhetorical structure, is evenharder to annotate. We would like to be able to an-notate some types of scoping relations as well, es-pecially the cases in which an NP is in the scopeof negation as this may license the use of polarity-sensitive items such as any. Another important fac-tor is the role of the information which the text plan-ner has decided to realize: e.g., once the text plannerhas decided to generate both the proper name of dis-course entity � , Alphonse Mucha, and the fact that �
is a Czech painter, the decision to use the THE-NPthe Czech painter Alphonse Mucha is more or lessforced on us. And of course, nothing in the schemediscussed above allows us to study the conditionsunder which a generator may decide to produce aquantifier or a coordinated NPs.
Among the issues raised by this work, an im-portant one is how much of the information thatwe annotated by hand could be automatically ex-tracted. We believe that a lot of the syntactic in-formation we rely on (
�unit � and
�ne � identifica-
tion,�unit � attributes, basic syntactic attributes of�
ne � ) could be extracted automatically using recentadvances in robust parsing; this would already cutdown the amount of work considerably. The prob-lem is what to do with semantic information: e.g.,whether suitable approximations could be found.
Another important question is whether our char-acterization of NP realization is plausible. One pos-sible objection is that NP type determination goeshand-in-hand with content determination, and thetwo problems can only be attacked simultaneously.The problem with this type of objection is that it’svery difficult to study content determination. Thisis because of a more general problem with themethodology we are using: there is a mismatch be-tween what a system knows and what an annotatormay know about an object–i.e., between the featuresthat a generation system may use and the features
that can be annotated, and it’s not clear this mis-match can be resolved.
For one thing, the need to choose features that canbe annotated reliably imposes serious constraints:features that a generation system can easily set upby itself (e.g., the ILEX system keeps track of whatit thinks the current topic is) can be difficult for twoannotators to annotate in the same way. Second,some information that a generation system can usewhen deciding on the type of NP to generate maysimply be impossible to annotate. For example, wealready seen that the form of an NP often depends onhow much information the system intends to com-municate to the user about a given entity, or howmuch information the system believes the user has.In order to build a model of this decision process,we would need to specify for each NP how much in-formation it conveys, and of what type; it’s not atall clear that it will be feasible to do this by hand,except in domains in which the annotator knows ev-erything that there is to know about a given object(see, e.g., Jordan’s work on the COCONUT domain(Jordan, 1999)).
Conversely, some information that can be anno-tated - indeed, that is easy to annotate - may not beavailable to some systems. E.g., we do not knowof any system with a lexicon rich enough to spec-ify whether a given entry is functional or not. Asolution in this case may be to develop algorithmsto extract this information from an annotated cor-pus, or perhaps just using the syntactic distributionof the predicate as an indication (e.g., a predicate Xoccurring in a the X of Y construction may be func-tional).
In other words, we believe that the present workis only a first step towards developing an appropriatemethodology for empirical investigation and evalu-ation of generation algorithms, which we neverthe-less feel will become more and more necessary. Butwe believe that, already, this type of work can raisea number of interesting issues concerning semanticannotation and agreement on semantic judgments,which we hope to discuss at the workshop.
Acknowledgments
I wish to thank the other members of the GNOME
project, without whom this work would not havebeen possible– in particular Hua Cheng, Kees vanDeemter, Barbara di Eugenio, Renate Henschel,Rodger Kibble, and Rosemary Stevenson. The cor-pus is being annotated by Debbie De Jongh, Ben

Donaldson, Marisa Flecha-Garcia, Camilla Fraser,Michael Green, Shane Montague, Carol Rennie,and Claire Thomson. I also wish to thank JanetHitzeman, Pam Jordan, Alistair Knott, Chris Mel-lish, Johanna Moore, and Jon Oberlander. TheGNOME project is supported by the UK ResearchCouncil EPSRC, GR/L51126. Massimo Poesio issupported by an EPSRC Advanced Research Fel-lowship.
ReferencesA. Berger, S. Della Pietra, and V. Della Pietra. 1996. A
maximum entropy approach to natural language pro-cessing. Computational Linguistics, 22(1):39–72.
L. Breiman, J. H. Friedman, R. A Olshen, and C. J.Stone. 1984. Classification and Regression Trees.Chapman and Hall.
J. Carletta. 1996. Assessing agreement on classificationtasks: the kappa statistic. Computational Linguistics,22(2):249–254.
N. A. Chinchor and B. Sundheim. 1995. Message Un-derstanding Conference (MUC) tests of discourse pro-cessing. In Proc. AAAI Spring Symposium on Empiri-cal Methods in Discourse Interpretation and Genera-tion, pages 21–26, Stanford.
S. C. Garrod and A. J. Sanford. 1983. Topic dependenteffects in language processing. In G. B. Flores D’Ar-cais and R. Jarvella, editors, The Process of LanguageComprehension, pages 271–295. Wiley, Chichester.
B. J. Grosz, A. K. Joshi, and S. Weinstein. 1995. Cen-tering: A framework for modeling the local coherenceof discourse. Computational Linguistics, 21(2):202–225. (The paper originally appeared as an unpub-lished manuscript in 1986.).
J. K. Gundel, N. Hedberg, and R. Zacharski. 1993. Cog-nitive status and the form of referring expressions indiscourse. Language, 69(2):274–307.
R. Henschel, J. Bateman, and C. Matthiessen. 1999. Thesolved part of NP generation. In R. Kibble and K. vanDeemter, editors, Proc. of the ESSLLI Workshop onGenerating Nominals, Utrecht.
J. Hitzeman, A. Black, P. Taylor, C. Mellish, and J. Ober-lander. 1998. On the use of automatically generateddiscourse-level information in a concept-to-speechsynthesis system. In Proc. of the International Con-ference on Spoken Language Processing (ICSLP98),,page Paper 591, Australia.
P. Jordan. 1999. An empirical study of the communica-tive goals impacting nominal expressions. In R. Kib-ble and K. van Deemter, editors, Proc. of the ESSLLIworkshop on The Generation of Nominal Expressions,Utrecht. University of Utrecht, OTS.
S. Loebner. 1987. Definites. Journal of Semantics,4:279–326.
D. Marcu. 1999. Instructions for manually annotat-
ing the discourse structures of texts. Unpublishedmanuscript, USC/ISI, May.
A. Mikheev. 1998. Feature lattices for maximum en-tropy modeling. In Proc. of ACL-COLING, pages845–848, Montreal, CA.
J. Oberlander, M. O’Donnell, A. Knott, and C. Mellish.1998. Conversation in the museum: Experiments indynamic hypermedia with the intelligent labelling ex-plorer. New Review of Hypermedia and Multimedia,4:11–32.
R. Passonneau and D. Litman. 1993. Feasibility of auto-mated discourse segmentation. In Proceedings of 31stAnnual Meeting of the ACL.
R. Passonneau. 1997. Instructions for applying dis-course reference annotation for multiple applications(DRAMA). Unpublished manuscript., December.
R. Passonneau. 1998. Interaction of discourse structurewith explicitness of discourse anaphoric noun phrases.In M. A. Walker, A. K. Joshi, and E. F. Prince, editors,Centering Theory in Discourse, chapter 17, pages327–358. Oxford University Press.
M. Poesio and R. Stevenson. To appear. Salience: Com-putational Models and Psychological Evidence. Cam-bridge University Press, Cambridge and New York.
M. Poesio and R. Vieira. 1998. A corpus-based investi-gation of definite description use. Computational Lin-guistics, 24(2):183–216, June. Also available as Re-search Paper CCS-RP-71, Centre for Cognitive Sci-ence.
M. Poesio, F. Bruneseaux, and L. Romary. 1999a. TheMATE meta-scheme for coreference in dialogues inmultiple languages. In M. Walker, editor, Proc. of theACL Workshop on Standards and Tools for DiscourseTagging, pages 65–74.
M. Poesio, R. Henschel, J. Hitzeman, R. Kibble, S. Mon-tague, and K. van Deemter. 1999b. Towards anannotation scheme for Noun Phrase generation. InB. Krenn H. Uszkoreit, T. Brants, editor, Proc. of theEACL workshop on Linguistically Interpreted Cor-pora (LINC-99).
E. F. Prince. 1992. The ZPG letter: subjects, def-initeness, and information status. In S. Thompsonand W. Mann, editors, Discourse description: diverseanalyses of a fund-raising text, pages 295–325. JohnBenjamins.
T. Reinhart. 1981. Pragmatics and linguistics: An analy-sis of sentence topics. Philosophica, 27(1). Also dis-tributed by Indiana University Linguistics Club.
D. Scott, R. Power, and R. Evans. 1998. Generation as asolution to its own problem. In Proc. of the 9th Inter-national Workshop on Natural Language Generation,Niagara-on-the-Lake, CA.

����������� ����������������������� ��� ���!�#"%$��'&(��)!*���+���,$-*�)+�'&.�/�102�' �3 ���#��*��#&4�� ��� 56��879�� �
:�;=<?>A@B;/CED(F(D ;HG2DIJ�JLK�MONPN2Q�R�SUTWVYXZS[MOR�\]T^S[_`R�T^_9a'VcbAMOdeVYXZMOdZSU_^f
gihkjPl S[m?Vcd!S[n VYSpo(\q_^SUmYV h Tsr�M�o \qMOQ�dZVcmtQ hvu Q(Rwo8x#yOMcXZM{zq|~} h��Ogc����� Vc� VYR� �c�(���~�������t�����Y���p�(���������]�]���Z�t�����Y�
�����`� <iD � � ¢¡t£¥¤�¦]§W¦�¨s©�¦t©�ª~¦�ªi¤v¨�¤§«¦t©!§~¬e�£®¬s§~¯�£®°Yv¨s±~©+§Wv¨�²E¨�°O³´ £µ©�ªi°t¶�¨�°Y�·[ª~©�¨e¸cv©!§~¬e�£®°�±#©+¹t¯µ¨�¤�·[ª~©º�¡t¨�§~°t§W¦q¡�ª~©+§©�¨�¤vªi¯¥¹��£µªi°»ª~·�¼s¨s©�ª1¦t©�ªi°tªi¹t°t¤½·[©�ªi¶¾¶�ªi°�ªi¯¥£®°�±i¹t§~¯§~°t²q¿`ª~©2À]£¥¯®£®°�±i¹t§~¯/¬eª~©�¦�ª~©+§OÁ� ¢¡t£®¤Â¶�¨s�¡�ªO²Ã�§WÄ~¨�¤£®°YvªÂ§~¬s¬eªi¹]°?��¡�¨Å¦t©+§~¬e�£®¬s§~¯w¤�£®�¹t§W�£µªi°{·Uª~©�¶½§WÄO£®°�±©�¨�¤vªi¯¥¹��£µªi°2©+¹t¯®¨�¤�ª~·w¼s¨s©�ªÆ¦t©�ªi°�ªi¹t°]¤º£¥°�¤v¦�¨�¬s£ÈÇq¬�²�ªW³¶½§~£®°«v¨e¸c�¤sÉq�¡�¨��ÊY¦�¨�¤¢ª~·Ë¹t¤+§WÀ]¯µ¨�¬eª~©�¦�ª~©+§PÌͶ½ªi°�ªW³¯®£®°t±i¹t§~¯8§~°t²q¿`ª~©�À]£¥¯®£®°�±i¹t§~¯[Î'·[ª~©�¨e¸O§~¶½£¥°t£®°�±9�¡�¨Ï¨e¸c³v©+§~¬e�£µªi°�ª~·¢©+¨�¤vªi¯®¹��£µªi°E©+¹t¯®¨�¤Ï¡t§ ´ ¨ÂÀ�¨s¨�°�¬+¡t§~°t±~¨�²²�¨s¦�¨�°t²t£¥°�±1ªi°.�¡�¨E�ÊY¦�¨Eª~·ÆÐ�ÑÓÒÔ¤vÊO¤vv¨�¶Õ¹]¤�£®°�±¨e¸Ov©+§~¬ev¨�²Ö©�¨�¤vªi¯¥¹��£µªi°«©!¹t¯µ¨�¤sÁ� ¢¡�¨¨e¸cv©+§~¬e�£®ªi°�¦t©�ªW³¬e¨�¤�¤v¨�¤�ª~·�©�¨�¤vªi¯®¹��£®ªi°�©+¹t¯µ¨�¤Ë£¥°#�¡�¨¢¨�° ´ £µ©+ªi°t¶�¨�°Y�§W©�¨¬s¯®§~¤�¤+£ÈÇ]¨�²6£®°?vªEÇ ´ ¨�¬eªi¶�¦�ªi°�¨�°YÂ�§~¤�Äc¤s×BÌkØÙÎ2Ú(¨s©�ªÒ'©+ªi°�ªi¹t°»Ûp²�¨�°Y�£ÈÇq¬s§W�£®ªi° ÜÌHÝiÎÂÞ�°?v¨�¬e¨�²�¨�°Y«Þ�°t°�ªW³�§W�£µªi° Ü2ÌHßiÎ{ࢨpáv¨�¬e�£µªi°.ª~·9âc¨�°?v¨�°]¬e¨�¤Öã�°t¤+¹t£µ�§WÀ]¯µ¨·[ª~©½à/¹t¯µ¨�ä'¸cv©+§~¬e�£®ªi° Ü�Ì[åYÎÅà�¹t¯µ¨2ä˸Ov©+§~¬e�£µªi° Ü�§~°t²ÌHæiÎ#ä'¸cv©+§~¬ev¨�²»à/¹t¯®¨2Þ�¦t¦]¯¥£®¬s§W�£µªi°1§~°t²1ç{ªc²]£ÈÇq¬s§^³�£µªi° ÁBÞ�°Ã§~¹�vªi¶½§W�£¥¬P¦t©+ªc¬e¨�¤�¤9§~°t²q¿`ª~©Â§è¶½§~°c¹t§~¯¦t©�ªO¬e¨�¤�¤Óé/£µ�¡§/¹t¤v¨s© ·[©+£µ¨�°t²t¯®Ê�¡c¹t¶½§~°Å£®°?v¨s©+·[§~¬e¨�¬s§~°À�¨�¹t¤v¨�²�vªP§~¬!¡t£µ¨ ´ ¨½¨�§~¬!¡è¬eªi¶�¦�ªi°�¨�°Y��§~¤vÄ(Á½ ¢¡t£®¤¨�° ´ £µ©+ªi°t¶�¨�°Y�é�§~¤�£®¶�¦]¯®¨�¶�¨�°?v¨�²Â£®°Â�¡�¨�êi§W¦]§~°t¨�¤v¨e³vªW³ëä�°t±i¯®£®¤�¡6¶½§~¬+¡]£®°�¨ìv©+§~°t¤�¯®§W�£®ªi°»¤vÊO¤vv¨�¶�Ü�íÂî�ï�ðñ òcó Üt·[ª~©�êi§W¦q§~°�¨�¤v¨�¼s¨s©�ª½¦]©�ªi°�ªi¹t°2©�¨�¤�ªi¯®¹��£µªi° Áô õ`ö � <i>Ë÷�ø�� � ;ë> öÛk°Â°]§W�¹�©+§~¯ ¯®§~°�±i¹]§W±~¨�¤sÜ�¨�¯µ¨�¶�¨�°Y�¤��¡t§W¢¬s§~°2À�¨�¨�§~¤k³£®¯µÊù²�¨�²]¹t¬e¨�²úÀcÊû§ü©+¨�§~²�¨s©Ö§W©�¨è·[©�¨�ýc¹�¨�°?�¯®Êùªi¶½£µk³v¨�²L·[©�ªi¶ ¨e¸c¦]©�¨�¤�¤�£µªi°]¤E£®°þv¨e¸O�¤ûÌÍÿ�¹t°tª�Ü�Ø������iÎ!Á ¢¡t£¥¤w¦]¡�¨�°�ªi¶�¨�°tªi°½¬s§~¹t¤v¨�¤º¬eªi°t¤�£®²t¨s©+§WÀ]¯µ¨�¦t©+ª~À]¯µ¨�¶½¤£®°�Ð�ÑAÒ ¤vÊO¤vv¨�¶½¤¤�¹t¬!¡è§~¤Åç{ �ÜÓv¨e¸c#¤�¹t¶Æ¶½§W©+£µ¼�§^³�£µªi°�§~°]²Öv¨e¸c©�¨sv©+£µ¨ ´ §~¯HÁ�Ûk°Ö¦]§W©��£¥¬s¹t¯®§W©�Ü �¡�¨9¤�¹�À�³áv¨�¬e§~°t²èª~ÀOák¨�¬eŧW©�¨Æª~·[v¨�°Eªi¶½£µvv¨�²è£¥°èêi§W¦]§~°t¨�¤v¨~Üé/¡�¨s©+¨�§~¤��¡�¨sÊ4§W©�¨ü°tª~©+¶½§~¯®¯µÊùª~Àq¯®£µ±i§Wvª~©�Ê.£®°4ä�°O³±i¯®£®¤+¡��ZÁËÛk°2êi§W¦]§~°�¨�¤�¨e³=vªW³ëä�°�±i¯®£¥¤�¡9¶Æ§~¬+¡t£®°t¨�v©+§~°]¤�¯®§^³�£µªi°�¤vÊO¤vv¨�¶½¤sÜ �¡t¨s©�¨s·Uª~©+¨~Ü8£µ�£®¤�°t¨�¬e¨�¤�¤�§W©�Êìvª�£®²�¨�°O³�£µ·[Ê-¬s§~¤v¨B¨�¯µ¨�¶�¨�°Y�¤ ªi¶½£µvv¨�²þ·[©�ªi¶ �¡�¨»ª~©!£µ±i£®°t§~¯êi§W¦q§~°�¨�¤v¨EÌ�k¼s¨s©�ªE¦t©�ªi°�ªi¹]°t¤�?η[ª~©½�¡�¨�£µ©½§~¬s¬s¹�©!§Wv¨v©+§~°t¤+¯®§W�£µªi°�£®°YvªÆä�°t±i¯®£®¤�¡Â¨e¸O¦t©�¨�¤�¤�£®ªi°t¤sÁâc¨ ´ ¨s©!§~¯�§~¯µ±~ª~©!£µ�¡t¶½¤�¡]§ ´ ¨2À�¨s¨�°�¦t©�ª~¦�ªi¤v¨�²�é/£µ�¡©�¨s±i§W©+²,vª �¡t£®¤L¦t©�ª~Àq¯µ¨�¶ ÌÍÿ�§~¶�¨sÊi§~¶½§OÜ Ø����� cÉ
� ªi¤�¡t£¥¶�ª~vª�ÜAØ������cÉ���§~¯®Ä~¨s©/¨s/§~¯HÁµÜ8Ø������OÉ���ªi¡t¤�§WÄW§OÜ������������� �"!$#%�'&�(�)������*�����*+',-�'�"./(0(��21432� 50�6�7#%�7�"��8�(�59.%8
:2;'< 50�78=(��78�37�75>.%8?, ; 8$��@A50!$��!����B���0(�.%37#%�75B@A)�.%3C)D)��2E�9(��GF�����H!$#%.%37./(�#/ID(0�J� 8$50#K� (��71L.%8�(��*M�8�N'#%.%50)PO
Ø����^åYÎ!ÁRQ�ªÙ麨 ´ ¨s©�ÜY£® £®¤ °�ª~w¦�ªi¤�¤�£µÀq¯µ¨'vª�§W¦t¦]¯µÊ��¡t¨�¤v¨¶�¨s�¡�ªO²t¤�²t£®©�¨�¬e�¯µÊPvª«§«¦t©+§~¬e�£®¬s§~¯Ë¶½§~¬!¡t£®°�¨�v©!§~°t¤k³¯®§W�£µªi°E¤vÊO¤vv¨�¶�À�¨�¬s§~¹t¤v¨Æª~·��¡�¨�£µ©Ï¯µª`é�¦t©+¨�¬s£®¤�£µªi°Öª~·©�¨�¤vªi¯¥¹��£µªi°Ã§~°]²Ã�¡�¨�¯®§W©�±~¨ ´ ªi¯®¹t¶½¨Pª~·�ÄO°�ªÙé�¯µ¨�²�±~¨©�¨�ýc¹t£µ©�¨�²8Á Óª»ª ´ ¨s©+¬eªi¶�¨1�¡�¨�¤�¨EÄO£®°t²t¤«ª~·½¦t©�ª~À]¯®¨�¶½¤sÜ�¤v¨ ´ ³¨s©+§~¯�¶½¨s�¡�ªc²]¤ù¡t§ ´ ¨ À(¨s¨�° ¦]©�ª~¦�ªi¤v¨�² ÌÍÐ�§WÄW§~£µé�§
§~°t²PÛ�Ä~¨�¡t§W©!§OÜ Ø����~ÝcÉ Ð�§WÄ^§~£µé�§Æ§~°]²«ÛpÄ~¨�¡t§W©+§OÜwØ����~æcÉÐ�§WÄ^§~£µé�§-§~°t² Û�Ä~¨�¡t§W©!§OÜEØ����� iÎ!Á /¡�¨ù·UªO¬s¹t¤1ª~·�¡�¨�¤v¨�¶½¨s�¡�ªc²]¤�£®¤ºªi°«§W¦t¦]¯®£¥¬s§W�£µªi°t¤�·Uª~©¢§#¦t©!§~¬e�£®¬s§~¯¶½§~¬!¡t£®°�¨2v©+§~°t¤+¯®§W�£µªi° ¤vÊO¤vv¨�¶ é/£µ�¡ §~°1¹t°]¯®£®¶½£µv¨�²v©+§~°t¤+¯®§W�£µªi°2�§W©�±~¨s�§W©�¨�§OÁ
�B£µ�¡2�¡�¨�¤v¨�¶½¨s�¡�ªc²]¤sÜ�¡�ªÙ麨 ´ ¨s©�Üq£®�£¥¤�°�¨�¬e¨�¤�¤�§W©�Êvªè¶½§WÄ~¨P©�¨�¤vªi¯®¹��£®ªi°E©!¹t¯µ¨�¤Å·Uª~©Æ¼s¨s©�ª�¦t©�ªi°tªi¹t°t¤ÅÀYÊ¡t§~°t²8Á ã�°t·Uª~©��¹]°t§Wv¨�¯µÊ~ÜÆ£µè�§WÄ~¨�¤E§ú¯®ª~�ª~·2�£®¶�¨§~°t²»¨S(ª~©+9·[ª~©9�¡t¨P¨e¸O¦(¨s©+�¤Æª~·��¡�¨�Ð�ÑAÒL¤vÊO¤vv¨�¶vª«¶½§WÄ~¨½�¡t¨�¤v¨�©+¹t¯µ¨�¤�©+ª~À]¹t¤v�§~°t²Öé/£®�¡{é�£®²�¨#¬eª ´ ³¨s©+§W±~¨~Á*Tt¹�©��¡t¨s©+¶�ª~©�¨~Üt©+¨�¤vªi¯®¹��£µªi°2©!¹t¯µ¨�¤�ª~·[v¨�°P¡t§ ´ ¨vªÂÀ(¨¶½§~²�¨²t¨s¦(¨�°]²t£®°�±�ªi°{�¡�¨Ï�§W©+±~¨s�²tªi¶½§~£®°«ª~·�¡�¨�²�ªO¬s¹t¶�¨�°Y�¤sÜt§~°t²2�¡]£®¤�§~¯®¤vª�©�¨�ýc¹t£µ©+¨�¤��¡t¨��£®¶�¨e³¬eªi°t¤�¹]¶½£®°�±Ö¯®§WÀ�ª~©�ª~·�¨e¸c¦�¨s©��¤sÁVUº¨�¬s§~¹t¤�¨«ª~·��¡t¨�¤v¨¦t©�ª~Àq¯µ¨�¶½¤sÜ��¡�¨s©�¨P£®¤Æ§�°�¨s¨�²1·[ª~©9§~°1¨S�¨�¬e�£ ´ ¨�§~°t²¨W9¬s£µ¨�°Y¶½¨s�¡�ªc²èª~·¢¶½§WÄO£®°�±«©�¨�¤�ªi¯®¹��£µªi°Ö©!¹t¯µ¨�¤�·[ª~©¼s¨s©�ª½¦]©�ªi°�ªi¹t°t¤�Á �ÊY¦q£®¬s§~¯ ¶�¨s�¡�ªO²t¤�·[ª~©¢�¡t£®¤�¦q¹�©�¦�ªi¤v¨�£®°t¬s¯®¹t²t¨�¨e¸c³
v©+§~¬e�£®°t±©�¨�¤�ªi¯®¹��£µªi°Æ©+¹t¯µ¨�¤�·Uª~©º¼s¨s©�ª#¦t©�ªi°�ªi¹]°t¤Ë·[©�ªi¶¶�ªi°�ªi¯¥£®°�±i¹t§~¯�¬eª~©�¦�ª~©+§�ÌÍÐ�§~¤�¹�ÄW§�é�§OÜúØ����� cÉ4çì¹O³©+§W�§{§~°t²èÐ�§W±i§Wª�Ü¢Ø������~Î!ÜË·U©+ªi¶ÔÀ]£®¯®£¥°�±i¹t§~¯w¬eª~©�¦�ª~©+§ÌÍÐ�§WÄ^§~£µé�§OܽØ������^§OÉ�Ð�§WÄW§~£µé�§OÜ�Ø������`À(Î!Ü�§~°t²B·[©�ªi¶¶�ªi°�ªi¯¥£®°�±i¹t§~¯Ë¬eª~©�¦�ª~©+§«é/£µ�¡Ö�§W±i¤Å·[ª~©§~°Yv¨�¬e¨�²�¨�°?�¤ª~·A¼s¨s©+ª�¦t©�ªi°�ªi¹t°]¤�ÌÍÞ�ªi°�¨�§~°t²XUº¨�°t°�¨svsÜ8Ø����~æcÉ � §^³¶½§~¶�ª~vªÂ§~°t²PâO¹t¶Æ£µ�§OÜ8Ø������iÎ!Áç{ªi°�ªi¯®£®°t±i¹t§~¯�¬eª~©�¦�ª~©+§ù§W©�¨ü©+¨�¯®§W�£ ´ ¨�¯µÊ.¨�§~¤vÊ vª
¬eªi¯®¯µ¨�¬esÁ ç{¨s�¡�ªc²]¤{¹t¤+£®°�±Ã¶�ªi°tªi¯®£®°�±i¹t§~¯¬eª~©�¦�ª~©+§OÜ¡�ª`é�¨ ´ ¨s©�Ü¢¡]§ ´ ¨{²]£YW9¬s¹t¯µ�£®¨�¤�£®° ¨e¸cv©!§~¬e�£®°�±è©+¨�¤vªi¯®¹O³�£µªi°ì©+¹t¯®¨�¤/ª~·'¼s¨s©+ªÂ¦]©�ªi°�ªi¹t°t¤�é/¡�ªi¤�¨©�¨s·[¨s©�¨�°Y�¤�§W©�¨°�ª~©+¶Æ§~¯®¯µÊ9¹]°�¨e¸c¦]©�¨�¤�¤v¨�²2£®°«ê?§W¦]§~°�¨�¤v¨~Áç{¨s�¡�ªO²t¤w¹t¤�£®°�±�¤v¨�°Yv¨�°t¬e¨e³ë§~¯®£µ±i°�¨�²#Àq£®¯®£®°�±i¹]§~¯~¬eª~©v³
¦�ª~©+§è§W©+¨PÀ�¨svv¨s©9�¡]§~°Ã�¡�ªi¤�¨ì¹t¤+£®°�±�¶�ªi°�ªi¯¥£®°�±i¹t§~¯¬eª~©�¦�ª~©+§OÁ' ¢¡]£®¤'£®¤�¦]§W©��£®¬s¹t¯¥§W©+¯µÊ¤�ªé/£®�¡½§ÏÀq£®¯®£®°�±i¹]§~¯¬eª~©�¦]¹]¤�ª~·A²]£®¤�¤�£®¶Æ£®¯®§W©'¯®§~°�±i¹]§W±~¨�¤�¤�¹t¬+¡Â§~¤¢êi§W¦q§~°�¨�¤v¨§~°t²�ä�°�±i¯®£®¤�¡Âé/¡tªi¤v¨�¯®§~°�±i¹t§W±~¨�·Í§~¶½£®¯¥£µ¨�¤�§W©�¨Ï¤vª½²t£®·¥³·[¨s©�¨�°?�§~°]²Öé/¡�¨s©�¨#�¡�¨½²]£®¤vv©+£µÀq¹��£µªi°t¤/ª~·�¼s¨s©�ªP¦t©�ªW³°�ªi¹t°]¤Ï§W©�¨Â§~¯®¤vª{ýc¹t£µv¨Â²t£YS�¨s©�¨�°YsÁZQ/ª`é�¨ ´ ¨s©�Ü�À]£®¯®£®°�³±i¹t§~¯�¬eª~©�¦�ª~©+§�§W©�¨ì©�¨�¯®§W�£ ´ ¨�¯µÊü²]£YW9¬s¹t¯µÆvª ¬eªi¯¥¯µ¨�¬esÜ

¨�¤v¦�¨�¬s£®§~¯®¯®Ê9¤v¨�°Yv¨�°t¬e¨e³ë§~¯®£µ±i°t¨�²«¬eª~©�¦�ª~©+§OÁ�B£µ�¡ ¶�¨s�¡�ªO²t¤4¹]¤�£®°�± ¶½ªi°�ªi¯®£®°�±i¹]§~¯�¬eª~©�¦�ª~©+§
é/£µ�¡9§~°?v¨�¬e¨�²t¨�°?��§W±i¤sÜt£®�£®¤�¦�ªi¤�¤�£µÀ]¯®¨�vª¨W9¬s£®¨�°?�¯µÊ¶½§WÄ~¨»¨S(¨�¬e�£ ´ ¨6©�¨�¤vªi¯¥¹��£µªi°�©+¹]¯µ¨�¤ÖÀcÊ.©+¨�¯µÊc£¥°�±ùªi°�¡�¨#§~°t°�ª~�§Wv¨�²�£®°�·[ª~©+¶½§W�£®ªi° Á Q�ªÙ麨 ´ ¨s©�Ü �¡�¨s©�¨#§W©�¨ªi°t¯µÊ§�·U¨sé1¬eª~©�¦�ª~©+§�é/£µ�¡#§~°Yv¨�¬e¨�²�¨�°Y'�§W±i¤Ë·[ª~©Ë¼s¨s©�ª¦t©�ªi°tªi¹t°t¤sÁ« ¢¡t¨9¤v�§~°t²]§W©+²t£µ¼�§W�£µªi°è·Uª~©�§~°t°tª~�§W�£®°�±¼s¨s©�ª9¦t©�ªi°�ªi¹t°]¤¢§~°t²«�¡t¨�£µ©�§~°Yv¨�¬e¨�²�¨�°Y�¤�£®¤¢¤v�£®¯¥¯ ªi°O³±~ªi£®°�±1Ì Q�§~¤�£®²t§OÜ�Ý������?Î!Á � ªi°t¤v¨�ýc¹�¨�°Y�¯µÊ~Ü'£®°�§~¬e�¹t§~¯¤�£µ�¹]§W�£µªi°t¤sÜ�§~°]§~¯µÊc¤��¤#é/¡�ª�麧~°Y�vª�¶½§WÄ~¨«©+¨�¤vªi¯®¹O³�£µªi°Ö©!¹t¯µ¨�¤�·[ª~©Ï¼s¨s©�ª«¦]©�ªi°�ªi¹t°t¤�§~¯¥¤vª«¡t§ ´ ¨9vª{¯®§WÀ�ªW³©+£µªi¹]¤�¯µÊç~°t°tª~�§Wv¨è§~°?v¨�¬e¨�²t¨�°?{�§W±i¤Pvª1¼s¨s©�ªÃ¦t©�ªW³°�ªi¹t°]¤A£®°Ï�¡�¨º¬eª~©+¦]¹t¤ÓÀYÊ�¡t§~°]² Ü^§~¤ ¦t©+¨ ´ £µªi¹]¤�¯µÊ�¶�¨�°O³�£µªi°�¨�²8Á» ¢¡�¨s©+¨s·Uª~©�¨~Ü�§~°»§~°t°�ª~�§W�£µªi°»vªYªi¯/·Uª~©9�¡�¨§~°Yv¨�¬e¨�²�¨�°?�¤ºª~·(¼s¨s©�ªÏ¦]©�ªi°�ªi¹t°t¤Ë£¥°#�¡�¨¢v¨e¸O�¤�ÌÍÞ�ªi°�¨§~°t² Uº¨�°t°�¨svsÜ�Ø����^åYÎ�£¥¤�°�¨s¨�²�¨�² ·[ª~©��¡�¨�¨S(¨�¬e�£ ´ ¨§~²t²t£®�£µªi°2ª~·Ó�§W±i¤�vª½¼s¨s©�ªÆ¦t©�ªi°�ªi¹t°]¤sÁ Óªü¬e©�¨�§Wv¨�©�¨�¤�ªi¯®¹��£µªi°6©+¹t¯®¨�¤9ª~·¼s¨s©�ªü¦t©+ªi°�ªi¹t°t¤
£®°ù§ v¨e¸O«ª~·#§1¤v¦�¨�¬s£ÈÇq¬�²�ªi¶½§~£®°8Ü/麨�¬eªi¶½¶�ªi°t¯µÊ¹t¤v¨�ªi°]¯µÊŶ½ªi°�ªi¯®£®°�±i¹]§~¯�¬eª~©�¦�ª~©+§�£®°#�¡�¨/¤�¦(¨�¬s£µÇq¬�²�ªW³¶½§~£®°�é/£µ�¡�ªi¹� §~°Yv¨�¬e¨�²�¨�°YÓ�§W±i¤Ó·Uª~©A¼s¨s©�ª¢¦t©�ªi°tªi¹t°t¤sÁÞ�¬s¬eª~©+²t£®°�±i¯®Ê~ÜÓ§~°t§~¯µÊO¤v�¤§~°t°�ª~�§Wv¨Æ�§W±i¤vªP�¡t¨Æ§~°O³v¨�¬e¨�²�¨�°Y�¤½ª~·�¨ ´ ¨s©�ÊE¼s¨s©+ªÖ¦t©�ªi°�ªi¹t° £®°��¡�¨«¬eª~©+¦]¹t¤vª«¶½§WÄ~¨�¨S�¨�¬e�£ ´ ¨�©�¨�¤vªi¯¥¹��£µªi°ì©+¹t¯µ¨�¤�Á Q/ª`é�¨ ´ ¨s©�ÜÓvª§~¬s¬eªi¶�¦]¯¥£®¤�¡�¡t£®¤ £®°¶Æ§~¬+¡t£®°t¨�v©+§~°t¤+¯®§W�£µªi° Ü~£µw£®¤ §~¯®¤vª¦�ªi¤�¤�£µÀq¯µ¨�vª9¹t¤�¨ÏÀ]£®¯¥£®°�±i¹t§~¯�¬eª~©�¦�ª~©+§9£®°«�¡�¨Å¤v¦�¨�¬s£ÈÇq¬²�ªi¶½§~£¥° Ü�¤�¹t¬+¡P§~¤/§#·[ª~©+¶�¨s© ´ ¨s©+¤+£µªi°�ª~·w§�v¨e¸c/�¡t§W¡t§~¤Ë§~¯µ©+¨�§~²�Ê�À�¨s¨�°Åv©+§~°t¤�¯®§Wv¨�²#ª~©ËÀq£®¯®£®°�±i¹]§~¯i¬eª~©�¦�ª~©+§¹t¤v¨�²ü·Uª~©9v©+§~°t¤�¯®§W�£®ªi°1¶�¨�¶�ª~©�Ê1¤vÊO¤vv¨�¶½¤sÁ»Ûp°ü�¡t£®¤¬s§~¤v¨~ÜŶ�¨s�¡�ªO²t¤��¡t§Wì§~¹�vªi¶½§W�£®¬s§~¯®¯®Ê6¨e¸Ov©+§~¬eì�¡�¨©�¨�¤vªi¯¥¹��£µªi°9©+¹t¯µ¨�¤�ª~·A¼s¨s©�ª#¦t©+ªi°�ªi¹t°t¤�·U©+ªi¶ Àq£®¯®£®°�±i¹]§~¯¬eª~©�¦�ª~©+§ìÌÍÐ�§WÄW§~£µé�§OÜ Ø������^§OÉ8Ð�§WÄ^§~£®éº§OÜwØ������`À(Î�¬s§~°À�¨º¹]¤v¨�² ÁwÞ�°#§~¹�vªi¶½§W�£¥¬�¨e¸cv©+§~¬e�£®ªi°�¦t©�ªO¬e¨�¤�¤sÜi¡�ª`é�³¨ ´ ¨s©�Ü ¬s§~°t°�ª~�¶½§WÄ~¨Å¦�¨s©�·U¨�¬e�©+¹t¯®¨Ï¤v¨s�¤sÁ� ¢¡�¨s©�¨s·[ª~©�¨~Ü�¡�¨1§~¹�vªi¶½§W�£¥¬s§~¯®¯µÊû¨e¸Ov©+§~¬ev¨�²�©!¹t¯µ¨�¤�¡t§ ´ ¨1vªùÀ�¨¬eªi°OÇ]©!¶�¨�²�ÀcÊÖ¡Y¹t¶Æ§~°è£®°Yv¨s©+§~¬e�£µªi°èÀ(¨s·[ª~©�¨Æ§~²]²t£®°�±�¡�¨�©+¹t¯µ¨¢¤v¨sº¹t¤v¨�²½£¥°Æ§~°t§W¦]¡tª~©+§�©�¨�¤vªi¯¥¹��£µªi°½£®°ÆÐ�ÑÓÒ¤vÊO¤vv¨�¶½¤�£µ· ¡]£µ±i¡t¯µÊ½©+¨�¯®£®§WÀ]¯µ¨�©+¹]¯µ¨�¤�¤�¹t¬!¡P§~¤/²tªi¶½§~£®°O³£®°t²t¨s¦(¨�°]²�¨�°?8²t¨s·[§~¹t¯® ©+¹t¯µ¨�¤Ó§W©�¨�©�¨�ýc¹t£µ©+¨�² ÁBTt¹�©+�¡�¨s©v³¶�ª~©�¨~ÜO�¡�¨�¡c¹t¶½§~°2£®°Yv¨s©+§~¬e�£µªi°2¶¹]¤v��§WÄ~¨�£¥°?vª#§~¬Z³¬eªi¹t°Y'�¡�¨�¨W9¬s£®¨�°t¬eÊ#ª~·(§~¬sýc¹t£µ©+£¥°�±�©�¨�¤vªi¯®¹��£®ªi°©!¹t¯µ¨�¤·[©�ªi¶ À�ª~�¡«¶�ªi°�ªi¯¥£®°�±i¹t§~¯�§~°t²2À]£¥¯®£®°�±i¹t§~¯(¬eª~©�¦�ª~©+§OÁ� ªi°]¤�£®²�¨s©+£¥°�±��¡�¨�¤v¨�¦t©+§~¬e�£®¬s§~¯(¬eªi°t²t£µ�£®ªi°t¤Ë·[ª~©�¨e¸c³
v©+§~¬e�£®°t±ì�¡t¨Â©+¨�¤vªi¯®¹��£µªi°�©+¹]¯µ¨�¤Ïª~·�¼s¨s©�ª�¦t©�ªi°tªi¹t°t¤sÜ�¡t£®¤�¦]§W¦�¨s©�¦t©�ª~¦�ªi¤v¨�¤�§P¦t©+§~¬e�£®¬s§~¯�£®°?v¨s±~©!§Wv¨�²èvªcªi¯¬s§W¦]§WÀ]¯®¨Ãª~·�¨e¸Ov©+§~¬e�£®°�±4©+¹t¯µ¨�¤è·Uª~©E�¡�¨»§~°t§W¦q¡�ª~©+§©�¨�¤vªi¯¥¹��£µªi°»ª~·�¼s¨s©�ª1¦t©�ªi°tªi¹t°t¤½·[©�ªi¶¾¶�ªi°�ªi¯¥£®°�±i¹t§~¯§~°t²q¿`ª~©/À]£®¯®£®°t±i¹t§~¯q¬eª~©+¦(ª~©!§OÁ� � >A@���> ö��qö ��� D � F � >�� � � >� ëø � ;ë> ö
��ø� ����� � <iD � � ;=> ö >�� � <?>��9<i> ö >Aø ö ��Ö¨�¬s¯®§~¤�¤�£®·UÊÖ�¡�¨2¤�¹�À]�§~¤vÄc¤·[ª~©Å¨e¸Ov©+§~¬e�£®°t±ì©+¨�¤vªi¯®¹O³�£µªi° ©+¹]¯µ¨�¤Å·U©�ªi¶ ¬eª~©+¦(ª~©!§ì£¥°?vª��¡�¨�·[ªi¯®¯µª`é/£®°�±{Ç ´ ¨¬eªi¶�¦�ªi°�¨�°Y��§~¤vÄc¤�×#ÌkØÙÎ�Ú(¨s©+ª2Ò�©�ªi°�ªi¹t°ìÛk²�¨�°Y�£ÈÇq¬s§^³
�£µªi° ÜËÌHÝiÎ�Þ�°Yv¨�¬e¨�²�¨�°Y�Þ�°t°tª~�§W�£µªi° Ü'ÌHßiÎ�ࢨpáv¨�¬e�£µªi°ª~·�âO¨�°?v¨�°t¬e¨�¤�·Uª~©�à�¹t¯µ¨�ä˸Ov©+§~¬e�£µªi° Ü�Ì[åYÎ�à/¹t¯µ¨#ä˸c³v©+§~¬e�£µªi°8Üϧ~°t² ÌHæiΫä˸Ov©+§~¬ev¨�².à/¹t¯µ¨EÞ/¦t¦q¯®£®¬s§W�£µªi°§~°t²«ç{ªO²t£ÈÇq¬s§W�£µªi°8Á����� ��� �"!$#%�"!'&(!')*&�+-,(�.&0/2143*5768/219!'& ¢¡�¨Å¼s¨s©�ª�¦t©+ªi°�ªi¹t°ì£®²�¨�°Y�£ÈÇq¬s§W�£µªi°ì¦t©�ªO¬e¨�¤�¤�£®²�¨�°Y�£È³Ç]¨�¤�¼s¨s©�ªP¦t©�ªi°�ªi¹t°]¤��¡]§W�¶¹t¤��À�¨#©�¨�¤vªi¯ ´ ¨�²�£®°�§~°Ð�ÑAÒ ¤vÊO¤vv¨�¶Õ¹]¤�£®°�±ü¨e¸Ov©+§~¬ev¨�².©�¨�¤vªi¯¥¹��£µªi°ú©!¹t¯µ¨�¤sÁT�ª~©�¨e¸�§~¶�¦]¯µ¨~Ü/ê?§W¦]§~°�¨�¤v¨~Ü�é/¡t£®¬!¡Ã£®¤Â§E·U©�¨s¨ì麪~©+²O³ª~©+²�¨s©'¯¥§~°�±i¹t§W±~¨~Ü?ª~·[v¨�°½¡t§~¤�°�ª�¨e¸c¦q¯®£®¬s£µw¬s¹�¨¢¡�¨�¯µ¦]·[¹t¯£®°Å²�¨sv¨s©+¶½£¥°t£®°�±¢ª~Àq¯®£µ±i§Wvª~©�ÊϬs§~¤�¨º¨�¯®¨�¶�¨�°?�¤�Áw /¡�¨s©�¨e³·[ª~©�¨~Ü(£¥°«�¡t£®¤�¯®§~°�±i¹t§W±~¨~Ü(�¡�¨Å£®²�¨�°Y�£ÈÇq¬s§W�£µªi°Pª~·Ë¼s¨s©�ª¦t©�ªi°tªi¹t°t¤'£®°½�¡�¨/¬eª~©�¦]¹]¤�£®¤'§~¯¥¤vª£®¶½¦(ª~©+�§~°?Ë·[ª~©�¨e¸c³v©+§~¬e�£®°t±Ï©�¨�¤vªi¯¥¹��£µªi°½©!¹t¯µ¨�¤sÁ Tt¹�©��¡t¨s©+¶�ª~©�¨~ÜO²�¨s¦�¨�°t²O³£®°�±Åªi°Â�¡�¨�Ð�ÑÓÒü¤vÊO¤vv¨�¶�ÜO�¡�¨�¼s¨s©�ª#¦t©�ªi°tªi¹t°t¤��¡t§W¶Å¹t¤v�À�¨�©�¨�¤vªi¯ ´ ¨�²ú§W©+¨�²t£YS�¨s©�¨�°?sÁ T�ª~©{¨e¸O§~¶½¦]¯µ¨~Üçì »¤vÊO¤vv¨�¶½¤ºªi°t¯®Ê½°�¨s¨�²ÆvªÅ©�¨�¤vªi¯ ´ ¨�¼s¨s©�ª#¦t©+ªi°�ªi¹t°t¤�¡t§W�¶¹]¤v�À�¨¨e¸c¦]¯¥£®¬s£µ�¯µÊ2v©+§~°t¤+¯®§Wv¨�²{£¥°?vªÂ�¡�¨Å�§W©v³±~¨ssÁËÛk°Å§�ê?§W¦]§~°�¨�¤v¨�¤v¨�°Yv¨�°t¬e¨ÏÌkØÙÎ!Üi�¡�¨�¤�¹tÀOák¨�¬e¢Ì�:<;Z³¬s§~¤v¨`Î�£¥¤�°�ª~�¨e¸c¦]©�¨�¤�¤v¨�²«£¥°2ê?§W¦]§~°�¨�¤v¨�Àq¹��À�¨�¬eªi¶�¨�¤ª~¦t�£µªi°]§~¯Aé/¡t¨�°Pv©+§~°]¤�¯®§Wv¨�²�£®°YvªÂä�°�±i¯®£®¤�¡8ÜtÀ�¨�¬s§~¹t¤v¨£µ�£®¤�¦�ªi¤�¤+£µÀ]¯µ¨Åvª«v©+§~°t¤+¯®§Wv¨��¡t£®¤�ÀcÊì¹]¤�£®°�±2�¡�¨�¨e¸c³¦t©�¨�¤+¤�£µªi° Ü��+Ú(ªcªi¤¢©+§~£¥¤v¨�¯®£µªi°t¤sÁ%OÁ= �?> =A@CBEDGF > HGIKJ-LMJONQPRJOS?T-UEHGS V FKW IKT-UEI X F JZY
[M\]\ B_^Z` acb \Kd B_egfih jKkMkMlm \]\KnpoRq b n k0acb \Kdin Y
¢¡�¨s©+¨s·Uª~©�¨~Ü9£®° �¡�¨ü¼s¨s©�ªû¦t©�ªi°�ªi¹t°�£¥²�¨�°?�£µÇq¬s§W�£µªi°¦t©�ªO¬e¨�¤�¤sÜ��¡t¨�§~°t§~¯µÊO¤�£®¤º©�¨�¤�¹t¯®�¤�ª~·Ó�¡�¨�Ð�ÑAÒ»¤vÊO¤vv¨�¶¶Å¹t¤v�À�¨��§WÄ~¨�°P£®°YvªÆ§~¬s¬eªi¹t°YsÁÚ(¨s©+ªù¦t©�ªi°�ªi¹t°�£¥²�¨�°?�£µÇq¬s§W�£µªi° £®°�¶�ªi°�ªi¯¥£®°�±i¹t§~¯
¬eª~©�¦�ª~©+§�ªi°]¯µÊ#©�¨�¯®£µ¨�¤Ëªi°Æ�¡�¨/§~°t§~¯®Êc¤�£¥¤Ë©�¨�¤�¹t¯®�¤Ëª~· �¡�¨Ð�ÑAÒè¤�Êc¤vv¨�¶«ÁËÛp°�Àq£®¯®£®°�±i¹]§~¯Y¬eª~©�¦�ª~©+§OÜc¡�ªÙ麨 ´ ¨s©�Üc�¡�¨v©+§~°t¤+¯®§W�£µªi°�¨�ýY¹]£ ´ §~¯®¨�°?Ū~·¢¼s¨s©�ªÖ¦t©+ªi°�ªi¹t°t¤£®¤#§~¯®¤vª¹t¤�§WÀq¯µ¨è§~¤ì§Ãv©+£®±~±~¨s©{·[ª~©ì²t¨sv¨s©+¶½£®°t£¥°�±1¼s¨s©�ª6¦t©�ªW³°�ªi¹t°]¤��¡t§W/¶Å¹t¤v�À�¨�©�¨�¤vªi¯ ´ ¨�²8Á���E� í &0/2�<5r� ,*� &0/ í &*&�!p/g68/219!0& ¢¡�¨4§~°?v¨�¬e¨�²�¨�°Yù§~°t°�ª~�§W�£µªi° ¦t©�ªO¬e¨�¤�¤»£®²�¨�°Y�£ÈÇ]¨�¤§~°Yv¨�¬e¨�²�¨�°?�¤'ª~·]¼s¨s©�ª�¦t©�ªi°tªi¹t°t¤Ó�¡t§WË°�¨s¨�²Åvª�À�¨º©�¨e³¤vªi¯ ´ ¨�²8Á�Ûp°Ö¶�ªi°tªi¯®£®°�±i¹t§~¯w¬eª~©�¦�ª~©+§OÜÓ§~°t§~¯µÊO¤v�¤�¶Å¹t¤vÀ]§~¤�£¥¬s§~¯®¯µÊ§~°]°�ª~�§Wv¨/§~°Yv¨�¬e¨�²�¨�°?�¤�ª~·�¼s¨s©�ª�¦t©+ªi°�ªi¹t°t¤¶½§~°c¹t§~¯®¯µÊ~Á Q�ªÙ麨 ´ ¨s©�Ü�¨ ´ ¨�°ù£®°»�¡�¨Ö¶½§~°c¹t§~¯�¦t©�ªW³¬e¨�¤�¤sÜ��¡t¨«·Uªi¯¥¯µªÙé/£¥°�±Ö·[§~¬evª~©!¤9¶Å¹t¤v9À(¨��§WÄ~¨�°B£®°Yvª§~¬s¬eªi¹t°YsÁ
s Ú�¨s©�ª�¦t©�ªi°�ªi¹]°t¤ é/£µ�¡#�¡�¨/¤+§~¶�¨¢¤vÊO°?�§~¬e�£®¬�§~°t²¤�¨�¶½§~°?�£¥¬{·[¨�§W�¹�©�¨�¤�Ìͤ+¹t¬+¡ù§~¤2¶�ªO²t§~¯�¨e¸c¦]©�¨�¤k³¤+£µªi°t¤sÜ �¡�¨9¶½¨�§~°t£®°�±{ª~· ´ ¨s©�À]¤sÜ˧~°t²�¬eªi°^á�¹t°t¬Z³�£®ªi°t¤!Î9§W©�ªi¹t°t²B�¡t¨�¶ £®°6�¡�¨�¬eª~©�¦]¹t¤�¤+¡�ªi¹t¯®²À�¨¢±~©+ªi¹�¦�¨�²½§~°t²Æ²]£®¤v¦]¯®§ÙÊ~¨�²½§W��¡t¨/¤�§~¶�¨��£®¶�¨é�¡�¨�°2�¡�¨�£µ©/§~°Yv¨�¬e¨�²�¨�°Y�¤�§W©+¨Ï§~°t°�ª~�§Wv¨�² ÁÚ�¨s©�ªÏ¦t©+ªi°�ªi¹t°t¤�é/£µ�¡½�¡t¨�¤�§~¶�¨�·[¨�§W�¹�©�¨�¤�v¨�°t²vª�¡]§ ´ ¨«�¡�¨«¤+§~¶�¨«ëÊc¦�¨2ª~·�§~°Yv¨�¬e¨�²�¨�°Y�¤ÆÀ�¨e³¬s§~¹]¤v¨��¡�¨Ö·[¨�§W�¹�©�¨�¤PÀ(¨�¬eªi¶½¨�Ä~¨sÊB·[§~¬evª~©+¤{£®°

²t¨sv¨s©+¶½£®°t£¥°�±«�¡�¨�£µ©#§~°Yv¨�¬e¨�²�¨�°?�¤�Á� ¢¡�¨s©�¨s·[ª~©�¨~ܧ~°]§~¯µÊc¤��¤A¬s§~°�á�¹t²�±~¨�§~°?v¨�¬e¨�²�¨�°Y�¤w·[ª~©A¼s¨s©�ª�¦t©�ªW³°tªi¹t°t¤Ëé/£®�¡��¡�¨/¤�§~¶½¨/·[¨�§W�¹�©�¨�¤'¨�§~¤+£®¯µÊ�§~°t²½¨s·U³Ç(¬s£µ¨�°?�¯®Ê~Á
s Þ�°Yv¨�¬e¨�²�¨�°?ù¬s§~°t²]£®²t§Wv¨�¤üª~·Ö¼s¨s©+ª ¦t©+ªi°�ªi¹t°t¤¤+¡�ªi¹t¯®²EÀ�¨9¨�§~¤vÊEvª�¤v¨�¯µ¨�¬e�·[©�ªi¶ ¨�¯µ¨�¶�¨�°Y�¤�£®°�¡t¨»v¨e¸O ª~© ²t¨�£®¬e�£®¬»¨�¯µ¨�¶�¨�°Y�¤Eªi¹t�¤�£®²�¨6�¡�¨v¨e¸OsÁ /¡�¨s©�¨Ô§W©�¨ �¡�©�¨s¨Ô�ÊY¦�¨�¤Lª~·.¦(ªi¤+¤�£µÀ]¯µ¨ §~°O³v¨�¬e¨�²t¨�°?¢¬s§~°t²]£®²t§Wv¨�¤�·[ª~©�¨�§~¬+¡�¼s¨s©�ª#¦t©+ªi°�ªi¹t° ׬s§~°]²t£®²t§Wv¨�¤�£®°«�¡t¨¤�§~¶�¨Å¤v¨�°Yv¨�°t¬e¨«ÌÍ£®°?v©!§~¤v¨�°O³v¨�°Y�£®§~¯UÎ!ÜÓ¬s§~°t²t£®²t§Wv¨�¤�£®°�§~°�ª~�¡t¨s©Ï¤v¨�°Yv¨�°t¬e¨½£®°�¡t¨Öv¨e¸cèÌÍ£®°Yv¨s©+¤v¨�°Yv¨�°Y�£®§~¯UÎ!Ü�§~°t²ù¬s§~°t²t£¥²t§Wv¨�¤�¡]§W'§W©�¨¢°�ª~˨e¸O¦]¯®£®¬s£µ�¯®Ê�¨e¸c¦t©+¨�¤�¤v¨�²�£®°Å�¡�¨�v¨e¸OÌͲt¨�£®¬e�£®¬ÙÎ!ÁüÛk°?v©!§~¤v¨�°?v¨�°Y�£®§~¯�§~°t²ü£®°Yv¨s©+¤v¨�°Yv¨�°O³�£¥§~¯Ó§~°Yv¨�¬e¨�²�¨�°Y�¬s§~°]²t£®²t§Wv¨�¤�§W©�¨#§~¬e�¹t§~¯®¯µÊ�¨e¸c³¦]©�¨�¤�¤v¨�²½£¥°#�¡�¨¢v¨e¸OsÁ� ¢¡�¨�£µ©'¬eªi°]²t£µ�£µªi°t¤Ë£¥°��¡�¨©+¨�¤vªi¯®¹��£µªi°ì©+¹]¯µ¨�¤�£¥° ´ ªi¯ ´ ¨��¡t¨�£µ©�¤vÊc°Y�§~¬e�£®¬#¦�ªW³¤+£µ�£µªi°t¤�§~°t²q¿`ª~©�¤v¨�°Yv¨�°?�£®§~¯(©�¨�¯¥§W�£µªi°t¤�¡t£®¦]¤'¤�¹t¬!¡§~¤P²t£®¤v�§~°t¬e¨~Ü�©+¡�¨svª~©!£®¬s§~¯�©�¨�¯®§W�£®ªi° Ü�§~°]²B©�¨�¯®§^³�£ ´ ¨'©�¨�¯®§W�£µªi°Ï£®°��¡�¨�²]£®¤�¬eªi¹�©+¤�¨'¤vv©+¹t¬e�¹�©+¨/Ì[¨~Á ±�ÁµÜ§Ã¬s§~°t²t£®²t§Wv¨�£¥°B�¡�¨Ö�£µ�¯µ¨Öª~·#§ü¤v¨�¬e�£µªi°4§~°t²§ ¼s¨s©+ª1¦t©�ªi°�ªi¹t°B£®°B§1¤v¨�°Yv¨�°t¬e¨è£¥°»�¡t¨�¤v¨�¬Z³�£®ªi°qÎ�ÌÍÐ�§WÄW§~£µéº§�§~°t²ÅÛpÄ~¨�¡t§W©+§OÜ]Ø����~ÝcÉcÐ�§WÄW§~£µé�§§~°]²ÏÛpÄ~¨�¡t§W©+§OÜtØ����~æiÎ!Á' ¢¡t¨s©�¨s·Uª~©+¨~Ü~ÀYÊ�±~©�ªi¹t¦]£®°�±£¥°?v©+§^³Å§~°t²Ã£®°Yv¨s©+¤v¨�°Yv¨�°Y�£®§~¯�¬s§~°]²t£®²t§Wv¨�¤Æé/£µ�¡�¡t¨B¤+§~¶�¨ú¤vÊO°?�§~¬e�£®¬ú¦(ªi¤+£µ�£µªi°þ§~°t² ¤v¨�°Yv¨�°O³�£¥§~¯w©�¨�¯®§W�£µªi°t¤+¡t£µ¦�£®°ì�¡�¨#v¨e¸csÜ §~°t²�ÀYÊ�¤�¡�ª`é�³£¥°�±{�¡t¨«¤�§~¶�¨2ëÊc¦�¨�¤�ª~·�¬s§~°t²]£®²t§Wv¨�¤#·[ª~©�¼s¨s©�ª¦]©�ªi°�ªi¹t°t¤§W�¡t¨Â¤�§~¶½¨9�£®¶½¨~Ü éº¨2¬s§~°�¤�¨�¯µ¨�¬e�¡t¨�§~¬e�¹t§~¯(§~°Yv¨�¬e¨�²�¨�°?�¨�§~¤+£®¯µÊ½§~°t²9¨W9¬s£µ¨�°Y�¯µÊ~ÁÞ�¶�ªi°�±�²�¨�£®¬e�£¥¬9§~°Yv¨�¬e¨�²�¨�°YƬs§~°t²t£®²]§Wv¨�¤sÜË�¡�¨§~°Yv¨�¬e¨�²�¨�°Y�¤ v¨�°t²þvª4À�¨6¯®£®¶½£µv¨�²�¨�¯µ¨�¶�¨�°Y�¤¤+¹t¬+¡ §~¤ ���������� ¿��� � ;� ��� ª~© ��� ;�� ��� ¿�� � ; ����ÌÍÐ�§WÄW§~£µéº§�§~°t²»Û�Ä~¨�¡]§W©+§OÜÏØ����� iÎ!Á ¢¡�¨s©�¨s·[ª~©�¨~ܯ¥£®¤v�£®°�±Ö�¡t¨P¦�ªi¤�¤�£µÀq¯µ¨«§~°?v¨�¬e¨�²t¨�°?�¬s§~°t²t£¥²t§Wv¨�¤À�¨s·[ª~©�¨P�¡t¨ì§~°t°tª~�§W�£µªi°6¦t©�ªO¬e¨�¤�¤2§~°t²»¤�¨�¯µ¨�¬ek³£¥°�±��¡�¨/§~¬e�¹t§~¯(§~°Yv¨�¬e¨�²�¨�°?º·[©�ªi¶-�¡�¨/¦(ªi¤+¤�£µÀ]¯µ¨§~°Yv¨�¬e¨�²�¨�°Y�¬s§~°t²]£®²t§Wv¨/¯®£¥¤v˶½§WÄ~¨¢�¡�¨/§~°]°�ª~�§^³�£®ªi°«¦t©�ªO¬e¨�¤�¤/ª~·w²t¨�£®¬e�£®¬�§~°Yv¨�¬e¨�²�¨�°Y�¤�·Uª~©�¼s¨s©�ª¦]©�ªi°�ªi¹t°t¤�¶Å¹t¬!¡�¨�§~¤�£µ¨s©/§~°]²«¶�ª~©�¨�¨W¬s£µ¨�°?sÁ
Ûk°L�¡�¨û¬s§~¤v¨ûª~·{À]£¥¯®£®°�±i¹t§~¯Â¬eª~©�¦�ª~©+§OÜP£¥° §~²t²t£È³�£µªi° vª �¡t¨4¶½§~°c¹t§~¯{¦t©�ªO¬e¨�¤�¤»¹]¤v¨�² ·[ª~©ù¶�ªi°�ªW³¯®£®°t±i¹t§~¯�¬eª~©�¦�ª~©+§OÜ��¡�¨Öv©+§~°t¤�¯¥§W�£µªi°ùª~·#§ü¤v¨�°Yv¨�°t¬e¨é/£µ�¡ú¼s¨s©�ª»¦]©�ªi°�ªi¹t°ú¬s§~°4À�¨è¹t¤v¨�²úvª6²�¨sv¨s©!¶½£®°�¨�¡�¨è§~°Yv¨�¬e¨�²�¨�°YPª~·#�¡�¨Ö¼s¨s©�ª»¦t©�ªi°�ªi¹]° Á T�ª~©P¨e¸c³§~¶�¦]¯®¨~ܺ£®°üê?§W¦]§~°�¨�¤v¨«§~°]²üä�°�±i¯¥£®¤�¡�À]£®¯®£¥°�±i¹t§~¯º¬eª~©v³¦�ª~©+§OÜ��¡�¨�¤�¹�ÀOáv¨�¬e{§~°]²ûª~ÀOáv¨�¬e�§W©�¨èª~·[v¨�°.ªi¶½£µk³v¨�² £®° ê?§W¦]§~°�¨�¤v¨~Ü�é/¡t¨s©�¨�§~¤1�¡�¨sÊþ§W©�¨ú°�ª~©+¶½§~¯¥¯µÊª~À]¯®£®±i§Wvª~©�Ê»£®°Bä�°�±i¯®£®¤�¡8Á /¡�¨s©�¨s·[ª~©�¨~Ü�ÀcÊ»§~¯¥£µ±i°t£®°�±¼s¨s©�ª¦t©�ªi°�ªi¹t°]¤Ë£®°½êi§W¦]§~°t¨�¤v¨/§~°t²��¡t¨�£µ©'v©+§~°t¤+¯®§W�£µªi°¨�ýc¹t£ ´ §~¯µ¨�°?�¤£®°�ä�°�±i¯®£®¤�¡8ÜA§~°?v¨�¬e¨�²t¨�°?#ª~·�¼s¨s©�ª{¦t©�ªW³°�ªi¹t°]¤8¬s§~°ÏÀ�¨�§~¹tvªi¶½§W�£®¬s§~¯®¯µÊ�£®²t¨�°?�£ÈÇq¨�²ÆÌÍÐ�§WÄW§~£µé�§OÜØ������`À(Î!Á
����� � ���C� 5 /219!'&�!���� � &0/g�.&(5r����� & �g)*14/g6"!$#9�� !p�%� )	� ó(' /g�26p5 /219!'&
¢¡�¨�·[ªi¯®¯µª`é/£®°�±#�ÊY¦�¨�¤¢ª~·Ë¤v¨�°Yv¨�°t¬e¨�¤/é/£µ�¡�¼s¨s©�ªÆ¦t©�ªW³°�ªi¹t°]¤�§~°t²(¿`ª~©�§~°Yv¨�¬e¨�²�¨�°Y�¤¢£®°9�¡�¨�¬eª~©�¦]¹t¤º§W©�¨�°�ª~¤�¹t£®�§WÀ]¯µ¨9§~¤½�¡�¨�¤vªi¹�©+¬e¨�¤v¨�°Yv¨�°t¬e¨�¤�·[ª~©#¨e¸cv©+§~¬e�£¥°�±©+¹t¯®¨�¤sÁÌͧ?Î9âO¨�°?v¨�°t¬e¨�¤Â£®°Ãé/¡t£®¬!¡1�¡�¨{§~°]§~¯µÊc¤+£®¤½¶½§~²�¨{¨s©v³
©+ª~©+¤2£®°B£®²�¨�°Y�£µ·UÊO£®°�±E�¡�¨�¦t©�¨�²t£¥¬s§Wv¨~Ü/¨~Á ±�ÁµÜ�§~°§~² ´ ¨s©�À]£®§~¯ ¨e¸O¦t©�¨�¤�¤�£®ªi° Ü(¶½ªc²t§~¯ ¨e¸O¦t©�¨�¤�¤+£µªi° Ü�ª~©¦�ªi¤vv¦�ªi¤�£®�£µªi°t§~¯8¦q¡�©+§~¤v¨#§~¤�§Â¦t©�¨�²t£®¬s§Wv¨~Á ¢¡t£®¤�ÊY¦�¨�ª~·Ë¨s©+©�ª~©�£®²t¨�°?�£ÈÇq¨�¤�¼s¨s©�ªÆ¦]©�ªi°�ªi¹t°t¤¢¨s©�©�ªW³°t¨sªi¹t¤�¯µÊ~Á
Ì[À(Î� Ó©+§~°t¤+¯®§W�£µªi°O³=¨�ýc¹t£ ´ §~¯µ¨�°Yè¤v¨�°Yv¨�°t¬e¨�¤1£®° À]£®¯®£®°�³±i¹]§~¯9¬eª~©�¦�ª~©+§û�¡t§W�é�¨s©�¨6·[©�¨s¨�¯µÊ�v©+§~°t¤+¯®§Wv¨�²ÀcÊL§-¡Y¹]¶½§~° Á Q/¨s©+¨~Ü{£µü£®¤ ´ ¨s©+ÊL²]£YW9¬s¹t¯µvªú£¥²�¨�°?�£®·UÊù�¡�¨ v©+§~°]¤�¯®§W�£µªi°.¨�ýc¹t£ ´ §~¯µ¨�°?�¤�ª~·�¡t¨�¼s¨s©�ªè¦t©+ªi°�ªi¹t°t¤Åé/£µ�¡]£®°��¡�¨«v©+§~°t¤+¯®§W�£µªi°O³¨�ýc¹t£ ´ §~¯µ¨�°Y�¤v¨�°Yv¨�°t¬e¨�£®°P�¡�¨Å§~¹tvªi¶½§W�£®¬Å£®²�¨�°O³�£µÇq¬s§W�£µªi°�¦t©+ªc¬e¨�¤�¤�Á
¢¡�¨�¦]©�ª~À]¯µ¨�¶½§W�£¥¬�¤v¨�°?v¨�°]¬e¨�¤Ïé/£®�¡�¼s¨s©�ªP¦t©+ªi°�ªi¹t°t¤§~°t²q¿`ª~©Ó¨s©�©�ªi°�¨sªi¹]¤A¼s¨s©�ª�¦t©�ªi°�ªi¹]°t¤8£®°��ÊY¦�¨�Ìͧ?Î8¡t§ ´ ¨vª�À�¨�§~°t°�ª~�§Wv¨�²è§~¤*) ¹]°t¤�¹t£µ�§WÀq¯µ¨,+qÀ�¨s·[ª~©�¨#¨e¸cv©!§~¬ek³£®°�±Â©+¹t¯®¨�¤/·[©�ªi¶ ¤v¨�°Yv¨�°t¬e¨�¤�é/£µ�¡ì¼s¨s©�ª2¦t©+ªi°�ªi¹t°t¤�£®°�¡�¨2¬eª~©�¦]¹t¤�ÁP ¢¡�¨Â§~°?v¨�¬e¨�²�¨�°Y�¤�ª~·�¼s¨s©�ª�¦t©+ªi°�ªi¹t°t¤£®°û¦t©�ª~À]¯µ¨�¶Æ§W�£®¬�¤v¨�°Yv¨�°t¬e¨�¤Ö£®°ûëÊc¦(¨BÌ[À(ÎP¡t§ ´ ¨�vªÀ�¨�¶Æ§~°Y¹t§~¯¥¯µÊ½§~°t°�ª~�§Wv¨�²2¨ ´ ¨�°2é/£®�¡ÆÀ]£¥¯®£®°�±i¹t§~¯]¬eª~©v³¦�ª~©+§OÁ���.- � )/#9� ó(' /g�"6 5 /219!0& ¢¡�¨#©+¹]¯µ¨¨e¸Ov©+§~¬e�£µªi°�¦t©�ªO¬e¨�¤�¤�¨e¸cv©!§~¬e�¤�©�¨�¤vªi¯¥¹��£µªi°©+¹t¯®¨�¤Eª~·{¼s¨s©�ª�¦t©�ªi°tªi¹t°t¤�é/£µ�¡L§~°Yv¨�¬e¨�²�¨�°?Ã�§W±i¤£®°6�¡�¨Ö¬eª~©�¦]¹]¤sÁ�Ûp°6�¡t£¥¤9¦]©�ªc¬e¨�¤+¤sÜ�¤vÊO°Y�§~¬e�£®¬Ö§~°t²¤v¨�¶½§~°Y�£®¬6·[¨�§W�¹�©�¨�¤ §W©�ªi¹t°t²þ¼s¨s©�ª ¦t©+ªi°�ªi¹t°t¤�§~°t²§W©�ªi¹t°]²Æ�¡�¨�£®©�§~°]°�ª~�§Wv¨�²�§~°?v¨�¬e¨�²t¨�°?�¤�§W©�¨�¹t¤v¨�²2§~¤§½¬eªi°t²]£µ�£µªi°�£®°2�¡�¨�©+¨�¤vªi¯®¹��£µªi°2©!¹t¯µ¨�¤sÁ ¢¡t¨s©�¨�§W©�¨��é�ª½é�§�Ê�vªÆ¨e¸cv©+§~¬e�©+¹t¯µ¨�¤�×
Ìͧ?νÞ�¹�vªi¶½§W�£¥¬�ä˸Ov©+§~¬e�£µªi°Ûk°��¡t£¥¤�¦t©�ªO¬e¨�¤�¤sÜt©+¨�¤vªi¯®¹��£µªi°«©+¹t¯µ¨�¤¢¬s§~°PÀ�¨Ï§~¹O³vªi¶Æ§W�£®¬s§~¯®¯µÊ ¨e¸Ov©+§~¬ev¨�²Ã·[©�ªi¶ ¼s¨s©�ªè¦t©+ªi°�ªi¹t°t¤é�£µ�¡#§~°?v¨�¬e¨�²�¨�°Y'�§W±i¤/Ì=âO¨�¬e�£µªi°½ÝcÁ ÝiÎw§~°t²#¤vÊO°O³�§~¬e�£¥¬�§~°t²ú¤v¨�¶Æ§~°?�£®¬�·U¨�§W�¹�©+¨�¤P§W©�ªi¹t°]²B¼s¨s©�ª¦]©�ªi°�ªi¹t°t¤�§~°t²��¡�¨�£®©�§~°]°�ª~�§Wv¨�²�§~°Yv¨�¬e¨�²�¨�°?�¤ÀcÊ §þ¶½§~¬+¡]£®°�¨4¯®¨�§W©+°t£®°�± v¨�¬+¡t°]£®ýY¹t¨þÌÍÞ�ªi°�¨§~°]² Uº¨�°t°�¨svsÜtØ����~æcÉ � §~¶½§~¶�ª~vª�§~°t²Åâ�¹t¶½£µ�§OÜØ������iÎAª~© ÀYÊ�¤��§W�£®¤v�£®¬s§~¯Y¦t©�ªO¬e¨�¤�¤�£®°t±ÌÍÐ�§WÄW§~£µé�§OÜØ������^§?Î!Á
Ìͧ?νçì§~°c¹t§~¯8ä˸Ov©+§~¬e�£µªi°Ûk°��¡t£¥¤�¦t©�ªO¬e¨�¤�¤sÜ�¼s¨s©�ª½¦]©�ªi°�ªi¹t°t¤�§W©+¨�±~©�ªi¹�¦�¨�²²t¨s¦(¨�°]²t£®°�±¢ªi°#�¡t¨�£µ©Ë¤vÊc°Y�§~¬e�£®¬�¦�ªi¤�£µ�£®ªi° ÜW�¡�¨�£µ©§~°]°�ª~�§Wv¨�² §~°?v¨�¬e¨�²t¨�°?sÜP§~°]² �¡t¨6¤vÊO°Y�§~¬e�£®¬§~°]²Æ¤v¨�¶½§~°Y�£®¬/·U¨�§W�¹�©+¨�¤º§W©+ªi¹t°t²��¡�¨�¼s¨s©�ªÅ¦t©�ªW³°tªi¹t°t¤sÁ à/¨�¤vªi¯®¹��£®ªi°ù©+¹t¯µ¨�¤2·[ª~©P�¡t¨�±~©�ªi¹�¦�¨�²¼s¨s©+ª�¦t©�ªi°�ªi¹t°]¤�§W©+¨Å¨e¸Ov©+§~¬ev¨�²èÀYÊ{¨e¸O§~¶½£¥°t£®°�±¡tªÙé4¶Æ§~°?Ê�¬eª~©�©�¨�¬e�§~°Yv¨�¬e¨�²�¨�°?�¤�·[ª~©/�¡�¨Ï¼s¨s©�ª

¦]©�ªi°�ªi¹t°t¤Æ¬s§~°»À�¨P¬eª ´ ¨s©�¨�²ù¹t°t²t¨s©½�¡�¨�¤�§~¶�¨·[¨�§W�¹�©�¨�¤�Á
����� ó ' /2�26 5r/g�<, � )/#9��� í���� #R145768/219!'& 6p&(,� ! , 143*5768/219!'&
¢¡�¨9¨e¸cv©!§~¬ev¨�² ©+¹t¯µ¨�¤£®°è¤v¨�¬e�£®ªi° ÝcÁ å�§W©�¨2¹t¤v¨�²EÀYÊ�¡�¨2Ð�ÑÓÒ�¤vÊO¤vv¨�¶ £®°��¡�¨Â©�¨�¤vªi¯¥¹��£µªi°Eª~·¢¼s¨s©�ªì¦t©�ªW³°�ªi¹t°]¤½£®°1¤v¨�°Yv¨�°t¬e¨�¤Â£®°1�¡�¨P¬eª~©+¦]¹t¤½¹t¤�¨�²1·Uª~©9�¡�¨©+¹t¯®¨�¨e¸cv©+§~¬e�£®ªi° Á � ªi°t¤�£¥²�¨s©+£®°�±2�¡�¨9©�¨�¤�¹t¯®�¤�ª~·��¡�¨§W¦t¦]¯¥£®¬s§W�£µªi°ª~·]¨e¸Ov©+§~¬ev¨�²½©+¹]¯µ¨�¤A·[ª~©Ë¼s¨s©�ª�¦t©�ªi°tªi¹t°t¤sÜ麨�¨e¸O§~¶½£¥°�¨�¡t¨½¤�¹t£µ�§WÀ]£¥¯®£µëÊ2ª~·�©+¹t¯µ¨�¤�·[ª~©��¡�¨�¬eª~©v³¦]¹t¤�Á4Ûp·��¡�¨s©�¨Ö§W©�¨Ö¤vªi¶½¨{¦t©+ª~À]¯µ¨�¶½¤Â£®°»�¡�¨{©+¨�¤vªW³¯®¹��£®ªi° ©+¹t¯µ¨�¤sÜ��¡�¨«¦t©+ª~À]¯µ¨�¶½§W�£®¬2©!¹t¯µ¨�¤�§~°t²q¿`ª~©9�¡�¨¦t©+£®ª~©+£µ�£µ¨�¤ºª~· �¡�¨�©+¹t¯®¨�¤�§W©�¨Ï¶�ªO²t£ÈÇ]¨�²8Á ¢¡t¨Ï©+¹t¯®¨Ï¤v¨s�é/£µ�¡«�¡t¨Å¶�ªO²t£ÈÇq¨�²�©+¹t¯µ¨�¤�£®¤�§W±i§~£®°
¹t¤v¨�²þÀcÊ �¡t¨BÐ�ÑAÒ ¤vÊc¤�v¨�¶ ·Uª~©1�¡�¨ú¤+§~¶�¨ù¬eª~©v³¦]¹t¤�Üq§~°t²{�¡�¨¤+¹t£µ�§WÀ]£®¯¥£µëʪ~·Ë©+¹t¯µ¨¶�ªc²]£ÈÇq¬s§W�£µªi°t¤�£®¤¬+¡t¨�¬�Ä~¨�²½£®°Ï�¡�¨�¤�§~¶�¨�¶½§~°t°�¨s©ÙÁÓ ¢¡�¨�©+¹t¯µ¨º¶�ªO²t£ÈÇq¬s§^³�£µªi°#§~°t²©�¨e³ë§W¦t¦]¯¥£®¬s§W�£µªi°·Uª~©w¼s¨s©�ª�¦t©�ªi°tªi¹t°t¤8é�£µ�¡t£®°�¡�¨º¬eª~©�¦]¹t¤Ó§W©�¨�£µv¨s©!§Wv¨�²¹t°Y�£®¯?©�¨�§~¤vªi°t§WÀ]¯®¨'©+¹t¯µ¨�¤Ó§W©�¨¨e¸Ov©+§~¬ev¨�² Á� õ @��� � @ �]ö � � ÷ � <?����; � � � � ø�< � k>8<
��� � <iD � � ; ö � � � >� ëø � ;=> ö �Öø � � >� � <?>��9<i> ö >Aø ö � k<i>A@ � >8<r��>8<iD
� ªi°t¤+£®²�¨s©+£®°t±è�¡�¨�Ç ´ ¨�¬eªi¶½¦(ªi°t¨�°?�¤«²t¨�¤�¬e©+£µÀ�¨�²B£®°¤v¨�¬e�£µªi°«ÝcÜO麨�¡t§ ´ ¨�£¥¶�¦]¯µ¨�¶�¨�°Yv¨�²Â§~°Â§W©!¬+¡t£µv¨�¬e�¹t©�¨·[ª~©{§~¹�vªi¶½§W�£¥¬s§~¯®¯µÊù§~°t²q¿`ª~©ì¶½§~°Y¹]§~¯®¯µÊ6¨e¸cv©+§~¬e�£¥°�±©�¨�¤vªi¯¥¹��£µªi°�©+¹t¯®¨�¤�·Uª~©Óê?§W¦]§~°�¨�¤v¨�¼s¨s©�ª/¦t©+ªi°�ªi¹t°t¤(·[©�ªi¶êi§W¦q§~°�¨�¤v¨#§~°t²Pä�°�±i¯®£®¤�¡«À]£®¯®£®°t±i¹t§~¯ ¬eª~©�¦�ª~©+§Æ§~°]²q¿`ª~©êi§W¦q§~°�¨�¤v¨#¶�ªi°�ªi¯®£®°t±i¹t§~¯8¬eª~©�¦�ª~©+§OÁLT £®±i¹�©�¨ÆØŤ�¡�ª`é/¤§~°9ª ´ ¨s© ´ £µ¨séBª~·8�¡�¨�¤vÊO¤vv¨�¶�ÁwÛp°9�¡�¨�Ç]©+¤v�¤vv¨s¦8ÜO�¡�¨êi§W¦q§~°�¨�¤v¨�§~°t²9ä�°�±i¯®£®¤+¡½¤v¨�°Yv¨�°t¬e¨�¤�£®°9�¡�¨�Àq£®¯®£®°�±i¹]§~¯¬eª~©�¦]¹]¤ì§~°]²q¿`ª~©Ö�¡�¨üêi§W¦]§~°t¨�¤v¨1¤v¨�°?v¨�°]¬e¨�¤�£®°.�¡�¨¶�ªi°�ªi¯¥£®°�±i¹t§~¯Ó¬eª~©�¦]¹t¤�§W©�¨#¤v¨s¦]§W©+§Wv¨�¯®Ê{§~°t§~¯µÊc¼s¨�²ìÀYÊêi§W¦q§~°�¨�¤v¨�§~°t²Æä�°�±i¯®£®¤�¡½¦]§W©+¤v¨s©+¤�Á Ûk°9�¡�¨�°�¨e¸O�¤vv¨s¦8Ü�¡�¨6§~°?v¨�¬e¨�²�¨�°Y�¤ ª~·�¼s¨s©�ª4¦t©�ªi°�ªi¹t°]¤Öé/£µ�¡t£¥°��¡�¨êi§W¦q§~°�¨�¤v¨�¤v¨�°Yv¨�°t¬e¨�¤Ï£®°ì�¡�¨�¬eª~©�¦q¹t¤�§W©�¨½£®²�¨�°Y�£ÈÇ]¨�²§~¹�vªi¶½§W�£¥¬s§~¯®¯µÊ2·U©+ªi¶ êi§W¦]§~°t¨�¤v¨Ï§~°t²{ä�°�±i¯®£¥¤�¡2§~°t§~¯È³ÊO¤�£®¤#©�¨�¤�¹]¯µ�¤#£®° �¡�¨�À]£®¯¥£®°�±i¹t§~¯�¬eª~©�¦]¹t¤sÁ T�©�ªi¶ �¡�¨¶�ªi°�ªi¯¥£®°�±i¹t§~¯i¬eª~©+¦]¹t¤sÜW¡�ªÙ麨 ´ ¨s©�Ü~ªi°t¯®Ê��¡t¨ºêi§W¦q§~°�¨�¤v¨§~°t§~¯µÊO¤�£®¤9©�¨�¤�¹]¯µ�¤½é/£®�¡Ã�¡�¨Ö¤vÊO°Y�§~¬e�£®¬ì¦(ªi¤+£µ�£µªi°üª~·¼s¨s©�ª ¦t©�ªi°tªi¹t°t¤è§W©+¨»¨e¸Ov©+§~¬ev¨�² Á ¢¡�¨ùêi§W¦q§~°�¨�¤v¨§~°t§~¯µÊO¤�£®¤P©�¨�¤�¹t¯®�¤�é/£µ�¡q¿`é�£µ�¡�ªi¹�P§~°Yv¨�¬e¨�²�¨�°Y��§W±i¤·[ª~©�¼s¨s©�ª2¦t©�ªi°�ªi¹t°]¤�§W©�¨½¤�vª~©�¨�²Ö§~¤*) êi§W¦]§~°t¨�¤v¨ � ª~©v³¦]¹t¤¢é/£µ�¡«Þ�°?v¨�¬e¨�²t¨�°?� Ó§W±i¤ +q§~¤�¤�¡�ªÙé�°«£®°��¡�¨ÏÇ]±W³¹�©�¨~Á�ä�§~¬+¡{¼s¨s©�ª9¦]©�ªi°�ªi¹t°«£¥°��¡�¨¬eª~©+¦]¹t¤/£¥¤/¶½§~°c¹O³§~¯®¯µÊ{¨e¸O§~¶Æ£®°�¨�²Ö£®°ìª~©+²�¨s©�vª{§~°t°�ª~�§Wv¨½�¡�¨½¬eª~©+©�¨�¬e§~°Yv¨�¬e¨�²�¨�°?P�§W±i¤sÜ�£®·�©�¨�ýc¹t£µ©�¨�² Á T�©+ªi¶¾�¡�¨Ö§~°t°�ªW³�§Wv¨�²�£®°�·[ª~©+¶½§W�£®ªi° ÜY©+¨�¤vªi¯®¹��£µªi°9©+¹t¯®¨�¤�·[ª~©�¼s¨s©�ª#¦t©�ªW³°�ªi¹t°]¤º§W©+¨�¨e¸Ov©+§~¬ev¨�²«¶Æ§~°Y¹t§~¯¥¯µÊ½ª~©�§~¹�vªi¶½§W�£®¬s§~¯¥¯µÊ~Áçì§~°Y¹t§~¯c¨e¸Ov©+§~¬e�£µªi°½£¥¤A¦t©+¨s·U¨s©+§WÀq¯µ¨�·[ª~©Ë§~¬sýY¹]£µ©+£®°�±�©�¨e³¯®£®§WÀq¯µ¨9©!¹t¯µ¨�¤sÜ�À]¹�#©�¨�ýc¹t£µ©�¨�¤�§Ö¡t£®±i¡1¬eªi¤vsÁüÛk°1¬eªi°O³v©+§~¤vsÜ��¡�¨�§~¹tvªi¶½§W�£®¬Ö¨e¸Ov©+§~¬e�£µªi°ù¦]©�ªc¬e¨�¤+¤�¡t§~¤«§
Aligned Sentence PairJapanese Sentence
"hon-o yomi-tai."
Japanese and English Bilingual Corpus
Japanese Sentence
Japanese Mono- lingual Corpus
Japan-ese
Analy-
zer
(ALT-J/E)
Automatic Alignment of Japanese Zero Pronouns and their Antecedents
Alignment of Japanese Zero Pronouns and their Antecedents
Words / Phrases Alignment
Rejection of Unsuitable Aligned Sentence Pairs
ø = "I" hon (book) :NOUN
yomu (read) :VERB
Japanese Corpus with Antecedent Tags
U-SENT tense : PRESENT modal: "-tai " (HOPE) VSA: SUBJ's Bodily Action, SUBJ's Thinking Action
Manual Annotation of Japanese Zero Pronouns
and their Antecedents
Antecedent Annotation
Grouping Zero Pronoun Candidates
Zero Pronoun Annotation
Grouping Antecedent Candidates
English Analyzer
English Sentence"I want to read a book."
Manual Rule Extraction
Rule Creation
Automatic Rule Extraction
Machine Learning of Rules
Extracting Features Grouping Features
Extracted Resolution Rules for Japanese Zero PronounsIF SUBJ = ø & modal = "-tai " (HOPE)THEN ø <-- "watashi " (I)
SUBJ (ga) PREDOBJ (o)
Tw£µ±i¹�©�¨�ØW×ÏÒ�©�ªO¬e¨�¤�¤�·Uª~©ä˸Ov©+§~¬e�£µªi°Öª~·�ࢨ�¤vªi¯¥¹��£µªi°à/¹]¯µ¨�¤�·Uª~©�êi§W¦]§~°�¨�¤�¨ÅÚ(¨s©�ª½Ò�©�ªi°�ªi¹t°t¤¡t£µ±i¡9¦�ªi¤�¤�£µÀq£®¯®£µ�ʪ~·Ó¨e¸cv©+§~¬e�£¥°�±�¦t©�ª~À]¯®¨�¶½§W�£®¬¢©!¹t¯µ¨�¤sÁâO¹t¬!¡P�ÊY¦�¨�¤�ª~·�§~¹�vªi¶½§W�£¥¬s§~¯®¯µÊ�¨e¸Ov©+§~¬ev¨�²�©+¹t¯µ¨�¤/©�¨e³ýc¹t£µ©�¨P¡c¹t¶½§~°»¬+¡�¨�¬+Äc¤�§~°]²Ã¶�ªO²t£ÈÇq¬s§W�£®ªi°t¤�·[ª~©9¨e¸c³v©+§~¬e�£®°t±½©�¨�¯®£®§WÀq¯µ¨�©!¹t¯µ¨�¤v¨s�¤sÁÛk°þ�¡�¨6°t¨e¸c1¤vv¨s¦8Ü2�¡�¨B¨e¸Ov©+§~¬ev¨�²L©�¨�¤vªi¯¥¹��£µªi°
©+¹t¯®¨�¤«§W©�¨è¹t¤�¨�²ù·Uª~©{�¡�¨è§~°t§W¦q¡�ª~©+§1©�¨�¤�ªi¯®¹��£µªi°ùª~·êi§W¦q§~°�¨�¤v¨2¼s¨s©�ª�¦t©�ªi°�ªi¹]°t¤£¥°è�¡�¨2¬eª~©�¦�ª~©+§{ÀYÊE�¡�¨êi§W¦q§~°�¨�¤v¨9§~°]§~¯µÊY¼s¨s©ÙÁ ¢¡t¨Æ¤�§~¶�¨Â¤v¨�°?v¨�°]¬e¨�¤Å£¥°Ö�¡�¨¶�ªi°�ªi¯¥£®°�±i¹t§~¯Å§~°t²q¿`ª~©ÖÀ]£¥¯®£®°�±i¹t§~¯Ï¬eª~©�¦�ª~©+§B§W©�¨ü£®°O³¦]¹�vv¨�²Ãvªè�¡�¨ì¤vÊO¤vv¨�¶ §~°t²Ã©�¨�¤vªi¯®¹t�£µªi°1©+¹t¯®¨�¤½§W©�¨§W±i§~£®°è¨e¸cv©+§~¬ev¨�²�§~°t²�¶½ªc²t£µÇ]¨�²ì·Uª~©�¡�¨9êi§W¦q§~°�¨�¤v¨¼s¨s©�ªü¦]©�ªi°�ªi¹t°t¤�Áþ ¢¡t¨�¤v¨Ö¦t©�ªO¬e¨�¤�¤v¨�¤«§W©+¨�©�¨s¦�¨�§Wv¨�²¹t°Y�£®¯ �¡�¨¤vÊc¤�v¨�¶ ¬s§~°t°tª~¢¨e¸cv©!§~¬e�§~°YÊ«¶�ª~©�¨�©+¨�¤vªW³¯®¹��£®ªi°�©+¹t¯®¨�¤�·[ª~©�¡�¨�êi§W¦q§~°�¨�¤v¨Â¼s¨s©�ª{¦]©�ªi°�ªi¹t°t¤£®°�¡�¨Ï¬eª~©+¦(ª~©!§OÁ ¢¡]£®¤B¶�¨s�¡�ªO²�¡t§~¤ùÀ�¨s¨�°�£®¶½¦]¯µ¨�¶�¨�°Yv¨�²Ô£®°Ô§
êi§W¦q§~°�¨�¤v¨e³=vªW³ëä�°t±i¯®£®¤�¡Ô¶½§~¬!¡t£®°�¨ v©+§~°]¤�¯®§W�£µªi° ¤vÊO¤k³v¨�¶�ÜtíÂî ï�ð ñ òcó Ì[Û�Ä~¨�¡]§W©+§#§~°t²Â¨s�§~¯=ÁµÜ(Ø����OØÙÎ!Áº ¢¡�¨¤vÊO¤vv¨�¶ £®°XTw£µ±i¹t©�¨½Ø�¬s§~°«¨e¸Ov©+§~¬e/ä�°�±i¯®£®¤�¡Âv©+§~°]¤�¯®§^³�£µªi°Å¨�ýc¹t£ ´ §~¯µ¨�°?�¤ ª~·�êi§W¦]§~°�¨�¤�¨º¼s¨s©+ª�¦]©�ªi°�ªi¹t°t¤Ó·[©�ªi¶§~¯®£µ±i°t¨�²�¤v¨�°Yv¨�°t¬e¨6¦]§~£µ©+¤sÁ Þ�¬s¬eª~©+²t£®°t±i¯µÊ~ÜÆ�¡�¨»©�¨e³¤�¹t¯®�¤�¬s§~°Â§~¯®¤vªÏÀ�¨/¹]¤v¨�²½vªÅ¨e¸cv©!§~¬eº©!¹t¯µ¨�¤Ë·[ª~©�v©!§~°t¤k³¯®§W�£®°t±èêi§W¦]§~°�¨�¤�¨�¼s¨s©�ª�¦t©�ªi°tªi¹t°t¤�£®°Yvª�ä�°�±i¯¥£®¤�¡ £®°

§�êi§W¦]§~°t¨�¤v¨e³=vªW³ëä�°�±i¯¥£®¤�¡ì¶½§~¬+¡t£¥°�¨v©!§~°t¤�¯®§W�£µªi°ì¤vÊO¤k³v¨�¶�Á T�ª~©A¨W¬s£µ¨�°?Ó¡Y¹t¶Æ§~°�£®°?v¨s©!§~¬e�£µªi°�£®°��¡�¨�¶½§~°O³¹t§~¯?¦t©�ªO¬e¨�¤�¤sÜ^é�¨º¹t¤v¨'�¡�¨º£®°Yv¨s©�·[§~¬e¨�ª~·t§¢é/£¥²�¨�¯µÊ�¹t¤v¨�²� � � Àt©�ª`é/¤v¨s©�Üt¤�¹]¬+¡2§~¤¢Ð�¨s�¤�¬s§W¦�¨�Ð�§ ´ £µ±i§Wvª~©�ª~©Ûk°?v¨s©+°t¨s/ä˸O¦]¯µª~©�¨s©ÙÁÛk°P�¡t¨·[ªi¯®¯µª`é/£®°�±Â¤�¹�À]¤v¨�¬e�£®ªi°t¤sÜ(é�¨#²�¨�¤�¬e©+£®À(¨�¡�¨
²�¨s�§~£®¯¥¤�ª~·�§~¹�vªi¶½§W�£®¬s§~¯®¯®Ê�§~°]²è¶½§~°c¹t§~¯®¯µÊ{¨e¸cv©!§~¬ek³£®°�±{©�¨�¤vªi¯®¹t�£µªi°�©+¹]¯µ¨�¤�·[ª~©�¡t¨2ê?§W¦]§~°�¨�¤v¨Â¼s¨s©�ªì¦t©�ªW³°�ªi¹t°]¤�£®°2�¡�¨Ï¬eª~©�¦�ª~©+§OÁ� ��� í &(6 # � �g1�� !�� ñ 6 � 6p&(���C� 6p&(, ó &���#R1����
���.&0/g�.&�5r� �êi§W¦q§~°�¨�¤v¨�¤v¨�°Yv¨�°t¬e¨�¤'§~°t²#ä�°t±i¯®£®¤�¡¤v¨�°?v¨�°]¬e¨�¤'£®°Å�¡�¨¬eª~©�¦�ª~©+§�§W©�¨§~°t§~¯µÊc¼s¨�²«£®°2�¡�¨�·[ªi¯®¯µª`é/£®°�±�¶½§~°]°�¨s©�Á� ���p�R� í &�6 # � �g1�� ! � ñ 6 � 6p&(���g� � � &0/2� &(5r� �êi§W¦q§~°�¨�¤v¨#¤v¨�°?v¨�°]¬e¨�¤�§W©+¨Å§~°t§~¯®ÊY¼s¨�²ìé/£µ�¡P�¡�¨#¶�ª~©v³¦]¡�ªi¯®ª~±i£®¬s§~¯Hܽ¤vÊO°?�§~¬e�£¥¬WÜƧ~°t²-¤v¨�¶Æ§~°?�£®¬Ã§~°t§~¯µÊc¼s¨s©+¤ª~·�êi§W¦]§~°�¨�¤�¨P£®°1íÂî�ï�ð ñ òcó Ì[ÛpÄ~¨�¡t§W©+§�§~°t²ü¨sƧ~¯HÁµÜØ����OØÙÎ!ÁÔ ¢¡�¨�¤vÊO°Y�§~¬e�£®¬è§~°t²û¤v¨�¶½§~°Y�£®¬�¤vv©+¹]¬e�¹�©�¨ª~·/�¡t¨�ê?§W¦]§~°�¨�¤v¨«¤�¨�°?v¨�°t¬e¨«£¥¤ÏÇq©+¤v�¬e©�¨�§Wv¨�² Á� ¢¡�¨êi§W¦q§~°�¨�¤v¨ ¤vv©+¹t¬e�¹�©+¨�£®¤ì¹t¤v¨�²4·[ª~©ì�¡t¨�§~¹�vªi¶Æ§W�£®¬v©+§~°t¤+¯®§W�£µªi° £®°YvªÔä�°�±i¯®£¥¤�¡ £®° í9î ï�ð ñ òcó ÁÖ ¢¡�¨êi§W¦q§~°�¨�¤v¨�¤vv©+¹]¬e�¹�©�¨~Ü��¡�¨s©�¨s·[ª~©�¨~Üt£®°]¬s¯®¹t²�¨�¤��¡�¨�¤vÊO°O³�§~¬e�£®¬Å¦�ªi¤�£µ�£µªi°]¤�ª~·'�¡�¨#êi§W¦]§~°�¨�¤�¨¼s¨s©�ªÂ¦t©�ªi°tªi¹t°t¤sÜé/¡t£¥¬+¡�¶Å¹t¤v�À�¨�v©+§~°t¤�¯®§Wv¨�²P£®°?vª½ä�°�±i¯®£®¤+¡ Üc§~°]²��¡�¨¤v¨�¶½§~°Y�£®¬�¬eªi°]¤vv©+§~£®°Y�¤�·[ª~©¢�¡�¨ê?§W¦]§~°�¨�¤v¨�¼s¨s©�ªÆ¦t©�ªW³°�ªi¹t°]¤·[ª~©+¬e¨�² ÀcÊè�¡�¨ ´ ¨s©+À1é/£µ�¡t£®°è�¡�¨Pêi§W¦q§~°�¨�¤v¨¤v¨�°Yv¨�°t¬e¨~Á �6¡�¨�°E§�¼s¨s©�ª{¦t©�ªi°�ªi¹t°Ö£¥¤�©�¨�¤vªi¯ ´ ¨�²èÀYʧ�©+¹t¯®¨~Ü�§Ö²�¨sv¨s©+¶½£¥°�¨�²1§~°?v¨�¬e¨�²t¨�°?§~°t²1§~°1Û7� ª~·�¡�¨#§W¦t¦]¯®£®¨�²«©+¹t¯®¨�·Uª~©�¨�§~¬!¡�¼s¨s©�ª9¦]©�ªi°�ªi¹t°ì§W©�¨#§~¯®¤vª§~°t°�ª~�§Wv¨�²8ÁB /¡t£®¤�£®°�·[ª~©+¶½§W�£®ªi°1£®¤½¹t¤v¨�²Ãvª2á�¹t²�±~¨é/¡�¨s�¡t¨s©A¨e¸�£®¤v�£®°�±�©!¹t¯µ¨�¤ é/£¥¯®¯^©�¨�¤vªi¯ ´ ¨�¼s¨s©�ª/¦t©+ªi°�ªi¹t°t¤¤�¹t¬s¬e¨�¤+¤v·[¹]¯®¯µÊ~Ü/§~°t²6é/¡]£®¬+¡6¼s¨s©�ª1¦t©+ªi°�ªi¹t°t¤9©�¨�ýc¹t£µ©�¨·Í¹�©��¡�¨s©�©�¨�¤�ªi¯®¹��£µªi°2©+¹]¯µ¨�¤sÁ
T�ª~©#¨e¸�§~¶�¦]¯µ¨~ÜË·[©�ªi¶%�¡�¨�êi§W¦]§~°�¨�¤�¨9¤v¨�°Yv¨�°t¬e¨�£®°�¡�¨�§~¯®£µ±i°�¨�²¤v¨�°Yv¨�°t¬e¨�¦]§~£µ©ºÌHÝiÎÓ£®° Tw£µ±i¹�©�¨�ØWÜ~�¡�¨�·[ªi¯È³¯µª`é/£®°�±2¤vÊO°?�§~¬e�£®¬Æ§~°t²�¤v¨�¶½§~°Y�£®¬�¤vv©+¹t¬e�¹t©�¨�£®¤�¬e©�¨e³§Wv¨�² Á=�� > =A@CBEDGF > �OIKT-UEI �GI W U N FKW� \]\ j]B eCfih o k q � B��8^��C`��_`-e��� q d���9\*o k q � q � \]\ j Y=�� > ��� d��9q ��� b ��q d�� � k � q d�� b � � �4o"!����#!io k \ $&%Gq l q d k n k� k d� k d�� k�=�� >'((((((((((((()
* + ,.-./�021/3547653 829;:2<=: �C`?> 82:�9;@:7A `7B C : ^ <=82:2A `D2E5FGH N FKW7=JIge 8�: >K�+ L <=M fOh :2A `ON < I M�P ^�� ^ A `�B e��Q><=M fOh :2A `ON < `7I�BR��S�BR��T ^ A `7B e��U V, W2021 X Y G7Z�4\[3 ] ^ �GI.(J`_?VES F H a�bc L+ ,�021 d#e G�653f]3HOg eCfih :7A ` _ I a-.U�021 �OIKTh_ L9I I X ajic Lk ,�l m n e5o�p5q ] q HOr s=t�u�vw.x�l m y;z={p5q Y o5|} Z e\e ~�|7p�} ] o Z |}2p I t������7�
����������������
��������� �������#�����"�����h�f�����=�"�� ¢¡¤£��j¥�£���¦§£��¨ª©�«§¬��®¯°®.±�©&².±�©�³�±�®µ´O¶�±·´Q©�´Q¬¹¸�º;±�»½¼&¸°¾¿¶��¬�¬ ÀÁ®Â¨Ã©�Ä«§¬��®�¯·Å�´O«Q«Q±;¶ÇÆ=¾¿¶��¬È¬�ɪÊ�ËQËQ̧Í\´Q©�»·²¯�±ÏÎ��©�зÑÒ¶�´QÓÔÄÓÕ´O¶×ÖØ´O¶�®.±;¶ÙÆ ÚÛ¬¹±�´O².ÜQ¶Ý´Q©�»ÞÅ�±�Óàߤ±;¶�¬¹±;¸QÉáÊ�ËQË�Ê�Í2âãä±�å�²;Éز¯Û±Â®.¸�©&²´Q³�²�³Â®.².¶�æ�³�²æ�¶±Ï�®\³�ܧ©èçQ±;¶².±�»é�©&².Ü´êß�´O¶²�´Q¬�®¸�©&²´Q³�²�³h®².¶�æ�³�²æÛ¶±QÉ�ëh¯�ȳ�¯Õ�®Ã®�ÓÕȬ�´O¶ì².ܲ¯Û±íÈ©è².±;¶�©�´Q¬�¨ª©Û«§¬�È®¯�®.².¶�æ�³�²æÛ¶�±fÜQî ��ï�ðêñòôó�� âõÛÜQ¶ö±�åÛ´QÓàß�¬¹±QÉíî#¶Ü§Ó÷²¯Û±é¨ª©Û«§¬È�®¯¢®.±�©&².±�©�³�±é�©´Q¬�¹«§©�±�»·®.±�©&².±�©�³�±�ß�´Q¹¶�Æ�̧Í2É첯۱Õî"ܧ¬�¬¹Üøëh�©Û«ùß�´O¶²�´Q¬®.¸�©è²´Q³�²È³ê®.².¶�æ�³�²æ�¶±ê�®`³�¶±�´O².±�»�âúJû�ü�ýèþ ÿ����Áþ��������"þ�� ���������#ÿ���������ÿ������èþ������������������ ���� �� � ú! ü"############$
% k�&.w�'�l�(x�)�&�*2l�( n�+-,/.�021�3547698 u;:�s=<R�?>/@A:CB 826 s 6 �?D�@+-1!EF3 D2G+-H�I=.�J 3 47698 u;:�u���s 6LK G 8 � �M�N k�&�l�( d e5o�p5qPOq HOr s=t�u7v 6�Q Dw.x�l�( R +�ST3VU B 6�8 s�G����CWXB 8 G��?G�t���Y iM�N k�&�l m "#$[Z o�p5q\Oq HOr^]C< 826�Q D_G�u�v 6�Q Dw.x�l m n +[. 3 ] 6 D 698 �`<R� 6�8+�a�EFE[b 3 �7G�t��c:s=<R�7>�tCW � 8 G 8 ����s�s � ����
������������������È� �ed�¥��gf �Û¥?�#¦Ç���=�"���hf £��j¥Õ���hò��ji�����£���£k £�l?�nm\l?�����odô���Â���qp ¥ø �£���l�Â�j¥ø£&¦§£�pô£��j¥�� õÛ¶Ü§Ó ²¯Û±Ï´Q©�´Q¬¹¸�®��®Ò¶±�®æ�¬�²®fÜQîsr§´Oß�´Q©�±�®.±Ï´Q©�»·¨Ã©�Ä«§¬��®�¯ ´Q¬È¹«§©Û±�»Ô®.±�©&².±�©�³�± ß�´Q¹¶�®�ÉQ²¯Û± ®.¸�®².±�Ó ±�å�².¶2´Q³�²®ß�´Q¹¶2®äÜQîtr§´Oß�´Q©Û±�®.±àë¿ÜQ¶�»�®�uøß�¯�¶�´Q®.±�®f´Q©�»ö²¯Û±��¶Ò¨Ã©�Ä«§¬��®�¯×±Cv�æ�¹çO´Q¬¹±�©è² ëÃÜQ¶2»�®�uøß�¯Û¶2´Q®.±�® ¼�¸Ý³�ܧÓàß�´O¶��©Û«²¯Û± ² ë¿Ü®².¶�æ�³�²æÛ¶±�®�âhÅ`¯Û±�©�É�¼�´Q®.±�» ܧ© ²¯Û±\»�È®³;æ�® Ä®¹Ü§© �© ®.±�³�²¹Ü§© Ì�âxw�É`´Q¬�¹«§©Û±�» ®.±�©è².±�©�³�±µß�´Q¹¶2®Õ©ÛÜQ²®æ��²´O¼�¬¹±¿î#ÜQ¶ì²¯Û± ±�å�².¶�´Q³�²¹Ü§©ÕÜQî�¶±�®.ܧ¬ÈæÛ²¹Ü§© ¶�æ�¬¹±�®ôî"ÜQ¶r§´Oß�´Q©Û±�®.±hº;±;¶�Üíß�¶Ü§©�ܧæ�©�® ´O¶± ´QæÛ².ܧÓÕ´O²�³;´Q¬È¬¹¸à�»Û±�©�IJ!y�±�»Â¹î�´Q©&¸ÕÜQî�²¯Û± î"ܧ¬�¬¹Ü�ëä�©Û«\³�ܧ©�»�¹²¹Ü§©�®Ã´O¶±ÒÓà±;²;âz Åh¯Û±;¶±ÃÈ®�´ »�!{¤±;¶±�©�³�±ª¼¤±;²�ëñ;±�© ²¯Û± ©&æ�Óí¼¤±;¶�ÜQî³;¬È´Qæ�®.±�® ëh¯Ûܧ®±|r§´Oß�´Q©Û±�®±fçQ±;¶¼µ�® ©ÛÜQ²`´Q¬È¹«§©Û±�»ëä¹²¯�´Q©�¨Ã©Û«§¬��®¯�©Ûܧæ�©�É�ëh¹²¯��©à²¯Û±\r§´Oß�´Q©Û±�®.±´Q©�´Q¬¹¸�®��®Ò¶±�®æ�¬�²;É�´Q©�» ²¯Û±Ï©�æ�Ó\¼¤±;¶fÜQ;¬�´Qæ�®.±�®ëä¹²¯��©Â²¯Û±ê¨Ã©Û«§¬��®¯�´Q©�´Q¬�¸�®È® ¶±�®æ�¬¹²;âz Åh¯Û±~} Å ®¸�®.².±�Ó î"´Q�¬È®é².Ü ².¶�´Q©�®¬�´O².± ®.ܧÓà±ë¿ÜQ¶�»�®�âz Åh¯Û±`¨ª©Û«§¬È�®¯ÔÖØ´O¶�®.±;¶ÃÈ®ìæ�©�´O¼�¬¹± ².Ü ÓÕ´OÐQ±h´fî=æ�¬�¬®¸�©&²´Q³�²�³ê®.².¶2æ�³�²æÛ¶±Qâãä±�å�²;É ²¯Û±�r§´Oß�´Q©Û±�®.± º;±;¶Ü ß�¶Ü§©Ûܧæ�©�®Ù�©÷²¯Û±r§´Oß�´Q©Û±�®.±à®.±�©&².±�©�³�±�®f´Q©�» ²¯Û±Ô².¶�´Q©�®¬È´O²¹Ü§©µ±Cv�æ�¹çO´?Ĭ¹±�©&²®ÔÜQî`²¯Û±�¹¶à´Q©&².±�³�±�»Û±�©&²®Ï�© ¨ª©Û«§¬È�®¯ ®.±�©è².±�©�³�±�®´O¶±é±�å�².¶�´Q³�².±�»×æ�®È©Û« Ê2�½¯�´Q©�»�Ä »Û±;çQ±�¬¹ÜQߤ±�» ´Q¬�¹«§©�ÄÓà±�©&²`¶�æ�¬�±�®;âõÛÜQ¶�±�åÛ´QÓàß�¬¹±QÉ î"¶Ü§Ó ²¯Û± º;±;¶�Ü ß�¶Ü§©�ܧæ�© �© ²¯Û±��� Ä ³;´Q®.± Æ=®æ�¼`� ±�³�²2Íù�©½²¯Û±�rè´Oß�´Q©Û±�®.±·®±�©è².±�©�³�± �©
�[���7�A���7� �2���������A���A�t���A���t���2� �����2�_�7���x�7��� �7���9�x�A�����t���2��t�[� �7�C�s�?� �����������2�¡ h��¢�����£��¡¤T ���¢�����£��?¥�¦�§§¨9��©-ª

´Q¬�¹«§©�±�» ®±�©è².±�©�³�±hß�´Q¹¶hÆ�̧Í2É&�²®ì´Q©è².±�³�±�»Û±�©&²ÃÈ®ì´QæÛ².ÜOÄÓÕ´O²�³;´Q¬È¬¹¸ù»Û±;².±;¶�ÓÕ�©�±�»µ´Q® ²¯Û±Ô®æÛ¼`�.±�³�²ä�©µ²¯Û±\¨Ã©�Ä«§¬��®�¯µ®.±�©&².±�©�³�±ÇÆ ����� Í2É�´Q®Ò®¯ÛÜ�ëä© È©Ç²¯Û±�� r§´Oß�´Q©�±�®.±� ÜQ¶ß�æ�®fëh¹²¯� ©&².±�³�±�»Û±�©è²ÔÅô´O«§®;À�¼�¬�Ü�³�ÐöÈ© õô�«§æÛ¶±ÊOâ����� ����d���� ���ô����¥��Û¥ø�"��� ���hò��ji�����£���£k £�l?�nm\l?�����odô���Â���qp ¥ø �£���l�Â�j¥ø£&¦§£�pô£��j¥���°¹²¯ r§´Oß�´Q©�±�®.± Óàܧ©Ûܧ¬��©�«§æ�´Q¬&³�ÜQ¶�ßjÜQ¶2´�Éè´Q©à´Q©�´Q¬¹¸�®.²ëh¯ÛÜäë¿´Q©&²®ô².Ü ÓÏ´OÐQ±¿¶�±�®.ܧ¬�æÛ²¹Ü§©í¶�æ�¬¹±�®�î#ÜQ¶Xr§´Oß�´Q©Û±�®.±º;±;¶Ü¢ß�¶Ü§©Ûܧæ�©�® ȩᲯ۱ ³�ÜQ¶ß¤ÜQ¶�´½Ó æ�®.² ´Q©�©ÛÜQ²´O².±²¯Û±�¹¶Â´Q©è².±�³�±�»�±�©è²®�¼�¸ ¯�´Q©�»�â½Å�Ü ´Q³2¯�¹±;çQ± ´Q© ±;î#Äy�³;¹±�©&² ´Q©�©ÛÜQ²´O²¹Ü§©�ß�¶Ü�³�±�®�®;É�ëñê¯�´�çQ±ê»Û±;çQ±�¬¹ÜQߤ±�»ù´².Ü�ܧ¬èî"ÜQ¶ô´Q©�©ÛÜQ²´O²�©Û« ´Q©è².±�³�±�»Û±�©&²®ØÜQîorè´Oß�´Q©Û±�®.±Ãº;±;¶Üß�¶Ü§©�ܧæ�©�® �© rè´Oß�´Q©Û±�®.±ê®.±�©&².±�©�³�±�®äëh¹²¯�È©�²¯�±ê³�ÜQ¶.ÄߤÜQ¶�´�â�Åh¯��®fß�¶�Ü�³�±�®®íæ�®.±�®ê²¯�±Ï´Q©�´Q¬¹¸�®�®f¶�±�®æ�¬¹²®fÜQîr§´Oß�´Q©Û±�®.±Ô®.±�©è².±�©�³�±�®ÏÆ=®.±�³�²¹Ü§© w�â�ÊOâ�Ê�Í2âíÅh¯Û± »�±;²´Q�¬�®ÜQîÛ²¯��®�ß�¶Ü�³�±�®®�´O¶±¿»Û±�®³�¶��¼j±�»í�©f²¯Û±Ãî#ܧ¬�¬�Ü�ëh�©�«`®.±�³7IJ¹Ü§©�®�â�������=� �2p�£��j¥ø�"� ���=��� k £�lø��m\lø�j���gd����� ³;³�ÜQ¶�»��©Û«µ².Ü ²¯Û±Ï¶±�®æ�¬¹²®íÜQî ²¯Û±erè´Oß�´Q©Û±�®.±Â´Q©�´Q¬�ĸ�®�®à�© ´�r§´Oß�´Q©Û±�®±�Ä ².ÜOÄ ¨ª©Û«§¬�È®¯ } Å ®.¸�®.².±�ÓùÉ ²¯Û±º;±;¶Ü ß�¶Ü§©Ûܧæ�©�®�²¯�´O²ôÓ\æ�®²�¼¤± ±�å�ß�¬��³;¹²¬�¸h².¶�´Q©�®�¬�´O².±�»�©·¨Ã©Û«§¬��®�¯ ´O¶±Ï±�å�ß�¬��³;�²¬¹¸ ´Q©�©�ÜQ²´O².±�» �©·²¯Û±Ï®.¸�©�IJ´Q³�²�³ ´Q©�»°®.±�ÓÏ´Q©è²�³ö®.².¶2æ�³�²æÛ¶±öÜQîí²¯�±öÈ©Ûß�æÛ².².±�»r§´Oß�´Q©Û±�®.± ®±�©è².±�©�³�±�® Æ"±QâR«Ûâ¹Éä±�å�´QÓàß�¬¹± Æ�w§Í.Í2â� hÜøë ı;çQ±;¶�Éè´Q®Ø뿱 »��®³;æ�®®.±�»íÈ©\®.±�³�²�ܧ©ÕÌ�âxw�ɧ²¯Û± ®.±�©&².±�©�³�±´Q©�´Q¬¹¸�®�®\±;¶¶ÜQ¶à³;´Qæ�®±�®\±;¶�¶Ü§©Û±;ܧæ�® º;±;¶Üöß�¶Ü§©�ܧæ�©�®;âÅ`¯Û±;¶�±;î#ÜQ¶±QÉ첯�±�´Q©�´Q¬¹¸�®² Ó æ�®.²à´Q©�©ÛÜQ²´O².±ùëä¯Û±;²¯Û±;¶²¯Û± º;±;¶Ü ß�¶Ü§©Ûܧæ�©¢³;´Q©�»��»�´O².±�® �©¢²¯�± r§´Oß�´Q©Û±�®.±´Q©�´Q¬¹¸�®�® ¶±�®�æ�¬¹²ö´O¶± ´Q³�²æ�´Q¬�¬¹¸ º;±;¶Ü½ß�¶Ü§©�ܧæ�©�® ÜQ¶©ÛÜQ²;â õÛÜQ¶Ç±���³;�±�©�³�¸QÉÒ²¯Û± r§´Oß�´Q©Û±�®±·´Q©�´Q¬¹¸�®�®Â¶±�Ä®æ�¬�²®Õ´O¶±µ«Q¶�ܧæÛߤ±�» ¼�´Q®.±�» ܧ© ëh¯Û±;²¯�±;¶Ï²¯Û± ®´QÓà±î"±�´O²æÛ¶±�® ´O¶±f´O¶Ü§æ�©�»�º;±;¶�Üàß�¶Ü§©Ûܧæ�©Â³;´Q©�»�È»�´O².±�® ´Q®î"ܧ¬�¬¹Ü�ëä®;âÆ Ê�ÍÕ®¸�©&²´Q³�²�³ ߤܧ®¹²¹Ü§© ÜQîêº;±;¶Ü ß�¶�ܧ©Ûܧæ�© ³;´Q©�»��Ä»�´O².±�® Æ"±QâR«Ûâ¹É ������������� Æ Ú�æÛ¼`�.±�³�²2Í2É�� ��������� Æ��Ò�Ķ�±�³�²�� ¼`�.±�³�²2Í.Í2âÆ�̧ÍÕ®¸�©&²´Q³�²�³ ´Q©�» ®±�ÓÕ´Q©è²È³ ®.².¶�æ�³�²æÛ¶± ´O¶�ܧæ�©�»º;±;¶�ܽß�¶Ü§©Ûܧæ�© ³;´Q©�»�È»�´O².±�® Æ"±QâR«Ûâ¹ÉÕ²¯Û±é² ¸�ߤ±�®ÜQî�³�ܧ©��.æ�©�³�²¹Ü§©�®;É?çQ±;¶¼�´Q¬�®.±�ÓÏ´Q©è²�³¿´O².².¶�¹¼�æÛ².±�®;É´Q©�»�²¯Û±ê² ¸�ߤ±�® ÜQîìÓàÜ�»�´Q¬¤±�å�ß�¶±�®®¹Ü§©�®¿È©ùæ�©�¹²®±�©è².±�©�³�±�®hëh¹²¯�º;±;¶Ü�ß�¶Ü§©Ûܧæ�©�® ³;´Q©�»��»�´O².±�®7Í2âõع«§æÛ¶±ÔÌÏ®�¯ÛÜ�ëh® ´Q© ±�å�´QÓàß�¬¹±íÜQî첯۱Ի��®ß�¬�´�¸�´Oî"².±;¶«Q¶Ü§æÛß��©Û«àº;±;¶Ü�ß�¶Ü§©Ûܧæ�©µ³;´Q©�»��»�´O².±�®ä´Q³;³�ÜQ¶�»��©�«Õ².ܲ¯Û±�¹¶ ®.¸�©è²´Q³�²�³Ïߤܧ®¹²¹Ü§©�®�â�� ®í®¯�Ü�ëh© �© ²¯Û± y�«OÄæÛ¶±QÉìã Ê Æ �/� Ä ³;´Q®.±øÍ �®í²¯Û±ÂÓÕܧ®.²\³�ܧÓÕÓÕܧ© ®¸�©&²´Q³7IJ�³äߤܧ®¹²¹Ü§©�ÜQî�º;±;¶ÜÔß�¶Ü§©�ܧæ�©�®¿�©Ï²¯�±Ò³�ÜQ¶�ß�æ�®ÒÆ! �"�"�©�®²´Q©�³�±�®f�© � Ì�#µ®.±�©&².±�©�³�±�®2Í2ÉØ´Q©�» ãÒÌ Æ$�7Ä ³;´Q®.±øÍí�®²¯Û± ©Û±�å�²ùÓàܧ®.²ù³�ܧÓÕÓàܧ©×Æ Ê�Ì�%é�©�®.²´Q©�³�±�®��©áÊQÊ&"®.±�©&².±�©�³�±�®2Í2â
��������� ��������¥���¥ø�=��� �Â�j¥ø£&¦§£�pô£��j¥��Ï��� k £�lø�m\l?�����odô����äî#².±;¶ �»Û±�©&²¹î"¸��©�«fº;±;¶Ü\ß�¶Ü§©Ûܧæ�©�®Ã�©à²¯Û±Pr§´Oß�´Q©Û±�®.±®.±�©&².±�©�³�±�®;ɤ´Q© ´Q©&².±�³�±�»Û±�©&²äî"ÜQ¶h±�´Q³2¯ º;±;¶ÜÏß�¶�ܧ©Ûܧæ�©�®f´Q©�©�ÜQ²´O².±�»�â'� ®fëh¹²¯ ²¯Û±Õß�¶Ü�³�±�®�®ÒÜQîú;±;¶Üµß�¶ÜOÄ©Ûܧæ�© �»Û±�©&²!y�³;´O²�ܧ©�É�º;±;¶�ÜÂß�¶Ü§©Ûܧæ�©�®ä´O¶±Ô«Q¶Ü§æÛߤ±�»¼�´Q®.±�» ܧ© ²¯Û± ß�¶±�®.±�©�³�± ÜQîí²¯Û± ®�´QÓà± ³�¯�´O¶�´Q³�².±;¶Ä�®.²È³;®ê´O¶Ü§æ�©�»·²¯Û±Ïº;±;¶Ü ß�¶Ü§©Ûܧæ�©�®;â�Å�ÜDZ���³;�±�©è²¬¹¸´Q©�©ÛÜQ²´O².±�²¯Û±Õ´Q©&².±�³�±�»Û±�©è²®\ÜQî º;±;¶ÜÇß�¶�ܧ©Ûܧæ�©�®;ɤ뿱´Q¬�®.Üá«Q¶Ü§æ�ß �©è².¶2´Q®.±�©è².±�©&²�´Q¬ù´Q©�» �©&².±;¶�®.±�©&².±�©&²�´Q¬´Q©�´Oß�¯�ÜQ¶�´ ³;´Q©�»��»�´O².±�®Â´Q³;³�ÜQ¶�»��©�« ².Ü鲯۱ö³�¯�´O¶2´Q³7IJ.±;¶��®²�³;®`´O¶Ü§æ�©�»�²¯Û±í³;´Q©�»�È»�´O².±�®`´Q® î"ܧ¬�¬¹Üøëh®�(Æ Ê�ÍÕ®¸�©&²´Q³�²�³�ßjܧ®�¹²¹Ü§©·ÜQîä´Q© ´Q©&².±�³�±�»Û±�©&²Õ³;´Q©�»��Ä»�´O².±Æ�̧ÍÕ®¸�©&²´Q³�²�³ö´Q©�»°®.±�ÓÕ´Q©&²�³ ®.².¶�æ�³�²æÛ¶�±�®Â´O¶�ܧæ�©�»´Q©µ´Q©è².±�³�±�»Û±�©&²Ò³;´Q©�»��»�´O².±Æ�w§ÍÕ®¸�©&²´Q³�²�³Â¶±�¬�´O²¹Ü§©�®¯�¹ß·¼¤±;²�ëñ;±�©é´öæ�©�¹²\®.±�©�IJ.±�©�³�± ëä¹²¯µ´Âº;±;¶ÜÂß�¶Ü§©Ûܧæ�© ´Q©�» ´Âæ�©�¹² ®.±�©�IJ.±�©�³�±àëh¹²¯ ´Q© ´Q©è².±�³�±�»Û±�©&²í³;´Q©�»��»�´O².±à�© ²¯Û±®�´QÓà± ®.±�©è².±�©�³�±íÆ=�©è².¶2´Q®.±�©è².±�©&²�´Q¬#Í Æ"±QâR«Ûâ¹É�´Òæ�©�¹²®±�©è².±�©�³�±éëh�²¯ ´ º;±;¶Ü°ß�¶Ü§©Ûܧæ�© �® »�¹¶±�³�²¬�¸³�ܧ©�©Û±�³�².±�» ².Ü ´Q©ÛÜQ²¯Û±;¶öæ�©��²µ®.±�©&².±�©�³�± ¼�¸¢´³�ܧ©;�.æ�©�³�²¹Ü§©�ÍÆ)#&ÍÕ»��®³�ܧæÛ¶�®±°®².¶�æ�³�²æÛ¶�´Q¬Â¶±�¬È´O²¹Ü§©�®¯��ß Æ"ÜQ¶ »��® IJ´Q©�³�±�®2Í�¼¤±;² 뿱;±�©à´f®.±�©è².±�©�³�± ëh¹²¯ ´äº;±;¶�Üfß�¶ÜOÄ©�ܧæ�©¢´Q©�»¢´ ®.±�©&².±�©�³�± ëh�²¯¢´Q© ´Q©&².±�³�±�»Û±�©&²³;´Q©�»��»�´O².±íÆ=�©&².±;¶�®.±�©&².±�©&²�´Q¬#Í Æ"±QâR«Ûâ¹É�´ê®.±�©&².±�©�³�±ëä¹²¯ ´ º;±;¶Ü ß�¶Ü§©Ûܧæ�© �®à²¯Û± ©Û±�å�²Â®.±�©&².±�©�³�±î"ܧ¬�¬¹Üøëh�©Û« ´ ®±�©è².±�©�³�±½ëä¹²¯ ´Q© ´Q©&².±�³�±�»Û±�©&²³;´Q©�»��»�´O².±øÍõÛÜQ¶ Æ�w§Í2Éí²¯�± ®.¸�©&²´Q³�²�³ ®².¶�æ�³�²æÛ¶±�®µÜQîÕæ�©�¹² ®.±�©�IJ.±�©�³�±�® ëh¹²¯ º;±;¶Ü ß�¶Ü§©Ûܧæ�©�®Ç´O¶±é³;¬�´Q®®!y�±�»�Éê´Q©�»²¯Û±·®.±�©&².±�©�³�±�®µëh¹²¯°²¯Û±·®´QÓÕ±·² ¸�ߤ±�®ùÜQî ®¸�©&²´Q³7IJ�³ ®.².¶2æ�³�²æÛ¶±�®Ç´O¶�± ±�å�´QÓÕÈ©Û±�»�â õÛÜQ¶ Æ)#&Í2Éf²�¸&ß��³;´Q¬´Q©&².±�³�±�»Û±�©è²à³;´Q©�»��»�´O².±Ï¶�±�¬�´O²¹Ü§©�®¯�¹ß�®Òî"ÜQ¶í²¯Û±�²´O¶.Ä«Q±;²\³�ÜQ¶�ß�æ�®í´O¶�±�®.±�¬¹±�³�².±�» �©·´Q»�ç?´Q©�³�±QâùõÛÜQ¶ ±�åÛ´QÓÔÄß�¬¹±QÉ�È© ©�±;ëh®.ß�´Oߤ±;¶f´O¶²�³;¬¹±�®�É�²¯Û± y�¶�®.²f®.±�©&².±�©�³�±ÕÜQî´Q©á´O¶²�³;¬¹± ÜQî"².±�© ³�ܧ©&²´Q�©�®ö²¯�± ´Q©&².±�³�±�»Û±�©&² ÜQî�´º;±;¶ÜÂß�¶Ü§©Ûܧæ�©µ�©Ç´Q©�ÜQ²¯Û±;¶f®.±�©è².±�©�³�± �©µ²¯Û±\´O¶�²�³;¬¹±Æ=ã ´OÐ?´Q¹ë ´Â´Q©�»+*5ÐQ±�¯�´O¶�´�ÉØÊ�ËQËQ̧Í2âäÅ`¯�±í¶±�¬�´O²�ܧ©�®¯�¹ß¼¤±;² 뿱;±�©Õ®.±�©&².±�©�³�±�® ®¯�ܧæ�¬�»\¼j± ®.±�¬�±�³�².±�»à»Û±;ߤ±�©�»��©Û«Ü§©Â²¯Û±Ò²´O¶«Q±;²`»ÛܧÓÕ´QÈ©�².Üà´Q³2¯�¹±;çQ±ê´Q©�±���³;¹±�©&² ´Q©�Ä©ÛÜQ²´O²�©�«Âß�¶Ü�³�±�®�®;â,�ä©ö´Q©�´Q¬¹¸�®.²f´Q©�©ÛÜQ²´O².±�®f»�±��³�²�³´Q©&².±�³�±�»Û±�©è²®ÔÜQîhº;±;¶Ü ß�¶Ü§©Ûܧæ�©�®ê¼&¸ y�¶�®.²í®.±�¬�±�³�²�©Û«² ¸�ß��³;´Q¬ ´Q©&².±�³�±�»Û±�©è²ù³;´Q©�»��»�´O².±�®Ï®�æ�³�¯ ´Q® � *�uø뿱 � É� ¸Qܧæ � É�ÜQ¶ � ¹² � �©à´Q»ÛçO´Q©�³�±h´Q©�»à²¯�±�©Õ®.±�¬¹±�³�²�©�«ê²¯Û±»�¹±�³�²È³¿´Q©&².±�³�±�»Û±�©&²ªÜQҺ;±;¶Üfß�¶Ü§©�ܧæ�©Ôî#¶�ܧÓᲯ۱�Óùâ�äî#².±;¶ ´Q©Â´Q©è².±�³�±�»Û±�©&² î"ÜQ¶¿´\º;±;¶Ü ß�¶Ü§©Ûܧæ�©��®¿´Q©�©ÛÜOIJ´O².±�»�ɤÜQ²¯Û±;¶f´Q©&².±�³�±�»Û±�©è²f³;´Q©�»��»�´O².±�®äî#ÜQ¶Ò²¯Û±\º;±;¶Üß�¶Ü§©�ܧæ�©Ï´O¶±Ò»��®ß�¬�´�¸Q±�»Â´Q® � ©Û±;«§´O²¹çQ±ê³;´Q©�»�È»�´O².±�® ��©�²¯Û±\»��®.ß�¬È´�¸ÕÜQîز¯Û±f«Q¶Ü§æ�ß��©Û«Ô¶±�®æ�¬¹²;⾿¸Ý«Q¶�ܧæÛß��©Û«á´Q©&².±�³�±�»Û±�©è² ³;´Q©�»��»�´O².±�® ¯�´�ç��©Û«²¯Û±`®´QÓÕ±`³�¯�´O¶�´Q³�².±;¶2�®.²�³;®;É�´Q©�´Q¬¹¸�®.²®ì³;´Q©à±���³;�±�©è²¬¹¸

õع«§æÛ¶±ÂÌ ( �Ò�®.ß�¬�´�¸ ÜQîäÑ ¶Ü§æÛß��©Û«��`±�®æ�¬¹²êÜQî��j±;¶Ü Ö ¶Ü§©Ûܧæ�©�® � ´Q©�»��»�´O².±�®ê´Q³;³�ÜQ¶�»��©Û«Ç².Ü ²¯Û±�¹¶ Ú�¸�©&²´Q³�²�³Öôܧ®¹²¹Ü§©�®´Q©�©ÛÜQ²´O².± ´Q©è².±�³�±�»Û±�©&²®ÇÜQî\º;±;¶Ü ß�¶Ü§©�ܧæ�©�®Â¼&¸ ¶±�Äî"±;¶¶��©Û«Ô².Ü�²¯Û±í´Q©&².±�³�±�»Û±�©è²Ò³;´Q©�»�È»�´O².±�® ëh¹²¯��©�²¯Û±®´QÓà±ù²�¸&ߤ±ÇÜQîÒ³�ܧ©&².±�å�²;â õ�æÛ¶²¯Û±;¶�ÓÕÜQ¶±QÉü�¸é´Q©�©ÛÜOIJ´O²�©Û«ö´Q©&².±�³�±�»Û±�©è²®Õî#¶Ü§Ó ²¯Û±�³�ܧ©è².±�å�²Ôëh¹²¯ ¯�¹«§¯î"¶±Cv&æ�±�©�³�¸�².ܬ¹Ü�ë î#¶±Cv�æÛ±�©�³�¸QÉ�´Q©µ´Q©�´Q¬¹¸�®.²`³;´Q© ±��Õij;¹±�©&²¬¹¸ ´Q©�©ÛÜQ²´O².±Õ´Q©è².±�³�±�»�±�©è²®\�© ²¯Û±à±�´O¶�¬¹¸µ®²´O«Q±ÜQîز¯Û±ê´Q©�©ÛÜQ²´O²È©Û«Õß�¶Ü�³�±�®®;â����� �ed�¥��gf �Û¥?�#¦ù����¥?l?��¦Q¥?�#�j� ���� £������=d�¥ø�"��� � d��"£��Ú�¸�©è²´Q³�²È³ ´Q©�» ®.±�ÓÕ´Q©&²�³ î#±�´O²æ�¶±�®é´O¶Ü§æ�©�»Ýº;±;¶Üß�¶Ü§©�ܧæ�©�®�´Q©�»°²¯Û±�¹¶Ç´Q©&².±�³�±�»Û±�©&²® ´O¶�±·±�å�².¶2´Q³�².±�»î"¶Ü§Ó rè´Oß�´Q©Û±�®.±é®.±�©&².±�©�³�±�®öëh¹²¯ r§´Oß�´Q©Û±�®.±é´Q©�´Q¬�ĸ�®�®ö¶±�®æ�¬¹²® ´Q©�» ëh�²¯ ²´O«§® î"ÜQ¶·º;±;¶Ü¢ß�¶�ܧ©Ûܧæ�©�®´Q©�» ²¯Û±�¹¶ ´Q©è².±�³�±�»Û±�©&²®;âöÅ`¯Û±�î#ܧ¬�¬�Ü�ëh�©�«ùî#±�´O²æÛ¶�±�®;ɲ¯Û±à±�{¤±�³�²®êÜQî¿ëh¯��³2¯öëñ;¶�±Ï»��®³;æ�®®.±�»ö�©öãä´OÐO´Q¹ë ´Æ Ê�ËQËQÌ�Ê�ËQË�%�Ê�ËQË�"§Í´O¶±ùæ�®.±�»é´Q®à³�ܧ©�»�¹²¹Ü§©�®\ÜQîh±�å�IJ.¶�´Q³�².±�»µ¶±�®.ܧ¬�æÛ²�ܧ©�¶�æ�¬¹±�®;â
z çQ±;¶�¼�´Q¬�®.±�ÓÕ´Q©&²�³Ò´O².².¶�¹¼�æ�².±�®êÆ=ãä´OÐO´Q¹ë ´à±;²`´Q¬�â¹ÉÊ�ËQË�#&Íz ²�¸&ߤ±fÜQîìÓàÜ�»�´Q¬¤±�å�ß�¶±�®®�ܧ©·Æ��ê´�ë ´Q�É�Ê�Ë� � Íz ²�¸&ߤ± ÜQîÛ³�ܧ©��æ�©�³�²�ܧ©f¼¤±;² 뿱;±�©í´`æ�©�¹²�®.±�©&².±�©�³�±ëä¹²¯ ´ º;±;¶Ü ß�¶Ü§©Ûܧæ�© ´Q©�» ´ æ�©��²Ï®.±�©&².±�©�³�±ëä¹²¯ù¹²®`´Q©&².±�³�±�»Û±�©&²z ®¸�©&²´Q³�²�³Â¶±�¬�´O²¹Ü§©�®¯�¹ß·¼¤±;²�ëñ;±�©é´öæ�©�¹²\®.±�©�IJ.±�©�³�± ëä¹²¯µ´Âº;±;¶ÜÂß�¶Ü§©Ûܧæ�© ´Q©�» ´Âæ�©�¹² ®.±�©�IJ.±�©�³�±�ëh�²¯ ¹²® ´Q©è².±�³�±�»�±�©è²ÇÆ=�©&².¶�´Q®.±�©&².±�©è²È´Q¬#Íz »��®³�ܧæÛ¶�®±°®².¶�æ�³�²æÛ¶�´Q¬Â¶±�¬È´O²¹Ü§©�®¯��ß Æ"ÜQ¶ »��® IJ´Q©�³�±øÍüj±;²�ëñ;±�©µ´ ®±�©è².±�©�³�±fëä¹²¯�´\º;±;¶�Üàß�¶ÜOÄ©�ܧæ�©¢´Q©�»¢´ ®.±�©è².±�©�³�± ëh�²¯½¹²®µ´Q©&².±�³�±�»Û±�©&²Æ=È©è².±;¶�®±�©è².±�©&²�´Q¬#Í�äæ�¬¹±�®�´O¶±·´QæÛ².ܧÓÕ´O²È³;´Q¬�¬¹¸ ±�å�².¶�´Q³�².±�»¢¼&¸°´ »Û±�ij;�®�ܧ©½².¶±;±é¬¹±�´O¶�©��©�« ß�¶ÜQ«Q¶�´QÓùÉ � %�âA� Æ� Òæ��©�¬�´Q©�â¹ÉÊ�ËQË� §Í2⪨ å�².¶�´Q³�².±�»Ï¶�æ�¬¹±�®ì´O¶�±h³�ܧ©èçQ±;¶�².±�»Ï².Ü겯�± ¶�æ�¬¹±î"ÜQ¶�ÓÕ´O²hæ�®±�»ù�© �Âï¤ðêñòôó�� â
����� ����d����¿����¥?l?��¦Q¥ø�"�j� ��� � £&���j�=d�¥ø�"�j�� dô�"£&�õÛÜQ¶Ç²¯�± ±�å�².¶�´Q³�²�ܧ©½ÜQî\ÓàÜQ¶�± ¶±�¬��´O¼�¬�±µ¶±�®.ܧ¬ÈæÛ²¹Ü§©¶�æ�¬�±�®Øëh¹²¯Õ¯�æ�ÓÕ´Q©ÕÈ©è².±;¶�´Q³�²�ܧ©�É&´êÓÏ´Q©&æ�´Q¬�¶�æ�¬¹± ±�å�IJ.¶�´Q³�²¹Ü§© ß�¶Ü�³�±�®®äî#¶�Ü§Ó rè´Oß�´Q©Û±�®.± ®.±�©è².±�©�³�±�® æ�®�©Û«r§´Oß�´Q©Û±�®.±ê´Q©�´Q¬¹¸�®�®¿¶±�®�æ�¬¹²® ´Q©�»�²´O«§®hî#ÜQ¶`º;±;¶�Üàß�¶ÜOÄ©Ûܧæ�©�® ´Q©�» ²¯�±�¹¶f´Q©è².±�³�±�»Û±�©&²® �®Ò�Óàß�¬¹±�ÓÕ±�©è².±�» �©²¯Û±Â®.¸�®².±�Óùâ *5© ²¯Û±�®�´QÓà±�ÓÕ´Q©�©Û±;¶\´Q® �© ®±�³�²¹Ü§©w�âxw�É�²¯�± y�çQ±à² ¸�ßj±�®ÒÜQîÃî#±�´O²æ�¶±�®ê´O¶Ü§æ�©�» º;±;¶�Üùß�¶ÜOÄ©Ûܧæ�©�®¿´Q©�»�²¯Û±�¹¶`´Q©&².±�³�±�»Û±�©è²®äæ�®.±�»ù�©�®.±�³�²�ܧ© w�â #´O¶± «Q¶Ü§æÛߤ±�» ´Q©�»Ô®.ÜQ¶².±�» ¼�¸ê²¯Û± î#¶�±Cv&æÛ±�©�³;¹±�®�ÜQî�²¯Û±«Q¶Ü§æÛߤ±�»·�².±�ÓÕ®;â�Å`¯Û±;¶±;î"ÜQ¶±QÉ�ëä�»Û±Õ³�Ü�çQ±;¶2´O«Q±Â¶2æ�¬¹±�®´O¶±`±��³;¹±�©è²¬�¸\±�å�².¶�´Q³�².±�»Â�©à²¯Û±`±�´O¶2¬¹¸ ®²´O«Q±hÜQ¯Û±±�å�².¶�´Q³�²¹Ü§©Õß�¶Ü�³�±�®�®;âôÅh¯��®ì�®ì´Q¬�®Üf±�{j±�³�²¹çQ±äî#ÜQ¶ª¶�æ�¬¹±±�å�².¶�´Q³�²¹Ü§©Ô¼�¸í²´OÐ��©Û«Ò�©è².Üf´Q³;³�ܧæ�©&²ìº;±;¶Üfß�¶�ܧ©Ûܧæ�©�®ëh¹²¯é²¯�±µ®´QÓà±Ç²�¸&ߤ±�®àÜQîf³�ܧ©&².±�å�²;â°Å`¯Û±ù¶�±�¬��´O¼��¬¹Ä¹²�¸ ÜQîí²¯Û± ±�å�².¶�´Q³�².±�»½¶�æ�¬�±�®Ï�®�´Q¬�®.Ü ±�åÛ´QÓÕ�©Û±�» �©²¯��® ®²´O«Q±í¼�¸Â³;´Q¬�³;æ�¬�´O²�©Û«à²¯Û±\©&æ�Ó\¼¤±;¶ ÜQîô´Oß�ß�¬�¹±�»º;±;¶Ü�ß�¶Ü§©�ܧæ�©�®äî#ÜQ¶Ò±�´Q³�¯·¶�æ�¬¹± ´Q©�» ²¯Û±à©&æ�Ó\¼¤±;¶äÜQî®æ�³;³�±�®�®.î"æ�¬�¬¹¸Ô¶±�®.ܧ¬¹çQ±�»Âº;±;¶Üàß�¶Ü§©Ûܧæ�©�®ª¼&¸Ï¶±;î#±;¶�¶��©Û«².Ü ´Q©è².±�³�±�»�±�©è²ù²´O«§®�î"ÜQ¶�º;±;¶Üéß�¶Ü§©Ûܧæ�©�®;â ¾¿±;î"ÜQ¶±²¯Û± ±�å�².¶�´Q³�².±�» ¶�æ�¬¹±�®�´O¶± ´Q»�»Û±�»°².Ü ²¯Û±·¶2æ�¬¹±ö®.±;²æ�®.±�» �© �Âï�ðfñòôó�� ÉÃ�©�³;¬�æ�®�¹Ü§©é¶±�¬�´O²¹Ü§©�®¯�¹ß�® ¼¤±�IJ 뿱;±�©é¶�æ�¬�±�®í´O¶±Â±�å�´QÓÏ�©Û±�» ´Q©�» ²¯Û±Âß�¶��ÜQ¶�¹²¹±�®fÜQî±�å�².¶�´Q³�².±�»µ¶2æ�¬¹±�® ëh¹²¯��©Â²¯Û±f¶�æ�¬¹±f®.±;²ä´O¶±í®.±;²;â
� ��������������� �!�#"%$'&!�(��)*�,+���-.�Å`¯Û± ߤ±;¶î"ÜQ¶�ÓÕ´Q©�³�± ÜQî ²¯�± ´QæÛ².ܧÓÕ´O²�³·±�å�².¶�´Q³�²�ܧ©ß�¶Ü�³�±�®®µî#¶Ü§Ó ´Q¬�¹«§©�±�»¢®.±�©&².±�©�³�±éß�´Q¹¶�®Ç¯�´Q®µ¼¤±;±�©¶±;ߤÜQ¶².±�» �© Æ=ã ´OÐ?´Q�ë¿´�ÉØÊ�ËQË � ´/�ãä´OÐO´Q¹ë ´�ÉôÊ�ËQË � ¼¤Í2â� ³;³�ÜQ¶�»��©Û« ².Ü ²¯Û±Ç±;çO´Q¬�æ�´O²�ܧ© ¶±�®æ�¬¹²àܧ© ²¯Û± ´Qæ�IJ.ܧÓÕ´O²�³ ´Q¬�¹«§©�Óà±�©&²ùÜQî r§´Oß�´Q©Û±�®±·º;±;¶Ü ß�¶�ܧ©Ûܧæ�©�®´Q©�»f²¯�±ª¨ª©Û«§¬È�®¯Ò±Cv�æ�¹çO´Q¬¹±�©è²®�ÜQî�²¯�±�¹¶�´Q©&².±�³�±�»Û±�©è²®�ÉË� �â #10 ÜQîà´Q¬�¬Òß�´Q¹¶�®�뿱;¶±·´QæÛ².ܧÓÕ´O²�³;´Q¬È¬¹¸ ´Q¬È¹«§©Û±�»³�ÜQ¶¶±�³�²¬�¸ �© ²¯Û±ö².¶�´QÈ©��©Û«é»�´O²´ ´Q©�»¢Ë�#10 ÜQî ´Q¬�¬ß�´Q¹¶2® È© æ�©�®.±;±�© ².±�®.² »�´O²´�â õ�æÛ¶²¯Û±;¶�ÓÕÜQ¶±QÉÕ´Q³7ij�ÜQ¶�»�È©Û« ².Ü ²¯Û±��¶Ç±;ç?´Q¬Èæ�´O²¹Ü§©½ÜQîÔ±�å�².¶�´Q³�².±�» ¶2æ�¬¹±�®î"ÜQ¶hº;±;¶ÜÕß�¶Ü§©Ûܧæ�©�®`ëh¹²¯ù»Û±��³�²È³f¶±;î"±;¶±�©�³�±�®;É�²¯�ܧ®.±

¶�æ�¬�±�®¿³�¶�±�´O².±�»µ´QæÛ².ܧÓÕ´O²È³;´Q¬�¬¹¸Ïî"¶Ü§Ó ®.±�©&².±�©�³�±êß�´Q¹¶�®³�ÜQ¶¶±�³�²¬�¸ ¶±�®.ܧ¬¹çQ±�» ËQË�âA� 0 ÜQîÒ²¯Û± º;±;¶Ü ß�¶�ܧ©Ûܧæ�©�®�© ²¯Û±½².¶�´QÈ©��©Û« »�´O²´ ´Q©�» �%�âA� 0 ÜQî ²¯�±½º;±;¶Üß�¶Ü§©�ܧæ�©�®ù�©½´Q© æ�©�®.±;±�©½².±�®²µ»�´O²´�â Å`¯Û±;¶±;î"ÜQ¶±QÉ뿱 ܧ©�¬¹¸Õ±;çO´Q¬�æ�´O².±Ò²¯Û±fÓÕ´Q©�æ�´Q¬j±�å�².¶�´Q³�²�ܧ©�ß�¶Ü�³�±�®®î"¶Ü§Ó r§´Oß�´Q©Û±�®.±íÓàܧ©�ܧ¬��©Û«§æ�´Q¬¤³�ÜQ¶ß¤ÜQ¶�´�âÃÅ`¯Û±f±�{¤±�³7IJ¹çQ±�©Û±�®�®ÃÜQî�²¯Û±äß�¶ÜQߤܧ®.±�»ÏÓà±;²¯�Ü�»�ÜQî�ÓÕ´Q©�æ�´Q¬�¶�æ�¬¹±±�å�².¶�´Q³�²¹Ü§©ö¯�¹«§¯�¬�¸�¶±�¬È¹±�®hܧ© ²¯Û±�¹¶ä«Q¶Ü§æÛß�È©Û«Ïî=æ�©�³7IJ¹Ü§©�â Å`¯�±;¶±;î#ÜQ¶�±QÉ��©ù²¯��®`±;çO´Q¬�æ�´O²¹Ü§©�É�ëñ\±�å�´QÓÏ�©Û±²¯Û±�±�{j±�³�²¹çQ±�©�±�®®ÔÜQî ²¯Û±�ÓÏ´Q©&æ�´Q¬ª¶�æ�¬¹±Ï±�å�².¶�´Q³�²�ܧ©ëh¹²¯�ÜQ¶hëh¹²¯ÛܧæÛ² ²¯�±f«Q¶Ü§æÛß��©�« î=æ�©�³�²�ܧ©�â����� � � ���=d��Û¥ø�"��� £è¥? ���p ���� ����d���� � d��"£� ��¥7lø��¦§¥ø�"���Å`¯Û±à±�{¤±�³�²¹çQ±�©Û±�®�®\´Q©�»ö±��³;¹±�©�³�¸öÜQî¿ÓÏ´Q©&æ�´Q¬ ¶�æ�¬¹±±�å�².¶�´Q³�²¹Ü§©��®Ã±�å�´QÓÕÈ©Û±�»Ï¼�¸Õ±�å�².¶�´Q³�²�©Û« ¶�æ�¬�±�® î"¶Ü§Ów � Ê�Ëer§´Oß�´Q©Û±�®±í®.±�©&².±�©�³�±�®äÈ©Ç´à².±�®.² ®.±;²`î"ÜQ¶h±;çO´Q¬�æ�Ä´O²�©Û« r§´Oß�´Q©Û±�®.±�Ä ².ÜOÄ ¨ª©�«§¬��®¯ } Å ®.¸�®.².±�Ó Æ)*�ÐQ±�¯�´O¶�´±;²Õ´Q¬�â¹É Ê�ËQË�#&Í2â �ä© ´Q©�´Q¬¹¸�®² ëä¯ÛÜ �®à´Q©é±�å�ߤ±;¶²àÜQîº;±;¶ÜÂß�¶Ü§©Ûܧæ�©Ç¶±�®.ܧ¬ÈæÛ²¹Ü§©µÈ© �Âï�ðfñòôó�� Éj±�å�².¶2´Q³�²®¶±�®.ܧ¬ÈæÛ²¹Ü§©·¶2æ�¬¹±�®êæ�®��©Û«Ç²¯Û±Â�Óàß�¬�±�Óà±�©è².±�» ®.¸�®.².±�Ó�© ®.±�³�²¹Ü§©~w�É`ëh¯��³�¯ �®Â�©�®.²´Q¬�¬�±�» �©½Ú��äã Ú�ß�´O¶�³¨ª©&².±;¶ß�¶2�®.±\w;������ÉjÈ©�²¯Û±fî#ܧ¬È¬¹Ü�ëhÈ©Û«àÓÕ´Q©�©Û±;¶�â�\âè å�².¶2´Q³�²¹Ü§©Çæ�®È©Û«Ô²¯Û± Ñ ¶Ü§æ�ß��©Û«àõ�æ�©�³�²¹Ü§©Åh¯Û± «Q¶Ü§æÛß�È©Û«ÛÉ ´Q©�©ÛÜQ²´O²¹Ü§©¢´Q©�»¢±�å�².¶�´Q³�²�ܧ©´O¶�±í³�ܧ©�»�æ�³�².±�»µ´Q®`î"ܧ¬�¬¹Ü�ëä®;âÚ�².±;ß Ê �j±;¶ÜÇß�¶Ü§©Ûܧæ�© ³;´Q©�»��»�´O².±�®í´O¶�±Õ«Q¶Ü§æÛߤ±�»´Q³;³�ÜQ¶�»��©�«�².Ü�²¯Û±�¹¶Ò®.¸�©è²´Q³�²È³Ôßjܧ®�¹²¹Ü§©�® ²¯Û± ³;´Q©�»��»�´O².±�®ö�© ²¯Û± ÓÕܧ®.² ³�ܧÓÏÓàܧ©®.¸�©è²´Q³�²�³ ߤܧ®�²¹Ü§©�ÉQã\ÊêÆ �/� Ä ³;´Q®.±øÍ ´O¶± ®.±�Ĭ¹±�³�².±�» ( �"�"�È©�®.²´Q©�³�±�® �© � Ì�#Ç®.±�©è².±�©�³�±�®Æ=õع«§æÛ¶±í̧ÍÚ�².±;ß Ì Ú�±�¬¹±�³�².±�»�³;´Q©�»�È»�´O².±�® ´O¶± «Q¶Ü§æÛߤ±�»�´O«§´Q�©´Q³;³�ÜQ¶�»��©�«Õ².Üϲ¯Û±��¶ä®.¸�©è²´Q³�²È³í®.².¶�æ�³�²æÛ¶±#²¯Û± ³;´Q©�»��»�´O².±�®ö�© ²¯Û± ÓÕܧ®.² ³�ܧÓÏÓàܧ©®.¸�©è²´Q³�²�³Ï®.².¶�æ�³�²æÛ¶�±QÉ�ëh¯Û±;¶±à´ùæ�©�¹²f®.±�©�IJ.±�©�³�±�ëh¹²¯ ´ º;±;¶Üöß�¶Ü§©Ûܧæ�© �® »�¹¶±�³�²¬�¸³�ܧ©�©Û±�³�².±�» ëh¹²¯·´Q©�ÜQ²¯Û±;¶\æ�©�¹²ê®.±�©&².±�©�³�±¼&¸Â´Ô³�ܧ©��.æ�©�³�²¹Ü§©�ÉÛ´O¶±f®.±�¬¹±�³�².±�» (�w�Ê&%Ô�©�Ä®.²´Q©�³�±�®Ú�².±;ß w �j±;¶Ü ß�¶Ü§©Ûܧæ�©�®Ï´O¶±ö´Q©�©ÛÜQ²´O².±�»°î"ÜQ¶�²¯Û±®.±�¬¹±�³�².±�»Â³;´Q©�»��»�´O².±�®�( Ì� �%íܧæ�²ªÜQî w�Ê&% �©�Ä®.²´Q©�³�±�®Ú�².±;ß+# �ä©&².±�³�±�»Û±�©&²®hÜQîØ®.±�¬¹±�³�².±�»µº;±;¶ÜÕß�¶�ܧ©Ûܧæ�©�®´O¶± ´Q©�©ÛÜQ²´O².±�»½î"ÜQ¶µÌ� �% º;±;¶Ü ß�¶�ܧ©Ûܧæ�©�®´Oî#².±;¶ «Q¶�ܧæÛß��©Û« ²¯Û±°² ¸�ߤ± ÜQî ³�ܧ©��æ�©�³7IJ¹Ü§©�®;âÚ�².±;ß % õعçQ±f¶�æ�¬¹±�® ´O¶±f±�å�².¶�´Q³�².±�»µî#¶Ü§Ó Ì� �%àº;±;¶Üß�¶Ü§©Ûܧæ�©�® ´Q©�»Ý²¯Û± ¶±Cv&æ�¹¶±�»×²ÈÓà± î"ÜQ¶ÓÕ´OÐ��©Û«Ô²¯Û±ê¶�æ�¬¹±�® �® ¶±�³�ÜQ¶�»�±�»�â¾ âè å�².¶2´Q³�²¹Ü§© ëh¹²¯ÛܧæÛ²áæ�®È©Û«Ù²¯Û± Ñ ¶Ü§æ�ß��©Û«õ�æ�©�³�²¹Ü§©
�äæ�¬¹±�® ´O¶± ±�å�².¶�´Q³�².±�» î"¶Ü§Ó ®.±�©&².±�©�³�±�® ëh¹²¯
º;±;¶�Üùß�¶Ü§©Ûܧæ�©ö³;´Q©�»��»�´O².±�®fܧ©Û±Ô¼�¸ ܧ©�±àëh¹²¯�Äܧæ�² æ�®�©Û«Ò²¯Û± «Q¶�ܧæÛß��©Û«Òî=æ�©�³�²¹Ü§©Ô�©Ô²¯�± ²�Óà±�² ²´OÐQ±�®h².ÜÏÓÏ´OÐQ±ê²¯Û±Py�çQ±f¶2æ�¬¹±�® �©�².±�®.²��íâÅ`¯Û±ä¶±�®æ�¬�²®ªÜQî�²�ëÃÜÔ².±�®.²® ´O¶±Ò³�ܧÓàß�´O¶�±�»�¼�¸à±�åÛ´QÓÔÄ�©�È©Û«ê¯ÛÜ�ë î=´Q®.²ª²¯Û±Ò´Q©&².±�³�±�»Û±�©è²® ÜQî�º;±;¶�Ü\ß�¶�ܧ©Ûܧæ�©�®³;´Q©Õ¼¤±`±��³;¹±�©è²¬�¸Ô´Q©�©ÛÜQ²´O².±�»�´Q©�»Ï¯ÛÜøë ÓÕ´Q©&¸Ôº;±;¶Üß�¶Ü§©�ܧæ�©�® ³;´Q©ö¼j±Ô®æ�³;³�±�®�®.î"æ�¬�¬¹¸ù¶±�®.ܧ¬�çQ±�»ö¼&¸µæ�®�©Û«±�å�².¶�´Q³�².±�»µ¶2æ�¬¹±�®;â���È� � � ���=d��Û¥ø�"��� � £&�?dô�#¥Åô´O¼�¬¹±ÏÊê®�¯ÛÜ�ëh®h²¯Û±ê¶±�®�æ�¬¹²® ÜQîز¯Û±ê±;çO´Q¬�æ�´O²�ܧ©�â � ®®¯ÛÜøëh©¢�©¢²¯��®ù²´O¼�¬�±QÉfº;±;¶Ü ß�¶Ü§©�ܧæ�©�®Ç´Q©�»¢²¯Û±�¹¶´Q©&².±�³�±�»Û±�©è²®ö뿱;¶± ±���³;¹±�©&²¬¹¸½´Q©�©ÛÜQ²´O².±�»á�© ².±�®.²� Æ ÊOâ�Ê·ÓÕ�©ou?�².±�Ó ´Q©�» ÊOâ � ÓÕ�©ou?¹².±�Ó æ�®�©Û« ²¯Û±«Q¶Ü§æÛß��©Û«·î=æ�©�³�²¹Ü§© Æ"².±�®.² �ÒÍ2É ´Q©�»°Ì�â % ÓÕÈ©ou?¹².±�Ó´Q©�» Ì�âA� ÓÕ�©gu?¹².±�Ó ëh¹²¯�ܧæÛ²Ïæ�®È©Û« ²¯Û±Ç«Q¶Ü§æ�ß��©Û«î=æ�©�³�²¹Ü§©¢Æ"².±�®.²Â¾`Í2ɪ¶±�®.ߤ±�³�²¹çQ±�¬�¸ÛÍ2â õ�æÛ¶²¯Û±;¶2ÓàÜQ¶±Qɲ¯Û±ä¶�æ�¬¹±`±�å�².¶�´Q³�²¹Ü§©Â²�ÓÕ±ä´Q©�»�¹²®Ã´Oß�ß�¬��³;´O²¹Ü§©�´Q©�»±;çO´Q¬�æ�´O²¹Ü§©Ï²�Óౠ뿱;¶±ä´Q¬�®Üí®¯ÛÜQ¶².±;¶¿�©à².±�®.² � ²¯�´Q©�© ².±�®.²ù¾ Æ ÊOâ�Ê ÓÕ�©ou?�².±�Ó ´Q©�»¢Ì�â�ÌéÓÏ�©ou?¹².±�Ó �©².±�®.² �íÉ¿´Q©�» "�âA� ÓÕ�©ou?�².±�Ó ´Q©�» Ê2��âA� ÓÕÈ©�â u?¹².±�Ó�© ².±�®.²Â¾ É¿¶±�®.ߤ±�³�²¹çQ±�¬¹¸�Í2â Å`¯��®Õ¶±�®�æ�¬¹²Ï�©�»��³;´O².±�®²¯�´O² «Q¶Ü§æÛß�È©Û«µ¶±�®�æ�¬¹²®\ëh¹²¯ ´Q©�©ÛÜQ²´O².±�» �©Ûî"ÜQ¶�ÓÕ´?IJ¹Ü§©ÕÈ® ¯Û±�¬¹ß�î=æ�¬�î"ÜQ¶ÃÓÕ´OÐ��©Û«f¶�æ�¬¹±�®ìëh¹²¯Ôëä�»Û±`³�Ü�çQ±;¶Ä´O«Q±ê¼�¸Ï²´OÐ��©Û«à�©&².Üà´Q³;³�ܧæ�©è²h²¯Û±Ò±�®.²�ÓÕ´O².±�»ù¶�±�®æ�¬¹²ÜQî�´Q©Õ±�å�².¶�´Q³�²�©Û«\¶�æ�¬¹± î"ÜQ¶ªº;±;¶�Üíß�¶Ü§©�ܧæ�©�®ì²¯�´O²Ãëh�¬�¬¼¤± ´Oß�ß�¬�¹±�»�â �`±;«§´O¶2»��©Û«Â²¯Û± v&æ�´Q¬È¹² ¸ÇÜQîñ�å�².¶2´Q³�².±�»¶�æ�¬�±�®;É�².±�®.²Ò¾½±�å�².¶�´Q³�².±�» ¼j±;².².±;¶ ¶�æ�¬�±�® ²¯�´Q© ².±�®.²��Æ�Ë�w 0 È© ².±�®.² � ´Q©�» Ê2��� 0 È© ².±�®.²�¾`Í2â hÜøë ı;çQ±;¶�É�²¯�±¡y�çQ±fß�¶ÜQ¼�¬¹±�ÓÏ´O²�³ º;±;¶Üàß�¶Ü§©Ûܧæ�©�® �©Â².±�®.²� 뿱;¶± ´Q¬¹¶�±�´Q»Û¸ ©ÛÜQ²�³�±�» ¼&¸ ²¯Û± ´Q©�´Q¬¹¸�®.²Ï´O²Â²¯Û±¶�æ�¬�±�±;çO´Q¬�æ�´O²¹Ü§© ®.².±;ß�â Å`¯Û±;¶±;î"ÜQ¶±QÉ¿©Û±;ë ¶�æ�¬¹±�® î"ÜQ¶²¯Û±`º;±;¶�Üêß�¶Ü§©Ûܧæ�©�®ôëh¹²¯à´ê»Û±;²´QȬ¹±�»Õ³�ܧ©�»��²¹Ü§©Ôëh�¬�¬¼¤±f±�å�².¶2´Q³�².±�»µ±�´Q®È¬¹¸Ï¼�¸�¶�±;î#±;¶¶2�©Û«Ô².ÜÕ²¯��®`¶±�®æ�¬¹²;âÅô´O¼�¬¹±ÒÊ (.�`±Cv�æ�¹¶�±�»íÅ`�ÓձôQ©�» � ³;³;æÛ¶�´Q³�¸êÜQî } ´Q©�æ�Ä´Q¬�¬¹¸f¨ å�².¶�´Q³�².±�» �äæ�¬¹±�® ¤!� ���2����� ����� �A�t�o���[�����[� �h�?� ��7����������£�� �A� ���9� ���2� �7�������F©
� ÿ�����������2��� ������ �������äú� �ü ���������äú���ü� ���/�����#ÿ=þ���������� ����F� � � {
� � ÿ��Øý&ÿ����� ���� { ��� ��� 9��� �2� þ[������ ú { � { ü ú! �� �ü
�j���9���Rÿ���� g���� � ����� 9� û �� {�! � ��� 9��� �2� þ[������ ú { � ".ü ú! �� ! ü� ����� "�" � !�#
$ �&%X� �'�9�"ÿ"þ�� ������ ú { � { ü ú # � ! ü� �����( )�*����� z { ��� � {�!��þ[������ þ�*� ú! �� ü ú {�! � ! ü
+ %X���, �'-.þ�����þ[������$ ���=þ�� {�! û . {�! û #ú # � ! ü ú ! � �ü
� ���' )�*��������� � � ÿ��Øý&ÿ����� "� � {� ����/`�.ÿ#ÿ�� ����� �0�j� ����� -���� # " � {� � ÿ��Øý�ÿ����� ú1.�� 2Øü ú {�!�! 2Øü

� � - ��� ��)�� ��-.���Å`¯�È®ªß�´Oߤ±;¶¿ß�¶ÜQߤܧ®.±�»�´ ß�¶�´Q³�²�³;´Q¬¤�©&².±;«Q¶�´O².±�»�².Ü�ܧ¬î"ÜQ¶ ±�å�².¶�´Q³�²�©Û« ¶�æ�¬¹±�®·î#ÜQ¶ ²¯Û± ´Q©�´Oß�¯ÛÜQ¶�´¢¶�±�®.ܧ¬�æ�IJ¹Ü§©�ÜQîôº;±;¶Üàß�¶Ü§©�ܧæ�©�®¿î#¶�Ü§Ó Óàܧ©Ûܧ¬��©�«§æ�´Q¬�´Q©�»ouøÜQ¶¼��¬È�©Û«§æ�´Q¬&³�ÜQ¶ß¤ÜQ¶�´�â �ä³;³�ÜQ¶�»��©Û«f².Ü겯۱ ß�¶±�¬��ÓÕÈ©�´O¶¸±;çO´Q¬�æ�´O²¹Ü§© ÜQî ²¯Û± ÓÕ´Q©&æ�´Q¬ä¶2æ�¬¹± ±�å�².¶�´Q³�²�ܧ©°ß�¶ÜOij�±�®®;Éô´Q©è².±�³�±�»�±�©è²\²´O«§®êî"ÜQ¶êº;±;¶ÜÇß�¶�ܧ©Ûܧæ�©�®Ò³;´Q©·¼¤±±���³;¹±�©&²¬¹¸ ´Q©�©ÛÜQ²´O².±�»Õ´Q©�» ¶�æ�¬¹±�®Ø´O¶± ±���³;¹±�©&²¬¹¸í±�å�IJ.¶�´Q³�².±�» î"¶Ü§Ó rè´Oß�´Q©Û±�®.±àÓàܧ©Ûܧ¬È�©Û«§æ�´Q¬ô³�ÜQ¶ß¤ÜQ¶�´Â¼&¸æ�®È©Û« ²¯�±Ç².Ü&ܧ¬ ÀÁ®à«Q¶Ü§æÛß�È©Û« î=æ�©�³�²�ܧ©�â * ©é²¯Û±ùî=æ�IJæÛ¶±QÉäëñöëhȬ�¬`±�åÛ´QÓÕ�©Û± ²¯Û±ö±�{¤±�³�²¹çQ±�©Û±�®®ùÜQî\²¯Û±ß�¶ÜQߤܧ®.±�» Óà±;²¯ÛÜ�» î"ÜQ¶ ¼¤ÜQ²¯ Óàܧ©Ûܧ¬È�©Û«§æ�´Q¬ ´Q©�»¼��¬È�©Û«§æ�´Q¬f³�ÜQ¶ß¤ÜQ¶�´�â � ± ëhȬ�¬ê´Q¬�®.Ü ±�åÛ´QÓÕ�©Û± ²¯Û±Óàܧ®.²Â±�{¤±�³�²¹çQ±·³�ܧÓí¼��©Û±�» ®.².¶�´O².±;«§¹±�®�î"ÜQ¶�²¯�± ±�å�IJ.¶�´Q³�²¹Ü§©µÜQîض±�®.ܧ¬�æÛ²�ܧ©ù¶�æ�¬¹±�® ¼�¸ùæ�®�©�«à¼jÜQ²¯µ´QæÛ².ÜOÄÓÕ´O²�³í´Q©�»ùÓÕ´Q©�æ�´Q¬�ß�¶Ü�³�±�®®.±�®�â� ��� � �������/��/`����;þ[����� g���Øþ�*�¡��� ������ � �`� ������� � { .�. û*� �o����� ����ÿ���� �"þ�� z������ ��������þ�*� ������� ����ÿ���� z �=þ�������� %h��� ������������;þ��g�F�.ÿ �C�.ÿ=þ�� � � H�E�����E�� 1��I�S�021T.�H�0C.�1�� E�0C.�� ��E�H�b����E��PE�0! "��.�H�.9a�� I$#�.�1�%H�.��& .�0('�%�.)'9I+*jI)�=E�%�H,�=I)�.- ��þ����F� " {./ "�" �/`����;þ[����� g����êþ��� ��� �����0 � �`�F�������� { .�.���� o�����% þ[�����þ������������ ������ ��� þ��þ �����.ÿ=þêÿ�� ������������� ���"ÿ"þ[��� ����� � � � ��E�H�b�1� 0('2#�E�1TI)�¡E��!3 3 3oS4 5�CH�� 0('6 87�9 ��E��.��%(9: 7IFH�� I���;�<=9 �>�xH���1�=.��@?_I-1��EFJ��A� 00B�������E�%�H���IhS�021TIFHC�CH�IF1T.�1�� E�0\.�0CJEDjI-0CIFH�.�1F� E�0"-�;þ���� � {./ " ���ÿ������ÿ������1� { .�.� �� ���&% ������ÿ������ zCG þ������ �;þ ÿ������ � �C� � �=�¡�"þ������ ÿ �
� � H�E����/EH�I3J# &K� 1,L�M5- �;þ���� � { �� /�{ �����N ����O����g�����"þ�P þ�� { .�. û*� � ��� 9��� � ������t�����Ãÿ���� � ÿ�� ����h���JQþ �;þ��� ���R � ÿ�� z ��ÿ���������� G þ������ �� ��ÿ"þ���% þ[�����s� ��*��� ������ ������ ÿ ��ÿ����"þ z������ �TS H�.�0"��.��-1�� E�0�E��oS � 8U(- ���7ú {�! ü U � û / û ! � � VQþ �;þ��� ��� �N ��� ���AW�þ����&�;þ�� !�!�! � � ��� G þ�� ����� �*%X� ��`þ������"þ[������ ú � � ¤ü �X }.}�Y[Z]\�\)^�^�^ r q } HOr�_ ~ rC` Y(\ q } H \�| H \ba * N \ ��7þ[���.ÿ�� � P�� �;þ ÿ"þ þ�*�\�7þ[�������� �����Rÿ=þ���� �ôþ��1� { .�. { � $ �)c�þ ÿ �ed $����������%fc � ��������� ��ÿ�� z ���� ������ / ��g?� ��������� ���c %X������ ������hjilk�m�nKo"p / � � � H�E)�b��E��J? S 8%(9A9A�x1/S�S�S.- �;þ���� � {�!7{./�{�!�# �ú X }.}�Y[Z]\�\bq�q�q r�H o5| HOr�_ ~br5\ obs�p�\ Z t Y l.H�_ \�u�v (�w�w5w�x ü ��7þ[���.ÿ�� � P�� �;þ ÿ"þ - �7þ[��������� �9���Rÿ=þ�� - þ�*� N � ��=þ ÿ��zyg���7ÿ=þ�� { .�. û*�/�ÿ�� ��� ÿ��Áþ�� �.ÿ���- þ����;þ[������ �����/����������������������;þ���� �T�����{Qþ �;þ��� ��� z ��� z������������ % þ��=�������"ÿ"þ�����Áþ[�������� U�E�%�H�0C.��oE��|U� {3oS�- .7ú��ü U � # . /� " .��d�� ���*%X� N þ %X����þ % þ�� { .�� # �� ��ÿ����?� ÿ��T� z ���;þ ÿ������ ������"ÿ"þ���9�g��� �F���� ÿ�����*� � � H�E���� E��L1��I�M)}�1��43g020"%�.��~?sI=IF1�� 0('tE��A3A� & -�;þ���� �g !�!)/ !�# �
������� N þ�c�þ��1� { .�� " �~d�� �;þ���� �T� - ��� �����þ�*� þ�� �C� ���g���Qþ �;þ��� ��� z��� z ������������ �"ÿ"þ�����Áþ[������ ���������% � $ z Q5�[�)� � � H�E)�b� EH�1��I���}�1���3g020"%�.��4��E�0"���VE�� S � 8U5- ��þ����F� { û � /�{ û # � � Qþ �;þ��� ������������*%h� N ���*� { . " ��� B�.�02,/. 0CE0�%0���EFE � $ þ������9�{P5þ�\ý/� G �1�/`�*� - $ ��P���� - Qþ �;þ��� � VQþ �;þ��� �����d þ��=þ.þ�P9�Kd��7ÿ=þ[�"þôþ�*��d þ�P������$�jþ��þ��*� { .�. " � o�� �����&% þ[����������ÿ���� � ÿ�� 9�������)��ÿ���������X��EQþ �;þ��� ������� ���� �� � �L��������_� �7þ % z����� ��þ�*�h����ÿ���þ�� � ��� ��ÿ��F������������ U�E�%�H�0C.���E���#�.�1�%�H�.�� & .�0('�%.b'�I� H�E��=I)�.�H� 0('�- û�ú { ü U � " /�{�! .��Wo�Rÿ���%X�J��þ�P þ�� c�þíþ�*� �7þ[���.ÿ�� � P�� �;þ ÿ=þ�� { .�.� �� � � ÿ�� ��ÿ��������ÿ�� �������������� ��Ïþ6Qþ �;þ��� ��� z ��� z �/���������� % þ��=������s�"ÿ"þ�����Áþ[����������������% G �\������� -�� ÿ G þ��g����% þ�������¿þ[���#ÿ�� G ���� ��� � � H�E�����EH�3J# &K� 1,L�M5- �;þ���� �� !7{./ ! ���Wo�Rÿ���%X��jþ�P þ�� cÛþ þ�*� �7þ[���.ÿ�� � P�� �;þ ÿ"þ�� { .�.���� � ��#ÿ=þ���� ���� ����Áþ��ÿ�� �������������������Qþ �;þ��� ��� R � ÿ��(��ÿ����������`��Øþ % þ��=������`�#ÿ=þ�����Áþ z������V����������% ��������h����% þ�9������þ�*� �7ÿ=þ���% þ[�������F�����#ÿ=þ��������� � � H�E�����E�� S ?�S�1,L���- �;þ���� � . #)/�{�! ���Wo�Rÿ���%X�"�jþ�P5þ�� c�þ�þ�*���7þ[���.ÿ�� � P�� �;þ ÿ=þ�� { .�. # �� g;þ ����.ÿ=þ�ÿ�� ������� z
������s����Qþ �;þ��� ��� R � ÿ�� ��ÿ�����������c � ��� ��� ���������Øÿ���� � ÿ�� �� � � � � H�E�����E��$�� & S�#|D=1,L(�b- �;þ���� �)� { / � { " �Wo�Rÿ���%X�[�jþ�P þ�� cÛþ - P9�����/��P���� - þ�*�P�7þ[���.ÿ�� � P�� �;þ ÿ=þ�� { .�. û*� ����������% ��� -�� ÿ G þ��/����% þ�9����� þ[���"ÿ�� G ����F� � �9� �������¡�������X���� z�=þ���������� �.ÿ#ÿ�� � �C��*��� �� � G ���Cc � � �Qþ �;þ��� ���¿þ�*� ������������� � � H�E�����E��$�� & S�#|D=1,L�}{- �;þ���� � # "� / # " ���Wo�Rÿ���%X����þ�P þ�� c�þ�� { .�. " þ�� g�����% þ[����� � �9�"ÿ"þ��������� ���êÿ������ �� �.ÿ þ��þ �����.ÿ=þhÿ�� ��������������|���+Qþ �;þ��� ��� R � ÿ�� ��ÿ���������X��ÿ���%þ����������� ��� 9��� �� � ��þ��Rÿ�� � � � H�E)�b�_E��23A� & 1�L(�H��<~3A� & 1,L����E�H�b����E�� E�0�����I-H�.�1�� E�0C.��J�;.5�F1TE�H��4� 0 � H�.��-1F�F�=.�� ;�* E�a�%��=1�;3g0C.��{�E�H�.j*jI���E�� %�1�� E�0A��E�H���02H�I)�=1!H����-1!I=J S I���1F�.- ��þ����F� � / �.�� )/=�'�Wo�Rÿ���%X���jþ�P5þ�� c�þ�� { .�. " G � o�����% þ[�����`�&��� ���� ����þ[������h��� R � ÿ��)��ÿ�� z��������þ�*�X����� �RÿÛþ�����F� ����� �����c � ������ þ����������X��� 9��� �� � �;þ��Rÿ����� � H�E����/EH��1��IA��1��2�2� & �@- �;þ���� � { " /�{ û { �
$ ���������þV��þ����{P5þ�c�þ�� { .�. # � 2����� z ��� ��� ��ÿ��9� �F�������� U � % ��ÿ���-����Ãþ��ÿ=þ�������� þ��l��Oý ���������% G þ������L��X����ÿ���þ�� �o��� �.ÿ % þ[������Ac � ������������F��������9��� � � H�E����/EH�$��� & SH#$D=1,L��b- ��þ����F�)�� û / �� �.��Q*� �j����� �g������Áþ��� { .�.���� X }.}�Y[Z]\�\)^�^�^ r O�� H q�����q�p�} r Z ~ t \ ��¤þ����� �j�9����þ[���.ÿØþ���E�¤þ�-9� $ ��% �C� ÿ������ � { .�. { ��ýèþ ÿ�������������������c � ��� þV����{P_�.ÿ=þ % % þ ÿ�� ��.�H�0CI]'�� Ij?sI���� E�0���0"���[I-H��.�x1�7E��E�9A1�>%1TIFH� l��� IF0>�=I S I.����0"�F�=.��l* I���E�H�1�- �;þ���� �(/=d!� / / � / . {./�{ . # �d þ ÿ���� ���äþ�� P�� ÿ - d þ��=þ ��� � �&��þ - þ�����9�;þ ÿ��� /`����� � { .�. ! � /`� z��� ÿ����� ��¡Qþ �;þ��� ��� ������ ����ÿ������ � � H�E����XE��z��� & SH#$D=1�L5¢�-�;þ���� � {./ # �N þ R �����&���4��þ % þ %X�����êþ�*� �/�����=���Rÿ��|���*%X� �"þ�� { .�.���� 2� þ���� G ��� z� �T� �����*��� � �.ÿq� �����&��������ÿ�� �������������P�� ���Áþ���������� � G � % þ��=����� z��� þ ÿ���������� �=���&������� � � H�E�����E��4��� & S�#|D=1F3A� & 1,L�£�- �;þ���� �{ û� �� /�{ û � û*�N � ���/�������&%X�����*� { .������ � ��� 9��� � ������ R � ÿ�� ��ÿ����������o��VQþ �;þ��� ������Áþ������������ � � H�E�����EH�|��� & SH#$D=1�£�£�- �;þ���� � "�" . / " � û*�

DISCOURSE STRUCTURE ANALYSIS FOR NEWS VIDEO
Yasuhiko Watanabe† Yoshihiro Okada† Sadao Kurohashi‡ Eiichi Iwanari†
† Dept. of Electronics and Informatics, Ryukoku University, Seta, Otsu, Shiga, Japan‡Graduate School of Informatics, Kyoto University, Yoshida-Honmachi, Sakyo, Kyoto, Japan
ABSTRACT
Various kinds of video recordings have discoursestructures. Therefore, it is important to determinehow video segments are combined and what kindof coherence relations they are connected with. Inthis paper, we propose a method for estimating thediscourse structure of video news reports by ana-lyzing the discourse structure of their transcripts.
1. INTRODUCTION
A large number of studies have been made on videoanalysis, especially segmentation, feature extrac-tion, indexing, and classification. On the otherhand, little attention has been given to the dis-course structure (DS) of video data.
Various kinds of video recordings, such as dra-mas, documentaries, news reports, and sports cast-ings, have discourse structures. In other words,each video segment of these video recordings is re-lated to previous ones by some kind of relation(coherence relation) which determines the role ofthe video segments in discourse. For this reason,it is important to determine how video segmentsare combined and what kind of coherence relationsthey are connected with. In addition, Nagao et.alproposed a method for multimedia data summa-rization using GDA tags [Nagao 00]. However, thecost of making GDA tagged data is great. Ourmethod will be helpful in reducing the annotationcost.
In this paper, we propose a method for estimat-ing the discourse structure of video news reports.Coherence relations between video segments are es-timated in the following way:
1. a video news article is segmented into shotsby using DCT components,
2. consecutive shots are merged by using speechinformation, and
discoursestructure
news video
discourseunit
shots
discourse structure analysis( using transcripts )
merge shots( using speech information)
segmentation( using image information)
Figure 1: Procedure of discourse structure analysisfor news video
3. coherence relations are estimated by usingthree kinds of clues in the transcript of thenews video:
• clue expressions indicating a certain re-lation,
• occurrence of identical/synonymous words/phrases in topic chaining or topic-dominantchaining relation, and
• similarity between two sentences in listor contrast relation.
Figure 1 shows the procedure of discourse structureanalysis for news video. We applied our method toNHK1 News 2. This method is aimed to make theprocess of retrieval, summarization, and informa-tion extraction more efficient.
1Nippon Hoso Kyokai (Japan Broadcasting Corporation)2NHK news reports do not have closed captions. Instead
of closed captions, we used scripts which were read out bynewscasters as transcripts.

shot (a) shot (b) shot (c)
(I) The US dollar inched up against the yen as the stock marketcontinued the selling trend in Tokyo today.
(II) The US currency traded at145.63–65 yen at 5 p.m. Tokyo.
Figure 2: An example of shots and their transcript in a news video (NHK evening news, August/3/1998)
2. DISCOURSE STRUCTURE ANDVIDEO
Little attention has been given to discourse struc-ture of video data in image processing. This is be-cause it is difficult to determine it only by analyzingimage data. In contrast to this, discourse structureis the subject of a large number of studies in nat-ural language processing. So several methods forestimating the discourse structure of a text havebeen explored[Sumita 92] [Kurohashi 94]. There-fore, these methods can be applied to language dataof video data in order to determine discourse struc-ture in video data.
In addition, some researchers in natural lan-guage processing showed that the information ofdiscourse structure is useful for extracting signifi-cant sentences and summarizing a text [Miike 94][Marcu 97]. It suggests that information of videodiscourse structure is utilized for extracting signifi-cant video segments and skimming. It may be use-ful to look at video skimming and extraction ofsignificant segments before we discuss some pointsabout discourse structure analysis because they areclosely related to the discourse structure estima-tion.
One of the simple ways to skim a video is byusing the pair of the first frame/image of the firstshot and the first sentence in the transcript. How-ever, this representative pair of image and languageis often a poor topic explanation. To solve thisproblem, Zhang, et.al, proposed a method for key-frame selection by using several image features suchas colors, textures, and temporal features includ-ing camera operations [Zhang 95]. Also, Smith andKanade proposed video skimming by selecting videosegments based on TFIDF, camera motion, human
face, captions on video, and so on [Smith 97]. Thesetechniques are broadly applicable, however, stillhave problems. One is the semantic classificationof each segment. To solve this problem, Naka-mura and Kanade proposed the spotting by asso-ciation method which detects relevant video seg-ments by associating image data and language data[Nakamura 97]. Also, Watanabe, et.al, proposeda method for analyzing telops (captions) in videonews reports by using layout and language informa-tion [Watanabe 96]. However, these studies did notdeal with coherence relations between video seg-ments.
In contrast to this, several works on discoursestructure have been made by researchers in naturallanguage processing. Pursuing these studies, we areconfronted with two points of discourse structureanalysis:
• available knowledge for estimating discoursestructure, and
• definition for discourse units and coherencerelations.
First, we shall discuss the available knowledgefor estimating discourse structure. Most studieson discourse structure have focused on such ques-tions as what kind of knowledge should be em-ployed, and how inference may be performed basedon such knowledge (e.g., [Grosz 86], [Hobbs 85],[Zadrozny 91]). In contrast to this, Kurohashi andNagao pointed out that a detailed knowledge basewith broad coverage is unlikely to be constructedin the near future, and that we should analyze dis-courses using presently available knowledge. Forthese reasons, they proposed a method for estimat-ing discourse structure by using surface information

in sentences [Kurohashi 94]. In video analysis, thesame problems occurred. Therefore, we proposehere a method for estimating the discourse struc-ture in a news report by using surface informationin the transcript.
Next, we shall discuss the definition for dis-course unit and coherence relation. As mentioned,discourses are composed of segments (discourse units),and these are connected to previous ones by co-herence relations. However, there has been a vari-ety of definitions for discourse unit and coherencerelation. For example, a discourse unit can be aframe, a shot, or a group of several consecutiveshots. In this study, we consider as a discourseunit, one or more shots which are associated withone part of announcer’s speech. For example, shot(a), (b), and (c) in Figure 2 represent consecutiveshots in the news video “Both yen and stock weredropped”(Aug/3/1998), while sentence (I) and (II)are parts of the transcript. Sentence (I) was spokenin shot (a) and (b), and correspondingly, sentence(II) was spoken in shot (c). As a result, shot (a)and (b) were merged and the result was consideredas one discourse unit. On the other hand, shot (c)alone constituted one discourse unit. We will ex-plain how to extract the discourse units in Section3.1.
In contrast to this, coherence relations stronglydepend on the genre of video data: dramas, docu-mentaries, news reports, sports castings, and so on.From the number of coherence relations suggestedso far, we selected the following relations for ourtarget, news reports:
List: Si and Sj involve the same or similar eventsor states, or the same or similar importantconstituents
Contrast: Si and Sj have distinct events or states,or contrasting important constituents
Topic chaining: Si and Sj have distinct predica-tions about the same topic
Topic-dominant chaining: A dominant constituentapart from a given topic in Si becomes a topicin Sj
Elaboration: Sj gives details about a constituentintroduced in Si
Reason: Sj is the reason for Si
Cause: Sj occurs as a result of Si
Example: Sj is an example of Si
where Si denotes the former segment and Sj thelatter.
3. ESTIMATION OF DISCOURSESTRUCTURE
Our determination of how video segments are com-bined and what kind of coherence relations are in-volved is made in the next way:
1. extract discourse units from a news report,
2. extract three kinds of clue information fromtranscripts, and then, transform them intoreliable scores for some relations, and
3. choose the connected sentence and the rela-tion having the maximum reliable score. Iftwo or more connected sentences have thesame maximum score, the chronological near-est segment is selected.
3.1. Extraction of Discourse Units
A shot is generally regarded as a basic unit in videoanalysis. In this study, however, not only a shotbut also more consecutive ones are considered abasic unit (discourse unit). This is because thereare some cases where several consecutive shots cor-respond with one sentences in a transcript. In thiscase, these consecutive shots should be regardedas a discourse unit. In contrast to this, one shotshould be regarded as a discourse unit when it cor-respond with one or more sentences in a transcript.In both cases, the start/end point of a discourseunit often lies in the pause because the announcerneeds to take breath at the end of a sentence. Asa result, discourse units are extracted in the nextway:
1. detect scene cuts in a video by using DCTcomponents [Iwanari 94],
2. detect speech pauses in the video, and
3. extract the start/end points of discourse unitsby detecting the cuts in the pause.
For evaluating this method, we used 105 news re-ports of NHK News. The recall and precision ofdiscourse unit detection were 71% and 97%, respec-tively, while those of scene change detection were80% and 90%. We modified the extracted discourseunits by hand and used them in the discourse struc-ture analysis described in Section 3.2. In addition,each discourse unit was associated with the corre-sponding sentences in a transcript by hands. Thisis because NHK news reports do not have closedcaptions.

3.2. Detection of Coherence Relations
In order to extract discourse structure, we use threekinds of clue information in transcripts:
• clue expressions indicating some relations,
• occurrence of identical/synonymous words/phrasesin topic chaining or topic-dominant chainingrelation, and
• similarity between two sentences in list orcontrast relation.
Then they are transformed into reliable scores forsome relations. In other words, as a new sentence(NS) comes in, reliable scores for all possible con-nected sentences and relations are calculated by us-ing above three types of clues. As a final result, wechoose the connected sentence (CS) and the rela-tion having the maximum reliable score.
3.2.1. Detection of Clue Expressions
In this study, we use 41 heuristic rules for findingclue expressions by pattern matching and relatingthem to proper relations with reliable scores. Arule consists of two parts: (1) conditions for ruleapplication and (2) corresponding relation and re-liable score. Conditions for rule application consistof four parts:
• rule applicable range,
• relation of CS to its previous DS,
• dependency structure pattern for CS, and
• dependency structure pattern for NS.
Pattern for CS and NS are matched not for wordsequences but for dependency structures of bothsentences. We apply each rule for the pairs of a CSand NS. If the condition of the rule is satisfied, thespecified reliable score is given to the correspondingrelation between the CS and the NS.
For example, Rule-1 in Figure 3 gives a score (20points) to the reason relation between two adjoin-ing sentences if the NS starts with the expression“nazenara (because)”. Rule-2 in Figure 3 is appliednot only for the neighboring CS but also for fartherCSs, by specifying the occurrence of identical words“X” in the condition.
3.2.2. Detection of Word/Phase Chain
In general, a sentence can be divided into two parts:a topic part and a non-topic part. When two sen-tences are in a topic chaining relation, the same
Rule-2
range : *
relation of CS : *
CS :
*
relation : reason
score : 20
Rule-1
relation of CS : *
range : 1
CS : * NS : nazenara
*
X *
*
NS : *
X no
rei
*relation : exemplification-present
score : 30
( because )
( of )
( example )
Figure 3: Examples of heuristic rules for clue ex-pressions
topic is maintained through them. Therefore, theoccurrence of identical/synonymous word/phrase(the word/phrase chain) in topic parts of two sen-tences supports this relation. On the other hand,in the case of topic-dominant chaining relation, adominant constituent introduced in a non-topic partof a prior sentence becomes a topic in a succeedingsentence. As shown, the word/phrase chain from anon-topic part of a prior sentence to a topic partof a succeeding sentence supports this relation.
For these reasons, we detect word/phrase chainsand calculate reliable scores in the next way:
1. give scores to words/phrases in topic and non-topic parts according to the degree of theirimportance in sentences,
2. give scores to the matching of identical/synonymouswords/phrases according to the degree of theiragreement, and
3. give these relations the sum of the scores oftwo chained words/phrases and the score oftheir matching.
For example, by Rule-a and Rule-b in Figure 4,words in a phrase whose head word is followed bya topic marking postposition “wa” are given somescores as topic parts. Also, a word in a non-topicpart in the sentential style, “ga aru (there is ...)” isgiven a large score (11 points) by Rule-c in Figure 4because this word is an important new informationin this sentence and topic-dominant chaining rela-tion involving it often occur. Matching of phrases

Topic part
Rule-a
pattern : * wascore : 10
Rule-b
pattern : *
*
* wascore : 8
Non-topic part
pattern : * ga
aru
Rule-c
score : 11
Matching
Rule-d
pattern :
score : 5
X * x *
Rule-e
pattern :
X *
Y *
x *
y *score : 8
Rule-f
pattern :
X Y * y *
x noniyoru
score : 6( there is )
( of | by )
Figure 4: Examples of rules for topic/non-topicparts
like “A of B” is given a larger score (8 points) byRule-e than that of word like “A” alone by Rule-d(5 points) in Figure 4.
3.2.3. Calculation of Similarity between Sen-tences in a Transcript
When two sentences have list or contrast relation,they have a certain similarity. As a result, we mea-sure such a similarity for finding list or contrastrelation in the next way. First, the similarity valuebetween two words are calculated according to ex-act matching, matching of their parts of speech,and their closeness in a thesaurus dictionary. Sec-ond, the similarity value between two word-stringsis calculated roughly by combining the similarityvalues between words in the two word-strings withthe dynamic programming method for analyzingconjunctive structures [Kurohashi 94]. Then, wegive the normalized similarity score between a CSand an NS to their list and contrast relations as areliable score.
4. EXPERIMENTS AND DISCUSSION
For evaluating this method, we used 22 news re-ports of NHK News. Each report was a few min-utes in length. The experimental results are shownin Table 1. As mentioned, news reports of NHKNews do not have closed captions. For this reason,each video segment (discourse unit) was associatedwith the corresponding sentences in a transcript byhands.
Table 1: Analysis resultsRelation Success FailureList 2 1Contrast 1 0Topic chaining 38 11Topic-dominant chaining 20 2Elaboration 0 3Reason 0 0Cause 4 0Example 0 0Total 65 17
Figure 5 shows the video news report we usedin our experiment. As shown, shot (b) and (c)were merged together because there was no pauseat the cut point between them. Sentence (I), (II),(III), (IV), and (V) were associated with shot (a),(b)(c), (d), (e), and (f), respectively. Coherence re-lations between video segments were estimated inthe following way: a topic-dominant chaining re-lation was estimated between shot (a) and (b)(c)because “Prime Minister Obuchi” was found in thetopic part of sentence (II) and in the non-topic partof sentence (I). The same relation was also esti-mated between shot (b)(c) and (d) because “theFiscal Structural Reform Law” was found in thetopic part of sentence (III) and in the non-topicpart of sentence (II). On the contrary, topic chain-ing relation was estimated between shot (a) and(e) because “the Ministry of Finance” was foundin the topic parts of sentence (I) and (IV). In thiscase, the system detected also another relation: atopic-dominant chaining relation between shot (b)and (e). However, the system selected the formerone because the former exceeded the latter in score.The system also determined a topic chaining rela-tion between shot (e) and (f). In this case, thesystem additionally detected two other relations:topic chaining relation between shot (a) and (f),and topic-dominant chaining relation between shot(b) and (f). But the relation between (a) and (f)was chosen, because its reliable score was greaterthan the score between (b) and (f) and equal to thescore between (e) and (f), but there the distancebetween the shots was greater. Figure 6 shows theresult of this analysis.
As shown in Table 1, 11 topic chaining and2 topic-dominant chaining relations could not beextracted. The reasons were (1) the topic wordsof the following sentences were omitted 3 and (2)
3There are many ellipses in Japanese sentences.

shot transcript
(a)
(I) In accordance with instructions of Prime MinisterObuchi, the Ministry of Finance will decide about newguidelines for budget requests which is free from the re-strictions of the Fiscal Structural Reform Law.
(b)
(II) Prime Minister Obuchi called Vice Minister Tanami,the Ministry of Finance, into the Official Residence, andinstructed him to make new budget request guidelines inline with the freeze policy of the Fiscal Structural ReformLaw.
(c)
(d)(III) The Fiscal Structural Reform Law sets upper limitsfor expenditures in all categories but social security.
(e)
(IV) In accordance with prime minister’s instruction, theMinistry of Finance establishes new guidelines in whichkey government expenditures, for example, public worksprojects, are permitted to go beyond the limits of the Law.
(f)
(V) the Ministry of Finance will decide about the newguidelines by the middle of the next week, and governmentministries and agencies will submit their budget requests inaccordance with this guideline by the end of the month.
Figure 5: An example of news video (“New guidelines for budget requests”, NHK evening news, Au-gust/3/1998)

a
b, c
d
e
f
topic−dominantchaining relation
topic−dominantchaining relation
( Prime Minister Obuchi )
( the Ministry of Finance )
( the Ministry of Finance )
( Fiscal Structural Reform Law )
topic chaining relation
topic chaining relation
Figure 6: The result of discourse structural analysisfor the news video shown in Figure 5
the topic word was changed (e.g., driver → manwho drove the car) or abbreviated. Also, 3 elabo-ration relations could not be extracted. This wasbecause there were no clue expressions for the elab-oration relation in the sentences. However, the sys-tem could mostly detect clue expressions and oc-currence of identical/synonymous words/ phrases.In some cases (e.g., a compound sentence), therewere many clues for an NS supporting various re-lations to several CSs. The system could detectthem, however, extracted only one CS and relation.In this study, we introduce a reliable score for de-termining the most plausible CS and relation. Asshown in Table 1, this method is useful, however,we should investigate a method for extracting moreCSs and relations than one when several CSs andrelations exist.
In this study, we assumed that image and lan-guage data correspond to the same portion of anews report. For this reason, it is likely that the re-lation between images slightly differs from the anal-ysis result when image and language are taken formdifferent portions (correspondence problem betweenimage and language).
At the end of this section, we discuss video sum-marization using discourse structure information.First, we consider summarization of the news videoshown in Figure 5 with the summarization topicconcerning the Ministry of Finance. The summa-rization system traces topic chaining relations andgenerates video summarization which consists ofshots (a), (e), and (f). Next, we consider summa-rization of the same news video with the summa-rization topic concerning the Prime Minister. Thesystem traces a topic-dominant chaining relationand generates video summarization which consistsof shot (a), (b), and (c).
References
[Grosz 86] Grosz and Sidner: Attention, Intentions,and the Structures of Discourse, ComputationalLinguistics, 12-3, (1986).
[Hobbs 85] Hobbs: On the Coherence and Structureof Discourse, Technical Report No. CSLI-85-37,(1985).
[Iwanari 94] Iwanari and Ariki: Scene Clustering andCut Detection in Moving Images by DCT compo-nents, (in Japanese), technical report of IEICE,PRU-93-119, (1994).
[Kurohashi 92] Kurohashi and Nagao: Dynamic Pro-gramming Method for Analyzing ConjunctiveStructures in Japanese, COLING-92, (1992).
[Kurohashi 94] Kurohashi and Nagao: Automatic De-tection of Discourse Structure by Checking SurfaceInformation in Sentences, COLING-94, (1994).
[Marcu 97] Marcu: From Discourse Structures to TextSummaries, ACL workshop on Intelligent ScalableText Summarization, (1997).
[Miike 94] Miike, Itoh, Ono, and Sumita: A Full-TextRetrieval System with a Dynamic Abstract Gen-eration Function, SIGIR-94, (1994).
[Nagao 00] Nagao, Shirai, and Hashida: MultimediaData Summarization Based on the Global Doc-ument Annotation, (in Japanese), 6th AnnualMeeting of The Association for Natural LanguageProcessing, (2000).
[Nakamura 97] Nakamura and Kanade: SemanticAnalysis for Video Contents Extraction – Spottingby Association in News Video, ACM Multimedia97, (1997).
[Smith 97] Smith and Kanade: Video Skimming andCharacterization through the Combination of Im-age and Language Understanding Techniques,IEEE CVPR, (1997).
[Sumita 92] Sumita, Ono, Chino, Ukita, and Amano:A Discourse Structure Analyzer for JapaneseText, International Conference of Fifth GenerationComputer Systems, (1992).
[Watanabe 96] Watanabe, Okada, and Nagao: Se-mantic Analysis of Telops in TV Newscasts, (inJapanese), technical report of Information Pro-cessing Society of Japan, NL-116–16, (1996).
[Zadrozny 91] Zadrozny and Jensen: Semantics ofParagraphs, Computational Linguistics, 17-2,(1991).
[Zhang 95] Zhang, Low, Smoliar, and Wu: Video Pars-ing, Retrieval and Browsing: An Integrated andContent-Based Solution, ACM Multimedia 95,(1995).

60

61
SECTION 3
Semantic Annotation of Document Segments

62

�������������� ������������������� �"!$#%�& ('��)+*� ��,���-�/. 01�������
��2�����3�������,�4�5����6�78�����:9"'��);8� ! �<���=#>�?,@<ACBEDGFIHEJGKLB(@8MONQPSR @:BETLBVU(WYXZN[@ J\N]D_^`M)R:N/ab@ Kdc2N]DfeGKdJgW�BEAhMiBEj`W=B k
lnmpo(mGqsrtB(@�UVB ^<uwv<@ j`W2B<^xMOB(j`W+B ^:yEzt{5zt| qVqnoEm,}=}VoVo~ JfH(@ KdF�v D\H ^�@:H(jEHVU=H���H��V�bDnk��xTpk�KdJ\PVk�v m�J\B(j`W=B<k�HVPVk �g�
���h9] n��� �V �����n���S�V�]�C�O�������������������f���¡ £¢t�w���S¤n¢"¥b�����£¦g§�\¢"¥Z�¨�"�f���<�f©`ª�«8¥��,�f�)�h¬Q�¥����i¦g�£¢n����¢��,��®��¡��¯�b��¦g���¡�n�±°w�>�¨²"���C�i¤"�C�Z��¯n�Z¢�¤n�´³n���¨�\©µ�Z�S�,�S���¢Z�G�£¦g¯Z�C��¢n����¢"¦g�µ�\©��C�(���G¦g¯¶���¡¢n�£·Q��¯n���C�£¤n¢"¥��¡¢n ���¡�Z�)�¡¢%�¸�C�£¤n¢"¥������£¦�§¹�\¢"¥s��¯n�t�C¯n�£�´¦g¯"�\¢n S����¡�Z�O��¢º��¯n�¨�w�£�����S¢¸�����\ S�¨���b�\�¡�� S¢¸��¯n���»�\�n¼�n���S½Q�¡�)�f�������£°2ª�¯n��¢w®����"���C©¾�S���3¿À��)�f�,¦�¯n��¢n ���i�f���¡ £¢)�h�C�GÁ[¤n��¢"¦g�5�f©+®��£��¥n�x�S³n�,�f��¢n�G¥O©¾���£�3��C�(���G¦g¯Â���G¦g�S £¢n�¡���¡�£¢¶�C�_�C�����8�\�n�n�¡���G¥O���h���C�£¤n¢"¥�����£¦g§´®��¡��¯��G�£¦g¯)�C��¢n����¢"¦g�5�f© ���"���G¦g¯����¡¢n�G�:��¢t���¦g���¡�n�±°tÃ<�£¢�²E¥���¢n�¦g�S�����G�C�(�S¢"¥��±¢"¦g�G�O�S³n�,�f��¢n�G¥©¾���£�Ä��¯n�Å¿hÀÆ���\��¦,¯n��¢n ¸�\©���¯n�)®��S�,¥n�O�S¦g�Z�£���¯n���n��¬Q�S�,�����¨�¡�Z�n���£¬\���\�¡�� S¢n�Z��¢�� �£¦�¦g¤n�,�S¦g�Z�¡��¼���,�f���¡¬Q���¡�[°Yªµ¯n�t���G�C¤n�����Å�C¯n�S®Ç��¯"�\�)�\���£¤n¢"¥È�¯"�\�É©`�f©`��¯n�h�C��¢n����¢(¦g�G����¢��i��¦g�����n��®��������f���¡ £¢n�G¥®��¡��¯n�¡¢���¯n�h¥��ÉÊ=������¢"¦g�G�:�\©`¤n�����´��®:�w�C�G¦g�S¢"¥n��°Ë Ì �� n���µ�O���V _�����Í5�¡�� S¢n�Z��¢n���\©)¬Q�¥��������È����½Q�º��Î�G���C��¢����Ï�f�¨����)�f§Q�ŬQ�Ï¥�����¦g�£¢n����¢����¨Ð"��½Q�¡³n���>����¤"���\³n�¡�£°1Í���¼��¯n�S¤n £¯��¡���C�������¹���8³(�I�n���£�w�Ï�C��¢n Y©¾�£�/��¯n���n¤n���"�]�C�´���b�\�n�n�¡�Î�)�C�V���G¦�¯¸���G¦g�S £¢n�¡���¡�£¢º���G¦�¯n¼¢n�£�¡�£ S�Ñ���Ò��¯n�/�C�S¤n¢"¥����,�£¦g§>�\©w�¹¬Q�¥����%¦g�£¢n¼����¢n��·)�C�V���G¦�¯3���G¦g�£ S¢n�������S¢-©Ó�£�Ñ�ƪµ« ¥����\����£�Å�/©¾�G�f��¤n���¸²"�¡�Ô�Ï���£¦g��¤"�\���¡�I¥���Õ�¦g¤n����°Öª�¯n��)�f×&�£���S³"�C�,�S¦Ø�¡�¹�C�¡ £¢n�ɲE¦��\¢n���¡¢Ù�%¥��,�\���Ò�\¢"¥²"��� ��Å��¯n���(�]�S�t�£¦�¦g¤n���£¦g�I�\©w�C�V���G¦,¯È���G¦g�S £¼¢n�������S¢+°1¿�¤n�t���>��¯n�t³"�S¦g§Q S���S¤�¢"¥��Z¤"�C�¦\·���¯n�¢n�£��C��©¾���S�Ú��¯n�µ��¢�¬Q�¡���S¢n�Z��¢��+�¡¢Z�5�¡��¦��f���¡�£¢´�\¢"¥�\¤"¥��¡�w¦g�S�Z�n���G�����¡�£¢Z���¡§Q��ÛÎÀ:Ü�Ýi·Q��¯n���S¦�¦g¤n�,�£¦g��\©2�C�(���G¦g¯¶���G¦g�£ S¢n�����¡�£¢Z�Ï���£¢n���´�f���S¤n¢"¥bÞ±ß\¼LàSßQá�°ªµ¯n¤"����¯n�h���G�C¤n�¡���f©��C�V���G¦,¯����â¦g�S £¢n�¡���¡�£¢¸������¯n��C�£¤n¢"¥i�����£¦g§h�\©2�h¥����\�����£��²"�¡�-¥��]�G� ¢n�S��¯"�\¬\���¢n�£¤n S¯ÙÁ[¤"�f���¡���Ñ���%¥������G¦g���¡�È����¤"������¯n��¬Q�Ï¥����¦g�£¢n����¢[�,�Ø°Í�����¯n�£¤n £¯º��¯n�¨���G�C¤n�¡��\©µ�C�"���G¦g¯¸���G¦g�S £¢n�¡���¡�£¢
�Ï�V�\©_¢n��¤"�C� ³n�5�����C����©�·G®�� �C���¡���£¯"�f¬[�2��¯n�:��¦g�����n�+�f©
�b¥����\�)�Å�S��²"�¡�t°wã5��¢"¦g�)�f��������¢"�f���¡¬[�´�w�±��¯n��¥��x���h�f���¡ £¢¶��¯n�µ��¦g���¡���`�f©=��¥����\�����£�+²"�¡�Ú���h��¯n�¬Q�¥�����°�ä[��¬]���,�\���n���S�(�S�,���f�Ï��¯"�\¬£��³V����¢¶�)�S¥��5����C�£�¡¬Q�Å��¯n��w�n���S³n�����b°Ñåµ�f £�¡¢]¤n���Î���)�\�d°5æ¾åµ�f £¼�¡¢n¤n�)�Ò�\¢"¥ÙäQ�\§£�f¤"¦,¯n�ç·OÞGèSè£é]ê��n���£�"�]�C�G¥Y�����Z��f���¡ £¢n�w��¢��)�\©w�>ª�«Ä¥����\����³n�>��¯n���n¯n�_�C�Ϧ��f��C¯n�£�¹¦g¯"�f¢n £�G�b��¢4¬]�Ï¥����n·¶��¯n�ѬQ�S��¤n�w�¹��¢4��¯n��C�£¤n¢"¥È�����£¦g§Ò�\¢"¥���¯n�/¢Q¤n�¶³n�����f©´¦g¯"�\���£¦g�����,��¡¢Ò��¯n�t�C�V���G¦�¯����¡¢��G�i�\©���¯n�t��¦g�����n�±°�ã5�£®:��¬£����·��¯n�t�S¦�¦g¤n�,�S¦g�/�\©��f���¡ £¢n�w��¢n�³n�º��¯n�����¶�w����¯n��¥�S¦g¯n����¬£�G¥´�S¢n���)ëfß]á1©¾�£�µ�O�C��¢�����¢"¦g��¥�¤n�5���¨��£¦g§�f©��C�(���G¦g¯����G¦g�£ S¢n�������S¢b�¡¢¸��¯n���¡���Z����¯n��¥V°��¯n�¡���O�C�(���G¦g¯����G¦g�£ S¢��¡���¡�£¢�¦��f¢b�¡�Z�n���£¬\����¯n�
�S¦�¦g¤n�,�S¦g�È�f©´�\�¡�� S¢n�Z��¢n�±·µ®��΢n���G¥%���Ò�C�S��¬Q�¸�¦g�S¤n�n���/�f©´�n���£³n�¡���)�����%�\�n�n�¡���C�"���G¦g¯%���G¦g�S £¼¢n�¡���¡�£¢����Î�¸�C�£¤n¢"¥����,�S¦g§t�\©��Î¥����\���Å�£�²"���b°Í1�C���\����¼d�\©¾¼d��¯n��¼L�\�����C�V���G¦,¯Z���G¦g�S £¢n�¡���¡�£¢��C�_�C������V���&©¾�S���)���C�V���G¦,¯È���G¦g�£ S¢n�����¡�£¢È�¡¢Y�Ò�C��¢�����¢"¦g��¼���£¼L�C��¢n����¢"¦g�µ���\¢n¢n���±° ìç¢)�£¥n¥��������S¢����O��¯"�f�±·��\�n¼�n�¡�Q��¢n i�C�"���G¦g¯i���G¦g�S £¢n�¡�����S¢�¥��¡���G¦g�����¨���i��®�¯n�S����¡��¢n £��¯4�\©b���S¤n¢"¥Æ���,�£¦g§(·w���G�8àSß��w��¢n¤n���G�Î�£��¡�£¢n S���±·\�¡¢�¬£�£�¡¬[�G�(¤n¢n���G�\�¡�Ï�C���¦�¦g�]�C���=�¡¢O³V�S��¯Â���¡�Z��f¢"¥Î�w���Z�S���]°�ã5��¢"¦g�´���C�£¤n¢"¥b���,�S¦g§�¢n���G¥n�����³V��¥���¬Q�¥��G¥w�¡¢n���O�C��¢Q����¢"¦g�G���n���¡�£�<���i�f�n�n���Q�¡¢n i��C�V���G¦�¯b���G¦g�£ £¢n�¡���¡�£¢t�C�_�C�����b°�¿�¤n�¨���w��¯n�¨��\�� £�¢n¤n�´³n���5�\© �C��¢n����¢"¦g�G�:��¢Î�wªµ«4¥_���\���_·_�¡�5�)�f����G��¤n�¡��¡¢¸��¢�©Ó�������S���£¦�¦g¤n�,�S¦g������¥_�¡¬Q�¥��Z�w®�¯n�£����C�£¤n¢"¥È�����£¦�§��¡¢���������¢n����¢"¦g�G�Ø°1���Φ��\¢��\¬\�S�Ï¥��¯n�Ï�h³n�Î¥��¡¬Q�Ï¥��¡¢n ¸�Å�C�£¤n¢"¥º�����£¦g§t���£¤n £¯n�¡�t²"�,�C��¡¢n���n·\���f�[·��¡�£ S�Ϧ��f����¦g��¢n�G�Ø° ª�¯n��¢i®����f�n�n���Â�w�£����n���G¦g�Ï�C�¨�C�� S�Z��¢n���\�����S¢�³"�£�C�G¥��S¢b��¯n�h����¢n����¢"¦g�G����)��¯n�Â�¡�£ S�Ϧ��f�2��¦g��¢n�G��°���¨¥���¬Q���¡�£�n�G¥¸�w�C�_�C�����í�����\���¡ £¢��G�£¦g¯t�C��¢n¼
����¢"¦g�Ú�f©��C�"���G¦g¯î�¡��¢n�G�%��¢ï�-��¦g���¡�n�È®�����������¢�¡¢%ð[�f�"�\¢n�G�C��������¯n�Ŧg�S�����G�C�V�£¢"¥��¡¢n Î�"�\���¶�f©Â��C�£¤n¢"¥����,�S¦,§´�S¦�¦g�£�w�"�\¢n�Q�¡¢n h��¯n�h��¦g�����n���C�(�S§Q��¢�¡¢sð[�f�"�\¢n�G�C�£°�ñ5¤n���n���£�"�]�C�¡¢n Å�C�_�C�����ï¦g�S¢"�C�Ï�C�,��f© ���¡½)�Z��¥�¤n�¡�G��° ò`�¡ £¤n���wÞ��¯n�S®��:��¯n�Â�f�,¦g¯n�¡���G¦g¼

��¤n�����\©2�£¤n���C�_�C�����b°��5�£������¯"�f�������\�¡�� S¢n�Z��¢Q����Z�G�f¢"���,�\�¡�� S¢n�Z��¢����\© �C�GÁ[¤n��¢"¦g�G�:©¾�£���Z�G¥�©¾���S����´�¡¢¸��¯n�h���G�C���f©x��¯n����"�\�"���±°
Sentencealignment
Speechrecognition
Wordalignment
Feedback
A sound track
Number of morasin a sentence
A language modelgenerated from
speech lines
The sound trackaligned to thespeech lines
Sentences ofthe speech linesResults of
alignment
Roughly alignedsentences
Recognizedwords
Pivots Logical scenealignment
Number of morasin a logical scene
Adjustment oflogical scene boundaries
Time ofshot change
in motion image
Roughly alignedlogical scenes
Alignedlogical scenes
ò��¡ £¤n���ZÞ:ªµ¯n�O�\�,¦g¯n�¡���G¦g��¤n�����f©<�S¤n�5�����C�����ìç¢í�C�G¦g���¡�£¢���·Î®��Y¥_�G��¦g����³"�1���S £�¦��\����¦g��¢n�
�\�¡�� S¢n�Z��¢n�Î�\¢"¥Ù���S £�¦��\�w��¦g��¢n�ѳ"�£¤n¢"¥n�f���8�£¥�¼×&¤"�C���Z��¢n�±°Yªµ¯n�Î�C��¢n����¢"¦g�Î�\�¡�� S¢n�Z��¢��Z�w��¥�¤n����Ï��¥����¦g¤"���C�G¥Ò�¡¢Y�C�G¦g�����S¢Èà_°1���b¥��G��¦g���¡³V�t��¯n��C�(���G¦g¯���G¦g�£ S¢n�������S¢O�w��¥�¤n��� ��¢� �° ä[�G¦g���¡�£¢��µ¥���¼�,�f�������¯n�µ®��S�,¥i�f���¡ £¢n�w��¢n���w��¥�¤n���£° ª�¯n���w�G¦g¯n¼�\¢n��C� �f©�©Ó���â¥�³"�S¦g§t�Ï�i¥����¦g¤"���C�G¥��¡¢��C�G¦g���¡�£¢�é�°���´�n���G�C��¢����£¤n�Â��½Q�"�����¡�Z��¢n�,�f�x���G��¤n�¡�,���¡¢��C�G¦g¼���¡�£¢ºë¶�\¢"¥�¦g�£¢"¦g�¡¤"¥_�h�¡¢¸�C�G¦g���¡�£¢���°� � �������=�<�t���=���8�������µ�h�-��� ªµ¯n�Å®��S�,¥��f���¡ £¢n�w��¢n�i�w��¥�¤n���Å��¢��£¤n�Z�C�_�C������Ï�/¦±�f�"�\³n�¡�Ñ�\©¸�\���¡ £¢n�¡¢n Ù�1��¦g��¢n�Ñ�f©��S¢��¡�Ö¤n������\���£¤n¢"¥Y�C��¬Q�����\����¯n�£¤"���\¢"¥%®��S�,¥n�Ø·µ�S�¸�C��¬Q¼���,�f�µ�Z�¡¢n¤n���G�Ø°�ÍÇ��¦g��¢n���¡�£¢n S���¶��¯"�f¢+·����G�£·µÞGß�Z�¡¢n¤n���G�<¦��\¢n¢n�£��³V�h�\�¡�� S¢n�G¥�¥������G¦g���¡�Z³n�¶®��£��¥�¼���S¼d®��S�,¥��)�f¢n¢n����®�����¯%���n���£¦g���¦��\��¦g�S�Z�n¤n�,�f¼���¡�£¢"�f��¦g�]�C�±°:ã5��¢"¦g�¨®��h¢n���G¥Å���Å¥���¬£�����S�b�S��¯n����Z�G�f¢"���f©µ�\�n�n���£½]�����\���i�\�¡�� S¢n�Z��¢n��¦��\�"�\³n�¡�´�\©¯"�\¢"¥��¡��¢n �����¦g��¢n�Â�f©µÞGßf¼Là£ß´�w��¢n¤n���G�Ø°
Íí�¡�£ £�¦��\����¦g��¢n�Å��¢Ñ�s��¦g�����n�Z¦��f¢Ò³E�t�f¢%�f��¼������¢"�f���Z�f©���®��£��¥¸���¸�\�¡�� S¢��b�C�£¤n¢"¥º�����£¦,§t����s��¦g���¡�n�±°IÍÇ���S £�¦��\����¦g��¢n�t¯"�£�i��¯n��©¾�S���¡�£®���¢n ©¾�G�f��¤n���G��� Íï�¡�£ S�Ϧ��f����¦g��¢n��¦��\¢%³E�t��½Q�����£¦g���G¥Ò©¾���S��Î��¦g�����n�¨�S�¨�G�S�C���¡�/�S�i��®��£��¥V°)Í3���Q�n�¦��\����S £�¦��\����¦g��¢n�´¦g�£¢"�C��C�,���\© ��¯n�i��¦g��¢n�¨¢Q¤n�Z¼³"�����f¢"¥i��¯n�5���������£·\©¾�S���¡�f®��G¥O³n�Â��¯n���C�(���G¦g¯���¡¢n�G���f¢"¥¸¥������G¦g���¡�£¢"�Ø°
� Í1�¡�£ S�Ϧ��\�+��¦g��¢n�h��¢��´�w�£�����S¢b�¡�)�f £�h�\©¾����¢³"�� £��¢"���f¢"¥I��¢"¥n���\�Å�>�C¯n�£��¦g¯"�f¢n £�£°YìL�¦��\¢Ñ³V�Î¥������G¦g���G¥Ò³n�¹��¯n���C¯n�£�)¥������G¦g�����S¢�C�_�C����� ®�¯n�Ϧg¯È¤"�C¤"�\�¡���I¤"���G����¯n�¹¦g¯"�f¢n £��\© ¦g�S���S��¯n�Ï�C���£ £���\���µ³"����®<����¢��w¦g�£¤n�n���h�\©¦g�£¢"�C�G¦g¤n����¬Q�5©Ó�,�\�w�G�µ�¡¢¸�w�w�£���¡�£¢������\ S�£°
ª�¯n�G���t©ç�S¦g�,�����w�n���Ñ��¯"�\�)�¹�¡�£ S�Ϧ��f�h��¦g��¢n�Φ��\¢³V�O��½Q�����£¦g���G¥b³(�S��¯b©Ó���S�ï����¦g���¡�n��f¢"¥b�Z�S���¡�£¢�¡�)�f £�£°:ã5��¢"¦g��®��h�£¥��S�n���O���S £�Ϧ��f�=��¦g��¢n�h�S�µ�f¢�f��������¢"�f����¬]�Â�f©µ�Z®��S�,¥b�����\�¡�� £¢Î�)�C�S¤n¢"¥Î���,�S¦,§���b��¯n�w��¦g���¡����°Oªµ¯n�´�n���S³n�����ï�����¯"�\�h�)�¡�£ £�¦��\���¦g��¢n�h�)�G�)¦g�S¢(�C��C���f©`¢n�£�µ�w�C��¢n S����³n¤n���C��¬Q�����\��C¯n�£���Ø° ªµ¯n¤"��¥�¤n���\�����S¢w�f©=���¡�£ S�Ϧ��\�n��¦g��¢n��¢n���G¥n�����³(�)�G�C�������\���G¥s¤"�C�¡¢n ���¯n�Å�C�"���â¦g¯/���¡¢n�G�O�\©����¦g���¡�n�±°ìL�º��ή������O§Q¢n�f®�¢Ù�¡¢4ð[�f�"�\¢n�G�C���¡��¢n S¤n�Ï�C���Ϧ��
�f¢"¥��n¯n�£¢n�����¦�� ��¯"�\�µ�Â�¡��¢n £��¯��\©=¤n�������,�f¢"¦g�h¥�¤n¼���\�����S¢���¢�ð[�\�"�f¢n�G�C�)�Ï�h³"�S���¦��\�¡�����n���S�V�£�����¡�£¢"�f�������¯n�Å¢n¤n�´³n�±�´�\©���¯n�Å�Z�S�,�S�´�¡¢Ò��¯n��¤n���������G¥®��£��¥¸æ��¤n³V����£¢n�n·=ÞGèSè£è]ê,°µÃ:�S¤n¢����¡¢n ´��¯n�Ï�µ©d�£¦g�±·®��Î�C����§Ñ��¯n�Î�C���\������¢n ��\¢"¥%��¢"¥���¢n ����¡�Z�Î�\©O��"�f�����f©E��¯n���C�£¤n¢"¥i���,�S¦,§Â®�¯n�Ϧg¯¶¦g�S�����G�C�(�S¢"¥n�x����b���S £�¦��\�:��¦g��¢n�)��¢s��¯n�Å��¦g���¡�n�¨�£�O��¯n�´²"�,�C�¨�\�n¼�n���£½Q�¡�)�f���¡�£¢+·(�C�)��¯"�\�5��¯n�i¥�¤����\�����S¢º�\©:���S¤n¢"¥�¼�¡¢n Ò�C�� £�w��¢��)¦g�£�����G�C�(�S¢"¥���¢n ����s��¬Q�����¹�¡�£ S�Ϧ��f���¦g��¢n�)�\©���¯n�Å��¦g���¡�n�i S���,�O�n���S�V�S�������£¢"�f�����Î��¯n�¢n¤n�´³n���¶�\©��Z�S�,�S�¨�¡¢Ò��¯n�)���S £�¦��\����¦g��¢n�£°�ªµ¯n��C���\������¢n º�\¢"¥s��¢"¥��¡¢n t�����w�Å�\���Z��¯n��¢��£¥f×&¤"�C���G¥������¯n� ¢n�G�\���G���2��¯n�S�`¦g¯"�\¢n S�x���¡�Z� ��¢Â��¯n� �Z�S���¡�£¢�¡�)�f £�£°:ªµ¯n�O�C�£¤n¢"¥���¢n ��C�� S�Z��¢Q�,�:��¢���¯n�O�C�£¤n¢"¥���,�S¦g§¹�\������½]���,�S¦g���G¥�³n�¹¦g�S�Z�"�\����¢n ��"�S®:���i�f©��¬Q���������f�)�C�G¦��"�����¡��¥Ò��¢%��¯n�Î�C�£¤n¢"¥Ò���,�S¦,§¹�����¯n�º�n���G¥����������Z�¡¢n�G¥Ò��¯n���G��¯n�S�Ï¥V°Yªµ¯n�t¢n¤n�O³(����f©��Z�£���£�i��¢Ñ�t�¡�£ S�Ϧ��f����¦g��¢n����w¦g�£�w�n¤n���G¥s³n���¯n���n���£¢n¤n¢"¦g�Ï�f���¡�£¢/�\©���¯n��®��£��¥n�O��¢���¯n�)�¡�£ S��¼¦��f�2��¦g��¢��h�S³����\�¡¢n�G¥w©¾���£�Ç�O�Z�£���n¯n�£�¡�£ S�Ϧ��f�2�\¢n¼�f����������°����¹�f�n�n�����Ò¦g�£�Z�w���,¦g��\�i��¦g��¢n�¹¦g¤n����_�S� æLã������£¦g¯n�ç·��+��¥V°�·2Þ±è£èQëSê<����¥������G¦g����¯n�¨�C¯n�£�¦g¯"�f¢n £�G�:��¢t��¯n�h�Z�£�����S¢b�¡�)�f £�£°

� ����� nx���+8�����������x�µ Í-���S £�¦��\�µ��¦g��¢n�w £��¢n���,�f���¡�¹¦g�S¢"����C�,�h�f©5�C��¬]�±���\��C��¢n����¢"¦g�G�Ø°�ã��£®���¬\���±·�¤n¢��¡��§]�º��½]�����£¦g����¢n I��¯n����S £�¦��\����¦g��¢n�G�w�¡¢%��®�¯n�S���b¥��,�f�)��·����´�Ï��¥��ÉÕ)¼¦g¤n���µ���w��½Q���,�S¦g����¯n�¨�C��¢Q����¢"¦g�G��¥��¡���G¦g�����Z©¾���£�Ç��C�£¤n¢"¥º�����£¦g§t�£�¨�b�C�GÁ[¤n��¢"¦g�w�\©µ�����\ S�¶©¾���\�w�â�Ø°ª��b�C�� £�w��¢n��£¤n�Â�G�S¦g¯s�C��¢n����¢"¦g�¶�¡¢s��¯n�)�C�£¤n¢"¥�����£¦g§(·£®����f�n�n���)��¯��h�w�±��¯n��¥����¶¤(�C����¯n�¢n¤n�w¼³"���,���\©��w�£���£��\¢"¥¸��¯n�w¥�¤n�,�f���¡�£¢º�f©��C�£¤n¢"¥��¡¢n �C�� £�w��¢n�,�:¥��G��¦g����³V�G¥���¢��C�G¦g���¡�£¢ �_·���½_¦g���n����¯"�f�®�� �C����§h���"�\���+�\©���¯n�:���S¤n¢"¥h���,�S¦g§h¦g�£�����G�C�(�S¢"¥�¼��¢n %���%¢n�£�t�Ò���S £�¦��\�i��¦g��¢n�¹³n¤n�Î�I�C��¢�����¢"¦g�£°ä[��¢"¦g�i�\¢¸¤n���������\¢"¦g�¨�f©����C�V���G¦,¯����¡¢n�¨�)�f��¢n�S�³"�� £��¢¶�S����¢"¥¶�\�<��C¯n�£�x¦g¯"�\¢n S�£·\®����Z��¥��É©¾�¨��¯n��\�¡�� S¢n�Z��¢n�5�Z����¯n��¥¸�n���£�V�[�C�G¥Î�¡¢��C�G¦g���¡�£¢ �)³n��£�w�������¡¢n ¸�£¥f×&¤"�C���Z��¢����\©µ�C���\������¢n ¸�f¢"¥���¢"¥���¢n ���¡�Z�h������¯n�¢n�G�f���G�C�5�C¯n�£�5¦g¯"�f¢n £�������w�[°� ���´2`�+'��È`�=�����5�& n�������� � ����������������������������� �"!�$#%���&�(')�ìç¢��£¤n�´�����C�����t·2��¯n�)®��£��¥n�����γ"�)¤n���������G¥��f��� £�¡¬Q��¢��S�´��¯n�b�C�(���G¦g¯��¡��¢n�G�i�\©h����¦g���¡�n�¶��¢È�S¥�¼¬£�\¢"¦g�£°:Í1®��S�,¥�³n�� S�,�f���Ï�f¢n £¤"�f £�¨�w��¥����`¤"�C�G¥¥�¤n���¡¢n ����E���â¦�¯¸���G¦g�S £¢n�¡���¡�£¢¸��� £��¢n���,�f���G¥�©¾���S���¯n��®�¯n�S���>�C�"���G¦Ø¯È�¡��¢n�G�b���Ò�¡�Z�n���£¬£�Î��¯n�>�£¦g¼¦g¤n�,�S¦g�º�f©��t�C�V���G¦�¯º���G¦g�£ S¢n�������S¢��C�_�C�����b°)Ü ¬]¼�����ή��£�,¥º��¢¹�Å�Ï�f¢� S¤"�\ S�)�Z��¥����:�Ï�¤����������G¥s�f����G�S�C�¶�£¢"¦g�£·:�\¢"¥�¢n���£��¯n���i®��£��¥n�i�\���Ťn���������G¥®��¡��¯$��¯n��>�,�f���¡�£���G¥3��\¢n S¤"�\ £�1�w��¥����ç° ªµ¯n���\¬\�S�Ï¥n�����G¦g�S £¢n� ���¡¢n Ò®��S�,¥n�Å¢n�S�t�\�n�"�G�\����¢n %��¢��¯n�O�C�V���G¦,¯����¡¢n�G�Ø°ìç�Ñ�f�Ï�C�-³n����¢n [�I�f³"�£¤n�È�Ƴ(���������I�£¦�¦g¤n���£¦g�
��¢��C�V���G¦�¯����G¦g�£ S¢n�������S¢����Ò¦g¯n�S�]�C�/��¯n�/�S¦g�£¤"�C¼���¦1�Z��¥������S¥n�\�n���G¥3©Ó�£���4���E�G�\§£���±° ã5�S®�¼��¬Q����·µ�¹ S��¢n���,�f���Z����¯n��¥%�\©´�C�V�G�\§£���)�£¥n�f�n�,�f¼���¡�£¢�¯"�£�b�C�S�Z�Î�)�f×&�£���n���£³n�¡���)�Å�¡¢È�£¤n�t�C�_�C¼�����b·µ��¯"�f���Ï�Ø·µ��¯n�Î�C�V�G�\§£���,�w�¡¢È��¯n�Î�C�� £�w��¢n�,��\©���¯n�b�C�£¤n¢"¥s�����£¦�§¹�\���)¢n�£�¨ £�¡¬Q��¢��S�O��¯n�Å��¢n¼�n¤n�±°iò"¤�����¯n�����Z�S���£·�¢n�£�Â�S¢n���t�S¢n�¶³n¤n�¨�C��¬£���,�f��C�(�G�f§Q�����)���\�Ѥn����������¢1�Ò���¡¢n £�¡�¹�C�� £�w��¢��)�\©��¯n�i���S¤n¢"¥Å���,�S¦g§E° ª�¯n¤"��®��h¦��\¢n¢n�S�¥����������w��¢n��Y��¤n�¡�,�f³n���%�£¦g�£¤"�C���ϦÑ�Z��¥����w�n�����S�s���8�C�V���G¦�¯���G¦g�S £¢n�¡���¡�£¢+°iìL¢º�S�,¥����Â�������S��¬]�¨��¯n��h�n���S³n�����b·®��b�(���&©¾�£��� �C�V���G¦,¯È���G¦g�£ S¢n�����¡�£¢È®�����¯��w¤n������¼�n���w�S¦g�£¤"�C���¦Â�w��¥�����OæLÛt��¢n �����f�ç°¡·xÞGèSè£è]ê,·V���f�©¾�����\�¡�´�\¢"¥b���\�¡�¨�Z�Q¥_����Ø·E³"�G¦��\¤"�C�¨��¯n�i¥���ÊV����¼��¢"¦g���f©E��¯n�G�C���&®����Z�n¥����Ï���GÊV�G¦g�,�2��¯����£¦�¦g¤n���£¦g��\©��Å�C�(���G¦g¯¸���G¦g�£ S¢n�������S¢s�C�_�C����� �C�� S¢n��²E¦��f¢����¡�£°ª��´�V���&©¾�£���Ç�C�(���G¦g¯����G¦g�£ S¢n�������S¢º�C���Z�n�¡�Q·]��¯n�G�C�
�S¦g�£¤"�C���¦t�Z��¥�����Å�f���t¤"�C�G¥Ò�¡¢È�"�\�,�f���¡���ç°Yªµ¯n���f���¡�£®5�Ť"�Å���%���w�n���S¬\�/��¯n�>�£¦�¦g¤n�,�S¦g�I�\©)�C��¢n¼����¢"¦g�¨�f���¡ £¢n�w�±¢Q��®�����¯n�£¤n���Z����C���¡�G¦g���¡¢n w�´�C¤n�¡��¼�f³n�����£¦g�S¤"�C���¦<�Z�n¥����ç·S¥��G��¦g����³"�G¥O��¢Z�C�G¦g�����£¢��_° �_°���+* �-,�./�(�0�2143��0��������!+�5!)���6,879� �5�0:
�����<;�!)'=�"�0>5!�&�?���9�A@$��!)� 74BC��>5�&�
���µ¤"�C�5ð�D �`ìEDÂäZæçìL���h�����f�ç°¡·_ÞGèSè��]êx�£���h�C�V���G¦,¯���G¦g�£ S¢n�����¡�£¢-�����������t° ÍÄ�Ï�f¢n £¤"�f £�Ñ�w��¥����´�Ï� S��¢n���,�f���G¥�³n�/�f�n�n���Q�¡¢n s��ð[�\�"�f¢n�G���)�w�£���n¯n�£¼�¡�£ S�Ϧ��f�>�\¢"�f���_�C���8ð0D�ÛºÍ � æ �¤n���£¯"�S�C¯n�>�\¢"¥���f ]�f��·ÒÞGèSèQëSêÑ�\¢"¥�Ã�Û�D5¼CÃ��\�w³n���¥_ S�Öä��2Ûª��]�£�¡§Q�¡��æ&Ã:��\��§_�C�£¢+·(ÞGèSèQëSê����´��¯n�h���"���G¦g¯¶���¡¢n�G��°���)¤"�C�Åã�ÛÎÛÎ�¨�f©¨Þ±éÎ�Z�¡½Q�G¥�¥���¢"�C���&�º©¾�S�i�����¡¼�n¯n�S¢n�G�x�f©=à£ßSߣß��C�,�f���G���£�2��¯n�5�S¦g�£¤"�C���Ϧ<�w��¥�����Ø°ã�ÛÎÛÎ�=©¾�S�V©¾���)�f�����\¢"¥�)�\�¡�µ�C�"�â�f§Q�����=�f���:¤"���G¥�¡¢¸�"�\���\�¡�����d°���/�(�[�C���n����¦g�G���t��¯n�/���G¦g�£ S¢n� ���G¥Y®��£��¥n�Å��¢
�S�,¥��������Ò�¡�Z�n���£¬£�t��¯n�s�£¦�¦g¤n���£¦g�I�\©w�C��¢n����¢"¦g��f���¡ £¢n�w��¢���° Í �C�V���G¦,¯ ���G¦g�S £¢n�¡���¡�£¢ï�C�_�C����������G�f�,�h¤n¢n¤n����������¢n �¥�¤n�,�f���¡�£¢s�¡¢������S¤n¢"¥����,�S¦g§�S�w�¸¦g�£�Z���t�S�¶�Å©¾¤n�����C���S�+°�ã5�f®���¬[����·`��¯n�G���¥��h¢n�S��¤"�C¤"�\�¡���¨���\��¦g¯i�����¯n��¦g�£�w�)�S� �f¢"¥O©¾¤n����C���£�"�µ�¡¢b��¯n�¨�C�"���G¦g¯����¡¢n�G��°�ªµ¯n¤"��¦g�£�w�)�S�µ�f¢"¥©¾¤n�¡���C���S�"����¢i��¯n�����G¦g�£ S¢n� ���G¥i®��£��¥n���\¢"¥i�C�V���G¦�¯�¡��¢n�G���\���5�f�n�"�\����¢������h¢n�£�Ï�C���¡¢¶®��£��¥i�\�¡�� S¢n�Z��¢n�±°����²"�������<�£¤n�<��¯n�G�C��¢n�£����´®��S�,¥n�2©¾���£�-��¯������G¦g¼�S £¢n� ���G¥s®��£��¥n��\¢"¥s��¯n�)®��S�,¥n�h�¡¢s��¯n�Å���"���G¦g¯�¡��¢n�G���n�����S�����w®��£��¥��\���¡ £¢n�w��¢n�±°
F G �����������������x�µ �#%�& ('»0IHJÔ�� n�+'5�,���
ìç¢���¯n��O�Z��¥�¤n�¡�£·x®����\���¡ £¢s©Ó�£�Â�G�£¦g¯/�\©5�¡�£ S�Ϧ��f���¦g��¢n�G� ��¯n���C�GÁ[¤n��¢"¦g�G�x�f©=��¯n�µ���G¦g�S £¢n� ���G¥w®��£��¥n����I��¯n�¹�C��¢�����¢"¦g�G�Å�\©´��¯n�s���"���G¦g¯È���¡¢n�G�ų"�£�C�G¥�S¢���¯n�����¡�Z�¡�Ï�f���¡���>³(����®�����¢È�/�"�f���)�\©¨®��£��¥��Ø°ª�¯n�1�C���w����\�����&�Ö³"����®:����¢�®��£��¥n�¹�¡¢�¬£�£�¡¬£�â¥Ú��¢��¯n�Ï�¸�\�¡�� S¢n�Z��¢n�)�Ï�¸¦g�£�w�n¤n���G¥�³n�Ñ�E���C©¾�S���w��¢n �w�£���\¼d³"�£�C�G¥È¿À3�)�f�,¦g¯n�¡¢n �°8Ût�£���Î�n���G¦g������¡�Q·�S¤n��®��£��¥��\�¡�� S¢n�Z��¢n�¶�C�_�C����� ¦g�S¢"�C�Ï�C�,�i�\©���®���¡��¬Q���µ�f���¡ £¢n�w��¢��i�w��¥�¤n���G� K��ήµ�S�,¥��f���¡ £¢n�w��¢n��w��¥�¤n�¡�Z©¾�£�¨�b�"�\�¡�i�f©��C��¢n����¢"¦g�G�¥��G��¦g����³E�â¥s�¡¢�C�G¦g���¡�£¢ ��° �Å�f¢"¥¸�)�w�£���)�f���¡ £¢n�w��¢n��©Ó�£���)�"�\�¡��f©E®��£��¥��+¥��G��¦g���¡³V�G¥O��¢´���G¦g�����S¢ �_°¡Þ£°�ª����n����¦g���G¥��¯n�Z®��S�,¥º�f���¡ £¢n�w��¢��5©¾�£�¨�C��¢�����¢"¦g�G�Ø·=��¯n�Z®��£��¥�f���¡ £¢n�w��¢����w��¥�¤n���¹�¡¢�¬£�£§£�G�)��¯n�¹�Z�S�,�Ò�f���¡ £¢n¼�w��¢n���w��¥�¤n�¡�©¾�S��®��S�,¥n�:�¡¢n�������£¦g���¡¬\�����£°

�8� #%��>5�?� ')!)���&: �(� ��� ��> B ��>5������w¥��G��¦g����³E�Z��¢���¯n�Ï�Â���G¦g�����S¢��£¤n�Â�w�£�,�f¼d³"�£�C�G¥¿À ���\��¦g¯n��¢n �° �=������� ³"�I�Y���GÁ£¤n��¢"¦g�Ñ�\©�Z�S�,�S�2�\©(�5®��£��¥h�¡¢¶���C��¢n����¢"¦g� �\©E���C�V���G¦,¯Â���¡¢n���¢º��¯n�Z��¦g�����n��·2�\¢"¥���Ù³"�w�����G¦g�£ S¢n� ���G¥¸®��£��¥�\©=��¯n�5�C�V���G¦�¯w�¡��¢n�£·£���G���E�G¦g���¡¬[���¡�[°�ªµ¯n���w�\����¥���¼²"¢n�G¥º�£��©¾�£�¡���f®5�ØæLÍÆ��¤n³"��¦g�����n��f©���C�,�f¢"¥n�5©Ó�£��´�w�£�,�]ê���� ���������������������������������������������� �!¸æ�Þ\ê� � ��" ��� �#" ��� ����������" �%$ �&�����&��" ��' !�æ �Qê®�¯n�����(�����h�Ï����¯n�*)¾��¯��Z�S�,�>��¢1�¹®��S�,¥%�f©´��C��¢n����¢"¦g�£·+" �%$ �Ï����¯n�-,]��¯��w�£���Â�¡¢Z�h���G¦g�£ S¢n� ���G¥®��S�,¥V·&.��Ï�V��¯n��¢Q¤n�´³n�±�=�\©"�w�£���£�V��¢Â��¯n� ®��S�,¥��f©�h�C��¢�����¢"¦g�£·£�f¢"¥0/)�Ï����¯n�:¢n¤��´³n���x�\©"��¯n�µ�Z�S�,�S���¢��O���G¦g�S £¢n� ���G¥�®��S�,¥V°�ªµ¯n��¢�®���¥��g²"¢n�h�´�C���w¼����\�������¨³(����®:����¢Z�h�"�\�¡�<�\©=�Z�S�,�S��·�1#�ºæ2�����2�#"3�%$�ê�£�:©¾�S���¡�£®5� 1 � æ4� ��� ��" �%$ ê5 6778 779
à æ2� ��� :" �%$ ê� ; ñ5¢n���Å��¯n�¨¬£�f®����E�f©<� ��� �Ï��GÁ[¤"�f�`���w��¯n�h¬Q�f®:���(�\©=" �%$?>ß æ �5�S¢n�Â�f©5��¯n�O�\³"�£¬£�\ê
æLà]êÍÚ¬]�f®:���=��¢/�w���G¦g�S £¢n� ���G¥b®��S�,¥��Ï���w�£���´¦g�£¢�²"¼¥���¢n�5��¯"�f¢��Ŧg�S¢"���S¢"�\¢n����¢º £��¢n�����\�d°Zª�¯n¤"��®�� £�¡¬Q�h�w�C�¡�Z����\�������Z���Å�´�"�f�����f©<�w�£���£��®�����¯b��¯n��Ï¥���¢n���Ϧ��f�µ¬£�\®������f¢"¥%¥���ÊV������¢��Z¦g�£¢"�C�S¢"�\¢n���w�£�®����¡�ç°�D��C��¢n i��¯n����½]�����G���C���S¢sæçàQê�·Q®����������,�f���h�f¢��½Q�n���G���C�¡�£¢ÑæLé]ê�®�����¯º��¯n�Z�¡¢n�����Ï�f�:¦g�£¢"¥��¡���¡�£¢"�h�f©��½Q�n���G���C�¡�£¢"�:æ _ê=�\¢"¥�æ �Qê=�S�=©¾�£�¡���S®��V���¦g�£�w�n¤n���@ � æ4� �� ��" ��' ê @ �¸æ2��������"3���gêA �ß æ _ê@ � æ4� ��� ��" ��� ê� @ � æ4� ��� ��" �%$ ê5 CB=D æ��]ê@ �ºæ2�����E��"3�%$�ê5 Ñ�)�f½GF2HI�KJ �KJ LML LMJ N�OP�6778 779@ � æ2� ���QOPFEOP� �R" �%$SOP� êUTV1 � æ4� ���QOPF �R" �%$ ê@ � æ2� ���QOP� ��" �%$SOP� êUTW1 � æ4� ��� ��" �%$ ê@ � æ2� ���QOP� ��" �%$SOPFEOP� êUTV1 � æ4� ��� ��" �%$SOPF êTYX FZ HI� 1 � æ4� ��� ��" �%$SOPF2[ Z ê æLé]ê
®�¯n�����]\s�Ï�O�Å�"�f�,�\�w�������Â���t©¾�S��³n�¥s�C�������,¦�¯n��¢n �\¢"¥��C¯n���¡¢n§Q��¢n ^\Å�£���w�£���Â�w�£���£���¡��¦��\�¡���]°ò`�� S¤n��� �Ò��¯n�S®�����¯n������¦��f�O¦g�£¢"�C�����\�¡¢n���f¢"¥
��¯n��®����� S¯���� ��¢���¯n����½]�n���G���C���S¢sæçéQê�° ªµ¯n�h³n�Ï�S¦,§¥��£�����C¯n�£®s��¯"�\�`��¯n�µ�f���¡ £¢n�w��¢n�+�"�\��¯"��¦��\¢i S���f®©¾���£� ��¯n�G�C�t¥��S�,�O���Òæ4)K�_,�ê,°�ª�¯n��¢Q¤n�¶³n�����w�S¦g¼¦g�£�w�"�\¢n�¡�G¥>³Q�/��¯n�Å�"�\��¯"�i�\������¯n�)®����¡ £¯����h�f©
p
p
(i-p+1,j)
(i-p,j-1)
(i-1,j-p)
(i,j)
(i-1,j-1)
111
111 1
1
1
1
A’
B’
a’mi
b’m
jb’
mj-
1
a’mi-1
ò`�� S¤n��� � ªµ¯n�-�¡��¦��f�>¦g�£¢"�C���,�f��¢Q�Ù�f¢"¥ ��¯n�®����� S¯��,�:�f©x��¯n�¨�"�f��¯"�µ�¡¢��Z�£���w�\�¡�� S¢n�Z��¢n�
��¯n���t°hª�¯n�Ï��¦g�S¢"�����,�f��¢n�5�S����¤n���G����¯"�f���¯��O�V�]�C¼�C�¡³��¡�)�)�f½Q�¡�¶¤n� �f© @ � æ4� �� a` �R" ��'b` ê�¥��_�G�¢��S�¥����V��¢"¥È�£¢c/ � °$���/�¡�������\���/��¯n�/��½Q�n���G���C�¡�£¢æçéQêx¤n¢����¡� @ �ºæ2���� ` ��"3��' ` ê` S���,�:¦g�S�Z�n¤n���G¥V° ò��¡¼¢"�f���¡�Q·=��¯n�w�C���w����\�������t³(����®:����¢Y��8�\¢"¥d�e�Ù��¥��g²"¢n�G¥¸�S��©¾�S���¡�£®5��f � æ4� � �S� � êA 68 9 @ �Îæ4���� ���"3��'QêUT �2gh KO+' h [I� æ2��ji k���êl @ � æ4� �� �#" ��' êUT �2gh KO+' h [I�#m � æ2� � k� � ê
æCëSêª�¯n�´�C�G¦g�£¢"¥b���������¡¢¸��¯n�¨��½]�n���G���C���S¢sæ&ë£ê��Ï����¢n¼¦g�¡¤"¥��G¥����%¥����¦g�£¤n�,�f £���)�f�,¦�¯n��¢n >®��£��¥n�w®��¡��¯��½_¦g�G���:¥��ÉÊV������¢"¦g�µ³(����®:����¢¶��¯n�µ¢�¤n�´³n����� �\©E��¯n��w�£���£�Ø° 쾩?�<� ��5·Â�d° �£°Ç��¯n����¯"�\¬\����¯n��¥���¢n���¦��\�x�n���£¢n¤n¢"¦g��\�����£¢t®��¡��¯s�G�S¦g¯º�£��¯n���±·=®����Á[¤"�f��� @ �ºæ4���� n`A��"S��'K`�êT �2gh n`�OP'3` h [I� ���% £�¡¬[�¯n�¡ £¯n�����C���w���Ï�f���¡�&�Z���¶��¯n�G�C�®��£��¥n��¦g�£�����G�C�(�S¢"¥�¼�¡¢n ¹�����G�£¦�¯��£��¯n���±°>���)¤"���of � æ4� � ��� � êÂ�¡¢®��£��¥%�\�¡�� S¢n�Z��¢��¶©¾�S�)����¢n����¢"¦g�G��·�¥��G��¦g����³E�G¥Ò��¢�C�G¦g���¡�£¢ �_° �_°�8�+* B ��>5����'!)����: �(� ��� ��>�,��0�9�"�0�����0����S�,¥È�\�¡�� S¢n�Z��¢Q���\�¡ £�S���¡��¯n� ©Ó�£�t�C��¢�����¢"¦g�â�����f�Ï�C��¿À>�)�f�,¦g¯n�¡¢n w�S�:®������(�S�µ��¯n���Z�S�,�w�f���¡ £¢n¼�w��¢n��©Ó�£�®��£��¥n���Ï�Ø° �=�±�]p5q��f¢"¥�r�qs³V�w�Å�C��¼Á[¤n��¢"¦g�)�f©5®��£��¥n�h��¢¹�Î�C��¢n����¢(¦g�w�f¢"¥��Å���G¦g�£ S¼¢n� ���G¥Ò®��£��¥s�\©Â��¯n�t�C�"���G¦g¯����¡¢n�£·<���G�C�V�G¦g���¡¬[���¡�£°ª�¯n���)�\���h¥��g²"¢n�G¥��£� ©¾�S���¡�\®5�ØæLÍ��C¤n³"��¦g�����n���\©-s

�C�,�f¢"¥n��©¾�S���´®µ�S�,¥(ê p q � � q ��� � q �����&����� � q �2�&�����&� � q �! æ �Qêr^q ����q � ����q � �����&������q $ �����&������q ' !�æçèQê®�¯n����� � q � �����¯n�0)¾��¯s®��£��¥Î�¡¢º��¯n�Z®�¯n�£�¡�)�C��¢n¼����¢"¦g�h�\© ��¯n�O�C�V���G¦,¯����¡¢n�£·�� q $ �����¯n�e,]��¯b®��£��¥��¢º��¯n�¶���G¦g�£ S¢n� ���G¥¸®��£��¥n�Ø· .)�Ï����¯n�´¢n¤n�¨³"����f©®��S�,¥n���¢���¯��)®�¯n�£�¡�Å�C��¢n����¢"¦g�G�Ø·x�f¢"¥ /È�Ï�O��¯n�¢n¤n�¨³"���¶�\©���¯n�t���G¦g�S £¢n� ���G¥>®��£��¥n�Ø°>ªµ¯n��¢%®��¥��g²"¢n�)�����¡�Z�¡�Ï�f���¡���t³"����®:����¢/�Å�"�\�¡��f©�®��£��¥n�Ø·1 q æ � q � ��� q $ ê�¤"���¡¢n ���¯n�¹���G�C¤n�����Î�f©���¯n�¹�Z�S�,��\�¡�� S¢n�Z��¢n�E�Z�n¥�¤n���<©Ó�£�+®��£��¥n�2¥��G��¦g���¡³(�G¥O�¡¢¶�C�G¦g¼���¡�£¢ �_°¡Þi�£�:©¾�£�¡���f®5� 1 q æ � q � ��� q $ ê5 Cf � æ4� ��� ��� �%$ ê æ�Þ±ßQê®�¯n����� � ��� �\¢"¥ � �%$ �f���Ò��¯n�I�C�GÁ[¤n��¢"¦g�G���f©�Z�S�,�S�µ�¡¢���¯n�h®��£��¥n� � q � �f¢"¥�� q $ ���G�C�V�G¦g����¬£�����£·�\¢"¥�f � æ2� ��� �R� �%$ ê5��O¥��g²"¢n�G¥��¡¢���¯n�Z��½]�n���G�C¼�C���S¢�æCëSê,° D��C��¢n ���¯n�¨��½]�n���G���C���S¢�æ�Þ±ßQê�·"®��Â�¡������¼�\�����f¢���½Q�n���G�����¡�£¢tæ�Þ±àQê`®�����¯Z��¯n����¢n�¡����\�(¦g�£¢"¥��¡¼���¡�£¢"���f©<��½]�����G���C���S¢"�hæ�ÞSÞ\êµ�f¢(¥/æ�Þ �Qêµ�£�µ©¾�S���¡�f®�����Z¦g�£�Z�n¤n��� @ q æ � q ��� q ' ê�@ q æ � q � ��� q � ê5 Iß æ�Þ£Þfê@ q æ � q � ��� q � ê5 @ æ � q � ��� q $ ê5 jB=D æ�Þ �Qê@ q æ � q � ��� q $ ê� I�)�f½ F2HI�KJ �KJML LML J NROP�6777778 777779
@ q æ � q � OPFEOP�#��� q $SOP�ØêUT���1 q æ � q � OPFb��� q $pêT X FZ HI� 1 q æ ��� � OPF2[ Z ��� q $ ê@ q æ � q � OP�#��� q $SOP�pêUT ��1 q æ � q ����� q $gê@ q æ � q � OP�#��� q $SOPFEOP�ØêUT���1 q æ � q �2��� q $SOPF,êT�X FZ HI� 1 q æ � q �2��� q $SOPFE[ Z ê æ�Þ±àQê®�¯n�����]\s�Ï�O�Å�"�f�,�\�w�������Â���t©¾�S��³n�¥s�C�������,¦�¯n��¢n �\¢"¥��C¯n���¡¢n§Q��¢n ^\Å�£���w�£���®��£��¥n�:���n¦��\�¡���£°ò`�� S¤n���sàÒ��¯n�S®�����¯n������¦��f�O¦g�£¢"�C�����\�¡¢n���f¢"¥
��¯n�>®����¡ £¯Q�¸�f©)��¯n�>�"�\��¯"�Ø° ªµ¯n�>³n�Ï�S¦g§1¥��S�,��C¯n�£® ��¯"�\����¯n�1�f���¡ £¢n�Z��¢Q���"�f��¯"�Ò¦��f¢î £���£®©¾���£� ��¯n�G�C�t¥��S�,�O���Òæ4)K�_,�ê,°�ª�¯n��¢Q¤n�¶³n�����w�S¦g¼¦g�£�w�"�\¢n�¡�G¥>³Q�/��¯n�Å�"�\��¯"�i�\������¯n�)®����¡ £¯����h�f©��¯n���b°µª�¯n�Â��½Q�n���G�����¡�£¢"�Oæ�Þ£Þfê��f¢"¥�æ�Þ �]ê���¢"��¤n�����¯"�f�5��¯n�²"�����5®��£��¥n�µ��¢t��¯n�´�C�GÁ[¤n��¢"¦g�G���f��®��G�_�¦g�£�����G�C�"�£¢"¥Y���I�G�S¦,¯Y�S��¯n����°í�����������,�f���/��¯n���½Q�n���G���C�¡�£¢�æ�ÞGà]ê<¤n¢n���¡� @ q æ � q ��� q ' ê� S���,��¦g�£�w¼�n¤n���G¥V°�8� ,��0'�0�2�"!)���<�G���"1������2�"����')'=7��9� �5�0>5�0�
� ��>5���Í�� �w��¢n���¡�£¢n�G¥O�¡¢��C�G¦g�����£¢ �·]®����S³n�,�f��¢Z��®:�Â�C�±¼Á[¤n��¢"¦g�G���\©E���G¦g�£ S¢n� ���G¥i®��S�,¥n�2®�����¯´©Ó���)�\�¡���\¢"¥
p
p
(i-p+1,j)
(i-p,j-1)
(i,j-p+1)
(i-1,j-p)
(i,j)
(i-1,j-1)
11
1
1
2
2
2
2
222
1
1
Aw
Bw
a wi
bw
jb
wj-
1
a wi-1
ò`�� S¤n���3à ªµ¯n�-�¡��¦��f�>¦g�£¢"�C���,�f��¢Q�Ù�f¢"¥ ��¯n�®����� S¯��,���\©���¯n�´�"�\��¯(���¡¢º¿hÀÈ�)�\��¦g¯n��¢n w�f©���¯n�®��£��¥����GÁ£¤n��¢"¦Ø�G�
���\�¡�)�£¦g�S¤"�C���¦¶�Z�Q¥��±��h���G���"�G¦g���¡¬Q���¡�[°iìç¢��S�,¥�������Å�C���¡�G¦g����¯n�´�£¦g��¤"�\�¡���Ťn���������G¥b®��£��¥n��¥��]¢"�\�Z¼�¦��\�¡���>³(����®:����¢Ò��¯n�G�C����®:�s�C�GÁ[¤n��¢"¦g�G�Ø·<®��Å¥���¼¬Q���¡�£�n�G¥��Å�w����¯n�n¥����Î�C���¡�G¦g�i��¯n�)�\�n�n���£�n���Ï�f����C�GÁ[¤n��¢"¦g�t¤n�V�S¢>²"¢"¥��¡¢n >��®��£��¥�� � OP� ¤n�����±���G¥�n�����S����� � � °
timeuttering duration
female
male
d2wj
d1wj’-1
d1wj’
d2wj-1
ò`�� S¤n��� ��ä[�����G¦g�����S¢��\©=®��S�,¥n� ¤n���������G¥w�n���¡�£������ �q $ò��¡ £¤n��� º��¯n�S®���£¤n�¶�w����¯n��¥����º�����¡�G¦g�¶��¯n�
®��£��¥n�´¤n���������G¥��������S�Z����� �q $ ©¾���S� ��¯n�t®��£��¥n����G¦g�£ S¢n� ���G¥O³n�h�£¦g�S¤"�C���¦<�Z��¥�����=©¾�£�+©¾�����\�¡�µ�\¢"¥���\�¡�£°/���)�C���¡�G¦g�i©¾���S�Ä�G�£¦�¯��\©5��¯n��®��S�,¥��C��¼Á[¤n��¢"¦g�G�w��¯n��®��S�,¥n�O®��¡��¯���¯n�b¢n�â�f���G�C�¶��¢"¥��¡¢n �����w�����i��¯n�5³"�� £�¡¢n¢n��¢n i���¡�Z���\©�� �q $ ©¾���S���f�����f©��¯n��®µ�S�,¥n��®��¡��¯���¯n�5��¢"¥��¡¢n ´�����Z�G���n���¡�£�<���i��¯n�³V�� S��¢n¢n�¡¢n w���¡�Z���f©�� �q $ °�ò"�S�:��½��\�w�n���£·_®��5²(¢"¥� �q $�� OP� �\¢"¥�� �q $SOP� �£����¯n�´®��£��¥n��¤n���������G¥¸�n���¡�£������ �q $ ��¢º²" £¤n��� n°wªµ¯n��¢s�G�S¦,¯º�\©�� �q $ � OP� �\¢"¥� �q $SOP� ��w�C¤n³"�C���¡��¤n���G¥Ò��¢Q����� q $SOP� ���s¦g�£�w�n¤n���@ q l � q �E��� �q $ m °Oªµ¯n��¢º��¯n�´®��£�,¥���¯"�f� £�¡¬Q�G����¯n�

¯n�� S¯n�G�C� @ q l � q �2��� �q $ m ����C�����G¦g���G¥¸�£� � q $SOP�±°� Ì �C�h������x����< Ò�����``��h� �"!���Î���w�n���S¬[�Î��¯n�s�£¦�¦g¤n���£¦g���f©Z�f���¡ £¢n�w��¢n��³n�²"½Q�¡¢n Ò¦g�£¢�²E¥���¢n��¦g�S�����G�C�(�S¢"¥���¢"¦g�G�)�¡¢Y��¯��Î����¼�C¤n���<�f©`��¯n��®��£�,¥Z�\�¡�� S¢n�Z��¢Q�:�w��¥�¤n����¥��Ï��¦g¤"���C�G¥��¢Ñ�C�G¦g���¡�£¢ ���S�¨²"½Q�G¥s�n�¡¬Q�£���O��¢��¡�£ S�Ϧ��f����¦g��¢n��\�¡�� S¢n�Z��¢n��°Í ¦g�S¢�²E¥���¢n�Ȧg�£�����G�C�"�£¢"¥���¢"¦g�-�C¯n�S¤n�Ï¥ ¢n�£�
¦g�£¢"�C��C�i�f©Â�C¯n�S���¨®��£��¥n�Ø°/ä[¯n�£���¶®��£��¥n�O��¢��S¤���C�_�C�����3���g©¾���µ���´��¯n�®��S�,¥n�:�f©`�£¢n�¡�)�£¢n���£����®���Z�S�,�S�Ø°ÇÛt�]�C�¸�f©Z�C¤"¦g¯È��¯n��®��S�,¥n���\���/©¾¤n¢"¦g¼���¡�£¢"�f�_®��£��¥n�2��¢Zð[�\�"�f¢n�G���£°�ªµ¯n���´�f�n�(�G�f�<Á[¤n�¡���©¾���GÁ[¤n��¢n���¡���¡¢��f¢��¸���"���G¦g¯º���¡¢n�G��°wÛt�£�����£¬\����·2��C�(���G¦g¯Z���G¦g�S £¢n�¡�����S¢��C�_�C�����3�)�f�¨�Z������G¦g�£ S¢n� ���¤n�������,�f¢"¦g�G�2�£�`��¬Q��¢Â¢n�£����G�2������¢"¥O¤n�i®��¡��¯¶�C�n¤n¼���¡�£¤"�O©¾¤n¢"¦g���¡�£¢"�f��®��£��¥n�Ø°�ñ5¢���¯n�t¦g�S¢n�����\���\· �¦g�£�����G�C�"�£¢"¥���¢"¦g�Z�f©����S¢n Å®��£��¥n��®��¡��¯/�\¢º�Ï¥���¢n¼���¦��\�(�n���S¢�¤n¢"¦g��\�����£¢)¦��\¢�³"�h¦g�£¢�²E¥���¢n��°<ä[¤"¦,¯)�¦g�£�����G�C�"�£¢"¥���¢"¦g�Å�C¯n�£®5�h��¯"�f�Â��¯n�)¤n���������\¢"¦g�)�Ï����G¦g�S £¢n� ���G¥%¦g�£�����G¦g�����>®��¡��¯È���)�f�,¦�¯n��¢n �®��£��¥��¢���¯n���C�"���G¦g¯����¡¢n�G�Ø°�Ã:�S¤n¢�����¢n O��¯n�G�C��©d�£¦g����·]®��¥��g²"¢n�Î�s¦g�£¢�²E¥���¢��Z¦g�S�����G�C�V�£¢"¥��¡¢n ¹®��S�,¥��"�\�¡��£�:©¾�S���¡�£®5� � ªµ¯n�O¦g�£�����G�C�"�£¢"¥��¡¢n )®��S�,¥n��¯(�f¬\�O�\¢��Ï¥���¢n¼���¦��\�=�n���£¢Q¤n¢"¦Ø��\�����S¢+°� ªµ¯n���n���S¢�¤n¢"¦g��\���¡�£¢Z�C¯n�£¤n�¥w¯"�f¬[���h����¢n S��¯�\© �f�����G�S������¯n�����O�Z�£���£�Ø°
���t�n�¦g§�¤n�Y��¯n��¦Ø�S�����G�C�(�S¢"¥���¢"¦g�G�b���\���Ï� ©¾�Q�¡¢n ³"�£��¯Ò�f©5��¯n�G�C�Ŧg�£¢"¥��¡���¡�£¢"�i�C¯n�£®�¢��f³(�S¬[�´©¾���S���¯n�µ���G��¤n�¡���f©E®��S�,¥i�f���¡ £¢n�w��¢n���S�x��¯n��¦g�£¢�²E¥���¢��¦g�£�����G�C�"�£¢"¥���¢"¦g�G�Ø° D����¡¢n ���¯n�G�C�´¦g�£¢�²E¥���¢n�5¦g�S��¼���G�C�"�£¢"¥���¢"¦g�G��£��²"½Q�G¥b�n�¡¬Q�£���Ø·"®��¨���G�\�¡�� S¢���¯n��C�£¤n¢"¥��¡¢n ��C�� £�Z��¢Q�,�:�f©<�C�S¤n¢"¥Å���,�S¦g§¶®�����¯b�G�S¦g¯���S £�¦��\�i��¦g��¢n�G�Î�f¢"¥Ù�C��¢n����¢"¦g�G�Å�f©Z��¯n�>�C�"���G¦g¯���¡¢n�G�Ø· �\¢"¥º�����V���&©¾�£��� ��¯n�Å�C�V���G¦,¯/���G¦g�S £¢n�¡���¡�£¢�\¢"¥i®��£��¥i�\�¡�� S¢n�Z��¢n�x¥��G��¦Ø����³"�G¥w�¡¢Z���G¦g�����S¢ �\¼���·���G�C�"�G¦g���¡¬Q�����£°� �b* �i`��������� n� � �È`9����& n9������¬£�\�¡¤"�\���G¥���¯n�O�\�¡�� S¢n�Z��¢��µ�£¦�¦g¤n���£¦g�)�\©x�S¤n��C�_�C����� ��½Q�(�������w��¢n�,�f���¡�[°8ª��f³n���¹Þº��¯n�S®��w��¯n����\�w�n���O��¦g��¢n�©¾�£���S¤n����½Q�"�����¡�Z��¢n��°���/²"���C��¦g�S¤n¢����â¥Y©¾�S�º�G�£¦g¯Ú¦g�_¦g�¡�Ñ�f©��¡������¼
�\�����S¢Ù��¯n��¢n¤n�¨³(�����f©Z��¯n�����G¦g�S £¢n� ���G¥Y®��£��¥n�®��¡��¯Z��¯n�����5�S�:�w�£���µ�Z�S�,�£�<�\¢"¥w��¯n�5¢n¤n�¨³"�����f©��¯n���\�¡�� S¢n�G¥��C��¢n����¢"¦g�G����¢"¦g�¡¤(¥��¡¢n ¸�\�Â�¡�G�£�C��S¢n�
ª �f³n���wÞ�:ä��f�Z�n�¡�¨��¦g��¢n��5¤n�´³"�����\©x���S £�¦��\�2��¦g��¢n�G� � �5¤n�w³n�����\©:�C��¢�����¢"¦g�G� è_Þ�5¤n�Z³n���5�f©�®��£��¥n�:®��¡��¯
�£ß���¯n���±�h�S���Z�S���h�Z�S�,�£�¿�¤n���\�����S¢¸�\©x��¯��O�C�£¤n¢"¥ Þ� � �����£¦g§ �Z�¡¢ �C�G¦��
�n�¡¬Q�£��° ªµ¯n�h���G�C¤n�¡�,���\���O�C¯n�f®�¢��¡¢Å²" S¤n��� �w�\¢"¥à�·"���G�C�(�G¦g����¬Q���¡�£°
ª��\³n�¡� � Ǫ�¯n�È¢n¤n�O³(�����¹�f©º��¯n�È���G¦g�£ S¢n� ���G¥®��£��¥n��®�����¯¸��¯n�����Â�S���Z�S���h�Z�S�,�S�
ìL�����,�f���¡�£¢ �5��° �\©x®��£��¥n�Ã<�_¦g�¡�)Þ �£èÃ<�_¦g�¡��� �QëÃ<�_¦g�¡�´à �£è
ª��\³n�¡��à sªµ¯n�΢n¤n�¨³(�������\©¨��¯����f���¡ £¢n�G¥È�C��¢n¼����¢"¦g�G��®��¡��¯t�\���¡�G�£�C�5�£¢n�h�n��¬£�£�
ìç�����,�f���¡�£¢ �5�n°x�\© �C��¢n����¢"¦g�G�Ã:�_¦g�¡�wÞ à_ÞÃ:�_¦g�¡� � àQëÃ:�_¦g�¡�Oà à£é
Í5����¯n�£¤n S¯i��¯n� ¢�¤n�´³n���,�+�\©_���G¦g�S £¢n� ���G¥h®��£��¥n��C¯n�£®�¢O�¡¢i���\³n�¡� ��¥���¢n�£�x¦g�£¬\���`�f���]�\©E��¯n��®��£��¥n��¡¢%��¯n�Î��¦g�����n��·µ®µ�b¦��\¢I�������¡���\�n�n���S½Q�¡�)�f���Å��¯n��S¦�¦g¤n�,�S¦g���f©��C�(���G¦g¯/���G¦g�S £¢n�¡���¡�£¢�³n�Î��¯n�G�C�)����¼�C¤n�����ذǪµ¯n�s�£¦�¦g¤n���£¦g���f©Z�C�"���G¦g¯����G¦g�£ S¢n�������S¢�C���\�£�G¥¸�\���£¤n¢"¥ÒÞ �Qá�·E�¡¢"¥��Ϧ��\����¢n ¸���V�]�£�hÁ[¤"�\�¡¼�¡�����\©���¯n�����f�Z�n�¡���C�S¤n¢"¥O�����£¦g§E° �5��¬]������¯n�����G���V���¯n����¥��\©`��¯n���C��¢n����¢"¦g�G� ®��������f���¡ £¢n�G¥�®��¡��¯Z�n��¬Q¼�S�,�Ø° ìç¢��£¥n¥��¡���¡�£¢+·£®��µ [�\�¡¢n�G¥�Á[¤n�¡������©Ó��®I¢n¤n�w¼³V���Z�\©h¢n��®��¡�Ñ�f���¡ £¢n�G¥%�C��¢�����¢"¦g�G�w�S�w�������,�f���¡�£¢�n����¦g���G¥n�Ø·��S���C¯n�f®�¢��¡¢b���\³n�¡�¨à�°�ª�¯n�G�C�Â���G��¤n�¡�,��¡�Z�n�¡�Z��¯"�f����¯n�Â�n�¡¬[�S�,� �¡¢��´�C��¢n����¢"¦g�5�£³n���\�¡¢n�G¥�¡¢w��¯n�<²"�����x¦g�_¦g�¡�µ¥���ÊV¤"�C��������¯n��¢n���� S¯n³n�£¤n�x�C��¢�¼����¢"¦g�G��°ìL¢Ù�S�,¥����t�����¡¢�¬£�G�C���� [�\���/��¯n�¹�gÊ=�G¦g�t�\©w��¯n�
�n�¡¬Q�£�) ]�f��¢��C¯n�£®�¢%��¢��,�f³��¡��à_·�®��Î��¬£�\�¡¤"�\���G¥

��¯n�b�£¦�¦g¤n���£¦g�¹�f©Â�f���¡ £¢n�w��¢n�i³Q�/��¯n�)©¾�S�����S®��¡¢n �Z����¯n��¥V° ���¹�w�G�£�C¤n���G¥Æ��¯n�Ñ¥��ÉÊV������¢"¦g�>³V��¼��®<����¢s��¯��)¤n���������\¢"¦g�)³V�� S��¢n¢n�¡¢n � ��¢"¥���¢n Î�����w��\©3��¯n�Ä���G¦g�£ £¢n� ���G¥ ®��S�,¥ �\�¡�� S¢n�⥠��� ��¯n�²"�,�C� � ��£�C��®��£��¥��\©x�G�S¦g¯��C��¢n����¢"¦g�h�f¢"¥)��¯n�O¦Ø�S��¼���G¦g�µ¤����������\¢"¦g�h³V�� £�¡¢n¢n��¢n � ��¢"¥��¡¢n w���¡�Z�h�\© ��¯n��C��¢n����¢"¦g�£·�®�¯n�¦g¯¸�Ï����½Q�n���G���C�G¥º�£����� � ����¯n��¢"¦g��¼©¾�S����¯+°t���)��¯n��¢�¦g�S¤n¢����G¥º��¯n�Å¢�¤n�´³n���i�f©���¯n��C��¢n����¢"¦g�G�����\���Ï� ©¾�Q�¡¢n ������� Ù®�¯n�������x�Ï�:���¡��¯n���� � �S��� � �\¢"¥� Y�Ï�2�S¢n���\©2Þ£·£à��£� ���C�G¦g�S¢"¥n��°�ªµ¯n��\¬\�����\ S�t�f©�����+©Ó�£����¯n�t®�¯n�£���¸����¢n����¢"¦g�G�Ø·µÍ5¬E°®��S�O�f�Ï�C�s¦g�£�w�n¤n���G¥V°�ª�¯n�)���G�C¤n�����w�f���Å�C¯n�£®�¢��¢����\³n��� �°
ª��\³n�¡�� hª�¯n�´¢�¤n�´³n���,���\©µ��¯n�w�C��¢�����¢"¦g�G�h���f��¼�Ï� ©Ó�Q��¢n ������� ��f¢"¥Å��¯n�´�G¬[�����\ S���\©�����
ìL�����,�f���¡�£¢ � Í5¬E° � �Þ � � à � � � � �Ã:��¦g���wÞ � � Þfë à�Þ � ÞGé�° è
� � ë ��Þ à�� Þ ��° àÃ:��¦g��� � ��� à� �ë é£ß ��°
��� Þ±é àSé �£à ÞGß�°�ÞÃ:��¦g���Oà ��� à�Þ �� é�� è�° è
��� Þ±è [à �£à Þ ��° ß
���w¦��f¢������\���Z©¾���S� ��¯n�G�C�)���G�C¤n�����h��¯(�f�i�S¤n��\�¡�� S¢n�Z��¢n�h����������� ¦��\¢��f���¡ £¢s¢n�S�i�S¢n�����Î�C��¢n¼����¢"¦g�����G¦g�S £¢n� ���G¥w¦g�S�����G¦g���¡�¶³n¤n���f�Ï�C�h�¡�,� ¢n���¡ £¯n¼³"�£���C��¢�����¢"¦g�G�Ø°�ñ5¢¸��¯n�Â�S��¯n����¯"�f¢"¥V·"��¯n�¨�f¬\����¼�\ S�h�\©����Q¥��¥�¢n�£���¡¢"¦g���G�£�C�h��¢�¦g�_¦g�¡�Oਲ਼V�G¦��f¤"�����¯n�h�¡�±¬]���E�f©�¢n�S�Ï�C�h®��S�:��½Q�������Z���¡��¯n�¡ £¯n������¯"�\¢��¯n������¬Q�����\©´¤n�������,�f¢"¦g�º©¾�S� �_Þs�C��¢n����¢"¦g�G��¤n��¼�������G¥>�¡¢È�Î��¤n¢n¢n��¢n s�����\�¡¢+°Ñ¿�¤n�t���º��¯n�t�"�]�£��£¦�¦g¤n���£¦g�I�\©´�C�V���G¦�¯È���G¦g�£ S¢n�������S¢È�\©´��¯n�G�C� ��Þ�C��¢n����¢"¦g�G�Ø·\®����S³n�,�f��¢n�G¥i�S¢n��� �Â�n�¡¬Q�S�,���\�<�w�]�C�©¾���£� ��¯n�G�C�Ò����¢n����¢"¦g�G�Ø·¨��¢"¥���¢n �¤n�4®�����¯Æ��¯n��Ï�f�� S�¨Í�¬E° ���C¯n�f®�¢���¢¸���\³n�¡�� n°
� � ���5�+�,��9�����������n���£�"�]�C�G¥¶�h�C�_�C�����-���O�\�¡�� S¢Z�h�C�£¤n¢"¥i�����£¦�§�\¢"¥��>�C�GÁ[¤n��¢"¦g�/�f©¶�¡�)�f £�t©¾���\�w�G�Å®��¡��¯1�C��¢n¼����¢"¦g�G��\©��C�V���G¦,¯º���¡¢n�G�O��¢��bª�«�¥����\���_°Åñ5¤n�¢n��½Q�º���\�� £���t�Ï�Î���I�¡�Z�n���£¬\�¹��¯n�>�£¦�¦g¤n���£¦g�1�\©�C�(���G¦g¯/���G¦g�S £¢n�¡�����S¢��\¢"¥s�����C����§¹�b�n���S�Z����¡¢n �\�n�n�¡�Ϧ��f���¡�£¢t�\���G�Z�f©x�£¤n�5�f���¡ £¢n�w��¢n���Z����¯n��¥V°
���=!�5�`#I��2�h��x��x�: ª�¯n�Ï��®��S��§h�Ï���C¤n�n�V�£�����G¥Â��¢¶�"�\����³��h��¯n��Ý����\¢n��¼�¡¢n¼LÍ5�Ï¥%©¾�£�ºÃ<���G�f���¡¬Q���µ�£�C�¦����G�C�G�\��¦g¯ >Ût¤n�����Ût�G¥��Ï�iÛt�G¥��Ï�\�����S¢�Ût�G¦g¯"�\¢n�Ï�C�bæLßSè���À�Þ [ß_Þfê,·£�\©��¯n�ÎÛt��¢n�Ï�C�����>�\©OÜ:¥�¤"¦��\�����S¢+·�äQ¦g����¢"¦g�£·5ä[�"�£���,��f¢"¥�Ã:¤n�¡��¤n���£·�ð[�\�"�\¢+°�È`�p`��x���+29À�¯n�����¡� Ã:��\��§_�C�£¢+° Þ±è£è]ë]° ªµ¯n�Ã�Û�D5¼CÃ��f�Z³n���Ï¥� S� �C�,�f����C���Ϧ��f� ��\¢n¼ £¤"�f £� �Z��¥����¡��¢n �����£�¡§Q��� ¬ ��°������� ��!�!#"�$&%('*)�)�),+�-/.�0,+�1�23�+�2�14+65�78!9��&%(1;:=<;!/�8>�>�?*7A@�,+B���C3A? °
ã5�¡�,�S¦g¯n�ç· �=�,¥V°ÄÞ±è£è]ë]°»Ût�G¥��Ï�S¦g¯n�g© � à D�ª ©¾�S����¡¢"¥��£®5��è��_°
�Â�f�,�C¤n¢n�£³n¤/ìç���n·2ª �f�,�C¤n�£� �Â�\®��f¯"�\���_· �Â� ��¤n�_�ª �f§[�G¥n��·1�f¢"¥ ��¡�Q�£¯n�¡��� ä[¯n��§£�f¢n��° Þ±è£è���°ð]�f�"�\¢n�G�C� ¥��¦g�,�\�����S¢ �����S��§Q�¡�±° D,E�F�G*HIFKJLNM8OQP�RSLNMUT�V(V;W&X/Y[Z F V J O E O=V G O F\J^] X`_8XSVaOcbOdeFfGhg OiLKj JhFSE T E L g k Gg X*Yml`V&L�OnYoY gqp OrV G O ° æçìç¢ð]�f�"�\¢n�G�C�\ê�°
ã��f��¤n� �¤n³"�����£¢n�n°1Þ±è£èSè_°�s�g M F V p�F V Fut V&vb�O g\wxD M F V8OiL gxG b g V ] Xi_aXSV8Ocb�O6y ° ìç®��\¢"�f�Z�ä[¯n�£����¢ÎÀ ¤n³n����C¯n���,�Ø°µæçìL¢tð[�\�"�f¢n�G���\ê�°
äQ�S¥n�\� �¤n���S¯"�£�C¯n� �f¢"¥ºÛº�f§Q�£��� ���\ [�\�n· ÞGèSèQë[°] X`_8XSV8Ocb�O�z FCE _(M F Y Fcp�gxG X*Y�T{V;X*Y|j=b g b d j=b`L�O ]~} z^T s�� O ErH ��(�����6�^���*�8�/�(����/�c�
�f���^�|�(�(�����(�|���|�����*�(�8�#���[�/������� �S¡��=¢��*��¡=����*�����¤£�¢��(��r� �*�8¥�¦§�¨�S�C©nªm�S«¬�|¡���^®h¯C¯C¯&���«¬�(��°f±��|�(� ���a�=�©`� ���©`°C�f�(�|¡���°C� �8�=��²³°f��´«µ�*�a©`�·¶(�¤¸8�����;��«¹¸(�|¡��|´B«¬°�¥&�=�º�/�(�(��°��f©n�(��r�»¼¾½º¿;¿;ÀÂÁSÁ/�e®fÃ|®hÄ#®iÅa®hÄ/Æ(�
ÇÈ�ÉÇ �/�f�|��¸(«µ� �/�8¥ �Ê�Ë���*ªC�/¸8©c�(�6� ®h¯C¯fÄ#�̨°f�;¡��=�&¡�´B¶8�C���¥Í¥&�n�*«µ���¥&�|¡��|�(��¶8�C���¥Î°f�Î�|�(´¡��=��«¹�¥&�o�Ï�����8©n�(��°C�(��Ð�/¡��|°f��ÑÀ�Ò�Ó�Ô*�ÕÓKÖØ×NÙ;Ú»�Û¨Û�Û ¼�ÓCܺÝAÞS×�Ú=ÒÏ¿eÓ�Ôß³Úi×�à=áI»`â&×�ÚrÒ`â(ã/×KßxÓSâ(ã/伨ÓSâiÖÚ=ÒiÚ=â;ÔnÚ ÓSâæå¤ÞSäç×KßoܹÚ�è�ßxãȼ¨ÓfܺÝéÞS×�ßxâfêÈãSâ(è¿eà=ë`×�Ú`Ü�ë¤ì Á�í�#�8�/�f���,îCïfï�Å�îCïf¯#�;Ä&�

Semantic Transcoding:Making the World Wide Web More Understandable and Usable
with External Annotations
Katashi NagaoIBM Research,
Tokyo Research [email protected]
Shingo HosoyaKeio University
Yoshinari ShiraiNTT CommunicationScience Laboratories
Kevin SquireUniv. of Illinois
Abstract
This paper proposes an easy and simple method forconstructing a super-structure on the Web whichprovides current Web contents with new value andnew means of use. The super-structure is based onexternal annotations to Web documents. We havedeveloped a system for any user to annotate anyelement of any Web document with additional in-formation. We have also developed a proxy thattranscodes requested contents by considering anno-tations assigned to them. In this paper, we classifyannotations into three categories. One is linguisticannotation which helps the transcoder understandthe semantic structure of textual elements. Thesecond is commentary annotation which helps thetranscoder manipulate non-textual elements such asimages and sounds. The third is multimedia annota-tion, which is a combination of the above two types.All types of annotation are described using XML,and correspondence between annotations and docu-ment elements is defined using URLs and XPaths.We call the entire process “semantic transcoding”because we deal with the deep semantic content ofdocuments with annotations. The current semantictranscoding process mainly handles text and videosummarization, language translation, and speechsynthesis of documents including images.
1 Introduction
The conventional Web structure can be consideredas a graph on a plane. In this paper, we pro-pose a method for extending such planar graph to athree-dimensional structure that consisting of multi-ple planar layers. Such metalevel structure is basedon external annotations on documents on the Web.
Figure 1 represents the concept of our approach.A super-structure on the Web consists of layers
of content and metacontent. The first layer cor-rensponds to the set of metacontents of base doc-uments. The second layer corresponds to the set ofmetacontents of the first layer, and so on. We gen-erally consider such metacontent an external anno-tation. A famous example of external annotations isexternal links that can be defined outside of the set
Figure 1: Super-structure on the Web
of link-connected documents. These external linkshave been discussed in the XML community butthey have not yet been implemented in the currentWeb architecture (W3C XML, 2000).
Another popular example of external annotationis comments or notes on Web documents created bypeople other than the author. This kind of annota-tions is helpful for readers evaluating the documents.For example, images without alternative descrip-tions are not understandable for visually-challengedpeople. If there are comments on these images, thesepeople will understand the image contents by listen-ing to them via speech transcoding. This example isexplained later in more detail.
We can easily imagine that an open platform forcreating and sharing annotaions would greatly ex-tend the expressive power and value of the Web.
1.1 Content Adaptation
Annotations do not just increase the expressivepower of the Web but also play an important rolein content reuse. An example of content reuse is, forexample, the transformation of content dependingon user preferences.
Content adaptation is a type of transcoding whichconsiders a users’ environment such as devices, net-work bandwidth, profiles, and so on. Such adapta-

tion sometimes also involves a deep understandingof the original document contents. If the transcoderfails to analyse the semantic structure of a docu-ment, then the results may cause user misunder-standing.
Our technology assumes that external annota-tions help machines to understand document con-tents so that transcoding can have higher quality.We call such transcoding based on annotation “se-mantic transcoding.”
1.2 Knowledge Discovery
Another use of annotations is in knowledge discov-ery, where huge amounts of Web contents are au-tomatically mined for some essential points. Unlikeconventional search engines that retrieve Web pagesusing user specified keywords, knowledge miners cre-ate a single document that satisfies a user’s request.For example, the knowledge miner may generate asummary document on a certain company’s productstrategy for the year from many kinds of informationresources of its products on the Web.
Currently, we are developing an information col-lector that gathers documents related to a topic andgenerates a document containing a summary of eachdocument.
There are many unresolved issues before we canrealize true knowledge discovery, but we can say thatannotations facilitate this activity.
2 External Annotation
We have developed a simple method to associate ex-ternal annotations with any element of any HTMLdocument. We use URLs, XPaths, and documenthash codes (digest values) to identify HTML ele-ments in documents. We have also developed anannotation server that maintains the relationshipbetween contents and annotations and transfers re-quested annotations to a transcoder.
Our annotations are represented as XML format-ted data and divided into three categories: linguistic,commentary, and multimedia annotation. Multime-dia (especially video) annotation is a combination ofthe other two types of annotation.
2.1 Annotation Environment
Our annotation environment consists of a client sideeditor for the creation of annotations and a serverfor the management of annotations.
The annotation environment is shown in Figure 2.
The process flows as follows (in this example case,HTML files are processed):
1. The user runs the annotation editor and re-quests an URL as a target of annotation.
2. The annotation server accepts the request andsends it to the Web server.
Figure 2: Annotation environment
3. The annotation server receives the Web docu-ment.
4. The server calculates the document hash code(digest value) and registers the URL with thecode to its database.
5. The server returns the Web document to theeditor.
6. The user annotates the requested document andsends the result to the server with some personaldata (name, professional areas, etc.).
7. The server receives the annotation data and re-lates it with its URL in the database.
8. The server also updates the annotator profiles.
2.2 Annotation Editor
Our annotation editor, implemented as a Java appli-cation, can communicate with the annotation serverexplained below.
The annotation editor has the following functions:
1. To register targets of annotation to the annota-tion server by sending URLs
2. To specify any element in the document usingthe Web browser
3. To generate and send annotation data to theannotation server
4. To reuse previously-created annotations whenthe target contents are updated
An example screen of our annotation editor isshown in Figure 3.
The left window of the editor shows the documentobject structure of the HTML document. The rightwindow shows some text that was selected on theWeb browser (shown on the lower right corner). Theselected area is automatically assigned an XPath(i.e., a location identifier in the document) (W3CXPath, 2000).

Figure 3: Annotation editor
Using the editor, the user annotates text with lin-guistic structure (grammatical and semantic struc-ture, described later) and adds a comment to anelement in the document. The editor is capable ofnatural language processing and interactive disam-biguation. The user will modify the result of theautomatically-analyzed sentence structure as shownin Figure 4.
Figure 4: Annotation editor with linguistic structureeditor
2.3 Annotation Server
Our annotation server receives annotation data fromany annotator and classifies it according to the an-notator. The server retrieves documents from URLsin annotation data and registers the document hashcodes with their URLs in its annotation database.The hash codes are used to find differences betweenannotated documents and updated documents iden-tified by the same URL. A hash code of document in-ternal structure or DOM (Document Object Model)enables the server to discover modified elements inthe annotated document (Maruyama et al., 1999).
The annotation server makes a table of annotatornames, URLs, XPaths, and document hash codes.When the server accepts a URL as a request froma transcoding proxy (described below), the serverreturns a list of XPaths with associated annotationfiles, their types (linguistic or commentary), and ahash code. If the server receives an annotator’s nameas a request, it responds with the set of annotationscreated by the specified annotator.
We are currently developing a mechanism for ac-cess control between annotation servers and normalWeb servers. If authors of original documents donot want to allow anyone to annotate their docu-ments, they can add a statement about it in thedocuments, and annotation servers will not retrievesuch contents for the annotation editors.
2.4 Linguistic Annotation
The purpose of linguistic annotation is to makeWWW texts machine-understandable (on the ba-sis of a new tag set), and to develop content-basedpresentation, retrieval, question-answering, summa-rization, and translation systems with much higherquality than is currently available. The new tagset was proposed by the GDA (Global DocumentAnnotation) project (GDA, 2000). It is based onXML (Extensible Markup Language), and designedto be as compatible as possible with HTML, TEI(TEI, 2000), CES (CES, 2000), EAGLES (EAGLES,2000), and LAL (Watanabe, 1999). It specifiesmodifier-modifiee relations, anaphor-referent rela-tions, word senses, etc.
An example of a GDA-tagged sentence is as fol-lows:
<su><np rel="agt" sense="time0">Time</np><v sense="fly1">flies</v><adp rel="eg"><ad sense="like0">like</ad><np>an <n sense="arrow0">arrow</n></np></adp>.</su>
<su> means sentential unit.<n>, <np>, <v>, <ad> and <adp> mean noun, nounphrase, verb, adnoun or adverb (including preposi-tion and postposition), and adnominal or adverbialphrase, respectively1 .
The rel attribute encodes a relationship in whichthe current element stands with respect to theelement that it semantically depends on. Itsvalue is called a relational term. A relationalterm denotes a binary relation, which may be athematic role such as agent, patient, recipient,etc., or a rhetorical relation such as cause, con-cession, etc. For instance, in the above sen-tence, <np rel="agt" sense="time0">Time</np>depends on the second
1 A more detailed description of the GDA tag set can be
found at http://www.etl.go.jp/etl/nl/GDA/tagset.html.

element <v sense="fly1">flies</v>. rel="agt"means that Time has the agent role with respect tothe event denoted by flies.
The sense attribute encodes a word sense.Linguistic annotation is generated by automatic
morphological analysis, interactive sentence parsing,and word sense disambiguation by selecting the mostappropriate paraphrase. Some research issues on lin-guistic annotation are related to how the annota-tion cost can be reduced within some feasible levels.We have been developing some machine-guided an-notation interfaces that conceal the complexity ofannotation. Machine learning mechanisms also con-tribute to reducing the cost because they can gradu-ally increase the accuracy of automatic annotation.
In principle, the tag set does not depend on lan-guage, but as a first step we implemented a semi-automatic tagging system for English and Japanese.
2.5 Commentary Annotation
Commentary annotation is mainly used to annotatenon-textual elements like images and sounds withsome additional information. Each comment can in-clude not only tagged texts but also other imagesand links. Currently, this type of annotation ap-pears in a subwindow that is overlayed on the orig-inal document window when a user locates a mousepointer at the area of a comment-added element asshown in Figure 5.
Figure 5: Comment overlay on the document
Users can also annotate text elements with infor-mation such as paraphrases, correctly-spelled words,and underlines. This type of annotation is used fortext transcoding that combines such comments ontexts and original texts.
Commentary annotaion on hyperlinks is also avail-able. This contributes to quick introduction of tar-get documents before clicking the links. If there arelinguistic annotations on the target documents, thetranscoders can generate summaries of these docu-
ments and relate them with hyperlinks in the sourcedocument.
There are some previous work on sharing com-ments on the Web. For example, ComMentor isa general meta-information architecture for anno-tating documents on the Web (Roscheisen et al.,1995). This architecture includes a basic client-server protocol, meta-information description lan-guage, a server system, and a remodeled NCSA Mo-saic browser with interface augmentations to pro-vide access to its extended functionality. ComMen-tor provides a general mechanism for shared an-notations, which enables people to annotate arbi-trary documents at any position in-place, share com-ments/pointers with other people (either publicly orprivately), and create shared “landmark” referencepoints in the information space.
Such systems are often limited to particular doc-uments or documents shared only among a few peo-ple. Our annotation and transcoding system canalso handle multiple comments on any element ofany document on the Web. Also, a communitywide access control mechanism can be added to ourtranscoding proxy. If a user is not a member of aparticular group, then the user cannot access thetranscoding proxy that is for group use only. In thefuture, transcoding proxies and annotation serverswill communicate with some secured protocol thatprevents some other server or proxy from accessingthe annotation data.
Our main focus is adaptation of WWW contentsto users, and sharing comments in a communityis one of our additional features. We apply bothcommentary and linguistic annotations to semantictranscoding.
2.6 Multimedia Annotation
Our annotation technique can also be applied tomultimedia data such as digital video. Digital videois becoming a necessary information source. Sincethe size of these collections is growing to huge num-bers of hours, summarization is required to effec-tively browse video segments in a short time with-out losing the significant content. We have devel-oped techniques for semi-automatic video annota-tion using a text describing the content of the video.Our techniques also use some video analysis methodssuch as automatic cut detection, characterization offrames in a cut, and scene recognition using similar-ity between several cuts.
There is another approach to video annotation.MPEG-7 is an effort within the Moving Picture Ex-perts Group (MPEG) of ISO/IEC that is dealingwith multimedia content description (MPEG, 2000).
Using content descriptions, video coded in MPEG-7 is concerned with transcoding and delivery ofmultimedia content to different devices. MPEG-7

will potentially allow greater input from the con-tent publishers in guiding how multimedia contentis transcoded in different situations and for differ-ent client devices. Also, MPEG-7 provides object-level description of multimedia content which allowsa higher granularity of transcoding in which individ-ual regions, segments, objects and events in image,audio and video data can be differentially transcodeddepending on publisher and user preferences, net-work bandwidth and client capabilities.
Our method will be integrated into tools for au-thoring MPEG-7 data. However, we do not cur-rently know when the MPEG-7 technology will bewidely available.
Our video annotation includes automatic segmen-tation of video, semi-automatic linking of video seg-ments with corresponding text segments, and inter-active naming of people and objects in video frames.
Video annotation is performed through the follow-ing three steps.
First, for each video clip, the annotation systemcreates the text corresponding to its content. Weemployed speech recognition for the automatic gen-eration of a video transcript. The speech recognitionmodule also records correspondences between thevideo frames and the words. The transcript is notrequired to describe the whole video content. Theresolution of the description effects the final qualityof the transcoding (e.g., summarization).
Second, some video analysis techniques are ap-plied to characterize scenes, segments (cuts andshots), and individual frames in video. For exam-ple, by detecting significant changes in the color his-togram of successive frames, frame sequences can beseparated into cuts and shots.
Also, by searching and matching prepared tem-plates to individual regions in the frame, the anno-tation system identifies objects. The user can specifysignificant objects in some scene in order to reducethe time to identify target objects and to obtain ahigher recognition success ratio. The user can nameobjects in a frame simply by selecting words in thecorresponding text.
Third, the user relates video segments to text seg-ments such as paragraphs, sentences, and phrases,based on scene structures and object-name corre-spondences. The system helps the user to selectappropriate segments by prioritizing based on thenumber of objects detected, camera movement, andby showing a representative frame of each segment.
We developed a video annotation editor capableof scene change detection, speech recognition, andcorrelation of scenes and words. An example screenof our video annotation editor is shown in Figure 6.
Figure 6: Video annotation editor
3 Semantic Transcoding
Semantic transcoding is a transcoding techniquebased on external annotations, used for contentadaptation according to user preferences. Thetranscoders here are implemented as an extensionto an HTTP (HyperText Transfer Protocol) proxyserver. Such an HTTP proxy is called a transcodingproxy.
Figure 7 shows the environment of semantictranscoding.
Figure 7: Transcoding environment
The information flow in transcoding is as follows:
1. The transcoding proxy receives a request URLwith a client ID.
2. The proxy sends the request of the URL to theWeb server.
3. The proxy receives the document and calculatesits hash code.
4. The proxy also asks the annotation server forannotation data related to the URL.

5. If the server finds the annotation data of theURL in its database, it returns the data to theproxy.
6. The proxy accepts the data and compares thedocument hash code with that of the alreadyretrieved document.
7. The proxy also searches for the user preferencewith the client ID. If there is no preference data,the proxy uses a default setting until the usergives the preference.
8. If the hash codes match, the proxy attemptsto transcode the document based on the an-notation data by activating the appropriatetranscoders.
9. The proxy returns the transcoded document tothe client Web browser.
3.1 Transcoding Proxy
We employed IBM’s WBI (Web Intermediaries) asa development platform to implement the seman-tic transcoding system (WBI, 2000). WBI is acustomizable and extendable HTTP proxy server.WBI provides APIs (Application Programming In-terfaces) for user level access control and easy ma-nipulation of input/output data of the proxy.
The transcoding proxy based on WBI has the fol-lowing functionality:
1. Maintenance of personal preferences
2. Gathering and management of annotation data
3. Activation and integration of transcoders
3.2 Text Transcoding
Text transcoding is the transformation of text con-tents based on linguistic annotations. As a first step,we implemented text summarization.
Our text summarization method employs aspreading activation technique to calculate the im-portance values of elements in the text (Nagao andHasida, 1998). Since the method does not employany heuristics dependent on the domain and styleof documents, it is applicable to any linguistically-annotated document. The method can also trim sen-tences in the summary because importance scoresare assigned to elements smaller than sentences.
A linguistically-annotated document naturally de-fines an intra-document network in which nodescorrespond to elements and links represent thesemantic relations. This network consists ofsentence trees (syntactic head-daughter hierar-chies of subsentential elements such as wordsor phrases), coreference/anaphora links, docu-ment/subdivision/paragraph nodes, and rhetoricalrelation links.
The summarization algorithm works as follows:
1. Spreading activation is performed in such away that two elements have the same activa-tion value if they are coreferent or one of themis the syntactic head of the other.
2. The unmarked element with the highest activa-tion value is marked for inclusion in the sum-mary.
3. When an element is marked, the following ele-ments are recursively marked as well, until nomore elements are found:
• the marker’s head
• the marker’s antecedent
• the marker’s compulsory or a priori impor-tant daughters, the values of whose rela-tional attributes are agt (agent), pat (pa-tient), rec (recipient), sbj (syntactic sub-ject), obj (syntactic object), pos (posses-sor), cnt (content), cau (cause), cnd (con-dition), sbm (subject matter), etc.
• the antecedent of a zero anaphor in themarker with some of the above values forthe relational attribute
4. All marked elements in the intra-document net-work are generated preserving the order of theirpositions in the original document.
5. If a size of the summary reaches the user-specified value, then terminate; otherwise goback to Step 2.
The size of the summary can be changed by sim-ple user interaction. Thus the user can see the sum-mary in a preferred size by using an ordinary Webbrowser without any additional software. The usercan also input any words of interest. The corre-sponding words in the document are assigned nu-meric values that reflect degrees of interest. Thesevalues are used during spreading activation for cal-culating importance scores.
Figure 8 shows the summarization result on thenormal Web browser. The top document is the orig-inal and the bottom one is the summarized version.
Another kind of text transcoding is languagetranslation. We can predict that translation basedon linguistic annotations will produce a much betterresult than many existing systems. This is becausethe major difficulties of present machine translationcome from syntactic and word sense ambiguities innatural languages, which can be easily clarified inannotation. An example of the result of English-to-Japanese translation is shown in Figure 9.
3.3 Image Transcoding
Image transcoding is to convert images into these ofdifferent size, color (full color or grayscale), and res-olution (e.g., compression ratio) depending on user’s

Figure 8: Original and summarized documents
Figure 9: Translated document
device and communication capability. Links to theseconverted images are made from the original images.Therefore, users will notice that the images they arelooking at are not original if there are links to similarimages.
Figure 10 shows the document that is summarized
in half size of the original and whose images are re-duced to one-third. In this figure, the preferencesetting subwindow is shown on the right hand. Thewindow appears when the user double-clicks the iconon the lower right corner (the transcoding proxy au-tomatically inserts the icon). Using this window, theuser can easily modify the parameters for transcod-ing.
Figure 10: Image transcoding (and preference set-ting window)
By combining image and text transcodings, thesystem can, for example, convert contents to just fitthe client screen size.
3.4 Voice Transcoding
Voice synthesis also works better if the content haslinguistic annotation. For example, a speech synthe-sis markup language is being discussed in (SABLE,2000). A typical example is processing proper nounsand technical terms. Word level annotations onproper nouns allow the transcoders to recognize notonly their meanings but also their readings.
Voice transcoding generates spoken language ver-sion of documents. There are two types of voicetranscoding. One is when the transcoder synthesizessound data in audio formats such as MP3 (MPEG-1 Audio Layer 3). This case is useful for deviceswithout voice synthesis capability such as cellularphones and PDAs. The other is when the transcoderconverts documents into more appropriate style forvoice synthesis. This case requires that a voice syn-thesis program is installed on the client side. Ofcource, the synthesizer uses the output of the voicesynthesizer. Therefore, the mechanism of documentconversion is a common part of both types of voicetranscoding.
Documents annotated for voice include some textin commentary annotation for non-textual elementsand some word information in linguistic annota-tion for the reading of proper nouns and unknown

words in the dictionary. The document also con-tains phrase and sentence boundary information sothat pauses appear in appropriate positions.
Figure 11 shows an example of the voice-transcoded document in which icons that representthe speaker are inserted. When the user clicks thespeaker icon, the MP3 player software is invoked andstarts playing the synthesized voice data.
Figure 11: Voice transcoding
3.5 Video Transcoding
Video transcoding employs video annotation thatconsists of linguistically-marked-up transcripts suchas closed captions, time stamps of scene changes,representative images (key frames) of each scene,and additional information such as program names,etc. Our video transcoding has several variations,including video summarization, video to documenttransformation, video translation, etc.
Video summarization is performed as a by-product of text summarization. Since a summa-rized video transcript contains important informa-tion, corresponding video sequences will produce acollection of significant scenes in the video. Sum-marized video is played by a player we developed.An example screen of our video player is shown inFigure 12.
There are some previous work on video sum-marization such as Infomedia (Smith and Kanade,1995) and CueVideo (Amir et al., 1999). They createa video summary based on automatically extractedfeatures in video such as scene changes, speech, textand human faces in frames, and closed captions.They can transcode video data without annotations.However, currently, an accuracy of their summariza-tion is not practical because of the failure of auto-matic video analysis. Our approach to video sum-marization has sufficient quality for use if the datahas enough semantic annotation. As mentioned ear-lier, we have developed a tool to help annotators
Figure 12: Video player with summarization func-tion
to create semantic annotation data for multimediadata. Since our annotation data is task-independentand versatile, annotations on video are worth creat-ing if the video will be used in different applicationssuch as automatic editing and information extrac-tion from video.
Video to document transformation is another typeof video transcoding. If the client device does nothave video playing capability, the user cannot accessvideo contents. In this case, the video transcodercreates a document including important images ofscenes and texts related to each scene. Also, theresulting document can be summarized by the texttranscoder.
Video translation is a combination of text andvoice transcodings. First, a video transcript withlinguistic annotation is translated by the texttranscoder. Then, the result of translation isconverted into voice-suitable text by the voicetranscoder. Synchronization of video playing andvoice synthesis makes another language version ofthe original video clip. This part has not yet beenimplemented, but this function will be integratedinto our video player.
The above described transcodings are automat-ically combined according to user demand, so thetranscoding proxy has a planning machanism to de-termine the order of activation of each transcodernecessary for the requested content and user prefer-ences (including client device constraints).
4 Future Plans
We are planning to apply our technology to knowl-edge discovery from huge online resources. Anno-tations will be very useful to extract some essen-tial points in documents. For example, an anno-tator adds comments to several documents, and heor she seems to be a specialist of some particularfield. Then, the machine automatically collects doc-uments annotated by this annotator and generatesa single document including summaries of the anno-tated documents.

Also, content-based retrieval of Web documentsincluding multimedia data is being pursued. Suchretrieval enables users to ask questions in naturallanguage (either spoken or written).
While our current prototype system is running lo-cally, we are also planning to evaluate our systemwith some open experiments.
5 Concluding Remarks
We have discussed a full architecture for creatingand utilizing external annotations. Using the anno-tations, we realized semantic transcoding that au-tomatically customizes Web contents depending onuser preferences.
This technology also contributes to commentaryinformation sharing and device dependent transfor-mation for any device. One of our future goals is tomake contents of the WWW intelligent enough toanswer our questions asked using natural language.We imagine that in the near future we will not usesearch engines but will instead use knowledge discov-ery engines that give us a personalized summary ofmultiple documents instead of hyperlinks. The workin this paper is one step toward a better solution ofdealing with the coming information deluge.
Acknowledgments
The authors would like to acknowledge the contrib-utors to the project described in this paper. KoitiHasida gave the authors some helpful advices to ap-ply the GDA tag set to our linguistic and multi-media annotations. Hideo Watanabe developed theprototype of English-to-Japanese language transla-tor. Shinichi Torihara developed the prototype ofvoice synthesizer.
References
A. Amir, S. Srinivasan, D. Ponceleon, and D.Petkovic. CueVideo: Automated indexing ofvideo for searching and browsing. In Proceedingsof SIGIR’99. 1999.
Corpus Encoding Standard (CES). Corpus Encod-ing Standard. http://www.cs.vassar.edu/CES/.
Expert Advisory Group on Language Engineer-ing Standards (EAGLES). EAGLES online.http://www.ilc.pi.cnr.it/EAGLES/home.html.
Koiti Hasida. Global Document Annotation.http://www.etl.go.jp/etl/nl/gda/.
IBM Almaden Research Center. Web Intermediaries(WBI). http://www.almaden.ibm.com/cs/wbi/.
Hiroshi Maruyama, Kent Tamura, and NaohikoUramoto. XML and Java: Developing Web ap-plications. Addison-Wesley, 1999.
Moving Picture Experts Group (MPEG).MPEG-7 Context and Objectives.
http://drogo.cselt.stet.it/mpeg/standards/mpeg-7/mpeg-7.htm.
Katashi Nagao and Koiti Hasida. Automatic textsummarization based on the Global DocumentAnnotation. In Proceedings of COLING-ACL’98.1998.
Martin Roscheisen, Christian Mogensen, and TerryWinograd. Shared Web annotations as a platformfor third-party value-added information providers:Architecture, protocols, and usage examples.Technical Report CSDTR/DLTR. Computer Sci-ence Department, Stanford University, 1995.
The SABLE Consortium.A Speech Synthesis Markup Language.
http://www.cstr.ed.ac.uk/projects/ssml.html.Michael A. Smith and Takeo Kanade. Video skim-
ming for quick browsing based on audio and imagecharacterization. Technical Report CMU-CS-95-186. School of Computer Science, Carnegie MellonUniversity, 1995.
The Text Encoding Initiative (TEI). Text EncodingInitiative. http://www.uic.edu:80/orgs/tei/.
Hideo Watanabe. Linguistic Annotation Language:The markup langauge for assisting NLP programs.TRL Research Report RT0334. IBM Tokyo Re-search Laboratory, 1999.
World Wide Web Consortium. Extensible MarkupLanguage (XML). http://www.w3.org/XML/.
World Wide Web Consortium.XML Path Language (XPath) Version 1.0.
http://www.w3.org/TR/xpath.html.

From Manual to Semi-automatic Semantic Annotation: AboutOntology-based Text Annotation Tools
M. Erdmann, A. Maedche, H.-P. Schnurr, S. StaabInstitute AIFB, Karlsruhe University, 76128 Karlsruhe, Germany�
erdmann, maedche, schnurr, staab � @aifb.uni-karlsruhe.dehttp://www.aifb.uni-karlsruhe.de/WBS
AbstractSemantic Annotation is a basic technology for intelli-gent content and is beneficial in a wide range of content-oriented intelligent applications. In this paper we presentour work in ontology-based semantic annotation, whichis embedded in a scenario of a knowledge portal appli-cation. Starting with seemingly good and bad manualsemantic annotation, we describe our experiences madewithin the KA � -initiative. The experiences gave us thestarting point for developing an ergonomic and knowl-edge base-supported annotation tool. Furthermore, theannotation tool described are currently extended withmechanisms for semi-automatic information-extractionbased annotation. Supporting the evolving nature ofsemantic content we additionally describe our idea ofevolving ontologies supporting semantic annotation.
1 IntroductionThe KA � -initiative (Knowledge Annotation initiative ofthe Knowledge Acquisition community) was launched atEKAW in 1997 in order to provide semantic access to in-formation stored in web pages in the WWW. It built onmanual semantic annotation for integration and retrievalof facts from semantically annotated web pages, whichbelonged to members of the knowledge acquisition com-munity (Decker et al., 1999; Benjamins et al., 1999). Theinitiative recently developed into a more comprehensiveconcept viz. the KA � community portal, which allows forproviding, browsing and retrieving information throughvarious means of ontology-based support (Staab et al.,2000). All along the way, the usage of semantic anno-tation as the underpinning for semantics-based fact re-trieval, integration, and presentation has remained one ofthe major cornerstones of the system.
The content of the paper is organized as follows. InSection 2 we start with a brief introduction to our notionof a community web portal to set up the context of ouruse of semantic annotations. Then, we present the prac-tical problems we have encountered with manual annota-tions and the lessons learned from these experiences (cf.Section 3). In Section 4 the development of annotationtools is sketched that facilitate manual semantic anno-tation by following ergonomic considerations about theprocess that someone who is annotating information goesthrough and inferencing support that provides a compre-
hensive view on what has been annotated, so far. The de-velopment of an information extraction-based system forsemi-automatic annotation that proposes annotations tothe human who is performing annotations is presented inSection 5. We conceive semantic annotation as a cyclicprocess between the actual task of annotating documentsand the development and adaptation of a domain ontol-ogy. Incoming information that is to be annotated doesnot only require some more annotating, but also contin-uous adaptation to new semantic terminology and rela-tionships. This cyclic process of evolving ontologies isshown in Section 6. Our objective here is to give thereader a comprehensive picture of what semantic annota-tion has meant in our application and where it is headingnow.
2 Scenario: Semantic Community WebPortal
Community web portals serve as high quality informa-tion repositories for the information needs of particularcommunities on the web. A prerequisite for fulfillingthis role is the accessibility of information. In commu-nity portals this information is typically provided by theusers of the portal, i.e. the portal is driven by the com-munity for the community. We have been maintaining aweb portal for the Knowledge Acquisition community 1
and, thus, have gained some experience with the difficul-ties of providing information for that portal by semanticannotations.
We here give only a very brief sketch of the KA com-munity web portal. A broader introduction to the meth-ods and tools developed in this context can be found in(Staab et al., 2000). The portal’s main component is On-tobroker (Decker et al., 1999), that uses ontologies toprovide an integrated view on distributed, heterogenousinformation sources. The ontology is the means for cap-turing domain knowledge in a generic way that providesa commonly agreed understanding of a domain, whichmay be reused and shared within communities or appli-cations. The ontology can be used to semantically anno-tate web pages that are accessed by Ontobroker
The Ontobroker system consists of (i) a crawling com-ponent, (ii) a knowledge base, (iii) an inference engine,and (iv) a query interface. The crawler collects informa-
1http://ka2portal.aifb.uni-karlsruhe.de

tion contained in registered web pages and stores it in theknowledge base. The HTML pages are manually anno-tated with special semantic tags, a proprietary extensionto HTML that is compatible with common web browsers.This annotation language is presented in the next section.Thus, the web crawler establishes the core of the knowl-edge base, that is enhanced by applying axioms from theontology to these ground facts. The ontology is repre-sented in Frame Logic (Kifer et al., 1995), an object-oriented and logics-based language. Thus, axioms can beformulated using a subset of first order logic statementsincluding object oriented modelling primitives. Finally,the information stored in the knowledge base or derivedby the inference engine can be accessed using FrameLogic queries.
3 Manual Semantic Annotations3.1 HTML-A
The main source of information for the KA portal stemsfrom distributed web pages maintained by members ofthe KA community. These web pages have been man-ually annotated to explicitely represent the semantics oftheir contents (cf. Figure 1). Since a huge amount of rel-evant information for most communities is represented inHTML, we chose to enhance HTML with few semanti-cally relevant extensions. The resulting annotation lan-guage HTML-A (Decker et al., 1999) adds to HTMLprimitives for tagging instances of concepts, for relat-ing these instances, and for setting their properties, i.e.the ontology serves as a schema for semantic statementsin these pages. For all these primitives the HTML an-chor tag <A> has been extended with a special attributeonto. This decision implies that the original informa-tion sources hardly have to be changed to provide se-mantically meaningful information. The semantic tagsare embedded in the ordinary HTML text in such a waythat standard browsers can still process the HTML pagesand, at the same time, Ontobroker’s crawler can ex-tract the semantic annotations from them. This kindof semantic annotation resembles Knuth’s literate pro-gramming (Knuth, 1984), where few semantically rele-vant and formal statements are embedded in unstructuredprose text. In Ontobroker, objects (instances of concepts)are uniquely identified by a URI, i.e. resources in the webare interpreted as surrogates for real objects like persons,organizations, and publications. To associate (in HTML)such an object with a concept from the ontology oneof the following statements can be made in the HTMLsource.
<A onto="’http://www.aifb.uni-karlsruhe.de/studer’:Researcher"></A>
<A onto="’www9’:InProceedings"></A><A onto="page:Institute"></A>
In the schema <A onto="�: � "></A> of these ex-
pressions � represents the instance and � represents theconcept. � can either be a global URI, a local part ofa URI (that is expanded by the crawler to a global one),or one of the special keywords page, body, href, or
tag. These special keywords represent resources rel-ative to the current tag and the current web page, e.g.the keyword page represents the URI of the webpageof this statement. The following statements both defineformally the value of the name attribute of the object rep-resented by the current page:
<A onto="page[name=’Rudi Studer’]"></A><A onto="page[name=body]">Rudi Studer</A>
The keyword body refers to the content of the anchortag. Thus, the actual information is rendered by a webbrowser and at the same time interpreted formally bythe crawler. Including semantics in this way into HTMLpages reduces redundancy and enhances maintainability,since changes in the prose part of the page are immedi-ately reflected in the formal part, as well.
To establish relationships between two objects similarstatements can be made, since binary relations can bemodelled as attributes:
<A onto="page[affiliation=’http://www.aifb.uni-karlsruhe.de’]"></A>
<A onto="page[affiliation=href]"href="http://www.aifb.uni-karlsruhe.de">
Institut AIFB</A><A onto="page[authorOf=href]"
href="publications.html#www9">Semantic Community Web Portals</A>
The href keyword defines the target of the hypertextlink as an object representing the value of the attribute. Ifthis link is relative it is expanded to its global URI beforeputting the facts into the knowledge base.
Docs
Annotated
Docs
Annotator
OntologyKnowledge Base
ASCII Editor
Dsdfdsfsdf
sdfsdfsdfsdfsdfsdfsd
sdfsdfdsfsdfsdfsdfsdfsdfocs
sdfsdfsdfsdfsdfsdfsd
sdfsdfdsfsdfsdfsdfsdfsdfocs
sdfsdfsdfsdfsdfsdfsd
sdfsdfdsfsdfsdfsdfsdfsdfocs
sdfsdfsdfsdfsdfsdfsd
sdfsdfdsfsdfsdfsdfsdfsdfocs
Crawler
Figure 1: Manually annotating HTML pages with se-mantic information.
3.2 ExperiencesOur experiences with the KA2 initiative were quite dis-appointing, concerning the information providing pro-cess. There were about 30 people willing to provide in-formation from their web pages to Ontobroker. About15 accepted and were (more or less) able to annotatetheir pages. The other 15 needed rather extensive sup-port from the Ontobroker team. One of our students pre-pared annotated versions of their homepages. Since the

annotation task was not supported by any tool, severeproblems appeared. First of all, a lot of annotations weresimply syntactically incorrect, i.e. have been rejected bythe parser, for reasons like missing brackets or quotationmarks. This problem has been remedied by providing asyntax checker that is available online and tests annotatedpages for syntactic correctness.
A second major problem concerned terminology.Since the ontology was fixed from the beginning, the an-notations had to strictly conform to the concept and at-tribute names defined in the ontology. Typing errors, e.g.online-Version instead of onlineVersion, werethe most prominent in this category.
The last group of problems deals with the semantics ofthe annotations:
� The class of some objects had been defined in atoo general manner, e.g. most publications in theKA2 knowledge base have been categorized sim-ply as Publication instead of JournalArticle,TechnicalReport or another more specific con-cept. The intention of some ontological terms havenot been completely understood by some providers.This resulted in things like the classification of aweb page containing a list of publications of someresearcher to be defined as the value of his pub-lication attribute. This set valued attribute wasintended to contain a set of publication objectsand not a single container object. Application ofaxioms in the ontology yielded the fact that thispublication list was categorized as a Publicationwhich was not intended. On the other hand, query-ing the knowledge base for all publications of thisresearcher resulted in an acceptable answer, namelya link to this list page. Additionally, each objectshould be identified by a single URI. But we expe-rienced major problems with the use of object iden-tifiers to refer to certain objects in an unambiguousway.
� Often, instead of introducing a URI or referring toan existing object identifier to denote an object, in-formation providers simply used text from the webpage, e.g. a co-author of a publication was oftenidentified by a string like “John Doe” instead of theURI for his home page.
� Similarly, even if object identifiers, i.e. URIs, wereused to refer to remote objects like co-authors, theseURIs often did not match. An implication of thesemismatches is the creation of several objects thatshould have been unified into one, e.g. our colleagueDieter Fensel at some time was represented in theknowledge base by three object identifiers, each de-noting an object with some information linked to it.These information could be integrated only after thesources of the mismatch had been identified.
� Finally, the overall quantity of semantic annotationscould have been larger, i.e. although some infor-mation was textually present on the annotated webpages, this information has not been annotated and,
thus, was invisible for Ontobroker and for its users.This problem especially occured on pages anno-tated by our student, due to her lack of deep domainknowledge.
3.3 Lessons learnedAfter reviewing the different types of problems, we cameup with a set of lessons learned that may be summarizedby:
� Keep the ontology simple and explain its meaning!� Support annotators with interactive, graphical tools!
– to help avoid syntax errors and typos of onto-logical entities,
– to help to correctly choose the most specificconcepts for instances, and
– to provide a list of all known objects of a cer-tain concept to reduce false co-references (witha kind of repository of objects)
� Allow importing information from other sourcesto avoid annotations where possible, e.g. importBiBTeX-files for the publications of researchers.
4 Ergonomic and knowledgebase-supported Annotation
Targeting to an ergonomic and intuitive support of the an-notation task within documents, we developed the anno-tation tool. It allows the quick annotation of facts withinany document by tagging parts of the text and semanti-cally defining its meaning via interacting with the dialogshown in the screenshot of Figure 2. To illustrate the an-notation process using the annotation tool, we sketch inthe following a small annotation scenario using the an-notation tool.
Given an ontology, the annotation process usuallystarts with tagging one or more phrases in the docu-ment, an HTML file in our example. This selectionis indicated in the fact (FAKT) field in the right col-umn of Figure 2. The user selects the appropriate con-cept in the ontology, depicted in the KLASSE field inthe right column of Figure 2 as an explorer tree view.In our example, [email protected] ischosen and the concept AcademicStaff is selected inthe ontology. Therefore, the annotation tool supportsthe intuitive and correct choice of the most specific con-cept for the selected instance. Now, as described infurther detail in (Schnurr and Staab, 2000) the conceptchoice of the user triggers the F-Logic inference engineto search for all known objects of this certain conceptin the knowledge base. The third row (OBJEKT) in theright column in Figure 2 shows these objects, in our ex-ample a list of objects of the concept AcademicStaff.Thus, the user may insert references to the known ob-jects or add a new object to the knowledge base. Inour example, the user selects http://www.aifb.uni-karlsruhe.de/Staff/studer.en.html, the pri-mary key of the researcher with the last name Studer,

Figure 2: Annotation Dialog.
to add his EMAIL address to the knowledge base. Ifthere would be no corresponding known object in theknowledge base, the user would have to select Aca-demicStaff Neu to add a new instance. Thereby,the system automatically creates a primary key for thatnew object. In the middle of the right column ofFigure 2, the attributes of the highlighted concept areshown. The selected part of the document, [email protected] in our example,may now be moved via drag-and-drop to the appropri-ate attribute, in our example the attribute EMAIL. Theuser thereby annotates the selected part of the document.Clicking the ”R”-button in the middle of the right col-umn in Figure 2 shows a list of relations linked to thechosen concept. Selecting one of the indicated relationsgives a list of possible instances, where the relation maypoint to. The user picks up the appropriate instance andthus, links both concepts with the selected relation. Thedialog shown in Figure 2 offers the whole range of an-notation support to the user. With the features of ourannotation tool, we support annotators with an interac-tive, graphical means helping to avoid syntax errors. Wesupport them in choosing the most appropriate conceptsfor instances and provide an object repository to identifyexisting instances. As indicated in Figure 3, the annota-tion tool integrates the ontology and the knowledge baseinto the editing environment to allow for ergonomic andknowledge base-supported annotating.
5 Semi-Automatic AnnotationBased on our experiences and the existing annotationtool for supporting ontology-based semantic annotation
DocsAnnotated
Docs
User
Annotation Tool V1.0
Dsdfdsfsdf
sdfsdfsdfsdfsdfsdfsd
sdfsdfdsfsdfsdfsdfsdfsdfocs
sdfsdfsdfsdfsdfsdfsd
sdfsdfdsfsdfsdfsdfsdfsdfocs
sdfsdfsdfsdfsdfsdfsd
sdfsdfdsfsdfsdfsdfsdfsdfocs
sdfsdfsdfsdfsdfsdfsd
sdfsdfdsfsdfsdfsdfsdfsdfocs
Figure 3: Ergonomic and inference-supported Annota-tion.
of texts, we now approach semi-automatic annotationof natural language texts. We conceive an informa-tion extraction-based appraoch for semi-automatic anno-tation, which has been implemented on top of SMES(Saarbrucken Message Extraction System), a shallowtext processor for German (cf. (Neumann et al., 1997)).This is a generic component that adheres to several prin-ciples that are crucial for our objectives. (i), it is fast androbust, (ii), it realizes a mapping from terms to ontologi-cal concepts, (iii) it yields dependency relations betweenterms, and, (iv), it is easily adaptable to new domains.2
We here give a short survey on SMES in order to pro-vide the reader with a comprehensive picture of what un-derlies our system. The architecture of SMES comprisesa tokenizer based on regular expressions, a lexical anal-
2The interlinkage between the information extraction system SMESand domain ontologies is described in further detail in (Staab et al.,1999).

ysis component including a word and a domain lexicon,and a chunk parser. The tokenizer scans the text in orderto identify boundaries of words and complex expressionslike “$20.00” or “Mecklenburg-Vorpommern” 3, and toexpand abbreviations. The lexicon contains more than120,000 stem entries and more than 12,000 subcatego-rization frames describing information used for lexicalanalysis and chunk parsing. Furthermore, the domain-specific part of the lexicon associates word stems withconcepts that are available in the concept taxonomy. Lex-ical Analysis uses the lexicon to perform, (1), morpho-logical analysis, i.e., the identification of the canonicalcommon stem of a set of related word forms and theanalysis of compounds, (2), recognition of name enti-ties, (3), retrieval of domain-specific information, and,(4), part-of-speech tagging. While the steps (1),(2) and(4) can be a viewed as standard for information extrac-tion approaches (cf. (Appelt et al., 1993; Neumann et al.,1997)), the step (3) is of specific interest for our annota-tion task. This step associates single words or complexexpressions with a concept from the ontology if a corre-sponding entry in the domain-specific part of the lexiconexists. E.g., the expression “Hotel Schwarzer Adler” isassociated with the concept Hotel.
DocsAnnotated
Docs
User
Annotation Tool V2.0
Dsd fdsfsdf
sdfsdf sdfsdfsdfsdfsdsdfsdfdsfsdfsdfsdfsdfsdfocssdf sdfsdf sdfsdfsdfsdsdfsdfdsfsdfsdfsdfsdfsdfocs
sdfsdfs dfsd fsdfsdfsdsdfsdfdsfsdfsdfsdfsdfsdfocssdfsdf sdfsd fsdfsdfsdsdfsdfdsfsdfsdfsdfsdfsdfocs
Information
Extraction
Domain Lexicon
Figure 4: Semi-automatic Annotation.
SMES includes a chunk parser based on weighted fi-nite state transducers to efficiently process phrasal andsentential patterns. The parser works on the phrasallevel, before it analyzes the overall sentence. Gram-matical functions (such as subject, direct-object) are de-termined for each dependency-based sentential structureon the basis of subcategorizations frames in the lexicon.Our primary output derived from SMES consists of de-pendency relations (Hudson, 1990) found through lexi-cal analysis (compound processing) and through parsingat the phrase and sentential level. Thereby, the gram-matical dependency relation need not even hold directlybetween two conceptually meaningful entities. For in-stance, in the sentence ”The Hotel Schwarzer Adlerin Rostock celebrates Christmas.“, “Hotel SchwarzerAdler” and “Rostock”, the concepts of which appear inthe ontology as Hotel and City, respectively, are not di-rectly connected by a dependency relation. However, thepreposition “in” acts as a mediator that incurs the con-ceptual pairing of Hotel with City.
Figure 4 depicts the architecture of the semi-automatic
3Mecklenburg-Vorpommern is a region in the north east of Ger-many.
annotation tool. Incoming documents are processed us-ing the information extraction system SMES. SMES as-sociates single words or complex expressions with a con-cept from the ontology, connected through the domainlexicon linkage. Recognized concepts and dependencyrelations between concepts are highlighted as suggestedannotations. This mechanism has the advantage that allrelevant information in the document with regard to theontology is recognized and proposed to the annotator.The actual process of annotation is delegated to the an-notation tool described in section 4.
6 Evolving OntologiesIn the previous sections 3, 4 and 5 we have abstractedfrom the interlinkage between evolving ontologies andthe different annotation mechanisms. However, in anyrealistic application scenario, incoming information thatis to be annotated does not only require some more an-notating, but also continuous adaptation to new seman-tic terminology and relationships. Terms evolve in theirmeanings, or take on new meanings as new technologiesare developed, and as existing ones evolve.
The abstraction from the interlinkage between annota-tion and evolving ontologies resulted in problems, (i) ifthe meaning of ontological elements changed, (ii) if theelements in the ontology became unnecessary and havebeen eliminated, or (iii) if new elements have been addedto the ontology. Our experiences have shown that anno-tation and ontology development and maintenance mustbe considered as a cyclic process. Thus, in a realistic an-notation scenario a feedback loop and tight integration isrequired, so that new conceptual structures can be addedto the ontology for supporting the actual task of annotat-ing documents towards evolving ontologies.
Manual Ontology Engineering. Starting with manualsemantic annotation as described in Section 3 the ontol-ogy was represented as an ASCII file in FLogic. Therewas only few documentation, no browsing was possible,and it was fixed from the beginning. The process of man-ual semantic annotation didn’t incorporate the ontology,so that typing errors were not unusual. One of the morefundamental problems were incorrect coreferences, be-cause no interlinkage between new annotated facts andexisting facts was supported.
As described in Section 4 our experiences showedus the necessity for ergonomic and knowledge base-supported annotation. We developed a tool which in-cludes the domain ontology directly in its interface, de-fines automatically identifiers and references to exist-ing facts contained in the knowledge base. We also de-veloped an ontology engineering environment OntoEdit 4
supporting the ontology engineer in modeling conceptualstructures.
Semi-Automatic Ontology Engineering. Currentlywe are working on the tight integration between seman-
4A comprehensive description of the ontology engineering environ-ment OntoEdit and the underlying methodology is given in (Staab andMaedche, 2000).

tic annotation and ontology engineering. Lexical re-sources are directly mapped onto concepts and relationscontained in the ontology. The coding nature of ontolo-gies makes it necessary to account for changes. Hence,we have been developing methods that propose new con-ceptual structures to the maintainer of the ontology (cf.(Maedche and Staab, 2000a)). In parallel, linguisticresources are gathered, which connect the conceptualstructures with the information extraction system. Theinformation extraction system supports the engineeringof evolving ontologies as well as the process of extract-ing annotation-relevant information. The underlying ideais that acquired domain specific knowledge and linguis-tic resources are connected to natural language using atight interplay between ontology and domain lexicon.
In (Maedche and Staab, 2000b) we describe our workin semi-automatic engineering and learning of domainontologies from text. A comprehensive architecture laysthe foundation for acquiring domain ontologies and lin-guistic resources. The main components of the archi-tecture are (i) the Text & Processing Management, (ii)the Information Extraction Server (SMES), (iii) a Lexi-cal Database and Domain Lexicon, (iv) a Learning Mod-ule, and (v) the Ontology Engineering Environment On-toEdit. The architecture has been fully implementedin the “Ontology Learning”-Environment Text-To-Ontoand lays the foundation for supporting the developmentof evolving ontologies from text.
7 Related WorkAn approach similar to our first tries of annotatingHTML using ontologies has been developed at the Uni-versity of Maryland. The SHOE system (Luke et al.,1997) defines additional tags that can be embedded inthe body of HTML pages. In SHOE there is no di-rect relationship between the new tags and the originaltext of the page, i.e. SHOE tags are not annotations in astrict sense. In (Heflin et al., 1999), the authors reportof similar observations of the “annotation” process as wepresent here.5
When talking about semantic annotations, terms likeXML (Bray et al., 1998) and RDF (Lassila and Swick,1999) must not be absent. Especially XML (ExtensibleMarkup Language) earned a lot of attention in the lasttwo years since its standardisation. XML allows the defi-nition of individual tags that can be interpreted accordingto the user’s will. E.g. XHTML represents an HTML-like vocabulary to describe the layout of web pages forbrowsers, SMIL defines tags that describe complete mul-timedia documents, or with XMLNews-tags the text ofnews can be annotated with rich semantic meaning suchas the location and date of an event. Pure XML vocabu-laries like these are not sufficient as means for represent-ing deep semantics, but they can be complemented byontologies to achieve a flexible and well understood wayto represent and transfer content (via XML) and at the
5For a further comparison of several ways to represent knowledgein the WWW (often by means like semantic annotations) refer to (vanHarmelen and Fensel, 1999).
same time to embed the represented facts in a formal andmachine interpretable model of discourse (via the ontol-ogy). In (Erdmann and Studer, 1999) we show how toestablish such a close coupling automatically.
We expect the relationship of semantic annotations orsemantic metadata with ontologies to be central for thesuccess of semantic information processing in the future.The Resource Description Framework (RDF), an (XML-based) representation format for meta data defined bythe W3C could take a central part in this development,since an ontology representation mechanism has beendefined on top of the basic RDF primitives. A core lan-guage introducing notions of classes and relationshipshas been proposed to the W3C as RDFS (Brickley andGuha, 1999). Even richer languages for more elaboratemodeling primitives like symmetric relationships, part-ofrelations, or Description-Logic-like subsumption hierar-chies were proposed in (Erdmann et al., 2000) or (Hor-rocks et.al., 2000). Thus, RDF could become the meansto represent metadata and ontologies in an open, widely“spoken” representation and interchange format.
Concerning our mechanisms for semi-automatic se-mantic annotation described in Section 5 there has beendone only little research. Pustejovsky et al. (Pustejovskyet al., 1997) describe their approach for semantic index-ing and typed hyperlinking. As in our approach finitestate technologies support lexical acquisition as well assemantic tagging. The goal of the overall process is thegeneration of so called lexical webs that can be utilizedto enable automatic and semi-automatic construction ofweb-based texts.
In (Bod et al., 1997) approaches for learning syntacticstrctures from syntactically tagged corpus has been trans-ferred to the semantic level, too. In order to tag a textcorpus with type-logical formulae, they created tool en-vironment called SEMTAGS for semi-automatically en-riching trees with semantic annotations. SEMTAGS in-crementally creates a first order markov model based onexisting annotations and proposes a semantic annotationof new syntactic trees. The authors report promising re-sults: After the first 100 sentences of the corpus had beenannotated, SEMTAGS already produced the correct an-notations for 80% of the nodes for the immediately sub-sequent sentences.
8 DiscussionBased on the KA
�
community portal scenario we haveshown in Section 3 how information has been providedin the beginning. Our lessons learned from this expe-rience gave us a starting point for developing more ad-vanced and more user friendly methods for semanticallyannotating documents. The methods are combined withan information extraction system that semi-automaticallyproposes new annotations to the user. Our experienceshave shown that semantic annotation and ontology engi-neering must be considered a cyclic process.
In the future much work remains to be done. First,wewill have to build an integrated system of annotationand ontology construction. This system will combine

knowledge base-supported, ergonomic annotation, withan environment and methods for ontology engineeringand learning from text supporting evolving ontologies.Second, we have to evaluate our annotation mechanisms.Evaluation in our annotation architecture can be splittedinto several sub-evaluation phases: ergonomic evalua-tion, evaluation of the ontology, evaluation of the semi-automatic suggestions, evaluation of the user’s annota-tions. Third, we will support the RDF standard for rep-resenting metadata on the web, representing both ontolo-gies and generated annotated facts in RDF(S). This stan-dard will make annotated facts reusable and machine-processable on the web (Decker et al., 2000).Acknowledgements. We thank Stefan Decker for initi-ating the first version of an annotation tool. We thank ourstudents Mika Maier-Collin and Jochen Klotzbuecher forthe Annotation Tool; Dirk Wenke for the Ontology Engi-neering Environment OntoEdit; Raphael Volz for the On-tology Learning Environment Text-To-Onto; DFKI lan-guage technology group, in particular Guenter Neumann,for their dedicated support in using SMES. This workwas partially supported by grant GETESS and by Onto-prise GmbH.
ReferencesD. Appelt, J. Hobbs, J. Bear, D. Israel, and M. Tyson. 1993.
FASTUS: A finite state processor for information extractionfrom real world text. In Proceedings of IJCAI-93, Cham-bery, France, August.
R. Benjamins, D. Fensel, and S. Decker. 1999. KA2: Build-ing Ontologies for the Internet: A Midterm Report. Interna-tional Journal of Human Computer Studies, 51(3):687.
R. Bod, R. Bonnema, and R. Scha. 1997. Data-oriented se-mantic interpretation. In In Proceedings of the Second In-ternational Workshop on Computational Semantics (IWCS),Tilburg, 1997.
T. Bray, J. Paoli, and C.M. Sperberg-McQueen. 1998. Exten-sible markup language (XML) 1.0. Technical report, W3C.http://www.w3.org/TR/1998/REC-xml-19980210.
D. Brickley and R.V. Guha. 1999. Resource descrip-tion framework (RDF) schema specification. Techni-cal report, W3C. W3C Proposed Recommendation.http://www.w3.org/TR/PR-rdf-schema/.
S. Decker, M. Erdmann, D. Fensel, and R. Studer. 1999. Onto-broker: Ontology Based Access to Distributed and Semi-Structured Information. In R. Meersman et al., editors,Database Semantics: Semantic Issues in Multimedia Sys-tems, pages 351–369. Kluwer Academic Publisher.
S. Decker, J. Jannink, P. Mitra, S. Staab, R. Studer, andG. Wiederhold. 2000. An information food chain for ad-vanced applications on the www. In Proceedings of theFourth European Conference on Research and AdvancedTechnology for Digital Libraries.
M. Erdmann and R. Studer. 1999. Ontologies as ConceptualModels for XML Documents. In Proceedings of the 12th In-ternational Workshop on Knowledge Acquisition, Modellingand Mangement (KAW’99), Banff, Canada, October.
M. Erdmann, M. Maedche, S. Staab, and S. Decker. 2000. On-tologies in RDF(S). Technical Report 401, Institute AIFB,Karlsruhe University.
J. Heflin, J. Hendler, and S. Luke. 1999. Applying Ontologyto the Web: A Case Study. In Proceedings of the Inter-
national Work-Conference on Artificial and Natural NeuralNetworks, IWANN’99.
I. Horrocks et.al. 2000. The ontology interchange lan-guage oil: The grease between ontologies. Technicalreport, Dep. of Computer Science, Univ. of Manch-ester, UK/ Vrije Universiteit Amsterdam, NL/ AIdmin-istrator, Nederland B.V./ AIFB, Univ. of Karlsruhe, DE.http://www.cs.vu.nl/˜dieter/oil/.
R. Hudson. 1990. English Word Grammar. Basil Blackwell,Oxford.
Michael Kifer, Georg Lausen, and James Wu. 1995. Logicalfoundations of object-oriented and frame-based languages.Journal of the ACM, 42.
D. E. Knuth. 1984. Literate programming. The ComputerJournal, 27:97–111.
O. Lassila and R. Swick. 1999. Resource descrip-tion framework (RDF) model and syntax specifica-tion. Technical report, W3C. W3C Recommendation.http://www.w3.org/TR/REC-rdf-syntax.
S. Luke, L. Spector, D. Rager, and J. Hendler. 1997. Ontology-based Web Agents. In Proceedings of First InternationalConference on Autonomous Agents, LNCS.
A. Maedche and S. Staab. 2000a. Discovering conceptual re-lations from text. In Proceedings of ECAI-2000. IOS Press,Amsterdam.
A. Maedche and S. Staab. 2000b. Semi-automatic engineer-ing of ontologies from text. In Proceedings of the 12th In-ternal Conference on Software and Knowledge Engineering.Chicago, USA, July, 5-7, 2000. KSI.
G. Neumann, R. Backofen, J. Baur, M. Becker, and C. Braun.1997. An information extraction core system for real worldgerman text processing. In In Proceedings of ANLP-97,pages 208–215, Washington, USA.
J. Pustejovsky, B. Boguraev, M. Verhagen, P. Buitelaar, andM. Johnston. 1997. Semantic indexing and typed hyper-linking. In Proceedings of AAAI Spring Symposium, NLPfor WWW.
H.-P. Schnurr and S. Staab. 2000. A proactive inferencingagent for desk support. In Proceedings of the AAAI Sympo-sium on Bringing Knowledge to Business Processes, Stan-ford, CA, USA. AAAI Technical Report, Menlo Park.
S. Staab and A. Maedche. 2000. Ontology engineering beyondthe modeling of concepts and relations. In Proceedings ofthe ECAI’2000 Workshop on Application of Ontologies andProblem-Solving Methods.
S. Staab, C. Braun, A. Dusterhoft, A. Heuer, M. Klettke,S. Melzig, G. Neumann, B. Prager, J. Pretzel, H.-P. Schnurr,R. Studer, H. Uszkoreit, and B. Wrenger. 1999. GETESS —searching the web exploiting german texts. In Proceedingsof the 3rd Workshop on Cooperative Information Agents,LNCS, Berlin. Springer.
S. Staab, J. Angele, S. Decker, M. Erdmann, A. Hotho,A. Maedche, R. Studer, and Y. Sure. 2000. Semantic Com-munity Web Portals. In Proceedings of the 9th World WideWeb Conference (WWW-9), Amsterdam, Netherlands.
F. van Harmelen and D. Fensel. 1999. Practical KnowledgeRepresentation for the Web. In Proceedings of the IJCAIWorkshop on Intelligent Information Integration.