what are the mechanisms by which targets for saccades are selected?
DESCRIPTION
What are the mechanisms by which targets for saccades are selected?. Neurophysiological studies of LIP suggest it serves to identify region in the image that may the target of the next saccade. (Goldberg, Colby etc) - PowerPoint PPT PresentationTRANSCRIPT

What are the mechanisms by which targets for saccades are selected?

Neurophysiological studies of LIP suggest it serves to identify region in the image that may the target of the next saccade. (Goldberg, Colby etc)
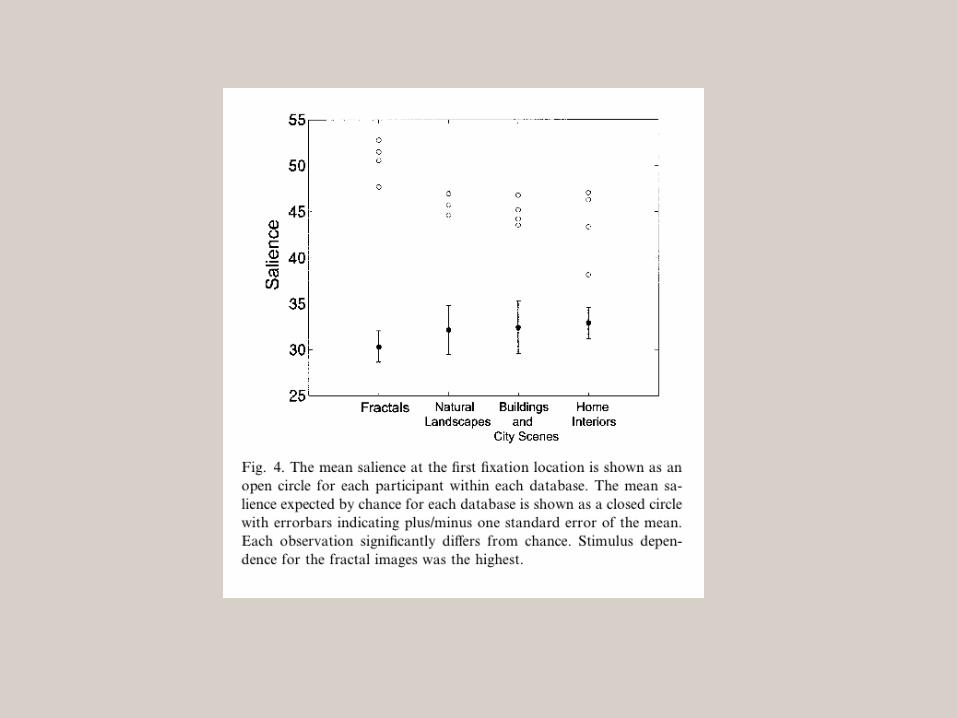
Data shows, for steadily presented targets, activity in receptive fields that are behaviorally relevant - usually the target for the next saccade.
Commonly thought that LIP extracts something like “salience”.
(Note Andersen claims it represents intention to move, not attention or salience.)

Idea of “salience”: a difference in stimulus properties from the surrounding region - eg red object in a green background.
Proposal: saccadic eye movements are generated by salient regions in the image.

Original Saliency models - Itti & Koch
Parkhurst, Law & Neibur, Vision Res 2002)

Explanation for preference to fixate center in terms of fall off in resolutionprobably wrong (note: fixations linked to display - different in natural scenes)

Issues with Saliency models:
- Choice of feature maps
- Separate feature maps unphysiological
- Inhibition of return is a fudge - IOR grossly overblown, but deeper issue is that saliency models have no mechanism for predicting sequences of fixations
-Predictions are not very good, even on 2D images. Veryinconsistent with data in natural contexts. Also is an object fixated because it’s a blob or because it’s semantically meaningful?
-Important things may not be salient
-Salient things may not be important
-Incredible lack of invariance in the image (illumination etc, also things like traffic density)

More specific question: how do we locate things we are looking for? - ie visual search

Cave & Wolfe - Guided Search model - feature maps similar to saliency models, modulated by top down goals.Hence feature search is easy because target is already salient. Conjunctive serch may need to go item by item because the target doesn’t get a boost from saliency.

Rao et al model (Vision Res 2002):

In a high-dimensional space, image points are sparsely representedie a long distance from each other, so are easy to distinguish.



