unconference for georgia southern computer science march 31, 2015
TRANSCRIPT

Unconference

TopicsAgile in the real world
CareerKafka
DevOpsCloud and aaS
NoSQL: MongoDBNoSQL: RedisBloomFilters
Speed Round (5 topics in 8 minutes)Big Data (Hadoop, Spark)
Actor Systems (Akka)Streaming (Storm, InfoSphere Streams)

Agile

Scrum, Kanban
Processes for managing work Team is not just software engineers
− QA, test automation− Product Analyst− Documentation− Production/Operations Engineers
Co-location

Kanban
Limits amount of work team is working on Visually displays what is being worked on,
waiting Some online tools, but teams usually work on
the walls

Video

Kafka

Message Queues
What if you had billions of messages each day? Any couldn't lose any of them?
'current' technology is a queue, held in memory or RDBMS
Lots of problems with holding in memory Lots of RDBMS activity Broker needs to know who consumed a
message so he can delete it
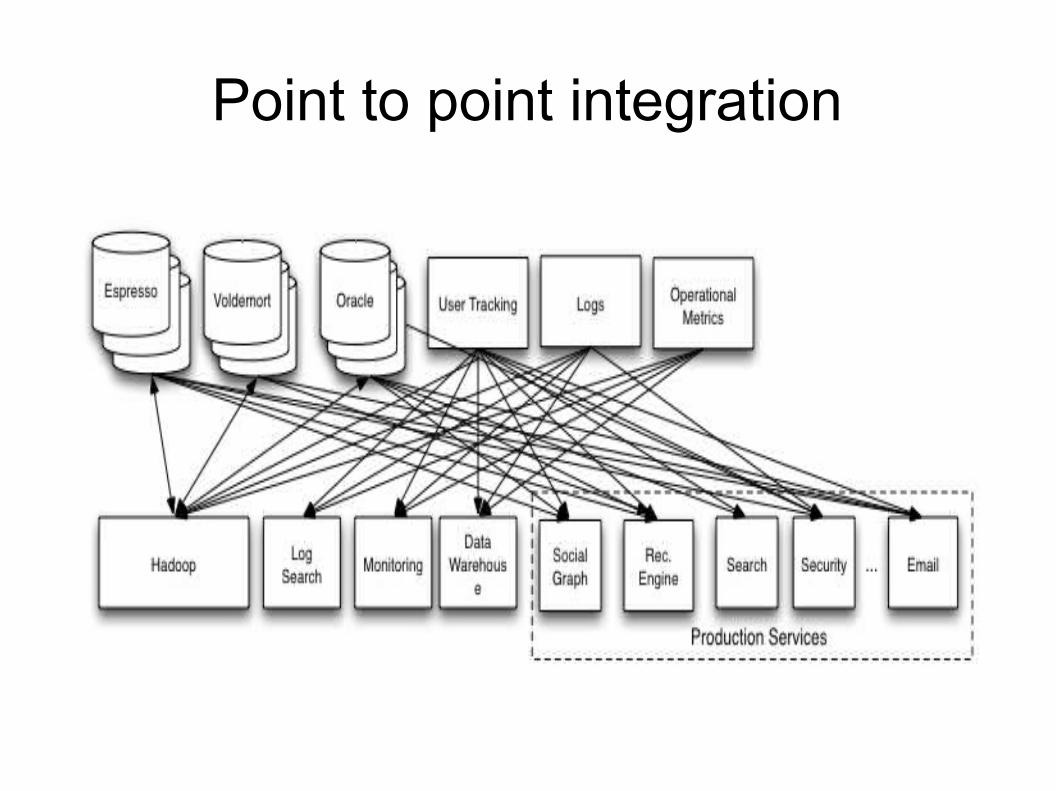
Point to point integration
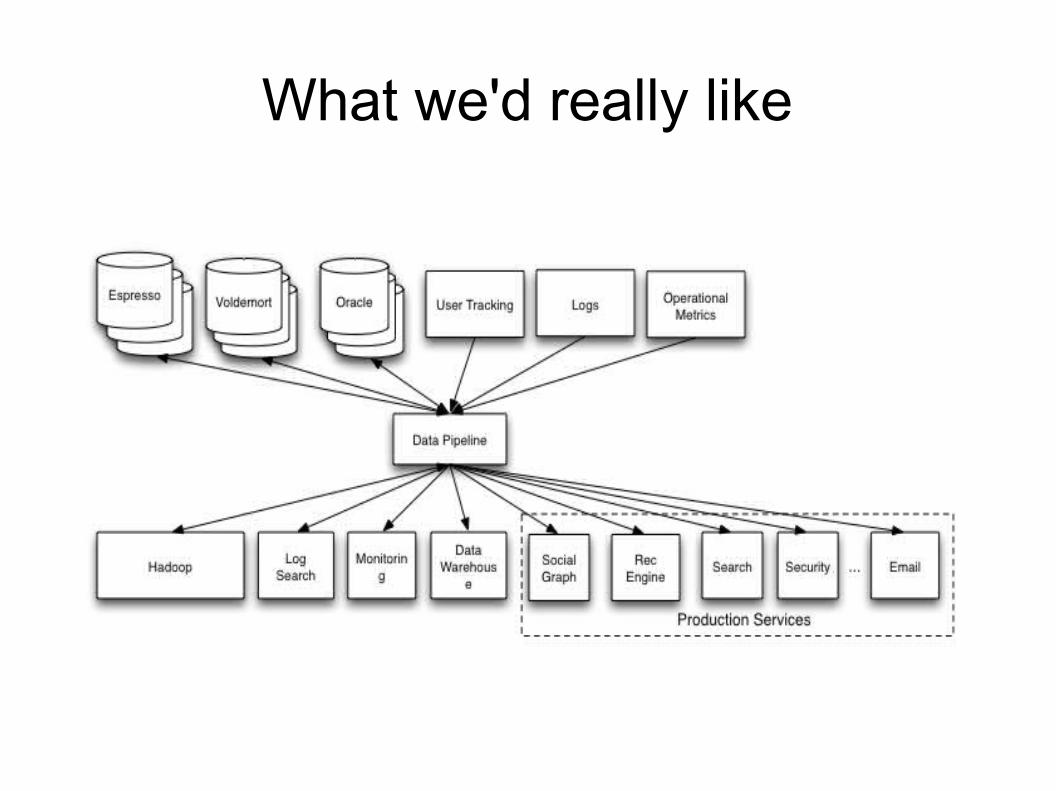
What we'd really like

Changing the Paradigm
Kafka uses disk as the primary store Kernel level writes directly to disk controller =
FAST Kafka doesn't care if anyone consumed an
event Consumers ask for a specific offset in a topic Consumers can listen for new events

Cool Tech: Commit Logs

Use Cases
Huge volumes of input data > memory Consumers at different times/rates Replay for support, developers

DevOps

Old Way *
Someone gives you a 2” thick specification You code it for 6 months Test it for 3 months Give it to operations to run Get bug reports Fix them, deploy them monthly *unfortunately a lot of people still do this

Old Way - Operations
Manually build a server Hope you got everything on it Deploy the software, hope you got everything Manually test that the software works If the server fails, repeat Upgrades take hours

DevOps and Agile Way
Customer presents stories to team Team asks questions, scopes and defines tests Team develops code, tests, talks with client Production engineers learn what team is
building, what tech etc. Continuous Integration builds make sure it
works Minimum Viable Product is produced Operations runs a command, code is deployed

DevOps - Operations
Template for a server is defined (OS, software etc.) Template for software release is defined (versions,
dependencies, automated tests) Deployment: Stock OS server is booted Deployment command is run UrbanCode/Chef downloads Server templates,
application templates and automated tests. Runs all of them, tells operations it is ready.
Server failure? Boot new machine and repeat Scale? Boot new machine and repeat

DevOps Software
Lots of features added to a release to support in production
Alerts, monitoring, metrics Automated testing Interfaces for 'probing' what is going on inside New Tech is vetted with operations during
development, not 'throw it over the wall'

Cloud and aaS

Cloud
Most hyped technology in the last 10 years (Big Data is a close 2nd) Basic idea: someone deploys thousands
(millions in Amazon's case) of servers and makes it easy for you to use them
No capital costs. Pay for what you use Infinite* capacity if you built it right Vendors are continually adding new features

Why?
$0.20 an hour servers IT Doesn't know about it ... Site gone viral? Spin up 100 more app servers,
bigger database server (see DevOps discussion)
No capital up front. $100/month until the hockey stick, then revenue covers usage

As a Service (*aaS)
Business model for making $$ on the cloud Offer a service to business at a cost less than if
they did it themselves IaaS – Infrastructure as a Service (Amazon,
SoftLayer) PaaS – Platform as a Service (BlueMix, Azure,
AppEngine) SaaS – Software as a Service (Silverpop,
Hotmail, Gmail, LinkedIn)

AaS terminology
Virtual Machine Software Defined Networking Multi-tenancy Scalability, Redundancy and Disaster Recovery Netflix

Tips
See how far you can get with PaaS, but be wary of vendor-specific features
Look for standard databases (MySQL, MongoDB, Redis, SQL Server) PaaS before you stand up your own
Docker Shut it down when you aren't using it!

NoSQL: MongoDB

Document Databases
Schema-less Store JSON, search by JSON, retrieve JSON Document is the transaction layer

Sharding & Partitioning
Lots of scale problems are addressed by splitting the data
Partitioning is the data is grouped by a key in the data. The location is usually fixed (or takes a lot to move).
Sharding is the data is grouped by a key, but the location can change.
Example: shard on event timestamp.
− Partition: all 12/2015 go into the same disk− Shard: all 12/2015 could start in the same disk, but
be divided by smaller date ranges as volume increases

“Internet Scale”
Adding new nodes is easy Shards 'move' based on load Perfect for event storage with no or in place
changes

But ...
Not for documents that grow JSON is tricky to query Schema-less sounds great, until you have to
manage database someone else built No substitute for good design

NoSQL: Redis

Data Structure Server
CS 101 data structures: list, set, string CS 101 operations: push, pop, add, delete Very, very fast. Very simple 100% in memory Single threaded Lots of people use it as an application cache Big O notation documented for every operation

So?
Lets you build shared state across lots of consumers
Pushes operations to the server, so they are atomic
For example: set the 1000th bit on a bit array and increment a population counter. Without pulling the data back to the client

Use Cases
BloomFilters Work queue for thousands of worker threads
(Akka) without continual database polling Cache of web sessions “For the cost of an Oracle Enterprise License I
can give you 64 cores and 3 TB of memory”

BloomFilters

Bloom Filters
From WikiPedia (Don't tell my kid's teacher!)
"A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set. False positive matches are possible, but false negatives are not, thus a Bloom filter has a 100% recall rate"

Hashing
Apply 'x' hash functions to the key to be stored/queried
Each function returns a bit to set in the bitset
Mathematical equations to determine how big to make the bitset, how many functions to use and your acceptable error level
http://hur.st/bloomfilter?n=4&p=1.0E-20

Example

False Positives
Perfect hash functions aren't worth the cost to develop
Sometimes existing bits for a key are set by many other keys
Make sure you understand the business impact of a false positive
Remember, never a false negative

Question
How would you keep track of the number of unique visitors to a website today?
What if I wanted to know if a specific user had visited today?
SQL Query? List of visitors in memory?

Examples
Redis-backed− Unique visitor counts this week− White lists/black lists− What ad to show a visitor? (hash cookie id)− Client side joins (time based population counts)
Databases− Is this key in the page?
Fail Fast

Speed Round
Things we could talk about for hours. In minutes

Version Control
Git is free. Use it Local repository, keep copies of all your work Very helpful when you're working on a project
and need to revert
Plus a good thing to talk about on an interview

Google Docs
Huh? Get a Gmail account (or custom domain, more
about this later) Use Gmail's 10 GB of free storage to put all
your class assignments. No risk of losing school work. Can access from
any computer

IntelliJ
For the Java Users Eclipse is 'difficult'. Sorry, but it is (So is vi, don't get me started on emacs) Community edition is free Syntax highlighting, multiple language support

Clustering
Technology for building a set of processes that work together
Auto detect (and launch) of process failures Keeps your service available 24x7 ZooKeeper, Mesos are common technologies If done right, failure of a server isn't a 'wake up
the team!' event.

Replication
Usually requires Clustering One process is the 'master' of the data or
processing. One or more 'slaves' listen to updates/actions
of the master silently If the master dies, Clustering will promote a
slave to master and the processing continues Sometimes you can read from slaves for read
performance increases since they should be identical (or nearly) to the master

Bonus: Online Resources
Let me Google that for you HighScalability.com StackOverflow.com Infoq.com Feedly.com – RSS isn't dead yet

Big Data

What?
2nd most hyped concept in the last 5 years (Cloud is #1)
Basically, we generate too much data Companies are afraid to throw it away But don't know what to do with it, or if it is even
valuable

How to store it?
Often unstructured Lots and lots of it (sensor logs) Can't store it on one disk, can't risk losing it if
that disk is lost Can't back it up HDFS – Hadoop File System Distributed, multiple copies, multiple servers

How to access it?
Not in a RDBMS Not in a typical NoSQL (Redis, MongoDB etc.) Hadoop is one common tool for making sense
out of it Still need to write code (Cascading is my
favorite)

Map/Reduce

Other Approaches
Spark− Actor based approach to processing data− Uses HDFS, but holds results in memory as long as
possible− Still need to write code− Very, very fast
Hbase− Non-relational database with columns and rows− Most JDBC drivers can talk to it

Careers
Data Scientist− Apply knowledge of statistics and algorithms to the
big data− Find actionable insights in the data to drive the
business− Build Predictive models based on data to determine
what might happen next− Both coding and math skills

Actor Systems

Your phone is more powerful than the Space Shuttle's computers
Typical phone has 2 cores (some 4) Typical laptop has 4 cores Typical server has 8 cores Being able to do things in parallel is necessary
to scale

Multi-threading is really hard
Books written about it Courses taught about it Java got it wrong TWICE so far Concurrency bugs are very difficult to debug
and fix Servers are so cheap now, concurrency across
machines is very common

Actors
So rather than writing the code yourself, why not rely on a concurrency model?
Actors are called with a piece of work to do, respond with an answer
All the threading, clustering, messaging in handled by it.
Akka for Java. Scala Actors (or Akka for Scala)

Use case
Redis list with all the tasks to be performed Akka actor tells 'manager' it is ready for work Manager pops item from Redis into a key
specific for that worker and tells the worker what to do.
When done, the worker tells the manager and the key is removed (or more tasks are created)
Scales to thousands of machines, 10 threads per machine

Streaming

Real time and over time processing
Some events need to be responded to immediately
Some events need to be compared to other events in the last 'x' time periods to understand what to do about them
Some events can be discarded quickly, but need to evaluate them to determine that

Used to be $$$$ to use
Storm changed that Open Source Event Processing System used
by Twitter You write code to evaluate events as they
occur, not to query a set of events at rest Not 'everyone in the last hour who bought more
than $100' Rather 'this person just bought >$100' so do
something. Don't wait

Use Cases
Combined with Kafka for event ingestion Every purchase request, check if the
geographic coordinates match the last 5 purchases, or their home zip code + 5 miles
Every download of a white paper, see if they are a sales prospect and alert the salesperson the customer is on the site and interested

Careers
Security and anti-fraud Online marketing Securities Trading (Wall Street)

Career
Managing your career before you have one

Linked In
Get one This is not Facebook or Instagram Who would you want to work with in 5 years? Who wouldn't you? Stay in touch with Intern/co-op co-workers Lots of useful information, follow 'smart' people

Internships
Get one, even on campus LinkedIn to search for them Nepotism is okay!

Open Source
Find an interesting project Does it have a 'startup guide'? Or a poorly
written one? Get an example working and submit a
documentation update Another thing to talk about during an interview

Study Groups
Get several! No, not organized cheating What you understand someone else doesn't Eventually you won't be the smartest in a group Interview discussion topic

Resumes
Gold Award? Eagle Scout? List courses in major Describe your impact on the business (even if a
cook or waiting tables) One page. Really. Vanity Emails – time to get rid of them
− Seriously consider a Google-hosted domain ($50 year)

Interviews
Prepare, prepare, prepare Details about course work How will your internship help the company? Test First Development during coding examples Ask questions Be ready: What else do you do for fun?

Life
Have one outside of computers Have non-CS friends Get a hobby Exercise (Google 'The Hackers diet')
Why? Burn out

Other things
Learn about Mobile
Learn about JavaScript client libraries (JQuery, Angular.js etc.) even if you want to do backend work
Learn about security, both building secure and the tools for testing
Data Science has a lot of buzz (Learn R, Predictive Analytics)
Internet of Things (IoT)

Finally
Never stop asking why?
Never stop taking things apart
Never stop listening and learning

Finally
Never stop asking why?
Never stop taking things apart
Never stop listening and learning