uva cs 4501: machine learning lecture 3: linear regression ... · machine learning lecture 3:...
TRANSCRIPT

UVACS4501:MachineLearning
Lecture3:LinearRegressionBasics
Dr.YanjunQi
UniversityofVirginiaDepartmentofComputerScience
9/13/18
Dr.YanjunQi/UVACS
1

SUPERVISED LEARNING
• Find function to map input space X to output space Y
• Generalisation:learnfuncCon/hypothesisfrompastdatainorderto“explain”,“predict”,“model”or“control”newdataexamples
9/13/18 2
Dr.YanjunQi/
KEY

ADataset
• Data/points/instances/examples/samples/records:[rows]• Features/a0ributes/dimensions/independentvariables/covariates/
predictors/regressors:[columns,exceptthelast]• Target/outcome/response/label/dependentvariable:specialcolumntobe
predicted[lastcolumn]
9/13/18 3
Dr.YanjunQi/
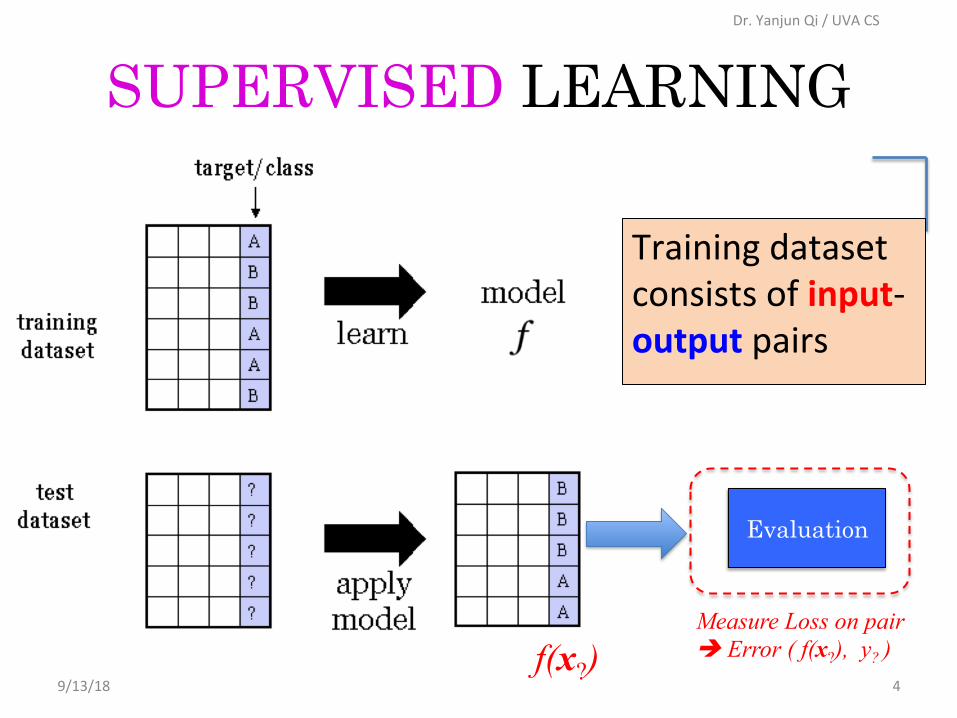
SUPERVISED LEARNING
9/13/18 4f(x?)
Trainingdatasetconsistsofinput-outputpairs
Evaluation
Measure Loss on pair è Error ( f(x?), y? )
Dr.YanjunQi/UVACS

5
Notation
• Inputs – X, Xj (jth element of vector X ) : random variables written
in capital letter – p #inputs, N #observations – X : matrix written in bold capital – Vectors are assumed to be column vectors – Discrete inputs often described by characteristic vector
(dummy variables)
• Outputs – quantitative Y – qualitative C (for categorical)
• Observed variables written in lower case – The i-th observed value of X is xi and can be a scalar or a
vector

Wherearewe?FivemajorsecConsofthiscourse
q Regression(supervised)q ClassificaCon(supervised)q Unsupervisedmodelsq Learningtheoryq Graphicalmodels
9/13/18 6
YanjunQi/UVACS
YisaconCnuous
Yisadiscrete
NOY
Aboutf()
AboutinteracConsamongX1,… Xp

ADatasetforregression
• Data/points/instances/examples/samples/records:[rows]• Features/a0ributes/dimensions/independentvariables/covariates/
predictors/regressors:[columns,exceptthelast]• Target/outcome/response/label/dependentvariable:specialcolumntobe
predicted[lastcolumn]
9/13/18 7
conCnuousvaluedvariable
Dr.YanjunQi/UVACS

SUPERVISED Regression
• When,targetYisaconCnuoustargetvariable
9/13/18 8f(x?)
Dr.YanjunQi/
Trainingdatasetconsistsofinput-outputpairs
10
12
1
5
7

9/13/18 9
Xtrain =
−− x1T −−
−− x2T −−
! ! !−− xn
T −−
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
!ytrain =
y1y2"yn
!
"
#####
$
%
&&&&&
Xtest =
−− xn+1T −−
−− xn+2T −−
! ! !−− xn+m
T −−
"
#
$$$$$
%
&
'''''
!ytest =
yn+1yn+2"yn+m
!
"
#####
$
%
&&&&&
Dr.YanjunQi/UVACS

Multivariate Linear Regression Variations in a Nutshell
Regression: y continuous
Y = Weighted linear sum of X’s
Normal Equation based close form solution
Linear algebra / GD / SGD
Regression coefficients
y = f (x) =θ T x9/13/18 10
Dr.YanjunQi/UVACS
Task: y
Representation: x, f()
Score Function: L()
Search/Optimization : argmin()
Models, Parameters : f(), w, b

Regression(supervised)q Fourwaystotrain/performopCmizaConforlinearregressionmodelsq NormalEquaConq GradientDescent(GD)q StochasCcGDq Newton’smethod
q Supervisedregressionmodels
q Linearregression(LR)q LRwithnon-linearbasisfuncConsq LocallyweightedLRq LRwithRegularizaCons
9/13/18 11
Dr.YanjunQi/UVACS

Today
q Linearregression(akaleastsquares)q LearntoderivetheleastsquaresesCmatebynormalequaCon
9/13/18 12
Dr.YanjunQi/UVACS

Review:f(x)isLinear when X is 1D
• f(x)=wx+b?
b
w
Aslopeof2(i.e.w=2)meansthatevery1-unitchangeinXyieldsa2-unitchangeinY.
9/13/18
Dr.YanjunQi/UVACS
13
y
x

Review:f(x)isLinear when X is 1D
• f(x)=wx+b?
b
w
Aslopeof2(i.e.w=2)meansthatevery1-unitchangeinXyieldsa2-unitchangeinY.
9/13/18
Dr.YanjunQi/UVACS
14
y
x

Oneconcreteexample
9/13/18
Dr.YanjunQi/UVACS
15

Oneconcreteexample
9/13/18
Dr.YanjunQi/UVACS
16

9/13/18
17
rent
LivingareaasX
rent
Livingarea
LocaGon
Dr.YanjunQi/UVACS
(Livingarea,LocaGon)asX
yf(x)=wx+b
y = f (x) =θ0 +θ1x1 +θ2x2

Linear SUPERVISED Regression
e.g. Linear Regression Models
9/13/18 18
y = f (x) =θ0 +θ1x1 +θ2x2=>Featuresx:
e.g.,Livingarea,distancetocampus,#bedroom…=>Targety:
e.g.,RentèConCnuous
Dr.YanjunQi/UVACS

Review:SpecialUsesforMatrixMulGplicaGon
• Dot(orInner)ProductoftwoVectors<x,y>
whichisthesumofproductsofelementsinsimilarposiConsforthetwovectors
9/13/18 19
<x,y>=<y,x>
Dr.YanjunQi/UVACS
Where<x,y>=

20
AnewrepresentaConoff(x)(foreachsingledatasample)
• Assumethateachsamplexisacolumnvector,– Hereweassumeapseudo"feature"x0=1(thisistheinterceptterm),andRE-definethefeaturevectortobe:
– theparametervectorisalsoacolumnvector
9/13/18
Dr.YanjunQi/UVACS
xT=[(x0=1), x1, x2, … ,xp]
θ =
θ0
θ1
!θ p
⎡
⎣
⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥
θ
!!!
y = f (x)= xTθ =θTx

21
TrainingSettoMatrixForm• NowrepresentthewholeTrainingset(withnsamples)asmatrixform:
X =
−− x1T −−
−− x2T −−
! ! !−− xn
T −−
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
=
x1,0 x1,1 … x1,px2,0 x2,1 … x2,p! ! ! !xn ,0 xn ,1 … xn ,p
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
Y =
y1y2!yn
!
"
#####
$
%
&&&&&
9/13/18
Dr.YanjunQi/UVACS

9/13/18
Dr.YanjunQi/UVACS
22
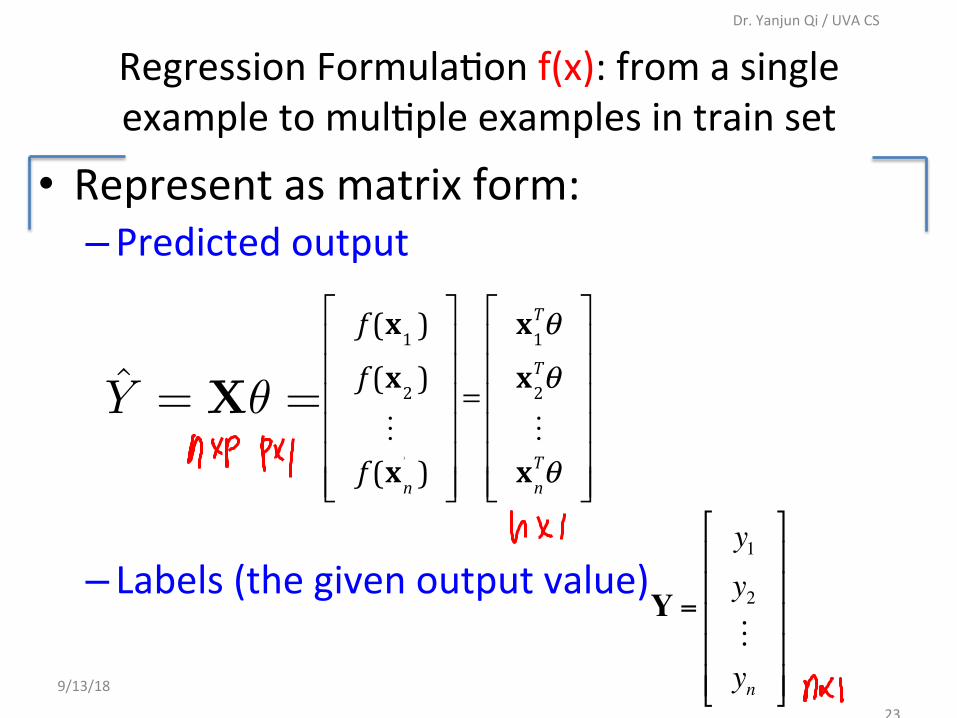
23
• Representasmatrixform:– Predictedoutput
– Labels(thegivenoutputvalue)
9/13/18
Dr.YanjunQi/UVACS
f (x1T )f (x2T )!
f (xnT )
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
=
x1Tθ
x2Tθ
!xnTθ
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
= Xθ = ⌢yY = X✓ =
Y =
y1y2!yn
!
"
#####
$
%
&&&&&
RegressionFormulaConf(x):fromasingleexampletomulCpleexamplesintrainset

NowthelossfuncCon:
• Usingmatrixform,wegetthefollowinggeneralrepresentaConofthelinearregressionfuncCon:
• OurgoalistopicktheopCmalthatminimizethefollowinglost/costfuncCon:
9/13/18
Dr.YanjunQi/UVACS
24
θ
!!!J(θ )= 12 ( f (x i )− yi )2
i=1
n
∑
Y = X✓
SSE:Sumofsquarederror
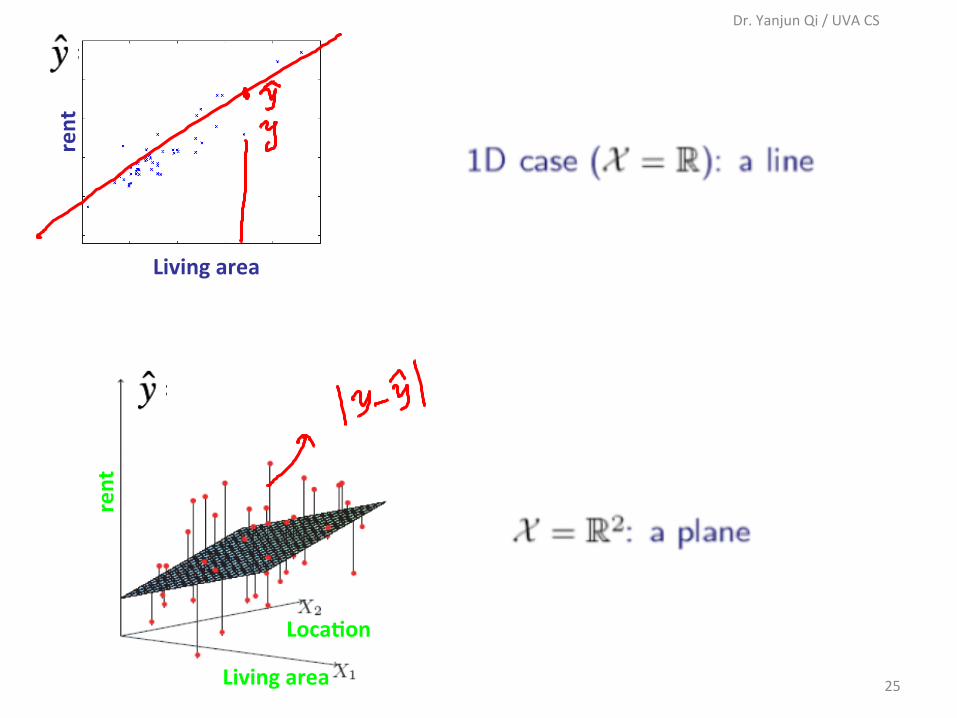
9/13/18
25
rent
Livingarea
rent
Livingarea
LocaGon
Dr.YanjunQi/UVACS

Today
q Linearregression(akaleastsquares)q LearntoderivetheleastsquaresesCmatebyNormalEquaCon
9/13/18 26
Dr.YanjunQi/UVACS

27
MethodI:normalequaConstominimizetheloss
• WritethecostfuncConinmatrixform:
TominimizeJ(θ),takederivaCveandsettozero:
( ) ( )
( )yyXyyXXX
yXyX
yJ
TTTTTT
T
n
ii
Ti
!!!!
!!
+−−=
−−=
−= ∑=
θθθθ
θθ
θθ
212121
1
2)()( x
⇒ XTXθ = XT !yThenormalequaGons
!! θ* = XTX( )−1 XT !y
⇓
9/13/18
Dr.YanjunQi/UVACS
X =
−− x1T −−
−− x2T −−
! ! !−− xn
T −−
"
#
$$$$$
%
&
'''''
!y =
y1y2"yn
⎡
⎣
⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥

Review(I):SpecialUsesforMatrixMulCplicaCon
• SumtheSquaredElementsofaVectorequalsVectordotproducttoitself
⎡ ⎤⎢ ⎥=⎢ ⎥⎣ ⎦
52 8
a
aT = 5 2 8!"
#$
aTa = 5 2 8⎡⎣
⎤⎦
528
⎡
⎣⎢⎢
⎤
⎦⎥⎥ = 52 +22 + 82 = 93
9/13/18 28
Dr.YanjunQi/UVACS
J(θ )= 12 (x iTθ − yi )2i=1
n
∑

Next:seeWhiteBoard
9/13/18
Dr.YanjunQi/UVACS
29
a=
x1Tθ − y1x2Tθ − y2!
xnTθ − yn
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
= Xθ − "y
2 J(θ )= (x iTθ − yi )2i=1
n
∑aTa =

Review(II):gradientoflinearform
9/13/18
Dr.YanjunQi/
30
f (w)=wTa = w1 ,w2 ,w3⎡⎣ ⎤⎦
123
⎛
⎝
⎜⎜⎜
⎞
⎠
⎟⎟⎟=w1 +2w2 +3w3
OneConcreteExample
∂f∂w
= ∂wTa∂w
= a =123
⎛
⎝
⎜⎜⎜
⎞
⎠
⎟⎟⎟
∂(θT XT y)∂θ
= XT y

Review(III):GradientofQuadraCcForm
• SeeL2-note.pdf->Page17,Page23-24• Seewhiteboard
9/13/18
Dr.YanjunQi/UVACS
31
∂(θT XT Xθ )
∂θ= ∂(θTGθ )
∂θ=2Gθ =2XTXθ

-3
-2
-10
1
2
3
4
5
6
-3 -2 -1 1 2 3x
2 3y x= −
2y x′ =
Review(IV):DerivaCveofaQuadraCcFuncCon
9/13/18 32
Dr.YanjunQi/UVACS
ThisconvexfuncConisminimized@theuniquepointwhosederivaCve(slope)iszero.èWhenfindingzerosofthederivaCveofthisfuncCon,wealsofindtheminima(ormaxima)ofthatfuncCon.
y" = 2

Review:SingleVar-FunctoMulCvariate
SingleVar-FuncGon
MulGvariateCalculus
DerivaCveSecond-orderderivaCve
ParCalDerivaCveGradientDirecConalParCalDerivaCveVectorFieldContourmapofafuncConSurfacemapofafuncConHessianmatrixJacobianmatrix(vectorin/vectorout)
9/13/18
Dr.YanjunQi/
33

Review(IV):DefiniConsofgradient(Matrix_calculus/Scalar-by-vector)
9/13/18 34
• Sizeofgradientisalwaysthesameasthesizeofvariable
if
Dr.YanjunQi/
Inprinciple,gradientsareanaturalextensionofparCalderivaCvestofuncConsofmulCplevariables.

Oneconcreteexample
9/13/18
Dr.YanjunQi/UVACS
35

9/13/18 36
Dr.YanjunQi/UVACS

9/13/18 37
Dr.YanjunQi/UVACS
OurlossfuncCon’sHessianisPosiCveSemi-definite
(seenext2ExtrapagesandBack-ExtraPageaboutPSD)

Extra:ConvexfuncCon• IntuiCvely,aconvexfuncCon(1Dcase)hasasinglepointatwhichthederivaCvegoestozero,andthispointisaminimum.
• IntuiCvely,afuncConf(1Dcase)isconvexontherange[a,b]ifafuncCon’ssecondderivaCveisposiCveevery-whereinthatrange.
• IntuiCvely,ifamulCvariatefuncCon'sHessiansispsd(posiCvesemi-definite!),this(mulCvariate)funcConisConvex– IntuiCvely,wecanthink“PosiCvedefinite”matricesasanalogytoposiCvenumbersinmatrixcase
9/13/18
Dr.YanjunQi/UVACS
38
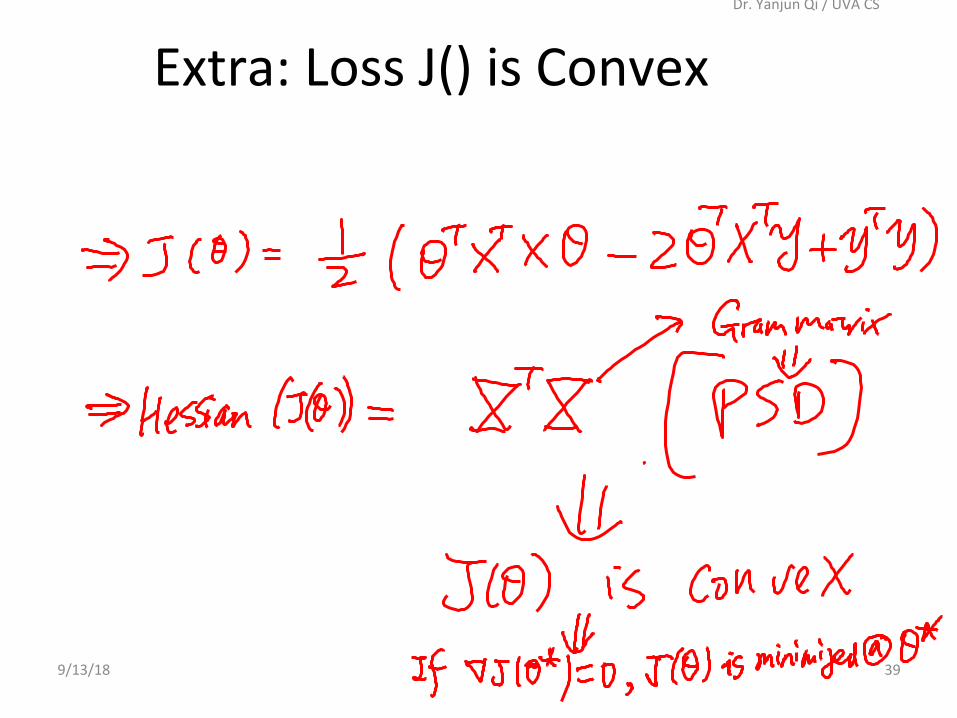
9/13/18
Dr.YanjunQi/UVACS
39
Extra:LossJ()isConvex

9/13/18
Dr.YanjunQi/UVACS
40
θ* = XTX( )−1 XT !y
∇θ J(θ )= XTXθ − XT !y= XT(Xθ − !y)
∇θ J(θ )=0
ClosedformsoluCon

Review(V):Rank of a Matrix
• rank(A) (the rank of a m-by-n matrix A) is = The maximal number of linearly independent columns =The maximal number of linearly independent rows
• If A is n by m, then
– rank(A)<= min(m,n) – If n=rank(A), then A has full row rank – If m=rank(A), then A has full column rank
Rank=? Rank=?
9/13/18 41
Dr.YanjunQi/
IfAisn*n,rank(A)=niffAisinverCble
rank(AB)<=min(rank(A),rank(B))

42
Extra:CommentsonthenormalequaCon
• InmostsituaConsofpracCcalinterest,thenumberofdatapointsnislargerthanthedimensionalitypoftheinputspaceandthematrixXisoffullcolumnrank.IfthiscondiConholds,thenitiseasytoverifythatXTXisnecessarilyinverCble.
• TheassumpConthatXTXisinverCbleimpliesthatitisposiCvedefinite,thusthecriCcalpointwehavefoundisaminimum.
• WhatifXhaslessthanfullcolumnrank?àregularizaCon(later).
9/13/18
Dr.YanjunQi/UVACS

Extra:ComputaConalCost(Naïve..)
9/13/18
Dr.YanjunQi/UVACS
43

44
NaïveMatrixMulCply{implementsC=C+A*B}fori=1tonforj=1ton
fork=1ton C(i,j)=C(i,j)+A(i,k)*B(k,j)
= + * C(i,j) C(i,j) A(i,:)
B(:,j)
Algorithm has 2*n3 = O(n3) Flops and operates on 3*n2 words of memory

9/13/18
Dr.YanjunQi/
45
Extra:Scalabilitytobigdata?

ManyarchitecturedetailsandAlgorithmdetailstoconsider
• DataparallelizaConthroughCPUSIMD/MulCthreading/GPUparallelizaCon/….
• Memoryhierarchical/locality• Be~eralgorithms,likeStrassen’sMatrixMulCplyandmanyothers
9/13/18
Dr.YanjunQi/UVACS
46

BasicLinearAlgebraSubrouCnes(BLAS)ènumpy:awrapperlibraryofBLAS
• Industrystandardinterface(evolving)– www.netlib.org/blas,www.netlib.org/blas/blast--forum
• Vendors,otherssupplyopGmizedimplementaGons• History
– BLAS1(1970s):• vectoroperaGons:dotproduct,saxpy(y=a*x+y),etc• m=2*n,f=2*n,q=f/m=computaGonalintensity~1orless
– BLAS2(mid1980s)• matrix-vectoroperaGons:matrixvectormulGply,etc• m=n^2,f=2*n^2,q~2,lessoverhead• somewhatfasterthanBLAS1
– BLAS3(late1980s)• matrix-matrixoperaGons:matrixmatrixmulGply,etc• m<=3n^2,f=O(n^3),soq=f/mcanpossiblybeaslargeasn,soBLAS3ispotenGallymuch
fasterthanBLAS2
• GoodalgorithmsuseBLAS3whenpossible(LAPACK&ScaLAPACK)– See www.netlib.org/{lapack,scalapack}
source: Stanford Optim EE course

9/13/18
Dr.YanjunQi/UVACS
48
BLASperformanceisverymuchsystemdependent,e.g.,h~ps://www.hoffman2.idre.ucla.edu/blas_benchmark/
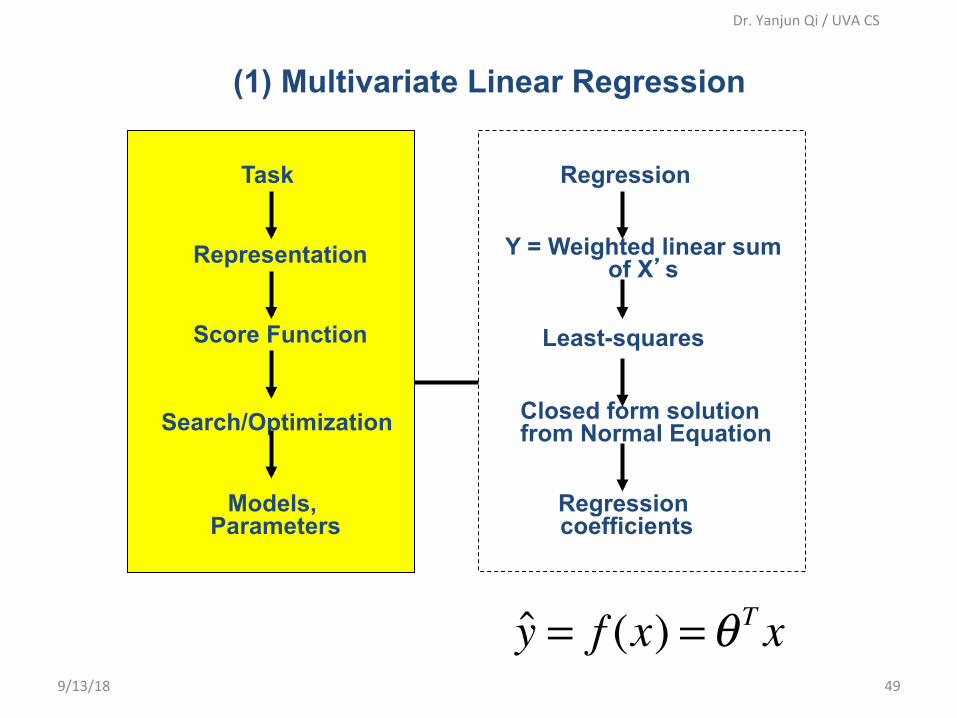
(1) Multivariate Linear Regression
Regression
Y = Weighted linear sum of X’s
Least-squares
Closed form solution from Normal Equation
Regression coefficients
Task
Representation
Score Function
Search/Optimization
Models, Parameters
y = f (x) =θ T x9/13/18 49
Dr.YanjunQi/UVACS

References
• BigthankstoProf.EricXing@CMUforallowingmetoreusesomeofhisslides
q h~p://www.cs.cmu.edu/~zkolter/course/15-884/linalg-review.pdf(pleaseread)
q Prof.AlexanderGray’sslides
9/13/18 50
Dr.YanjunQi/UVACS

EXTRA
9/13/18
Dr.YanjunQi/UVACS
51

NormalEquaConforTrainingLR
9/13/18
Dr.YanjunQi/UVACS
52
⇒ XTXθ = XT !yThenormalequaGons
!! θ* = XTX( )−1 XT !y
⇓

9/13/18 53
Dr.YanjunQi/UVACS
J(θ )= 12 (x iTθ − yi )2i=1
n
∑

9/13/18
Dr.YanjunQi/UVACS
54
èIffindingzerosofthederivaCveofthisfuncCon,wecanalsofindminima(ormaxima)ofthatfuncCon.
AconvexfuncConisminimized@pointwhose
ü derivaCve(slope)iszeroü gradientiszerovector
(mulCvariatecase)

-3
-2
-10
1
2
3
4
5
6
-3 -2 -1 1 2 3x
2 3y x= −
2y x′ =
Review(IV):DerivaCveofaQuadraCcFuncCon
9/13/18 55
Dr.YanjunQi/UVACS
ThisconvexfuncConisminimized@theuniquepointwhosederivaCve(slope)iszero.èIffindingzerosofthederivaCveofthisfuncCon,wecanalsofindminima(ormaxima)ofthatfuncCon.
y" = 2

Extra:ConvexfuncCon• IntuiCvely,aconvexfuncCon(1Dcase)hasasinglepointatwhichthederivaCvegoestozero,andthispointisaminimum.
• IntuiCvely,afuncConf(1Dcase)isconvexontherange[a,b]ifafuncCon’ssecondderivaCveisposiCveevery-whereinthatrange.
• IntuiCvely,ifamulCvariatefuncCon'sHessiansispsd(posiCvesemi-definite!),this(mulCvariate)funcConisConvex– IntuiCvely,wecanthink“PosiCvedefinite”matricesasanalogytoposiCvenumbersinmatrixcase
9/13/18
Dr.YanjunQi/UVACS
56
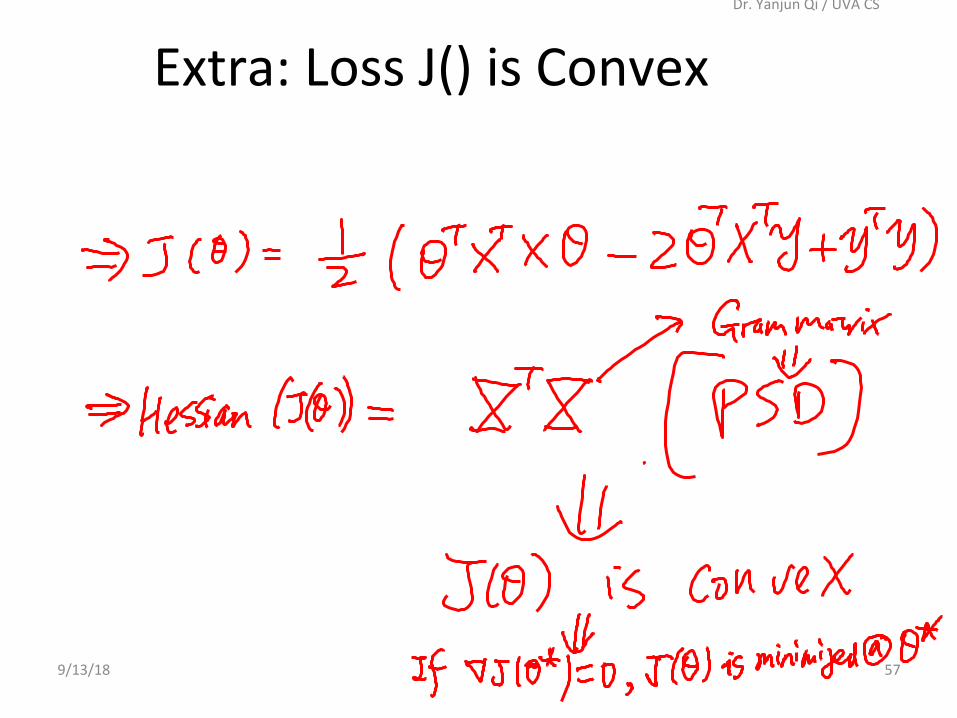
9/13/18
Dr.YanjunQi/UVACS
57
Extra:LossJ()isConvex

Extra:posiCvesemi-definite!
9/13/18
Dr.YanjunQi/UVACS
58
L2-Note:Page17
SeeproofonL2-Note:Page18

Extra:GramMatrixisalwaysposiCvesemi-definite!
9/13/18
Dr.YanjunQi/UVACS
59
G = XTX
aT XT Xa =|Xa|22≥0
Becauseforanyvectora
Besides,whenXisfullrank,GisinverCble
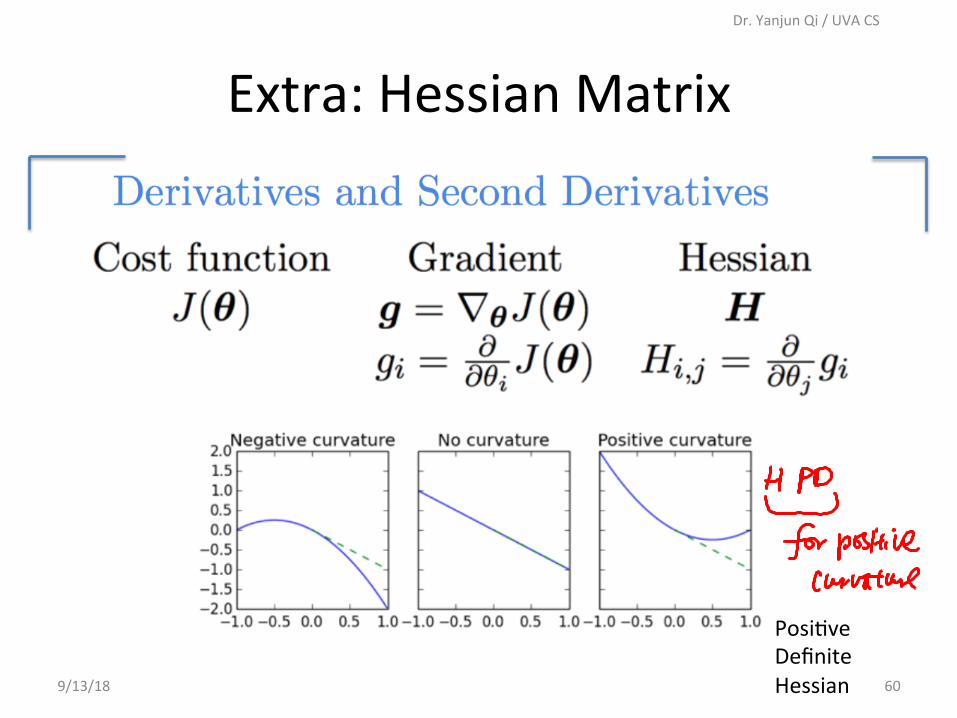
Extra:HessianMatrix
9/13/18
Dr.YanjunQi/UVACS
60
PosiCveDefiniteHessian

Extra:Scalabilitytobigdata?
• TradiConalCSview:PolynomialCmealgorithm,Wow!
• Large-scalelearning:SomeCmesevenO(n)isbad!=>Manystate-of-the-artsoluCons(e.g.,lowrank,sparse,hardware,sampling,randomized…)
9/13/18
Dr.YanjunQi/UVACS
61

9/13/18
Dr.YanjunQi/
62
FromWiki

ManyarchitecturedetailsandAlgorithmdetailstoconsider
• DataparallelizaConthroughCPUSIMD/MulCthreading/GPUparallelizaCon/….
• Memoryhierarchical/locality• Be~eralgorithms,likeStrassen’sMatrixMulCplyandmanyothers
9/13/18
Dr.YanjunQi/UVACS
63
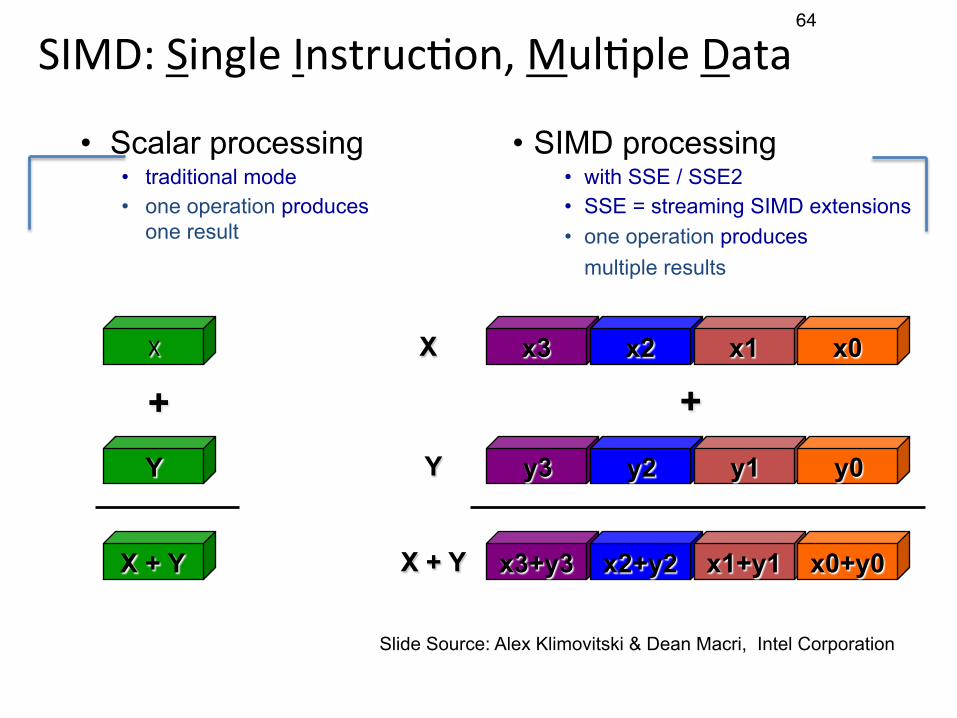
64
SIMD:SingleInstrucCon,MulCpleData
+
• Scalar processing • traditional mode • one operation produces
one result
• SIMD processing • with SSE / SSE2 • SSE = streaming SIMD extensions • one operation produces
multiple results
X
Y
X + Y
+x3 x2 x1 x0
y3 y2 y1 y0
x3+y3 x2+y2 x1+y1 x0+y0
X
Y
X + Y
Slide Source: Alex Klimovitski & Dean Macri, Intel Corporation

65
MemoryHierarchy• Mostprogramshaveahighdegreeoflocalityintheiraccesses
– spaGallocality:accessingthingsnearbypreviousaccesses– temporallocality:reusinganitemthatwaspreviouslyaccessed
• Memoryhierarchytriestoexploitlocalitytoimproveaverage
on-chip cache registers
datapath
control
processor
Second level
cache (SRAM)
Main memory
(DRAM)
Secondary storage (Disk)
Tertiary storage
(Disk/Tape)
Speed 1ns 10ns 100ns 10ms 10sec
Size KB MB GB TB PB
http://www.cs.berkeley.edu/~demmel/cs267_Spr12/

66NoteonMatrixStorage• Amatrixisa2-Darrayofelements,butmemory
addressesare“1-D”• ConvenConsformatrixlayout
– bycolumn,or“columnmajor”(Fortrandefault);A(i,j)atA+i+j*n
– byrow,or“rowmajor”(Cdefault)A(i,j)atA+i*n+j– recursive(later)
• Columnmajor(fornow)
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
0
4
8
12
16
1
5
9
13
17
2
6
10
14
18
3
7
11
15
19
Column major Row major
cachelines Blue row of matrix is stored in red cachelines
Column major matrix in memory
http://www.cs.berkeley.edu/~demmel/cs267_Spr12/

67
NaïveMatrixMulCply{implementsC=C+A*B}fori=1tonforj=1ton
fork=1ton C(i,j)=C(i,j)+A(i,k)*B(k,j)
= + * C(i,j) C(i,j) A(i,:)
B(:,j)
Algorithm has 2*n3 = O(n3) Flops and operates on 3*n2 words of memory
http://www.cs.berkeley.edu/~demmel/cs267_Spr12/

Strassen’sMatrixMulCply• ThetradiConalalgorithm(withorwithoutCling)hasO(n3)flops• StrassendiscoveredanalgorithmwithasymptoCcallylowerflops
– O(n2.81)• Considera2x2matrixmulCply,normallytakes8mulCplies,4adds
– Strassendoesitwith7mulCpliesand18adds
Let M = m11 m12 = a11 a12 b11 b12
m21 m22 = a21 a22 b21 b22
Let p1 = (a12 - a22) * (b21 + b22) p5 = a11 * (b12 - b22)
p2 = (a11 + a22) * (b11 + b22) p6 = a22 * (b21 - b11)
p3 = (a11 - a21) * (b11 + b12) p7 = (a21 + a22) * b11
p4 = (a11 + a12) * b22
Then m11 = p1 + p2 - p4 + p6
m12 = p4 + p5
m21 = p6 + p7
m22 = p2 - p3 + p5 - p7
Extends to nxn by divide&conquer
http://www.cs.berkeley.edu/~demmel/cs267_Spr12/

69
Strassen(conCnued)T(n) = Cost of multiplying nxn matrices = 7*T(n/2) + 18*(n/2)2 = O(n log2 7) = O(n 2.81)
• Asymptotically faster • Several times faster for large n in practice• Cross-over depends on machine• “Tuning Strassen's Matrix Multiplication for Memory Efficiency”,
M. S. Thottethodi, S. Chatterjee, and A. Lebeck, in Proceedings of Supercomputing '98
• Possible to extend communication lower bound to Strassen • #words moved between fast and slow memory
= Ω(nlog2 7 / M(log2 7)/2 – 1 ) ~ Ω(n2.81 / M0.4 ) (Ballard, D., Holtz, Schwartz, 2011)
• Attainable too http://www.cs.berkeley.edu/~demmel/cs267_Spr12/