understanding and designing new server …chong/290n-w10/warehouseworkloadsisca08.pdf ·...
TRANSCRIPT

Understanding and Designing New Server Architecturesfor Emerging Warehouse-Computing Environments
Kevin Lim*, Parthasarathy Ranganathan+, Jichuan Chang+,Chandrakant Patel+, Trevor Mudge*, Steven Reinhardt*†
* University of Michigan, Ann Arbor + Hewlett-Packard Labs †Reservoir Labs{ktlim,tnm,stever}@eecs.umich.edu, {partha.ranganathan, jichuan.chang, chandrakant.patel}@hp.com
Abstract
This paper seeks to understand and design next-generation servers for emerging “warehouse-computing” environments. We make two keycontributions. First, we put together a detailedevaluation infrastructure including a new benchmarksuite for warehouse-computing workloads, anddetailed performance, cost, and power models, toquantitatively characterize bottlenecks. Second, westudy a new solution that incorporates volume non-server-class components in novel packaging solutions,with memory sharing and flash-based disk caching.Our results show that this approach has promise, witha 2X improvement on average in performance-per-dollar for our benchmark suite.
1. Introduction
The server market is facing an interesting inflectionpoint. Recent market data identifies the “internetsector” as the fastest growing segment of the overallserver market, growing by 40-65% every year, andaccounting for more than 65% of low-end serverrevenue growth last year. By contrast, the rest of theserver market is not growing. Indeed, several recentkeynotes [3,6,19,25,26,33,36] point to growingrecognition of the importance of this area.
However, the design of servers for this market posesseveral challenges. Internet sector infrastructures havemillions of users often running on hundreds ofthousands of servers, and consequently, scale-out is akey design constraint. This has been likened to thedesign of a large warehouse-style computer [3], withthe programs being distributed applications like mail,search, etc. The datacenter infrastructure is often thelargest capital and operating expense. Additionally, asignificant fraction of the operating costs is power andcooling.
These constraints, in turn, lead to several designdecisions specific to internet sector infrastructures. The
focus on costs motivates leveraging the “sweet spot” ofcommodity pricing and energy efficiency, and alsoreflects in decisions to move high-end hardwarefeatures into the application stack (e.g., high-availability, manageability). Additionally, the highvolume in this market and the relative dominance of afew key players – e.g., Google, Yahoo, eBay, MSN(Microsoft), Amazon – allow for exploring options likecustom-designed servers in “green-field” datacentersbuilt from scratch. Indeed, Google and MSN’spurchase of real estate near the internet backbone orpower grid for this purpose has received a lot of recentpress [19].
All these trends motivate the need for research inunderstanding these workloads, and on new systemarchitectures targeted at this market with compellingcost/performance advantages. This paper seeks toaddress this challenge. In particular, we make thefollowing contributions. We put together a detailedevaluation infrastructure including the first-everbenchmark suite for warehouse-computing workloads,along with detailed performance, cost, and powermodels and metrics. Using these tools, we identify fourkey areas for improvement (CPU, packaging, memory,disk) and study a new system architecture that takes aholistic approach at addressing these bottlenecks. Ourproposed solution has novel features including the useof low-cost, low-power components from the high-volume embedded/mobile space and novel packagingsolutions, along with memory sharing and flash-baseddisk caching. Our results are promising, combining toprovide a two-fold improvement in performance-per-dollar, for our benchmark suite. More importantly, theypoint to the strong potential of cost-efficient ensemble-level design for this class of workloads.
2. Evaluation Environment
A challenge in studying new architectures forwarehouse-computing environments has been the lackof access to internet-sector workloads. The proprietarynature and the large scale of deployment are key
International Symposium on Computer Architecture
1063-6897/08 $25.00 © 2008 IEEEDOI 10.1109/ISCA.2008.37
315
International Symposium on Computer Architecture
1063-6897/08 $25.00 © 2008 IEEEDOI 10.1109/ISCA.2008.37
315
Authorized licensed use limited to: Univ of Calif San Diego. Downloaded on October 4, 2008 at 19:57 from IEEE Xplore. Restrictions apply.

impediments in duplicating these environments. Theseenvironments have a strong focus on cost and powerefficiency, but there are currently no complete system-level cost or power models publicly available, furtherexacerbating the difficulties.
2.1 A benchmark suite for the internet sector
In order to perform this study we have created a newbenchmark suite with four workloads representative ofthe different services in internet sector datacenters.
Websearch: We choose this to be representative ofunstructured data processing in internet sectorworkloads. The goal is to service requests to searchlarge amounts of data within sub-seconds. Ourbenchmark uses the Nutch search engine [21] runningon the Tomcat application server and Apache webserver. We study a 20GB dataset with a 1.3GB index ofparts of www.dmoz.org and Wikipedia. The keywordsin the queries are based on a Zipf distribution of thefrequency of indexed words, and the number ofkeywords is based on observed real-world querypatterns [40]. Performance is measured as the numberof requests per second (RPS) for comparable Quality ofService (QoS) guarantees. This benchmark emphasizeshigh throughput with reasonable amounts of dataprocessing per request.
Webmail: This benchmark seeks to representinteractive internet services seen in web2.0applications. It uses PHP-based SquirrelMail serverrunning on top of Apache. The IMAP and SMTPservers are installed on a separate machine usingcourier-imap and exim. The clients interact with theservers in sessions, each consisting of a sequence ofactions (e.g., login, read email and attachments,reply/forward/delete/move, compose and send). Thesize distributions are based on statistics collectedinternally within the University of Michigan, and theclient actions are modeled after MS Exchange ServerLoadSim “heavy-usage” profile [35]. Performance ismeasured as the number of RPS for comparable QoSguarantees. Our benchmark includes a lot of network
activity to interact with the backend server.Ytube: This benchmark is representative of web2.0
trends of using rich media types and models mediaservers servicing requests for video files. Ourbenchmark consists of a heavily modifiedSPECweb2005 Support workload driven withYoutube™ traffic characteristics observed in edgeservers by [14]. We modify the pages, files, anddownload sizes to reflect the distributions seen in [14],and extend the QoS requirement to model streamingbehavior. Usage patterns are modeled after a Zipfdistribution. Performance is measured as the number ofrequests per second, while ensuring that the QoSviolations are similar across runs. The workloadbehavior is predominantly IO-bounded.
Mapreduce: This benchmark is representative ofworkloads that use the web as a platform. We model acluster running offline batch jobs of the kind amenableto the MapReduce [7] style of computation, consistingof a series of “map” and “reduce” functions performedon key/value pairs stored in a distributed file system.We use the open-source Hadoop implementation [13]and run two applications – (1) mapreduce-wc thatperforms a word count over a large corpus (5 GB), and(2) mapreduce-write that populates the file system withrandomly-generated words. Performance is measuredas the amount of time to perform the task. Theworkload involves both CPU and I/O activity.
For websearch and webmail, the servers areexercised by a Perl-based client driver, which generatesand dispatches requests (with user-defined think time),and reports transaction rate and QoS results. The clientdriver can also adapt the number of simultaneousclients according to recently observed QoS results, toachieve the highest level of throughput withoutoverloading the servers. For ytube we use a modifiedSPECweb2005 client driver, which has similarfunctionality to the other client drivers.
We believe that our benchmark suite is a goodrepresentative of internet sector workloads for thisstudy. However, this suite is a work in progress, andSection 4 discusses further extensions to model our
Table 1: Summary details of the new benchmark suite to represent internet sector workloads.
Workload Emphasize Description Perf metricwebsearch the role of
unstructureddata
Open source Nutch-0.9, Tomcat 6 with clustering, and Apache2. 1.3GB indexcorresponding to 1.3 million indexed documents, 25% of index terms cached inmemory. 2GB Java heap size. QoS requires >95% queries take <0.5 seconds.
Request-per-sec (RPS) w/QoS
webmail interactiveinternetservices
Squirrelmail v1.4.9 with Apache2 and PHP4, Courier-IMAP v4.2 and Exim4.5.1000 virtual users with 7GB of mail stored. Email/attachment sizes and usagepatterns modeled after MS Exchange 2003 LoadSim heavy users. QoS requires>95% requests take <0.8 second.
RPS w/ QoS
ytube the use ofrich media
Modified SPECweb2005 Support workload with Youtube traffic characteristics.Apache2/Tomcat6 with Rock httpd server.
RPS w/ QoS
mapreduce web as aplatform
Hadoop v0.14 with 4 threads per CPU and 1.5GB Java heap size. We study twoworkloads - distributed file write (mapred-wr) and word count (mapred-wc)
Executiontime
316316
Authorized licensed use limited to: Univ of Calif San Diego. Downloaded on October 4, 2008 at 19:57 from IEEE Xplore. Restrictions apply.

target workloads even more accurately.
2.2 Metrics and models
Metrics: The key performance/price metric forinternet sector environments is the sustainableperformance (Perf) divided by total cost of ownership(abbreviated as TCO-$). For performance, we use thedefinition specific to each workload in Table 1. Fortotal lifecycle cost, we assume a three-yeardepreciation cycle and consider costs associated withbase hardware, burdened power and cooling, and real-estate. In our discussion of specific trends, we alsoconsider other metrics like Performance-per-Watt(Perf/W) and performance per specific costcomponents such as infrastructure only (Perf/inf-$) andpower and cooling (Perf/P&C-$).
Cost model: The two main components of our costmodel are (1) the base hardware costs, and (2) theburdened power and cooling costs. For the basehardware costs, we collect the costs of the individualcomponents – CPU, memory, disk, board, power andcooling (P&C) components such as power supplies,fans, etc. – at a per-server level. We cumulate thesecosts at the rack level, and consider additional switchand enclosure costs at that level. We use a variety ofsources to obtain our cost data, including publicly-available data from various vendors (newegg, Micron,Seagate, Western Digital, etc.) and industry-proprietarycost information through personal communicationswith individuals at HP, Intel/AMD, ARM, etc.Wherever possible, we also validated the consistencyof the overall costs and the breakdowns with priorpublications from internet-sector companies [3]. Forexample, our total server costs were similar to thatlisted from Silicon Mechanics [16].
For the power and cooling costs, we have twosubcomponents. We first compute the rack-level powerconsumption (P_consumed). This is computed as a sumof power at the CPU, memory, disk, power-and-cooling, and the rest of the board, at the per-serverlevel, and additional switch power at the rack level.Given that nameplate power is often overrated [11], wetried to obtain the maximum operational powerconsumption of various components from spec sheets,power calculators available from vendors[1,8,17,18,24,30,32], or personal communications withvendors. This still suffers from some inaccuracies sinceactual power consumption has been documented to belower than worst-case power consumption [27]. We usean “activity factor” of 0.75 to address this discrepancy.As validation, we compared the output of our model tosystems that we had access to and our model wasrelatively close to the actual consumption. (We alsostudied a range of activity factors from 0.5 to 1.0 andour results are qualitatively similar, so we don’t presentthem.)
Second, we use P_consumed as input to determinethe burdened cost of power using the methodologydiscussed by Patel et al. [27,28].
consumedgrids,1211 P*U*)L*KLK(1ostPowerCoolC
This model considers the burdened power and coolingcosts to consist of electricity costs at the rack level, theamortized infrastructure costs for power delivery (K1),the electricity costs for cooling (L1) and the amortizedcapital expenditure for the cooling infrastructure (K2).For our default configuration, we use published data ondefault values for K1, L1, and K2 [28]. There is a widevariation possible in the electricity tariff rate (from$50/MWHr to $170/MWhr), but in this paper, we use adefault electricity tariff rate of $100/MWhr [27].Figure 1 illustrates our cost model.
Performance evaluation: To evaluateperformance, we used HP Labs' COTSon simulator[10], which is based on AMD's SimNow™ [5]infrastructure. It is a validated full-system x86/x86-64simulator that can boot an unmodified Linux OS andexecute complex applications. The simulator guest runs64-bit Debian Linux with the 2.6.15 kernel. Thebenchmarks were compiled directly in the simulatedmachines where applicable. Most of the benchmarksuse Java, and were run using Sun’s Linux Java SDK5.0 update 12. C/C++ code was compiled with gcc4.1.2 and g++ 4.0.4. We also developed an offlinemodel using the simulation traces to evaluate memorysharing; this is discussed more in Section 3.4.
$3,249$5,758Total costs ($)
$1,561$2,4643-yr power & cooling
1.33 / 0.8 / 0.667K1 / L1 / K2
0.750.75Activity factor
4040Server qty per rack
4040Switch/rack power
3540Power + fans
4050Board + mgmt
1015Disk
2525Memory
105210CPU
215340Server power (Watt)
$2,750$2,750Switch/rack cost
$250$500Power + fans
$250$400Board + mgmt
$120$275Disk
$350$350Memory
$650$1,700CPU
$1,620$3,225Per-server cost ($)
Srvr2Srvr1Details
$3,249$5,758Total costs ($)
$1,561$2,4643-yr power & cooling
1.33 / 0.8 / 0.667K1 / L1 / K2
0.750.75Activity factor
4040Server qty per rack
4040Switch/rack power
3540Power + fans
4050Board + mgmt
1015Disk
2525Memory
105210CPU
215340Server power (Watt)
$2,750$2,750Switch/rack cost
$250$500Power + fans
$250$400Board + mgmt
$120$275Disk
$350$350Memory
$650$1,700CPU
$1,620$3,225Per-server cost ($)
Srvr2Srvr1Details
Disk
P&C
2%
Board
P&C
9%
Rack P&C 0%
MemP&C
6%
Board
HW 8%
Mem
HW
11%
Disk
HW 4%
Rack
HW 2%
CPU
P&C
22% Fan
HW 8%
CPU HW
20%
Fans P&C 8%
Srv2 Costs Breakdown
(a) (b)
Figure 1: Cost models and breakdowns.
317317
Authorized licensed use limited to: Univ of Calif San Diego. Downloaded on October 4, 2008 at 19:57 from IEEE Xplore. Restrictions apply.
3. A New Server Architecture
3.1 Cost Analysis and Approach Taken
Figure 1(a) lists the hardware component costs, thebaseline power consumption, and the burdened costs ofpower and cooling for two existing serverconfigurations (srvr1 and srvr2). Figure 1(b) presents apie-chart breakdown of the total costs for srvr2separated as infrastructure (HW) and burdened powerand cooling (P&C). Our data shows several interestingtrends. First, power and cooling costs are comparableto hardware costs. This is consistent with recent studiesfrom internet sector workloads that highlight the sametrend [11]. Furthermore, the CPU hardware and CPUpower and cooling are the two largest components oftotal costs (contributing 20% and 22% respectively).However, it can be seen that a number of othercomponents together contribute equally to the overallcosts. Consequently, to achieve truly compellingperformance/$ advantages, solutions need toholistically address multiple components.
Below, we examine one such holistic solution.Specifically, we consider four key issues: (1) Can wereduce overall costs from the CPU (hardware andpower) by using high-volume lower-cost lower-power(but also lower-performance) non-server processors?(2) Can we reduce the burdened costs of power bynovel packaging solutions? (3) Can we reduce theoverall costs for memory by sharing memory across acluster/ensemble? (4) Can we reduce the overall costsfor the disk component by using lower-power (butlower performance) disks, possibly with emerging non-volatile memory?
Answering each of these questions in detail is notpossible within the space constraints of this paper. Ourgoal here is to evaluate first, if considerable gains arepossible in each of these areas when the architecture isviewed from the ensemble perspective rather than as a
collection of individual systems, and second, if thecombination of the improvements in each of these areascan lead to an overall design that improvessignificantly on the current state of the art.
Below, we evaluate each of these ideas in isolation(3.2-3.5), and then consider the net benefits when thesesolutions are used together (3.6).
3.2 Low-power low-cost CPUs
Whereas servers for databases or HPC havetraditionally focused on obtaining the highestperformance per server, the scale-out nature of theinternet sector allows for a focus on performance/$ byutilizing systems that offer a superior performance/$.Indeed, publications by large internet sector companiessuch as Google [4] exhibit the usefulness of buildingservers using commodity desktop PC parts. Theintuition is that volume drives cost; compared toservers that have a limited market and higher pricemargins, commodity PCs have a much larger marketthat allows for lower prices. Additionally, theseprocessors do not include cost premiums for featureslike multiprocessor support and advanced ECC that aremade redundant by reliability support in the softwarestack for internet sector workloads.
In this section, we quantitatively evaluate thebenefits of such an approach studying the effectivenessof low-end servers and desktops for this market. Wetake this focus on performance/$ one step further,exploring an alternative commodity market – theembedded/mobile segment. Trends in transistor scalingand embedded processor design have broughtpowerful, general purpose processors to the embeddedspace, many of which are multicore processors.Devices using embedded CPUs are shipped in evenmore volume than desktops – leading to even bettercost savings. They are often designed for minimalpower consumption due to their use in mobile systems.Power is a large portion of the total lifecycle costs, sogreater power-efficiency can help reduce costs. Thekey open question, of course, is whether these cost andpower benefits can offset the performance degradationrelative to the baseline server.
In this section, we consider six different systemconfigurations (Table 2). Srvr1 and srvr2 representmid-range and low-end server systems; desk representsdesktop systems, mobl represents mobile systems, andemb1 and emb2 represent a mid-range and low-endembedded system respectively. All servers have 4 GBof memory, using FB-DIMM (srvr1, srvr2), DDR2(desk, mobl, emb1) or DDR1 (emb2) technologies.Srvr1 has a 15k RPM disk and a 10 Gigabit NIC, while
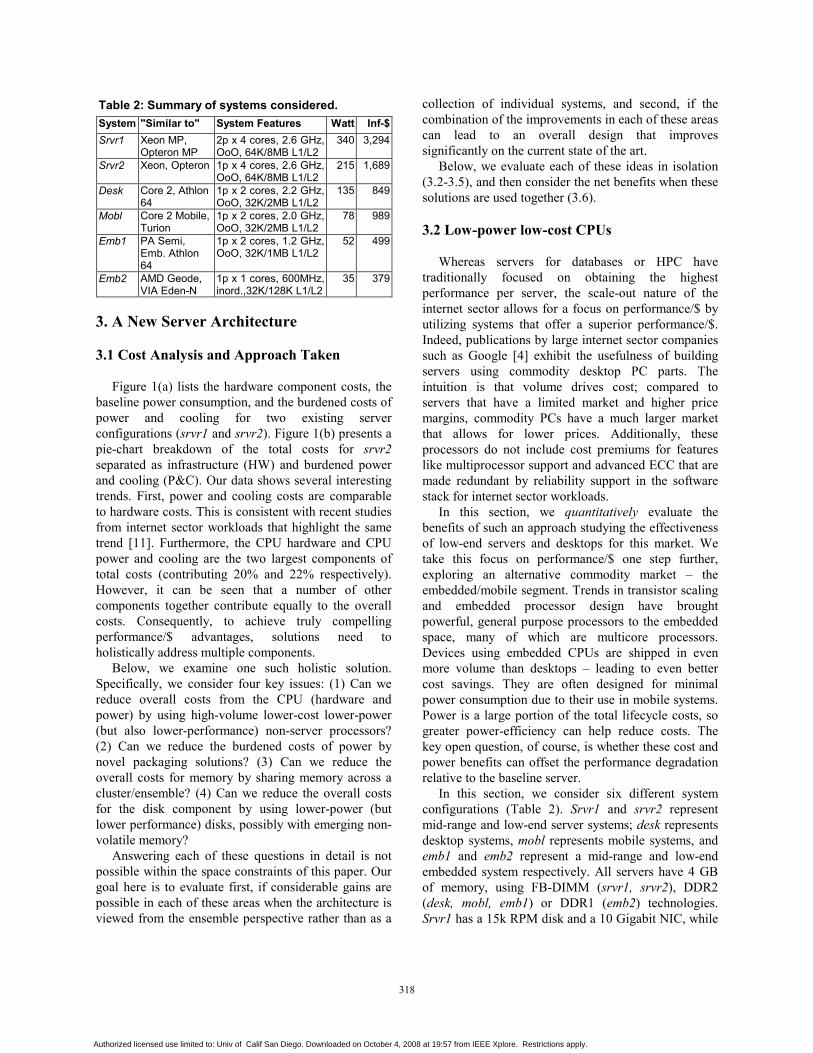
Table 2: Summary of systems considered.
System "Similar to" System Features Watt Inf-$
Srvr1 Xeon MP,Opteron MP
2p x 4 cores, 2.6 GHz,OoO, 64K/8MB L1/L2
340 3,294
Srvr2 Xeon, Opteron 1p x 4 cores, 2.6 GHz,OoO, 64K/8MB L1/L2
215 1,689
Desk Core 2, Athlon64
1p x 2 cores, 2.2 GHz,OoO, 32K/2MB L1/L2
135 849
Mobl Core 2 Mobile,Turion
1p x 2 cores, 2.0 GHz,OoO, 32K/2MB L1/L2
78 989
Emb1 PA Semi,Emb. Athlon64
1p x 2 cores, 1.2 GHz,OoO, 32K/1MB L1/L2
52 499
Emb2 AMD Geode,VIA Eden-N
1p x 1 cores, 600MHz,inord.,32K/128K L1/L2
35 379
318318
Authorized licensed use limited to: Univ of Calif San Diego. Downloaded on October 4, 2008 at 19:57 from IEEE Xplore. Restrictions apply.
all others have a 7.2k RPM disk and a 1 Gigabit NIC.Note that the lower-end systems are not balanced froma memory provisioning point of view (reflected in thehigher costs and power for the lower-end systems thanone would intuitively expect). However, our goal is toisolate the effect of the processor type, so we keepmemory and disk capacity constant (but in the differenttechnologies specific to the platform). Later sectionsexamine changing this assumption.
Evaluation: Figure 2 presents our evaluationresults. The break down of infrastructure costs and theburdened power and cooling costs are summarized inFigures 2(a) and 2(b) respectively. Figure 2(c) showsthe variation in performance, performance/$ andperformance/Watt; for better illustration of the benefits,performance/$ is shown as performance/total costs andperformance/infrastructure costs (performance/power-and-cooling-costs can be inferred). Also listed is theaverage computed as the harmonic mean of the
throughput and reciprocal of execution times across thebenchmarks.
Looking at Figure 2(a), we can see that, at a per-system level, the hardware costs are dramatically lowerfor the consumer systems. The biggest costs reductioncome in the CPU component. The use of consumertechnologies, like DDR2 for memory, lead toreductions in other components as well. The desksystem is only 25% of the costs of the srvr1 system,while the emb1 is only 15% of the costs. The moblsystem sees higher costs relative to the desktop becauseof the higher premium for low-power components inthis market. Similar trends can be seen for power andcooling costs in Figure 2(b). As one would expect, thedesktop system has 60% lower P&C costs compared tosrvr1, but the emb1 system does even better, saving85% of the costs. Unlike with hardware costs, there is amore gradual progression of savings in the power andcooling.
Figure 2(c) highlights several interesting trends forperformance. As expected, the lower-end systems seeperformance degradation compared to srvr1. However,the relative rate of performance degradation varies withbenchmark and the system considered. The mapreduceworkloads and ytube see relatively smallerdegradations in performance compared to websearchand webmail and also see a much more dramaticinflection at the transition between emb1 and emb2systems. This is intuitive given that these workloads arenot CPU-intensive and are primarily network or diskbound. The desktop system sees 10-30% performancedegradation for mapreduce and ytube and 65-80%performance loss for websearch and webmail. Incomparison the emb1 system sees 20-50% degradationsfor the former two workloads and 75-90% loss theremaining two. Emb2 consistently underperforms forall workloads.
Comparing the relative losses in performance to thebenefits in costs, one can see significant improvementsin performance/Watt and performance/$ for the desk,mobl, and emb1; emb2 does not perform as well. Forexample, emb1 achieves improvements of 3-6X inperformance/total costs for ytube and mapreduce andan improvement of 60% for websearch compared tosrvr1. Webmail achieves a net degradation inperformance/$ because of the significant decrease inperformance, but emb1 still performs competitivelywith srvr1, and does better than the other systems.Performance/W results show similar trends except forstronger improvements for the mobile systems.
Overall, our workloads show a benefit in improvedperformance per costs when using lower-end consumerplatforms optimized for power and costs, compared to
Workload Srvr2 Desk Mobl Emb1 Emb2
Perf websearch 68% 36% 34% 24% 11%
webmail 48% 19% 17% 11% 5%
ytube 97% 92% 95% 86% 24%
mapred-wc 93% 78% 72% 51% 12%
mapred-wr 72% 70% 54% 48% 16%
HMean 71% 42% 38% 27% 10%Perf/Inf-$ websearch 133% 139% 112% 175% 93%
webmail 95% 72% 55% 83% 44%ytube 188% 358% 315% 629% 206%
mapred-wc 181% 302% 241% 376% 101%
mapred-wr 141% 272% 179% 350% 140%
Hmean 139% 162% 125% 201% 91%Perf/W websearch 107% 90% 147% 157% 103%
webmail 76% 47% 73% 75% 49%
ytube 152% 233% 413% 566% 229%mapred-wc 146% 197% 315% 338% 113%
mapred-wr 114% 177% 235% 315% 157%
Hmean 112% 105% 164% 181% 101%Perf/TCO-$ websearch 120% 113% 124% 167% 97%
webmail 86% 59% 62% 80% 46%
ytube 171% 291% 351% 600% 215%
mapred-wc 164% 246% 268% 359% 106%
mapred-wr 128% 221% 200% 334% 147%
Hmean 126% 132% 140% 192% 95%
(a) Inf.-$ breakdown (b) P&C-$ breakdown
(c) Performance, cost and power efficiencies
0%
20%
40%
60%
80%
100%
Srv
r1
Srv
r2
Desk
Mobl
Em
b1
Em
b2
0%
20%
40%
60%
80%
100%
Srv
r1
Srv
r2
Desk
Mobl
Em
b1
Em
b2
Rack+switchPower+fanBoard+mgmtDiskMemoryCPU
Figure 2: Summary of benefits from using low-costlow-power CPUs from non-server markets.
319319
Authorized licensed use limited to: Univ of Calif San Diego. Downloaded on October 4, 2008 at 19:57 from IEEE Xplore. Restrictions apply.

servers such as srvr1 and srvr2. Our desk configurationperforms better than srvr1 and srvr2 validating currentpractices to use commodity desktops [4]. However, akey new interesting result for our benchmark study isthat going to embedded systems has the potential tooffer more cost savings at the same performance; butthe choice of embedded platform is important (e.g.emb1 versus emb2). It must be noted that these resultshold true for our workloads, but more study is neededbefore we can generalize these results to all variationsof internet sector workloads.
Studying embedded platforms with larger amountsof memory and disk added non-commodity costs to ourmodel that can be further optimized (the memory bladeproposed in Section 3.4 addresses this). Additionally,srvr1 consumes 13.6KW/rack while emb1 consumesonly 2.7KW/rack (for a standard 42U rack). We do notfactor this in our results, but this difference can eithertranslate into simpler cooling solutions, or smallerform-factors and greater compaction. The next sectionaddresses the latter.
3.3 Compaction and Aggregated Cooling
Our discussion in Section 3.1 identifies that after theprocessor, inefficiencies in the cooling system are thenext largest factor of cost. Lower-power systems offerthe opportunity for smaller form factor boards, whichin turn allow for optimizations to the cooling system.Below, we discuss two such optimizations. We use
blade servers as the exemplar for the rest of ourdiscussions, since they are well-known in the market.
Dual-entry enclosures with directed airflow:Figure 3(a) shows how a server level enclosure can beredesigned to enable blades to be inserted from frontand back to attach to a midplane. The key intuition is topartition the air flow, and allow cold air to be directedvertically through the blades. This is done byincreasing the volume of the enclosure to create an inletand exhaust plenum, and direct the air flow in thedirections indicated by the arrows in the picture. Theair flow is maintained through all the blades in parallelfrom intake plenum to exhaust plenum. (This is akin toa parallel connection of resistances versus a serial one.)Compared to conventional blade enclosures whichforce air directly from front to back, this results inshorter flow length (distance traversed by the air),lower pre-heat (temperature of the air hitting theblades), reduced pressure drop and volume flow. Ourthermo-mechanical analysis of the thermal resistanceair flow improvements with this design (calculationsomitted for space) show significant improvements incooling efficiencies (~50%). Compared to the baselinethat can allow 40 1U “pizza box” servers per rack, ournew design can allow 40 blades of 75W to be insertedin a 5U enclosure, allowing 320 systems per rack.
Board-level aggregated heat removal: Figure 3also shows an even more radical packaging design.With low-power systems, one can consider blades ofmuch smaller form factors that are integrated onconventional blades that fit into an enclosure. Asshown in Figure 3(b), we propose an innovativepackaging scheme that aggregates the powerdissipating components at the device and packagelevel. The smaller form factor server modules areinterspersed with planar heat pipes that transfer the heatat an effective conductivity three times that of copperto a central location. The aggregated heat is removedwith a larger optimized heat sink that enableschanneling the flow through a single heat sink asopposed to multiple separate conventional heat sinks.The increased conductivity and the increased area forheat extraction lead to more effective cooling. Thesmaller blades can be connected to the blades throughdifferent interfaces – ATC or COMX interfaces aregood candidates [29]. Figure 4 shows an example witheight such smaller 25W modules aggregated on abigger blade. With higher power budgets, four suchsmall modules can be supported on a bigger blade,allowing 1250 systems per rack.
These cooling optimizations have the potential toimprove efficiencies by 2X and 4X. Although they usespecialized designs, we expect our cooling solutions to
(a) Dual-entry enclosure with directed airflow
(b) Aggregated cooling of microblades
Figure 3: New proposed cooling architectures.Aggregated cooling and compaction can bringdown total costs without affecting performance.
320320
Authorized licensed use limited to: Univ of Calif San Diego. Downloaded on October 4, 2008 at 19:57 from IEEE Xplore. Restrictions apply.
be effective in other enterprise environments. Whencombined with the significant and growing fraction ofthe market represented by warehouse computingenvironments, these designs should have enoughvolume to drive commoditization.
3.4 Memory Sharing
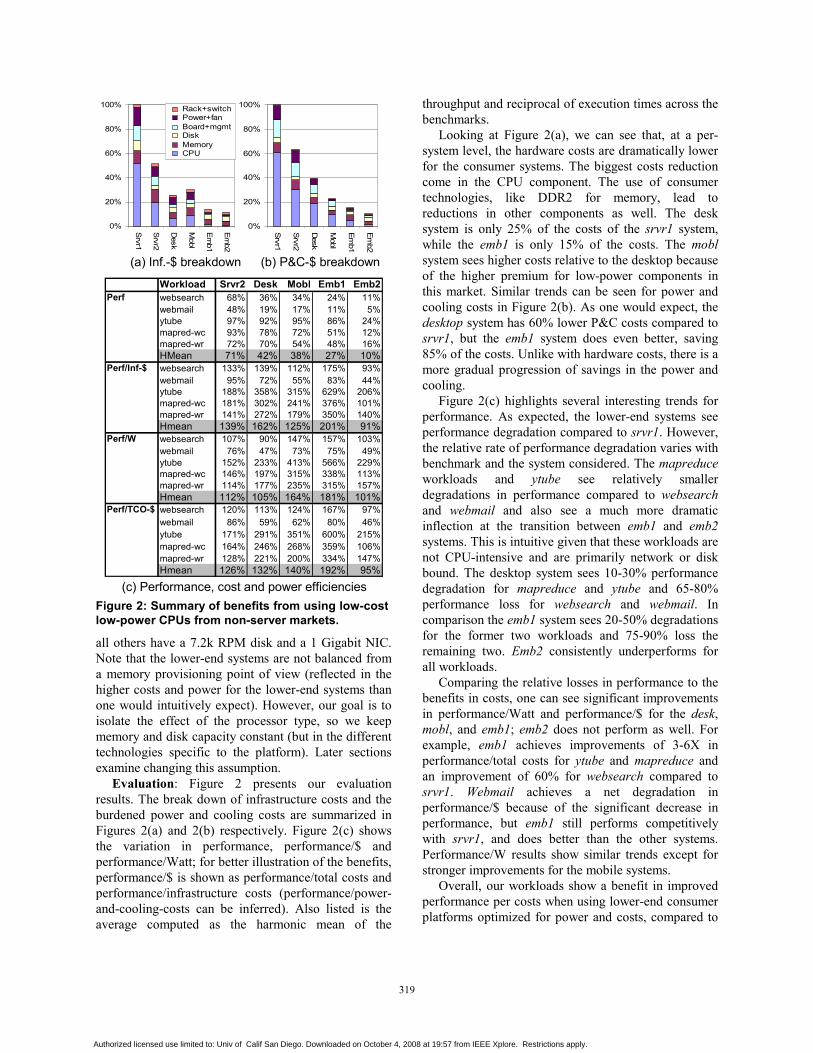
Memory costs and power are an important part ofthe system level picture, especially as the cost andpower of other components are reduced. Yet at adatacenter level, it can be difficult to properly choosethe amount of memory in each server. The memorydemands across workloads vary widely, and paststudies have shown that per-server sizing for peakloads can lead to significant ensemble-leveloverprovisioning [11,31]. To address memoryoverprovisioning, we provision memory at a coarsergranularity (e.g., per blade chassis), sizing each largerunit to meet the expected aggregate peak demand. Ourdesign provides a remote memory pool which isdivided among all the attached servers. This allows usto provision memory more accurately across servers,and allows the attached servers to have smaller localmemories by exploiting locality to maintain highperformance. By right provisioning memory in such ahierarchical environment, we obtain power and costssavings and enable further optimizations.
Basic architecture: Our design is illustrated inFigure 4(a). Each server blade has a smaller localmemory, and multiple servers are connected to amemory blade, which provides the remote memorypool and handles accesses on a page-size granularity.Within a single enclosure, the server and memoryblades are connected via a high-speed internalinterconnect such as PCIe. A hardware controller onthe memory blade handles the blade’s management,sending pages to and receiving pages from theprocessor blades, while enforcing the per-servermemory allocation to provide security and faultisolation. An access to a page in the remote memoryblade is detected as a TLB miss, invoking a light-weight trap handler in the OS or hypervisor (firstdescribed by Ekman and Stenstrom [9]). The handleridentifies a local victim page and initiates a DMAtransfer to swap it with the desired remote page,implementing an exclusive caching hierarchy. Sinceour second-level memory is remote and attached viaPCIe, additional intelligence is required in the server’sPCIe bridge (relatively minor and in firmware) to setup the address range corresponding to the remotememory initially and to assist in sending and receivingpages. By keeping a small pool of free local page
frames, the critical-path page fetch can be decoupledfrom the victim page writeback (and requisite TLBshootdown, on multicore blades). Once the incomingDMA transfer completes, a page-table entry maps thereferenced address to the new local copy, andexecution continues.
Critical-block first optimization: The page-granularity transfers incur relatively high latenciesbecause accessing data located on the memory bladerequires an entire page to be transferred prior to use.We investigate a critical-block-first (CBF) optimizationthat requires only modest hardware support, perhaps inthe local memory controller or as a separate simplecoherence agent. This additional logic would use thecoherence protocol to stall accesses to a block on apage in transit until the block is transferred. Thusaddress mapping for a remote page can be installed assoon as the incoming DMA is set up, and the faultingaccess can be completed as soon as the needed block(which would be scheduled first) arrives. Thisoptimization requires custom hardware that goesagainst the preference for commodity components inthe basic server. However, these hardware changes areminor extensions to commodity components and likelyto drive other markets, and their costs are amortizedacross multiple servers; so we evaluate this design as afuture-looking option.
Performance evaluation: In this work, we areprimarily concerned with estimating the performancecost savings of ensemble-level memory sharing. Ratherthan exhaustively studying page replacement policies,we only model LRU and random replacement,
111%116%106%Dynamic
108%116%102%Static
Perf/TCO-$Perf/WPerf/Inf-$
111%116%106%Dynamic
108%116%102%Static
Perf/TCO-$Perf/WPerf/Inf-$
(a) Memory blade architecture
0.2%0.2%0.4%0.1%1.2%CBF (0.5 µs)
0.7%0.7%1.4%0.2%4.7%PCIe x4 (4 µs)
mapred-wrmapred-wcytubewebmailwebsearch
0.2%0.2%0.4%0.1%1.2%CBF (0.5 µs)
0.7%0.7%1.4%0.2%4.7%PCIe x4 (4 µs)
mapred-wrmapred-wcytubewebmailwebsearch
(b) Slowdowns using random replacement for25% first-level memory size
(c) Net cost and power efficiencies
PCIe x42x1 GB/s
CPU CPU
Memory ControllerHub (Northbridge)
Front System Bus
PCIe Bridge
Dis
k
So
uth
brid
ge
DIMM
PCIe Bridge +Memory Blade Controller
DIMM
DIMM DIMM
DIMM
DIMM
DIMM DIMM
DIMM
PCIe x42x1 GB/s
…...CPU CPU
Memory ControllerHub (Northbridge)
Front System Bus
PCIe Bridge
iLO
Dis
k
So
uth
brid
ge
DIMM
iLO
Figure 4: Memory sharing architecture and results.
321321
Authorized licensed use limited to: Univ of Calif San Diego. Downloaded on October 4, 2008 at 19:57 from IEEE Xplore. Restrictions apply.

expecting that an implementable policy would haveperformance between these points. Due to the largememory capacities involved, we use trace-drivensimulation for performance evaluation. We gathertraces on our benchmark suite using the emb1processor model. We then use the traces with a simplesimulator to determine the number of misses to thesecond-level memory by modeling various first-levelmemory sizes and replacement policies. The latenciesof such misses are estimated based on published PCIeround-trip times [15] plus DRAM and bus-transferlatencies, and then factored into the final performanceresults. We arrive at latencies of 4 µs for 4KB pages ona PCIe 2.0 x4 link, and 0.75µs for the critical-block-first (CBF) optimization. While our trace-basedmethodology cannot account for the second-orderimpact of PCIe link contention or consecutive accessesto the missing page in the CBF case, it includes enoughdetails to provide good estimates for our evaluation.
Using the baseline of emb1 (our deployment targetin Section 3), Figure 4(b) shows the relativeperformance of our two-level configuration usingrandom replacement. We studied baselines of both 4GB and 2 GB, but report only 2 GB results to beconservative about our scaled down workloads. Westudy two scenarios, one having 25% of memory belocal, and the other having 12.5% of the memory belocal. Our results show that baseline memory sharingcan cause slowdowns of up to 5% for 25%, and 10%for 12.5% local-remote split. But the CPF optimizationcan bring these numbers down to ~1% for 25% and2.5% for 12.5% local-remote split. The workloadswith larger memory usage, websearch and ytube, havethe largest slowdown, as we would expect. The CBFoptimization has a greater impact than increasing thelocal memory capacity. LRU results (not shown) arenearly the same as Figure 4(b); random performs aswell as LRU on the benchmarks with high miss rates,while the benchmarks where LRU outperforms randomhave low absolute miss rates and thus the performanceimpact is minimal. These initial results indicate that atwo-level memory hierarchy with a first-level memoryof 25% of the baseline would likely have minimalperformance impact even on larger workloads. Weexpect these trends to hold into the future as well, asworkload sizes and memory densities both increase.
Cost evaluation: Our shared multi-level memoryarchitecture reduces hardware cost in two ways. First,the total DRAM capacity of each blade enclosure maybe reduced relative to a conventional system in whicheach processor blade is provisioned for peak memoryrequirements. Second, the reduced density andperformance requirements of the second-level memory
enable the use of lower-cost low-density DRAMdevices. Thus the memory blade can use devices at the“sweet spot” of the commodity DRAM market, at asignificant cost savings relative to devices of thehighest available density.
This new memory architecture reduces powerconsumption in two ways: by reducing the total amountof DRAM, and correspondingly the power, but by alsoenabling the extended use of lower-power DRAMcomponents and modes on the memory blades.Accesses to the memory blades are less frequent, arealways at page granularity, and their latency isdominated by transfer time across the PCIe link. As aresult, we can leave all of the memory-blade DRAM inactive power-down mode, which reduces power bymore than 90% in DDR2 [24], paying a relativelyminor latency penalty (6 DRAM cycles) to wake thenecessary devices and banks once on each access tofetch an entire page worth of data.
The memory blade does incur cost and poweroverheads, mainly due to the custom PCIe memorycontroller. However, this overhead is amortized overmultiple servers. We use a per-server (x4 lane) cost of$10 and power consumption of 1.45W in our estimates,based on analysis of commercially available PCIeswitches [30] and memory controllers [18].
We calculate the cost and power saving for twoscenarios, both assuming that the processor blades have25% of the baseline’s local memory, while remotememory blades use devices that are slower but 24%cheaper [8]. The static partitioning scheme uses thesame total amount of DRAM as the baseline, with theremaining capacity (75%) on the memory blades. Thedynamic provisioning scheme assumes that 20% of theblades use only their local memory, allowing the totalsystem memory to be 85% of the baseline (25% local,60% on memory blades). We assume 2% slowdownacross all benchmarks. Figure 4(c) shows that bothschemes provide good benefits (16%) in system-levelperf/P&C-$. The static scheme provides a negligible(2%) improvement system perf/Inf-$, since it uses thesame total amount of DRAM, but the dynamic schemegains an additional 6% improvement there. Thesefigures combine to give 8% (static) and 11% (dynamic)benefits in perf/TCO-$. Additionally, we expectmemory sharing to pay off in other ways, for exampleby enabling the use of commodity embeddedprocessors/boards with limited support for memoryexpansion, allowing greater compaction of processorblades due to the reduced DRAM physical and powerfootprints, and opening up the possibility of otheroptimizations such as memory compression [37],content-based page sharing across blades [38], and
322322
Authorized licensed use limited to: Univ of Calif San Diego. Downloaded on October 4, 2008 at 19:57 from IEEE Xplore. Restrictions apply.
DRAM/flash hybrid memory organizations. Overall,though our current results indicate only modestbenefits, we believe additional effort in this area willyield further substantial gains.
3.5 Flash as disk-cache with low-power disks
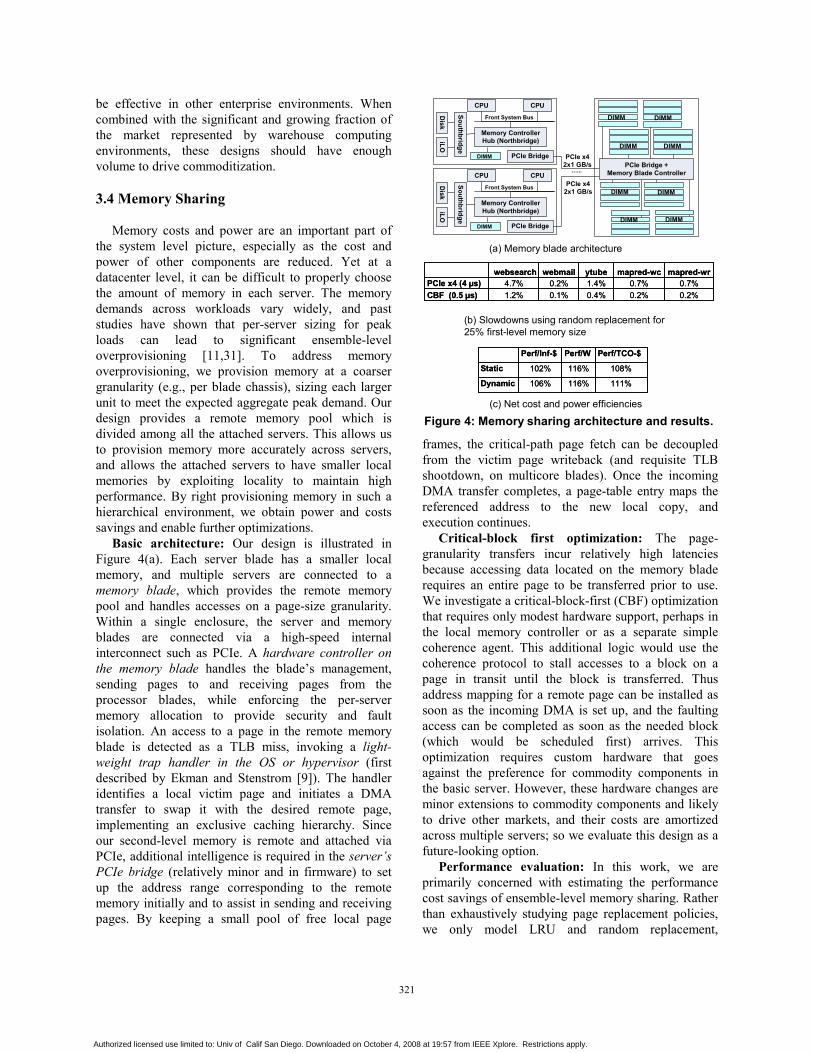
Continuing our theme of using lower-powercomponents and optimizing for the ensemble, thissection addresses the benefits from using lower-powerlaptop disks. In addition to lower power, these have thebenefit of a smaller form factor allowing greatercompaction for aggregated cooling (like in Section3.3), but come with the tradeoffs of lower performanceand higher price. We consider using the laptop disksmoved to a basic Storage Area Network (SAN)interfaced through the SATA interface. By utilizing aSAN, individual server blades do not have to bephysically sized to fit a disk, allowing the small moduleform factor in Section 3.3 to be used.
Additionally, we also examine the use of non-volatile flash technology. As seen in Table 3(a), Flashhas desirable power, performance, and costcharacteristics well aligned with our goals. However,one of the limitations of using flash is that it “wearsout” after 100,000 writes (assuming currenttechnology). While this is an important drawback,predicted future technology and software fixes [20],along with the typical 3-year depreciation cycles andsoftware-failure tolerance in internet workloads stillargue for examining flash in these environments. In thispaper, we explore using a flash-based disk cachingmechanism [20], with the flash being located on theserver board itself. The flash holds any recentlyaccessed pages from disk. Any time a page is not foundin the OS’s page cache, the flash cache is searched bylooking up in a software hash table to see if the flashholds the desired page.
Evaluation: We evaluate using a remote SATAlaptop drive (with very conservative bandwidth andlatency values) with our emb1 configuration, andobtain performance numbers with and without a 1 GBflash cache. Our runs are normalized to the baselineconfiguration of having a local desktop-class disk, andthe configurations are listed in Table 3(a).
Our results in Table 3(b) show that just using low-power laptop disks alone is not beneficial from aperformance/$ perspective for our benchmarks. Theloss in performance dominates the savings in power.However, using a flash disk cache is able to provide an8% performance improvement over the remote laptopdisk, providing better performance/$ compared to thebaseline desktop case. Our results with a cheaperlaptop disk (laptop-2) show better results (close to 10%better performance/$), pointing to greater benefits iflaptop disk prices come down to desktop disk levels.This may be a realistic scenario as laptop drivesbecome more commoditized.
3.6 Putting It All Together
So far, we considered solutions targeted at specificsubsystems and evaluated their benefits in isolation. Inthis section, we show how these optimizations worktogether.
Two unified designs: Based on the observationsabove, we consider two new architectures for theinternet sector. Our N1 design represents a solutionpractical in the near-term; it uses mobile blades withdual-entry enclosures and directed airflow, but does notinclude memory sharing or flash-based disk cachingwith mobile disks. Our N2 design represents a likelylonger-term solution; it uses embedded blades withaggregated cooling housed in an enclosure withdirected air-flow. We use memory sharing and remotelow-power disks with flash-based disk caching to allowthis level of compaction. Some of the changes requiredfor the N2 configuration assume custom components,but as discussed, the changes are likely to become cost-effective in a few years with the volumes in this market.
Evaluation: Figure 5 shows how our two solutionsprovide significant improvements to cost and powerefficiencies compared to the baseline srvr1 system.Focusing on the ytube and mapreduce benchmarks, theperformance/TCO-$ (Figure 5) improves by 2X-3.5Xfor the current-generation solution (N1) and by 3.5X-6X for the next-generation solution (N2). Figure 5shows that these benefits are equally frominfrastructure costs and power savings. As before,websearch gets lower benefits of 10%-70%improvement, and webmail sees degradations (40% for
Table 3: Low-power disks with flash disk caches.
110%109%110%Remote Laptop-2 + Flash
104%109%99%Remote Laptop + Flash
96%100%93%Remote Laptop
Perf/TCO-$Perf/WattPerf/Inf-$Disk type
110%109%110%Remote Laptop-2 + Flash
104%109%99%Remote Laptop + Flash
96%100%93%Remote Laptop
Perf/TCO-$Perf/WattPerf/Inf-$Disk type
(a) Listing of flash and disk parameters
(b) Net cost and power efficiencies
$120$40$80$14Price10220.5Power (W)500 GB200 GB200 GB1 GBCapacity
1.2 msec erase(local)(remote)(remote)200 µsec write
4 msec avg.15 msec avg.15 msec avg.20 µsec readAccess time
70 MB/s20 MB/s20 MB/s50 MB/sBandwidthDesktop DiskLaptop-2 DiskLaptop DiskFlash
$120$40$80$14Price10220.5Power (W)500 GB200 GB200 GB1 GBCapacity
1.2 msec erase(local)(remote)(remote)200 µsec write
4 msec avg.15 msec avg.15 msec avg.20 µsec readAccess time
70 MB/s20 MB/s20 MB/s50 MB/sBandwidthDesktop DiskLaptop-2 DiskLaptop DiskFlash
323323
Authorized licensed use limited to: Univ of Calif San Diego. Downloaded on October 4, 2008 at 19:57 from IEEE Xplore. Restrictions apply.

N1, and 20% for N2). Figure 5 also shows the harmonicmean across our benchmarks. Overall, our solutionscan improve sustained throughput per totalinfrastructure dollar by 1.5X (with N1) to 2.0X (withN2). The same result can be restated differently. Forthe same performance as the baseline, N2 gets a 60%reduction in power, and 55% reduction in overall costs,and consumes 30% less racks (assuming 4 embeddedblades per blade, but air-cooled).
Though not presented here, we also compared ournew proposed solutions to a baseline based on srvr2and desk. We continue to get significant benefits. N2,in particular, gets average improvements of 1.8-2Xover the corresponding baselines, and the ytube andmapreduce benchmarks gets 2.5-4.1X and 1.7X-2.5Xbetter performance/$ compared to srvr2 and deskrespectively. N1 also continues to get betterperformance for ytube and mapreduce, but the benefitsare also scaled down (1.1X to 2X).
4. Discussion
While our work is a first step in the study andoptimization of warehouse-computing environments,several caveats and opportunities for future work exist.
Benchmark suite: We have tried to make ourbenchmarks as realistic as possible, using real-worldtraces and insights from previous studies, and makingsure that our benchmarks replicate behavior describedin the limited public documentation in this space. But afew points need to be noted. In actual deployments,requests follow a time-of-day distribution [11], but weonly study request distributions that focus on sustainedperformance. Real deployments operate on much largerdata sets, but we often scaled data sizes for practicalsimulation times while striving to keep the same trends(e.g., our scaled websearch workload matches priorpublished work with larger-scale experiments [21]).We also study only one representative benchmark for
each workload that best mimics previously-publisheddata, but in reality, a workload (e.g., websearch) canhave multiple flavors based on the nature of the request(e.g., data set, etc). Again it must be noted that furtherstudy is needed to understand the applicability of theresults of our benchmark suite to all internet sectorworkloads. Given different workload behavior (e.g.,heavily CPU bound and I/O intensive), it is possiblethat srvr1 will be a more effective solution than emb1,given its higher compute power and I/O bandwidth.
Metrics & models: The design of good models thatfold single-system metrics into a more complex clusterlevel metric is an open research area. In the absence ofsuch models and practical cluster-level full-systemsimulation, our performance model makes thesimplifying assumption that cluster-level performancecan be approximated by the aggregation of single-machine benchmarks. This needs to be validated, byprototyping, or by study of real environments.
Our cost model data was collected from a variety ofsources, mostly public. However, a few of the valueswere derived from confidential communication andindustry estimates, and more work is needed inderiving an open and public cost model for the broadercommunity. Ideally, personnel and real-estate costs,though harder to characterize, would also be includedin such a model.
Amdahl’s law limits on scale-out: Our proposedsolution assumes that the workload can be partitionedto match the new levels of scale-out. In reality, thiscannot be taken to extremes. Particularly, forworkloads like search, there are potential overheadswith this approach in terms of decreased efficiency ofsoftware algorithms, increased sizes of software datastructures, increased latency variabilities, greaternetworking overheads, etc. The minimum capacity andbalance at the individual server where Amdahl’s lawfactors in, is again an interesting open question, andsomething this study simplistically ignores. This is an
0%
100%
200%
300%
400%
500%
600%
700%
websear
ch
webmai
l
ytub
e
map
red-
wc
map
red-
wr
Hmea
n
Pe
rf/I
nf-
$
N1 N2
0%
100%
200%
300%
400%
500%
600%
700%
800%
websear
ch
webmai
l
ytub
e
map
red-
wc
map
red-
wr
Hmea
n
Pe
rf/W
N1 N2
0%
100%
200%
300%
400%
500%
600%
700%
websear
ch
webmai
l
ytub
e
map
red-
wc
map
red-
wr
Hmea
n
Pe
rf/T
CO
-$
N1 N2
Figure 5: Cost and power efficiencies for two unified designs that bring together individual solutions.
324324
Authorized licensed use limited to: Univ of Calif San Diego. Downloaded on October 4, 2008 at 19:57 from IEEE Xplore. Restrictions apply.

important caveat since it can bias the conclusionstowards overestimating benefits for smaller platformsfor some workloads. Similarly, we only address latencyto the extent our individual benchmark definitions haveQoS constraints on query response times (websearch,webmail), but primarily focus on throughput. Moreaggressive simplification of the platform can haveimplications on single-system performance.
Architectural enhancements: Architecturally, aninteresting extension to our work is to consider minimalchanges to commodity manycore processors that canfurther improve the performance, but without addingtoo much costs. Our memory sharing design can befurther improved by having DMA I/O going directly tothe second-level memory; other interestingarchitectures to support critical-block-first andhardware TLB handlers are also possible. Ourpackaging solutions also offer new opportunities forextensions at the datacenter level. More study is neededof the use of flash memory at other levels of thememory hierarchy, as well as a disk replacement.
5. Related work
To the best of our knowledge, we are the first studyto perform a detailed quantitative analysis of tradeoffsin system architectures and evaluate new designalternatives for the emerging internet-sector workloads.
We are not aware of any work that has looked atembedded processors in this space. Similarly, we arenot aware of prior work on the dual-entry blade designor the aggregated cooling with naked packages that wediscuss. Other approaches for multi-level memory havebeen proposed for compressed memory (such as IBMMXT [37]), memory banks in power-down mode [22]or cooperative file caching [12]. We use similarmechanisms to support two-level memory as Ekmanand Stenstrom [9]. Previously NOR Flash wasproposed as a replacement or supplement to disk [39].The use of NAND flash as a disk buffer was proposedby Kgil and Mudge [20]; our approach uses similarmethodology but aimed at internet sector workloads.
Sun, APC, and HP have all discussed the notion of a“datacenter in a container” [2,26,28]. Our approachesare orthogonal to this design philosophy. Some internetcompanies are designing Greenfield datacenters, butthere is limited technical information on these, mainlyon Google [3,4,11]. Our desk system probably comesclosest to modeling some of these approaches, butacross our benchmarks, our solutions can achieve bettercost-performance efficiency.
Fan et al. discuss webmail, websearch, andmapreduce as three representative workloads for the
Google datacenter [11]. Our benchmark suite addressesthese three workloads and adds an additional workloadto model Youtube™-like behavior. A recent proposalfrom Sun discusses Web20Bench [34] focusing on oneinteractive benchmark. We are in touch with thedevelopers and hope to use it when it becomes publiclyavailable.
6. Conclusions
Emerging internet sector companies using"warehouse scale" computing systems represent a largegrowth market. Their large volume and willingness totry custom solutions offer an interesting opportunity toconsider new server architectures with a strongemphasis on cost, power and cooling, and scale-out. Inthis paper, we seek to develop benchmarks and metricsto better understand this space and to leverage thisunderstanding to design solutions targeted at theseenvironments.
We make several contributions. We put together anew benchmark suite intended to model workloads andbehavior common to this sector. We also develop costmodels and evaluation metrics relevant to this space,including an overall metric of performance per unittotal cost of ownership (Perf/TCO-$). We identify fourkey areas for improvement from the Perf/TCO-$perspective (CPU, packaging, memory, and disk), andstudy initial solutions that provide benefits relative tothe status quo in each of these areas. We show thatusing embedded processors and flash memory canprovide significant Perf/TCO-$ advantages for ourbenchmarks. We also propose and evaluate novelensemble-level Perf/TCO-$ optimizations in packagingand cooling, and in the main memory/disk system. Oursimulation results show that these techniques arebeneficial individually, but together, they demonstratethe potential for significant improvements: 2X betterperformance/$ on average, and 3.5-6X on many of ourbenchmarks.
These proposed techniques are not intended to bethe final word on warehouse-computing designs, butmerely to provide evidence for the substantialimprovements achievable when system architects takean ensemble-level view. Key next steps in our futurework are to expand our benchmark suite to address thecaveats discussed in Section 4 and to validate ourbenchmarks against real-world warehouseenvironments. These steps will allow us to determinewith confidence how broadly our techniques apply inthis sector. We also plan to study additionaloptimizations and possibly prototype our designs.
325325
Authorized licensed use limited to: Univ of Calif San Diego. Downloaded on October 4, 2008 at 19:57 from IEEE Xplore. Restrictions apply.

Further out, there are other interesting open areas ofresearch for the storage and network architecturessupporting our solution. For example, I/Oconsolidation and improved switch design make naturalfits to our architecture [23]. We are also examining theapplicability of our solutions for conventionalenterprise server workloads. Overall, as enterprisesgravitate towards ever more cost-conscious anddatacenter-level solutions, we believe that holisticapproaches like the ones used in this paper are likely tobe a key part of future system designs.
7. Acknowledgements
We would like to thank Luiz Barroso, ManasChaliha, and Dean Cookson for their encouragementand useful comments. We would also like toacknowledge Reza Bacchus, Gary Campbell, ThomasFlynn, Rich Friedrich, Mike Schlansker, John Sontag,Niraj Tolia, Robert Van Cleve, Tom Wenisch, and theanonymous reviewers for their feedback.
8. References
[1] AMD. AMD Geode LX™ Processor Family.http://www.amd.com/geodelx900.[2] APC. InfraStruXure® Express On-demand Mobile DataCenter. http://www.apc.com.[3] L. Barroso. Warehouse-scale Computers. Invited talk at theUSENIX Annual Technical Conference, Santa Clara, CA, June2007.[4] L. Barroso, J. Dean, and U. Holzle. Web Search for a Planet:The Google Cluster Architecture. IEEE Micro, 23(2), March/April2003.[5] R. Bedichek. SimNow™: Fast Platform Simulation Purely inSoftware. In HotChips 16, 2004.[6] R. Bryant. Data Intensive Super Computing. In FCRC, 2007.Keynote.[7] J. Dean and S. Ghemawat. MapReduce: Simplified DataProcessing on Large Clusters. In OSDI-6, 2004.[8] DRAMeXchange. DRAM Price Quotes.http://www.dramexchange.com.[9] M. Ekman and P. Stenstrom. A Cost-Effective Main MemoryOrganization for Future Servers. In PDPS, 2005.[10] A. Falcon, P. Faraboschi, and D. Ortega. CombiningSimulation and Virtualization through Dynamic Sampling. InISPASS, 2007.[11] X. Fan, W. Weber, and L. Barroso. Power Provisioning for aWarehouse-sized Computer. In ISCA-34, 2007.[12] W. Felter, T. Keller, M. Kistler, C. Lefurgy, K. Rajamani, R.Rajamony, F. Rawson, B. Smith, and E. Van Hensbergen. On thePerformance and Use of Dense Servers. IBM Journal of Rearch andDevelopment, 47(5/6), 2003.[13] Apache Software Foundation. Hadoop.http://lucene.apache.org/hadoop/index.html.[14] P. Gill, M. Arlitt, Z. Li, and A. Mahanti. YouTube TrafficCharacterization: A View From the Edge. In Internet MeasurementConference, 2007.
[15] B. Holden. Latency Comparison Between HyperTransport andPCI-Express in Communication Systems. Technical report,HyperTransport Consortium White Paper, November 2006.[16] Silicon Mechanics Inc. Xeon 3000 1U Server.http://www.siliconmechanics.com/i7573/xeon-3000-server.php.[17] Intel. Intel Microprocessor Family Quick Reference Guide.http://www.intel.com/pressroom/kits/quickreffam.htm.[18] Intel. Intel Server/Workstation Chipsets Comparison Chart.http://developer.intel.com/products/chipsets/index.htm.[19] R. Katz. Research Directions in Internet-Scale Computing.Keynote presentation, 3rd International Week on Management ofNetworks and Services, 2007.[20] T. Kgil and T. Mudge. FlashCache: a NAND Flash MemoryFile Cache for Low Power Web Servers. In CASES'06, 2006.[21] R. Khare, D. Cutting, K. Sitaker, and A. Rifkin. Nutch: AFlexible and Scalable Open-Source Web Search Engine. TechnicalReport CN-TR-04-04, CommerceNet Labs, November 2004.[22] A.R. Lebeck, X. Fan, H. Zeng, and C. Ellis. Power AwarePage Allocation. In ASPLOX-IX, 2000.[23] K. Leigh, P. Ranganathan, and J. Subhlok. FabricConvergence Implications on Systems Architecture. In HPCA 14,2008.[24] Micron. DDR2 Memory Power Calculator.http://download.micron.com/downloads/misc/ddr2_power_calc_web.xls.[25] C. Moore. A Framework for Innovation. Keynote, FCRC,2007.[26] G. Papadopoulos. Redshift: The Explosion of Massive ScaleSystems. Analyst Summit, 2007.[27] C. Patel and P. Ranganathan. Enterprise Power and Cooling:A Chip-to-DataCenter Perspective. In HotChips 19, August 2007.Tutorial.[28] C. Patel and A. Shah. Cost Model for Planning, Developmentand Operation of a Data Center. Technical Report HPL-2005-107R1, Hewlett Packard Technical Report, 2005.[29] PCIMG. Advanced TCA Specification.http://www.picmg.org/pdf/PICMG_3_0_Shortform.pdf.[30] PLX. PLX PCIe Switch Power Consumption. http://www.plxtech.com/pdf/technical/expresslane/Power_Consumption_Explained.pdf.[31] P. Ranganathan, P. Leech, D. Irwin, and J. Chase. Ensemble-level Power Management for Dense Blade Servers. In ISCA-33,2006.[32] Seagate. Barracuda 7200.10 Data Sheet.http://www.seagate.com/docs/pdf/datasheet/disc/ds_barracuda_7200_10.pdf.[33] H. Simon. Energy Efficiency and Computing. In LawrenceBerkeley National Laboratory, 2007. Keynote.[34] A. Sucharitakul. Benchmarking in the Web 2.0 Era. In IISWC2007, 2007. Panel Session.[35] Microsoft Technet. Tools for Performance Stressing Exchange2003 Servers. 2003, http://technet.microsoft.com/en-us/library/aa996207.aspx.[36] C. Thacker. Rethinking Data Centers. Invited talk at StanfordUniversity Networking Seminar, October 2007.[37] R. Tremaine, P. Franaszek, J. Robinson, C. Schulz, T, Smith,M. Wazlowski, and P. Bland. IBM Memory Expansion Technology(MXT). IBM Journal of Rearch and Development, 45(2), 2001.[38] C.A. Waldspurger. Memory Resource Management inVMware ESX Server. In OSDI-4, 2002.[39] M. Wu and W. Zwaenepoel. eNVy: A Non-Volatile, MainMemory Storage System. In ASPLOS, 1994.[40] Y. Xie and D. O'Hallaron. Locality in Search Engine Queriesand Its Implications for Caching. In Infocomm, 2002.
326326
Authorized licensed use limited to: Univ of Calif San Diego. Downloaded on October 4, 2008 at 19:57 from IEEE Xplore. Restrictions apply.