vldb’2007 review denis mindolin. vldb’07 program
TRANSCRIPT

VLDB’2007 review
Denis Mindolin

VLDB’07 program

VLDB’07 program

Outline
Probabilistic Skylines on Uncertain Data,
Jian Pei et al
Lazy Maintenance of Materialized Views,
Jingren Zhou et al

Probabilistic Skylines on Uncertain Data
Based on the VLDB’07 paper of
Jian Pei et al

Skyline. General picture
For a dataset D = {p1,..,pn}, the skyline S is the set of all pi s.t. there is no other pj that dominates pi
pi dominates pj if pi is better than pj in at least one dimension, and
not worse than pj in all other dimensions
Single game results: S = {Eddie, Carl}

Uncertain data
Multiple game results: S=?
Use some aggregate function? Can’t capture distribution! Can be biased by outliers!

Probabilistic dominance relationUncertain data Uncertain object U={u1,..,ul} Uncertain objects are independent Pr(ui) = Pr(uj)
Probabilistic dominance relation Given two uncertain objects
U={u1, …, ul1}, V={v1, …, vl2} The prob. that V dominates U is given by

Probabilistic dominance relation. Example Smaller values of X and Y are better

p-Skyline
Let U={u1,…,ul}. For all u U, probability of u in skyline :=
Probability u not dominated by any other object
Skyline probability of U
p-Skyline

The bottom up skyline algorithm Bounding
Compute upper and lower bounds of skyline prob. for objects
Pruning If the lower bound of Pr(U) is larger than p, then U is in the
skyline. If the upper bound of Pr(U) is smaller than p, U is not in the skyline
Refining If p is between the lower and the upper bounds, then we need
to get tighter bounds of the skyline probabilities by the next iteration of the algorithm

Bounding
umin=(mini=1{ui.D1},…,min{ui.Dl})
umax=(maxi=1{ui.D1},…,max{ui.Dl})
Lemma If ui1 < ui2 then Pr(ui1) ≥ Pr(ui2)
Pr(umin) ≥ Pr(U) ≥ Pr(umax)

Pruning
Rule1. For an uncertain object U and probability threshold p, if Pr(Umin) < p, then U is not in the p-skyline. If Pr(Umax) ≥ p, then U is in the p-skyline.
Rule2. For each instance u U, let Pr+(u) and Pr-(u) be the upper and lower bounds of Pr(u) If , then U is not in the p-skyline If , then U is in the p-skyline
Rule3. Let U and V be two different uncertain objects.
If u U and Vmax < u, then Pr(u) = 0

Pruning
Rule4. Let U and V be two uncertain objects and
U’ U be a subset of instances of U such that
U’max Vmin. If , then Pr(V) < p and thus V is not in the p-skyline
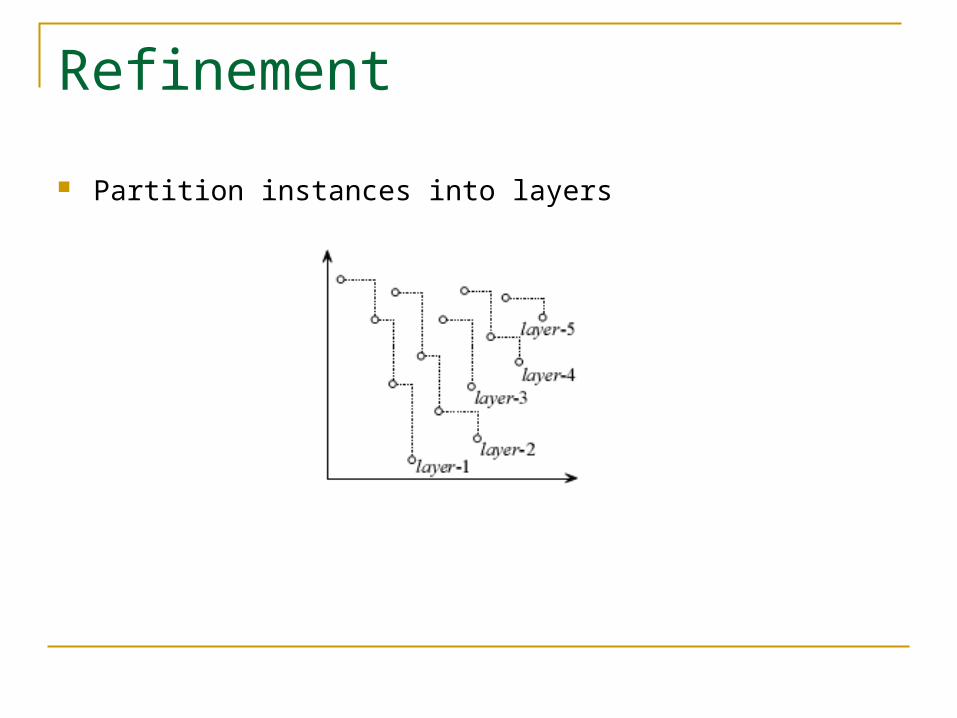
Refinement
Partition instances into layers

Algorithm summary
Complexity: O(Wtotal*R) Wtotal – number of instances whose skyline probabilities
are computed by the algorithm
R – average cost of querying local R-tree of possible dominating objects
Wtotal is much smaller than the total number of instances
Top-down algorithm: see the paper

Lazy Maintenance of Materialized Views
Based on the VLDB’07 paper of Jingren Zhou et al

Eager and Deferred Materialized View Maintenance
T1
V
T2
Eager:
User tran: {upd(T1), upd(T2)}
Executed: {upd(T1), upd(T2), recomp(V)}
Deferred:
User tran: {upd(T1), upd(T2)}
Executed: {upd(T1), upd(T2)}
…
User tran: {recomp(V)}
…
User tran: {Q(V)}
Executed: {Q(V)}

Lazy Materialized View Maintenance
T1
V
T2
Lazy:
User tran: {upd(T1), upd(T2)}
Executed: {upd(T1), upd(T2)}
…
Executed: {recomp(V)}
…
User tran: {Q(V)}
Executed: {Q(V)}

System architecture
Based on MS SQL Server 2005

How it works

Delta tables
Table1: {(transIDi, stmtIDi, rowIDi, actioni)}
…
Tablen: {(transIDi, stmtIDi, rowIDi, actioni)}
tranID – transaction id stmtID – statement id rowID – updated row id action = (ins|del) All “update” actions are converted into pairs of del/ins actions

Maintenance and its optimization Maintenance task is created for each view affected by
a transaction Views updated incrementally using Delta tables “Smart” maintenance task scheduler
Maintenance tasks are scheduled as low-priority jobs Maintenance tasks are combined using the Condense
operator Proper times slot is allocated for each task

Delta stream Condense operator Intuition:
Tran: {A:=1,…,A:=2,…,A:=3}=>{…,A:=3} Operator definition
INS/INS condense:
{ins1(rowa), …, insk(rowa)}=>{…, insk(rowa)}
INS/DEL condense:
{ins1(rowa), …, delk(rowa)}=>{…}
DEL/DEL condense:
{del1(rowa), …, delk(rowa)}=>{…, delk(rowa)}

Performance results
Response time is low Query response time is low Maintenance cost eager view update cost Overhead is low