university of fribourg informatics department seminar...
TRANSCRIPT

University of Fribourg
Informatics Department
Seminar in Electronic Business
Recommender systems and content-based filtering
Seminar
Michael Dejen
&
Hamed Sekandary
Adviser
Prof. Andreas Meier
Assistant
Daniel Fasel
Date
May 14, 2008

2
Table of contents
1 Introduction .............................................................................................. 4
2 Content filtering methods .......................................................................... 5
2.1 Content-based filtering ................................................................................................. 5
2.2 Collaborative filtering .................................................................................................. 7
2.3 Hybrid recommender systems ...................................................................................... 8
3 Personalization ........................................................................................11
3.1 Gathering personal information ................................................................................. 11
3.2 Degrees of personalization ......................................................................................... 12
3.3 Explicit feedback VS Implicit feedback ..................................................................... 16
4 Privacy concerns .....................................................................................18
4.1 Main aspects ............................................................................................................... 18
4.2 Privacy policies .......................................................................................................... 19
4.3 Platform for Privacy Preferences ............................................................................... 21
5 Marketing perspectives ............................................................................23
5.1 Contributions to E-Commerce ................................................................................... 23
5.2 Business Models for cost recovery ............................................................................. 24
5.3 Recommendation delivery .......................................................................................... 24
6 Conclusion ...............................................................................................26

3
Table of figures
Figure 1 : The PRES architecture ............................................................................................... 6
Figure 2 : The Fab hybrid recommender system architecture .................................................. 10
Figure 3 : Recommender websites and applications classification .......................................... 13
Figure 4 : Amazon Delivers E-mail Subscriptions ................................................................... 14
Figure 5 : Movielens – Movie recommender system ............................................................... 15
Figure 6 : An example of Reel.com’s “Movie Match” recommendations ............................... 15
Figure 7 : Amazon's "Customers Who Bought" recommender ................................................ 16

4
1
Introduction
« Recommender systems support users by identifying interesting products and
services in situations where the number and complexity of offers outstrips the user’s
capability to survey them and reach a decision. » (Alexander Felfernig 2007)
Given the overload of information on the internet today, users are having more and
more difficulties to find the exact information they need and are asking for
personalization technologies. Recommender systems can help them in their
searching process by offering recommendations based on their interests, tastes or
previous actions.
Nowadays, recommender systems are used in almost every category of e-
commerce, going from books recommendations to personalized financial services.
Indeed most of largest e-commerce websites (e.g. Amazon.com) are using
recommender systems to help their customers find what they need and in that way
enhance their sales and obtain customer satisfaction and loyalty.
It can also be noticed that there are more and more websites requiring user
contributions. The reason for that collaboration asked from the users’ side is because
recommender systems are fueled with user contributions and it is through those
contributions that all recommendations will be generated.
The aim of this seminar is, initially, to understand how a recommender system works,
what the different content filtering methods are and which advantages and
disadvantages do they have. Secondly, the aspect of personalization is treated to
see how personal information about a user is gathered by the recommender system
and which are the different degrees of personalization. Then privacy concerns and
are discussed in order to see what are the privacy risks recommender system users
can be confronted with and what is done to avoid those risks. Finally, marketing
perspectives have been studied to reveal which benefits the use of a recommender
system can bring to e-commerce websites.

5
2
Content filtering methods
2.1 Content-based filtering
This type of filtering is made using the user’s profile containing the user’s preferences
and tastes collected explicitly by the user or deduced from his past ratings or
purchases. The user’s profile is generated through features of items he has rated or
purchased in the past and it’s based on these features that the recommendations will
be done. This means that the content presented to the user will be in agreement with
his preferences and the items he has liked or bought in the past.
Indeed, the recommended items will be selected based on the correlation between
the content of the item and the user’s preferences.
To understand better how this kind of recommender system works, we can take the
example of the pure content-based recommender system PRES (Personalized
Recommender System) which makes recommendations for a website that contains a
collection of textual documents about do it yourself home improvements. PRES
makes recommendations by comparing a user profile with the content of each
document in the collection.
The content of each document is represented by a set of terms which are extracted
from that document.
On the other hand the user’s profile is fed with the terms of documents the user has
found interesting and to determine which documents have interested a user, explicit
(i.e. rating of the document) or the or implicit feedback (inferred by observing the
user’s actions) are used.
To evaluate the importance of those extracted terms the term frequency/inverse
document frequency (TF-IDF) measure is used. The latter will give a weight to each
keyword using the formula bellow:

6
𝑤𝑖 = 𝑡𝑓𝑖 ∗ 𝑙𝑜𝑔 𝑛
𝑑𝑓𝑖
Where wi is the weight of the term ti, tfi is the number of occurrence of term ti in a
document D, n the total number of documents in the collection of documents and dfi
the number of documents in which term ti appears at least once.
The TF-IDF makes two assumptions based on the characteristics of text documents:
1. The more times a term appears in a document, the more relevant it is to the
topic of the document
2. The more times a term occurs in all documents in the collection, the more
poorly it discriminates between documents
Using these techniques each document will be represented by keywords which best
describe its content and in this way accurate recommendations can be made by the
recommender system.
Figures 1, illustrates the PRES architecture and gives an overview of how it works.
Figure 1 : The PRES architecture (Robin van Meteren 2000)
In this figure, we can see that the user profile is learned from feedback given by the
user. The user profile is compared with the document in the collection by the

7
recommender system. And the documents which best suit the user’s interests appear
as hyperlink on the web page. (Robin van Meteren 2000)
But the problem with content-based filtering is that it has several shortcomings
(Marko 1997; Gediminas Adomavicius 2005):
Recommendation diversity limitation: the diversity of the content presented to
the user will be limited because the recommendations depend of the user’s
past actions. Indeed the recommender system will only recommend items for
which the user has shown interest before. That is a really annoying problem
for new users who have empty or restricted profiles because the
recommender system will not be able to make any recommendations for them
and it will take time until those become really accurate and corresponding to
the user’s interests.
Eliciting user feedback: the process of giving a feedback or rating for an item
is somewhat annoying for the user because it requires an investment in time
an effort. But those evaluations are essential for the performance of the
recommender system because all the future recommendations will be based
on them given the fact that the content-based filtering is made through the
user’s profile which is partly filled in with the characteristics of items rated in
the past.
Limited content analysis: each item is described by a set of terms directly
extracted from it. That will work correctly with text-based items but not with
multimedia data such as images or videos. The only solutions for that would
be the explicit feature specification of each item but this too restrictive to do in
real life. In addition to that, even with text-based items, there can be a
problem sometimes. Indeed, if two items are described by the same terms,
which can happen for example with two news articles talking about the same
event, the recommender system will not be able to make a distinction
between them even if they differ regarding the quality of the redaction.
2.2 Collaborative filtering
This type of filtering method doesn’t depend of the user’s profile for making
recommendations but on the experiences of a community of users who have the

8
same tastes as the user looking for the product or service. To define that community,
collaborative filtering algorithms such as the “nearest neighbor” are used which
selects a set of users with whose past ratings there is the strongest correlation.
With this kind of filtering, there is no analysis of the items required by the system; the
only specification needed is an identifier for each item. That means that, unlike the
content-based filtering, the features of an item aren’t taken into consideration at all.
The collaborative filtering method overcomes the weaknesses of content-based
filtering. Indeed, the diversity of the content presented to the user isn’t limited any
more since the recommendations are made from the feedbacks left by a bunch of
“similar” users and this also drops the importance of the quantity of own ratings the
user has to give.
But this method isn’t perfect and also has its shortcomings (Marko 1997):
No recommendations for new items: any new item introduced in the database
will not be recommended to the users until it has been rated by them and
since there are no recommendations there can be a considerable period of
time until that item is presented to the customers by the system.
Fewer recommendations for users with unusual tastes: since the
recommendations are made from the similarities between users, the one who
has non common tastes will get less or no recommendations at all.
No matching between users who haven’t rated the same item: since each item
is only referred by an identifier, to be part of the same community two users
have to rate the same item and in the same way. For example if a user rated
positively the flight ticket search engine Expedia.com and another user rated
positively the eBookers.com one, these two users will not necessarily be
nearest neighbors.
2.3 Hybrid recommender systems
Since both content-based and collaborative filtering methods have weak but also
strong points, hybrid recommender systems have been introduced to build the
advantages of both methods into one system.

9
The authors of (Gediminas Adomavicius 2005) state that there are four different ways
to combine collaborative and content-based methods into a hybrid recommender
system :
1. Implementing collaborative and content-based methods separately and
combining their predictions
2. Incorporation some content-based characteristics into a collaborative
approach
3. Incorporating some collaborative characteristics into a content-based
approach
4. Constructing a general unifying model that incorporates both content-based
and collaborative characteristics which is the case of the hybrid recommender
system presented bellow.
To illustrate this kind of recommender systems, we will take the case of “Fab” which
is a hybrid recommender system for the Web developed in the University of Stanford.
Figure 2.1 represents the “Fab” recommender architecture. It is composed of three
main components (Marko 1997):
Collection agents: their task is to find pages for specific topics depending of
the interests of a community of users and maintain a profile generated through
words contained in Web pages which have been rated. This profile will be
used to collect the adapted pages as the interests of the community of users
will change over time. It is in fact, the best representation of a group of users’
interests.
Selection agents: their task is to find pages for a specific user and also to
maintain a profile representing the user’s interests.
Central router: its task is to forward pages found from the collection agents to
the users whose profile is matching.

10
Figure 2 : The Fab hybrid recommender system architecture (Marko 1997)
Once the recommendations have been made to the users, the latter will have to
provide a rating for each recommended page. These feedbacks will be used to
update the user’s selection agent’s profile and will be submitted back to the collection
agents. In addition to that, each highly evaluated page will be transmitted to the
user’s nearest neighbors which have, as seen before, the same interests.
Through this example, we can clearly see the advantages of an hybrid recommender
system (Marko 1997):
Thanks to collaborative filtering, the feedbacks of other users can be used to
make recommendations.
With content-based filtering, new items with no previous ratings by other users
can also be recommended.
Collaborative recommendations are now possible between users who haven’t
rated exactly the same item as long as they have rated similar items. This is
due to the fact that the profiles take into consideration the features of items.
Recommendations can also be made for users who have unusual tastes since
the profiles are made from the content of items.
With the selection agents, items that are too similar will not be recommended
twice to the user because these agents will filter them out.

11
3
Personalization
3.1 Gathering personal information
The goal of personalization is to recommend a product or service that best suits the
customer’s needs. For that to be possible, the recommender system has to collect
personal information about the users in order to know their preferences. That can be
done by giving them the opportunity to rate items they have seen or used in the past
e.g. the recommender system can ask a user to select a list of movies he has already
watched and give a rating for each of them or ask him which meals he likes the most
etc.. But the questions asked or the items presented to the new user have to be
ideally defined so that with the given responses the system can extract useful
personal information about each user. This means that asking a user if he or she
does like chocolate will gather absolutely no useful information to the system for
personalization purpose simply because most people like chocolate and that
information will not differentiate that user form another one.
The authors of (Al Mamunur 2002) have defined several strategies for the selection
of the items to present to a new user in order to best encircle his preferences :
Random strategies: the items are selected randomly from a database. Among
that random selection the items are sorted by two criteria:
o Popularity: the items will be presented from the most popular to the
least one based on the ratings of other users. In this way, the
probability that a user knows the presented items and is thus able to
them is higher. The main problem of this strategy is that most people
like popular items e.g. best-seller novels and that will only provide low
value information about a particular user to the system.
o Pure entropy: to have a diverse selection, the items will be selected by
their level of entropy sorted in descending. An item with high entropy is

12
for example a movie that has an equal number of good and bad ratings.
The problem in this case, is that the selection will probably contain
many items unknown by the user.
Personalized strategies: to simplify the signing up process and demand less
effort from new users, there are personalized strategies like item-to-item
personalized strategy. Instead of presenting the new user a long list of items
he potentially may know and ask him to rate them in order to let the
recommender system create him a profile for further recommendations, one
single rating (at least) will be sufficient for the system. This strategy is based
on similarity between items, so once the system gets the rate of the user
about one item it will compute other items which have a relation with the
initially rated item and that this user may also have seen. In this way the user
will be presented a list of items he has a high probability to know. The problem
with this strategy is that knowing an item e.g. having read a book means liking
it in many cases. So the information gathered will be of less value.
3.2 Degrees of personalization
Recommendations generated by a recommender system may have several degrees
of personalization (J. Ben Schafer 1999; J. Ben Schafer 2001):
Non-personalized: the same recommendations are made to all users. In this
case the preferences of the users are not taken into consideration at all. Many
e-commerce recommendations do this e.g. presenting the top sellers or
editor’s choice to the customers.
Ephemeral personalization: recommendations are generated in response to
the customer’s navigation and selection on a web site. This kind of
personalization is often based on item-to-item correlation (as seen in section
3.1) or attribute-based recommendation. The latter generates
recommendations based on the features on an item e.g. if a user searches for
the movie “Indiana Jones”, the system will recommend other adventure
movies like “Robin Hood” or “Jurassic Park”. In addition, ephemeral
personalization will not remember the user’s interests from one visit on the
website to the next one.

13
Persistent personalization: recommendations will differ for each user. Here
attribute-based recommendation, item-to-item correlation or user-to-user
correlation will be employed but in this case the user’s interests will be saved
by the system for further visits (thus a user profile will be created). User-to-
user correlation also called “collaborative filtering” (seen in section 2.2) will
produce recommendation based on the similarities between users who have
purchased products or services from a given website.
In Figure 3.1 a few recommendation websites and applications are classified in a two
dimensions graph.
Figure 3 : Recommender websites and applications classification (J. Ben Schafer 1999)
The horizontal axis represents the automation level. A recommendation can be
manual or automatic or both. Manual means that explicit effort by the user is
required. The vertical axis represents the persistence level. A recommendation can
be ephemeral or persistent.

14
On this figure, we can see the “Amazon.com Delivers” is a manual and persistent
application. This feature is an email subscriptions feature that let the user choose
among a list of categories as shown in Figure 4 bellow, in order to be notified by
email of the latest recommendations concerning that category of product. It is manual
because the user has to specify explicitly in which categories he is interested and
persistent because the selected categories will be saved for each user.
Figure 4 : Amazon Delivers E-mail Subscriptions (Amazon.com)
We can use Movielens as an example for the Persistent – Auto zone in the diagram
Figure 2 above. MovieLens is a research site run by GroupLens Research at the
University of Minnesota which is a movie recommender where we indicate some
number of our preferred movies at least 15 to be exact and the website generates
movie recommendations using the technology collaborative filtering. It is automatic
because the recommendations are generated automatically and it is persistent
because it recalls the customer each time he connects, to retrieve his profiles which
allow it to give him a movie recommendations that are somehow close to what he
desires.
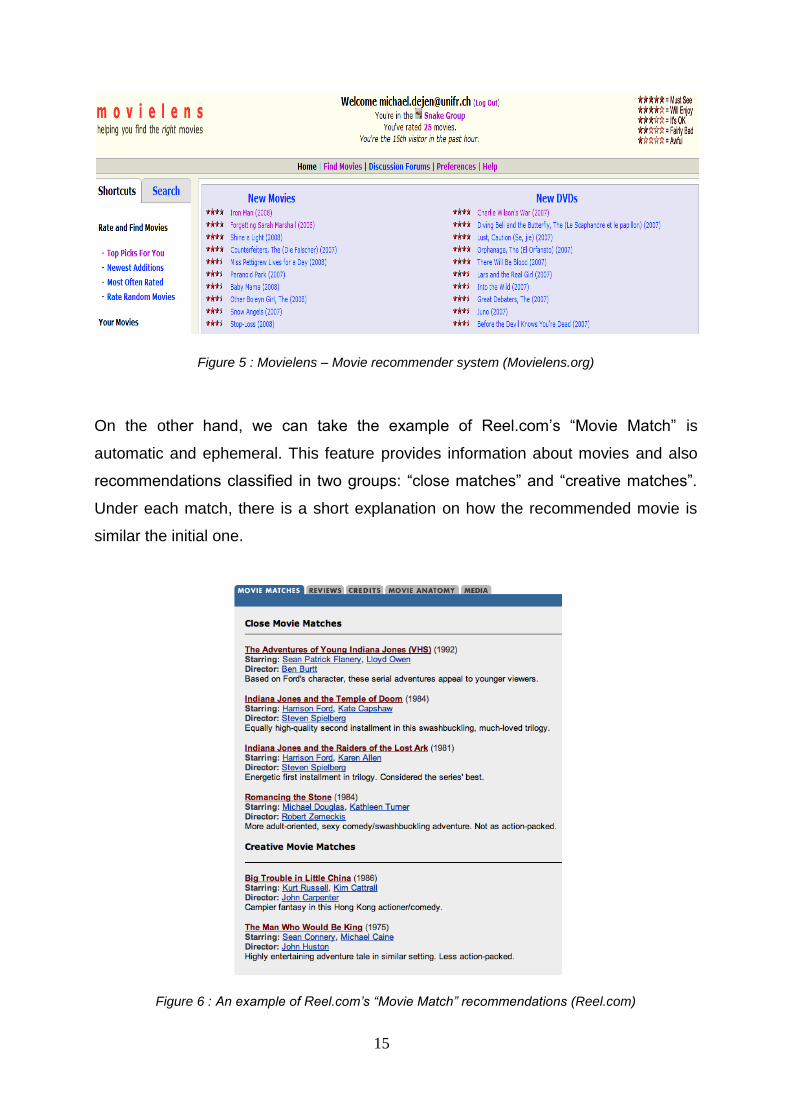
15
Figure 5 : Movielens – Movie recommender system (Movielens.org)
On the other hand, we can take the example of Reel.com’s “Movie Match” is
automatic and ephemeral. This feature provides information about movies and also
recommendations classified in two groups: “close matches” and “creative matches”.
Under each match, there is a short explanation on how the recommended movie is
similar the initial one.
Figure 6 : An example of Reel.com’s “Movie Match” recommendations (Reel.com)

16
It is automatic because the movie recommendations are made without any effort of
the user and ephemeral because previous searches and navigations aren’t saved by
the system.
We can use again as an example the Amazon’s “Customers who Bought” theory for
the zone Ephemeral – Auto in the Recommender websites and applications
classification diagram Figure 3 above. “Customer who Bought” proposal from
Amazon is automatic because there is no human (client) interference; it’s the system
which recommends the other related products (books) which were bought by
previous clients who bought the product which we are about to buy. It is Ephemeral
because once we quit the page and return back after a while the system do not recall
us.
Figure 7 : Amazon's "Customers Who Bought" recommender (Amazon.com)
3.3 Explicit feedback VS Implicit feedback
The information saved in a user’s profile can be collected through either explicit or
implicit feedback. The former is the most widely used in today’s recommender
systems and the most common example for an explicit feedback is asking a user to
give a rating for item he has purchased on a sliding scale. But this kind of feedback’s
main disadvantages is that the user has to provide an effort and give ratings on items
he has purchased or used (e.g. a read article) to make the recommender system
work.
On the other side, implicit feedback is based on observations of a user’s behavior in
order to extract conclusions about his preferences and tastes and in that way
automate the rating process. The observable behaviors can be the following:
navigation on a page, mouse clicks, period of time spent on a page, bookmarking of
a page, following a hyperlink, cutting and pasting potion of text etc. All these

17
behaviors indicate different degrees of interest for a particular product or service.
Thus a user bookmarking a page which contains an article about sport cars will
indicate a strong interest of that user for that subject. But on the other hand, following
a hyperlink isn’t an important enough action to make conclusions about a user’s
preferences. In order to measure the relation between implicit and explicit feedback,
(Mark 2001) have implemented a recommender system that records the entire user’s
actions on a web browser and also asks for explicit rating of each page of the
website he visits. Through that experimental web interface, several observations
have been made like:
When a user spends a long time on a single webpage he also gives a good
explicit rating for that webpage. So this means that the period of time spent on
a page is a good interest indicator.
Mouse clicks aren’t a good interest indicator because the users who have
made a lot of clicks on a page haven’t all given a good explicit rating for that
page.
These results prove that an implicit feedback recommender system is a possible
solution and that would make such systems become more user friendly for
customers. (Wikipedia.org; Douglas W. Oard 1998; Mark 2001)

18
4
Privacy concerns
4.1 Main aspects
For the recommendations to be as accurate and useful as possible for the
customers, the recommender system needs to know as much as possible about
them. This collection of personal information can be done with or without the user’s
awareness. Indeed the personal data collected by an e-commerce website is done
through several ways like:
Web forms in which users provide their identification information (name,
address, e-mail address, phone number) or transactional information (account
number, shipping address).
Explicit ratings on products or services which will reveal the customers
preferences and tastes.
Implicit feedback (as seen in section 3.3) or identification information such as
the IP address of the user’s machine.
Due to this lack of anonymity, customers want to be able to control how their
personal information are being treated by e-commerce websites and be sure that
their data will not be used in some fraudulent manner.
As seen in section 2.2, collaborative filtering recommendations are based on a
community of users having similar interests but who don’t necessary know each
other. This linking between users can cause non respect of privacy concerns. Given
the fact that the preferences of one customer are used to compute recommendations
to another the question that has to be taken into consideration is which information
about that initial customer will be revealed to the recommendation user? This is why
there should be a balance between the opportunities for community building and the
respect of privacy concerns. For a better understanding of that aspect, we can take

19
the example of the collaborative filtering website PHOAKS (People Helping One
Another Know Stuff) which was created to help people help each other to find
appropriate and relevant web resources. As explained on the PHOAKS’ website, this
recommender system works in the following way (Phoaks.com): people post their
opinions of web resources in Usenet Netnews. Around the clock, PHOAKS reads,
classifies, abstracts and tallies those opinions automatically. PHOAKS' pages here
reflect the results. So this means that people who posted their opinions on the
original web resource don’t know how theirs opinions will be treated by PHOAKS
neither who is going to access this information.
To avoid privacy problems, one solution would be to get the information out of its
context so that people accessing it afterwards can’t know form where it comes and
who originated it. But this would put a limit on community building and giving the
users the opportunity to contact the people with who they have common interests.
One other solution that would provide a good balance between community building
and privacy is to create a notion of trust between the users and the recommender
system in a way that the latter only puts both parties in contact but let them chose
which information they would like to share with each other.
In the context of e-commerce websites, privacy polices have been founded in order
to insure their customers that their personal data will not be used in a fraudulent
way.(Loren Terveen 2001)
4.2 Privacy policies
Privacy policies are used by e-commerce websites in order to explain their customers
which information they collect, how it will be used, who will be able to access this
personal information and which security measures are taken to avoid unwanted
dissemination or use of their customers personal data (Wikiperdia.org). Each
company has its own privacy policy which contains several statements like:
The information collected will not be provided to any third party without the
customer’s awareness and authorization.
The customer’s email address or phone number will not be used for
advertising purpose.
Etc.

20
The privacy policies will help customers have a more trustful relationship with
businesses as they expect that the statements made will to be respected which is not
always the case.
Indeed in many cases, those statements are written in a confusing way which makes
them difficult to understand for the users. In addition, some companies reserve the
right to change those statements without having to notice their customers and to sell
or exchange their personal data with third parties.
A user can’t be absolutely sure that privacy policies will be followed by the
companies who state them as long as there is no standardization. Fortunately, those
standards exist and are represented by banners which e-commerce websites can put
on their pages to legitimate their privacy policy in order to reduce the lack of
confidence and build a more trusting environment for customers. Two of those
brands are TRUSTe and BBBOnline. This kind of standard can have several
advantages according to a survey conducted by (Businessweek.com 1998):
Customers who already use web services declare that they would increase
their use if privacy was guaranteed
Security of the personal data would affect the customer’s decision to make
online purchases
Customers who are reticent to use web services would begin using them if
their privacy was assured.
In order to have the right of putting the banner of a brand like TRUSTe, e-commerce
websites have to agree to the following requirements (Paola 1999):
Notice: The Web site must post a privacy statement linked from the home
page, which includes disclosure of the site’s information gathering and
dissemination practices. TRUSTe works with the Web site to develop
comprehensive privacy statements that are easy to read and understand.
Choice: The Web site must provide, at a minimum, the ability for users to opt-
out of having their personal information used by third parties for secondary
purposes.
Security: The Web site must implement reasonable procedures to protect
personal information from loss, misuse, or unauthorized alteration.

21
Data quality and access: The Web site must provide a mechanism for
consumers to correct inaccuracies in their information.
Verification and oversight: TRUSTe provides assurance to users that the site
is following its stated privacy practices through initial and periodic reviews,
seeding, and compliance reviews.
But regrettably not all e-commerce websites have adopted these privacy seal
program and there are still many having privacy issues. (J. Ben Schafer 2001)
4.3 Platform for Privacy Preferences
“The Platform for Privacy Preferences Project (P3P) enables Websites to express
their privacy practices in a standard format that can be retrieved automatically and
interpreted easily by user agents. P3P user agents will allow users to be informed of
site practices (in both machine- and human-readable formats) and to automate
decision-making based on these practices when appropriate. Thus users need not
read the privacy policies at every site they visit” (W3C 2007).
This technology provides a user friendly solution for user’s of a website to deal with
privacy policies and it has several benefits:
Many websites post privacy policies but only a few users will read them. And
most of those who take the time to read them, will not understand all
statements. With P3P, users only have to specify their privacy settings to their
agent (i.e. their web browser or other web tools) and the latter will read and
evaluate privacy policies on their behalf. This automation is made possible
because website’s privacy policies are encoded in an XML machine-readable
format.
Users can control their personal data and decide which information they want
to share with websites. For example a customer might want to share his email
address only if the e-commerce website agrees to use it for a particular
transaction in order to avoid any spamming.
Since customers entrust their personal information to their agent, they do not
have to retype them every time they access a new website.

22
To avoid the sharing of customers personal data between e-commerce websites,
P3P agents establish a unique cryptographic identity called Pairwise Unique Identifier
(PUID) with each website. In this way, each e-commerce website knows a given
customers by a different PUID and there no link made between this PUID and the
customer’s real identity. In addition, this mechanism will not prevent a collaborative
recommender system to make good recommendations because it only needs to
know the user’s actions on a website to generate those recommendations.
An individual can also create multiple identities to represent multiple shopping
modalities. For instance, parents can choose to have different identities while
shopping for themselves and while shopping for their children. That would facilitate
the generation of recommendations since the system will know what category of
products should be recommended. (J. Ben Schafer 2001; Cranor 2003)

23
5
Marketing perspectives
5.1 Contributions to E-Commerce
According to (Pine 1993), companies need to shift from the old world of mass
production where “standardized products, homogenous markets, and long product
life and development were the rule” to the new world where “variety and
customization supplant standardized products”. Indeed the degree of competition in
the virtual world of e-commerce is very high and companies can’t limit themselves to
produce a single product to satisfy all their customers’ needs but products and
services have to be personalized for each of them. But this variety has increased the
load of information given to the customers and thus made it more complicated to find
what best suits their needs. This is where recommender systems will help by making
recommendations based on customers’ interests and preferences.
These systems will boots sales of e-commerce websites in three different ways (J.
Ben Schafer 1999):
Making browsers become buyers: by helping customers to find what they
need, recommender systems will enhance the buying process
More cross-sell: additional products will be suggested to customers in order to
increase the size of their cart. For instance, Amazon.com recommends
products that have been frequently purchased by customers who purchased
the selected product.
Build Loyalty: the value-added relationship created by recommender systems
between e-commerce website and their customers will help building loyalty.
Website which best understand customers needs and suggest personalized
products and service will have loyal customers who will prefer that particular
website or their future purchase even if competitors proposes the same items.

24
5.2 Business Models for cost recovery
To cover a recommender system’s maintenance costs, business models have to be
considered. (Paul 1997) suggest several possible solutions:
Charge recipients of recommendations either through subscriptions or pay-
per-use.
Websites using a recommender system can demand advertiser support i.e.
companies can advertise their products on the recommender website. But
there is a risk of corruption here because recommendation can be biased in
favor to the advertisers. Indeed since the latter are paying a fee for their ads to
be displayed and because the website needs that financial support such
practices often occur. Therefore, recommender systems have to be careful
that users will be able to make the difference between a recommendation and
an advertisement in order to remain credible to them.
Charge owners of the items being recommend i.e. a publisher who wants his
books to be recommended by the system has to pay a fee. In this case the
same problem as the preceding point can happen since recommendations are
subject to a fee the item owners will want their products to be recommended in
priority.
5.3 Recommendation delivery
The way how recommendations are delivered to the customers is an important
aspect that has to be taken into consideration during the design process of a
recommender system. There are three main technologies e-commerce websites can
use to deliver recommendations to their customers (J. Ben Schafer 2001):
Push technology: the main goal of this technology is to reach the customer
when he is not interacting with the e-commerce website in order to make him
come back to make further purchases. E-mails are the most common means
used for this kind of recommendation delivery. For instance, eBay is sending
periodically emails containing new items sold by customers’ favorite sellers in
order to solicit their interest.

25
Pull technology: the recommendation display is controlled by the customer in
this case. The system will inform the customer that recommendations are
available but will not display them he requests them. Top 10 list of products is
an example of pull technology.
Passive technology: in this case, recommendations will be delivered to
customers while they are interacting with the e-commerce website and thus
are receptive to the idea of receiving recommendations. An example of
passive recommendation delivery is Amazon.com’s “Customer Who Bought”
which displays the products which customers who bought the selected item
also purchased. This technology will help increasing cross-sells as seen in
section 5.1. One weakness passively delivered recommendations delivered
could have is not to be noticed by the customers.
The most used technologies in today’s e-commerce websites are push and passive
technologies. The former to bring customers back and the latter to make
recommendations on their website.

26
6
Conclusion
During this seminar we have seen that recommender systems have made it possible
for users to find products and services that best match their needs and preferences.
Indeed given the overload of information on the World Wide Web, this technology is
an adapted response to the users’ need for personalization and helps e-commerce
websites to create value for their customers in order to build customer satisfaction
and loyalty.
The contribution asked from the user’s side has its advantages and drawbacks.
Ratings and reviews will let users share their opinions on products and services they
have purchased and will give the opportunity for users looking for a particular product
or service to know what other users have experienced with those items. On the other
hand, asking a user to leave feedback about items is a time consuming effort and
only customers who are aware of what recommender systems can offer will provide
that effort constantly. Indeed users’ profile has to be kept update in order for the
recommendation to be always accurate and in relation with users’ current interests
and preferences. That being said, we believe that further work has to be done in
gathering personal information through implicit feedback, without decreasing the
accuracy of recommendations, which will make recommender systems much more
user friendly.
Given the increasing popularity of mobile business, we believe that recommender
systems should integrate contextual information in order to make recommendations
not only based on users’ interests but also on users’ current location. That would
make recommender systems even more attracting for customers who will get
recommendations everywhere.

27
References
Al Mamunur, R. I., Albert Dan, Cosley Shyong, K. Lam Sean, M. McNee Joseph, A. Konstan
John, Riedl (2002). Getting to know you: learning new user preferences in recommender
systems. Proceedings of the 7th international conference on Intelligent user interfaces. San
Francisco, California, USA, ACM.
Alexander Felfernig, G. F., Lars Schmidt-Thieme (2007). "Guest Editors' Introduction :
Recommender Systems." IEEE Intelligent Systems 22(3): 18-21.
Amazon.com. "Amazon Delivers." Retrieved 01.05.08, from
https://www.amazon.com/gp/gss.
Amazon.com. "Customer Who Bought." Retrieved 01.05.08, from http://www.amazon.com.
Businessweek.com. (1998). "A Little Net Privacy, Please." Retrieved 28.04.08, from
http://www.businessweek.com/1998/11/b3569104.htm.
Cranor, L. F. (2003). "P3P: Making Privacy Policies More Useful." IEEE Security and
Privacy 1(6): 50-55.
Douglas W. Oard, J. K. (1998). "Implicit Feedback for Recommender Systems." Proceedings
of the American Association for Artifcial Intelligence Workshop of Collaborative Systems.
Gediminas Adomavicius, A. T. (2005). "Toward the Next Generation of Recommender
Systems: A Survey of the State-of-the-Art and Possible Extensions." IEEE Transactions on
Knowledge and Data Engineering 17(6): 734-749.
J. Ben Schafer, J. A. K., John Riedl (2001). E-Commerce Recommendation Applications,
Kluwer Academic Publishers. 5: 115-153.
J. Ben Schafer, J. K., John Riedi (1999). Recommender systems in e-commerce. Proceedings
of the 1st ACM conference on Electronic commerce. Denver, Colorado, United States, ACM.
Loren Terveen, W. H. (2001). Beyond Recommender Systems: Helping People Help Each
Other. HCI In the New Millennium. J. Carroll, Addison-Wesley: 1-21.
Mark, C. P., Le Makoto, Wased David, Brown (2001). Implicit interest indicators.
Proceedings of the 6th international conference on Intelligent user interfaces. Santa Fe, New
Mexico, United States, ACM.
Marko, B. Y., Shoham (1997). Fab: content-based, collaborative recommendation, ACM. 40:
66-72.

28
Movielens.org. "Movielens - Movie recommender system." Retrieved 01.05.08, from
http://www.movielens.org.
Paola, B. (1999). TRUSTe: an online privacy seal program, ACM. 42: 56-59.
Paul, R. H., R. Varian (1997). Recommender systems, ACM. 40: 56-58.
Phoaks.com. "People Helping One Another Know Stuff (PHOAKS)." Retrieved 29.04.08,
from http://www.cs.indiana.edu/~sithakur/l542_p3/index.html.
Pine, B. J. (1993). Mass Customization: The New Frontier in Business Competition. Boston,
Massachusetts, Havard Business School Press.
Reel.com. "Movie Match." Retrieved 02.05.08, from www.reel.com.
Robin van Meteren, M. v. S. (2000). Using Content-Based Filtering for Recommendation.
University of Amsterdam, Netherlands.
W3C. (2007). "Platform for Privacy Preferences Project - Enabling smarter Privacy Tools for
the Web." Retrieved 29.04.08, from http://www.w3.org/P3P/.
Wikipedia.org. "Recommender System." Retrieved 25.04.08, from
http://en.wikipedia.org/wiki/Recommender_system.
Wikiperdia.org. "Privacy Policies." Retrieved 28.04.08, from
http://en.wikipedia.org/wiki/Privacy_policy.