unified framework for big data fdw
TRANSCRIPT

Shivram Mani ( Pivotal)
Unified Framework for Big Data Foreign Data Wrappers
@ FOSDEM PGDay 2016

Agenda
● Introduction to Hadoop Ecosystem
● Why Postgres SQL on Hadoop
● Current state of SQL on Hadoop (FDW/Big data wrappers)
● PXF - Design & Architecture
● Demo
● Benefits of using PXF with FDW
● Q&A

Agenda
➢ Introduction to Hadoop Ecosystem
● Why Postgres SQL on Hadoop
● Current state of SQL on Hadoop (FDW/Big data wrappers)
● PXF - Design & Architecture
● Demo
● Benefits of using PXF with FDW
● Q&A

What is Hadoop/Big Data
Apache Hadoop is an open source framework for distributed processing of large data sets across clusters of computers.
● Commodity Hardware● Scale out ● Fault tolerance● Support multiple file formats
Mapreduce HBase
Hive Pig
Clustered File System
DistributedData Processing
Top levelAbstractions
ETL Tools BI Tools RDMS
Hadoop Distributed File System (HDFS)
Top levelInterfaces

Agenda
● Introduction to Hadoop Ecosystem
➢ Why Postgres SQL on Hadoop
● Current state of SQL on Hadoop (FDW/Big data wrappers)
● PXF
● Demo
● Benefits of using PXF with FDW
● Q&A
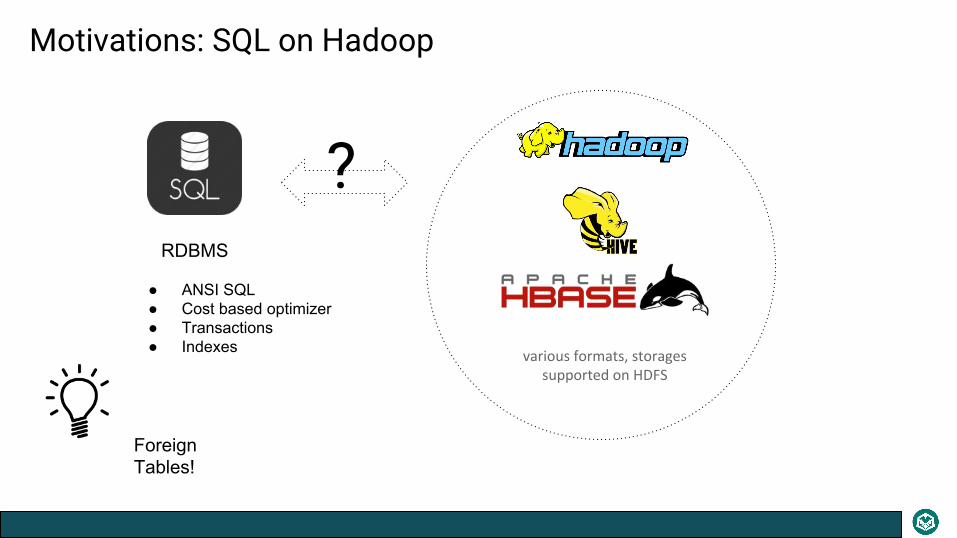
Motivations: SQL on Hadoop
RDBMS
?
various formats, storages supported on HDFS
● ANSI SQL● Cost based optimizer● Transactions● Indexes
Foreign Tables!

Agenda
● Introduction to Hadoop Ecosystem
● Why Postgres SQL on Hadoop
➢ Current state of SQL on External Hadoop - FDW/Big data wrappers
● PXF - Design & Architecture
● Demo
● Benefits of using PXF with FDW
● Q&A

Foreign Data Wrappers (FDW)
Foreign tables and foreign data wrapper is postgres way to read external data.
1. Create FDW (compiled C functions in the handler)
2. Declare the extension (FDW)
3. Create server that uses the wrapper
4. Create table that uses the server
CREATE FOREIGN DATA WRAPPER hadoop_fdw HANDLER hadoop_fdw_handler NO VALIDATOR;
CREATE EXTENSION hadoop_fdw;
CREATE SERVER hadoop_server FOREIGN DATA WRAPPER hadoop_fdw OPTIONS (address '127.0.0.1', port '10000');
CREATE FOREIGN TABLE retail_history (name text,
price double precision )SERVER hadoop_serverOPTIONS (table 'example.retail_history');

Foreign Data Wrappers - Implementation
Creating a new foreign data wrapper simply consists of implementing the API of the FDW as c-language functions.
Scanning a foreign table requires implementation of the following:
● GetForeignRelSize - Estimate of the relation size
● GetForeignPaths - Get access paths for the foreign data
● GetForeignPlan - Plan the foreign paths of this table
● BeginForeignScan - Start scan. Open connections, etc
● IterateForeignScan - Perform scan and return tuples
● EndForeignScan - End scan. Close connection, etc

Big Data Wrappers (Multicorn, BigSQL EnterpriseDB)
Create a Hive table corresponding to HDFS file/HBase table
Create Extension, Server & Foreign Table
schema and necessary Options
Results mapped to postgres table
Query connects to HiveServer via thrift client
Hive server executesmapreduce jobs
Query Foreign Table

Big Data Wrapper - Communication
libthriftFDW
MetaStore

Agenda
● Introduction to Hadoop Ecosystem
● Why Postgres SQL on Hadoop
● Current state of SQL on Hadoop - FDW/Big data wrappers
➢ PXF - Design & Architecture
● Demo
● Benefits of using PXF with FDW
● Q&A

● HAWQ is an MPP SQL engine on HDFS (evolved from Greenplum Database)
● PXF is an extensible framework that allows HAWQ to query external data.
● PXF includes built-in connectors for accessing data in HDFS files, Hive & HBase tables.
● Users can create custom connectors to other parallel data stores or processing engines.
HAWQ Extension Framework - PXF

PXF - Communication
Apache Tomcat
PXF WebappREST API
Java API
libhdfs3, written in C, segments
External Tables
Native Tables
HTTP, port: 51200
Java API
Java API

Architecture - Deployment
HAWQMaster Node NN
pxf
HBase Master
DN4
pxf
HAWQseg4
DN1
pxf
HAWQseg1
HBase Region Server1
DN2
pxf
HAWQseg2
HBase Region Server2
DN3
pxf
HAWQseg3
HBase Region Server3
* PXF needs to be installed on all DN* PXF is recommended to be installed on NN

Design - Components(PXF)
Fragmenter Get the locations of fragments for an external tableImplicitly provides stats to query optimizer
Accessor Understand and read/write the fragment , return records
Resolver Convert records to HAWQ consumable format (Data Types)

CREATE EXTENSION hadoop_fdw;
CREATE SERVER hadoop_server FOREIGN DATA WRAPPER hadoop_fdw OPTIONS (address '127.0.0.1', port '10000');
CREATE FOREIGN TABLE retail_history (name text,
price double precision )SERVER hadoop_serverOPTIONS (table 'example.retail_history');
CREATE PROTOCOL PXF;
DDL Comparison
LOCATION('pxf://127.0.0.1:51200/
example.retail_history?
CREATE EXTERNAL TABLE retail_history name text, price double precision )
PROFILE = HIVE
FORMAT 'CUSTOM' (formatter='pxfwritable_import');
PXF FDW
* Items with the same color have similar action

Architecture - Data Flow: Query (HDFS)
HAWQMaster Node NN
pxf
DN1
pxf
HAWQseg1
select * from ext_table0
pxf://<namenode><port>/path/to/data
getFragments() REST
1
Fragments JSON2
7
3
Split mapping(fragment -> segment)
DN1
pxf
HAWQseg1
DN1
pxf
HAWQseg1
Query dispatched to Segment 1,2,3… (Interconnect)
5
Read() REST
6 records
8
query result
records (stream)
Fragmenter
Resolver
Accessor
4

PXF Plugins, Profiles
• Built-in with HAWQ (Profiles)
• HDFS: HDFSTextSimple(R/W), HDFSTextMulti(R), Avro(R)
• Hive(R): Hive, HiveRC, HiveText
• HBase(R): HBase
• Community (https://bintray.com/big-data/maven/pxf-plugins/view )
• JSON HAWQ-178
• Cassandra
• Accumulo
• ...

Agenda
● Introduction to Hadoop Ecosystem
● Why Postgres SQL on Hadoop
● Current state of SQL on Hadoop - FDW/Big data wrappers
● PXF - Design & Architecture
➢ Demo
● Benefits of using PXF with FDW
● Q&A

Demohttps://github.com/shivzone/pxf_demo

● Implement FDW callback functions that will interact with PXF.
● Use the enhanced libcurl library - libchurl
PXF as Big Data Wrapper Abstraction
Apache Tomcat
PXF WebappREST API Java API
HTTP, port: 51200
Java API
Java API
FDW

Agenda
● Introduction to Hadoop Ecosystem
● Why Postgres SQL on Hadoop
● Current state of SQL on Hadoop - FDW/Big data wrappers
● PXF - Design & Architecture
● Demo
➢ Benefits of using PXF with FDW
● Q&A

Benefits of using PXF with FDW
● FDW isolated from underlying hadoop ecosystem APIs
● Direct access of HDFS data.
● Access Hive data without overhead of underlying execution framework
● Access HBase data without mapped Hive table
● Supports Single node & parallel execution
● Extensibility/ease of building extensions
● Support for multiple versions of underlying distributions
● Built in filter push down and support for stats

Resources
● Github
https://github.com/apache/incubator-hawq/tree/master/pxf
● Documentation
http://hawq.docs.pivotal.io/docs-hawq/topics/PivotalExtensionFrameworkPXF.html
● Wiki
https://cwiki.apache.org/confluence/display/HAWQ/PXF

Q & A