usage meets link analysis: towards improving intranet and site specific search via usage statistics...
Post on 22-Dec-2015
219 views
TRANSCRIPT

Usage Meets Link Analysis:Towards Improving Intranet and Site Specific Search via Usage Statistics
by Bilgehan Uygar Oztekin
Thesis committee: Vipin Kumar, George Karypis, Jaideep Srivastava, Gediminas Adomavicius
Dept. of Computer Science, University of Minnesota200 Union Street SE, Minneapolis, MN 55455
Final Oral PresentationJuly 20, 2005

Outline
Aim: Improve ranking quality by incorporating usage statistics.Summary of what is and is not addressed in this study.Ranking methods
Existing link analysis approaches: PageRank and HITSUsage based modifications/approaches: UPR, UHITS, and Counts
Infrastructure/modules.Experimental result
Global comparisons/observationsQuery dependent comparisons
Discussions

Ranking in search engines
Given a description of what the user is looking for:
How to select relevant documents?
How to order them?
Typically, a large number of items that match the criteria.
Coverage/recall tend to be relatively high without much effort.
Precision/ordering are the primary concerns.

Quality signals come to aid
Modern search engines use various quality measures.
Some are used to increase recall• Stemming• Synonyms/concept indexing• Query modification (expansion/rewrite).
More effort is spent for better precision/ordering:
• One of the important milestones: Link analysis, in particular, PageRank [Brin98].
• Topic sensitive link analysis 2002.• What is next? Usage statistics?

Why usage?
Most classical link analysis approaches see the world from author’s or site administrator’s point of view.
Algorithms mostly depend on static link structure, and to a small degree, on the page content.
Usage statistics offer additional, valuable information, telling the story from the user’s perspective.If collected properly, it can be used to estimate
The probability that the average user will go to a particular page directly (page visit statistics).The probability that the average user will follow a particular link (link usage statistics).

Question
Can we improve ranking quality by employing usage statistics?
How can we design and test usage based ranking algorithms?
Don’t have the resources, more importantly, the data to test it on a global scale.
We can test it in our own domain, i.e. intranet/site specific search.
• Full usage statistics are available.

Internet vs. intranets
Are intranets similar to the Internet? In some ways, yes.We still have documents and links of similar nature.Smaller scale.
Major differences of particular interest:Intranets tend to have poorer connectivity
• Link analysis algorithms are not as effective as in the case of web search.
Heuristics that work well for link analysis on web search may not be applicable (e.g. site level aggregation approaches, applying link analysis on the site level).Extensive usage statistics for the domain/intranet is available.There is no incentive for spamming the search results within a single organization. Aim is to provide the information as best as possible (mostly cooperation, not competition).
Some of these observations make intranet/site specific search a prime candidate for usage based signals.

Scope of the project: Algorithms
Developed and implemented a number of usage based quality measures:
UPR, Usage Aware PageRank [Oztekin03], a novel PageRank variant incorporating usage statistics.UHITS, usage augmented HITS (Hypertext Induced Topic Search), a generalization of [Miller02].A naïve usage based quality measure, a baseline benchmark.
Developed an improvement to UPR, which makes spamming more difficult/expensive using a modified counting scheme.Implemented two major classical link analysis algorithms:
PageRankHITS

Scope: Infrastructure
Implemented a simple crawler and took a snapshot of *.cs.umn.edu domain (20K core URLs with full usage statistics, 65K total URLs).
Processed 6 months worth of usage logs around the snapshot.
Built static and usage based site-graphs.
Developed a full fledged site specific search engine, USearch, http://usearch.cs.umn.edu/, along with various supporting components to evaluate the algorithms in a real-life search setting.

Scope: Experiments
Studied the effects of adding various degrees of usage information.
Sample the parameter space.Studied the effects of the suggested improvement (modified counting scheme).Compared various methods in terms of
Distinguishing power they offer.The nature of the score distributions they provide.How they are correlated with other methods.How well they perform in a query based setting.
• Designed 3 sets of query based experiments: two experiments based on blind human evaluations. one experiment independent of user judgments.

Items that are not addressed
Test the algorithms on a larger scale Large intranets (e.g. a few million pages).Internet.
Test a few aspects that did not occur in our domain.Spamming.Uneven usage availability.
• Gracefully converges to PageRank, but studying this on larger scale would have been interesting.
Conduct implicit user judgment based evaluations which may offer higher coverage/statistical significance.
Not enough usage base.
Parallel/distributed implementations of UPR or other methods.
Have ideas/suggestions for reasonable implementations.

PageRank [Brin98]
Based on a random walk modelRandom walk user has:
Equal probability to follow each link in a given pageEqual probability to go to each page directly
Under certain conditions, forms a probability distribution.Relatively inexpensive.Stable: In general, changing a subsets of nodes / links does not affect overall scores dramatically.It scales well to the Web.Relatively resistant against spamming.

Usage aware PageRank
PageRank (PR) Usage aware PageRank (UPR)
pi total
link
pi
direct
iW
piWiUPRa
iC
pUPRa
d
pWan
ad
pUPR
)(
)()(
)(
)(1
)(1
1
)(
2
2
11
pi iC
iPRd
nd
pPR
)(
)(
1)1(
)(
d is the damping factor.n is the total number of pages in the dataset.a1 controls the usage emphasis in initial weights of pages.a2 controls the usage emphasis on the links.C(i) is the number of outgoing links from page i.Wdirect(p) : estimated probability to go to page p directly.Wlink(i→p) : weight of the link from page i to page p in the usage graph.Wtotal(i) : total weight of outgoing links from page i in the usage graph.

UPR implementation
Web logs:Referrer field is empty: user visited the page directly.Referrer field is non-empty: user followed a link from the referrer page to the target page.
Simple approach: Directly use counts to approximate the probabilities.
Wdirect(p)=count(directly visiting p)/∑icount(directly visiting i)Wlink(i→p)=count(link from page i to p is traversed)Wtotal(i)=total number of times an outgoing link from page i is traversed.Wlink(i→p)/Wtotal(i)=estimated probability of following the link i→p, given that the user follows a link from page i.

Improvement
Idea: Many people accessing a page/link a total of x times should count more than few people accessing the page/link a total of x times. Divide the dataset into time windows. For each window, use modified_count=log2(1+count)
Same as counts if everybody accesses the page once.If the same person (IP number) accesses the page/link more than once in the same time window, subsequent contributions are lowered.Makes the system more robust against usage based spamming and reduces some undesirable effects (e.g. browser homepages).

UPR properties
Inherits basic PageRank properties.Usage information can be updated incrementally and efficiently.UPR iterations have similar time complexity as PageRank iterations (only a very small constant times more expensive).Usage importance can be controlled smoothly via the parameters a1 and a2 (used as sliders, 0=pure static structure, 1=pure usage).Can also work with limited usage information (it gradually converges to PR, as less and less usage information is available. At the extreme case it reduces to PR).

HITS [Kleinberg99]
Two scores are assigned to each page: Hub and authority.
A good authority is a page that is pointed by good hubs, and a good hub is a page that points to good authorities.
Not as stable and scalable as PageRank
Mostly used for limited number of documents (e.g. in the context of focused crawling).
ipip
piip
ah
ha
it
i
ii
hAa
aAh
1
1

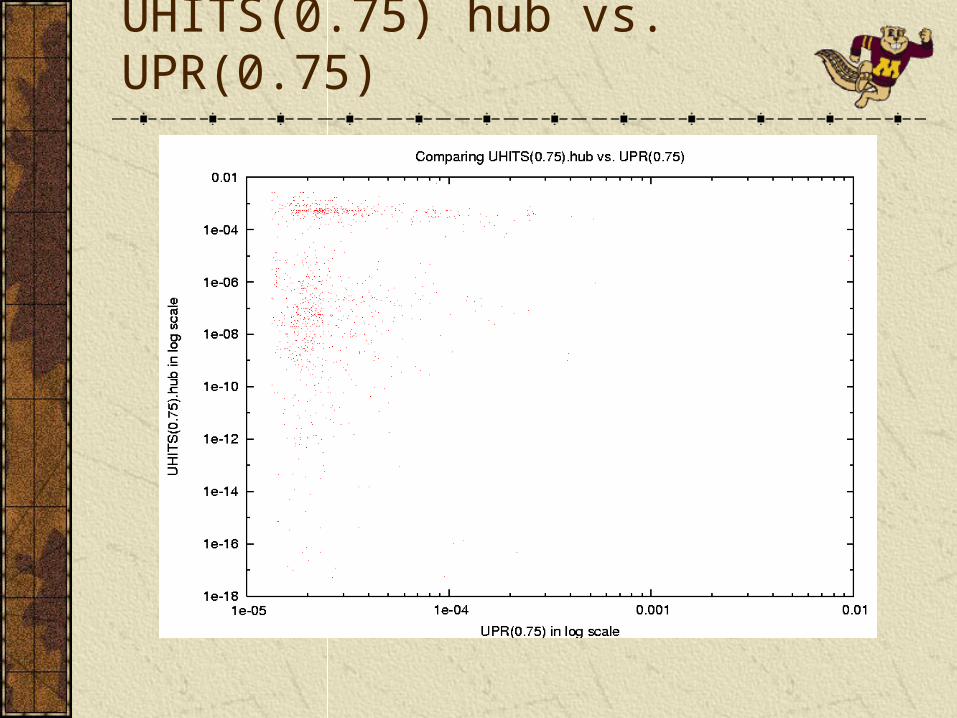
UHITS
HITS UHITS
itmi
imi
hAa
aAh
1
1
a is the authority score vector.h is the hub score factor.A is the adjacency matrix.A(i,j) is nonzero if there is a link from i to j, 0 otherwise.Am is the modified adjacency matrix.Astatic (same as A) is the adjacency matrix in static linkage graph.Ausage is the adjacency matrix in usage based linkage graph.α controls usage emphasis.Adjacency matrices are normalized on outgoing links.UHITS is a generalization of [Miller01]
it
i
ii
hAa
aAh
1
1usagestaticm AAA )1(

Naïve approach
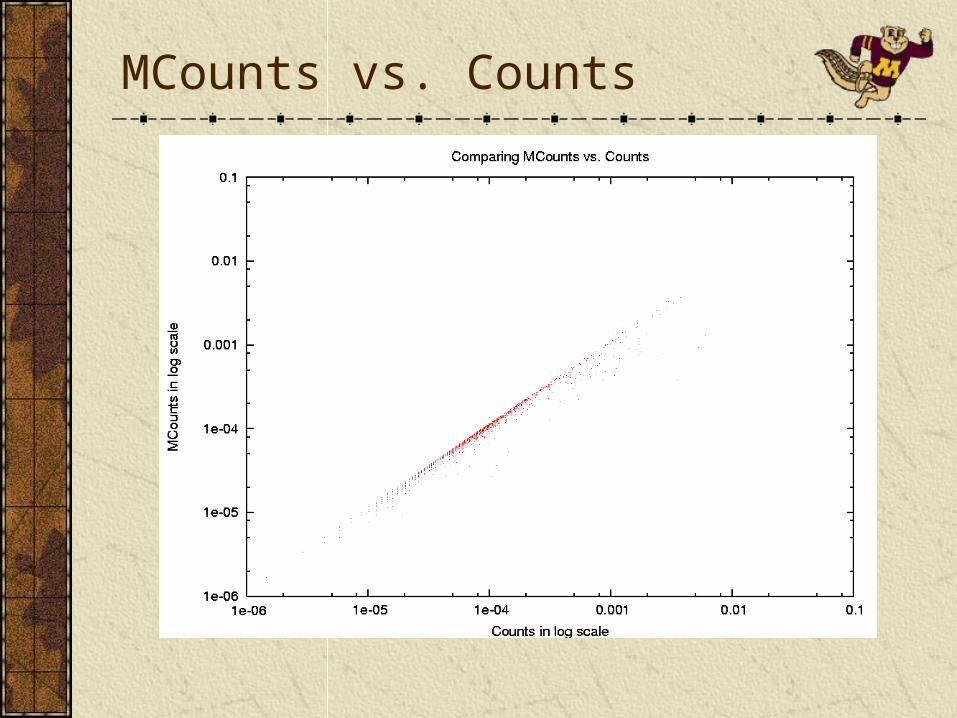
Counts: use number of visits to a page as a direct quality measure for that page.
Score(p)=count(p)/∑count(i)
MCounts: instead of direct counts, use modified counts (log transform)
Score(p)=mcount(p)/∑mcount(i)For a given time window, contribution of subsequent accesses from the same IP number is reduced.
Sum of scores is 1.

Previous usage based approaches
[Schapira99] or Directhit approach.A page’s score is proportional to the number of times users clicked the URL of the page from search engine results (if you record them).Somewhat similar to naïve approaches considered in this study, but instead of using global statistics, statistics available to the search engine’s web server are used.Potential self-reinforcement problem.
[Miller01]: Modification to HITS. Adjacency matrix is replaced by usage based adjacency matrix (similar to UHITS where parameter α is set to 1).
Unlike UHITS, if a link does not appear within the usage based graph, it is ignored. Thus scores of many pages may converge to zero.Practically no experimental results.
[Zhu01]: PageRate, claims to be a modification of PageRank, but has very different properties.
Does not have the basic PageRank properties.Normalization is done on incoming links.Requires non-trivial additional nodes, or normalization steps.Score of a page is not distributed to the pages it points to, proportional to the weights of the links.Unlike UPR, it does not use page visit statistics.No experimental results provided.

Impact of proposed algorithms
In particular UPR has a number of properties previous two approaches of incorporating usage statistics into link analysis did not offer:
Ability to control usage emphasis.
Ability to work with limited usage.
Inherits basic PageRank properties:• Stable
• Scalable
• Normalized scores
• Intuitive interpretation


Overview
Global comparisonsEffects of usage.Correlation between various methods.Distinguishing power different methods offer.
Query dependent comparisonsCompare a representative of each method in a query dependent setting via blind evaluations.Design an experiment in which the relevant documents can be selected objectively without user feedback (A very specific query type).

Experimental Setup
Methods under comparison:Counts: use number of visits to pages as a direct quality measureMCounts: similar to Counts, but contribution of the same IP in the same time window is decaying after the first visit (modified counting scheme).PR: PageRank (Brin and Page)UPR: sampled a1 and a2 in 0.25 increments. A total of 25 score vectors computed for UPR (a1=a2=0 is the same as PR). Damping factor was set to 0.85.HITS: authorities and hubs (Kleinberg).UHITS: HITS modified via usage statistics. Usage emphasis is sampled in 0.25 increments (0 is the same as HITS). Total of 5 samples from each of the score vectors (authority, hub).

Effects of usage: PR vs. UPR
Using PR, pages with high connectivity such as manual pages, FAQs, and discussion groups dominate top ranks. Department’s main page is at the 136th position.As more usage emphasis is introduced, increasing number of highly used pages (e.g. user home pages) start to appear in top ranks. For a1=a2=0.25, department’s main page is at the 6th position, for values above 0.5, it is the highest ranked page.Divided PR by UPR(a1=a2=1.0) and sorted the list in ascending order: 389 out of top 500 pages have “~” in the URL, compared to 79 out of 500 at the bottom of the list. UPR boosts highly used pages including user homepages.
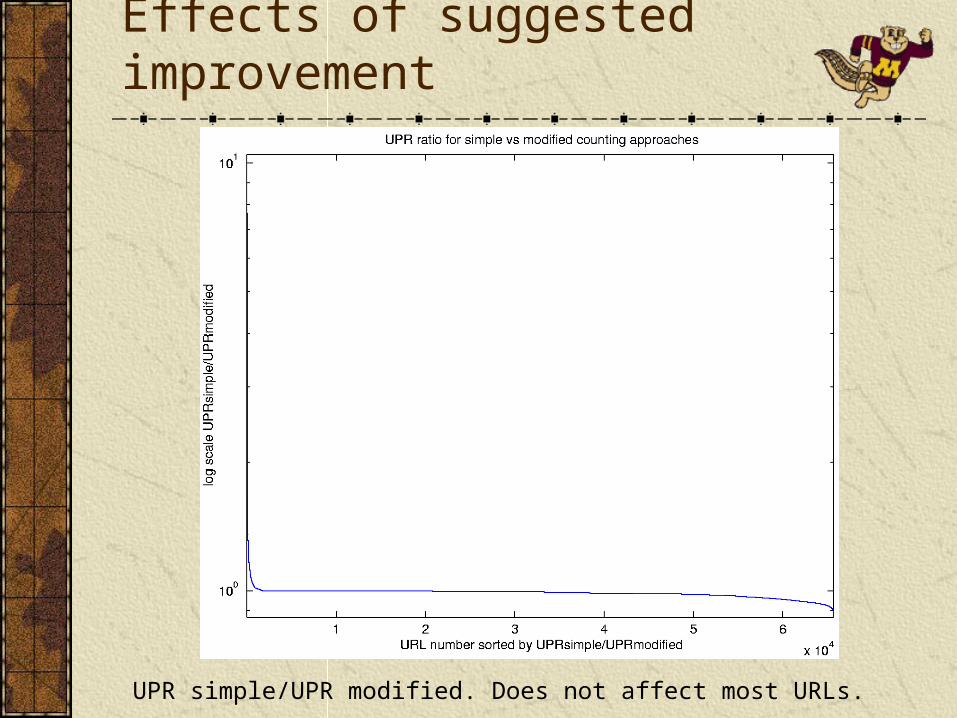
Effects of suggested improvement
UPR simple/UPR modified. Does not affect most URLs.

Effects of suggested improvement
UPR simple/UPR modified. Top and bottom 500 pages.

Effects of suggested improvement
Scores of most pages did not change dramatically.However, it helped reduce the scores of pages that are accessed by very few users a large number of times.
www-users.cs.umn.edu/~*userone*/ip• Likely to be used as a poor man’s dynamic DNS solution: Home
computer’s IP address uploaded periodically, and checked frequently to obtain the latest IP.
• Ranks with emphasis values 1, 0.75, 0.5: UPR simple: 2nd, 6th, 10th
UPR modified: 130th, 180th, 329th
www-users.cs.umn.edu/~*usertwo*/links.html• Gateway to various search engines, as well as local and global links.
Used as homepage by a few graduate students, producing a hit every time they open up a browser.
• Ranks with emphasis values 1, 0.75, 0.5: UPR simple: 3rd, 10th, 18th
UPR modified: 40th, 67th, 116th





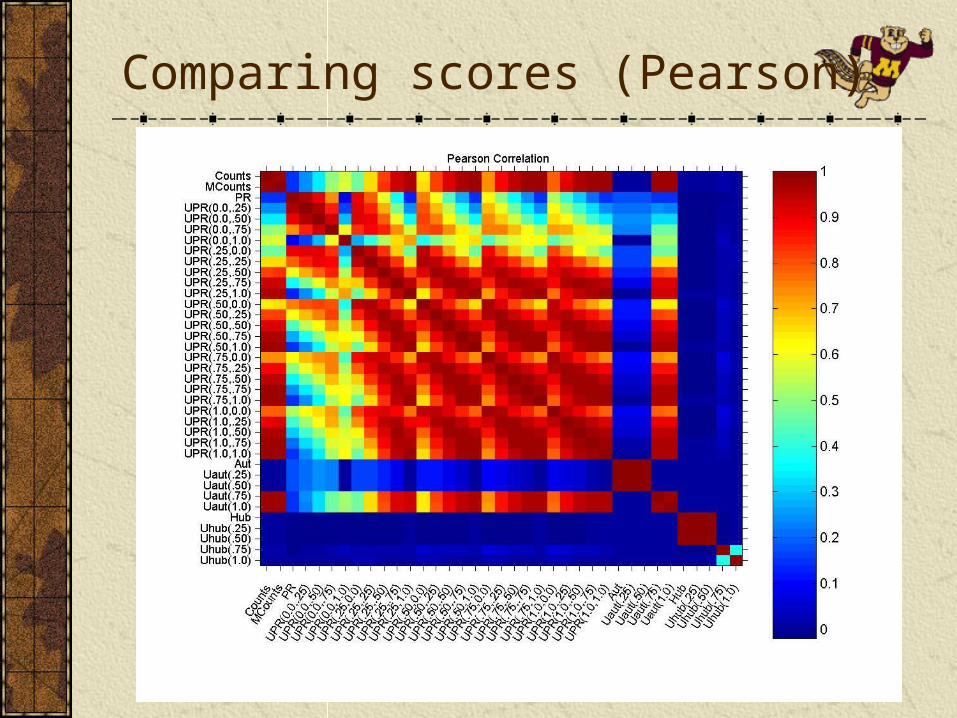
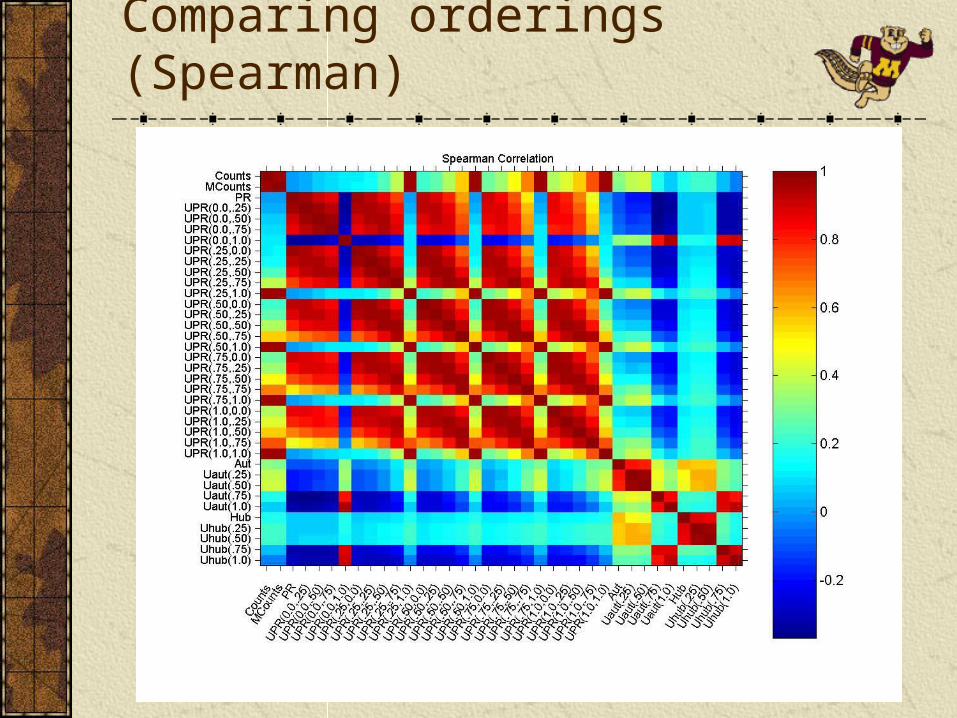
Pairwise correlations
Focusing on the internal 20k nodes, for each method pair, calculate
Pearson correlation (compares scores)Spearman correlation (compares ordering)
Pearson correlation does not tell the whole story: Score distribution in link analysis is often exponential. Pearson correlation effectively measures the correlation between highly scored pages.Spearman correlation focuses on the ordering. Seemingly highly correlated scores may suggest relatively different rank order:
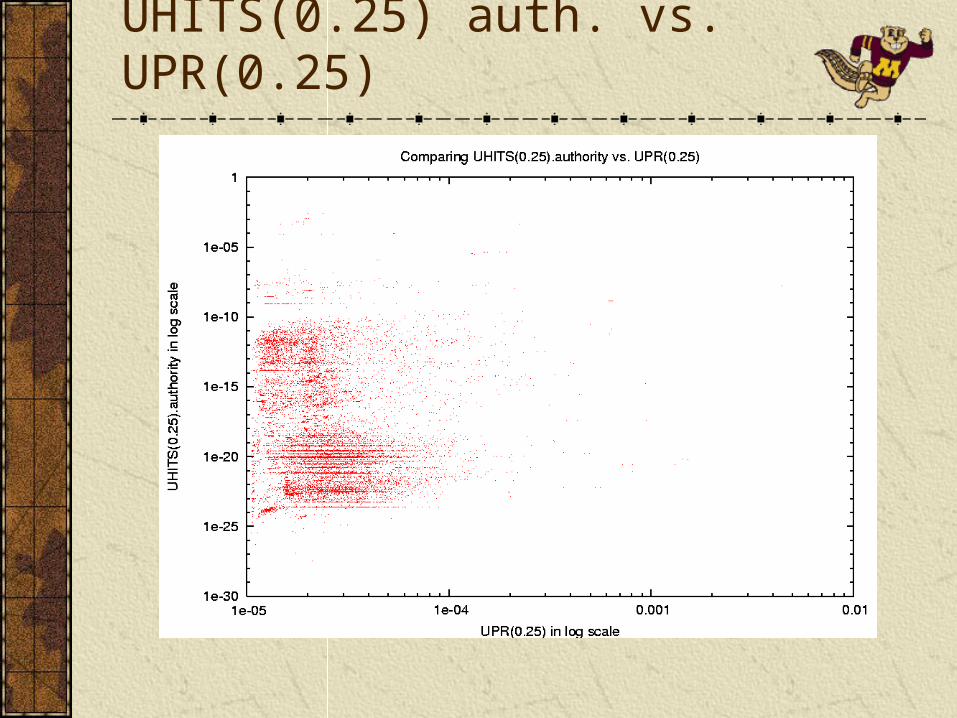
UPR(0.5, 0.5) vs. Counts has a Pearson correlation of 0.96, the Spearman correlation is relatively lower, 0.38. It is likely that different methods suggest different orderings even in top 5 positions.

Observations
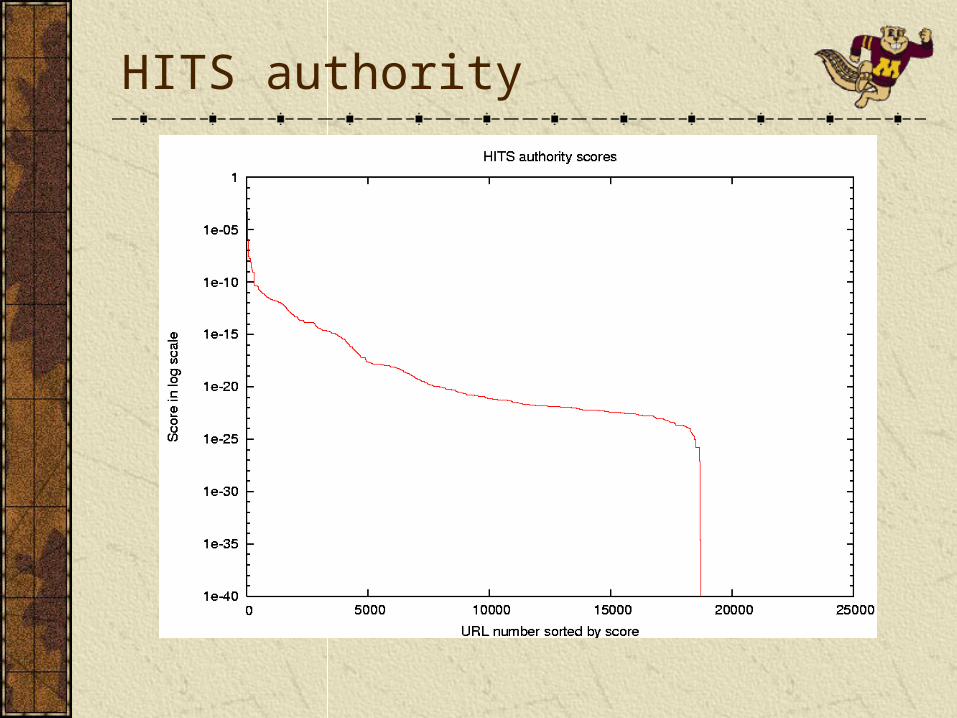
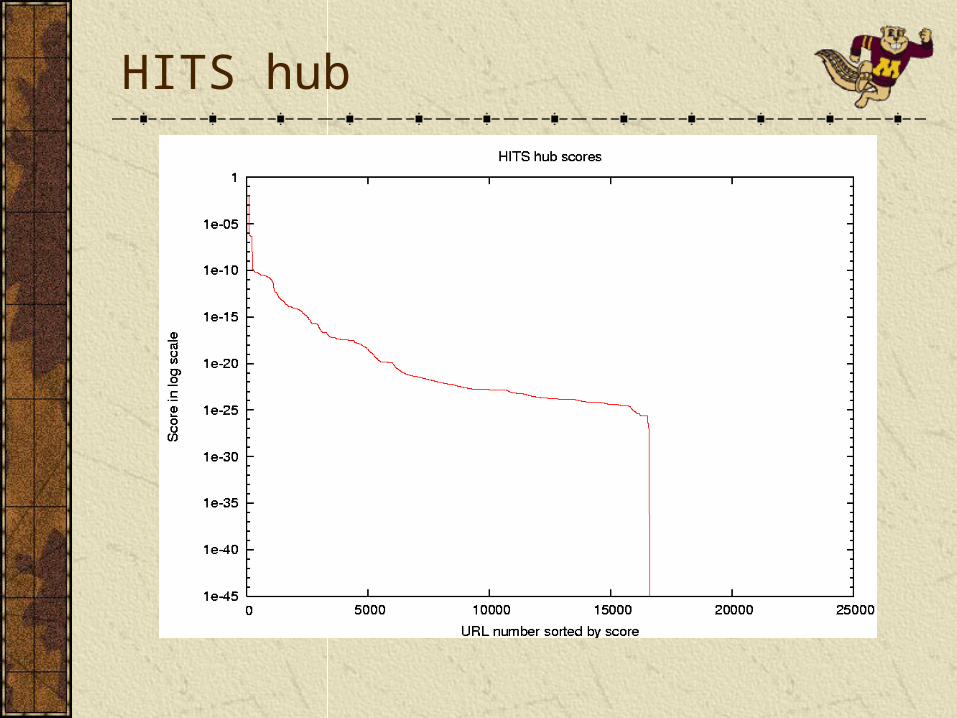
PageRank variants offer a global ordering and behaves smoothly as the parameters are changed.UPR is more correlated with PR when usage emphasis is low, and more correlated with Counts/MCounts when usage emphasis is high.Counts/MCounts behave reasonably well, but have a step-like behavior.HITS variants fail to offer a smooth global ordering between pages. A significant portion of scores converge to zero, especially with higher usage emphasis.


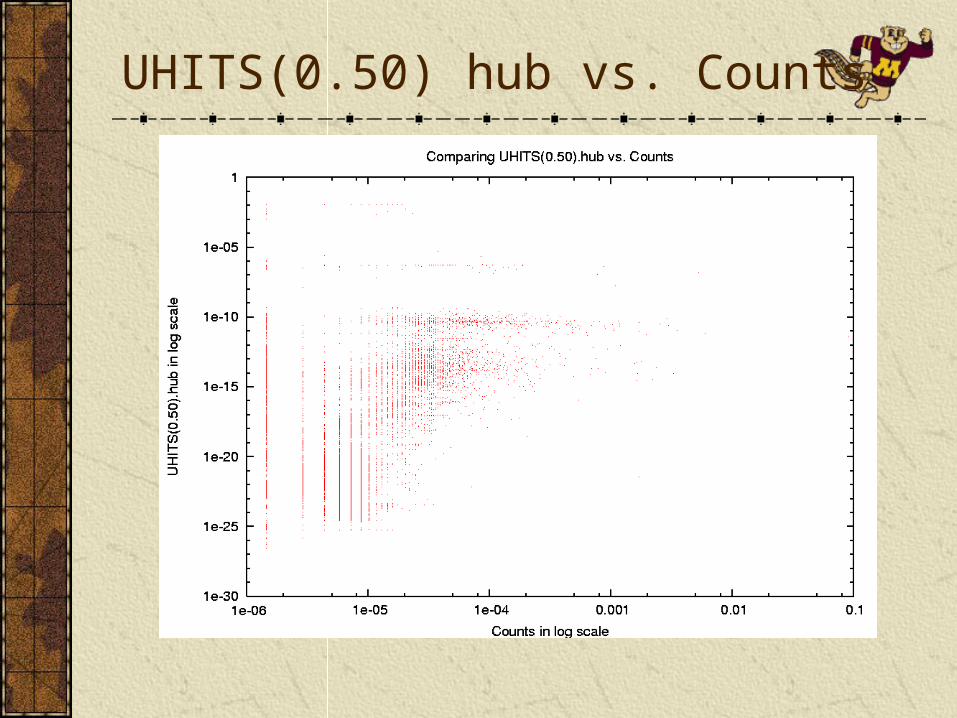

Query dependent evaluations
Evaluation version of USearchTop 50 documents according to similarity to query are presented to the user.
• no selection of methods, always uses cosine similarity.
User selects up to 5 relevant documents.Top 50 results are reranked with methods under comparison.Average position of the selected documents are calculated for each method (lower is better).
Selected methods:PageRank, UPR(0.75), MCounts, HITS authority/hub, UHITS(0.75) authority/hub.


Query dependent comparisons
3 set of experiments with different characteristics:Public evaluations (106 queries):
• Everyone can participate. Announced to grads/faculty.• Queries selected by users.• Less accurate results per query. • Queries tend to be more general.• Presentation bias probable.
Arbitrated set (22 queries)• Queries selected and evaluated by 5 grad students depending on their interests.• More specific queries.• Good quality results are discussed before issuing the query.• Results examined and discussed by at least 2 raters.• Presentation bias is less likely.
Name search (25 queries)• 25 users are randomly selected from CS directory.• Finger utility is used to obtain the username.• Last name is issued as the query.• Average position of the user homepages is calculated for each method.• Presentation bias is not applicable.
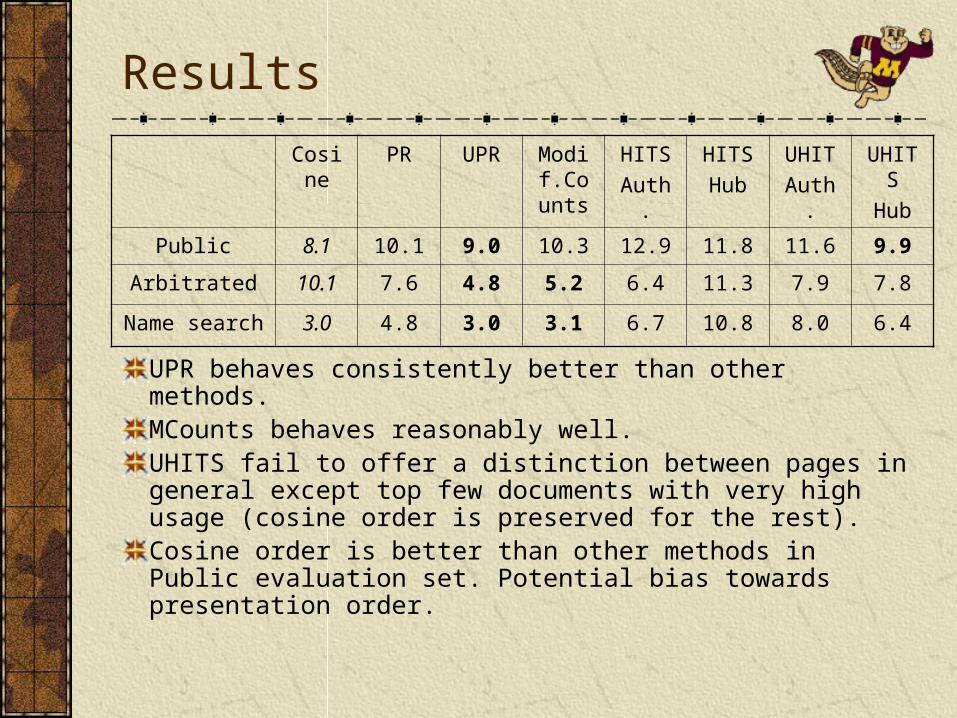
Results
Cosine PR UPR Modif.Counts
HITS
Auth.
HITS
Hub
UHIT
Auth.
UHITS
Hub
Public 8.1 10.1 9.0 10.3 12.9 11.8 11.6 9.9
Arbitrated 10.1 7.6 4.8 5.2 6.4 11.3 7.9 7.8
Name search 3.0 4.8 3.0 3.1 6.7 10.8 8.0 6.4
UPR behaves consistently better than other methods.MCounts behaves reasonably well.UHITS fail to offer a distinction between pages in general except top few documents with very high usage (cosine order is preserved for the rest).Cosine order is better than other methods in Public evaluation set. Potential bias towards presentation order.

Discussions
Applicability to web searchSearch engines can also collect general usage information:
• Specialized browsers/tools/proxies (e.g. toolbars, Google web accelerator).
There is no reason why UPR can not be computed on a larger scale:
Leading search engines have the infrastructure to compute UPR. For Google:
• MapReduce [Dean 2004]: Divide the data set between large number of machines. Minimal inter-communication requirements. UPR can be implemented in terms of almost embarrassingly parallel tasks.
• GFS [Ghemawat 2003]: Transparent, large scale storage.

Discussions (cont)
Is there a reason why web search engines may be reluctant to use extensive usage information?
Spamming…
An arms race.As long as cost of spamming is relatively low compared to its commercial benefits, spamming is likely to remain an issue.Search engines introduce new signals to increase the cost of spamming.

Discussions (cont)
Early search engines primarily used term frequency and tf-idf based approaches
Results practically depend on the page alone.Spammers use keyword stuffing.
Link analysisScore depends on multiple pages/links.Spammers use link exchanges/farms (relatively more expensive, requires modifications to multiple pages).
Usage augmented link analysisNot only links/pages need to be created/modified, they need to be supported by a sustained traffic from multiple sources.But, if implemented poorly, usage based spamming may become more cost effective than link based or other types of spamming.

Discussions (cont)
UPR with modified counts (log transform):Reduces subsequent contributions of the same source in a given time window.
Effectively, increases the cost of usage based spamming.
Alternative approaches are also possible:Use more aggressive functions.
• E.g. contribution of 0 or 1 per time window.
Cluster or group users, networks, IP ranges etc., treat them as a single (or similar) source.

Bottom line
Search engines employ a large number of signals.They constantly need to check benefits/costs.
Develop new signals.
Maintain existing ones.
Swap in/out signals when dynamics change.
An ideal quality signal:Has high benefit
• Improve rankings in many situations.
With minimal cost• Does not harm rankings in other situations (ignoring
computational and other considerations).

Bottom line (cont)
In real life, we settle with good benefit/cost ratio.For intranet/site specific search, among all quality measures that are examined, UPR has the best behavior.
• It has desirable properties.
• Visibly improved the ranking quality in various settings.
• Practically did not harm the results in any of the experiments.
Added benefit depends on existing signals.If existing signals cover usage statistics and/or link analysis extensively. UPR may not offer the same impact.

Concluding remarks
Question: Can we improve ranking quality over existing link analysis approaches in intranet/site specific search domain?Experimental results suggest that the answer is positive:
UPR provided the best quality signal among all methods examined.MCounts, a rather simplistic usage based method performed reasonably well.
There is no incentive for spamming the results in a single organization.
Unlike web search, relatively simple usage based approaches can safely be used to improve ranking quality in intranet/site specific search.

References
[Brin98] S. Brin, and L. Page. “The anatomy of a large-scale hypertextual Web search engine”. Computer Networks and ISDN Systems, 30(1–7):107–117, 1998.[Kleinberg99] J. M. Kleinberg. “Authoritative sources in a hyperlinked environment”. Journal of the ACM, 46(5):604–632, 1999.[Schapira99] A. Schapira. “Collaboratively searching the web – an initial study”. Master’s thesis, 1999.[Zhu01] J. Zhu, J. Hong, J. G. Hughes. “Pagerate: counting web users’ votes”. In Proceedings of the 12th ACM Conference on Hypertext and Hypermedia, pages 131–132, Rhus, Denmark, 2001.[Miller01] J. Miller, G. Rae, and F. Schaefer. “Modifications of Kleinberg’s HITS Algorithm Using Matrix Exponentiation and WebLog Records”. In ACM SIGIR Conference posters, September 9-13, 2001, New Orleans, Louisiana, USA, pages 444–445.[Dean 2004] J. Dean, and S. Ghemawat. “MapReduce: Simplified Data Processing on Large Clusters”, OSDI'04: Sixth Symposium on Operating System Design and Implementation,San Francisco, CA, December, 2004.

Previous work in search/IR
Mearf (http://mearf.cs.umn.edu)A meta search engine with expert agreement and content based reranking, online since 2000.All modules/libraries are implemented in C++.Flexible, efficient, scalable, and highly portable.4 new merging/reranking approaches are compared to 2 existing methods and the results of a single search engine (Google).User clicks are logged for a period of one year, and processed to compare the methods. Average position of clicks metric is introduced, various bias sources examined.Publications:
• B. U. Oztekin, G. Karypis, V. Kumar, “Expert agreement and content based reranking in a meta search environment using Mearf”. In proceedings of the Eleventh International World Wide Web Conference, May 7-11, 2002, Honolulu, Hawaii.
• B. U. Oztekin, G. Karypis, V. Kumar, “Average position of user clicks as an automated and non-intrusive way of evaluating ranking methods”. UMN, Computer Science and Engineering, TR 03-009

Previous work in search/IR (cont)
UPR, Usage aware PageRank.Early version of the paper describing UPR has appeared in WWW2003:
• B. U. Oztekin, L. Ertoz, V. Kumar, and J. Srivastava. “Usage Aware PageRank”. In WWW12 Poster Proceedings”, May 20-24, 2003, Budapest, Hungary.
Scout (http://scout.cs.umn.edu)Another meta search engine, based on Mearf’s core library.New approaches in search are tried:
• Indexing/clustering interface• Profile based reranking• Relevance feedback
Publications:• S. Kumar, B. U. Oztekin, L. Ertoz, S. Singhal, E-H. Han, and V.
Kumar. “Personalized profile based search interface with ranked and clustered display”. In International Conference on Intelligent Agents, Web Technologies and Internet Commerce, July 2001, Las Vegas.

Internet, a brief history
70s – Arpanet, limited number of nodes1974 TCP specification
80s – Continuous expansion, transition to TCP/IP1984 – DNS introduced, 1000 hosts.1987 – 10,000 hosts.1989 – 100,000 hosts.
Early 90s – Transition to WWW, need for search engines emerges.
1991 – World Wide Web, Gopher1992 – 1,000,000 hosts1993 – Mosaic, first widespread web browser. WWW Wonderer, first widely acclaimed Web robot.1994 – Galaxy, first searchable directory. Lycos search engine indexes 54K documents.

Search engines
Late 90s – Search engine boom1995 – Infoseek is launched (Feb), Metacrawler launched (June), Altavista is launched and has instant popularity (Dec)
1996 – Inktomi founded, Hotbot claims to have the ability to index 10M pages/day.
1997 – Ask Jeeves, Northern Light
1998 – Open Directory Project. Page and Brin introduces Google (Sep). MSN Search is launched, Directhit uses click information in ranking.
1999 – Fast search indexes 200M Web pages.

Algorithms
1995 – Early search engines use term index and frequency for retrieval and ranking.
Spammers use hidden list of keywords to improve chances of getting a hit.
1998 PageRank published, Google is in infant stage.1999 HITS is used for focused crawling and improves ranking quality of early search engines at the expense of bandwidth and computation.2000s Transition to link analysis, major search engines use link analysis to improve ranking.
Spammers now have to modify more than a single document to boost the ranking considerably.
2002 Topic sensitive link analysis and ranking.What is next? Usage statistics?

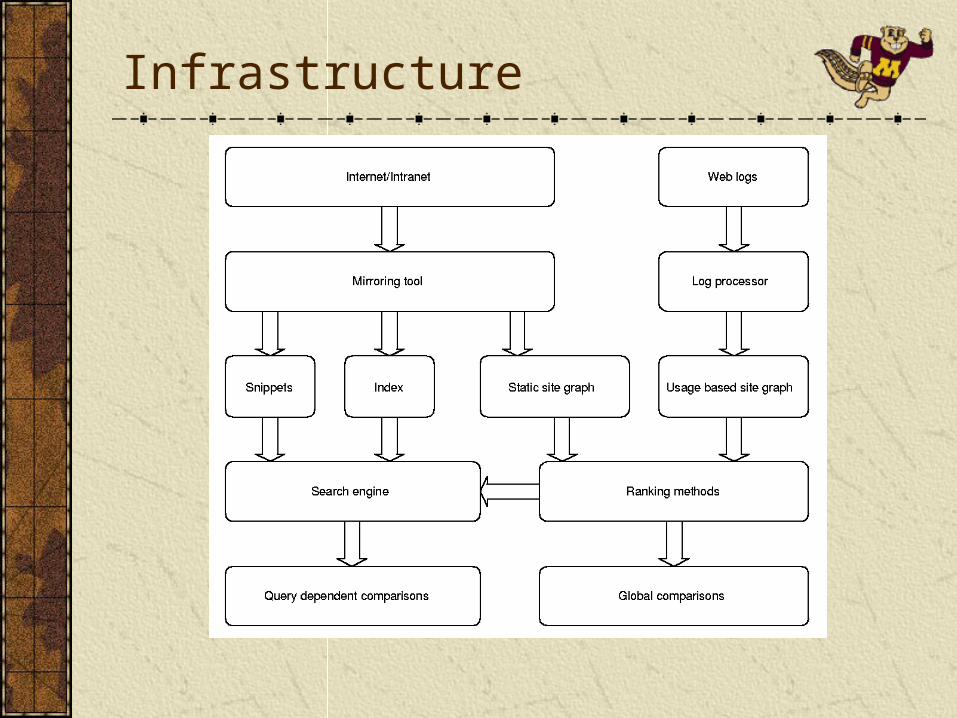
Infrastructure
Mirroring toolObtaining a site mirror.Indexing.Snippet extraction.Building the static linkage graph.
Processing the logsBuilding the usage based site graph.
Ranking modules use static and usage based site graphs to produce various ranking vectors.Ranking vectors are incorporated in a site specific search engine (USearch).

UMirror, the mirroring tool
Ability to focus on a domain/site via regular expression matching.
Ability to select the types of items to be mirrored.
Offers a unique mapping from a given URL to local copy and vice versa (most existing open source alternatives do not).
Portable.
UMirror uses WGet to retrieve a single file, but uses its own queuing, parsing, and matching modules.

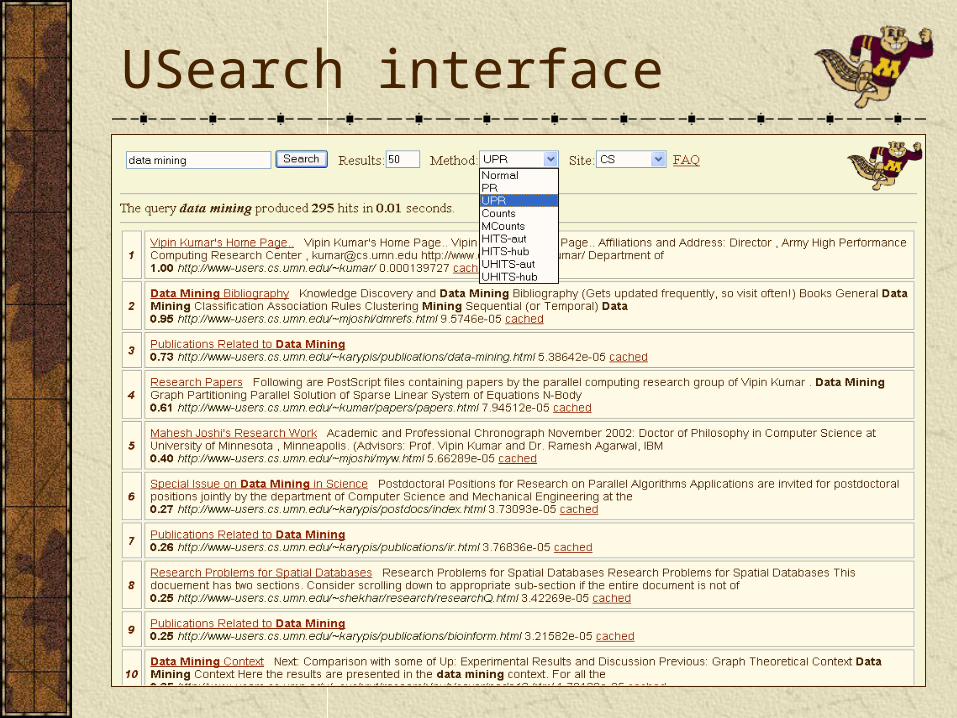
USearch, site specific search engine
Supports boolean queriesUses cosine similarity to query, and an optional, additional ranking vector to rerank the documents.Flexible and modular design. Adding a new site or a new ranking method is easy.Stable and robust.Relatively scalable. It should scale well up to medium size sites, as well as to higher traffic given enough resources/bandwidth.Portable. The search engine can be hosted on many platforms. The service is accessible using a wide range of browsers.USearch is available at http://usearch.cs.umn.edu/
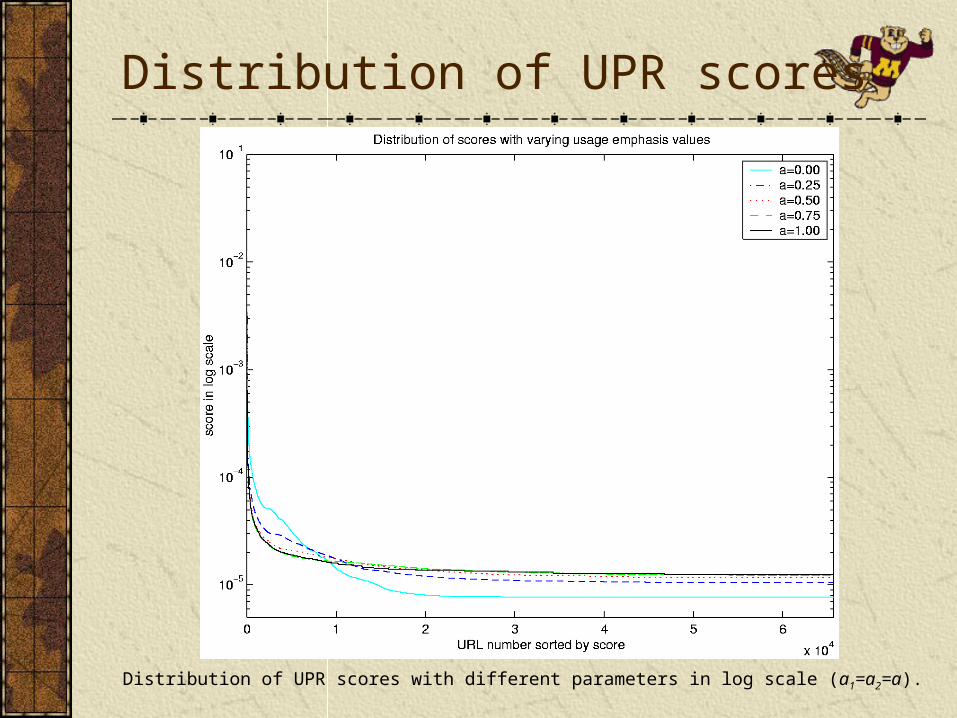
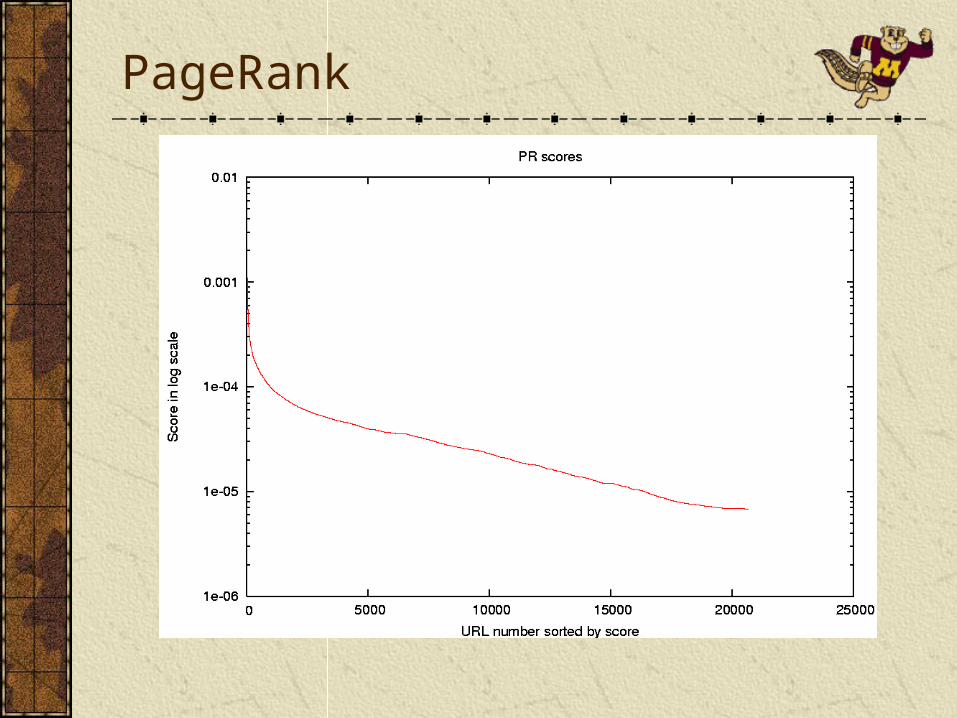
Distribution of UPR scores
Distribution of UPR scores with different parameters in log scale (a1=a2=a).





Usage based spamming
Modify page visit statisticsIssue get requests to pages you want to boost without sending a referrer field.
Modify link usage statisticsIssue get requests simulating an existing link.
Create ghost linksSend requests as if a high ranked page sends users to your page.
• Wow! a lot of people come to this page from Yahoo!, it must be an important page!
Solution: make sure to verify the existence of a link before building the usage based graph or while merging the two graphs.