untangling text data mining stanford digital libraries seminar may 11, 1998
DESCRIPTION
Untangling Text Data Mining Stanford Digital Libraries Seminar May 11, 1998. Marti Hearst UC Berkeley SIMS www.sims.berkeley.edu/~hearst. Caveat Emptor:. I do information access. I do not do text data mining (yet). This talk is an attempt to explore the relationship between the two. - PowerPoint PPT PresentationTRANSCRIPT

5/11/98 1
Untangling Text Data Mining
Stanford Digital Libraries SeminarMay 11, 1998
Marti Hearst UC Berkeley SIMS
www.sims.berkeley.edu/~hearst

5/11/98 2
Caveat Emptor:
I do information access. I do not do text data mining (yet).
This talk is an attemptto explore the relationshipbetween the two.

5/11/98 3
Talk Outline Definitions
– What is Data Mining?– What is Information Access?– What is Text Data Mining?
Empirical Computational Linguistics Real text data mining tasks Conclusions and Future Directions

5/11/98 4
The Knowledge Discovery from Data Process (KDD)KDD: The non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data. (Fayyad, Shapiro, & Smyth, CACM 96)
Note: data mining is just one step in the process

5/11/98 5
What is Data Mining? (Fayyad & Uthurusamy 96, Fayyad 97)
Fitting models to or determining patterns from very large datasets.
A “regime” which enables people to interact effectively with massive data stores.
Deriving new information from data.– finding patterns across large datasets– discovering heretofore unknown
information

5/11/98 6
What is Data Mining? Potential point of confusion:
– The extracting ore from rock metaphor does not really apply to the practice of data mining
– If it did, then standard database queries would fit under the rubric of data mining• Find all employee records in which employee
earns $300/month less than their managers– In practice, DM refers to:
• finding patterns across large datasets• discovering heretofore unknown information

5/11/98 8
Why Data Mining? Because the data is there. Because current DBMS technology
does not support data analysis. Because
– larger disks– faster cpus– high-powered visualization – networked information
are becoming widely available.

5/11/98 9
DM Touchstone Applications
(CACM 39 (11) Special Issue) Finding patterns across data sets:
– Reports on changes in retail sales• to improve sales
– Patterns of sizes of TV audiences• for marketing
– Patterns in NBA play
• to alter, and so improve, performance – Deviations in standard phone calling behavior
• to detect fraud• for marketing

5/11/98 10
DM Touchstone Applications
(CACM 39 (11) Special Issue) Separating signal from noise:
– Classifying faint astronomical objects
– Finding genes within DNA sequences
– Discovering novel tectonic activity

5/11/98 12
What’s new here?
Sounds like statistical modeling or machine learning.
Main Difference: scale and availability (Fayyad 97)
– Datasets too large for classical analysis– Increased opportunity for access
• end user is often not a statistician– New issues in sampling

5/11/98 13
Statistician’s Viewpoint(David Hand 97)
What’s new about DM?– Returns statisticians to their empirical
roots• exploration rather than modeling
– Hypothesis testing may be irrelevant• given the large data sizes everything is
significant– Data was collected for some other
purpose than what it is being analyzed for now

5/11/98 15
Talk Outline Definitions
– What is Data Mining?– What is Information Access?– What is Text Data Mining?
Empirical Computational Linguistics Real text data mining tasks Conclusions and Future Directions

5/11/98 17
Information Access(Information Retrieval more broadly
construed)
Problem:– Huge amounts of online textual information
Goal: – Build systems to help people discover, create
use, re-use, and understand information
Approach:– Leverage off of users’ smarts
– Combine stats, text analysis, user interfaces
5/11/98 18
Information RetrievalA restricted form of Information
Access The system has available only pre-
existing, “canned” text passages. Its response is limited to selecting from
these passages and presenting them to the user.
It must select, say, 10 or 20 passages out of millions!

5/11/98 19
Needles in Haystacks
The emphasis in IR (and standard DB) is in answering ad hoc queries.
5/11/98 20
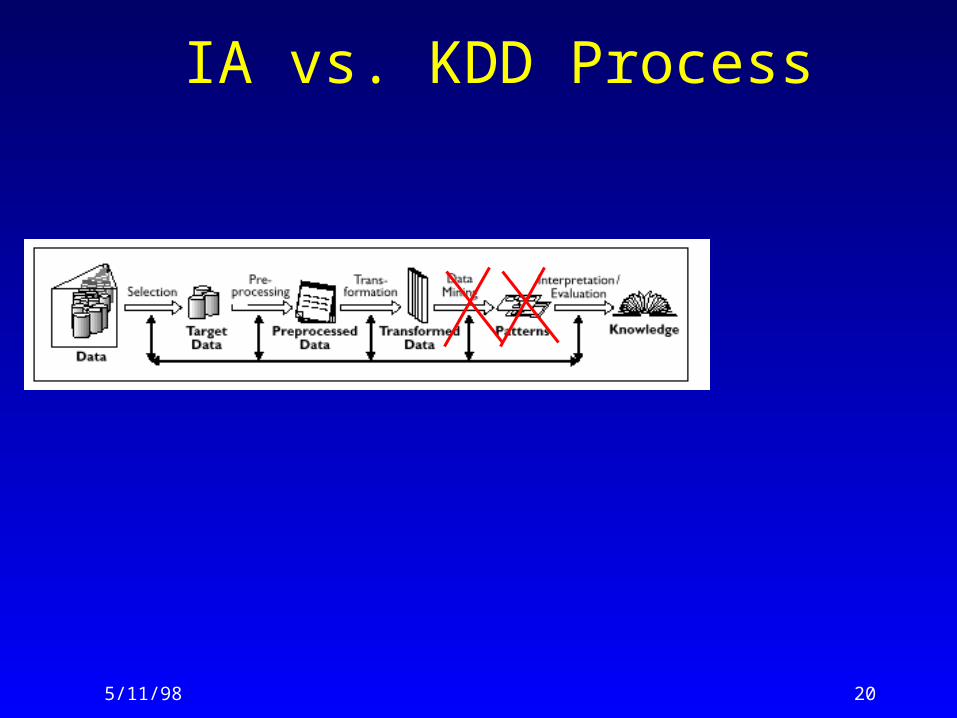
IA vs. KDD Process
5/11/98 21
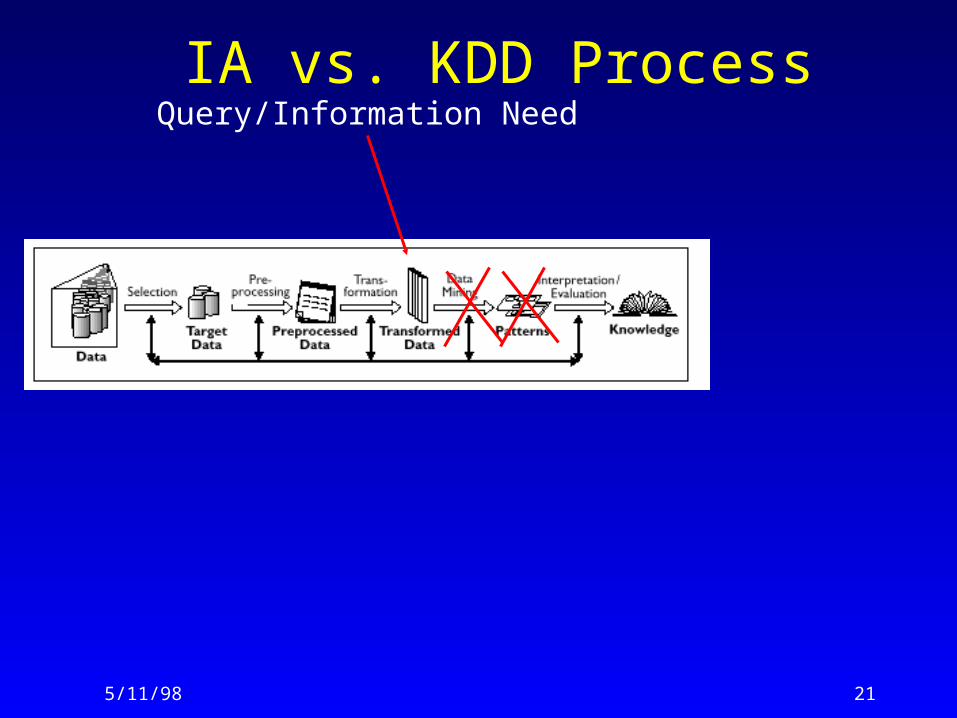
IA vs. KDD ProcessQuery/Information Need
5/11/98 22
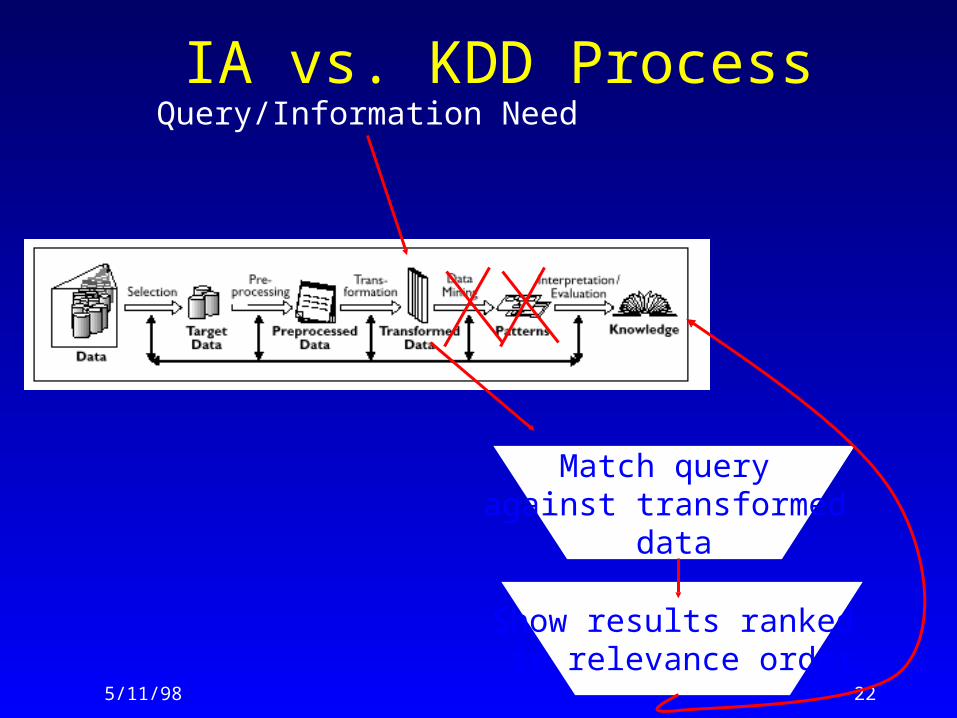
IA vs. KDD ProcessQuery/Information Need
Match query against transformed
data
Show results ranked in relevance order

5/11/98 24
Talk Outline Definitions
– What is Data Mining?– What is Information Access?– What is Text Data Mining?
Empirical Computational Linguistics Real text data mining tasks Conclusions and Future Directions

5/11/98 25
What is Text Data Mining?
Peoples’ first thought: – Make it easier to find things on the Web.– But this is information retrieval!
The metaphor of extracting ore from rock:– Does make sense for extracting
documents of interest from a huge pile.– But does not reflect notions of DM in
practice:• finding patterns across large collections• discovering heretofore unknown
information

5/11/98 26
Real Text DM
What would finding a pattern across a large text collection really look like?
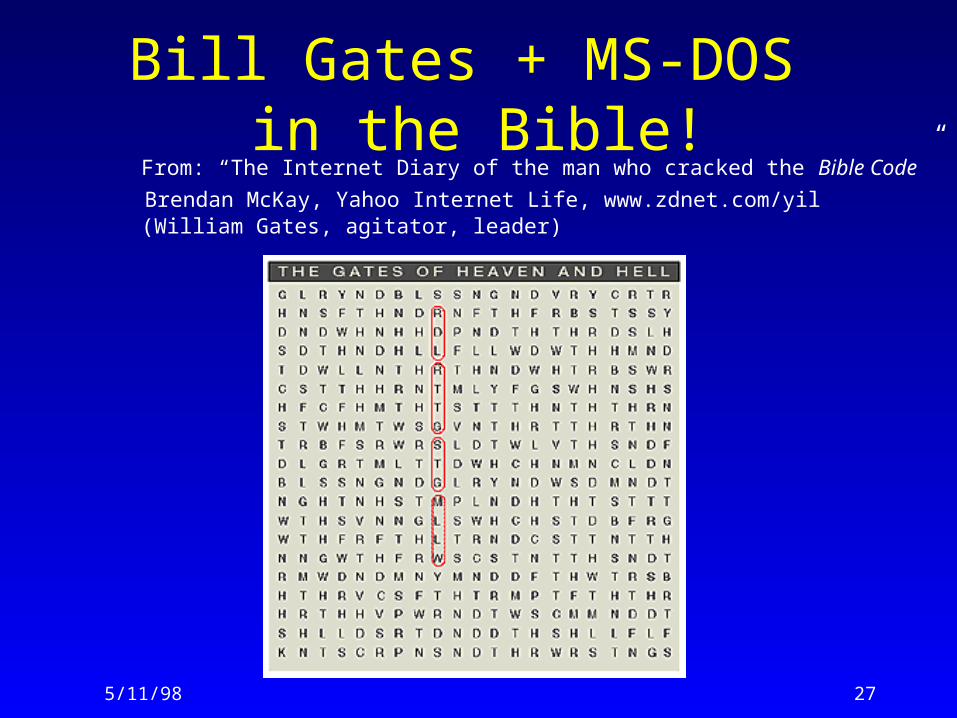
5/11/98 27
From: “The Internet Diary of the man who cracked the Bible Code” Brendan McKay, Yahoo Internet Life, www.zdnet.com/yil (William Gates, agitator, leader)
Bill Gates + MS-DOS in the Bible!
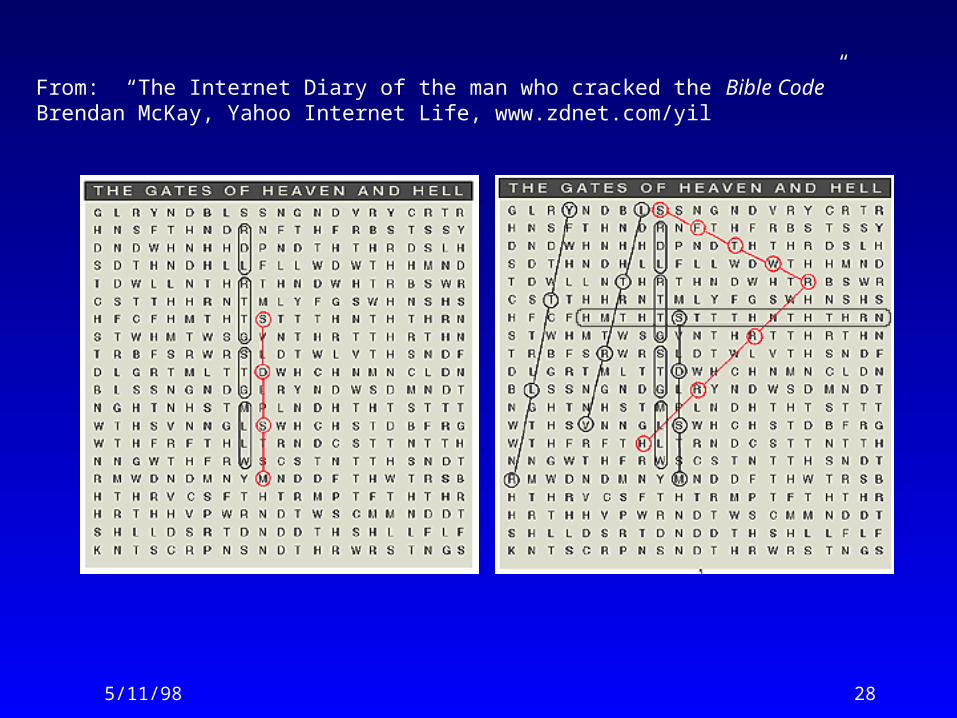
5/11/98 28
From: “The Internet Diary of the man who cracked the Bible Code”Brendan McKay, Yahoo Internet Life, www.zdnet.com/yil

5/11/98 29
Real Text DM
The point:– Discovering heretofore unknown
information is not what we usually do with text.
– (If it weren’t known, it could not have been written by someone!)
However:– There is a field whose goal is to learn
about patterns in text for its own sake ...

5/11/98 30
Observation
Research that exploits patterns in text does so mainly in the service of
computational linguistics, rather than for learning about and exploring text
collections.

5/11/98 31
Talk Outline Definitions Empirical Computational Linguistics
– Special and important properties of text– Relationship to TDM– Examples of TDM as CL
Real text data mining tasks Conclusions and Future Directions

5/11/98 32
Recent Trends in NLP (CL)
Previously: AI, full understanding Current: Corpus-based, Statistical
• ACL proceedings: from 3 corpus-based papers in 1991 to at least half in 1996
• Stat NLP was tried long ago (Z. Harris)
Simple Often Wins• Echoes results in IR
Interesting direction: • Statistics + Linguistics (Klavans & Resnik 96)

5/11/98 33
Text Analysis (CL) Tasks
Word Sense Disambiguation Automatic Lexicon Augmentation Discourse Analysis Parsing
• Phrase Identification• Phrase Attachments• Predicate/Argument Structure• Scope of Conjunctions• ...

5/11/98 34
Why Text is Tough
– Abstract concepts difficult to represent (AI-Complete)
– “Countless” combinations of subtle, abstract relationships among concepts
– Many ways to represent similar conceptsspace ship, flying saucer, UFO, figment of imagination
– Concepts are difficult to visualize– High dimensionality
Tens or hundreds of thousands of features

5/11/98 35
Why Text is Tough
Language is:– ambiguous (many different meanings
for the same words and phrases)– different combinations imply different
meanings

5/11/98 36
Why Text is Tough
I saw Pathfinder on Mars with a telescope. Pathfinder photographed Mars. The Pathfinder photograph mars our
perception of a lifeless planet. The Pathfinder photograph from Ford has
arrived. The Pathfinder forded the river without
marring its paint job.

5/11/98 37
Why Text is Easy
Highly redundant in bulk Just about any simple
algorithm can get “good” results for coarse tasks– Pull out “important” phrases– Find “meaningfully” related words– Create summary from document– Major problem: Evaluation

5/11/98 38
Stupid Text Tricks
– Coarse IR, Clustering• Don’t need dimension reduction (except
stopwords)
• Don’t need morphological analysis• Don’t need word sense disambiguation
– Partial parsing:• Simple, greedy transformation rules• Cascading finite state machines
– Categorization• Assume independence

5/11/98 39
Text “Data Cleaning”
Pre-process text as follows: Tokenization Morphological Analysis
(Stemming)inflectional, derivational, or crude IR methods
Part-of-Speech TaggingI/Pro see/VP Pathfinder/PN on/P Mars/PN ...
Phrase Boundary Identification[Subj I] [VP saw] [DO Pathfinder] [PP on Mars] [PP
with a telescope].

5/11/98 40
CCL Methodology
Describe here the standard methodology for corpus-based computational linguistics algorithms

5/11/98 41
CCL Examples
Place here examples of the kinds of output generated for computational linguistics applications

5/11/98 42
Inducing MetaData for Documents
Assigning bibliographic metadata – author, genre, time, region
Subject/Topic assignments– category labels: MeSH, LoC, ACM keywords
Information Extraction (MUC)– MUC: terrorist incidents
• who did the bombing• where did the bombing take place• what weapon(s) were used• when did it happen

5/11/98 43
Inducing MetaData for Collections
Indexes Hierarchical Categorization Overviews of Connectivity
• hyperlinks• co-citation links
Overviews of Subject Matter• 2D• 3D• dynamic

5/11/98 44
A Main Point:
Empirical CL is usually not helpful for improving Information Access.
However, it can produce– metadata– overviews– associations
that are indirectly useful for IA.

5/11/98 45
Talk Outline Definitions Empirical Computational Linguistics Real text data mining tasks
– TDM not using text– TDM using text
Conclusions and Future Directions

5/11/98 46
TDM using Metadata (instead of Text)
(Dagan, Feldman, and Hirsh, SDAIR ‘96)– Data:
• Reuter’s newswire (22,000 articles, late 1980s)• Categories: commodities, time, countries,
people, and topic– Goals:
• distributions of categories across time (trends)• distributions of categories between collections• category co-occurrence (e.g., topic|country)
– Interactive Interface:• lists, pie charts, 2D line plots

5/11/98 47
Combining Text with Metadata
(images, hyperlinks)
Examples– Text + Links to find “authority pages”
(Kleinberg at Cornell, Page at Stanford)
– Usage + Time + Links to study evolution of web and information use (Pitkow et al. at PARC)
– Images + Text to improve image search

5/11/98 48
Talk Outline Definitions The New Empirical Computational
Linguistics Real text data mining tasks
– TDM not using text– TDM using text
Conclusions and Future Directions

5/11/98 49
Ore-Filled Text Collections
Newspaper/Newswire Medical Articles
– Patterns associated with symptoms, drugs
Patent Law– Recent Study Justifying Scientific
Funding– Hypotheses for New Inventions
“Corporate Memory”

5/11/98 50
True Text Data Mining:Don Swanson’s Medical
Work Given
– medical titles and abstracts– a problem (incurable rare disease)– some medical expertise
find causal links among titles– symptoms– drugs– results

5/11/98 51
Swanson Example (1991) Problem: Migraine headaches (M)
– stress associated with M– stress leads to loss of magnesium– calcium channel blockers prevent some M– magnesium is a natural calcium channel blocker– spreading cortical depression (SCD)implicated in M– high levels of magnesium inhibit SCD– M patients have high platelet aggregability– magnesium can suppress platelet aggregability
All extracted from medical journal titles

5/11/98 52
Swanson’s TDM
Two of his hypotheses have received some experimental verification.
His technique– Only partially automated– Required medical expertise
Few people are working on this.

5/11/98 53
Text Collection Overviews
Clusters/Unsupervised Overviews– Chalmers: BEAD, Networks of Words– Lin,Chen: Kohonen Feature Maps– Xerox PARC: Local Clusters– Pacific Northwest: ThemeScapes– Rennison: Galaxy of News

5/11/98 54
Text Overviews
– Huge 2D maps may be inappropriate focus for information retrieval • can’t see what documents are about• documents forced into one position in
semantic space• space difficult to browse for IR purposes
– Perhaps more suited for pattern discovery• problem: often only one view on the
space

5/11/98 55
Talk Outline Definitions The New Empirical Computational
Linguistics Real text data mining tasks
– TDM not using text– TDM using text
Conclusions and Future Directions

5/11/98 56
Conclusions
Currently, what might be construed as Text Data Mining is really Computational Linguistics– Text is tricky to process, but rich and abundant (now)– There are many CL tools available
Data Mining directly from text – tells us about language– produces meta-information that may be useful for
information access

5/11/98 57
Conclusions, continued Information Access != Text Data Mining
– IA = finding needle in haystack– TDM = finding patterns or discovering new information
However, Information Access may potentially be served by Text Data Mining techniques:– automated metadata assignment– collection overviews
The synthesis of ideas from TDM and IA: – Perhaps a new field of exploratory data analysis over
text!

5/11/98 58
Promising Research Directions
Text Data Mining Problems:– Patterns within sets of documents:
• What is the latest in this field?• How is this field related to that field?
– Chains of evidence embedded in text:• What drugs have been tested for this
symptom?• What effects did this funding have on that field?
– Human use of information over time, • How does information diffuse across the web?