web intelligence contents basic web technology, html, cgi, http xml-based standards xslt, xpath web...
Post on 18-Dec-2015
216 views
TRANSCRIPT

WEB Intelligence
Contents
• Basic Web technology, HTML, CGI, HTTP• XML-based standards XSLT, XPATH• Web services, SOAP• Computational Intelligence (as for instance
Neural Networks)• Web Crawlers and focused Web crawlers• XML indexing/retrieval• Ranking

The Origins of the WWW
• WWW was invented by Tim Berners-Lee at CERN (1989)
• Hypertext across the Internet (replacing FTP)• Three constituents: HTML + URL + HTTP
• HTML is an SGML language for hypertext• URL is an notation for locating files on serves• HTTP is a high-level protocol for file transfers

Web Servers
Web Client
BrowserWeb server
HTTP request
Response: HTML code
–Client - Server model
–Stateless

Network Layers
THE NETWORK INTERFACE LAYER
THE INTERNET LAYER
THE TRANSPORT LAYER
THE APPLICATION LAYER
OUR APPLICATIONS
IP
TCP, UDP
HTTP, FTP, SMTP, DNS
Ethernet

HTTP
HTTP request
GET http://www.it.lth.se/
HTTP response
1. Envelope
2. A blank line
3. HTML code

HTTP response exampleHTTP/1.1 200 OK
Date: Fri, 10 Feb 2006 13:50:53 GMT
Server: Apache/1.3.29 (Debian GNU/Linux) PHP/4.3.3
Content-Length: 170
Content-Type: text/html
Last-Modified: Fri, 10 Feb 2006 13:49:58 GMT
<html>
<head><title>Example HTML file</title></head>
<body>
<h1>Anders Ardö</h1>
He is teacher at Department of Information
Technology.
</body>
</html>
2
1
3

Anatomy of a WebPage
• Head– Title– Meta: <meta name=”keywords” content=”HTML, WebPage”>
– Style sheets
• Body– Formating tags: H1, table, B, P, BR, UL, …– Input forms– Links: <a href="http://www.it.lth.se/">IT</a>
– Styles

Hypertext
• Collections of document connected by hyperlinks• Paul Otlet, philosophical treatise (1934)• Vannevar Bush, hypothetical Memex system
(1945)• Ted Nelson introduced hypertext (1968)• Hypermedia generalizes hypertext beyond text

Markup Languages
• Notation for adding formal structure to text• Charles Goldfarb, the INLINE system (1970)• Standard Generalized Markup Language, SGML
(1986

The Design of HTML
• Simple, purist design principles• HTML describes the logical structure of a
document• Browsers are free to interpret tags differently• HTML is a lightweight file format• Size of file containing just ”Hello World!”:
Postscript 11,274 bytes
PDF 4,915 bytes
MS Word 19,456 bytes
HTML 28 bytes

Simple Formatting (1/2)
<html> <head> <title>Good Advice</title> </head> <body> <h1>Good Advice for Everyday Life</h1> <h2>For UNIX programmers</h2> <b>Never</b> type: <p><tt>rm -rf /*</tt><p> on your computer. <h2>For Nuclear Scientists</h2> <b>Never</b> press the <i>Big <font color="red">Red</font> Button</i>. </body></html>
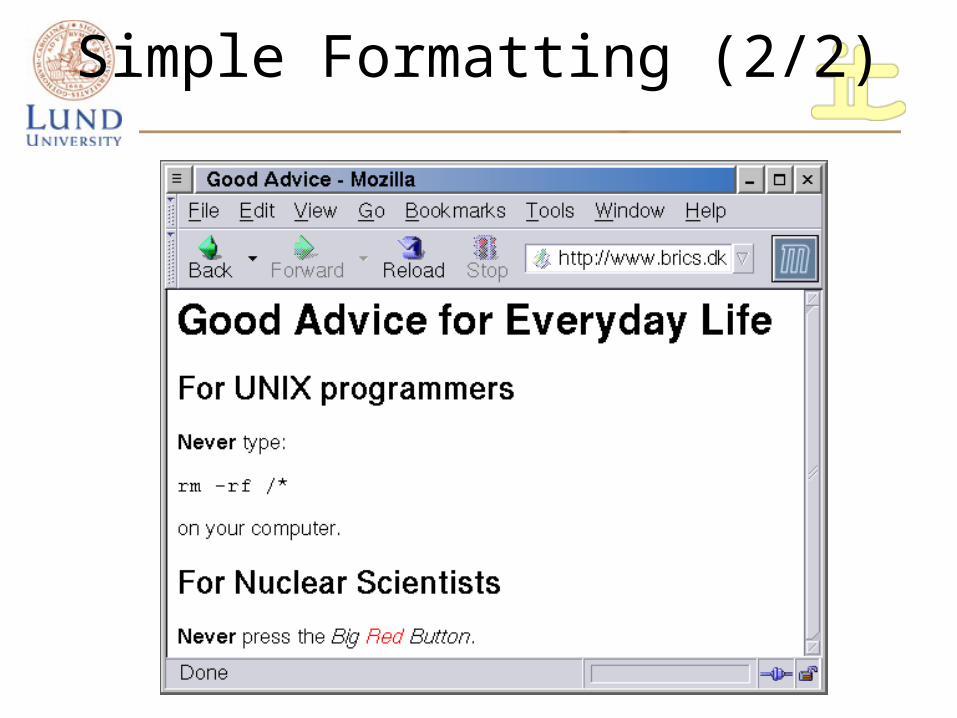
Simple Formatting (2/2)

Hyperlinks: Source Document
<html> <head> <title>Source Document</title> </head> <body> <a href="target.html#danger">Better look here</a>. </body></html>

Hyperlinks: Target Document<html> <head> <title>Target Document</title> </head> <body> ... <a name="danger"></a> <h2>Chapter 17: Dangerous Shell Commands</h2> Never execute a shell command that inadvertently changes all vowels to the character 'x'. </body></html>

HTML Validity
• HTML has a formal syntax specification• 800 lines of DTD notation• A validator gives syntax errors for invalid documents• Most HTML documents on the Web are invalid:
• Valid documents may contain this logo:
www.microsoft.com 123 errors
www.cnn.com 58 errors
www.ibm.com 30 errors
www.google.com 27 errors
www.sun.com 19 errors

Reasons for Invalidity
• Ignorance of the HTML standard• Lack of testing
– ”This page is optimized for the XYZ browser”– ”This page is best viewed in 1024x768”
• Automatic tools generate invalid HTML output• Forgiving browsers try to interpret invalid input
<h2>Lousy HTML</h1><li><a>This is not very</b> good.<li><i>In fact, it is quite bad</em></ul>But the browser does <a naem="goof">something.

Problems with Invalidity
• There are several different browsers• Each browsers has many different
implementations• Each implementation must interpret invalid HTML• There are many arbitrary choices to make
• The HTML standard has been undermined• HTML renders differently for most clients

HTTP requests
• GET: GET /path/to/file/index.html HTTP/1.0
• HEAD: HEAD /path/to/file/index.html HTTP/1.0
• POST: Adds data in the message body
• and others …

GET /search?q=Introduction+to+XML+and+Web+Technologies HTTP/1.1Host: www.google.comUser-Agent: Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.7.2) Gecko/20040803Accept: text/xml,application/xml,application/xhtml+xml, text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5Accept-Language: da,en-us;q=0.8,en;q=0.5,sw;q=0.3Accept-Encoding: gzip,deflateAccept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7Keep-Alive: 300Connection: keep-aliveReferer: http://www.google.com/
Request line (methods: GET, POST, ...)Header linesRequest body (empty here)
HTTP example

HTTP ResponsesHTTP/1.1 200 OK Status lineConnection: closeDate: Thu, 16 Mar 2006 12:39:12 GMTAccept-Ranges: bytesETag: "63062-0-41342c03"Server: Apache/1.3.29 (Debian GNU/Linux) PHP/4.3.3Content-Length: 2820Content-Type: text/htmlLast-Modified: Tue, 31 Aug 2004 07:42:59 GMTClient-Date: Thu, 16 Mar 2006 12:39:12 GMTClient-Peer: 130.235.4.69:80Client-Response-Num: 1
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"><html>...</html>
Response Body
Head
er lin
es

HTTP return codes
• 1xx informational message• 2xx success
200 OK• 3xx redirect
301 Moved permanently• 4xx client error
400 Bad Request
401 Unauthorized
403 Forbidden
404 Not Found• 5xx server error
500 Server error
503 Service Unavailable

Static vs Dynamic Pages
• Static - just copy a file from server to client
• Dynamic - do some data processing
• Parameters - CGI, Forms

Dynamic Web Pages
• Answers to database queries
• Animated Web Pages
• User Dialogs
• Checking user input
May be handled client side (JavaScript, Java applets, Flash, …
Or server side

Dynamic, server side
• CGI – Perl, Python, C, …
• ASP
• PHP
• Java Servlets
• Java Server Pages - JSP
• etc

CGI - Common Gateway Interface
• Webserver gets a request for a page with a special URL (/cgi-bin/…)
• The CGI-script is started as an OS process
• Script read parameters
• Scipt outputs HTML-code
• Script process terminates

CGI problems
• OS processes are expensive
• State between invocations
• Synchronization between processes

Parameters HTML forms
• HTML form<h3>Search Lund University Departments</h3><form action="http://www.lu.se/search.phtml“ method=“get">Which database? <select name=“db"><option value=“LTH">LTH</option><option selected value=“LU">All LU</option><option value=“IT">IT</option></select><br>Please enter your question: <input type="text" name=“query"><br><input type="submit" name="send" value="Go!"></form>

Parameters
• Encoded in the URL: – GET
GET /cgi-bin/search.phtml?db=LU&query=masters+thesis HTTP/1.0
• Encoded in the message body:– POST
POST /cgi-bin/search.phtml HTTP/1.0
Content-Type: application/x-www-form-urlencoded
Content-Length: 26
db=LU&query=masters+thesis

Encoding of Form Data
• Encoding to query string (URL encoding):db=LU&query=masters+thesis&send=Go%21
Name Valuedb LU
query masters thesis
send Go!
• POST: place query string in request body
• GET: place parameter string in request URL http://.../search.phtml?db=LU&query=mast...

Server side scripting
• general-purpose scripting language• suited for Web development• can be embedded into HTML• Have a lot of predefined modules and
interfaces
PHP

PHP example
<html> <head> <title>PHP Test</title> </head> <body> <?php echo "<p>Hello World</p>\n"; ?>
The time is <?php echo date(‘H:I:s’); ?> </body></html>

Uniform Resource Locator
• A Web resource is located by a URL
http://www.w3.org/TR/html4/
• Relative URL
sgml/dtd.html
• Fragment identifier
http://www.w3.org/TR/HTML4/#minitoc
scheme server path

URIs, URNs
• Uniform Resource Identifier (URI)
scheme:scheme-specific-part
Conventions about use of /, #, and ?
• Uniform Resource Name (URN)
urn:isbn:0-471-94128-X

Sessions
• But what if I’d like to implement a
hit counter?
Stateless => problems

Session Management
Techniques
– URL rewriting
– Hidden form fields
– Cookies
– SSL sessions

Cookies
• Extension of HTTP that allows servers to store data on the clients– limited size and number– may be disabled by the client
• Set-Cookie: sessionid=21A9A8089C305319; path=/
• Cookie: sessionid=21A9A8089C305319

Regular expressions
• is a very powerful way of extracting information (pieces of text) from a large document
• Describes a pattern that is matched against the text

Regular expressions
• /Heja/ matches the string 'Heja' • /Heja?/ matches the string 'Hej' and 'Heja' • /^http:/ matches all lines that begin with 'http:' • /\bFred\b/ matches 'Fred' but not 'Fredrick' • /(\d+):(\d+):(\d+)/ matches for example times like
12:30:01 and groups hours into group 1, minutes into group 2, and seconds into group 3.
• /http:\/\/([^\/]+)(\/[^\s]+)\s/ matches URLs and places the server in group 1 and the path in group 2.

Regular expressions
• What is an ISBN number?
• Format?
• /isbn:?\s*([\d-x]+)/i
How match and extract ISBN numbers?