umbra ignite 2015: jérémy virga – dishonored 2 rendering engine architecture overview – moving...
TRANSCRIPT

Dishonored 2 rendering engine architecture overview
Jérémy Virga, Arkane Studios ( Lyon / France)
Intro Why we’re doing this ? (except because programmers want to have fun…)
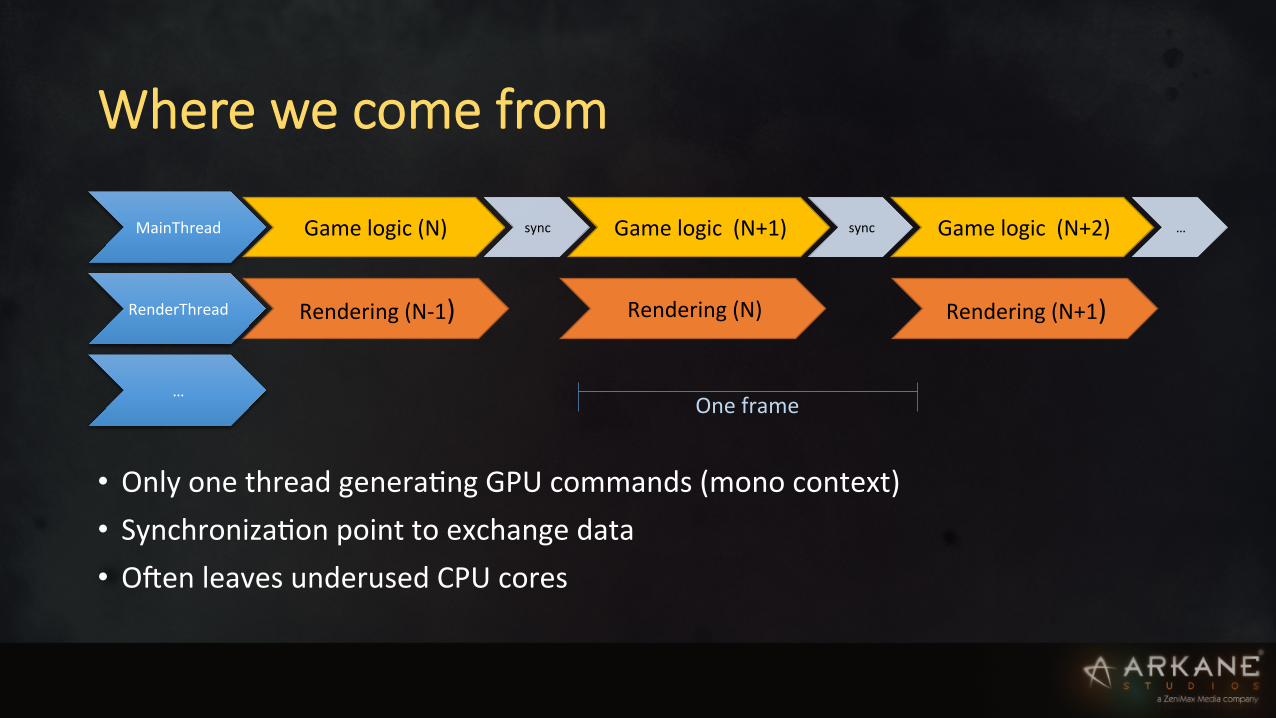
Where we come from
• Only one thread generaIng GPU commands (mono context) • SynchronizaIon point to exchange data • ONen leaves underused CPU cores
MainThread Game logic (N) sync Game logic (N+1) sync Game logic (N+2) …
RenderThread Rendering (N-‐1) Rendering (N) Rendering (N+1)
… One frame

Where we want to go
• SequenIal but spread on all cores • Removes an extra frame latency & data copies
• Requires both game logic and rendering completely mulIthreaded
MainThread … Game logic (N) RenderLoop (tasks creaIon & submit) (N) …
Worker1 Task Task Task
Task
Task Task Task
Worker2 Task Task Task Task Task
Worker3 Task Task Task Task Task
Worker4 Task Task
Task
Task Task Task Task
Worker5 Task Task Background task
… One frame

Where we want to go
Let’s focus on rendering part…
MainThread … Game logic RenderLoop (tasks creaIon & submit) …
Worker1 Task Task Task
Task
Task Task Task
Worker2 Task Task Task Task Task
Worker3 Task Task Task Task Task
Worker4 Task Task
Task
Task Task Task Task
Worker5 Task Task Background task
…
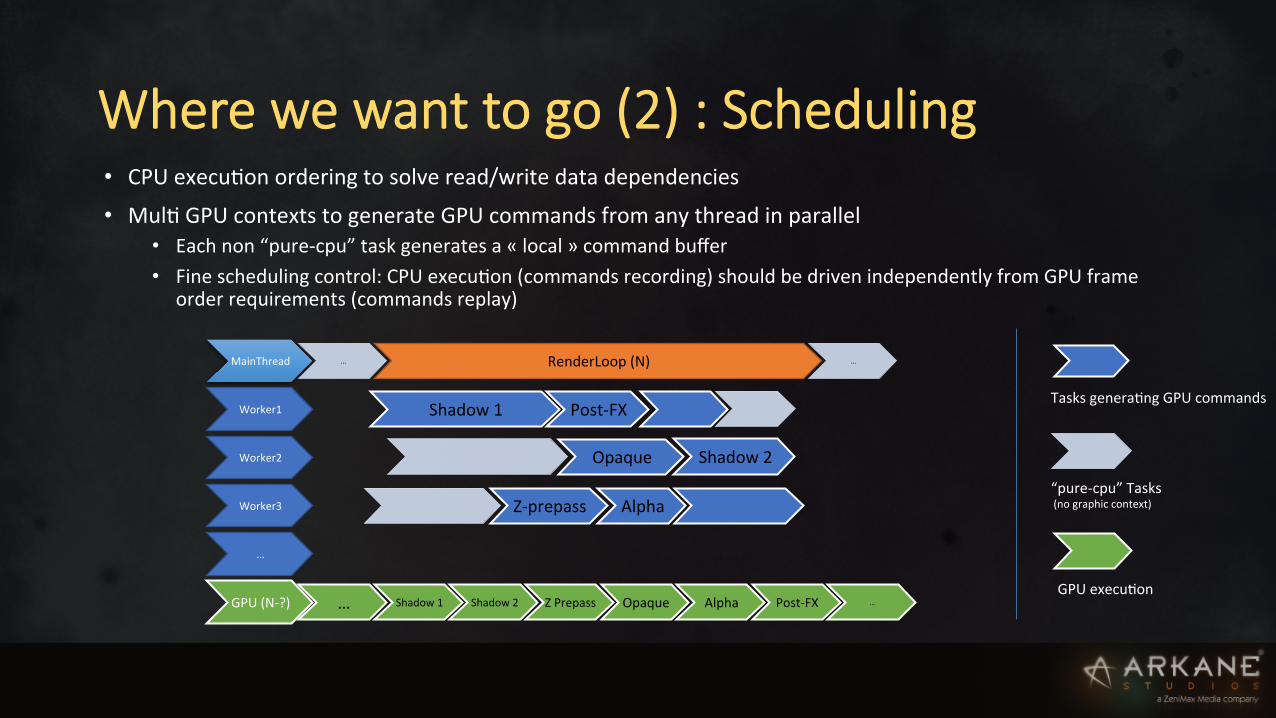
Where we want to go (2) : Scheduling
MainThread … RenderLoop (N) …
Worker1 Shadow 1 Post-‐FX
Worker2 Opaque Shadow 2
Worker3 Z-‐prepass Alpha
…
GPU (N-‐?) … Shadow 1 Shadow 2 Z Prepass Opaque Alpha Post-‐FX …
Tasks generaIng GPU commands
“pure-‐cpu” Tasks (no graphic context)
GPU execuIon
• CPU execuIon ordering to solve read/write data dependencies • MulI GPU contexts to generate GPU commands from any thread in parallel
• Each non “pure-‐cpu” task generates a « local » command buffer • Fine scheduling control: CPU execuIon (commands recording) should be driven independently from GPU frame
order requirements (commands replay)

Where we want to go (2) : Scheduling
MainThread … RenderLoop (N) …
Worker1 Shadow 1 Post-‐FX
Worker2 Opaque Shadow 2
Worker3 Z-‐prepass Alpha
…
GPU (N-‐?) … Shadow 1 Shadow 2 Z Prepass Opaque Alpha Post-‐FX …
Tasks generaIng GPU commands
“pure-‐cpu” Tasks (no graphic context)
GPU execuIon
• CPU execuIon ordering to solve read/write data dependencies • MulI GPU contexts to generate GPU commands from any thread in parallel
• Each non “pure-‐cpu” task generates a « local » command buffer • Fine scheduling control: CPU execuIon (commands recording) should be driven independently from GPU frame
order requirements (commands replay)

VoidEngine & Dishonored 2 rendering facts
• Environments/architecture created from small blocks + more details than previous game Ø Lot of objects to process, Thousands of draw calls
• Instanced batch draws Ø batches generated based on visibility results from Umbra
• Dedicated culling for shadow casters • Lot of shadow casIng lights, all dynamic with cache system, nothing pre-‐baked
• Several passes • Z prepass for opaque, separate Z prepass for alpha,
Tiled forward shading with PBR, extra passes dedicated to effects, etc…
• In-‐house indirect lighIng system & IBL cubemaps network • …

VoidEngine & Dishonored 2 rendering facts
• Lot of « almost-‐independent » passes, lot of data, lot of work. • Became a mess to organize, mulIthreading will make it worst.
• Over performances, ideal architecture requirements are: • User-‐friendly: Easy to setup and insert new work. • Readable: Easy to understand & follow frame sequence • Modular: Easy to organize/rearrange/split/remove passes & work
…but you know world is not ideal. So let’s try to make it not too ugly ;)

Split the renderLoop Rendering task setup

Rendering task setup: dependencies
• Two singular dependency kinds • « CPU dependencies » for execuIon scheduling / data synchronizaIon
• -‐> most criIcal for performances, could create « holes » in the execuIon Imeline • « GPU dependencies » for submissions ordering
• -‐> very small performance impact in general, required to have consistent GPU frame but doesn’t affect CPU parallelism
Task A Task B Task C
Task A
Task B
Task C
“CPU” dependencies “GPU” dependencies
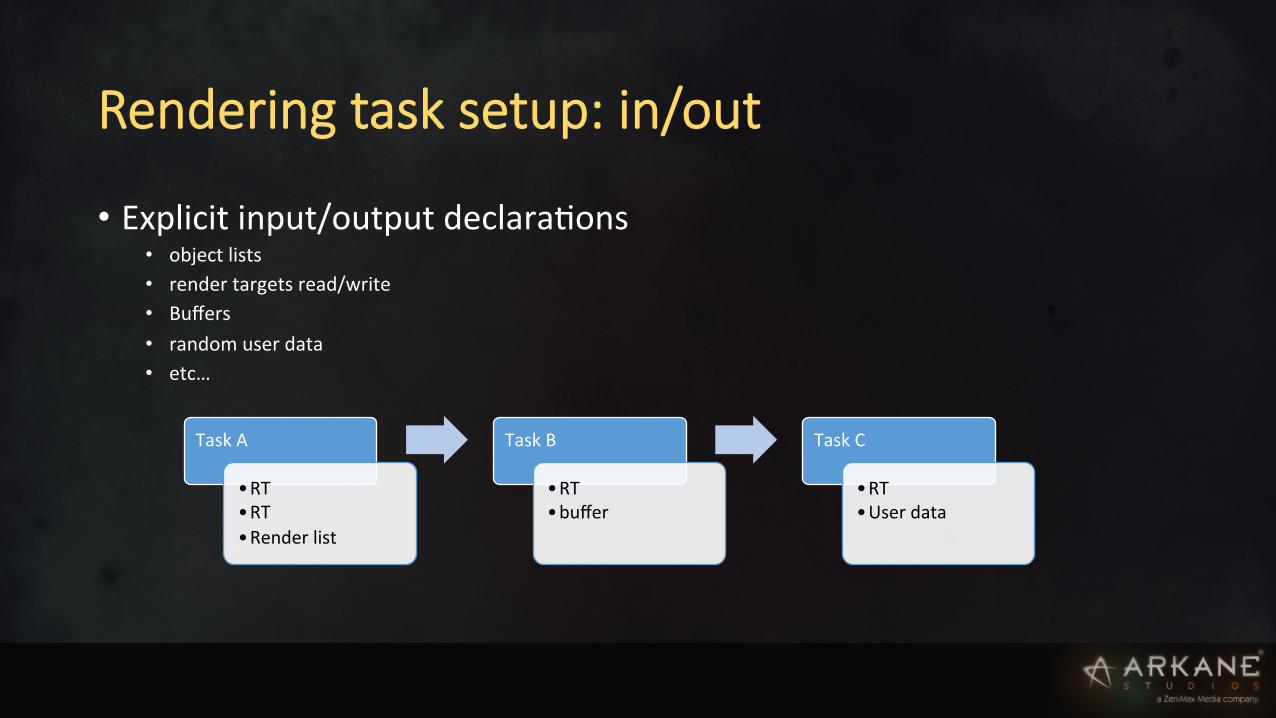
Rendering task setup: in/out
• Explicit input/output declaraIons • object lists • render targets read/write • Buffers • random user data • etc…
Task A
• RT • RT • Render list
Task B
• RT • buffer
Task C
• RT • User data
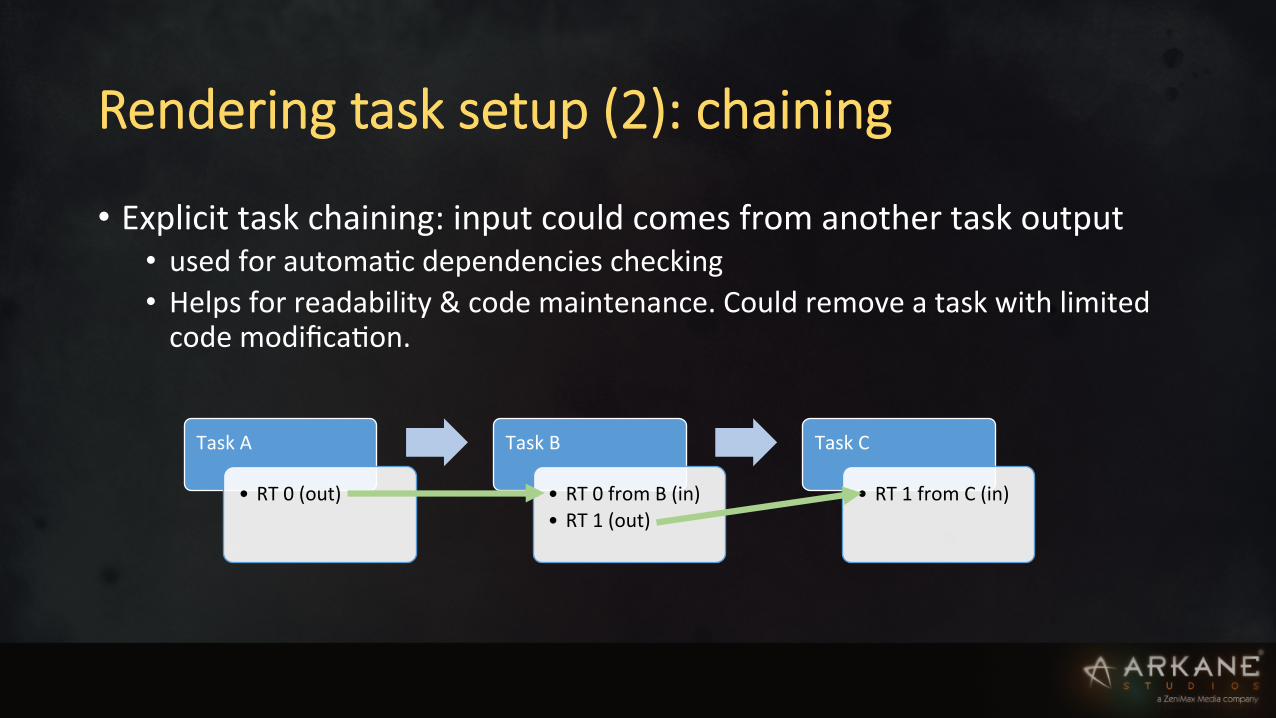
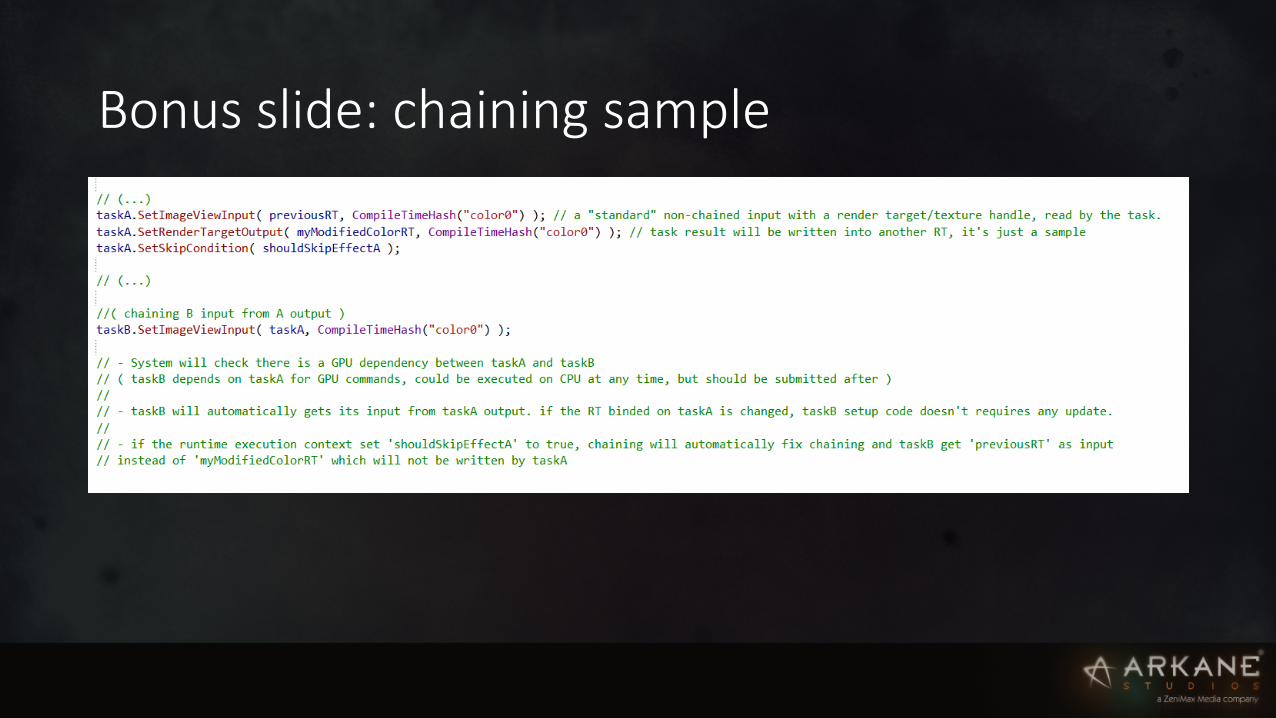
Rendering task setup (2): chaining
• Explicit task chaining: input could comes from another task output • used for automaIc dependencies checking • Helps for readability & code maintenance. Could remove a task with limited code modificaIon.
Task A
• RT 0 (out)
Task B
• RT 0 from B (in) • RT 1 (out)
Task C
• RT 1 from C (in)
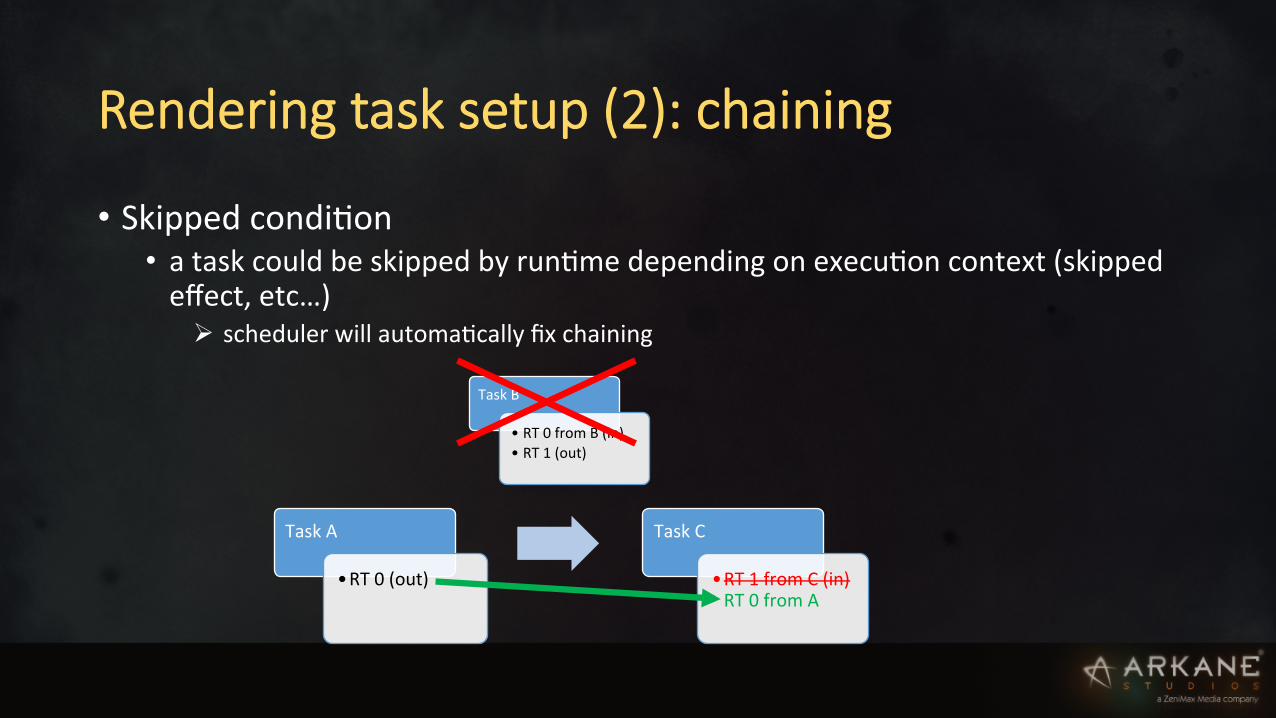
Rendering task setup (2): chaining
• Skipped condiIon • a task could be skipped by runIme depending on execuIon context (skipped effect, etc…) Ø scheduler will automaIcally fix chaining
Task A
• RT 0 (out)
Task C
• RT 1 from C (in) RT 0 from A
Task B
• RT 0 from B (in) • RT 1 (out)

Rendering task setup (3): advanced opFons
• « Background » task: low priority, render loop doesn’t wait for it at end of frame • Submiqed on a next frame if not ready
• « forced immediate » task: actually executed inline during submission • Uses the main “immediate” graphic context • To workaround graphic middleware or plarorm specific API limitaIons • Keeps frame ordering consistency

Spreading the world: AddiFonal helpers
• Supports spawn of new tasks from another one • -‐>MulIple producers, mulIple consumers scheduling • RunAsync( … );
• To convert any piece of code into asynchronous call • ParallelFor(…);
• To split processing on several workers in just one line of code • Interface similar to Intel TBB[1], MicrosoN PPL[2], …
• RenderPass • EncapsulaIon of several tasks sharing dependencies and/or inputs. • Scheduling sIll fully flexible at task-‐level • E.g. each shadow slice/part is a task, encapsulated into only one shadow pass.

Rendering task examples
• Umbra visibility jobs (cpu) • Drawing batches gathering/sorIng (cpu) • Lights sorIng (cpu) • DirecIonal shadow cascades draws (cpu/gpu) • Local (point/spot/area light) shadows update (cpu/gpu) • Opaque pass draws (cpu/gpu) • Alpha pass draws (cpu/gpu) • … etc ~50-‐70 tasks currently (~half are cpu/gpu)

Results, issues & guidelines

Results
• We got ~40-‐60% renderLoop duraIon Ime saved on first draN (on 6-‐8 cores hardware) • Excellent results on latest consoles. SIll improving over SDK updates • We are expecIng the best results on latest PC APIs (Mantle/DX12/Vulkan)
• We improved those results significantly by tweaking tasks (see guidelines) • we have to do that constantly during game development as things are moving
• MulItask overhead VS overall performances • Scheduling cost, submission cost • Cache misses easier to raise (when cache is shared through cores) • You should sIll get benefits
Issues
• NOT for every environment: • PC D3D11, efforts were made on some recent drivers, but result depends on IHV (independent hardware vendor) • From really good improvements to horrible performances loss • Could rely on D3D11_FEATURE_DATA_THREADING::DriverCommandLists with recent drivers
• We fallback on an hybrid mode when not correctly supported • only pure-‐cpu tasks are parallelized, gpu-‐tasks run on just one worker, with only one graphic context.
• Gpu dependencies converted to cpu ones to keep frame ordering consistency
Issues
• …easy to break rendering with random arIfacts hard to understand. • We developed in-‐house debug tools & commands
• Could switch on the fly to single threaded execuIon • Could display on-‐screen intermediate task’s RT outputs • ExecuIon Imeline recording • Could record submissions ordering of a buggy frame and replay it • Dependency graphs generaIon
• … sIll evolving

Issue example: the « renaming » case
Update a dynamic GPU resource on task A. Use it in a command buffer in task B
• Doesn’t require an extra CPU dependency between them. From the CPU, execuIng update(A) before, during or aNer binding(B) is completely valid.
MainThread … RenderLoop …
Worker1 A (update)
Worker2 B (binding)
…

Issue example: the « renaming » case
• On PC D3D11, driver handles this for you • On update, it « renames » the resource = it creates another copy version • On binding use, it adds « split point » in the command buffer each Ime the actual copy version behind a dynamic resource is unknown (= not updated within the same local command buffer).
• On submission, it patches all the split points of the command buffer according to other preceding submissions • -‐> bad performances overhead !
• On consoles & new PC APIs: manual management • Much more efficient • Requires your knowledge of the actual renamed « version » to use in the binding task(B) • -‐> Input/output task chaining gives that

To be conFnued: guidelines
• Bench it ! • Use low-‐level profiling tools to observe stalls, holes in the Imeline, preempIon • PC: MicrosoN Concurrency Visualizer [3], …
• Improve work split / CPU dependencies to prevent holes / improve code paqerns to prevent CPU stalls / etc…. will increase results significantly • Be careful to not have too many thread context switches. • Tweak core affiniIes of your tasks (consoles) • Granularity of split: overhead vs performance gain

To be conFnued: next steps
• Use extra GPU engine (Asynchronous compute, DMA, …) to also improve GPU parallelism – consoles & new PC APIs only • Re-‐use tasks GPU dependencies to manage GPU queues synchronizaIons
• Thinking about a system allowing tasks generaIng very small command buffers to give it to another task at the end, instead of registering for submission directly. • -‐> hard to manage correctly submission ordering

QuesFons ?
jvirga@arkane-‐studios.com

Bonus slide: kill mutexes
• Mutexes are your nemesis. • There is oNen a more efficient paqern or primiIve to avoid using them. • Use spin lock when you know the lock duraIon Ime is really small • Use lockless queues, etc… • Pre-‐allocate containers and use them with atomic indexes increment • Use Read/Write mutex when you know there are much more read than write on the data (several concurrent reads allowed, exclusive write) • Use thread local storage in code called concurrently • …

Bonus slide: scheduler implementaFon details
• RenderLoop • (A) For each Task, PushTask()
• readyToStart (CPU dependencies + task not skipped by runIme) && there’s an available worker ? • Send signal to the worker
• else • Place in queue
• (B) Wait for a pending task submission. • (C) For each pending submission
• readyToSubmit (GPU dependencies) ? • Send command buffer to GPU queue • Release/Recycle it (plarorm dependent)
• Repeat (B) and (C) unIl all frame tasks are completed & submiqed – except for “background” tasks

Bonus slide: scheduler implementaFon details
• Worker • (A) Wait for a task readyToStart signal • (B) If the task requires command buffer, assign it a graphic context • (C) Execute the task • (D) Close the command buffer • (E) Place task into pending submission queue if command buffer actually filled • (D) check for any other available task to run in scheduler queue
• return to (B) else return to (A)

Bonus slide: Concurrency Visualizer • Low-‐level: catch CPU core stalls, memory management, preempIon, sleep, IO
• Blocking & unblocking call stacks
• Timings
• Markers API to make it readable
• Observe context switches
Catch context switches

Bonus slide: parallelFor sample
Bonus slide: chaining sample
References
• [1] Intel Threading Building Blocks (library) hqps://www.threadingbuildingblocks.org/ • [2] MicrosoN Parallel Paqerns Library hqps://msdn.microsoN.com/en-‐us/library/vstudio/dd492418.aspx • [3] MicrosoN Concurrency Visualizer (PC profiling tool)
• Bundled with Visual Studio 2012 • OpIonal extension since 2013 hqps://visualstudiogallery.msdn.microsoN.com/24b56e51-‐fcc2-‐423f-‐b811-‐f16f3fa3af7a