using depth and appearance features for informed robot ... · using depth and appearance features...
TRANSCRIPT

Using Depth and Appearance Features for
Informed Robot Grasping of Highly Wrinkled
Clothes
Arnau Ramisa
XXXIV Jornadas de Automática
September, 2013

Introduction

Introduction
Grasping:
Detection of 3D objects models

Introduction
Grasping:
Detection of 3D objects models
Rigid objects: pose (6 DoF)

Introduction
Grasping:
Detection of 3D objects models
Rigid objects: pose (6 DoF)Textile objects: pose+deformation

Introduction
Grasping:
Detection of 3D objects models
Rigid objects: pose (6 DoF)Textile objects: pose+deformation
Current approaches use multiple re-grasps
Image credit: J. Maitin-Shepard et al. "Cloth grasp point detection based on multiple-view geometric cues with
application to robotic towel folding", ICRA10

Introduction
Grasping:
Detection of 3D objects models
Rigid objects: pose (6 DoF)Textile objects: pose+deformation
Current approaches use multiple re-grasps
Our contribution: computer vision basedapproach to shorten manipulation timeusing depth and appearance information

Proposed Method - Appearance and depth features
Appearance: Scale Invariant Feature
Transform (SIFT)
Depth: Geodesic Depth Histogram
(GDH). Its original names is Geodesic
Intensity Histogram (GIH)1, but we
apply it to depth data
1: Ling and Jacobs, Deformation Invariant Image Matching, ICCV05

Proposed Method - Bag of visual and depth words

Proposed Method - Bag of visual and depth words
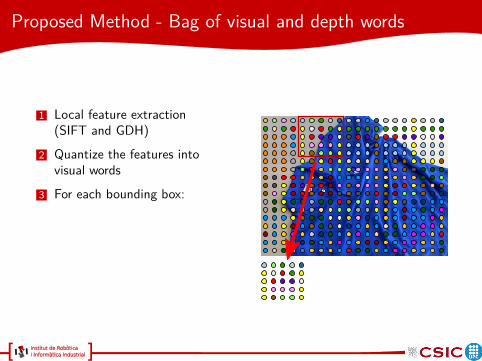
1 Local feature extraction(SIFT and GDH)

Proposed Method - Bag of visual and depth words
1 Local feature extraction(SIFT and GDH)
2 Quantize the features intovisual words

Proposed Method - Bag of visual and depth words
1 Local feature extraction(SIFT and GDH)
2 Quantize the features intovisual words
3 For each bounding box:

Proposed Method - Bag of visual and depth words
1 Local feature extraction(SIFT and GDH)
2 Quantize the features intovisual words
3 For each bounding box:

Proposed Method - Bag of visual and depth words
1 Local feature extraction(SIFT and GDH)
2 Quantize the features intovisual words
3 For each bounding box:

Proposed Method - Bag of visual and depth words
1 Local feature extraction(SIFT and GDH)
2 Quantize the features intovisual words
3 For each bounding box:

Proposed Method - Bag of visual and depth words
1 Local feature extraction(SIFT and GDH)
2 Quantize the features intovisual words
3 For each bounding box:
Proposed Method - Bag of visual and depth words
1 Local feature extraction(SIFT and GDH)
2 Quantize the features intovisual words
3 For each bounding box:

Proposed Method - Bag of visual and depth words
1 Local feature extraction(SIFT and GDH)
2 Quantize the features intovisual words
3 For each bounding box:
4 Accumulate visual wordsin a histogram

Proposed Method - Bag of visual and depth words
1 Local feature extraction(SIFT and GDH)
2 Quantize the features intovisual words
3 For each bounding box:
4 Accumulate visual wordsin a histogram
5 Classify the histogramwith logistic regression

Proposed Method - Bag of visual and depth words
1 Local feature extraction(SIFT and GDH)
2 Quantize the features intovisual words
3 For each bounding box:
4 Accumulate visual wordsin a histogram
5 Classify the histogramwith logistic regression

Proposed Method - Bag of visual and depth words
1 Local feature extraction(SIFT and GDH)
2 Quantize the features intovisual words
3 For each bounding box:
4 Accumulate visual wordsin a histogram
5 Classify the histogramwith logistic regression

Proposed Method - Bag of visual and depth words
1 Local feature extraction(SIFT and GDH)
2 Quantize the features intovisual words
3 For each bounding box:
4 Accumulate visual wordsin a histogram
5 Classify the histogramwith logistic regression
Proposed Method - Bag of visual and depth words
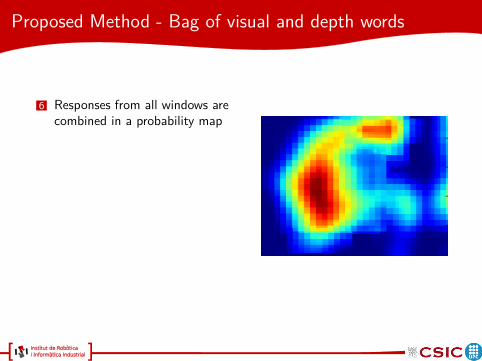
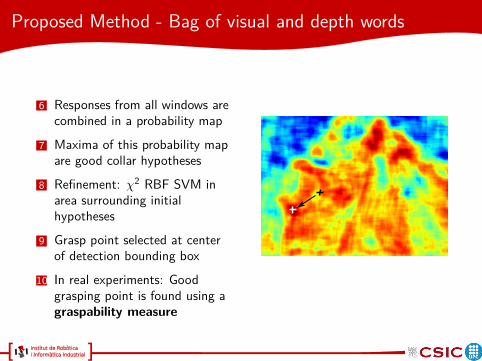
6 Responses from all windows arecombined in a probability map

Proposed Method - Bag of visual and depth words
6 Responses from all windows arecombined in a probability map
7 Maxima of this probability mapare good collar hypotheses

Proposed Method - Bag of visual and depth words
6 Responses from all windows arecombined in a probability map
7 Maxima of this probability mapare good collar hypotheses
8 Refinement: χ2 RBF SVM inarea surrounding initialhypotheses

Proposed Method - Bag of visual and depth words
6 Responses from all windows arecombined in a probability map
7 Maxima of this probability mapare good collar hypotheses
8 Refinement: χ2 RBF SVM inarea surrounding initialhypotheses

Proposed Method - Bag of visual and depth words
6 Responses from all windows arecombined in a probability map
7 Maxima of this probability mapare good collar hypotheses
8 Refinement: χ2 RBF SVM inarea surrounding initialhypotheses
9 Grasp point selected at centerof detection bounding box
Proposed Method - Bag of visual and depth words
6 Responses from all windows arecombined in a probability map
7 Maxima of this probability mapare good collar hypotheses
8 Refinement: χ2 RBF SVM inarea surrounding initialhypotheses
9 Grasp point selected at centerof detection bounding box
10 In real experiments: Goodgrasping point is found using agraspability measure

Evaluation - Polo dataset
Dataset of polos and other clothes
Manually annotated ground truthbounding boxes
Acquired with a Kinect camera
Divided in three subsets
Blue polo: 70% train 30% testOthers: Polos and shirts otherthan the blue poloMixed: Polos mixed with pants,t-shirts, etc.
Evaluation criterion: Collarcorrectly detected if final grasppoint lies inside the ground truthbounding box

Evaluation - Polo dataset
Dataset of polos and other clothes
Manually annotated ground truthbounding boxes
Acquired with a Kinect camera
Divided in three subsets
Blue polo: 70% train 30% testOthers: Polos and shirts otherthan the blue poloMixed: Polos mixed with pants,t-shirts, etc.
Evaluation criterion: Collarcorrectly detected if final grasppoint lies inside the ground truthbounding box

Evaluation - Polo dataset
Dataset of polos and other clothes
Manually annotated ground truthbounding boxes
Acquired with a Kinect camera
Divided in three subsets
Blue polo: 70% train 30% testOthers: Polos and shirts otherthan the blue poloMixed: Polos mixed with pants,t-shirts, etc.
Evaluation criterion: Collarcorrectly detected if final grasppoint lies inside the ground truthbounding box

Evaluation - Polo dataset
Dataset of polos and other clothes
Manually annotated ground truthbounding boxes
Acquired with a Kinect camera
Divided in three subsets
Blue polo: 70% train 30% testOthers: Polos and shirts otherthan the blue poloMixed: Polos mixed with pants,t-shirts, etc.
Evaluation criterion: Collarcorrectly detected if final grasppoint lies inside the ground truthbounding box
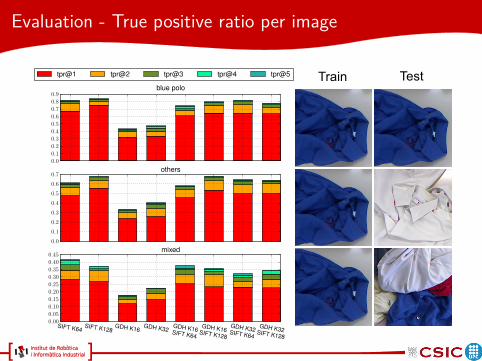
Evaluation - True positive ratio per image
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
blue polo
tpr@1 tpr@2 tpr@3 tpr@4 tpr@5
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7others
SIFT K64SIFT K128
GDH K16GDH K32
GDH K16SIFT K64
GDH K16SIFT K128
GDH K32SIFT K64
GDH K32SIFT K128
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45mixed
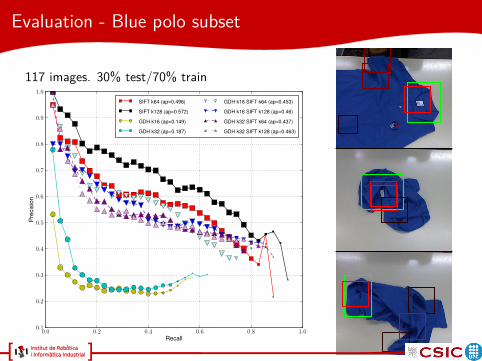
Evaluation - Blue polo subset
117 images. 30% test/70% train
0.0 0.2 0.4 0.6 0.8 1.0
Recall
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Pre
cis
ion
SIFT k64 (ap=0.496)
SIFT k128 (ap=0.572)
GDH k16 (ap=0.149)
GDH k32 (ap=0.187)
GDH k16 SIFT k64 (ap=0.453)
GDH k16 SIFT k128 (ap=0.46)
GDH k32 SIFT k64 (ap=0.437)
GDH k32 SIFT k128 (ap=0.463)
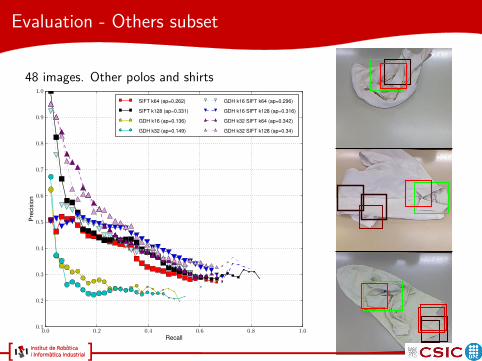
Evaluation - Others subset
48 images. Other polos and shirts
0.0 0.2 0.4 0.6 0.8 1.0
Recall
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Pre
cis
ion
SIFT k64 (ap=0.262)
SIFT k128 (ap=0.331)
GDH k16 (ap=0.136)
GDH k32 (ap=0.149)
GDH k16 SIFT k64 (ap=0.296)
GDH k16 SIFT k128 (ap=0.316)
GDH k32 SIFT k64 (ap=0.342)
GDH k32 SIFT k128 (ap=0.34)
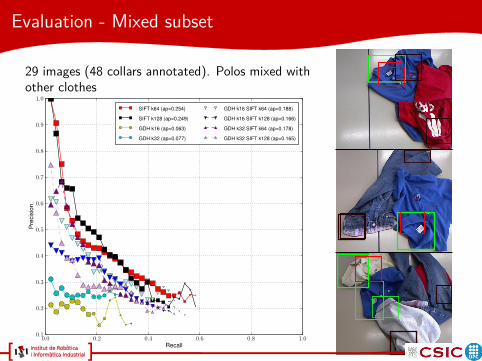
Evaluation - Mixed subset
29 images (48 collars annotated). Polos mixed withother clothes
0.0 0.2 0.4 0.6 0.8 1.0
Recall
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Pre
cis
ion
SIFT k64 (ap=0.254)
SIFT k128 (ap=0.249)
GDH k16 (ap=0.063)
GDH k32 (ap=0.077)
GDH k16 SIFT k64 (ap=0.188)
GDH k16 SIFT k128 (ap=0.166)
GDH k32 SIFT k64 (ap=0.178)
GDH k32 SIFT k128 (ap=0.165)
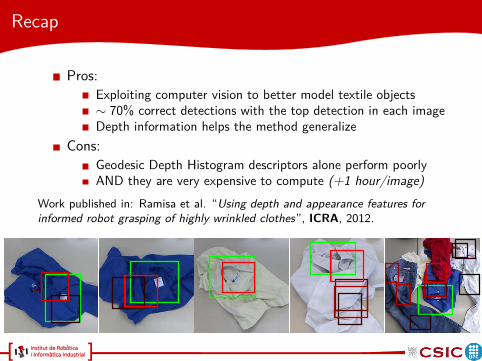
Recap
Pros:
Exploiting computer vision to better model textile objects∼ 70% correct detections with the top detection in each imageDepth information helps the method generalize
Cons:
Geodesic Depth Histogram descriptors alone perform poorlyAND they are very expensive to compute (+1 hour/image)
Work published in: Ramisa et al. “Using depth and appearance features for
informed robot grasping of highly wrinkled clothes”, ICRA, 2012.

The FINDDD descriptor
Most current 3D descriptors are expensive to compute

The FINDDD descriptor
Most current 3D descriptors are expensive to compute
Searching neighbors in an unstructured point cloud

The FINDDD descriptor
Most current 3D descriptors are expensive to compute
Searching neighbors in an unstructured point cloudComputing an invariant reference frame

The FINDDD descriptor
Most current 3D descriptors are expensive to compute
Searching neighbors in an unstructured point cloudComputing an invariant reference frame
In a garment manipulation scenario things can be simplified

The FINDDD descriptor
Most current 3D descriptors are expensive to compute
Searching neighbors in an unstructured point cloudComputing an invariant reference frame
In a garment manipulation scenario things can be simplified
Actions are intrinsically coupled to viewpoint

The FINDDD descriptor
Most current 3D descriptors are expensive to compute
Searching neighbors in an unstructured point cloudComputing an invariant reference frame
In a garment manipulation scenario things can be simplified
Actions are intrinsically coupled to viewpointUsing a range image (aka structured point cloud) allows usingIntegral Images

The FINDDD descriptor
Most current 3D descriptors are expensive to compute
Searching neighbors in an unstructured point cloudComputing an invariant reference frame
In a garment manipulation scenario things can be simplified
Actions are intrinsically coupled to viewpointUsing a range image (aka structured point cloud) allows usingIntegral Images
We propose new depth descriptor that takes advantage of thesesimplifications to be two orders of magnitude faster

The FINDDD descriptor

The FINDDD descriptor
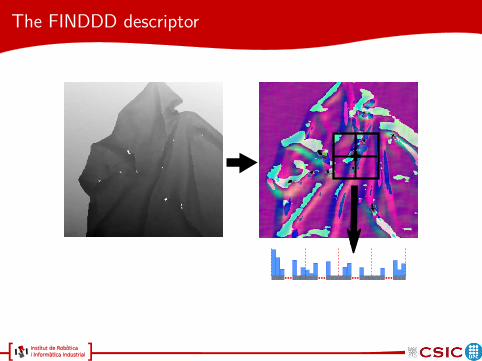
The FINDDD descriptor

The FINDDD descriptor
Best representation of the normals to define bin boundaries?

The FINDDD descriptor
Best representation of the normals to define bin boundaries?
Spherical coordinates: bins defined as intervals in φ and θ
(φ, θ) =(
arccos(z
r
)
, arctan(y
x
))

The FINDDD descriptor
Best representation of the normals to define bin boundaries?Spherical coordinates: bins defined as intervals in φ and θ
(φ, θ) =(
arccos(z
r
)
, arctan(y
x
))

The FINDDD descriptor
Best representation of the normals to define bin boundaries?Spherical coordinates: bins defined as intervals in φ and θ
Cartesian coordinates: quasi-equidistant bins defined bytessellating a half-sphere

The FINDDD descriptor
Best representation of the normals to define bin boundaries?
Spherical coordinates: bins defined as intervals in φ and θ
Cartesian coordinates: quasi-equidistant bins defined bytessellating a half-sphere
Soft voting used to gain robustness to aliasing

The FINDDD descriptor
Best representation of the normals to define bin boundaries?
Spherical coordinates: bins defined as intervals in φ and θ
Cartesian coordinates: quasi-equidistant bins defined bytessellating a half-sphere
Soft voting used to gain robustness to aliasing
Integral Images make cost independent of local region size
20 40 60 80 100 120patch side size
0
10
20
30
40
50
60
70
80
compu
tatio
n tim
e (sec
)
Integral ImagesNo Integral Images
Σ = A + B − C − D

The FINDDD descriptor: Results
Computational time
Descriptor Time (s) Time per desc. (ms)
FINDDD (B=13) 4.0 0.015FINDDD (B=41) 10.5 0.040SHOT 482.5 1.98FPFH 313.5 1.28
Evaluated on a 3Ghz Linux machine. Result obtained extracting a descriptor for every
point in a 640 × 480 structured point cloud (average of 10 runs).

The FINDDD descriptor: Results
Wrinkle Retrieval
B S SV mAPFINDDD 13 21 T 59.8
13 21 F 52.213 43 T 80.513 43 F 80.613 65 T 85.913 65 F 86.1
41 21 T 61.241 21 F 57.141 43 T 82.241 43 F 77.641 65 T 86.041 65 F 81.8
FPFH 62.0SHOT 50.6
B: Number of binsS: Local area sizeSV: Soft voting
The FINDDD descriptor: Results
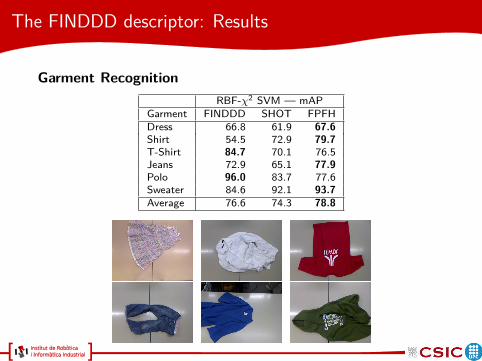
Garment Recognition
RBF-χ2 SVM — mAPGarment FINDDD SHOT FPFHDress 66.8 61.9 67.6
Shirt 54.5 72.9 79.7
T-Shirt 84.7 70.1 76.5Jeans 72.9 65.1 77.9
Polo 96.0 83.7 77.6Sweater 84.6 92.1 93.7
Average 76.6 74.3 78.8
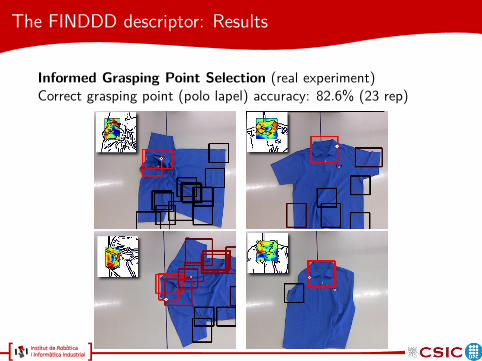
The FINDDD descriptor: Results
Informed Grasping Point Selection (real experiment)Correct grasping point (polo lapel) accuracy: 82.6% (23 rep)

Recap
Pros:Novel shape descriptor for textile manipulationCompetitive performance with competing approachesFast computation time thanks to simplifications
Cons:Reduced invariance to viewpointNot robust to strong depth discontinuities
Work published in: Ramisa et al. “FINDDD: A Fast 3D Descriptor to
Characterize Textiles for Robot Manipulation”, IROS, 2013.

ROBOCUP13
Proposed method used in Robocup@Home’13 by Reem@IRI team

ROBOCUP13
Robocup@Home is a competition for domestic robots(Reem@IRI finished 7 out of 21 teams)
Tasks include person following and interaction, objectrecognition and grasping or emergency situation detection(fire and smoke)
Also an Open Challenge to demonstrate unique abilities of therobot
Reem grasped and hung a polo in a hanger (worth ∼ 42% ofits total score)

ROBOCUP13

Conclusions
Thank You!
Questions?