using computer vision to simulate the motion of virtual agents
TRANSCRIPT

COMPUTER ANIMATION AND VIRTUAL WORLDSComp. Anim. Virtual Worlds 2007; 18: 83–93Published online in Wiley InterScience(www.interscience.wiley.com) DOI: 10.1002/cav.163...........................................................................................Using computer vision to simulate themotion of virtual agents
By Soraia R. Musse*, Claudio R. Jung, Julio C. S. Jacques Jr andAdriana Braun..........................................................................
In this paper, we propose a new model to simulate the movement of virtual humans basedon trajectories captured automatically from filmed video sequences. These trajectories aregrouped into similar classes using an unsupervised clustering algorithm, and anextrapolated velocity field is generated for each class. A physically-based simulator is thenused to animate virtual humans, aiming to reproduce the trajectories fed to the algorithmand at the same time avoiding collisions with other agents. The proposed approach providesan automatic way to reproduce the motion of real people in a virtual environment, allowingthe user to change the number of simulated agents while keeping the same goals observed inthe filmed video. Copyright © 2007 John Wiley & Sons, Ltd.
Received: 19 October 2006; Revised: 18 January 2007; Accepted: 19 January 2007
KEY WORDS: crowd simulation; panic situations; computer vision
Introduction
The behavior of virtual humans has been investigatedby several research groups, with a variety of purposes.For instance, virtual human modeling can be used inentertainment areas, to simulate convincingly the motionof several virtual agents (e.g., movies and games); topopulate immersive virtual environments aiming toimprove the sense of presence (e.g., collaborative virtualenvironments); and to supply simulation of virtualhuman motion for the evaluation of constrained andcomplex environments (e.g., to simulate the flow ofpeople leaving a football stadium after a match). Also,crowd models can play an important role in order todetermine the level of comfort and security of people inlarge public spaces, as in architecture, urban planning,and emergency management.
Several challenges are involved in strategies forsimulating the motion of virtual humans. In some works,the behavior of virtual humans is in some way pre-programed, usually related to constraints of the virtualenvironment. In general, such techniques illustrate avirtual world ‘artificially populated’ by people that seemto behave in a random way. In other works, the user
*Correspondence to: S. R. Musse, Graduate Program onComputer Science, PUCRS, 90619-900, Porto Alegre, RS, Brazil.E-mail: [email protected]
can observe real life data to calibrate the simulation, andempirically reproduce main directions, attraction points,etc. Such methods may produce realistic simulationresults, but demand a considerable amount of userinteraction. Yet another class of techniques is focusedon the simulation of a large number of virtual agents.However, most of the approaches for crowd simulationare focused on panic situations, and it is still a challengeto develop simulation methods that mimic accuratelyreal life situations (concerning virtual human motion andbehavior for non-panic situations).
This paper presents a new approach for simulatingthe motion of virtual agents based on examples, usinginput information captured from real life. As it will beexplained later, our system uses the trajectories of trackedpeople in filmed video sequences to simulate virtualhumans in normal life (meaning typically observedsituations), being able to extrapolate the number ofsimulated people while keeping motion characteristicsof real filmed people. For instance, if a video sequencecontains only 10 people, the proposed model can usethe trajectories of these individuals and extrapolate thenumber of virtual people in a simulated environment(e.g., 1000 people), trying to keep the same motioncharacteristics (such as velocities, spatial occupation,etc.). In fact, video captured data are used as examplesto provide more realistic control of virtual humans, aswell as to provide information for validation, what is
............................................................................................Copyright © 2007 John Wiley & Sons, Ltd.

S. R. MUSSE ET AL............................................................................................
in particular an important challenge in the domain ofsimulated people motion. Since we capture real life data,we are also able to compare the results of our simulationwith filmed sequences in similar conditions.
In summary, the main contribution of this work is tosimulate the motion of virtual humans from examples,which are extracted from real video sequences usingcomputer vision algorithms. The proposed technique isfully automatic, and does not require user intervention. Avery brief overview of this method is shown in Reference[1], focusing on editable trajectories to provide bettercontrol to the animator.
Related Work
Virtual agents and groups have been studied since theearly days of behavioral animation. Reynolds2 simulatedflocks of bird-like entities called boids. He obtainedrealistic animation by using only simple local rules.Tu and Terzopoulos3 created groups of artificial fishesendowed with synthetic vision and perception of theenvironment, which control their behavior. Bouvier,Cohen and Najman4 have studied crowd movementswith adapted particle systems. In their work, the motionof people is modeled with charges and decision fields,which are based on the interactions between electriccharges and electric fields.
Goldenstein et al.5 developed a dynamic non-linearmodel to simulate the movement of a large number ofagents in a virtual environment that can be modifiedin real time. Helbing and collaborators6,7 presenteda model to simulate groups of people in panicsituations. Helbing’s model is physically based, andcrowd movement is determined by attraction andrepulsion forces between simulated people and theenvironment. Braun et al.8 extended this model by addingindividualities to agents and including the concept ofgroups, focusing on panic situations. More recently,Helbing’s team9 presented a paper where they discussedpossible validations of their results based on empiricallyobserved situations.
Musse and Thalmann10 proposed a model withhierarchically structured crowds having different levelsof autonomy. In their model, the behavior is based on aset of rules dealing with the information contained inthe groups of individuals. This work also introducedthe KSI methodology, in which agents and groups arerepresented by their knowledge, status, and intentions.More recently, Ulicny and Thalmann11 proposed a modelfor crowd simulation based on combination of rules and
Finite State Machines for controlling agents’ behaviors ina multi-layer approach.
Metoyer and Hodgins12 proposed a method forgenerating reactive path following based on the user’sexamples of the desired behavior. In their approach, thegross character motion is specified by the user via desiredpaths, while the fine details of the navigation (such asobstacle avoidance and path following) are implementedwith automatic reactive navigation techniques.
Lai et al.13 used a data-driven animation technique,namely Group Motion Graphs, to simulate the move-ment of groups of discrete agents, such as flocks, herds,or small crowds. Pelechano14 proposed an approach thatapplies a combination of psychological and geometricalrules layered on top of a social force model tosimulate large and dense crowds of autonomous agents.Treuille et al.15 presented a real-time crowd modelbased on continuum dynamics. In their model, adynamic potential field simultaneously integrates globalnavigation with moving obstacles.
Some work have also been done to determine thedesired velocities for agents in crowd simulation. Broganand Johnson16 presented an approach based on empiricalobservation of real life situations to describe pathplanning during a suite of experiments. They comparedtheir pedestrian model with the observed path andalso with the A* model, by using metrics like distance,area, and speed of individual trajectories. The modeluses these metrics to compare individual trajectories,but determining similarity patterns between groups ofpeople is a different problem. Other methods presentedtechniques to design velocity fields based on proceduralflow generators to describe the motion of a large numberof entities. Chenney17 presented a model for representingand designing velocity fields through a natural userinterface. Crowdbrush18 was presented by Ulicny et al.,and aims to provide an authoring tool to describe initiallocations, orientations, texture colors, emotions, andpaths for crowds, in real time. Pettre et al.19 introduceda framework for real-time simulation and rendering ofcrowds navigating in a virtual environment. In theirwork, the 3D environment is automatically structuredinto a graph to capture its topology, and then a navigationplanning method is used to produce a variety of paths.
All the techniques described in this Section requiresome kind of stimulus to guide the motion ofvirtual agents. Such stimulus (desired velocity or newposition) can be generated using several differentapproaches, such as local rules,2,10,11,13,14 physicallybased systems,4,6,8,15 and user-based interfaces.12,16–19
Although several of these techniques may be used
............................................................................................Copyright © 2007 John Wiley & Sons, Ltd. 84 Comp. Anim. Virtual Worlds 2007; 18: 83–93
DOI: 10.1002/cav

SIMULATING THE MOTION OF VIRTUAL AGENTS...........................................................................................
to simulate normal life situations, they require theobservation of real life and a manual calibration ofparameters (stimuli), demanding considerable user in-teraction. In this paper, we capture the desired velocitiesautomatically using computer vision algorithms andfeed such information to a virtual human simulator,without any user intervention.
Automatic People TrackingUsing Computer Vision
As it will be discussed in Section ‘The Simulation Model,’our simulation algorithm requires that each agent musthave a desired velocity at each position. In this work, weuse computer vision techniques to track individuals fromexisting video sequences, and generate extrapolatedvelocity fields to feed the simulation algorithm. Thetracking algorithm is briefly explained next, and thegeneration of extrapolated velocity fields is provided inSection ‘Using Tracked Trajectories to Obtain DesiredVelocities.’
Several vision-based techniques for people trackingin video sequences have been proposed in the pastyears,20–24 most of them with surveillance purposes. Inthese applications, an oblique (or almost lateral) viewof the scene is required, so that faces of the individualscan be recognized. However, such camera setups oftenresult in occlusions, and mapping from image pixels toworld coordinates may not be accurate (due to cameraprojection). Since our main goal is to extract trajectoriesfor each individual, we chose a camera setup thatprovides a top-down view (thus, reducing perspectiveproblems and occlusions). In fact, the general plane-to-plane projective mapping is given by:
x = au + bv + c
gu + hv + i, y = du + ev + f
gu + hv + i(1)
where (u, v) are world coordinates, (x, y) are imagecoordinates, and a, b, c, d, e, f, g, h, i are constants. Intop-down view camera setups, it is easy to show thatEquation (1) reduces to:
x = au, y = ev (2)
and the mapping from image to world coordinates istrivial. Furthermore, Equation (2) indicates that personshave the same dimensions at all positions, indicating thatan area thresholding technique may be used for peopledetection.
The first step of the tracking procedure is toapply the background subtraction algorithm describedin Reference [25], which consists of obtaining amathematical model of the scene background (assumingthat the camera is static), and subtracting each frame ofthe video sequence from this model. Extracted pixels aretested for shadow detection, and the remaining pixelsform connected foreground pixels (called blobs).
In the first frame that a new person enters the scene, itis expected only a portion of his/her body to be visible.As the person keeps moving, a larger portion of thebody will be visible, until he/she enters completely inthe viewing area of the camera. Hence, each new blobthat appears is analyzed, and its area is computed intime. If this blob is related to a real person, then itsarea will increase progressively, until it reaches a certainthreshold that represents the minimum area allowed fora valid person (such threshold is determined a priori,based on average person sizes in a specific camerasetup).
Once a person is fully detected in the scene, it mustbe tracked across time. Several tracking algorithms thatrely on lateral or oblique camera setups explore theexpected longitudinal projection of a person to performthe tracking, as in References [20,24,26]. However, suchhypothesis clearly does not apply in this work, requiringa different strategy for people tracking.
In top-down view (or almost top-down view) camerasetups, a person’s head is a relatively invariant feature,indicating that tracking can be performed throughtemplate matching. To find the approximate position ofthe center of the head, the Distance Transform (DT) isapplied to the negative of each foreground blob (i.e.,background pixels are used as the binary image requiredto compute the DT). The global maximum of the DTwithin each foreground blob corresponds to the centerof the largest circle that can be inscribed in the blob, andit provides an estimate of the person’s head center. Thebounding box of such circle is used as the template T to bematched in subsequent frames. Figure 1(a) illustrates ourbackground subtraction and shadow removal algorithm,along with the selection of the initial correlation template(red square).
The next step is to identify template T in the followingframe. Although there are several correlation metricsdesigned for matching a small template within a largerimage, Martin and Crowley’s study27 indicated thatthe Sum of Squared Differences (SSD) provides a morestable result than other correlation metrics in genericapplications, leading us to choose the SSD as thecorrelation metric.
............................................................................................Copyright © 2007 John Wiley & Sons, Ltd. 85 Comp. Anim. Virtual Worlds 2007; 18: 83–93
DOI: 10.1002/cav

S. R. MUSSE ET AL............................................................................................
Figure 1. (a) Initial detection of a person, and determination of the correlation template; (b) Several tracked trajectories (circlesindicate start-points).
Also, it does not make sense to compute the correlationover the entire image, since a person moves with limitedspeed. We use a reduced correlation space, taking intoconsideration the frame rate of the sequence, and themaximum speed allowed for each person. For example,if the acquisition rate is 15 frames per second (FPS) andthe maximum allowed speed is 5 m/s, then the center ofthe template cannot be displaced more that 5 × 1/15 =0.33 m in the subsequent frame (for the camera setupshown in Figure 1; 0.33 m correspond to approximately35 pixels). Since the template center must be movedto a foreground pixel, the correlation space is furtherreduced by removing all background pixels. The SSDbetween the template T and the correlation space is thencomputed, and the center of the template is moved tothe point related to the global minimum of the SSD. Suchcorrelation procedure is repeated for all the subsequentframes, until the person disappears from the cameraview.
Although the head is a good choice for the correlationtemplate, head tilts and illumination changes may varythe graylevels within the template. Also, the procedurefor selecting the initial template may not detect exactlythe center of the head. To cope with such situations, T isupdated every Nf frames (we used Nf = 5 for sequencesacquired at 15 FPS). An example of several trajectoriestracked using the proposed automatic procedure isillustrated in Figure 1(b).
As a result of our tracking procedure, we candetermine the trajectory (hence, the velocity) of eachperson captured by the camera. Extracted trajectoriescan be used directly in some simulators,12,16 but othersimulators require a vector field that provides the desired
velocity for each person at each point of the image.6–8,17
In the next Section, we describe our implementation ofa virtual human simulator that requires the full velocityfield, along with a method for obtaining such velocityfield from a (probably sparse) set of tracked trajectories.
The Simulation Model
One advantage of simulation models based on Physicsis the possibility of easily including attraction andrepulsion forces, that can be used for collisionavoidance. One of the physically based models widelyreferred in the literature was proposed by Helbinget al.,7 who developed a model based on Physicsand Sociopsychological forces in order to describethe behavior of human crowds in panic situations.Such model is in fact a particle system where eachparticle i of mass mi has a predefined velocity vg
i
(goal velocity, typically pointing toward exits of thevirtual environment) to which it tends to adapt itsinstantaneous velocity vi within a certain time intervalτi. Simultaneously, each particle i tries to keep a velocity-dependent distance from other entities j and walls w,controlled by interaction forces fij and fiw, respectively.The change of velocity in time t for each particle i is givenby the following dynamical equation:
mi
dvi
dt= mi
vg
i − vi(t)τi
+∑
j �=i
fij +∑
w
fiw (3)
Although Helbing’s equation has been exhaustivelyused to simulate panic situations, its usage for ‘normal
............................................................................................Copyright © 2007 John Wiley & Sons, Ltd. 86 Comp. Anim. Virtual Worlds 2007; 18: 83–93
DOI: 10.1002/cav

SIMULATING THE MOTION OF VIRTUAL AGENTS...........................................................................................
life’ behaviors is unknown to us, since it is not trivialto obtain the goal velocities vg
i . Next, we describe analgorithm to obtain such velocities from trajectoriesextracted in video sequences. We also emphasize that wechose Helbing’s model in this work because it would bea very easy shift from normal life to panic situations,which is also an important research topic. For panicsituations, the only required change would be to replacev
g
i with velocity vectors pointing to pre-defined escapeareas, which could be implemented dynamically in thesimulation. However, any other crowd simulator can beused since it can adopt the velocity field generated in thiswork, as will be presented next.
Using Tracked Trajectories toObtain Desired Velocities
A fundamental problem for animating or simulatingvirtual humans during normal life is how to obtaindesired velocities vg
i (intentions) for each agent i, inorder to mimic virtual situations observed in reallife. In fact, a few approaches have been proposedin the past years, as discussed in the related work.However, these techniques are somewhat empirical,and require considerable interactivity. In this work,we use trajectories of tracked people in filmed videosequences as examples to feed our simulator in normallife situations, so that virtual agents tend to mimic thebehavior of tracked people.
It is important to notice that our goal is to extractthe actual intention of each tracked person. In densercrowds, the movement of each person includes notonly their desired paths, but also a great amount ofinteractions with the environment and other people (inthe sense of collision avoidance), as noticed in Reference[28]. Consequently, the focus of this work is to usereal life scenarios where people intentions can be bettercaptured (i.e., non-dense crowds). Furthermore, we canincrease the number of simulated people and include, inthe simulation model, the expected interactions amongpeople in the dense crowd using Equation (3). On theother hand, if we have a footage of a dense crowd (whichcontains the inherent interactions among people), it is noteasy to simulate the same scenario with a smaller numberof agents without ‘undoing’ the registered interactions.
Once we have the individual trajectories, thenext step is to generate a velocity field that canprovide the desired velocity for virtual agents ateach position. There are different approaches to obtaindense vector fields from sparse ones, varying from
traditional interpolation/extrapolation techniques, suchas nearest neighbor, linear, cubic, and splines29 tomore sophisticated methods, such as gradient vectorfields.30 In most of our experiments, there were notracked trajectories at image borders, indicating thatextrapolation techniques should be used. In fact,interpolation by nearest neighbor can be easily extendedfor extrapolation, and does not propagate the error inthe extrapolated regions as much as other interpolationtechniques (such as linear or cubic), because it is basicallya piecewise-constant function.
In several scenarios, there are people walking inopposite directions (for instance, there are also somepeople moving downwards in the pathway illustratedin Figure 1). A single velocity field generated from allthe tracked trajectories would clearly lead to incoherentresults, since the same pixel may present two velocityvectors pointing to opposite directions. Furthermore,the velocity field would probably contain severaladjacent vectors with opposite directions, which wouldproduce unrealistic oscillating trajectories. To solve suchproblems, we generate different ‘layers’ of velocityfields, where each layer is produced using only coherenttrajectories.
The definition of coherent (or similar) trajectoriesis very application-dependent. For instance, Junejoet al.31 used envelope boundaries, velocity, and curvatureinformation as features to group similar trajectories.Makris and Ellis32 also used envelope boundaries todetermine main routes from filmed video sequences.In both approaches, the spatial distance betweentrajectories is an important feature in the clusteringprocedure. For our purposes, coherent trajectories arethose having approximately the same displacementvector (e.g., two trajectories going from left to rightare coherent, regardless of their mean speed and thedistance between them). For automatic classification andgrouping of coherent trajectories, we first extract relevantfeatures and then apply an unsupervised clusteringtechnique, as explained next.
Let (x(s), y(s)), s ∈ [0, 1], denote a trajectoryreparametrized by arclength (normalized to unity),so that (x(0), y(0)) is the start point and (x(1), y(1))is the end point of the trajectory. Each trajectory isthen characterized by a set of N displacement vectorsdi = (�xi, �yi) computed at equidistant arclengths:
di = (x(ti+1) − x(ti), y(ti+1) − y(ti)) (4)
where ti = i/N, for i = 0, . . . , N − 1. Then, each trajectoryj is represented by a 2N-dimensional feature vector
............................................................................................Copyright © 2007 John Wiley & Sons, Ltd. 87 Comp. Anim. Virtual Worlds 2007; 18: 83–93
DOI: 10.1002/cav

S. R. MUSSE ET AL............................................................................................
Figure 2. (a) Result of trajectory clustering applied to Figure 1(b); (b)–(c) Extrapolated velocity fields for the two trajectoryclusters showed in (a).
fj , obtained by combining the N displacement vectorsassociated with the trajectory:
fj = (�x0, �y0, �x1, �y1, . . . , �xN−1, �yN−1) (5)
Coherent trajectories tend to produce similar featurevectors f . Hence, a set of coherent trajectories is expectedto produce a cluster in the 2N-dimensional space,which is modeled as a Gaussian probability distributioncharacterized by its mean vector and covariance matrix.Since each cluster relates to a different Gaussian function,the overall distribution considering all the feature vectorsfj is a mixture of Gaussians. The number of Gaussiansin the mixture (which corresponds to the number ofclusters), as well as the distribution parameters of eachindividual distribution can be obtained automaticallyusing the unsupervised clustering algorithm describedin Reference [33].
The number N of displacement vectors used toassemble fj is chosen based on how structured the flow ofpeople is. For relatively simple trajectories, small valuesof N can capture the essence of the trajectories. On theother hand, more complicated trajectories (with manyturns) are better characterized using larger values ofN. In general, public spaces (such as sidewalks, parks,center towns, among others) tend to present main flowdirections, and N = 1 or N = 2 are usually enough toidentify different clusters. It should be noticed that, as Nincreases, the dimensions of the feature vectors increase,and a larger number of samples are needed for a reliableestimation of the Gaussian distributions. At the sametime, unstructured motion (e.g., football players in amatch, or kids playing), requires a larger value of Nto summarize the desired trajectories, and a very largenumber of samples would be needed for the clusteringalgorithm. Hence, the proposed method is, in general,not suited for unstructured motion.
Figure 2(a) illustrates the clustering procedure appliedto the trajectories illustrated in Figure 1(b). Trajectoriesgoing upwards and downwards were correctly placedinto two different clusters, and were marked in differentcolors (red and green, respectively). The correspondingextrapolated velocity fields are shown in Figure 2(b)and (c).
Finally, the desired velocity vg
i of agent i is obtainedfrom one layer of the extrapolated velocity fields vtracked
at the agent’s current position, and Equation (3) is usedto perform the simulation. It should be noticed that,when a virtual agent ‘is born,’ it is associated with onlyone layer of velocity field. However, it can ‘see’ all theagents in all the layers (and also information aboutthe virtual environment such as walls and obstacles,which are accessible for all the agents in all the layers).Moreover, the radial repulsion force introduced byagents and obstacles in Helbing’s model (see Equation(3)) guarantees collision-free trajectories. Hence, agentstend to follow main directions provided by vtracked, andat the same time they avoid collisions with obstacles andother agents. In fact, that is exactly our claim: for a fewagents, they will follow mainly the extrapolated velocityfields (desired velocities); for denser simulated crowds,agents will have more interactions with other agents andobstacles, so that they probably will not be able to followtheir desired trajectories.
It should be noticed that scenarios where people movewith varying velocities can be successfully simulated byour algorithm. For instance, if a video sequence containspeople walking with a different speed depending onthe terrain (e.g., faster on dry surfaces and sloweron wet/snowy terrains), the velocity fields wouldkeep such characteristic, and simulated agents wouldtry to reproduce approximately the same movements.In particular, the virtual reproduction of such kindof behavior requires a considerable amount of userinteraction in competitive approaches (such as in
............................................................................................Copyright © 2007 John Wiley & Sons, Ltd. 88 Comp. Anim. Virtual Worlds 2007; 18: 83–93
DOI: 10.1002/cav

SIMULATING THE MOTION OF VIRTUAL AGENTS...........................................................................................
Reference [17]), but can be done automatically in theproposed method. Results in the next Section illustratethis kind of behavior.
Results and Discussion
In this Section, we show some results to illustrate thepotential of the proposed model. In particular, we showsome quantitative comparisons between the real filmedsequences and the simulated version using the proposedmodel, and the transition from ‘normal life’ to a panicsituation.
T-intersection Scenario
In this case study, we used a T-shaped region of our cam-pus (T-intersection scenario). This scenario presents somediversity of trajectories, resulting in four trajectory clus-ters (layers), as illustrated with different colors in Figure 3(circles indicate starting points of each trajectory).
This scenario presents particular characteristics thatmake people move with different speeds depending on
Figure 3. Different layers of velocity fields for the T-intersection scenario.
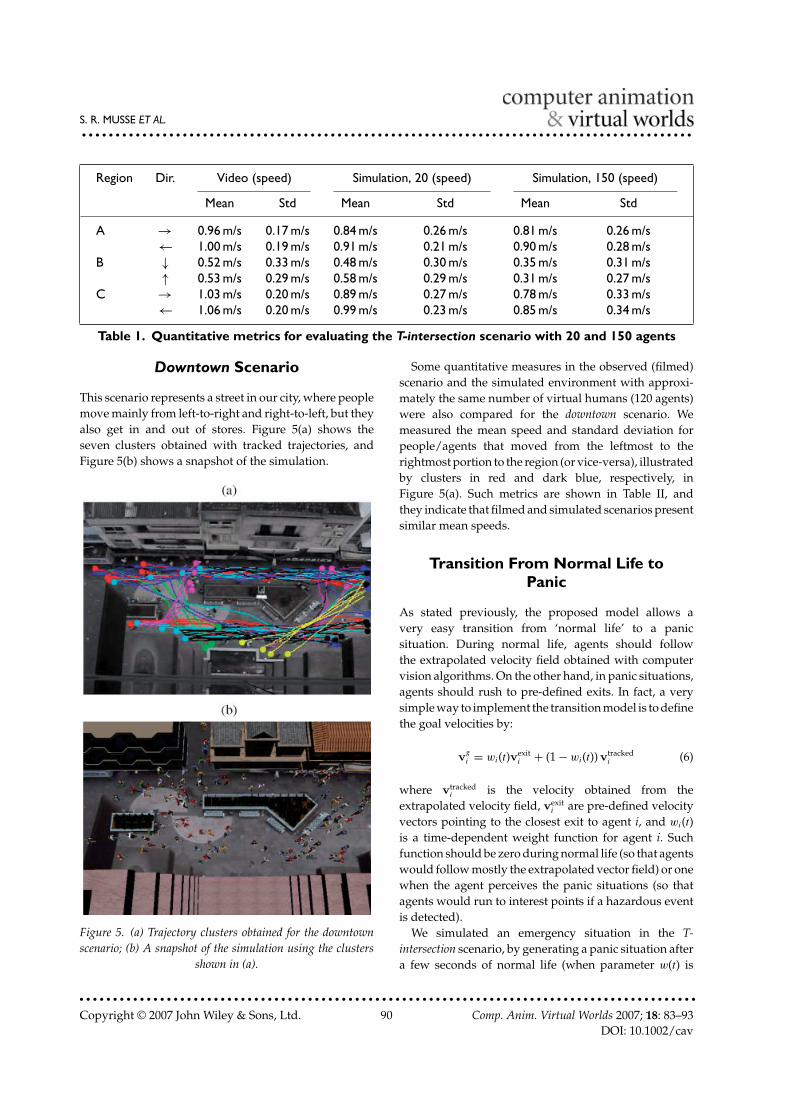
the region they are walking on. In particular, there is a setof stairs (marked as region B in Figure 4(a)) that connectstwo roughly flat plateaus (for camera calibration andsimulation purposes we considered that the whole regionis planar, since the difference of the plane heights is smallif compared to the height of the camera). In fact, Table Iindicates that filmed people clearly slow down whenclimbing up or down the stairs when compared to flatregions (A and C in Figure 4(a)).
We simulated this environment with approximatelythe same number of people as in the filmed videosequence (a snapshot is depicted in Figure 4(b)). Asshown in Table I, the simulated experiment presentedresults similar to the filmed sequence, and virtualhumans also kept the tendency of reducing their speedin the region of the stairs. It should be emphasized thatvelocity fields used in this simulation were obtained in afully automatic way (from people tracking to automaticclustering).
We also analyzed the influence of increasing the num-ber of simulated agents, using the velocity fields obtainedwith a smaller number of people. Such experimentscan be useful to predict the flow of people in publicspaces during special occasions (e.g., a shopping mallnear Christmas). We extrapolated the number of peoplefor the T-intersection scenario from 20 to 150 agents, asillustrated in Figure 4(c). Average speeds in regions A–Cfor this experiment are shown in Table I. As expected,such average speeds were reduced when compared tothe experiment performed with 20 agents, particularly inregion B. In fact, this crowded scenario produces trafficjams, which can be observed more evidently in regionswith spatial constraints, such as the relatively narrowstairway. It is important to observe that all the crowdsin this scenario (filmed, simulated with same number ofagents as filmed sequence and extrapolating number ofagents) present similar characteristics (spatial formation,decreasing velocities as a function of stairs andcorridors).
Figure 4. (a) Regions used for quantitative validation; (b) Snapshot of simulation with a small number of agents; (c) Snapshot ofsimulation with a large number of agents.
............................................................................................Copyright © 2007 John Wiley & Sons, Ltd. 89 Comp. Anim. Virtual Worlds 2007; 18: 83–93
DOI: 10.1002/cav
S. R. MUSSE ET AL............................................................................................
Region Dir. Video (speed) Simulation, 20 (speed) Simulation, 150 (speed)
Mean Std Mean Std Mean Std
A → 0.96 m/s 0.17 m/s 0.84 m/s 0.26 m/s 0.81 m/s 0.26 m/s← 1.00 m/s 0.19 m/s 0.91 m/s 0.21 m/s 0.90 m/s 0.28 m/s
B ↓ 0.52 m/s 0.33 m/s 0.48 m/s 0.30 m/s 0.35 m/s 0.31 m/s↑ 0.53 m/s 0.29 m/s 0.58 m/s 0.29 m/s 0.31 m/s 0.27 m/s
C → 1.03 m/s 0.20 m/s 0.89 m/s 0.27 m/s 0.78 m/s 0.33 m/s← 1.06 m/s 0.20 m/s 0.99 m/s 0.23 m/s 0.85 m/s 0.34 m/s
Table 1. Quantitative metrics for evaluating the T-intersection scenario with 20 and 150 agents
Downtown Scenario
This scenario represents a street in our city, where peoplemove mainly from left-to-right and right-to-left, but theyalso get in and out of stores. Figure 5(a) shows theseven clusters obtained with tracked trajectories, andFigure 5(b) shows a snapshot of the simulation.
Figure 5. (a) Trajectory clusters obtained for the downtownscenario; (b) A snapshot of the simulation using the clusters
shown in (a).
Some quantitative measures in the observed (filmed)scenario and the simulated environment with approxi-mately the same number of virtual humans (120 agents)were also compared for the downtown scenario. Wemeasured the mean speed and standard deviation forpeople/agents that moved from the leftmost to therightmost portion to the region (or vice-versa), illustratedby clusters in red and dark blue, respectively, inFigure 5(a). Such metrics are shown in Table II, andthey indicate that filmed and simulated scenarios presentsimilar mean speeds.
Transition From Normal Life toPanic
As stated previously, the proposed model allows avery easy transition from ‘normal life’ to a panicsituation. During normal life, agents should followthe extrapolated velocity field obtained with computervision algorithms. On the other hand, in panic situations,agents should rush to pre-defined exits. In fact, a verysimple way to implement the transition model is to definethe goal velocities by:
vg
i = wi(t)vexiti + (1 − wi(t))vtracked
i (6)
where vtrackedi is the velocity obtained from the
extrapolated velocity field, vexiti are pre-defined velocity
vectors pointing to the closest exit to agent i, and wi(t)is a time-dependent weight function for agent i. Suchfunction should be zero during normal life (so that agentswould follow mostly the extrapolated vector field) or onewhen the agent perceives the panic situations (so thatagents would run to interest points if a hazardous eventis detected).
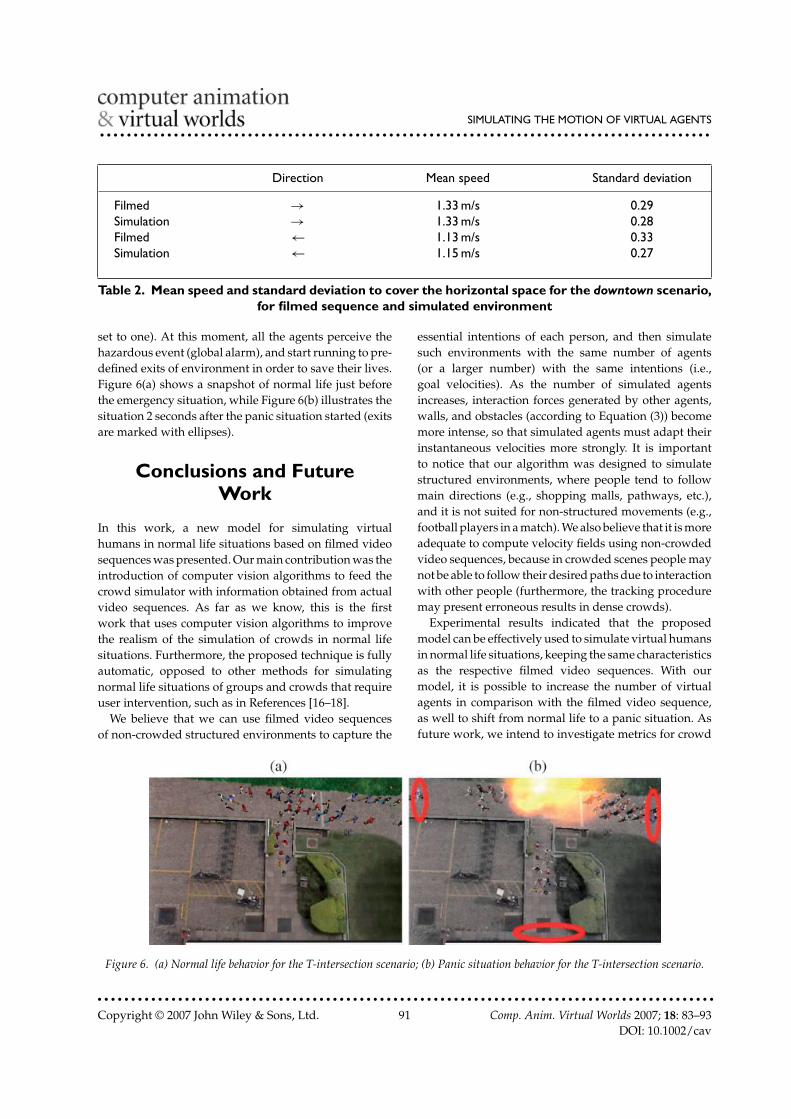
We simulated an emergency situation in the T-intersection scenario, by generating a panic situation aftera few seconds of normal life (when parameter w(t) is
............................................................................................Copyright © 2007 John Wiley & Sons, Ltd. 90 Comp. Anim. Virtual Worlds 2007; 18: 83–93
DOI: 10.1002/cav
SIMULATING THE MOTION OF VIRTUAL AGENTS...........................................................................................
Direction Mean speed Standard deviation
Filmed → 1.33 m/s 0.29Simulation → 1.33 m/s 0.28Filmed ← 1.13 m/s 0.33Simulation ← 1.15 m/s 0.27
Table 2. Mean speed and standard deviation to cover the horizontal space for the downtown scenario,for filmed sequence and simulated environment
set to one). At this moment, all the agents perceive thehazardous event (global alarm), and start running to pre-defined exits of environment in order to save their lives.Figure 6(a) shows a snapshot of normal life just beforethe emergency situation, while Figure 6(b) illustrates thesituation 2 seconds after the panic situation started (exitsare marked with ellipses).
Conclusions and FutureWork
In this work, a new model for simulating virtualhumans in normal life situations based on filmed videosequences was presented. Our main contribution was theintroduction of computer vision algorithms to feed thecrowd simulator with information obtained from actualvideo sequences. As far as we know, this is the firstwork that uses computer vision algorithms to improvethe realism of the simulation of crowds in normal lifesituations. Furthermore, the proposed technique is fullyautomatic, opposed to other methods for simulatingnormal life situations of groups and crowds that requireuser intervention, such as in References [16–18].
We believe that we can use filmed video sequencesof non-crowded structured environments to capture the
essential intentions of each person, and then simulatesuch environments with the same number of agents(or a larger number) with the same intentions (i.e.,goal velocities). As the number of simulated agentsincreases, interaction forces generated by other agents,walls, and obstacles (according to Equation (3)) becomemore intense, so that simulated agents must adapt theirinstantaneous velocities more strongly. It is importantto notice that our algorithm was designed to simulatestructured environments, where people tend to followmain directions (e.g., shopping malls, pathways, etc.),and it is not suited for non-structured movements (e.g.,football players in a match). We also believe that it is moreadequate to compute velocity fields using non-crowdedvideo sequences, because in crowded scenes people maynot be able to follow their desired paths due to interactionwith other people (furthermore, the tracking proceduremay present erroneous results in dense crowds).
Experimental results indicated that the proposedmodel can be effectively used to simulate virtual humansin normal life situations, keeping the same characteristicsas the respective filmed video sequences. With ourmodel, it is possible to increase the number of virtualagents in comparison with the filmed video sequence,as well to shift from normal life to a panic situation. Asfuture work, we intend to investigate metrics for crowd
Figure 6. (a) Normal life behavior for the T-intersection scenario; (b) Panic situation behavior for the T-intersection scenario.
............................................................................................Copyright © 2007 John Wiley & Sons, Ltd. 91 Comp. Anim. Virtual Worlds 2007; 18: 83–93
DOI: 10.1002/cav

S. R. MUSSE ET AL............................................................................................
comparisons, and extend our algorithms to simulateunstructured environments. Also, we intend to testour model by integrating it with other algorithms thathandle interactions among people, like Reynolds2 orGoldenstein5, for instance.
ACKNOWLEDGEMENTS
This work was developed in collaboration with HP Brazil R&D.
References
1. Musse SR, Jung CR, Jacques JCS, Jr, Braun A. Simulatingthe motion of virtual agents based on examples. In Bookletof Posters & Demos of the Eurographics/ACM SIGGRAPHSymposium on Computer Animation, Cani M-P, O’Brien JF(eds). Eurographics: Aire-la-Ville, Switzerland, 2006; 35–36.
2. Reynolds C. Flocks, herds and schools: a distributedbehavioral model. In SIGGRAPH’87. ACM Press: New York,NY, USA, 1987; 25–34.
3. Xiaoyuan Tu, Demetri T. Artificial fishes: physics, locomo-tion, perception, behavior. In SIGGRAPH’94. 1994; 43–50.
4. Bouvier E, Cohen E, Najman L. From crowd simulationsto airbag deployment: particle system, a new paradigm ofsimulation. Journal of Eletronic Imaging 1997; 6(1): 94–107.
5. Goldenstein S, Large E, Metaxas D. Non-linear dynamicalsystem approach to behavior modeling. The Visual Computer1999; 15(7/8): 349–364.
6. Helbing D, Molnar P. Self-organization phenomena inpedestrian crowds. In Self-Organization of Complex Structures:From Individual to Collective Dynamics, Schweitzer F (ed).Gordon and Breach: London, 1997; 569–577.
7. Helbing D, Farkas I, Vicsek T. Simulating dynamical featuresof escape panic. Nature 2000; 407(6803): 487–490.
8. Braun A, Bodmann BEJ, Oliveira LPL, Musse SR. Modellingindividual behavior in crowd simulation. In Proceedings ofComputer Animation and Social Agents 2003, IEEE ComputerSociety: New Brunswick, USA, 2003; pp. 143–148.
9. Werner T, Helbing D. The social force pedestrian modelapplied to real life scenarios. In Pedestrian and EvacuationDynamics, Galea ER (ed). University of Greenwich, UnitedKingdom: Greenwich, UK, 2003; 17–26.
10. Musse SR, Thalmann D. Hierarquical model for real timesimulation of virtual human crowds. IEEE Transactions onVisualization and Computer Graphics 2001; 7(2): 152–164.
11. Ulicny B, Thalmann D. Crowd simulation for interactivevirtual environments and vr training systems. In Proceedingsof Eurographics Workshop on Animation and Simulation’01,Springer-Verlag, 2001; pp. 163–170.
12. Metoyer RA, Hodgins JK. Reactive pedestrian pathfollowing from examples. The Visual Computer 2004; 20(10):635–649.
13. Lai Y, Chenney S, Fan S. Group motion graphs. Proceedingsof the ACM SIGGRAPH/Eurographics Symposium on ComputerAnimation, Los Angeles, California, 2005; pp. 281–290.
14. Pelechano N, Badler N. Modeling realistic high densityautonomous agent crowd movement: social forces, com-
munication, roles and psychological influences. Phd Thesis,University of Pennsylvania, 2006.
15. Treuille A, Cooper S, Popovic Z. Continuum crowds.SIGGRAPH’06: ACM SIGGRAPH 2006 Papers, Boston,Massachusetts, 2006; pp. 1160–1168.
16. Brogan DC, Johnson NL. Realistic human walking paths.In Proceedings of Computer Animation and Social Agents 2003,IEEE Computer Society, 2003; pp. 94–101.
17. Chenney S. Flow tiles. In Symposium on Computer Animation2004, Grenoble FR (ed.). ACM and Eurographics Associa-tion: Aire-la-Ville, Switzerland, Switzerland, 2004; 233–242.
18. Ulicny B, Ciechomski PH, Thalmann D. Crowdbrush: inter-active authoring of real-time crowd scenes. In Symposium onComputer Animation 2004, Grenoble FR (ed.). EurographicsAssociation: Aire-la-Ville, Switzerland, Switzerland, 2004;243, 252.
19. Pettre J, de Heras Ciechomski P, Maım J, Yersin B, LaumondJ, Thalmann D. Real-time navigating crowds: scalablesimulation and rendering: research articles. ComputerAnimation Virtual Worlds 2006; 17(3/4): 445–455.
20. Elgammal AM, Duraiswami R, Harwood D, Davis LS.Background and foreground modeling using nonparametrickernel density estimation for visual surveillance. Proceeed-ings of the IEEE 2002; 90(7): 1151–1163.
21. Cucchiara R, Grana C, Piccardi M, Prati A. Detectingmoving objects, ghosts, and shadows in video streams. IEEETransactions on Pattern Analysis and Machine Intelligence 2003;25(10): 1337–1342.
22. Ning H, Tan T, Wang L, Hu W. People tracking basedon motion model and motion constraints with automaticinitialization. Pattern Recognition 2004; 37(7): 1423–1440.
23. Tian YL, Lu M, Hampapur A. Robust and efficientforeground analysis for real-time video surveillance.IEEE Computer Vision and Pattern Recognition 2005; 1:1182–1187.
24. Cheng FH, Chen YL. Real time multiple objects tracking andidentification based on discrete wavelet transform. PatternRecognition 2006; 39(6): 1126–1139.
25. Jacques JCS Jr, Jung CR, Musse SR. A backgroundsubtraction model adapted to illumination changes. InProceedings of the IEEE International Conference on ImageProcessing, Atlanta, GA, 2006; pp. 1817–1820.
26. Haritaoglu I, Harwood D, Davis LS. W4: real-timesurveillance of people and their activities. IEEE Transactionson Pattern Analysis and Machine Intelligence 2000; 22(8): 809–830.
27. Jerome M, James LC. Comparison of correlation techniques.In Conference on Intelligent Autonomous Systems, Karsluhe,Germany, March 1995.
28. Helbing1 D, Buzna L, Johansson A, Werner T. Self-organizedpedestrian crowd dynamics: experiments, simulations,and design solutions. Transportation Science 2005; 39(1):1–24.
29. Watson DE. Contouring: A Guide to the Analysis and Display ofSpatial Data. Pergamon (Elsevier Science, Inc.): Tarrytown,NY, 1992.
30. Xu CY, Prince JL. Snakes, shapes, and gradient vector flow.IEEE Transactions on Image Processing 1998; 7(3): 359–369.
31. Junejo IN, Javed O, Shah M. Multi feature path modelingfor video surveillance. In International Conference on PatternRecognition, 2004; pp. II: 716–719.
............................................................................................Copyright © 2007 John Wiley & Sons, Ltd. 92 Comp. Anim. Virtual Worlds 2007; 18: 83–93
DOI: 10.1002/cav

SIMULATING THE MOTION OF VIRTUAL AGENTS...........................................................................................
32. Makris D, Ellis T. Learning semantic scene models fromobserving activity in visual surveillance. IEEE Transactionson Systems, Man, and Cybernetics—Part B 2005; 35(3): 397–408.
33. Figueiredo MAT, Jain AK. Unsupervised learning of finitemixture models. IEEE Transactions on Pattern Analysis andMachine Intelligence 2002; 24(3): 381–396.
Authors’ biographies:
Soraia Raupp Musse earned a Ph.D. in ComputerScience from EPFL – Switzerland in 2000 supervised byDaniel Thalmann. Her current research interests includecrowd simulation and virtual humans animation. Sheis currently an Adjunt Professor at PUCRS – GraduateProgram in Computer Science, where she manage someresearch projects with significant budgets, with privatecompanies (e.g. HP Brazil). She has been reviewer ofmany journals such as IEEE TVCG and CG&A, and con-ferences as SIGGRAPH and Eurographics. She is currentlyPC chair of CGI 2007. Soraia is organizing, as requestedby Brazilian Government, the Brazilian Network onVisualization, specifically in the context of Security,where she has applied her efforts in crowds simulation.
Claudio R. Jung received the B.S. and M.S. degreesin Applied Mathematics, and the Ph.D. degree in
Computer Sciences, from Universidade Federal doRio Grande do Sul, Brazil, in 1993, 1995 and 2002,respectively. He is currently an Assistant Professor atUniversidade do Vale do Rio dos Sinos, Brazil. Hiscurrent research interests include image denoising andenhancement, image segmentation, multiscale imageanalysis, intelligent vehicles, object tracking and humanmotion analysis.
Julio C. S. Jacques Junior received the B.S. inComputer Science in 2003, from Universidade Luteranado Brasil, and M.S. in Applied Computer in 2006, fromUniversidade do Vale do Rio dos Sinos (UNISINOS),Brazil. He is currently a researcher at Cromos Laboratoryat UNISINOS. His current research interests includeobject tracking, human motion analysis and crowdsimulations.
Adriana Braun is licensed on Physics and received herM.S. degree on Applied Computing from Universidadedo Rio dos Sinos, Brazil, in 2001 and 2004, respectively.Currently she is an Assistant Professor on Physics andMathematics at Centro Universitário IPA Metodista,Brazil. Her research interests include physically basedanimation and crowd simulation.
............................................................................................Copyright © 2007 John Wiley & Sons, Ltd. 93 Comp. Anim. Virtual Worlds 2007; 18: 83–93
DOI: 10.1002/cav