web search engines and web data mining basic techniques, architectures, tools, and current trends...
Post on 20-Dec-2015
216 views
TRANSCRIPT

Web Search Engines and Web Data Mining
basic techniques, architectures, tools, and current trends
CATT Short Course - July 12, 2002
Instructor: Prof. Torsten Suel
Department of Computer and Information Science
Polytechnic University
http://cis.poly.edu/suel/

This material was developed for a one-day short course on search engines and search technology taught at Polytechnic University in Brooklyn on June 11, 2004. The course was organized by the Center for Advanced Technology in Telecommunication (CATT) at Polytechnic University; seehttp://catt.poly.edu for more information.
An electronic version of these slides (except for handwritten additions) is available at
http://cis.poly.edu/suel/webshort/
Which also contains a detailed list of additional pointers andbibliographic references.
© 2004 Torsten Suel ([email protected])

Goal of this course:
• learn how search engines work• learn about other types of web search tools and applications
• learn how to build and deploy such tools - basic information retrieval techniques - what software tools to use - system architectures and performance
Target Audience:• technically oriented people interested in how it works• developers who may need to build or deploy tools

Overview:• Part I - Introduction: - Motivation (why web search tools?) - Examples of search tools - How the web works - Basic search engine structure - Introduction to Information Retrieval
(coffee break: 11:00-11:15)
• Part II – Search Engine Basics - Search engine architecture - Web crawling basics: following links, robot exclusion, .. - Storage - Text indexing - Querying and term-based ranking - Basic link-based ranking
(lunch: 12:30-1:30)

Overview: (cont.)
• Part III – Applications, Systems, and Tools - Types of search tools - Available software tools - Search and DBMSs - Application scenarios: * Major search engine * Focused Data Collection and Analysis * Browsing/Search Assistants * Site and Enterprise Search * Geographic Web Search
- Example: citeseer system - Example: Internet Archive - Using search engines - Search engine optimization and manipulation
(break 2:45 -3:00)

Overview: (cont.)
• Part IV - Advanced Techniques
- High-performance crawling
- Recrawling and focused crawling - Link-based ranking (Pagerank, HITS)
- Structural analysis of the web graph
- Optimizing query execution
- Parallel search engines and scaling
- Meta search engines
- Document clustering and duplicate detection

Not Covered:• Semi-structured data and XML• Web accessible databases - crawling the hidden web - efficient query processing on remote data sources - wrapper construction
• Extracting relational data from the web• Shopping bots• Image and multimedia search• Peer-to-peer search technologies• advanced IR: categorization, clustering, ...
• natural language processing (NLP)

1 – Introduction and Motivation: What is the Web?

• pages containing (fairly unstructured) text
• images, audio, etc. embedded in pages
• structure defined using HTML (Hypertext Markup Language)
• hyperlinks between pages!
• over 10 billion pages
• over 150 billion hyperlinks
a giant graph!
What is the web? (another view)

• pages reside in servers
• related pages in sites
• local versus global links
• logical vs. physical structure
How is the web organized?
Web Server (Host)
Web Server (Host)
Web Server (Host)
www.poly.edu
www.cnn.com
www.irs.gov

• more than 10 billion pages • more than 150 billion hyperlinks• plus images, movies, .. , database content
How do we find pages on the web?
we need specialized tools for findingpages and information

2 - Overview of web search tools
• Major search engines (google, fast, altavista, teoma, wisenut)
• Web directories (yahoo, open directory project)
• Specialized search engines (citeseer, achoo, findlaw)
• Local search engines (for one site or domain)
• Meta search engines (dogpile, mamma, search.com, vivisimo)
• Personal search assistants (alexa, google toolbar)
• Comparison shopping (mysimon, pricewatch, dealtime)
• Image search (ditto, visoo (gone), major engines)
• Natural language questions (askjeeves?)
• Deep Web/Database search (completeplanet/brightplanet)

Major search engines:

Basic structure of a search engine:
Crawler
disks
Index
indexing
Search.comQuery: “computer”
look up

Ranking: • return best pages first• term- vs. link-based approaches

• coverage (need to cover large part of the web)
• good ranking (in the case of broad queries)
• freshness (need to update content)
• user load (up to 10000 queries/sec - Google)
• manipulation (sites want to be listed first)
Challenges for search engines:
need to crawl and store massive data sets
smart information retrieval techniques
frequent recrawling of content
many queries on massive data
naïve techniques will be exploited quickly


• designing topic hierarchy• automatic classification: “what is this page about?”• Yahoo and Open Directory mostly human-based
Topic hierarchy: everything
sports politics healthbusiness
baseball
hockey
soccer
….
foreign
domestic
....
....
....
....
....
Challenges:

Specialized search engines: (achoo, findlaw)
• be the best on one particular topic• use domain-specific knowledge• limited resources do not crawl the entire web!• focused crawling techniques or meta search
• uses other search engines to answer questions• ask the right specialized search engine, or• combine results from several large engines• may need to be “familiar” with thousands of engines
Meta search engines: (dogpile, vivisimo, search.com, mamma)

Personal Search Assistants: (Alexa, Google Toolbar)
• embedded into browser
• can suggest “related pages”
• search by “highlighting text” can use context
• may exploit individual browsing behavior
• may collect and aggregate browsing information
privacy issues
• architectures:
- on top of crawler-based search engine (alexa, google), or
- based on meta search (MIT Powerscout)
- based on limited crawls by client or proxy (MIT Letizia, Stanford PowerBrowser)

Perspective:
algorithms
systemsinformation retrieval
databases
machine learning
natural languageprocessin
g
AI
library &information
science

Example #1:
• Ragerank (Brin&Page/Google)
“significance of a page depends on significance of those referencing it”
• HITS (Kleinberg/IBM)
“Hubs and Authorities”
Link-based ranking techniques

Example #2:
• crawler architecture
• networking requirements
• data structures: size and robustness
• crawling etiquette
• concerns for webmasters
Crawling 100 million pages

Example #3:
• What does the web look like? (diameter, connectivity, in-degree)
• Why are there so many bipartite cliques? (IBM) (and why do we care?)
• How do you compute with a 500 million node graph?
Analysis of the web graph
(2,3-clique)

Example #4:
• given 1 billion pages, find duplicates (15 TB)
• more difficult: find very similar pages (clustering)
• find mirror sites and replicated collections
• process collection to account for duplicates
Finding near duplicates on the web

3 - How the web works (more details)
Desktop(with browser)
give me the file “/world/index.html”
here is the file: “...”
Web Server
www.cnn.com
Fetching “www.cnn.com/world/index.html”

Three Main Ingredients:
• Naming: URL (uniform resource locators) (used to identify and locate objects)
• Communication: HTTP (hypertext transfer protocol) (used to request and transfer objects)
• Rendering: HTML (hypertext markup language) (used to defined how object should be presented to user)
Client Server Paradigm:
• Client (browser) used HTTP to ask server (web
server) for object identified by URI, and renders this
object according to rules defined by HTML

Domain Name Service:
desktop(or crawler)
local DNS server
where is www.poly.edu located?
answer: 123.238.24.10
where is www.cnn.com located?
root DNS server
DNS serverfor cnn.com
1.
2.3.
4.
5.6.

Names, addresses, hosts, and sites
• one machine can have several host names and IP addresses• one host name may correspond to several machines• one host can have several “sites” (what is a site?)• one “site” on several hosts• issues: detecting duplicates, crawling, local vs. global links
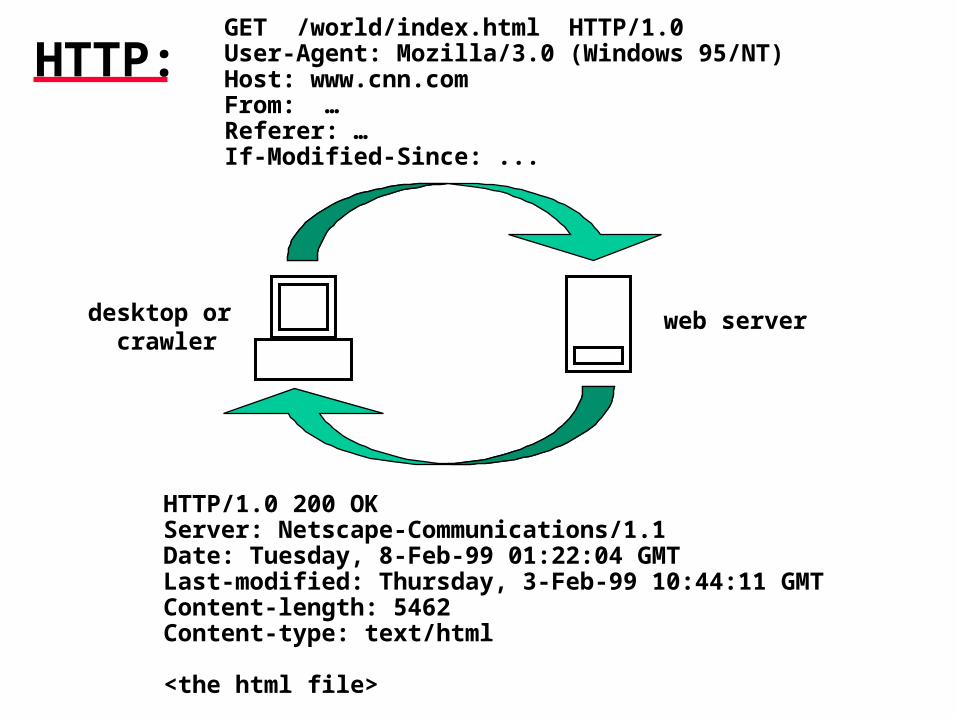
HTTP:
desktop or crawler
web server
GET /world/index.html HTTP/1.0User-Agent: Mozilla/3.0 (Windows 95/NT)Host: www.cnn.comFrom: …Referer: …If-Modified-Since: ...
HTTP/1.0 200 OKServer: Netscape-Communications/1.1Date: Tuesday, 8-Feb-99 01:22:04 GMTLast-modified: Thursday, 3-Feb-99 10:44:11 GMTContent-length: 5462Content-type: text/html
<the html file>

HTML:

HTTP & HTML issues:
• “dynamic” URLs:
http://www.google.com/search?q=brooklyn
http://www.amazon.com/exec/obidos/ASIN/1558605703/qid%3D9…
http:/cis.poly.edu/search/search.cgi
• result file can be computed by server in arbitrary manner!
• persistent connections in HTTP/1.1
• mime types and extensions
• frames
• redirects
• javascript/java/JEB/flash/activeX ????????

4 – Basic Search Engine Structure:
Crawler
disks
Index
indexing
Search.comQuery: “computer”
look up

Crawling
Crawler
disks
• fetches pages from the web• starts at set of “seed pages”• parses fetched pages for hyperlinks• then follows those links (e.g., BFS)• variations: - recrawling - focused crawling - random walks

Indexing
disks
• parse & build lexicon & build index
• index very large
I/O-efficient techniques needed
“inverted index”
indexing
aardvark 3452, 11437, ….......arm 4, 19, 29, 98, 143, ...armada 145, 457, 789, ...armadillo 678, 2134, 3970, ...armani 90, 256, 372, 511, ........zebra 602, 1189, 3209, ...

Querying
Boolean queries: (zebra AND armadillo) OR armani
compute unions/intersections of lists
Ranked queries: zebra, armadillo
give scores to all docs in union
look up
aardvark 3452, 11437, ….......arm 4, 19, 29, 98, 143, ...armada 145, 457, 789, ...armadillo 678, 2134, 3970, ...armani 90, 256, 372, 511, ........zebra 602, 1189, 3209, ...

(Information Retrieval from Memex to Google)
• (a) Introduction: What is IR?
• (b) Historical development of IR (plus Information Science and Library Science)
• (c) Fundamentals: Indexing, search, data acquisition
• (d) Mathematical Techniques: vector space model, ranking and classification
5 – Introduction to Information Retrieval

(a) Introduction:
“IR is concerned with the representation, storage, organization of, and access to information items”
• focus on automatic processing (indexing, clustering, search) of unstructured data (text, images, audio, ...)
• subfield of Computer Science, but with roots in Library Science, Information Science, and Linguistics
• In this course, we focus on text data• Applications: - searching in a library catalog - categorizing a collection of medical articles by area - web search engines
Information Retrieval (IR):

(a) Introduction:
• WW2 era computers built for number crunching: ballistics computations, code breaking
• since earliest days, also used to “organize information” - Memex (Vannevar Bush, 1945)
• today, this is the main application! - store and organize data and documents - model organizations and work processes
• Computer Organizer
• … however, no clean separation
Historical Perspective:

(a) Introduction:
• IR: lesser known cousin of field of Databases• Databases: focus on structured data
• IR: unstructured data: “documents”• Information retrieval vs. data retrieval• IR focused on human user (?)• Challenges: semistructured data, closing the gap
Structured vs. Unstructured Data:
- scientific articles, novels, poems, jokes, web pages

Recall: the fraction of the relevant documents (R) that is successfully retrieved:
Recall =
(a) Introduction:
|Ra||R|
Precision: the fraction of the retrieved documents (A) that are relevant:
Precision =|Ra||A| Collection
Answer Set |A|Relevant Docs |R|
Relevant Documents in Answer Set |Ra|
• fundamental trade-off• policy ramifications

(a) Introduction:
• Indexing: create a full-text or keyword index
• Querying/ranking: find documents (most) relevant to query
• Clustering: group documents in sets of similar ones
• Categorization: assign documents to given set of categories
• Citation Analysis: find frequently cited or influential papers
• (Extraction/tagging: identify names of people, organizations)• (Summarization: automatically create a summary)• (Translation: translate text between languages)
Note: not the same as NLP, string processing
Text IR Operations:

(a) Introduction:
• Digital Libraries and Library Catalog Systems - full-text indexing and search of electronic documents - keyword search for other documents - categorization of medical or news articles - browsing by categories and relationships
• Web Search Engines - very large amounts of data, data acquisition problem - many short documents, very informal, manipulation
• National Security and Competitive Intelligence: - web surveillance (extremist sites, competitors) - filtering and querying intercepted communications - searching internal documents (files from branch offices) - analyzing phone call graphs, server and search engine logs
Text IR Applications:

(a) Introduction:
• how to automatically find interesting patterns and rules in data• or how to find exceptions to rules (outliers)• no clear boundary between data mining and OLAP• relevant to structured and unstructured data• example: association rules - products, words, links, books
Data Mining:
• scenario: analyst posing questions (queries) to a system• preferably based on powerful query language (e.g., SQL)• goal: to discover properties of the data• for text/IR: need query language (VQL?)
Online Analytical Processing: (OLAP)

(a) Introduction:
• IR does not analyze grammar, local structure (document as a set or bag or words)
• NLP analyzes sentence structure, grammar (shallow/deep parsing)
• IR: simple statistical methods, good for search & categorization• NLP: good for automatic translation, summarization, extraction
• IR is largely language independent
• NLP uses knowledge about the language (WordNet, thesaurus)
• NLP: rooted in linguistics, grammar vs. statistical NLP
• web search: so far, NLP has not proven that critical yet
IR versus NLP: (Natural Language Processing or Computational Linguistics)

(a) Introduction:
• symbolic/logic vs. statistical approaches• set of general statistical techniques for learning from past data (how to profile correctly)
• widely used in IR and increasingly in NLP
Machine Learning: (sometimes part of AI)
• IR based on statistical techniques• IR “fuzzy”, many different techniques• databases: very precisely defined semantics• databases: “pounding reality into table form”
IR versus databases:

(b) Historical Development
• Babylonians, Greeks, Romans, etc• Indexing and creation of concordances - “algorithms for full-text indexing” ! - e.g., Dobson 1940-65 Byron concordance: “last handmade one”
• Library of Congress and Dewey Classification• Documentalism• Bibliometric and Informetric distributions: - Bradford, Lotka, Zipf, Pareto, Yule (1920s-40s)
• Citation Analysis and Social Network Analysis• Microfilm rapid selectors: - E. Goldberg 1931 - V. Bush 1939
Before 1945:

(b) Historical Development
• distributions observed in many fields of science• some things occur much more frequently than others “some words are used much more often than others “some authors are much more often cited than others” “some people have much more money than others” “some animal species are more common than others”
• follows a particular class of distributions: f(i) ~ i
• large z means large skew • heavy-tailed: “some have a lot more, but most wealth is held by the many”
Zipf and Bibliometric/Informetric Distributions
-z

(b) Historical Development
• “who has written the most influential papers?”• “who is the most influential person in a social network?”• maybe the person who knows the largest number of people?• or someone who knows a few influential people very well?
graph-theoretic approaches to analyzing social networks and citation graphs
• national security applications: - funding, communication, coordination - telephone call graphs
Citation and Social Network Analysis

(b) Historical Development
• “As We May Think”, Atlantic Monthly, 1945 (mostly written 1939)
Memex: Vannevar Bush (1890-1974)

(b) Historical Development
• device for storing and retrieving information• storage based on microfilm• users can store all their experiences and knowledge and retrieve information later
• trails (hyperlinks): users can connect different pieces of information
• surprising earlier history …
Memex:

(b) Historical Development
• microfilm for storage of large amounts of data• storage density in MB per square inch (1925)• but how can we search such massive data?• idea: - add index terms to microfilm boundaries - build rapid selection machines that can scan index
• Rapid Microfilm Selectors: - use light and photo cells to find matches in index terms - hundreds of index cards per second
Rapid Microfilm Selectors:
Source: M. Buckland, UC BerkeleySee http://www.sims.berkeley.edu/~buckland/goldbush.html

(b) Historical Development
Rapid Microfilm Selectors:

(b) Historical Development

(b) Historical Development
• * Moscow 1881 – Tel Aviv 1970• director at Zeiss Ikon (Dresden)• multiple invention in photo technologies• inventor of rapid microfilm selector
Emanuel Goldberg:
Documentalism:• predecessor of library and information sciences• goal: “organize and share knowledge to make it widely available” • The Bridge: organization to design a “world brain”• Otlet, Ostfeld, Schuermeyer, ….• Also related: H.G. Wells
Source: M. Buckland, UC BerkeleySee http://www.sims.berkeley.edu/~buckland/goldbush.html and links in page

(b) Historical Development
"But what a revolution for information retrieval and especially for libraries television can bring! Perhaps one day we shall see our reading rooms deserted and in their place a room without people in which books requested by telephone are displayed, which the users read in their homes using television equipment." (Schuermeyer 1936)
"We should have a complex of associated machines which would achieve the following operations simultaneously or sequentially: 1. Conversion of sound into text; 2. Copying that text as many times as is useful; 3. Setting up documents in such a way that each datum has its own identity and its relationships with all the others in the group and to which it can be re-united as needed; 4. Assignment of a classification code to each datum; [division of the document into parts, one for each datum, and] rearrangement of the parts of the document to correspond with the classification codes; 5. Automatic classification and storage of these documents; 6. Automatic retrieval of these documents for consultation and for delivery either for inspection or to a machine for making additional notes; 7. Mechanized manipulation at will of all the recorded data in order to derive new combinations of facts, new relationships between ideas, new operations using symbols.” (Otlet, 1934)

(b) Historical Development (after Bush)• early work by H.-P. Luhn (KWIC index, SDI, abstraction)
• hypertext (Nelson, Engelbart, 1960s) - links between different documents and sections - Xanadu - hypertext community (HT conferences)
• vector space model and ranking methods - Salton et al (Cornell), 1960s - cosine measure, SMART system
• automatic text classification - manually generated classifiers (since 1960s) - machine learning approach (1980s- now)
• WWW - “the Web”, Berners-Lee, ~1992 - earlier: gopher, archie, WAIS - 1994: Mosaic browser, breakthrough in size - 1994/1995: first crawler-based search engines

• a data structure that for supporting IR queries• most popular form: inverted index structure• like index in a book
Text Index:
inverted index
aalborg 3452, 11437, ….......arm 4, 19, 29, 98, 143, ...armada 145, 457, 789, ...armadillo 678, 2134, 3970, ...armani 90, 256, 372, 511, ........zz 602, 1189, 3209, ...
disks with documents
indexing
(c) Fundamentals of IR Systems

Boolean querying:
Boolean queries:
(zebra AND armadillo) OR armani
unions/intersections of lists
look up
aalborg 3452, 11437, ….......arm 4, 19, 29, 98, 143, ...armada 145, 457, 789, ...armadillo 678, 2134, 3970, ...armani 90, 256, 372, 511, ........Zz 602, 1189, 3209, ...
(see Managing Gigabytes book)
(c) Fundamentals of IR Systems
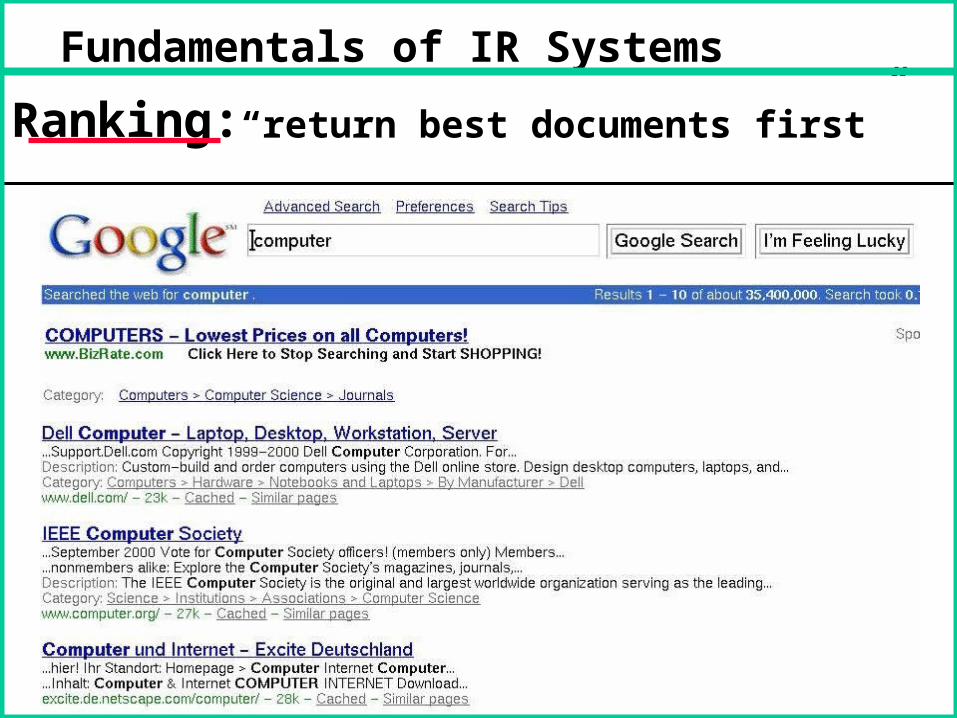
Ranking: “return best documents first”
(c) Fundamentals of IR Systems

• designing topic hierarchy• automatic classification: “what is this page about?”• Yahoo and Open Directory mostly human-based
Text classification: everything
sports politics healthbusiness
baseball
hockey
soccer
….
foreign
domestic
....
....
....
....
....
Challenges:
(c) Fundamentals of IR Systems

Basic structure of a very simple IR system:
disks
Index
indexing
user interfaceQuery: “computer”
look up
(c) Fundamentals of IR Systems
store
document collection

Simple IR system:
• constructs and maintain inverted index on documents
• supports Boolean and ranked queries
• may use automatic or manual classification
• may support other clustering techniques
• may support advanced browsing operations
• “searching vs. browsing”
• often well-structured collections (news, medical articles)
• queries with multiple keywords (up to hundreds)
(c) Fundamentals of IR Systems

Basic structure of a search engine:
(c) Fundamentals of IR Systems
Crawler
disks
Index
indexing
Query: “brooklyn”
look up
web pages

Differences to traditional IR systems:
• data acquisition important (crawling the web)
• collections are much larger (3 billion pages = 50 TB)
• documents are of very mixed quality and types
• queries are VERY short (less than 3 words on average)
• traditional stat. techniques do not work as well
• but additional sources of information:- hyperlink structure- usage data / logs
• search engine manipulation!!!
(c) Fundamentals of IR Systems

• each document D represented as set of words
• a query Q is also just a set of words
• let L be the set of all words in the collection, |L| = m
• D and Q correspond to m-dimensional vectors - if word does not occur in D resp. Q, the corresponding element is set to 0 - otherwise, element is positive
• score of D with respect to query Q is D * Q
• return documents with highest k scores
Vector-Space Model
(d) Mathematical Techniques

• Example: put a 1 into vector for each word
L = {a, alice, bob, book, like, reads}, m = 6doc1: “Bob reads a book” D1 = ( 1, 0, 1, 1, 0, 1 )
doc2: “Alice likes Bob” D2 = ( 0, 1, 1, 0, 1, 0 )
doc3: “book” D3 = ( 0, 0, 0, 1, 0, 0 )
query: “bob, book” Q = ( 0, 0, 1, 1, 0, 0 )
D1*Q = 2, D2 * Q = 1, D3 * Q = 1
• very primitive ranking function: “how many words in common?”
• smarter functions: assign appropriate weights to doc vectors
• vector-matrix multiplication to score are documents
Vector-Space Model
(d) Mathematical Techniques

• higher score for more occurrences of a word• higher score for rare words• lower score for long documents• example: “cosine measure” (and many others)
• f_d,t = number of occurrences of term t in document d• f_t = total number of occurrences of t in the collection
Vector-Space Model for Ranking
(d) Mathematical Techniques

• vast amount of vector space work in IR (see Witten/Moffat/Bell and Baeza-Yates/Ribeiro-Neto for intro & pointers)
• many different ranking functions
• additional factors in ranking (mainly for web): - higher weight if word in title, in large font, in bold face - search engines: higher score if word in URL, in anchortext - distance between terms in text (near, or far away?) - user feedback or browsing behavior? - hyperlink structure
• execution: “compute score of all documents containing at least one query term, by scanning the inverted lists”
Vector-Space Model
(d) Mathematical Techniques

• given a topic hierarchy, assign pages automatically to topics• learning-based approaches• document generation models• naïve Bayes, Support Vector Machines (SVM), many more …
Text classification: everything
sports politics healthbusiness
baseball
hockey
soccer
….
foreign
domestic
....
....
....
....
....
(d) Mathematical Techniques

• document generation model: e.g., baseball vs. football - a person decides to creates a web page
- with probability 0.2 creates a page about football, with probability 0.8 creates a page about baseball
- now fills the page with words according to some probability distribution that depends on the chosen topic
- say, if topic is baseball, word “pitcher” more probably likely to occur
- now under this model, given a page, what is the likelihood that this page was intended to be about baseball?
• compare to testing for rare disease: - only one out of a million people has the disease - but one out of 10000 tests results in a false positive - given a person that tests positive, what is the likelihood of him being sick? - in this example, a person that tests positive is most likely healthy
Naïve Bayes:
(d) Mathematical Techniques

• Pr[a & b] = Pr[a | b] * Pr[b] = Pr[b | a] * Pr[a]
Pr[a | b] = Pr[b | a] * Pr[a] / Pr[b]
• let b be the event that we get a particular page p• let a be the event that the page is about baseball
• so given page p, we would like to know Pr[a | b]
• to do this, we need to know Pr[b | a], Pr[a], and Pr[b]
• suppose we are given 1000 labeled pages, that is, presentative pages that have been marked as football or baseball (by a human expert)
• estimate Pr[a] by counting number of football and baseball pages
• estimate Pr[b | a] and Pr[b] by estimating topic-dependent word distributions: if 1.2% of all words in baseball pages are “pitcher” then assume word pitcher is generated with probability 0.012 in each step
Naïve Bayes: (cont.)
(d) Mathematical Techniques
Pr[