webinar: faster log indexing with fusion
TRANSCRIPT


GC Tuning
Call for Papers open through May 8 lucenerevolution.org
October 13-16 � Austin, TX

• Time-based partitioning scheme
• Transient collections for high-volume indexing
• Schema design considerations
• Q&A
Webinar: Fast Log Indexing with Fusion / Solr

Large-scale log analytics • Index billions of log events per day, near real-time
• Analyze logs over time: today, recent, past week, past 30 days, …
• Easy to use dashboards to visualize common
questions and allow for ad hoc analysis • Ability to scale linearly as business grows …
with sub-linear growth in costs!
• Easy to setup, easy to manage, easy to use
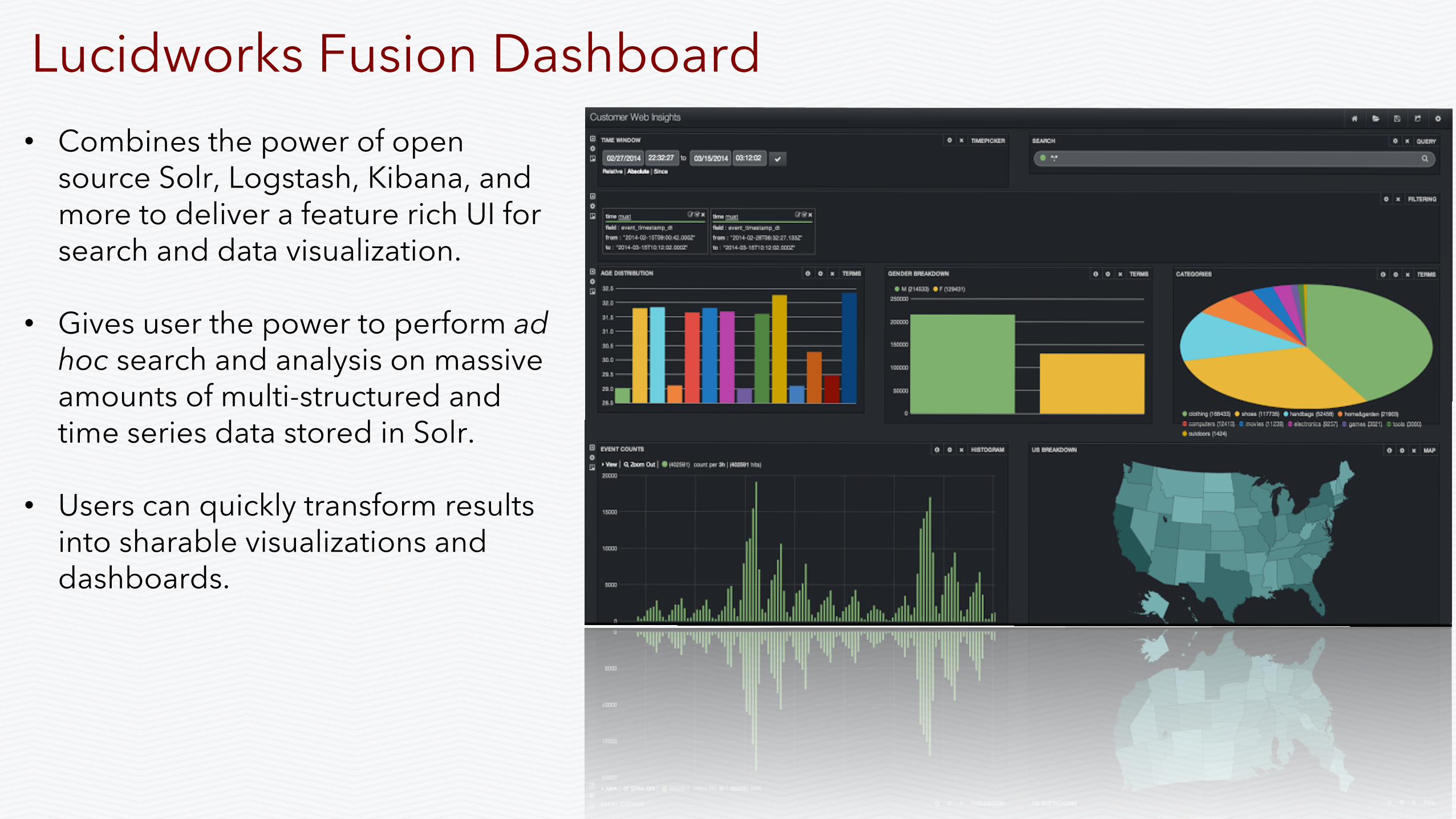
• Combines the power of open source Solr, Logstash, Kibana, and more to deliver a feature rich UI for search and data visualization.
• Gives user the power to perform ad hoc search and analysis on massive amounts of multi-structured and time series data stored in Solr.
• Users can quickly transform results into sharable visualizations and dashboards.
Lucidworks Fusion Dashboard
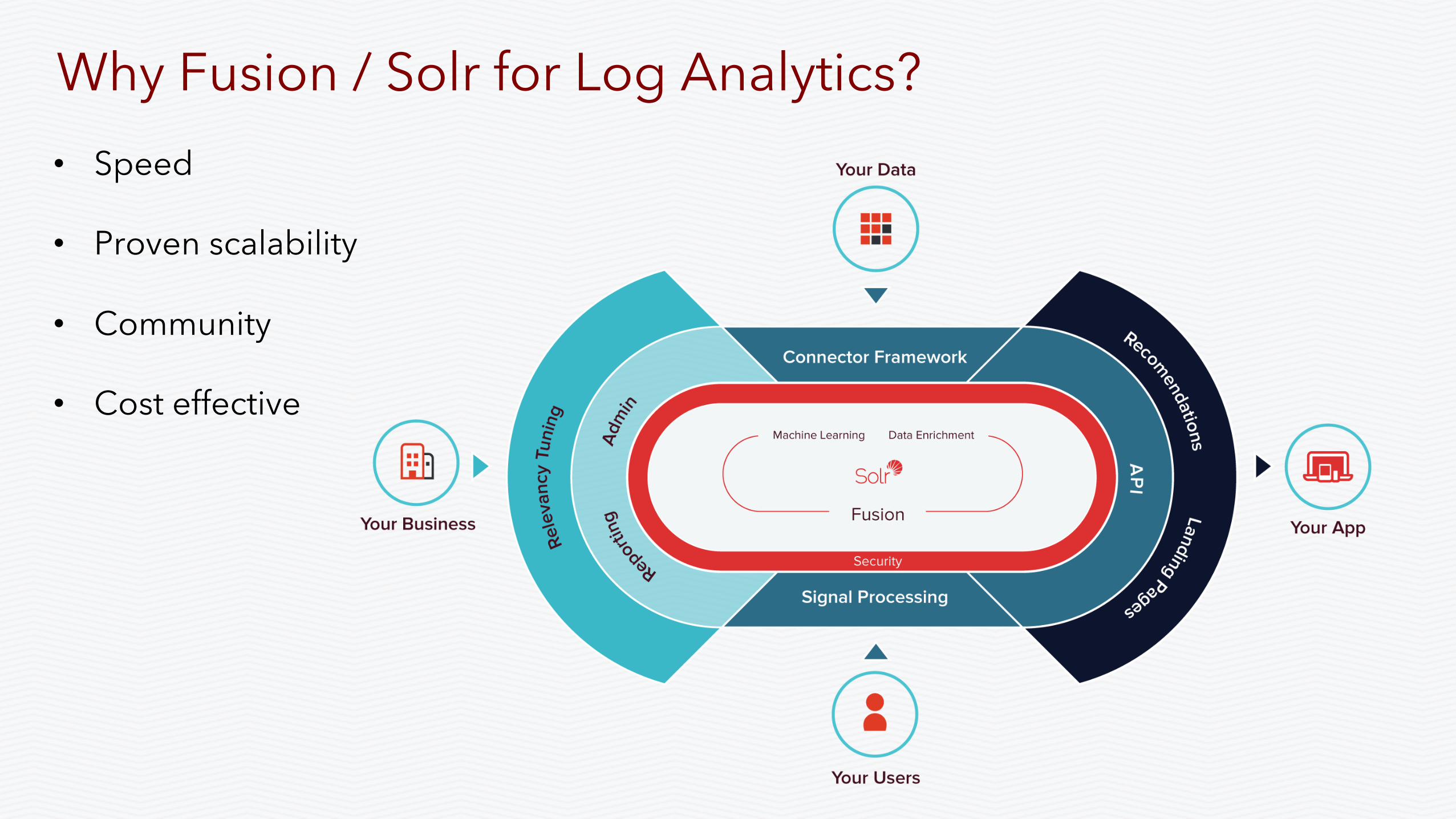
Why Fusion / Solr for Log Analytics? • Speed
• Proven scalability
• Community
• Cost effective

Fusion Collection A collection is a distributed index defined by:
• configuration stored in ZooKeeper (schema.xml, solrconfig.xml, …)
• one or more shards: documents are distributed across N partitions of the index
• document routing strategy: how documents get assigned to shards
• replication factor: how many copies of each document in the collection
• replica placement strategy: rack awareness, etc (see SOLR-6620)
Sharding increases parallelism during indexing and query execution Replication enables load-balancing and fault-tolerance
https://twitter.com/bretthoerner/status/476830302430437376
Fusion Log Analytics Dashboard
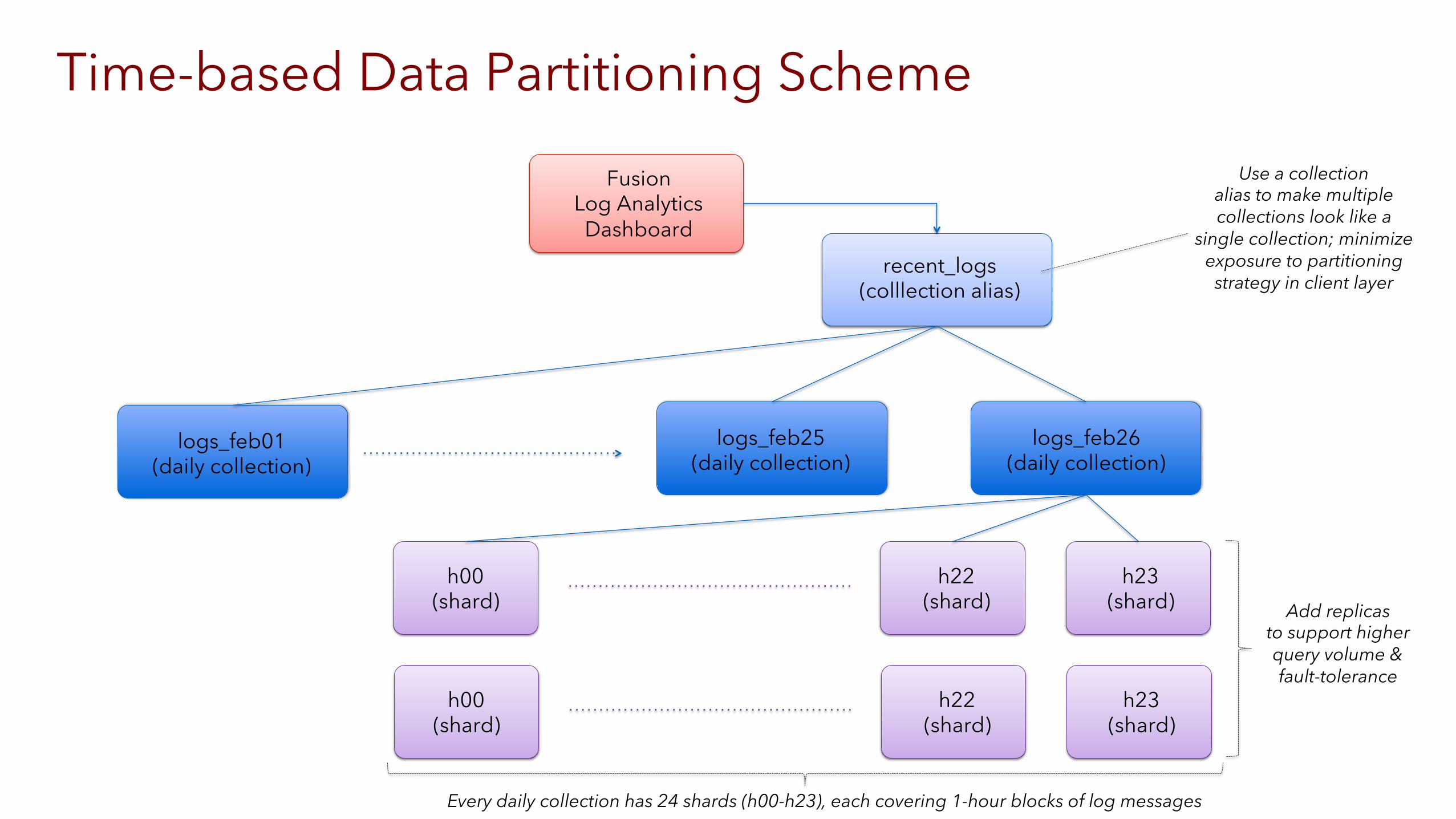
logs_feb26 (daily collection)
logs_feb25 (daily collection)
logs_feb01 (daily collection)
h00 (shard)
h22 (shard)
h23 (shard)
h00 (shard)
h22 (shard)
h23 (shard)
Add replicas to support higher query volume & fault-tolerance
recent_logs (colllection alias)
Use a collection alias to make multiple collections look like a
single collection; minimize exposure to partitioning strategy in client layer
Every daily collection has 24 shards (h00-h23), each covering 1-hour blocks of log messages
Time-based Data Partitioning Scheme

Time-based Data Partitioning Benefits • Optimizing read performance for write-once, read-many-times
type data
• Recent data stays “hot” in Solr memory-based caches and OS cache
• Queries can be directed to specific partitions based on time range filters Show me errors occurring in my database layer in the past 10 minutes Visualize activity for the past 2 hours …
• Easy to drop or move older data to more cost-effective hardware
• Easier to scale-out by adding more nodes, no shard-splitting, rebalancing, or reindexing
But …

Time-based Data Partitioning Limitations • Indexing into a single hourly shard cannot keep up with write-volume
• 15-20K docs/sec per shard is normal
• Not unusual to need an avg. of 50K docs/sec with ability to scale to 120K
• Shard being written to would be a hotspot that would hurt query performance
• Partitioning details exposed to indexing applications
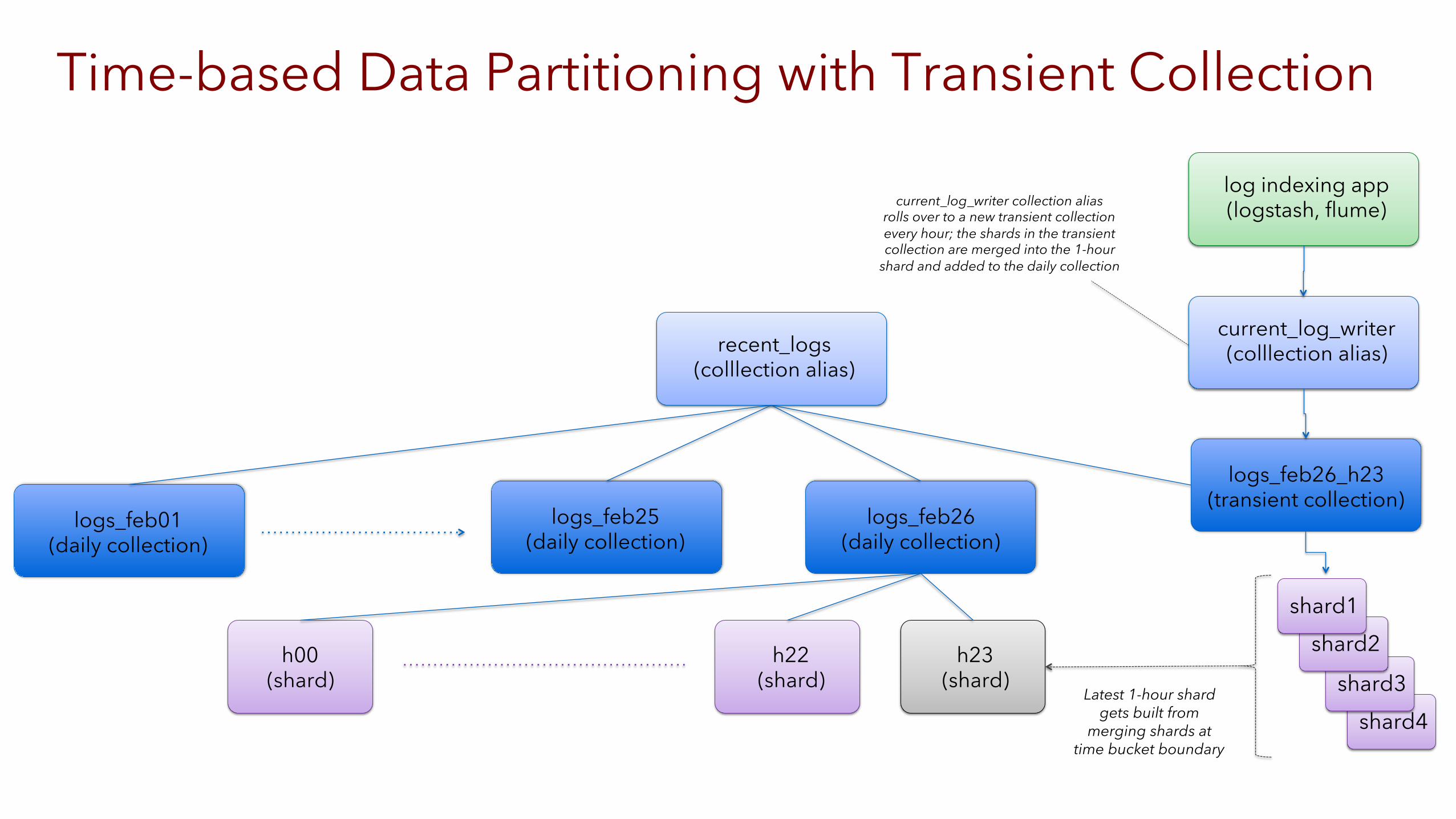
logs_feb26 (daily collection)
logs_feb25 (daily collection)
logs_feb01 (daily collection)
h00 (shard)
h22 (shard)
h23 (shard)
recent_logs (colllection alias)
Time-based Data Partitioning with Transient Collection
shard4 shard3
shard2 shard1
Latest 1-hour shard gets built from
merging shards at time bucket boundary
logs_feb26_h23 (transient collection)
current_log_writer (colllection alias)
log indexing app (logstash, flume) current_log_writer collection alias
rolls over to a new transient collection every hour; the shards in the transient collection are merged into the 1-hour
shard and added to the daily collection

Transient Collection Highlights • Hash-based document routing across all shards
• Scale up the number of shards to meet peak write-volume reqts.
• Indexing applications write to an alias, e.g. “current_log_writer”
• Rollover to a new transient collection every hour
• Use Solr merge index support to create a single, immutable hourly shard
• Read alias includes current transient collection (to query very recent data)
• Achieved >120K docs per second with replication in a cluster with 20 servers

Direct Updates to Leaders
server-side client-side

logs_feb26 (daily collection)
logs_feb25 (daily collection)
h00 (shard)
h22 (shard)
h23 (shard)
recent_logs (colllection alias)
Merge Transient Collection into Daily Collection
current_log_writer (colllection alias)
log indexing app (logstash, flume)
shard4 shard3
shard2 shard1
logs_feb26_h23 (transient collection)
logs_feb27_h00 (transient collection)
h23 (shard)
2015-02-27 00:00:00
Solr merge

Nuts and Bolts • Most features are provided out-of-the-box with Fusion
- Connectors - Banana Dashboard - SolrCloud & Solr Scale Toolkit - Collection Management - Monitoring, security, etc …
• Transient collection rollover - Custom Solr UpdateRequestProcessor - Creates new transient collection when needed - Updates collection aliases (reads and writes) - Tricky in a distributed cluster, uses ZooKeeper to coordinate
• Merge transient shards into single hourly shard - Custom Python script - Pulls shards from transient collection to a single host (throttled) - Runs Solr merge to create 1 index from many shards - Activates new hourly shard & removes old transient - Adds replicas for new hourly shard

Moving older data to less expensive storage • SSD preferred for recent data, older data can be on “spinning rust” • Move older data off SSD to slower disks
- ADDREPLICA API to add new replica on another host - Solr 5+ supports throttling replication transfer speed
- or, simply scp –l 500 … (-l for limit copy at 0.5 Mbit/s)

Schema Design • At large scale, disk (SSD) and memory are still expensive!
• Balance flexibility with performance and efficiency (disk usage)
• Fast unique IDs Use UUID v1 if possible: http://johannburkard.de/software/uuid/ http://blog.mikemccandless.com/2014/05/choosing-fast-unique-identifier-uuid.html
• DocValues for fields that you facet and sort on frequently
• Trie-based date for range queries
• Catch all text field for improved recall

DocValues • Faster sorting and faceting, both of which are used extensively in log analytics
• Column-oriented view of a field in a Solr index (uninverted)
• Disk & OS cache vs. Java Heap “… we tuned everything about the default codec to keep all the data structures on disk but still be fast.” Robert Muir, Lucene/Solr Committer, LUCENE-5761
• Helps reduce pressure on Java GC

GC Tuning
• Dashboards put a lot of pressure on the Java GC
• Stop-the-world GC pauses can lead to ZooKeeper session expiration (which is always bad)
• Good success with 32gb max heap (-Xmx32g) but have to tune it …
• MMapDirectory relies on sufficient memory available to the OS cache (off-heap)
• Enable verbose GC logging (even in prod) so you can troubleshoot issues:
-‐verbose:gc –Xloggc:gc.log -‐XX:+PrintHeapAtGC -‐XX:+PrintGCDetails \ -‐XX:+PrintGCDateStamps -‐XX:+PrintGCCause \ -‐XX:+PrintTenuringDistribution -‐XX:+PrintGCApplicationStoppedTime

GC Tuning -‐XX:CMSTriggerPermRatio=80
-‐XX:CMSFullGCsBeforeCompaction=1 -‐XX:+ParallelRefProcEnabled -‐XX:+CMSParallelRemarkEnabled
-‐XX:CMSMaxAbortablePrecleanTime=6000 -‐XX:CMSInitiatingOccupancyFraction=50 -‐XX:+UseCMSInitiatingOccupancyOnly -‐XX:PretenureSizeThreshold=128m -‐XX:+CMSScavengeBeforeRemark
-‐XX:ParallelGCThreads=9 -‐XX:ConcGCThreads=9 -‐XX:+UseParNewGC
-‐XX:+UseConcMarkSweepGC -‐XX:MaxTenuringThreshold=12 -‐XX:TargetSurvivorRatio=90
-‐XX:SurvivorRatio=6 -‐XX:NewRatio=5
-‐Xmx32g -‐Xms16g -‐Xss256k

Thank you.
Download Fusion: http://lucidworks.com/fusion/ Webinar recording will be available soon.
Questions?
