universidad distrital francisco jose de caldas facultad de...
TRANSCRIPT

UNIVERSIDAD DISTRITAL
FRANCISCO JOSE DE CALDAS
FACULTAD DE INGENIERÍA
TRABAJO DE GRADO
ESPECIALIZACIÓN EN PROYECTOS INFORMÁTICOS – INGENIERÍA DE
SOFTWARE
DISEÑO DE UN COMPONENTE PROTOTIPO PARA MEJORAR EL PROCESO DE
INSCRIPCIÓN AUTOMÁTICA DE ESPACIOS ACADÉMICOS EN EL SISTEMA DE
GESTIÓN ACADÉMICA DE LA UNIVERSIDAD DISTRITAL.
AUTORES:
JENNY PAOLA ORTIZ PIMIENTO 20162199012
DEIVID ALEXANDER SUAREZ NIÑO 20162099024
DIRECTOR:
PH.D, MSC. ROBERTO FERRO ESCOBAR.
CODIRECTOR
JHON CASTELLANOS JIMENEZ
BOGOTÁ 2017

RESUMEN
En la actualidad, la tecnología ha pasado a ser parte de la vida de la sociedad y por ende del
sistema educativo introduciendo los avances tecnológicos en las instituciones educativas, a pesar
de la resistencia de los sistemas educativos para integrarlos (Blázquez, 2001). En este sentido, las
aplicaciones de software han implantado la gestión académica de diferentes centros educativos
como ayuda para administrativos, docentes y alumnos de los diferentes campos del saber
(Becker, 1999-2011).
Este trabajo tiene como meta el análisis del proceso de inscripción automática de espacios
académicos, existente dentro del sistema de gestión académica de la Universidad Distrital,
teniendo en cuenta sus componentes, comportamiento, rendimiento y efectividad en la tarea que
debe realizar, con la finalidad de proponer otra alternativa que permita la mejora en su
funcionamiento y la calidad de sus resultados, buscando así minimizar el impacto que puede
causar a los estudiantes y a la universidad, y los posibles problemas o deficiencias en la
inscripción automática de sus espacios académicos.
Teniendo en cuenta lo anterior en este documento se plasma el proceso seguido en el
desarrollo del DISEÑO DE UN COMPONENTE PROTOTIPO PARA MEJORAR EL
PROCESO DE INSCRIPCIÓN AUTOMÁTICA DE ESPACIOS ACADÉMICOS, EN EL
SISTEMA DE GESTIÓN ACADÉMICA DE LA UNIVERSIDAD DISTRITAL. En primer
lugar, se realiza una breve descripción de la organización, estructura y normatividad vigentes con
los que cuenta la Universidad Distrital y que se deben tener en cuenta en el desarrollo de este
proyecto, seguido a ello se realiza el análisis del actual funcionamiento del sistema de gestión
académico, en el proceso de inscripción automática y registro de datos de espacios académicos
teniendo en cuenta sus diferentes variables, para determinar la información necesaria para su
modelado, así mismo se realiza el levantamiento de información, tratamiento, selección y
depuración de la misma.
Posteriormente se valida la implementación con el tratamiento de reglas, ejecución,
optimización, almacenamiento, y construcción de dicho diseño y sus pruebas de funcionalidad.
Por último, se muestran las conclusiones obtenidas de este proyecto.
Palabras Clave
Sistema de gestión académica, espacios académicos, efectividad, calidad.

ABSTRACT
Nowadays, technology has become part of the life of society and therefore of the
educational system, introducing technological advances in educational institutions, despite the
resistance of educational systems to integrate them (Blázquez, 2001). In this sense, software
applications have implemented the academic management of different educational centers as an
aid to administrative staff, teachers and students of different fields of knowledge (Becker, 1999-
2011).
This work aims at analyzing the process of automatic enrollment of academic spaces,
existing within the academic management system of the District University, taking into account
its components, behavior, performance and effectiveness in the task that must be performed, with
the aim of To propose another alternative that allows the improvement in its operation and the
quality of its results, thus seeking to minimize the impact it can cause to students and the
university, and the possible problems or deficiencies in the automatic registration of their
academic spaces.
Considering the foregoing in this document, the process followed in the development of the
DESIGN OF A PROTOTYPE COMPONENT TO IMPROVE THE PROCESS OF
AUTOMATIC INSCRIPTION OF ACADEMIC SPACES, IN THE ACADEMIC
MANAGEMENT SYSTEM OF THE DISTRICT UNIVERSITY. First, a brief description of the
organization, structure and regulations in force with which the District University is being
carried out and which must be taken into account in the development of this project, followed by
the analysis of the current operation of the system Of academic management, in the process of
automatic registration and registration of data of academic spaces taking into account their
different variables, to determine the information necessary for its modeling, as well as the
information gathering, treatment, selection and purification of the same.
Later, the implementation is validated with the treatment of rules, execution, optimization,
storage, and construction of such design and its functional tests. Finally, the conclusions drawn
from this project are shown.
Keywords
System of academic management, academic spaces, effectiveness, quality

AGRADECIMIENTOS
A nuestros padres, por su apoyo y comprensión incondicional.
A la Universidad Distrital Francisco José de Caldas, en su Facultad de Ingeniería al
permitirnos realizar nuestra especialización.
A nuestro compañero de la oficina asesora de sistemas por orientarnos atentamente en el
desarrollo de este proceso.
A nuestro director Roberto Ferro por su acompañamiento, disponibilidad, lineamientos y
conocimiento en el desarrollo de este proyecto.
A cada uno de nuestros profesores y compañeros quienes nos acompañaron en nuestro
proceso de formación.

TABLA DE CONTENIDO
RESUMEN ............................................................................................................................ 2
ABSTRACT .......................................................................................................................... 3
INTRODUCCIÓN .............................................................................................................. 11
PARTE I FUNDAMENTACIÓN DE LA INVESTIGACIÓN ....................................... 12
CAPÍTULO 1 DESCRIPCIÓN DE LA INVESTIGACIÓN .......................................... 12
1.1. Planteamiento Del Problema ..................................................................................... 12
1.2. Objetivos de la Investigación ..................................................................................... 13
1.2.1 Objetivo General .................................................................................................. 13
1.2.2 Objetivos Específicos ........................................................................................... 14
1.3 Justificación de la Investigación ................................................................................. 14
1.3.1 Justificación Teórica ............................................................................................ 14
1.3.2 Justificación Práctica ............................................................................................ 14
1.4 Hipótesis de la Investigación ...................................................................................... 15
1.5 Aspectos Metodológicos ............................................................................................. 15
1.5.1 Tipo De Estudio ................................................................................................... 15
1.5.2 Método de investigación ...................................................................................... 16
1.5.3 Fuentes y técnicas para la recolección de la información .................................... 16
1.5.4 Tratamiento de la información ............................................................................. 18
CAPÍTULO 2 MARCOS DE REFERENCIA ................................................................. 18
2.1 Marco Institucional ..................................................................................................... 18
2.1.1 Reseña Histórica de la Universidad Distrital ....................................................... 18
2.2 Marco Teórico ............................................................................................................. 19
2.2.1 Cobertura estudiantil ............................................................................................ 21
2.2.2 Aspectos Normativos ........................................................................................... 21
2.2.3 Sistema de Gestión Académica (SGA) – Cóndor .................................................... 23
2.2.4 Operación del sistema de gestión académica Cóndor .............................................. 24
2.2.5 Situación de la retención de estudiantes .................................................................. 24
2.2.6 La institución Educativa ....................................................................................... 25

6
2.2.7 Ejemplos de Sistemas de Gestión Académica en Colombia ................................ 26
2.2.8 Importancia de la gestión académica ................................................................... 29
2.3 Algoritmos de Optimización o Solución de Problemas ............................................. 30
2.4 Aspectos Legales ........................................................................................................ 32
PARTE II DESARROLLO DE LA INVESTIGACIÓN................................................. 33
CAPITULO 3 DESCRIPCIÓN DE LA SOLUCIÓN ...................................................... 33
3.1 Levantamiento de la información ............................................................................... 33
3.2 Análisis y selección de la información mediante la herramienta de ayuda Weka ...... 34
3.3 Selección de Las Herramientas De Desarrollo ........................................................... 35
3.3.1 Sistemas basados en Reglas ................................................................................. 35
3.3.2 Ventajas ................................................................................................................ 35
3.3.3 Aplicaciones Existentes........................................................................................ 35
3.3.4 Optaplanner .......................................................................................................... 37
3.3.5 Wildfly 10 ............................................................................................................ 38
3.3.6 Kie workbench (Drools workbench) .................................................................... 38
3.3.7 JBoss Drools ......................................................................................................... 39
CAPITULO 4 COMPONENTE DE INSCRIPCIÓN AUTOMATICA ........................ 39
4.1. Análisis proceso de inscripción automática de espacios académicos. ....................... 39
4.2 Análisis de documentación existente .......................................................................... 41
4.3 Análisis del módulo actual .......................................................................................... 41
4.3.1 Arquitectura de la solución .................................................................................. 41
4.3.2 Análisis de código fuente y algoritmo de solución .............................................. 42
4.3.3 Análisis integración del componente actual ......................................................... 45
4.4 Análisis y diseño del componente .............................................................................. 45
4.4.1 Infraestructura tecnológica ................................................................................... 46
4.5 Componentes de software para operación e integración............................................. 48
4.5.1 Optaplanner Solution............................................................................................ 48
4.5.2 Solución de planificación ..................................................................................... 49
4.6 Modelo de Datos Oracle ............................................................................................. 52
4.7 Modelo De Datos Mysql ............................................................................................. 55
4.8 Implementación del componente ................................................................................ 56
4.9 Implementación de componentes de software ............................................................ 57
4.9.1Componentes propios de operación ...................................................................... 57
4.9.2 Componentes de integración o interoperabilidad ................................................. 61
4.9.3 Implementación de reglas de negocio .................................................................. 62
4.10 Pruebas del componente ........................................................................................... 67
4.10.1 Pruebas de ejecución e integración .................................................................... 67
4.10.2 Estudio Experimental con algoritmos ................................................................ 72
PARTE III CIERRE DE LA INVESTIGACIÓN ........................................................... 76
CAPITULO 5 CONCLUSIONES ..................................................................................... 76
5.1 Verificación, Contraste y Evaluación de los Objetivos .............................................. 76

7
5.2 Síntesis del Modelo Propuesto .................................................................................... 77
5.3 Aportes Originales ...................................................................................................... 77
CAPITULO 6 TRABAJOS O PUBLICACIONES DERIVADAS ................................ 77
6.1 Líneas de Investigación Futuras ................................................................................. 77
6.2 Trabajos de Investigación Futuros .............................................................................. 78
BIBLIOGRAFÍA ................................................................................................................ 79
PARTE V ANEXOS ........................................................................................................... 82
ANEXO A. ANÁLISIS Y SELECCIÓN DE LA INFORMACIÓN MEDIANTE LA
HERRAMIENTA DE AYUDA WEKA ............................................................................ 82
1. ¿Qué es la minería de datos? ..................................................................................... 83
2. Árbol de decisión ...................................................................................................... 85
3. Algoritmo J48 ............................................................................................................ 86
4. ¿Qué es la herramienta Weka? .................................................................................. 87
5. Fases del análisis de datos ......................................................................................... 87
5.1 Fase de Selección .................................................................................................... 87
6. Resultados ................................................................................................................. 89
ANEXO B. DICCIONARIO DE DATOS MODELO ORACLE ................................... 99
ANEXO C. DICCIONARIO DE DATOS MODELO MYSQL ................................... 109
ANEXO D. MANUAL TÉCNICO .................................................................................. 110
Objetivo .............................................................................................................................. 110
Alcance ............................................................................................................................... 110
1. Configuración de Kie-Workbench 6.5.0.................................................................. 110
2. Configuración del proyecto en Kie Workbench ...................................................... 115
3. Configuración de la aplicación para realizar el llamado del componente de reglas y
configuración de workbench. .......................................................................................... 124
4. Configuración de componente PreinscripcionAuto ................................................. 125
5. Configuración bases de datos PreinscripcionAuto .................................................. 126
Configuración nivel de logging ...................................................................................... 126
6. Configuración del solucionador .............................................................................. 127

8
TABLA DE FIGURAS
Figura 1 Ejemplos haciendo uso de Optaplanner ................................................................. 38
Figura 2 Diagrama de Procesos inscripción automática de espacios académicos ................ 40
Figura 3 Diagrama de componentes preinscripción automática actual ................................ 41
Figura 4 Diagrama de secuencia componente actual............................................................ 45
Figura 5 Componentes nueva preinscripción automática ..................................................... 47
Figura 6 Componentes que conforman la preinscripción automática .................................. 48
Figura 7 Explicación dominio de solución de Optaplanner ................................................. 49
Figura 8 Modelo de Datos Oracle......................................................................................... 54
Figura 9 Estructuras de datos MySql .................................................................................... 56
Figura 10 Diagrama de despliegue componte preinscripción automática ............................ 57
Figura 11 Librerías usadas en el desarrollo del proyecto ..................................................... 58
Figura 12 Clases del dominio de solución de planificación ................................................. 60
Figura 13 Integración con el KieWorkbench ....................................................................... 61
Figura 14 Generación de calendarios ................................................................................... 75
Figura 15 Mapa conceptual de Minería de datos .................................................................. 84
Figura 17Cargue de información mediante conexión a base de datos PostgreSQL ............. 90
Figura 18 Detalle Variable Proyecto Curricular ................................................................... 91
Figura 19 Detalle Variable Estrato ....................................................................................... 91
Figura 20 Detalle Variable Género ....................................................................................... 92
Figura 21 Detalle Variable Acuerdo ..................................................................................... 93
Figura 22 Detalle Variable Localidad .................................................................................. 93
Figura 23 Detalle Variable Asignatura ................................................................................. 94
Figura 24 Detalle Variable Creditos_asignatura .................................................................. 94
Figura 25 Detalle Variable Estado_Actual ........................................................................... 95
Figura 26 Detalle Variable Edad .......................................................................................... 95
Figura 27 Detalle Variables veces Cursó y Aprobó ............................................................. 96
Figura 28 Detalle Variable Numero Asignatura ................................................................... 96
Figura 29 Informe de salida en la calidad del modelo de clasificación ................................ 97
Figura 30 Árbol de decisión generado bajo el algoritmo J48 ............................................... 98
Figura 31 Reglas encontradas con algoritmo de asociación weka.associations.Apriori -N 10
-T 0 -C 0.9 -D 0.05 -U 1.0 -M 0.1 -S -1.0 -c -1 .................................................................... 98

9
ÍNDICE DE TABLAS
Tabla 1 Fuentes Para la recolección de la información. Fuente: Elaboración Propia ......... 17
Tabla 2 Acuerdos Normativos Expedidos por el Consejo Superior Universitario. Fuente:
Elaboración Propia ............................................................................................................... 22
Tabla 3 Situación de retención de estudiantes. Fuente: Oficina Asesora de sistemas (OAS)
24
Tabla 4 Tabla Comparativa de Soluciones y motores de planificación. Fuente: Elaboración
Propia 37
Tabla 5 Descripción Método REST Obtener Mejor solución. Fuente: Elaboración Propia 50
Tabla 6 Descripción Método REST Solicitar Planificación de Asignaturas. Fuente:
Elaboración Propia .............................................................................................................. 50
Tabla 7 Descripción Método REST Terminar la planificación de forma temprana. Fuente:
Elaboración Propia .............................................................................................................. 51
Tabla 8 Descripción Método REST Consultar estado de planificación. Fuente: Elaboración
Propia 51
Tabla 9 Descripción Método REST Publicar Horarios. Fuente: Elaboración Propia ......... 52
Tabla 10 Reglas de restricción fuertes negativas. Fuente: Elaboración Propia ................... 65
Tabla 11 Reglas de restricción suave negativas. Fuente: Elaboración Propia..................... 66
Tabla 12 Reglas de restricción suave positivas. Fuente: Elaboración Propia ..................... 66
Tabla 13 Descripción caso de prueba Ejecución del motor de planificación. Fuente:
Elaboración Propia .............................................................................................................. 68
Tabla 14 Descripción Caso de prueba Consulta estado de planificación. Fuente:
Elaboración Propia .............................................................................................................. 70
Tabla 15 Descripción caso de prueba Terminado temprano de planificación. Fuente:
Elaboración Propia .............................................................................................................. 71
Tabla 16 Descripción caso de uso Publicar Horarios. Fuente: Elaboración Propia ............ 72
Tabla 17 Casos de prueba para los algoritmos de heurísticas. Fuente: Elaboración Propia 72
Tabla 18 Máquina usada para las pruebas. Fuente: Elaboración Propia ............................. 73
Tabla 19 Puntajes obtenidos con algoritmos de construcción. Fuente: Elaboración Propia 74
Tabla 20 Contraste Objetivos Vs Evidencias Cumplimiento. Fuente: Elaboración Propia 77
Tabla 21Detalle Tabla ACCALEVENTOS .......................................................................... 99
Tabla 22 Detalle Tabla ACCRA ......................................................................................... 100
Tabla 23 Detalle Tabla ACCURSOS ................................................................................. 102
Tabla 24 Detalle Tabla ACEST .......................................................................................... 103

10
Tabla 25 Detalle Tabla ACESTADO ................................................................................. 104
Tabla 26 Detalle Tabla ACHORARIOS ............................................................................ 105
Tabla 27 Detalle Tabla ACINS .......................................................................................... 106
Tabla 28 Detalle Tabla ACINSDEMANDA ...................................................................... 107
Tabla 29 Detalle Tabla ACINSPRE ................................................................................... 107
Tabla 30 Detalle Tabla ACTABLAHOMOLOGACION .................................................. 108
Tabla 31Detalle Tabla sga_clasificacion_estudiantes ....................................................... 109
Tabla 32 Detalle Tabla sga_ejecuta_inscripcion_auto ....................................................... 109
Tabla 33 Detalle Tabla sga_rankingpreinsdemanda ........................................................... 109

11
INTRODUCCIÓN
Las universidades e instituciones de educación superior se enfrentan en la actualidad a
un reto grande: garantizar la articulación de los procesos administrativos con el desarrollo
propio de la academia; es decir, la optimización de la administración de sus recursos y el
enfoque hacia la calidad en la prestación de sus servicios (De Alba, 1992).
En este sentido, los sistemas de información y de comunicación posibilitan la
realización y mejora de los procesos académico-administrativos, de manera transparente y
pública, apoyando la toma de decisiones, como debe ser en toda universidad (García de
Fanelli, 1998).
El cambio en los sistemas de información y especialmente en lo referente a la
utilización de Internet, en nuestro país, mostró un aumento del 27% en 2003 al 64% en
2011 como lo indica (Ávila, 1999-2011). Partiendo de ello la universidad sin ser ajena al
desarrollo de las tecnologías de información requirió adaptar su sistema de información
académica a esta nueva tendencia y esto dio como resultado la creación de un sistema que
permitiera tanto a sus estudiantes como a sus docentes interactuar con la universidad desde
sus casas. De allí surge el Sistema de Información “Cóndor” de la Universidad Distrital en
la Web, el cual, permite a la Comunidad Universitaria tener acceso, desde cualquier sitio, a
la información actual e histórica y realizar los procesos que antes no eran posibles.
Este sistema de información ha sido desarrollado a la medida por el área de tecnología
de la propia universidad y el centro de datos que lo alberga es también propiedad de la
institución. Ha pasado por varias etapas de desarrollo y refinamiento para mantener su
funcionamiento y garantizar la Alta Disponibilidad.
Como parte de la evolución del sistema se concibió la implementación de un
componente de inscripción automática de espacios académicos que redujera la cantidad de
operaciones administrativas destinadas a la inscripción de espacios académicos en los
proyectos curriculares.
De esta forma se ha llevado a cabo un seguimiento y evaluación al Sistema de Gestión
Académica “Cóndor”, teniendo en cuenta el uso de buenas prácticas en diferentes temas
para mantener su funcionamiento y aunque su objetivo base es brindar la posibilidad de
conectar a cada estudiante con la universidad y así a los procesos de registro de espacios
académicos y visualizarlos pudiera realizarse desde cualquier computador con acceso a
internet este proceso presenta algunas deficiencias en su operación.
Esto lleva a pensar en la necesidad que existe por parte de la universidad, de fortalecer
el funcionamiento eficiente de cada componente del sistema de gestión Académica Cóndor,
centrando la atención en el módulo de inscripción automática de espacios académicos y
como optimizarlo de forma tal que su funcionamiento sea el esperado y se solventen las
problemáticas que se presentan actualmente al realizar este proceso.

12
Por tal motivo el presente trabajo busca brindar una posible solución a este proceso, en
donde se hará un análisis previo de su funcionamiento y las mejoras que se pueden
implementar por medio de nuevas herramientas, teniendo en cuenta la información vigente
y los avances que ya se han hecho en el tema.
PARTE I FUNDAMENTACIÓN DE LA INVESTIGACIÓN
CAPÍTULO 1 DESCRIPCIÓN DE LA INVESTIGACIÓN
1.1. Planteamiento Del Problema
Actualmente la universidad Distrital Francisco José de Caldas cuenta con el sistema de
gestión académica “Cóndor”, este sistema abarca diferentes procesos académicos y se
establece como la herramienta de software más importante que soporta las actividades
académicas de la universidad.
Para soportar las actividades académicas semestrales de inscripción de espacios
académicos de los estudiantes, se crearon en el sistema componentes para estos procesos.
Inicialmente se crearon servicios para programar por demanda los espacios académicos de
los estudiantes, donde los mismos deben configurar sus horarios de acuerdo a sus
necesidades, obviamente sometiéndose a las restricciones posibles de cupos, horarios
cruzados, materias perdidas etc., esta actividad debe llevarse a cabo en un tiempo
determinado por el calendario académico.
Buscando disminuir la cantidad de actividades administrativas dedicadas a la
inscripción de espacios académicos, se crearon módulos de inscripción automática,
mediante los cuales se logró que el sistema inscribiera de forma automática espacios
académicos luego del cierre de semestre. Mediante una lógica básica el sistema realizaba la
inscripción de espacios académicos sin tener en cuenta muchos de los aspectos importantes
para los estudiantes, esto llevaba a que siguieran existiendo problemas.
En el primer semestre de 2013, se realizó un cambio en el proceso de inscripción de
espacios académicos agregando una restricción del pago de la matrícula para acceder a los
procesos de inscripción, lo que contribuyó a reducir los problemas generados por inscribir
espacios académicos a personas que no oficializaban matricula (Nieto, 2013) en el Informe
De Auditoria Al Funcionamiento Del Sistema De Información Cóndor.
También fueron creados servicios para la preinscripción de asignaturas, de los que se
esperaban facilitaran la inscripción automática, sin embargo, el sistema no garantiza que
estas sean las que queden inscritas automáticamente, lo que conlleva nuevamente a que se
deba recurrir al módulo de inscripción por demanda el cual posee ya una problemática
definida.

13
De esta forma el proceso de inscripción automática de espacios académicos presenta
inconvenientes en su operación, las cuales tienen repercusiones inmediatas en los
estudiantes, quienes no logran cursar los espacios académicos que pretenden durante los
diferentes periodos académicos o deben lidiar con horarios difíciles de administrar, ya sea
por falta de horarios compactos, o horas de clase que no pueden tomar, estas situaciones
impactan negativamente a los estudiantes, incrementando la cantidad de semestres
necesarios para terminar las materias, dificultando la asistencia a otras, generando
consecuencias institucionales en espacio físico y presupuestales, consecuencias para el
estudiante y consecuencias para la sociedad como lo afirma la oficina asesora de planeación
y control en su informes del año 2011.
Todos estos componentes de software involucrados en la inscripción automática
implementados fuera de la planeación inicial del sistema se crearon informalmente, fuera
de un proceso detallado y analítico, implementando soluciones para atender los problemas
inmediatos de la comunidad estudiantil.
Al no existir un proceso formal no se cuenta con documentación de su funcionamiento,
las reglas de negocio que intervienen, ni las variables que tienen influencia en el mismo. De
esta forma el proceso termina asemejándose a una caja negra, y demanda una fuerte curva
de aprendizaje para comprender su funcionamiento. Por otra parte, su implementación
actual, posee una lógica acoplada, donde las reglas de negocio y el algoritmo de solución
están plasmados en el código fuente, lo que restringe la modificación de las reglas de
negocio (que puede ocurrir al cambiar aspectos de la legislación universitaria), y limita la
parametrización del algoritmo de solución.
Si no se implementan mejoras en los componentes del SGA, los sistemas creados no
lograran mejorar la calidad de sus resultados, y seguirán presentándose los mismos
problemas, adicionalmente es probable que su funcionamiento deficiente facilite la llegada
de la obsolescencia tecnológica al SGA de la universidad.
Una alternativa que se plantea a las debilidades antes mencionadas, consiste en realizar
una mejora al proceso de inscripción automática de espacios académicos, mediante el uso
de un motor de planificación, que permita disminuir estas debilidades; aportando de esta
forma al buen funcionamiento del sistema de gestión académica Cóndor.
1.2. Objetivos de la Investigación
Los objetivos planteados en esta investigación son:
1.2.1 Objetivo General
Diseñar e implementar un componente prototipo que brinde una alternativa, de
solución tecnológica al proceso de inscripción automática de espacios académicos, del

14
sistema de gestión académica de la universidad Distrital, mejorando la arquitectura,
mantenibilidad y capacidad de extensión mediante el uso de motores de planificación.
1.2.2 Objetivos Específicos
Analizar el módulo actual de inscripción automática de espacios académicos,
para obtener el detalle de las reglas aplicadas en el proceso, identificando los
posibles problemas y características que intervienen en el mismo.
Implementar el componente prototipo de inscripción automática con una
arquitectura que facilite la extensión y modificación de la operación de
planificación de espacios académicos
Diseñar un caso de estudio para verificar la validez del prototipo propuesto.
1.3 Justificación de la Investigación
A continuación, se describe la justificación práctica teórica y práctica para la presente
investigación.
1.3.1 Justificación Teórica
Es necesaria la mejora del proceso de inscripción y registro de espacios académicos en
el sistema de gestión académico, para impulsar cambios y contrarrestar deficiencias en su
operación, las cuales tienen repercusiones inmediatas para el estudiante al no poder
completar el horario con las materias que pretende ver durante el semestre y ocasiona
retrasos en el proceso de inicio de su periodo académico, aumentando así el tiempo de
atención y trámites por parte del personal administrativo de la universidad, para formalizar
los procesos mencionados en el Calendario Académico.
Al realizar esta mejora en el proceso de inscripción automática mediante el uso de
motores de planificación se espera minimizar las deficiencias de operación y contribuir a
fortalecer y enriquecer el proceso de inscripción y registro de espacios académicos en el
sistema de gestión académico, apoyando a su vez el riesgo de que un estudiante entre en
prueba académica, exista retención de estudiantes principalmente en el área de ciencias
básicas, la creación de nuevos grupos con mayor cantidad de alumnos y mayor tiempo de
culminación de los estudios para graduarse.
1.3.2 Justificación Práctica
Debido a la necesidad que existe por parte de la universidad, de fortalecer el
funcionamiento eficiente de cada componente del sistema de gestión Académica y
garantizar su alta disponibilidad, en un mejoramiento continuo y progresivo en el proceso
de enseñanza/aprendizaje de estudiantes, y en busca de una mejor calidad de educación y
acreditación, se busca diseñar un componente prototipo para mejorar el proceso de
inscripción automática de espacios académicos en el sistema de gestión académica de la

15
universidad Distrital; de manera tal que se logre el cumplimiento de sus funciones y alcance
un estado de madurez, en donde se considere que la optimización del uso de recursos es
satisfactoria.
1.4 Hipótesis de la Investigación
La alternativa de mejora del proceso de inscripción y registro de espacios académicos
en el sistema de gestión académico mediante el uso de motores de planificación
contrarresta deficiencias que se puedan presentar en su operación, y permite que su
funcionamiento sea eficiente, reduce el tiempo de atención a los estudiantes y disminuye
trámites para formalizar los procesos mencionados en el Calendario Académico
complementando la gestión de la información académica depositada en el SGA de la
Universidad.
1.5 Aspectos Metodológicos
A continuación, se describen los aspectos metodológicos que comprenden la
planeación y organización de los procedimientos que se van a establecer para desarrollar la
presente investigación.
1.5.1 Tipo De Estudio
De acuerdo a los objetivos, el presente tipo de investigación es descriptivo que
permitirá conocer el comportamiento del proceso de inscripción y registro de datos de
espacios académicos con el fin de analizar los resultados y plantear un posible escenario
que optimice su operación.
Para ello se seguirán los siguientes pasos:
a. Análisis del actual funcionamiento del sistema de gestión académico en el proceso
de inscripción automática y registro de datos de espacios académicos, sus diferentes
variables, las normas vigentes, para determinar la información necesaria para su
modelado.
b. Levantamiento de la información por medio de la consulta de los datos necesarios a
través del Sistema de Información Académica de la Universidad Distrital, que
contiene el registro de las inscripciones de espacios académicos. Para esto, se
acotará el contexto a las inscripciones automáticas realizadas desde el año 2010 al
2016/I, sede Bogotá, Facultad de Ingeniería.
c. Tratamiento y depuración de la información donde se verifique que la información
sea válida y completa, para determinar cuáles son los datos que para el caso de

16
estudio tendrán la mejor calidad y serán más relevantes en el proceso de análisis y
desarrollo del componente prototipo.
d. Análisis de la información luego de haber sido depurada mediante la herramienta de
ayuda Weka, con el fin de seleccionar la información más relevante.
e. Instalación de toda la plataforma de software que soportara la separación de capas
lógicas, ejecución de reglas y optimización de salidas mediante motores de
planeación, haciendo uso de KIE como el abanico de soluciones Open Source
especializadas para el tratamiento de reglas, ejecución, optimización,
almacenamiento, y construcción.
f. Registro de los resultados obtenidos y posibles conclusiones del proceso.
1.5.2 Método de investigación
En la investigación se hacen uso de diferentes métodos que nos permitirán conocer,
entender, comprender, saber y proponer soluciones a los problemas expresados e hipótesis
planteadas, en esta investigación, de manera transversal mediante el método dialectico
estaremos continuamente obteniendo información relevante de todo el proceso con los
actores participantes, enfocándonos en las personas de la OAS principalmente. Mediante el
método de observación esperamos obtener una visión general del proceso para entenderlo,
estructurarlo y documentarlo, observaremos también los procesos existentes para identificar
rasgos específicos y luego pasaremos al método de análisis para entender su
funcionamiento.
Durante la búsqueda de posibles problemas del componente actual estaremos usando el
método deductivo e inductivo para entender las relaciones establecidas entre las salidas
erróneas o problemas generados con el sistema y las variables de entrada. Igualmente, al
construir las reglas del nuevo sistema deberemos usar el método inductivo para visualizar el
comportamiento de las reglas ya dentro de un proceso en ejecución.
También habremos de usar el análisis para estructurar la infraestructura tecnológica del
nuevo componente y su arquitectura lógica.
Se deberán usar diferentes métodos de investigación, debido a su naturaleza
interdisciplinar, en la que se aplica una construcción teórica, y una hipótesis corroborable
en el campo practico, por medio de la implementación de la solución planteada.
1.5.3 Fuentes y técnicas para la recolección de la información
Como técnica inicial se usará la entrevista con los interesados del proyecto designados
por la OAS para el seguimiento, usaremos la documentación de las observaciones

17
realizadas en las distintas etapas del proceso investigativo, lo que permitirá no perder de
vista detalles importantes del proceso no documentados.
También se recogerá la información suministrada por los interesados, relacionada o
relevante al tema de investigación, al alcance del personal de la OAS.
Adicional a la información suministrada por el personal de OAS se realizará una
búsqueda para obtener información relacionada con la implementación de sistemas basados
en motores de reglas y motores de planificación, como también se buscará información de
trabajos realizados basados en la misma problemática.
FUENTES SECUNDARIAS DE INFORMACIÓN RECOLECTADAS
DOCUMENTO FUENTE FECHA
PUBLICACIÓN
Informe de auditoría al funcionamiento
Del sistema de información cóndor
Documentos públicos de OAS Marzo 2013
Plan maestro de informática y
telecomunicaciones – Resumen
Ejecutivo
Documentos públicos de OAS 2013
PESI/PETI Universidad distrital
vigencia 2007 – 2016
Documentos públicos de OAS Octubre 2007
Estatuto Estudiantil – diciembre 1993 Documentos públicos de la
Universidad Distrital – Consejo
Superior Universitario
Diciembre 1993
Acuerdo 004 – Modificaciones al
régimen de liquidación de matrículas
para los estudiantes de la universidad.
Documentos públicos de la
Universidad Distrital – Consejo
Superior Universitario
Enero 2006
Acuerdo 004 Documentos públicos de la
Universidad Distrital – Consejo
Superior Universitario
Agosto 2011
Acuerdo 07 Documentos públicos de la
Universidad Distrital – Consejo
Superior Universitario
16 de diciembre de
2009
Acuerdo 027 Documentos públicos de la
Universidad Distrital – Consejo
Superior Universitario
1993
Compendio de variables de información
histórica solicitadas a OAS
Información Solicitada a OAS N/A
Documentación técnica Jboss Drools Información pública jboss.org Versión 6.2.0
Documentación técnica Optaplanner Información pública jboss.org Versión 6.0.0
Documentación técnica Guvnor Información pública jboss.org Versión 5.4.0 Tabla 1 Fuentes Para la recolección de la información. Fuente: Elaboración Propia

18
1.5.4 Tratamiento de la información
La información recogida mediante las entrevistas, observaciones y anotaciones
tomadas durante todo el proceso se tabularán y visualizará dependiendo de la categoría y
contexto del dato.
Parte de la información relevante para la tabulación y graficación será la obtenida
gracias a la observación del proceso actual, y la resultante después de la ejecución del
nuevo componente.
Se solicitará información de variables académico-administrativas, socioeconómicas,
académicas, de distribución geográfica y personal que se clasificara, se tabularán, y
graficarán, para sintetizar su comportamiento e identificar las interrelaciones, e influencia
de unas sobre otras.
La medición del rendimiento del componente y calidad de su salida se comparará
contra los resultados históricos de la herramienta actual, solicitados a la OAS.
CAPÍTULO 2 MARCOS DE REFERENCIA
A continuación, se realiza una descripción de la Historia de la Universidad Distrital
“Francisco José de Caldas”, se indica la organización, estructura y normatividad con la que
cuenta, las cuales están relacionadas en el desarrollo de este proyecto.
2.1 Marco Institucional
La Universidad Distrital “Francisco José de Caldas” se define como un ente
universitario autónomo de carácter público del orden Distrital que concibe la educación
como factor de cambio social y mejoramiento de la calidad de vida. En esa perspectiva, a lo
largo de sus 59 años de existencia ha generado impactos en diferentes campos de
conocimiento y acción relacionados con sus programas académicos.
2.1.1 Reseña Histórica de la Universidad Distrital
La Universidad Distrital fue fundada en 1948, por iniciativa del presbítero Daniel de
Caicedo quien además fue su primer rector (Villate, 2004) con el propósito de
ofrecer educación a los jóvenes de los sectores menos favorecidos de la ciudad, en
carreras de corta duración que apuntaban a resolver necesidades de la
modernización y la urbanización.
En el año de 1950, mediante la Resolución 139 del Ministerio de Defensa, la
Universidad recibió el nombre de Universidad Municipal “Francisco José de

19
Caldas”. Posteriormente, al erigirse la ciudad de Bogotá como Distrito Especial,
recibió el nombre de Universidad Distrital Francisco José de Caldas.
En 1960 la Universidad ya contaba con dos facultades: Ingeniería Forestal e
Ingeniería Electrónica, en las cuales se ofrecían respectivamente las carreras de
Expertos Forestales y Expertos Radiotécnicos (de carácter nocturno). Igualmente
existían las secciones de Dibujo Lineal y de Topografía y Cartografía.
En 1972 fueron creados dos nuevos programas de gran importancia: Ingeniería
Industrial e Ingeniería de Sistemas,
En la década de los 90, se definieron nuevos alcances institucionales alrededor de
conceptos como la autonomía universitaria y la democracia participativa.
Para los años de 1993 y 1994, surgió la Facultad Tecnológica en el marco del Plan
de Desarrollo “Formar Universidad”, se fortaleció la Facultad de Ingeniería y se
creó la Facultad de Medio Ambiente y Recursos Naturales, que ha sido la gran
ventana de la Universidad hacia la sociedad y el resto del mundo académico.
En 1999 se integró a la Universidad la Academia Superior de Artes de Bogotá
(ASAB), creándose así la Facultad de Artes.
Posteriormente se formuló el Plan de Desarrollo 2001-2005: “Educación de calidad
para la equidad social”, con el propósito de aportar al mejoramiento de la calidad de
la formación universitaria en los ámbitos de la integralidad humana, el sentido de
ciudadanía y el manejo de saberes.
En diciembre del año 2005 se creó la Facultad de Artes – ASAB a partir de la
integración definitiva de la Academia Superior de Artes de Bogotá a la Universidad
Distrital.
En la Actualidad la Universidad cuenta con cinco facultades: Ciencias y Educación;
Medio Ambiente y Recursos Naturales; Ingeniería; Tecnológica; y Artes – ASAB,
donde la ampliación de cobertura con calidad constituye su mayor reto.
El recorrido de los principales hitos de la Universidad Distrital indica que sus acciones
se han orientado a alcanzar una mayor pertinencia y calidad, asumiendo la formación de
profesionales comprometidos con la construcción de “conocimientos y saberes e
investigación de alto impacto para el desarrollo humano y social.
2.2 Marco Teórico
A continuación, se describe la organización, estructura y normatividad vigentes con los
que cuenta la Universidad Distrital y que se deben tener en cuenta en el desarrollo de este
proyecto.

20
Misión
La misión de la Universidad Distrital “Francisco José de Caldas” es la democratización
del acceso al conocimiento para garantizar, a nombre de la sociedad y con participación del
Estado, el derecho social a una Educación Superior con criterios de excelencia, equidad y
competitividad mediante la generación y difusión de saberes y conocimientos, con
autonomía y vocación hacia el desarrollo sociocultural para contribuir fundamentalmente al
progreso de la Ciudad - Región de Bogotá y el país.
Visión
La Universidad Distrital Francisco José de Caldas, en su condición de Universidad
autónoma y estatal del Distrito Capital, será reconocida nacional e internacionalmente por
su excelencia en la construcción de saberes, conocimientos e investigación de alto impacto
para la solución de los problemas del desarrollo humano y transformación sociocultural,
mediante el fortalecimiento y la articulación dinámica, propositiva y pertinente de sus
funciones universitarias en el marco de una gestión participativa, transparente y
competitiva.
Plan Estratégico 2007 - 2016: Saberes, conocimientos e investigación de alto
impacto para el desarrollo humano y Social
Con este Plan, la comunidad universitaria cuenta con la orientación estratégica que
guiará la acción universitaria en los próximos 10 años y será la base para la definición de
metodologías para la alimentación del Banco de Proyectos de la Universidad Distrital,
BPUD, para establecer la prioridad en la asignación de recursos y para la elaboración de los
Planes de Desarrollo Trianuales de las distintas unidades académicas y administrativas de la
Universidad y su desglose en planes de acción anuales.
Como estrategia general, se caracteriza por ser indicativo y flexible en cuanto a la
capacidad de adaptarse a los cambios y transformaciones de sociedad y el Estado, el
entorno regional, nacional y mundial. Por lo tanto, se constituye en una carta de navegación
que orientará las acciones y decisiones institucionales.
Objetivos Generales del Plan Estratégico de Desarrollo
a. Articular las acciones de la Universidad Distrital con las de otras instancias
educativas, científicas, empresariales, políticas y culturales a fin de liderar la
formulación de políticas públicas y acciones de impacto social en los campos
estratégicos institucionales.
b. Ampliar la cobertura mediante la diversificación de las modalidades educativas y
áreas de conocimiento; niveles y ciclos de formación pertinentes, a través del
desarrollo de mecanismos internos e interinstitucionales nacionales e

21
internacionales, que generen condiciones para la inclusión social, bajo principios
de calidad y eficiencia.
c. Generar las condiciones académicas para que la Universidad Distrital pueda
proyectarse como una universidad investigativa de alto impacto en la solución de
problemas de la Ciudad - Región y el país, la formación de profesionales integrales
en las diversas áreas del conocimiento y la oferta de programas de educación
continua.
d. Planear las estrategias para garantizar la adecuada asignación de los recursos por
parte del Estado, racionalizar su ejecución e incrementar y diversificar la
generación de ingresos.
e. Sentar las bases para alcanzar una gestión incluyente, pertinente transparente que
reconozca la participación y los aportes de los actores de comunidad académica,
soportada en una estructura orgánica, apropiada para desarrollo de las funciones
misionales y las diversas dimensiones de Universidad Distrital.
f. Contar con una infraestructura física, tecnológica, de conectividad y de medios
educativos adecuados y coherentes para garantizar el desarrollo de las funciones
misionales de la Universidad Distrital, la comunicación y el bienestar institucional.
2.2.1 Cobertura estudiantil
La Universidad Distrital consciente de su función de democratización del acceso al
conocimiento y al derecho de Educación Superior con criterios de excelencia, equidad y
competitividad, ha mantenido en los últimos tres años la oferta académica con muy poca
variación según el Informe De Avance Sobre El Plan Indicativo De Gestión (CBN 1013)
(CALDAS, 2013)
Al finalizar el año 2012 la Universidad Distrital contaba con un total de 29.937
estudiantes matriculados, de los cuales 27.788 cursaban proyectos curriculares de pregrado,
1.212 en los proyectos de especialización, 842 en maestría y 95 en doctorado (CBN 1013,
2008-2016).
2.2.2 Aspectos Normativos
El Estatuto estudiantil Acuerdo Nº 027 (diciembre 23 de 1993), el acuerdo 7 de 2009 y
el Acuerdo 004 de (agosto de 2011), expedidos por el Consejo Superior Universitario,
establecen el Reglamento estudiantil vigente a la fecha, en cuanto a las condiciones de
registro de los espacios académicos así:

Acuerdo 027 de 1993
Acuerdo No. 7 de 2009 Acuerdo 004 de 2011
Cobija a los estudiantes matriculados activos y
que ingresaron de 2009-3 hacia atrás y que no se
acojan al acuerdo 004.
Cobija a los estudiantes matriculados activos y que
reingresaron de 2010-1 a 2011-3 y que no se acogieron al
acuerdo 004 de 2011.
Cobija a los estudiantes que se matriculen en 2012-1 en adelante.
Capítulo 5: Transferencias, Retiros y otras
situaciones académicas.
Artículo 29 Es el acto mediante, el cual el
estudiante registra las asignaturas que ha de
cursar en un período académico.
El estudiante admitido por primera vez debe
registrar todas las asignaturas del primer semestre
de su plan de estudios. El estudiante que pierda
una o más asignaturas debe cursarlas en el
período inmediatamente siguiente. El estudiante
de segundo semestre en adelante debe registrar y
cursar por lo menos la mitad de las asignaturas
que esté obligado a tomar según su plan de
estudios. Los casos especiales son autorizados
por el consejo de carrera.
Que el Estatuto Estudiantil, Acuerdo 027 de diciembre
23 de 1993, señala en su
artículo 22: “El estudiante no puede cursar una misma
asignatura más de tres
(3) veces. El estudiante que haya cursado el setenta
(70%) por ciento o más de
su plan de estudios, puede cursar hasta por cuarta vez la
misma asignatura”.
Artículo 7°. - Evaluación de las asignaturas con alto
nivel de repitencia o deserción. Con el fin de identificar
las causas de los altos niveles de repitencia o deserción
en asignaturas o programas que muestren índices
superiores al promedio del Proyecto Curricular, los
coordinadores de proyectos curriculares, deberán
convocar semestralmente un comité de evaluación
integrado por el
coordinador, quien lo presidirá, un delegado de los
profesores de la asignatura o programa que muestre estos
índices y los estudiantes que pertenezca al Consejo de
Proyecto Curricular, con el fin de identificar las causas y
recomendar los correctivos necesarios para superarlas.
Artículo 8°. Todo estudiante de la Universidad Distrital
Francisco José de Caldas al matricularse, acepta las
condiciones académicas definidas por la Universidad, y
en particular las establecidas en el presente Acuerdo,
como parte integral del
Estatuto Estudiantil.
Artículo 9°. (Transitorio) Los estudiantes que se
encuentren en prueba académica finalizada el periodo
2009, bajo cualquiera de las modalidades, deberán
superarla en el primer periodo del 2010.
Artículo 10º. El presente Acuerdo rige a partir de la
fecha de su expedición y deroga todas las normas que le
sean contrarias, en especial los artículos 22 y 23 del
Estatuto Estudiantil, Acuerdo 027 de 1993.
Artículo Séptimo: Del registro de los espacios académicos. El
registro de los espacios académicos se realizará de la siguiente
manera:
a. A los estudiantes que ingresen a primer semestre se les
registrará la totalidad de espacios académicos que deben
cursar según su plan de estudios.
b. Los estudiantes antiguos deberían realizar preinscripción de
los espacios académicos en el sistema de información
académica de la universidad dentro de los cinco (5) días
calendario siguientes a la fecha final de cierra de notas
establecida en el calendario académico. Los espacios
académicos que cuenten con cupos disponibles, podrán ser
adicionados en los plazos establecidos, aunque no se haya
realizado la preinscripción. El sistema de información
académico preinscribirá y registrara los espacios académicos
reprobados por el estudiante a los cuales no pueden ser
cancelados. El estudiante debe preinscribir por lo menos la
mitad de los espacios académicos o créditos correspondientes
al semestre que vaya a cursar.
c. El sistema de información académica asignara
automáticamente franjas y jornadas de disponibilidad horario
y número de grupos, según los cupos definidos por los
proyectos curriculares teniendo en cuenta las solicitudes
previamente realizadas en la preinscripción.
d. El registro de espacios académicos y la aprobación de cargas
académicas se realizará dentro de los siguientes diez (10) días
hábiles de cumplido con el tiempo de preinscripción, bajo la
responsabilidad de las decanaturas, los proyectos curriculares
y la oficina asesora de sistemas, o las que hagan sus veces.
e. Los estudiantes podrán registrar y cursar por primera vez o
repetir espacios académicos teóricos en periodos intermedios
según lo establecido en su plan de estudios.
Tabla 2 Acuerdos Normativos Expedidos por el Consejo Superior Universitario. Fuente: Elaboración Propia

2.2.3 Sistema de Gestión Académica (SGA) – Cóndor
La Universidad Distrital Francisco José de Caldas en armonización con el Plan de
Desarrollo Distrital “Bogotá Positiva” y tomando en cuenta las necesidades de la
Institución en lo que respecta a la modernización y fortalecimiento de la infraestructura
tecnológica, desde el año 2008, crea el proyecto 188 “Sistema Integral de Información y
Telecomunicaciones” cuyo objetivo es “Fortalecer y mejorar la infraestructura informática
y de telecomunicaciones suministrando a la comunidad universitaria herramientas que
faciliten el trabajo y ayuden al manejo de la información en cuanto a conectividad, telefonía
y capacidad de alojamiento de información”.
Una de estas herramientas es el sistema de gestión académica el cual es un sistema de
Administración de Información Académico, basado en tecnologías Web, orientado a
servicios sobre plataforma de software libre, escalable, modular, ajustado a las necesidades
de la Universidad que provee servicios web académicos.
Según el Informe de Avance sobre el Plan Indicativo de Gestión (CBN 1013) del Plan
de Desarrollo 2008-2016 “Saberes, Conocimiento e Investigación de Alto Impacto para el
Desarrollo Humano y Social”, como avances del Sistema de Gestión Académica se
presenta el desarrollo del Módulo de configuración de planes de estudios de créditos para
los usuarios coordinador, asesor de Vicerrectoría Académica, 72 estudiantes.
De igual manera, se configuraron los siguientes módulos: Portafolio de electivas
externas, inscripciones para realizar adición, cancelación y cambio de grupo a estudiante de
horas y créditos de pregrado para los usuarios estudiante y coordinador, inscripción de
estudiantes de créditos de postgrados para el usuario coordinador, inscripción ágil para
facilitar a los proyectos curriculares el proceso de adición de espacios académicos a
estudiantes, comunicaciones para soportar el proceso de consejerías y el módulo de
consejerías que permite al docente consejero realizar mayor seguimiento a los estudiantes
asignados a su cargo, proporcionando información de horario, situación académica y
comunicación vía web con el estudiante.
Se realizó la implementación de seguridad en el servidor Cóndor mediante el protocolo
HTTPS y prevención de ataques contra robots (programas automáticos de ataque).
Igualmente se desarrollaron los módulos de envío de recibos de pago al Correo
Institucional, el de novedades de espacios académicos en Cóndor, el Web de equivalencias
en el Sistema Cóndor. En cuanto a los ajustes realizados se encuentra el módulo de
admisiones, el de evaluación docente según necesidades de la comunidad universitaria.

24
2.2.4 Operación del sistema de gestión académica Cóndor
El lenguaje de programación con el que se desarrolla “Cóndor” es PHP versión 5.4.9
La base de datos utilizada por el Sistema de gestión académico Cóndor se encuentra en la
versión 11g de Oracle (Informe De Auditoria Al Funcionamiento Del Sistema De
Información Cóndor. Marzo De 2013).
En el funcionamiento del sistema de gestión académico “Cóndor” se tienen diferentes
subsistemas: siendo cinco (5) los clave en el proceso de inscripción y registro de datos de
asignaturas: Cierre de semestre, preinscripción por demanda, inscripción automática,
inscripciones y Notas. Anteriormente el sistema realizaba una búsqueda de las asignaturas
que secuencialmente debería cursar y las inscribía automáticamente después del cierre de
semestre. Esto conducía a que estudiantes que querían cursar otras asignaturas o asignaturas
en horarios diferentes, las cancelaran y comenzaran el proceso de adición de las materias de
su preferencia.
Para el primer semestre de 2013, el registro e inscripción de asignaturas tuvo menos
inconvenientes debido al siguiente cambio en el proceso: como según las normas vigentes
es estudiante activo quién realiza el proceso de matrícula, es decir quién entre otras haya
efectuado el pago de su recibo, los estudiantes que no hayan realizado pago de matrícula al
momento de la inscripción por demanda, no son tenidos en cuenta para su inscripción
automática, es decir no se le adiciona ninguna materia y tienen que posteriormente entrar a
buscar dentro de los cupos que se hallen disponibles.
2.2.5 Situación de la retención de estudiantes
Con base en la información obtenida de la Oficina Asesora de Sistemas (OAS) (2011),
para la población estudiantil de 2011-I, se encontró que 7.016 estudiantes que representan
el 25,6% de la población estudiantil de pregrado se encuentran por fuera del tiempo teórico
de graduación. La situación académica de los retenidos se clasificó dependiendo del estado
en que aparecen reportados en la OAS. Activos: los estudiantes que se encuentran activos,
los estudiantes que se encuentran matriculados pero que NO reportaron notas. Prueba
Académica: corresponde a todos los estudiantes que hayan tenido alguna relación con esta
situación. Terminaron Materias: Estudiantes que ya terminaron sus materias pero que aún
no se han graduado1.
Estudiantes
Retenidos Totales
Terminó Materias Prueba Académica Activos
7016 2044 1675 3297
Participación % 29.1% 23.9% 47.0% Tabla 3 Situación de retención de estudiantes. Fuente: Oficina Asesora de sistemas (OAS)
1 Se tiene en cuenta para el estudio un semestre adicional, es decir, son estudiantes retenidos aquellos que llevan más de 12 semestres para ciclo profesional y 8 para el tecnológico.

25
2.2.6 La institución Educativa
Las instituciones nacen de la consolidación de las organizaciones sociales, las cuales
surgen al existir una o varias necesidades humanas que se convierten en una meta u
objetivo, para alcanzar un beneficio mayor en una comunidad o un grupo social
determinado, con lo cual estas unidades sociales se unifican en un mismo sentido, dándole a
su organización un nombre, una identidad, un proceso para satisfacerla, una dirección y
normas que les permitan alcanzar su fin (Martínez, 2012).
Actualmente, las instituciones educativas y demás empresas que ofrecen servicios, se
enfrentan al contexto que propone los cambios tecnológicos, la globalización y el internet.
En relación, autores como (Pedraza, 2013) Farías, Lavín y Torres, comentan que “las
tecnologías de información y comunicación (TIC) han revolucionado los diferentes campos
de la vida cotidiana (laboral, salud, financiero, fiscal, comercial y de entretenimiento, por
mencionar algunos), y precisamente uno de los ámbitos en los que mayor impacto ha
representado su incorporación es el sector educativo”.
Ante este panorama, surgen conceptos como los servicios en línea que permiten que el
usuario acceda a diferentes prestaciones de la institución de manera virtual. El Manual para
la Implementación de la Estrategia de Gobierno en línea en las entidades del orden nacional
de la República de Colombia del Ministerio de Tecnologías de la Información y
Comunicaciones (2012) menciona que:
Si bien la penetración del internet en 2012 aún dista de ser la ideal, las conexiones de
banda ancha vienen incrementando gradualmente y en mayo de este año ya llegaban a 5,2
millones. De forma paralela los usuarios de las entidades cada vez más hacen parte la
generación digital (el 66% de los internautas son menores de 35 años2) y a su vez
reconocen en los medios electrónicos una oportunidad para obtener de forma ágil servicios
del Estado (el 88% de los ciudadanos y el 89% de las empresas sabe que puede relacionarse
con el Estado haciendo uso del internet. Por otra parte, el 47% de los ciudadanos y el 73%
de las empresas han hecho uso de trámites en línea) Manual para la implementación de la
Estrategia de Gobierno en línea en las entidades del orden nacional de la República de
Colombia, 2012.
Para ello, se presentan herramientas como las tecnologías de información y
comunicación que logran entregar al usuario la información y el servicio de manera no
presencial, como lo es para la universidad Distrital, el proceso de inscripción y registro de
datos de asignaturas. (Cobo, 2009) Conceptualiza las tecnologías de información y
comunicación (TIC) como:
Dispositivos tecnológicos (hardware y software) que permiten editar, producir,
almacenar, intercambiar y transmitir datos entre diferentes sistemas de información que
cuentan con protocolos comunes. Estas aplicaciones, que integran medios de informática,
telecomunicaciones y redes, posibilitan tanto la comunicación y colaboración interpersonal

26
(persona a persona) como la multidireccional (uno a muchos o muchos a muchos). Estas
herramientas desempeñan un papel sustantivo en la generación, intercambio, difusión,
gestión y acceso al conocimiento.
Es así que, para garantizar un alto nivel de calidad en el servicio, es necesario
representar el comportamiento y establecer los principales elementos que lo componen, por
medio de un modelo, ya que de esta manera el sistema que compone el servicio se vuelve
medible y mejorable. Para (Pidd, 2009) un modelo “es una representación explícita y
externa de parte de la realidad como la ven las personas que desean usar el modelo para
entender, cambiar, gestionar y controlar dicha parte de la realidad”.
2.2.7 Ejemplos de Sistemas de Gestión Académica en Colombia
La estructuración y procesamiento de los datos en el sector académico, posee un
especial interés e importancia por parte de las instituciones educativas, debido a que
permite identificar, organizar, caracterizar, gestionar, controlar, motivar prevenir,
categorizar, agrupar y segmentar los elementos que componen la academia (Crane,
2008).Una vez identificados, analizados y procesados, se pueden obtener grandes
resultados como la consolidación de información, el ahorro de tiempo, el control de
conjuntos homogéneos, la identificación de singularidades, la gestión semiautomática de
estudiantes, el monitoreo constante e incluso retroalimentaciones automáticas.
Por ello la accesibilidad, usabilidad y navegación, se convierten en elementos
indispensables a tener en cuenta cuando un sistema presenta la información de manera
estructurada y la consolidación de los datos como sustento en la toma de decisiones.
Algunos ejemplos de sistemas de gestión académico que han venido mejorando sus
procesos son:
SIGA: Sistema Integrado de Gestión Académica, Administrativa y Ambiental
Es el modelo básico de referencia desarrollado por la Universidad Nacional de
Colombia para el diagnóstico, aplicación, seguimiento, evaluación y análisis de la
transformación necesaria o pertinente en el ámbito de gestión institucional, visualizada
desde la identificación de aspectos comunes en materia Académica, Administrativa y
Ambiental.
Este sistema facilita la gestión en todos los aspectos académico-Administrativos de la
universidad, comenzando con el control en los procesos de preinscripción, inscripción,
selección y admisión de los aspirantes a cada programa académico, hasta el proceso de
graduación, se puede hacer la planeación y la gestión de todo el proceso de matrícula
académica de la universidad. Permite hacer el control de cupos disponibles para una
asignatura, con base en restricciones originados en la organización logística, el reglamento
estudiantil, el currículo de cada pensum, los prerrequisitos y correquisitos de cada

27
asignatura, el número de créditos máximo a matricular evitando el cruce de horarios y
teniendo en cuenta la carga académica del estudiante para cada semestre (UNAL).
Actualmente ha sido implementado en universidades como, la universidad de la
sabana, la Uniagustiniana, universidad de ciencias aplicadas y ambientales U.D.C.A y La
corporación Universitaria Comfacauca, entre otras.
Para el caso de la Universidad de la Sabana SIGA este ha sido el nuevo sistema de
información implementado de acuerdo con Plan de Desarrollo Institucional al 2019, el cual
busca impulsar la evolución, modernización y desarrollo de nuevos modelos de gestión
universitaria, ampliar y mejorar el portafolio de productos y servicios de base tecnológica
para los estudiantes, profesores, administrativos, directivos y grupos interesados. En el
sistema se planean, registran, ejecutan y controlan diferentes procesos Académicos,
Financieros y de Gestión Humana, que se llevan a cabo en la Universidad
La UDCA ha implementado el Sistema Integrado de Gestión Ambiental (SIGA), junto
al Subsistema Académico para coordinar y ejecutar acciones con los cuerpos académicos y
de investigación de la Universidad, buscando incluir el componente ambiental dentro del
currículo y la investigación, razón por la que debe brindar, para los diferentes escenarios,
los lineamientos de indicadores de sostenibilidad para universidades. Igualmente será el
encargado de liderar las acciones correspondientes a la conservación de la flora y la fauna
del campus (UDCA, 2014).
Plataforma SAU: Sistema de Gestión Académico de la Institución Universitaria
Bellas Artes Y Ciencias De Bolívar
El Sistema académico universitario es la herramienta con la cual se realiza la
inscripción y matrícula académica de las carrereas profesionales y de Educación para el
trabajo y el desarrollo humano. Igualmente se realiza la inscripción, matrícula académica y
financiera de los cursos de Proyección social. En la plataforma SAU los estudiantes
consultan sus notas y los docentes las suban (UNIBAC).
Mango: Módulo Académico Nacional de Gestión estudiantil Online, Universidad
Antonio Nariño.
Durante el plan de desarrollo 2005 – 2010, la universidad menciona en el Eje 4.
Optimización del modelo de gestión y desarrollo humano de la UAN que para la
Universidad es de gran importancia establecer un modelo de gestión que le permita llevar a
término el plan de desarrollo institucional y el plan de mejoramiento establecido de común
acuerdo con el Ministerio de Educación y por ello obliga a desarrollar sistemas de
información de alta calidad, que contribuyan con el establecimiento de parámetros,
indicadores y estándares que faciliten la toma de decisiones y los correctivos que sean
pertinentes (UAN).

28
Como apoyo a este módulo y las actividades de la universidad de han creado los
siguientes:
PERA: Plataforma Educativa de Registro Académico docente
UVA: Unidad de Verificación y gestión Académico administrativa
Sigma: Sistema Integrado de Gestión Académico-Administrativo de la Universidad
Pedagógica y Tecnológica de Colombia (UPTC)
La Universidad en Desarrollo de su Política Académica, ha implementado y adoptado
el Sistema Integrado de Gestión Académico Administrativo SIGMA mediante la
Resolución Nº 1685 del 18 ABRIL 2008. Este integra el Sistema de Gestión de la Calidad
bajo la NTC ISO 9001:2000, ampliando su alcance a todos los procesos de la Universidad
propendiendo por el mantenimiento y conservación de dicha certificación.
Este sistema ha ido mejorando continuamente la gestión y desempeño eficiente, y
efectivo del Sistema Integrado de Gestión de la universidad con actividades que involucran
el aseguramiento, la implementación, sostenibilidad y mejora del Sistema Integrado de
Gestión Académico Administrativo en la UPTC, así mismo se han ido corrigiendo las
desviaciones, ajustes de los procesos y procedimientos para subsanar los problemas que se
han ido presentado con el propósito de lograr la eficacia, eficiencia y efectividad en el
cumplimiento de los fines misionales (UPTC).
Sigan: Sistema Integrado de Gestión Académica Normalizada de la Universidad
Pedagógica Nacional
La Universidad Pedagógica Nacional, con el firme compromiso de mejorar
continuamente la prestación del servicio para el beneficio de sus usuarios, se ha dado a la
tarea de implementar un Sistema de Gestión Integral que contempla como base de la
operación el modelo de acreditación institucional, el modelo de gestión de calidad y el
modelo estándar de control interno.
La implementación del Sistema Integrado de Gestión, se concibe como un proceso de
construcción colectiva en el cual la participación de los funcionarios académicos y
administrativos es fundamental para su planeación, desarrollo, control y retroalimentación.
La integración de los modelos de Calidad y MECI, se ha realizado con base en los
lineamientos definidos en la guía de armonización MECI-CALIDAD, expedida por el
Departamento Administrativo de la Función Pública.
PAW: Plataforma Académica Web de la Universidad Católica de Colombia
La Plataforma Académica Web (PAW) es el sistema de información centralizado en
Internet que ofrece la Universidad Católica de Colombia a sus estudiantes, egresados,

29
profesores y personal administrativo, para que puedan realizar las labores académicas
propias de su actividad. La información y los servicios presentados en línea, se han ido
presentando bajo un solo menú de opciones de acuerdo con el perfil del usuario, evitándole
hacer recorridos por diferentes secciones del sitio web de la Universidad (UCATOLICA).
Este sistema permite a los usuarios de la comunidad universitaria realizar la mayor parte de
las actividades y de los trámites académicos vía Internet, a través un único punto de acceso,
agilizando su realización. De esta manera, los estudiantes, profesores y personal
administrativo, encontrarán en un sólo lugar las opciones que les permitirán ejecutar
procesos, así como, consultar la información que necesitan para su actividad diaria.
2.2.8 Importancia de la gestión académica
La gestión es un elemento determinante de la calidad del desempeño de las
organizaciones; ella incide en el clima organizacional, en las formas de liderazgo y
conducción institucional (Gobierno), en el aprovechamiento óptimo de los talentos, en la
planificación de las tareas y la distribución del trabajo y su productividad, en la eficiencia
de la administración y el rendimiento de los recursos materiales y, por cada uno de esos
conceptos, para el caso de las instituciones educativas, en la calidad de los procesos
educativos. Además, la gestión juega un papel de vital importancia en el sector de la
educación superior, para mejorar los índices de eficiencia y eficacia, como aporte al
mejoramiento de la calidad de la educación.
Acorde con las tendencias mundiales, las Instituciones de Educación Superior (IES),
han venido desarrollando sistemas de gestión de calidad, para lo cual utilizan diversos
modelos, destacándose por su reconocimiento internacional las Normas ISO, los sistemas
de acreditación de programas e instituciones que se han desarrollado particularmente en el
ámbito de la educación superior, y los premios (nacionales e internacionales) de calidad que
en algunos casos incluyen galardones de excelencia a la gestión escolar.
Pero hoy la principal ventaja competitiva de las organizaciones exitosas, no sólo radica
en los modelos de gestión de calidad que estén implementando, sino en la calidad de su
gestión, la cual involucra además de la gestión de la calidad, la de sus áreas clave: Talento
humano, financiera, comercial y tecnológica entre otras.
En Colombia, el Consejo Nacional de Acreditación (CNA), ha establecido unos
lineamientos para la acreditación de los programas académicos, los cuales más que
orientadores se han tornado obligatorios para todos aquellos programas que aspiran a
alcanzar la acreditación de calidad, la que tiene carácter de voluntaria.
Dado lo anterior se puede decir que la gestión académica constituye el criterio clave de
la calidad de la gestión de las Instituciones de Educación Superior, tema de esta ponencia.

30
2.3 Algoritmos de Optimización o Solución de Problemas
En el presente trabajo se nombran algunos algoritmos para la solución de problemas de
satisfacción u optimización de requerimientos, los cuales se describen a continuación:
Depth-First Search o Backtrack Simple construye el árbol de búsqueda a
profundidad, si existe una asignación parcial que no puede ser completada sin violar
una restricción, el algoritmo continúa su búsqueda retornando al último punto de
elección (Solson, 2010).
Iterative Forward Search es un Algoritmo basado en ideas de métodos de búsqueda
local. Sin embargo, opera sobre soluciones factibles, pero no necesariamente completas
(a diferencia de los algoritmos tradicionales de búsqueda local) (Rudov, 2004).
Algoritmo de Arco Consistencia Una variable es arco consistente si cada valor en su
dominio satisface las restricciones binarias de la variable. Para mantener el arco
consistencia mientras se construye una asignación parcial A, se filtra el dominio de cada
variable no asignada xi eliminando cada valor vi tal que exista una variable no asignada
xj cuyo dominio no soporte (xi, vi). En otras palabras, se remueve vi de D (xi) si existe
un xj tal que, para cada valor vj ∈ D(xj ), la asignación parcial {(xi,vi),(xj ,vj )} es
inconsistente (Solson, 2010).
Por otro lado, se tienen algoritmos de heurísticas y meta heurísticas para la resolución
de problemas de optimización de restricciones. A continuación, se definirán ciertos
términos antes de describir cada uno de los algoritmos usados:
Una Entidad de Planificación es un objeto del problema que puede cambiar durante la
planificación. Por ejemplo, un bloque de horario cambia constantemente salones,
profesores y materias durante la resolución del problema.
La Dificultad de una Entidad de Planificación viene dada por una función que estima
la dificultad de la entidad. En concreto, la dificultad de un bloque de horario puede estar
dada por el número de restricciones que posea.
La Fuerza de un Valor de Planificación es una estimación sobre la inclinación que
tiene un valor de satisfacer a una entidad de planificación. Por ejemplo, un profesor que
tiene más horas de clase puede ser colocado en más bloques de horario.
Algoritmos de búsqueda Local con búsqueda Meta heurística
La idea básica de la meta heurística es la de mejorar la búsqueda local incorporando
ideas de la búsqueda global, minimizando la probabilidad de quedarse el proceso de
búsqueda atrapado en óptimos locales a través de la introducción de componentes de
decisión estocásticos y métodos bio-inspirados.

31
Los métodos meta heurísticos son métodos aproximados diseñados para resolver
problemas difíciles de optimización combinatoria en que los métodos heurísticos clásicos
no son efectivos. Se sitúan conceptualmente por encima de los heurísticos y son
procedimientos iterativos que modifican o modulan la decisión heurística subordinada
durante el proceso de búsqueda para producir eficientemente soluciones de alta calidad
(Ruescas, 2014-2015) . Estas características hacen que los métodos meta heurísticos:
Utilicen poca memoria
Sean capaces de obtener respuestas iniciales rápidamente que continúan
optimizándose.
Mejoren las búsquedas locales sin la complejidad espacial y temporal de la
búsqueda global.
Sean de fácil implementación
Algunos de estos algoritmos o métodos son:
Tabú Search El objetivo de Tabú Search es evitar una heurística integrada que retorne
a ´áreas anteriormente visitadas del espacio de búsqueda, referido como realizar un
ciclo. La estrategia del enfoque es mantener una memoria a corto plazo de los cambios
específicos de movimientos hechos recientemente en el espacio de búsqueda y prevenir
movimientos futuros de deshacer dichos cambios (Brownlee, 2011).
Simulated Annealing Está inspirado en el proceso de recocido en la metalurgia. En
este proceso el material es calentado y enfriado lentamente en condiciones controladas
para incrementar el tamaño de los cristales en el material y reducir sus defectos. El plan
de acción del algoritmo consiste en probar nuevamente el espacio de búsqueda del
problema, aceptando soluciones nuevas sobre otras ya obtenidas mediante una función
probabilística que se vuelve más receptiva sobre el costo de las soluciones que acepta
en la medida que pasa el tiempo de ejecución del algoritmo. Esta función está basada en
el algoritmo de Metropolis-Hasting para simular muestras en un sistema termodinámico
(Brownlee, 2011).
Late Acceptance Hill Climbing Es un algoritmo de búsqueda iterativa que acepta
movimientos mientras no decrementen la puntuación actual o si al menos llevan a una
puntuación igual o menor a la de la puntuación tardía o late score. De esta manera
puede aceptar movimientos que no mejoran la puntuación (ByKov, 2012).
Step Counting Hill Climbing Es una variación del algoritmo de Hill Climbing en
donde se mantiene un umbral del costo actual de la mejor solución por un número de
pasos determinados, durante ese tiempo pueden elegirse soluciones que empeoren el
puntaje, pero pasen el umbral. Después del número de pasos determinados se actualiza
el umbral y se sigue iterando (Petrovic, 2013)

32
2.4 Aspectos Legales
Programas de licenciamiento libre.
No es necesario comprar licencias.
Leyes colombianas respecto al Software Libre
Desde los principios de la década de 1990, nuestro país no ha sido ajeno al desarrollo
del movimiento del software libre o de código abierto (Open Source), y es así como tanto
en el sector privado como en el sector público la adopción, implementación y usos exitosos
de este tipo de herramientas es una realidad latente.
El medio académico, científico y de investigación, han sido el medio propicio para que
el movimiento del Software Libre se abra paso en Colombia. La Universidad Nacional de
Colombia, la Pontificia Universidad Javeriana, la Universidad de los Andes, la Universidad
de Antioquia, la Universidad del Valle, la Escuela de Administración de Negocios, la
Universidad de Manizales, la Universidad de san Buena ventura, la Universidad Distrital
Francisco José de caldas, la Universidad Industrial de Santander y muchas más; se
constituyen en los escenarios donde el movimiento del software libre en Colombia ha
tenido una acogida y desarrollo real.
El sector privado y el sector oficial también han mostrado un avance significativo en el
aprovechamiento del Free Software, lo cual se ha traducido en ventajas comparativas frente
al uso del software propietario.
Por una iniciativa parlamentaria, presentada a principios del año 2002, Colombia
cuenta y discute en el seno del Congreso de la Republica, la posibilidad de adoptar a nivel
positivo una legislación que regule y establezca de manera imperativa las políticas de uso y
empleo del Software Libre en sus sistemas de información, al interior de las entidades e
instituciones del Estado y las empresas donde el estado posea mayoría accionaría.
El proyecto consta de veintiuno artículos, a través de los cuales se busca regular y
obtener un control sobre los sistemas de información evitando depender de proveedores
únicos, promover la igualdad en el acceso a la información pública por parte de los
ciudadanos, garantizar la transparencia de las tecnologías que utiliza el Estado para su
funcionamiento salvo casos de seguridad nacional, evitar el acceso a la información por
parte de terceros no autorizados según la constitución y la ley garantizando la seguridad
nacional y la privacidad de los ciudadanos, y lograr la promoción y el desarrollo de una
industria de software nacional (Dávila, 2012).
El artículo primero del proyecto de Ley establece una serie de definiciones, y para tal
efecto entra a definir lo que es un programa o software como: “Instrucciones, reglas,
procedimientos y documentos almacenados electrónicamente de manera tal que un

33
dispositivo de procesamiento pueda utilizarlas para llevar a cabo una tarea específica o
resolver un problema determinado”.
Así mismo y como característica principal de lo que es un software libre, se debe
garantizar que los usuarios del software tengan acceso a su código fuente y que éste se
encuentre en un formato abierto.
El diseño del Componente Prototipo según las normas existentes de uso de software
libre es viable de desarrollar y usar desde el ámbito legal.
PARTE II DESARROLLO DE LA INVESTIGACIÓN
En este apartado se describe el desarrollo del diseño de un componente prototipo para
mejorar el proceso de inscripción automática de espacios académicos en el sistema de
gestión académica de la universidad distrital, se muestra el análisis realizado, los factores
que se tuvieron en cuenta para el diseño e implementación, las pruebas y los resultados
obtenidos en un estudio experimental mediante el uso de algoritmos de meta heurística.
CAPITULO 3 DESCRIPCIÓN DE LA SOLUCIÓN
En este capítulo se explicarán los pasos realizados para el desarrollo del diseño de un
componente prototipo para mejorar el proceso de inscripción automática de espacios
académicos en el sistema de gestión académica de la universidad distrital. Se explicará la
investigación que fue realizada para obtener la solución que mejor se adaptara a las
necesidades del problema, el proceso del levantamiento y tratamiento de la información, la
selección de herramientas de desarrollo, el análisis de código fuente y la integración del
componente actual, la mejora del proceso, el dominio del problema, el diseño y detalles de
implementación culminando con las pruebas realizadas para verificar la precisión de los
resultados.
3.1 Levantamiento de la información
Se realiza el levantamiento de información por medio de la consulta de los datos
necesarios a través del Sistema de Información Académica de la Universidad Distrital
Francisco, que contiene el registro de las inscripciones de espacios académicos. Para esto,
se acoto el contexto a las inscripciones automáticas realizadas desde el año 2009 al 2015,
sede Bogotá, Facultad de Ingeniería.
Algunas de las fuentes de información fueron:
Zonificación y discriminación por Programa, área del Conocimiento, condiciones
sociales.
ICFES.
Organigrama organizacional.

34
Pensum.
Área de vinculación.
Acuerdo académico en el que se encuentran los estudiantes.
3.2 Análisis y selección de la información mediante la herramienta de ayuda Weka
Teniendo en cuenta el gran avance en los sistemas de minería de datos en los últimos
tiempos, las entidades educativas y empresariales han buscado maneras de explotar al
máximo la información existente en sus sistemas de información, esto basándose en
técnicas y software especializados que permiten la interpretación fácil y real de los
resultados. Es así que, para dar apoyo en la toma de decisiones a niveles administrativos o
gerenciales, se crean metodologías especializadas y técnicas de extracción adecuada de la
información, haciendo que el usuario final pueda ver los resultados con pocos pasos.
Con base en lo anterior y la información obtenida por parte de la oficina asesora de
sistemas, y la Universidad Distrital sobre los inconvenientes en la operación del sistema de
gestión académica dentro de las actividades administrativas y en particular en el módulo de
inscripción de espacios académicos, las cuales tienen repercusiones inmediatas en los
estudiantes, quienes no logran cursar los espacios académicos que pretenden cursar durante
los diferentes periodos académicos o deben encontrarse con horarios difíciles de
administrar, se evidencian problemas como la cantidad de semestres necesarios para
terminar las materias, dificultando la asistencia a otras, generando consecuencias
institucionales en espacio físico y presupuestales, retención de estudiantes y la deserción
escolar, lo que implica consecuencias para el estudiante y consecuencias para la sociedad.
Es así como en el entorno de la educación en Colombia se ha evidenciado en los
últimos años un crecimiento significativo en los niveles de retención y deserción por parte
de los estudiantes de cursos de Educación Superior. Se han realizado estudios acerca de
estas problemáticas, como por ejemplo el gobierno nacional ha realizado investigaciones
sobre la deserción estudiantil, en donde se hace uso de la metodología SPADIES que
permite establecer diferentes categorías por las cuales se puede presentar la deserción
estudiantil, dentro de las cuales se destacan las regiones y/o departamentos en los cuales se
encuentran las instituciones, el carácter institucional, el nivel de formación del estudiante,
las áreas del conocimiento y aun la modalidad de estudio (Guzmán & Duran & Franco &
Castaño & Gallón & Guzmán & Gómez & Vásquez, 2009).
A partir de la implementación de esta metodología se ha podido llegar a explicar
mediante la identificación de algunas variables las posibles causas por las cuales se
presenta la deserción y retención estudiantil, dentro de las cuales se destaca una gran
influencia de los resultados en el examen de estado ICFES, se reconocen variable
socioeconómicas tales como los ingresos de la familia, si trabaja y estudia al mismo tiempo,
entre otras; por otro lado se logró identificar al realizar una discriminación por género se

35
encontró que los hombres son más propensos a desertar y demorarse en terminar sus
carreras que las mujeres. (Sánchez, Márquez 2012)
Es por esta razón que se quiere realizar un análisis de la información y así lograr
obtener un diseño de un componente prototipo para mejorar el proceso de inscripción
automática de espacios académicos en el sistema de gestión académica de la Universidad
Distrital con el fin de poder disminuir parte de las problemáticas presentadas en los
estudiantes y sus carreras, pero así mismo se pretende determinar cuáles son las causas que
conllevan a que los estudiantes estén “retenidos” y permanezcan más de lo estipulado en la
Universidad y en algunos casos no culminen sus estudios, para ello se analizarán datos de
estudiantes de la Facultad de Ingeniería entre los años 2009 y 2015, y para realizar dicho
análisis se hará uso de una de las técnicas de análisis de datos más utilizada llamada
Minería de Datos. Ver Anexo A- Análisis y selección de la información mediante la
herramienta de ayuda Weka
3.3 Selección de Las Herramientas de Desarrollo
A continuación, se describen las herramientas de software que soportaran la separación
de capas lógicas, ejecución de reglas y optimización de salidas mediante motores de
planeación, haciendo uso de KIE como el abanico de soluciones Open Source
especializadas para el tratamiento de reglas, ejecución, optimización, almacenamiento, y
construcción.
3.3.1 Sistemas basados en Reglas
Esta metodología se basa en el seguimiento de un conjunto de premisas o reglas para
llevar a cabo la solución que sea más óptima y sencilla. Cada una de las reglas se basa en la
relación existente entre dos objetos donde se tiene en cuenta el problema que se quiere
abordar y la solución a la que se quiere llegar. Estas reglas están definidas por un humano,
quien toma el rol de experto (Pastor, 2017).
3.3.2 Ventajas
Los sistemas expertos tienen como ventaja que trabajan rápidamente llegando a una
buena solución con un buen nivel de fiabilidad, y son capaces de manejar grandes
cantidades de datos. Además, estas técnicas pueden ser usadas en diferentes áreas (no solo
en el área de la computación) como economía, medicina, biología, etc. Otra de las ventajas
es su modularidad, es decir que se pueden ir añadiendo más reglas sin necesidad de realizar
un cambio en el resto de las reglas existentes.
3.3.3 Aplicaciones Existentes
Planificación de negocio: actualmente existen un gran conjunto de aplicaciones de
planificación de negocio y recursos. Para encontrar un antecedente del proyecto y la

36
solución mejor adaptada a las necesidades de la Universidad Distrital se consideraron
soluciones comerciales, libres, frameworks o librerías y lenguajes para la resolución de
restricciones.
Las alternativas comerciales se consideraron únicamente para percibir la competencia
existente en el mercado, las necesidades que estás satisfacen y el precio que poseen. No
eran viables ya que no permitían una integración con el sistema de gestión académica de la
universidad ni proporcionaban control total sobre el código fuente. Además, el uso de una
solución comercial aumentaría considerablemente el precio del servicio.
Para tomar una decisión entre las alternativas libres encontradas se realizó una matriz
ponderada con los siguientes puntos: mantenibilidad, documentación, facilidad de integrar a
un sistema web, portabilidad y velocidad. Se usó una escala de 1 a 5 que indicaba si dicha
característica de la solución era buena (5) o mala (1). Se confió en la documentación de la
solución en lo que respecta a la velocidad.
De las soluciones encontradas libres, las únicas que se concentraban en generar
horarios académicos o una alternativa similar eran FET y UNITIME.
FET, Free Timetabling Software o Software de generación de horarios libre, usa un
algoritmo propio basado en heurísticas para la solución de horarios complejos. Según la
documentación encontrada, realiza un Fit Firts Decreasing y una vez construida la solución
inicial intercambia horarios de manera recursiva para dar espacio a otros horarios. El
problema con esta alternativa es que no provee una librería para desarrollo web, funciona
solamente por interfaz gráfica como aplicación para el usuario. Tampoco permite cambiar
el algoritmo ni tiene buena documentación para el desarrollo (FET, s.f.).
Unitime es un sistema de planificación de horarios educacionales que permite
desarrollar horarios de cursos y exámenes, administrar cambios a estos, entre otras
funcionalidades. Este dado como un sistema web para universidades o sus departamentos.
La búsqueda realizada para encontrar la solución está basada en un algoritmo de Iterative
Forward Search, el problema con esta alternativa es que su documentación solo cuenta con
Javadocs y la tesis en la cual se basaron (Muller, 2005)
Por otra parte, se tiene como lenguaje para la solución de problemas de restricciones a
EclipseCLP. Este lenguaje fue descartado ya que al ser un superconjunto del lenguaje
declarado Prolog hubiese dificultado la mantenibilidad del módulo. Así mismo realizar una
aplicación web escrita en EclipseCLP hubiese necesitado la incorporación de otro lenguaje
con mayor cantidad de librerías web que interactuara con el solucionador escrito en
EclipseCLP, como java o Ruby. Es importante señalar que la velocidad de retorno de
solución del lenguaje EclipseCLP depende del solver con quien interactúe.
Por facilidad de integración a un sistema web se procedió a considerar alternativas
basadas en java ya que el lenguaje tiene un considerable número de librerías como jersey o
REST que permiten a otras aplicaciones interactuar con la solución desarrollada mediante

37
el protocolo HTTP. Entre las alternativas encontradas se tienen: Optaplanner, Choco, jOpt
y JaCop.
Choco es una librería que java para la programación de restricciones, permite variar
entre distintas estrategias de búsqueda basadas en búsqueda local. El control que se tiene
sobre las estrategias de búsqueda no es tan explícito y la forma que provee la librería de
modelar las variables es complicado en comparación con otras alternativas.
JOpt fue descartado por su documentación y el hecho de que el código fuente no había
sido actualizado desde hacer 7 años. Se basa en algoritmo de arco consistencia para la
resolución de CSPs (Problemas de satisfacción de restricciones).
JaCop es una librería de java que ofrece métodos para encontrar una sola solución de
un CSP de manera eficiente, usa Depth First Search. Fue descartado por su documentación
y la dificultad de modelar el problema.
Optaplanner fue escogido por las siguientes características:
Facilidad para modelar problemas mediante clases de java permitirá a otros
desarrolladores mantener el modulo.
Excelente documentación y libertad para cambiar algoritmos
Escrito en java lo que permite una fácil integración a sistemas web
Poseer una librería para realizar benchmarks, lo que facilita el estudio de algoritmos
escogidos.
Solución
Mantenibilidad
Documentación
Portabilidad
Velocidad
Integración Sistema
Web
FET 2 3 4 4 2
OptaPlanner 4 5 4 4 4
EclipseCLP 3 4 3 - 3
Unitime 4 3 5 4 4
Choco 3 3 5 4 3
JOpt 2 2 4 4 3
JaCop 3 3 5 4 3
Tabla 4 Tabla Comparativa de Soluciones y motores de planificación. Fuente: Elaboración Propia
3.3.4 Optaplanner
Optaplanner es un planificador con satisfacción de restricciones escrito en java, puede
optimizar la planificación de recursos de negocio, como por ejemplo rutas vehiculares,
planificación de turnos de trabajo, optimización de clouds, programación de tareas y
muchos más. Es un motor de planificación ligero e integrable, el cual ayuda a resolver
problemas de satisfacción de restricciones eficiente sin la necesidad de construir difíciles
ecuaciones matemáticas.

38
Optaplanner combina optimización heurística y meta heurísticas como (Búsqueda
Tabú, Recorrido Simulado y Aceptación Tardía) con un muy eficiente cálculo de puntaje
(Ruescas, 2014-2015). Está patrocinado por Red Hat como parte de la comunidad JBoss y
es muy cercano a otros proyectos como son Drools y jBMP en el KIE group.
Figura 1 Ejemplos haciendo uso de Optaplanner
Fuente: Tomada de: ¿Qué es OptaPlanner? https://unpocodejava.wordpress.com/2013/05/13/que-es-optaplanner/
3.3.5 Wildfly 10
Conocido anteriormente como JBoss Aplication Server JBoss AS es un servidor de
aplicaciones Java Enterprise de código abierto, implementado en java, y basado en la
especificación de Java Enterprise. Multiplataforma bajo la máquina virtual de java. Wildfly
es completamente gratis y de código abierto, disponible para ser usada en muchas
plataformas.
Sus principales características son:
Despliegue rápido y la habilidad de editar recursos estáticos sin redespliegue.
Cada servicio puede ser iniciado y detenido en aislamiento.
Peso ligero a través de gestión de memoria eficiente.
Enfoque modular.
3.3.6 Kie workbench (Drools workbench)
Es una aplicación web que provee un entorno web genérico para creación y
administración de reglas. Puede ser usado también para probar y desplegar reglas.
Anteriormente llamado también Guvnor.

39
3.3.7 JBoss Drools
JBoss Drools es un Sistema de gestión de reglas de negocio. Este provee un motor de
reglas de negocio, que permite la creación y administración de reglas mediante una
aplicación web llamada Drools Workbench (Kie Workbench), ofrece todo un entorno para
soportar la creación de tablas de decisión, ejecución de pruebas de reglas de negocio, editor
de reglas y editor de árboles de decisión guiado.
Ver anexo D. Manual Técnico
CAPITULO 4 COMPONENTE DE INSCRIPCIÓN AUTOMATICA
En este capítulo se explicarán los componentes que hacen parte de la inscripción
automática teniendo en cuenta el análisis del proceso de inscripción de espacios académicos
actual, se dará a conocer el diseño del componente prototipo propuesto y las variables
involucradas en su implementación.
4.1. Análisis proceso de inscripción automática de espacios académicos.
Aunque el proceso de inscripción automática de espacios académicos es un proceso
puntual, no se tiene formalmente un diagrama de procesos que pueda aclarar cuáles son los
pasos del mismo, debido a esto se solicitaron reuniones con el equipo de la oficina de
sistemas para obtener una descripción del proceso clara, precisa y coherente.
Teniendo en cuenta lo anterior el siguiente diagrama muestra los pasos que hacen parte
del proceso:

40
Figura 2 Diagrama de Procesos inscripción automática de espacios académicos. Fuente: Elaboración Propia
Basados en la información obtenida, el proceso inicia al finalizar el semestre, donde se
analiza y se obtiene que asignaturas podrá preinscribir el estudiante en su siguiente
semestre, basados en las diferentes variables que pueden influir en este resultado como lo
son las materias reprobadas, estado del estudiante es decir si se encuentra en prueba
académica, nuevas materias de pensum etc., seguido a ello al iniciar el nuevo semestre
lectivo el consejo académico generará los horarios para cada coordinación una vez existan
los horarios generales de las asignaturas y grupos, así el estudiante podrá indicar que
asignaturas le gustaría cursar el siguiente semestre.
Una vez preinscritas las asignaturas por los estudiantes (llamada preinscripción por
demanda) cada coordinación se encargará de generar los horarios de los mismos basados en
su preinscripción de asignaturas ya realizada, una vez preinscritas los coordinadores puede
verificar con estadísticas el cumplimiento del mismo y publicar los horarios.
Por supuesto el proceso es mucho más complejo de lo que se ve, pero de forma
simplificada estas son las actividades que hacen parte del proceso de preinscripción
automática.

41
4.2 Análisis de documentación existente
Se encontró una debilidad en la documentación existente, ya que es poca la
documentación del proceso actual, gracias a la información recolectada y al análisis del
código fuente se estructuran diagramas y conceptos de su funcionamiento teniendo en
cuenta algunas fuentes de información como:
Zonificación y discriminación por Programa, área del Conocimiento, condiciones
sociales.
ICFES.
Organigrama organizacional.
Pensum.
Área de vinculación.
Acuerdo académico en el que se encuentran los estudiantes.
4.3 Análisis del módulo actual
A continuación, se describe la arquitectura, componentes, código fuente y otras
características que componen el módulo actual de preinscripción automática de espacios
académicos.
4.3.1 Arquitectura de la solución
Figura 3 Diagrama de componentes preinscripción automática actual. Fuente: Elaboración Propia

42
El componente de preinscripción automática actual hace parte del sistema de gestión
académica, ofrece como punto de entrada a la funcionalidad una clase específica, y desde
dentro de su implementación posee acceso a las bases de datos de la universidad para
obtener la información que usara en su procesamiento.
Dentro de su implementación también retorna código de interfaz de usuario en algunas
secciones, el código no es orientado a objetos, parece que debido a alguna compatibilidad
con el framework de desarrollo o con un estándar de facto en la implementación. Debido a
esto se pueden puntualizar ciertos anti patrones como clases gordas, ambigüedad en
responsabilidades, falta de estructura clara, etc.
4.3.2 Análisis de código fuente y algoritmo de solución
En este momento el proceso de inscripción automática de espacios académicos es un
módulo del sistema de gestión académica, el cual obedece a una serie de archivos PHP, con
el código fuente de su funcionamiento dentro del código del SGA. La ruta dentro del
código fuente según la estructura de carpetas es:
funcionarios/academicopro/bloque/preinscripción/admin_inscripcionAutomaticaCoordin
ador
El eje central del código de la preinscripción automática esta subdividido en 5 archivos
con código fuente, al analizar la estructura parece que el nombre y la disposición de los
archivos obedece a algún framework de PHP, pareciese que el código fuente no obedece la
orientación a objetos, se encontró repetición de código a lo largo del SGA, a pesar de esto
los 5 archivos guardan cierta clasificación de funciones como se evidencia a continuación:
Bloque.php
Punto de entrada a todo el módulo de preinscripción automática, recibe las peticiones
http para iniciar los procesos que realiza el módulo.
Function.class.php
Esta es una clase gorda que contiene toda la lógica del algoritmo para generar los
horarios, es la clase con más participación en el proceso, desde ella se llama a sql.class para
hacer todas las operaciones que involucran a la base de datos, es el Core del algoritmo,
contiene la función más importante para la construcción de la preinscripción.
Sql.class.php
Contiene todas las consultas SQL a los diferentes motores de bases de datos, en este
caso realiza consultas hacia el motor de Oracle y MySql, de la preinscripción automática y
del sistema de gestión académica.

43
HorariosBinarios.class.php
Esta clase contiene los métodos necesarios para hacer la transformación de los horarios
normales a horarios binarios, una clase auxiliar que permite la rápida comparación para
detectar las colisiones o cruces de espacios académicos de los horarios.
El planteamiento básico para la creación de la clase es que teniendo los horarios en los
formatos binarios existe una mayor facilidad en su comparación.
Combinaciones.class
Esta clase se encarga de generar las combinaciones posibles de horarios para el
estudiante. Según lo observado en el código fuente el sistema puede construir al menos
80000 combinaciones diferentes antes de terminar.
A continuación, se detalla un poco más la interacción entre las clases php mediante un
diagrama de secuencia.

44

45
Figura 4 Diagrama de secuencia componente actual. Fuente: Elaboración Propia
Los puntos centrales del funcionamiento del algoritmo están en:
1. La construcción de los horarios binarios necesarios para hacer las comparaciones y
descartar cruces. (En la clase de horarios binarios)
2. La ejecución mediante el ranking de los estudiantes, lo que permite que el orden de
construcción de horarios este supeditado a la clasificación obtenida de los alumnos.
3. La combinatoria implementada para ofrecer diferentes opciones de horarios.
4. La ponderación de horarios que permite determinar la cantidad total de espacios.
4.3.3 Análisis integración del componente actual
Actualmente la integración del SGA con el componente de preinscripción automática
es directa, dado que el código del componente hace parte del código del SGA, el
componente no tiene la necesidad de establecer interfaces comunes para las
comunicaciones, simplemente el SGA hace uso de las funciones ofrecidas dentro del
componente de preinscripción automática.
El punto de entrada para el acceso a la funcionalidad es la clase Bloque.php desde la
cual se procesan todas las solicitudes realizadas mediante la interfaz.
4.4 Análisis y diseño del componente
Antes de realizar cualquier implementación para un nuevo componente, es imperativo
realizar un buen diseño que permita a la implementación adquirir requerimientos no

46
funcionales y que permitan hacerla extensible, de fácil modificación, simple para la
comprensión etc.
4.4.1 Infraestructura tecnológica
Dentro del diseño del nuevo componente existen ciertas características que se
buscaban entre ellas las siguientes:
4.4.1.1 Mejora en la arquitectura y comprensión de la misma:
Actualmente el componente es similar a una caja negra completa, se posee poca
documentación sobre su funcionamiento (documentos técnicos), la documentación del
código fuente es buena sin embargo hay partes en la implementación que están sin
documentar. El detalle del algoritmo es confuso y requiere de una gran curva de
aprendizaje para poder realizar un cambio en su estructura. El nuevo componente contará
con mayor cantidad de documentación de su implementación, estructura, comportamiento,
y demás características desconocidas en el componente actual.
4.4.1.2 Facilidad de modificación de su comportamiento y flexibilidad del algoritmo
La implementación actual no tiene un comportamiento que pueda variarse fácilmente,
cualquier cambio sobre las reglas de negocio obliga a el cambio en el código fuente, el cual
puede tornarse en un proceso demorado dependiendo de los niveles de trámite a la hora de
realizar los cambios y desplegar las soluciones. Cambiar el comportamiento del algoritmo
requiere un amplio conocimiento del mismo, el cual posee una estructura de difícil
discernimiento.
4.4.1.3 Facilidad de escalamiento
Un nuevo componente puede basarse en una arquitectura sin estado que facilite su
escalamiento y potencie su capacidad de procesamiento, que podría mejorar los tiempos de
respuesta y la calidad de las salidas.
4.4.1.4 Facilidad de integración con SGA
Dado que es necesario que el nuevo componente actué tal como el anterior sin afectar
sustancialmente la manera en la que se ejecuta el proceso por medio del SGA, es
importante establecer interfaces web claras desde las cuales se puedan ejecutar los procesos
de preinscripción automática, de una manera transparente para el usuario.
4.3.1.5 Mejora del proceso mediante motor de planificación
Este punto busca mejorar la implementación del algoritmo usado para el cálculo de
posibilidades y obtención de mejores respuestas, para esto en vez de implementar un
algoritmo de 0 se decide usar un motor de planificación con restricciones, llamado
Optaplanner, el cual brinda una amplia gama de algoritmos de solución configurables.

47
Se toma la decisión de confiar en un producto con más de 10 años de creado, el cual ha
sido implantado en cientos de organizaciones para solucionar problemas de planificación
específicos.
El nuevo componente posee una arquitectura modular, donde se subdividen las tareas
de cálculo y manipulación de reglas, en servidores o instancias diferentes.
Figura 5 Componentes nueva preinscripción automática. Fuente: Elaboración Propia
4.3.1.6 Preinscripción Automática
Es el componente central que permite ejecutar y usar el motor de planificación para
solucionar el problema, contiene el dominio de solución que Optaplanner demanda para su
operación, componentes para la consulta y modificación de datos de los objetos de datos
relacionados con el cálculo y el API REST que permite acceder a su funcionalidad.
4.3.1.7 Función del Kie-Workbench

48
En kie-workbench se almacenarán las reglas con la finalidad de desacoplar su
funcionamiento del sistema de gestión académica, para desplegar esta aplicación es
preferible contar con el servidor wildfly 10 donde está probado su funcionamiento. Kie-
workbench ofrece una interfaz amigable para la administración de las reglas de negocio
pertenecientes al componente de preinscripción automática.
4.5 Componentes de software para operación e integración
A continuación, se pueden observar el detalle de componentes que conforman la
Preinscripción Automática, en general cuenta con 3 módulos internos que se encargan de
procesos específicos dentro del componente:
Figura 6 Componentes que conforman la preinscripción automática. Fuente: Elaboración Propia
4.5.1 Optaplanner Solution
Comprende todo el dominio de solución del problema de Optaplanner. Para la solución
de problemas el motor de planificación exige un conjunto de clases sobre las que se puede
explicar el problema a solucionar, estas clases son marcadas mediante anotaciones
especiales que indica al motor sobre cuales generar las diferentes opciones, de donde tomar
los valores de las opciones aleatorias, y restringir los mismos. Además de esto la

49
configuración de Optaplanner que indica que algoritmos debe usar el planificador, tiempos
por defecto de ejecución, naturaleza y complejidad del puntaje de las reglas.
4.5.2 Solución de planificación
La solución de planificación es el núcleo para la creación de una solución a un
problema de planificación, de su diseño correcto o incorrecto puede depender la calidad y
el correcto funcionamiento del motor.
La configuración de planificación de optaplanner establece que debe existir un objeto de
clase marcado con la anotación @PlanningSolution tal es la clase base para ejecutar el
proceso de planificación, la clase de planificación debe implementar las interfaces de
solución Solution<HardSoftScore> que establecen los hechos de la planificación, el puntaje
de la misma, y normalmente ofrecen los rangos de valores para las variables de
planificación, @PlanningVariable, en esta clase se construyen las listas de solución,
marcadas con la anotación @PlanningEntityCollectionProperty, esta lista está compuesta
de instancias de objetos marcados con la anotación @PlanningEntity.
Los objetos marcados con @PlanningEntity son quienes cambiaran durante la
planificación, el motor se encargará de encontrar las diferentes combinaciones posibles de
entidades de planificación que suplan las diferentes restricciones configuradas en el motor.
Figura 7 Explicación dominio de solución de Optaplanner. Fuente: Elaboración Propia
4.5.2.1 Acceso REST
Los módulos que brindan web implementan una API Rest que permite acceder a los
servicios del planificador, la creación, solución, terminación temprana, externalización y
demás servicios que hacen parte de su funcionalidad.
DESCRIPCIÓN METODOS API REST

50
Nombre: Obtener mejor solución
Ruta acceso: /rest/solution
Propósito Retorna en formato json un objeto de datos que contiene la
información de la mejor solución obtenida de la planificación
actual, puede accederse dentro de la planificación y una vez ha
finalizado.
Parámetros N/A
Retorno Objeto json con la solución de la planificación solicitada
Tipo de método http GET
Tipo de retorno Json
Tipo ejecución
Sincrónico
Tabla 5 Descripción Método REST Obtener Mejor solución. Fuente: Elaboración Propia
Nombre: Solicitar planificación de asignaturas
Ruta acceso: /rest/solution/solve
Propósito Realiza una solicitud de planificación para un caso específico
determinado mediante los parámetros suministrados, que son el
periodo, año y código del coordinador, el sistema se encarga de
verificar que códigos de carrera están asociados al coordinador,
para los cuales lanza un proceso de planificación.
Al terminar la planificación el sistema persiste la información de
la planificación en la tabla temporal ACINSPRE.
Parámetros anio: (Tipo entero) contiene el valor del año de la planificación
periodo: (Tipo entero) contiene el valor del periodo de la
planificación
codCoordinador: (Tipo long) contiene el valor del código del
coordinador
Retorno Objeto json que retorna un mensaje del estado de la solicitud
Tipo de método http GET
Tipo de retorno Json
Tipo ejecución
Asíncrono
Tabla 6 Descripción Método REST Solicitar Planificación de Asignaturas. Fuente: Elaboración Propia
Nombre: Terminar la planificación de forma temprana
Ruta acceso: /rest/solution/terminateEarly
Propósito Terminar de manera anticipada la planificación anteriormente

51
lanzada, que se encuentra en curso, el sistema busca la
planificación asociada a la sesión http y si esta activa la termina
de forma anticipada sin importar su puntuación mínima. A pesar
de acabar con la planificación al salir el algoritmo realiza las
demás actividades de terminación común de manera normal.
Parámetros N/A
Retorno Objeto Json que retorna un mensaje del estado de la solicitud
Tipo de método http GET
Tipo de retorno Json
Tipo ejecución
Sincrónico
Tabla 7 Descripción Método REST Terminar la planificación de forma temprana. Fuente: Elaboración Propia
Nombre: Consultar estado de planificación
Ruta acceso: /rest/solution/estado
Propósito Consultar el estado de una solicitud determinada por los
parámetros de entrada, en este caso año, periodo y código de
coordinador, el sistema verifica cual es el estado, de una posible
solicitud de planificación con estos parámetros y lo retorna en
forma de mensaje.
Parámetros anio: (Tipo entero) contiene el valor del año de la planificación
periodo: (Tipo entero) contiene el valor del periodo de la
planificación
codCoordinador: (Tipo long) contiene el valor del código del
coordinador
Retorno Objeto json que retorna un mensaje del estado de la solicitud
Tipo de método http GET
Tipo de retorno Json
Tipo ejecución
Sincrónico
Tabla 8 Descripción Método REST Consultar estado de planificación. Fuente: Elaboración Propia
Nombre: Publicar horarios
Ruta acceso: /rest/solution/persistir
Propósito Se encarga publicar la información de los horarios, migrando la
información de la tabla temporal ACINSPRE a la tabla de
horarios definitiva ACINS.
Parámetros anio: (Tipo entero) contiene el valor del año de la planificación
periodo: (Tipo entero) contiene el valor del periodo de la
planificación

52
codCoordinador: (Tipo long) contiene el valor del código del
coordinador
Retorno Objeto json que retorna un mensaje del estado de la solicitud
Tipo de método http GET
Tipo de retorno Json
Tipo ejecución
Sincrónico
Tabla 9 Descripción Método REST Publicar Horarios. Fuente: Elaboración Propia
4.5.2.2 Acceso a Datos
El módulo de acceso a datos mantiene toda la configuración de bases de datos
necesaria para soportar el acceso y mapeo objeto relacional de las fuentes de datos Oracle y
Mysql, además de soportar la configuración de repositorios necesarios para el acceso y
persistencia dela información.
Las fuentes de datos utilizadas en la aplicación provienen de 2 bases de datos
diferentes que son, la base de datos Oracle y la base de datos MySql.
Los objetos de datos de las diferentes fuentes alimentan los hechos de la planificación
de la solución, la configuración del comportamiento del algoritmo y la publicación de
espacios académicos preinscritos de manera automática.
4.6 Modelo de Datos Oracle
ACCALEVENTOS:
En esta tabla se registran los eventos que indican las planificaciones o ejecuciones del
algoritmo de solución, indica el estado de la planificación necesario para no realizar dos
ejecuciones con los mismos parámetros de año, periodo y carrera.
ACCRA:
Contiene la información de las carreras, mediante la cual se asocia la planificación a
un contexto de carrera especifico.
ACCURSOS:
Concentra la información de los diferentes cursos programados según los horarios
generados por consejo académico para el aprovechamiento semestral por parte de los
alumnos.
ACEST:

53
Contiene la información de los alumnos y los estados en los que se encuentran, estados
que determinan la participación en la planificación de asignaturas.
ACHORARIOS:
Contiene el detalle de los horarios de los espacios académicos programadas por el
consejo académico, días y horas asignadas a una asignatura.
ACINS:
Tabla de inscripción de espacios académicos definitiva, esta tabla se llena con la
información de la tabla ACINSPRE una vez que el coordinador elija publicar los horarios
generados.
ACINSDEMANDA:
Es el repositorio para los espacios académicos seleccionados por los estudiantes
mediante el proceso de inscripción por demanda, es uno de los insumos básicos para que el
motor de planificación pueda hacer su labor, dado que es en base a los espacios académicos
inscritos por demanda que él puede inscribir automáticamente asignaturas a los alumnos.
ACESTADO:
Catálogo que contiene las descripciones de los estados de los alumnos.
ACINSPRE:
Es la tabla temporal de trabajo, en la cual se consignarán los resultados de la
planificación, una vez se publiquen los resultados sus datos serán eliminados y pasaran a la
tabla de ACINS.
ACTABLAHOMOLOGACION:
La tabla de homologación permite verificar las equivalencias en los planes de estudios
de los estudiantes, con la finalidad de ampliar el rango de espacios académicos disponibles
ofertados.
Ver anexo B. Diccionario de datos Modelo Oracle

Figura 8 Modelo de Datos Oracle. Fuente: Elaboración Propia

4.7 Modelo De Datos Mysql
SGA_EJECUTA_INSCRIPCION_AUTO:
Esta tabla al igual que la tabla ACCEVENTOS registra la información de la ejecución
de la planificación, siendo más puntual a la hora de determinar si existe se ha lanzado la
ejecución de la planificación y cuál es su estado actual.
SGA_CLASIFICACION_ESTUDIANTES:
Este repositorio de información contiene la clasificación calculada de los estudiantes
del anterior semestre, esta clasificación permite dar una prioridad en la asignación de los
espacios académicos dentro de los estudiantes.
SGA_RANKINGPREINSDEMANDA:
Esta tabla de información contiene el ranking de asignaturas o espacios académicos
más importantes y solicitadas durante la carrera con la finalidad de dar prioridad a la
asignación de los espacios académicos de las mismas.
Ver Anexo C. Diccionario de datos Mysql

56
Figura 9 Estructuras de datos MySql. Fuente: Elaboración Propia
4.8 Implementación del componente
Inicialmente se investigó si para el motor de planificación existía una aplicación web
que permitiera desacoplar el funcionamiento del motor del aplicativo en cuestión, sin
embargo, tal implementación aún no existe para Optaplanner, y por el momento solo se está
en desarrollo.

57
Figura 10 Diagrama de despliegue componte preinscripción automática. Fuente: Elaboración Propia
4.9 Implementación de componentes de software
A continuación, se describen los componentes de software para el funcionamiento y
configuración del motor de planificación.
4.9.1 Componentes propios de operación
El componente implementado es una aplicación web java construida bajo el
Framework de Spring Boot, usando Maven como herramienta de administración de
dependencias.

58
La aplicación se configura en 3 subcomponentes que interactúan para brindar la
funcionalidad de planificación los cuales se describen así:
1. Clases de operación del motor de planificación, que constituye el dominio de
solución, los administradores o managers que se conectan y cargan los esquemas de
solución por defecto de la planificación, las extensiones a las funcionalidades de
DROOLS (dos acumuladores personalizados)
2. La persistencia y consulta de información, está constituida de toda la configuración
para diferentes accesos a datos, mapeo ORM a las tablas de cada motor, entidades,
repositorios de Sprint, servicios transaccionales para la consulta y persistencia de la
información.
3. La exposición de la funcionalidad mediante controladores REST de Spring, datos,
personalizados para las respuestas a las funciones, y construcción de JSON de
salida.
Algunas de las librerías usadas en el proyecto son:
Figura 11 Librerías usadas en el desarrollo del proyecto Fuente: Elaboración Propia
Kie-ci 6.5.0 Final: Api de los servicios de kie, usada en el desacople de las reglas de
negocio y configuración de solucionador desde kie workbench.
Mysql-connector-java 5.1.40: Driver de mysql para conexión con la base de datos de
Mysql de la universidad.

59
Ojdbc6 11.2.0: Driver de Oracle para conexión con la base de datos de oracle de la
universidad.
Lombok 1.16.10: Funcionalidades de lombok para la generación de getters y setters.
Logback-classic 1.1.7: Librería que brinda la funcionalidad de logging para la
aplicación.
Optaplanner-core 6.5.0. Final: Core del motor de planificación de optaplanner.
4.9.1.1 Solución Optaplanner
Siguiendo el diseño realizado para la base de datos, se desarrollaron una serie de clases
para modelar el dominio de la solución. A continuación, se describe:
Dominio de solución
Comprende todos los objetos necesarios para el funcionamiento y configuración del
motor de planificación, como punto central se encuentra el dominio del problema, el cual es
un conjunto de clases mediante las cuales se puede representar el problema a solucionar.
Sobre estas clases el motor de planificación genera los resultados según las restricciones
establecidas en las reglas de puntajes.

Figura 12 Clases del dominio de solución de planificación. Fuente: Elaboración Propia

4.9.2 Componentes de integración o interoperabilidad
A continuación, se describen los mecanismos de integración que hacen parte del
desarrollo de este proyecto.
4.9.2.1 Integración con SGA
La integración entre el componente de planificación y los demás componentes del
SGA se puede realizar mediante los servicios REST, la aplicación expone su funcionalidad
asociada a una sesión web, y mantiene deshabilitadas las cabeceras CORS dado que se
espera que el uso del planificador sea interno.
Su interacción es simple y fácil de implementar.
4.9.2.2. Integración con KieWorkbench
La integración con el Kie-Workbench se realiza mediante la API de KIE, que permite
acceder a los objetos del repositorio de workbench en otro servidor, esto permite que se
desacoplen los XML de solución y reglas de negocio.
Figura 13 Integración con el KieWorkbench. Fuente: Elaboración Propia
Para que las sesiones construidas en workbench puedan ser usadas se personaliza el
archivo kmodule dentro del artefacto de workbench, indicando el paquete base desde el
cual buscara y cargara las reglas en sesión.

62
4.9.3 Implementación de reglas de negocio
Para cada estado de un problema de optimización con restricciones es necesario un
cómputo eficiente y rápido del puntaje actual de la solución, ya que las puntuaciones
cambian por cada paso dado por los algoritmos y es necesario mantener el conteo de los
puntos para poder saber que modificación es la indicada para la optimización. Con esta
finalidad, se codificaron reglas para el cálculo del puntaje las cuales contienen restricciones
que limitan o mejoran las soluciones ofrecidas por el planificador. Para el proyecto, tales
restricciones se dividieron en tres grupos: reglas fuertes negativas, reglas suaves negativas
y reglas suaves positivas as o recompensas.
4.9.3.1 Restricciones fuertes negativas
Representan escenarios que no pueden ser permitidos por el planificador, reglas que no
se pueden romper, por tal motivo las soluciones que causan que se activen restricciones
fuertes negativas, serán descartadas automáticamente por el motor.
4.9.3.2 Restricciones suaves negativas
Representan escenarios que no deberían romperse si se pueden evitar, las reglas que
contienen estas restricciones disminuyen el puntaje de las soluciones.
4.9.3.3 Restricciones suaves positivas o recompensas
Representan escenarios que para el planificador deben cumplirse si es posible, el motor
dará prioridad a cumplir estas recompensas, estas recompensas mejoran el puntaje.
Dentro de las reglas escritas para cumplir el propósito de este proyecto se encuentran
las siguientes:
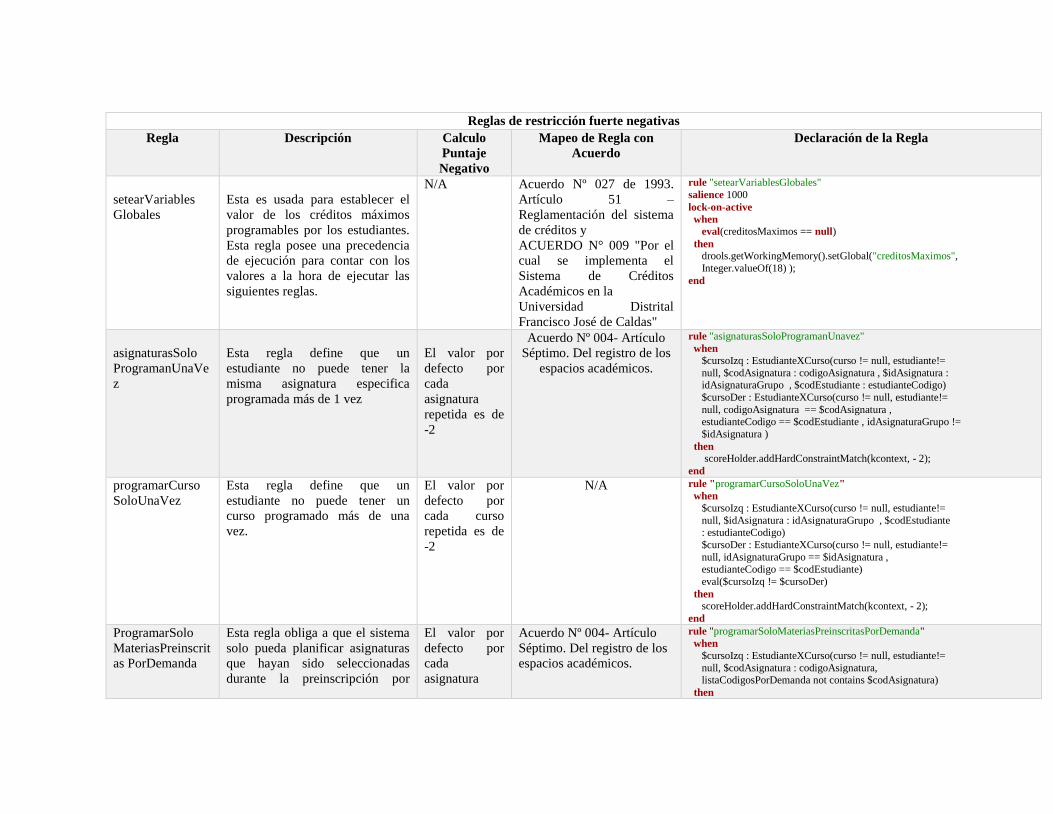
Reglas de restricción fuerte negativas
Regla Descripción Calculo
Puntaje
Negativo
Mapeo de Regla con
Acuerdo
Declaración de la Regla
setearVariables
Globales
Esta es usada para establecer el
valor de los créditos máximos
programables por los estudiantes.
Esta regla posee una precedencia
de ejecución para contar con los
valores a la hora de ejecutar las
siguientes reglas.
N/A Acuerdo Nº 027 de 1993.
Artículo 51 –
Reglamentación del sistema
de créditos y
ACUERDO N° 009 "Por el
cual se implementa el
Sistema de Créditos
Académicos en la
Universidad Distrital
Francisco José de Caldas"
rule "setearVariablesGlobales"
salience 1000
lock-on-active
when eval(creditosMaximos == null)
then drools.getWorkingMemory().setGlobal("creditosMaximos",
Integer.valueOf(18) );
end
asignaturasSolo
ProgramanUnaVe
z
Esta regla define que un
estudiante no puede tener la
misma asignatura especifica
programada más de 1 vez
El valor por
defecto por
cada
asignatura
repetida es de
-2
Acuerdo Nº 004- Artículo
Séptimo. Del registro de los
espacios académicos.
rule "asignaturasSoloProgramanUnavez"
when $cursoIzq : EstudianteXCurso(curso != null, estudiante!=
null, $codAsignatura : codigoAsignatura , $idAsignatura : idAsignaturaGrupo , $codEstudiante : estudianteCodigo)
$cursoDer : EstudianteXCurso(curso != null, estudiante!=
null, codigoAsignatura == $codAsignatura , estudianteCodigo == $codEstudiante , idAsignaturaGrupo !=
$idAsignatura )
then scoreHolder.addHardConstraintMatch(kcontext, - 2);
end
programarCurso
SoloUnaVez
Esta regla define que un
estudiante no puede tener un
curso programado más de una
vez.
El valor por
defecto por
cada curso
repetida es de
-2
N/A rule "programarCursoSoloUnaVez"
when
$cursoIzq : EstudianteXCurso(curso != null, estudiante!=
null, $idAsignatura : idAsignaturaGrupo , $codEstudiante : estudianteCodigo)
$cursoDer : EstudianteXCurso(curso != null, estudiante!=
null, idAsignaturaGrupo == $idAsignatura ,
estudianteCodigo == $codEstudiante)
eval($cursoIzq != $cursoDer)
then
scoreHolder.addHardConstraintMatch(kcontext, - 2);
end
ProgramarSolo
MateriasPreinscrit
as PorDemanda
Esta regla obliga a que el sistema
solo pueda planificar asignaturas
que hayan sido seleccionadas
durante la preinscripción por
El valor por
defecto por
cada
asignatura
Acuerdo Nº 004- Artículo
Séptimo. Del registro de los
espacios académicos.
rule "programarSoloMateriasPreinscritasPorDemanda"
when $cursoIzq : EstudianteXCurso(curso != null, estudiante!=
null, $codAsignatura : codigoAsignatura, listaCodigosPorDemanda not contains $codAsignatura)
then

64
demanda. planeada que
no ha sido
preinscrita por
demanda es de
-2.
scoreHolder.addHardConstraintMatch(kcontext, -2);
end
noPermitirCursos
MismosHorarios
Esta regla define que un
estudiante no puede tener más de
una asignatura con un mismo
horario en un mismo día, evita el
conflicto de horarios
Se determina
mediante el
conteo de
conflictos de
la clase
ConflictoCurs
os
N/A rule "noPermitirCursosMismoHorario"
when $courseConflict : ConflictoCursos($leftCourse : getLeftCourse(), $rightCourse : getRightCourse())
$leftEstudianteCurso : EstudianteXCurso(curso ==
$leftCourse, curso != $rightCourse, $estudiante : getEstudiante())
$rightEstudianteCurso : EstudianteXCurso(curso == $rightCourse, curso == $leftCourse, estudiante ==
$estudiante )
then scoreHolder.addHardConstraintMatch(kcontext, -
$courseConflict.getConflictCount());
end
noPermitirCursos
HomologadoseEn
Conflicto
Esta regla evita los conflictos
entre materias homologables y
homologadas, con la finalidad de
que solo aparezca una de las dos.
El valor por
defecto por
cada conflicto
programado es
de -2.
Acuerdo Nº 004 de 2011
Artículo Décimo Segundo.
Planes de transición y
Homologación Curricular.
rule "noPermitirCursosHomologadoseEnConflicto"
when
$leftEstudianteCurso : EstudianteXCurso(curso != null, estudiante!= null, $leftCourseId : idAsignaturaGrupo,
$codigoAlumno : estudianteCodigo )
$rightEstudianteCurso : EstudianteXCurso(curso != null, estudiante!= null, $rightCourseId : idAsignaturaGrupo,
idAsignaturaGrupo != $leftCourseId, estudianteCodigo ==
$codigoAlumno ) eval($leftEstudianteCurso != $rightEstudianteCurso)
$mapa :
Map(this[buildKeyInverse($leftCourseId,$rightCourseId)] > 0);
then
scoreHolder.addHardConstraintMatch(kcontext, -2);
end
EstudianteNo
PuedeExceder
Creditos
Esta regla restringe la
planificación para que evite
planificar más de 18 créditos que
son el máximo de un estudiante.
Cada
rompimiento
de esta regla
causa un
puntaje
negativo de -2
Acuerdo Nº 027 de 1993.
Artículo 51 –
Reglamentación del sistema
de créditos y
ACUERDO N° 009 "Por el
cual se implementa el
Sistema de Créditos
Académicos en la
rule "estudianteNoPuedeExcederCreditos"
when
$leftEstudianteCurso : EstudianteXCurso(curso != null,
estudiante!= null, $estudianteRef : estudiante )
$sumaCreditosEstudiante : Number() from accumulate(EstudianteXCurso(curso != null, estudiante ==
$estudianteRef, $creditos : creditos ), sum($creditos))
eval($sumaCreditosEstudiante > creditosMaximos)
then
scoreHolder.addHardConstraintMatch(kcontext, -2);

65
Universidad Distrital
Francisco José de Caldas"
end
cursosNoSobre
Ocupados
Evita que la cantidad de
estudiantes programados para un
curso sea mayor a la cantidad de
cupos disponibles para el mismo.
El total del
conteo de los
estudiantes
programados.
Acuerdo Nº 07 Artículo 6.
Conformación Grupo de
estudiantes para el programa
académico.
rule "cursosNoSobreOcupados"
when $estudianteCurso : EstudianteXCurso($cursoReferencia : getCurso())
$estudiantesProgramadosCount : Long() from
accumulate($cursoReferenciado : EstudianteXCurso(curso == $cursoReferencia, estudiante != null),
count($cursoReferenciado))
$estudianteCursoOk : EstudianteXCurso(curso == $cursoReferencia, curso.cupos <
$estudiantesProgramadosCount.intValue())
then scoreHolder.addHardConstraintMatch(kcontext, -
$estudiantesProgramadosCount.intValue());
end
Tabla 10 Reglas de restricción fuertes negativas. Fuente: Elaboración Propia
Reglas de restricción suave negativas
Regla Descripción Calculo Puntaje
Negativo
Mapeo de
Regla con
Acuerdo
Declaración de la Regla
peorPuntajeMasNulos Esta regla potencia la
funcionalidad del
planificador indicándole
que dejar nulas las
asignaturas no es óptimo.
Cada caso que
rompe la regla
causa un puntaje
negativo de -20.
N/A rule "peorPuntajeMasNulos"
when
$estudianteCurso : EstudianteXCurso(curso == null,
estudiante != null)
then
scoreHolder.addSoftConstraintMatch(kcontext, -20);
end

66
peorPuntajeMaterias
MenosCompactas
Define un puntaje
negativo para los espacios
entre asignaturas, se usan
las funciones de
acumulación y luego se
verifican los horarios por
día, obteniendo un valor
por cada espacio.
Se asigna un
puntaje negativo
por cada espacio
en la
programación
diaria.
N/A rule "peorPuntajeMateriasMenosCompactas"
when $estudianteRef : Estudiante()
$sumaCreditosEstudiante : Integer() from
accumulate(EstudianteXCurso(estudiante == $estudianteRef,curso != null, $cursoRef : getCurso()),
calcularHorariosNegativeScore($cursoRef.getHorarios()))
then scoreHolder.addSoftConstraintMatch(kcontext, -
$sumaCreditosEstudiante);
end
Tabla 11 Reglas de restricción suave negativas. Fuente: Elaboración Propia
Reglas de restricción suave positivas
Regla Descripción Calculo Puntaje Negativo Mapeo de Regla
con Acuerdo
Declaración de la Regla
mejorPuntaje
Estudiantes
RankingAlto
Define u puntaje positivo
para la mayor completitud
de las materias de los
estudiantes con mejores
rankings.
El score se calcula con una
función que relaciona el
ranking del estudiante y la
completitud de materias
preinscritas.
N/A rule "mejorPuntajeEstudiantesRankingAlto"
when $estudianteRef : Estudiante($listaCodigosDemanda
: getListaCodigosPorDemanda())
$listaCodigos : ArrayList() from accumulate(EstudianteXCurso(estudiante == $estudianteRef,curso !=
null, $cursoRef : getCurso()),
acumularListaCodAsignatura($cursoRef.getCodigoAsignatura()))
then scoreHolder.addSoftConstraintMatch(kcontext,calcularScoreCompletit
udAsignaturas($estudianteRef.getClasificacion(),valorarCompletitudAsignaturas($listaCodigos, $listaCodigosDemanda)).intValue());
end
mejorAsignaturas
Programadas
Ranking
Da un puntaje positivo a
las asignaturas
programadas con mayor
ranking
El score se calcula
mediante una relación del
ranking de la asignatura
dividido entre 100
N/A rule "mejorAsignaturasProgramadasRanking"
when
$estudiantexCurso : EstudianteXCurso($cursoleft : curso, $estudiante : estudiante, estudiante !=
null, curso !=null)
then scoreHolder.addSoftConstraintMatch(kcontext,
($cursoleft.getRanking()/100));
end
Tabla 12 Reglas de restricción suave positivas. Fuente: Elaboración Propia

4.10 Pruebas del componente
Se realizaron pruebas unitarias y de integración al componente prototipo utilizando la
librería de pruebas de java JUnit y postman y la correctitud de las soluciones se verifico
observando en la pantalla de postman los resultados de las consultas a los servicios.
4.10.1 Pruebas de ejecución e integración
A continuación, se describen los casos de prueba desde el motor de planificación y
desde Guvnor.
Casos de prueba
Nombre: Ejecución del motor de planificación
Propósito:
Verificar funcionamiento del motor de planificación
Prerrequisito 1. Tienen que existir cursos con horarios definidos
2. Tienen que existir alumnos que hayan realizado la preinscripción por
demanda y que estén en estado activo.
Datos de Prueba
1. De los datos de muestra suministrados por la Universidad distrital del
periodo 2017-1 se toman todos los Estudiantes con código menor a
20142025041. Para los cuales se realiza un filtro teniendo en cuenta
que tengan materias preinscritas por demanda. Se cuentan 488
alumnos.
2. Para el caso de los cursos se toma la muestra suministrada por la
Universidad distrital del periodo 2017-1, para los cuales se realiza un
filtro de aquellos que tengan horarios definidos, los cuales son 223
cursos.
3. Para la consulta deben indicarse los siguientes parámetros:
anio: 2017
periodo:1
codCoordinador:25
Pasos
1. Configurar una prueba get sobre la siguiente URL:
http://localhost:7778/PreinscripcionAuto/rest/solution/solve
2. Ingresar los parámetros de prueba indicados en ‘Datos de prueba’
anio: 2017
periodo:1
codCoordinador:25
3. Lanzar la prueba con Send
Herramientas utilizadas
en la prueba
Postman

68
Resultados esperados
1. Al iniciar la planificación la tabla de la base de datos Mysql llamada
sga_ejecuta_inscripcion_auto, debe agregar un registro con la
información del año, código de carrera, periodo, y el estado de la
planificación (7).
2. Se debe visualizar el Objeto con json con mensaje: ‘planificación
inicia’
3. Se espera que se dé inicio a la planificación, mediante el log del
sistema se puede observar el avance y culminación.
4. Se espera que la tabla ACINSPRE sea llenada con la información de
la planificación.
5. Al finalizar la planificación la tabla de la base de datos Mysql llamada
sga_ejecuta_inscripcion_auto, debe cambiar su estado ha finalizado
(14).
Registro ingresado en tabla sga_ejecuta_inscripción_auto
Validación
A continuacion se muestra la información de planificación almacenada en
la base de datos.
Información de la Planificación
Tabla 13 Descripción caso de prueba Ejecución del motor de planificación. Fuente: Elaboración Propia

69
Nombre: Consulta estado de planificación
Propósito:
Verificar el estado de la solicitud de planificación
Prerrequisitos N/A
Datos de Prueba
1. Deben indicarse los siguientes parámetros:
anio: 2017
periodo:1
codCoordinador:25
Pasos
1. Se configura una prueba get sobre la siguiente URL:
http://localhost:7778/PreinscripcionAuto/rest/solution/estado
2. Ingresar los parámetros de prueba indicados en ‘Datos de prueba’
anio: 2017
periodo:1
codCoordinador:25
Herramientas
utilizadas en la
prueba
Postman
Resultados
esperados
Dependiendo del estado del proceso (En ejecución, ya ejecutado o no existente)
puede retornar tres mensajes diferentes:
1. El proceso de planificacion para estas variables año:"+anio+"
periodo:<periodo> codigo carrera: <codCarrera> está en ejecución
2. Ya se ha ejecutado un proceso para las variables año: <anio>
periodo:<periodo> codigo carrera:<codCarrera
3. "No existe proceso para las variables año:<anio> periodo:<periodo>codigo
carrera: <codCarrera>
4. Terminado temprano
Validación
A continuación se muestra desde la URL el estado del proceso de planificación.
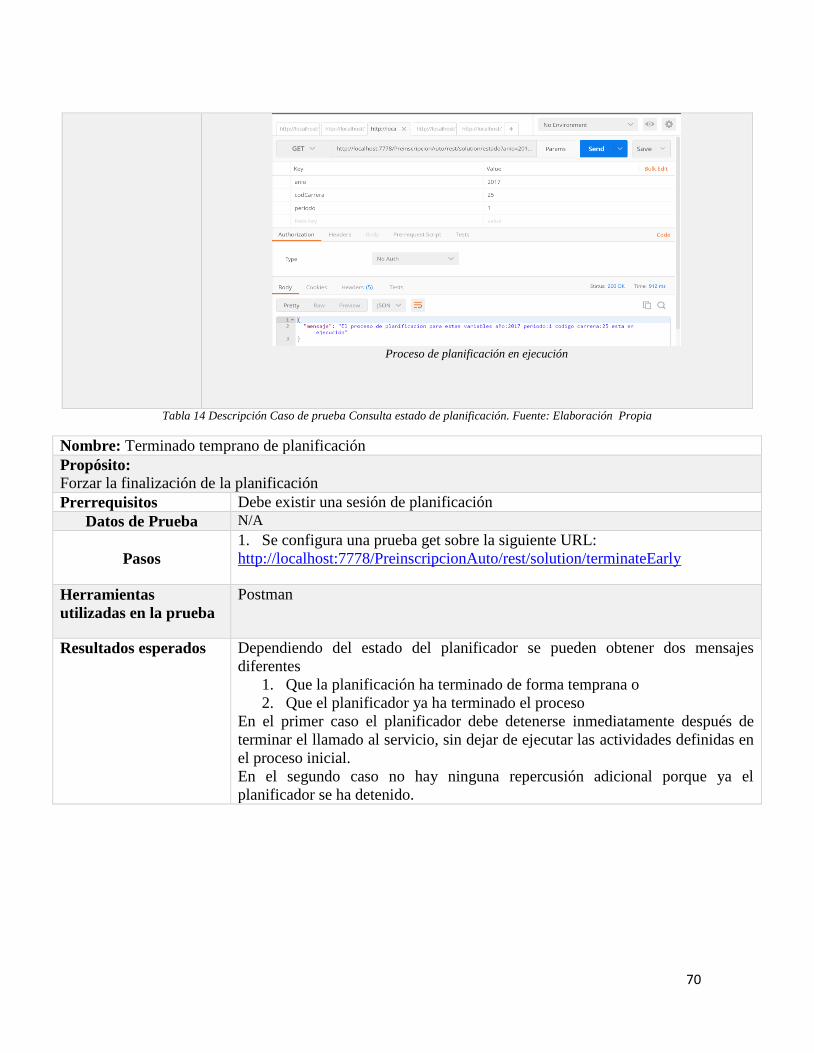
70
Proceso de planificación en ejecución
Tabla 14 Descripción Caso de prueba Consulta estado de planificación. Fuente: Elaboración Propia
Nombre: Terminado temprano de planificación
Propósito:
Forzar la finalización de la planificación
Prerrequisitos Debe existir una sesión de planificación
Datos de Prueba N/A
Pasos
1. Se configura una prueba get sobre la siguiente URL:
http://localhost:7778/PreinscripcionAuto/rest/solution/terminateEarly
Herramientas
utilizadas en la prueba
Postman
Resultados esperados Dependiendo del estado del planificador se pueden obtener dos mensajes
diferentes
1. Que la planificación ha terminado de forma temprana o
2. Que el planificador ya ha terminado el proceso
En el primer caso el planificador debe detenerse inmediatamente después de
terminar el llamado al servicio, sin dejar de ejecutar las actividades definidas en
el proceso inicial.
En el segundo caso no hay ninguna repercusión adicional porque ya el
planificador se ha detenido.

71
Validación
Planificador ha terminado su ejecución
Tabla 15 Descripción caso de prueba Terminado temprano de planificación. Fuente: Elaboración Propia
Nombre: Publicar horarios
Propósito:
Publicar la información de horarios en la tabla ACINS
Prerrequisitos Se debe haber ejecutado una planificación exitosa que haya registrado datos
en la tabla ACINSPRE
Datos de Prueba
Ingresar los parámetros de
anio: 2017
periodo:1
codCoordinador:25
Pasos
Se configura una prueba get sobre la siguiente URL:
http://localhost:7778/PreinscripcionAuto/rest/solution/persistir
Herramientas
utilizadas en la prueba
Postman
Resultados esperados
Se debe llenar la tabla ACINS con la información de la tabla ACINSPRE del
resultado de la planificación del proceso anterior.
Adicionalmente se debe borrar la información de la tabla ACINSPRE
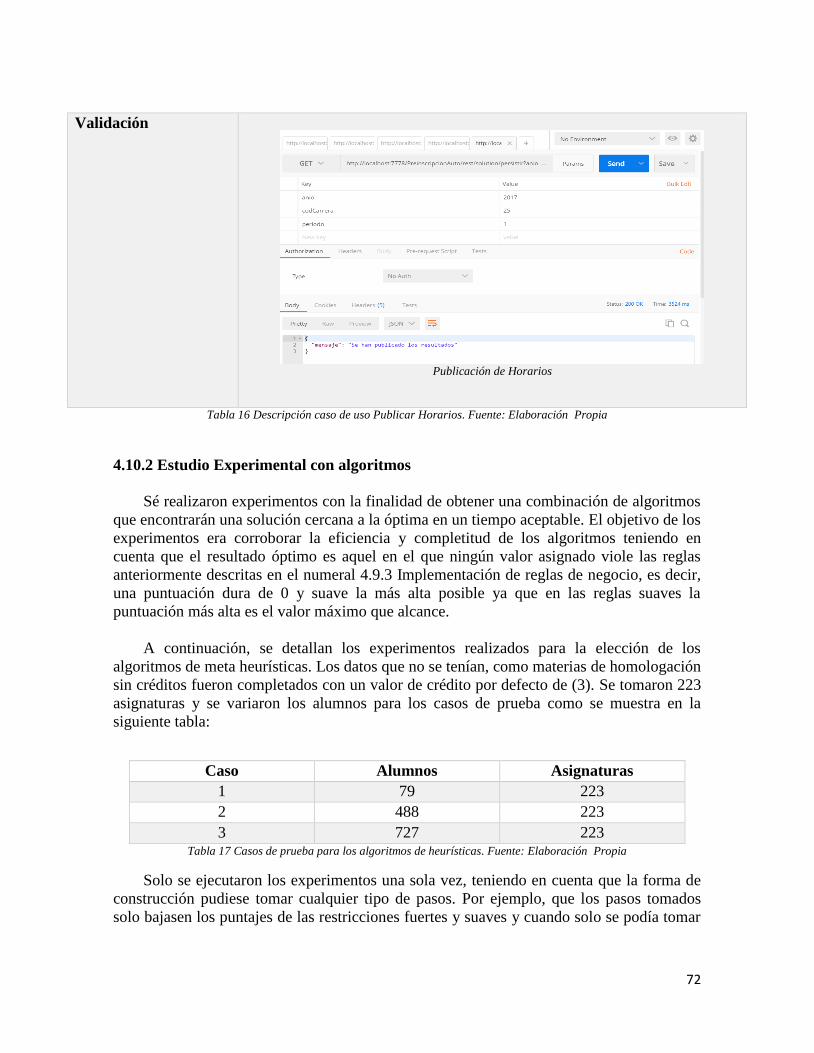
72
Validación
Publicación de Horarios
Tabla 16 Descripción caso de uso Publicar Horarios. Fuente: Elaboración Propia
4.10.2 Estudio Experimental con algoritmos
Sé realizaron experimentos con la finalidad de obtener una combinación de algoritmos
que encontrarán una solución cercana a la óptima en un tiempo aceptable. El objetivo de los
experimentos era corroborar la eficiencia y completitud de los algoritmos teniendo en
cuenta que el resultado óptimo es aquel en el que ningún valor asignado viole las reglas
anteriormente descritas en el numeral 4.9.3 Implementación de reglas de negocio, es decir,
una puntuación dura de 0 y suave la más alta posible ya que en las reglas suaves la
puntuación más alta es el valor máximo que alcance.
A continuación, se detallan los experimentos realizados para la elección de los
algoritmos de meta heurísticas. Los datos que no se tenían, como materias de homologación
sin créditos fueron completados con un valor de crédito por defecto de (3). Se tomaron 223
asignaturas y se variaron los alumnos para los casos de prueba como se muestra en la
siguiente tabla:
Caso Alumnos Asignaturas
1 79 223
2 488 223
3 727 223 Tabla 17 Casos de prueba para los algoritmos de heurísticas. Fuente: Elaboración Propia
Solo se ejecutaron los experimentos una sola vez, teniendo en cuenta que la forma de
construcción pudiese tomar cualquier tipo de pasos. Por ejemplo, que los pasos tomados
solo bajasen los puntajes de las restricciones fuertes y suaves y cuando solo se podía tomar

73
valores negativos para puntajes de restricciones fuertes. Los algoritmos fueron ejecutados
con tiempos de:
Caso 1: 2 minutos
Caso 2: 4 Minutos
Caso 3: 6 minutos
4.10.2.1 Meta heurísticas
Debido a que los algoritmos de meta heurísticas necesitan de una solución ya
construida para iniciar, fueron ejecutados en conjunto con los algoritmos de construcción.
Una vez vistos los resultados del experimento anterior, se seleccionaron algoritmos de
construcción para observar la influencia que tenían en los resultados y velocidad de
obtención de resultados sobre los algoritmos de meta heurísticas. Los algoritmos
seleccionados fueron los siguientes:
Tabú Search
Simulated Annealing
Step Counting Hill Climbing
Late Acceptance Hill Climbing
Step Counting
Cada uno de los algoritmos fue probado teniendo en cuenta los casos de prueba de la
tabla 17 y los tiempos de ejecución definidos para cada caso.
4.10.2.2 Máquina de Prueba
A continuación, se describen las especificaciones de la máquina en donde se realizaron
los experimentos con los diferentes algoritmos de construcción para las heurísticas y meta
heurísticas.
Ítem Máquina
Procesador Intel Core i7 6700HQ (Skylate
Memoria (RAM)
12Gb
Disco Duro 1 TB
Sistema Operativo
Windows 10
Versión Java Openjdk version ”1.8.0”
Tabla 18 Máquina usada para las pruebas. Fuente: Elaboración Propia

74
4.10.2.3 Resultados
Los resultados de los algoritmos se muestran a continuación
Nota: se debe tener en cuenta que las pruebas se hacen en el nivel de logging de info.
Algoritmo Caso 1 Caso 2 Caso 3
Hill Climbing 0hard/
5133soft
0hard/
87504 Soft
0hard/ 146689 Soft
Tabú Search
0hard/
5063Soft
-4956hard/
168994soft
-8320hard/
252647soft
Late Acceptance
0hard/
4114Soft
-1626hard/ 17736Soft
-3026hard/ 27037Soft
Step Counting 0hard/
4825Soft
-1604hard/ 11817Soft
-2738hard/ 8173 Soft
Strategic Oscillation 0hard/
4757Soft
-4996hard/ 169172Soft
-8162hard/ 251065Soft
Tabla 19 Puntajes obtenidos con algoritmos de construcción. Fuente: Elaboración Propia
Se tienen dos tipos de puntaje: uno hard o duro que representa el cumplimiento de las
reglas que son indispensables para tener un horario coherente y otro soft o suave que
representan el cumplimiento de las reglas que, a pesar de no ser indispensables, son
necesarias para representar un buen horario.
Se puede evidenciar que el algoritmo que mejor se adapta a la solución y brinda mejor
puntuación es el Hill Climbing el cual es una estrategia basada en optimización local. Sigue
la dirección de ascenso/descenso más empinada a partir de su posición y requiere muy poco
costo computacional, en este caso se evidencia que para los 3 casos da cumplimiento a las
reglas fuertes o indispensables mostrando una puntuación de 0 y en las suaves alcanza
valores altos positivos, lo que genera resultados óptimos.
Así mismo se realizó una página de prueba en angular que permite visualizar los
resultados obtenidos haciendo uso de los pluggins llamados UI Calendar y Full calendar los
cuales llaman a los servicios REST y construyen los calendarios de los alumnos según la
solución encontrada por el planificador como se evidencia a continuación.

75
Figura 14 Generación de calendarios. Fuente: Elaboración Propia

76
PARTE III CIERRE DE LA INVESTIGACIÓN
A continuación se describen las conclusiones, contraste de los objetivos con sus resultados
y líneas de investigación futuras del presente proyecto.
CAPITULO 5 CONCLUSIONES
En este apartado se plasmarán todas las conclusiones obtenidas a través del desarrollo
de los objetivos planteados, para la solución de este proyecto.
5.1 Verificación, Contraste y Evaluación de los Objetivos
Al contrastar los objetivos inicialmente propuestos, se identifica que se cumplió con la
totalidad de ellos. El contraste entre los objetivos y su evidencia de cumplimiento se
pueden visualizar en la siguiente tabla:
Objetivo Evidencia de Cumplimiento
Diseñar e implementar un componente prototipo
que brinde una alternativa, de solución
tecnológica al proceso de inscripción automática
de espacios académicos, del sistema de gestión
académica de la universidad Distrital,
mejorando la arquitectura, mantenibilidad y
capacidad de extensión mediante el uso de
motores de planificación.
Se implementó de manera efectiva el componente
prototipo, usando la arquitectura propuesta y descrita en
el capítulo 4, y teniendo en cuenta las recomendaciones
suministradas por parte de la oficina asesora de sistemas.
Se logró mejorar mediante Workbench la mantenibilidad
de las reglas de negocio involucradas en la planificación,
así mismo la facilidad de modificación, reduciendo la
curva de aprendizaje del componente.
Analizar el módulo actual de inscripción
automática de espacios académicos, para
obtener el detalle de las reglas aplicadas en el
proceso, identificando los posibles problemas y
características que intervienen en el mismo.
En el capítulo 3 se realiza el levantamiento análisis y
selección de la información, con la cual se analizó el
proceso y la aplicación de inscripción automática de
espacios académicos, logrando comprender las reglas de
negocio involucradas y la identificación de sus
características, gracias al apoyo del personal de la
oficina de asesora de sistemas y las fuentes de
información suministradas.
Así mismo en el capítulo 4 se realiza el análisis de
integración del componente actual, análisis del código
fuente
Implementar el componente prototipo de
inscripción automática con una arquitectura que
facilite la extensión y modificación de la
operación de planificación de espacios
académicos
Para mejorar la arquitectura del componente se separó la
configuración de planificación y las reglas de negocio
del motor, se expuso toda la funcionalidad del
componente vía servicios REST y se configuro para
darle acceso a los orígenes de datos (Mysql y Oracle).
Así mismo mediante Workbench se brinda la facilidad

77
de modificación a nivel de usuario de negocio.
Diseñar un caso de estudio para verificar la
validez del prototipo propuesto.
Con la información suministrada por parte de la Oficina
Asesora de sistemas y las fuentes consultadas se logra
verificar la validez del componente prototipo, haciendo
uso de información real ofuscada.
Para las pruebas del panificador se hace uso de las tablas
del sga suministradas por la OAS con datos de una
carrera de la facultad de ingeniería.
Para el caso del análisis y selección de la información
mediante la herramienta de ayuda Weka, se analizó la
información de estudiantes desde un archivo. arff que
contenía el registro de las inscripciones de espacios
académicos, realizadas desde el año 2010 al 2016/I, sede
Bogotá, Facultad de Ingeniería. Tabla 20 Contraste Objetivos Vs Evidencias Cumplimiento. Fuente: Elaboración Propia
5.2 Síntesis del Modelo Propuesto
La síntesis del componente prototipo propuesto se describe en el Capítulo 3 y 4, en
dónde se indica con detalle el análisis, la arquitectura y componentes aplicados en el
desarrollo de la solución.
5.3 Aportes Originales
Este proyecto propone el diseño e implementación de un componente prototipo que
brinde una alternativa de solución tecnológica al proceso de inscripción automática de
espacios académicos, del sistema de gestión académica de la universidad Distrital,
mejorando la arquitectura, mantenibilidad y capacidad de extensión mediante el uso de
motores de planificación. De acuerdo a la validación de las fuentes realizadas y la
información recolectada no existe un enfoque implementado similar al propuesto en la
universidad.
CAPITULO 6 TRABAJOS O PUBLICACIONES DERIVADAS
Entre las posibles líneas de investigación o trabajos futuros podemos encontrar:
6.1 Líneas de Investigación Futuras
El presente proyecto de grado plantea un punto de referencia, que, de acuerdo a la
investigación teórica realizada, no ha sido planteado previamente en la universidad
Distrital. En base a lo anterior se pueden definir líneas de investigación que busquen

78
realizar las tareas de programación de asignaturas, aulas y profesores de formas diferentes
que se adapten con facilidad a los cambios que ocurren en el mundo real.
Una de las líneas de investigación que se puede explorar es el uso de ontologías que
representen los actores de la información académica relacionada con la programación de
asignaturas, junto con el uso de técnicas de inteligencia artificial que brinden una
alternativa a la solución propuesta en el presente proyecto.
6.2 Trabajos de Investigación Futuros
De acuerdo a la línea de investigación propuesta, se pueden plantear los siguientes
trabajos de investigación futuros:
Mejorar el uso del planificador extendiendo el dominio de solución para que soporte
las construcciones heurísticas que no soportan el modelo actual.
Encontrar la mejor configuración de algoritmos de optimización mediante el uso del
módulo de benchmarking de Optaplanner.
Desarrollar un sistema computacional que utilice como optimizador el diseño del
prototipo propuesto incorporando diferentes opciones mediante una interfaz
amigable y que con su implementación sea posible automatizar el proceso de
generación de la programación de asignaturas, aulas, aumentando la calidad de las
programaciones, la flexibilidad ante cambios en los requerimientos, condiciones
deseables y la posibilidad de explorar múltiples escenarios.
Se espera que estas líneas de investigación futuras puedan ser desarrolladas dentro del
marco de un proyecto de grado para programas de pregrado o de especialización o como
tema de profundización para grupos de investigación.

79
BIBLIOGRAFÍA
Al-Barrak & Al-Razgan. (2016). Predicting Students Final GPA Using Decision Trees:
A Case Study. International Journal of Information and Education Technology. 528-
533.
Amaya Y. Barrientos E. & Heredia D. (2015). Student Dropout Predictive Model Using
Data Mining Techniques. IEEE LATIN AMERICA TRANSACTIONS, 13(9), 3127-
3134.
Ávila, N. T. (1999-2011). Evolución en Colombia del consumo de Internet. Marketing
News, p. 18-20.
Becker, T. (1999-2011). Evolución en Colombia del consumo de Internet. Marketing
News. Vol.006, No.0036, 18-20.
Blázquez, F. (2001). Sociedad de la Información y la educación. Mérida. Mérida: Junta
de Extremadura Consejeria de Educación, Ciencia y Tecnología Dirección general de
ordenación, Renovación y Centros.
C, G. (2009). Deserción Académica en la Educación Superior Colombiana.
CALDAS, U. D. (2013). INFORME DE AVANCE SOBRE EL PLAN INDICATIVO
DE GESTIÓN (CBN 1013) Plan de Desarrollo 2008-2016 “Saberes, Conocimiento e
Investigación de Alto Impacto para el Desarrollo Humano y Social. Obtenido de Enero:
https://www.udistrital.edu.co/files/PlanAccionInformeGestion/IG1.pdf
CNA. (s.f.). Consejo Nacional de Acreditación, República de Colombia. Recuperado el
2017, de http://www.cna.gov.co/1741/channel.html
Cobo, J. C. (2009). El concepto de tecnologías de la información. Benchmarking sobre
las definiciones de las TIC en la sociedad del conocimiento. Zer - Revista de Estudios
de Comunicación.
Collada, S. (2010). Clasificación de e-mails: Detección de spam. Obtenido de
http://www.it.uc3m.es/jvillena/irc/practicas/07-08/DeteccionSpam.pdf
Crane, B. (2008). Using WEB 2.0 tools in the K-12 classroom. Neal-Schuman
Publishers, Inc.
Data Mining with Open Source Machine Learning Software in Java. (s.f.). Obtenido de
http://www.cs.waikato.ac.nz/ml/weka/index.html
De Alba, A. (1992). Evaluación Curricular conformación conceptual del campo.
México: Universidad Nacional Autónoma de México.

80
Fayyad y Otros. (1996). From Data Mining to Knowledge Discovery in Databases.
García de Fanelli, A. (1998). GESTIÓN DE LAS UNIVERSIDADES PÚBLICAS La
experiencia internacional. Ministerio de Cultura y Educación Secretaría de Políticas
Universitarias Pizzurno 935: Buenos Aires, Argentina.
Garcia, M. (2010). Análisis de datos Weka- Pruebas de selectividad. Obtenido de
http://www.it.uc3m.es/jvillena/irc/practicas/06-07/28.pdf
Lopez Guzman & Gonzalez. (2015). A Model to Predict Low Academic Performance at
a Specific Enrollment Using Data Mining. IEEE REVISTA IBEROAMERICANA DE
TECNOLOGIAS DEL APRENDIZAJE-IEEE RITA, 10(3), 119-125.
Martínez, L. (2012). Administración educativa. Viveros de la Loma, Tlalnepantla.
Estado de México: Editorial Red Tercer Milenio S.C.
Molina y Otros. (2011). Modelling Overdispersion for Complex Survey Data.
Muñoz, V. (2010). Minería de datos aplicada a la Formación de. Obtenido de
http://www1.ahciet.net/actualidad/revista/Documents/rev121.swf
Nettleton, D. (2012). Técnicas para el análisis de datos clínicos. Ediciones Díaz de
Santos.
Nieto, M. C. (marzo de 2013). Informe De Auditoria Al Funcionamiento Del Sistema
De Información Cóndor. Obtenido de
https://www.academia.edu/18957288/Fx_Condor_Informe_FINAL.
Pedraza, N. F. (2013). Las competencias docentes en TIC en las áreas de negocios y
contaduría. Un estudio exploratorio en la educación superior Perfiles Educativos.
México.: Instituto de Investigaciones sobre la Universidad y la Educación Distrito
Federal vol. XXXV, núm. 139.
Pérez, M. (2014). Mineria de datos a traves de ejemplos. . RC Libros.
Pidd, M. (2009). Tools for Thinking: Modelling in Management Science, 3rd Edition.
Romero Ventura & García. (2008). Data mining in course management systems:
Moodle case study and tutorial. Computers & Education, 368-364.
Ros, N. (2015). Fundamentos de Ingeniería del Software. Obtenido de
http://froac.manizales.unal.edu.co/roap/uploads/4/12/145.pdf
Ruescas, A. (2014-2015). Aplicación de técnicas Meta heurísticas para la asignación de
turnos de trabajo. Obtenido de MÁSTER EN INTELIGENCIA ARTIFICIAL,

81
RECONOCIMIENTO DE FORMAS E IMAGEN DIGITAL:
https://riunet.upv.es/bitstream/handle/10251/75028/TFM%20Aplicaci%C3%B3n%20de
%20t%C3%A9cnicas%20metaheur%C3%ADsticas%20para%20la%20asignaci%C3%
B3n%20de%20turnos%20de%20trabajo.pdf?sequence=1
UAN. (s.f.). Módulo Académico Nacional de Gestión estudiantil Online. Recuperado el
2017, de http://service.uan.edu.co/mango/
UCATOLICA. (s.f.). Universidad Católica de Colombia. Recuperado el 2017, de
https://www.ucatolica.edu.co/portal/tag/paw/
UDCA. (30 de 04 de 2014). Acuerdo No 368. Obtenido de Acuerdo No 368:
http://www.udca.edu.co/wp-content/uploads/2014/12/acuerdo-368-de-2014.pdf
UNAL. (s.f.). SIGA: Sistema Integrado de Gestión Académica, Administrativa y
Ambiental. Recuperado el 2017, de SIGA: Sistema Integrado de Gestión Académica,
Administrativa y Ambiental: http://unal.edu.co/siga/
UNIBAC. (s.f.). Plataforma SAU. Recuperado el 2017, de
http://www.unibac.edu.co/plataforma-sau
UPTC. (s.f.). Sistema Integrado de Gestión Académico-Administrativo "SIGMA".
Recuperado el 2017, de http://desnet.uptc.edu.co/sigma/wfpoliticacalidad.aspx
Vallejos, S. (2006). Trabajo de adscripción mineria de datos. Corrientes, Argentina, 11-
14.
Villate, C. P. (2004). De sierra Morena Alta a Candelaria La Nueva: 8 años de la
Facultad Tecnológica. Bogotá: Universidad Distrital Francisco José de Caldas.
Viscaino, P. (2008). Aplicación de técnicas de inducción de árboles de decisión a
problemas de clasificación mediante el uso de Weka (Waikato environment For
Knowledge Analysis. Obtenido de
http://www.konradlorenz.edu.co/images/stories/suma_digital_sistemas/2009_01/final_p
aula_andrea.pdf

82
PARTE V ANEXOS
ANEXO A. ANÁLISIS Y SELECCIÓN DE LA INFORMACIÓN MEDIANTE LA
HERRAMIENTA DE AYUDA WEKA
Teniendo en cuenta el gran avance en los sistemas de minería de datos en los últimos
tiempos, las entidades educativas y empresariales han buscado maneras de explotar al
máximo la información existente en sus sistemas de información, esto basándose en
técnicas y software especializados que permiten la interpretación fácil y real de los
resultados. Es así que, para dar apoyo en la toma de decisiones a niveles administrativos o
gerenciales, se crean metodologías especializadas y técnicas de extracción adecuada de la
información, haciendo que el usuario final pueda ver los resultados con pocos pasos.
Con base en lo anterior y la información obtenida por parte de la oficina asesora de
sistemas, y la Universidad Distrital sobre los inconvenientes en la operación del sistema de
gestión académica dentro de las actividades administrativas y en particular en el módulo de
inscripción de espacios académicos, las cuales tienen repercusiones inmediatas en los
estudiantes, quienes no logran cursar los espacios académicos que pretenden cursar durante
los diferentes periodos académicos o deben encontrarse con horarios difíciles de
administrar, se evidencian problemas como la cantidad de semestres necesarios para
terminar las materias, dificultando la asistencia a otras, generando consecuencias
institucionales en espacio físico y presupuestales, retención de estudiantes y la deserción
escolar, lo que implica consecuencias para el estudiante y consecuencias para la sociedad.
Es así como en el entorno de la educación en Colombia se ha evidenciado en los
últimos años un crecimiento significativo en los niveles de retención y deserción por parte
de los estudiantes de cursos de Educación Superior. Se han realizado estudios acerca de
estas problemáticas, como por ejemplo el gobierno nacional ha realizado investigaciones
sobre la deserción estudiantil, en donde se hace uso de la metodología SPADIES que
permite establecer diferentes categorías por las cuales se puede presentar la deserción
estudiantil, dentro de las cuales se destacan las regiones y/o departamentos en los cuales se
encuentran las instituciones, el carácter institucional, el nivel de formación del estudiante,
las áreas del conocimiento y aun la modalidad de estudio (Guzmán & Duran & Franco &
Castaño & Gallón & Guzmán & Gómez & Vásquez, 2009).
A partir de la implementación de esta metodología se ha podido llegar a explicar
mediante la identificación de algunas variables las posibles causas por las cuales se
presenta la deserción y retención estudiantil, dentro de las cuales se destaca una gran
influencia de los resultados en el examen de estado ICFES, se reconocen variable
socioeconómicas tales como los ingresos de la familia, si trabaja y estudia al mismo tiempo,
entre otras; por otro lado se logró identificar al realizar una discriminación por género se
encontró que los hombres son más propensos a desertar y demorarse en terminar sus
carreras que las mujeres. (Sánchez, Márquez 2012)

83
Es por esta razón que se quiere realizar un análisis de la información y así lograr
obtener un diseño de un componente prototipo para mejorar el proceso de inscripción
automática de espacios académicos en el sistema de gestión académica de la Universidad
Distrital con el fin de poder disminuir parte de las problemáticas presentadas en los
estudiantes y sus carreras, pero así mismo se pretende determinar cuáles son las causas que
conllevan a que los estudiantes estén “retenidos” y permanezcan más de lo estipulado en la
Universidad y en algunos casos no culminen sus estudios, para ello se analizarán datos de
estudiantes de la Facultad de Ingeniería entre los años 2009 y 2015, y para realizar dicho
análisis se hará uso de una de las técnicas de análisis de datos más utilizada llamada
Minería de Datos.
1. ¿Qué es la minería de datos?
La Minería de Datos busca el procesamiento de información de forma clara para el
usuario, de tal forma que pueda clasificar la información de acuerdo a parámetros
inicialmente establecidos y de acuerdo a las necesidades que se buscan, es decir por medio
de la minería de datos se dan acercamientos claros a resultados estadísticamente factibles a
entendimiento y razón de una persona.
Según autores como (Vallejos, 2006) varios autores describen la minería de datos
como:
Reúne las ventajas de varias áreas como la Estadística, la Inteligencia Artificial, la
Computación Gráfica, las Bases de Datos y el Procesamiento Masivo,
principalmente usando como materia prima las bases de datos.
Un proceso no trivial de identificación válida, novedosa, potencialmente útil y
entendible de patrones comprensibles que se encuentran ocultos en los datos
(Fayyad y Otros, 1996)
La integración de un conjunto de áreas que tienen como propósito la identificación
de un conocimiento obtenido a partir de las bases de datos que aporten un sesgo
hacia la toma de decisión (Molina y Otros, 2011)
1.1 Características y objetivos de la minería de datos:
Explorar los datos que se encuentran en las profundidades de las bases de
datos.
El entorno de la minería de datos suele tener una arquitectura clientes-servidor.
Las herramientas de la minería de datos ayudan a extraer el mineral de la
información enterrado en archivos corporativos o en registros públicos,
archivados

84
Las herramientas de la minería de datos se combinan fácilmente y pueden
analizarse y procesarse rápidamente.
Debido a la gran cantidad de datos, algunas veces resulta necesario usar
procesamiento en paralelo para la minería de datos.
La minería de datos produce cinco tipos de información:
Asociaciones.
Secuencias.
Clasificaciones.
Agrupamientos
Pronósticos.
La minería de datos clasifica la información y la procesa para obtener un resultado,
para esto se debe pasar por ciertos procedimientos que se describen según los cursos de
investigación y recursos en inteligencia artificial como:
Figura 15 Mapa conceptual de Minería de datos
Fuente: Tomada de Aplicación De Técnicas De Inducción De Árboles De Decisión A Problemas De Clasificación
Mediante El Uso De Weka (Waikato Environment For Knowledge Analysis).
1.2 Minería de datos Educacional EDM
Dentro del análisis de datos relacionados con el campo de la educación dentro de la
minería de datos ha surgido en los últimos años un campo conocido como la Minería de

85
Datos Educacional (EDM) por sus siglas en inglés, el cual consiste en la aplicación de un
conjunto de técnicas y herramientas de la minería de datos que permitan ayudar a mejorar
los procesos educativos, pedagógicos que mejoren los niveles de aprendizaje y las técnicas
de enseñanza. Dentro de la sociedad internacional de la minería de datos definen EDM
como una disciplina que emerge de la minería de datos tradicional que se preocupa por
desarrollar métodos que expliquen los fenómenos relacionados con el ámbito de la
educación, con el fin de utilizar estos métodos para entender el entorno en que los
estudiantes se desenvuelven y poder mejorar las condiciones de enseñanza y aprendizaje.
(Lopez Guzman & Gonzalez, 2015).
Teniendo en cuenta lo anterior se realizó un modelo predictivo mediante el análisis de
los datos históricos suministrados por la oficina asesora de sistemas, bajo las técnicas de
minería de datos para poder determinar las principales causas de retención y deserción para
el caso de la universidad Distrital.
Para dicho análisis de realizaron las siguientes actividades:
Se realizó el levantamiento de la información académica de los estudiantes, desde el
año 2009, información de materias inscritas, canceladas, pérdidas, pasadas,
información socioeconómica de los estudiantes, con el fin de generar datos de
entrenamiento y datos de testeo para la generación y evaluación del modelo
obtenido.
Se depuro la información para determinar cuáles son los datos o variables más
relevantes que brindarán la mejor calidad en el proceso de análisis y desarrollo del
modelo.
Se analizó la información luego de haber sido depurada mediante la aplicación de la
técnica de árboles de decisión utilizando como algoritmo base el J48, para lo cual se
tomó como herramienta de ayuda la aplicación de minería de datos WEKA.
Para descubrir el conocimiento que tienen los datos analizados dentro de sí mismos, se
cuenta con dos técnicas de análisis de datos las cuales son las predictivas y descriptivas, sin
embargo, para el análisis realizado solo se tuvo en cuenta las técnicas predictivas (Pérez,
2014). Dentro de las técnicas predictivas se contemplan los modelos de regresión y la
clasificación ad hoc, que a su vez está compuesta por arboles de decisión y redes
neuronales, para este caso en particular se hizo énfasis en las técnicas relacionadas con los
arboles de decisión.
2. Árbol de decisión
Un árbol de decisión es un conjunto de condiciones o reglas organizadas en una
estructura jerárquica, de tal manera que la decisión final se puede determinar siguiendo las
condiciones que se cumplen desde la raíz hasta alguna de sus hojas (Viscaino, 2008). Son la

86
técnica de clasificación más utilizada para poder realizar un análisis a un sistema o un
problema de orden predictivo. Es de los más utilizados debido a su facilidad para realizar el
análisis de los datos, los pasos de aprendizaje y clasificación del árbol de decisión son
sencillos y rápidos.
Un árbol de decisión tiene unas entradas las cuales pueden ser un objeto o una
situación descrita por medio de un conjunto de atributos y a partir de esto devuelve una
respuesta la cual en últimas es una decisión que es tomada a partir de las entradas.
Los valores que pueden tomar las entradas y las salidas pueden ser valores discretos o
continuos. Se utilizan más los valores discretos por simplicidad. Cuando se utilizan valores
discretos en las funciones de una aplicación se denomina clasificación y cuando se utilizan
los continuos se denomina regresión (Ros, 2015).
Como ejemplo de un modelamiento por Arboles de decisión, se realizó el análisis de
rendimiento del algoritmo de árbol de decisión J48.
3. Algoritmo J48
Para los modelos de predicción, es importante tener un algoritmo robusto y que
permita realizar un análisis sencillo, pero a la vez, de mucha precisión, para lo cual este
algoritmo es útil. El J48 es una versión modificada del C4.5 y es utilizado para la
generación de Arboles de Decisión.
Es un algoritmo de inducción que genera una estructura de reglas o árbol a partir de
subconjuntos (ventanas) de casos extraídos del conjunto total de datos de “entrenamiento”.
En este sentido, su forma de procesar los datos es parecido al de Id3. El algoritmo genera
una estructura de reglas y evalúa su “bondad” usando criterios que miden la precisión en la
clasificación de los casos. Emplea dos criterios principales para dirigir el proceso dado por
(Nettleton, 2012):
Calcula el valor de la información proporcionada por una regla candidata (o rama del
árbol), con una rutina que se llama “info”.
Calcula la mejora global que proporciona una regla/rama usando una rutina que se
llama gain (beneficio).
El algoritmo J48 de WEKA es una implementación del algoritmo C4.5, uno de los
algoritmos de minería de datos más utilizado. Se trata de un refinamiento del modelo
generado con OneR22 Supone una mejora moderada en las prestaciones, y podrá conseguir
una probabilidad de acierto ligeramente superior al del anterior clasificador (Garcia, 2010).
El algoritmo J48 se basa en la utilización del criterio ratio de ganancia (gain ratio). De esta
manera se consigue evitar que las variables con mayor número de posibles valores salgan
2 Es un clasificador de los más sencillos y rápidos. Sus resultados pueden ser muy buenos en comparación con algoritmos mucho más complejos. Selecciona el atributo que mejor “explica” la clase de salida.

87
beneficiadas en la selección. Además, el algoritmo incorpora una poda del árbol de
clasificación una vez que éste ha sido inducido (Collada, 2010).
Para tareas de clasificación, el algoritmo J48 resulta muy simple y potente, este
algoritmo representa a su vez una evolución del algoritmo ID3. El procedimiento para
generar el árbol consiste en seleccionar un atributo como raíz, y crear una rama con cada
uno de los valores posibles de dicho atributo; con cada rama resultante se realiza el mismo
proceso. En cada nodo se debe seleccionar un atributo para seguir dividiendo, y para ello se
selecciona aquel que mejor separe los ejemplos de acuerdo a la clase (Muñoz, 2010). Se ha
seleccionado los árboles de clasificación por la sencillez del modelo, su accesibilidad a ser
representados gráficamente, la explicación que aporta a la clasificación y por su rapidez a la
hora de clasificar nuevos patrones.
4. ¿Qué es la herramienta Weka?
Es una de las herramientas de minería de datos más utilizada, la cual se ha
implementado ampliamente en las investigaciones de minería de datos educativos y para el
propósito de enseñar (Al-Barrak & Al-Razgan, 2016).
WEKA es un conjunto de algoritmos de aprendizaje automático para tareas de minería
de datos. Los algoritmos bien se pueden aplicar directamente desde la herramienta a un
conjunto de datos o ser llamados desde su propio código Java. WEKA contiene
herramientas para el procesamiento previo de datos, clasificación, regresión, clustering,
reglas de asociación, y la visualización. También es muy adecuado para el desarrollo de
nuevos sistemas de máquinas de aprendizaje (Data Mining with Open Source Machine
Learning Software in Java).
5. Fases del análisis de datos
5.1 Fase de Selección
En esta fase se procede a realizar un muestreo estadístico con el fin de poder
seleccionar de toda la información recolectada (población) una muestra significativa y
representativa que permita crear un modelo predictivo que refleje el comportamiento de
toda la población, obteniendo así una desviación o niveles de error bajos o aceptables
(Romero Ventura & García, 2008).Para poder cumplir con este propósito se usan varias
metodologías estadísticas dentro de las cuales se destacan las siguientes:
Muestreo estadístico
Muestreo aleatorio simple
Muestreo estratificado
Muestreo de conglomerados

88
5.2 Fase de Limpieza
La fase de limpieza consiste en poder depurar la información que fue seleccionada
mediante las metodologías de muestreo estadístico de la fase anterior, con el fin de
garantizar que los datos que se han e analizar cuentan con un alto nivel de calidad, para ello
es necesario detectar los valores atípicos, los valores desaparecidos y los valores erróneos
para así aplicar técnicas que permitan descartar los valores atípicos, completar los datos
desaparecidos mediante la imputación y corregir los valores erróneos, de tal manera que se
cuente con una muestra que refleje la realidad del problema estudiado y además se
garantice el correcto funcionamiento del algoritmo(s) aplicado(s) sobre la
información.(Romero et al., 2008)
5.3 Fase de codificación o transformación
Esta fase comprende el proceso mediante el cual los datos originales son
transformados con el fin de facilitar y ajustar los datos a los algoritmos que se quieren
ejecutar sobre dicha información, de tal manera que se obtenga un análisis correcto
mediante la aplicación del algoritmo que más se ajuste a la naturaleza de la información y
del problema, dando como resultado un modelo muy próximo a la situación real.(Romero et
al., 2008)
Para ello existen varios tipos de transformaciones, entre ellos se destacan los
siguientes:
Transformaciones Lógicas
Transformaciones Lineales
Transformaciones algebraicas
Transformaciones no lineales no monofónicas
5.4 Fase de análisis
La minería de datos tiene una serie de formalismos de representación tales como
probabilidades, las normas y los árboles. y una serie de tareas y métodos de aprendizaje de
máquinas, las estadísticas, la visualización y la inteligencia artificial.(Romero et al., 2008)
En el presente trabajo se empleará la forma de representación de árbol dado que aparte de
ser una de las técnicas más utilizadas es de las que mejor representa el conocimiento
inmerso en los datos (Amaya Y. Barrientos E. & Heredia D, 2015).
Esta técnica pertenece a la categoría de técnicas de clasificación(Romero et al., 2008)
de manera que el árbol de decisión generado cumplirá con la siguientes reglas, es necesario
escoger una variable que será la de segmentación, a partir de la cual se realizará de la
discriminación de modo que se pueda obtener una clasificación fehaciente en grupos
homogéneos, es decir, que los arboles de decisión agrupan un elemento poblacional
dependiendo de la evaluación de los valores que tomen las variables independientes del

89
modelo, por lo tanto lo que se busca es seleccionar las variables independientes que mayor
influencia tengan sobre la variable dependiente para así poder construir una regla de
decisión que permita clasificar a un elemento nuevo dentro de alguno de los grupos
resultantes.
5.5 Fase de Interpretación y Evaluación
En esta fase, el objetivo es validar la precisión y confiabilidad del modelo generado
por el o los algoritmos utilizados en la fase anterior, para ello de la información con la que
se generó el modelo, los algoritmos reservan un porcentaje de sus datos para realizar las
pruebas, estos son conocidos como datos de testeo, por ejemplo, en el algoritmo J48 se
puede establecer el porcentaje de los datos que serán tomados para la generación del
modelo y el porcentaje restante, será utilizado para evaluar el modelo.
Después de probar el algoritmo se procede a interpretar cada una de las respuestas
arrojadas por las diferentes pruebas con el fin de escoger o seleccionar el modelo que
mayor confiabilidad tenga, y a su vez se ajuste de una manera más adecuada al contexto del
problema planteado.
6. Resultados
Para el presente análisis se tuvo como base, Información académica de los estudiantes,
desde el año 2009, información de materias inscritas, canceladas, pérdidas, pasadas,
información de docentes, información socioeconómica de los estudiantes y sus
competencias académicas, información de los estudiantes que han desertado en los últimos
años en la Universidad, información del plan de estudio de cada uno de los proyectos
curriculares y la información académica por materias:
Se crea una base de datos sobre el motor de bases de datos PostgreSql 9.3 con los
siguientes atributos:
CREATE TABLE public."ProyectoSGA"
(
proyecto character varying(70),
total_materias integer,
estrato character varying(20),
genero character varying(11),
localidad character varying(30),
tipo_colegio character varying(11),
municipio_colegio character varying(30),
departamento_colegio character varying(15),
inscripcion character varying(50),
biologia integer,
quimica integer,
fisica integer,
aptitud_verbal integer,

90
espanol_literatura integer,
aptitud_matematica integer,
condicion_matematica integer,
filosofia integer,
idioma integer,
puntos_icfes integer,
codigo_estudiante bigint,
valor_matricula double precision,
acuerdo character varying(20),
asignatura character varying(100),
pensum character varying(20),
ingresos_anuales double precision,
estado_actual character varying(100),
edad double precision,
aprobo character varying(2),
veces_curso integer,
deserto character varying(2),
nota double precision,
nivel_asignatura character varying(8),
creditos_asignatura integer,
numero_asignaturas integer
)
WITH (
OIDS=FALSE
);
ALTER TABLE public."ProyectoSGA"
OWNER TO jenny;
Después de tener recopilada, y centrada la información se hace uso de WEKA con el
fin de seleccionar la información más relevante y sobre todo la que mejor calidad de
información tenga, se carga la información mediante una conexión sobre la base de datos
ingresando los datos de conexión en la interfaz que provee la aplicación así:
Figura 16Cargue de información mediante conexión a base de datos PostgreSQL

91
Después de realizar el cargue de la información se procede a evaluar una por una las
variables cargadas, se hace una selección de las variables más relevantes, es decir, las que
se tuvieron en cuenta al momento de generar el modelo mediante la aplicación del
algoritmo J48.
A continuación, se muestran algunas de las variables seleccionadas:
Proyecto Curricular: Dado que el proyecto se realizó para la facultad de ingeniería,
los proyectos curriculares que aquí se muestran son los ofrecidos por la Universidad en esta
área de conocimiento, esta variable es seleccionada ya que tiene una representación discreta
y además todos los registros tienen un valor para esta variable. En la tabla se puede
observar el detalle de cuantos estudiantes hay para cada uno de los proyectos curriculares.
Figura 17 Detalle Variable Proyecto Curricular
Estrato: Esta variable también presenta una buena calidad de datos, aunque hay 452
registros que no registran información para esta variable, la mayoría de los registros se
encuentran en los estratos 2 y 3, lo que concuerda totalmente con la realidad, puesto que la
Universidad Distrital al ser una institución de orden público abarca este sector de la
población.
Figura 18 Detalle Variable Estrato

92
Género: Esta variable también tiene una buena calidad, puesto que sobre una cantidad
total de 81151 registros solo 10 no presentan un valor para ésta, al igual que la variable
proyecto curricular esta tiene una representación discreta por lo que es adecuada usarla en
las técnicas de clasificación puesto que los rangos o grupos de clasificación pueden ser bien
definidos por el modelo. En esta variable se destaca el hecho de que el mayor porcentaje de
los registros están en el género Masculino, lo que muestra claramente que en el caso de la
Universidad Distrital para la facultad de Ingeniería la mayoría de la población son hombres
y por ende sería este género el que en mayor proporción este influyendo en la retención y
deserción académica.
Figura 19 Detalle Variable Género
Otras de las variables que se tuvieron en cuenta para el análisis y selección fueron las
que están relacionadas con los puntajes y resultados obtenidos por los estudiantes en las
pruebas del ICFES, de estas variables se cuenta con toda la información para cada uno de
los registros debido a que la Universidad exige estas calificaciones como uno de sus
requisitos para poder ser admitido en cualquiera de los cursos, por lo tanto, presenta una
buena calidad.
Acuerdo: La variable acuerdo hace referencia a las políticas que rigen al estudiante
según el semestre o periodo en el que haya ingresado a estudiar por medio de las cuales se
definen cada una de las normativas referentes a la nota mínima requerida para aprobar una
asignatura, la cantidad máxima de repitencia de una asignatura, el tiempo máximo que tiene
el estudiante para culminar sus estudios, las modalidades de grado, las causas por las que
puede ser suspendido, sancionado o expulsado de la institución, entre otras más. Esta
variable es relevante dado que dependiendo del acuerdo el estudiante puede o no contar con
más recursos que le ayuden en su proceso educativo.

93
Figura 20 Detalle Variable Acuerdo
Localidad: Esta variable también tiene una representación discretizada, además tiene
una correlación directa con la variable estrato puesto que el lugar donde se habita determina
el estrato socioeconómico. Dentro de las 20 localidades con las que cuenta Bogotá se puede
observar que la mayor cantidad de estudiantes vive en las siguientes:
Kennedy
Engativá
Suba
Fuera de Bogotá
Figura 21 Detalle Variable Localidad
Otras de las variables que se tuvieron en cuenta para el análisis y selección fueron las
que están relacionadas con los puntajes y resultados obtenidos por los estudiantes en las
pruebas del ICFES, de estas variables se cuenta con toda la información para cada uno de
los registros debido a que la Universidad exige estas calificaciones como uno de sus
requisitos para poder ser admitido en cualquiera de los cursos, por lo tanto, presenta una
buena calidad.

94
Asignatura: Esta variable también es discreta y presenta una buena calidad pues todos
los registros tienen valor para ella, las asignaturas que mayor cantidad de registros
presentan son aquellas que se ven en los primeros semestres y son transversales a todos los
proyectos curriculares, se puede notar una tendencia en que en más avanzado sea el
semestre al que pertenece la materia hay menor es el número de estudiantes que la toman,
por un lado esto se debe a las profundizaciones propias de cada proyecto donde ya no se
comparten asignaturas entre los diferentes planes de estudio pero por otro lado esto puede
ser debido a que en los primeros semestres es cuando mayor cantidad de deserción se
presenta y los estudiantes pierden más materias.
Figura 22 Detalle Variable Asignatura
Créditos _asignatura: Esta variable representa el número de créditos con la que
puede estar registrada una asignatura, siendo el máximo 4 créditos. Es importante tener en
cuenta esta variable ya que esta influye en el proceso que lleva un estudiante en su área
académica, e influye al momento de organizar el horario de espacios académicos ya que, a
mayor número de créditos que tenga una asignatura, menor será las que pueda cursar en el
semestre y si no se aprueba una de ellas se va atrasando el estudiante.
Figura 23 Detalle Variable Creditos_asignatura
Estado Actual: Esta variable hace referencia al estado en el que se encuentra el
estudiante matriculado, se puede evidenciar que un alto porcentaje de estudiantes se
encuentra en estado de prueba académica, el cual está definido como:

95
Estado transitorio de carácter académico en el cual queda incurso un estudiante de la
Universidad que al cierre de notas del periodo cursado se encuentre en alguna de las
siguientes situaciones:
a. Su Promedio académico acumulado sea inferior al mínimo definido de tres puntos
dos (3.2).
b. Haya reprobado tres (3) o más espacios académicos.
c. Tenga que cursar uno (1) o más espacios académicos por tercera (3ª) o por cuarta
(4ª) vez.
Y seguido a este se encuentra el estado de retiro voluntario, lo que demuestra una vez
más el problema de deserción. Esta variable es relevante dado que dependiendo del estado
en que se encuentre el estudiante puede o no contar con más recursos que le ayuden en su
proceso educativo.
Figura 24 Detalle Variable Estado_Actual
Edad: Esta variable es altamente significativa y hace referencia a la edad que tiene un
estudiante al momento de cursar cierta asignatura y no solamente la a la edad con la que
ingreso a la institución. Se puede observar que tiene una distribución entre los 15 y 46 años
siendo el rango entre los 19 a 20 años el que registra la mayor cantidad, por lo tanto, este
será el rango de edad más significativo para el modelo.
Figura 25 Detalle Variable Edad

96
Aprobó: En esta variable se registra SI, en caso de que el estudiante haya obtenido una
nota mayor a la mínima requerida según el acuerdo por el cual está regido, de no haber
alcanzado dicha nota mínima se registra un NO. Esta variable tiene una relación directa con
la variable veces_cursó que hace referencia a la cantidad de veces que un estudiante tuvo
que tomar una asignatura para poder aprobarla en caso de no haberla aprobado en la
primera vez.
Esta variable tiene buena calidad pues todos los registros cuentan con ella, además es
altamente relevante puesto que dependiendo de las veces que un estudiante curse una
materia y según el acuerdo que lo rige el estudiante está expuesto a perder la calidad de
estudiante; esta variable tiene una distribución entre 1 y 4 que es la máxima cantidad de
veces que según el acuerdo vigente un estudiante podría cursar una misma asignatura.
Figura 26 Detalle Variables veces Cursó y Aprobó
Por último se tuvo en cuenta la cantidad de materias que un estudiante cursa al mismo
tiempo y en un mismo periodo académico, la cal también tiene una buena calidad y tiene
una distribución entre 1 y 19 materias, hay que aclarar que la distribución en su gran
mayoría está concentrada entre 5 y 8 materias, en los casos que se tienen más de 8 materias
por lo general pertenecen a casos en los que se realizó una transferencia de un estudiante y
debido a las homologaciones realizadas se refleja una cantidad anormal de materias
cursadas; debido a que son muy pocas las ocurrencias de este fenómeno se concluye que la
variables es adecuada para ser analizada y tenida en cuenta en el momento de generar el
modelo.
Figura 27 Detalle Variable Numero Asignatura

97
Luego de tener la información que será analizada, se procede a realizar limpieza y
selección de datos, con el fin de depurarlos y así trabajar sobre las variables más relevantes
para evidenciar parte de la problemática planteada sobre la retención y deserción de los
estudiantes. Usando la herramienta WEKA la generación del modelo fue realizado usando
el algoritmo de asociación Apriori. Mediante algoritmos de asociación podemos realizar la
búsqueda automática de reglas que relacionan conjuntos de atributos entre sí. Son
algoritmos no supervisados, ya que no existen relaciones conocidas a priori con las que
contrastar la validez de los resultados, sino que se evalúa si esas reglas son estadísticamente
significativas.
Luego de haber aplicado el algoritmo de asociación Apriori, el cual busca los
conjuntos más frecuentes reduciendo el apoyo mínimo para crear la cantidad exacta de
reglas de asociación, y conseguir una eficiencia máxima optimizando el proceso, se obtuvo
que la confiabilidad del modelo de acuerdo a la relación de las variables que muestra la
herramienta es superior al 94.33% lo que indica que existe un grado de confianza alto.
Figura 28 Informe de salida en la calidad del modelo de clasificación
Después de validar que el porcentaje de confianza del modelo, es adecuado se
prosiguió con la generación del árbol de decisión mediante el algoritmo de análisis
conocido como Árbol de decisión (j48) que consiste principalmente en formar un grupo
principal con patrones similares que avanzan en cascada de acuerdo a patrones encontrados.
En este caso el objetivo fue contrastar el modelo de asociación obtenido con el algoritmo
Apriori y comparar resultados, dando como resultado el árbol de decisión que se muestra en
la siguiente imagen:

98
Figura 29 Árbol de decisión generado bajo el algoritmo J48
Unas de las mejores reglas encontradas son:
Figura 30 Reglas encontradas con algoritmo de asociación weka.associations.Apriori -N 10 -T 0 -C 0.9 -D 0.05 -U 1.0 -
M 0.1 -S -1.0 -c -1

ANEXO B. DICCIONARIO DE DATOS MODELO ORACLE
DETALLES DE TABLAS ORACLE Design Name Modelos Oracle
Version Date 07.05.2017
Version Comment Detalle de tablas con sus columnas y descripción
Model Name Tablas Oracle
Table Name ACCALEVENTOS Functional Name En esta tabla se registran los eventos que indican las planificaciones o
ejecuciones del algoritmo de solución, indica el estado de la planificación
necesario para no realizar dos ejecuciones con los mismos parámetros de
año, periodo y carrera.
Columns No Column Name PK FK M Data Type DT
kind Domain Name Formula
(Default Value) Security Abbreviation
1 ACE_COD_EVENTO P Y NUMERIC LT 2 ACE_CRA_COD P Y NUMERIC (3) LT 3 ACE_FEC_INI Date LT 4 ACE_FEC_FIN Date LT 5 ACE_TIP_CRA NUMERIC (2) LT 6 ACE_DEP_COD NUMERIC (3) LT 7 ACE_ANIO P Y NUMERIC (4) LT 8 ACE_PERIODO P Y NUMERIC (1) LT 9 ACE_ESTADO VARCHAR (1 BYTE) LT
10 ACE_HABILITAR_EX VARCHAR (1 BYTE) LT Tabla 21Detalle Tabla ACCALEVENTOS
Table Name ACCRA Functional Name Contiene la información de las carreras, mediante la cual se asocia la
planificación a un contexto de carrera especifico.
No Column Name PK FK M Data Type DT
kind Domain Name Formula
(Default Value) Security Abbreviation
1 CRA_COD P Y NUMERIC (3) LT 2 CRA_NOMBRE Y VARCHAR (80 BYTE) LT

100
3 CRA_DEP_COD Y NUMERIC (3) LT 4 CRA_ESTADO VARCHAR (1 BYTE) LT 'A' 5 CRA_COD_ICFES NUMERIC (30) LT 6 CRA_EMP_COD Y NUMERIC (5) LT 7 CRA_TIP_CRA Y NUMERIC (2) LT 8 CRA_RESOL_SUP VARCHAR (50 BYTE) LT 9 CRA_FECHA_APROB_ICFES Date (7) LT
10 CRA_FECHA_ULT_RENOV Date (7) LT 11 CRA_ABREV VARCHAR (30 BYTE) LT 12 CRA_JORNADA VARCHAR (10 BYTE) LT 13 CRA_PRO_COOR VARCHAR (15 BYTE) LT 14 CRA_EMP_NRO_IDEN NUMERIC (15) LT 15 CRA_SE_OFRECE Y VARCHAR (1 BYTE) LT 'S' 16 CRA_COD_SNIES NUMERIC (10) LT 17 CRA_JUST_COD NUMERIC (9) LT 18 CRA_IND_CICLO VARCHAR (1 BYTE) LT 'N' 19 CRA_NOTA_APROB NUMERIC (2) LT 0 20 CRA_EMAIL VARCHAR (200 BYTE) LT
Tabla 22 Detalle Tabla ACCRA
Table Name ACCURSOS Functional Name Concentra la información de los diferentes cursos programados según los
horarios generados por consejo académico para el aprovechamiento
semestral por parte de los alumnos.
Columns No Column Name PK FK M Data Type DT
kind Domain Name Formula
(Default Value) Security Abbreviation
1 CUR_ID P Y NUMERIC (10) LT 2 CUR_APE_ANO Y NUMERIC (4) LT 3 CUR_APE_PER Y NUMERIC (1) LT 4 CUR_ASI_COD Y NUMERIC (8) LT 5 CUR_GRUPO Y NUMERIC (5) LT 6 CUR_CRA_COD Y NUMERIC (3) LT 7 CUR_DEP_COD Y NUMERIC (4) LT 8 CUR_NRO_CUPO Y NUMERIC (3) LT

101
9 CUR_NRO_INS NUMERIC (3) LT 10 CUR_ESTADO VARCHAR (3 BYTE) LT 11 CUR_PAR1 NUMERIC (3) LT 12 CUR_PAR2 NUMERIC (3) LT 13 CUR_PAR3 NUMERIC (3) LT 14 CUR_PAR4 NUMERIC (3) LT 15 CUR_PAR5 NUMERIC (3) LT 16 CUR_PAR6 NUMERIC (3) LT 17 CUR_LAB NUMERIC (2) LT 18 CUR_EXA NUMERIC (2) LT 19 CUR_HAB NUMERIC (2) LT 20 CUR_CAP_MAX NUMERIC (3) LT 21 CUR_HOR_ALTERNATIVO NUMERIC (3) LT 22 CUR_TIPO NUMERIC (3) LT
Columns Comments No Column Name Description Notes
1 CUR_ID CODIGO DEL CURSO. INCREMENTAL 2 CUR_APE_ANO ANIO 3 CUR_APE_PER PERIODO 4 CUR_ASI_COD ASIGNATURA 5 CUR_GRUPO GRUPO 6 CUR_CRA_COD CARRERA 7 CUR_DEP_COD FACULTAD 8 CUR_NRO_CUPO CUPO 9 CUR_NRO_INS INSCRITOS
10 CUR_ESTADO ESTADO DEL REGISTRO 11 CUR_PAR1 NOTAR PARCIAL 1 12 CUR_PAR2 NOTAR PARCIAL 2 13 CUR_PAR3 NOTAR PARCIAL 3 14 CUR_PAR4 NOTAR PARCIAL 4 15 CUR_PAR5 NOTAR PARCIAL 5 16 CUR_PAR6 NOTAR PARCIAL 6 17 CUR_LAB NOTAR LABORATORIO

102
18 CUR_EXA NOTAR EXAMEN 19 CUR_HAB NOTAR HABILITACION 20 CUR_CAP_MAX CAPACIDAD MAXIMA DEL CURSO 21 CUR_HOR_ALTERNATIVO 0 HORARIO UNICO. 1 VARIOS HORARIOS 22 CUR_TIPO TIPO DE CURSO
Tabla 23 Detalle Tabla ACCURSOS
Table Name ACEST Functional Name Contiene la información de los alumnos y los estados en los que se
encuentran, estados que determinan la participación en la planificación de
asignaturas.
Columns No Column Name PK FK M Data Type DT
kind Domain Name Formula
(Default Value) Security Abbreviation
1 EST_COD P Y NUMERIC (11) LT 2 EST_CRA_COD F Y NUMERIC (3) LT 3 EST_NOMBRE Y VARCHAR (50 BYTE) LT 4 EST_NRO_IDEN NUMERIC (14) LT 5 EST_TIPO_IDEN VARCHAR (1 BYTE) LT 6 EST_LIB_MILITAR VARCHAR (14 BYTE) LT 7 EST_NRO_DIS_MILITAR NUMERIC (2) LT 8 EST_CORRESPONDENCIA VARCHAR (1 BYTE) LT 9 EST_DIRECCION VARCHAR (100 BYTE) LT
10 EST_TELEFONO NUMERIC (10) LT 11 EST_ZONA_POSTAL NUMERIC (6) LT 12 EST_EXENTO VARCHAR (1 BYTE) LT 13 EST_MOTIVO_EXENTO VARCHAR (2 BYTE) LT 14 EST_PORCENTAJE NUMERIC (3) LT 15 EST_RENTA_LIQUIDA NUMERIC (8) LT 16 EST_PATRIMONIO_LIQUIDO NUMERIC (10) LT 17 EST_VALOR_MATRICULA NUMERIC (8) LT 18 EST_ESTADO_EST F Y VARCHAR (1 BYTE) LT 19 EST_JORNADA VARCHAR (1 BYTE) LT 20 EST_ESTADO VARCHAR (1 BYTE) LT 'A'

103
21 EST_PEN_NRO NUMERIC (3) LT 22 EST_SEXO VARCHAR (1 BYTE) LT 23 EST_PBM NUMERIC (3) LT 24 EST_OPCION_MAT NUMERIC (1) LT 25 EST_INGRESOS_ANUALES NUMERIC (10) LT 26 EST_DIFERIDO VARCHAR (1 BYTE) LT 'N' 27 EST_IND_CRED CHAR (1 BYTE) LT 'N' 28 EST_NRO_IDEN_ANT NUMERIC LT 29 EST_TIPO_IDEN_ANT VARCHAR (1 BYTE) LT 30 EST_ACUERDO NUMERIC (7) LT 2011004 31 EST_FALLECIDO Y VARCHAR (1 BYTE) LT 'N'
Tabla 24 Detalle Tabla ACEST
Columns Comments No Column Name Description Notes
1 EST_COD CODIGO DE ESTUDIANTE 2 EST_CRA_COD CODIGO DE CARRERA DEL ESTUDIANTE 3 EST_NOMBRE NOMBRE DE ESTUDIANTE 4 EST_NRO_IDEN NUMERO DE IDENTIFICACIÓN DEL ESTUDIANTE 5 EST_TIPO_IDEN TIPO DE IDENTIFICACIÓN DEL ESTUDIANTE 6 EST_LIB_MILITAR ESTADO LIBRETA MILITAR 7 EST_NRO_DIS_MILITAR NUMERI DISTRITO MILITAR 8 EST_CORRESPONDENCIA CORRESPONDENCIA 9 EST_DIRECCION DIRECCION DEL ESTUDIANTE
10 EST_TELEFONO NÚMERO DE TELÉFONO DEL ESTUDIANTE 11 EST_ZONA_POSTAL ZONA POSTAL 12 EST_EXENTO ESTADO EXENTO DE MATRICULA 13 EST_MOTIVO_EXENTO MOTIVO EXENTO 14 EST_PORCENTAJE ESTADO PORCENTAJE 15 EST_RENTA_LIQUIDA ESTADO RENTA LIQUIDADA 16 EST_PATRIMONIO_LIQUIDO PATRIMONIO LIQUIDADO 17 EST_VALOR_MATRICULA VALOR DE MATRICULA DEL ESTUDIANTE 18 EST_ESTADO_EST ESTADO ESTUDIANTE 19 EST_JORNADA JORNADA 20 EST_ESTADO ESTADO

104
23 EST_PBM ESTADO PBM 24 EST_OPCION_MAT ESTADO MOTIV
Table Name ACESTADO Functional Name Catálogo que contiene las descripciones de los estados de los alumnos.
Columns No Column Name PK FK M Data Type DT
kind Domain Name Formula
(Default Value) Security Abbreviation
1 ESTADO_COD Y VARCHAR (1 BYTE) LT 2 ESTADO_NOMBRE VARCHAR (20 BYTE) LT 3 ESTADO_DESCRIPCION VARCHAR (50 BYTE) LT 4 ESTADO_ACTIVO VARCHAR (1 BYTE) LT 'N'
Tabla 25 Detalle Tabla ACESTADO
Table Name ACHORARIOS Functional Name Contiene el detalle de los horarios de las asignaturas programadas por el
consejo académico, días y horas asignadas a una asignatura.
Columns No Column Name PK FK M Data Type DT
kind Domain Name Formula
(Default Value) Security Abbreviation
1 HOR_ID P Y NUMERIC (10) LT 2 HOR_ID_CURSO F Y NUMERIC (10) LT 3 HOR_DIA_NRO Y NUMERIC (1) LT 4 HOR_HORA Y NUMERIC (2) LT 5 HOR_ALTERNATIVA Y NUMERIC (3) LT 6 HOR_ESTADO VARCHAR (3 BYTE) LT 7 HOR_SAL_ID_ESPACIO VARCHAR (45 BYTE) LT
No Column Name Description Notes
1 HOR_ID ID DE HORARIO. INCREMENTAL 2 HOR_ID_CURSO ID DEL CURSO ASOCIADO 3 HOR_DIA_NRO CODIGO DEL DIA 4 HOR_HORA CODIGO DE LA HORA 5 HOR_ALTERNATIVA 0 HORARIO UNICO. 1,2... ALTERNATIVOS 6 HOR_ESTADO ESTADO DEL REGISTRO 7 HOR_SAL_ID_ESPACIO CODIGO DEL SALON
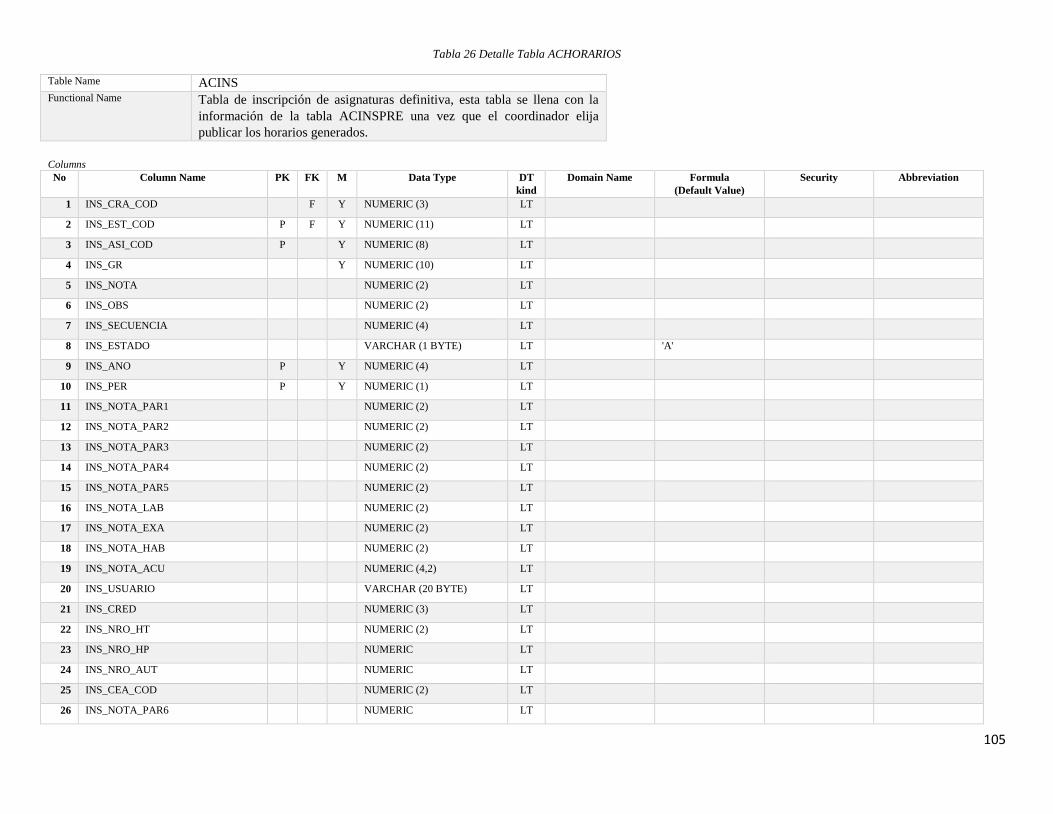
105
Tabla 26 Detalle Tabla ACHORARIOS
Table Name ACINS Functional Name Tabla de inscripción de asignaturas definitiva, esta tabla se llena con la
información de la tabla ACINSPRE una vez que el coordinador elija
publicar los horarios generados.
Columns No Column Name PK FK M Data Type DT
kind Domain Name Formula
(Default Value) Security Abbreviation
1 INS_CRA_COD F Y NUMERIC (3) LT 2 INS_EST_COD P F Y NUMERIC (11) LT 3 INS_ASI_COD P Y NUMERIC (8) LT 4 INS_GR Y NUMERIC (10) LT 5 INS_NOTA NUMERIC (2) LT 6 INS_OBS NUMERIC (2) LT 7 INS_SECUENCIA NUMERIC (4) LT 8 INS_ESTADO VARCHAR (1 BYTE) LT 'A' 9 INS_ANO P Y NUMERIC (4) LT
10 INS_PER P Y NUMERIC (1) LT 11 INS_NOTA_PAR1 NUMERIC (2) LT 12 INS_NOTA_PAR2 NUMERIC (2) LT 13 INS_NOTA_PAR3 NUMERIC (2) LT 14 INS_NOTA_PAR4 NUMERIC (2) LT 15 INS_NOTA_PAR5 NUMERIC (2) LT 16 INS_NOTA_LAB NUMERIC (2) LT 17 INS_NOTA_EXA NUMERIC (2) LT 18 INS_NOTA_HAB NUMERIC (2) LT 19 INS_NOTA_ACU NUMERIC (4,2) LT 20 INS_USUARIO VARCHAR (20 BYTE) LT 21 INS_CRED NUMERIC (3) LT 22 INS_NRO_HT NUMERIC (2) LT 23 INS_NRO_HP NUMERIC LT 24 INS_NRO_AUT NUMERIC LT 25 INS_CEA_COD NUMERIC (2) LT 26 INS_NOTA_PAR6 NUMERIC LT
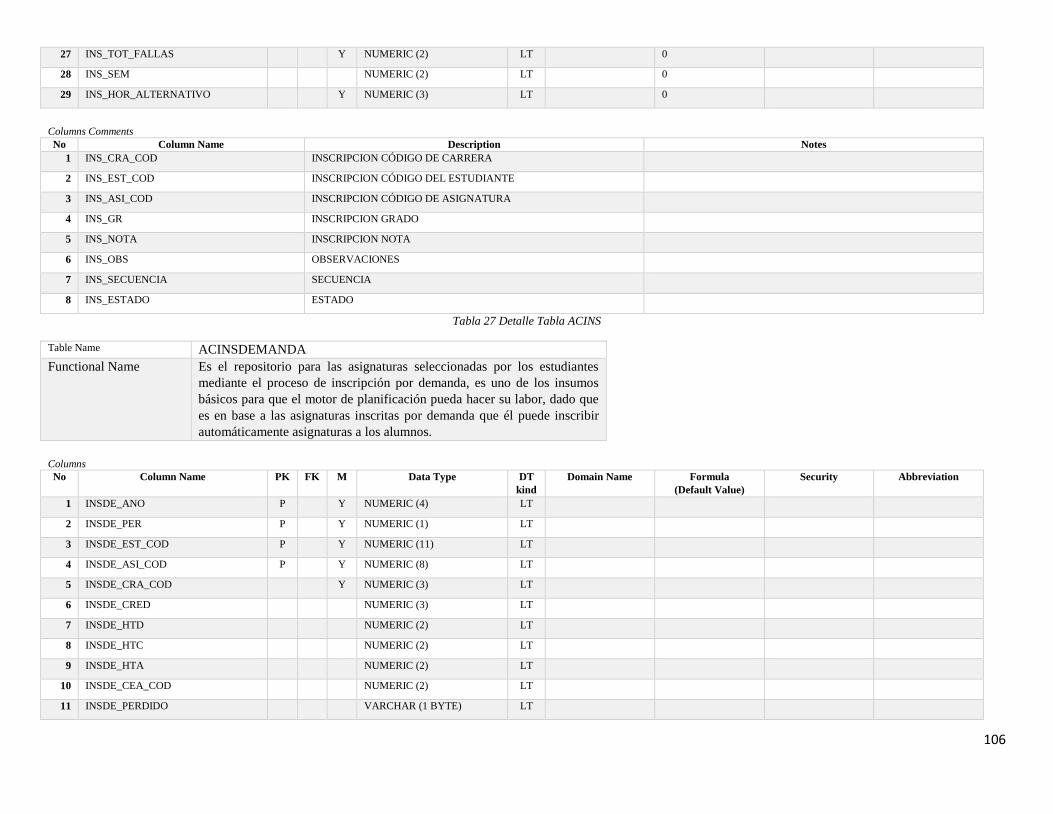
106
27 INS_TOT_FALLAS Y NUMERIC (2) LT 0 28 INS_SEM NUMERIC (2) LT 0 29 INS_HOR_ALTERNATIVO Y NUMERIC (3) LT 0
Columns Comments No Column Name Description Notes
1 INS_CRA_COD INSCRIPCION CÓDIGO DE CARRERA 2 INS_EST_COD INSCRIPCION CÓDIGO DEL ESTUDIANTE 3 INS_ASI_COD INSCRIPCION CÓDIGO DE ASIGNATURA 4 INS_GR INSCRIPCION GRADO 5 INS_NOTA INSCRIPCION NOTA 6 INS_OBS OBSERVACIONES 7 INS_SECUENCIA SECUENCIA 8 INS_ESTADO ESTADO
Tabla 27 Detalle Tabla ACINS
Table Name ACINSDEMANDA Functional Name Es el repositorio para las asignaturas seleccionadas por los estudiantes
mediante el proceso de inscripción por demanda, es uno de los insumos
básicos para que el motor de planificación pueda hacer su labor, dado que
es en base a las asignaturas inscritas por demanda que él puede inscribir
automáticamente asignaturas a los alumnos.
Columns No Column Name PK FK M Data Type DT
kind Domain Name Formula
(Default Value) Security Abbreviation
1 INSDE_ANO P Y NUMERIC (4) LT 2 INSDE_PER P Y NUMERIC (1) LT 3 INSDE_EST_COD P Y NUMERIC (11) LT 4 INSDE_ASI_COD P Y NUMERIC (8) LT 5 INSDE_CRA_COD Y NUMERIC (3) LT 6 INSDE_CRED NUMERIC (3) LT 7 INSDE_HTD NUMERIC (2) LT 8 INSDE_HTC NUMERIC (2) LT 9 INSDE_HTA NUMERIC (2) LT
10 INSDE_CEA_COD NUMERIC (2) LT 11 INSDE_PERDIDO VARCHAR (1 BYTE) LT

107
12 INSDE_ESTADO VARCHAR (1 BYTE) LT 'A' 13 INSDE_EQUIVALENTE NUMERIC (8) LT 0 14 INSDE_SEM NUMERIC (2) LT
Tabla 28 Detalle Tabla ACINSDEMANDA
Table Name ACINSPRE Functional Name Es la tabla temporal de trabajo, en la cual se consignarán los resultados de
la planificación, una vez se publiquen los resultados sus datos serán
eliminados y pasaran a la tabla de ACINS.
Columns No Column Name PK FK M Data Type DT
kind Domain Name Formula
(Default Value) Security Abbreviation
1 INS_ANO P Y NUMERIC (4) LT 2 INS_PER P Y NUMERIC (1) LT 3 INS_CRA_COD P Y NUMERIC (3) LT 4 INS_EST_COD P Y NUMERIC (11) LT 5 INS_ASI_COD P Y NUMERIC (8) LT 6 INS_GR Y NUMERIC (10) LT 7 INS_SEM Y NUMERIC (2) LT 8 INS_ESTADO VARCHAR (1 BYTE) LT 'A' 9 INS_CRED NUMERIC (3) LT
10 INS_NRO_HT NUMERIC (2) LT 11 INS_NRO_HP NUMERIC LT 12 INS_NRO_AUT NUMERIC LT 13 INS_CEA_COD NUMERIC (2) LT 14 INS_HOR_ALTERNATIVO Y NUMERIC (3) LT
Tabla 29 Detalle Tabla ACINSPRE
Table Name ACTABLAHOMOLOGACION Functional Name La tabla de homologación permite verificar las equivalencias en los planes
de estudios de los estudiantes, con la finalidad de ampliar el rango de
asignaturas disponibles ofertadas.
Columns No Column Name PK FK M Data Type DT
kind Domain Name Formula
(Default Value) Security Abbreviation
1 HOM_ID P Y NUMERIC (10) LT

108
2 HOM_CRA_COD_PPAL NUMERIC (3) LT 3 HOM_ASI_COD_PPAL NUMERIC (8) LT 4 HOM_CRA_COD_HOM NUMERIC (1) LT 5 HOM_ASI_COD_HOM NUMERIC (8) LT 6 HOM_TIPO_HOM NUMERIC (1) LT 7 HOM_ESTADO VARCHAR (1 BYTE) LT 8 HOM_FECHA_REG NUMERIC (10) LT
Tabla 30 Detalle Tabla ACTABLAHOMOLOGACION
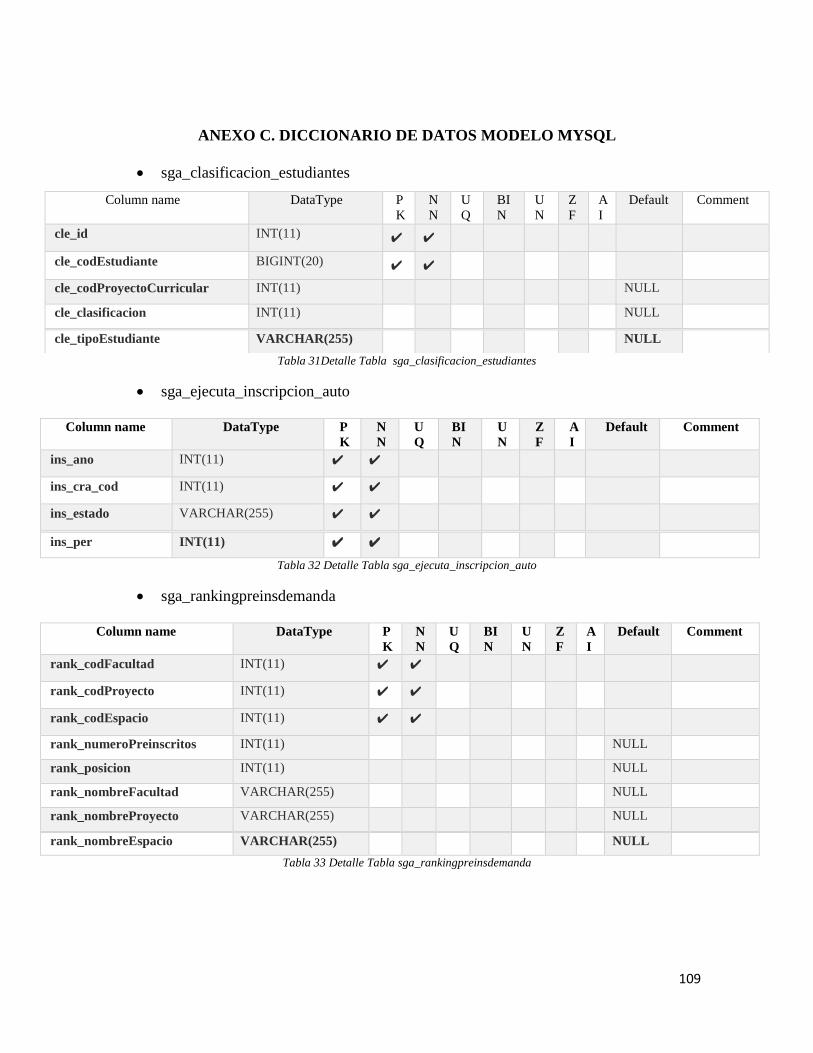
109
ANEXO C. DICCIONARIO DE DATOS MODELO MYSQL
sga_clasificacion_estudiantes
Tabla 31Detalle Tabla sga_clasificacion_estudiantes
sga_ejecuta_inscripcion_auto
Column name DataType P
K
N
N
U
Q
BI
N
U
N
Z
F
A
I
Default Comment
ins_ano INT(11) ✔ ✔
ins_cra_cod INT(11) ✔ ✔
ins_estado VARCHAR(255) ✔ ✔
ins_per INT(11) ✔ ✔
Tabla 32 Detalle Tabla sga_ejecuta_inscripcion_auto
sga_rankingpreinsdemanda
Column name DataType P
K
N
N
U
Q
BI
N
U
N
Z
F
A
I
Default Comment
rank_codFacultad INT(11) ✔ ✔
rank_codProyecto INT(11) ✔ ✔
rank_codEspacio INT(11) ✔ ✔
rank_numeroPreinscritos INT(11) NULL
rank_posicion INT(11) NULL
rank_nombreFacultad VARCHAR(255) NULL
rank_nombreProyecto VARCHAR(255) NULL
rank_nombreEspacio VARCHAR(255) NULL
Tabla 33 Detalle Tabla sga_rankingpreinsdemanda
Column name
DataType P
K
N
N
U
Q
BI
N
U
N
Z
F
A
I
Default Comment
cle_id INT(11) ✔ ✔
cle_codEstudiante BIGINT(20) ✔ ✔
cle_codProyectoCurricular INT(11) NULL
cle_clasificacion INT(11) NULL
cle_tipoEstudiante VARCHAR(255) NULL

110
ANEXO D. MANUAL TÉCNICO
Objetivo
El objetivo de este documento es el de brindar un recurso universal para comprender la
configuración del componente de preinscripción automática, el servidor de administración
de reglas, el planificador y demás temas críticos no conocidos por los profesionales que
puedan hacerse cargo del proyecto.
Alcance
Este documento se limita expresamente a la configuración del componente de
preinscripción automática y herramientas que lo soportan, mas no ahonda en más
contenidos, sobre el administrador y gestor de reglas, motor de planificación y
benchmarking de motor, se limita expresamente a explicar la configuración de lo que se
utiliza para que funcione el planificador.
1. Configuración de Kie-Workbench 6.5.0
Kie Workbench se distribuye como una aplicación web java, desplegable en un
contenedor EJB o en una versión opcional desplegable en un servidor de aplicaciones java,
la configuración menos dispendiosa requiere descargar el servidor Wildfly 10, de su página.
http://wildfly.org/news/2016/01/29/WildFly10-Released/
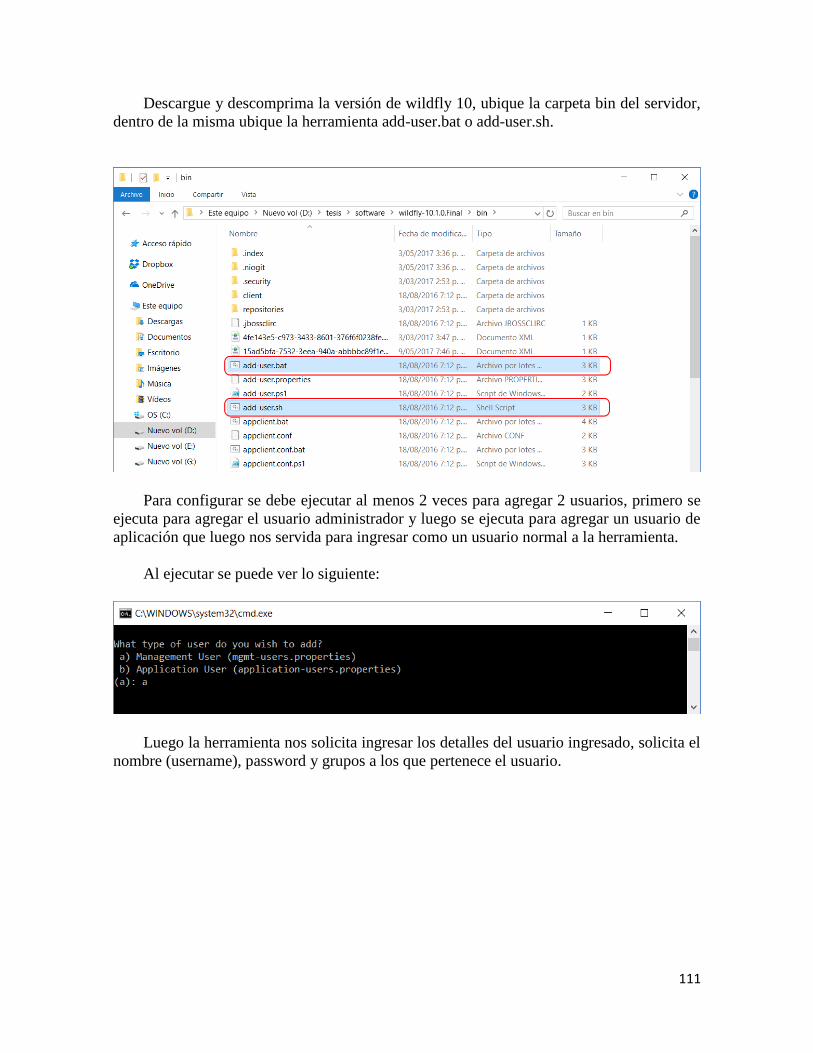
111
Descargue y descomprima la versión de wildfly 10, ubique la carpeta bin del servidor,
dentro de la misma ubique la herramienta add-user.bat o add-user.sh.
Para configurar se debe ejecutar al menos 2 veces para agregar 2 usuarios, primero se
ejecuta para agregar el usuario administrador y luego se ejecuta para agregar un usuario de
aplicación que luego nos servida para ingresar como un usuario normal a la herramienta.
Al ejecutar se puede ver lo siguiente:
Luego la herramienta nos solicita ingresar los detalles del usuario ingresado, solicita el
nombre (username), password y grupos a los que pertenece el usuario.

112
Por último la herramienta nos cuestiona si se añade el usuario al realm de administración y
nos pregunta si la actual instancia servirá como esclavo en una conexión remota esclavo a
esclavo.
Una vez creado, tendremos usuario administrador del servidor wildfly 10.
Los mismos pasos deberemos hacer para agregar el usuario de aplicación para poder
ingresar al kie workbench.
A diferencia del anterior, seleccionamos la opción (b) usuario de aplicación, e ingresamos
los datos de autenticación, luego cuando nos solicita los grupos a los que pertenece el
usuario escribimos, admin y kie-server.
Luego los dos pasos siguientes se realizan como el anterior usuario.

113
Con esto ya tendremos configurados los usuarios de acceso.
Es posible configurar de 2 formas Wildfly 10, posee dos modos operativos, como
servidor autónomo (standalone), o como dominio administrado (management domain), para
este ejercicio usaremos la configuración de servidor autónomo.
El ejecutable de la aplicación workbench es un empaquetado war, que se puede
descargar de la página del proyecto.
https://www.drools.org/download/download.html
El empaquetado puede tener un nombre como el siguiente, debe descargarse
explícitamente el destinado a wildfly 10, para no tener problemas con la configuración.
kie-drools-wb-6.5.0.Final-wildfly10.war
Para desplegar la aplicación se debe copiar el empaquetado war a la carpeta
/standalone/deployments del servidor y para iniciarlo en modo standalone en la carpeta bin

114
ejecutar el archivo standalone.bat o standalone.sh dependiendo de si su sistema operativo es
Windows o Linux.
Una vez inicia el servidor, wildfly automáticamente despliega el empaquetado y lo
habilita, una vez ha terminado el proceso se puede observar en el contexto de la aplicación
la siguiente página de bienvenida.
Para ingresar se debe digitar el usuario y password creado por medio de la opción (b)
de la herramienta de creación de usuarios.

115
2. Configuración del proyecto en Kie Workbench
Para poder desacoplar las reglas del aplicativo se debe configurar un nuevo proyecto
en kie workbench, inicialmente se debe configurar un nuevo repositorio de workbench.
Seleccionando Authoring/Administration
Creamos una nueva unidad organizacional, para nuestro proyecto
Se debe tener en cuenta que los datos de la unidad organizacional e id de grupo serán
usados por los aplicativos que deseen consultar el artefacto que se construirá.
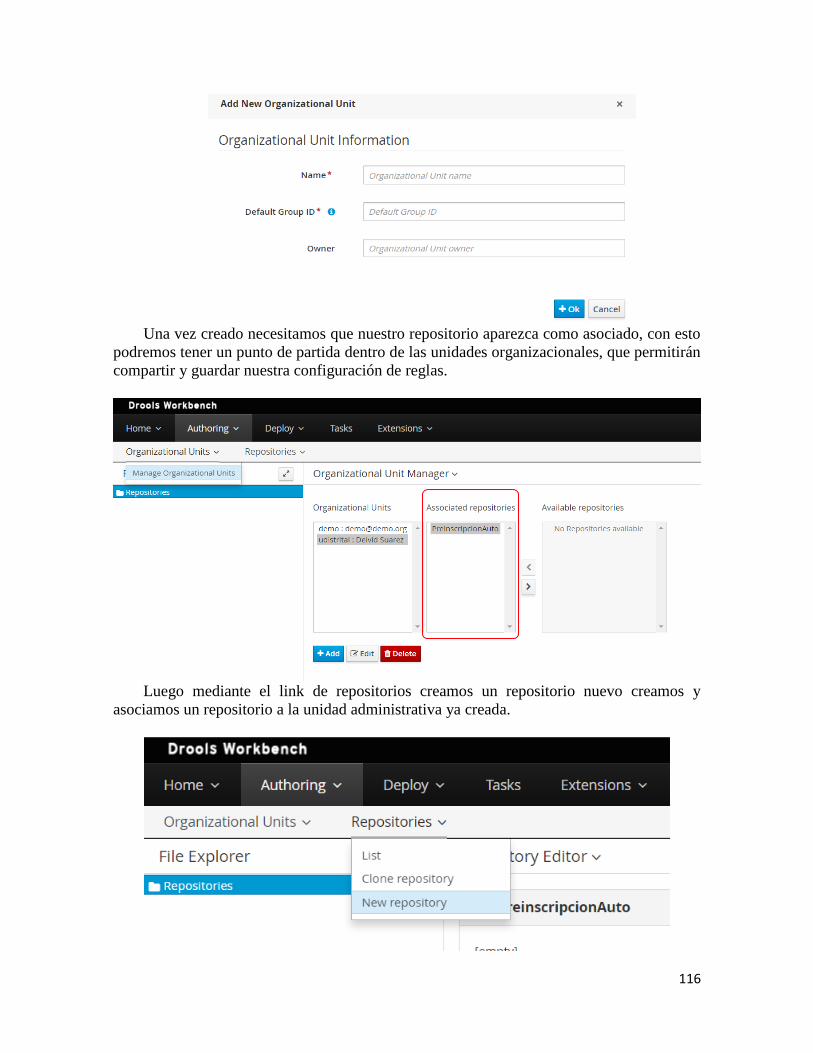
116
Una vez creado necesitamos que nuestro repositorio aparezca como asociado, con esto
podremos tener un punto de partida dentro de las unidades organizacionales, que permitirán
compartir y guardar nuestra configuración de reglas.
Luego mediante el link de repositorios creamos un repositorio nuevo creamos y
asociamos un repositorio a la unidad administrativa ya creada.

117
Una vez están creadas las unidades administrativas podremos crear proyecto que
generara la configuración como un artefacto maven.
Seleccionamos la unidad organizacional ya creada y sobre ella creamos un nuevo
proyecto.
Se ingresa la información del nuevo proyecto, es importante tener en cuenta que la
forma en la que registremos el artefacto que contendrá la configuración y las reglas, será el

118
punto de acceso para el mismo ya que workbench se basa en maven para la persistencia de
los artefactos.
La estructura definida en el group ID es muy importante para la configuración de
drools, dentro del aplicativo se estará solicitando a kie-workbench un artefacto con el id de
artefacto y el id de grupo que se ven en la anterior pantalla, si se cambia el group id debe
actualizarse el código fuente que realiza el llamado, igualmente si se cambia el nombre del
artefacto o la versión del mismo.
Al cambiarlo hay que actualizar la clase PreinscripcionAutomaticaSolverManagerImpl
en los parámetros usados por el método init que realiza la siguiente instrucción:
KieContainer kContainer = ks.newKieContainer
(ks.newReleaseId("edu.sga.udistrital.preinscripcionauto.solver","PreinscripcionAutoConfig
", "1.0"));
Dado que es allí donde se realiza la carga del componente proveniente de workbench.
Se debe intentar mantener una coherencia en la estructuración de paquetes y el
groupID con la finalidad de que sea fácil comprender su estructura interna, asi es preferible
crear una configuración acorde a lo expresado por el groupID.

119
Igualmente al subir las reglas a un paquete específico del componente hay que intentar
siempre que exista coherencia entre los recursos como reglas que expresan su paquete de
ubicación y el sitio donde se colocan estos recursos.
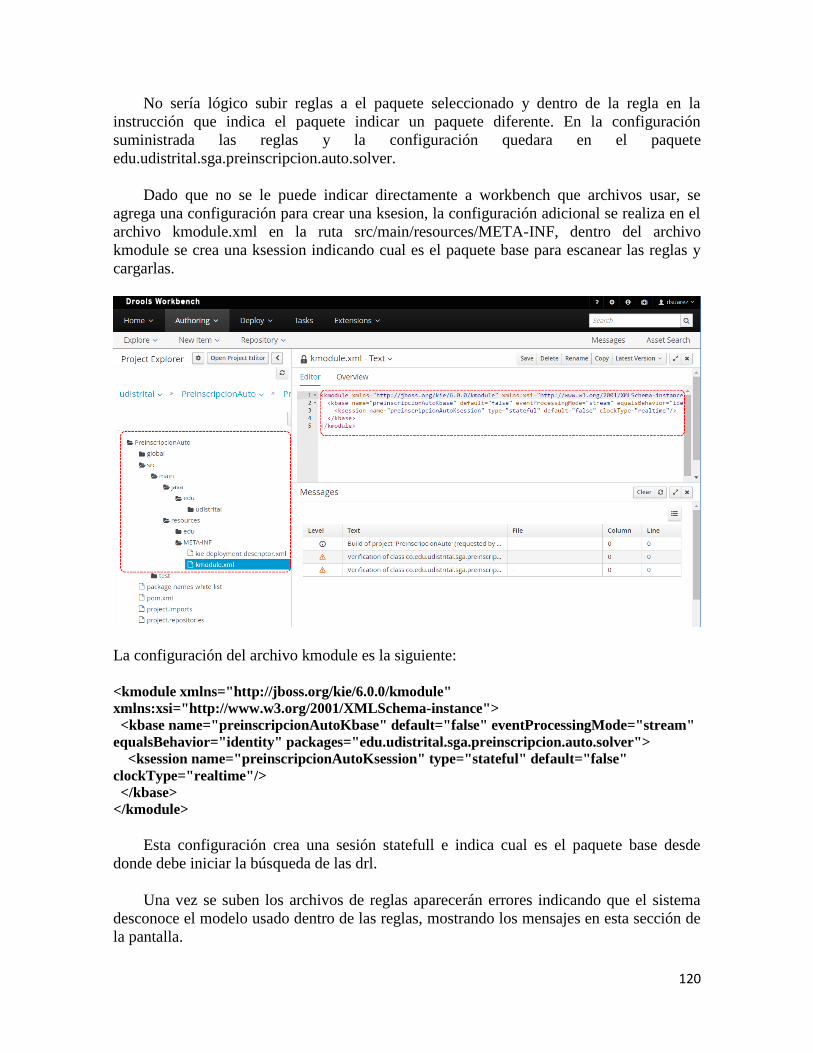
120
No sería lógico subir reglas a el paquete seleccionado y dentro de la regla en la
instrucción que indica el paquete indicar un paquete diferente. En la configuración
suministrada las reglas y la configuración quedara en el paquete
edu.udistrital.sga.preinscripcion.auto.solver.
Dado que no se le puede indicar directamente a workbench que archivos usar, se
agrega una configuración para crear una ksesion, la configuración adicional se realiza en el
archivo kmodule.xml en la ruta src/main/resources/META-INF, dentro del archivo
kmodule se crea una ksession indicando cual es el paquete base para escanear las reglas y
cargarlas.
La configuración del archivo kmodule es la siguiente:
<kmodule xmlns="http://jboss.org/kie/6.0.0/kmodule"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<kbase name="preinscripcionAutoKbase" default="false" eventProcessingMode="stream"
equalsBehavior="identity" packages="edu.udistrital.sga.preinscripcion.auto.solver">
<ksession name="preinscripcionAutoKsession" type="stateful" default="false"
clockType="realtime"/>
</kbase>
</kmodule>
Esta configuración crea una sesión statefull e indica cual es el paquete base desde
donde debe iniciar la búsqueda de las drl.
Una vez se suben los archivos de reglas aparecerán errores indicando que el sistema
desconoce el modelo usado dentro de las reglas, mostrando los mensajes en esta sección de
la pantalla.
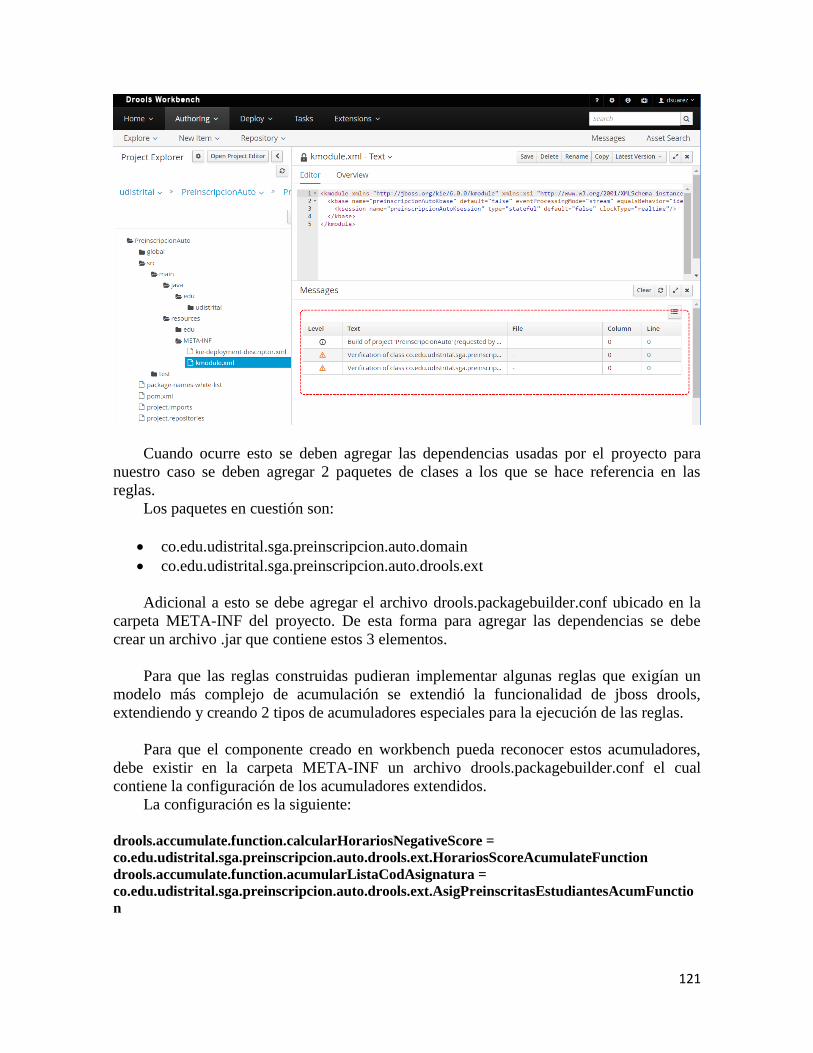
121
Cuando ocurre esto se deben agregar las dependencias usadas por el proyecto para
nuestro caso se deben agregar 2 paquetes de clases a los que se hace referencia en las
reglas.
Los paquetes en cuestión son:
co.edu.udistrital.sga.preinscripcion.auto.domain
co.edu.udistrital.sga.preinscripcion.auto.drools.ext
Adicional a esto se debe agregar el archivo drools.packagebuilder.conf ubicado en la
carpeta META-INF del proyecto. De esta forma para agregar las dependencias se debe
crear un archivo .jar que contiene estos 3 elementos.
Para que las reglas construidas pudieran implementar algunas reglas que exigían un
modelo más complejo de acumulación se extendió la funcionalidad de jboss drools,
extendiendo y creando 2 tipos de acumuladores especiales para la ejecución de las reglas.
Para que el componente creado en workbench pueda reconocer estos acumuladores,
debe existir en la carpeta META-INF un archivo drools.packagebuilder.conf el cual
contiene la configuración de los acumuladores extendidos.
La configuración es la siguiente:
drools.accumulate.function.calcularHorariosNegativeScore =
co.edu.udistrital.sga.preinscripcion.auto.drools.ext.HorariosScoreAcumulateFunction
drools.accumulate.function.acumularListaCodAsignatura =
co.edu.udistrital.sga.preinscripcion.auto.drools.ext.AsigPreinscritasEstudiantesAcumFunctio
n

122
Sin esta configuración especial, aunque se pase el dominio que contiene las clases
usadas en la parte de acumulación de las reglas, no lograra asociar la función de
acumulación creadas en el dominio.
Una vez se construya el jar se debe agregar mediante la opción
Authoring/ArtifactRepository

123
Ahora para configurar las dependencias se abre el editor del proyecto y se selecciona la
opción de dependencias en la lista de configuraciones generales de proyecto.
Se selecciona el botón de añadir desde el repositorio, se selecciona uno de la lista y
deberá quedar como aparece a continuación.
Una vez agregado construya el elemento mediante la opción build
El sistema le indicara que la construcción del componente ha sido exitosa, a partir de
allí podrá solicitar el componente mediante el api de kie.

124
3. Configuración de la aplicación para realizar el llamado del componente de
reglas y configuración de workbench.
Dentro de la aplicación deben tenerse en cuenta algunas características de
configuración con la finalidad de poder solicitar el componente a workbench.
Inicialmente verifique que el componente puede ser descargado, la estructura de
paquetes es correcta.
Para usar el api de KIE trate de usar la versión del api asociada a la versión de
workbench, en nuestro caso la 6.5.0 Final, la forma de llamarla desde su archivo de
configuración POM de maven es la siguiente:
<dependency>
<groupId>org.kie</groupId>
<artifactId>kie-ci</artifactId>
<version>6.5.0.Final</version>
</dependency>
También debe registrar el repositorio dentro de su archivo POM para que sea incluido
al solicitar el componente de configuración, de esta forma agrege el repositorio a su POM
de esta manera:
<repository>
<id>guvnor-m2-repo</id>
<name>Guvnor M2 Repo</name>
<url>http://localhost:9290/kie-drools-wb/maven2/</url>
</repository>
Para obtener una mayor exactitud de la ruta en la que estará disponible su componente,
puede entrar al repositorio de artefactos de workbench y solicitar una descripción del POM.
Dentro de la descripción obtendrá la información exacta de cómo debe realizar la
solicitud al servidor de artefactos, debe tener en cuenta que para maquinas diferentes debe
cambiar la IP de acceso al servidor y el puerto en el que está configurado.
También podremos observar las dependencias de nuestro componente y como se
encuentra registrado en el repositorio de artefactos.

125
En el código fuente gracias a la configuración echa en el archivo kmodule.xml no
haremos referencia a archivos de reglas como tal sino a una ksession, por este motivo tiene
tanta importancia que el componente compile y se construya de manera adecuada.
4. Configuración de componente PreinscripcionAuto
El componente de preinscripción automática es una aplicación web desarrollada en
spring boot, su manejo es sencillo, en una fase inicial estuvo pensado para tener un servidor
(tomcat) embebido y distribuirse como un .jar sin embargo el motor de planificación cuenta
con algunos problemas con los servidores embebidos lo que nos obligó a distribuirlo como
un .war, es desplegable en servidores livianos tomcat y jetty, no necesita un contenedor
EJB.
Para desplegar el componente basta con compilar y empaquetar en .war y situar el war
en la carpeta webapps del tomcat.
Preinscripción Automática es una aplicación realizada mediante java 1.8 hace uso de
las características del mediante spring data y el uso de lambdas para el manejo de
colecciones, por tal motivo recomendamos usar el servidor Tomcat 8.0 para su despliegue.

126
5. Configuración bases de datos PreinscripcionAuto
PreinscripcionAuto hace uso de spring-data para crear y configurar los datasources de
las bases de datos, posee solo una configuración de desarrollo, para modificar la
configuración se debe ingresar en el archivo application.properties y modificar los
siguientes bloques de código:
# -----------------------
# ORACLE DATABASE CONFIGURATION
# -----------------------
spring.oracle.datasource.url=jdbc:oracle:thin:@127.0.0.1:1521/XE
spring.oracle.datasource.username=MNTAC
spring.oracle.datasource.password=mntac
spring.oracle.datasource.driver-class-name=oracle.jdbc.driver.OracleDriver
spring.postgresql.datasource.driverClassName=oracle.jdbc.driver.OracleDriver
# ------------------------------
# MYSQL DATABASE CONFIGURATION
# ------------------------------
spring.mysql.datasource.url=jdbc:mysql://localhost:3306/udistrital
spring.mysql.datasource.username=root
spring.mysql.datasource.password=admin
spring.mysql.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.postgresql.datasource.driverClassName=com.mysql.jdbc.Driver
#------------------------------------------------------------------------
6. Configuración nivel de logging
Para cambiar los niveles de logging se debe modificar la configuración establecida en
el archivo logback-spring.xml, que contiene las siguientes líneas de código:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource= "org/springframework/boot/logging/logback/base.xml" />
<logger name="org.optaplanner" level="debug"/>
</configuration>
Esta configuración puede realizarse a la medida que se desee, se puede usar el api de
logback para enviar la traza a archivos, limitar los archivos, añadir, crear diferentes según
las fechas etc.
Los niveles de logging establecidos por optaplanner son los siguientes:
error: registra los errores, excepto aquellos que son lanzados por el código de
llamada como RuntimeException.
warn: Registra circunstancias sospechosas
info: Registra cada fase de el planificador
debug: registra cada paso en cada dase del planificador.
trace: Registra cada movimiento de cada paso de cada fase del planificador.

127
Debe recordar que entre mayor sea el nivel de log hay menor rendimiento del
planificador, el nivel trace es 4 veces más lento que un log común, una vez estabilizado no
hay existe la necesidad de registrar con tal detalle los movimientos, en lugar de eso se
deben utilizar los niveles complejos para solucionar errores y analizar situaciones
excepcionales.
7. Configuración del solucionador
El archivo de configuración del solucionador al igual que las reglas se encuentra en el
artefacto maven distribuido a través de workbench, sin embargo el aplicativo también
guarda una versión local de la solución y las reglas de negocio para efectos de pruebas.
La estructura del archivo de configuración de la solución es la siguiente:
Como se puede ver dependiendo de la forma en la que se ejecute el archivo puede
hacer referencia a la ksessionName asociada, si el caso es el de descargar las reglas de
negocio y configuración de workbench, o indica una a una los archivos de reglas asociadas
una a una.
En la segunda parte del archivo de configuración se puede ver la cantidad de fases y
algoritmo usado en cada fase, en este caso, solo hay una fase de meta heurística usando el
algoritmo HILL_CLIMBING, tiene una configuración de terminación que indica que los
cálculos deben acabar a los dos minutos y cuando el score mínimo sea de (0hard/0soft) esta
última condición para obligar a que la solución sea optima en las reglas fuertes que debe
cumplir y no romper, esta configuración puede variar mucho dependiendo de cómo se
quiere plantear la solución al problema, por ejemplo puede usar más de una fase con
algoritmos diferentes, puede usar heurísticas de construcción puede, querer solo usar una
fase y querer que se asigne todo el tiempo al algoritmo de tal fase, la configuración del
algoritmo de solución es variable, se deben tener en cuenta la cantidad de registros a
procesar. Cada algoritmo tiene un comportamiento diferente, y gastan recursos diferentes.
Para obtener una guía de que algoritmo funciona mejor se puede implementar la parte
de benchmarking de optaplanner, la cual permite comparar el funcionamiento de los
algoritmos en un set de datos de prueba. (La parte de benchmarking no fue abarcada por
este proyecto y queda propuesta como trabajos futuros de investigación).